
Incremental Nonnegative Tucker Decomposition with Block-Coordinate Descent and Recursive Approaches



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Related Works
1.2. Preliminaries
2. Incremental Tucker Decomposition
2.1. Model
2.2. Recursive Algorithm
| Algorithm 1:RI-NTD |
 |
2.3. Block Kaczmarz Algorithm
| Algorithm 2:BK-NTD |
 |
3. Numerical Simulations
3.1. Setup
- Benchmark I: the observed dataset was created according to model (3). Factor matrices for were generated using the zero-mean normal distribution, where and . Thus, such factors have the sparsity of 50%.
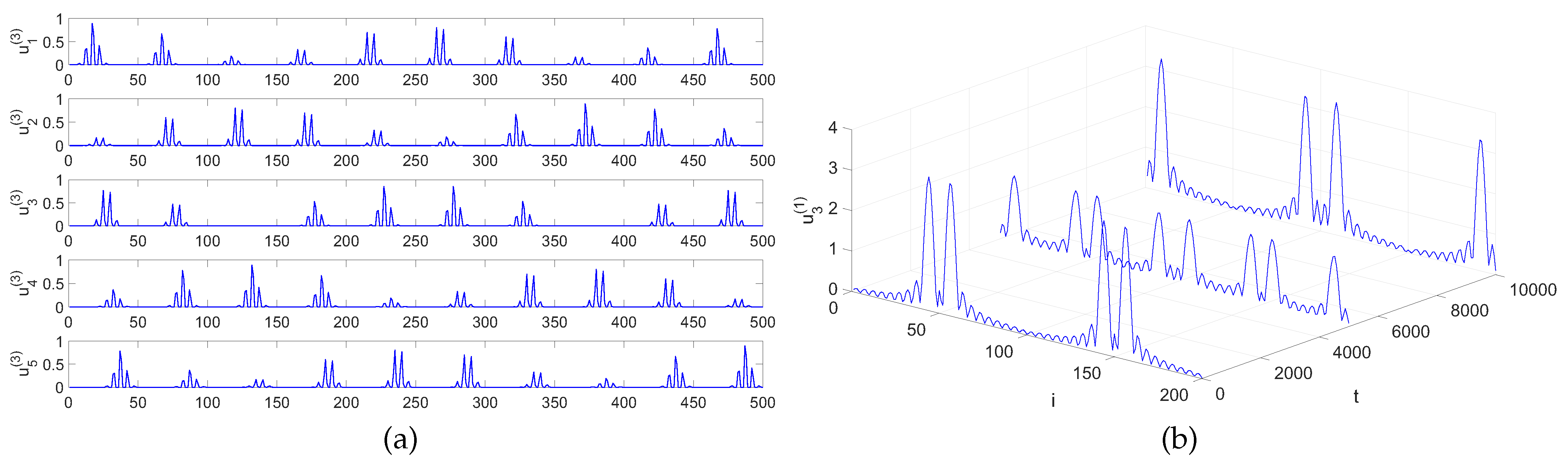
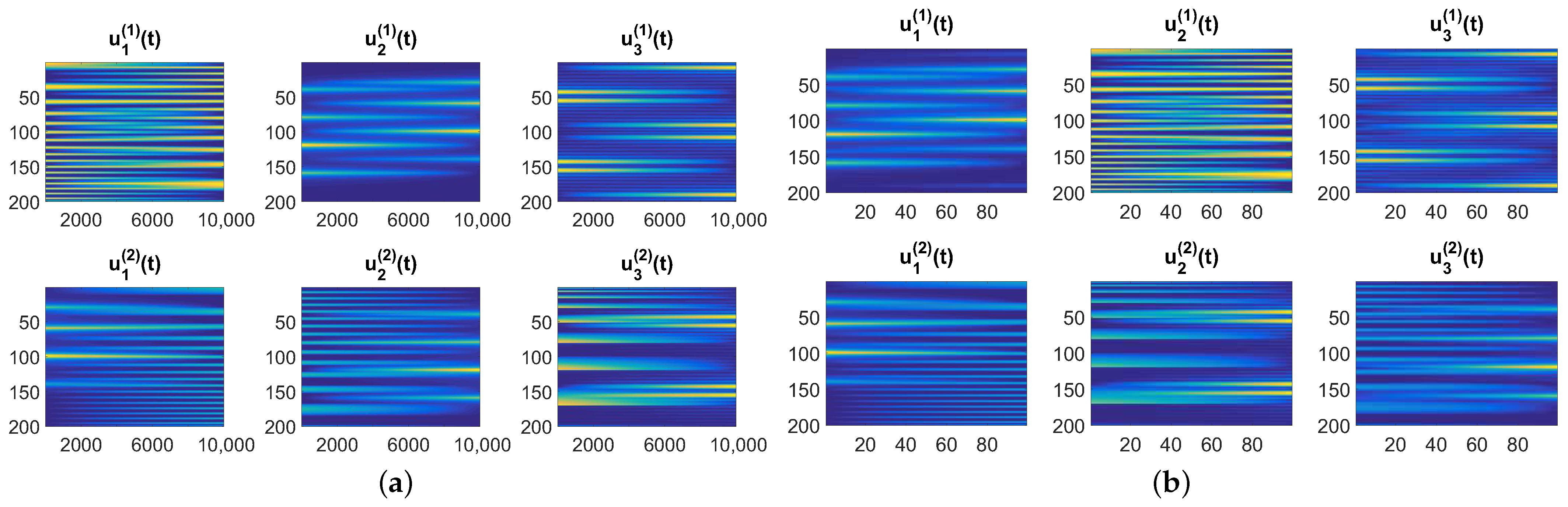
- Benchmark II: the observed dataset was also created using model (3). Factor matrices and were generated similarly as in Benchmark I. Each column in factor expresses the periodic Gaussian pulse train obtained by a repetition of Gaussian-modulated sinusoidal pulse, circularly shifted with a randomly selected time lag. The negative entries are replaced with a zero-value. One waveform of such a signal is plotted in Figure 1a. The frequency and the phase of the sinusoid signal was set individually for each component/column. Assuming represents source signals, the fibers in along the third mode can be regarded as mixed signals with a multi-linear mixing operator.
- Benchmark III: the observed dataset was created according to the dynamic NTD model in (38). For the whole set of temporal samples (), factors and take the form of three-way arrays and that contain and components, respectively. Each component is obtained by a linear interpolation of a pair of the spectral signals taken from the file AC10_art_spectr_noi in Matlab toolbox NMFLAB for Signal Processing [66]. Hence, and refer to spectral resolutions, while T denotes the number of time slots within the interpolated window. The example of one such component is illustrated in Figure 1b in the form of a 3D plot. Assuming the components in and are time-varying spectral signals, model (38) can be used to represent a time-varying multi-linear mixing process.
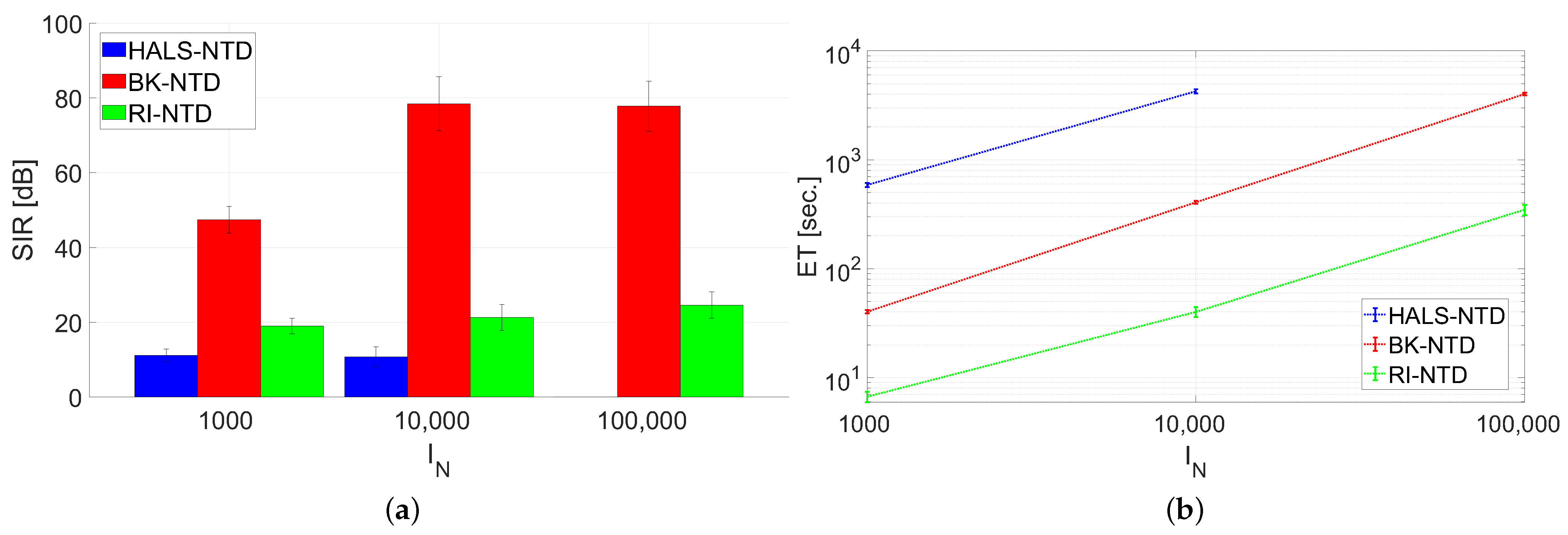
- Test A: Benchmark A was used in this test with settings: and in all the observed scenarios. The test was carried out for . No noisy perturbations were used in this test.
- Test B: Benchmark A was used in this test with settings: , , and in all the observed scenarios. The synthetically generated data were additively perturbed with the zero-mean Gaussian noise with . Note that the noise with is very strong – the power of noise is equal to the power of the true signal.
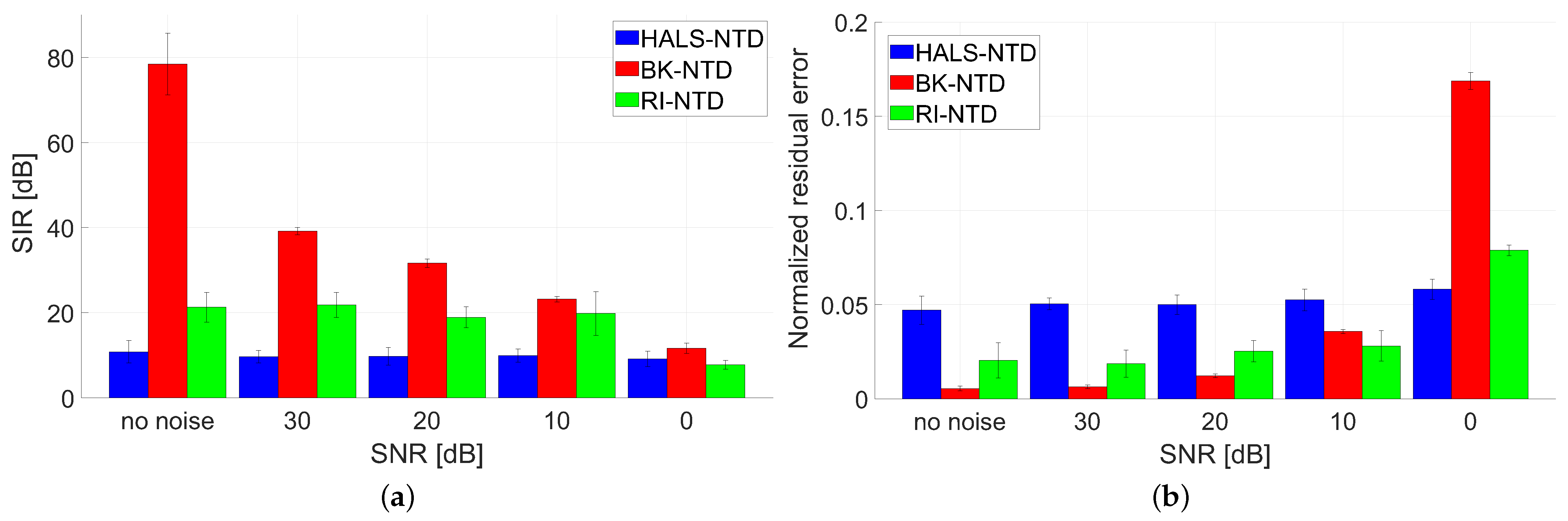
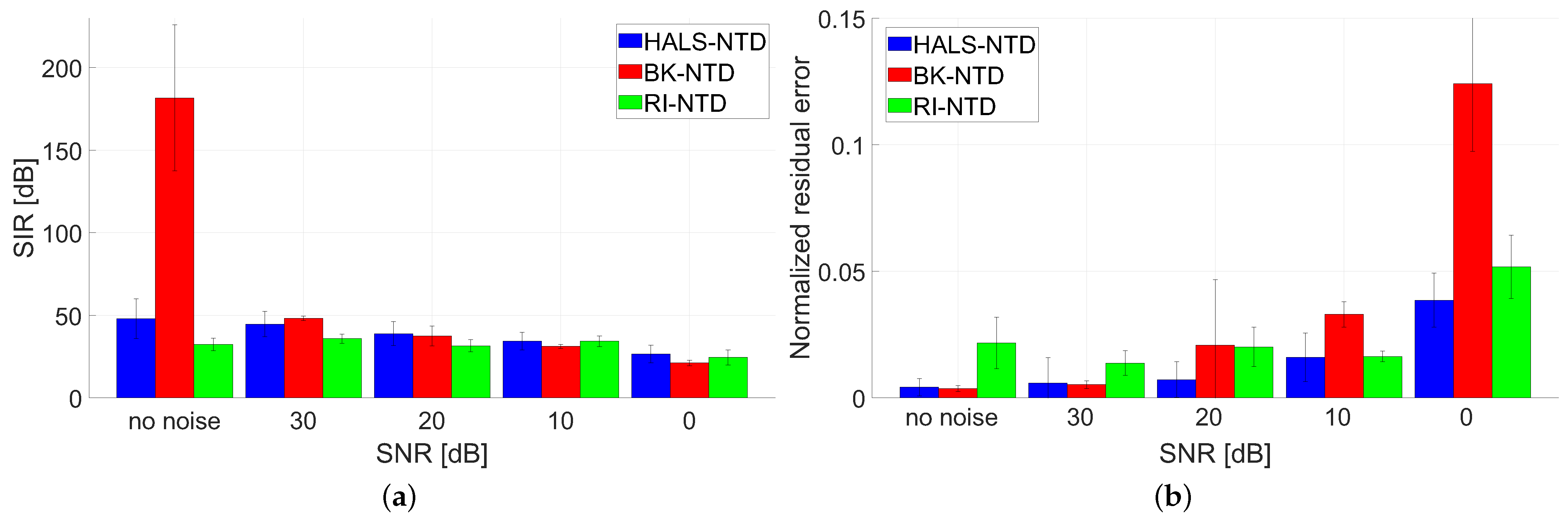
- Test C: Benchmark B was used in this test with settings: and , and . No noisy perturbations were used in this test.
- Test D: Benchmark B was used in this test with settings: , , and in all the observed scenarios. The synthetically generated data were additively perturbed with the zero-mean Gaussian noise with .
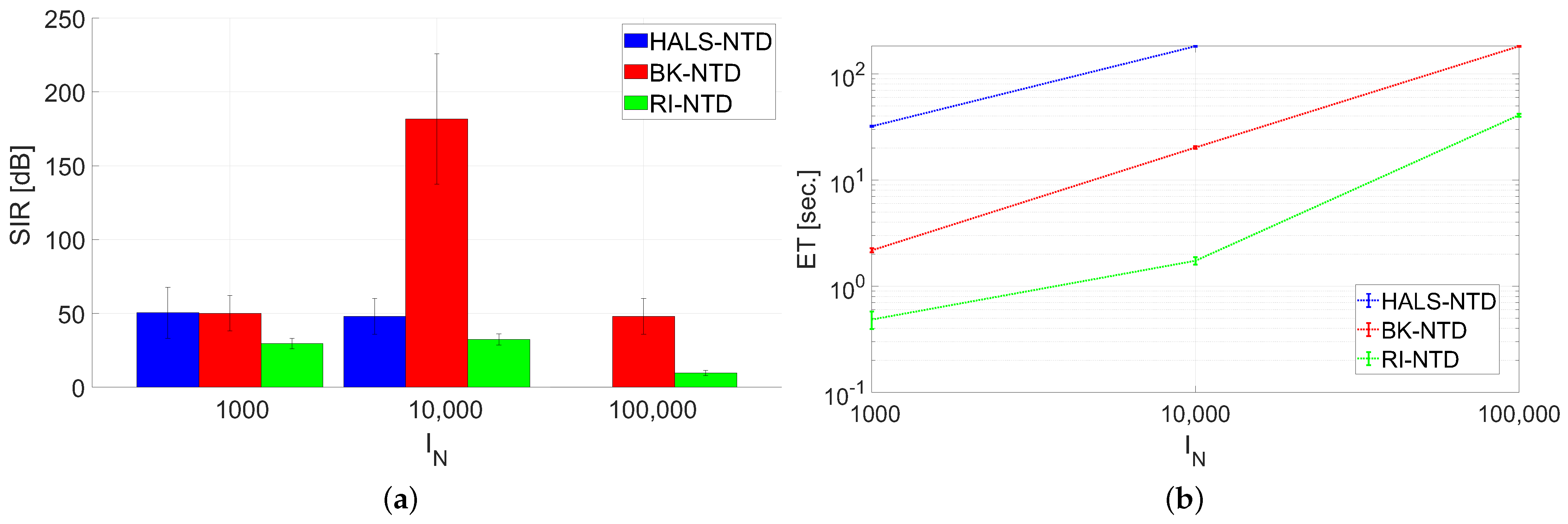
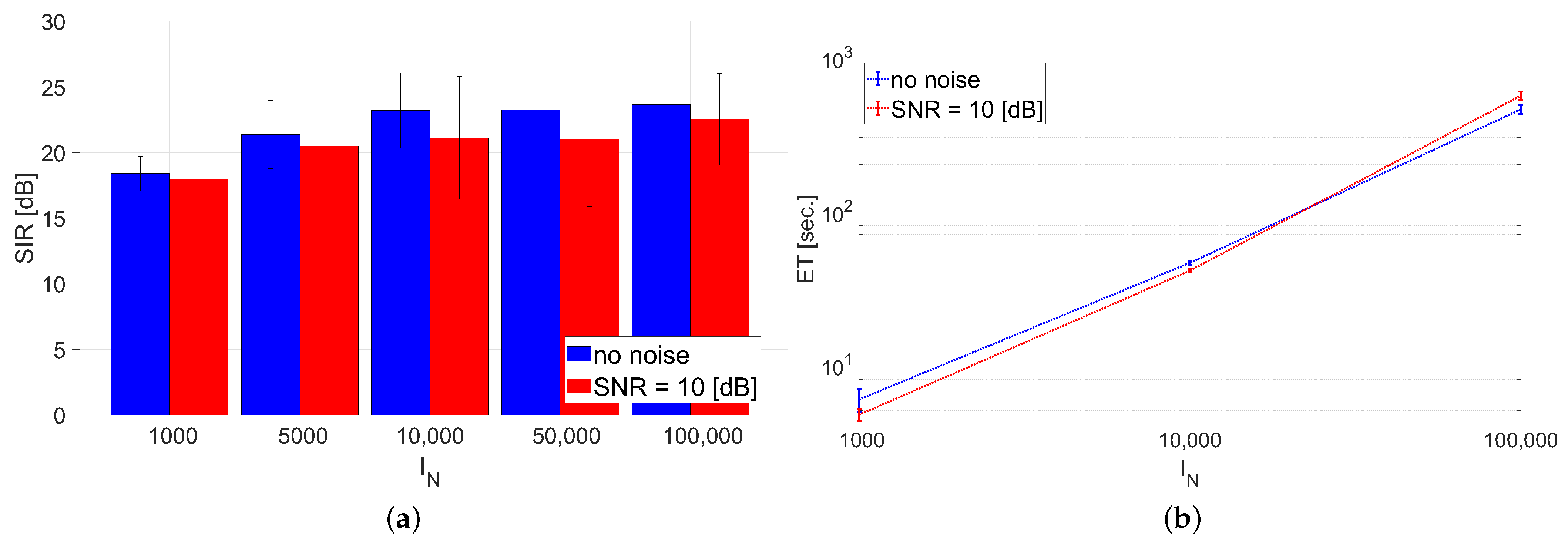
- Test E: Benchmark C was used in this test with settings: and , and . Noise-free and noisy data with were tested.The algorithms were quantitatively evaluated in terms of the signal-to-interference ratio (SIR) measure [1], elapsed time (ET) of running (in seconds), and normalized residual error: . Moreover, the selected estimated signals were also illustrated in the form of 2D plots.Since the optimization problem in the NTD model is non-convex and, hence, sensitive to initialization, we performed the Monte Carlo (MC) analysis with 10 runs. In each run, a new sample of dataset and a new initializer were randomly selected.
3.2. Results
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cichocki, A.; Zdunek, R.; Phan, A.H.; Amari, S.I. Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation; Wiley and Sons: Chichester, UK, 2009. [Google Scholar]
- Kisil, I.; Calvi, G.G.; Scalzo Dees, B.; Mandic, D.P. Tensor Decompositions and Practical Applications: A Hands-on Tutorial. In Recent Trends in Learning From Data: Tutorials from the INNS Big Data and Deep Learning Conference (INNSBDDL2019); Oneto, L., Navarin, N., Sperduti, A., Anguita, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 69–97. [Google Scholar]
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an n-way generalization of Eckart-Young decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Harshman, R.A. Foundations of the PARAFAC procedure: Models and conditions for an “explanatory”multimodal factor analysis. UCLA Work. Pap. Phon. 1970, 16, 1–84. [Google Scholar]
- Lim, L.H.; Comon, P. Nonnegative approximations of nonnegative tensors. J. Chemom. 2009, 23, 432–441. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Cong, F.; Ristaniemi, T. Sparse Nonnegative CANDECOMP/PARAFAC Decomposition in Block Coordinate Descent Framework: A Comparison Study. arXiv 2018, arXiv:abs/1812.10637. [Google Scholar]
- Alexandrov, B.S.; DeSantis, D.; Manzini, G.; Skau, E.W. Nonnegative Canonical Polyadic Decomposition with Rank Deficient Factors. arXiv 2019, arXiv:abs/1909.07570. [Google Scholar]
- Tucker, L.R. The extension of factor analysis to three-dimensional matrices. In Contributions to Mathematical Psychology; Gulliksen, H., Frederiksen, N., Eds.; Holt, Rinehart and Winston: New York, NY, USA, 1964; pp. 110–127. [Google Scholar]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef]
- Mørup, M.; Hansen, L.K.; Arnfred, S.M. Algorithms for Sparse Nonnegative Tucker Decompositions. Neural Comput. 2008, 20, 2112–2131. [Google Scholar] [CrossRef]
- Oh, S.; Park, N.; Lee, S.; Kang, U. Scalable Tucker Factorization for Sparse Tensors—Algorithms and Discoveries. In Proceedings of the 34th IEEE International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1120–1131. [Google Scholar]
- De Lathauwer, L.; de Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- Sheehan, B.N.; Saad, Y. Higher Order Orthogonal Iteration of Tensors (HOOI) and its Relation to PCA and GLRAM. In Proceedings of the Seventh SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 355–365. [Google Scholar]
- Hackbusch, W.; Kühn, S. A New Scheme for the Tensor Representation. J. Fourier Anal. Appl. 2009, 15, 706–722. [Google Scholar] [CrossRef] [Green Version]
- Oseledets, I.V. Tensor-Train Decomposition. SIAM J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Cichocki, A.; Lee, N.; Oseledets, I.V.; Phan, A.H.; Zhao, Q.; Mandic, D.P. Tensor Networks for Dimensionality Reduction and Large-scale Optimization: Part 1 Low-Rank Tensor Decompositions. Found. Trends Mach. Learn. 2016, 9, 249–429. [Google Scholar] [CrossRef] [Green Version]
- Cichocki, A.; Phan, A.H.; Zhao, Q.; Lee, N.; Oseledets, I.V.; Sugiyama, M.; Mandic, D.P. Tensor Networks for Dimensionality Reduction and Large-scale Optimization: Part 2 Applications and Future Perspectives. Found. Trends Mach. Learn. 2017, 9, 431–673. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhou, G.; Xie, S.; Zhang, L.; Cichocki, A. Tensor Ring Decomposition. arXiv 2016, arXiv:1606.05535. [Google Scholar]
- Liu, J.; Zhu, C.; Liu, Y. Smooth Compact Tensor Ring Regression. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Vasilescu, M.A.O.; Terzopoulos, D. Multilinear analysis of image ensembles: Tensorfaces. In European Conf. on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2002; Volume 2350, pp. 447–460. [Google Scholar]
- Wang, H.; Ahuja, N. Facial Expression Decomposition. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 958–965. [Google Scholar]
- Vlasic, D.; Brand, M.; Phister, H.; Popovic, J. Face transfer with multilinear models. ACM Trans. Graph. 2005, 24, 426–433. [Google Scholar] [CrossRef]
- Zhang, M.; Ding, C. Robust Tucker Tensor Decomposition for Effective Image Representation. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2448–2455. [Google Scholar]
- Zaoralek, L.; Prilepok, M.; Snael, V. Recognition of Face Images with Noise Based on Tucker Decomposition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 2649–2653. [Google Scholar]
- Savas, B.; Elden, L. Handwritten digit classification using higher order singular value decomposition. Pattern Recognit. 2007, 40, 993–1003. [Google Scholar] [CrossRef]
- Phan, A.H.; Cichocki, A. Tensor decompositions for feature extraction and classification of high dimensional datasets. IEICE Nonlinear Theory Its Appl. 2010, 1, 37–68. [Google Scholar] [CrossRef] [Green Version]
- Phan, A.H.; Cichocki, A.; Vu-Dinh, T. Classification of Scenes Based on Multiway Feature Extraction. In Proceedings of the 2010 International Conference on Advanced Technologies for Communications, Ho Chi Minh City, Vietnam, 20–22 October 2010; pp. 142–145. [Google Scholar]
- Araujo, D.C.; de Almeida, A.L.F.; Da Costa, J.P.C.L.; de Sousa, R.T. Tensor-Based Channel Estimation for Massive MIMO-OFDM Systems. IEEE Access 2019, 7, 42133–42147. [Google Scholar] [CrossRef]
- Sun, Y.; Gao, J.; Hong, X.; Mishra, B.; Yin, B. Heterogeneous Tensor Decomposition for Clustering via Manifold Optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 476–489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.; Ahmad, F.; Vorobyov, S.; Porikli, F. Tensor Decompositions in Wireless Communications and MIMO Radar. IEEE J. Sel. Top. Signal Process. 2021, 15, 438–453. [Google Scholar] [CrossRef]
- Li, R.; Pan, Z.; Wang, Y.; Wang, P. The correlation-based Tucker decomposition for hyperspectral image compression. Neurocomputing 2021, 419, 357–370. [Google Scholar] [CrossRef]
- Ebied, A.; Kinney-Lang, E.; Spyrou, L.; Escudero, J. Muscle Activity Analysis Using Higher-Order Tensor Decomposition: Application to Muscle Synergy Extraction. IEEE Access 2019, 7, 27257–27271. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor Decompositions and Applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Rabanser, S.; Shchur, O.; Günnemann, S. Introduction to Tensor Decompositions and their Applications in Machine Learning. arXiv 2017, arXiv:1711.10781. [Google Scholar]
- Kim, Y.D.; Choi, S. Nonnegative Tucker Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR07), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Li, X.; Ng, M.K.; Cong, G.; Ye, Y.; Wu, Q. MR-NTD: Manifold Regularization Nonnegative Tucker Decomposition for Tensor Data Dimension Reduction and Representation. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1787–1800. [Google Scholar] [CrossRef] [PubMed]
- Zhou, G.; Cichocki, A.; Zhao, Q.; Xie, S. Efficient Nonnegative Tucker Decompositions: Algorithms and Uniqueness. IEEE Trans. Image Process. 2015, 24, 4990–5003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiu, Y.; Zhou, G.; Zhang, Y.; Xie, S. Graph Regularized Nonnegative Tucker Decomposition for Tensor Data Representation. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8613–8617. [Google Scholar]
- Qiu, Y.; Zhou, G.; Wang, Y.; Zhang, Y.; Xie, S. A Generalized Graph Regularized Non-Negative Tucker Decomposition Framework for Tensor Data Representation. IEEE Trans. Cybern. 2020; 1–14, in press. [Google Scholar] [CrossRef]
- Bai, X.; Xu, F.; Zhou, L.; Xing, Y.; Bai, L.; Zhou, J. Nonlocal Similarity Based Nonnegative Tucker Decomposition for Hyperspectral Image Denoising. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 701–712. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Liu, Z. Compression of hyper-spectral images using an accelerated nonnegative tensor decomposition. Open Phys. 2017, 15, 992–996. [Google Scholar] [CrossRef] [Green Version]
- Marmoret, A.; Cohen, J.E.; Bertin, N.; Bimbot, F. Uncovering audio patterns in music with Nonnegative Tucker Decomposition for structural segmentation. arXiv 2021, arXiv:2104.08580. [Google Scholar]
- Zare, M.; Helfroush, M.S.; Kazemi, K.; Scheunders, P. Hyperspectral and Multispectral Image Fusion Using Coupled Non-Negative Tucker Tensor Decomposition. Remote Sens. 2021, 13, 2930. [Google Scholar] [CrossRef]
- Anh-Dao, N.T.; Le Thanh, T.; Linh-Trung, N.; Vu Le, H. Nonnegative Tensor Decomposition for EEG Epileptic Spike Detection. In Proceedings of the 2018 5th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 23–24 November 2018; pp. 194–199. [Google Scholar]
- Rostakova, Z.; Rosipal, R.; Seifpour, S.; Trejo, L.J. A Comparison of Non-negative Tucker Decomposition and Parallel Factor Analysis for Identification and Measurement of Human EEG Rhythms. Meas. Sci. Rev. 2020, 20, 126–138. [Google Scholar] [CrossRef]
- Sidiropoulos, N.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.; Faloutsos, C. Tensor Decomposition for Signal Processing and Machine Learning. IEEE Trans. Acoust. Speech Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Bjorck, A. Numerical Methods for Least Squares Problems; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Zdunek, R.; Kotyla, M. Extraction of Dynamic Nonnegative Features from Multidimensional Nonstationary Signals. In Proceedings of the Data Mining and Big Data, First International Conference, Bali, Indonesia, 25–30 June 2016; Tan, Y., Shi, Y., Eds.; Springer: Berlin, Germany, 2016. Lecture Notes in Computer Science. Volume 9714, pp. 557–566. [Google Scholar]
- Xiao, H.; Wang, F.; Ma, F.; Gao, J. eOTD: An Efficient Online Tucker Decomposition for Higher Order Tensors. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1326–1331. [Google Scholar]
- Needell, D.; Tropp, J.A. Paved with good intentions: Analysis of a randomized block Kaczmarz method. Linear Algebra Its Appl. 2014, 441, 199–221. [Google Scholar] [CrossRef] [Green Version]
- Needell, D.; Zhao, R.; Zouzias, A. Randomized block Kaczmarz method with projection for solving least squares. Linear Algebra Its Appl. 2015, 484, 322–343. [Google Scholar] [CrossRef]
- Zhou, S.; Erfani, S.M.; Bailey, J. Online CP Decomposition for Sparse Tensors. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1458–1463. [Google Scholar]
- Zeng, C.; Ng, M.K. Incremental CP Tensor Decomposition by Alternating Minimization Method. SIAM J. Matrix Anal. Appl. 2021, 42, 832–858. [Google Scholar] [CrossRef]
- Liu, H.; Yang, L.T.; Guo, Y.; Xie, X.; Ma, J. An Incremental Tensor-Train Decomposition for Cyber-Physical-Social Big Data. IEEE Trans. Big Data 2021, 7, 341–354. [Google Scholar] [CrossRef]
- Lubich, C.; Rohwedder, T.; Schneider, R.; Vandereycken, B. Dynamical Approximation by Hierarchical Tucker and Tensor-Train Tensors. SIAM J. Matrix Anal. Appl. 2013, 34, 470–494. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Tao, D.; Faloutsos, C. Beyond streams and graphs: Dynamic tensor analysis. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Sun, J.; Papadimitriou, S.; Yu, P.S. Window-based Tensor Analysis on High-dimensional and Multi-aspect Streams. In Proceedings of the Sixth International Conference on Data Mining, Hong Kong, China, 18–22 December 2006; pp. 1076–1080. [Google Scholar]
- Sun, J.; Tao, D.; Papadimitriou, S.; Yu, P.S.; Faloutsos, C. Incremental tensor analysis: Theory and applications. ACM Trans. Knowl. Discov. Data 2008, 2, 11:1–11:37. [Google Scholar] [CrossRef]
- Fanaee-T, H.; Gama, J. Multi-aspect-streaming tensor analysis. Knowl. Based Syst. 2015, 89, 332–345. [Google Scholar] [CrossRef] [Green Version]
- Gujral, E.; Pasricha, R.; Papalexakis, E.E. SamBaTen: Sampling-based Batch Incremental Tensor Decomposition. In Proceedings of the 2018 SIAM International Conference on Data Mining, San Diego Marriott Mission Valley, San Diego, CA, USA, 3–5 May 2018; pp. 387–395. [Google Scholar]
- Malik, O.A.; Becker, S. Low-Rank Tucker Decomposition of Large Tensors Using TensorSketch. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Traore, A.; Berar, M.; Rakotomamonjy, A. Online multimodal dictionary learning through Tucker decomposition. Neurocomputing 2019, 368, 163–179. [Google Scholar] [CrossRef] [Green Version]
- Fang, S.; Kirby, R.M.; Zhe, S. Bayesian streaming sparse Tucker decomposition. In Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence, Toronto, QC, Canada, 26–30 July 2021; Volume 161, pp. 558–567. [Google Scholar]
- Sobral, A.; Javed, S.; Ki Jung, S.; Bouwmans, T.; Zahzah, E.h. Online Stochastic Tensor Decomposition for Background Subtraction in Multispectral Video Sequences. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Chachlakis, D.G.; Dhanaraj, M.; Prater-Bennette, A.; Markopoulos, P.P. Dynamic L1-Norm Tucker Tensor Decomposition. IEEE J. Sel. Top. Signal Process. 2021, 15, 587–602. [Google Scholar] [CrossRef]
- Cichocki, A.; Zdunek, R. NMFLAB for Signal and Image Processing; Technical Report; Laboratory for Advanced Brain Signal Processing, BSI, RIKEN: Saitama, Japan, 2006. [Google Scholar]
- Phan, A.H.; Cichocki, A. Extended HALS algorithm for nonnegative Tucker decomposition and its applications for multiway analysis and classification. Neurocomputing 2011, 74, 1956–1969. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zdunek, R.; Fonał, K. Incremental Nonnegative Tucker Decomposition with Block-Coordinate Descent and Recursive Approaches. Symmetry 2022, 14, 113. https://doi.org/10.3390/sym14010113
Zdunek R, Fonał K. Incremental Nonnegative Tucker Decomposition with Block-Coordinate Descent and Recursive Approaches. Symmetry. 2022; 14(1):113. https://doi.org/10.3390/sym14010113
Chicago/Turabian StyleZdunek, Rafał, and Krzysztof Fonał. 2022. "Incremental Nonnegative Tucker Decomposition with Block-Coordinate Descent and Recursive Approaches" Symmetry 14, no. 1: 113. https://doi.org/10.3390/sym14010113