
A Distributed and Privacy-Preserving Random Forest Evaluation Scheme with Fine Grained Access Control


Abstract
:1. Introduction
1.1. Our Contributions
1.2. Related Works
1.3. Organization
2. Preliminaries
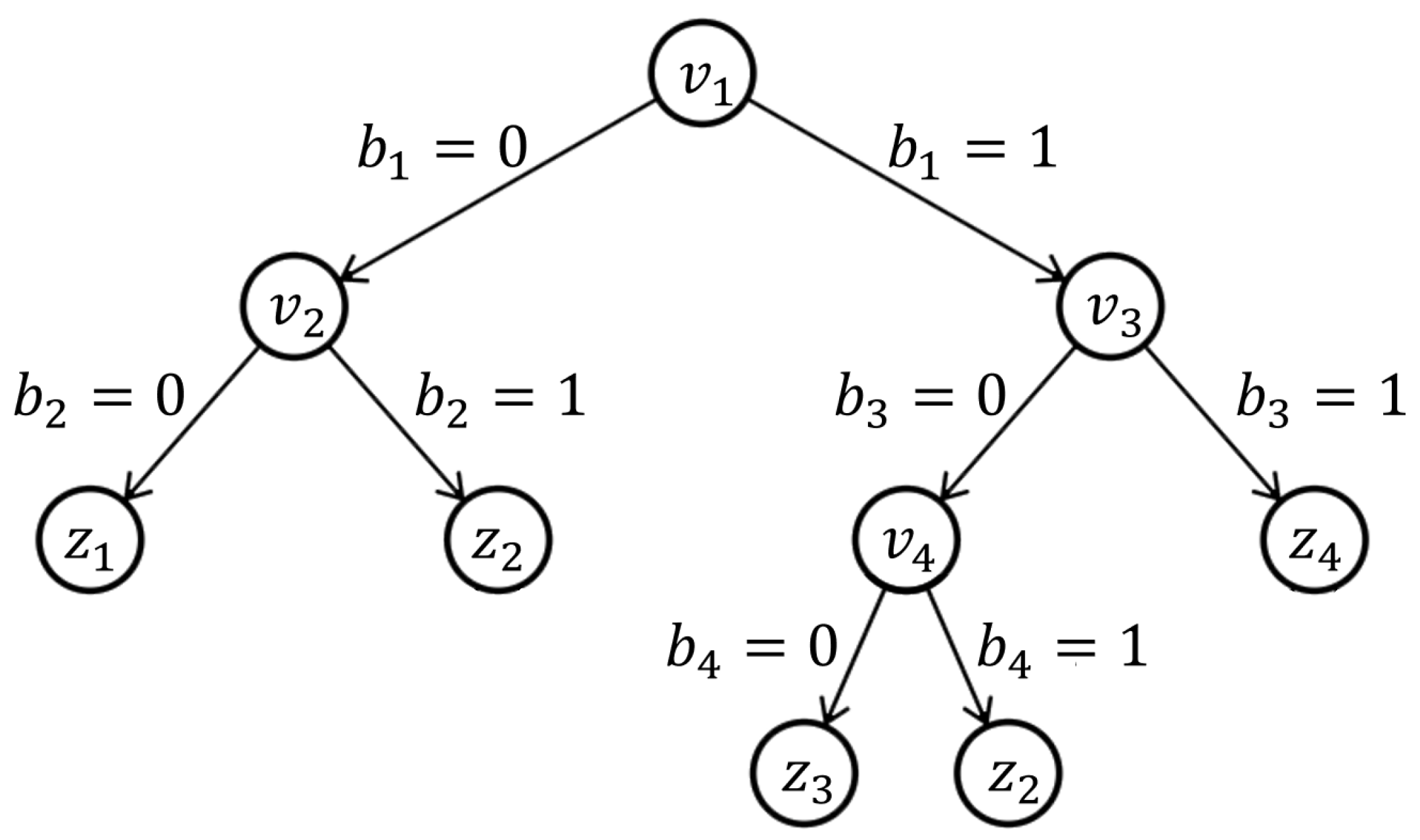
2.1. Decision Tree
2.2. Ensemble Learning and Random Forest
2.3. Secret Sharing Scheme
2.4. Distributed BCP Cryptosystem with Threshold Decryption
- Additive homomorphism: If , then can be calculated by
3. Models and Definitions
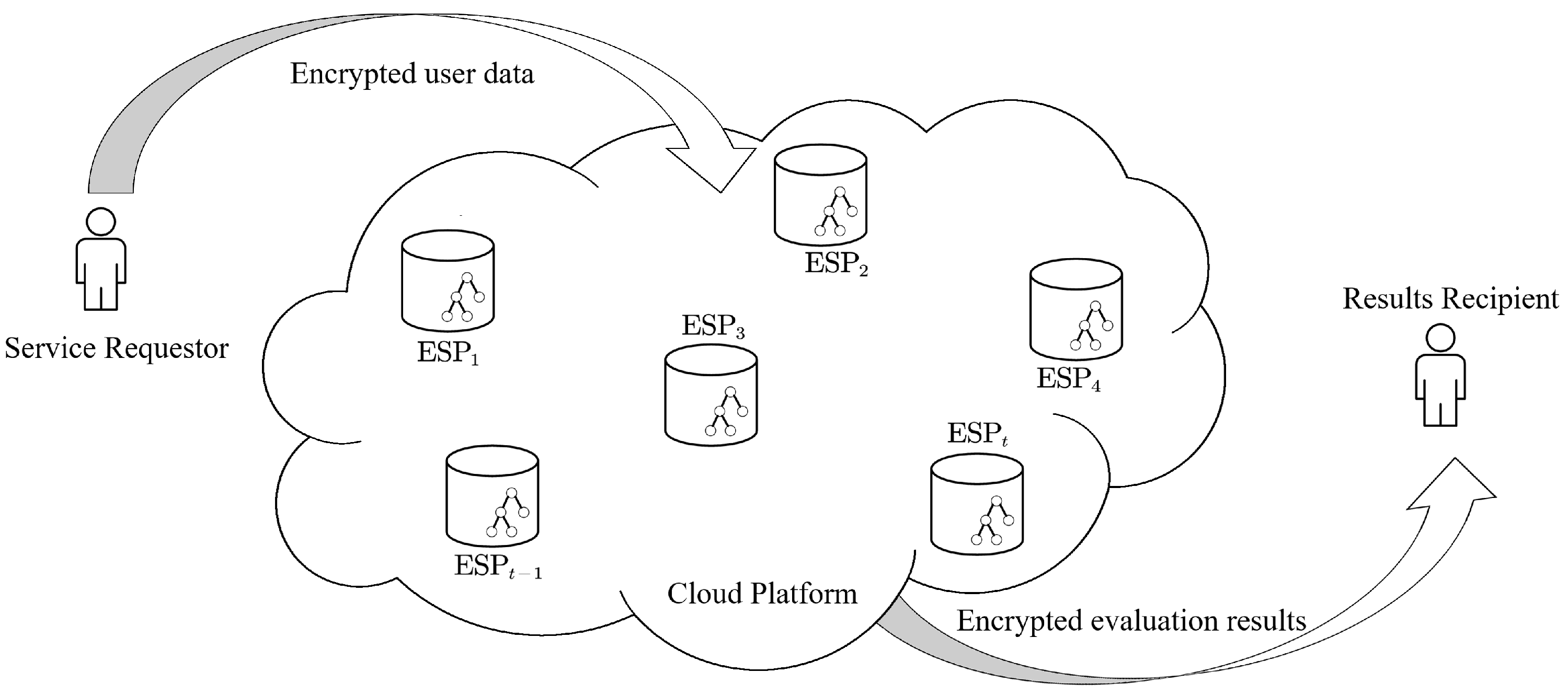
3.1. System Model
3.1.1. Evaluation Service Providers (ESPs)
3.1.2. Service Requestor (SR)
3.1.3. Results Recipient (RR)
3.2. Threat Model
3.3. Security Requirements
3.3.1. Correctness
3.3.2. Confidentiality
3.3.3. Flexibility
3.3.4. Robustness
4. The Proposed Scheme
4.1. Constructing Blocks
4.1.1. Distributed Multiplication Protocol
| Algorithm 1 Distributed multiplication protocol (). |
Input: ESP gives two ciphertexts encrypted with ; ESP own the key sharing share ; Public sharing parameters . Output: ESP obtains .
|
4.1.2. Distributed Comparison Protocol
| Algorithm 2 Distributed comparison protocol (). |
Input: ESP gives two ciphertexts encrypted with ; ESP own the key sharing share ; Public sharing parameters . Output: ESP obtains , We remark that indicates , and indicates .
|
4.1.3. Distributed Maximum Protocol
| Algorithm 3 Distributed maximum protocol (). |
Input: ESP gives two ciphertexts , encrypted with ; ESP own the key sharing share ; Public sharing parameters . Output: ESP obtains the corresponding to the maximum value.
|
4.1.4. Distributed Maximum_n Protocol
| Algorithm 4 Distributed maximum_n protocol (). |
Input: ESP gives some ciphertexts encrypted with ; ESP own the key sharing share ; Public sharing parameters . Output: ESP obtains the corresponding to the maximum value.
|
4.1.5. Distributed Re-Encryption Protocol
| Algorithm 5 Distributed re-encryption protocol (). |
Input: ESP gives a ciphertext encrypted with ; Public key of the assigned user; ESP own the key sharing share ; Public sharing parameters . Output: ESP obtains the re-encrypted ciphertext that can only be decrypted using the user’s private key u.
|
4.2. Initialization
4.2.1. Model Training
4.2.2. Public Parameters
4.2.3. Cloud Platform Private Key Share and Public Key
4.3. Privacy-Preserving Random Forest Evaluation(PPRE)
5. Security Analyses
5.1. Semantic Security of DTRS
5.2. Security of Multiplication Protocol
5.3. Security of Random Forest Evaluation
6. Efficiency Analyses
6.1. Analyses of Constructing Blocks
6.1.1. Analysis of Computation Complexity
6.1.2. Communication Overheads
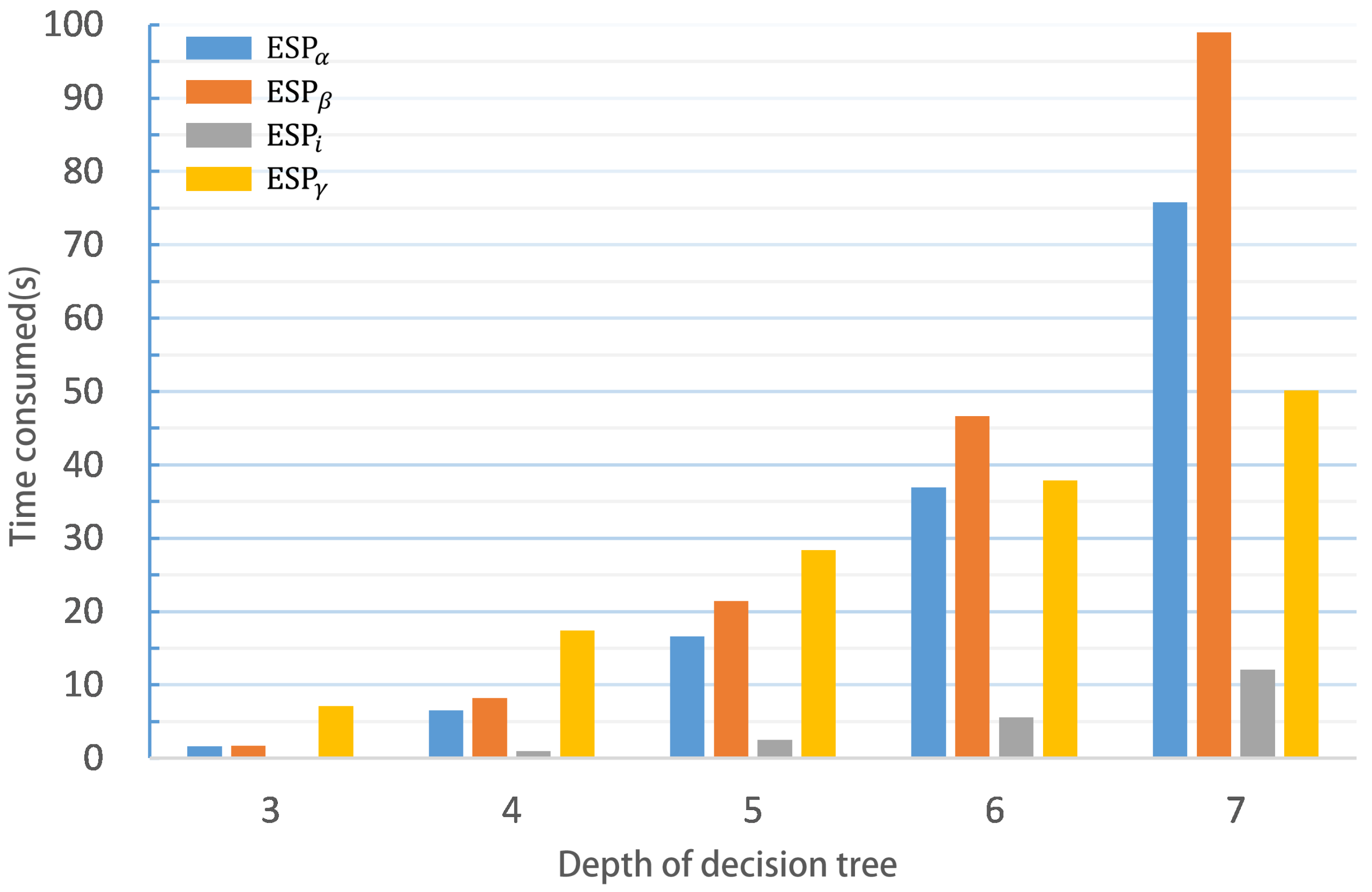
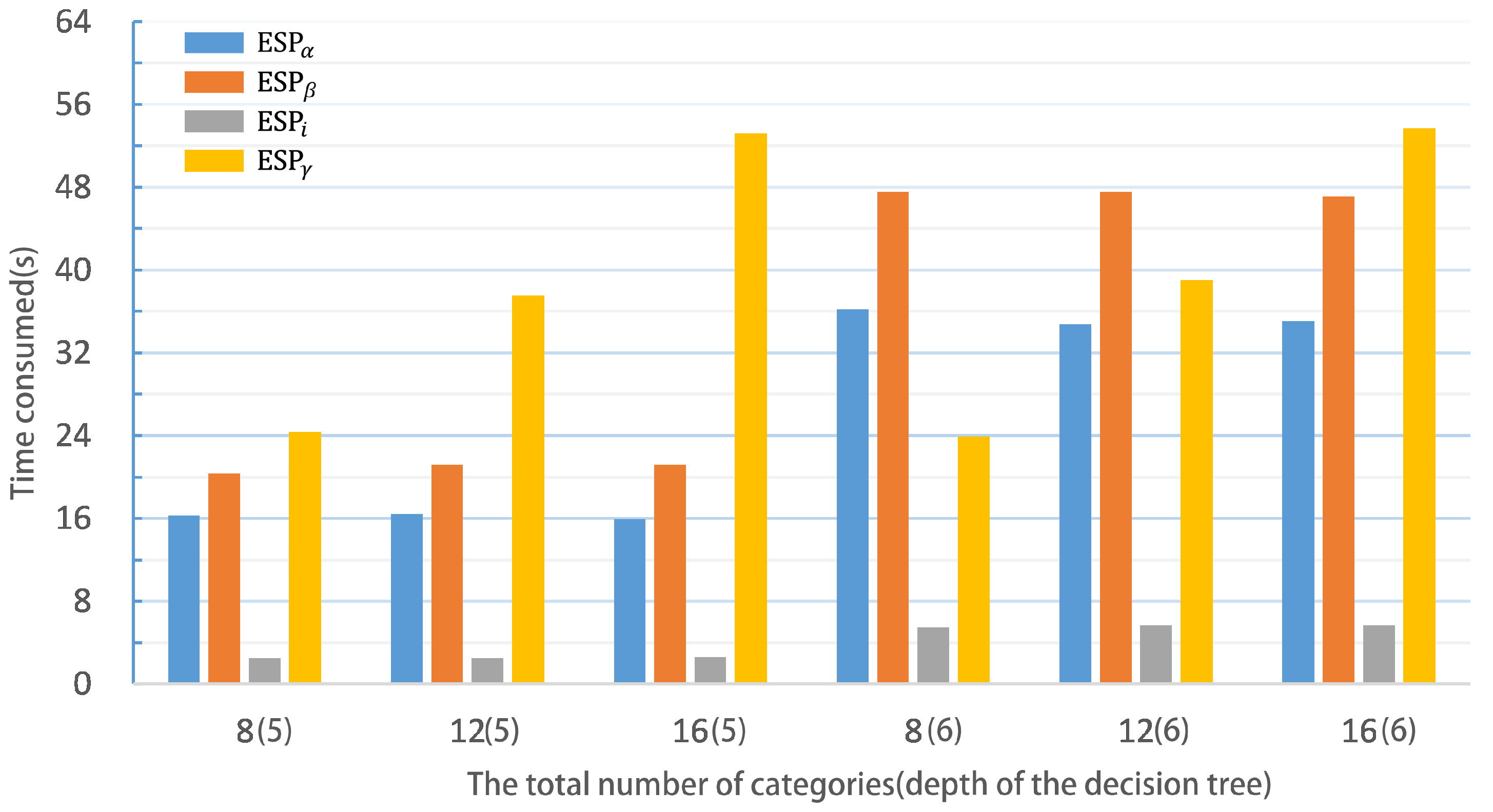
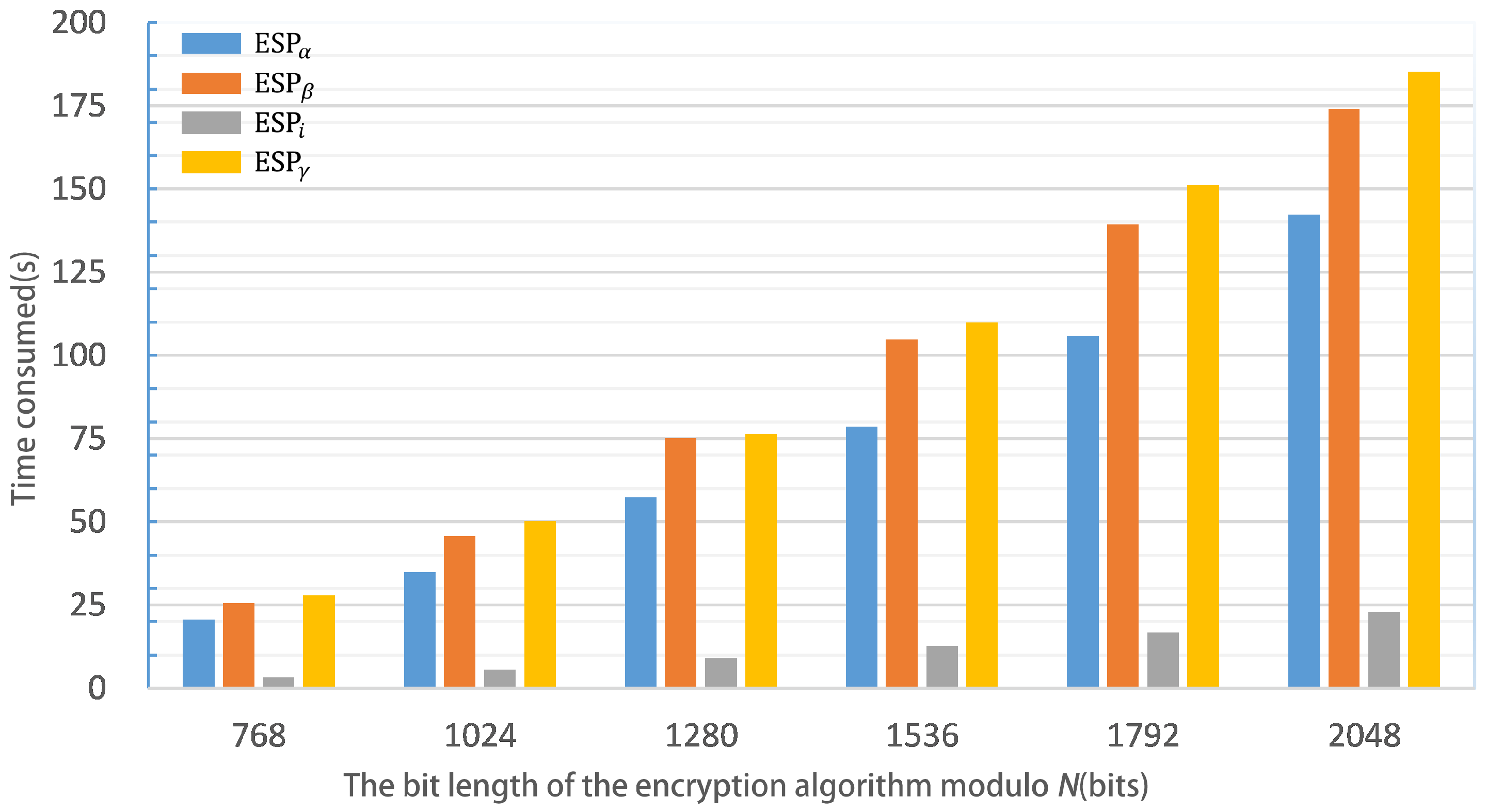
6.2. Analysis of Proposed Privacy Preserving Random Forest
6.3. Comparison with Existing Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alurkar, A.A.; Ranade, S.B.; Joshi, S.V.; Ranade, S.S.; Shinde, G.R.; Sonewar, P.A.; Mahalle, P.N. A comparative analysis and discussion of email spam classification methods using machine learning techniques. In Applied Machine Learning for Smart Data Analysis; Taylor & Francis Group: Abingdon, UK, 2019. [Google Scholar]
- Malekipirbazari, M.; Aksakalli, V. Risk assessment in social lending via random forests. Expert Syst. Appl. 2015, 42, 4621–4631. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, Y.; Lin, J. A Privacy-Preserving Optimization of Neighborhood-Based Recommendation for Medical-Aided Diagnosis and Treatment. IEEE Internet Things J. 2021, 8, 10830–10842. [Google Scholar] [CrossRef]
- Zhang, M.; Song, W.; Zhang, J. A secure clinical diagnosis with privacy-preserving multiclass support vector machine in clouds. IEEE Syst. J. 2020. [Google Scholar] [CrossRef]
- More Digital Assistants Than People by 2021, Says Ovum. Available online: https://internetofbusiness.com/digital-assistants-2021-ovum/ (accessed on 25 January 2022).
- Human-Centered Artificial Intelligence. Artificial Intelligence Index Report 2021. Available online: https://aiindex.stanford.edu/report/ (accessed on 25 January 2022).
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Mercuri, R.T. The HIPAA-potamus in health care data security. Commun. ACM 2004, 47, 25–28. [Google Scholar] [CrossRef]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10, p. 3152676. [Google Scholar]
- Gulia, A.; Vohra, R.; Rani, P. Liver patient classification using intelligent techniques. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 5110–5115. [Google Scholar]
- Zhang, M.; Chen, Y.; Xia, Z.; Du, J.; Susilo, W. PPO-DFK: A privacy-preserving optimization of distributed fractional knapsack with application in secure footballer configurations. IEEE Syst. J. 2020, 15, 759–770. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Shen, G. PPDDS: A Privacy-Preserving Disease Diagnosis Scheme Based on the Secure Mahalanobis Distance Evaluation Model. IEEE Syst. J. 2021. [Google Scholar] [CrossRef]
- Bost, R.; Popa, R.A.; Tu, S.; Goldwasser, S. Machine Learning Classification over Encrypted Data. In Proceedings of the 22nd Annual Network and Distributed System Security Symposium, NDSS 2015, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar] [CrossRef] [Green Version]
- van Dijk, M.; Gentry, C.; Halevi, S.; Vaikuntanathan, V. Fully Homomorphic Encryption over the Integers. In Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, France, 30 May–3 June 2010; pp. 24–43. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.J.; Feng, T.; Naehrig, M.; Lauter, K.E. Privately Evaluating Decision Trees and Random Forests. Proc. Priv. Enhancing Technol. 2016, 2016, 335–355. [Google Scholar] [CrossRef] [Green Version]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Proceedings of the International Conference on the Theory and Application of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar] [CrossRef] [Green Version]
- Tai, R.K.H.; Ma, J.P.K.; Zhao, Y.; Chow, S.S.M. Privacy-Preserving Decision Trees Evaluation via Linear Functions. In Proceedings of the 22nd European Symposium on Research in Computer Security, Oslo, Norway, 11–15 September 2017; pp. 494–512. [Google Scholar] [CrossRef]
- Cock, M.D.; Dowsley, R.; Horst, C.; Katti, R.S.; Nascimento, A.C.A.; Poon, W.; Truex, S. Efficient and Private Scoring of Decision Trees, Support Vector Machines and Logistic Regression Models Based on Pre-Computation. IEEE Trans. Dependable Secur. Comput. 2019, 16, 217–230. [Google Scholar] [CrossRef]
- Aloufi, A.; Hu, P.; Wong, H.W.H.; Chow, S.S.M. Blindfolded Evaluation of Random Forests with Multi-Key Homomorphic Encryption. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1821–1835. [Google Scholar] [CrossRef] [Green Version]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. In Proceedings of the Innovations in Theoretical Computer Science 2012, Cambridge, MA, USA, 8–10 January 2012; pp. 309–325. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Zhang, Z.; Wang, X. Batched Multi-hop Multi-key FHE from Ring-LWE with Compact Ciphertext Extension. In Proceedings of the Theory of Cryptography—15th International Conference, TCC 2017, Baltimore, MD, USA, 12–15 November 2017; pp. 597–627. [Google Scholar] [CrossRef]
- Smart, N.P.; Vercauteren, F. Fully Homomorphic Encryption with Relatively Small Key and Ciphertext Sizes. In Proceedings of the 13th International Conference on Practice and Theory in Public Key Cryptography, Paris, France, 26–28 May 2010; pp. 420–443. [Google Scholar] [CrossRef] [Green Version]
- Dai, B.; Chen, R.C.; Zhu, S.Z.; Zhang, W.W. Using random forest algorithm for breast cancer diagnosis. In Proceedings of the 2018 International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 6–8 December 2018; pp. 449–452. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Bresson, E.; Catalano, D.; Pointcheval, D. A Simple Public-Key Cryptosystem with a Double Trapdoor Decryption Mechanism and Its Applications. In Proceedings of the 9th International Conference on the Theory and Application of Cryptology and Information Security, Taipei, Taiwan, 30 November–4 December 2003; pp. 37–54. [Google Scholar] [CrossRef] [Green Version]
- Shoup, V. Practical Threshold Signatures. In Proceedings of the International Conference on the Theory and Application of Cryptographic Techniques, Bruges, Belgium, 14–18 May 2000; pp. 207–220. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Deng, R.H.; Choo, K.R.; Weng, J. An Efficient Privacy-Preserving Outsourced Calculation Toolkit With Multiple Keys. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2401–2414. [Google Scholar] [CrossRef]
- Cheng, K.; Wang, L.; Shen, Y.; Wang, H.; Wang, Y.; Jiang, X.; Zhong, H. Secure k-NN Query on Encrypted Cloud Data with Multiple Keys. IEEE Trans. Big Data 2017, 7, 689–702. [Google Scholar] [CrossRef]
- Ding, W.; Yan, Z.; Deng, R.H. Encrypted data processing with Homomorphic Re-Encryption. Inf. Sci. 2017, 409, 35–55. [Google Scholar] [CrossRef]
- de Souza, L.A.C.; Rebello, G.A.F.; Camilo, G.F.; Guimarães, L.C.; Duarte, O.C.M. DFedForest: Decentralized federated forest. In Proceedings of the 2020 IEEE International Conference on Blockchain, Rhodes, Greece, 2–6 November 2020; pp. 90–97. [Google Scholar]
- Algesheimer, J.; Camenisch, J.; Shoup, V. Efficient Computation Modulo a Shared Secret with Application to the Generation of Shared Safe-Prime Products. In Proceedings of the 22nd Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2002; pp. 417–432. [Google Scholar] [CrossRef] [Green Version]
- Kiss, Á.; Naderpour, M.; Liu, J.; Asokan, N.; Schneider, T. SoK: Modular and Efficient Private Decision Tree Evaluation. Proc. Priv. Enhanc. Technol. 2019, 2019, 187–208. [Google Scholar] [CrossRef] [Green Version]
- Tueno, A.; Kerschbaum, F.; Katzenbeisser, S. Private Evaluation of Decision Trees using Sublinear Cost. Proc. Priv. Enhancing Technol. 2019, 2019, 266–286. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Chen, R.; Liu, X.; Su, J.; Qiao, L. Towards Practical Privacy-Preserving Decision Tree Training and Evaluation in the Cloud. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2914–2929. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description |
|---|---|
| SR | Service requester |
| RR | Result recipient |
| CP | Cloud platform |
| ESPs | Evaluation service providers |
| t | Number of servers in the cloud platform |
| The key pair of RR | |
| The key pair of cloud platform | |
| or | Encryption of m under |
| ESP’s secret share of | |
| Bit length of m | |
| Number of elements within | |
| The raw data provided by SR | |
| Polynomial expression of decision tree | |
| The value of the non-terminal node in the tree | |
| Distributed comparison protocol | |
| Distributed multiplication protocol | |
| Distributed maximum protocol | |
| Distributed maximum_n protocol | |
| Distributed re-encryption protocol |
| Setup phase: |
|---|
| ESPs(CP): |
| 1. Perform the operations in Section 4.2 Initialization |
| 2. Obtain a polynomial expression for each decision tree model . |
| SR: |
| 1. Obtain public information from the CP. |
| 2. Generate data to be evaluated. |
| 3. Select RR and forward information from the CP to RR |
| RR: Generate a public-private key pair and give the public key to SR. |
| Phase1 Outsourcing: |
| SR encrypts the data with the public key of the CP. Send the ciphertext and RR’s public key to the CP. |
| Phase2 Evaluating: |
| 1. ESPs call to compare the received ciphertext with the value of the corresponding node in its own decision tree to get the result . |
| 2. ESPs use to compute the category coefficients of its own decision tree polynomials and merges the coefficients of the same categories to obtain . |
| 3. ESPs select an ESP as the aggregation server and send the computed decision tree polynomial to it. |
| Phase3 Aggregating: |
| 1. After receiving the decision tree polynomials results from all ESPs, ESP aggregates them using the additive homomorphism of DRTS to obtain . |
| 2. ESP encrypts and calls for sorting to get which corresponds to the maximum . |
| 3. ESP calls re-encrypts using RR’s public key, and the resulting ciphertext is sent to RR. |
| Phase4 Decrypting: |
| RR performs decryption of the received ciphertext to obtain the CP’s evaluation of the SR’s data. |
| Roles | Protocol | Computations | Communication Overhead |
|---|---|---|---|
| ESP | |||
| ESP | |||
| ESP | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Shen, H.; Zhang, M. A Distributed and Privacy-Preserving Random Forest Evaluation Scheme with Fine Grained Access Control. Symmetry 2022, 14, 415. https://doi.org/10.3390/sym14020415
Zhou Y, Shen H, Zhang M. A Distributed and Privacy-Preserving Random Forest Evaluation Scheme with Fine Grained Access Control. Symmetry. 2022; 14(2):415. https://doi.org/10.3390/sym14020415
Chicago/Turabian StyleZhou, Yang, Hua Shen, and Mingwu Zhang. 2022. "A Distributed and Privacy-Preserving Random Forest Evaluation Scheme with Fine Grained Access Control" Symmetry 14, no. 2: 415. https://doi.org/10.3390/sym14020415