
A DRL-Driven Intelligent Optimization Strategy for Resource Allocation in Cloud-Edge-End Cooperation Environments

 ,
,  ,
,
Abstract
:1. Introduction
- We formulate the optimal resource allocation problem as a maximal traffic offloading model in heterogeneous cloud-edge-end cooperation environments, where content caching and request aggregation mechanisms are utilized to ameliorate the situation of network content redundant transmission.
- We propose a novel DRL policy to improve content distribution by making cache replacement and task scheduling rely on the information about users’ history requests, in-network cache capacity, available link bandwidth and topology structure.
- We evaluate the performances of the proposed solution compared with conventional and baseline solutions in different network environments. The simulation results prove the effectiveness of the proposed mechanism and strategy.
2. System Model
2.1. Network Model
2.2. Content Popularity Model
2.3. Problem Formulation
| Algorithm 1: Static Cooperative Routing Process for a Content Request |
 |
3. DRL-Based Caching Replacement and Task Scheduling
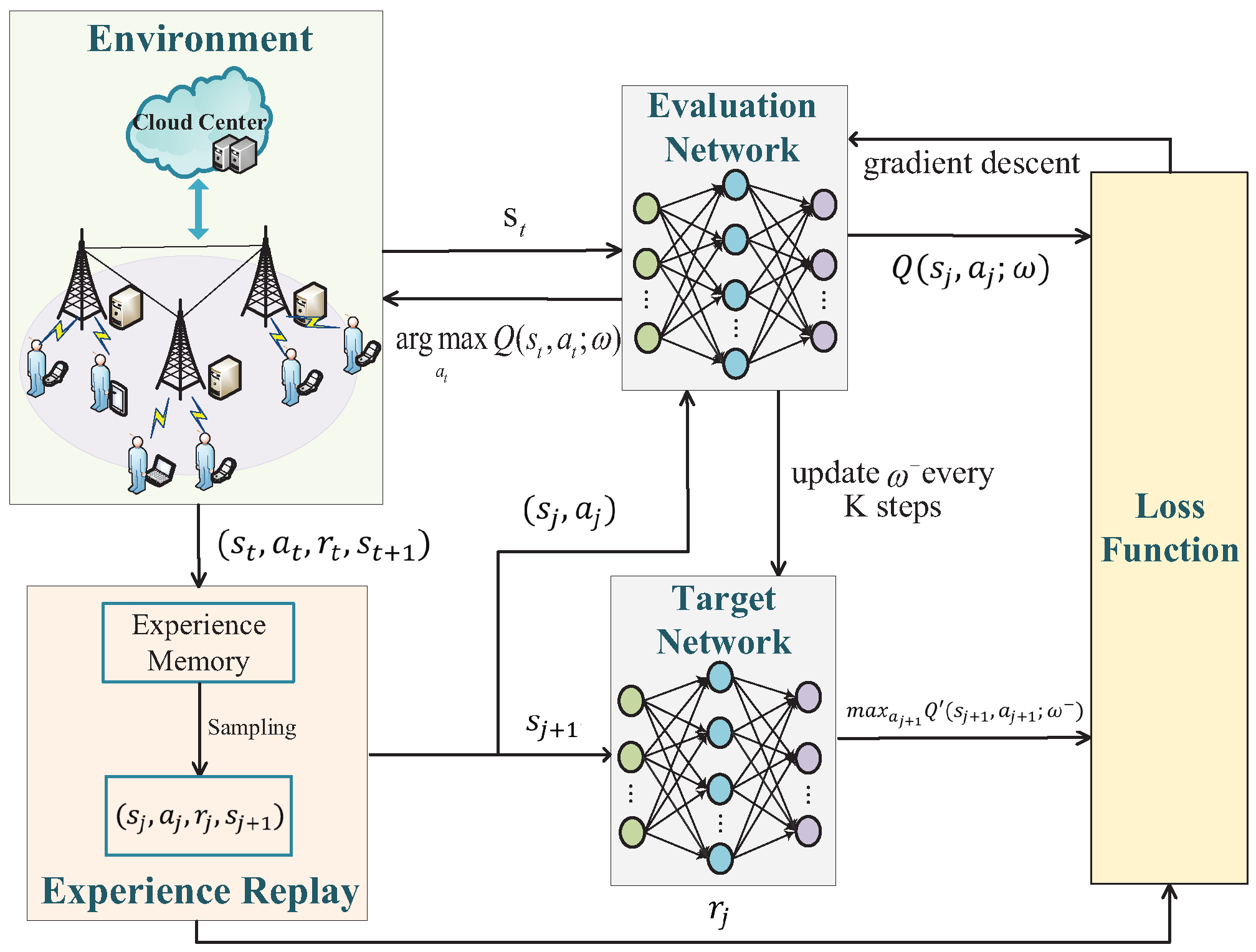
3.1. The DRL Framework
3.2. DQN-Based Caching Replacement and Task Scheduling
| Algorithm 2: Training process of DQN-Based Caching Replacement and Task Scheduling |
 |
3.3. Complexity Analysis
4. Simulation and Results
4.1. Simulation Setting
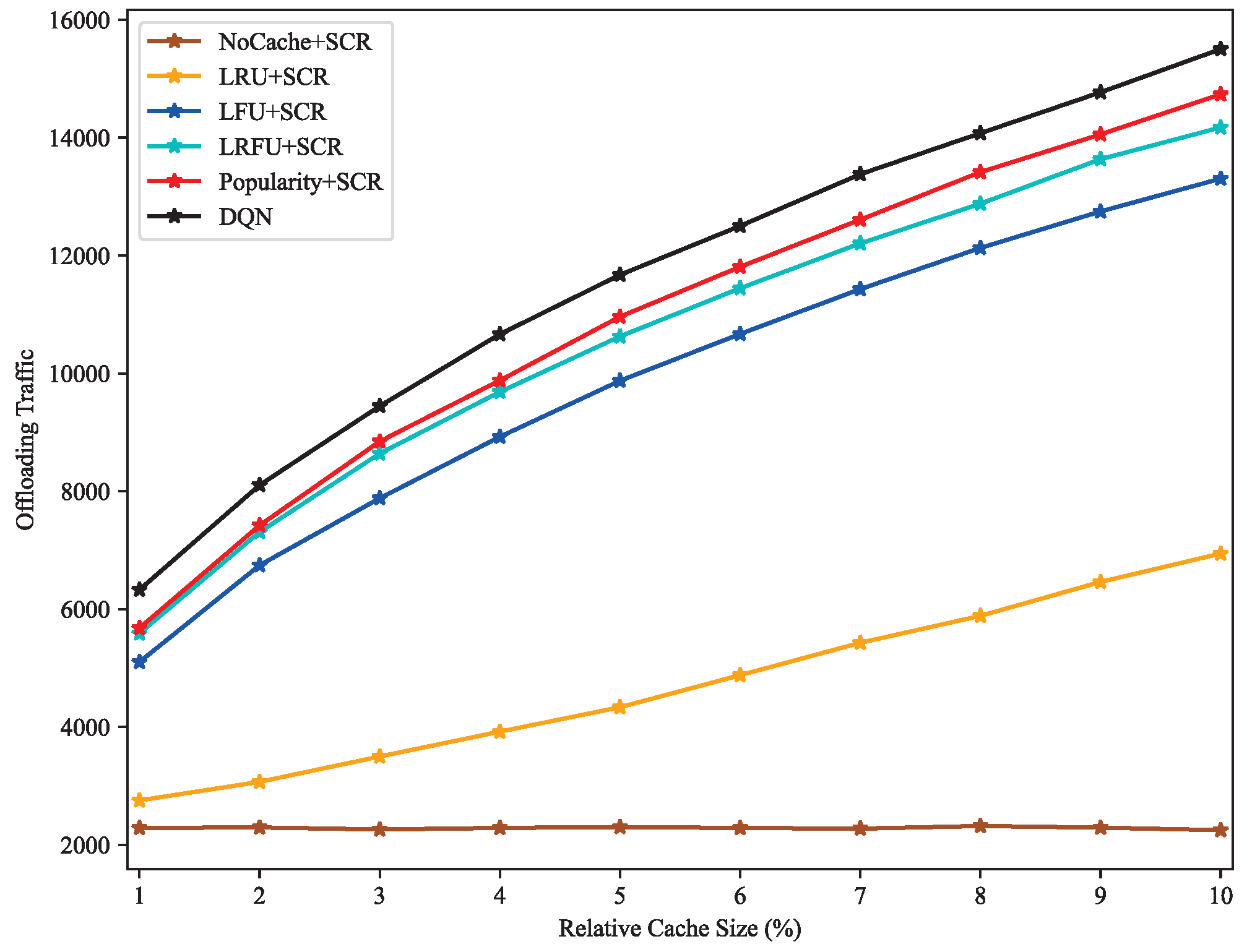
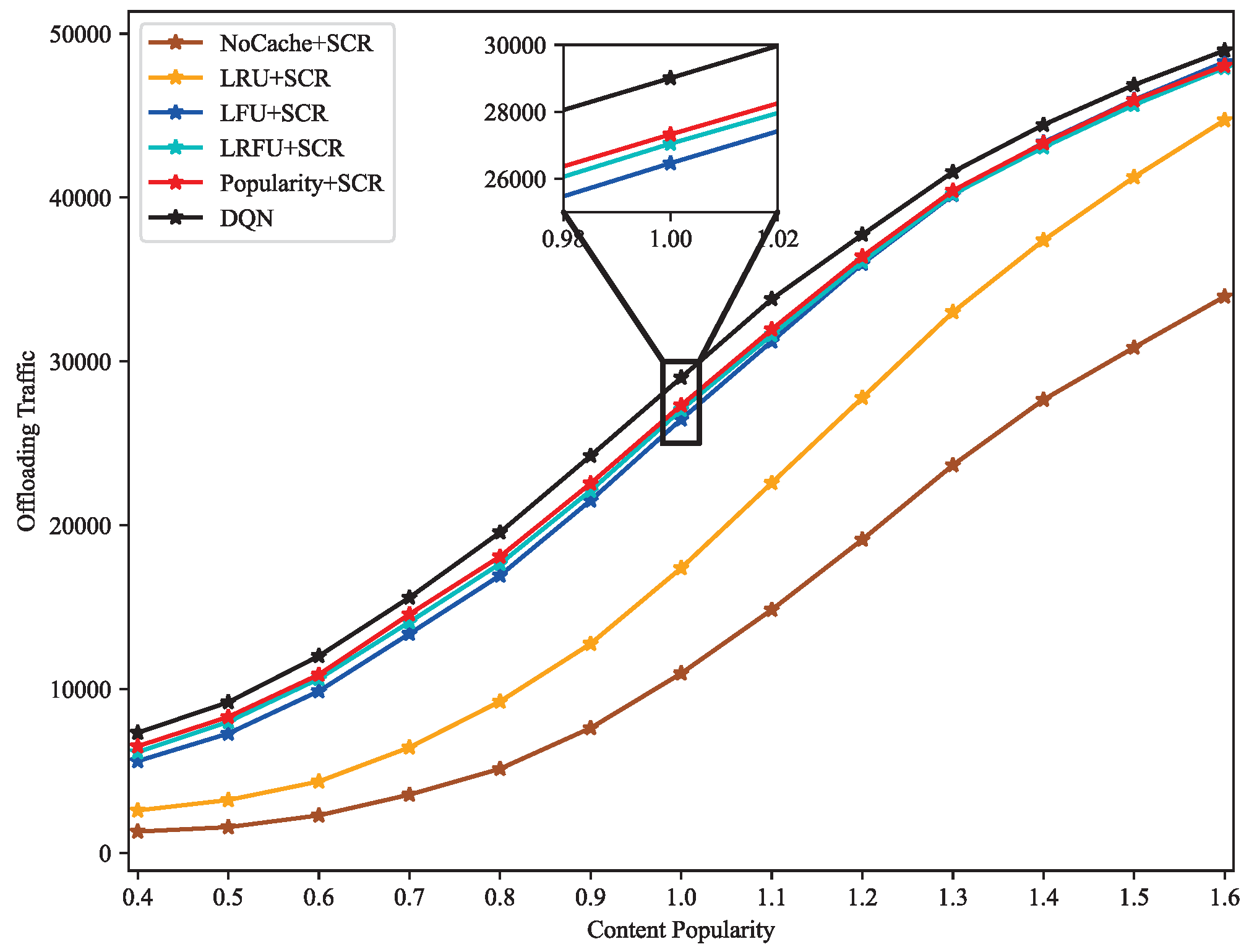
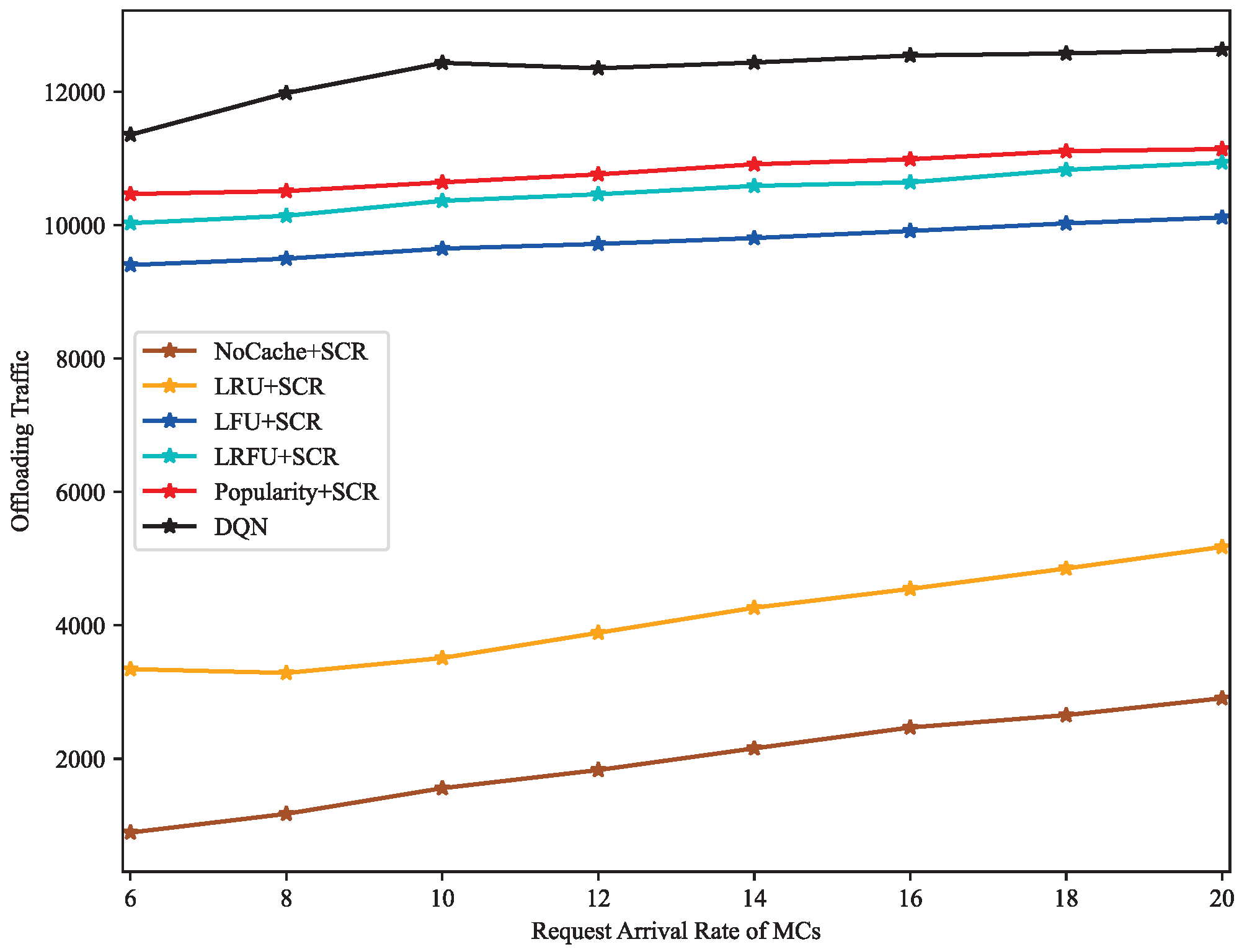
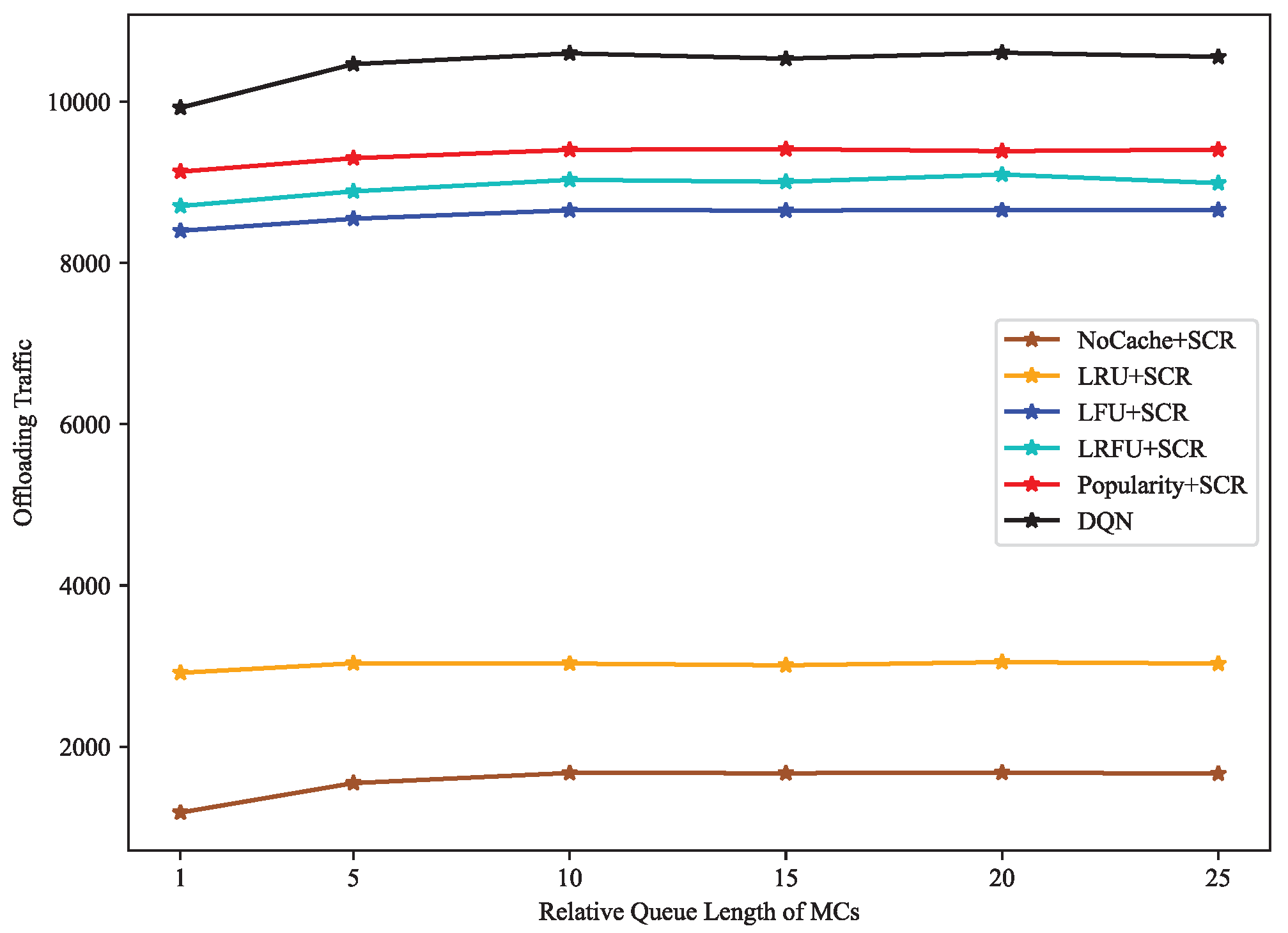
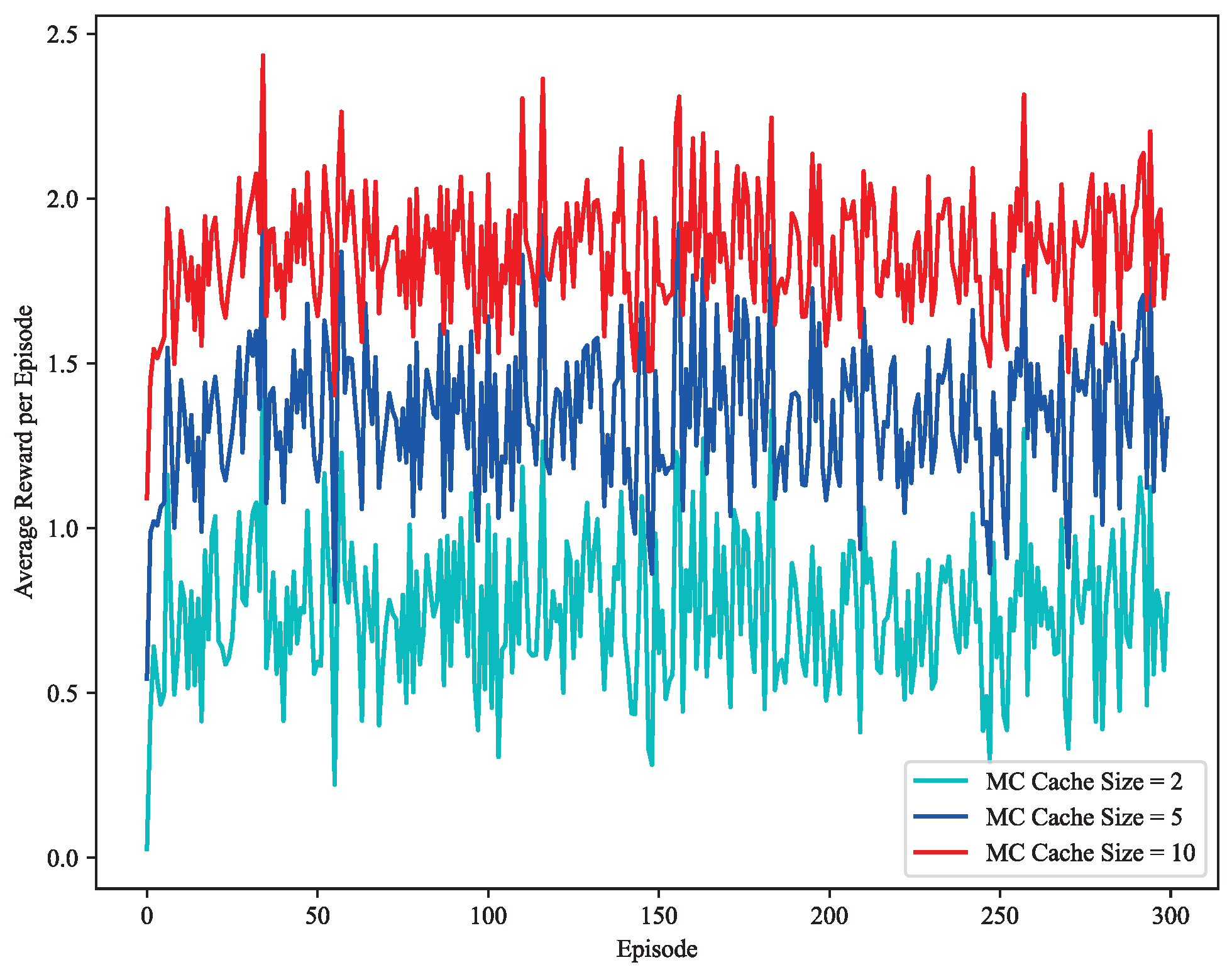
4.2. Result Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Luo, Q.; Hu, S.; Li, C.; Li, G.; Shi, W. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar] [CrossRef]
- Fang, C.; Yao, H.; Wang, Z.; Wu, W.; Jin, X.; Yu, F.R. A survey of mobile information-centric networking: Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 20, 2353–2371. [Google Scholar] [CrossRef]
- Kumar, M.; Sharma, S.C.; Goel, A.; Singh, S.P. A comprehensive survey for scheduling techniques in cloud computing. J. Netw. Comput. Appl. 2019, 143, 1–33. [Google Scholar] [CrossRef]
- Lopez, P.G.; Montresor, A.; Epema, D.; Datta, A.; Higashino, T.; Iamnitchi, A.; Barcellos, M.; Felber, P.; Riviere, E. Edge-Centric Computing: Vision and Challenges. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 37–42. [Google Scholar] [CrossRef] [Green Version]
- Fang, C.; Guo, S.; Wang, Z.; Huang, H.; Yao, H.; Liu, Y. Data-driven intelligent future network: Architecture, use cases, and challenges. IEEE Commun. Mag. 2019, 57, 34–40. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Mouradian, C.; Naboulsi, D.; Yangui, S.; Glitho, R.H.; Morrow, M.J.; Polakos, P.A. A comprehensive survey on fog computing: State-of-the-art and research challenges. IEEE Commun. Surv. Tutor. 2017, 20, 416–464. [Google Scholar] [CrossRef] [Green Version]
- Vaquero, L.M.; Rodero-Merino, L. Finding your way in the fog: Towards a comprehensive definition of fog computing. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 27–32. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Li, K.; Han, Z.; Leung, V.C. Collaborative multi-tier caching in heterogeneous networks: Modeling, analysis, and design. IEEE Trans. Wirel. Commun. 2017, 16, 6926–6939. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Xiao, S.; Leung, V.C. Delay performance analysis of cooperative cell caching in future mobile networks. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 5652–5657. [Google Scholar]
- Wang, C.; Li, Y.; Jin, D.; Chen, S. On the serviceability of mobile vehicular cloudlets in a large-scale urban environment. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2960–2970. [Google Scholar] [CrossRef]
- Chen, X.; Li, W.; Lu, S.; Zhou, Z.; Fu, X. Efficient resource allocation for on-demand mobile-edge cloud computing. IEEE Trans. Veh. Technol. 2018, 67, 8769–8780. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Liu, J. Collaborative computation offloading for multiaccess edge computing over fiber–wireless networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Chen, M.; Qian, Y.; Hao, Y.; Li, Y.; Song, J. Data-driven computing and caching in 5g networks: Architecture and delay analysis. IEEE Wirel. Commun. 2018, 25, 70–75. [Google Scholar] [CrossRef]
- Wang, Y.; Li, P.; Jiao, L.; Su, Z.; Cheng, N.; Shen, X.S.; Zhang, P. A data-driven architecture for personalized qoe management in 5g wireless networks. IEEE Wirel. Commun. 2016, 24, 102–110. [Google Scholar] [CrossRef]
- Jiang, K.; Sun, C.; Zhou, H.; Li, X.; Dong, M.; Leung, V.C. Intelligence-empowered mobile edge computing: Framework, issues, implementation, and outlook. IEEE Netw. 2021, 35, 74–82. [Google Scholar] [CrossRef]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Khoramnejad, F.; Erol-Kantarci, M. On joint offloading and resource allocation: A double deep q-network approach. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 1126–1141. [Google Scholar] [CrossRef]
- Xu, S.; Liu, X.; Guo, S.; Qiu, X.; Meng, L. Mecc: A mobile edge collaborative caching framework empowered by deep reinforcement learning. IEEE Netw. 2021, 35, 176–183. [Google Scholar] [CrossRef]
- Wu, G.; Zhao, Y.; Shen, Y.; Zhang, H.; Shen, S.; Yu, S. Drl-based resource allocation optimization for computation offloading in mobile edge computing. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 2–5 May 2022; pp. 1–6. [Google Scholar]
- Breslau, L.; Cao, P.; Fan, L.; Phillips, G.; Shenker, S. Web caching and zipf-like distributions: Evidence and implications. In Proceedings of the IEEE INFOCOM’99. Conference on Computer Communications. Proceedings. Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies, the Future Is Now (Cat. No. 99CH36320), New York, NY, USA, 21–25 March 1999; Volume 1, pp. 126–134. [Google Scholar]
- Dai, J.; Hu, Z.; Li, B.; Liu, J.; Li, B. Collaborative hierarchical caching with dynamic request routing for massive content distribution. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2444–2452. [Google Scholar]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation offloading and resource allocation for cloud assisted mobile edge computing in vehicular networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Fang, C.; Xu, H.; Yang, Y.; Hu, Z.; Tu, S.; Ota, K.; Yang, Z.; Dong, M.; Han, Z.; Yu, F.R.; et al. Deep-reinforcement-learning-based resource allocation for content distribution in fog radio access networks. IEEE Internet Things J. 2022, 9, 16874–16883. [Google Scholar] [CrossRef]
- Sun, C.; Li, H.; Li, X.; Wen, J.; Xiong, Q.; Wang, X.; Leung, V.C. Task offloading for end-edge-cloud orchestrated computing in mobile networks. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Hong, Z.; Chen, W.; Huang, H.; Guo, S.; Zheng, Z. Multi-hop cooperative computation offloading for industrial iot–edge–cloud computing environments. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2759–2774. [Google Scholar] [CrossRef]
- Wang, H.; Liu, T.; Kim, B.; Lin, C.-W.; Shiraishi, S.; Xie, J.; Han, Z. Architectural design alternatives based on cloud/edge/fog computing for connected vehicles. IEEE Commun. Surv. Tutor. 2020, 22, 2349–2377. [Google Scholar] [CrossRef]
- Dai, B.; Niu, J.; Ren, T.; Atiquzzaman, M. Towards mobility-aware computation offloading and resource allocation in end-edge-cloud orchestrated computing. IEEE Internet Things J. 2022, 9, 19450–19462. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep reinforcement learning for dynamic computation offloading and resource allocation in cache-assisted mobile edge computing systems. Intell. Converg. Netw. 2020, 1, 181–198. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.-C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Liu, S.; Zhang, C.; Huang, Y.; Lu, Z.; Yang, L. Multi-agent reinforcement learning based distributed transmission in collaborative cloud-edge systems. IEEE Trans. Veh. Technol. 2021, 70, 1658–1672. [Google Scholar] [CrossRef]
- Wang, X.; Chen, M.; Taleb, T.; Ksentini, A.; Leung, V. Cache in the air: Exploiting content caching and delivery techniques for 5g systems. IEEE Commun. Mag. 2014, 52, 131–139. [Google Scholar] [CrossRef]
- Lee, D.; Choi, J.; Kim, J.-H.; Noh, S.; Min, S.L.; Cho, Y.; Kim, C.S. Lrfu: A spectrum of policies that subsumes the least recently used and least frequently used policies. IEEE Trans. Comput. 2001, 50, 1352–1361. [Google Scholar]
- Li, J.; Liu, B.; Wu, H. Energy-efficient in-network caching for content-centric networking. IEEE Commun. Lett. 2013, 17, 797–800. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
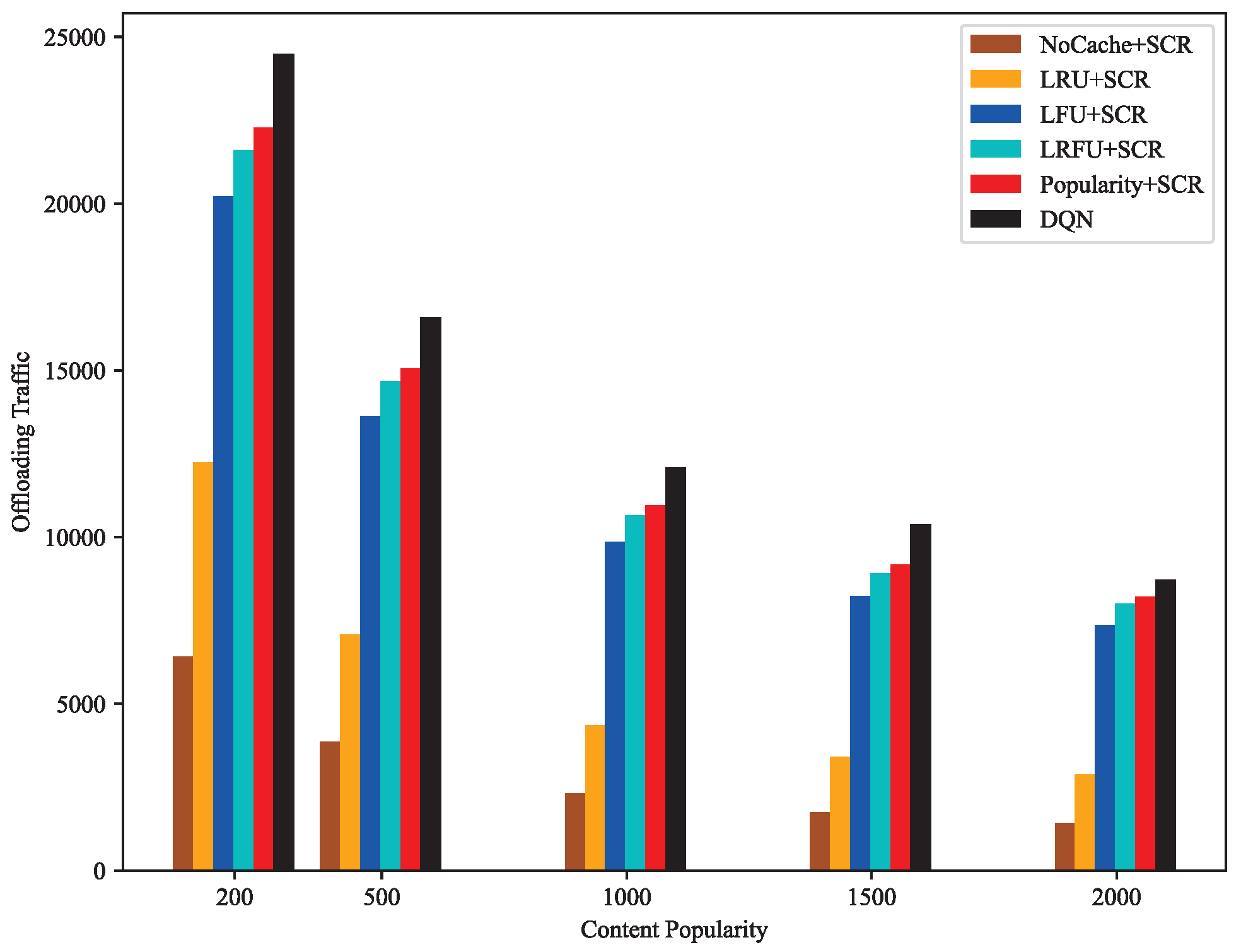{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Notations |
|---|---|
| , | Number and set of MCs accessed to the ith BS |
| , | Number and set of adjacent BSs of BS i |
| B, | Number and set of BSs in the system |
| F, | Number and set of different network contents |
| C | Maximal cache size of the MC or BS |
| Maximal queue capacity of node i | |
| Network link from node i to node j | |
| Maximal bandwidth about link | |
| File size of content k | |
| Boolean variable indicating whether content k is cached at node i | |
| Boolean variable indicating whether content k is in the queue of node i | |
| Boolean variable indicating whether there is an indirect link between MC m and MC n accessed to BS i | |
| Boolean variable indicating whether there is a direct link between BS i and BS j | |
| Request arrival rate about content k |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, C.; Zhang, T.; Huang, J.; Xu, H.; Hu, Z.; Yang, Y.; Wang, Z.; Zhou, Z.; Luo, X. A DRL-Driven Intelligent Optimization Strategy for Resource Allocation in Cloud-Edge-End Cooperation Environments. Symmetry 2022, 14, 2120. https://doi.org/10.3390/sym14102120
Fang C, Zhang T, Huang J, Xu H, Hu Z, Yang Y, Wang Z, Zhou Z, Luo X. A DRL-Driven Intelligent Optimization Strategy for Resource Allocation in Cloud-Edge-End Cooperation Environments. Symmetry. 2022; 14(10):2120. https://doi.org/10.3390/sym14102120
Chicago/Turabian StyleFang, Chao, Tianyi Zhang, Jingjing Huang, Hang Xu, Zhaoming Hu, Yihui Yang, Zhuwei Wang, Zequan Zhou, and Xiling Luo. 2022. "A DRL-Driven Intelligent Optimization Strategy for Resource Allocation in Cloud-Edge-End Cooperation Environments" Symmetry 14, no. 10: 2120. https://doi.org/10.3390/sym14102120