1. Introduction
CNNs have been widely applied in many applications, such as intelligent information processing, pattern recognition, feature extraction [
1,
2,
3,
4,
5], etc. As usual, slightly more hidden layer nodes were selected based on experience in neural networks. However, as is well known, too many nodes and weights in a deep network will increase the computational load, memory size and the risk of overfitting [
6]. In fact, some hidden layer nodes and weights have little contribution to improving the performance of the network [
7]. Therefore, choosing an appropriate number of hidden layer nodes and weights has become an important research topic in optimizing neural networks. Many algorithms have been proposed in order to optimize the number of nodes and weights in the neural network.
As one of the most effective methods to reduce the number of weights in the network, the regularization terms were introduced into the learning process. This is generally realized with
regularization, which penalizes the sum of the weight norm during training. The
norm is the sum of the absolute values of the elements in a vector, so as to make the weight value close to zero [
8]. In [
9], the
-norm was combined with the capped
-norm to denote the amount of information extracted through the filter and control regularization. Gou et al. [
10] proposed a discriminative collaborative representation-based classification (DCRC) method through
regularizations to improve the classification capabilities. Xu et al. adopted the
regularizer to transform a non-convex problem into a series of
regularizer problems, and showed many superior properties, such as robustness, sparsity and oracle properties, compared to the
and
regularizers [
11]. In [
12], Xiao introduced sparse logistic regression (SLR) based on
regularization to impose a sparsity constraint on logistic regression. The algorithms mentioned above successfully optimize the network only by pruning the weights.
Regularization methods have become more impressive than before, but all of them were designed mainly for pruning the superfluous weights, and the node can be deleted only if all its outgoing weights are close to zero. Then, researchers tried to prune the nodes to optimize the neural network. Simon et al. provided a group lasso method, which produced sparse effects both on and within the group, and showed the expected effect of group-wise and within-group sparsity [
13,
14,
15]. Moreover, [
16] considered a more general penalty and blended the lasso with the group lasso, which yielded solutions that are sparse at both the group and the individual feature level. For pruning the nodes of the network, the popular group lasso method (
) imposes sparsity at the group level, so that either all the weights between nodes in the fully connected layer and all nodes of the output layer approach zero simultaneously, or none of them are close to zero. In other words, the group lasso regularization prunes the nodes of the fully connected layer, but does not prune redundant weights of surviving nodes.
It was shown that combining the
regularization with the group lasso (
) for feedforward neural networks can prune not only hidden nodes but also the redundant weights of the surviving hidden nodes, and can achieve better performance in terms of of sparsity [
17]. However,
regularization is not smooth at the origin, which results in oscillation during the numerical computation and causes difficulty in the feasibility analysis. To overcome these issues, the regularizer was approximated with a continuous function in our early work [
18]. Furthermore, in [
19], the smooth
was applied to train the Sigma-Pi-Sigma neural network, and achieved better performance regarding both sparsity at the weight level and accuracy compared to the non-smooth
.
In this article, we combine the smooth regularization with the group lasso method, and propose a smooth group regularization algorithm. This novel algorithm inherits the advantages of the smooth function and regularization. As an application, the smooth group regularization algorithm is employed for the fully connected layer of CNNs. The main contribution of smooth group is to try to prune unnecessary nodes and control the magnitude of weights for the surviving nodes. In addition, due to the differentiability of the error function with smooth group regularization, it becomes easier to analyze the feasibility of the learning algorithm in theory. In the process of training the network, compared with , , and , smooth group regularization can not only prune the nodes and weights (improve the sparsity), but also overcome the oscillation in .
This paper is organized as follows. We first describe the simple process of the convolutional neural network and the smooth group
regularization in the next section. Then, in
Section 3, the feasibility analysis of the
algorithm in CNNs is given, in which the training convergence with the
term is proven theoretically. Numerical comparisons of several methods on four real-world datasets are carried out in
Section 4. Finally, some conclusions are drawn in
Section 5. In order to highlight the key points of this paper, the theorem proving process is included in the
Appendix A.
3. Feasibility Analysis of the Algorithm in CNNs
Now, it is enough to give the feasibility analysis of the algorithm. In order to obtain the convergence results, we first turn the CNN into mathematical formulae. Then, we proceed to give the convergence results.
3.1. Transform Convolution and Mean Pooling into Mathematical Equations
In regular neural networks, every layer is made up of a set of neurons, where each neuron is fully connected to all neurons in the next layer before. This operation is easily expressed by multiplying matrices. However, in CNNs, the neurons in one layer do not connect to all the neurons in the next layer but only to a small part of it. The convolution operation is often described graphically. Thus, our first task is to transform the convolution operation into mathematical equations.
Although the convolution filter is usually symmetrical, for universal applicability in the proof, we choose a general matrix. Let an input array be filtered by a
filter, where the padding is 0 and the step is 1. As shown in
Figure 1, when the filter slides over the input, a matrix multiplication of a submatrix of the input and the filter is performed and the sum of the convolution moves into the feature map, i.e., the output of this layer.
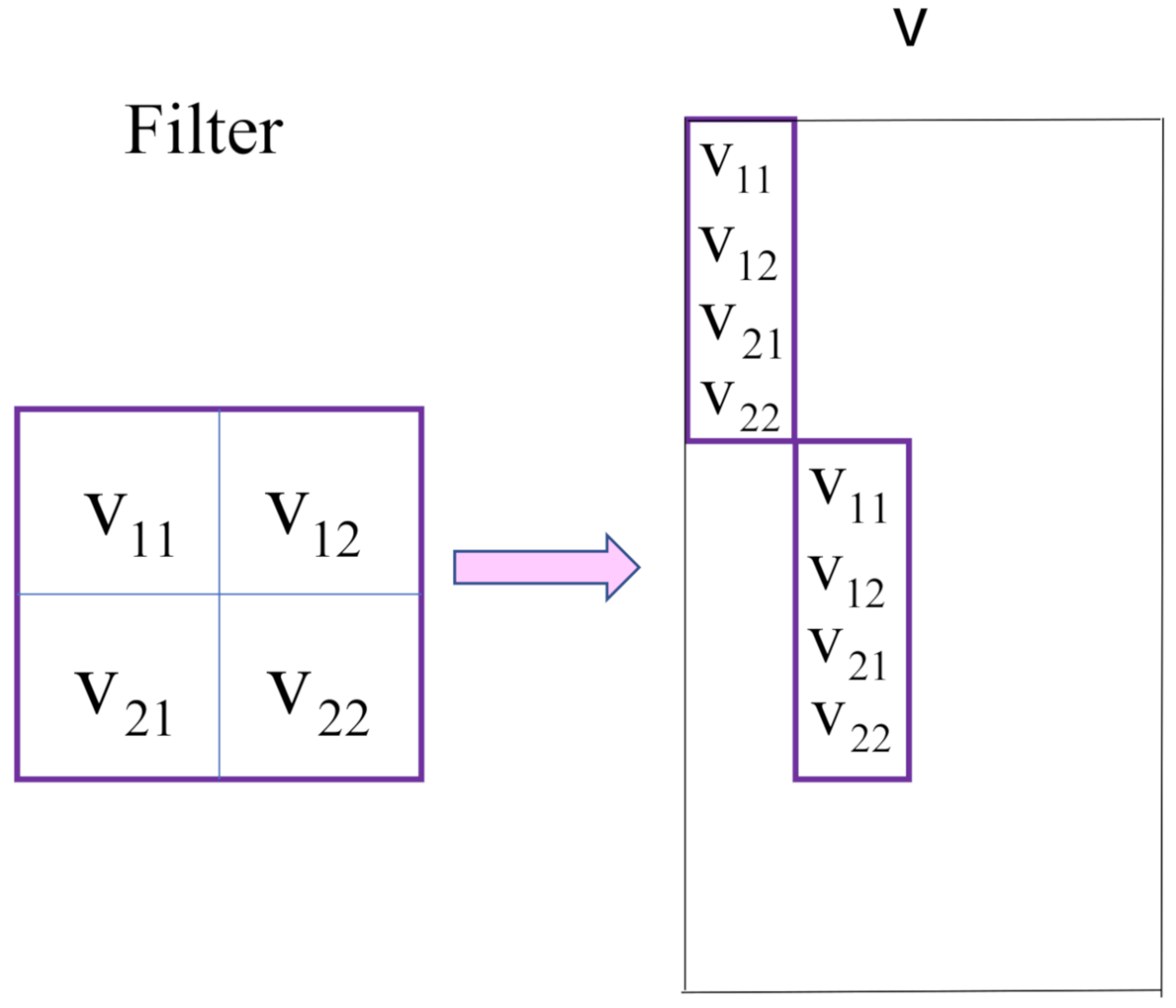
To express this operation with mathematical equations, we squash each submatrix that multiplies with the filter into a vector. More specifically, the red square of the input array in
Figure 2 is squashed into the vector
. Then, we put all squashed vectors into a matrix
X in order of the filter sliding, as shown in
Figure 2. The filter is also squashed with a vector
accordingly, and then is repeatedly put into the diagonal position of the matrix
V, as shown in
Figure 3. Other elements of
V are 0. With
X and
V, the operation of the convolutional layer can be described with the matrix multiplication of
X and
V, as shown in
Figure 4, i.e.,
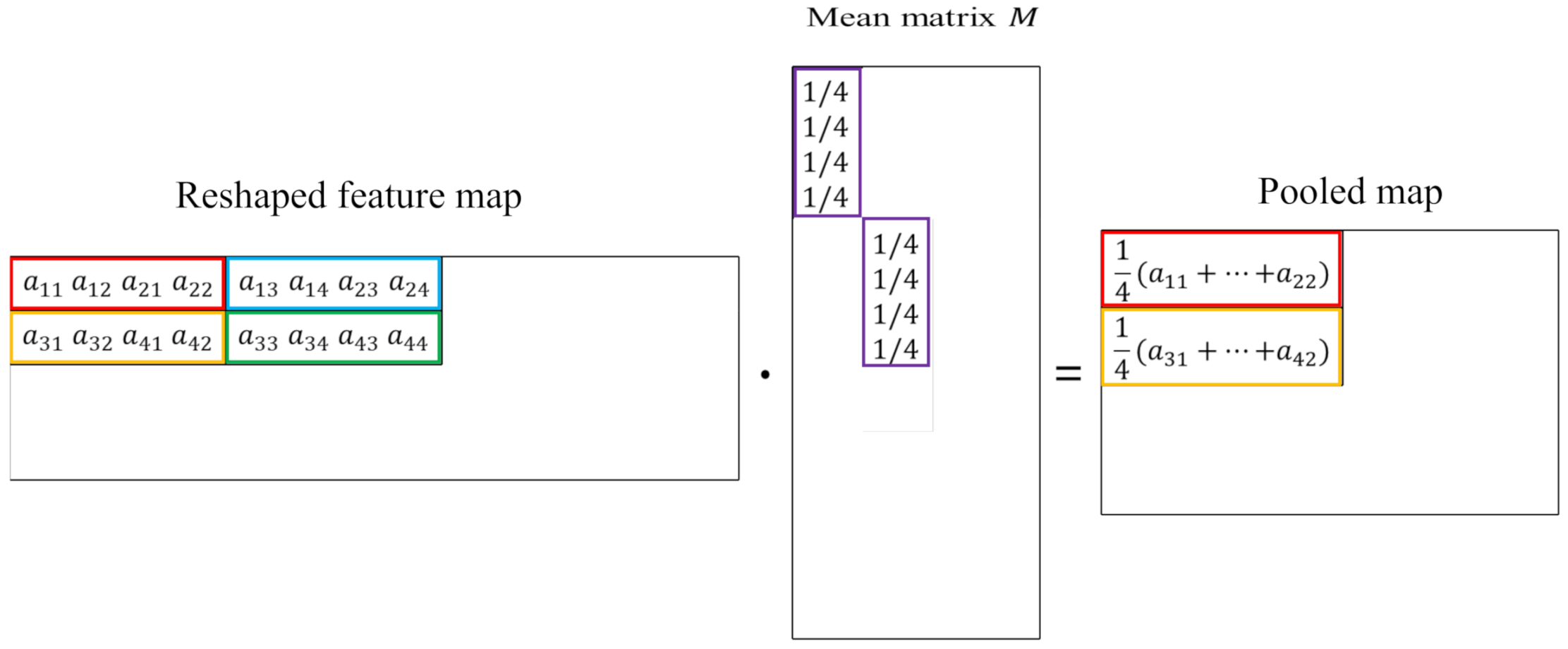
The mean pooling is assumed to be applied in
patches of the feature map with a stride of
. It can also be expressed with the matrix multiplication, as shown in
Figure 5. Each patch of the feature map is flattened into a vector and all the vectors are merged into a matrix as a reshaped feature map, as shown in
Figure 5. The sliding mean window is flattened as a vector
and is repeatedly put into the diagonal position of the mean matrix
M, as shown in
Figure 5. As in Equation (
10), the mean pooling operation can be expressed with the matrix multiplication:
Now, given an input array
X, the processing procedure from the convolution to the output layer can be expressed by mathematical equations. The output of the convolution layer is
where the function
G means the reshape operation shown in
Figure 2. After the ReLU layer, the matrix
is reshaped as
. In the pooling layer, the mean function is used
Then, the output matrix of the pooling layer is vectorized by column scan and this process is denoted by
where the function
F denotes the layer vectorized by the column. Finally, the fully connected layer is
3.2. Convergence Results
To prove that our proposed method is feasible, here, we give the convergence results. For ease of understanding, we take the simplest single-layer CNN case as an example. This CNN includes one convolution, one pooling and one fully connected layer, where the convolution filter size is and the mean pooling size is .
Given the training sample set
, each
is assumed to be the
input array and
is the
vector. According to Equations (
12)–(
15), the error function of Equation (
8) can be expressed as
where
,
is the
i-th row vector of
U.
Training a CNN involves finding a suitable
V and
U so that
E reaches the minimum [
27]. For this reason, the gradient descent method [
28] is adopted. Notice that the mean matrix
M does not need to be trained. In the backpropagation algorithm,
V and
U are changed according to the gradient descent direction of
E. The partial derivative of
E with respect to the element
of
U is as follows:
The partial derivative of
E with respect to the element
of the convolution filter
V is the same as the original CNN because the partial derivative of the penalty term in Equation (
16) with respect to
is zero. That is,
where
is the derivative function of the rectified linear units function:
Thus far, we have given the step direction of
U and
V by (
17) and (
18), respectively. Now, we proceed to give the step direction of the biases. The partial derivative of the biases can be computed similarly as shown in [
29]; the reader can refer to this article for more details.
We combine all weights and biases into a large vector
W. Then, the parameter updating algorithm of
is defined as follows:
where
is the learning rate and
n is the iteration step.
The convergence proof needs some Assumptions as follows:
- (1)
are uniformly bounded, where is the error of the n-th step.
- (2)
and are chosen to satisfy , where , and are constants defined below.
- (3)
There exists a compact set such that and contains finite points.
Theorem 1. Let the error function be Equation (8) and the weight sequence be generated by Equation (19) with any initial value . If Assumptions (1)–(2) are available, then - (i)
- (ii)
There exists , such that ;
- (iii)
The weak convergence holds, i.e., .
In addition, if the assumption (3) also holds, then the strong convergence result holds:
- (iv)
There exists a point such that .
The proof process is not the focus of this article, so we include it in the
Appendix A.
4. Numerical Experiments and Discussion
We evaluate
in different ways, such as nodes [
30] and weights sparsity [
31], training and testing accuracy, the norm of weight gradient and the convergence speed, on four typical benchmark datasets: Mnist [
32], Letter Recognition [
33], Cifar 10 [
34] and Crowded Mapping. For parameter sparsity,
is compared with some conventional and sparse algorithms including
,
and
. Moreover, we investigate the test accuracy by comparing
with the above regularization algorithms.
For the following numerical experiments, we refer to the arithmetic optimization algorithm [
35] and adopt a five-fold cross-validation technique [
36,
37,
38]. We randomly divide the dataset into five parts, where the sample size is equal (or almost equal). The network learning of these four algorithms is carried out five times. Each time, one of the five parts is selected in turn as the test sample set, and the other four parts are used as the training sample sets. Then, we rearrange the five-part samples and start the process again. This process is repeated twenty times. The experiment process is given in Algorithm 1.
| Algorithm 1 The experiment process. |
Step 1: Input the data and calculate the corresponding actual output; Step 2: Calculate the difference between the actual output and the ideal output; Step 3: Give the error function according to these four algorithms; Step 4: Update the weights of the fully connected layer according to the error function of step 3; Step 5: Keep iterating, repeat steps 2–4; Step 6: Calculate the pruned nodes, pruned weights of surviving weights and classification accuracies under these four methods, respectively; Step 7: Contrast.
|
Finally, for each dataset and algorithm, we obtain one hundred classification results. Each result contains the rate of pruned nodes (Rate of PN) (cf. Equation (
20)), the rate of pruned weights of the remaining nodes (Rate of PW) (cf. Equation (
21)), training accuracy (Training Acc.) and test accuracy (Test Acc.). The averages of these numerical results are listed in
Table 1,
Table 2,
Table 3 and
Table 4 for these four datasets.
For an output node, the ideal output value is 1 or 0. When we evaluate the error between the ideal and real output values, we use the following “40-20-40” standard [
39]: The actual output values of the output nodes between
and
are regarded as 0, values between
and
are regraded as 1, and values between
and
are regraded as uncertain and are considered incorrect.
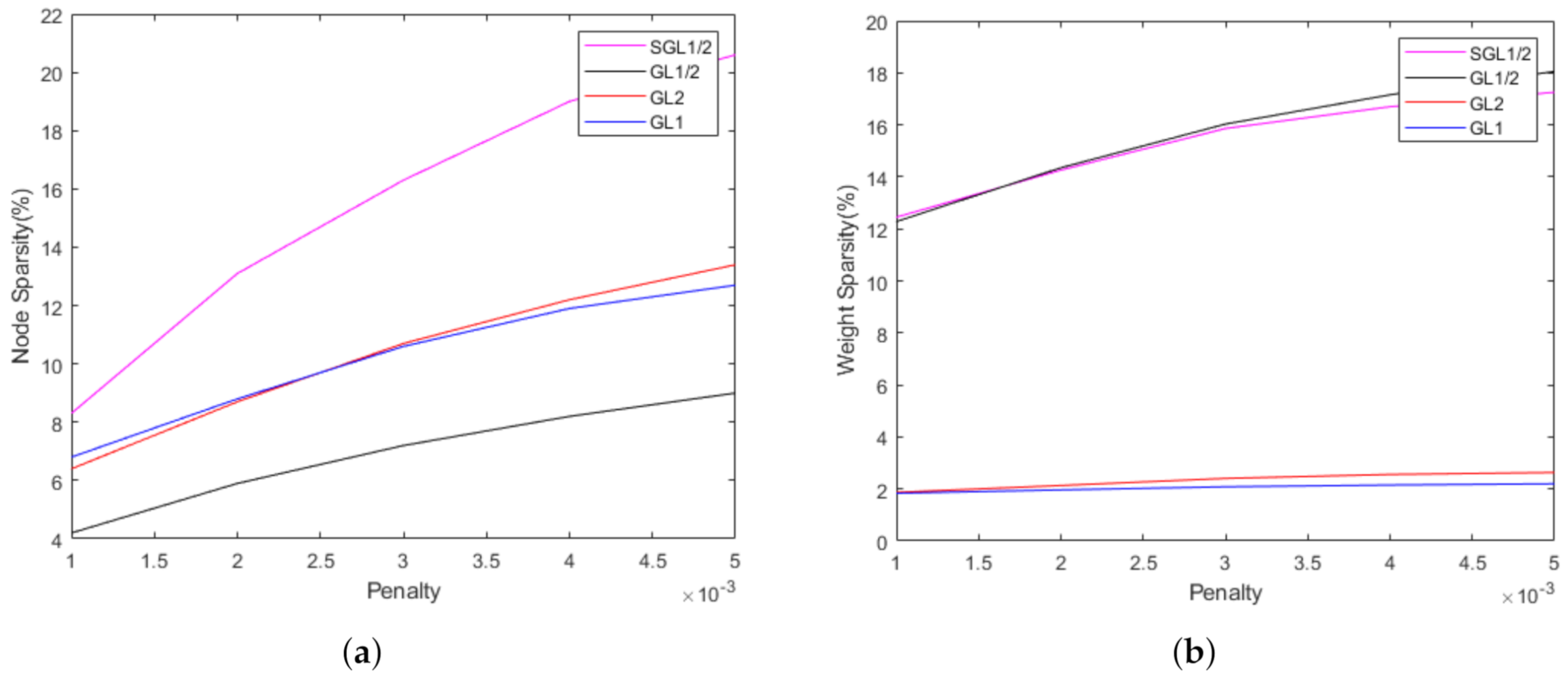
4.1. Mnist Problem
MNIST is a dataset for the study of handwritten numeral recognition, which contains 70,000 examples of
pixel images of the digits 0–9. For these four algorithms, we set the learning rate
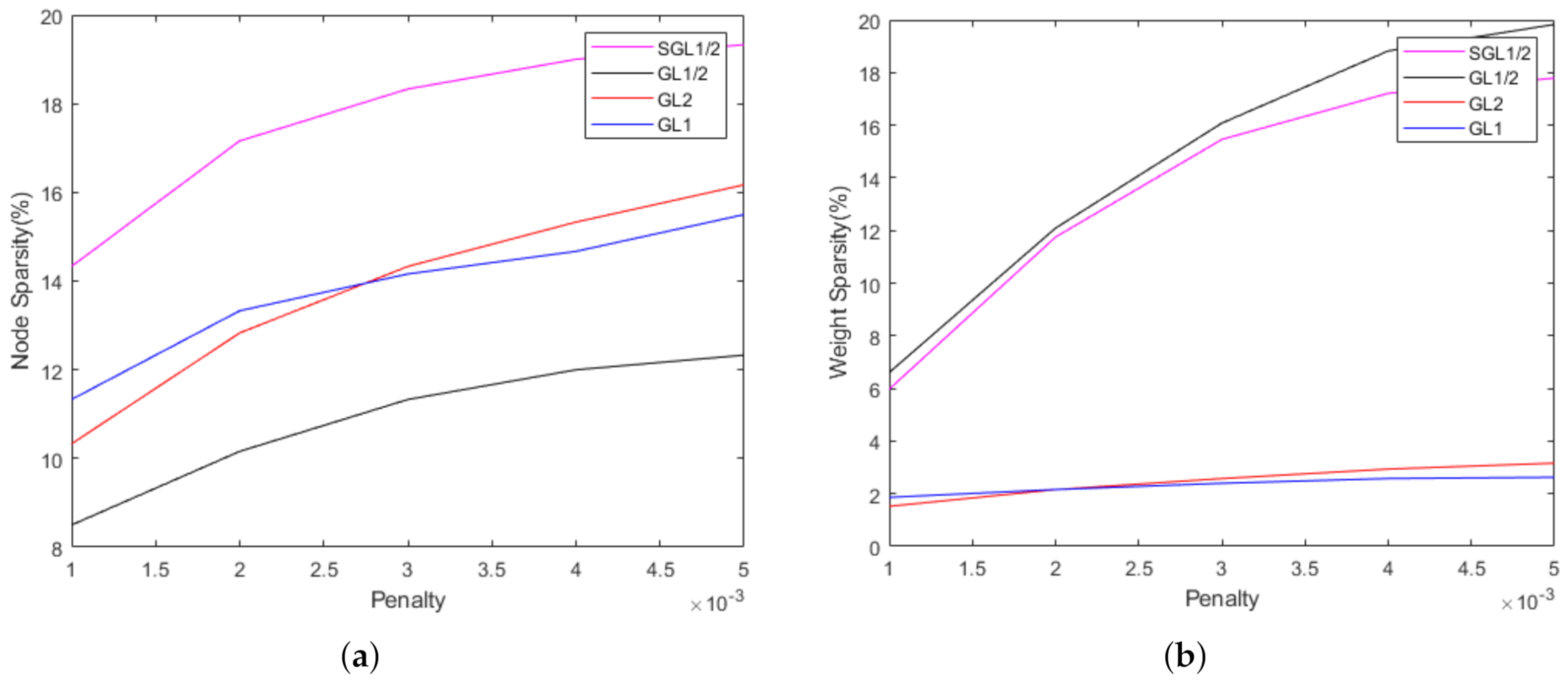
. The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for
of these four algorithms (see
Figure 6;
y-axis represents the percentage of the number of pruned nodes and pruned weights of the remaining nodes, respectively). The sparsity will become worse when
. Therefore, we choose
to compare these algorithms. The performances of these four group lasso algorithms are compared in
Table 1. We can see that, in terms of the sparsity, the performance of
is better than
,
and
. In terms of of accuracy,
is also the best.
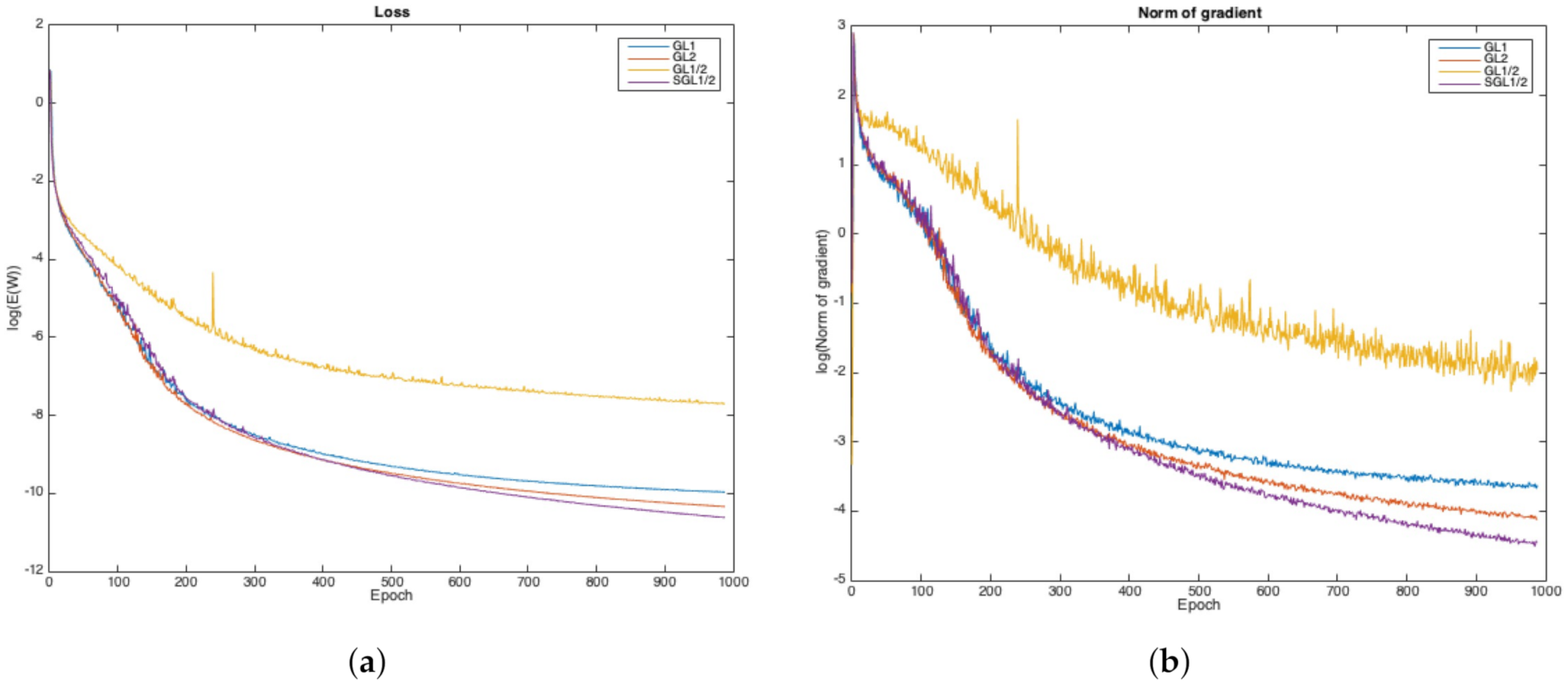
Figure 7a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the
approach has the lowest error after training, and
has a large fluctuation during the training process.
We show the gradient norms of
,
,
and
in
Figure 7b, where the oscillation [
40,
41] of
is presented. From
Figure 7, we find that the
regularizer eliminates the oscillation and guarantees the convergence, as predicted in Theorem 1.
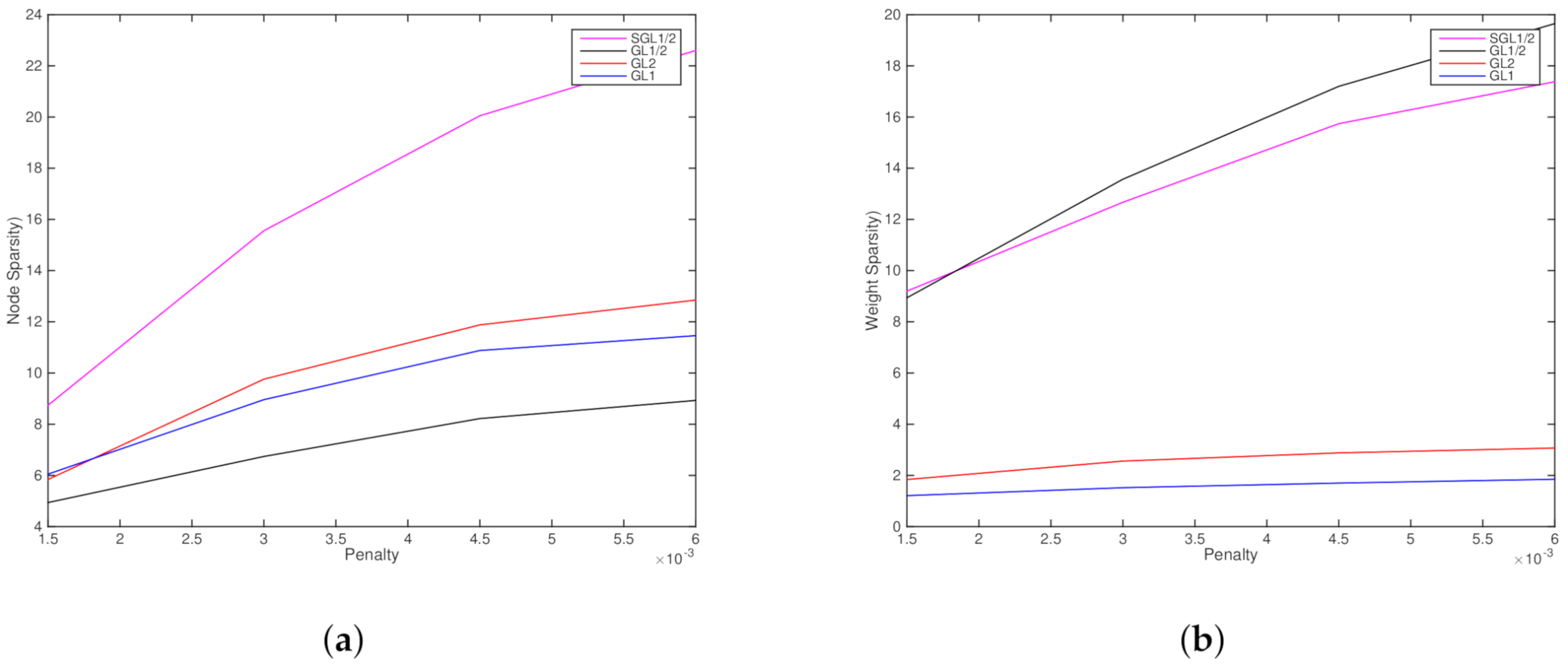
4.2. Letter Recognition Problem
The Letter Recognition dataset consists of 20,000 samples with 16 attributes. Each 16-dimensional instance within this database represents a capital typewritten letter in one of twenty fonts. For these four algorithms, we set the learning rate
. The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for
of these four algorithms (see
Figure 8). The sparsity will become worse when
. Therefore, we choose
to compare these algorithms. The performances of
,
,
and
are compared in
Table 2. We see that, in terms of sparsity, the performance of
is better than
,
and
. In terms of accuracy,
is also the best among the above-mentioned four algorithms.
Figure 9a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the
approach has the lowest error after training, and
has a large fluctuation during the training process.
We show the gradient norms of
,
,
and
in
Figure 9b, where the oscillation of
is presented. From
Figure 9, we find that the
regularizer eliminates the oscillation and guarantees the convergence, as predicted in Theorem 1.
4.3. Cifar 10 Problem
The Cifar 10 dataset consists of 60,000 images, each of which is a
color map. This dataset contains 10 classes (airplane, automobile, bird, cat, deer, dog, frog, horse, ship and truck), with 6000 images per class. There are 50,000 training images and 10,000 test images. For these four algorithms, we set the learning rate
. The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for
of these four algorithms (see
Figure 10). The sparsity will become worse when
. Therefore, we choose
to compare these algorithms. The performances of these four group lasso algorithms are compared in
Table 3. We see that, in terms of of sparsity, the performance of
is better than
,
and
. In terms of accuracy,
is also the best.
Figure 11a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the
approach has the lowest error after training, and
has a large fluctuation during the training process.
We show the gradient norms of
,
,
and
in
Figure 11b, where the oscillation of
is presented. From
Figure 11, we find that the
regularizer eliminates the oscillation and guarantees the convergence, as predicted in Theorem 1.
4.4. Crowded Mapping
The Crowded Mapping dataset consists of 10,546 samples with 28 attributes, and these samples are divided into six classes. For these four algorithms, we set the learning rate
. The maximum iteration training step is 1000. In order to show the sparsity, we give the node sparsity and weight sparsity performances for
of these four algorithms (see
Figure 12). The sparsity will become worse when
. Therefore, we choose
to compare these four algorithms. The performances of the
,
,
and
methods are compared in
Table 4. We see that, in terms of sparsity, the performance of
is better than
,
and
. In terms of accuracy,
is also the best among the above-mentioned four algorithms.
Figure 13a presents the loss functions of these four group lasso algorithms. Obviously, we can see that the
algorithm has the lowest error after training, and
has a large fluctuation during the training process.
We show the gradient norms of
,
,
and
in
Figure 13b, where the oscillation of
is presented. From
Figure 13, we find that the
regularizer eliminates the oscillation and guarantees the convergence, as predicted in Theorem 1.
From the above experiments on the four datasets, it is easy to see that the and algorithms have better sparsity at the node level, and the algorithm has better sparsity at the weight level. In some applications, the sparsity at the weight level is also of great significance. If the sparseness of the integrated node and weight level is better, the number of weights that need to be calculated and updated will be reduced in the process of training the CNNs. Furthermore, it also leads to a reduction in the amount of calculation and saves storage space. Compared with the and algorithms, the algorithm has better sparsity at the node level and the weight level, and can also improve the classification performance. Compared with the algorithm, the theoretical analysis and numerical experiment are carried out to verify that the algorithm improves the sparsity at the node level, and at the same time improves the classification performance.
4.5. Discussion
Table 1,
Table 2,
Table 3 and
Table 4, respectively, show the performance comparison of PN, PW, training accuracies and test accuracies under these four methods. In terms of the sparsity, the PN calculation results of the
method are much better than the other three methods, especially the
method. As for the PW, although the surviving node of the
has a higher rate of pruned weights of surviving weights, the rate of pruned nodes is too low, such that the sparsity of the
method is still far lower than that of the
method. In terms of classification accuracy, the
method is slightly higher than other methods, which means that this method can improve the sparsity without damaging the classification accuracy.
We can find that the specificity of CNNs is not actually used in the experiments, so the method can be widely applied to other neural network models.
5. Conclusions
Our main task was to introduce the algorithm. Based on the and algorithms, replacing 1-norm and 2-norm with -norm can greatly improve the sparsity of the network weight level, but it does not help to achieve better sparsity of the node level. The non-smooth penalty term at the origin is the root cause of the poor sparsity of the algorithm at the node level.
To this end, in this paper, a smooth group () regularization term is introduced into the batch gradient learning algorithm to prune the CNN. The feasibility analysis of the method for the fully connected layer of the CNN is performed. Numerical experiments show that the sparsity and convergence of give better results in terms of both the rate of pruned hidden nodes and weights of the remaining hidden nodes compared to , and . In addition, the regularizer not only overcomes the oscillation phenomenon during the training process, but also achieves better classification performance.
In fact, the regularization algorithm provides a strategy to improve the sparsity of hidden layers of neural networks, not only for CNNs. Therefore, the performance of the regularization algorithm on other neural network models is also worthy of further verification. However, the algorithm is not particularly obvious in improving the classification accuracy. In future work, we will focus on continuing to improve the algorithm to achieve better classification performance of the neural network.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}