1. Introduction
The slash distribution is the result of the quotient of two independent random variables, one with a standard normal distribution and the other with a uniform distribution on the interval (0, 1), with the following stochastic representation
where
is the location parameter and
is the scale parameter and
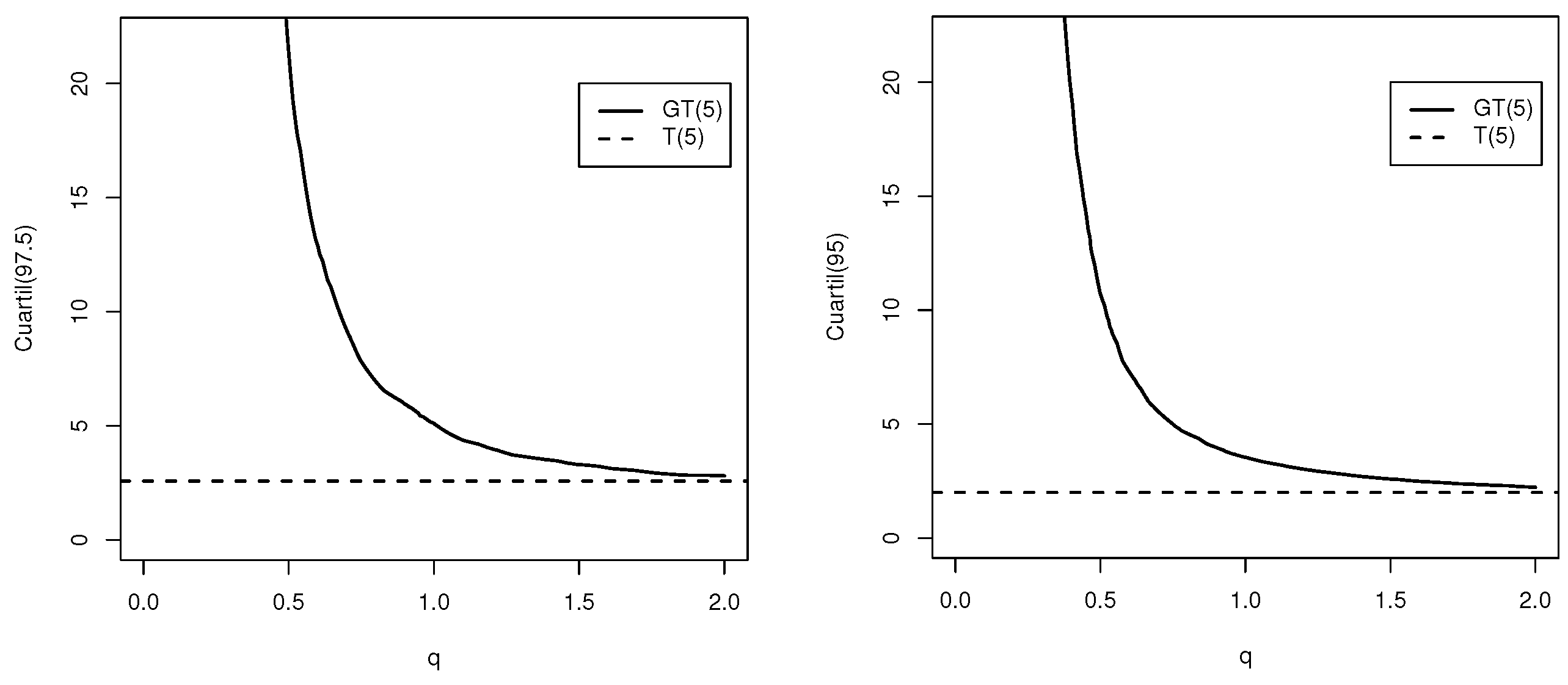
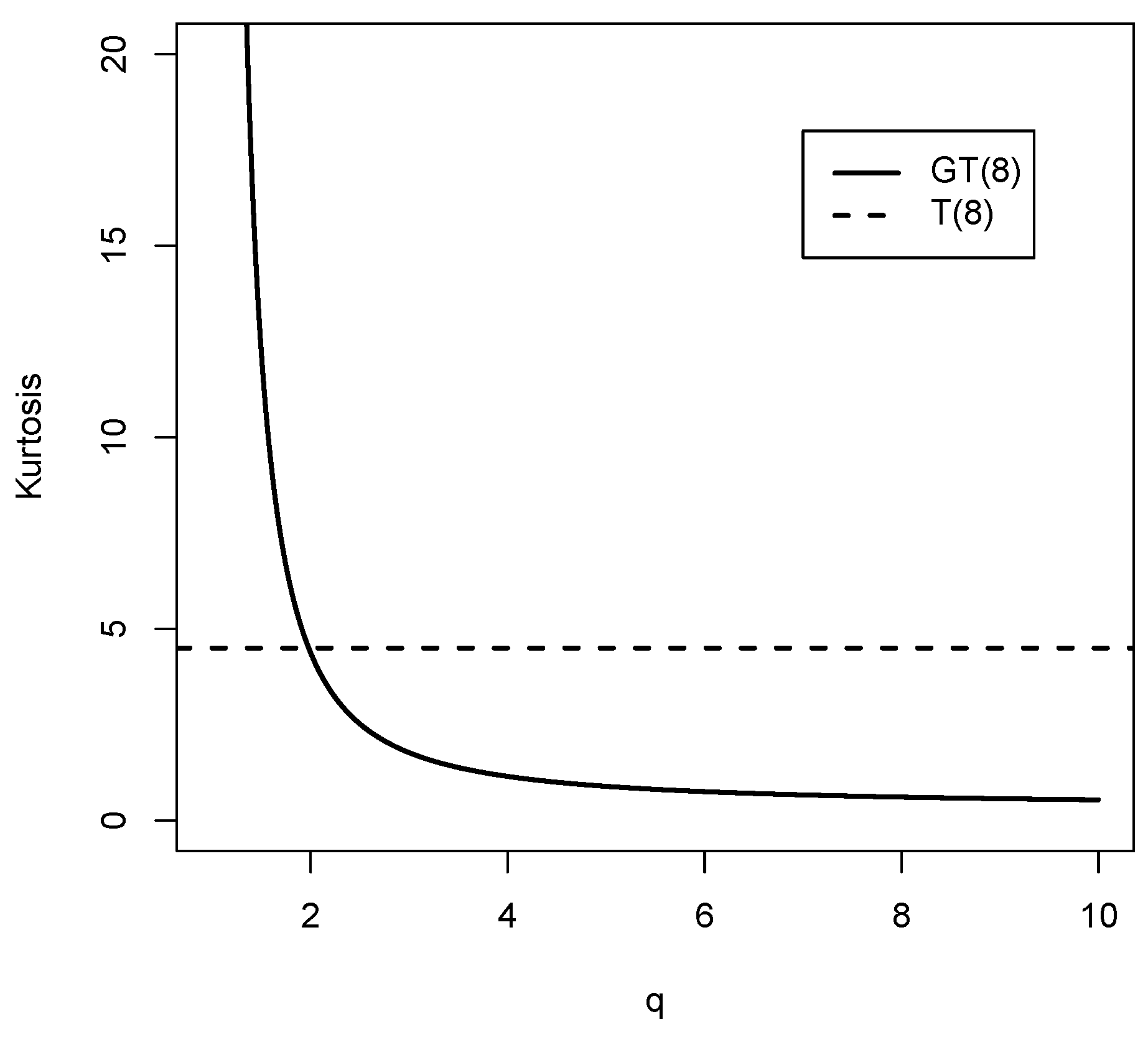
q is the parameter related to kurtosis. Will be denoted by
and its density function has the following expression
where
is the gamma function and
is the gamma function incomplete. This distribution presents heavier tails than the normal distribution, that is, it has more kurtosis. Properties of this family are discussed in Rogers and Tukey [
1] and Mosteller and Tukey [
2].
Maximum likelihood estimators for location and scale parameters are discussed in Kafadar [
3]. Wang and Genton [
4] described multivariate symmetrical and skew-multivariate extensions of the slash-distribution while Gómez et al. [
5] (and Erratum in Gómez and Venegas, 2008) extend the slash distribution by introducing the slash-elliptical family; asymmetric version of this family is discussed in work of Arslan [
6]. Genc [
7] discussed a symmetric generalization of the slash distribution. More recently, Gómez et al. [
8] utilize the slash-elliptical family to extend the Birnbaum–Saunders distribution.
In (
1),
and
, we retrieve the standard slash distribution. What is more
we obtain the canonical slash distribution. When
q tends to infinity, the standard normal distribution is recovered.
When
, in (
1), the distribution obtained is called modified slash distribution studied by Reyes et al. [
9]. Whose function of density is given by
and will be denoted by
, where
q is kurtosis parameter.
When
and
, in (
1), the distribution obtained is called extended slash (ES) distribution studied by Rojas et al. [
10]. Whose function of density is given by
is denoted as
with
,
,
,
and
denotes the pdf of the standard normal distribution (see Johnson et al. [
11]) and
denotes the beta function.
We will say that
X has a student’s t distribution with
degrees of freedom and with location parameter
and scale parameter
, which we will denote by
and you have a stochastic representation given by
and continuous probability density function is given by
with support on
.
The moment’s order
r of the random variable
X with student’s t distribution can be explained by the function Gamma. If
then
where
for
r even, then
,
, .
If
then
Rui Li-Saralees Nadarajah [
12] makes a review of all the generalizations of the student’s t distribution published to date, where they show that the main motivation of these extensions is to model heavy tails or data with high kurtosis.
In the study of symmetric distributions with heavy tails El-Bassiouny et al. [
13] present the generalized student’s slash t distribution. We will say that
, with parameter
, has pdf given by
where
q is kurtosis parameter and
denotes the beta function.
Another recent extension of the slash model was proposed by El-Morshedy, A. H. et al. [
14]. These authors introduced the double slash (DSL) distribution with density function given by
with
,
,
and
.
When
and
, in (
1), the distribution generalized modified slash distribution, denoted
, studied by Reyes, J., Barranco-Chamorro, I., and Gómez, H. W. [
15]. Whose function of density is given by
where
,
,
and
is the confluent hypergeometric function of the second kind. Details about this function can be seen in Abramowitz and Stegun, p. 505.
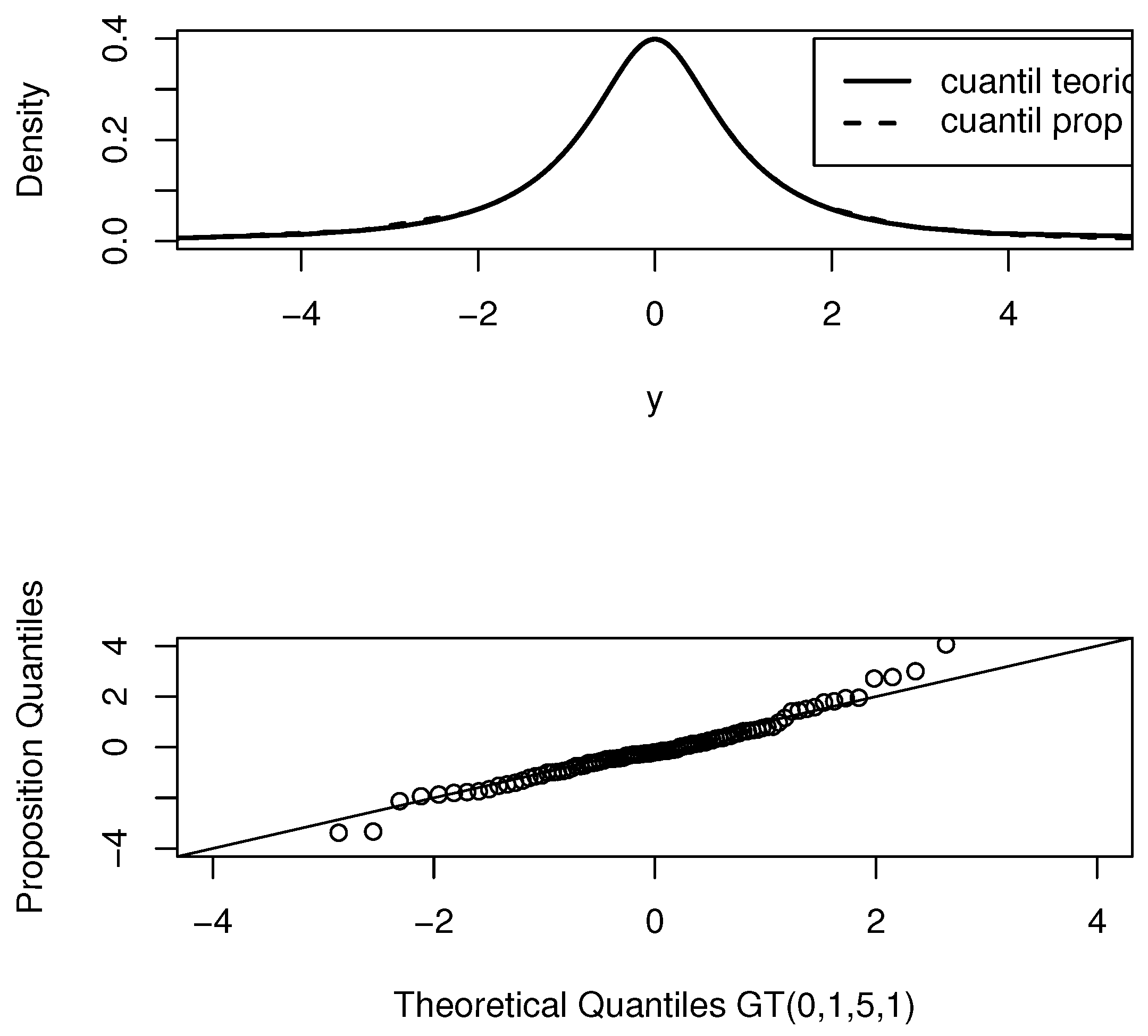
With the motivation of finding a distribution that is a generalization of the student’s t distribution and that presents heavier tails than the distributions found so far in the literature, in this article, we introduce a new generalization of the student’s t distribution (
GT) whose stochastic representation is given by
where
,
are independent with
and
and we will denote it as
.
The paper is organized as follows. In
Section 2 the probability density function (pdf) is given and some properties of the
distribution are presented and shows that the distribution student’s t is a particular case of the distribution
. Additionally, moments of order
r are obtained, including the kurtosis coefficient. In
Section 3 derivation of the moment and maximum likelihood estimators are discussed. A simulation study is presented to illustrate the behavior of the estimator of the parameters
,
, and
q, for
.
Section 4 results of using the proposed model in two real applications are reported.
Section 5 presents quantile regression.
Section 6 presents the main conclusions.
5. Quantile Regression
The quantile regression is used when the study objective focuses on the estimation of the different percentiles (such as the median) of a population of interest. An advantage of using quantile regression to estimate the median, rather than ordinary least squares regression current file (to estimate the mean), is that the quantile regression will be more robust in the presence of outliers. Quantile regression can be seen as a natural analogue in regression analysis when using different measures of central tendency and dispersion, in order to obtain a more complete and robust analysis of the data. Another advantage of this type of regression lies in the possibility of estimating any quantile, thus being able to assess what happens with extreme values of the population.
5.1. Quantile Regression Uni-Dimensional
Translating this concept of quantile to the regression line, we obtain the linear quantile regression.
If we assume that
with
and that the conditional expected value is not necessarily zero, but the
-ésimo quantile of the error with respect to the regressive variable is zero
, then the
-ésimo quantile of
with respect to X can be written as
The estimates of
y
are found by
being
y
.
To estimate the parameters, the function described in the equation should be minimized. For this, there is a way to approach the minimization problem as a linear programming problem. This allows us to obtain the regression line for the value of a certain quantile. Therefore, the first of the limitations will be solved raised at the end of the previous section, for simple linear regression. Furthermore, since the quartiles have robust properties, it is also possible to solve the second of the limitations that arose with the classical regression line.
5.2. Quantile Regression Student’s t
In this case, in the regression equation
the response variable
, it is possible to generate random numbers for the
distribution, which the parameters
,
and
they are estimated using maximum likelihood for the data. Then, one way to obtain the quantiles of
Y is using the stochastic representation.
Using this new variable quantile regression is applied to the data .
5.3. Quantile Regression Slash Logistic
In this case, in the regression equation
the response variable
, it is possible to generate random numbers for the
distribution, which the parameters
,
, and
q they are estimated using maximum likelihood for the data. Then, one way to obtain the quantiles of
Y is using the stochastic representation.
Simulate ;
Compute ;
Simulate ;
Compute .
Using this new variable quantile regression is applied to the data .
5.4. Quantile Regression Generalized Student’s t
In this case, in the regression equation
the response variable
, it is possible to generate random numbers for the
distribution, which the parameters
,
,
, and
q they are estimated using maximum likelihood for the data. Then, one way to obtain the quantiles of
Y is using the stochastic representation given in (
13)
Using this new variable quantile regression is applied to the data .
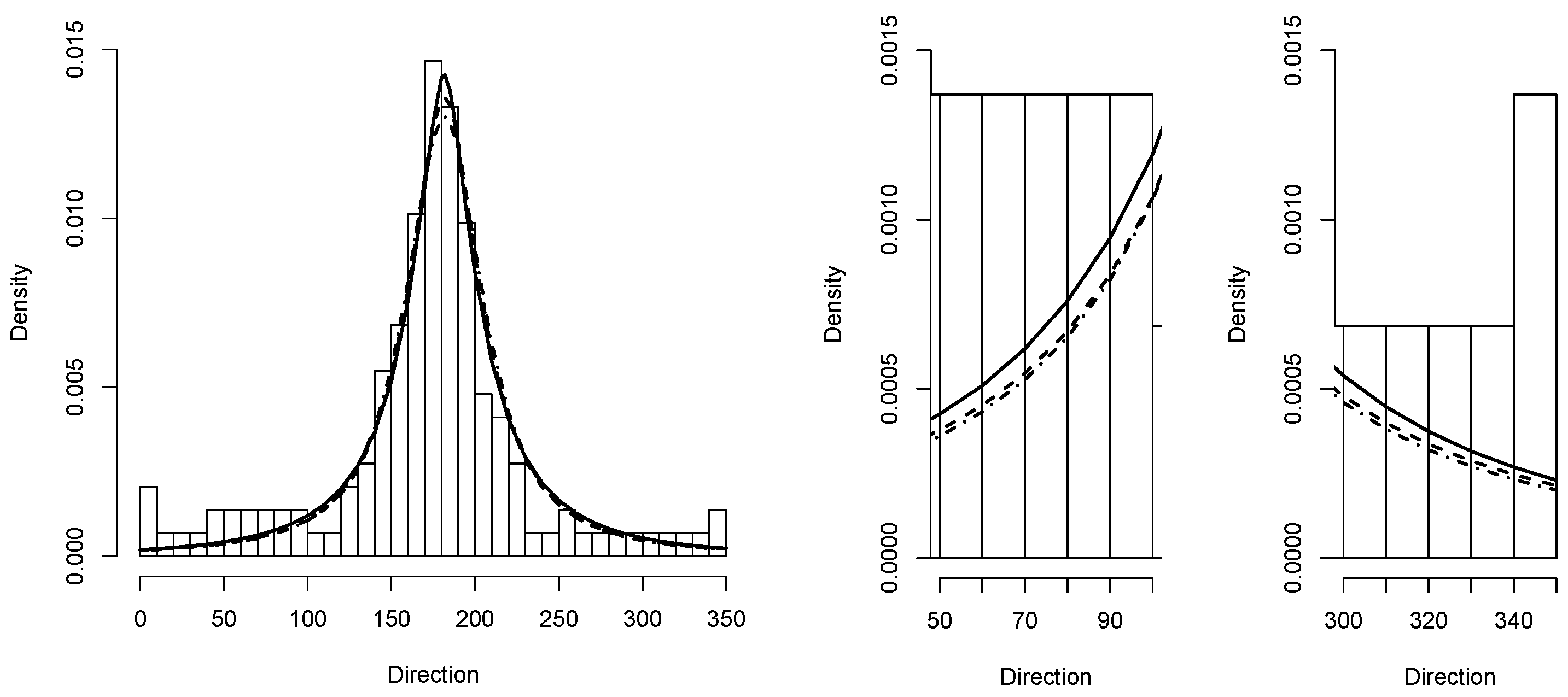
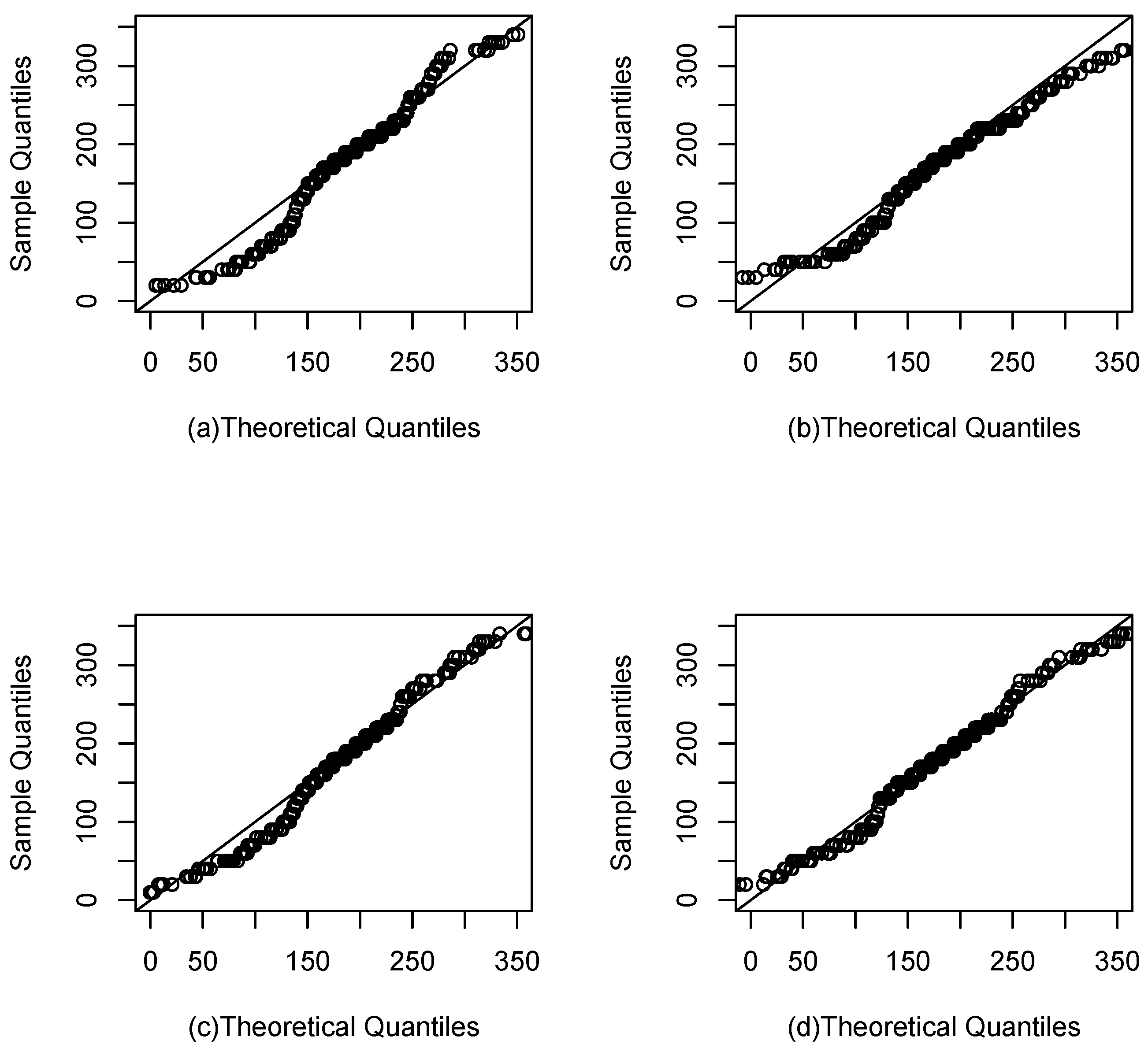
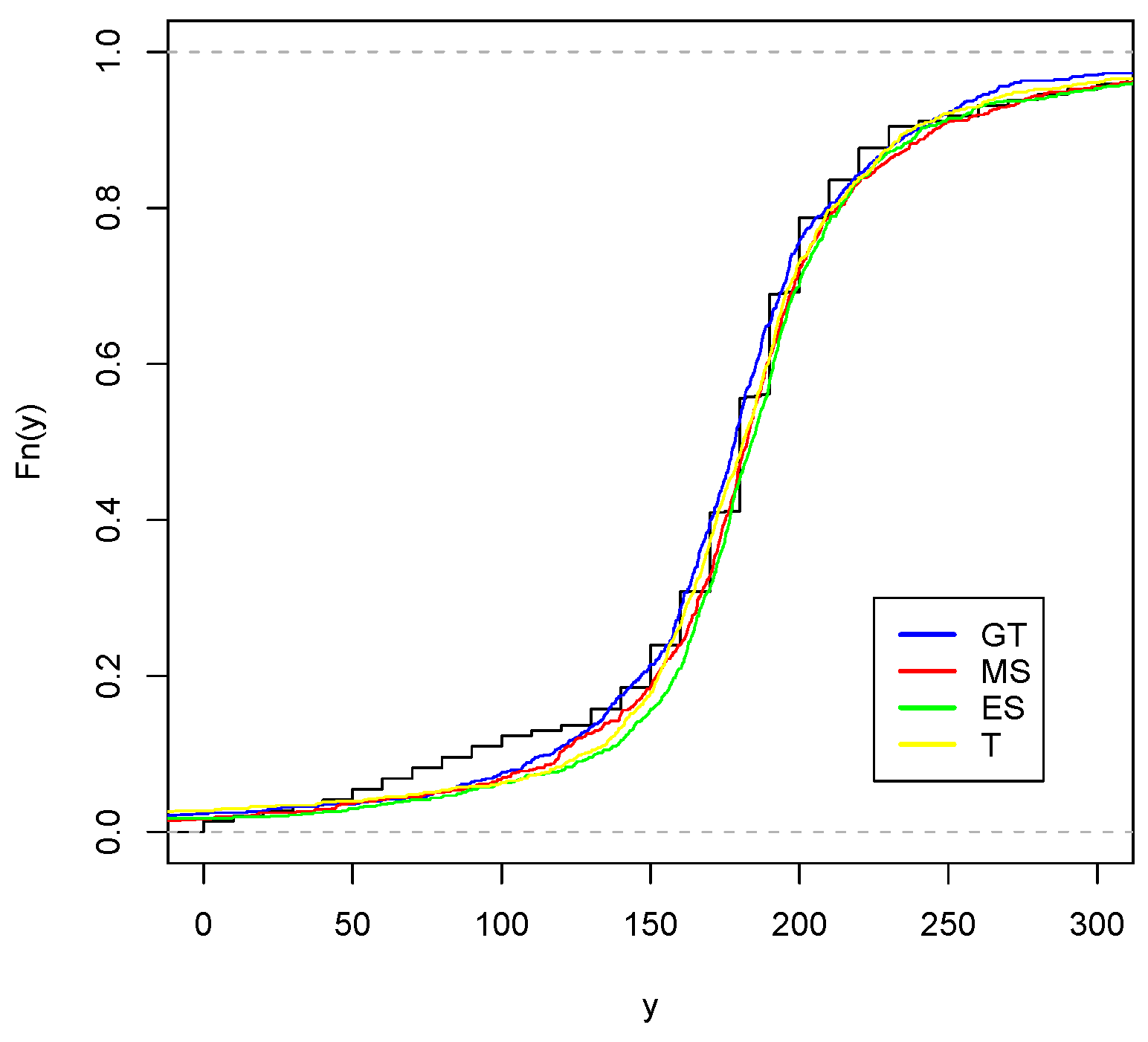
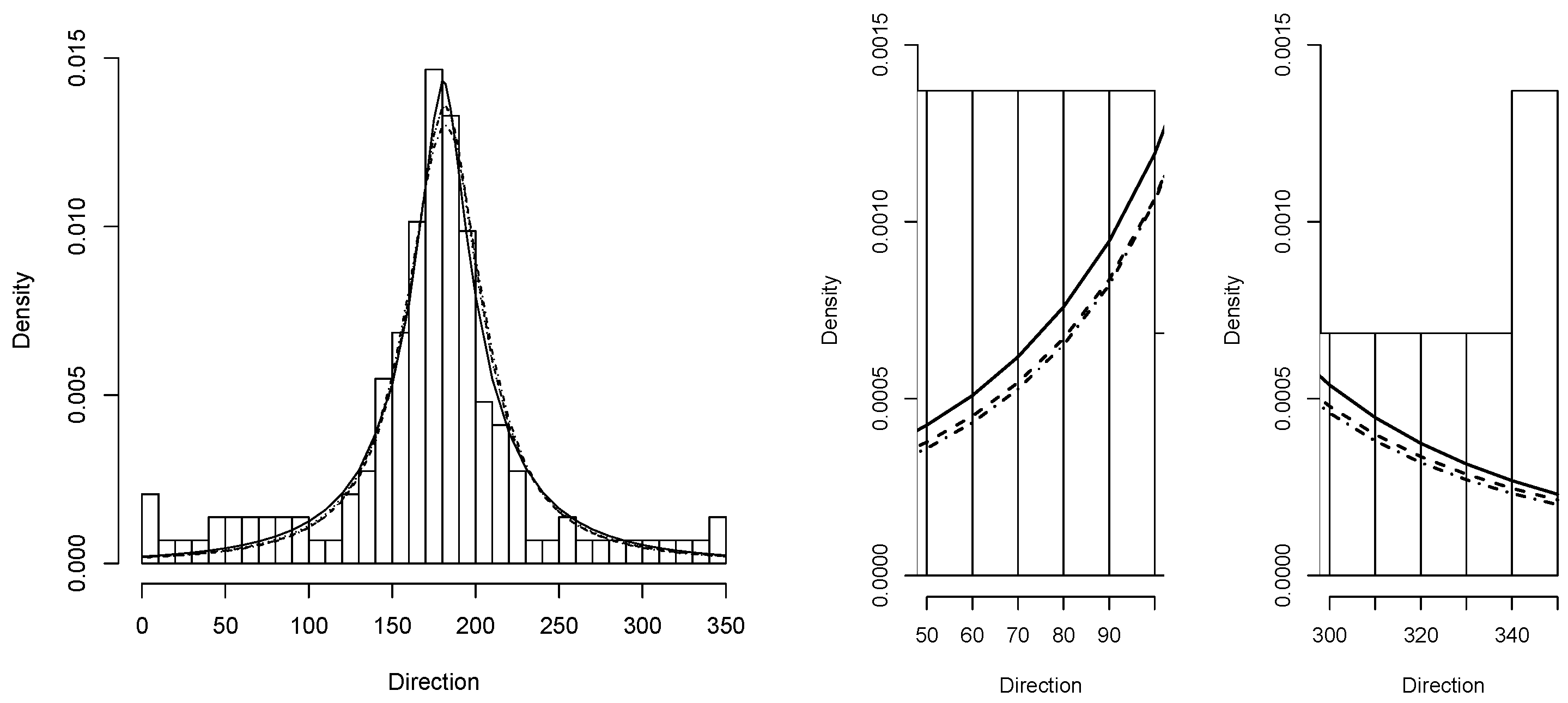
5.5. Application 2
We consider now data concerning the body mass index and Lean Body Mass of 202 Australian athletes. The data are available for download at
http://azzalini.stat.unipd.it/SN/index.html (accessed on 15 October 2021).
Table 8 shows statistics for these data for which the maximum likelihood estimators of (
,
) and its corresponding coefficients AIC and BIC fit models for data. are shown in
Table 9 and
Table 10, respectively.
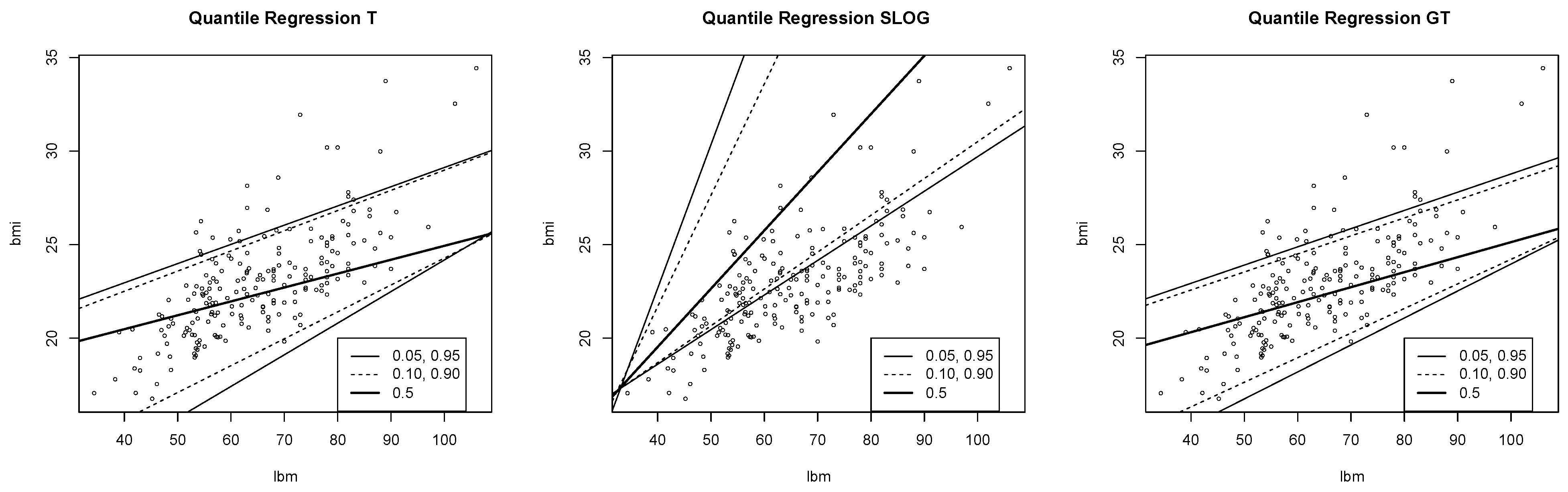
In
Figure 9 the quantile regression of the data is shown using the
T,
and
models.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}