1. Introduction
Artificial intelligence and processing technologies are important tools to improve the analysis of the different phenomena in nature; it is important to have an efficient infrastructure for data processing and analysis, which must be platform-independent [
1]. In relation to one of the techniques used in artificial intelligence, bio-inspired optimization algorithms have proven to be a suitable tool for troubleshooting engineering; however, because of their stochastic behavior they often require a large number of iterations such as a number of executions to get a useful solution. Therefore, it is necessary to establish an adequate infrastructure to run such algorithms—a virtualized distributed system being a suitable option.
1.1. Bio-Inspired Optimization
Bio-inspired optimization techniques (heuristics) are a suitable alternative when traditional methods cannot determine appropriate results or have limitations. In the field of bio-inspired optimization, there are different proposals based on behaviors and phenomena that exist in nature [
2]. In this regard, approaches of individuals among the algorithms are stochastic hill climbing (SHC) and simulated annealing (SA). Among the methods based on several individuals (populations), the genetic algorithms (GA), differential evolution (DE), ant colony optimization (ACO), bacterial chemotaxis (BCO), and particle swarm optimization (PSO). The stochastic hill climbing algorithm is based on the stochastic selection of neighboring solutions, which are accepted in cases wherein there is an improvement in the target function [
3]. Simulated annealing is a method that emulates the crystalline formation of a material by heating and cooling it, seeking to move from a higher to a lower energy state [
3]. Genetic algorithms and differential evolution seek to emulate the process of nature by improving a species over time [
3]. On the other hand, algorithms based on ant colonies, bacterial chemotaxis, and swarms of particles are inspired by the behavior of living beings searching for food [
4,
5,
6].
In order to test the processing system, we used the standard versions of genetic algorithms, differential evolution, and particle swarm optimization, which are widely known.
1.2. Distributed Processing Systems
Aggregate computing is an emerging approach to complex coordination engineering that results in distributed systems. This approach is based on the interactions of the visualization system in terms of information that is propagated across device groups and their interactions with their peers and environment [
7]. Some applications that involve data analysis typically perform the calculations in a data center or cloud environment. As these applications grow in scale, this centralized approach leads to bandwidth requirements and potentially impractical computational latencies. This has generated interest in computing wherein processing is in a distributed manner [
8].
According to [
9], the development of this technology shows the importance of teaching the aspects of parallel computing. In this regard, the authors of [
9] present a model for incorporating parallel and distributed computing (PDC) throughout an undergraduate computer science (CS) curriculum, presenting students with computer topics of distributed and parallel computation in the intermediate level.
Parallel and distributed computing is of importance when handling a large amount of data and the ability to process it; some applications of parallel computing are described below.
An application on renewable energy generation can be seen in [
10], where a distributed data processing system is presented to improve the estimation of urban solar potential by directly using a dense set of scanning points obtained from aerial laser scans (ALS) that allow incorporating true, complex, and heterogeneous elements common in most urban areas.
Another application on renewable energy can be seen in [
11], where a hybrid distributed computing system is used in Apache Spark for wind speed forecasting, which corresponds to an arduous task given the randomness of the wind speed. Using the distributed computing strategy, the system can divide large wind speed datasets into groups and use them in parallel.
In relation to a geomatics application, in [
1] a distributed computer framework is provided, allowing data collection and processing. According to the authors, the proposed system can support efficient range queries and large-scale spatial data processing in a Spark cluster and another in Flink, providing an effective cross-platform distributed computing solution for fast processing of large-scale spatial data.
Finally, an application in the field of agriculture can be seen in [
12], where it is necessary to evaluate the spatial distributions of crop yields under current and future climatic conditions. This task generally requires considerable effort in order to prepare the input data and post-process the results, which is why the authors developed a simulation support system to automate repetitive and tedious tasks using virtual machines connected over a local network, allowing for a clustered computer without workstations having to be dedicated.
1.3. Virtualization Systems
The concept of virtualization is applied in cloud computing systems to help users and owners achieve better use and efficient management of the cloud at the lowest cost [
13]. Live migration of virtual machines (VM) is an essential feature of virtualization, allowing one to migrate virtual machines from one location to another without suspending them. This process has many advantages for data centers, such as load balancing, inline maintenance, power management, and proactive fault tolerance [
13]. When a system such as a processor, memory, or I/O device is virtualized, its interface and all visible resources are mapped to a virtual interface in such a way that the actual system is transformed into a different virtual or even a set of multiple virtual systems [
14]. Virtualization technologies allow decoupling the architecture and user-perceived behavior of hardware and software resources from the physical deployment [
15].
According to [
16], virtualization has made it possible to completely isolate virtual machines from each other. When applications running inside virtual machines have real-time restrictions, threads that deploy virtual cores must be programmed in a predictable way over physical cores. Meanwhile, reference [
17] states that real-time virtual machines are suitable for tightly coupled computer systems wherein tasks are executed from the associated language. Here is an approach to support the transfer of tasks between freely attached computers in a real-time environment to add more features without updating the software.
Essentially, energy consumption is an important aspect of virtualization; in line with [
18], the high power consumption of cloud data centers presents a significant challenge from both an economic and environmental perspective. Server consolidation using virtualization technology is widely used to reduce the power consumption rates of data centers. The efficient virtual machine placement (VMP) of virtual machines plays an important role in server consolidation technology, this being a difficult problem of type NP (nondeterministic polynomial time) for which the optimal solutions are not possible. In addition, reference [
19] states that the assignment of a virtual to a physical machine affects the power consumption, manufacturing, and downtime of physical machines. According to [
20], the demand for power for cloud data centers has increased markedly; therefore, the consolidation of dynamic virtual machines, as one of the effective methods to reduce energy consumption, is widely used in large data centers in the cloud.
On energy-related work, a hybrid VMP algorithm based on an improved genetic algorithm using permutation and a multidimensional resource allocation strategy is proposed in [
18]. The proposed VMP algorithm aims to improve the rate of high power consumption of cloud data centers by minimizing the number of active servers that host virtual machines; it also seeks to achieve balanced use of resources (CPU, RAM, and bandwidth) of active servers, which in turn reduces wasted resources. Meanwhile, in [
19], the problem is formulated as an optimization of packaging to minimize the energy costs of operating machines and inactive machines. When considering the CPU and memory requirements of a virtual machine, the allocation is limited by the capabilities of the physical machine. Another work can be seen in [
20], where, in order to efficiently ensure quality of service (QoS), a VM approach is proposed that considers the current and future uses of resources through host overload detection.
1.4. Document Organization
Distributed processing and virtualization technologies are suitable tools when computing power is needed, as is the case with bio-inspired optimization algorithms, as their stochastic characteristics require running several times with different settings of their parameters. Therefore, this paper reviews a virtualized parallel processing scheme for the execution of bio-inspired optimization algorithms. The document is organized as follows. The first part reviews concepts on distributed computer systems and virtualization, and also presents the computer system used; then it describes the optimization of bio-inspired algorithms and the test functions considered, and subsequently presents the statistical results obtained, showing the configurations of the algorithms; finally, the conclusions of the work are established.
The objective of this work was to evaluate the virtualized distributed processing system located at the High Performance Computing Center (Centro de Computación de Alto Desempeño—CECAD) of the Universidad Distrital Francisco José de Caldas (UDFJC) which provides a distributed computing service in a virtualized way to the researchers of the UDFJC. The aim was to look at the characteristics of this system for the execution of bio-inspired optimization algorithms and the advantages that it has in relation to processing time.
2. Distributed Processing Systems
According to [
21], a distributed system is a collection of autonomous computer elements (nodes) visible to users as a single consistent system. Each of the computer elements can behave independently and can be hardware devices or a software process. In this way, users (people or applications) think they are dealing with a single system; this implies that collaboration between nodes must be presented, which is an important aspect in the development of distributed systems [
21]. A distributed system must have the following features to provide maximum performance to users:
Openness: This attribute ensures that a subsystem is continuously open to interaction with other systems, such as those designed to perform inter-machine interactions over a network by allowing distributed systems to expand and scale.
Scalable: A distributed system can function properly even if some aspect of the system scales to a larger size. Three components should be considered: the number of users and other entities that are part of the system, the distance between the farthest nodes of the system, and the number of organizations that exercise administrative control over parts of the system.
Predictable performance: Predictable performance is the ability to provide the desired responsiveness in a timely manner, according to a performance metric that may be the response time associated with the time elapsed between a query in a computer system and response. Another metric corresponds to the rate at which a network sends or receives data. Metrics associated with system utilization and network capacity can also be used to establish the performance.
Security: Security features are primarily intended to provide confidentiality, integrity, and availability; thus, distributed systems must allow communication between programs, users, and resources on different computers by applying the necessary security tools.
Fault-tolerant: Distributed systems consist of a large number of hardware and software modules that can fail in the long-term. Such component failures can result in a lack of service. Therefore, systems should be able to recover from component failures without performing erroneous actions.
Transparency: Distributed systems should be perceived by users and application developers as a whole and not as a collection of cooperating components. In this way, for the user the locations of the computer systems involved in the operations, data replication, failures, system recovery, etc., are not visible.
Types of Parallel Architecture
On the classification of parallel architectures, Michael Flynn proposed a taxonomy that simplified the categorization of different classes of architectures and control methods based on the relationships of data and instruction (control) with respect to the parallelism of the data flow [
22,
23].
There are different ways CPUs can be connected together; Flynn’s classification considers machines by the number of instruction flows and the number of data flows. Multiple instruction sequences mean that different statements can be executed simultaneously [
22,
23]. Data flows refer to memory operations whose four combinations are:
SISD (single instruction stream, single data stream): This classification corresponds to the traditional single-processor computer. It represents the conventional sequential (serial) processor structure where a single control thread, the flow of instructions, guides the sequence of operations performed on a single data set, one operating at a time.
SIMD (single instruction stream, multiple data streams): This architecture supports multiple streams of data to be processed simultaneously by replicating computer hardware. Single statement means that all data streams are processed using the same calculation logic. It can be seen as an array processor, where a single instruction operates in many data units in parallel.
MISD (multiple instruction stream, single data stream): Corresponds to a rare architecture, which operates in a single data flow but has multiple computing engines that use the same data flow. That is multiple processors, each with their own flow of instructions, working on the same data with which all the other processors operate. They could be used to provide fault tolerance with heterogeneous systems operating with the same data.
MIMD (multiple instruction stream, multiple data stream): This is the most generic parallel processing architecture where any type of distributed application is programmed. Multiple stand-alone processors running in parallel work in separate data flows. The logic of the applications running on these processors can also be very different. All distributed systems are recognized as MIMD architectures. At any time, a lot of operations are performed, but they do not have to be the same and are mostly different.
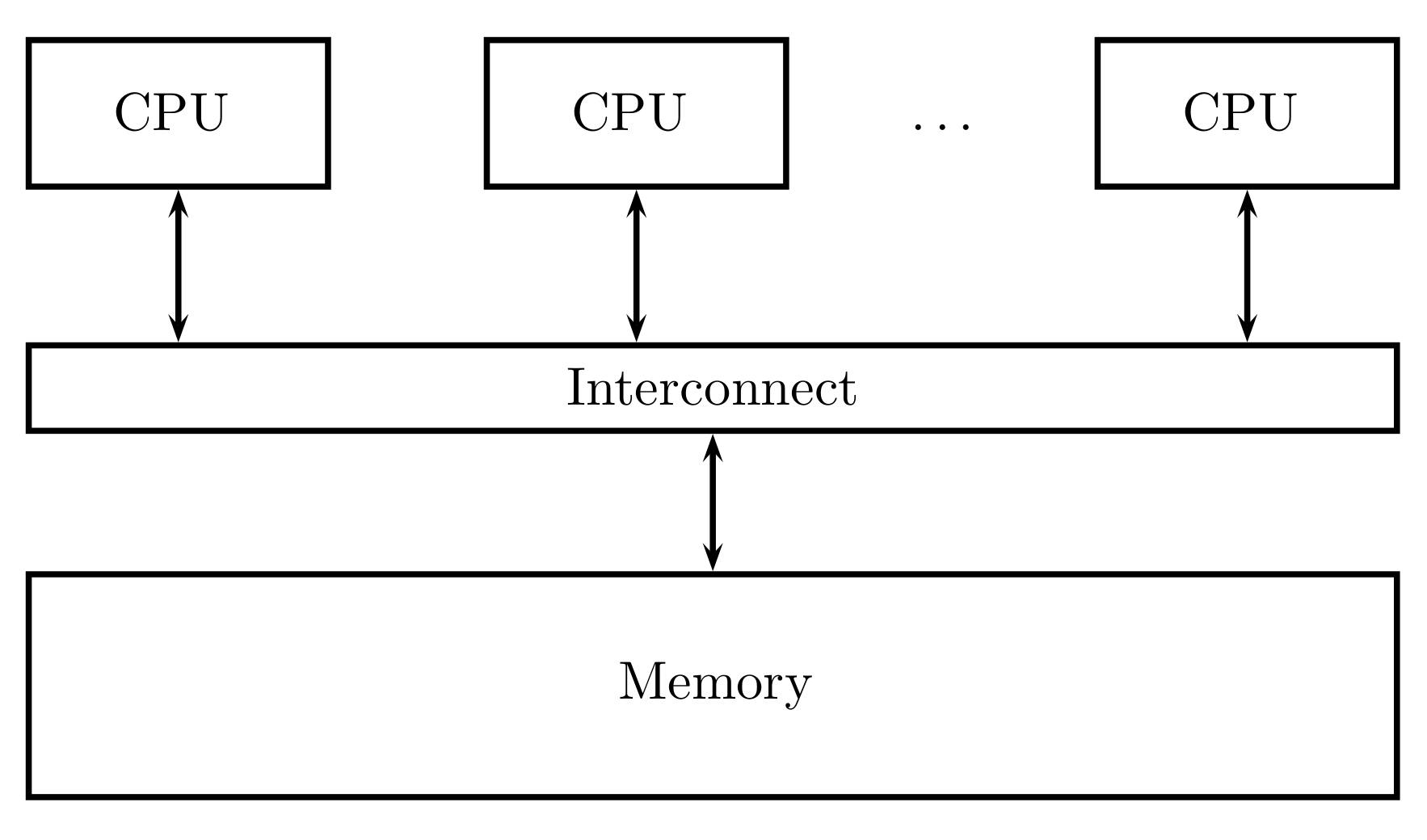
Shared memory and distributed memory systems are two main types of MIMD. In a shared memory system (
Figure 1), a collection of stand-alone processors is connected to a memory system over an interconnected network, and each processor can access each memory location. In a shared memory system, processors are usually implicitly communicated by accessing shared data structures.
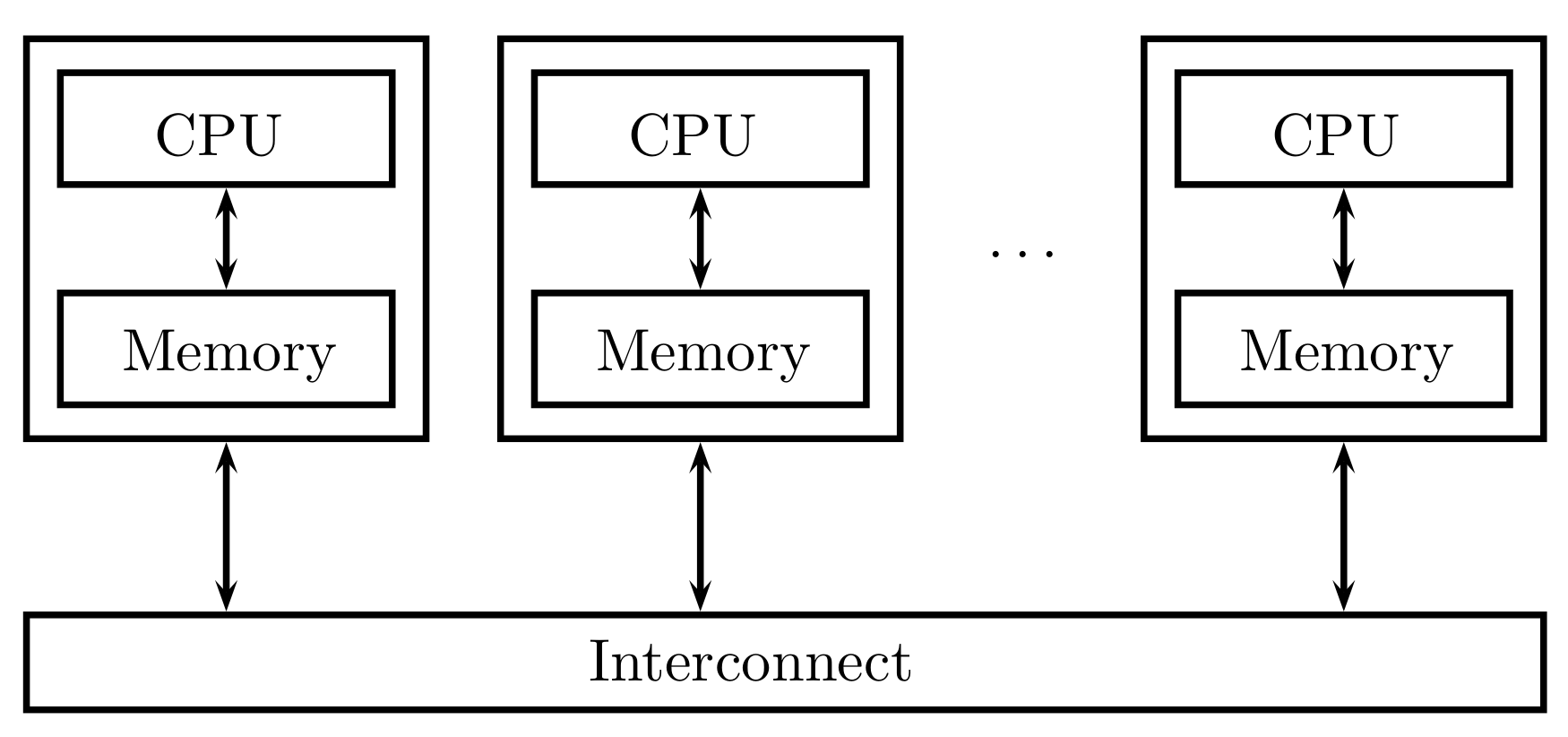
In a distributed memory system (
Figure 2), each processor is coupled with its own private memory, and processor-memory pairs communicate over an interconnected network. On distributed memory systems, processors generally communicate explicitly by sending messages or using special functions that provide access to the memory of another processor [
24].
3. Description of Virtualization Systems and Process
The strengthening of the cloud computing model has oriented bets on technological resources towards virtualization, and today this methodology has positioned itself as a computational requirement that all kinds of organizations demand for operation, due to the ability to access the information at all times and with the advantage that it allows them to significantly reduce the operating costs in terms of software and hardware resources.
When a cloud computing model becomes extensible, the use of virtualization is increasingly necessary; it is also essential to create new design and integration standards that regulate it. “Virtual infrastructure solutions are ideal for part-to-production environments because they run on industry-standard servers and desktops and are compatible with a wide range of operating systems and application environments, as well as infrastructure and storage” [
25].
In the field of computer applications, the infrastructure corresponds to the set of elements that are necessary for the development of an activity [
25,
26]. In general, two types of infrastructure are identified: hardware (physical) infrastructure and software (logical) infrastructure. The first consists of elements as diverse as air conditioners, sensors, cameras, servers, routers, firewalls, laptops, printers, phones, etc.
The set of logical or software elements ranges from operating systems (Linux, Windows, etc.) to general applications that enable the operation of other specific computer systems of services, such as databases, application servers, or office tools for the suite of applications and computer tools used in the office to optimize, automate, and improve related procedures or tasks.
On the other hand, the term virtualization can be understood as creating through software a virtual version of some technological resource such as a hardware platform, an operating system, a storage device, or another resource network [
27].
Nowadays, the consolidation of the cloud computing model has steered towards virtualization as a daily requirement within the technological resources that all kinds of companies require for their operation, permanently accessing and reducing their capital expenditures. The advantages of this model are summarized in three factors: economy, flexibility, and security. A cloud solution can add or remove workstations and servers, and modify their capabilities or configurations almost immediately [
28].
A virtualized system includes a new software layer, namely, a virtual machine manager (VMM). The primary function of VMMs is to arbitrate access to resources on the underlying physical host platform so that multiple operating systems (which are VMM guests) can share them. VMM presents each host OS (operating system) with a set of virtual platform interfaces that constitute a virtual machine. Despite once being confined to specialized servers and owners, and high-end mainframe systems, virtualization is now increasingly available. The resulting VMM can support a wider range of legacy and future operating systems while maintaining high performance [
29].
The classic benefits of virtualization include better utilization, manageability, and reliability of core framework systems. Multiple users with different operating system requirements can more easily share a virtualized server, operating system updates can be organized on virtual machines to minimize downtime, and the failures of the guest software can be isolated on the virtual machines on which they are produced. While these benefits have traditionally been considered valuable in high-end server systems, recent academic research and new VMM-based emerging products suggest that the benefits of virtualization have greater attractiveness in a wide range of both server and client systems [
29].
Virtualization can improve overall system security and reliability by isolating multiple software stacks into self proper virtual machines. Security can be improved because the instructions can be limited to the VM on which they occur, while reliability can be improved because the software failures on one VM do not affect the other VMs [
29].
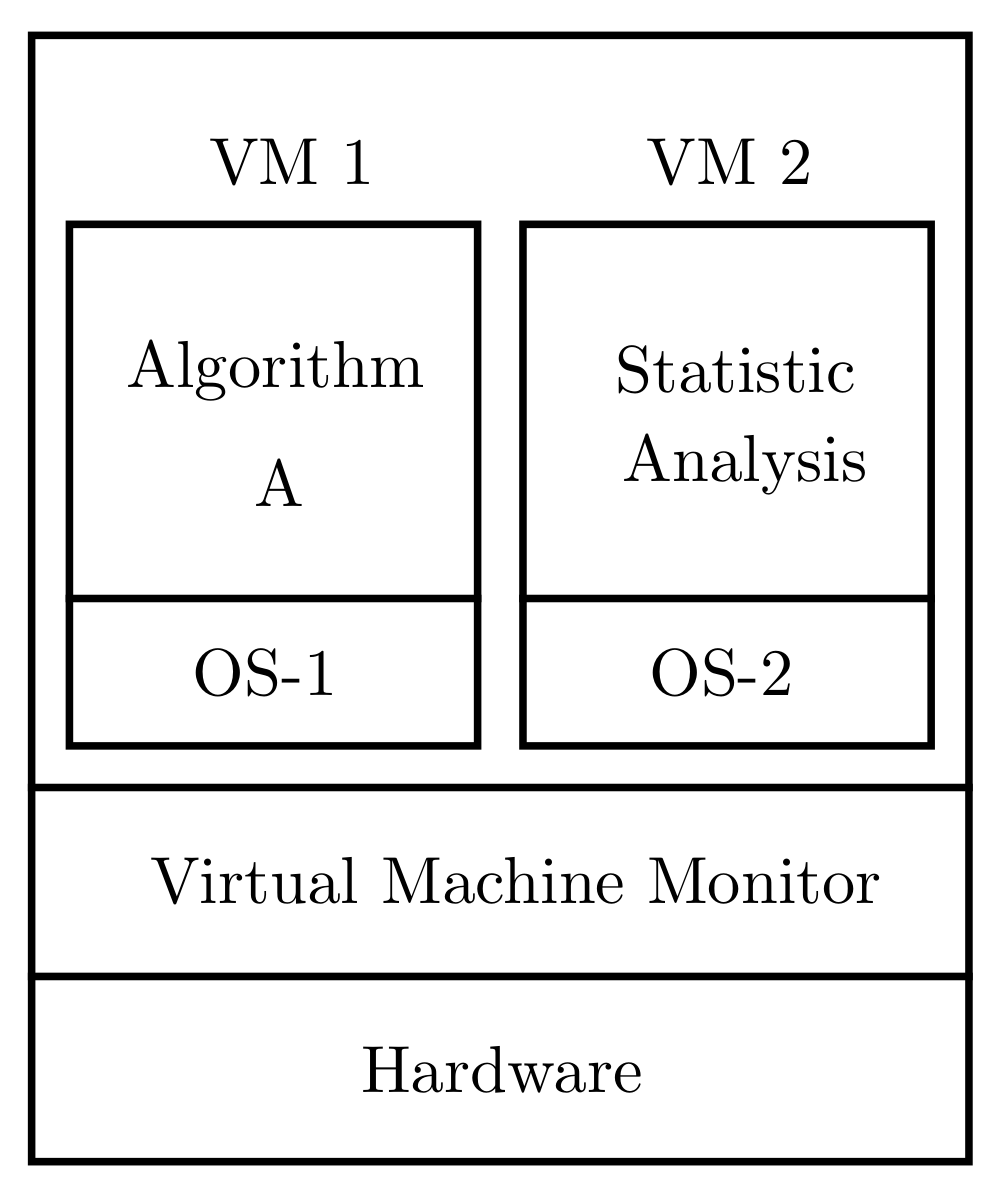
Virtualization allows running the two environments on the same machine, as can be seen in
Figure 3, so that these two environments are completely isolated from each other.
In the case of optimization algorithms, the GA algorithm runs on the OS1 operating system and the statistical analysis is executed on the OS2 operating system. Both operating systems run on top of the virtual machine monitor. VMM virtualizes all resources (for example, processors, memory, secondary storage, and networks) and allocates them to the various virtual machines running over VMM [
30].
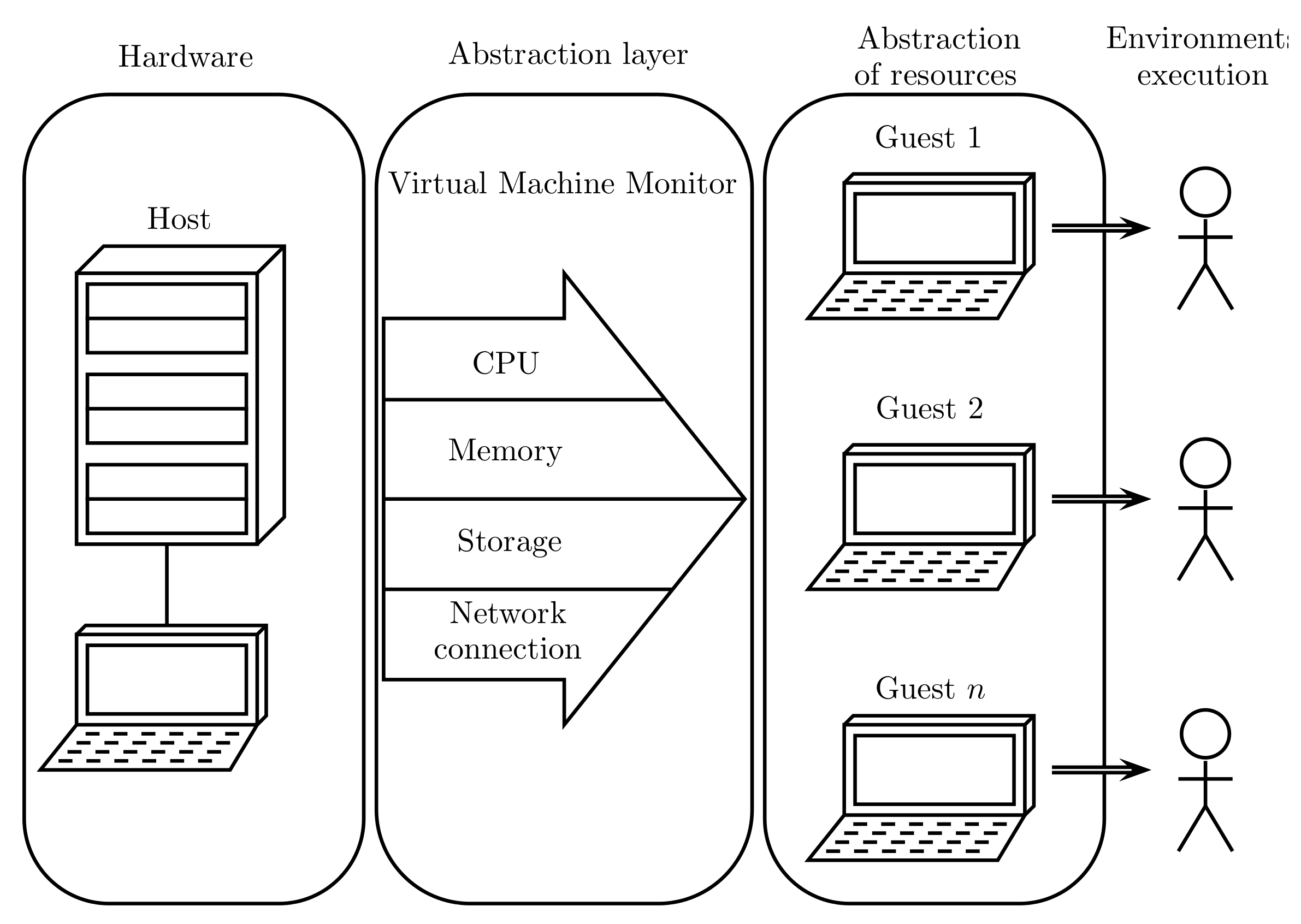
Figure 4 depicts the virtualization process, where the VMM creates an abstraction layer between the host hardware and the virtual machine operating system, appropriately managing its core resources (CPU, memory, storage, and network connections).
4. Virtualized Distributed Processing System Used
This section describes the virtualized distributed platform for executing bio-inspired optimization algorithms. The computer system consists of network modules, storage, and processing. In
Figure 5a is the network module, while
Figure 5b shows the storage, and finally,
Figure 5c shows the processing system.
This computer system corresponds to the High Performance Computing Center (Centro de Computación de Alto Desempeño—CECAD) of the Universidad Distrital Francisco José de Caldas (UDFJC) which provides a distributed computing service in a virtualized way to the researchers of the UDFJC. Once the resources requested by the researcher are allocated, access to the system can be done remotely.
Infrastructure Used
The characteristics of the infrastructure used are:
Operating system: Ubuntu Version 18.04.
RAM memory (GB): 14.5.
Number of processors: 16.
Main storage (GB): 80 GB.
Secondary storage (GB): not used.
Software used: Octave.
Figure 5c shows the physical appearance of the server used. The features of the R610 Server are:
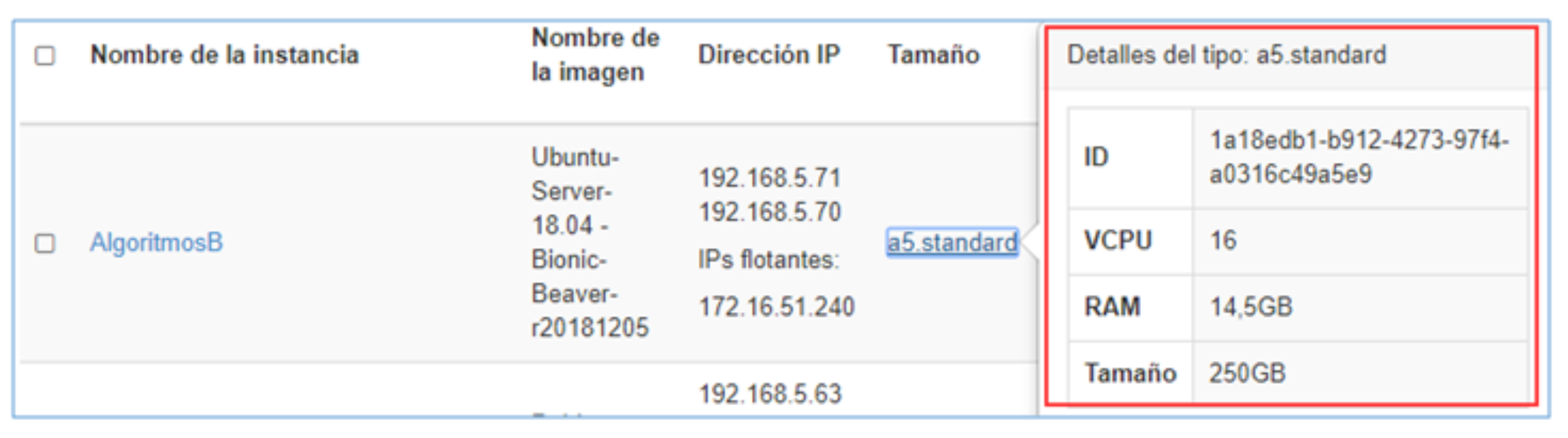
The CECAD private cloud has multiple R610 compute nodes, when using Openstack to provide infrastructure as a service (similar to Amazon EC2); this technology takes one of these servers to deploy the requested instance, in this case the "
AlgoritmosB" instance. On the other hand, even though the server storage is apparently limited (73 GB), it has been configured through an architecture that uses the CEPH File System tool, a feature that allows allocating higher storage, in this case of 250 GB, since CEPH is configured to allow nodes to access 100 TB storage from the CECAD SAN.
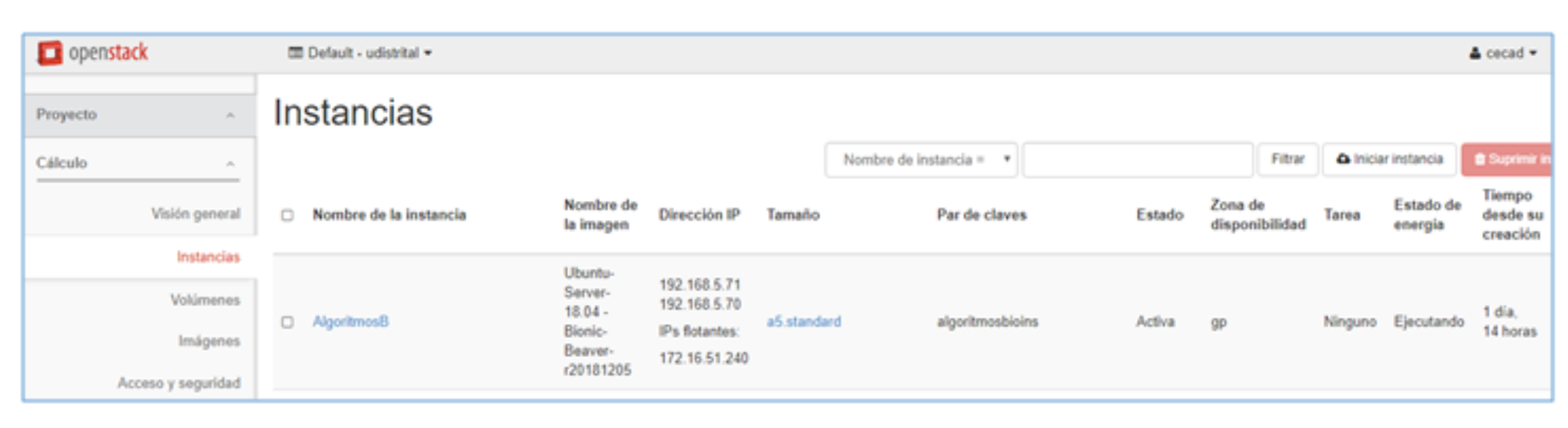
Figure 6 shows the instances using Openstack. The characteristics of the instance used are presented in
Figure 7.
5. Bio-Inspirated Optimization Algorithms
The bio-inspired optimization algorithms considered for the testing of the processing system are: genetic algorithms, differential evolution, and optimization based on swarms of particles. The following is the description of these algorithms; then the parameter configuration used is shown.
5.1. Genetic Algorithms
Genetic algorithms (GA) are one of the approaches to stochastic optimization, which is a reference to evolutionary computing algorithms that are based on principles of natural evolution and survival [
31]. A GA seeks to improve a population by establishing a point at which the performance function is optimized; thus, simultaneously, multiple candidate solutions are considered [
31]. The general steps of a genetic algorithm are as follows:
Start the population randomly.
Evaluate the performance of each individual.
Stochastically select the best individuals.
Apply the elitism operator.
Apply the crossover operator.
Apply the mutation operator.
If the completion criterion is not met, return to step 2.
Finish by meeting the stop criterion and establish the final solution.
In the first step an initial population is generated randomly and the fitness function is evaluated for each individual. Then it can use an elitist selection strategy where the best individuals determined by the aptitude assessment move on to the next generation. The next step is to stochastically apply the crossover operator where the parents are selected according to the aptitude value; in this way, individuals who have higher fitness values are selected more frequently. For each pair of parents, the respective crossing is made at random; when not crossing, two children are formed that are copies of the two parents. Subsequently, the operator of the mutation is applied where an element of the individual encoding that has been obtained in the previous step is changed randomly. Finally, the values of the objective function are calculated for the new population and the algorithm is terminated if the stop criterion is met [
31,
32].
5.2. Differential Evolution Algorithm
The differential evolution (DE) algorithm was initially proposed by Storn and Price [
33,
34]; this corresponds to an evolutionary computing algorithm where the next population is established considering the subtraction between individuals of the current population using a crossover/recombination operator after the mutation [
35]. The main steps of a DE algorithm are as follows:
Initialize the population in the solution space.
Apply the subtraction operator.
Apply the recombination operator.
Evaluate the performance of each individual.
Perform the selection process.
If the completion criterion is not met, return to step 2.
Finish by meeting the stop criterion and establishing the final solution.
In a first instance, the population is started randomly; then the subtraction operator is applied, followed by the recombination operator; in the next step, the selection process is performed. These processes are performed until the criterion is met.
Taking two randomly chosen individuals
and
from the population, the subtraction operator incorporates the difference between these individuals into a third individual
in such a way that it has a new
individual which corresponds to:
Using the mutation constant
, the subtraction between individuals is set. After the mutation, a recombination operation is performed on each
individual to generate a
individual which is constructed by mixing the
and
components. This is what a random number is used for
having the follow equation:
If an improvement of the objective function is achieved with the intermediate individual , this replaces the individual ; otherwise, it remains in the next generation.
5.3. Particle Swarm Optimization Algorithm
The concept of swarm-based optimization was proposed by James Kennedy and Russell Eberhart based on the social behavior of bird flocks [
6]. In general, the steps involved in the PSO (particle swarm optimization) algorithm are as follows:
Initialize the swarm in the solution space.
Evaluate the performance of each individual.
Find the best individual and collective performances.
Calculate the speed and position of each individual.
Move each individual to the new position.
If the completion criterion is not met, return to step 2.
Finish by meeting the stop criterion and establishing the final solution.
As it is appreciated, in a first instance the swarm is initialized in the solution space; then the performance of each individual is evaluated by finding the best individual and collective performances; with these values the speed of each particle is calculated. That is used to determine the displacement of each individual to the new position. The above processes are carried out until a completion criterion. The following expression is used to establish the position of each individual:
For the calculation of the speed there are different alternatives, one of the most representative ones being the one which incorporates an inertia factor described by the following equation:
In the above equations, and correspond to the velocity and position of the individual i-th. On the other hand, is the best position found by the i-th individual, and is the best position found by the swarm. Additionally, and are random numbers in the range . Finally, w is an inertia value, acceleration constant of the social part and acceleration of the cognitive part.
6. Experiments Configuration
The configuration of the algorithms is done considering two representative cases, which are executed on eight test functions with and without virtualization. With these experiments we sought to show that the virtualization scheme allows reducing the execution times of the algorithms without altering their performances.
6.1. Configuration for Genetic Algorithms
Two recommended standard configurations are used for the case considered. The first configuration uses 50 individuals with mutation probability of
and crossover probability of 0.6 [
36]. The second configuration has 30 individuals, mutation probability of
, and probability associated to the genes exchanged between individuals equal to
[
37].
Table 1 summarizes the deployed configurations.
6.2. Configuration for Differential Evolution
The method of differential evolution starts from a randomly initialized population, with which the following population establishes itself, considering the difference between individuals of that population. Two configurations of the differential evolution algorithm were used for this algorithm, considering the recommendations proposed by [
38].
The first configuration has 40 members, probability of crossing equal to
, and the step size of
; for the second configuration, taking into account the rule given by Price and Storn [
33], the number of members is 20, the probability of crossing is 1 since the high values guarantee the appropriate contour conditions for the evolution algorithm [
34], and the step size is
. The summary of the configurations is presented in
Table 2.
6.3. Particle Swarm Optimization Configuration
For PSO, the two configurations proposed by [
39] are used for the PSO algorithm with inertia factor. Parameter selection is based on an analysis of the dynamic behavior of the swarm. Both cases use 30 particles;
Table 3 shows the selected configurations.
7. Tests Functions
Ideally, the test functions chosen to evaluate an optimization algorithm should contain features similar to the real-world problem. However, specialized literature is characterized by the use of artificial functions to perform tests on these optimization algorithms.
The multi-dimensional test functions can be seen in
Table 4; the selection was made considering the reports [
40,
41,
42,
43], wherein they are used for testing with bio-inspired algorithms. The characteristics of the test functions can be seen in
Table 5. This table shows that the functions employed have different limits of the search space.
As noted in
Table 5, the test functions
,
, and
have the minimum localized value at a non-zero point, while for all other test functions the global minimum is located at zero.
8. Experimental Results
This section compares the performances of the selected bio-inspired algorithms with and without the virtualization scheme. The results are first reviewed considering the value obtained from the target function, and then the results obtained from the execution time (run-time) are analyzed.
In these results M2 corresponds to the distributed processing scheme, while M1 refers to the dedicated PC (personal computer) with the following characteristics.
In both cases, the algorithms and data collection were performed in the free Octave software. Each configuration ran 50 times for each test function (taking 10 dimensions).
In order to identify the results, the first part of the respective tag refers to the class of algorithm AG, DE, or PSO; then the type of configuration C1 or C2 is indicated; finally, the machine is M1 or M2, with which the algorithm was executed.
Here are used different source files for experiments; for the implementation of GA the source from GitHub posted by user "shenbennwdsl" in [
44] was used; in the case of DE, the files developed by Rainer Storn, Ken Price, Arnold Neumaier, and Jim Van Zandt posted in [
45]; for PSO the source file developed by Matthew P. Kelly downloaded from [
46]; for test functions, the archives developed by Brian Birge from [
47] were used; and Sonja Surjanovic and Derek Bingham posted in [
48]. Finally, all archives used in this work to implement the experiments and present the results can be downloaded from GitHub in [
49].
8.1. GA Algorithm Results
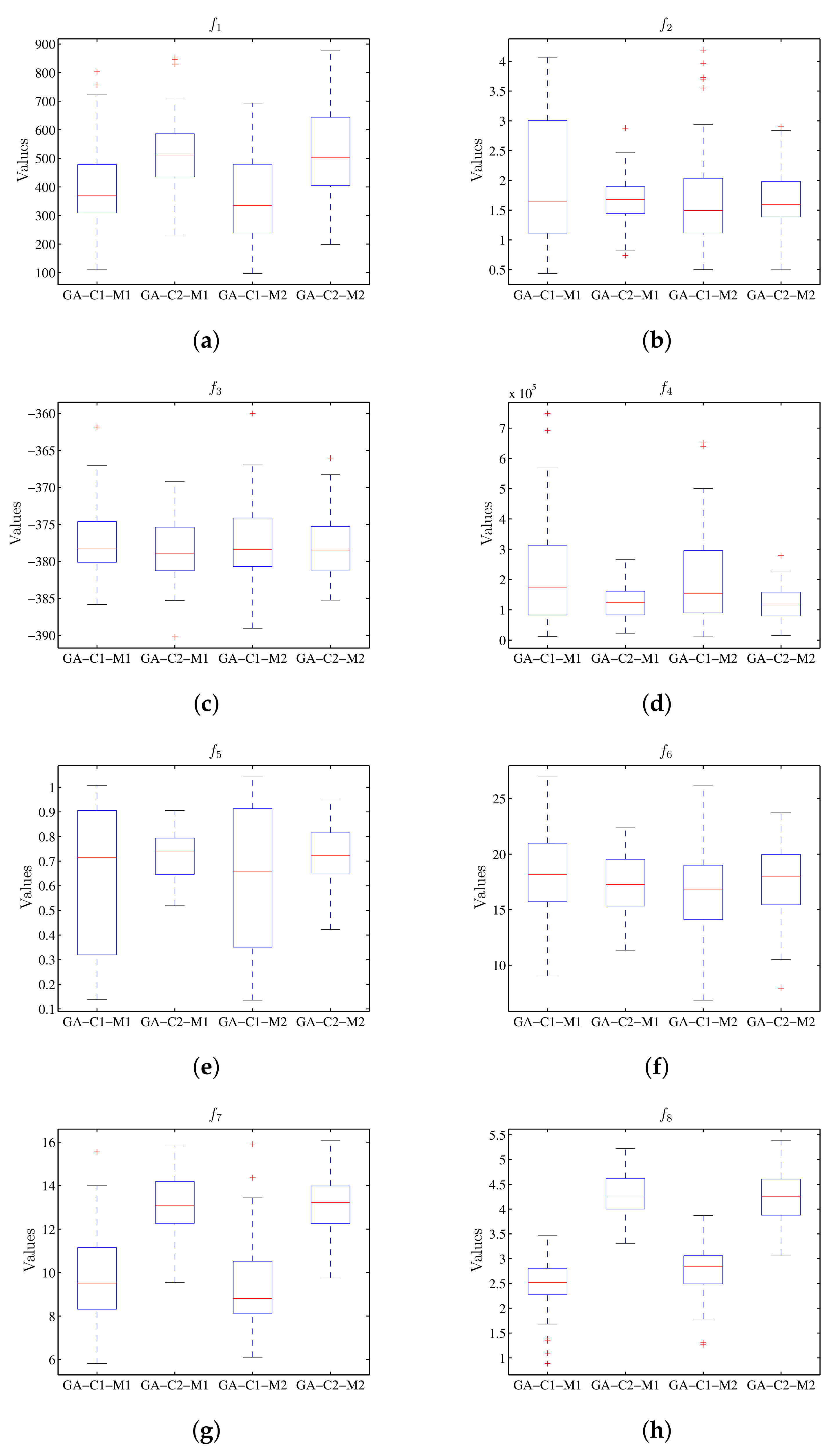
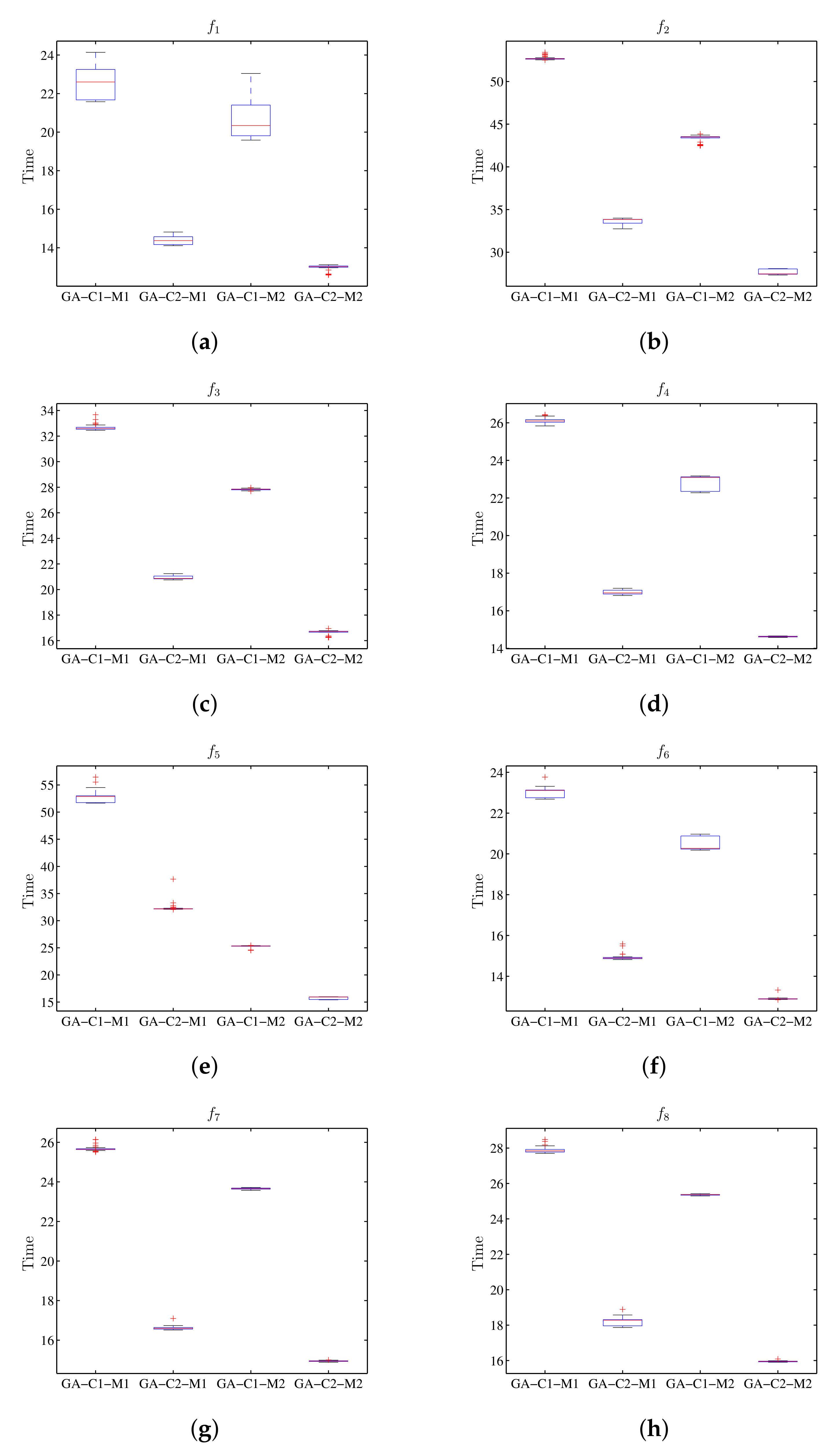
Table 6 shows the results when performing the execution of the genetic algorithm for the value of the target function, and
Table 7 shows the results for the run-time. Graphically, the results obtained for the values of the target function can be seen in a diagram of stems and sheets in
Figure 8 and
Figure 9 for run-time. In
Figure 8 the configurations associated to M1 and M2 present similar results for the objective functions; meanwhile, in
Figure 9 in all cases the processing time associated with machine M2 is less that than of M1.
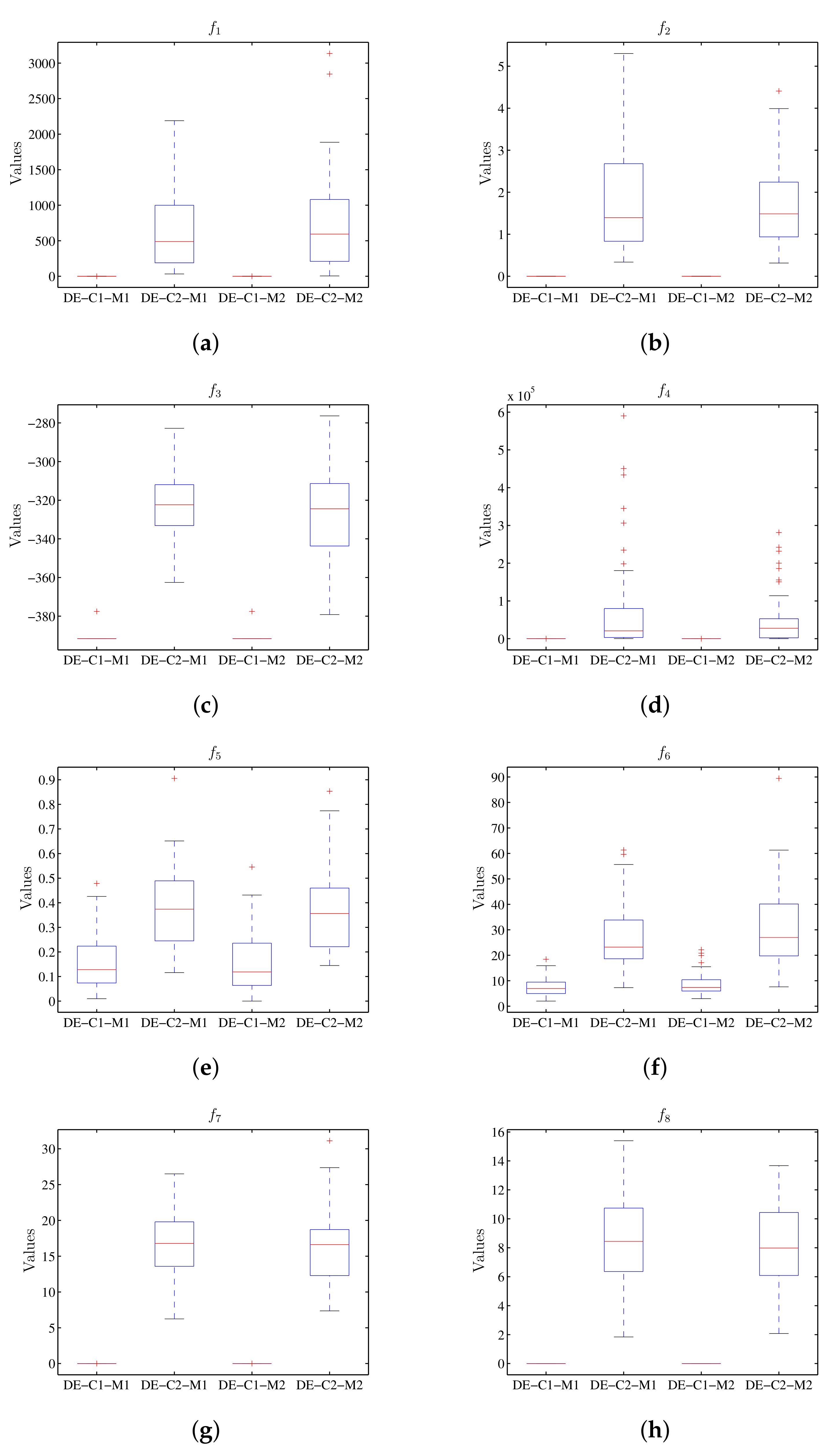
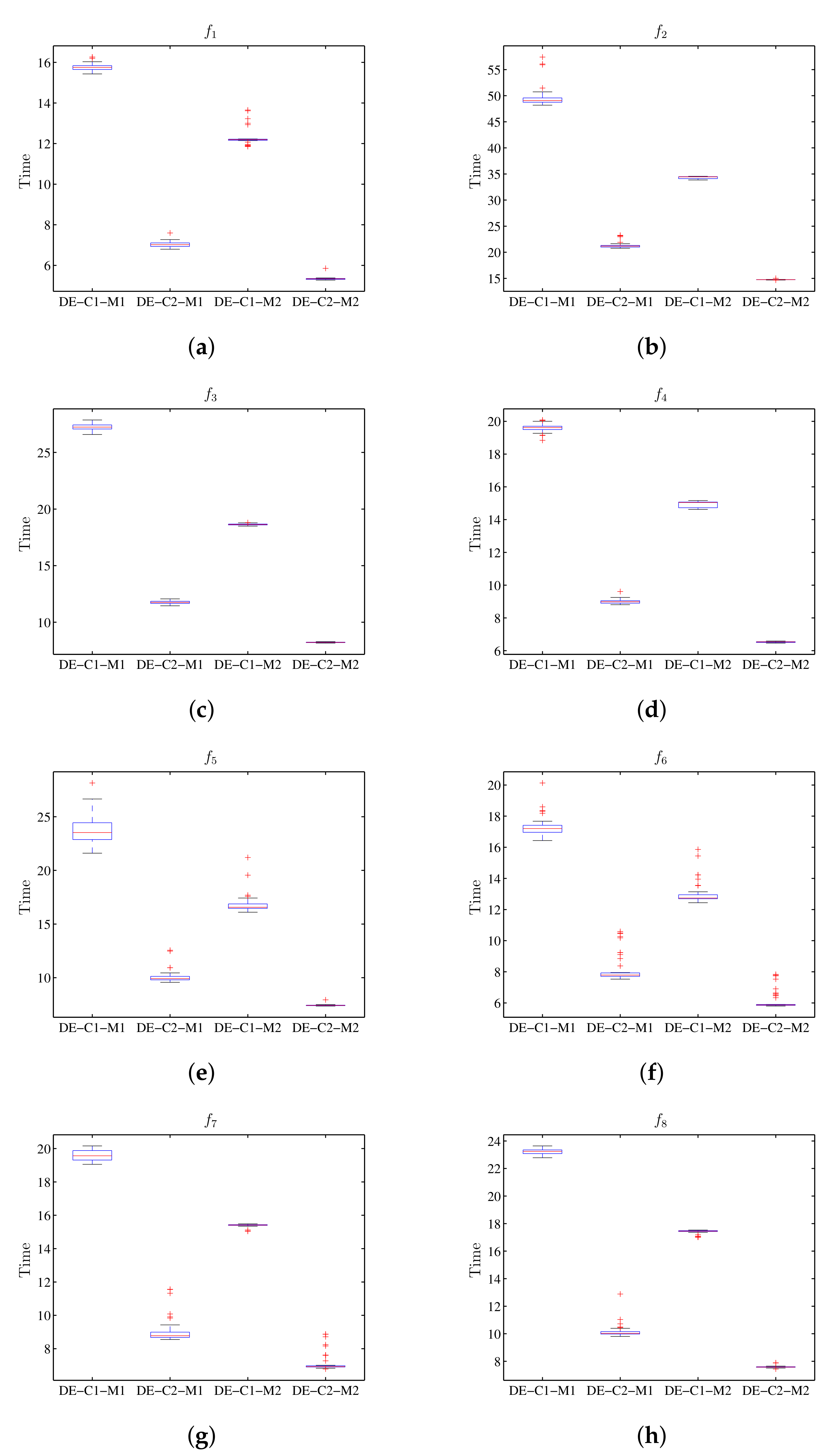
8.2. DE Algorithm Results
The execution of the differential evolution algorithm in
Table 8 shows the summary of the statistical results for the value of the target function, while
Table 9 has the run-time. The graphical presentation of the results obtained is shown in
Figure 10; the diagrams of stems and sheets for the value of the target function are also shown.
Figure 11 provides the diagrams of stems and sheets for the run-time. The results of
Figure 10 show that configuration C1 of the DE algorithm executed in machine M1 has similar results to those obtained in machine M2 for the value of objective function; the same happens using configuration C2 when executed in M1 and M2. Meanwhile, considering the run-time,
Figure 11 shows that when executing the configuration C1 in machine M2, less run-time is observed compared to the same execution using machine M1; for configuration C2 there is also less run-time when using M2.
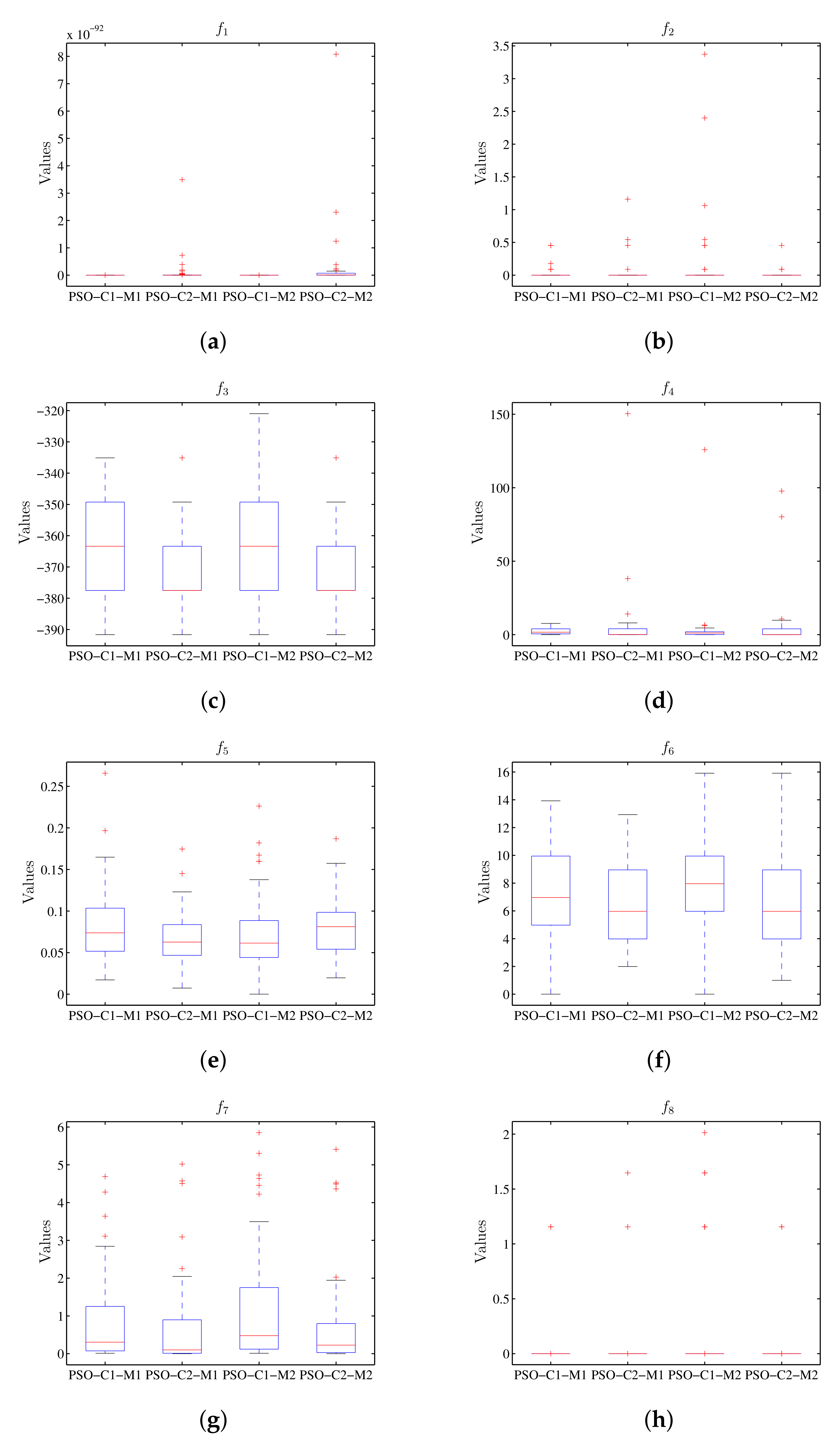
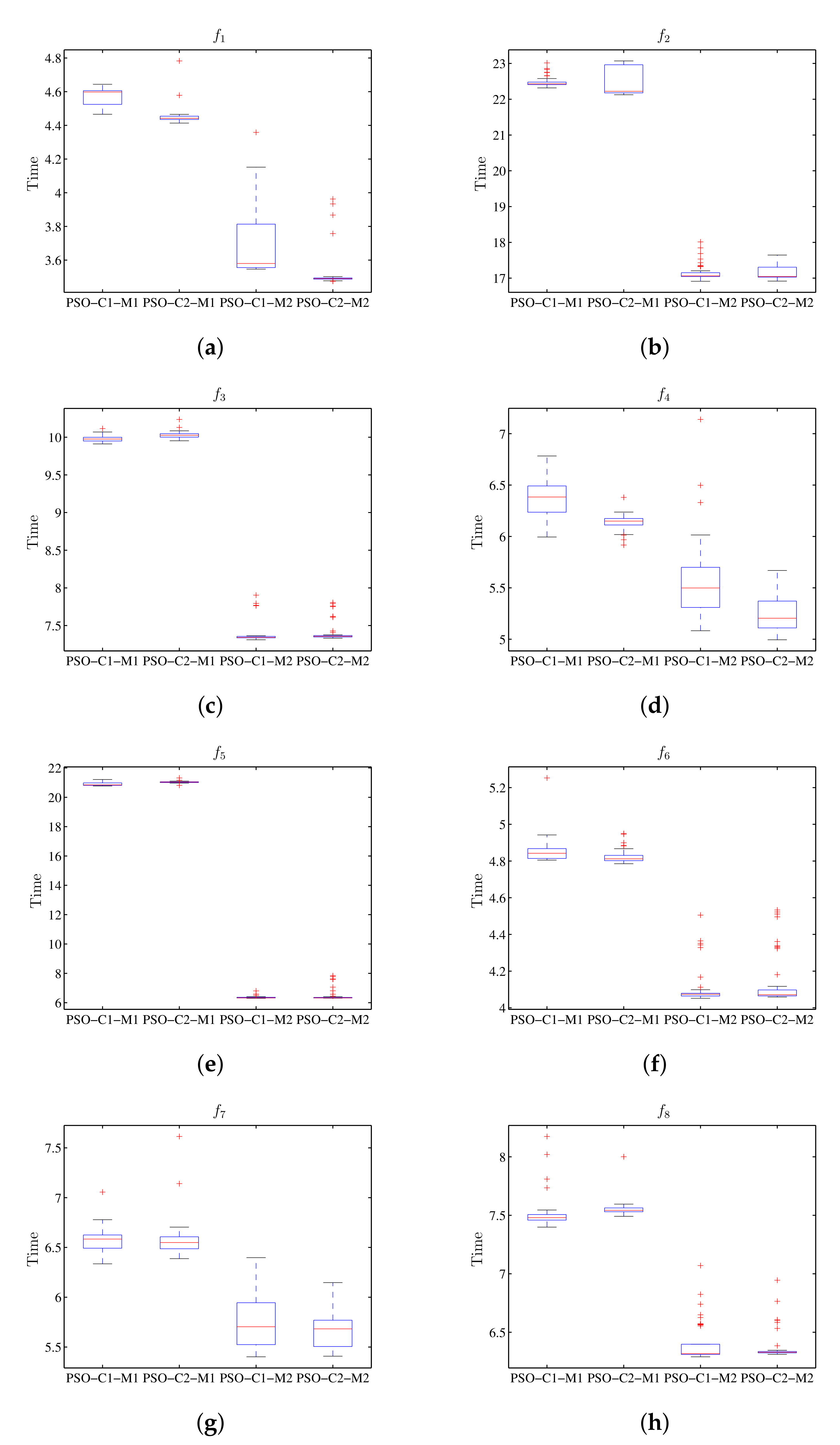
8.3. PSO Algorithm Results
Table 10 and
Table 11 display the statistical results for the value of the target function and the run-time for the PSO algorithm. The stem and leaf diagrams of the results can be seen in
Figure 12 and
Figure 13 for the values of the objective function and the execution time respectively. As observed in
Figure 12, the value of the target function is not affected by the distributed processing scheme, while the run-time is reduced by using this schema (
Figure 13).
8.4. Algorithm Comparison
It is worth pointing that this work is focused in the observations of the changes amidst the execution of each algorithm in the machines employed (M1 and M2); therefore, the results are presented separately for each algorithm; nevertheless, it is also important to bear in mind that after defining the hardware to implement the experiments, the study should be focused on the algorithm comparison (variation among them), which requires the organization of the results in a single table. As an example,
Table 12 displays the summary of results considering the objective function while
Table 13 displays the results for the execution time.
Usually, these tables highlight the best value reached by one of the algorithms (for each test function) in a way that a global comparison can be made for both the obtained value of the objective function and the execution time for the algorithms employed.
Table 12 and
Table 13 show an example each of the way by which the best obtained values can be noted.
8.5. Execution Time Analysis
As previously observed in the results obtained, the values of the target function for configurations C1 and C2 are not affected by the type of processing system—executed in M1 or M2, but the processing time is affected. For the above, this section only performs an analysis of the execution times of the algorithms, this in order to observe the difference present in the execution time.
First,
Table 14 contains the total run-time values for each configuration of the GA algorithm in each target function. Secondly, the total results for the time of execution of the DE algorithm can be seen in
Table 15. Finally, the total run-time values of the PSO algorithm are presented in the
Table 16.
The total values for the execution times of each algorithm can be seen in
Table 17. In this way, a total difference of 11,054 s that corresponds to 3.07 h in the execution of all algorithms can be seen, equivalent to
. In this order, the percentage corresponds to time gained for GA which is
for DE
and
for PSO. The percentage of time gained (TG) is calculated using the following equation:
9. Discussion
In the results, it can be seen that on average, the values obtained from the objective functions are not affected, which allows the experiments to be reproduced on different machines. It is also appreciated that when using the CECAD machine the processing time decreases, which was sought to verify with this work.
It should be noted that in this work that the effects of the parameters of the algorithms on the objective function were not closely analyzed, since we sought to observe that the same result was obtained on average for the two machines used. In order to carry out performance tests between algorithms, we first seek to establish the most appropriate computing system.
Although we observed the advantage that the virtualized distributed processing system has for the execution of the algorithms considered, only one possible configuration offered by CECAD was used, which was limited to the requests of the researchers at the time of executing the algorithms. To consider this aspect in additional work, the availability of resources held in CECAD for an average researcher as well as the time allocated for their use can be included in the study. About this, it is necessary to take in account the request in the way that the administration can manage these resources and not leave other researchers without access.
For further research, the report [
50,
51] can be taken as a reference since greater size and complexity of the test functions can be considered for testing the efficacy of the distributed system. In the first place, the report [
50] can be considered for the testing of bio-inspired algorithms using parallel PC cluster systems for large-scale multimodal functions; secondly, the functions discussed in [
51] can be used to observe the problem complexity.
Considering the restrictions of CECAD for extending this work, other computing systems can be considered, such as a non-homogeneous cluster of PCs; and a cluster with mini PCs, such as small single-board computers like Raspberry Pi. Additionally, we could consider evaluate various ways of distributing the execution of bio-inspired optimization algorithms.
10. Conclusions
Aiming at a wide range of experiments, the tests were performed with three bio-inspired algorithms under different parameter configurations using eight test functions which had different characteristics. To have comparable results, the well-known bio-inspired optimization algorithms GA, DE, and PSO were used.
The results showed that the value of the target function is not affected by the distributed virtualization scheme, while the run-time is reduced by using the distributed virtualization system. Thus, the algorithms can be executed on different machines without affecting the result.
Distributed and virtualization technologies can optimize performance and simplify the management of the information infrastructure, as they do when running bio-inspired optimization algorithms. As seen in the results, the processing time decreases when using the CECAD.
In the development of this work it was observed that the distributed virtualization system under consideration is an adequate platform for the execution of bio-inspired optimization algorithms. However, in the case of CECAD, the amount of resources and the computing capacity are subjected to the number of requests made by the researchers.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}