Validation of the Topp-Leone-Lomax Model via a Modified Nikulin-Rao-Robson Goodness-of-Fit Test with Different Methods of Estimation




Abstract
:1. Introduction and Motivation
- (1)
- Modeling the right skewed data sets especially the right skewed heavy tail data sets.
- (2)
- Modeling the right skewed and symmetric data sets especially in case of modeling a certain data for the first time ever.
- (3)
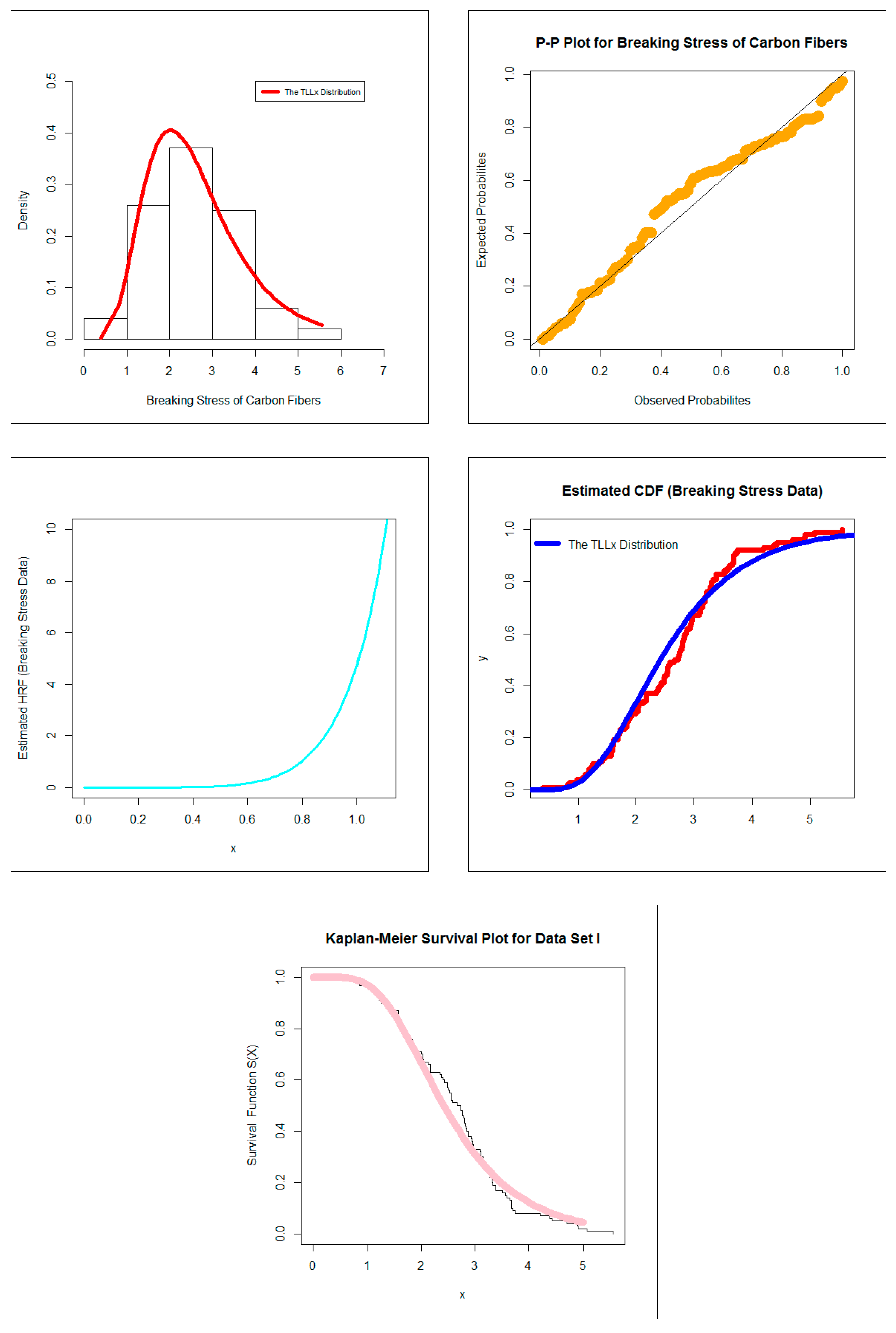
- In physics and reliability analysis, the TLLx model can be applied in modeling the breaking stress data. As shown in Tables 5 and 9, the TLLx model showed its superiority against the standard Burr XII, the Marshall-Olkin Burr XII, the Topp Leone Burr XII, the Zografos-Balakrishnan Burr XII, the five parameters beta Burr XII, the beta Burr XII, the beta exponentiated Burr XII, the five parameters Kumaraswamy Burr XII and Kumaraswamy Burr XII distributions.
- (4)
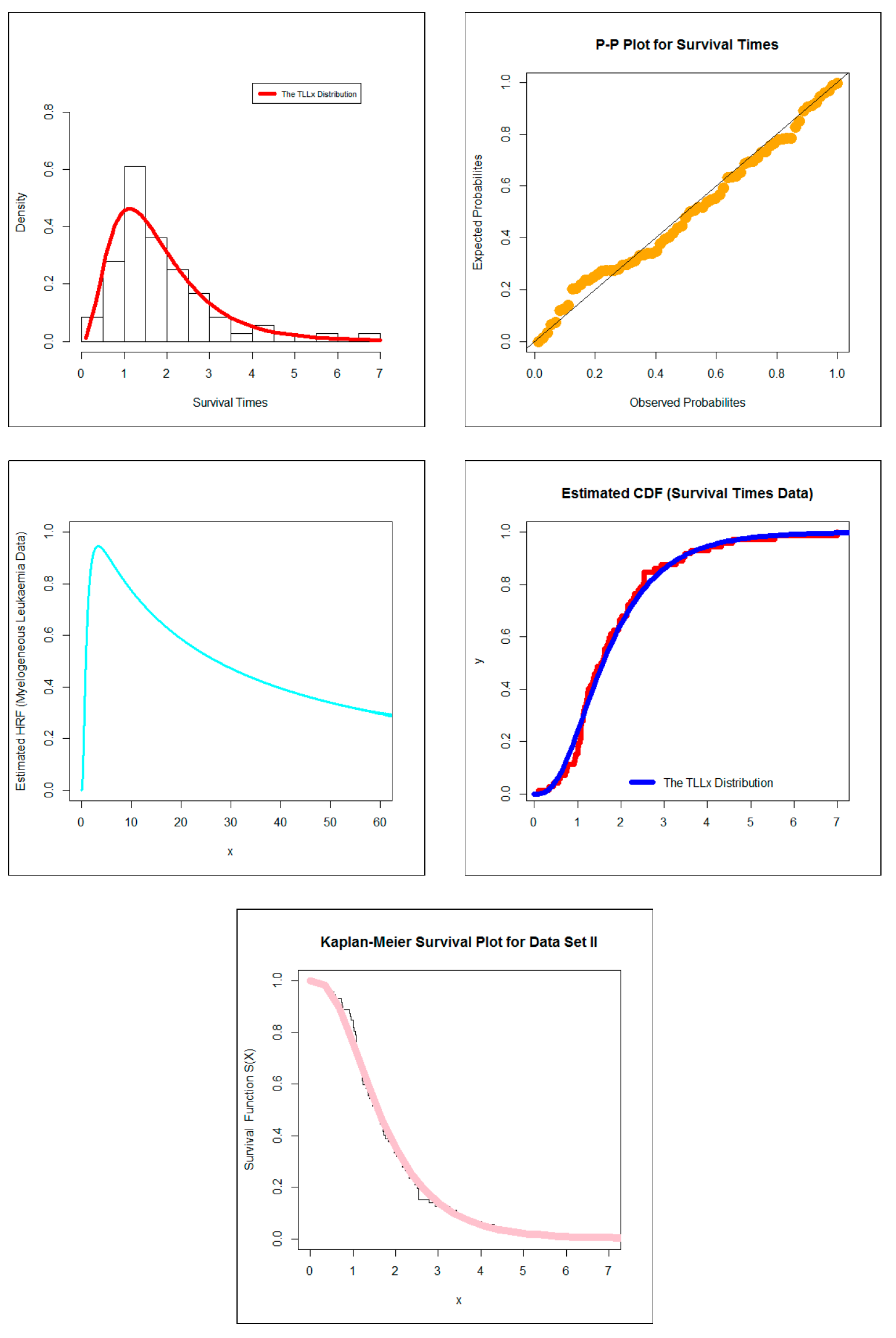
- In survival analysis, the new model can be chosen in modeling the survival times data. As illustrated in Tables 6 and 10, the new model showed its superiority against all competitive models as mentioned in Table 4.
- (5)
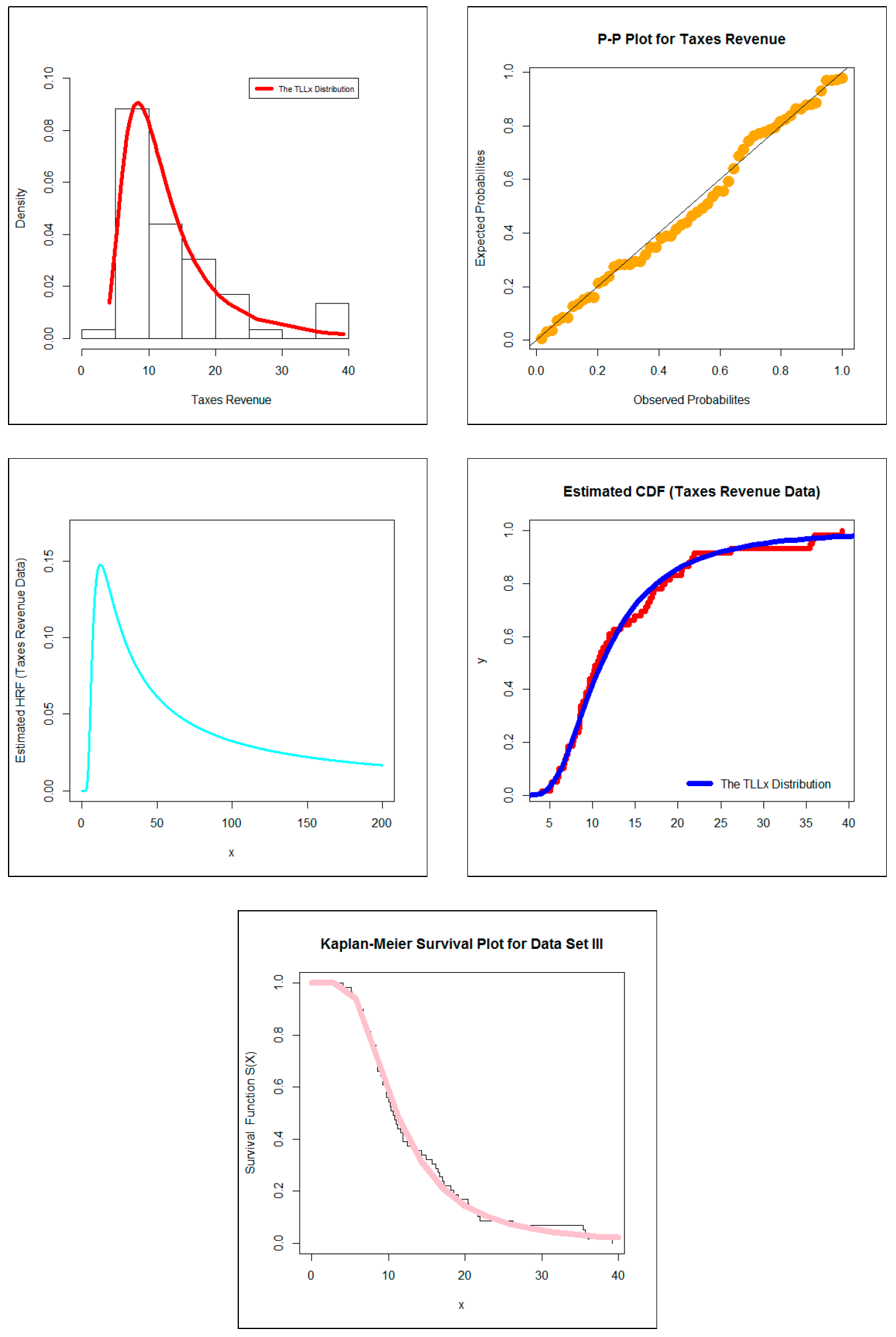
- In econometrics, the new model can be used in modeling the taxes revenue data. From Tables 7 and 11 we note that the new model showed its superiority against many well-known competitive models.
- (6)
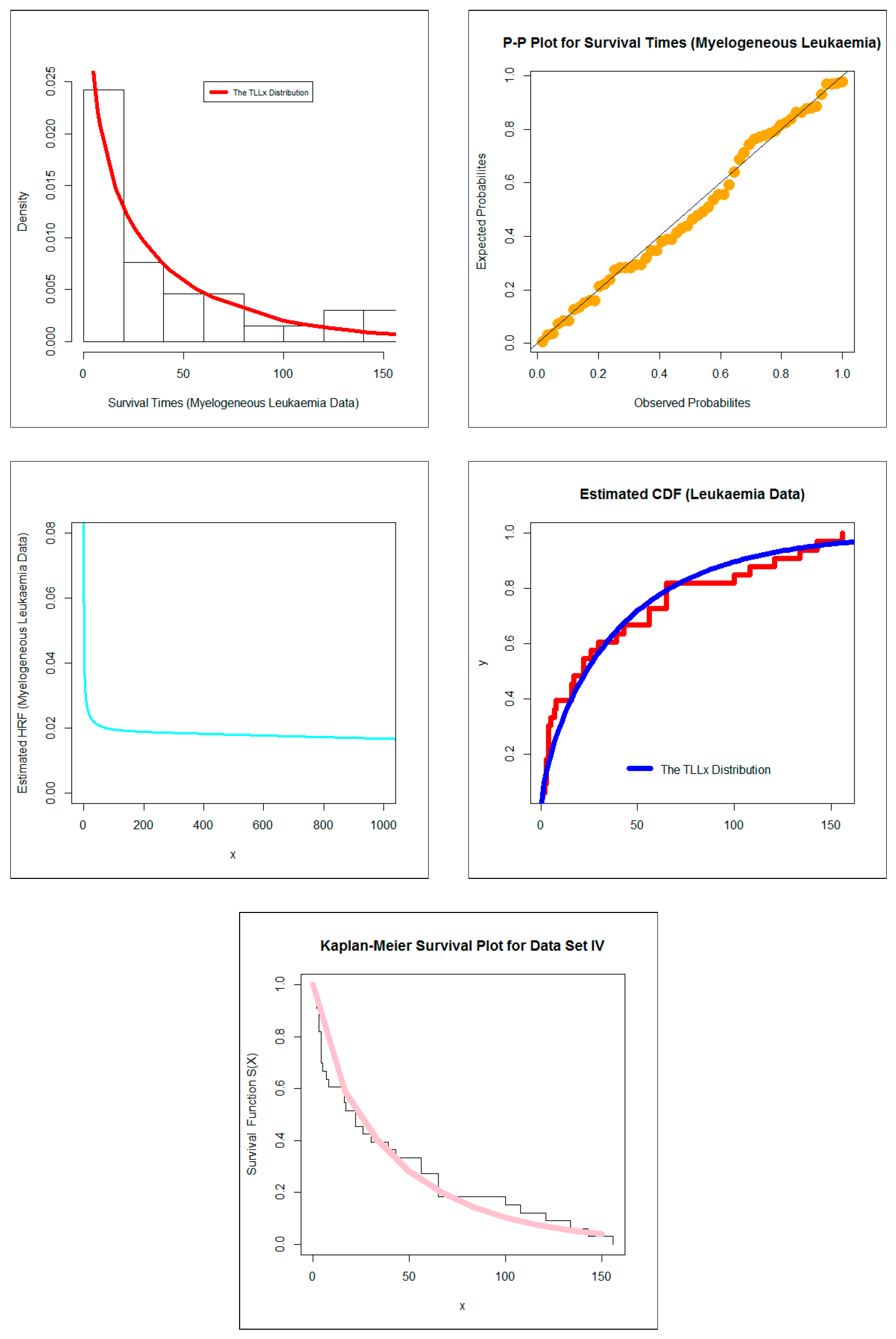
- In the medicine field, our new model can be applied in modeling the acute myelogenous leukemia data. The new model showed its superiority against many competitive models such as the standard Burr XII, the Marshall-Olkin Burr XII, the Topp Leone Burr XII, the Zografos-Balakrishnan Burr XII, the five parameters beta Burr XII, the beta Burr XII, the beta exponentiated Burr XII, the five parameters Kumaraswamy Burr XII and Kumaraswamy Burr XII models as shown in Tables 8 and 12.
2. The New Model and Simple Type Copula-Based Construction
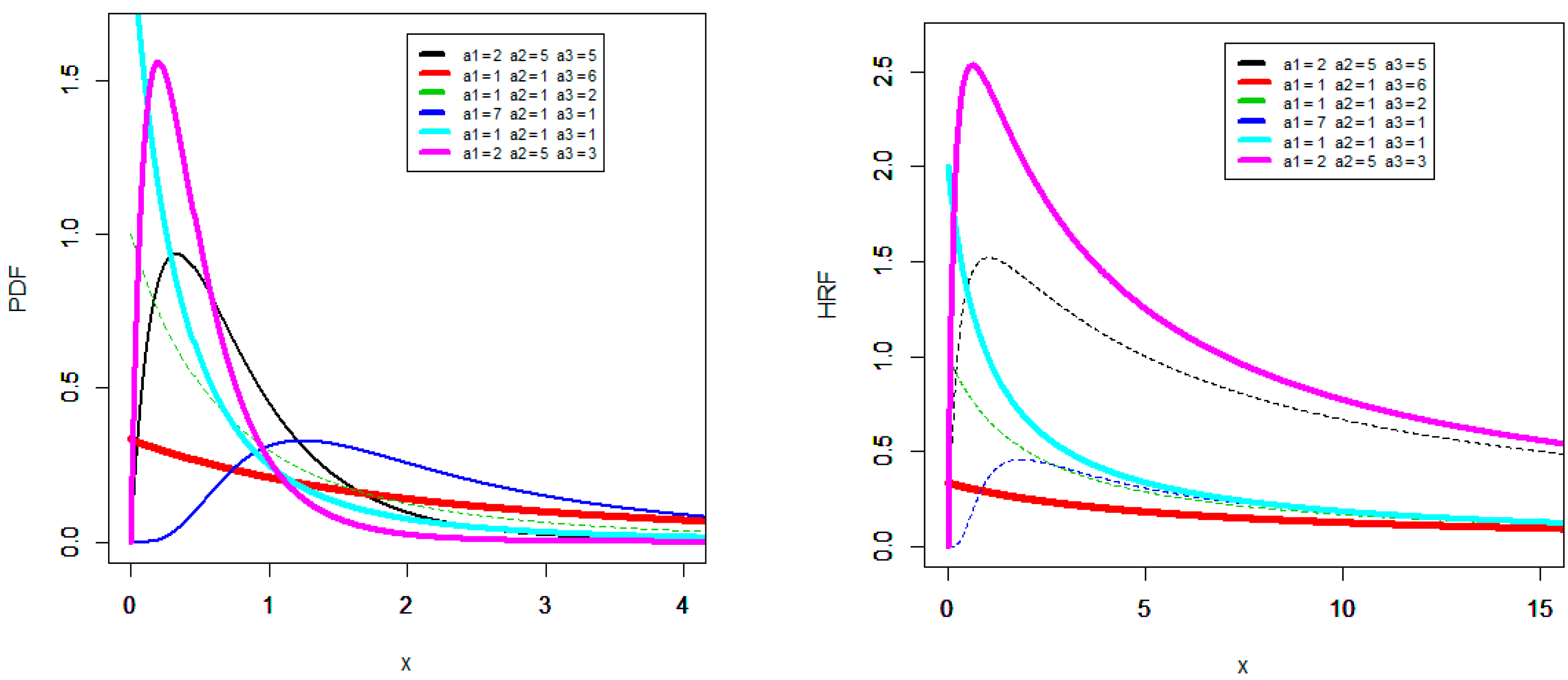
2.1. The New TLLx and Its Max-Mini Physical Interpretation.
2.2. Copula via Morgenstern Gamily
2.3. Copula Via Clayton Copula
2.3.1. The Bivariate Extension
2.3.2. The Multivariate Extension
3. Some Properties
4. Different Methods of Estimation
4.1. Maximum Likelihood Estimation (MLE)
4.2. Maximum Product Spacing Estimator
4.3. Method of Least Square (LS) and Weighted Least Square (WLS) Estimation
4.4. Method of Percentile Estimate
4.5. Method of Cramer-Von-Mises Estimation (CVME)
4.6. Methods of Anderson-Darling (ADE)
5. Monte Carlo (MC) Simulation Study
6. Modeling Real Data
- The Akaike Information Criterion (A_IC),
- Bayesian_IC (B_IC),
- Hannan-Quinn_IC (HQ_IC), and
- Consistent Akaike_IC (CA_IC).
7. Assessing the Performance of the Maximum Likelihood Estimations: Case of Complete Data
8. Assessing the Performance of the Maximum Likelihood Estimations: Case of Censored Data
8.1. The Maximum Likelihood Estimation (MLE)
8.2. Simulations: Right Censored Case
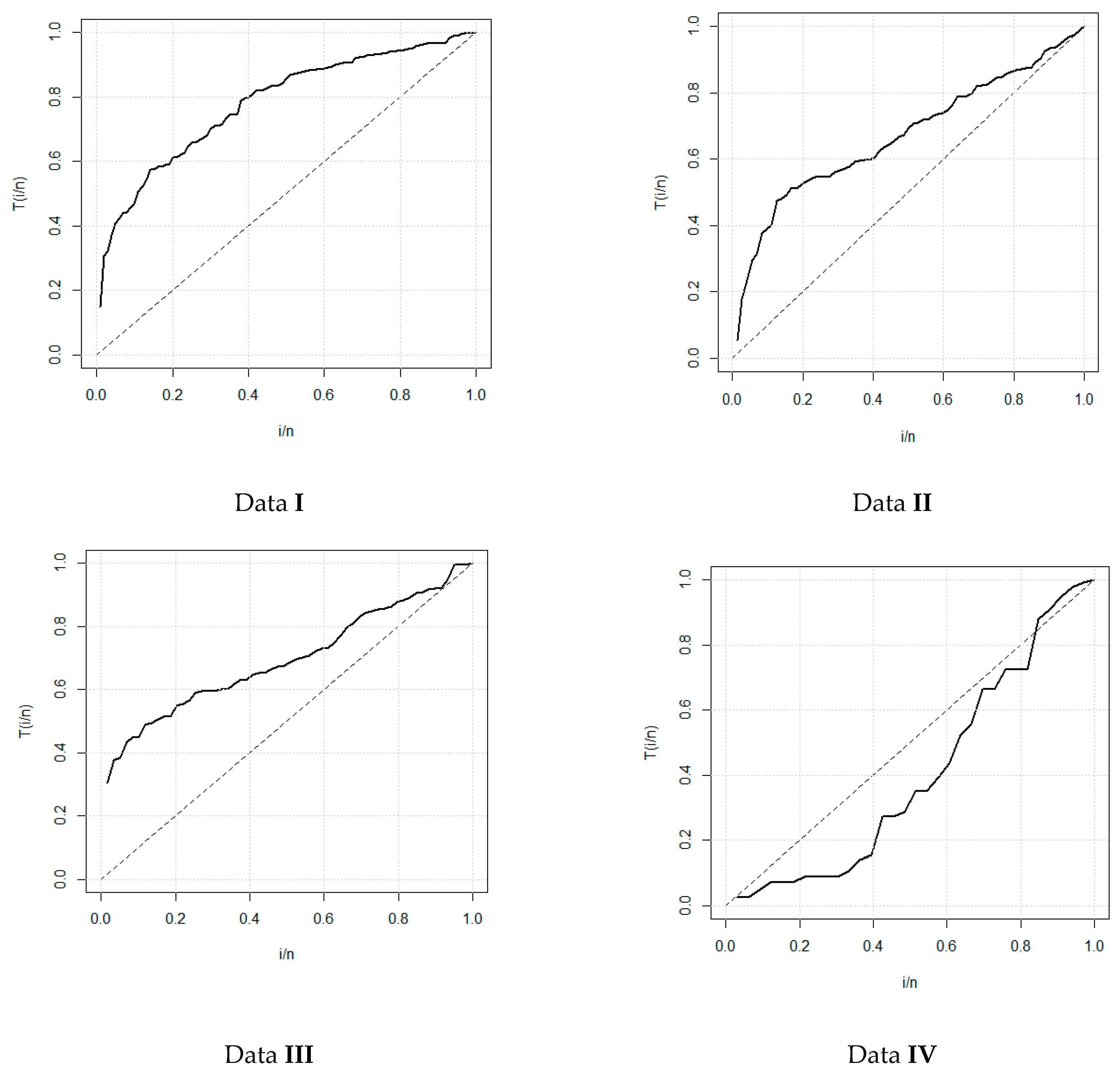
9. The Modified GOF Test
9.1. The N-R-R GOF Test
9.2. N-R-R Statistic for the TLLx Model
10. Applications to Real Data
Strengths of Glass Fibers
11. GOF Test for Right Censored Data
GOF Test for the TLLx Model in Case of Censored Data
12. GOF Test for the TLLx Model in Case of Censored Data
12.1. Simulation Study
12.2. Application to Real Data
Data of aluminum reduction cells
13. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Lomax, K.S. Business failures: Another example of the analysis of failure data. J. Am. Stat. Assoc. 1954, 49, 847–852. [Google Scholar] [CrossRef]
- Burr, I.W. Cumulative Frequency Functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Burr, I.W. On a general system of distributions, III. The simple range. J. Am. Stat. Assoc. 1968, 63, 636–643. [Google Scholar] [CrossRef]
- Burr, I.W. Parameters for a general system of distributions to match a grid of alpha 3 and alpha 4. Commun. Stat. 1973, 2, 1–21. [Google Scholar] [CrossRef]
- Rodriguez, R.N. A guide to the Burr type XII distributions. Biometrika 1977, 64, 129–134. [Google Scholar] [CrossRef]
- Burr, I.W.; Cislak, P.J. On a general system of distributions: I. Its curve-shaped characteristics; II. The sample median. J. Am. Stat. Assoc. 1986, 63, 627–635. [Google Scholar] [CrossRef]
- Tadikamalla, P.R. A look at the Burr and related distributions. Int. Stat. Rev. 1980, 48, 337–344. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Yousof, H.M.; Ramires, T.G.; Ortega, E.M.M. The Burr XII system of densities: Properties, regression model and applications. J. Stat. Comput. Simul. 2018, 88, 432–456. [Google Scholar] [CrossRef]
- Abdul-Moniem, I.B.; Abdel-Hameed, H.F. On exponentiated Lomax distribution. Int. J. Math. Arch. 2012, 3, 2144–2150. [Google Scholar] [CrossRef]
- Ghitany, M.E.; AL-Awadhi, F.A.; Alkhalfan, L.A. Marshall-Olkin extended Lomax distribution and its applications to censored data. Commun. Stat. Theory Methods 2007, 36, 1855–1866. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cordeiro, G.M. An extended Lomax distribution. Statistics 2013, 47, 800–816. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.M.; Popovic, B.V. The gamma-Lomax distribution. J. Stat. Comput. Simul. 2015, 85, 305–319. [Google Scholar] [CrossRef]
- Tahir, M.H.; Cordeiro, G.M.; Mansoor, M.; Zubair, M. The WeibullLomax distribution: Properties and applications. To appear in the Hacettepe. J. Math. Stat. 2015, 44, 461–480. [Google Scholar] [CrossRef]
- Afify, A.Z.; Nofal, Z.M.; Yousof, H.M.; El Gebaly, Y.M.; Butt, N.S. The transmuted Weibull Lomax distribution: Properties and application. Pak. J. Stat. Oper. Res. 2015, 11, 135–152. [Google Scholar] [CrossRef] [Green Version]
- Elbiely, M.M.; Yousof, H.M. A new extension of the Lomax distribution and its Applications. J. Stat. Appl. 2018, 2, 18–34. [Google Scholar] [CrossRef] [Green Version]
- Korkmaz, M.C.; Yousof, H.M.; Rasekhi, M.; Hamedani, G.G. Bayesian analysis, classical inference and characterizations for the odd Lindley Burr XII model. Mathematics and Computers in Simulation. J. Data Sci. 2018, 16, 327–354. [Google Scholar] [CrossRef] [Green Version]
- Altun, E.; Yousof, H.M.; Chakraborty, S.; Handique, L. Zografos-Balakrishnan. Burr XII distribution: Regression modeling and applications. Int. J. Math. Stat. 2018, 19, 46–70. [Google Scholar]
- Yousof, H.M.; Ahsanullah, M.; Khalil, M.G. A new zero-truncated version of the Poisson Burr XII distribution: Characterizations and properties. J. Stat. Theory Appl. 2019, 18, 1–11. [Google Scholar] [CrossRef]
- Gad, A.M.; Hamedani, G.G.; Salehabadi, S.M.; Yousof, H.M. The Burr XII-Burr XII distribution: Mathematical properties and characterizations. Pak. J. Stat. 2019, 35, 229–248. [Google Scholar]
- Oguntunde, P.E.; Khaleel, M.A.; Okagbue, H.I.; Odetunmibi, O.A. The Topp-Leone Lomax distribution with applications to air bone communication transceiver dataset. Wirel. Pers. Commun. 2019, 109, 349–360. [Google Scholar] [CrossRef]
- Rezaei, S.; Sadr, B.B.; Alizadeh, M.; Nadarajah, S. Topp-Leone generated family of distributions: Properties and applications. Commun. Stat. Theory Methods 2017, 46, 2893–2909. [Google Scholar] [CrossRef]
- Aarset, M.G. How to Identify a Bathtub Hazard Rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
- Nikulin, M.S. Chi-squared test for continuous distributions with shift and scal parameters. Theory Probab. Appl. 1973, 18, 559–568. [Google Scholar] [CrossRef]
- Rao, K.C.; Robson, D.S. A Chi-square statistic for goodness-of-fit tests within the exponential family. Commun. Stat. 1974, 3, 1139–1153. [Google Scholar] [CrossRef]
- Nichols, M.D.; Padgett, W.J. A Bootstrap Control Chart for Weibull Percentiles. Qual. Reliab. Eng. Int. 2006, 22, 141–151. [Google Scholar] [CrossRef]
- Bagdonavicius, V.; Nikulin, M. Chi-squared Goodness-of-fit Test for Right Censored Data. Int. J. Appl. Math. Stat. 2011, 24, 30–50. [Google Scholar] [CrossRef]
- Bagdonavicius, V.; Nikulin, M. Chi-squared tests for general composite hypotheses from censored samples. Comptes Rendus de l’académie des Sciences de Paris. Mathématiques 2011, 349, 219–223. [Google Scholar] [CrossRef]
- Bagdonavicius, V.; Kruopis, J.; Nikulin, M. Nonparametric Tests for Censored Data; John Wiley and Sons: Hoboken, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Goual, H.; Yousof, H. Validation of Burr XII inverse Rayleigh model via a modified chi-squared goodness-of-fit test. J. Appl. Stat. 2019, 47, 1–32. [Google Scholar] [CrossRef]
- Greenwood, P.E.; Nikulin, M.S. A Guide to Chi-Squared Testing; John Wiley and Sons: Hoboken, NJ, USA, 1996. [Google Scholar] [CrossRef]
- Whitmore, G.A. A regression method for censored inverse-gaussian data. Can. J. Stat. 1983, 14, 305–315. [Google Scholar] [CrossRef]
- Bjerkedal, T. Acquisition of resistance in guinea pigs infected with different doses of virulent tubercle bacilli. Am. J. Hyg. 1960, 72, 130–148. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MLEs | MPSEs | LSEs | WLSEs | PCEs | CVMEs | ADEs | ||
|---|---|---|---|---|---|---|---|---|
| 10 | (0.5, 0.5, 0.5) | 0.01008 | 0.02373 | 0.02226 | 0.02094 | 0.08493 | 0.01465 | 0.01563 |
| (0.5, 1.0, 1.5) | 0.12543 | 0.33736 | 0.32246 | 0.30148 | 0.72409 | 0.19723 | 0.21001 | |
| (1.5, 2.0, 2.5) | 0.31371 | 0.88351 | 0.82496 | 0.75896 | 1.44970 | 0.49314 | 0.54576 | |
| (2.0, 3.0, 3.0) | 0.44606 | 1.27362 | 1.20878 | 1.10863 | 1.98901 | 0.72271 | 0.79753 | |
| 20 | (0.5, 0.5, 0.5) | 0.00656 | 0.01403 | 0.01283 | 0.01127 | 0.08766 | 0.00938 | 0.00947 |
| (0.5, 1.0, 1.5) | 0.09008 | 0.21038 | 0.19087 | 0.16565 | 0.78616 | 0.13265 | 0.13290 | |
| (1.5, 2.0, 2.5) | 0.21962 | 0.55345 | 0.49357 | 0.42714 | 1.36895 | 0.33056 | 0.34406 | |
| (2.0, 3.0, 3.0) | 0.31295 | 0.79229 | 0.72985 | 0.61549 | 1.68717 | 0.49407 | 0.50163 | |
| 30 | (0.5, 0.5, 0.5) | 0.00505 | 0.01017 | 0.00928 | 0.00785 | 0.09154 | 0.00717 | 0.00700 |
| (0.5, 1.0, 1.5) | 0.07089 | 0.15961 | 0.14230 | 0.11896 | 0.84625 | 0.10387 | 0.10052 | |
| (1.5, 2.0, 2.5) | 0.17007 | 0.40040 | 0.36169 | 0.29692 | 1.26194 | 0.26226 | 0.25534 | |
| (2.0, 3.0, 3.0) | 0.25630 | 0.60591 | 0.52899 | 0.43968 | 1.56832 | 0.37853 | 0.37999 | |
| 50 | (0.5, 0.5, 0.5) | 0.00348 | 0.00649 | 0.00589 | 0.00494 | 0.09685 | 0.00477 | 0.00458 |
| (0.5, 1.0, 1.5) | 0.05220 | 0.10823 | 0.09792 | 0.07883 | 0.88316 | 0.07578 | 0.07042 | |
| (1.5, 2.0, 2.5) | 0.12082 | 0.25972 | 0.23951 | 0.18924 | 1.14838 | 0.18485 | 0.17351 | |
| (2.0, 3.0, 3.0) | 0.18020 | 0.38860 | 0.34791 | 0.27964 | 1.35617 | 0.26670 | 0.25607 | |
| 100 | (0.5, 0.5, 0.5) | 0.00200 | 0.00337 | 0.00325 | 0.00264 | 0.10417 | 0.00278 | 0.00255 |
| (0.5, 1.0, 1.5) | 0.03372 | 0.06235 | 0.05935 | 0.04628 | 0.95364 | 0.04939 | 0.04364 | |
| (1.5, 2.0, 2.5) | 0.07250 | 0.13811 | 0.13465 | 0.10455 | 1.00937 | 0.11050 | 0.09982 | |
| (2.0, 3.0, 3.0) | 0.10942 | 0.21029 | 0.19651 | 0.15155 | 1.03138 | 0.16098 | 0.14656 | |
| 200 | (0.5, 0.5, 0.5) | 0.00110 | 0.00168 | 0.00175 | 0.00139 | 0.11122 | 0.00156 | 0.00138 |
| (0.5, 1.0, 1.5) | 0.02063 | 0.03443 | 0.03389 | 0.02589 | 0.96237 | 0.02970 | 0.02537 | |
| (1.5, 2.0, 2.5) | 0.04454 | 0.07543 | 0.07582 | 0.05809 | 0.82964 | 0.06594 | 0.05745 | |
| (2.0, 3.0, 3.0) | 0.06072 | 0.10552 | 0.10310 | 0.07926 | 0.88312 | 0.08933 | 0.07856 |
| MLEs | MPSEs | LSEs | WLSEs | PCEs | CVMEs | ADEs | ||
|---|---|---|---|---|---|---|---|---|
| 10 | (0.5, 0.5, 0.5) | 0.01008 | 0.02373 | 0.02226 | 0.02094 | 0.08493 | 0.01465 | 0.01563 |
| (0.5, 1.0, 1.5) | 0.12543 | 0.33736 | 0.32246 | 0.30148 | 0.72409 | 0.19723 | 0.21001 | |
| (1.5, 2.0, 2.5) | 0.31371 | 0.88351 | 0.82496 | 0.75896 | 1.44970 | 0.49314 | 0.54576 | |
| (2.0, 3.0, 3.0) | 0.44606 | 1.27362 | 1.20878 | 1.10863 | 1.98901 | 0.72271 | 0.79753 | |
| 20 | (0.5, 0.5, 0.5) | 0.00656 | 0.01403 | 0.01283 | 0.01127 | 0.08766 | 0.00938 | 0.00947 |
| (0.5, 1.0, 1.5) | 0.09008 | 0.21038 | 0.19087 | 0.16565 | 0.78616 | 0.13265 | 0.13290 | |
| (1.5, 2.0, 2.5) | 0.21962 | 0.55345 | 0.49357 | 0.42714 | 1.36895 | 0.33056 | 0.34406 | |
| (2.0, 3.0, 3.0) | 0.31295 | 0.79229 | 0.72985 | 0.61549 | 1.68717 | 0.49407 | 0.50163 | |
| 30 | (0.5, 0.5, 0.5) | 0.00310 | 0.00973 | 0.00617 | 0.00541 | 0.03391 | 0.00372 | 0.00411 |
| (0.5, 1.0, 1.5) | 0.00211 | 0.00596 | 0.00408 | 0.00346 | 0.03379 | 0.00251 | 0.00271 | |
| (1.5, 2.0, 2.5) | 0.01259 | 0.04065 | 0.02628 | 0.02189 | 0.18025 | 0.01574 | 0.01740 | |
| (2.0, 3.0, 3.0) | 0.02034 | 0.06606 | 0.04764 | 0.04031 | 0.25969 | 0.02922 | 0.03113 | |
| 50 | (0.5, 0.5, 0.5) | 0.00348 | 0.00649 | 0.00589 | 0.00494 | 0.09685 | 0.00477 | 0.00458 |
| (0.5, 1.0, 1.5) | 0.05220 | 0.10823 | 0.09792 | 0.07883 | 0.88316 | 0.07578 | 0.07042 | |
| (1.5, 2.0, 2.5) | 0.12082 | 0.25972 | 0.23951 | 0.18924 | 1.14838 | 0.18485 | 0.17351 | |
| (2.0, 3.0, 3.0) | 0.18020 | 0.38860 | 0.34791 | 0.27964 | 1.35617 | 0.26670 | 0.25607 | |
| 100 | (0.5, 0.5, 0.5) | 0.00200 | 0.00337 | 0.00325 | 0.00264 | 0.10417 | 0.00278 | 0.00255 |
| (0.5, 1.0, 1.5) | 0.03372 | 0.06235 | 0.05935 | 0.04628 | 0.95364 | 0.04939 | 0.04364 | |
| (1.5, 2.0, 2.5) | 0.07250 | 0.13811 | 0.13465 | 0.10455 | 1.00937 | 0.11050 | 0.09982 | |
| (2.0, 3.0, 3.0) | 0.10942 | 0.21029 | 0.19651 | 0.15155 | 1.03138 | 0.16098 | 0.14656 | |
| 200 | (0.5, 0.5, 0.5) | 0.00110 | 0.00168 | 0.00175 | 0.00139 | 0.11122 | 0.00156 | 0.00138 |
| (0.5, 1.0, 1.5) | 0.02063 | 0.03443 | 0.03389 | 0.02589 | 0.96237 | 0.02970 | 0.02537 | |
| (1.5, 2.0, 2.5) | 0.04454 | 0.07543 | 0.07582 | 0.05809 | 0.82964 | 0.06594 | 0.05745 | |
| (2.0, 3.0, 3.0) | 0.06072 | 0.10552 | 0.10310 | 0.07926 | 0.88312 | 0.08933 | 0.07856 |
| MLEs | MPSEs | LSEs | WLSEs | PCEs | CVMEs | ADEs | ||
|---|---|---|---|---|---|---|---|---|
| 10 | (0.5, 0.5, 0.5) | 0.02899 | 0.03970 | 0.03952 | 0.03740 | 0.03441 | 0.03194 | 0.03298 |
| (0.5, 1.0, 1.5) | 0.09506 | 0.15280 | 0.14193 | 0.13502 | 0.14421 | 0.10672 | 0.10952 | |
| (1.5, 2.0, 2.5) | 0.17018 | 0.30772 | 0.29220 | 0.26216 | 0.25409 | 0.20156 | 0.21130 | |
| (2.0, 3.0, 3.0) | 0.30178 | 0.55647 | 0.53308 | 0.47841 | 0.47647 | 0.37621 | 0.38825 | |
| 20 | (0.5, 0.5, 0.5) | 0.01983 | 0.02496 | 0.02624 | 0.02317 | 0.03391 | 0.02238 | 0.02192 |
| (0.5, 1.0, 1.5) | 0.07009 | 0.10725 | 0.09527 | 0.08593 | 0.15301 | 0.07609 | 0.07597 | |
| (1.5, 2.0, 2.5) | 0.10424 | 0.17000 | 0.17015 | 0.14293 | 0.18852 | 0.12805 | 0.12322 | |
| (2.0, 3.0, 3.0) | 0.19277 | 0.32047 | 0.32465 | 0.26435 | 0.29089 | 0.24730 | 0.23534 | |
| 30 | (0.5, 0.5, 0.5) | 0.01514 | 0.01881 | 0.01943 | 0.01704 | 0.03608 | 0.01682 | 0.01634 |
| (0.5, 1.0, 1.5) | 0.05347 | 0.08219 | 0.07351 | 0.06428 | 0.16222 | 0.06034 | 0.05831 | |
| (1.5, 2.0, 2.5) | 0.07844 | 0.12492 | 0.12754 | 0.10453 | 0.11256 | 0.10095 | 0.09520 | |
| (2.0, 3.0, 3.0) | 0.14207 | 0.23859 | 0.22324 | 0.18213 | 0.19632 | 0.17281 | 0.16806 | |
| 50 | (0.5, 0.5, 0.5) | 0.01079 | 0.01282 | 0.01392 | 0.01215 | 0.03652 | 0.01249 | 0.01181 |
| (0.5, 1.0, 1.5) | 0.03868 | 0.05793 | 0.05255 | 0.04467 | 0.17758 | 0.04428 | 0.04107 | |
| (1.5, 2.0, 2.5) | 0.05110 | 0.07930 | 0.07936 | 0.06485 | 0.08187 | 0.06582 | 0.06055 | |
| (2.0, 3.0, 3.0) | 0.09797 | 0.14978 | 0.15032 | 0.12041 | 0.12336 | 0.12232 | 0.11570 | |
| 100 | (0.5, 0.5, 0.5) | 0.00637 | 0.00736 | 0.00807 | 0.00693 | 0.03740 | 0.00735 | 0.00682 |
| (0.5, 1.0, 1.5) | 0.02404 | 0.03556 | 0.03319 | 0.02708 | 0.19998 | 0.02912 | 0.02582 | |
| (1.5, 2.0, 2.5) | 0.02939 | 0.04134 | 0.04466 | 0.03594 | 0.04724 | 0.03853 | 0.03429 | |
| (2.0, 3.0, 3.0) | 0.05767 | 0.08263 | 0.08567 | 0.06715 | 0.06137 | 0.07373 | 0.06656 | |
| 200 | (0.5, 0.5, 0.5) | 0.00369 | 0.00411 | 0.00478 | 0.00404 | 0.04363 | 0.00448 | 0.00402 |
| (0.5, 1.0, 1.5) | 0.01561 | 0.02174 | 0.01984 | 0.01600 | 0.20472 | 0.01807 | 0.01582 | |
| (1.5, 2.0, 2.5) | 0.01690 | 0.02250 | 0.02390 | 0.01878 | 0.02330 | 0.02163 | 0.01860 | |
| (2.0, 3.0, 3.0) | 0.02660 | 0.03690 | 0.03807 | 0.02961 | 0.03066 | 0.03412 | 0.02953 |
| Model | Appreciation |
|---|---|
| Marshall-Olkin- | MO |
| Topp-Leone- | TL |
| Zografos-Balakrishnan- | ZB |
| Five Parameters beta- | FB |
| Five Parameters beta- | FB |
| Beta- | B |
| B exponentiated- | BE |
| Kumaraswamy- | Kum |
| FKum- | FKum |
| Model | Estimates |
|---|---|
| 5.941, 0.187 | |
| (1.279), (0.044) | |
| (3.43, 8.45), (0.10, 0.27) | |
| 1.192, 4.834, 838.73 | |
| (0.952), (4.896), (229.34) | |
| (0, 3.06), (0, 14.43), (389.22, 1288.24) | |
| 1.350, 1.061, 13.728 | |
| (0.378), (0.384), (8.400) | |
| (0.61, 2.09), (0.31, 1.81), (0, 30.19) | |
| 48.103, 79.516, 0.351, 2.730 | |
| (19.348), (58.186), (0.098), (1.077) | |
| (10.18, 86.03), (0, 193.56), (0.16, 0.54), (0.62, 4.84) | |
| 359.683, 260.097, 0.175, 1.123 | |
| (57.941), (132.213), (0.013), (0.243) | |
| (246.1, 473.2), (0.96, 519.2), (0.14, 0.20), (0.65, 1.6) | |
| 0.381, 11.949, 0.937, 33.402, 1.705 | |
| (0.078), (4.635), (0.267), (6.287), (0.478) | |
| (0.23, 0.53), (2.86, 21), (0.41, 1.5), (21, 45), (0.8, 2.6) | |
| 0.421, 0.834, 6.111, 1.674, 3.450 | |
| (0.011), (0.943), (2.314), (0.226), (1.957) | |
| (0.4, 0.44), (0, 2.7), (1.57, 10.7), (1.23, 2.1), (0, 7) | |
| 0.542, 4.223, 5.313, 0.411, 4.152 | |
| (0.137), (1.882), (2.318), (0.497), (1.995) | |
| (0.3, 0.8), (0.53, 7.9), (0.9, 9), (0, 1.7), (0.2, 8) | |
| TLLx | 8.07, 1.369 × e6, 2.65 × e6 |
| (0.796), (0.000), (22.57) | |
| (9.7, 6.5), -, (1023, 1114) |
| Model | Estimates |
|---|---|
| 3.102, 0.465 | |
| (0.538), (0.077) | |
| (2.05, 4.16), (0.31, 0.62) | |
| 2.259,1.533, 6.760 | |
| (0.864), (0.907), (4.587) | |
| (0.57, 3.95), (0, 3.31), (0, 15.75) | |
| 2.393, 0.458, 1.796 | |
| (0.907), (0.244), (0.915) | |
| (0.62, 4.17), (0, 0.94), (0.002, 3.59) | |
| 14.105, 7.424, 0.525, 2.274 | |
| (10.805), (11.850), (0.279), (0.990) | |
| (0, 35.28), (0, 30.65), (0, 1.07), (0.33, 4.21) | |
| 2.555, 6.058,1.800,0.294, | |
| (1.859), (10.391), (0.955), (0.466) | |
| (0, 6.28), (0, 26.42), (0, 3.67), (0, 1.21) | |
| 1.876, 2.991, 1.780, 1.341, 0.572 | |
| (0.094), (1.731), (0.702), (0.816), (0.325) | |
| (1.7, 2.06), (0, 6.4), (0.40, 3.2), (0, 2.9), (0, 1.21) | |
| 0.621, 0.549,3.838, 1.381, 1.665 | |
| (0.541), (1.011), (2.785), (2.312), (0.436) | |
| (0, 1.7), (0, 2.5), (0, 9.3), (0, 5.9), (0.8, 4.5) | |
| 0.558, 0.308, 3.999, 2.131, 1.475 | |
| (0.442), (0.314), (2.082), (1.833), (0.361) | |
| (0, 1.4), (0, 0.9), (0, 3.1), (0, 5.7), (0.76, 2.2) | |
| TLLx | 3.595, 12.08, 21.248 |
| (1.006), (28.25), (54.22) | |
| (1.6, 5.6), (0, 68), (0, 129) |
| Model | Estimates |
|---|---|
| 5.615, 0.072 | |
| (15.048), (0.194) | |
| (0, 35.11), (0, 0.45) | |
| 8.017, 0.419, 70.359 | |
| (22.083), (0.312), (63.831) | |
| (0, 51.29), (0, 1.03), (0, 195.47) | |
| 91.320, 0.012, 141.073 | |
| (15.071), (0.002), (70.028) | |
| (61.78, 120.86) (0.008, 0.02) (3.82, 278.33) | |
| 18.130, 6.857, 10.694, 0.081 | |
| (3.689), (1.035), (1.166), (0.012) | |
| (10.89, 25.36), (4.83, 8.89), (8.41, 12.98), (0.06, 0.10) | |
| 26.725, 9.756, 27.364, 0.020 | |
| (9.465), (2.781), (12.351), (0.007) | |
| (8.17, 45.27), (4.31, 15.21), (3.16, 51.57), (0.006, 0.03) | |
| 2.924, 2.911, 3.270, 12.486, 0.371 | |
| (0.564), (0.549), (1.251), (6.938), (0.788) | |
| (1.82, 4.03), (1.83, 3.99), (0.82, 5.72), (0, 26.08), (0, 1.92) | |
| 30.441, 0.584, 1.089, 5.166, 7.862 | |
| (91.745), (1.064), (1.021), (8.268), (15.036) | |
| (0, 210.26), (0, 2.67), (0, 3.09), (0, 21.37), (0, 37.33) | |
| 12.878, 1.225, 1.665, 1.411, 3.732 | |
| (3.442), (0.131), (0.034), (0.088), (1.172) | |
| (6.13, 19.62), (0.97, 1.48), (1.56, 1.73), (1.24, 1.58), (1.43, 6.03) | |
| TLLx | 33.197, 1.706391, 5.24 |
| (48.93), (0.765), (7.148) | |
| (0, 129), (0.3, 3.1), (0, 19) |
| Model | Estimates |
|---|---|
| 58.711, 0.006 | |
| (42.382), (0.004) | |
| (0, 141.78), (0, 0.01) | |
| 11.838, 0.078, 12.251 | |
| (4.368), (0.013), (7.770) | |
| (0, 141.78), (0, 0.01), (0, 27.48) | |
| 0.281, 1.882, 50.215 | |
| (0.288), (2.402), (176.50) | |
| (0, 0.85), (0, 6.59), (0, 396.16) | |
| 9.201, 36.428, 0.242, 0.941 | |
| (10.060), (35.650), (0.167), (1.045) | |
| (0, 28.912), (0, 106.30), (0, 0.57), (0, 2.99) | |
| 96.104, 52.121, 0.104, 1.227 | |
| (41.201), (33.490), (0.023), (0.326) | |
| (15.4, 176.8), (0, 117.8), (0.6, 0.15), (0.59, 1.9) | |
| 0.087, 5.007, 1.561, 31.270, 0.318 | |
| (0.077), (3.851), (0.012), (12.940), (0.034) | |
| (0, 0.3), (0, 12.6), (1.5, 1.6), (5.9, 56.6), (0.3,0.4) | |
| 15.194, 32.048, 0.233, 0.581, 21.855 | |
| (11.58), (9.867), (0.091), (0.067), (35.548) | |
| (0, 37.8), (12.7, 51.4), (0.05, 0.4), (0.45, 0.7), (0, 91.5) | |
| 14.732, 15.285, 0.293, 0.839, 0.034 | |
| (12.390), (18.868), (0.215), (0.854), (0.075) | |
| (0, 39.02), (0, 52.27), (0, 0.71), (0, 2.51), (0, 0.18) | |
| TLLx | 0.687, 61.7, 6391.98 |
| (0.147), (31.83), (2858.9) | |
| (0.4, 1), (0, 123), (674, 12,110) |
| Model | A_IC, B_IC, CA_IC |
|---|---|
| 210, 214, 210, 211 | |
| MO- | 210, 217, 210, 212 |
| TL- | 212, 219, 212, 215 |
| Kum | 209, 218, 209, 212 |
| 210, 220, 211, 214 | |
| 212, 224, 213, 217 | |
| 207, 218, 208, 211 | |
| FKum | 207, 218, 207, 211 |
| TLLx | 205, 212, 206, 208 |
| Model | A_IC, B_IC, CA_IC |
|---|---|
| 210, 214, 210, 211 | |
| MO- | 210, 217, 210, 212 |
| TL- | 212, 219, 212, 215 |
| Kum | 209, 218, 209, 212 |
| 210, 220, 211, 214 | |
| 212, 224, 213, 217 | |
| 207, 218, 208, 211 | |
| FKum | 207, 218, 207, 211 |
| TLLx | 205, 212, 206, 208 |
| Model | A_IC, B_IC, CA_IC |
|---|---|
| 518, 523, 519, 520 | |
| MO- | 386, 392, 386, 388 |
| TL- | 387, 390, 388, 390 |
| Kum | 386, 394, 386, 389 |
| 387, 397, 388, 391 | |
| 386, 394, 386, 389 | |
| 387, 397, 388, 391 | |
| FKum | 387, 397, 388, 391 |
| TLLx | 383, 389, 383, 385 |
| Model | A_IC, B_IC, CA_IC |
|---|---|
| 328, 331, 329, 329 | |
| MO- | 316, 320.01, 316, 317 |
| TL- | 316, 321, 317, 318 |
| Kum | 317, 323, 319, 319 |
| 316, 322, 318, 318 | |
| 318, 325, 320, 320 | |
| 318 325, 320, 320 | |
| FKum | 318, 325, 320, 320 |
| TLLx | 313, 314, 318, 315 |
| m = 30 | 100 | 250 | 400 | |
|---|---|---|---|---|
| 0.7427 | 0.7259 | 0.7206 | 0.7094 | |
| MSE | 0.04821 | 0.03751 | 0.03049 | 0.00756 |
| 2.6413 | 2.6284 | 2.6143 | 2.6081 | |
| MSE | 0.04661 | 0.0304 | 0.0031 | 0.0015 |
| 1.9304 | 1.9262 | 1.9187 | 1.9071 | |
| MSE | 0.04445 | 0.0181 | 0.0043 | 0.0010 |
| m = 30 | 100 | 250 | 400 | |
|---|---|---|---|---|
| 0.75548 | 0.75322 | 0.75176 | 0.75012 | |
| MSE | 0.0030 | 0.0018 | 0.0006 | 0.0002 |
| 2.46123 | 2.45812 | 2.45318 | 2.45103 | |
| MSE | 0.01814 | 0.00216 | 0.00203 | 0.0002 |
| 1.4856 | 1.4879 | 1.4964 | 1.5027 | |
| MSE | 0.0021 | 0.0012 | 0.0007 | 0.0004 |
| 0.02 | 0.05 | 0.01 | 0.1 | |
|---|---|---|---|---|
| n = 30 | 0.9829 | 0.9525 | 0.9931 | 0.9027 |
| 50 | 0.9821 | 0.9520 | 0.9919 | 0.9015 |
| 100 | 0.9817 | 0.9513 | 0.9911 | 0.9011 |
| 250 | 0.9810 | 0.9506 | 0.9906 | 0.9006 |
| 400 | 0.9804 | 0.9501 | 0.9905 | 0.9002 |
| 0.02 | 0.05 | 0.01 | 0.1 | |
|---|---|---|---|---|
| n = 30 | 0.9829 | 0.9519 | 0.9929 | 0.9022 |
| 150 | 0.9820 | 0.9510 | 0.9917 | 0.9015 |
| 250 | 0.9810 | 0.9507 | 0.9909 | 0.9008 |
| 400 | 0.9806 | 0.9504 | 0.9903 | 0.9002 |
| 1.8995 | 1.8995 | 1.8995 | 1.8995 | |
| −0.8325 | 0.5487 | 0.3518 | 0.03548 | |
| 0.9427 | 1.2106 | 1.6672 | 2.3025 | |
| 0.2548 | −0.2925 | 0.14879 | 0.12584 | |
| 4 | 3 | 5 | 8 | |
| 0.0925 | 0.03332 | −0.8850 | 0.16005 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yadav, A.S.; Goual, H.; Alotaibi, R.M.; H, R.; Ali, M.M.; Yousof, H.M. Validation of the Topp-Leone-Lomax Model via a Modified Nikulin-Rao-Robson Goodness-of-Fit Test with Different Methods of Estimation. Symmetry 2020, 12, 57. https://doi.org/10.3390/sym12010057
Yadav AS, Goual H, Alotaibi RM, H R, Ali MM, Yousof HM. Validation of the Topp-Leone-Lomax Model via a Modified Nikulin-Rao-Robson Goodness-of-Fit Test with Different Methods of Estimation. Symmetry. 2020; 12(1):57. https://doi.org/10.3390/sym12010057
Chicago/Turabian StyleYadav, Abhimanyu Singh, Hafida Goual, Refah Mohammed Alotaibi, Rezk H, M. Masoom Ali, and Haitham M. Yousof. 2020. "Validation of the Topp-Leone-Lomax Model via a Modified Nikulin-Rao-Robson Goodness-of-Fit Test with Different Methods of Estimation" Symmetry 12, no. 1: 57. https://doi.org/10.3390/sym12010057