

Housing Price Prediction Using Machine Learning Algorithms in COVID-19 Times


Abstract
:1. Introduction
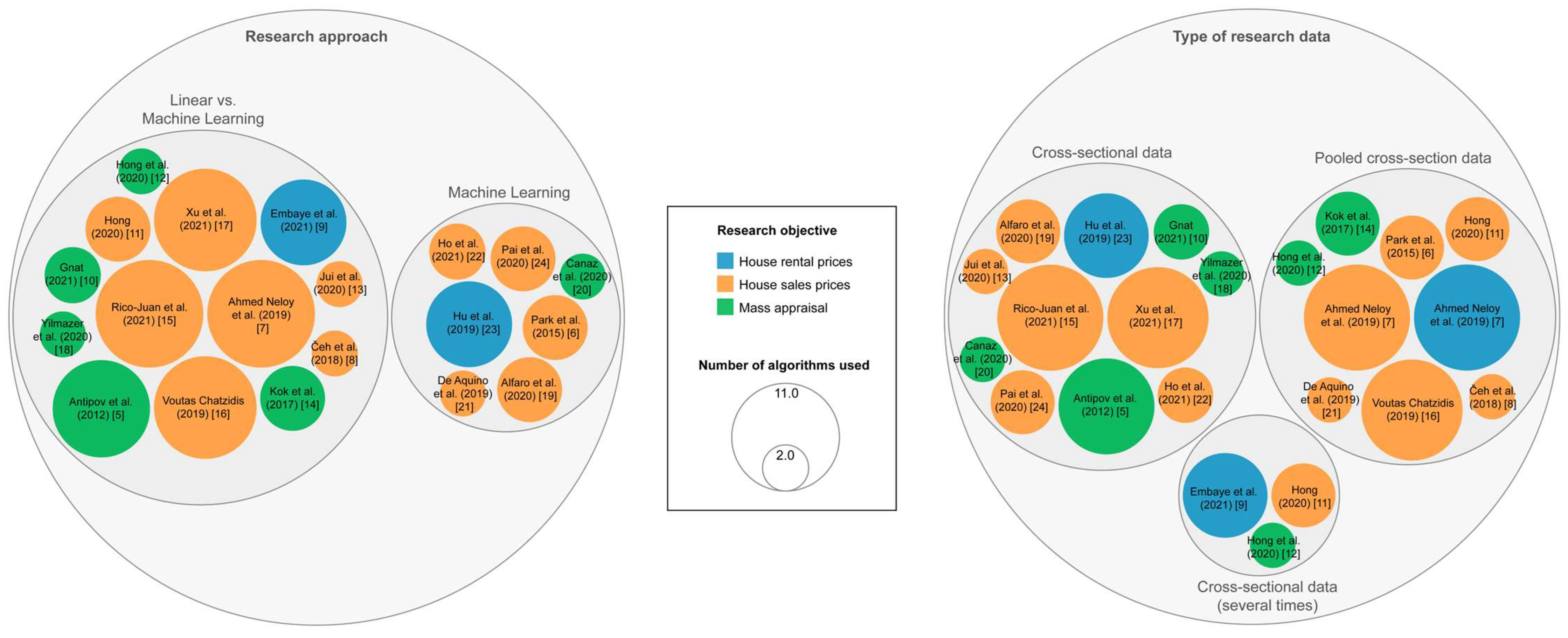
1.1. House Prices and Machine Learning
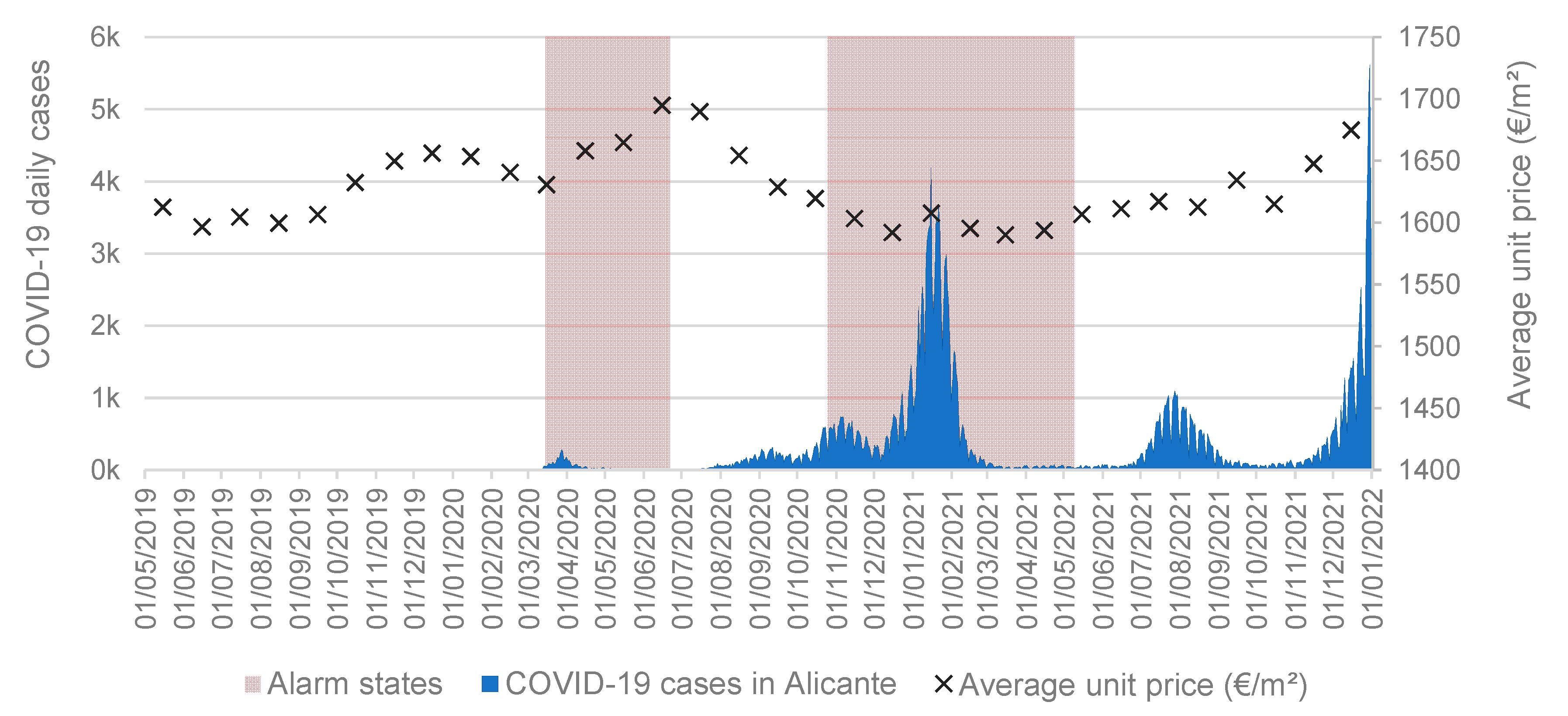
1.2. House Prices and COVID-19
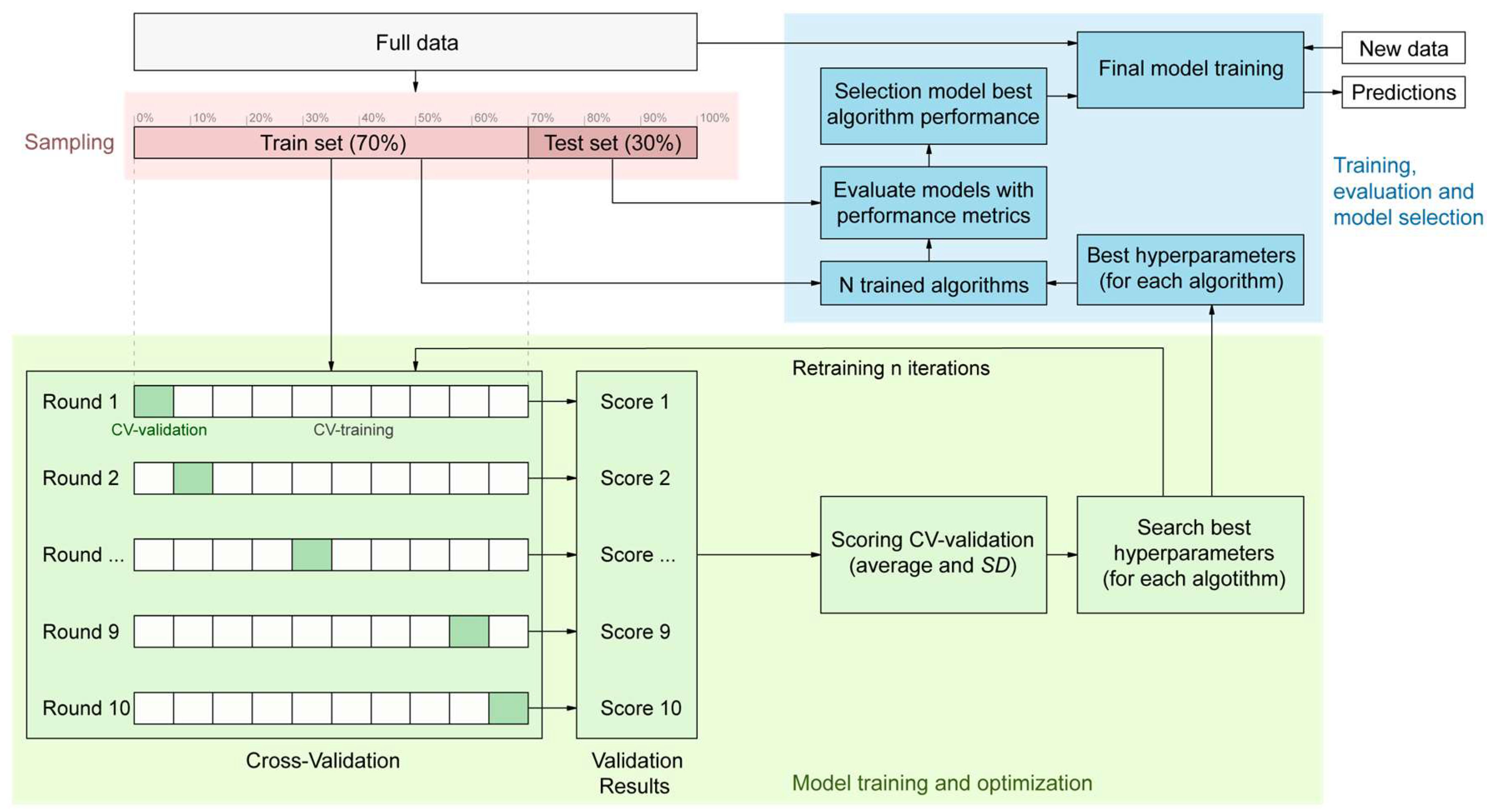
2. Materials and Methods
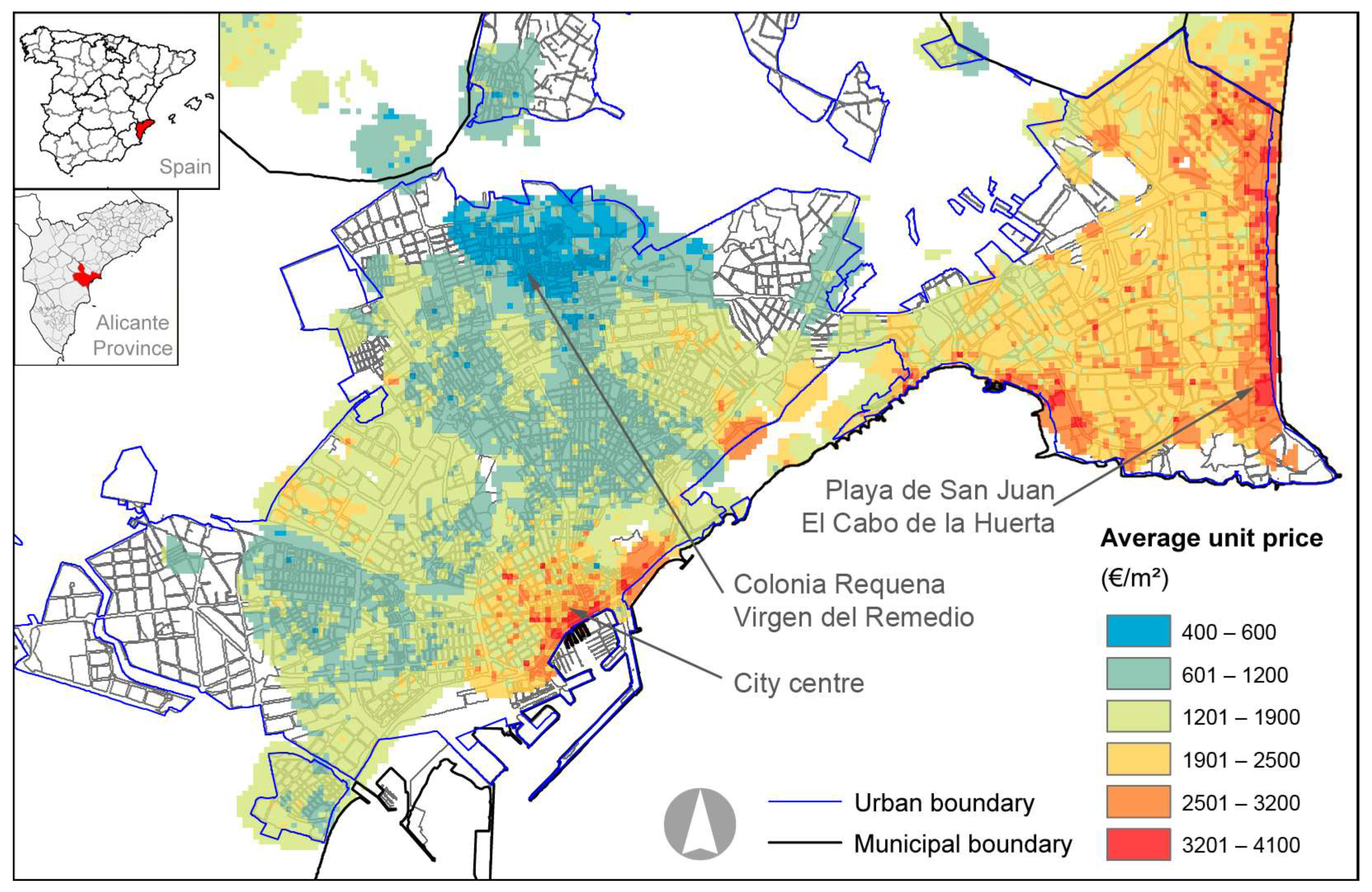
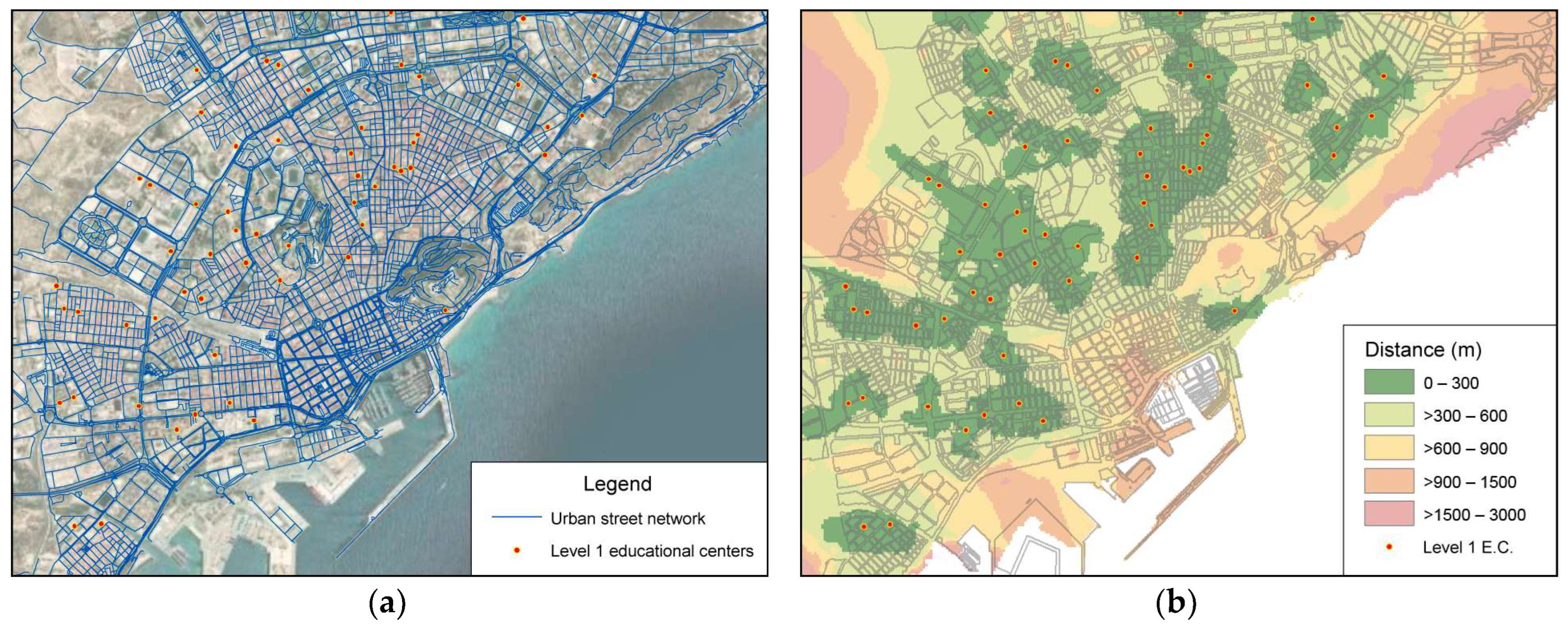
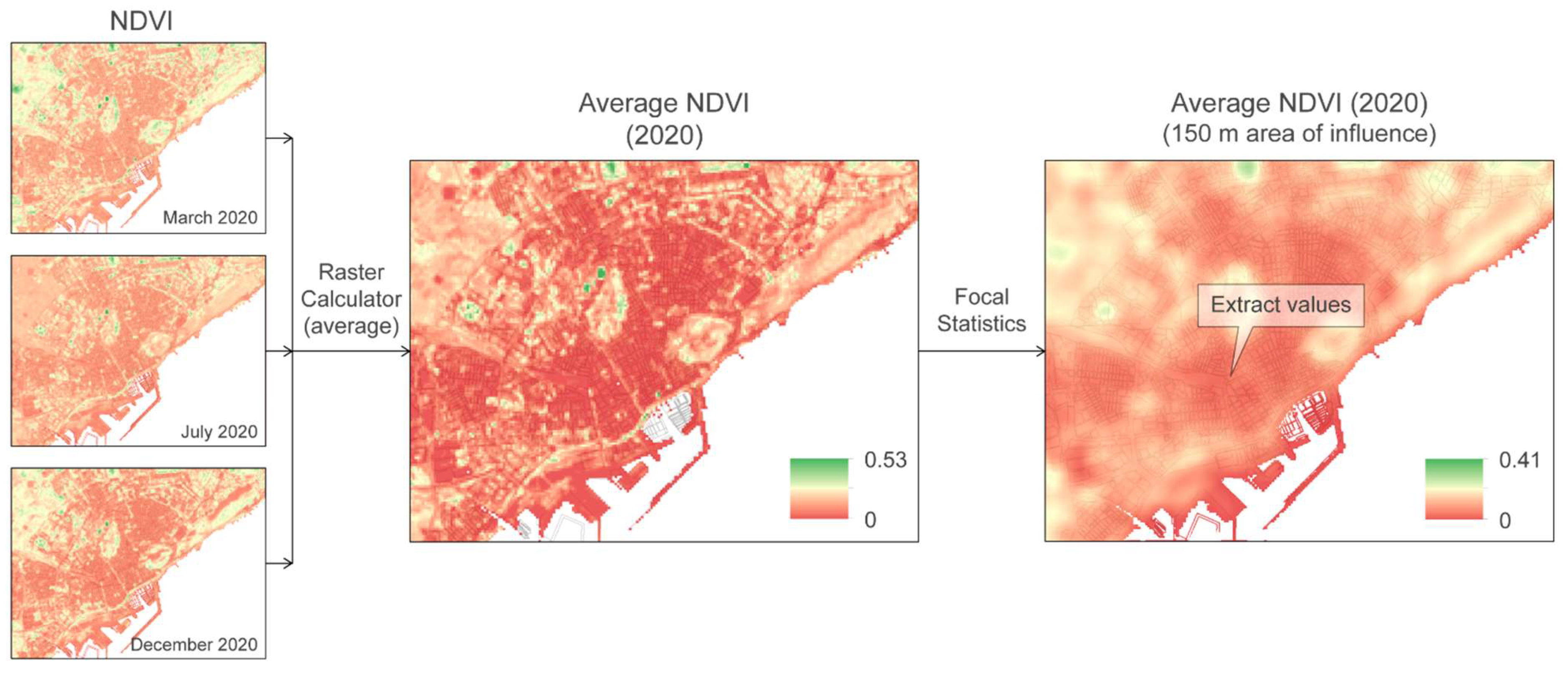
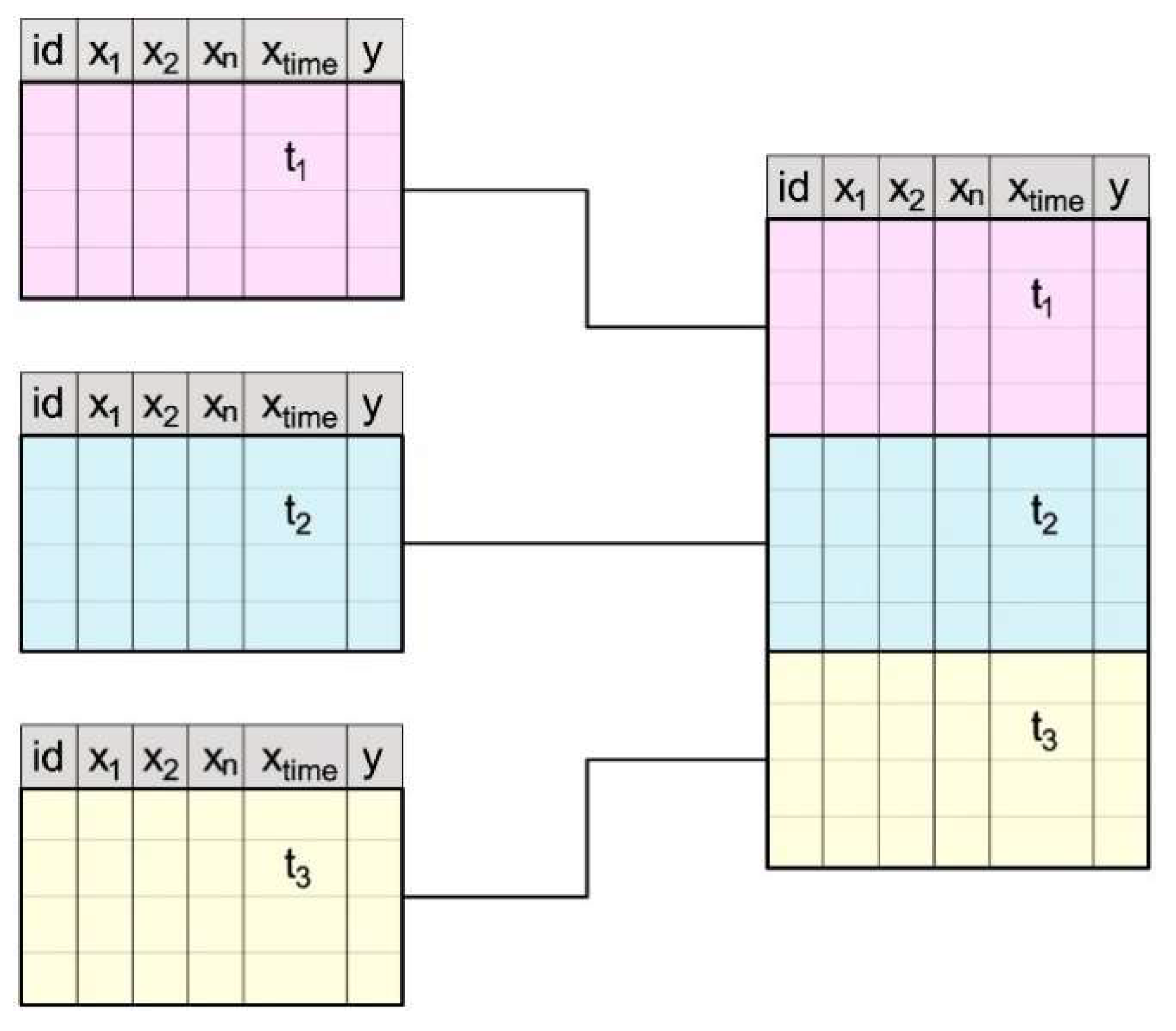
2.1. Study Area, Information Sources, and Database
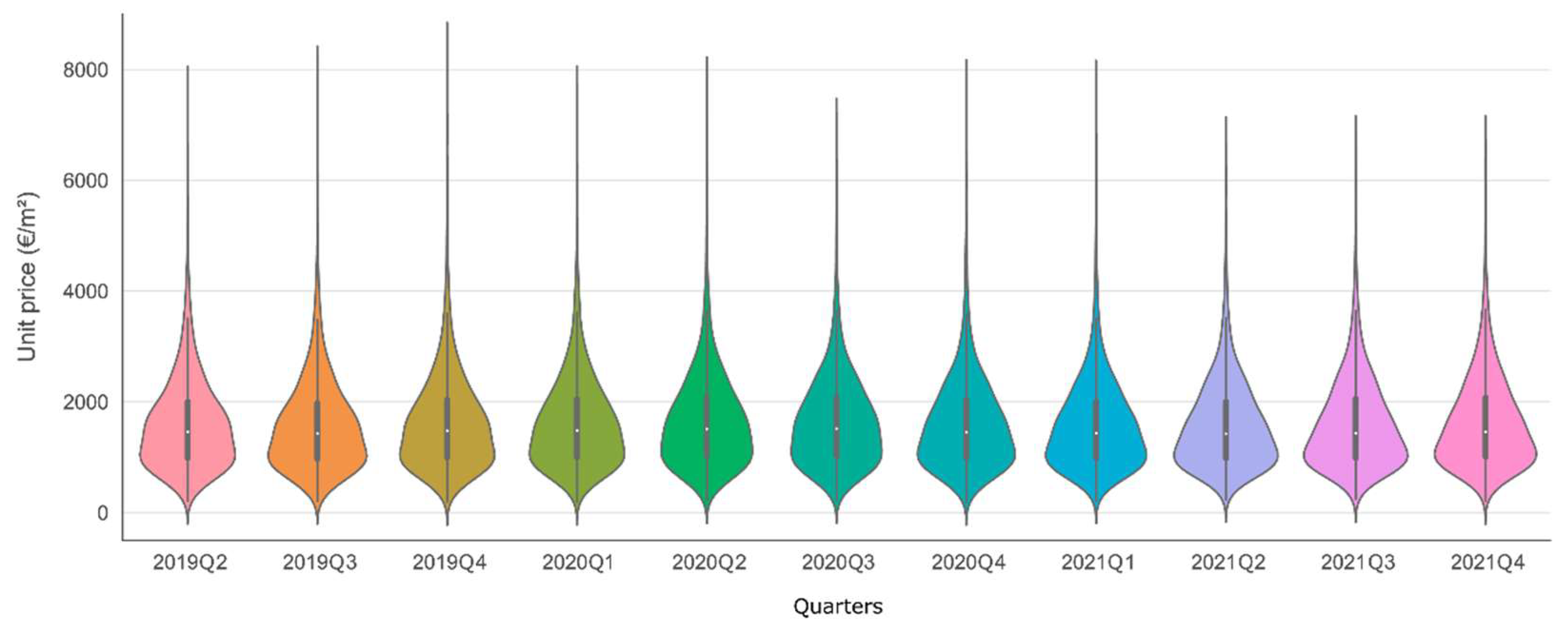
2.2. Descriptive Statistics
2.3. Methodology
3. Results
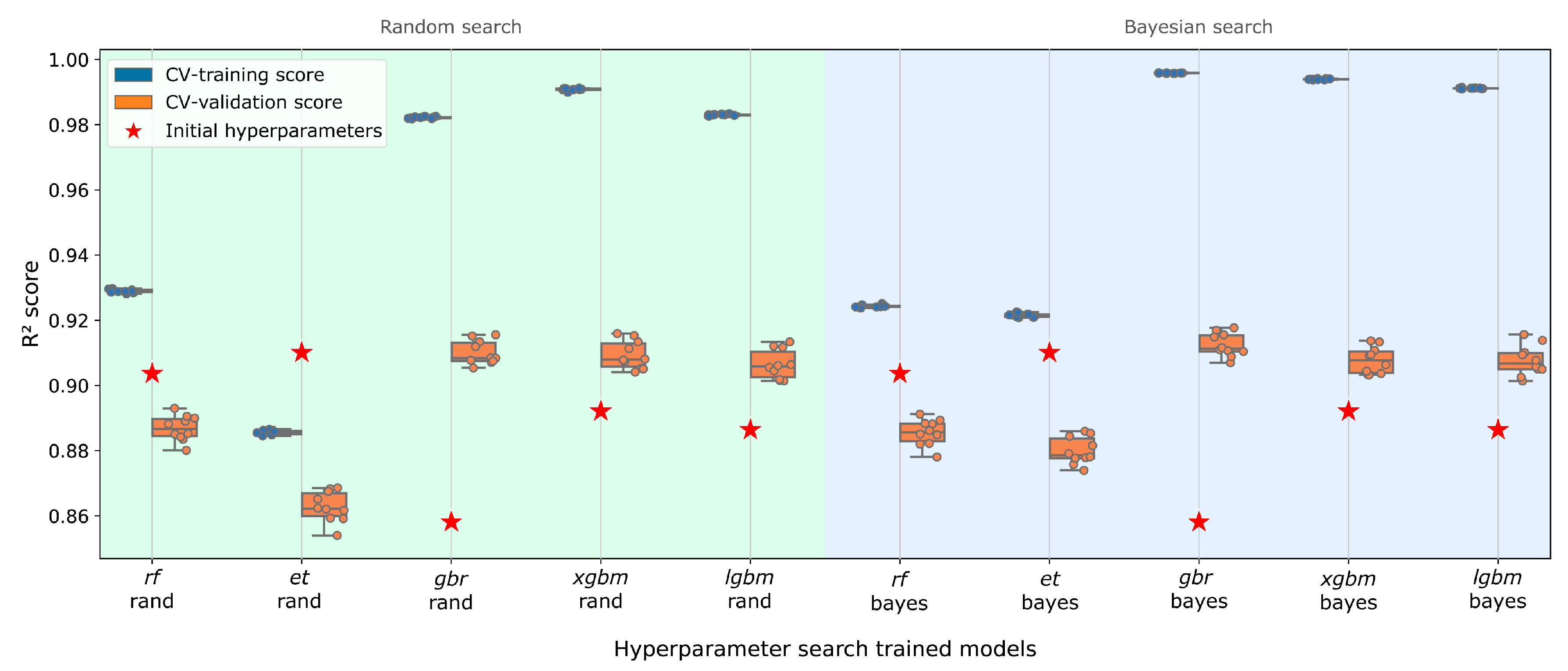
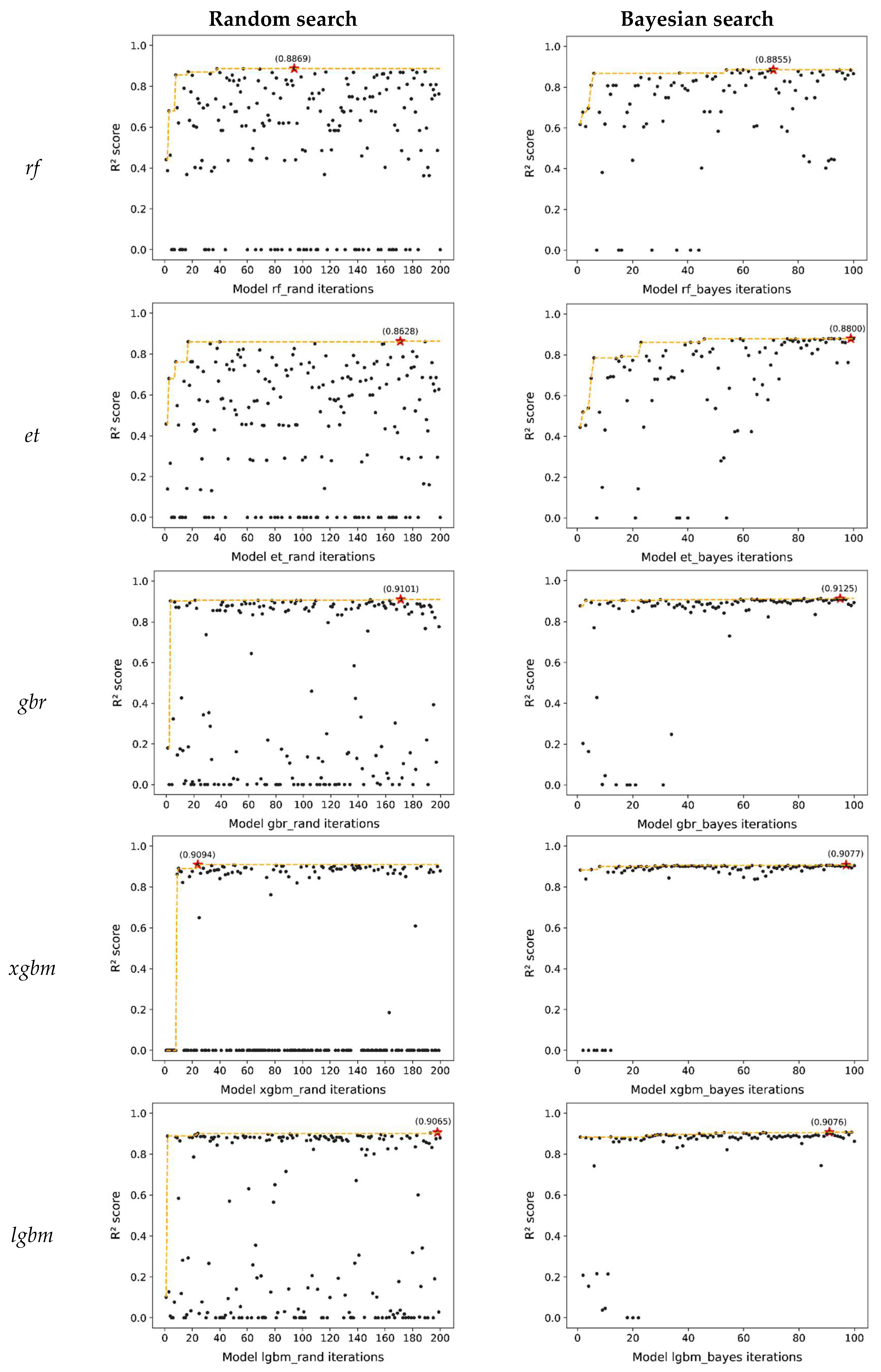
3.1. Model Training and Optimization
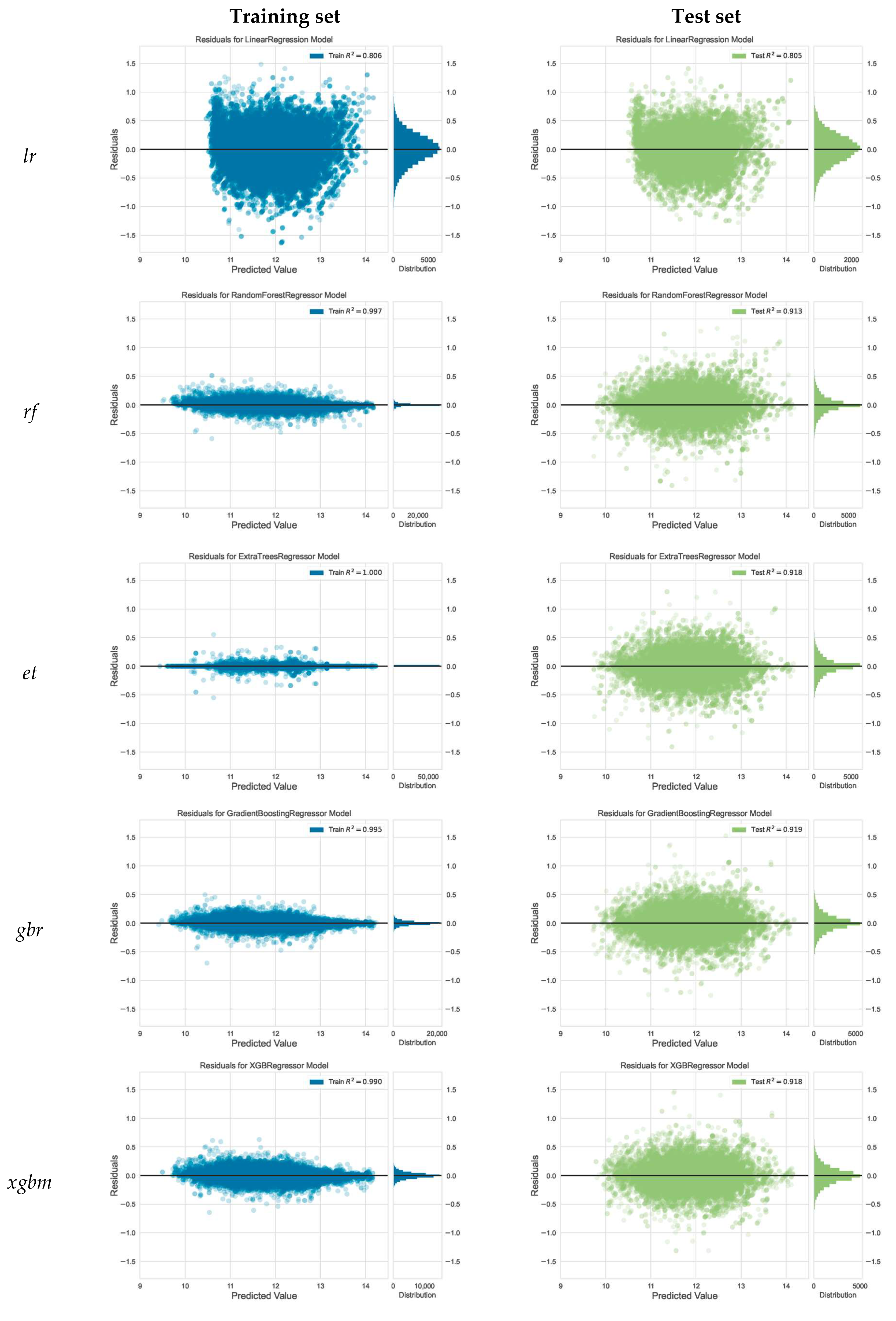
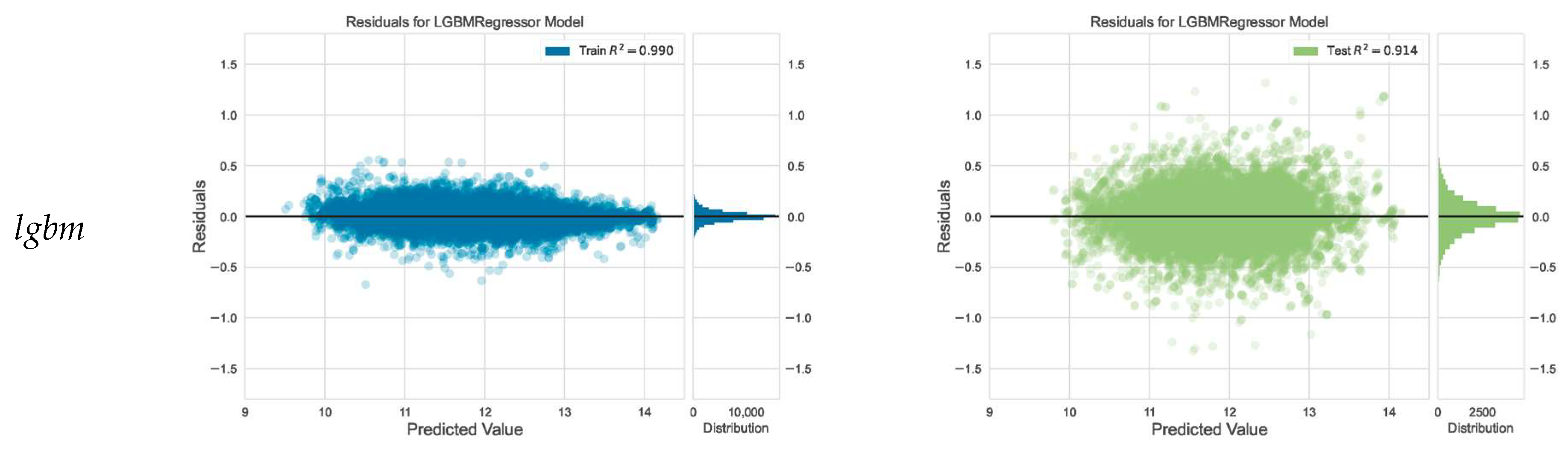
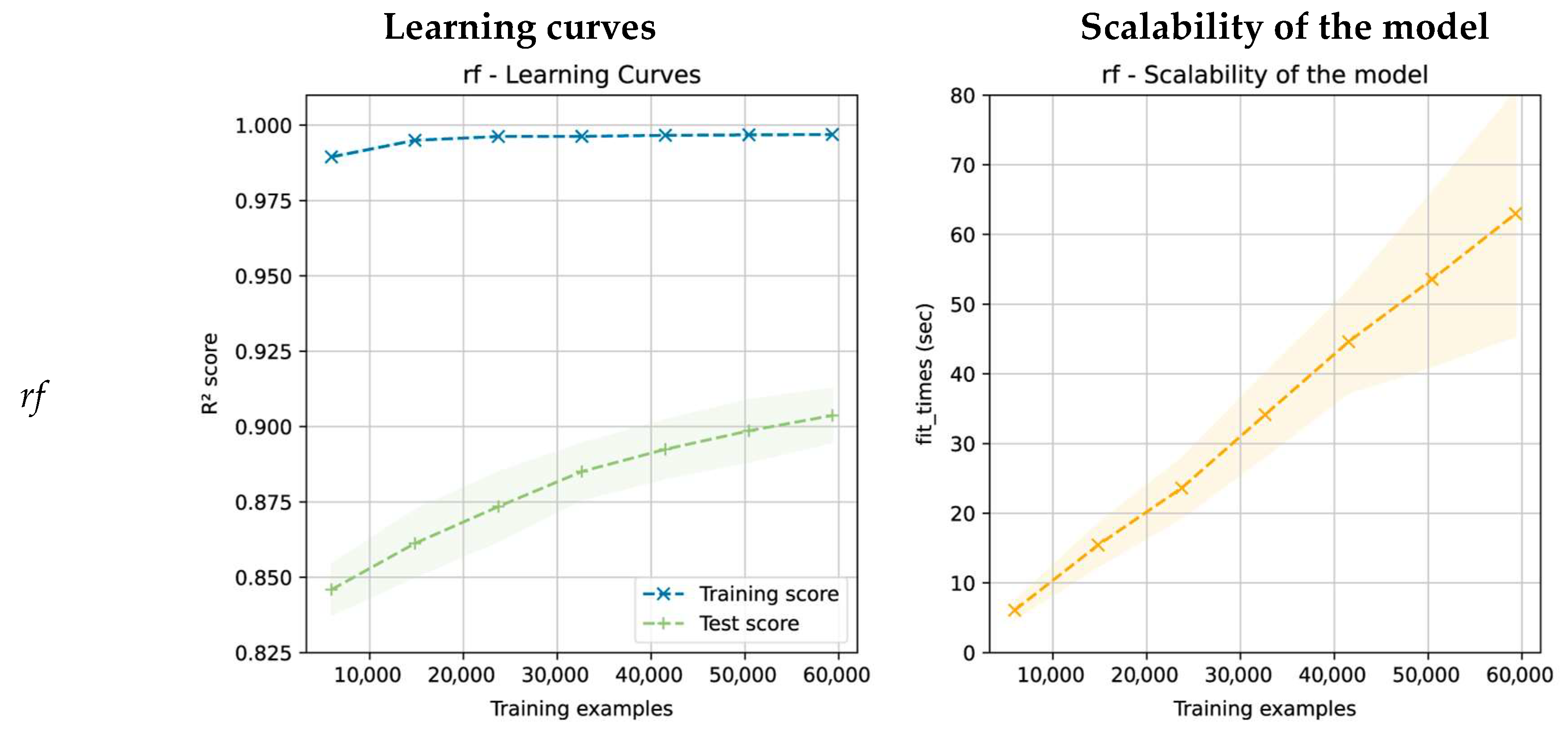
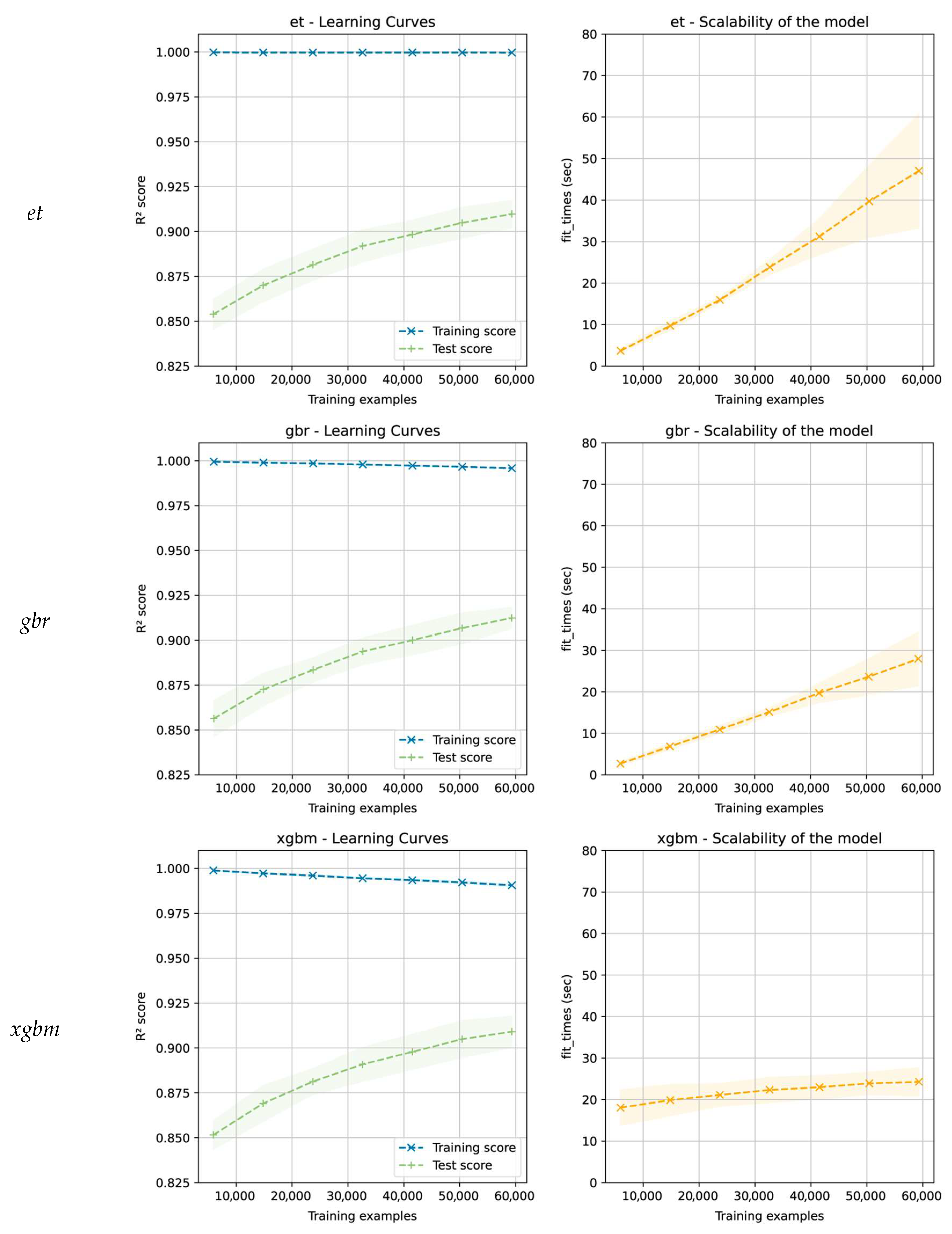
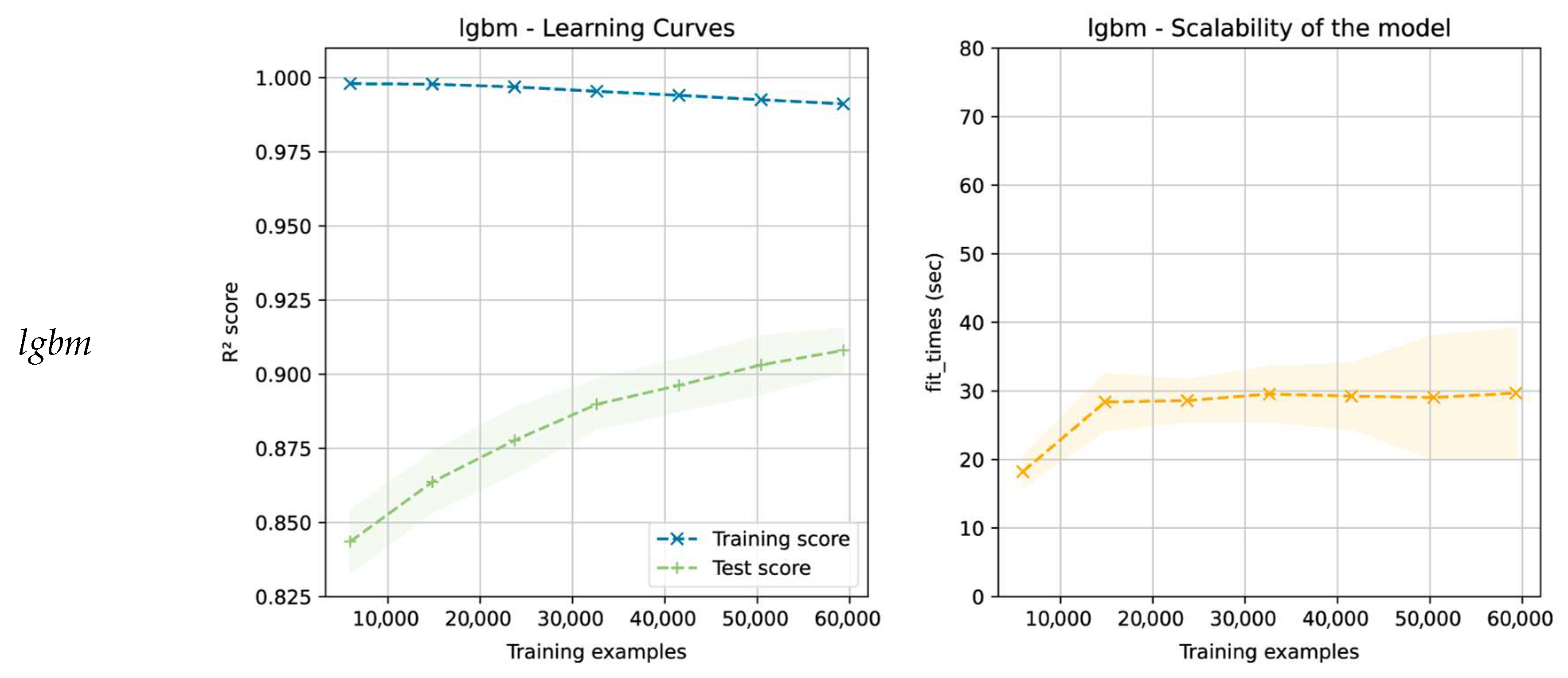
3.2. Model Evaluation and Selection
- The difference in performance between the algorithms (in this case being minimal, varying between 0.9135 and 0.9192 (R² score));
- The need to select an algorithm that has no overfitting problems and generalizes well with unseen data (in this case, the xgbm and lgbm algorithms may be good candidates);
- The need to choose an algorithm with low prediction variability in the cross-validation process (low variance) (the gbr algorithm has had the lowest variability);
- The need to consider the necessary times for the training and optimization of the hyperparameters and whether they adapt to the project deadlines (in this case, the xgbm and lgbm algorithms are the best options);
- The need to consider the file sizes of the models required for deployment (in this case, the lgbm algorithm generates the smallest file and the rf and et algorithms generate the largest (77 to 112 times larger than the lgbm algorithm)).
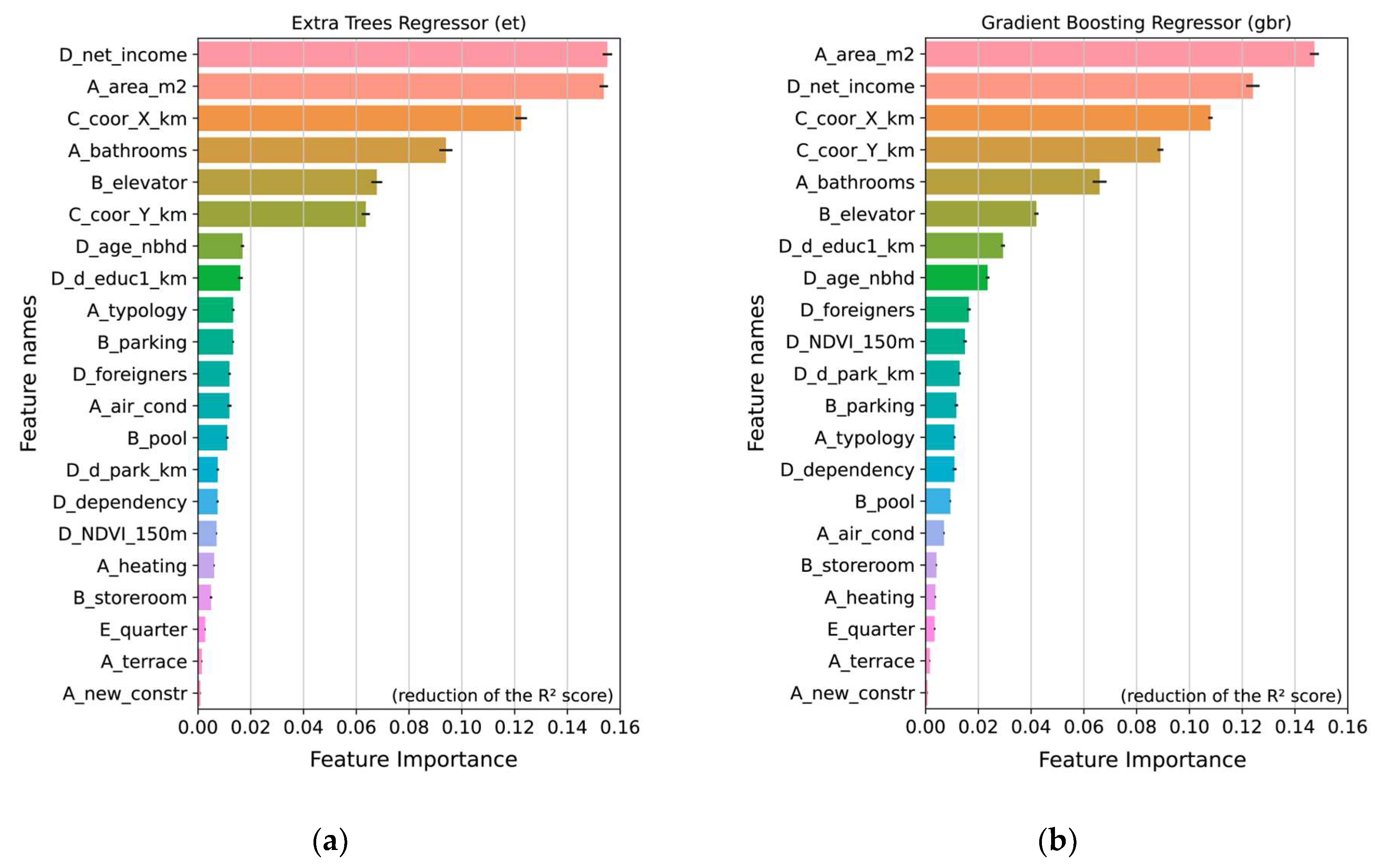
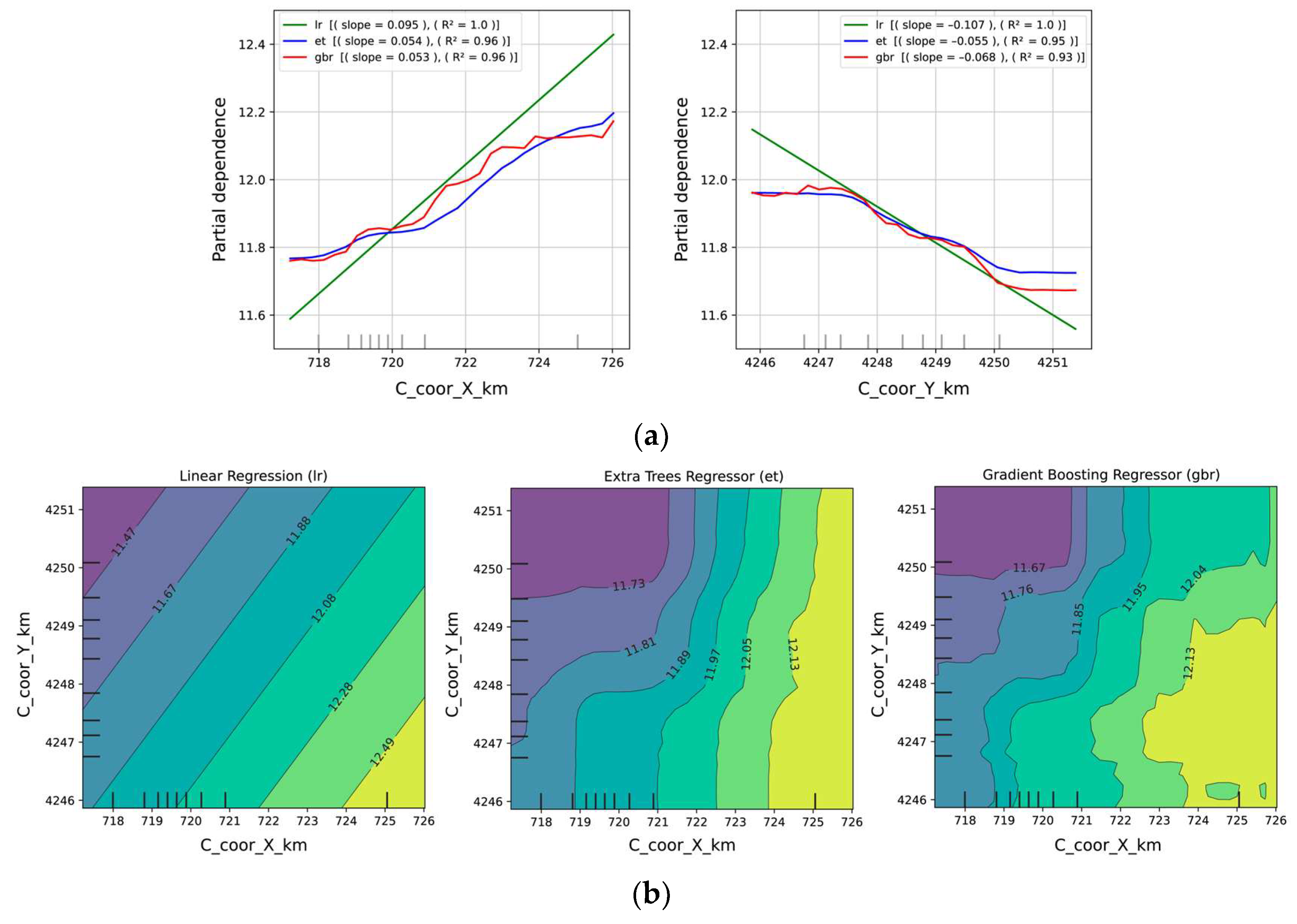
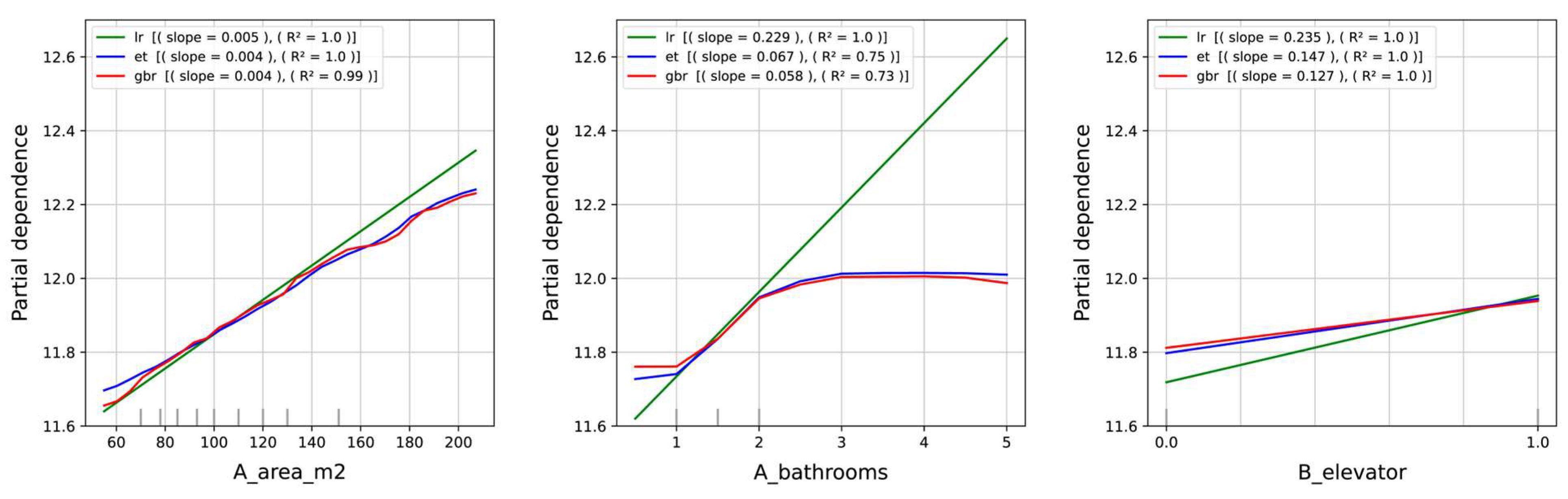
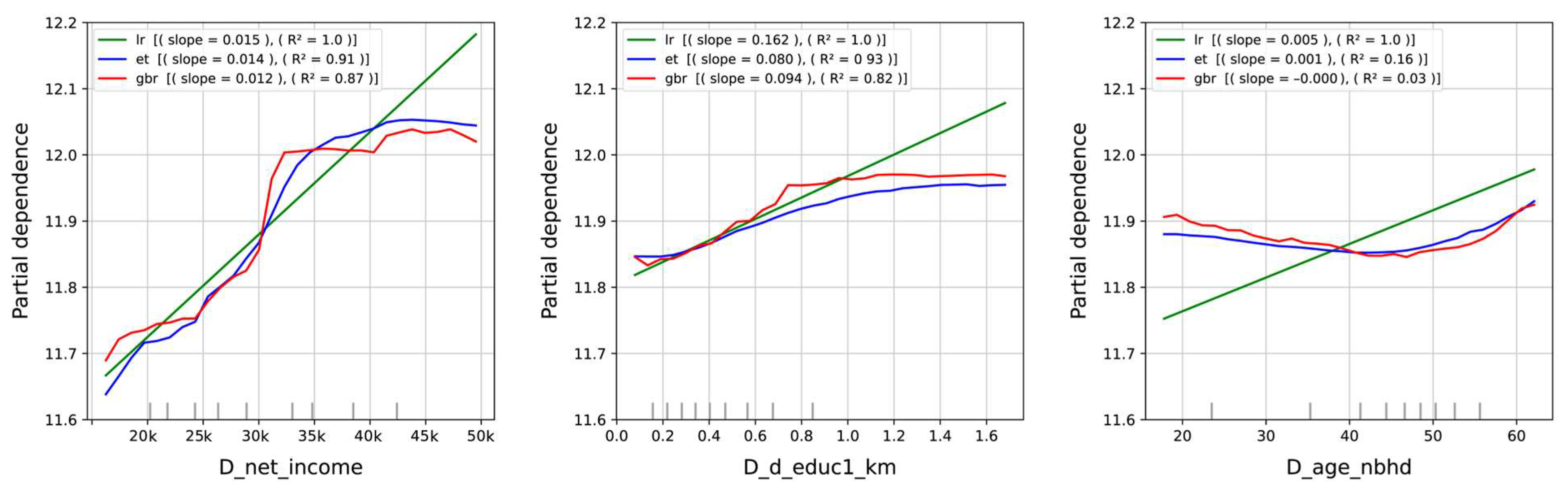
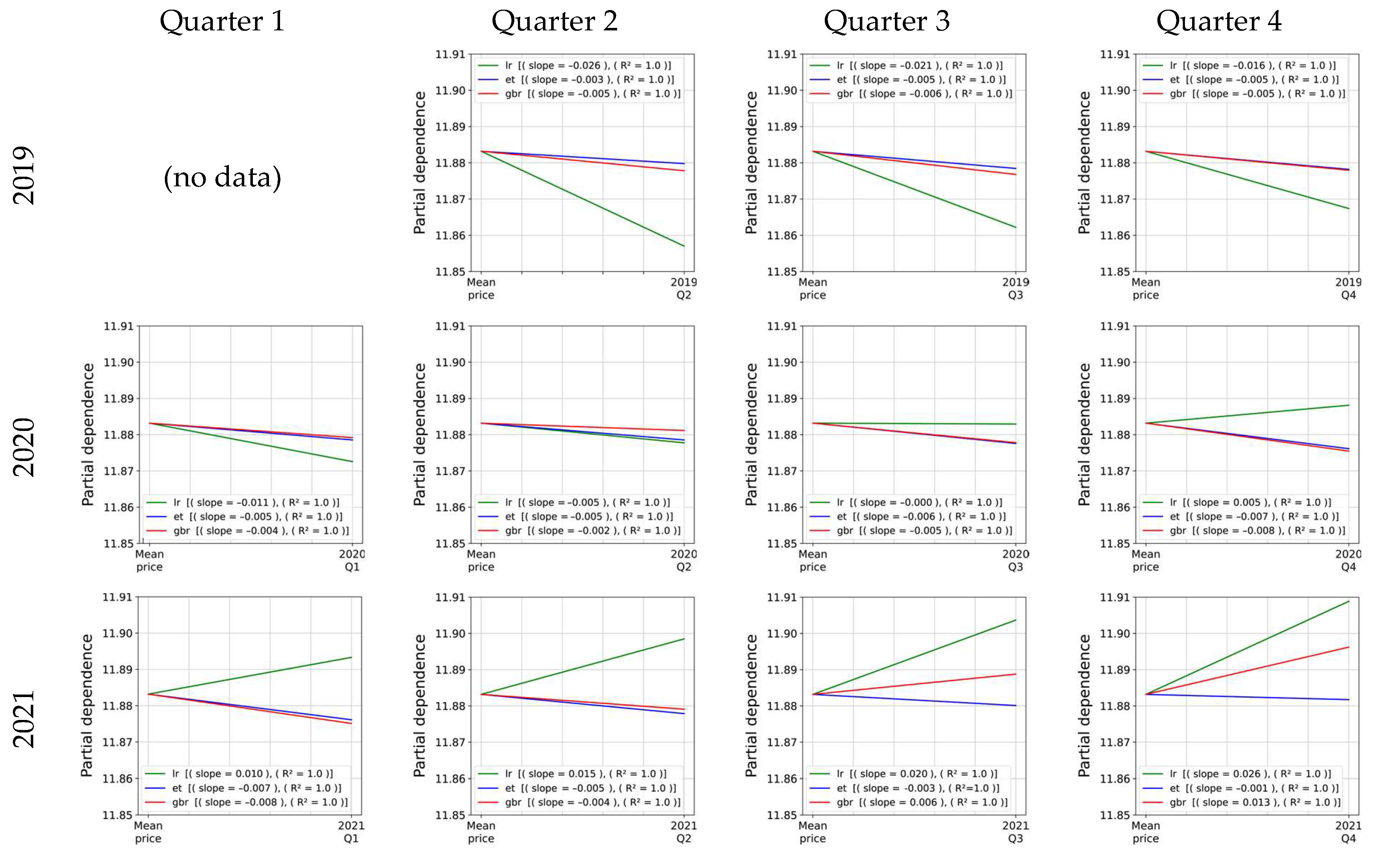
3.3. Model Interpretation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CART | Classification and Regression Tree |
| CECD | Consejería de Educación, Cultura y Deporte (Regional Ministry of Education, Culture and Sports) |
| CHAID | Chi-squared Automatic Interaction Detector |
| DGC | Dirección General de Catastro (Spanish General Directorate of Cadastre) |
| DT | Decision Tree |
| EPSG | European Petroleum Survey Group |
| ETR | Extra-Trees Regressor |
| ETRS89 | European Terrestrial Reference System 1989 |
| GBR | Gradient Boosting Regressor |
| HPM | Hedonic Price Models |
| ICV | Institut Cartogràfic Valencià (Valencian Cartographic Institute) |
| IDEV | Infraestructura de Datos Espaciales Valenciana (Valencian Spatial Data Infrastructure) |
| IDW | Inverse Distance Weighting |
| IGN | Instituto Geográfico Nacional (Spanish National Geographic Institute) |
| INE | Instituto Nacional de Estadística (Spanish National Institute of Statistics) |
| K-NN | K-Nearest Neighbours |
| LGBM | Light Gradient Boosting Machine |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MLP-NN | Multi-Layer Perceptron Neural Network |
| MSE | Mean Square Error |
| NDVI | Normalized Difference Vegetation Index |
| NN | Neural Networks |
| OLS | Ordinary Least Squares regression |
| PDP | Partial Dependence Plot |
| RF | Random Forest |
| RMSE | Root Mean Squared Error |
| SVM | Support Vector Machines |
| USGS | U.S. Geological Survey |
| UTM | Universal Transverse Mercator coordinate system |
| VIF | Variance Inflation Factor |
| XGBM | Extreme Gradient Boosting |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train Set | Test Set | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Features | B | Std. Error | Sig. | VIF | B | Std. Error | Sig. | VIF | |
| (Constant) | 394.693 | 7.570 | 0.000 | 390.866 | 4.942 | 0.000 | |||
| A_typology | A_flat | reference | reference | ||||||
| A_apartment | 0.081 | 0.007 | 0.000 | 1.076 | 0.053 | 0.004 | 0.000 | 1.080 | |
| A_penthouse | 0.149 | 0.007 | 0.000 | 1.144 | 0.172 | 0.005 | 0.000 | 1.127 | |
| A_duplex | 0.012 | 0.017 | 0.462 | 1.033 | −0.004 | 0.010 | 0.679 | 1.049 | |
| A_studio_flat | −0.052 | 0.027 | 0.057 | 1.020 | −0.105 | 0.020 | 0.000 | 1.015 | |
| A_loft | 0.231 | 0.027 | 0.000 | 1.018 | 0.204 | 0.020 | 0.000 | 1.008 | |
| A_area_m2 | 0.004 | 0.000 | 0.000 | 1.856 | 0.005 | 0.000 | 0.000 | 1.872 | |
| A_bathrooms | 0.229 | 0.004 | 0.000 | 2.034 | 0.230 | 0.003 | 0.000 | 2.057 | |
| A_air_cond | 0.060 | 0.004 | 0.000 | 1.256 | 0.068 | 0.002 | 0.000 | 1.285 | |
| A_heating | 0.062 | 0.004 | 0.000 | 1.319 | 0.060 | 0.003 | 0.000 | 1.326 | |
| A_terrace | 0.010 | 0.006 | 0.043 | 1.195 | 0.005 | 0.004 | 0.146 | 1.187 | |
| A_new_constr | 0.212 | 0.010 | 0.000 | 1.061 | 0.181 | 0.007 | 0.000 | 1.057 | |
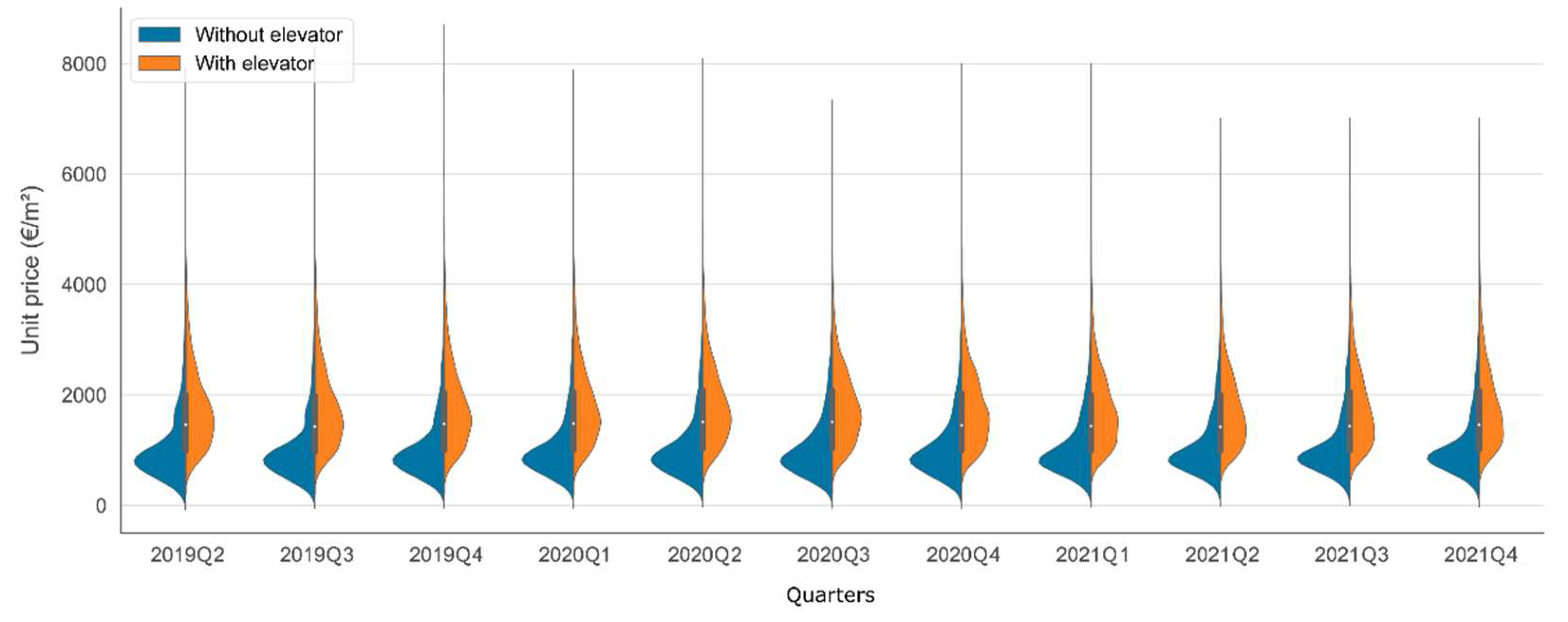
| B_elevator | 0.238 | 0.004 | 0.000 | 1.472 | 0.234 | 0.003 | 0.000 | 1.442 | |
| B_parking | 0.075 | 0.005 | 0.000 | 1.653 | 0.057 | 0.003 | 0.000 | 1.735 | |
| B_storeroom | 0.049 | 0.005 | 0.000 | 1.303 | 0.051 | 0.003 | 0.000 | 1.310 | |
| B_pool | 0.081 | 0.006 | 0.000 | 1.983 | 0.077 | 0.004 | 0.000 | 2.023 | |
| C_coor_X_km | 0.093 | 0.001 | 0.000 | 3.093 | 0.095 | 0.001 | 0.000 | 3.206 | |
| C_coor_Y_km | −0.106 | 0.002 | 0.000 | 2.716 | −0.106 | 0.001 | 0.000 | 2.740 | |
| D_age_nbhd | 0.005 | 0.000 | 0.000 | 2.606 | 0.005 | 0.000 | 0.000 | 2.645 | |
| D_dependency | −0.058 | 0.020 | 0.003 | 1.585 | −0.046 | 0.013 | 0.000 | 1.595 | |
| D_foreigners | −0.004 | 0.000 | 0.000 | 2.347 | −0.004 | 0.000 | 0.000 | 2.342 | |
| D_net_income | 0.017 | 0.000 | 0.000 | 2.695 | 0.016 | 0.000 | 0.000 | 2.693 | |
| D_d_educ1_km | 0.156 | 0.006 | 0.000 | 1.844 | 0.163 | 0.004 | 0.000 | 1.875 | |
| D_d_park_km | −0.094 | 0.006 | 0.000 | 1.713 | −0.092 | 0.004 | 0.000 | 1.705 | |
| D_NDVI_150m | −1.813 | 0.084 | 0.000 | 2.664 | −1.826 | 0.056 | 0.000 | 2.731 | |
| E_quarter | 2019Q2 | −0.018 | 0.009 | 0.041 | 1.766 | −0.023 | 0.006 | 0.000 | 1.736 |
| 2019Q3 | −0.024 | 0.009 | 0.005 | 1.872 | −0.030 | 0.006 | 0.000 | 1.854 | |
| 2019Q4 | −0.022 | 0.008 | 0.008 | 1.974 | −0.020 | 0.005 | 0.000 | 1.940 | |
| 2020Q1 | −0.011 | 0.008 | 0.178 | 1.987 | −0.011 | 0.005 | 0.037 | 1.959 | |
| 2020Q2 | reference | reference | |||||||
| 2020Q3 | −0.020 | 0.008 | 0.018 | 1.974 | −0.016 | 0.005 | 0.003 | 1.979 | |
| 2020Q4 | −0.014 | 0.008 | 0.072 | 2.125 | −0.012 | 0.005 | 0.021 | 2.066 | |
| 2021Q1 | −0.007 | 0.008 | 0.367 | 2.122 | −0.010 | 0.005 | 0.067 | 2.066 | |
| 2021Q2 | 0.003 | 0.008 | 0.729 | 2.091 | 0.001 | 0.005 | 0.806 | 2.074 | |
| 2021Q3 | 0.016 | 0.008 | 0.043 | 2.115 | 0.024 | 0.005 | 0.000 | 2.103 | |
| 2021Q4 | 0.022 | 0.008 | 0.005 | 2.156 | 0.032 | 0.005 | 0.000 | 2.117 | |
| N | 65,905 | 28,119 | |||||||
| R2 | 0.807 | 0.808 | |||||||
| Adj. R2 | 0.807 | 0.808 | |||||||
| Std. Error | 0.2810 | 0.2812 | |||||||
| F (sig.) | 3461.9 (p < 0.001) | 8147.0 (p < 0.001) | |||||||
| Durbin–Watson | 1.742 | 1.705 | |||||||
References
- Kauko, T.; d’Amato, M. Introduction: Suitability Issues in Mass Appraisal Methodology. In Mass Appraisal Methods; Blackwell Publishing Ltd.: Oxford, UK, 2008; pp. 1–24. [Google Scholar] [CrossRef]
- Grover, R. Mass valuations. J. Prop. Investig. Financ. 2016, 34, 191–204. [Google Scholar] [CrossRef]
- IAAO, International Association of Assessing Officers. Standard on Mass Appraisal of Real Property (2017); International Association of Assessing Officers: Kansas City, MI, USA, 2019; p. 22. Available online: https://www.iaao.org/media/standards/StandardOnMassAppraisal.pdf (accessed on 22 August 2022).
- Wang, D.; Li, V.J. Mass Appraisal Models of Real Estate in the 21st Century: A Systematic Literature Review. Sustainability 2019, 11, 7006. [Google Scholar] [CrossRef] [Green Version]
- Antipov, E.A.; Pokryshevskaya, E.B. Mass appraisal of residential apartments: An application of Random forest for valuation and a CART-based approach for model diagnostics. Expert Syst. Appl. 2012, 39, 1772–1778. [Google Scholar] [CrossRef] [Green Version]
- Park, B.; Bae, J.K. Using machine learning algorithms for housing price prediction: The case of Fairfax County, Virginia housing data. Expert Syst. Appl. 2015, 42, 2928–2934. [Google Scholar] [CrossRef]
- Ahmed Neloy, A.; Sadman Haque, H.M.; Ul Islam, M. Ensemble Learning Based Rental Apartment Price Prediction Model by Categorical Features Factoring. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; pp. 350–356. [Google Scholar] [CrossRef]
- Čeh, M.; Kilibarda, M.; Lisec, A.; Bajat, B. Estimating the Performance of Random Forest versus Multiple Regression for Predicting Prices of the Apartments. ISPRS Int. J. Geo-Inf. 2018, 7, 168. [Google Scholar] [CrossRef] [Green Version]
- Embaye, W.T.; Zereyesus, Y.A.; Chen, B. Predicting the rental value of houses in household surveys in Tanzania, Uganda and Malawi: Evaluations of hedonic pricing and machine learning approaches. PLoS ONE 2021, 16, e0244953. [Google Scholar] [CrossRef]
- Gnat, S. Property Mass Valuation on Small Markets. Land 2021, 10, 388. [Google Scholar] [CrossRef]
- Hong, J. An Application of XGBoost, LightGBM, CatBoost Algorithms on House Price Appraisal System. Hous. Financ. Res. 2020, 4, 33–64. [Google Scholar] [CrossRef]
- Hong, J.; Choi, H.; Kim, W.-S. A house price valuation based on the random forest approach: The mass appraisal of residential property in South Korea. Int. J. Strateg. Prop. Manag. 2020, 24, 140–152. [Google Scholar] [CrossRef] [Green Version]
- Jui, J.J.; Imran Molla, M.M.; Bari, B.S.; Rashid, M.; Hasan, M.J. Flat Price Prediction Using Linear and Random Forest Regression Based on Machine Learning Techniques. In Embracing Industry 4.0. Selected Articles from MUCET 2019; Mohd Razman, M.A., Mat Yahya, N., Zainal Abidin, A.F., Mat Jizat, J.A., Myung, H., Abdul Karim, M.S., Eds.; Springer: Singapore, 2020; Volume 678, pp. 205–217. [Google Scholar] [CrossRef]
- Kok, N.; Koponen, E.-L.; Martínez-Barbosa, C.A. Big Data in Real Estate? From Manual Appraisal to Automated Valuation. J. Portf. Manag. 2017, 43, 202–211. [Google Scholar] [CrossRef]
- Rico-Juan, J.R.; Taltavull de La Paz, P. Machine learning with explainability or spatial hedonics tools? An analysis of the asking prices in the housing market in Alicante, Spain. Expert Syst. Appl. 2021, 171, 114590. [Google Scholar] [CrossRef]
- Voutas Chatzidis, I. Prediction of Housing Prices based on Spatial & Social Parameters using Regression & Deep Learning Methods. Master’s Thesis, University of Thessaloniki, Thessaloniki, Greece, 2019. [Google Scholar] [CrossRef]
- Xu, L.; Li, Z. A New Appraisal Model of Second-Hand Housing Prices in China’s First-Tier Cities Based on Machine Learning Algorithms. Comput. Econ. 2021, 57, 617–637. [Google Scholar] [CrossRef]
- Yilmazer, S.; Kocaman, S. A mass appraisal assessment study using machine learning based on multiple regression and random forest. Land Use Policy 2020, 99, 104889. [Google Scholar] [CrossRef]
- Alfaro-Navarro, J.-L.; Cano, E.L.; Alfaro-Cortés, E.; García, N.; Gámez, M.; Larraz, B. A Fully Automated Adjustment of Ensemble Methods in Machine Learning for Modeling Complex Real Estate Systems. Complexity 2020, 2020, 5287263. [Google Scholar] [CrossRef]
- Canaz Sevgen, S.; Aliefendioğlu, Y. Mass Apprasial With A Machine Learning Algorithm: Random Forest Regression. Bilişim Teknol. Derg. 2020, 13, 301–311. [Google Scholar] [CrossRef]
- De Aquino Afonso, B.K.; Carvalho Melo, L.; Dihanster, W.; Sousa, S.; Berton, L. Housing Prices Prediction with a Deep Learning and Random Forest Ensemble. In Proceedings of the Anais do XVI Encontro Nacional de Inteligência Artificial e Computacional (ENIAC 2019), Salvador de Bahia, Brazil, 15–18 October 2019; pp. 389–400. [Google Scholar] [CrossRef]
- Ho, W.K.O.; Tang, B.-S.; Wong, S.W. Predicting property prices with machine learning algorithms. J. Prop. Res. 2021, 38, 48–70. [Google Scholar] [CrossRef]
- Hu, L.; He, S.; Han, Z.; Xiao, H.; Su, S.; Weng, M.; Cai, Z. Monitoring housing rental prices based on social media: An integrated approach of machine-learning algorithms and hedonic modeling to inform equitable housing policies. Land Use Policy 2019, 82, 657–673. [Google Scholar] [CrossRef]
- Pai, P.-F.; Wang, W.-C. Using Machine Learning Models and Actual Transaction Data for Predicting Real Estate Prices. Appl. Sci. 2020, 10, 5832. [Google Scholar] [CrossRef]
- Renigier-Biłozor, M.; Źróbek, S.; Walacik, M.; Janowski, A. Hybridization of valuation procedures as a medicine supporting the real estate market and sustainable land use development during the covid-19 pandemic and afterwards. Land Use Policy 2020, 99, 105070. [Google Scholar] [CrossRef]
- Banerjee, D.; Dutta, S. Predicting the housing price direction using machine learning techniques. In Proceedings of the 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017; pp. 2998–3000. [Google Scholar] [CrossRef]
- Fan, C.; Cui, Z.; Zhong, X. House Prices Prediction with Machine Learning Algorithms. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macau, China, 26–28 February 2018; pp. 6–10. [Google Scholar] [CrossRef]
- Iyer, S.R.; Simkins, B.J. COVID-19 and the Economy: Summary of research and future directions. Financ. Res. Lett. 2022, 47, 102801. [Google Scholar] [CrossRef]
- Mohammed, J.K.; Aliyu, A.A.; Dzukogi, U.A.; Olawale, A.A. The Impact of COVID-19 on Housing Market: A Review of Emerging Literature. Int. J. Real Estate Stud. 2022, 15, 66–74. [Google Scholar] [CrossRef]
- Li, X.; Zhang, C. Did the COVID-19 Pandemic Crisis Affect Housing Prices Evenly in the U.S.? Sustainability 2021, 13, 12277. [Google Scholar] [CrossRef]
- Ouazad, A. Resilient Urban Housing Markets: Shocks Versus Fundamentals. In COVID-19: Systemic Risk and Resilience; Linkov, I., Keenan, J.M., Trump, B.D., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 299–331. [Google Scholar] [CrossRef]
- Duca, J.V.; Hoesli, M.; Montezuma, J. The resilience and realignment of house prices in the era of Covid-19. J. Eur. Real Estate Res. 2021, 14, 421–431. [Google Scholar] [CrossRef]
- Battistini, N.; Falagiarda, M.; Gareis, J.; Hackmann, A.; Roma, M. The euro area housing market during the COVID-19 pandemic. Eur. Cent. Banc Econ. Bull. 2021, 2021, 115–132. Available online: https://www.ecb.europa.eu/pub/pdf/ecbu/eb202107.en.pdf (accessed on 17 August 2022).
- Alves Álvarez, P.A.; San Juan del Peso, L. The Impact of the COVID-19 Health Crisis on the Housing Market in Spain. Boletín Económico Del Banco De España 2021, 2021, 1–15. Available online: https://repositorio.bde.es/handle/123456789/16551 (accessed on 17 August 2022).
- Trojanek, R.; Gluszak, M.; Hebdzynski, M.; Tanas, J. The COVID-19 Pandemic, Airbnb and Housing Market Dynamics in Warsaw. Crit. Hous. Anal. 2021, 8, 72–84. [Google Scholar] [CrossRef]
- Cheung, K.S.; Yiu, C.Y.; Xiong, C. Housing Market in the Time of Pandemic: A Price Gradient Analysis from the COVID-19 Epicentre in China. J. Risk Financ. Manag. 2021, 14, 108. [Google Scholar] [CrossRef]
- Qian, X.; Qiu, S.; Zhang, G. The impact of COVID-19 on housing price: Evidence from China. Financ. Res. Lett. 2021, 43, 101944. [Google Scholar] [CrossRef]
- Tian, C.; Peng, X.; Zhang, X. COVID-19 Pandemic, Urban Resilience and Real Estate Prices: The Experience of Cities in the Yangtze River Delta in China. Land 2021, 10, 960. [Google Scholar] [CrossRef]
- Hu, M.R.; Lee, A.D.; Zou, D. COVID-19 and Housing Prices: Australian Evidence with Daily Hedonic Returns. Financ. Res. Lett. 2021, 43, 101960. [Google Scholar] [CrossRef]
- Kartal, M.T.; Kılıç Depren, S.; Depren, Ö. Housing prices in emerging countries during COVID-19: Evidence from Turkey. Int. J. Hous. Mark. Anal. 2021. ahead-of-print. [Google Scholar] [CrossRef]
- Kaynak, S.; Ekinci, A.; Kaya, H.F. The effect of COVID-19 pandemic on residential real estate prices: Turkish case. Quant. Financ. Econ. 2021, 5, 623–639. [Google Scholar] [CrossRef]
- INE, Instituto Nacional de Estadística. Padrón de Población por Municipios. Cifras Oficiales de Población de los Municipios Españoles: Revisión del Padrón Municipal. Available online: https://www.ine.es/dyngs/INEbase/categoria.htm?c=Estadistica_P&cid=1254734710990 (accessed on 10 April 2021).
- MITMA, Ministerio de Transportes, Movilidad y Agenda Urbana. Transacciones Inmobiliarias (Compraventa). Available online: https://www.fomento.gob.es/be2/?nivel=2&orden=34000000 (accessed on 5 July 2022).
- ISCIII, Instituto de Salud Carlos III. COVID-19—Documentación y Datos (cnecovid.isciii.es). Available online: https://cnecovid.isciii.es/covid19/#documentaci%C3%B3n-y-datos (accessed on 5 July 2022).
- Malpezzi, S. Hedonic Pricing Models: A Selective and Applied Review. In Housing Economics and Public Policy; O’Sullivan, T., Gibb, K., Eds.; Blackwell Science: Great Britain, UK, 2003; pp. 67–89. [Google Scholar] [CrossRef]
- Horowitz, J.L. The role of the list price in housing markets: Theory and an econometric model. J. Appl. Econom. 1992, 7, 115–129. [Google Scholar] [CrossRef]
- Knight, J.; Sirmans, C.F.; Turnbull, G. List Price Information in Residential Appraisal and Underwriting. J. Real Estate Res. 1998, 15, 59–76. [Google Scholar] [CrossRef]
- Shimizu, C.; Nishimura, K.G.; Watanabe, T. House prices from magazines, realtors, and the land registry. BIS Pap. 2012, 64, 29–38. Available online: https://www.bis.org/author/chihiro_shimizu.htm (accessed on 11 October 2022).
- INE, Instituto Nacional de Estadística. Cartografía digitalizada de Secciones Censales. Available online: https://www.ine.es/ss/Satellite?L=es_ES&c=Page&cid=1259952026632&p=1259952026632&pagename=ProductosYServicios%2FPYSLayout (accessed on 10 April 2021).
- INE, Instituto Nacional de Estadística. Estadística Experimental. Atlas de Distribución de Renta de los Hogares. Available online: https://www.ine.es/experimental/atlas/exp_atlas_tab.htm (accessed on 5 July 2021).
- SEC, Sede Electrónica del Catastro Inmobiliario. Información Alfanumérica y Cartografía Vectorial. Available online: https://www.sedecatastro.gob.es/ (accessed on 10 April 2021).
- Mora-Garcia, R.T. Modelo explicativo de las Variables Intervinientes en la Calidad del Entorno Construido de las Ciudades. Ph.D. Thesis, Universidad de Alicante, Alicante, Spain, 2016. Available online: http://hdl.handle.net/10045/65829 (accessed on 8 April 2020).
- IGN, Instituto Geográfico Nacional. Centro Nacional de Información Geográfica (CNIG), Centro de descargas. Available online: https://centrodedescargas.cnig.es/ (accessed on 5 July 2022).
- CECD, Conselleria de Educación, Cultura y Deporte. Centros Docentes de la Comunidad Valenciana. Available online: https://ceice.gva.es/es/web/centros-docentes/descarga-base-de-datos (accessed on 10 April 2020).
- ICV, Institut Cartogràfic Valencià. IDEV, Infraestructura de Datos Espaciales Valenciana. Available online: https://idev.gva.es/ (accessed on 10 April 2020).
- Mora-Garcia, R.T.; Marti-Ciriquian, P.; Perez-Sanchez, R.; Cespedes-Lopez, M.F. A comparative analysis of manhattan, euclidean and network distances. Why are network distances more useful to urban professionals? In Proceedings of the 18th International Multidisciplinary Scientific Geoconference SGEM 2018, Albena, Bulgaria, 30 June–9 July 2018; pp. 3–10. [Google Scholar] [CrossRef]
- USGS, U.S. Geological Survey. EarthExplorer. Available online: https://earthexplorer.usgs.gov (accessed on 5 July 2020).
- Perez-Sanchez, R.; Mora-Garcia, R.T.; Perez-Sanchez, J.C.; Cespedes-Lopez, M.F. The influence of the characteristics of second-hand properties on their asking prices: Evidence in the Alicante market. Informes de la Construcción 2020, 72, e345. [Google Scholar] [CrossRef]
- Mora-Garcia, R.T.; Cespedes-Lopez, M.F.; Perez-Sanchez, R.; Marti-Ciriquian, P.; Perez-Sanchez, J.C. Determinants of the Price of Housing in the Province of Alicante (Spain): Analysis Using Quantile Regression. Sustainability 2019, 11, 437. [Google Scholar] [CrossRef] [Green Version]
- Cespedes-Lopez, M.F.; Mora-Garcia, R.T.; Perez-Sanchez, R.; Marti-Ciriquian, P. The Influence of Energy Certification on Housing Sales Prices in the Province of Alicante (Spain). Appl. Sci. 2020, 10, 7129. [Google Scholar] [CrossRef]
- Cespedes-Lopez, M.F.; Perez-Sanchez, R.; Mora-Garcia, R.T. The influence of housing location on energy ratings price premium in Alicante, Spain. Ecol. Econ. 2022, 201, 107579. [Google Scholar] [CrossRef]
- Kain, J.F.; Quigley, J.M. Housing Markets and Racial Discrimination: A Microeconomic Analysis; National Bureau of Economic Research: New York, NY, USA, 1975; p. 393. Available online: https://EconPapers.repec.org/RePEc:nbr:nberbk:kain75-1 (accessed on 16 March 2022).
- Sirmans, G.S.; Macpherson, D.A.; Zietz, E.N. The composition of hedonic pricing models. J. Real Estate Lit. 2005, 13, 3–43. Available online: http://www.jstor.org/stable/44103506 (accessed on 16 March 2022). [CrossRef]
- Kleinbaum, D.; Kupper, L.; Nizam, A.; Rosenberg, E. Applied Regression Analysis and Other Multivariable Methods, 5th ed.; Cengage Learning: Boston, MA, USA, 2013; p. 1072. [Google Scholar]
- Chatterjee, S.; Simonoff, J.S. Handbook of Regression Analysis; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2013; p. 240. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R, 2nd ed.; Springer: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Korobov, M. Explaining behavior of Machine Learning models with eli5 library. In Proceedings of the EuroPython Congress 2017, Rimini, Italy, 9–16 July 2017. [Google Scholar] [CrossRef]
- Korobov, M.; Lopuhin, K. ELI5 Python Package. Available online: https://eli5.readthedocs.io/ (accessed on 15 September 2021).
- Johnson, J.W.; Lebreton, J.M. History and Use of Relative Importance Indices in Organizational Research. Organ. Res. Methods 2004, 7, 238–257. [Google Scholar] [CrossRef]
- Grömping, U. Relative Importance for Linear Regression in R: The package relaimpo. J. Stat. Softw. 2006, 17, 27. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Molnar, C. (Ed.) Interpretable Machine Learning. A Guide for Making Black Box Models Explainable; Christoph Molnar Online. , 2021. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 15 September 2021).
- McGreal, W.S.; Taltavull de la Paz, P. Implicit house prices: Variation over time and space in Spain. Urban Stud. 2013, 50, 2024–2043. [Google Scholar] [CrossRef] [Green Version]
- Allen-Coghlan, M.; McQuinn, K.M. The potential impact of Covid-19 on the Irish housing sector. Int. J. Hous. Mark. Anal. 2021, 14, 636–651. [Google Scholar] [CrossRef]
- Aassve, A.; Arpino, B.; Billari, F.C. Age Norms on Leaving Home: Multilevel Evidence from the European Social Survey. Environ. Plan. A Econ. Space 2013, 45, 383–401. [Google Scholar] [CrossRef]
- Mulder, C.H. Family dynamics and housing: Conceptual issues and empirical findings. Demogr. Res. 2013, 29, 355–378. [Google Scholar] [CrossRef] [Green Version]
- Moreno Mínguez, A. The youth emancipation in Spain: A socio-demographic analysis. Int. J. Adolesc. Youth 2018, 23, 496–510. [Google Scholar] [CrossRef] [Green Version]
- Aparicio Fenoll, A.; Oppedisano, V. Fostering the Emancipation of Young People: Evidence from a Spanish Rental Subsidy. IZA Discuss. Paper 2012, 6651, 1–32. [Google Scholar] [CrossRef]
- Venhoda, O. Application of DSTI and DTI macroprudential policy limits to the mortgage market in the Czech Republic for the year 2022. Int. J. Econ. Sci. 2022, 11, 105–116. [Google Scholar] [CrossRef]
- Vandenbussche, M.; Verhenne, M. On the relation between unemployment and housing tenure: The European baby boomer generation. Master’s Thesis, Ghent University, Ghent, Belgium, 2014. Available online: https://lib.ugent.be/catalog/rug01:002164589 (accessed on 27 September 2022).
- Hromada, E.; Cermakova, K. Financial unavailability of housing in the Czech Republic and recommendations for its solution. Int. J. Econ. Sci. 2021, 10, 47–58. [Google Scholar] [CrossRef]
- European Commission. EPOV Member State Report–Spain; Directorate-General for Energy: Spain, 2020; p. 4. Available online: https://energy-poverty.ec.europa.eu/discover/practices-and-policies-toolkit/publications/epov-member-state-report-spain_en (accessed on 27 September 2022).
- Mastropietro, P.; Rodilla, P.; Batlle, C. Emergency Measures to Protect Energy Consumers during the COVID-19 Pandemic: Global Review and Critical Analysis. Eur. Univ. Inst. 2020, 4. [Google Scholar] [CrossRef] [PubMed]
- Borgersen, T.A. Social housing policy in a segmented housing market: Indirect effects on markets and on individuals. Int. J. Econ. Sci. 2019, 8, 1–21. [Google Scholar] [CrossRef]
- López-Rodríguez, D.; Matea Rosa, M.d.l.L. Public intervention in the rental housing market: A review of international experience. Doc. Ocas. del Banco de España 2020, 2020, 1–54. Available online: https://repositorio.bde.es/handle/123456789/13302 (accessed on 27 September 2022).






















| Category | Features | Values | Feature Descriptions |
|---|---|---|---|
| Dwelling characteristics (A) | A_typology | (Categories) Flat, Apartment, Penthouse, Duplex, Studio_flat, Loft | Categorical feature identifying the dwelling typology: Flat, apartment, penthouse, duplex, studio flat, or loft |
| A_area_m2 | Numerical | Built dwelling surface (sqm), gross square meters of the dwelling | |
| A_bedrooms | Numerical | Number of bedrooms in the dwelling | |
| A_bathrooms | Numerical | Number of bathrooms (×1) and toilets (×0.5) of the dwelling | |
| A_air_cond | With (1), Without (0) | Availability of air conditioning | |
| A_heating | With (1), Without (0) | Availability of heating system | |
| A_terrace | With (1), Without (0) | Availability of terrace | |
| A_new_constr | New construction (1) Not new construction (0) | Newly build housing that can be a project, under construction, or less than 3 years old. | |
| Building characteristics (B) | B_elevator | With (1), Without (0) | Availability of elevator |
| B_parking | With (1), Without (0) | Availability of garage slot | |
| B_storeroom | With (1), Without (0) | Availability of storage room | |
| B_pool | With (1), Without (0) | Availability of swimming pool | |
| B_garden | With (1), Without (0) | Availability of garden | |
| Location characteristics (C) | C_coor_X_km | Numerical | Projected coordinates of the spatial location (in kilometers). Coordinate Reference Systems EPSG:25830, with ETRS89 datum and UTM30N projection |
| C_coor_Y_km | Numerical | ||
| Neighborhood characteristics (D) | D_age_nbhd | Numerical | Average age of the neighborhood (reference year 2021) |
| D_FAR | Numerical | Floor Area Ratio (total building floor area/gross sector area), 150 m around the building, in m² floor area/m² of the sector | |
| D_dependency | Numerical | Dependency ratio (sum of the population aged > 64 and <16/population aged 16–64). | |
| D_elderly | Numerical | Aging ratio (population aged > 64/population aged < 16) | |
| D_foreigners | Numerical | Percentage of foreign population | |
| D_net_income | Numerical | Net household income for 2019, in thousand euros | |
| D_d_educ1_km | Numerical | Distance from the dwelling to level 1 educational centers (infant and primary), in km | |
| D_d_educ2_km | Numerical | Distance from the dwelling to level 2 educational centers (secondary and high school), in km | |
| D_d_park_km | Numerical | Distance to urban green spaces (parks), in km | |
| D_d_coast_km | Numerical | Distance of the dwelling to the coastline, in km | |
| D_NDVI_150m | Numerical | Normalized Difference Vegetation Index. Average NDVI in a 150 m area of influence | |
| Temporal characteristics (E) | E_quarter | (Categories) 2019Q2, 2019Q3, 2019Q4, 2020Q1, 2020Q2, 2020Q3, 2020Q4, 2021Q1, 2021Q2, 2021Q3 and 2021Q4 | Categorical feature for modeling the time factor in 11 quarters |
| Dependent feature | ln_price | Numerical (natural log) | The natural log of the asking price offered by the seller (in Euro). |
| Category | Features | Continuous Features | Dummy/Categorical Features | ||||
|---|---|---|---|---|---|---|---|
| M | SD | Min. | Max. | Coding | Frequency | ||
| Dwelling characteristics (A) | A_typology | (Categories) Flat Apartment Penthouse Duplex Studio_flat Loft | 34,073 2758 2397 437 154 124 | ||||
| A_area_m2 | 106.0 | 37.6 | 20.0 | 340.0 | |||
| A_bedrooms | 2.9 | 0.8 | 1.0 | 6.0 | |||
| A_bathrooms | 1.6 | 0.6 | 0.5 | 5.0 | |||
| A_air_cond | With (1) Without (0) | 19,555 20,388 | |||||
| A_heating | With (1) Without (0) | 12,981 26,962 | |||||
| A_terrace | With (1) Without (0) | 4820 35,123 | |||||
| A_new_constr | New (1) No new (0) | 870 39,073 | |||||
| Building characteristics (B) | B_elevator | With (1) Without (0) | 27,600 12,343 | ||||
| B_parking | With (1) Without (0) | 13,493 26,450 | |||||
| B_storeroom | With (1) Without (0) | 8233 31,710 | |||||
| B_pool | With (1) Without (0) | 9259 30,684 | |||||
| B_garden | With (1) Without (0) | 4805 35,138 | |||||
| Location characteristics (C) | C_coor_X_km | 720.34 | 2.39 | 716.57 | 726.63 | ||
| C_coor_Y_km | 4248.35 | 1.44 | 4239.48 | 4252.26 | |||
| Neighborhood characteristics (D) | D_age_nbhd | 43.70 | 11.66 | 11.50 | 100.40 | ||
| D_FAR | 1.78 | 0.98 | 0.00 | 4.95 | |||
| D_dependency | 0.53 | 0.10 | 0.24 | 0.92 | |||
| D_elderly | 1.87 | 1.17 | 0.10 | 6.45 | |||
| D_foreigners | 15.90 | 8.39 | 1.70 | 48.00 | |||
| D_net_income | 30.08 | 8.87 | 13.61 | 64.96 | |||
| D_d_educ1_km | 0.49 | 0.37 | 0.01 | 2.76 | |||
| D_d_educ2_km | 0.56 | 0.47 | 0.01 | 5.94 | |||
| D_d_park_km | 0.52 | 0.36 | 0.00 | 2.90 | |||
| D_d_coast_km | 1.60 | 1.00 | 0.03 | 5.56 | |||
| D_NDVI_150m | 0.08 | 0.03 | 0.04 | 0.26 | |||
| Temporal characteristics (E) (*) | E_quarter | (Categories) 2019Q2 2019Q3 2019Q4 2020Q1 2020Q2 2020Q3 2020Q4 2021Q1 2021Q2 2021Q3 2021Q4 | 6264 7329 8203 8372 7232 8482 9516 9498 9462 9725 9941 | ||||
| Dependent feature (*) | ln_price | 11.88 | 0.64 | 9.44 | 14.27 | ||
| price | 178,123 | 129,611 | 12,600 | 1,578,000 | |||
| Id | Name | Model | Library |
|---|---|---|---|
| 1 | lr | Linear Regression | sklearn.linear_model.LinearRegression |
| 2 | rf | Random Forest Regressor | sklearn.ensemble. RandomForestRegressor |
| 3 | et | Extra Trees Regressor | sklearn.ensemble.ExtraTreesRegressor |
| 4 | gbr | Gradient Boosting Regressor | sklearn.ensemble. GradientBoostingRegressor |
| 5 | xgbm | Extreme Gradient Boosting | xgboost.XGBRegressor |
| 6 | lgbm | Light Gradient Boosting Machine | lightgbm.LGBMRegressor |
| Model | Name | Initial Hyperparameters | Hyperparameter Optimization | ||
|---|---|---|---|---|---|
| Random (200) | Bayesian (100) | Best | |||
| Linear Regression | lr | 0.8048 (0.0060) | - | - | - |
| Random Forest Regressor | rf | 0.9036 (0.0049) | 0.8869 (0.0037) [time 37 min 56 s] | 0.8855 (0.0038) [time 30 min 11 s] | Initial hyperparameters |
| Extra-Trees Regressor | et | 0.9101 (0.0040) | 0.8628 (0.0044) [time 20 min 7 s] | 0.8800 (0.0039) [time 38 min 42 s] | Initial hyperparameters |
| Gradient Boosting Regressor | gbr | 0.8581 (0.0054) | 0.9101 (0.0035) [time 53 min 28 s] | 0.9125 (0.0034) [time 39 min 32 s] | Bayesian |
| Extreme Gradient Boosting | xgbm | 0.8921 (0.0034) | 0.9094 (0.0041) [time 1 h 3 min 36 s] | 0.9077 (0.0039) [time 45 min 10 s] | Bayesian |
| Light Gradient Boosting Machine | lgbm | 0.8864 (0.0042) | 0.9065 (0.0043) [time 28 min 42 s] | 0.9076 (0.0044) [time 16 min 17 s] | Bayesian |
| Model | Name | CV-Validation in Training Set (SD) | R² Score | ||
|---|---|---|---|---|---|
| Training Set | Test Set | Overfitting (%) | |||
| Linear Regression | lr | 0.8048 (0.0060) | 0.8056 | 0.8052 | - |
| Random Forest Regressor | rf | 0.9036 (0.0049) | 0.9970 | 0.9135 | +9.1 |
| Extra-Trees Regressor | et | 0.9101 (0.0040) | 0.9997 | 0.9178 | +8.9 |
| Gradient Boosting Regressor | gbr | 0.9125 (0.0034) | 0.9952 | 0.9192 | +8.3 |
| Extreme Gradient Boosting | xgbm | 0.9094 (0.0041) | 0.9900 | 0.9178 | +7.9 |
| Light Gradient Boosting Machine | lgbm | 0.9076 (0.0044) | 0.9902 | 0.9140 | +8.3 |
| Model Name | Test Dataset (30%) | Complete Dataset (Training + Test, 100%) | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE | MSE | RMSE | R² | MAE | MSE | RMSE | R² | |
| lr | 0.2166 | 0.0797 | 0.2823 | 0.8052 | 0.2163 | 0.0799 | 0.2826 | 0.8055 |
| rf | 0.1252 | 0.0354 | 0.1882 | 0.9135 | 0.0178 | 0.0012 | 0.0348 | 0.9971 |
| et | 0.1219 | 0.0336 | 0.1834 | 0.9178 | 0.0019 | 0.0002 | 0.0142 | 0.9995 |
| gbr | 0.1264 | 0.0331 | 0.1818 | 0.9192 | 0.0364 | 0.0029 | 0.0536 | 0.9930 |
| xgbm | 0.1298 | 0.0336 | 0.1834 | 0.9178 | 0.0507 | 0.0051 | 0.0714 | 0.9876 |
| lgbm | 0.1322 | 0.0352 | 0.1876 | 0.9140 | 0.0525 | 0.0057 | 0.0753 | 0.9862 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mora-Garcia, R.-T.; Cespedes-Lopez, M.-F.; Perez-Sanchez, V.R. Housing Price Prediction Using Machine Learning Algorithms in COVID-19 Times. Land 2022, 11, 2100. https://doi.org/10.3390/land11112100
Mora-Garcia R-T, Cespedes-Lopez M-F, Perez-Sanchez VR. Housing Price Prediction Using Machine Learning Algorithms in COVID-19 Times. Land. 2022; 11(11):2100. https://doi.org/10.3390/land11112100
Chicago/Turabian StyleMora-Garcia, Raul-Tomas, Maria-Francisca Cespedes-Lopez, and V. Raul Perez-Sanchez. 2022. "Housing Price Prediction Using Machine Learning Algorithms in COVID-19 Times" Land 11, no. 11: 2100. https://doi.org/10.3390/land11112100