
Simple Optimal Sampling Algorithm to Strengthen Digital Soil Mapping Using the Spatial Distribution of Machine Learning Predictive Uncertainty: A Case Study for Field Capacity Prediction


Abstract
:1. Introduction
2. Materials and Methods
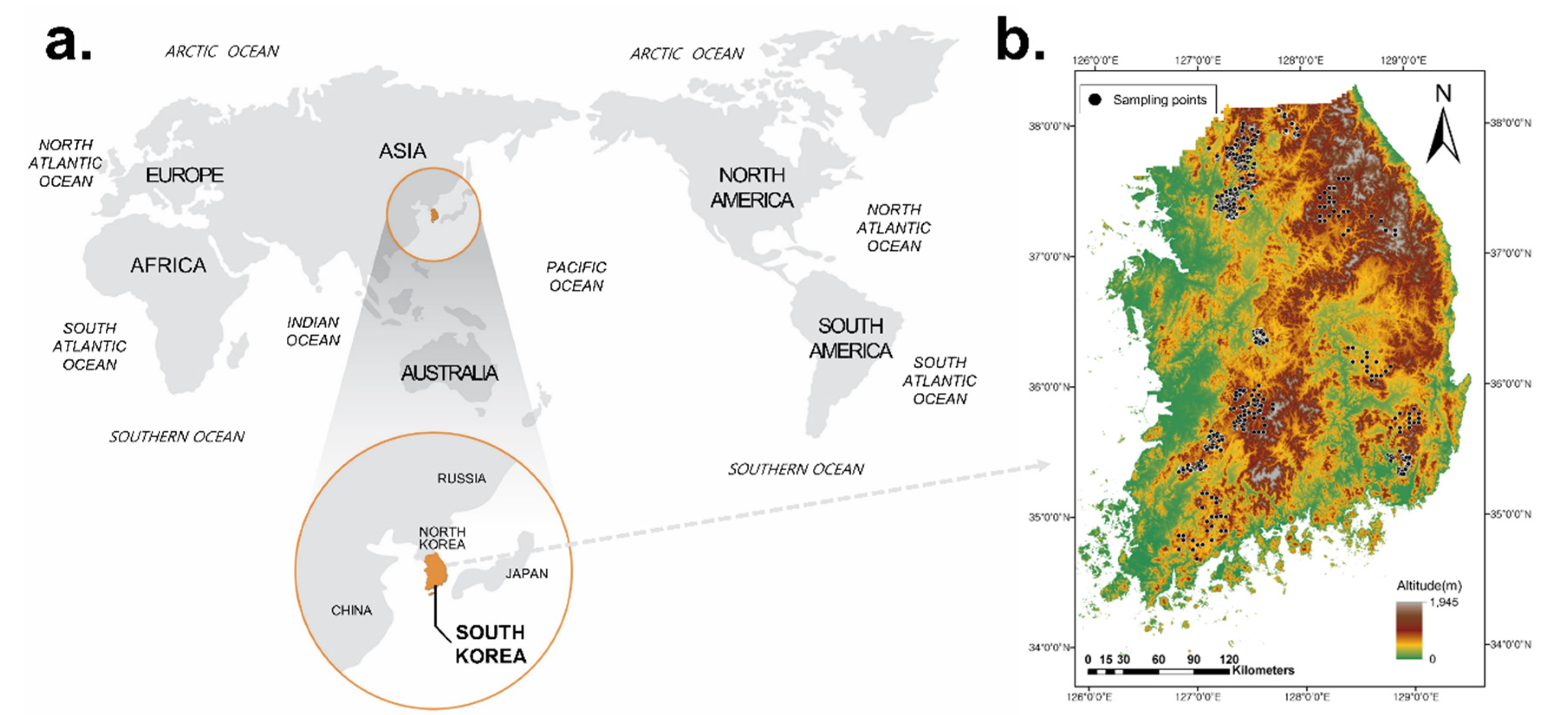
2.1. Study Sites
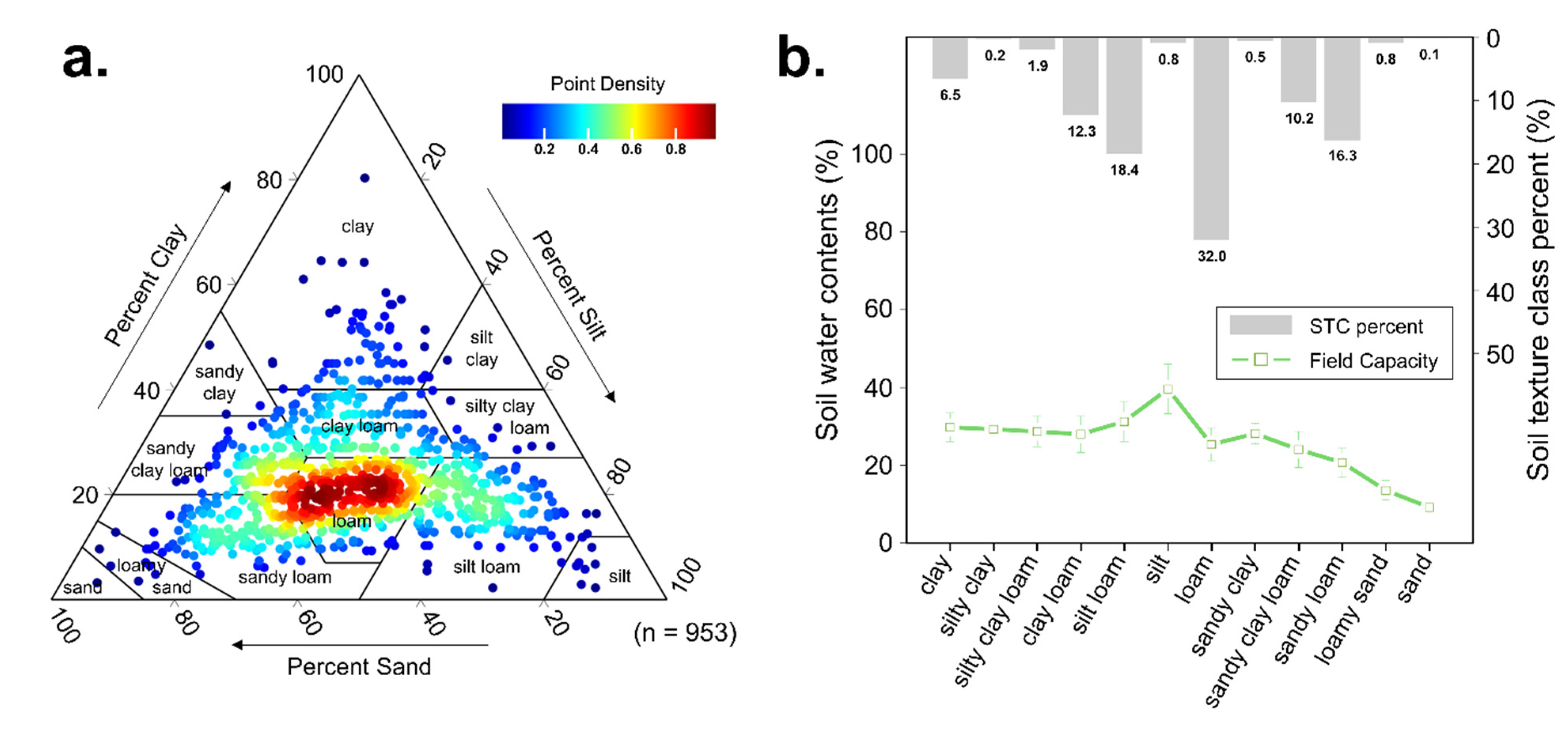
2.2. Collected Soil Samples and Their Properties
2.3. Forest Environmental Covariates
2.4. Machine Learning Algorithms
2.4.1. Gradient Boosting (GB)
2.4.2. Random Forest (RF)
2.4.3. K-Nearest Neighbors (KNN)
2.4.4. Multilayer Perceptron (MLP)
2.5. Variable Importance
2.5.1. Variance Inflation Factor (VIF)
2.5.2. Feature Importance
2.5.3. Permutation Importance
2.6. Predictor Set Hierarchy
2.7. Performance Evaluation
2.8. Statistical Analysis
3. Results and Discussion
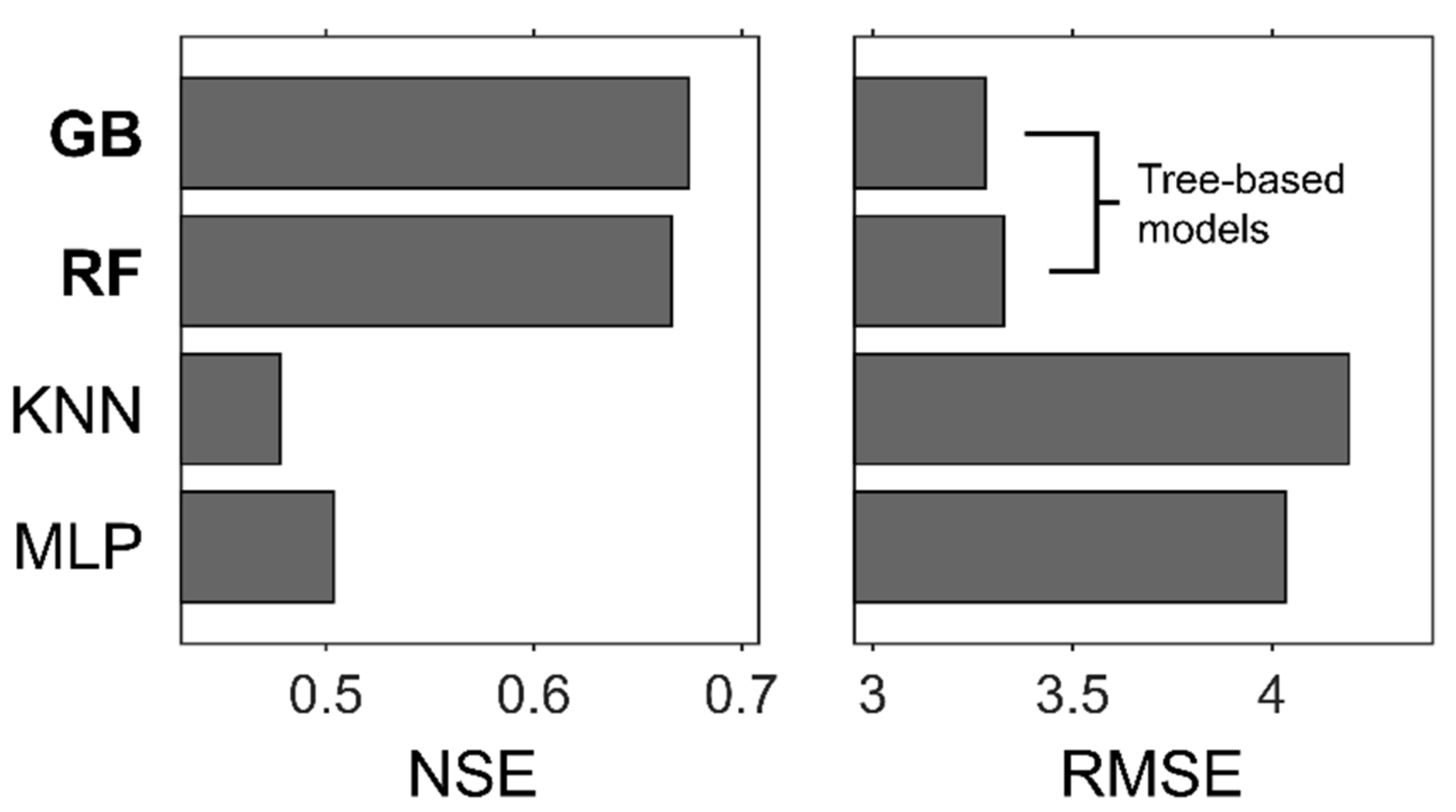
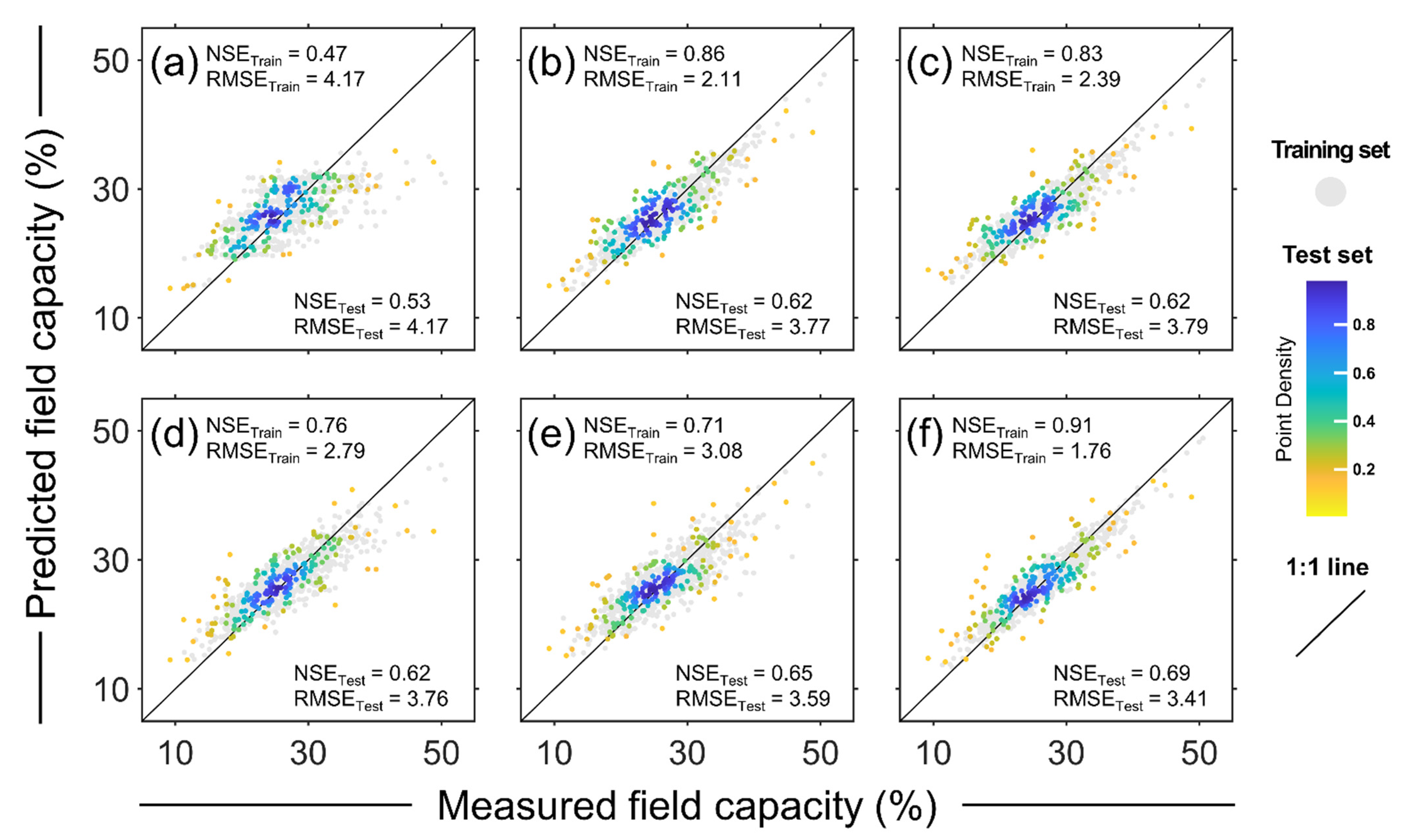
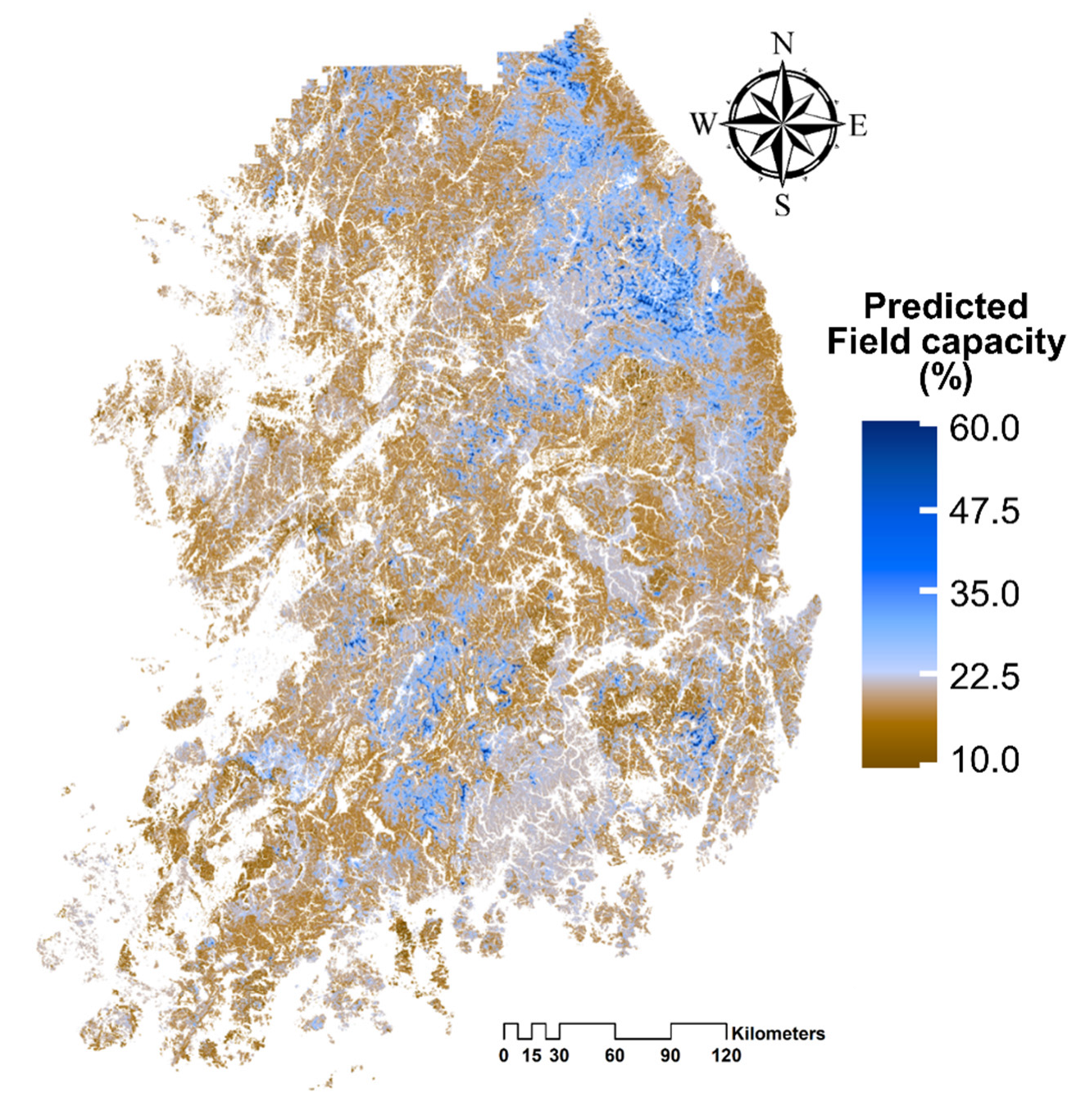
3.1. Optimal Machine Learning Algorithm for FC Prediction
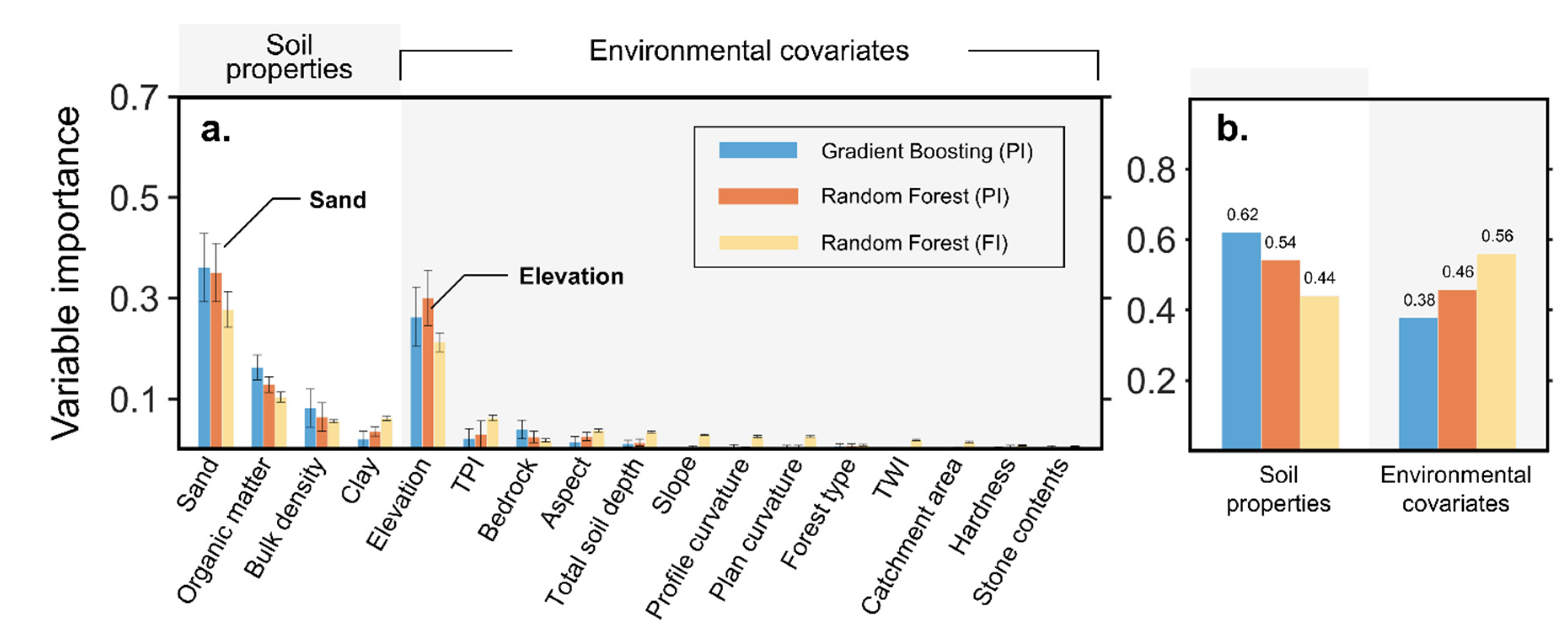
3.2. Relationship between Predictors and FC
3.3. Model Performance Evaluation by Different Predictor Set Hierarchies
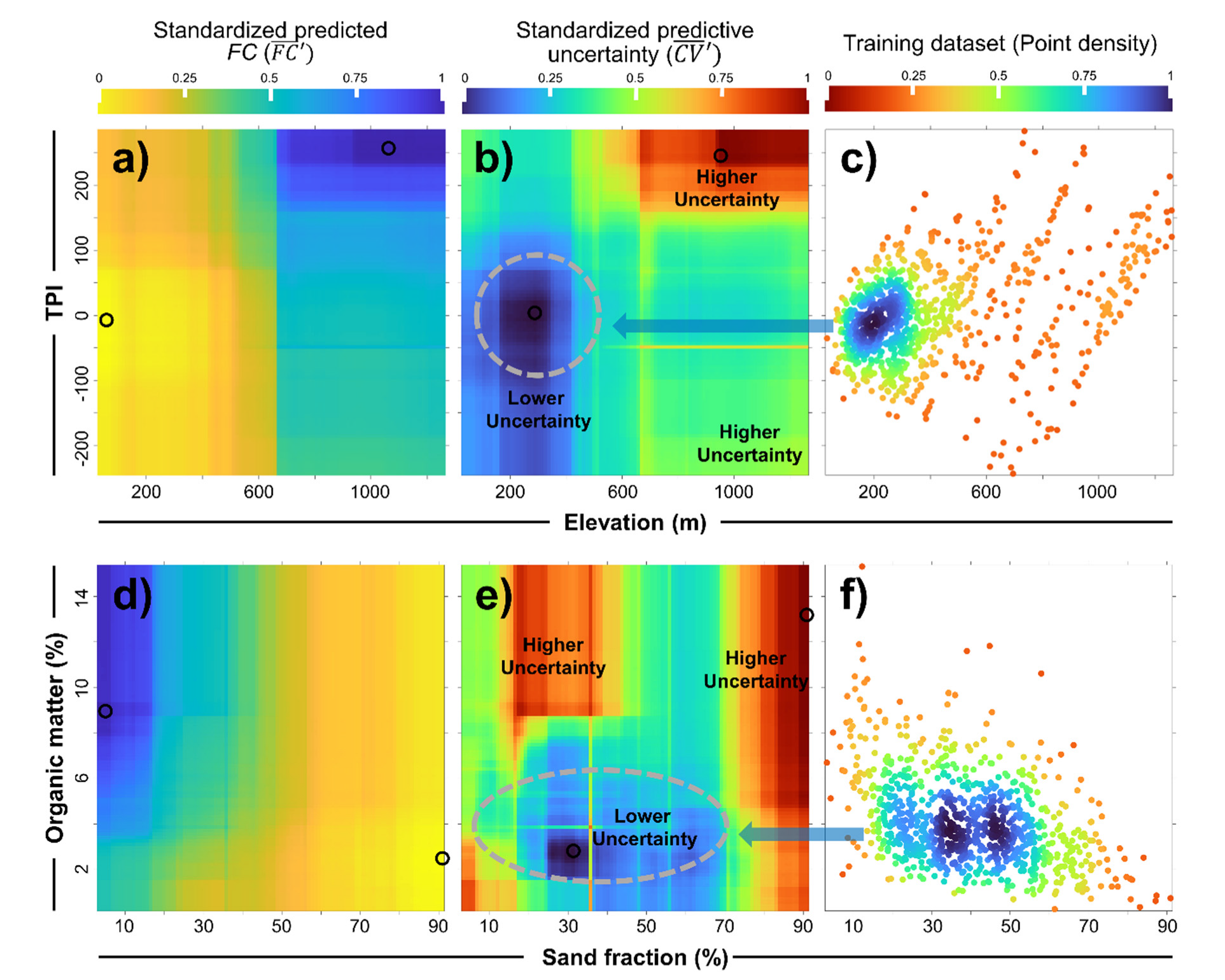
3.4. Relationship between Predictive Uncertainty and Distribution of Training Datasets
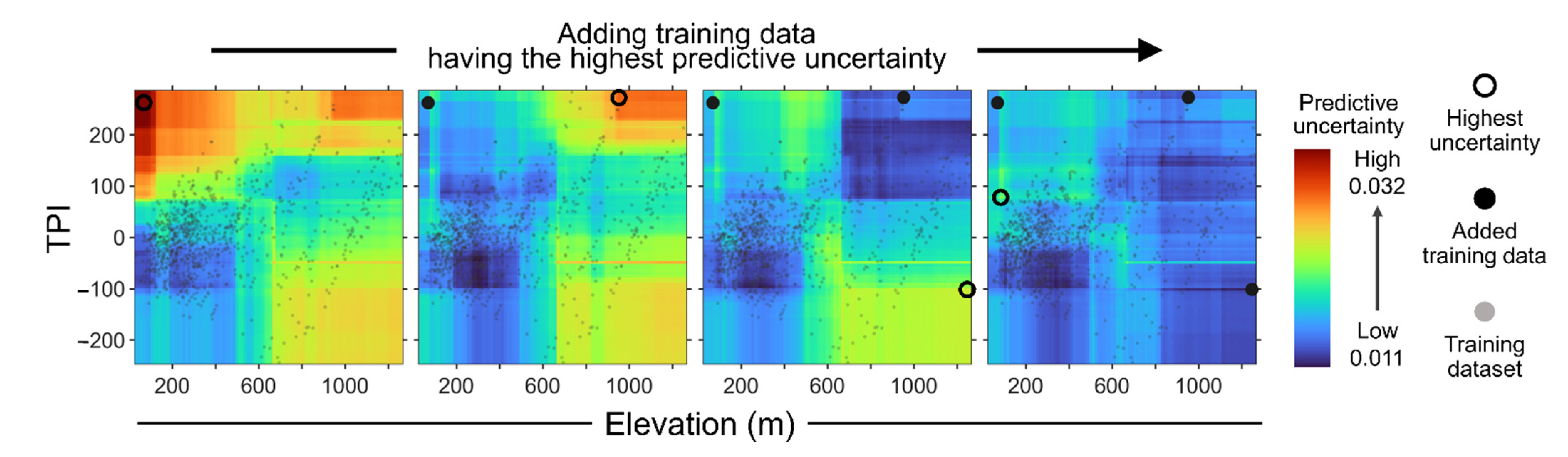
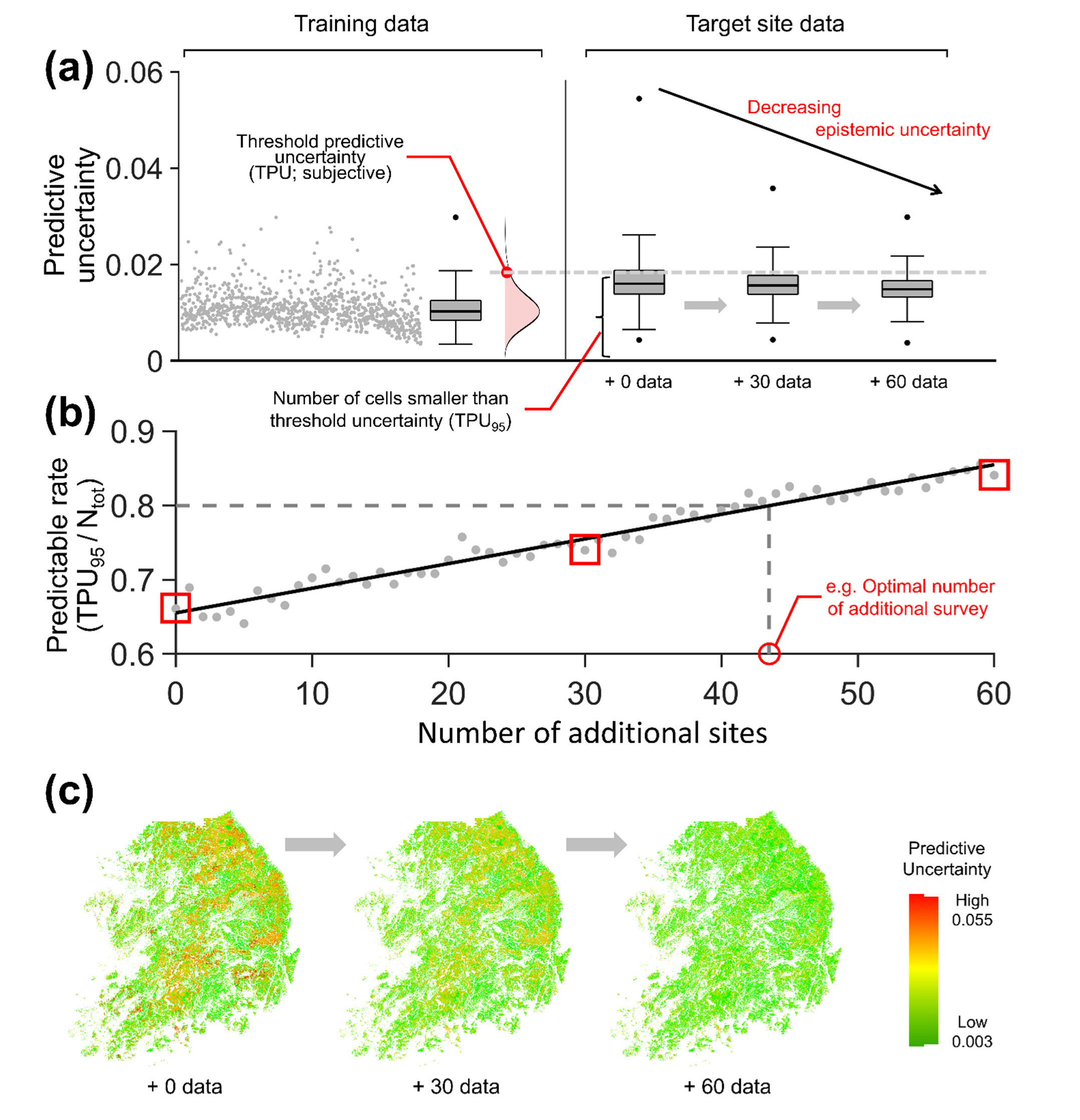
3.5. Our Simple Optimal Sampling Algorithm
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Branger, F.; McMillan, H.K. Deriving hydrological signatures from soil moisture data. Hydrol. Process. 2020, 34, 1410–1427. [Google Scholar] [CrossRef]
- Krause, P.; Bäse, F.; Bende-Michl, U.; Fink, M.; Flügel, W.; Pfennig, B. Multiscale investigations in a mesoscale catchment—Hydrological modelling in the Gera catchment. Adv. Geosci. 2006, 9, 53–61. [Google Scholar] [CrossRef] [Green Version]
- McKenzie, N.J.; Austin, M.P. A quantitative Australian approach to medium and small scale surveys based on soil stratigraphy and environmental correlation. Geoderma 1993, 57, 329–355. [Google Scholar] [CrossRef]
- Piikki, K.; Wetterlind, J.; Söderström, M.; Stenberg, B. Perspectives on validation in digital soil mapping of continuous attributes—A review. Soil Use Manag. 2021, 37, 7–21. [Google Scholar] [CrossRef]
- Chen, H.; Chen, J.; Ding, J. Data Evaluation and Enhancement for Quality Improvement of Machine Learning. IEEE Trans. Reliab. 2021, 70, 831–847. [Google Scholar] [CrossRef]
- Hagendorff, T. Linking Human and Machine Behavior: A New Approach to Evaluate Training Data Quality for Beneficial Machine Learning. Minds Mach. 2021, 31, 563–593. [Google Scholar] [CrossRef] [PubMed]
- De Gruijter, J.J.; McBratney, A.B.; Minasny, B.; Wheeler, I.; Malone, B.P.; Stockmann, U. Farm-scale soil carbon auditing. Geoderma 2016, 265, 120–130. [Google Scholar] [CrossRef]
- Domburg, P.; de Gruijter, J.J.; Brus, D.J. A structured approach to designing soil survey schemes with prediction of sampling error from variograms. Geoderma 1994, 62, 151–164. [Google Scholar] [CrossRef]
- Walvoort, D.J.J.; Brus, D.J.; de Gruijter, J.J. An R package for spatial coverage sampling and random sampling from compact geographical strata by k-means. Comput. Geosci. 2010, 36, 1261–1267. [Google Scholar] [CrossRef]
- Brus, D.J. Sampling for digital soil mapping: A tutorial supported by R scripts. Geoderma 2019, 338, 464–480. [Google Scholar] [CrossRef]
- Yang, H.; Yoo, H.; Lim, H.; Kim, J.; Choi, H.T. Impacts of Soil Properties, Topography, and Environmental Features on Soil Water Holding Capacities (SWHCs) and Their Interrelationships. Land 2021, 10, 1290. [Google Scholar] [CrossRef]
- Alifu, H.; Vuillaume, J.F.; Johnson, B.A.; Hirabayashi, Y. Machine-learning classification of debris-covered glaciers using a combination of Sentinel-1/-2 (SAR/optical), Landsat 8 (thermal) and digital elevation data. Geomorphology 2020, 369, 107365. [Google Scholar] [CrossRef]
- Araya, S.N.; Ghezzehei, T.A. Using Machine Learning for Prediction of Saturated Hydraulic Conductivity and Its Sensitivity to Soil Structural Perturbations. Water Resour. Res. 2019, 55, 5715–5737. [Google Scholar] [CrossRef]
- Lawrence, R. Classification of remotely sensed imagery using stochastic gradient boosting as a refinement of classification tree analysis. Remote Sens. Environ. 2004, 90, 331–336. [Google Scholar] [CrossRef]
- Lee, J.; Lee, S.; Hong, J.; Lee, D.; Bae, J.H.; Yang, J.E.; Kim, J.; Lim, K.J. Evaluation of Rainfall Erosivity Factor Estimation Using Machine and Deep Learning Models. Water 2021, 13, 382. [Google Scholar] [CrossRef]
- Yang, T.; Zhang, L.; Kim, T.; Hong, Y.; Zhang, D.; Peng, Q. A large-scale comparison of Artificial Intelligence and Data Mining (AI&DM) techniques in simulating reservoir releases over the Upper Colorado Region. J. Hydrol. 2021, 602, 126723. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Shi, W.; Xu, Z. Systematic comparison of five machine-learning models in classification and interpolation of soil particle size fractions using different transformed data. Hydrol. Earth Syst. Sci. 2020, 24, 2505–2526. [Google Scholar] [CrossRef]
- Motevalli, A.; Naghibi, S.A.; Hashemi, H.; Berndtsson, R.; Pradhan, B.; Gholami, V. Inverse method using boosted regression tree and k-nearest neighbor to quantify effects of point and non-point source nitrate pollution in groundwater. J. Clean. Prod. 2019, 228, 1248–1263. [Google Scholar] [CrossRef]
- Mansuy, N.; Thiffault, E.; Paré, D.; Bernier, P.; Guindon, L.; Villemaire, P.; Poirier, V.; Beaudoin, A. Digital mapping of soil properties in Canadian managed forests at 250m of resolution using the k-nearest neighbor method. Geoderma 2014, 235, 59–73. [Google Scholar] [CrossRef]
- Subasi, A. EEG signal classification using wavelet feature extraction and a mixture of expert model. Expert Syst. Appl. 2007, 32, 1084–1093. [Google Scholar] [CrossRef]
- Périé, C.; Ouimet, R. Organic carbon, organic matter and bulk density relationships in boreal forest soils. Can. J. Soil Sci. 2008, 88, 315–325. [Google Scholar] [CrossRef]
- Prévost, M. Predicting Soil Properties from Organic Matter Content following Mechanical Site Preparation of Forest Soils. Soil Sci. Soc. Am. J. 2004, 68, 943–949. [Google Scholar] [CrossRef]
- Huynh-Thu, V.A.; Irrthum, A.; Wehenkel, L.; Geurts, P. Inferring regulatory networks from expression data using tree-based methods. PLoS ONE 2010, 5, e12776. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Schaap, M.G.; Zha, Y. A High-Resolution Global Map of Soil Hydraulic Properties Produced by a Hierarchical Parameterization of a Physically Based Water Retention Model. Water Resour. Res. 2018, 54, 9774–9790. [Google Scholar] [CrossRef] [Green Version]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Hu, L.Y.; Huang, M.W.; Ke, S.W.; Tsai, C.F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brouwer, R.K. A feed-forward network for input that is both categorical and quantitative. Neural Netw. 2002, 15, 881–890. [Google Scholar] [CrossRef]
- Okada, S.; Ohzeki, M.; Taguchi, S. Efficient partition of integer optimization problems with one-hot encoding. Sci. Rep. 2019, 9, 13036. [Google Scholar] [CrossRef] [PubMed]
- Aldrees, A.; Nachabe, M. Capillary Length and Field Capacity in Draining Soil Profiles. Water Resour. Res. 2019, 55, 4499–4507. [Google Scholar] [CrossRef]
- Lal, R. Soil Organic Matter and Water Retention. Agron. J. 2020, 112, 3265–3277. [Google Scholar] [CrossRef]
- Hudson, B.D. Soil Organic Matter and Available Water Capacity. J. Soil Water Conserv. 1994, 49, 189–194. [Google Scholar]
- Rizinjirabake, F.; Tenenbaum, D.E.; Pilesjö, P. Data for Assessment of Soil Water Extractable and Percolation Water Dissolved Organic Carbon in Watersheds. Data Brief. 2019, 27, 104779. [Google Scholar] [CrossRef] [PubMed]
- Puckett, W.E.; Dane, J.H.; Hajek, B.F. Physical and Mineralogical Data to Determine Soil Hydraulic Properties. Soil Sci. Soc. Am. J. 1985, 49, 831–836. [Google Scholar] [CrossRef]
- Purushothaman, N.K.; Reddy, N.N.; Das, B.S. National-Scale Maps for Soil Aggregate Size Distribution Parameters Using Pedotransfer Functions and Digital Soil Mapping Data Products. Geoderma 2022, 424, 116006. [Google Scholar] [CrossRef]
- Lim, H.; Yang, H.; Chun, K.W.; Choi, H.T. Development of Pedo-Transfer Functions for the Saturated Hydraulic Conductivity of Forest Soil in South Korea Considering Forest Stand and Site Characteristics. Water 2020, 12, 2217. [Google Scholar] [CrossRef]
- Sun, J.; Lang, J.; Fujita, H.; Li, H. Imbalanced Enterprise Credit Evaluation with DTE-SBD: Decision Tree Ensemble Based on SMOTE and Bagging with Differentiated Sampling Rates. Inf. Sci. 2018, 425, 76–91. [Google Scholar] [CrossRef]
- Hüllermeier, E.; Waegeman, W. Aleatoric and Epistemic Uncertainty in Machine Learning: An Introduction to Concepts and Methods. Mach. Learn. 2021, 110, 457–506. [Google Scholar] [CrossRef]
- Senge, R.; Bösner, S.; Dembczyński, K.; Haasenritter, J.; Hirsch, O.; Donner-Banzhoff, N.; Hüllermeier, E. Reliable Classification: Learning Classifiers that Distinguish Aleatoric and Epistemic Uncertainty. Inf. Sci. 2014, 255, 16–29. [Google Scholar] [CrossRef] [Green Version]
- Hofer, E.; Kloos, M.; Krzykacz-Hausmann, B.; Peschke, J.; Woltereck, M. An Approximate Epistemic Uncertainty Analysis Approach in the Presence of Epistemic and Aleatory Uncertainties. Reliab. Eng. Syst. Saf. 2002, 77, 229–238. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T. Aleatoric Uncertainty Estimation with Test-Time Augmentation for Medical Image Segmentation with Convolutional Neural Networks. Neurocomputing 2019, 338, 34–45. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Soil Properties | Abb. | Unit | Min | Mean | Max | Std. | Skew. | Kurt. |
|---|---|---|---|---|---|---|---|---|
| Field capacity | % | 9.2 | 26.3 | 50.5 | 5.8 | 0.5 | 0.8 | |
| Sand fraction | Sand | % | 3.3 | 39.5 | 91.0 | 16.3 | 0.2 | −0.4 |
| Silt fraction | Silt | % | 1.5 | 37.6 | 87.3 | 15.7 | 0.6 | 0.0 |
| Clay fraction | Clay | % | 2.2 | 22.8 | 80.3 | 10.3 | 1.3 | 2.4 |
| Bulk density | g cm−3 | 0.4 | 1.0 | 1.5 | 0.2 | 0.1 | −0.3 | |
| Organic matter | OM | % | 2.1 | 11.2 | 38.1 | 4.5 | 1.1 | 2.4 |
| Hierarchy ID | Input Variables | Data Sources |
|---|---|---|
| E4-S0 | STC, TSD, SC, Hardness | FSSM |
| E12-S0 | STC, TSD, SC, Hardness, Elevation, Slope, Aspect, CA, TWI, TPI, ProC, PlanC | FSSM, DEM |
| E14-S0 | STC, TSD, SC, Hardness, Elevation, Slope, Aspect, CA, TWI, TPI, ProC, PlanC, Bedrock, FT | FSSM, DEM, GM, FTM |
| E0-S4 | In situ measurement | |
| E14-S2 | TSD, SC, Hardness, Elevation, Slope, Aspect, CA, TWI, TPI, ProC, PlanC, Bedrock, FT, Sand, Clay | FSSM, DEM, GM, FTM, in situ measurement |
| E14-S4 | FSSM, DEM, GM, FTM, in situ measurement |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Lim, H.; Moon, H.; Li, Q.; Nam, S.; Kim, J.; Choi, H.T. Simple Optimal Sampling Algorithm to Strengthen Digital Soil Mapping Using the Spatial Distribution of Machine Learning Predictive Uncertainty: A Case Study for Field Capacity Prediction. Land 2022, 11, 2098. https://doi.org/10.3390/land11112098
Yang H, Lim H, Moon H, Li Q, Nam S, Kim J, Choi HT. Simple Optimal Sampling Algorithm to Strengthen Digital Soil Mapping Using the Spatial Distribution of Machine Learning Predictive Uncertainty: A Case Study for Field Capacity Prediction. Land. 2022; 11(11):2098. https://doi.org/10.3390/land11112098
Chicago/Turabian StyleYang, Hyunje, Honggeun Lim, Haewon Moon, Qiwen Li, Sooyoun Nam, Jaehoon Kim, and Hyung Tae Choi. 2022. "Simple Optimal Sampling Algorithm to Strengthen Digital Soil Mapping Using the Spatial Distribution of Machine Learning Predictive Uncertainty: A Case Study for Field Capacity Prediction" Land 11, no. 11: 2098. https://doi.org/10.3390/land11112098