
Assessment of Different Machine Learning Methods for Reservoir Outflow Forecasting


Abstract
:1. Introduction
2. Materials and Methods
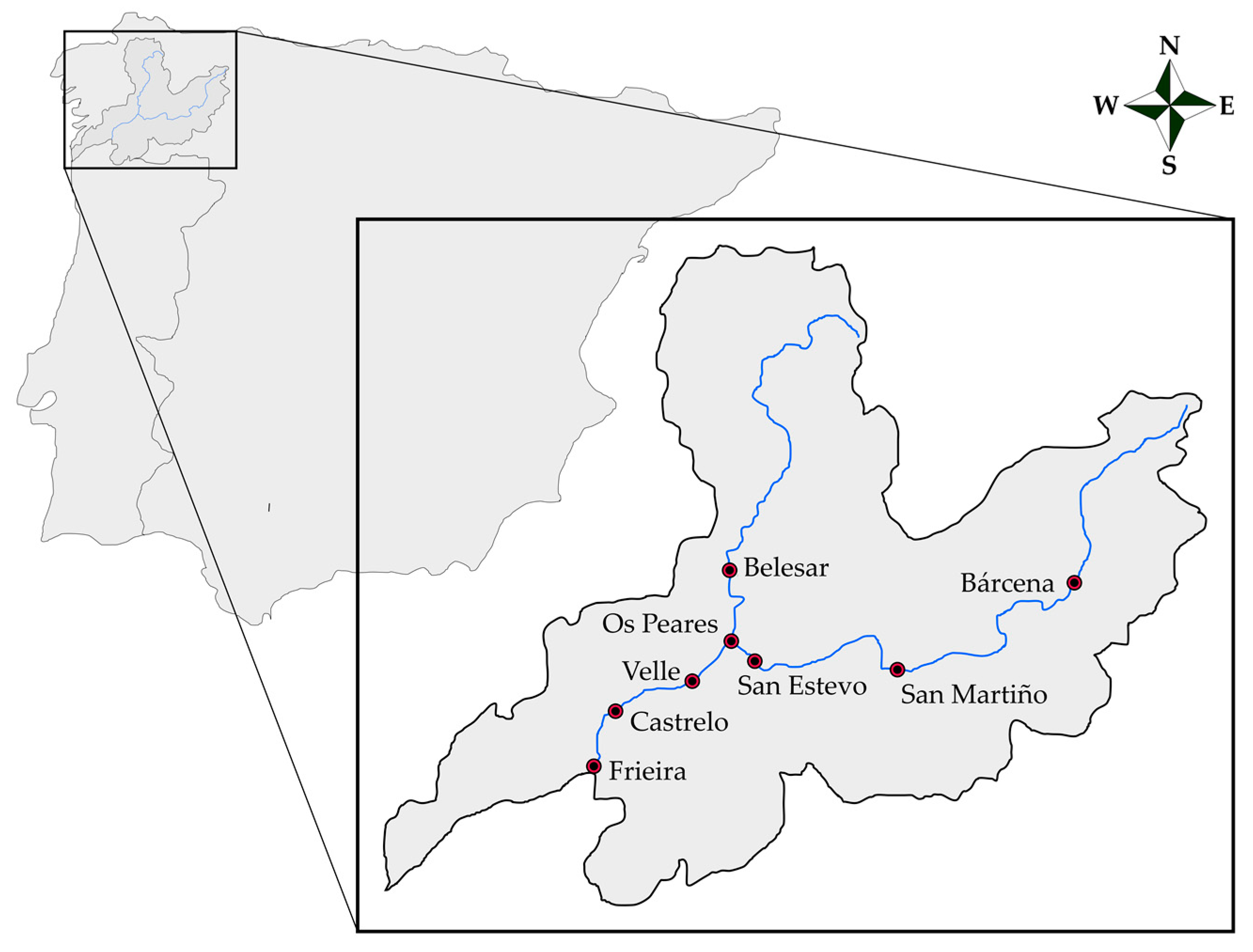
2.1. Area of Study
2.2. Data Used
2.3. Machine Learning Models
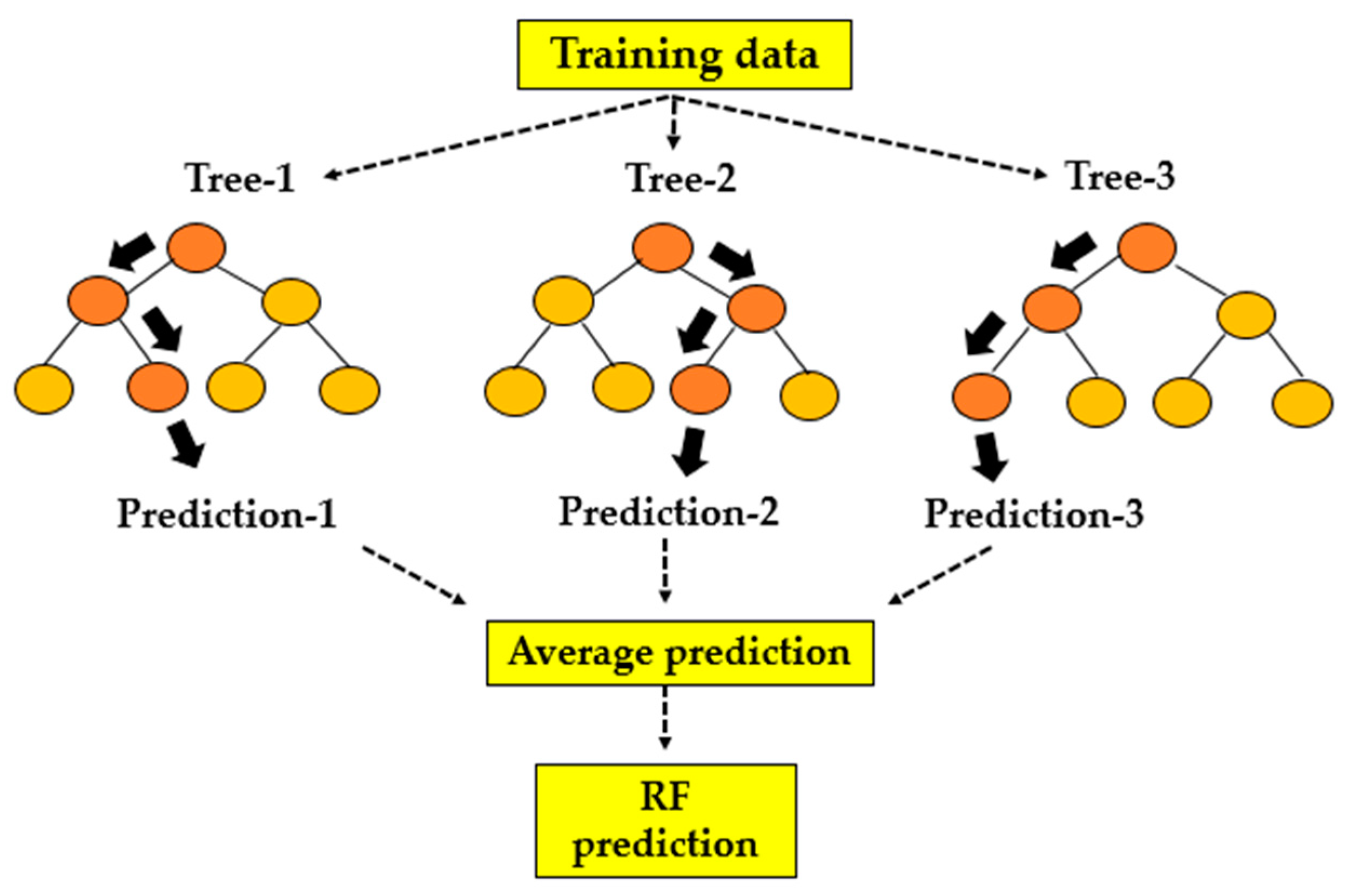
2.3.1. Random Forest
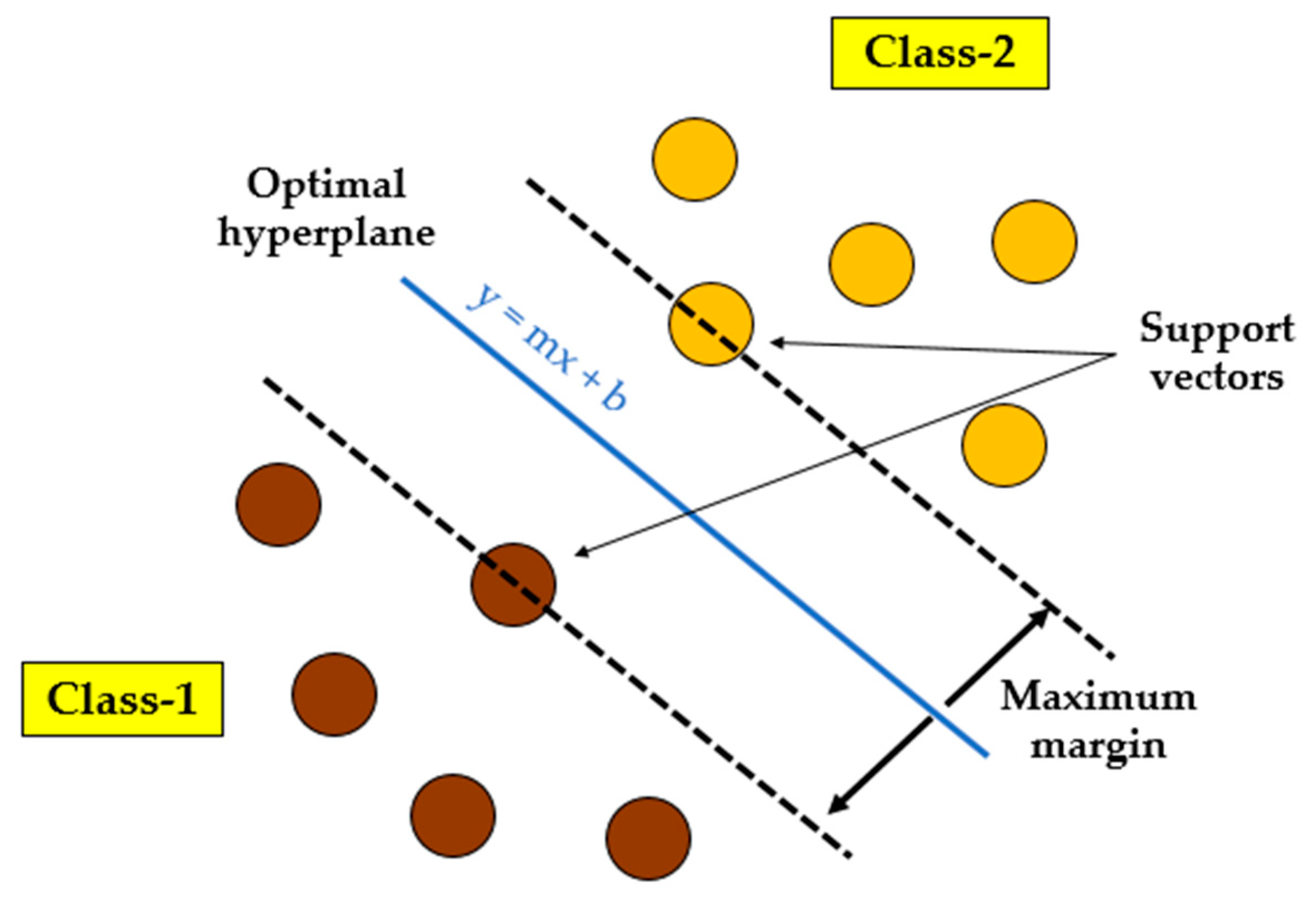
2.3.2. Support Vector Machine
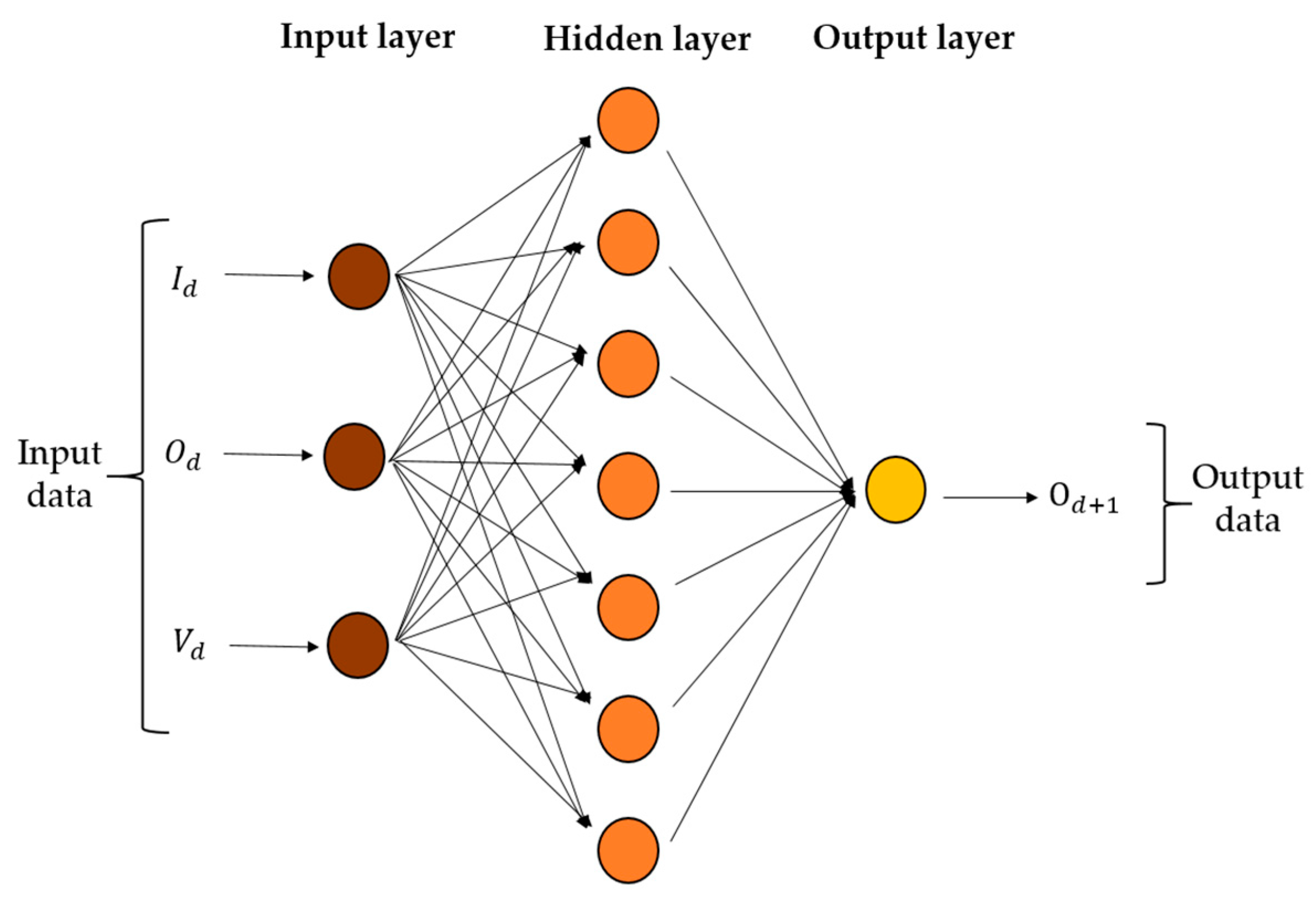
2.3.3. Artificial Neural Network
2.4. Metrics
3. Results and Discussion
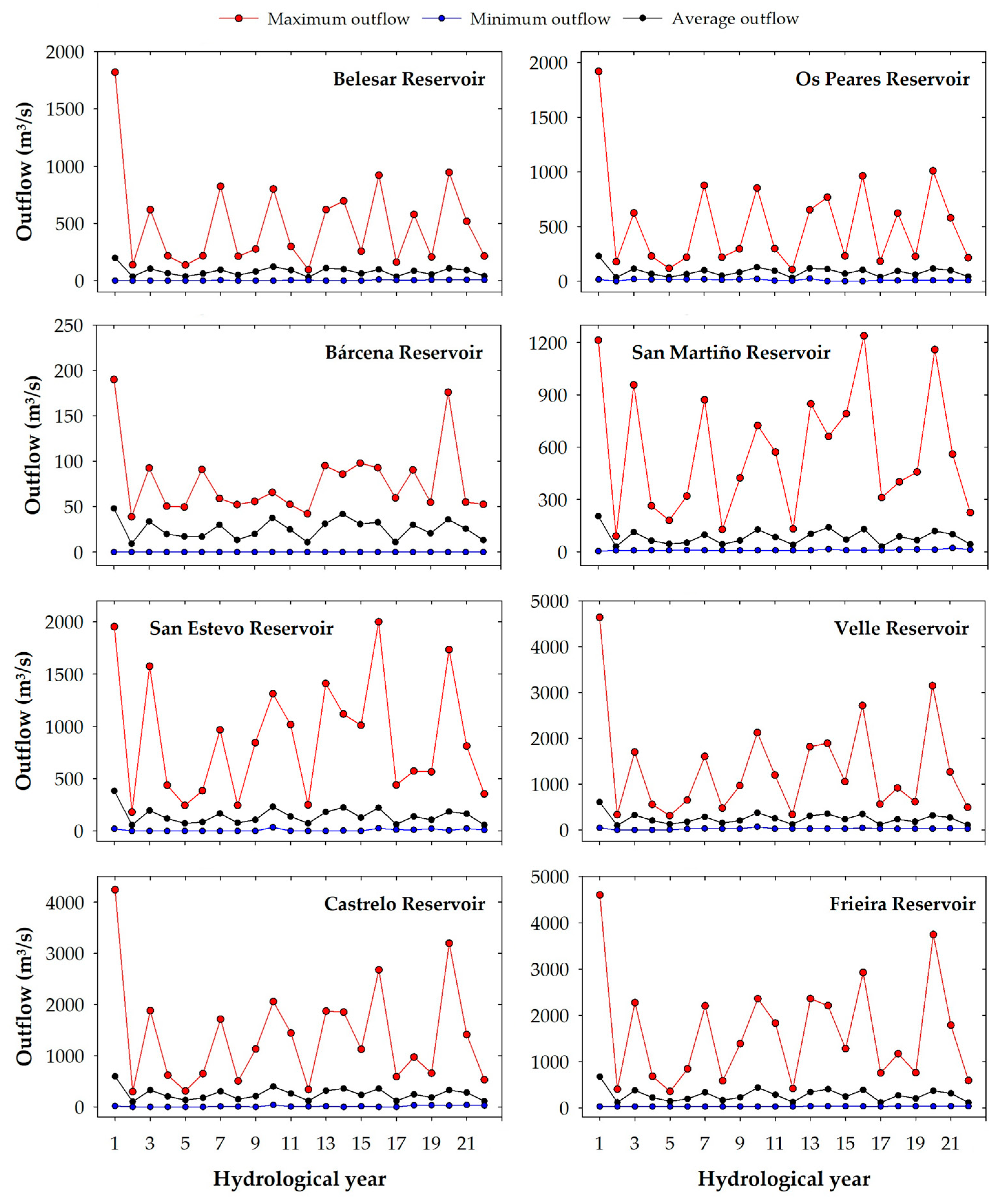
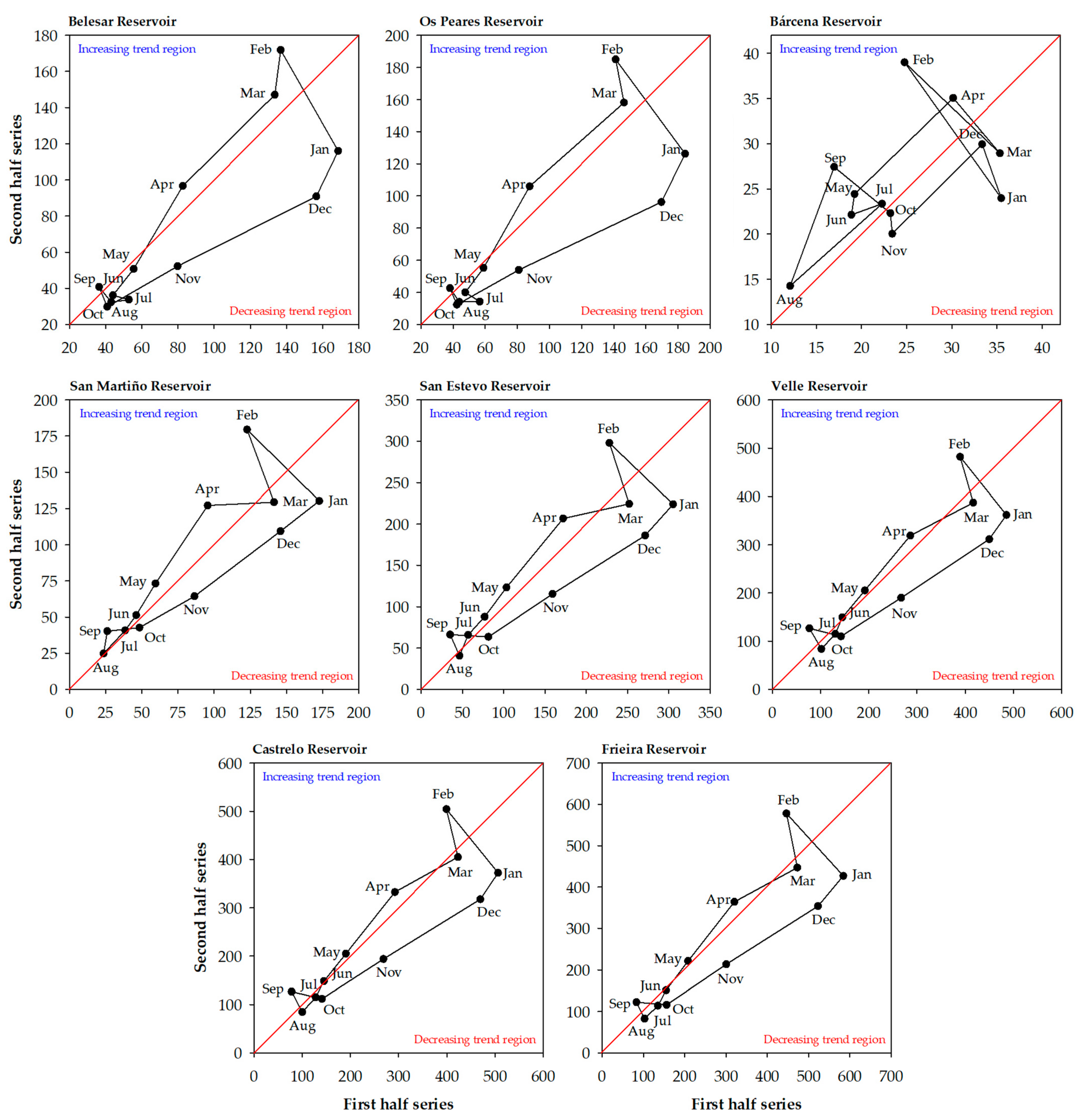
3.1. Data Analysis
3.2. Machine Learning Models Developed
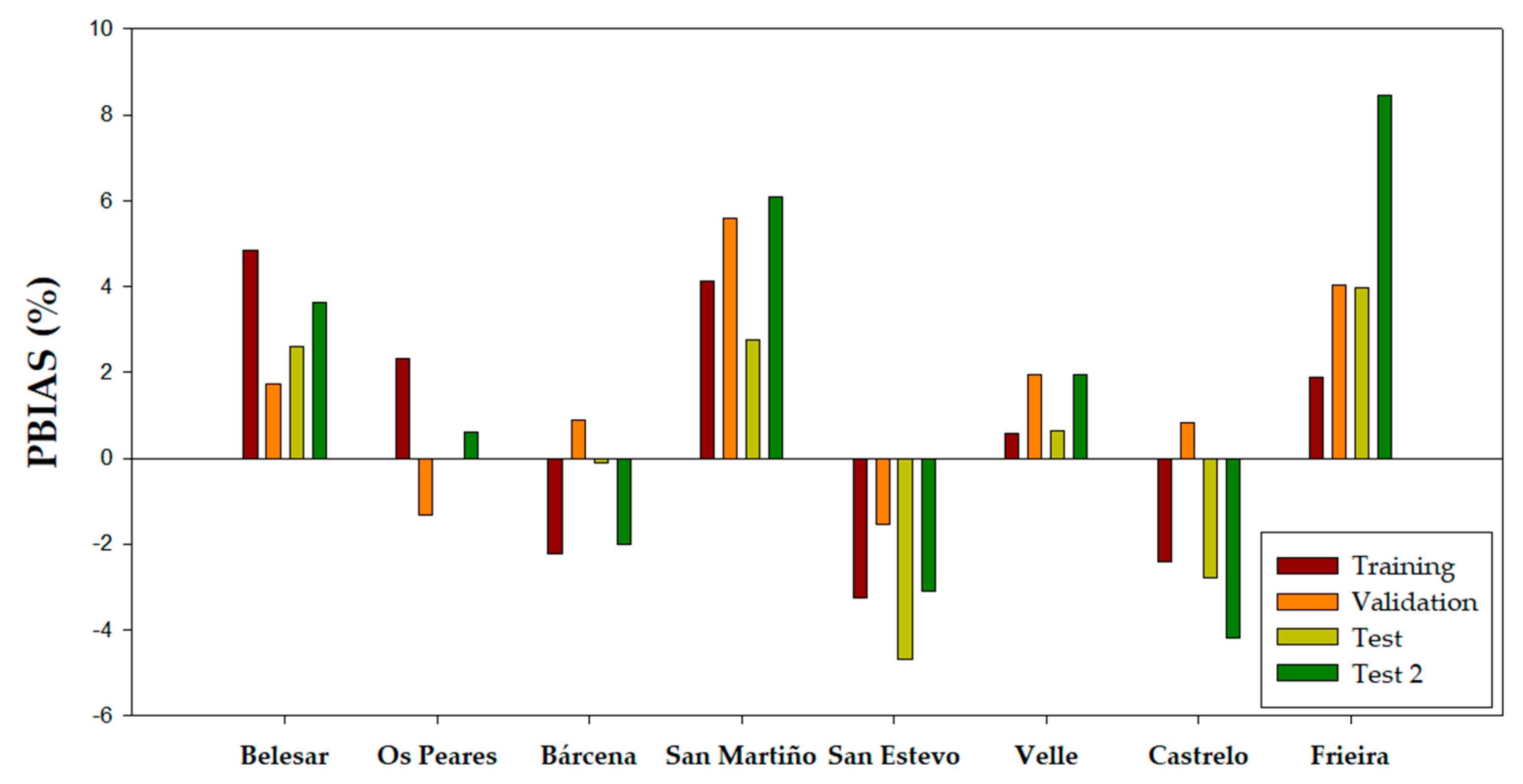
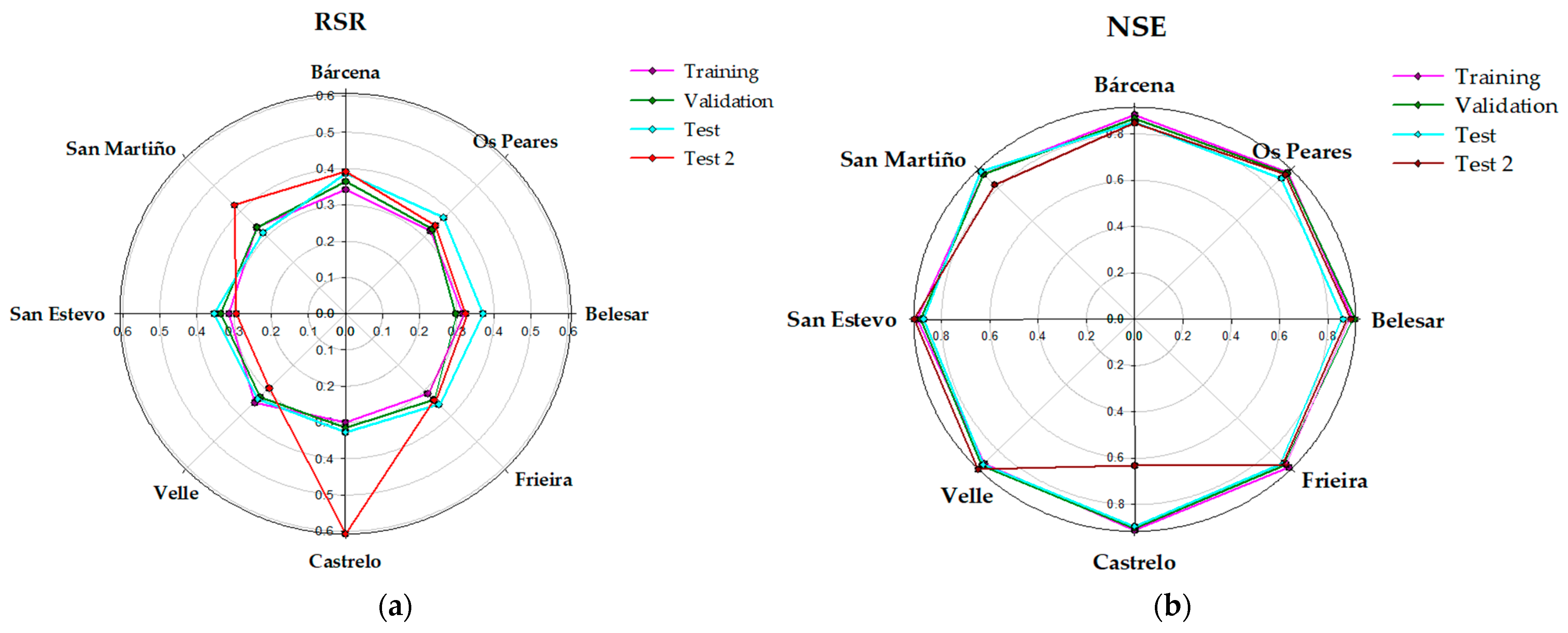
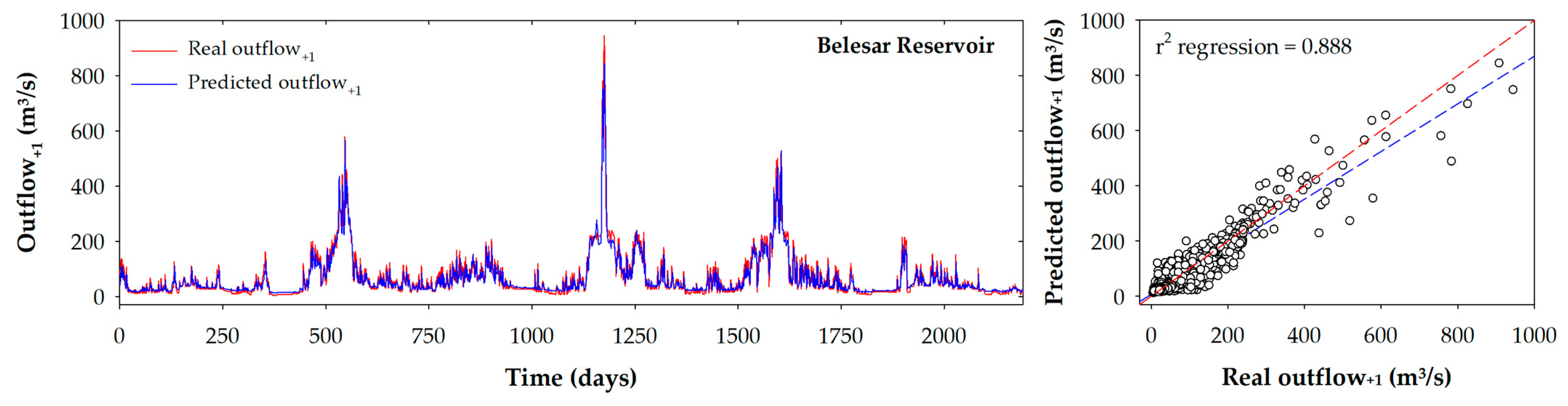
- ANNN-L was the best model for the Belesar reservoir. This model showed good fit in relation to RMSE and r value in the validation phase (RMSE = 30.2 m3/s and r = 0.955). The other two selected models presented RMSE values close to the ANNN-L model (31.4 m3/s and 31.0 m3/s for the RFND and the SVMN model, respectively). ANNN-L showed similar statistics in the training phase, with a slightly higher RMSE value of 32.8 m3/s. In the test phase, RMSE was 24.1 m3/s. However, the RMSE value increased to 32.1 m3/s in the test-2 phase. This increase in the test-2 phase was not unique for this model but was also observed in the rest of the models This behavior can be caused by the outflow range to test phase being less than the range in test-2 phase.
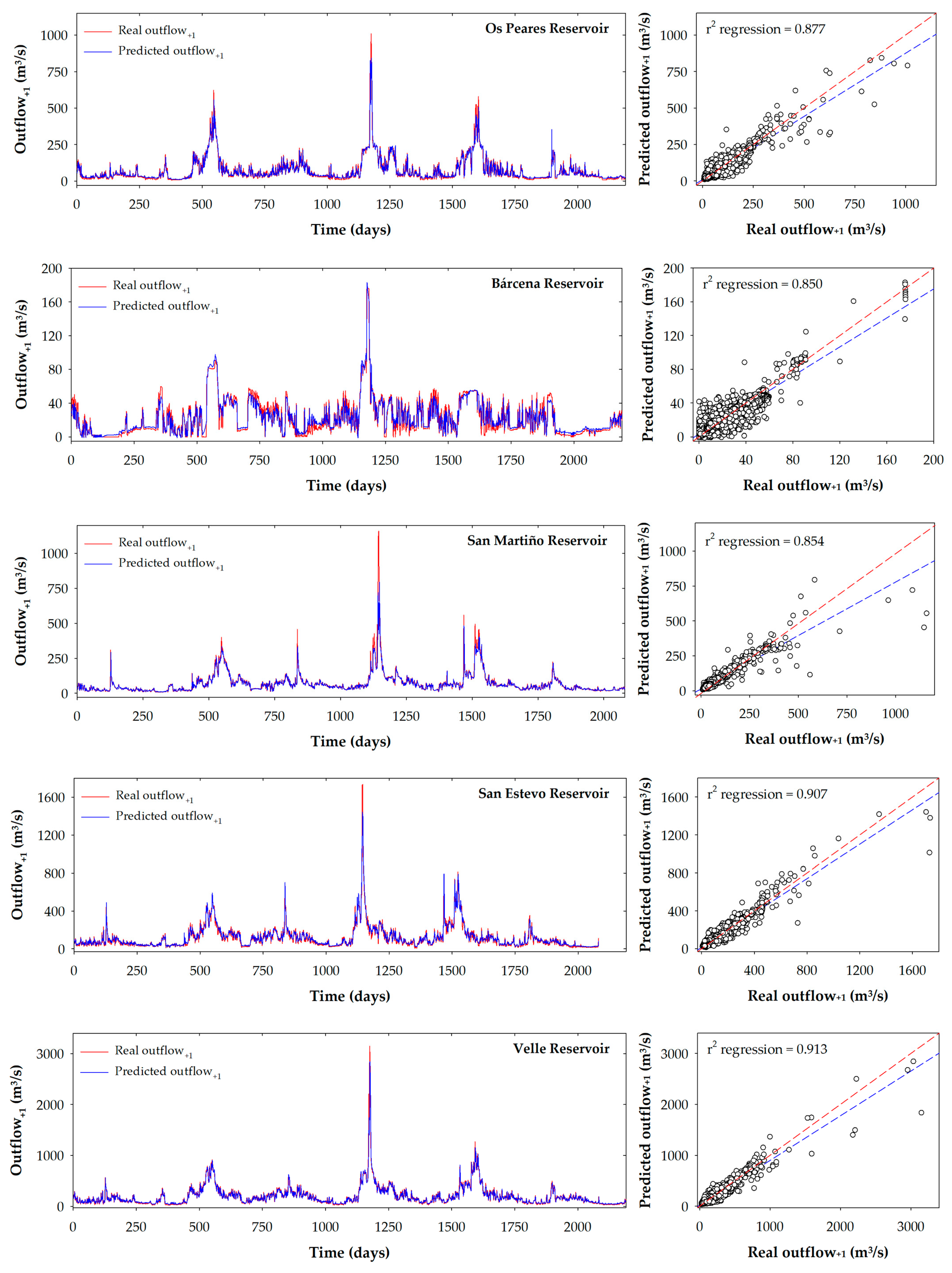
- Regarding the Os Peares reservoir, SVMND was the model that provided the best statistics in relation to the RMSE value in the validation phase (RMSE = 35.9 m3/). The good adjustments provided by this model during the validation phase were very close to the second best model, the RFN (36.0 m3/s). The model SVMND showed a similar behavior in the training phase with a slightly higher RMSE value of 37.8 m3/s. The RMSE value in the test phase was 26.6 m3/s. However, an increase in the value of the root mean squared error in the test-2 phase (36.0 m3/s) can be observed, as happened with the best model of the previous reservoir.
- Regarding Bárcena, the three models selected for this reservoir presented very similar RMSE adjustments for the validation phase with values between 8.9 and 9.0 m3/s. The ANNND-L model showed the lowest RMSE value (8.9 m3/s -8.86-) with an r of 0.933. This model presented similar statistics in the training phase, with a slightly lower RMSE value of 7.7 m3/s. The behavior shown by this model in the test phase was similar to the training and validation phase (RMSE = 7.9 m3/s), having an increase in its value for the test-2 phase (9.4 m3/s).
- In the case of San Martiño, all the selected models were in a very close RMSE value range for the validation phase, with values between 43.5 and 44.6 m3/s, with the SVML model being the best with an RMSE and r of 43.5 m3/s and 0.946, respectively. This model presented different statistics in the training and test phase, with an RMSE value of 34.9 m3/s and 17.5 m3/s, respectively. However, in the test-2 phase, the SVML model was similar to the validation phase, with a slightly higher RMSE value (44.6 m3/s).
- ANNND was the best model for the San Estevo reservoir, in which the RMSE value in the validation phase was 68.1 m3/s and r of 0.941. The other two selected models presented an RMSE value close to that shown by the ANNND model (70.5 and 69.6 m3/s for the RFND and the SVMND-L, respectively). The ANNND model presented a different behavior in the training and test phase with RMSE values of 58.5 m3/s and 31.3 m3/s, respectively. However, in the test-2 phase, the RMSE increased to 48.0 m3/s.
- For the Velle reservoir, the different selected models presented highly differentiated RMSE values (between 91.7 and 95.5 m3/s), which was not the case in the rest of the reservoirs (except Frieira). In this case, the best model was the ANNND model, showing the lowest RMSE (91.7 m3/s) and highest r value (0.946) in the validation phase. In the training phase, it presented a higher RMSE value of 100.2 m3/s and the behavior observed for the test and test-2 phases (47.8 and 78.4 m3/s) followed the same pattern as the rest of the models.
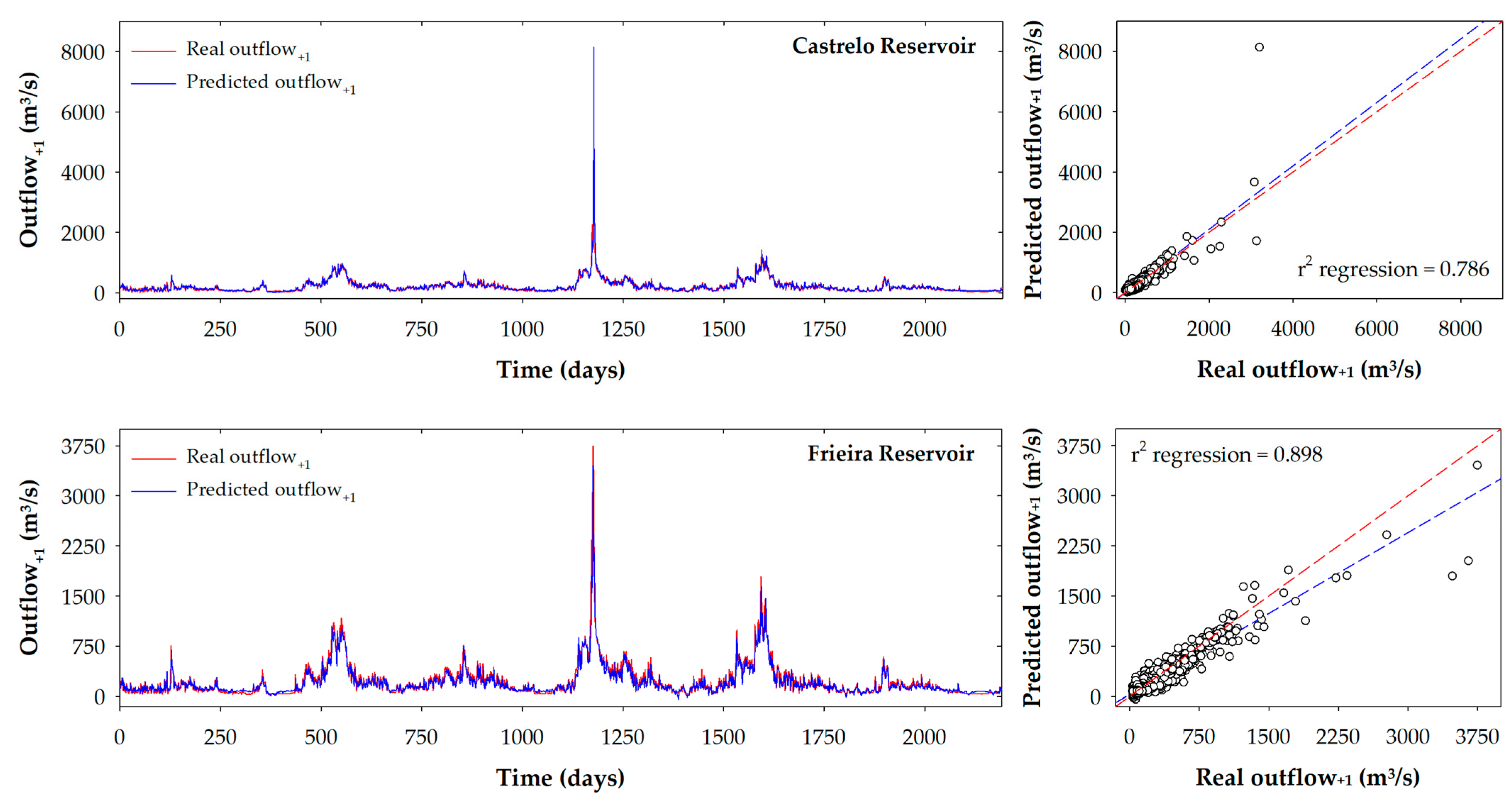
- The ANNND model was the best-selected model for the Castrelo reservoir, presenting the best statistics in the validation phase (RMSE = 94.1 m3/s). The other two models presented very similar values (94.9 m3/s for the RF model and 95.4 m3/s for the SMNN-L model). The ANNND model behavior in the training phase presented an RMSE value of 87.6 m3/s. Although for the test phase, the model presented good results (50.5 m3/s) for test-2 phase, the ANNND model presented a very high RMSE value (171.1 m3/s) compared to the rest of the phases.
- Finally, the best model of the Frieira reservoir (SVMND) showed an RMSE value for the validation phase of 118.5 m3/s and a higher r value (0.944). The rest of the selected models presented RMSE values of 122.6 m3/s (RFND) and 118.8 m3/s (ANNND) for this phase. The model presented different statistics for training and test phases, in which RMSE values were 104.7 m3/s and 65.6 m3/s, respectively. In the test-2 phase, the RMSE value increased to 111.7 m3/s.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- García-Feal, O.; González-Cao, J.; Fernández-Nóvoa, D.; Astray Dopazo, G.; Gómez-Gesteira, M. Comparison of Machine Learning Techniques for Reservoir Outflow Forecasting. Nat. Hazards Earth Syst. Sci. 2022, 22, 3859–3874. [Google Scholar] [CrossRef]
- Baba, A.; Tsatsanifos, C.; el Gohary, F.; Palerm, J.; Khan, S.; Mahmoudian, S.; Ahmed, A.; Tayfur, G.; Dialynas, Y.; Angelakis, A. Developments in Water Dams and Water Harvesting Systems throughout History in Different Civilizations. Int. J. Hydrol. 2018, 2, 150–166. [Google Scholar] [CrossRef]
- Marques, É.T.; Gunkel, G.; Sobral, M.C. Management of Tropical River Basins and Reservoirs under Water Stress: Experiences from Northeast Brazil. Environments 2019, 6, 62. [Google Scholar] [CrossRef]
- Hao, S.; Wörman, A.; Riml, J.; Bottacin-Busolin, A. A Model for Assessing the Importance of Runoff Forecasts in Periodic Climate on Hydropower Production. Water 2023, 15, 1559. [Google Scholar] [CrossRef]
- Gemechu, E.; Kumar, A. A Review of How Life Cycle Assessment Has Been Used to Assess the Environmental Impacts of Hydropower Energy. Renew. Sustain. Energy Rev. 2022, 167, 112684. [Google Scholar] [CrossRef]
- International Energy Agency Electricity Information: Overview. Available online: https://www.iea.org/reports/electricity-information-overview (accessed on 25 January 2021).
- Cernea, M.M. Social Impacts and Social Risks in Hydropower Programs: Preemptive Planning and Counter-Risk Measures; George Washington University: Bethesda, MD, USA, 2004. [Google Scholar]
- Panagiotou, A.; Zogaris, S.; Dimitriou, E.; Mentzafou, A.; Tsihrintzis, V.A. Anthropogenic Barriers to Longitudinal River Connectivity in Greece: A Review. Ecohydrol. Hydrobiol. 2022, 22, 295–309. [Google Scholar] [CrossRef]
- Grill, G.; Lehner, B.; Thieme, M.; Geenen, B.; Tickner, D.; Antonelli, F.; Babu, S.; Borrelli, P.; Cheng, L.; Crochetiere, H.; et al. Mapping the World’s Free-Flowing Rivers. Nature 2019, 569, 215–221. [Google Scholar] [CrossRef]
- Jeuland, M.; Baker, J.; Bartlett, R.; Lacombe, G. The Costs of Uncoordinated Infrastructure Management in Multi-Reservoir River Basins. Environ. Res. Lett. 2014, 9, 105006. [Google Scholar] [CrossRef]
- Marques, G.F.; Tilmant, A. The Economic Value of Coordination in Large-Scale Multireservoir Systems: The Parana River Case. Water Resour. Res. 2013, 49, 7546–7557. [Google Scholar] [CrossRef]
- Quinn, J.D.; Reed, P.M.; Giuliani, M.; Castelletti, A. What Is Controlling Our Control Rules? Opening the Black Box of Multireservoir Operating Policies Using Time-Varying Sensitivity Analysis. Water Resour. Res. 2019, 55, 5962–5984. [Google Scholar] [CrossRef]
- Rougé, C.; Reed, P.M.; Grogan, D.S.; Zuidema, S.; Prusevich, A.; Glidden, S.; Lamontagne, J.R.; Lammers, R.B. Coordination and Control—Limits in Standard Representations of Multi-Reservoir Operations in Hydrological Modeling. Hydrol. Earth Syst. Sci. 2021, 25, 1365–1388. [Google Scholar] [CrossRef]
- Shen, J.; Cheng, C.; Zhang, X.; Zhou, B. Coordinated Operations of Multiple-Reservoir Cascaded Hydropower Plants with Cooperation Benefit Allocation. Energy 2018, 153, 509–518. [Google Scholar] [CrossRef]
- Wei, N.; He, S.; Lu, K.; Xie, J.; Peng, Y. Multi-Stakeholder Coordinated Operation of Reservoir Considering Irrigation and Ecology. Water 2022, 14, 1970. [Google Scholar] [CrossRef]
- Kundzewicz, Z.W.; Kanae, S.; Seneviratne, S.I.; Handmer, J.; Nicholls, N.; Peduzzi, P.; Mechler, R.; Bouwer, L.M.; Arnell, N.; Mach, K.; et al. Flood Risk and Climate Change: Global and Regional Perspectives. Hydrol. Sci. J. 2014, 59, 1–28. [Google Scholar] [CrossRef]
- Hassan, Z.; Razali, N.H.M.; Kamarudzaman, A.N.; Salwa, M.Z.M.; Nordin, N.A.S. Preliminary Study on Flood Simulation Using the HEC-HMS Model for Muda River, Malaysia. IOP Conf. Ser. Earth Environ. Sci. 2023, 1135, 012021. [Google Scholar] [CrossRef]
- Nakamura, I.; Llasat, M.C. Policy and Systems of Flood Risk Management: A Comparative Study between Japan and Spain. Nat. Hazards 2017, 87, 919–943. [Google Scholar] [CrossRef]
- UNISDR Impact of Disasters since the 1992 Rio de Janeiro Earth Summit. Available online: https://www.unisdr.org/files/27162_infographic.pdf (accessed on 20 July 2023).
- European Environment Agency. Climate Change, Impacts and Vulnerability in Europe 2016 an Indicator-Based Report; European Environment Agency: Copenhagen, Denmark, 2017. [Google Scholar]
- Llasat, M.C.; Marcos, R.; Llasat-Botija, M.; Gilabert, J.; Turco, M.; Quintana-Seguí, P. Flash Flood Evolution in North-Western Mediterranean. Atmos. Res. 2014, 149, 230–243. [Google Scholar] [CrossRef]
- Fischer, S.; Schumann, A.; Bühler, P. Timescale-Based Flood Typing to Estimate Temporal Changes in Flood Frequencies. Hydrol. Sci. J. 2019, 64, 1867–1892. [Google Scholar] [CrossRef]
- Persiano, S.; Ferri, E.; Antolini, G.; Domeneghetti, A.; Pavan, V.; Castellarin, A. Changes in Seasonality and Magnitude of Sub-Daily Rainfall Extremes in Emilia-Romagna (Italy) and Potential Influence on Regional Rainfall Frequency Estimation. J. Hydrol. Reg. Stud. 2020, 32, 100751. [Google Scholar] [CrossRef]
- Hirabayashi, Y.; Mahendran, R.; Koirala, S.; Konoshima, L.; Yamazaki, D.; Watanabe, S.; Kim, H.; Kanae, S. Global Flood Risk under Climate Change. Nat. Clim. Chang. 2013, 3, 816–821. [Google Scholar] [CrossRef]
- Zhao, Y.; Weng, Z.; Chen, H.; Yang, J. Analysis of the Evolution of Drought, Flood, and Drought-Flood Abrupt Alternation Events under Climate Change Using the Daily SWAP Index. Water 2020, 12, 1969. [Google Scholar] [CrossRef]
- Wasko, C. Floods Differ in a Warmer Future. Nat. Clim. Chang. 2022, 12, 1090–1091. [Google Scholar] [CrossRef]
- Liu, C.; Guo, L.; Ye, L.; Zhang, S.; Zhao, Y.; Song, T. A Review of Advances in China’s Flash Flood Early-Warning System. Nat. Hazards 2018, 92, 619–634. [Google Scholar] [CrossRef]
- Wasko, C.; Nathan, R.; Stein, L.; O’Shea, D. Evidence of Shorter More Extreme Rainfalls and Increased Flood Variability under Climate Change. J. Hydrol. 2021, 603, 126994. [Google Scholar] [CrossRef]
- Berghuijs, W.R.; Aalbers, E.E.; Larsen, J.R.; Trancoso, R.; Woods, R.A. Recent Changes in Extreme Floods across Multiple Continents. Environ. Res. Lett. 2017, 12, 114035. [Google Scholar] [CrossRef]
- Westra, S.; Fowler, H.J.; Evans, J.P.; Alexander, L.V.; Berg, P.; Johnson, F.; Kendon, E.J.; Lenderink, G.; Roberts, N.M. Future Changes to the Intensity and Frequency of Short-Duration Extreme Rainfall. Rev. Geophys. 2014, 52, 522–555. [Google Scholar] [CrossRef]
- Min, S.-K.; Zhang, X.; Zwiers, F.W.; Hegerl, G.C. Human Contribution to More-Intense Precipitation Extremes. Nature 2011, 470, 378–381. [Google Scholar] [CrossRef]
- Donat, M.G.; Lowry, A.L.; Alexander, L.V.; O’Gorman, P.A.; Maher, N. More Extreme Precipitation in the World’s Dry and Wet Regions. Nat. Clim. Chang. 2016, 6, 508–513. [Google Scholar] [CrossRef]
- Fischer, E.M.; Beyerle, U.; Knutti, R. Robust Spatially Aggregated Projections of Climate Extremes. Nat. Clim. Chang. 2013, 3, 1033–1038. [Google Scholar] [CrossRef]
- De la Paix, M.J.; Lanhai, L.; Xi, C.; Ahmed, S.; Varenyam, A. Soil Degradation and Altered Flood Risk as a Consequence of Deforestation. L. Degrad. Dev. 2013, 24, 478–485. [Google Scholar] [CrossRef]
- Peptenatu, D.; Grecu, A.; Simion, A.G.; Gruia, K.A.; Andronache, I.; Draghici, C.C.; Diaconu, D.C. Deforestation and Frequency of Floods in Romania. In Water Resources Management in Romania; Negm, A.M., Romanescu, G., Zeleňáková, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 279–306. ISBN 978-3-030-22320-5. [Google Scholar]
- Rosburg, T.T.; Nelson, P.A.; Bledsoe, B.P. Effects of Urbanization on Flow Duration and Stream Flashiness: A Case Study of Puget Sound Streams, Western Washington, USA. J. Am. Water Resour. Assoc. 2017, 53, 493–507. [Google Scholar] [CrossRef]
- Wang, L.; Cui, S.; Li, Y.; Huang, H.; Manandhar, B.; Nitivattananon, V.; Fang, X.; Huang, W. A Review of the Flood Management: From Flood Control to Flood Resilience. Heliyon 2022, 8, e11763. [Google Scholar] [CrossRef] [PubMed]
- Elliott, J.; Deryng, D.; Müller, C.; Frieler, K.; Konzmann, M.; Gerten, D.; Glotter, M.; Flörke, M.; Wada, Y.; Best, N.; et al. Constraints and Potentials of Future Irrigation Water Availability on Agricultural Production under Climate Change. Proc. Natl. Acad. Sci. USA 2014, 111, 3239–3244. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Liu, Z.; Wu, J.; Pan, X.; Fang, Z.; Li, J.; Bryan, B.A. Future Global Urban Water Scarcity and Potential Solutions. Nat. Commun. 2021, 12, 4667. [Google Scholar] [CrossRef]
- Obahoundje, S.; Diedhiou, A.; Kouassi, K.L.; Youan Ta, M.; Mortey, E.M.; Roudier, P.; Kouame, D.G.M. Analysis of Hydroclimatic Trends and Variability and Their Impacts on Hydropower Generation in Two River Basins in Côte d’Ivoire (West Africa) during 1981–2017. Environ. Res. Commun. 2022, 4, 065001. [Google Scholar] [CrossRef]
- Wang, B.; Liang, X.J.; Zhang, H.; Wang, L.; Wei, Y.M. Vulnerability of Hydropower Generation to Climate Change in China: Results Based on Grey Forecasting Model. Energy Policy 2014, 65, 701–707. [Google Scholar] [CrossRef]
- Cools, J.; Innocenti, D.; O’Brien, S. Lessons from Flood Early Warning Systems. Environ. Sci. Policy 2016, 58, 117–122. [Google Scholar] [CrossRef]
- UNISDR Terminology on Disaster Risk Reduction. United Nations Office for Disaster Risk Reduction (UNIDR). Available online: https://www.undrr.org/publication/2009-unisdr-terminology-disaster-risk-reduction. (accessed on 21 April 2023).
- De la hoz, B.; Canchano, O.; Coronado, L.; Sánchez Sanchez, P. Redes Neuronales Para Pronóstico de Series de Tiempo Hidrológicas Del Caribe Colombiano. Investig. Y Desarro. En TIC 2019, 10, 18–31. [Google Scholar]
- Sánchez, P.; Velásquez, J.D. Problemas de Investigación En La Predicción de Series de Tiempo Con Redes Neuronales Artificiales. Rev. Av. En Sist. E Informática 2010, 7, 67–73. [Google Scholar]
- Gómez-Vargas, E.; Obregón, N.; Socarras, V. Aplicación Del Modelo Neurodifuso ANFIS vs Redes Neuronales, Al Problema Predictivo de Caudales Medios Mensuales Del Río Bogotá En Villapinzón. Rev. Tecnura 2010, 14, 18–29. [Google Scholar]
- Li, X.; Lin, W.; Guan, B. The Impact of Computing and Machine Learning on Complex Problem-Solving. Eng. Rep. 2023, 5, e12702. [Google Scholar] [CrossRef]
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2018, 9, 381–386. [Google Scholar] [CrossRef]
- Le, X.-H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef]
- Emami, S.; Parsa, J. Comparative Evaluation of Imperialist Competitive Algorithm and Artifcial Neural Networks for Estimation of Reservoirs Storage Capacity. Appl. Water Sci. 2020, 10, 177. [Google Scholar] [CrossRef]
- Behzad, M.; Asghari, K.; Coppola, E.A., Jr. Comparative Study of SVMs and ANNs in Aquifer Water Level Prediction. J. Comput. Civ. Eng. 2010, 24, 408–413. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar Singh, A. A Comparison between MLR, MARS, SVR and RF Techniques: Hydrological Time-Series Modeling. J. Hum. Earth Future 2022, 3, 90–98. [Google Scholar] [CrossRef]
- Géron, A. The Machine Learning Landscape. In Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow. Concepts, Tools, and Techniques to Build Intelligent Systems; Tache, N., Ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019; pp. 3–36. [Google Scholar]
- Sobrido Pouso, C. Predicción Del Caudal de Salida de Embalses de La Confederación Hidrográfica Del Miño-Sil Usando Técnicas de Machine Learning. Bachelor’s Thesis, University of Vigo, Ourense, Spain, 2023. [Google Scholar]
- Cartografía Digital. Infraestructura de Datos Espaciales Miño-Sil (IDE Miño-Sil). Available online: https://www.chminosil.es/es/ide-mino-sil (accessed on 14 August 2023).
- Mapa Físico de España 1:1.250.000. Mapas Impresos Escaneados. Mapas Generales Edición Impresa. Instituto Geográfico Nacional, Ministerio de Fomento, Gobierno de España. 2012. Available online: http://centrodedescargas.cnig.es/CentroDescargas/index.jsp# (accessed on 21 August 2023).
- Confederación Hidrográfica del Miño-Sil Anejo 2. Descripción General de La Demarcación. Plan Hidrologico Del Ciclo 2022–2027. Parte Española de La Demarcación Hidrográfica Miño-Sil. 2022, pp. 1–434. Available online: https://www.chminosil.es/images/planificacion/proyecto-ph-2022-2027/VMITERD/001.PHC/02._ANEJO_II---.pdf. (accessed on 28 July 2023).
- Confederación Hidrográfica del Miño-Sil Descripción. Available online: https://www.chminosil.es/es/chms/demarcacion/marco-fisico/descripcion (accessed on 28 July 2023).
- Confederación Hidrográfica del Miño-Sil Histórico de Embalses. Available online: https://www.chminosil.es/es/chms/planificacionhidrologica/recursos-hidricos/historico-de-embalses (accessed on 28 July 2023).
- Confederación Hidrográfica Miño-Sil. Available online: https://www.chminosil.es (accessed on 7 October 2022).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhang, H.; Quost, B.; Masson, M.-H. Cautious Weighted Random Forests. Expert Syst. Appl. 2023, 213, 118883. [Google Scholar] [CrossRef]
- Koch, J.; Stisen, S.; Refsgaard, J.C.; Ernstsen, V.; Jakobsen, P.R.; Højberg, A.L. Modeling Depth of the Redox Interface at High Resolution at National Scale Using Random Forest and Residual Gaussian Simulation. Water Resour. Res. 2019, 55, 1451–1469. [Google Scholar] [CrossRef]
- Das, S.; Imtiaz, M.S.; Neom, N.H.; Siddique, N.; Wang, H. A Hybrid Approach for Bangla Sign Language Recognition Using Deep Transfer Learning Model with Random Forest Classifier. Expert Syst. Appl. 2023, 213, 118914. [Google Scholar] [CrossRef]
- Kumar, S.; Mishra, A.K.; Choudhary, B.S. Prediction of Back Break in Blasting Using Random Decision Trees. Eng. Comput. 2022, 38, 1185–1191. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Cho, E.; Jacobs, J.M.; Jia, X.; Kraatz, S. Identifying Subsurface Drainage Using Satellite Big Data and Machine Learning via Google Earth Engine. Water Resour. Res. 2019, 55, 8028–8045. [Google Scholar] [CrossRef]
- Nasteski, V. An Overview of the Supervised Machine Learning Methods. Horizons 2017, 4, 51–62. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C.; Villa-Vialaneix, N. Random Forests for Big Data. Big Data Res. 2017, 9, 28–46. [Google Scholar] [CrossRef]
- Antonanzas-Torres, F.; Urraca, R.; Antonanzas, J.; Fernandez-Ceniceros, J.; Martinez-De-Pison, F.J. Generation of Daily Global Solar Irradiation with Support Vector Machines for Regression. Energy Convers. Manag. 2015, 96, 277–286. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995; ISBN 978-1-4757-2442-4. [Google Scholar]
- Fan, J.; Jing, F.; Fang, Z.; Tan, M. Automatic Recognition System of Welding Seam Type Based on SVM Method. Int. J. Adv. Manuf. Technol. 2017, 92, 989–999. [Google Scholar] [CrossRef]
- Rani, A.; Kumar, N.; Kumar, J.; Kumar, J.; Sinha, N.K. Chapter 6—Machine Learning for Soil Moisture Assessment. In Deep Learning for Sustainable Agriculture; Poonia, R.C., Singh, V., Nayak, S.R., Eds.; Cognitive Data Science in Sustainable Computing; Academic Press: Cambridge, MA, USA, 2022; pp. 143–168. ISBN 978-0-323-85214-2. [Google Scholar]
- Xiahou, X.; Harada, Y. B2C E-Commerce Customer Churn Prediction Based on K-Means and SVM. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 458–475. [Google Scholar] [CrossRef]
- Boualem, A.D.; Argoub, K.; Benkouider, A.M.; Yahiaoui, A.; Toubal, K. Viscosity Prediction of Ionic Liquids Using NLR and SVM Approaches. J. Mol. Liq. 2022, 368, 120610. [Google Scholar] [CrossRef]
- Cruz, R.C.; Reis Costa, P.; Vinga, S.; Krippahl, L.; Lopes, M.B. A Review of Recent Machine Learning Advances for Forecasting Harmful Algal Blooms and Shellfish Contamination. J. Mar. Sci. Eng. 2021, 9, 283. [Google Scholar] [CrossRef]
- Hsu, C.; Chang, C.; Lin, C. A Practical Guide to Support Vector Classification. 2003. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf. (accessed on 30 July 2023).
- Teke, C.; Akkurt, I.; Arslankaya, S.; Ekmekci, I.; Gunoglu, K. Prediction of Gamma Ray Spectrum for 22Na Source by Feed Forward Back Propagation ANN Model. Radiat. Phys. Chem. 2023, 202, 110558. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Lin, Y.-H.; Kung, C.-C.; Chung, M.-H.; Yen, I.-H. Design and Implementation of Cloud Analytics-Assisted Smart Power Meters Considering Advanced Artificial Intelligence as Edge Analytics in Demand-Side Management for Smart Homes. Sensors 2019, 19, 2047. [Google Scholar] [CrossRef] [PubMed]
- Jimeno-Sáez, P.; Senent-Aparicio, J.; Cecilia, J.M.; Pérez-Sánchez, J. Using Machine-Learning Algorithms for Eutrophication Modeling: Case Study of Mar Menor Lagoon (Spain). Int. J. Environ. Res. Public Health 2020, 17, 1189. [Google Scholar] [CrossRef]
- Fogelman, S.; Blumenstein, M.; Zhao, H. Estimation of Oxygen Demand Levels Using UV- Vis Spectroscopy and Artificial Neural Networks as an Effective Tool. Neural Comput. Appl. 2006, 15, 197–203. [Google Scholar] [CrossRef]
- Jimeno-Sáez, P.; Senent-Aparicio, J.; Pérez-Sánchez, J.; Pulido-Velazquez, D. A Comparison of SWAT and ANN Models for Daily Runoff Simulation in Different Climatic Zones of Peninsular Spain. Water 2018, 10, 192. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, S.; Xiong, L.; Liu, P.; Liu, D. Daily Runoff Forecasting Model Based on ANN and Data Preprocessing Techniques. Water 2015, 7, 4144–4160. [Google Scholar] [CrossRef]
- Govindaraju, R.S. Artificial Neural Network in Hydrology. I:Priliminary Concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar]
- Wali, A.S.; Tyagi, A. Comparative Study of Advance Smart Strain Approximation Method Using Levenberg-Marquardt and Bayesian Regularization Backpropagation Algorithm. Mater. Today Proc. 2020, 21, 1380–1395. [Google Scholar] [CrossRef]
- Dragović, S. Artificial Neural Network Modeling in Environmental Radioactivity Studies—A Review. Sci. Total Environ. 2022, 847, 157526. [Google Scholar] [CrossRef]
- Gue, I.H.V.; Ubando, A.T.; Tseng, M.L.; Tan, R.R. Artificial Neural Networks for Sustainable Development: A Critical Review. Clean Technol. Environ. Policy 2020, 22, 1449–1465. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations. Am. Soc. Agric. Biol. Eng. 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River Flow Forecasting through Conceptual Models Part I-A Discussion of Principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gupta, H.V.; Sorooshian, S.; Yapo, P.O. Status of Automatic Calibration for Hydrologic Models: Comparison with Multilevel Expert Calibration. J. Hydrol. Eng. 1999, 4, 135–143. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| T | V | Z | Z2 | |||||
|---|---|---|---|---|---|---|---|---|
| Model | RMSE | r | RMSE | r | RMSE | r | RMSE | r |
| Belesar | ||||||||
| RFND | 28.6 | 0.962 | 31.4 | 0.952 | 27.5 | 0.908 | 34.6 | 0.937 |
| SVMN | 31.9 | 0.952 | 31.0 | 0.953 | 24.8 | 0.926 | 33.5 | 0.942 |
| ANNN-L | 32.8 | 0.950 | 30.2 | 0.955 | 24.1 | 0.929 | 32.1 | 0.947 |
| Os Peares | ||||||||
| RFN | 30.8 | 0.965 | 36.0 | 0.944 | 27.2 | 0.924 | 39.5 | 0.927 |
| SVMND | 37.8 | 0.947 | 35.9 | 0.944 | 26.6 | 0.927 | 36.0 | 0.940 |
| ANN | 44.1 | 0.930 | 36.5 | 0.942 | 27.1 | 0.924 | 36.1 | 0.940 |
| Bárcena | ||||||||
| RFND | 7.2 | 0.948 | 9.0 | 0.930 | 8.1 | 0.918 | 9.7 | 0.917 |
| SVMN-L | 7.7 | 0.941 | 8.9 | 0.931 | 7.7 | 0.926 | 9.7 | 0.916 |
| ANNND-L | 7.7 | 0.940 | 8.9 | 0.933 | 7.9 | 0.922 | 9.4 | 0.920 |
| San Martiño | ||||||||
| RF | 34.3 | 0.943 | 44.6 | 0.939 | 18.6 | 0.942 | 37.8 | 0.936 |
| SVML | 34.9 | 0.943 | 43.5 | 0.946 | 17.5 | 0.950 | 44.6 | 0.915 |
| ANNND | 34.9 | 0.941 | 44.6 | 0.939 | 17.9 | 0.947 | 32.5 | 0.951 |
| San Estevo | ||||||||
| RFND | 47.3 | 0.967 | 70.5 | 0.937 | 30.9 | 0.937 | 47.2 | 0.957 |
| SVMND-L | 59.9 | 0.948 | 69.6 | 0.939 | 32.5 | 0.935 | 49.1 | 0.954 |
| ANNND | 58.5 | 0.950 | 68.1 | 0.941 | 31.3 | 0.937 | 48.0 | 0.956 |
| Velle | ||||||||
| RFND | 71.0 | 0.970 | 95.5 | 0.941 | 50.1 | 0.937 | 88.2 | 0.946 |
| SVMND-L | 101.9 | 0.937 | 92.4 | 0.945 | 51.0 | 0.935 | 79.7 | 0.959 |
| ANNND | 100.2 | 0.938 | 91.7 | 0.946 | 47.8 | 0.943 | 78.4 | 0.958 |
| Castrelo | ||||||||
| RF | 69.6 | 0.972 | 94.9 | 0.949 | 59.5 | 0.927 | 94.0 | 0.946 |
| SVMN-L | 91.7 | 0.951 | 95.4 | 0.950 | 51.0 | 0.944 | 88.8 | 0.955 |
| ANNND | 87.6 | 0.954 | 94.1 | 0.949 | 50.5 | 0.946 | 171.1 | 0.876 |
| Frieira | ||||||||
| RFND | 98.7 | 0.956 | 122.6 | 0.938 | 68.3 | 0.930 | 104.9 | 0.949 |
| SVMND | 104.7 | 0.951 | 118.5 | 0.944 | 65.6 | 0.939 | 111.7 | 0.949 |
| ANNND | 105.5 | 0.950 | 118.8 | 0.942 | 62.7 | 0.941 | 118.4 | 0.936 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soria-Lopez, A.; Sobrido-Pouso, C.; Mejuto, J.C.; Astray, G. Assessment of Different Machine Learning Methods for Reservoir Outflow Forecasting. Water 2023, 15, 3380. https://doi.org/10.3390/w15193380
Soria-Lopez A, Sobrido-Pouso C, Mejuto JC, Astray G. Assessment of Different Machine Learning Methods for Reservoir Outflow Forecasting. Water. 2023; 15(19):3380. https://doi.org/10.3390/w15193380
Chicago/Turabian StyleSoria-Lopez, Anton, Carlos Sobrido-Pouso, Juan C. Mejuto, and Gonzalo Astray. 2023. "Assessment of Different Machine Learning Methods for Reservoir Outflow Forecasting" Water 15, no. 19: 3380. https://doi.org/10.3390/w15193380