
Explainable Artificial Intelligence in Hydrology: Interpreting Black-Box Snowmelt-Driven Streamflow Predictions in an Arid Andean Basin of North-Central Chile

Abstract
:1. Introduction
2. Materials and Methods
2.1. A Case of XAI/iML Application to Prediction of Snowmelt-Driven Streamflows in a Basin of the Semi-Arid Region of North-Central Chile
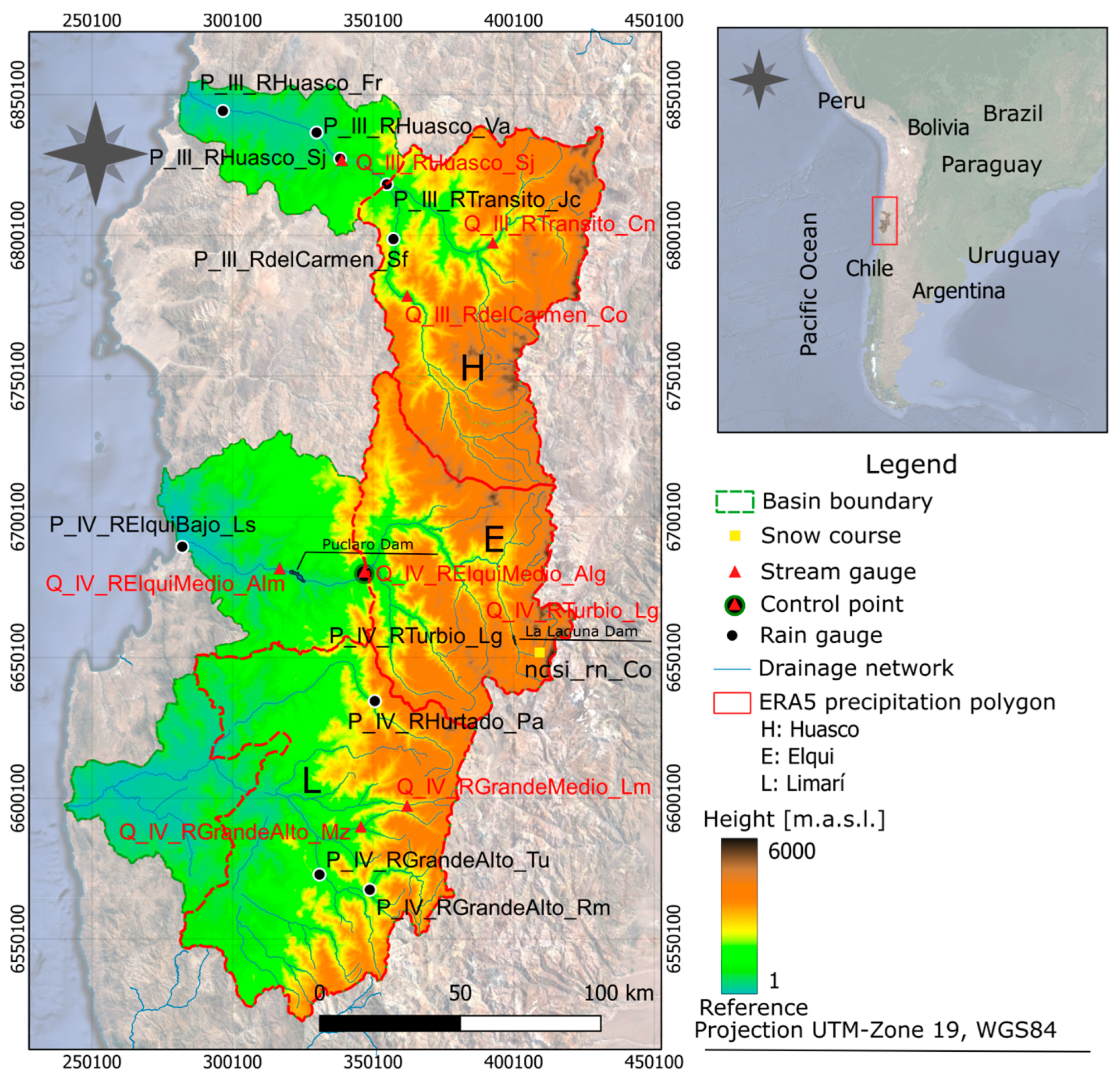
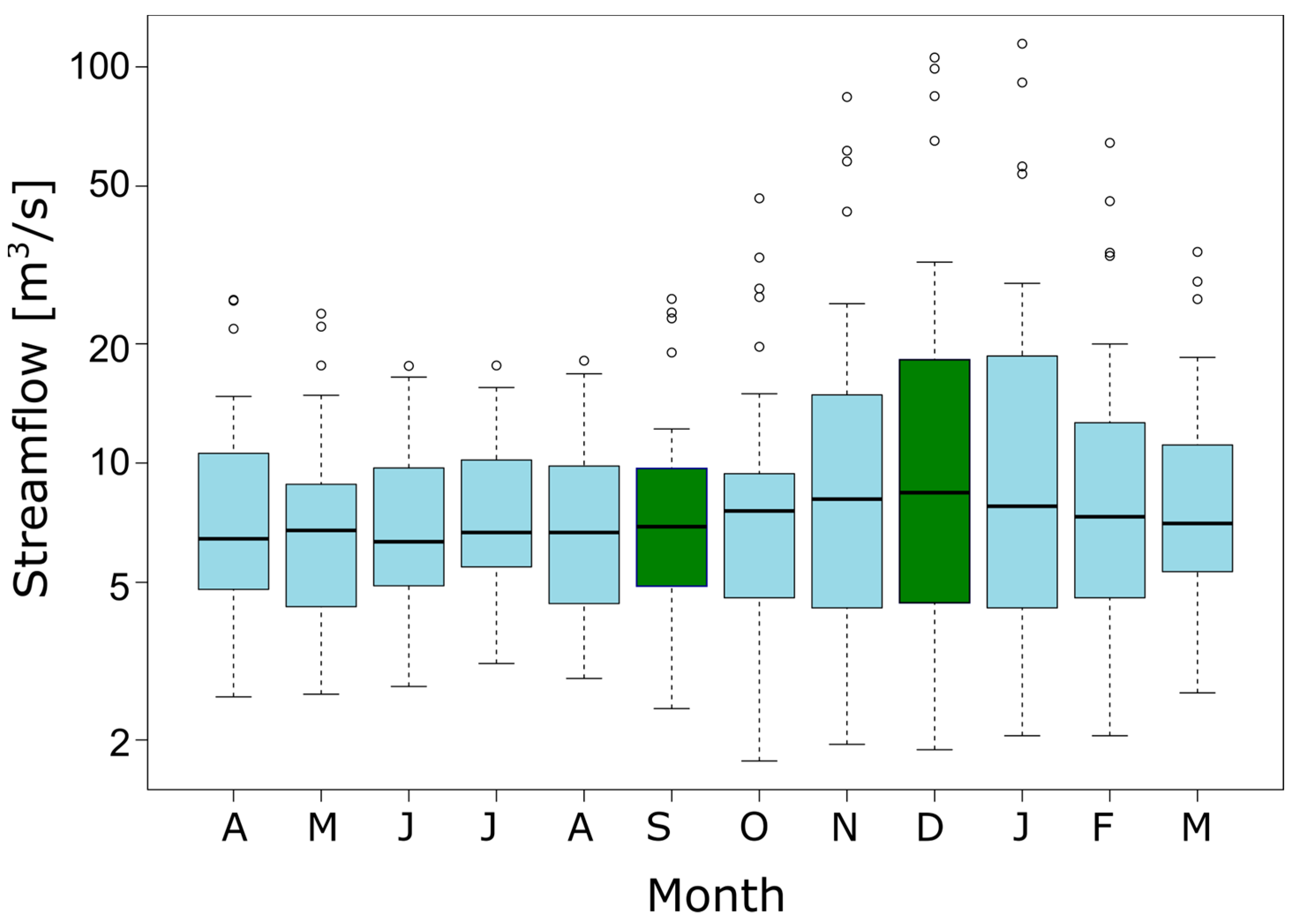
2.2. Study Area
2.3. Data Sources and Analysis Tools
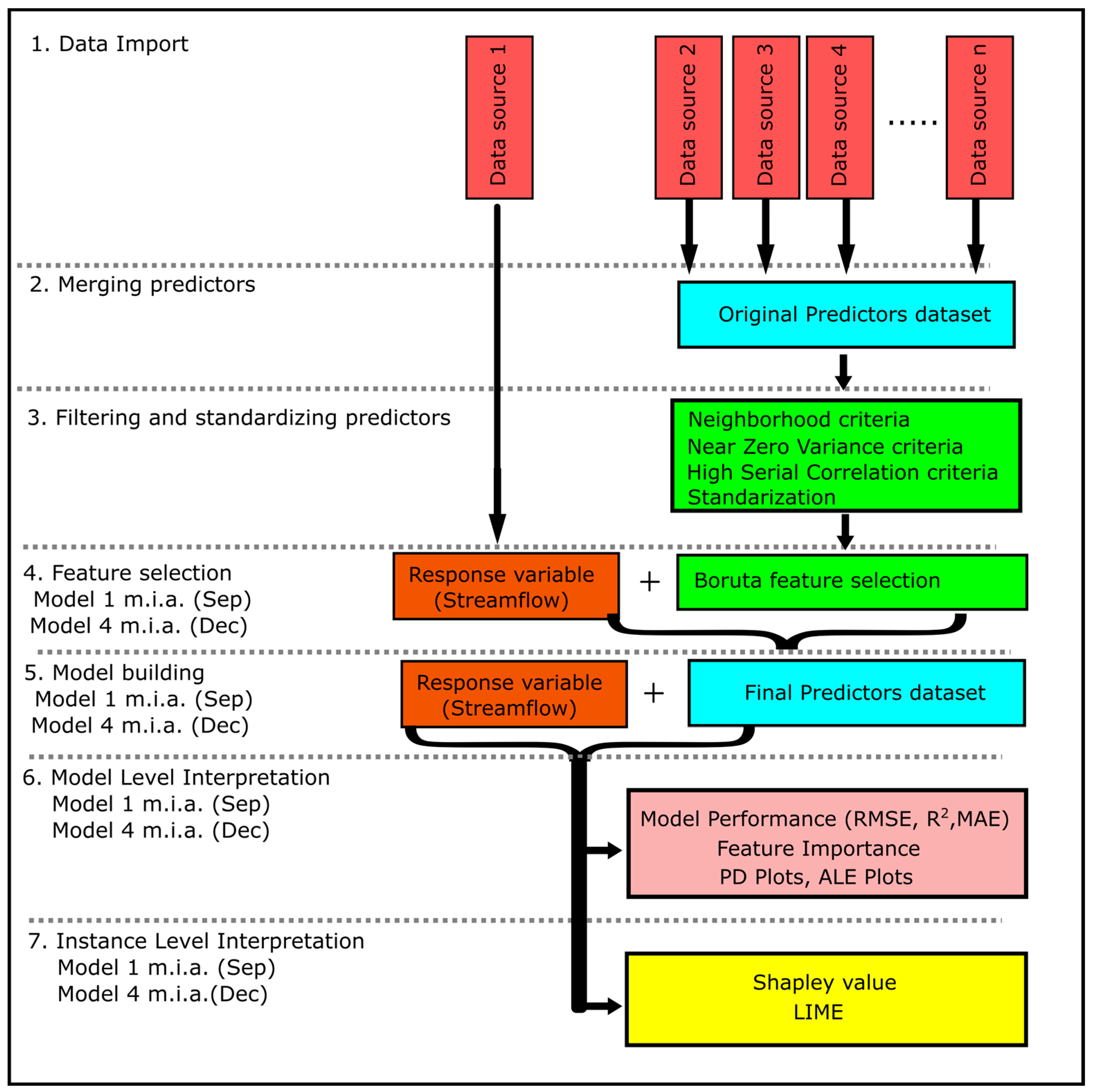
2.4. Procedure
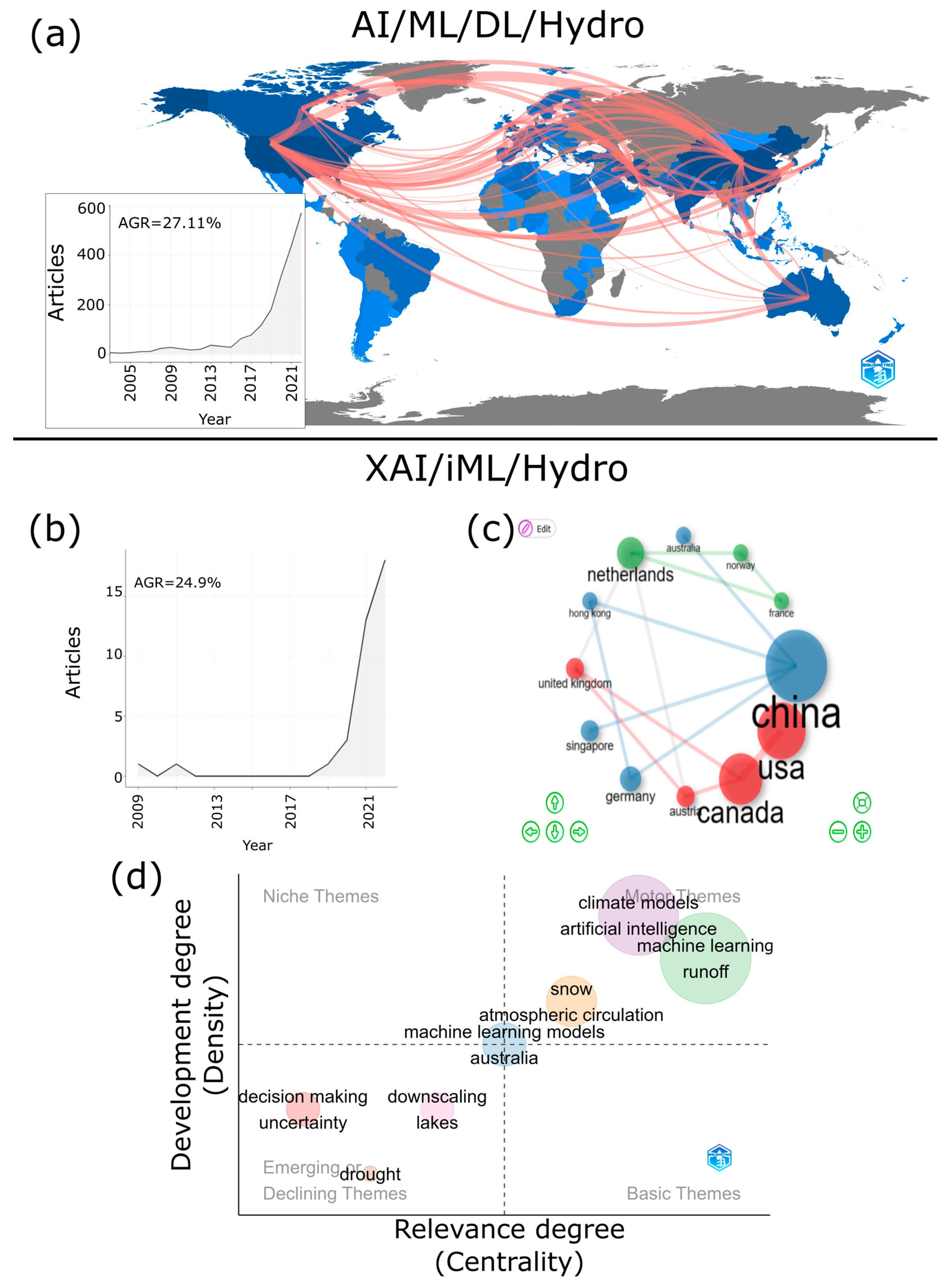
3. Results
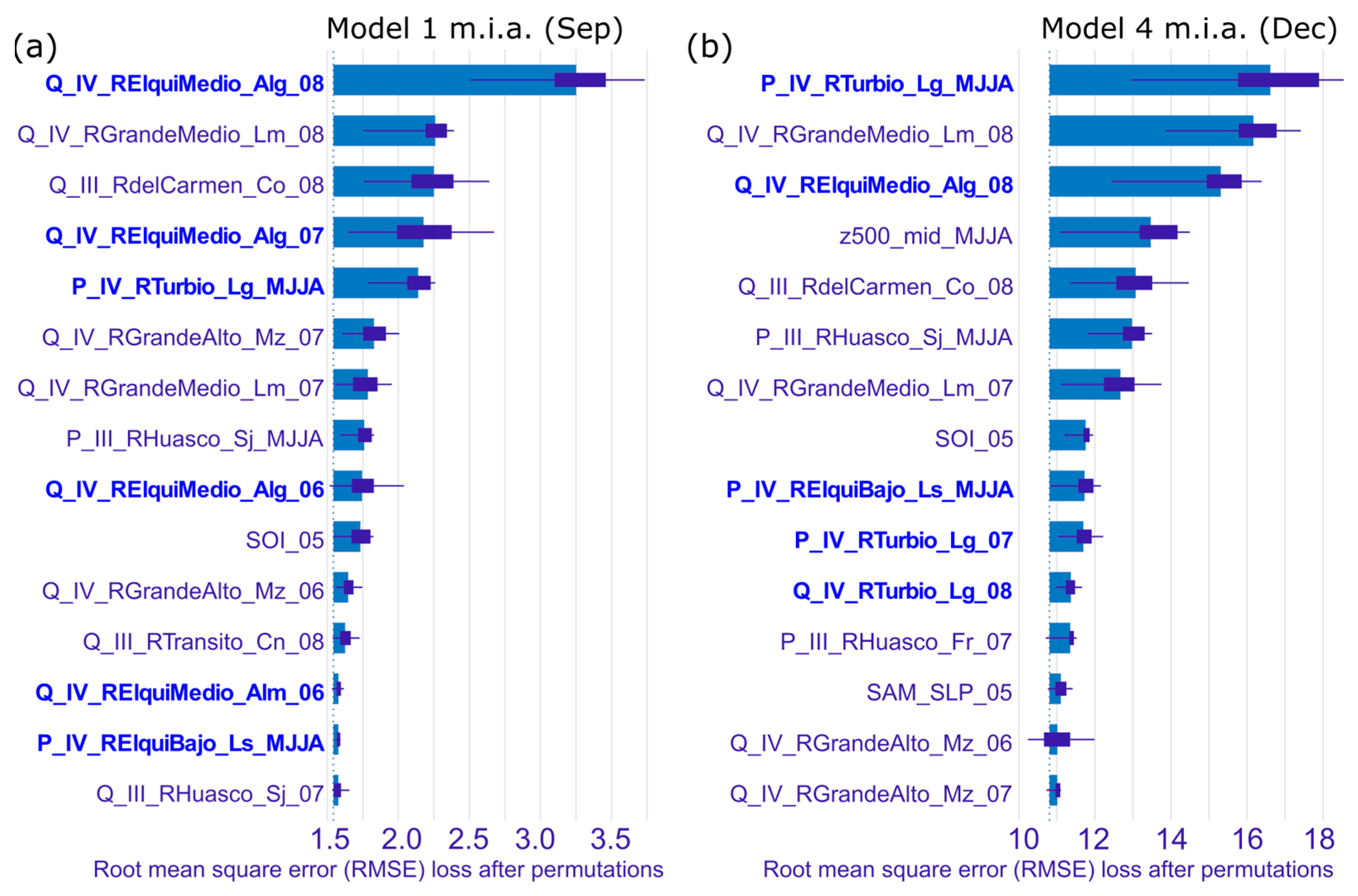
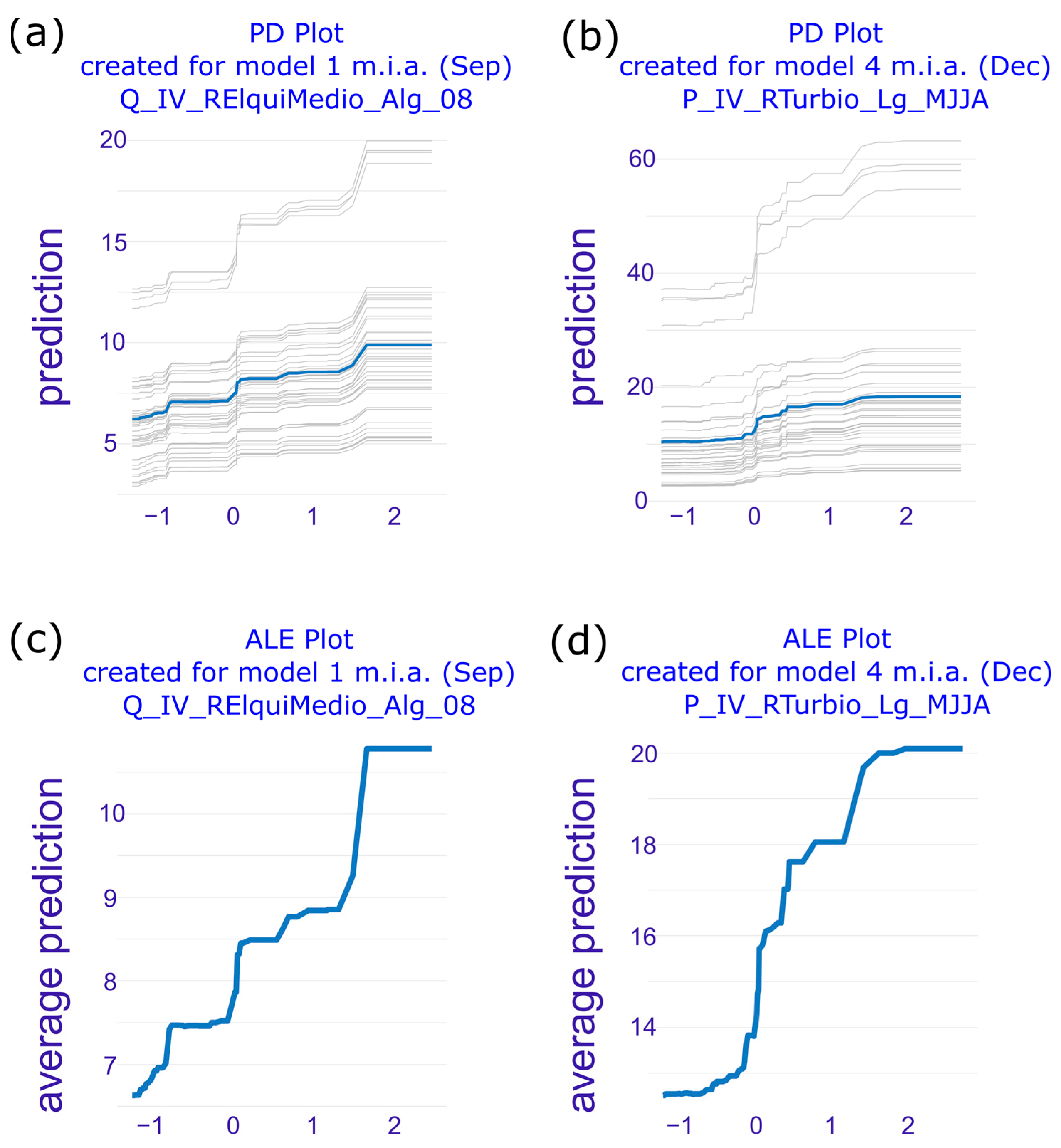
3.1. Model (Dataset)-Level Interpretation
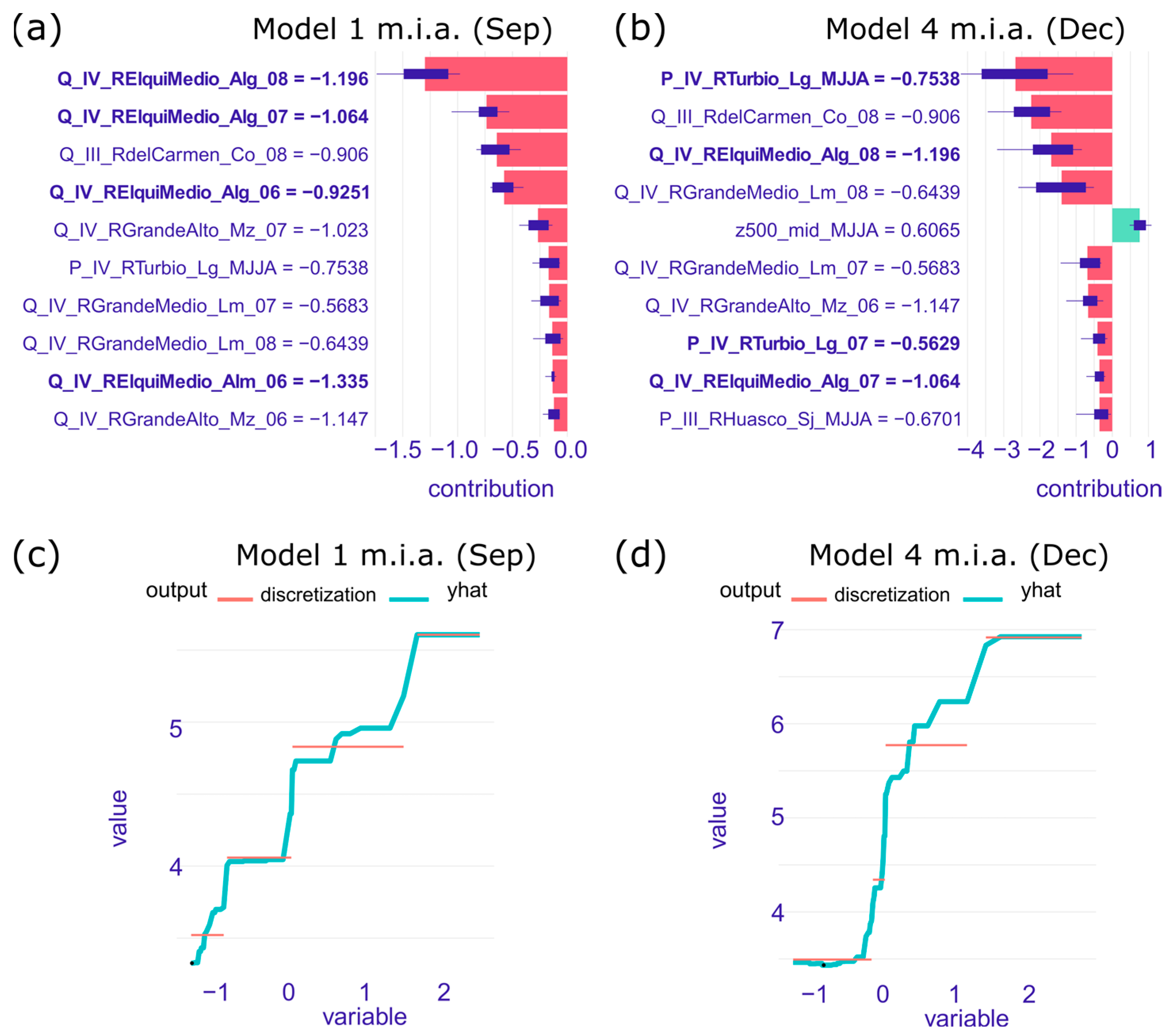
3.2. Local (Instance)-Level Interpretation
4. Discussion
- (a)
- Contribution to the understanding and progress of the discipline: The first reason for which it is considered not only important but also necessary to deepen the adoption of XAI/iML in hydrological research is that this discipline aids in facing the transparency limitations of the black-box techniques that have undergone major expansion in the discipline. This reason is argued by the authors of this paper, contrary to what is stated by those who, regarding the theory-guided approach, indicate that “It is only in this way that we can take full advantage of machine-aided knowledge discovery and advance our understanding of physical processes.” [35]. The reasons presented in hydrological applications of XAI/iML to date clearly reinforce this conviction. For example, some of the reasons expressed by researchers for including XAI/iML in their applications of AI/ML/DL are: that interpretable machine learning methods are adopted for better physical understanding [90]; to interpret the optimum modeling and understand how each input variable affects the selected output [80]; to extend the interpretability of machine learning models so the results can be better understood by humans [91]; to show that ML methods can provide accurate predictions for various tasks and that the hydrological processes involved can be interpreted so that results are more understandable to humans [92]; and to overcome black-box model limitations related to practical implications for water resource research [93]. Thus, as stated in other studies, in terms of contribution to the understanding of hydrological processes based on the application of AI/ML/DL, the authors of this paper also “recommend that the hydrological community makes more use of the novel methods of interpretable machine learning” [94].
- (b)
- Accountability in trustworthy AI/ML/DL for high-stakes decision-making systems: The second reason that XAI/iML can contribute significantly to hydrological research and practice, which has been tangentially recognized in the hydrology community, is the importance that ethical and regulatory issues concerning the use of AI/ML/DL overall have taken on [83,85,95,96,97,98]. The regulatory aspect has emerged as a natural extension of the ethical debate on AI toward the field of AI governance, the main objective of which is to achieve what has been called Trustworthy AI [99]. Hydrology, a discipline that throughout its history has known how to adapt to the context of technological development and social needs in which it is immersed [88], due to its own evolution, is inextricably linked to human affairs. And while an understanding of the processes and the progress of hydrological knowledge continue to be the main value of the discipline [19,20,21], the contribution of hydrology to solving the problems of society will require consideration of the ethical issues behind the solutions it provides [18,100]. This idea is reinforced when the discipline itself has explicitly recognized the increasingly substantial role of human–water interactions, and where communication of scientific knowledge and the acquisition of feedback from stakeholders are key factors in the progress of the discipline and its mission to be a “science for solutions” [101]. Various authors have begun to analyze and recognize the ethical and accountability implications brought about by the use of AI/ML/DL in hydrological research (see, for example, a recent discussion on the ethical aspects of DL in hydrology [3]), and it is expected that as the future of hydrology is increasingly connected to the provision of solutions to society’s water-related problems, the need to generate reliable solutions in a context in which many of them will be generated by AI/ML/DL, especially those linked to high-stakes decision-making, will be more pressing [8,47,89,102].
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Mukhamediev, R.I.; Popova, Y.; Kuchin, Y.; Zaitseva, E.; Kalimoldayev, A.; Symagulov, A.; Levashenko, V.; Abdoldina, F.; Gopejenko, V.; Yakunin, K.; et al. Review of Artificial Intelligence and Machine Learning Technologies: Classification, Restrictions, Opportunities and Challenges. Mathematics 2022, 10, 2552. [Google Scholar] [CrossRef]
- Lange, H.; Sippel, S. Machine Learning Applications in Hydrology. In Forest-Water Interactions; Levia, D.F., Carlyle-Moses, D.E., Iida, S., Michalzik, B., Nanko, K., Tischer, A., Eds.; Ecological Studies; Springer International Publishing: Cham, Switzerland, 2020; pp. 233–257. [Google Scholar] [CrossRef]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A Comprehensive Review of Deep Learning Applications in Hydrology and Water Resources. Water Sci. Technol. 2020, 82, 2635–2670. [Google Scholar] [CrossRef]
- Xu, T.; Liang, F. Machine Learning for Hydrologic Sciences: An Introductory Overview. WIREs Water 2021, 8, e1533. [Google Scholar] [CrossRef]
- Chang, F.-J.; Chang, L.-C.; Chen, J.-F. Artificial Intelligence Techniques in Hydrology and Water Resources Management. Water 2023, 15, 1846. [Google Scholar] [CrossRef]
- Stafford, N. Science in the Digital Age. Nature 2010, 467, S19–S21. [Google Scholar] [CrossRef]
- Jandrić, P. Digital: The Three Ages of the Digital; Brill: Leiden, The Netherlands, 2019; pp. 161–176. [Google Scholar] [CrossRef]
- Doorn, N. Artificial Intelligence in the Water Domain: Opportunities for Responsible Use. Sci. Total Environ. 2021, 755, 142561. [Google Scholar] [CrossRef]
- Luers, A.L. Planetary Intelligence for Sustainability in the Digital Age: Five Priorities. One Earth 2021, 4, 772–775. [Google Scholar] [CrossRef]
- Sun, Z.; Sandoval, L.; Crystal-Ornelas, R.; Mousavi, S.M.; Wang, J.; Lin, C.; Cristea, N.; Tong, D.; Carande, W.H.; Ma, X.; et al. A Review of Earth Artificial Intelligence. Comput. Geosci. 2022, 159, 105034. [Google Scholar] [CrossRef]
- Ho, Y.-S.; Wang, M.-H. A Bibliometric Analysis of Artificial Intelligence Publications from 1991 to 2018. COLLNET J. Scientometr. Inf. Manag. 2020, 14, 369–392. [Google Scholar] [CrossRef]
- See, L.; Solomatine, D.; Abrahart, R.; Toth, E. Hydroinformatics: Computational Intelligence and Technological Developments in Water Science Applications—Editorial. Hydrol. Sci. J. 2007, 52, 391–396. [Google Scholar] [CrossRef]
- Babovic, V.; Han, D.; Chen, Y. Artificial Intelligence within IAHR: Past, Present and Future. Hydrolink 2021-2 Artificial Intelligence. Available online: https://www.iahr.org/library/infor?pid=10796 (accessed on 15 October 2022).
- Raclot, D.; Puech, C. What Does Ai Contribute to Hydrology? Aerial Photos and Flood Levels. Appl. Artif. Intell. 2003, 17, 71–86. [Google Scholar] [CrossRef]
- Nearing, G.S.; Kratzert, F.; Sampson, A.K.; Pelissier, C.S.; Klotz, D.; Frame, J.M.; Prieto, C.; Gupta, H.V. What Role Does Hydrological Science Play in the Age of Machine Learning? Water Resour. Res. 2021, 57, e2020WR028091. [Google Scholar] [CrossRef]
- Li, J.; Huang, W. Paradigm Shift in Science with Tackling Global Challenges. Natl. Sci. Rev. 2019, 6, 1091–1093. [Google Scholar] [CrossRef] [PubMed]
- Nearing, G.; Kratzert, F.; Pelissier, C.; Klotz, D.; Frame, J.; Gupta, H. Machine Learning Is Central to the Future of Hydrological Modeling. In Proceedings of the EGU General Assembly 2020, Online, 4–8 May 2020. EGU2020-6111. [Google Scholar] [CrossRef]
- Blöschl, G.; Bierkens, M.F.P.; Chambel, A.; Cudennec, C.; Destouni, G.; Fiori, A.; Kirchner, J.W.; McDonnell, J.J.; Savenije, H.H.G.; Sivapalan, M.; et al. Twenty-Three Unsolved Problems in Hydrology (UPH)—A Community Perspective. Hydrol. Sci. J. 2019, 64, 1141–1158. [Google Scholar] [CrossRef]
- Wagener, T.; Sivapalan, M.; Troch, P.A.; McGlynn, B.L.; Harman, C.J.; Gupta, H.V.; Kumar, P.; Rao, P.S.C.; Basu, N.B.; Wilson, J.S. The Future of Hydrology: An Evolving Science for a Changing World. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Montanari, A.; Young, G.; Savenije, H.H.G.; Hughes, D.; Wagener, T.; Ren, L.L.; Koutsoyiannis, D.; Cudennec, C.; Toth, E.; Grimaldi, S.; et al. “Panta Rhei—Everything Flows”: Change in Hydrology and Society—The IAHS Scientific Decade 2013–2022. Hydrol. Sci. J. 2013, 58, 1256–1275. [Google Scholar] [CrossRef]
- McMillan, H.; Montanari, A.; Cudennec, C.; Savenije, H.; Kreibich, H.; Krueger, T.; Liu, J.; Mejia, A.; Van Loon, A.; Aksoy, H.; et al. Panta Rhei 2013–2015: Global Perspectives on Hydrology, Society and Change. Hydrol. Sci. J. 2016, 61, 1174–1191. [Google Scholar] [CrossRef]
- Erasmus, A.; Brunet, T.D.P.; Fisher, E. What Is Interpretability? Philos. Technol. 2021, 34, 833–862. [Google Scholar] [CrossRef]
- Beisbart, C.; Räz, T. Philosophy of Science at Sea: Clarifying the Interpretability of Machine Learning. Philos. Compass 2022, 17, e12830. [Google Scholar] [CrossRef]
- Abrahart, R.J.; Anctil, F.; Coulibaly, P.; Dawson, C.W.; Mount, N.J.; See, L.M.; Shamseldin, A.Y.; Solomatine, D.P.; Toth, E.; Wilby, R.L. Two Decades of Anarchy? Emerging Themes and Outstanding Challenges for Neural Network River Forecasting. Prog. Phys. Geogr. Earth Environ. 2012, 36, 480–513. [Google Scholar] [CrossRef]
- Elgin, C.Z. Interpretation And Understanding. Erkenntnis 2000, 52, 175–183. [Google Scholar] [CrossRef]
- Moreido, V.; Gartsman, B.; Solomatine, D.P.; Suchilina, Z. How Well Can Machine Learning Models Perform without Hydrologists? Application of Rational Feature Selection to Improve Hydrological Forecasting. Water 2021, 13, 1696. [Google Scholar] [CrossRef]
- Shen, C.; Chen, X.; Laloy, E. Editorial: Broadening the Use of Machine Learning in Hydrology. Front. Water 2021, 3, 681023. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Dziugaite, G.K.; Ben-David, S.; Roy, D.M. Enforcing Interpretability and Its Statistical Impacts: Trade-Offs between Accuracy and Interpretability. arXiv 2020, arXiv:2010.13764. [Google Scholar] [CrossRef]
- Bell, A.; Solano-Kamaiko, I.; Nov, O.; Stoyanovich, J. It’s Just Not That Simple: An Empirical Study of the Accuracy-Explainability Trade-off in Machine Learning for Public Policy. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, Seoul, Republic of Korea, 21–24 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 248–266. [Google Scholar] [CrossRef]
- Gosiewska, A.; Kozak, A.; Biecek, P. Simpler Is Better: Lifting Interpretability-Performance Trade-off via Automated Feature Engineering. Decis. Support Syst. 2021, 150, 113556. [Google Scholar] [CrossRef]
- Boge, F.J.; Grünke, P.; Hillerbrand, R. Minds and Machines Special Issue: Machine Learning: Prediction Without Explanation? Minds Mach. 2022, 32, 1–9. [Google Scholar] [CrossRef]
- Feng, D.; Liu, J.; Lawson, K.; Shen, C. Differentiable, Learnable, Regionalized Process-Based Models with Physical Outputs Can Approach State-of-the-Art Hydrologic Prediction Accuracy. arXiv 2022, arXiv:2203.14827. [Google Scholar] [CrossRef]
- Varadharajan, C.; Appling, A.P.; Arora, B.; Christianson, D.S.; Hendrix, V.C.; Kumar, V.; Lima, A.R.; Müller, J.; Oliver, S.; Ombadi, M.; et al. Can Machine Learning Accelerate Process Understanding and Decision-Relevant Predictions of River Water Quality? Hydrol. Process. 2022, 36, e14565. [Google Scholar] [CrossRef]
- Chadalawada, J.; Herath, H.M.V.V.; Babovic, V. Hydrologically Informed Machine Learning for Rainfall-Runoff Modeling: A Genetic Programming-Based Toolkit for Automatic Model Induction. Water Resour. Res. 2020, 56, e2019WR026933. [Google Scholar] [CrossRef]
- Başağaoğlu, H.; Chakraborty, D.; Lago, C.D.; Gutierrez, L.; Şahinli, M.A.; Giacomoni, M.; Furl, C.; Mirchi, A.; Moriasi, D.; Şengör, S.S. A Review on Interpretable and Explainable Artificial Intelligence in Hydroclimatic Applications. Water 2022, 14, 1230. [Google Scholar] [CrossRef]
- Kok, I.; Okay, F.Y.; Muyanli, O.; Ozdemir, S. Explainable Artificial Intelligence (XAI) for Internet of Things: A Survey. arXiv 2022, arXiv:2206.04800. [Google Scholar] [CrossRef]
- Vishwarupe, V.; Joshi, P.M.; Mathias, N.; Maheshwari, S.; Mhaisalkar, S.; Pawar, V. Explainable AI and Interpretable Machine Learning: A Case Study in Perspective. Procedia Comput. Sci. 2022, 204, 869–876. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-Tool for Comprehensive Science Mapping Analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Alkhammash, R. Bibliometric, Network, and Thematic Mapping Analyses of Metaphor and Discourse in COVID-19 Publications from 2020 to 2022. Front. Psychol. 2023, 13, 1062943. [Google Scholar] [CrossRef] [PubMed]
- Morante-Carballo, F.; Montalván-Burbano, N.; Quiñonez-Barzola, X.; Jaya-Montalvo, M.; Carrión-Mero, P. What Do We Know about Water Scarcity in Semi-Arid Zones? A Global Analysis and Research Trends. Water 2022, 14, 2685. [Google Scholar] [CrossRef]
- Garreaud, R.D.; Boisier, J.P.; Rondanelli, R.; Montecinos, A.; Sepúlveda, H.H.; Veloso-Aguila, D. The Central Chile Mega Drought (2010–2018): A Climate Dynamics Perspective. Int. J. Climatol. 2020, 40, 421–439. [Google Scholar] [CrossRef]
- Correa, H. Análisis de rutas de nieve y pronóstico de caudales en Chile Central: Variabilidad espacial y temporal. Tesis de Pregrado, Universidad de Chile, Santiago, Chile, 2013. Available online: https://repositorio.uchile.cl/handle/2250/115278 (accessed on 18 June 2023).
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; pp. 157–175. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Naretto, F.; Turini, F.; Pedreschi, D.; Giannotti, F. Stable and Actionable Explanations of Black-Box Models through Factual and Counterfactual Rules. Data Min. Knowl. Discov. 2022, 1–38. [Google Scholar] [CrossRef]
- Vergni, L.; Todisco, F. A Random Forest Machine Learning Approach for the Identification and Quantification of Erosive Events. Water 2023, 15, 2225. [Google Scholar] [CrossRef]
- Fleming, S.W.; Garen, D.C.; Goodbody, A.G.; McCarthy, C.S.; Landers, L.C. Assessing the New Natural Resources Conservation Service Water Supply Forecast Model for the American West: A Challenging Test of Explainable, Automated, Ensemble Artificial Intelligence. J. Hydrol. 2021, 602, 126782. [Google Scholar] [CrossRef]
- Cortés, C.; Yáñez, M. Pronóstico de Caudales de Deshielo en las Cuencas de los ríos HUASCO y Elqui, Chile Centro-Norte; Memoria; Universidad de La Serena: La Serena, Chile, 2021. [Google Scholar]
- Mayer, M. MissRanger: Fast Imputation of Missing Values. 2021. Available online: https://CRAN.R-project.org/package=missRanger (accessed on 9 September 2023).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Biecek, P. DALEX: Explainers for Complex Predictive Models in R. J. Mach. Learn. Res. 2018, 19, 3245–3249. [Google Scholar]
- Maksymiuk, S.; Gosiewska, A.; Biecek, P. Landscape of R Packages for EXplainable Artificial Intelligence. arXiv 2020, arXiv:2009.13248. [Google Scholar]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Biecek, P.; Burzykowski, T. Explanatory Models Analysis: Explore, Explain, and Examine Predictive Models; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A Comparison of Random Forest Variable Selection Methods for Classification Prediction Modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef]
- Song, Q.C.; Tang, C.; Wee, S. Making Sense of Model Generalizability: A Tutorial on Cross-Validation in R and Shiny. Adv. Methods Pract. Psychol. Sci. 2021, 4, 2515245920947067. [Google Scholar] [CrossRef]
- Bag, S.; Gupta, K.; Deb, S. A Review and Recommendations on Variable Selection Methods in Regression Models for Binary Data. arXiv 2022, arXiv:2201.06063. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Eertink, J.J.; Heymans, M.W.; Zwezerijnen, G.J.C.; Zijlstra, J.M.; de Vet, H.C.W.; Boellaard, R. External Validation: A Simulation Study to Compare Cross-Validation versus Holdout or External Testing to Assess the Performance of Clinical Prediction Models Using PET Data from DLBCL Patients. EJNMMI Res. 2022, 12, 58. [Google Scholar] [CrossRef]
- Molnar, C.; König, G.; Herbinger, J.; Freiesleben, T.; Dandl, S.; Scholbeck, C.A.; Casalicchio, G.; Grosse-Wentrup, M.; Bischl, B. General Pitfalls of Model-Agnostic Interpretation Methods for Machine Learning Models. In Proceedings of the xxAI-Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, Vienna, Austria, 18 July 2020; Revised and Extended Papers. Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.-R., Samek, W., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2022; pp. 39–68. [Google Scholar] [CrossRef]
- Schwalbe, G.; Finzel, B. A Comprehensive Taxonomy for Explainable Artificial Intelligence: A Systematic Survey of Surveys on Methods and Concepts. Data Min. Knowl. Discov. 2023, 1–59. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed.; Independent Publisher: Munish, Germany, 2022. [Google Scholar]
- Delorit, J.; Gonzalez Ortuya, E.C.; Block, P. Evaluation of Model-Based Seasonal Streamflow and Water Allocation Forecasts for the Elqui Valley, Chile. Hydrol. Earth Syst. Sci. 2017, 21, 4711–4725. [Google Scholar] [CrossRef]
- Núñez, J.; Rivera, D.; Oyarzún, R.; Arumí, J.L. Influence of Pacific Ocean Multidecadal Variability on the Distributional Properties of Hydrological Variables in North-Central Chile. J. Hydrol. 2013, 501, 227–240. [Google Scholar] [CrossRef]
- Núñez, J.; Vergara, A.; Leyton, C.; Metzkes, C.; Mancilla, G.; Bettancourt, D. Reconciling Drought Vulnerability Assessment Using a Convergent Approach: Application to Water Security in the Elqui River Basin, North-Central Chile. Water 2017, 9, 589. [Google Scholar] [CrossRef]
- Zhou, G.; Cui, M.; Wan, J.; Zhang, S. A Review on Snowmelt Models: Progress and Prospect. Sustainability 2021, 13, 11485. [Google Scholar] [CrossRef]
- Garen, D.C.; Marks, D. Spatially Distributed Energy Balance Snowmelt Modelling in a Mountainous River Basin: Estimation of Meteorological Inputs and Verification of Model Results. J. Hydrol. 2005, 315, 126–153. [Google Scholar] [CrossRef]
- Apley, D.W.; Zhu, J. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Mendoza, P.A.; Rajagopalan, B.; Clark, M.P.; Cortés, G.; McPhee, J. A Robust Multimodel Framework for Ensemble Seasonal Hydroclimatic Forecasts. Water Resour. Res. 2014, 50, 6030–6052. [Google Scholar] [CrossRef]
- Sproles, E.A.; Kerr, T.; Orrego Nelson, C.; Lopez Aspe, D. Developing a Snowmelt Forecast Model in the Absence of Field Data. Water Resour. Manag. 2016, 30, 2581–2590. [Google Scholar] [CrossRef]
- Araya, D. Evaluación de la metodología ESP para la generación de pronósticos de caudales de deshielo en cuencas de Chile Central. Tesis Pregrado, Memoria para optar al título de Ingeniero Civil, Universidad de Chile, Santiago, Chile, 2022. Available online: https://repositorio.uchile.cl/handle/2250/185501 (accessed on 18 June 2023).
- Breiman, L. Statistical Modeling: The Two Cultures (with Comments and a Rejoinder by the Author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Gelman, A. Reflections on Breiman’s Two Cultures of Statistical Modeling. Obs. Stud. 2021, 7, 95–98. [Google Scholar] [CrossRef]
- Palacio, S.; Lucieri, A.; Munir, M.; Hees, J.; Ahmed, S.; Dengel, A. XAI Handbook: Towards a Unified Framework for Explainable AI. arXiv 2021, arXiv:2105.06677. [Google Scholar] [CrossRef]
- Althoff, D.; Rodrigues, L.N.; da Silva, D.D. Addressing Hydrological Modeling in Watersheds under Land Cover Change with Deep Learning. Adv. Water Resour. 2021, 154, 103965. [Google Scholar] [CrossRef]
- Chakraborty, D.; Başağaoğlu, H.; Gutierrez, L.; Mirchi, A. Explainable AI Reveals New Hydroclimatic Insights for Ecosystem-Centric Groundwater Management. Environ. Res. Lett. 2021, 16, 114024. [Google Scholar] [CrossRef]
- Liu, Q.; Gui, D.; Zhang, L.; Niu, J.; Dai, H.; Wei, G.; Hu, B.X. Simulation of Regional Groundwater Levels in Arid Regions Using Interpretable Machine Learning Models. Sci. Total Environ. 2022, 831, 154902. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Wang, G.; Cao, F.; Zong, S.; Chai, X. Determining Optimal Probability Distributions for Gridded Precipitation Data Based on L-Moments. Sci. Total Environ. 2023, 882, 163528. [Google Scholar] [CrossRef]
- Saranya, A.; Subhashini, R. A Systematic Review of Explainable Artificial Intelligence Models and Applications: Recent Developments and Future Trends. Decis. Anal. J. 2023, 7, 100230. [Google Scholar] [CrossRef]
- Angelov, P.P.; Soares, E.A.; Jiang, R.; Arnold, N.I.; Atkinson, P.M. Explainable Artificial Intelligence: An Analytical Review. WIREs Data Min. Knowl. Discov. 2021, 11, e1424. [Google Scholar] [CrossRef]
- Graziani, M.; Dutkiewicz, L.; Calvaresi, D.; Amorim, J.P.; Yordanova, K.; Vered, M.; Nair, R.; Abreu, P.H.; Blanke, T.; Pulignano, V.; et al. A Global Taxonomy of Interpretable AI: Unifying the Terminology for the Technical and Social Sciences. Artif. Intell. Rev. 2022, 56, 3473–3504. [Google Scholar] [CrossRef]
- Islam, M.R.; Ahmed, M.U.; Barua, S.; Begum, S. A Systematic Review of Explainable Artificial Intelligence in Terms of Different Application Domains and Tasks. Appl. Sci. 2022, 12, 1353. [Google Scholar] [CrossRef]
- Larsson, S.; Heintz, F. Transparency in Artificial Intelligence. Internet Policy Rev. 2020, 9. [Google Scholar] [CrossRef]
- Speith, T. A Review of Taxonomies of Explainable Artificial Intelligence (XAI) Methods. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, Seoul, Republic of Korea, 21–24 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 2239–2250. [Google Scholar] [CrossRef]
- Sivapalan, M.; Blöschl, G. The Growth of Hydrological Understanding: Technologies, Ideas, and Societal Needs Shape the Field. Water Resour. Res. 2017, 53, 8137–8146. [Google Scholar] [CrossRef]
- Fleming, S.W.; Vesselinov, V.V.; Goodbody, A.G. Augmenting Geophysical Interpretation of Data-Driven Operational Water Supply Forecast Modeling for a Western US River Using a Hybrid Machine Learning Approach. J. Hydrol. 2021, 597, 126327. [Google Scholar] [CrossRef]
- Cheng, S.; Cheng, L.; Qin, S.; Zhang, L.; Liu, P.; Liu, L.; Xu, Z.; Wang, Q. Improved Understanding of How Catchment Properties Control Hydrological Partitioning Through Machine Learning. Water Resour. Res. 2022, 58, e2021WR031412. [Google Scholar] [CrossRef]
- Althoff, D.; Bazame, H.C.; Nascimento, J.G. Untangling Hybrid Hydrological Models with Explainable Artificial Intelligence. H2Open J. 2021, 4, 13–28. [Google Scholar] [CrossRef]
- Yang, Y.; Chui, T.F.M. Modeling and Interpreting Hydrological Responses of Sustainable Urban Drainage Systems with Explainable Machine Learning Methods. Hydrol. Earth Syst. Sci. 2021, 25, 5839–5858. [Google Scholar] [CrossRef]
- El Bilali, A.; Abdeslam, T.; Ayoub, N.; Lamane, H.; Ezzaouini, M.A.; Elbeltagi, A. An Interpretable Machine Learning Approach Based on DNN, SVR, Extra Tree, and XGBoost Models for Predicting Daily Pan Evaporation. J. Environ. Manag. 2023, 327, 116890. [Google Scholar] [CrossRef]
- Stein, L.; Clark, M.P.; Knoben, W.J.M.; Pianosi, F.; Woods, R.A. How Do Climate and Catchment Attributes Influence Flood Generating Processes? A Large-Sample Study for 671 Catchments Across the Contiguous USA. Water Resour. Res. 2021, 57, e2020WR028300. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Jobin, A.; Ienca, M.; Vayena, E. The Global Landscape of AI Ethics Guidelines. Nat. Mach. Intell. 2019, 1, 389–399. [Google Scholar] [CrossRef]
- Tidjon, L.N.; Khomh, F. The Different Faces of AI Ethics across the World: A Principle-Implementation Gap Analysis. arXiv 2022, arXiv:2206.03225. [Google Scholar] [CrossRef]
- Larsson, S. On the Governance of Artificial Intelligence through Ethics Guidelines. Asian J. Law Soc. 2020, 7, 437–451. [Google Scholar] [CrossRef]
- King, E.G.; O’Donnell, F.C.; Caylor, K.K. Reframing Hydrology Education to Solve Coupled Human and Environmental Problems. Hydrol. Earth Syst. Sci. 2012, 16, 4023–4031. [Google Scholar] [CrossRef]
- Brunner, M.I.; Slater, L.; Tallaksen, L.M.; Clark, M. Challenges in Modeling and Predicting Floods and Droughts: A Review. WIREs Water 2021, 8, e1520. [Google Scholar] [CrossRef]
- Sahoh, B.; Choksuriwong, A. The Role of Explainable Artificial Intelligence in High-Stakes Decision-Making Systems: A Systematic Review. J. Ambient Intell. Humaniz. Comput. 2023, 14, 7827–7843. [Google Scholar] [CrossRef]
- Yang, W.; Wei, Y.; Wei, H.; Chen, Y.; Huang, G.; Li, X.; Li, R.; Yao, N.; Wang, X.; Gu, X.; et al. Survey on Explainable AI: From Approaches, Limitations and Applications Aspects. Hum.-Centric Intell. Syst. 2023, 3, 161–188. [Google Scholar] [CrossRef]
- Knap, M. Model-Agnostic XAI Models: Benefits, Limitations and Research Directions. Bachelor’s Thesis, Delft University of Technology, Delft, The Netherlands, 2022. Available online: https://repository.tudelft.nl/islandora/object/uuid%3A34785364-3a1a-4ac0-be8b-668e4fd01721 (accessed on 16 August 2023).
- Müller, S.; Toborek, V.; Beckh, K.; Jakobs, M.; Bauckhage, C.; Welke, P. An Empirical Evaluation of the Rashomon Effect in Explainable Machine Learning. arXiv 2023, arXiv:2306.15786. [Google Scholar] [CrossRef]
- Schmidt, L.; Heße, F.; Attinger, S.; Kumar, R. Challenges in Applying Machine Learning Models for Hydrological Inference: A Case Study for Flooding Events Across Germany. Water Resour. Res. 2020, 56, e2019WR025924. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Data Source | Data Category | Index or Variable | Symbol in Database | Main Source |
|---|---|---|---|---|
| Oceanic–Atmospheric | El Niño | El Niño 3.4 SSTA Niño 1.2 SSTA | SST_34 SST_12 | HadISST, KNMI Climate Explorer and Met Office Hadley Center |
| Antarctic Oscillation | Antarctic Oscillation index Southern Annular Mode SLP | SAM_Z700 SAM_SLP | NOAA/NCEP/CPC Natural Environment Research Council (NERC) | |
| Geopotential height | Subtropical 500 hPa GH Amundsen Bellingshausen 500 hPa GH | Z500_sub Z500_mid | NCEP/NCAR Reanalysis V1 NCEP/NCAR Reanalysis V1 | |
| Pacific Decadal Oscillation | PDO Index | PDO | Joint Institute for the Study of the Atmosphere and Ocean (JISAO) | |
| Niño Modoki | El Niño Modoki Index | EMI | Japan Agency for Marine-Earth Science and Technology (JAMSTEC) | |
| Southern Oscillation | Southern Oscillation Index | SOI | NOAA/NCEP/CPC | |
| Maden Julian Oscillation | Maden Julian Oscillation | MJ for each phase [1,…10] | KNMI Climate Explorer and NOAA/NCEP/CPC | |
| Subtropical Southwest Pacific SST | Subtropical Southwest Pacific SST index | SST_SSP | NCEP/NCAR Reanalysis V1 | |
| Streamflow | Stream gauge monthly streamflow | Q_x_Ry_z: where x: region y: name of river z: name of place | General Water Directorate of Chile | |
| Precipitation | Precipitation record | P_x_Ry_z: where x: region y: name of main river z: acronym of rain gauge name | General Water Directorate of Chile | |
| Grid-based precipitation | ERA5 monthly precipitation | P_ERA5_i: where i: name of polygon location | ERA 5 Reanalysis | |
| Snow cover | Normalized Difference Snow Index (NDSI) | ndsi | Climate Engine |
| Model | RMSE | R2 | MAE | |||
|---|---|---|---|---|---|---|
| Train | Cross-V | Train | Cross-V | Train | Cross-V | |
| 1 m.i.a. (Sep) | 1.3313 | 2.5905 | 0.9421 | 0.8530 | 0.5517 | 1.8426 |
| 4 m.i.a. (Dec) | 5.6747 | 12.1906 | 0.9495 | 0.7282 | 1.5152 | 8.3943 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Núñez, J.; Cortés, C.B.; Yáñez, M.A. Explainable Artificial Intelligence in Hydrology: Interpreting Black-Box Snowmelt-Driven Streamflow Predictions in an Arid Andean Basin of North-Central Chile. Water 2023, 15, 3369. https://doi.org/10.3390/w15193369
Núñez J, Cortés CB, Yáñez MA. Explainable Artificial Intelligence in Hydrology: Interpreting Black-Box Snowmelt-Driven Streamflow Predictions in an Arid Andean Basin of North-Central Chile. Water. 2023; 15(19):3369. https://doi.org/10.3390/w15193369
Chicago/Turabian StyleNúñez, Jorge, Catalina B. Cortés, and Marjorie A. Yáñez. 2023. "Explainable Artificial Intelligence in Hydrology: Interpreting Black-Box Snowmelt-Driven Streamflow Predictions in an Arid Andean Basin of North-Central Chile" Water 15, no. 19: 3369. https://doi.org/10.3390/w15193369