Temperature Extremes: Estimation of Non-Stationary Return Levels and Associated Uncertainties

Abstract
:1. Introduction
“In order to apply any theory, we have to suppose that the data are homogeneous, i.e., that no systematical change of climate and no important change in the basin have occurred within the observation period and that no such changes will take place in the period for which extrapolations are made.”
2. Extreme Values in a Non-Stationary Environment—Theory
3. The Time-Varying Distribution and Methodology for Non-Stationarity
3.1. Time-Varying Distribution
3.2. Estimation of Non-Stationarity and Time-Varying Distribution Parameters
- : only the trend after the break date is considered;
- : both trends, before and after the break date, are considered;
- : there is no break date: a single trend over the entire dataset.
- : corresponds to an NS linear model for and a stationary one for ;
- : corresponds to an NS linear model for both and ;
- : corresponds to a stationary model for both and .
3.3. Break Dates
3.4. Uncertainty Associated with Non-Stationary Extreme Events
4. The NS Return Period—NSGEV Package Features
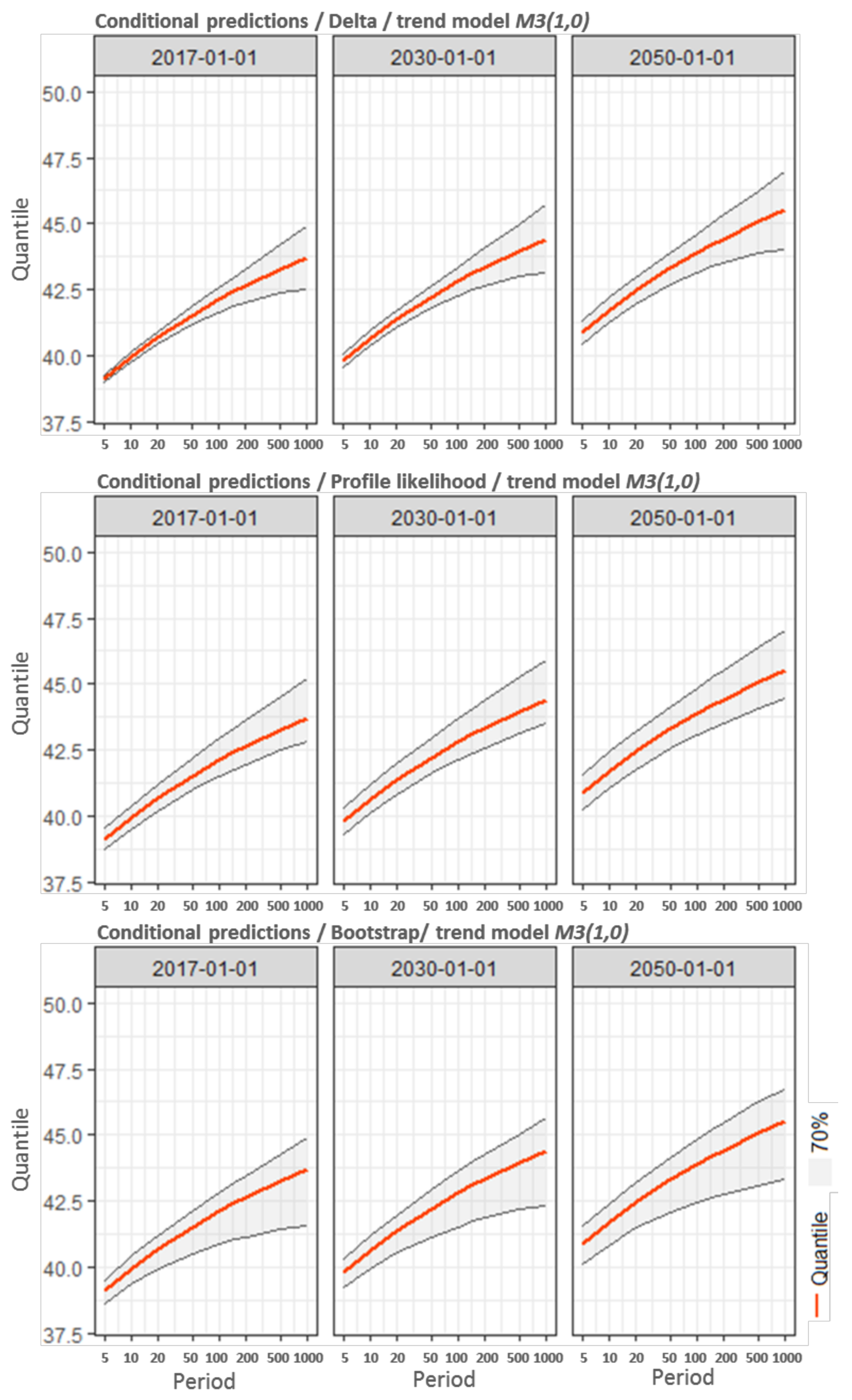
- Return period conditional to a fixed date: relative to a future block (i.e., 2030). It is conditional to the explanatory variable, which is the date of this block. In the introductory section, this is called the conditional prediction (CP).
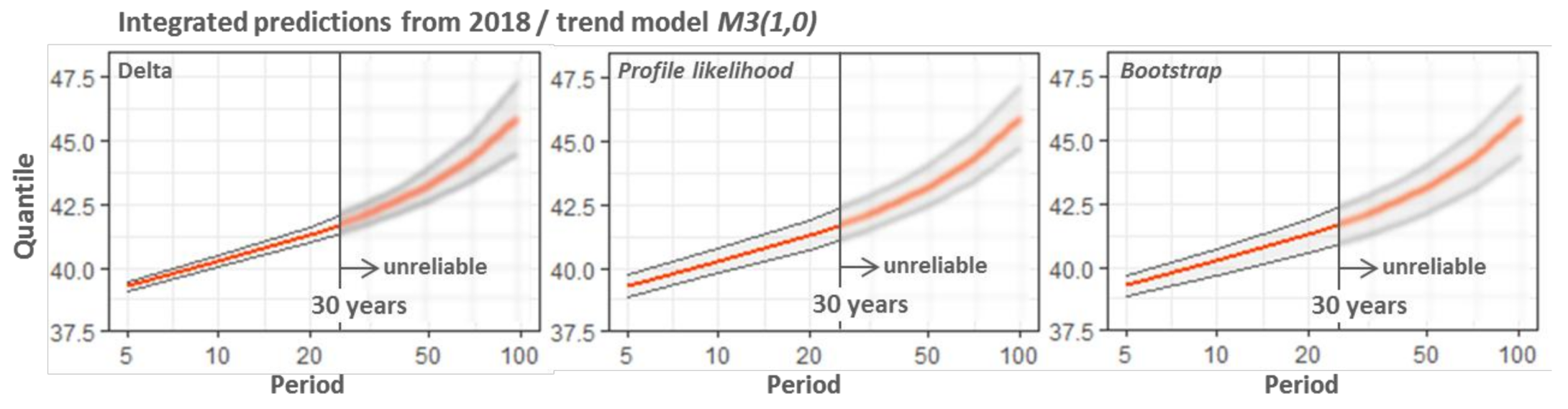
- Return period integrated over a future period: as proposed by Parey et al. [19], the calculated RL corresponds to an expected number of exceedances equal to one over this period. The user must select the first year of the projection and then calculate the predictions for different periods starting from this year. This is what we called the integrated predictions (IP).
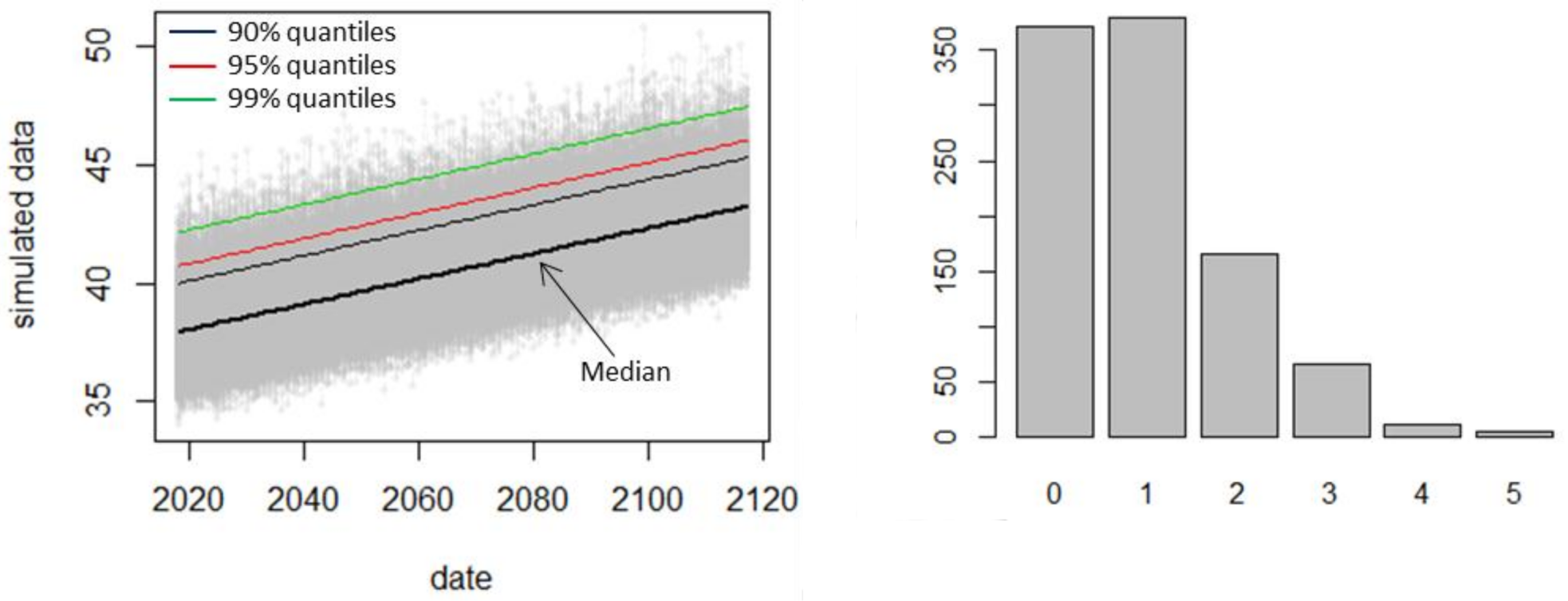
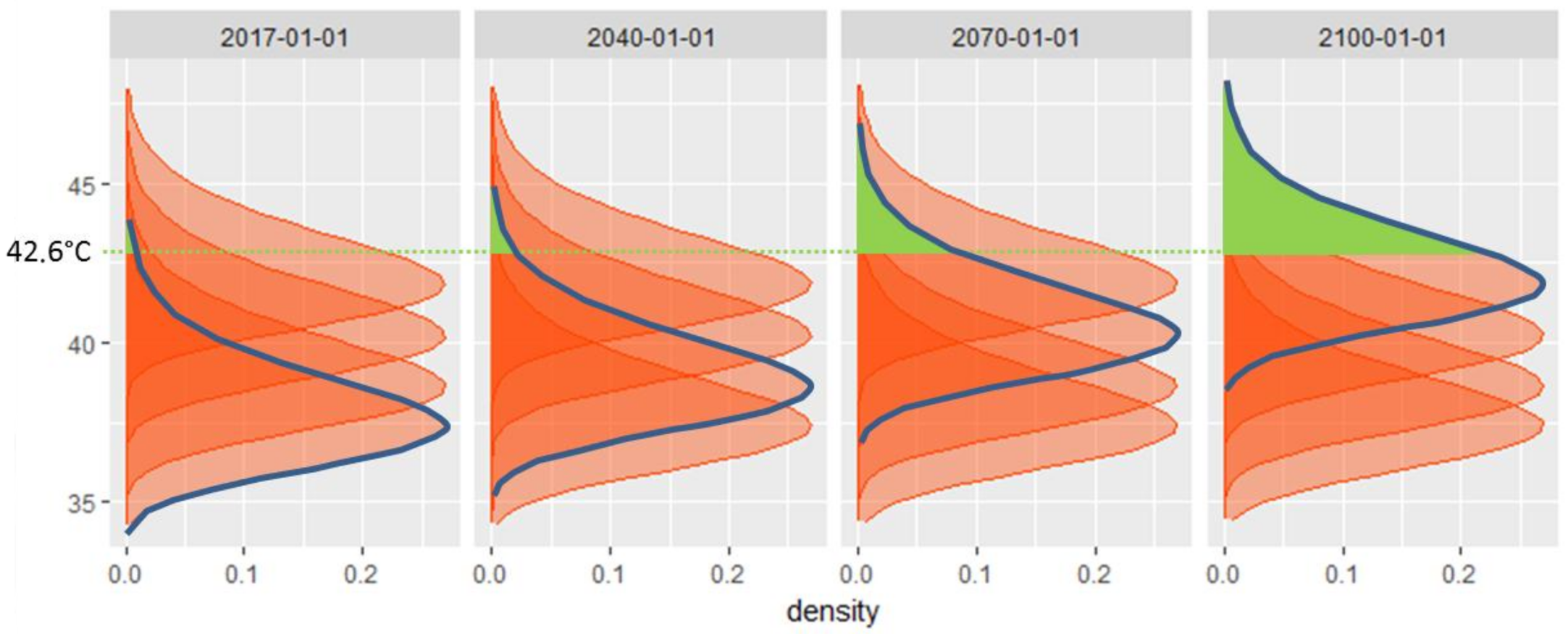
5. Case Study: The Orange Station in France
6. Results and Discussion
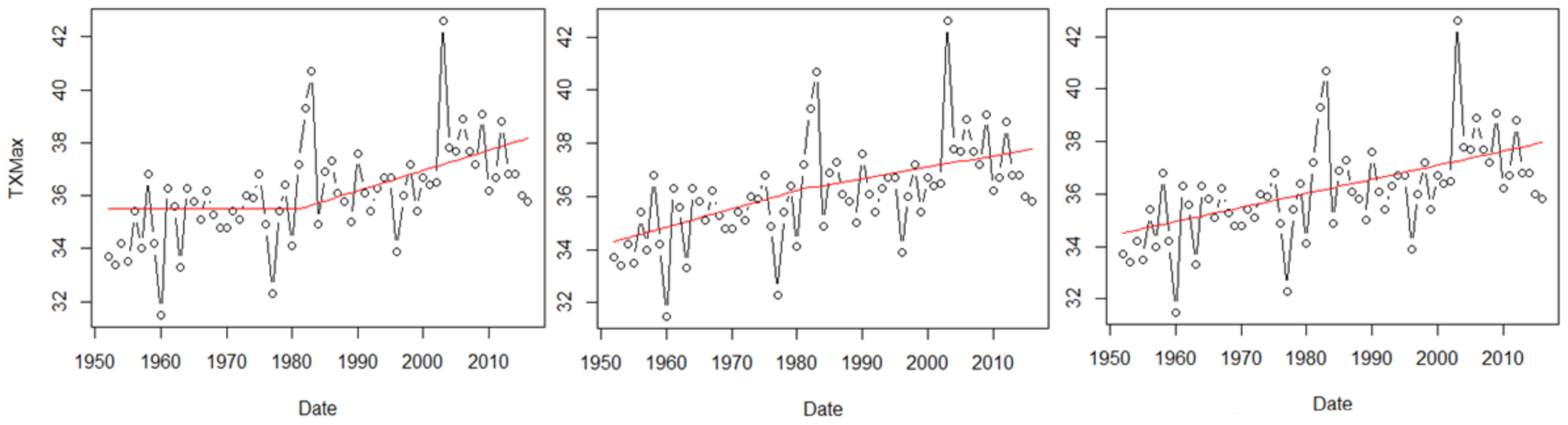
6.1. Optimal Trend
6.2. Conditional and Integrated Predictions
6.3. Further Results
7. Conclusions and Perspectives
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Delta, Profile Likelihood, and Bootstrap Methods for Computing Confidence Intervals
Appendix A.1. The Delta Method
Appendix A.2. The Profile Likelihood Method
Appendix A.3. The Bootstrap Method
- parametric bootstrap;
- case resampling bootstrap (also called random-t resampling);
- residual resampling bootstrap (also called fixed-t resampling).
Appendix B. The Code of the Analysis Presented in Section 6
References
- Mearns, L.O.; Katz, R.W.; Schneider, S.H. Extreme high-temperature events: Changes in their probabilities with changes in mean temperature. J. Clim. Appl. Meteorol. 1984, 23, 1601–1613. [Google Scholar] [CrossRef]
- Tank, A.M.G.K.; Zwiers, F.W.; Zhang, X. Guidelines on Analysis of Extremes in a Changing Climate in Support of Informed Decisions for Adaptation; World Meteorological Organization: Geneva, Switzerland, 2009; p. 56. [Google Scholar]
- Koutsoyiannis, D.; Montanari, A. Negligent killing of scientific concepts: The stationarity case. Hydrol. Sci. J. 2015, 60, 1174–1183. [Google Scholar] [CrossRef]
- Montanari, A.; Koutsoyiannis, D. Modeling and mitigating natural hazards: Stationarity is immortal! Water Resour. Res. 2014, 50, 9748–9756. [Google Scholar] [CrossRef]
- Serinaldi, F. Dismissing return periods! Stoch. Environ. Res. Risk Assess. 2015, 29, 1179–1189. [Google Scholar] [CrossRef]
- Serinaldi, F.; Kilsby, C.G. Stationarity is undead: Uncertainty dominates the distribution of extremes. Adv. Water Resour. 2015, 77, 17–36. [Google Scholar] [CrossRef]
- Tank, A.M.G.K.; Können, G.P. Trends in indices of daily temperature and precipitation extremes in Europe, 1946–1999. J. Clim. 2003, 16, 3665–3680. [Google Scholar] [CrossRef]
- Douglas, E.M.; Vogel, R.M.; Kroll, C.N. Trends in floods and low flows in the United States: Impact of spatial correlation. J. Hydrol. 2000, 240, 90–105. [Google Scholar] [CrossRef]
- Yan, Z.; Jones, P.D.; Davies, T.D.; Moberg, A.; Bergström, H.; Camuffo, D.; Cocheo, C.; Maugeri, M.; Demarée, G.R.; Verhoeve, T.; et al. Trends of Extreme Temperatures in Europe and China Based on Daily Observations. Clim. Chang. 2002, 53, 355–392. [Google Scholar] [CrossRef]
- Katz, R.W.; Parlang, M.B.; Naveau, P. Statistics of extremes in hydrology. Adv. Water Resour. 2002, 25, 1287–1304. [Google Scholar] [CrossRef]
- Katz, R.W. Statistical Methods for Nonstationary Extremes; Springer: Dordrecht, The Netherlands, 2013; Volume 65. [Google Scholar]
- Strupczewski, W.G.; Singh, V.P.; Mitosek, H.T. Nonstationary approach to at-site flood frequency modeling. III. Flood frequency analysis of Polish rivers. J. Hydrol. 2001, 248, 152–167. [Google Scholar] [CrossRef]
- Cheng, L.; AghaKouchak, A.; Gilleland, E.; Katz, R.W. Non-stationary Extreme Value Analysis in a Changing Climate. Clim. Chang. 2014, 127, 353–369. [Google Scholar] [CrossRef]
- Cooley, D. Extreme value analysis and the study of climate change, a commentary on Wigley 1988. Clim. Chang. 2009, 97, 77–83. [Google Scholar] [CrossRef]
- Cooley, D. Chapter 4, Extremes in a changing climate: Detection, analysis and uncertainty. In Return Periods and Return Levels under Climate Change; AghaKouchak, A., Easterling, D., Hsu, K., Eds.; Springer: New York, NY, USA, 2013; Volume 65. [Google Scholar]
- Du, T.; Xiong, L.; Xu, C.Y.; Christopher, J.G.; Shenglian, G.; Pan, L. Return period and risk analysis of nonstationary low-flow series under climate change. J. Hydrol. 2015, 527, 234–250. [Google Scholar] [CrossRef]
- Obeysekera, J.; Park, J. Scenario-Based Projection of Extreme Sea Levels. J. Coast. Res. 2013, 29, 1–7. [Google Scholar] [CrossRef]
- Olsen, J.R.; Lambert, J.H.; Haimes, Y.Y. Risk of extreme events under nonstationary conditions. Risk Anal. 1998, 18, 497–510. [Google Scholar] [CrossRef]
- Parey, S.; Malek, F.; Laurent, C. Trends and climate evolution: Statistical approach for very high temperatures in France. Clim. Chang. 2007, 81, 331–352. [Google Scholar] [CrossRef]
- Read, L.K.; Vogel, R.M. Reliability, return periods, and risk under nonstationarity. Water Resour. Res. 2015, 51, 6381–6398. [Google Scholar] [CrossRef]
- Salas, J.D.; Obeysekera, J. Revisiting the Concepts of Return Period and Risk for Nonstationary Hydrologic Extreme Events. J. Hydrol. Eng. 2014, 19, 554–568. [Google Scholar] [CrossRef]
- Wigley, T.M.L. The effect of changing climate on the frequency of absolute extreme events. Clim. Chang. 2009, 97, 67–76. [Google Scholar] [CrossRef]
- Wigley, T.M.L. The effect of changing climate on the frequency of absolute extreme events. Clim. Monit 1988, 17, 44–55, Reprinted in Clim. Chang. 2009, 97, 67–76. [Google Scholar] [CrossRef]
- Rootzen, H.; Katz, R.W. Design life level: Quantifying risk in a changing climate. Water Resour. Res. 2013, 49, 5964–5972. [Google Scholar] [CrossRef]
- Gumbel, E.J. The return period of flood flows. Ann. Math. Stat. 1941, 12, 163–190. [Google Scholar] [CrossRef]
- Parey, S.; Hoang, T.T.H.; Dacunha-Castelle, D. Different ways to compute temperature return levels in the climate change context. Environmetrics 2010, 21, 698–718. [Google Scholar] [CrossRef]
- Bisai, D.; Chatterjee, S.; Khan, A.; Barman, N.K. Statistical Analysis of Trend and Change Point in Surface Air Temperature Time Series for Midnapore Weather Observatory, West Bengal, India. Hydrol. Curr. Res. 2014, 5. [Google Scholar] [CrossRef]
- Pettitt, A.N. A non-parametric approach to the change-point problem. Appl. Stat. 1979, 28, 126–135. [Google Scholar] [CrossRef]
- Servat, E.; Paturel, J.E.; Lubès, H.; Kouamé, B.; Ouedraogoa, M.; Maason, J.M. Climatic variability in humid Africa along the Gulf of Guinea. Part I: Detailed analysis of the phenomenon in Côte d’Ivoire. J. Hydrol. 1997, 191, 1–15. [Google Scholar] [CrossRef]
- Yu, J.R.; Tzeng, G.H.; Li, H.L. General fuzzy piecewise regression analysis with automatic change-point detection. Fuzzy Sets Syst. 2001, 119, 247–257. [Google Scholar] [CrossRef]
- Xiong, L.; Guo, S. Trend test and change-point detection for the annual discharge series of the Yangtze River at the Yichang hydrological station. Hydrol. Sci. J. 2004, 49, 99–112. [Google Scholar] [CrossRef]
- Gilleland, E.; Katz, R.W. New software to analyze how extremes change over time. EOS 2011, 92, 13–14. [Google Scholar] [CrossRef]
- Cannon, A.J. GEVcdn: An R package for nonstationary extreme value analysis by generalized extreme value conditional density estimation network. Comput. Geosci. 2011, 37, 1532–1533. [Google Scholar] [CrossRef]
- Coles, S. An Introduction to Statistical Modeling of Extreme Values; Springer: New York, NY, USA, 2001. [Google Scholar]
- Gumbel, E.J. Statistics of Extremes; Dover Publications: Mineola, NY, USA, 1958. [Google Scholar]
- Hamdi, Y.; Bardet, L.; Duluc, C.-M.; Rebour, V. Use of historical information in extreme-surge frequency estimation: The case of marine flooding on the La Rochelle site in France. Nat. Hazards Earth Syst. Sci. 2015, 15, 1515–1531. [Google Scholar] [CrossRef]
- Zhang, X.; Harvey, K.D.; Hogg, W.D.; Yuzyk, T.R. Trends in Canadian streamflow. Water Resour. Res. 2001, 37, 987–998. [Google Scholar] [CrossRef]
- Salas, J.D.; Obeysekera, J. Return Period and Risk for Nonstationary Hydrologic Extreme Events. In Proceedings of the World Environmental and Water Resources Congress, Cincinnati, OH, USA, 19–23 May 2013; pp. 1213–1223. [Google Scholar]
- Adlouni, S.E.; Ouarda, T.B.M.J.; Zhang, X.; Roy, R.; Bobé, B. Generalized maximum likelihood estimators for the nonstationary generalized extreme value distribution. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Panagoulia, D.; Economou, P.; Caroni, C. Stationary and nonstationary generalized extreme value modelling of extreme precipitation over a mountainous area under climate change. Environmetrics 2014, 25, 29–43. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R.; Wood, E.F. Estimation of the generalized extreme-value distribution by the method of probability-weighted moments. Technometrics 1985, 27, 251–261. [Google Scholar] [CrossRef]
- Hosking, J.R.M. L-moments: Analysis and Estimation of Distributions Using Linear Combinations of Order Statistics. J. R. Stat. Soc. Ser. B 1990, 52, 105–124. [Google Scholar]
- Stephenson, A.G.; Tawn, J.A. Bayesian inference for extremes: Accounting for the three extremal types. Extremes 2004, 7, 291–307. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R. Regional Frequency Analysis: An Approach Based on L-Moments; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Beguería, S.; Angulo-Martínez, M.; Vicente-Serrano, S.M.; Lopez-Morenob, J.I.; El-Kenawyb, A. Assessing trends in extreme precipitation events intensity and magnitude using non-stationary peaks-over-threshold analysis: A case study in northeast Spain from 1930 to 2006. Int. J. Climatol. 2011, 31, 2102–2114. [Google Scholar] [CrossRef] [Green Version]
- Coles, S.G.; Dixon, M.J. Likelihood-based inference for extreme value models. Extremes 1999, 2, 5–23. [Google Scholar] [CrossRef]
- Martins, E.S.; Stedinger, J.R. Generalized maximum-likelihood generalized extreme-value quantile estimators for hydrologic data. Water Resour. Res. 2000, 36, 737–744. [Google Scholar] [CrossRef]
- Alexandersson, H. A homogeneity test applied to precipitation data. J. Clim. 1986, 6, 661–675. [Google Scholar] [CrossRef]
- Buishand, T.A. Some methods for testing the homogeneity of rainfall records. J. Hydrol. 1982, 58, 11–27. [Google Scholar] [CrossRef]
- Caroni, C.; Panagoulia, D. Non-stationary modelling of extreme temperatures in a mountainous area of Greece. REVSTAT 2016, 14, 217–228. [Google Scholar]
- Laurent, C.; Parey, S. Estimation of 100-year-return-period temperatures in France in a non-stationary climate: Results from observations and IPCC scenarios. Glob. Planet. Chang. 2007, 57, 177–188. [Google Scholar] [CrossRef]
- Kysely, J. A cautionary note on the use of nonparametric bootstrap for estimating uncertainties in extreme-value models. J. Appl. Meteorol. Climatol. 2008, 47, 3236–3251. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| After the Break Date | Before and After the Break Date | With No Break Date | ||||
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 1 | 0 | |
| 1 | (252.2; 263.1) | (251.0; 259.7) | (246.7; 261.9) | (244.6; 255.5) | (245.1; 256.0) | (243.1; 251.8) |
| 0 | * | (267.5; 256.0) | * | (267.5; 256.0) | * | (267.5; 256.0) |
| 100-Year RLs (°C) | 70% CIs (°C) | |||
|---|---|---|---|---|
| Delta | Profile Likelihood | Bootstrap | ||
| 2017 | 42.1 | 41.6–42.6 | 41.5–42.9 | 40.9–42.8 |
| 2030 | 42.8 | 42.3–43.4 | 42.1–43.7 | 41.5–43.6 |
| 2050 | 43.9 | 43.1–44.6 | 43.1–44.9 | 42.4–44.8 |
| T (years) | Corresponding Future Years | T-Year RLs (°C) | 70% CIs (°C) | |||
|---|---|---|---|---|---|---|
| Delta | Profile Likelihood | Bootstrap | ||||
| 5 | 2023 | 39.3 | 39.1–39.4 | 38.9–39.7 | 38.8–39.7 | |
| 10 | 2028 | 40.2 | 40.0–40.5 | 39.8–40.7 | 39.7–40.7 | |
| 20 | 2038 | 41.3 | 41.0–41.6 | 40.7–41.9 | 40.6–41.9 | |
| 30 | 2048 | 42.0 | 41.6–42.4 | 41.4–42.7 | 41.1–42.7 | |
| unreliable | 40 | 2058 | 42.6 | 42.1–43.1 | 41.9–43.4 | 41.6–43.4 |
| 50 | 2068 | 43.2 | 42.6–43.8 | 42.4–44.0 | 42.1–44.0 | |
| 70 | 2088 | 44.3 | 43.4–45.1 | 43.4–45.3 | 43.0–45.3 | |
| 100 | 2118 | 45.9 | 44.5–47.3 | 44.7–47.1 | 44.3–47.1 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamdi, Y.; Duluc, C.-M.; Rebour, V. Temperature Extremes: Estimation of Non-Stationary Return Levels and Associated Uncertainties. Atmosphere 2018, 9, 129. https://doi.org/10.3390/atmos9040129
Hamdi Y, Duluc C-M, Rebour V. Temperature Extremes: Estimation of Non-Stationary Return Levels and Associated Uncertainties. Atmosphere. 2018; 9(4):129. https://doi.org/10.3390/atmos9040129
Chicago/Turabian StyleHamdi, Yasser, Claire-Marie Duluc, and Vincent Rebour. 2018. "Temperature Extremes: Estimation of Non-Stationary Return Levels and Associated Uncertainties" Atmosphere 9, no. 4: 129. https://doi.org/10.3390/atmos9040129