1. Introduction
Environmental security is a global priority, and numerous challenges exist in this field. This topic is sensitive and holds great importance for society and the healthcare system. There are several very compelling reasons for this.
The first reason is ecological balance. The environment is a complex web of interconnected ecosystems and species. By safeguarding the environment, we ensure the preservation of biodiversity, which is vital for maintaining ecological balance and the overall health of the planet.
For society, the most important topic is the human health. Environmental degradation, pollution, and climate change have significant implications on human health. Air and water pollution, exposure to harmful chemicals, and climate-related disasters can lead to various health issues, including respiratory diseases, waterborne illnesses, and increased vulnerability to extreme weather events.
Environmental protection is closely linked to sustainable development. By conserving natural resources, promoting renewable energy, and adopting sustainable practices, we can meet the needs of the present generation without compromising the ability of future generations to meet their own needs.
The threat of climate change poses significant challenges to societies worldwide. Addressing climate change requires reducing greenhouse gas emissions, transitioning to cleaner energy sources, and adapting to the changing climate. Environmental protection plays a crucial role in mitigating the impacts of climate change and ensuring a sustainable future.
Environmental protection can contribute to economic growth and prosperity. The conservation of natural resources, sustainable agriculture, and the development of green technologies create new job opportunities and promote innovation. Additionally, investing in environmental protection can lead to long-term cost savings by reducing environmental risks and the need for expensive environmental remediation.
Environmental issues transcend national boundaries and require global cooperation. Environmental protection provides a common ground for countries to collaborate and work towards shared goals. International agreements and initiatives, such as the Paris Agreement, highlight the importance of collective action in addressing global environmental challenges.
Given these reasons, environmental protection is recognized as a top priority to ensure a sustainable and prosperous future for both current and future generations.
One of the notable findings emphasized in the International Panel for Climate Change’s (IPCC) Sixth Report (AR6), published in August 2021, is the consistent warming trend observed over the past four decades. According to the report, each successive decade has been warmer than any preceding decade (Paragraph A.1.2., in [
1] (p. 6)). This warming trend has direct implications for the levels of certain air pollutants, including those that can pose risks to plants, animals, and human health. As temperatures continue to rise, the impact of pollution can be significantly intensified.
The IPCC’s explicit statement regarding future temperature increases highlights the importance of investigating the influence of climate change on pollution levels. The relationship between temperature and pollutant concentrations carries significant implications, especially considering the anticipated climate changes. Understanding these dynamics is increasingly vital as we strive to comprehend the potential consequences of climate change.
We will utilize a digital twin named DIGITAL AIR, which falls under the increasingly popular trend of digital twin applications [
2,
3,
4,
5,
6]. DIGITAL AIR comprises a wide range of numerical algorithms, multiple splitting techniques, a plethora of graphical tools, a diverse set of useful scenarios, extensive meteorological and emission data files, and a comprehensive repository of geographical information. This includes detailed information about numerous cities in Europe and the borders of European countries. The study is employing several tools: the UNI-DEM mathematical model, which necessitates the implementation of efficient and accurate numerical algorithms on modern supercomputers; extensive datasets comprising meteorological, emission, and geographical information; carefully designed climatic scenarios that account for future temperature increases and the corresponding rise in natural (biogenic) emissions; and graphical programs for visualizing the numerical results obtained. More importantly, we introduce further investigation of DIGITAL AIR by conducting a sensitivity analysis using advanced stochastic methods.
We introduce an enhanced version of the lattice sequence with product- and order-dependent weights, which demonstrates some improvements compared to the best available stochastic sequences used to measure sensitivity indices in the digital ecosystem under investigation. We conduct a comprehensive comparison with the best available modifications of the Sobol sequences for multidimensional sensitivity analysis. This analysis aims to explore the model’s output concerning variations in input emissions of anthropogenic pollutants and assess the rates of various chemical reactions.
A brief overview of the structure of the primary tool utilized in DIGITAL AIR, which is the large-scale air pollution model UNI-DEM, is given in [
7]. For more extensive details about UNI-DEM and the various numerical procedures employed in its treatment, readers can refer to [
8,
9,
10,
11]. Moreover, other publications such as [
12,
13,
14] discuss different applications of this model. We will delve into the main principles underlying the climatic scenarios implemented in DIGITAL AIR. These principles align with those employed in several prior papers, as outlined in [
15,
16,
17,
18,
19]. However, we have also taken into consideration recommendations proposed in [
1]. To gain a more precise understanding of the study’s purpose, it is advisable to refer to the following sources as well [
20,
21,
22].
By utilizing DIGITAL AIR, the assessment of ozone levels extends beyond the context of Bulgaria and encompasses other European countries as well. Notably, findings for Denmark, Hungary, and countries within the Balkan Peninsula were presented in references [
14,
15,
19]. DIGITAL AIR has the capability to examine additional hazardous pollution levels, such as those resulting from emissions of sulfur dioxide (
) and nitrogen oxides (NO
), as outlined in [
18].
The paper is organized as follows:
Section 2 provides the key definitions of sensitivity analysis and Sobol sensitivity indices.
Section 3 offers a concise overview of the structure of UNI-DEM, the primary air pollution model utilized in DIGITAL AIR, along with its main climatic scenarios.
Section 4 presents the preliminary calculations conducted with the mathematical model and outlines the methodology for approximation stage before calculating the sensitivity indices. In
Section 5, a brief description of the stochastic algorithms based on Sobol and lattice sequences is provided.
Section 6 presents the numerical results obtained from employing advanced stochastic approaches to evaluate the sensitivity indices.
Section 7 presents discussion about the obtained results. Finally,
Section 8 concludes the paper with some closing remarks.
2. Sensitivity Analysis
Sensitivity analysis (SA) [
23,
24,
25,
26,
27,
28] is a technique used to assess the impact of changes in input variables on the output or outcome of a mathematical or computational model. It involves systematically varying the values of input parameters within a specified range and examining how these variations affect the model’s results. The goal of SA is to understand the relative importance and influence of different input factors or variables on the model’s output. By analyzing sensitivity, researchers can identify which variables have the most significant impact on the model’s behavior and outcomes, allowing for a better understanding of the system being studied. SA is widely used in various fields, including engineering, finance, environmental modeling, and decision-making processes, to gain insights into the robustness, reliability, and sensitivity of models and their outputs.
SA is a contemporary and promising approach utilized in the investigation of extensive systems, including ecological systems, as documented in references [
25,
29,
30]. This technique revolves around the estimation or prediction of a metric quantifying the responsiveness of model outputs to variations in input parameters through extensive computer simulations on complex mathematical models. Mathematically, this problem is formulated as a set of integrals with high dimensions.
Efficient Monte Carlo (MC and quasi-Monte Carlo (QMC) methods [
31,
32,
33] play a crucial role in conducting SA for large-scale computer models, ensuring optimal utilization of computational resources. These methods prove particularly valuable for analyzing intricate models characterized by a multitude of input parameters, as they can handle substantial volumes of data and yield rapid and accurate outcomes.
The rigid definition of SA in the book of Saltelli et al. [
34] is the following.
Definition 1. SA is the study of how the variation in the output values of a model can be distributed among the different sources of variation among the input parameters.“ SA consists of the following stages [24,25]: define the model and its input and output parameters,
determine the corresponding density functions for each input parameter,
generate the so-called “input matrix” of values with an appropriate random sample generation method,
compute the model output based on the generated values,
analyze the fluctuations in the model output,
estimate the influence (or relative importance) of the input parameters on the fluctuations in the output.
There are various approaches available for conducting sensitivity analysis (SA), as referenced in [
29]. The choice of SA method depends on the behavior of the model, including factors such as linearity, monotonicity, and additivity in the relationship between input parameters and output.
SA can be divided into two distinct classes: local and global. Local SA focuses on understanding how small changes in values around a fixed point impact the variability of output values. This method involves investigating the sensitivity of individual parameters while keeping other parameters constant and only allowing the selected parameter to vary. It is commonly known as the “one at a time” (OAT) technique. However, OAT experiments do not consider the joint influence of multiple parameters. On the other hand, global SA examines the entire range of variation in input parameter values. Parameter screening methods, such as the ones discussed in [
35], are specifically designed for models with a large number of input parameters or those that pose estimation challenges. Although these methods are useful for sensitivity analysis, they have a key limitation. They provide a qualitative estimation of sensitivity by grouping input parameters based on their influence, but they do not provide a quantitative measure of the individual importance of each parameter in relation to the others.
Variance-based methods (VBM) are widely used quantitative techniques for SA [
25]. These methods employ random samples and are particularly suitable for MC simulations. Input parameters are modeled as random variables characterized by probability density functions. The main objective of VBM is to identify the input parameters that have the most significant impact on output variations and determine which parameters require more accurate estimation to reduce uncertainties in output values.
When conducting a detailed analysis of concentration sensitivities in large mathematical models, it is beneficial to introduce stochastic variables and equations. Sobol’s work in [
36] provides a successful systematic framework for this theory.
Let the mathematical model be represented by a model function
is a vector of input parameters with joint probability density
. We assume that the output is a scalar and that the input parameters are independent and the probability density
is known. Therefore, the output parameter
is a random variable as a function of the random vector
.
We now introduce the measure of the degree of influence of an input parameter on the output.
Definition 2. (First-order sensitivity index [37])The basic indicator corresponding to a given input parameter (normalized between 0 and 1) is called the Sobol first-order sensitivity index (SI) [37] and is defined as followswhere is the variance of the conditional mathematical expectation of on , and is the full variance on . We now give a definition of the total SI.
Definition 3. Total sensitivity index (TSI) [27] is a measure of the overall influence (full effect) of an input parameter on variations in the output. The TSI of the input parameter is defined as follows [27,37]:where is called the main effect (first-order SI) of and is the -order SI (two-way interactions for and three-way interactions for , etc.) for the parameter . The degree of joint influence of the input parameters
on the variation of the result is described by the higher-order addends. In [
38], it is shown that small subsets of the input parameters will contribute significantly to the output in multivariate models. Therefore, higher-dimensional adders can be neglected and lower-order SIs can be used, but the contribution of higher-order adders can be controlled.
The set of input parameters is classified depending on the TSI as
[
24]: extremely important if
, important if
, unimportant if
, and insignificant if
.
We now consider one of the most commonly used VBMs, namely Sobol’s [
36,
37] method for computing global sensitivity indices (GSIs). The main advantage of this method is it computes not only first-order SIs but also higher-order SIs, and TSI can compute with only one integral (one subintegral function) for a given parameter by the MC method.
Sobol’s method for global SA relies on a decomposing the integrable model function f (in s-dimensional input parameter space) into addends of increasing dimensionality.
Definition 4. The high-dimensional model representation (HDMR representation) is defined aswhere is a constant. The total number of addends in Equation (4) is (see [39]). In general, this representation is not unique to [
37]. The key feature of (
1) is that it can be represented by small subsets of input parameters [
38,
40], and this assumption is the basis of (
4). Thus, functions on more variables describing the effect of the interaction of input parameters in (
4) can be neglected. This will reduce the dimensionality of the problem.
Definition 5. The representation (4) is unique and is called an ANOVA representation (analysis of variance, analysis of variance) of the model function [41], under the condition that for each additive is valid Sobol has proven [
36] that the decomposition (
4) is if and only if (
5) holds and the functions on the right-hand side can be represented in a unique way [
41]:
;
;
Because the above subsets of indices differ from each other by at least one element and the corresponding integral is equal to zero for the corresponding index by applying (
5), it follows that the addends in the ANOVA representation are mutually orthogonal
Definition 6. The quantitiesare called variances (total and partial variances, respectively) and are obtained after squaring and integrating over the Equation (4) under the assumption that has a summable square. Thus, we arrive at the following definition:
Definition 7. The total variance of the model output parameter is decomposed into the partial variances [36] in an analogous way to the decomposition of the model function, which is only an ANOVA-type representation: It will now be shown how the corresponding SI
are defined by the conditional expectation variances
,
(see Equation (
8)).
Definition 8 ([
36,
41]).
The quantitiesare called Sobol GSIs. This formula coincides with (
2) for
, and so, the measures defined correspond to the main effect and the interaction effect between the parameters. Now, dividing (
7) by
, it follows that the following properties of these indices hold:
Definition 9. Let us have a set of m variables ():and let be the set of the remaining variables, , and . Then, the variances corresponding to the sets of variables and are defined aswhere the complement of the subset K to the set of indices of all input parameters is denoted by , the first sum in (9) is over all subsets , where all indices belong to K and the full variance of the subset − is over all subsets , where at least one index belongs to K: . The procedure for calculating the GSI is based on the following representation of the variance
:
(see [
41]). The last equality allows for the construction of an MC algorithm to compute
and
, where
:
Therefore, for
and
:
Following the idea of Homa and Saltelli in [
27], a better first-order approximation of SI is obtained if
in (
6) is approximated directly using
instead of
. This follows from the Formula (
6), where the corresponding estimate of the first-order indices
tends to zero for the corresponding input parameter
if () [
30] is used and can be obtained from the formula:
Saltelli’s idea in [
30] for computing TSI is to use the following estimate for
:
The computational complexity of the aforementioned method for computing all first-order SIs and all TSIs is determined by the number of function evaluations required, which is proportional to (N values of the function for , values of the SIs function, and values of the TSIs function), where N represents the sample size and d is the number of dimensions.
In contrast, commonly used VBMs such as Sobol’s method and FAST have a computational complexity that scales linearly with
when estimating all first-order SIs and TSIs for the input parameters (see [
30]).
This illustrates that the core of the SA problem resides on the computation of TSIs (
3) and, more specifically, the Sobol GSIs of the corresponding order (
8). This computation can be reduced to the evaluation of multidimensional integrals:
where
is a summable square function in
and
is a probability density, such that
.
Consequently, we observe that the computation of the
integrals of the form (
6) is necessary to obtain the TSI
for a fixed parameter.
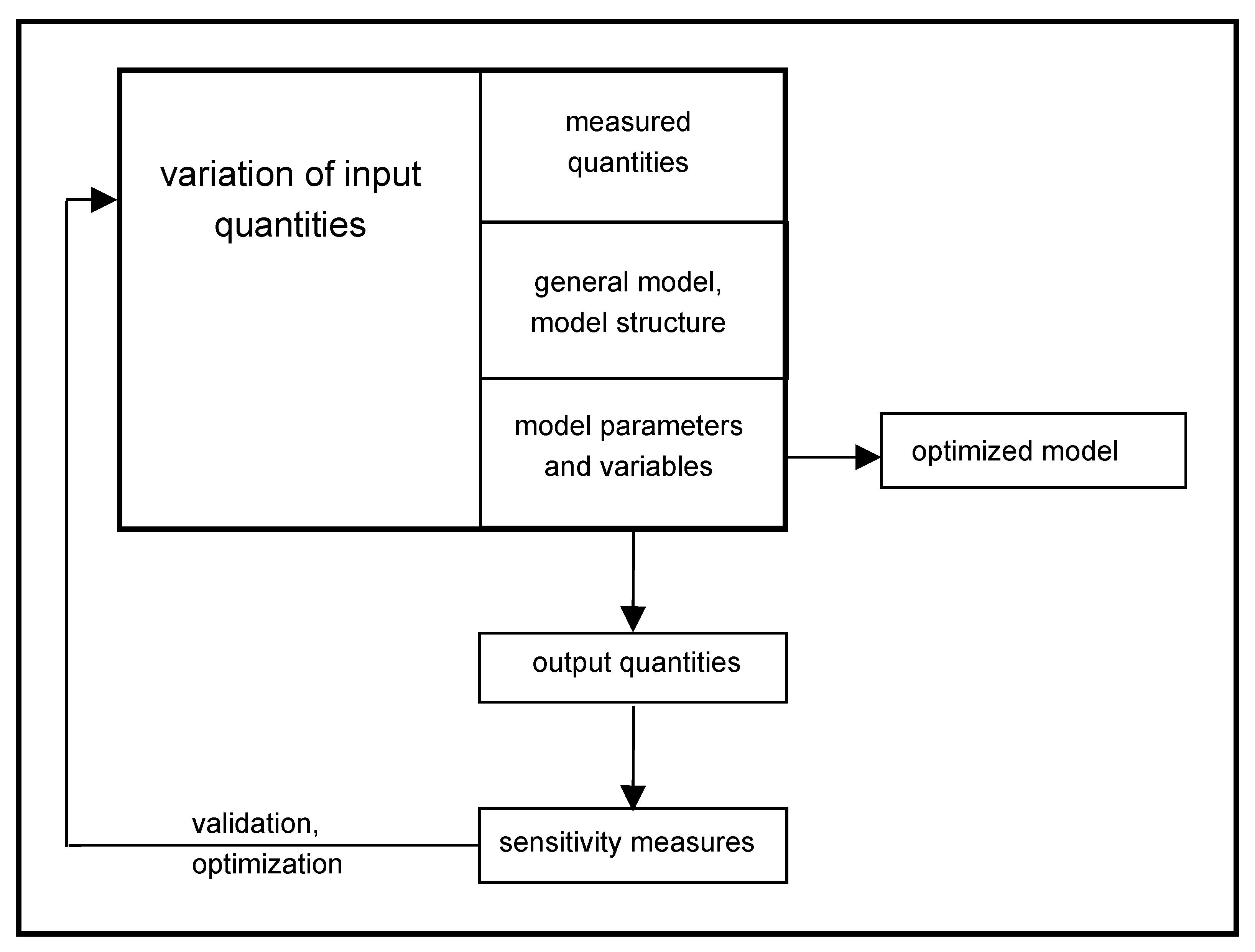
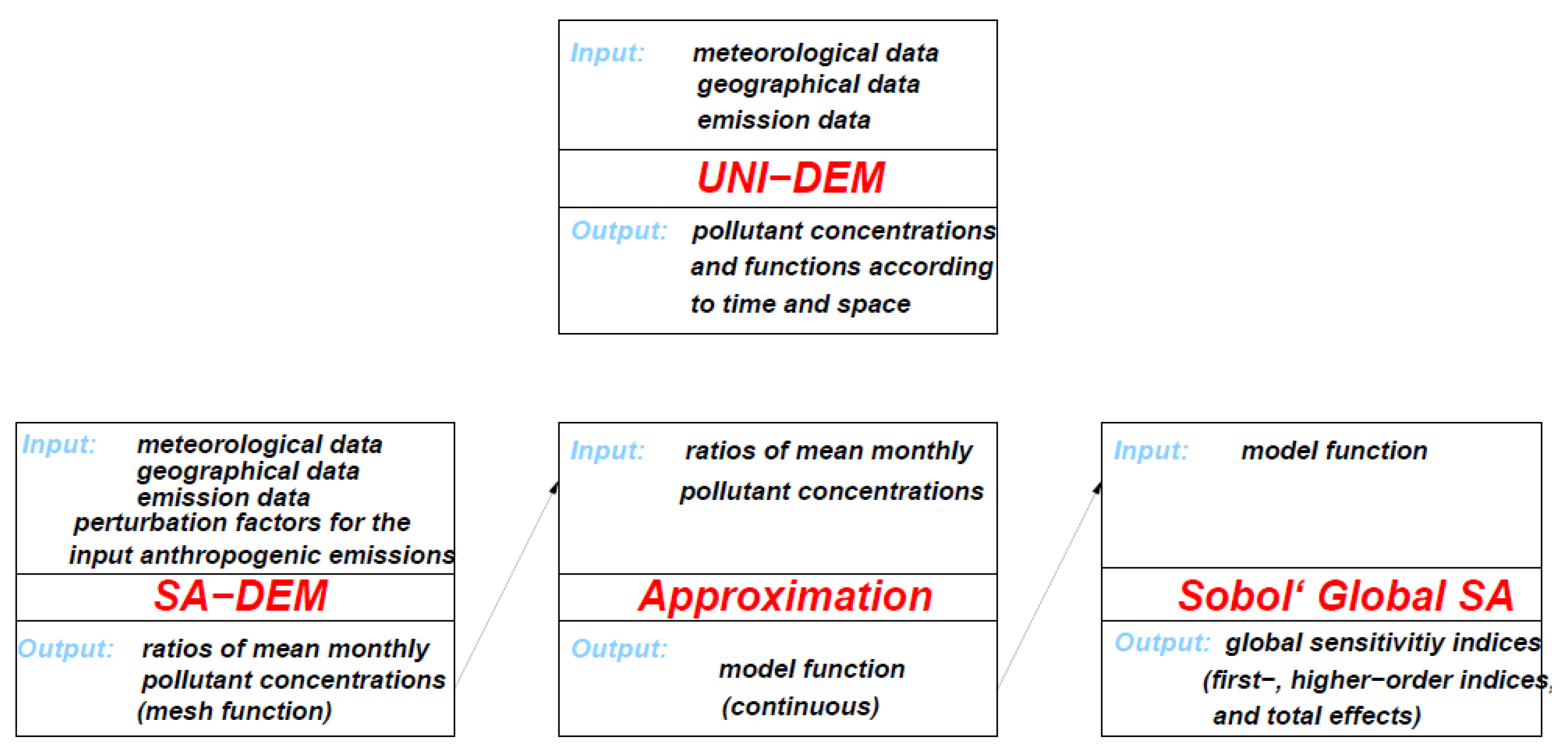
The whole methodology for performing SA is given on
Figure 1.
3. Mathematical Model UNI-DEM
Ongoing research and computational experiments have been conducted utilizing the unified Danish Euler model (UNI-DEM), also known as UNI-DEM, which has proven to be a robust mathematical framework for accurately capturing the relevant physical and chemical processes [
8,
9,
10,
42]. The integration of the unified Danish Eulerian model (UNI-DEM) with various suitable climatic scenarios holds a pivotal and highly significant position within the framework of DIGITAL AIR. Developed by Prof. Zahari Zlatev and their colleagues at the Danish National Institute for Environmental Research [
9], UNI-DEM possesses the ability to effectively calculate the concentrations of various hazardous pollutants. It has been widely employed for over two decades in interdisciplinary research and long-term simulations addressing air pollution. Importantly, the proposed SA methodology can be readily extended to other models, showcasing its versatility and applicability beyond UNI-DEM.
UNI-DEM serves as a simulation tool for studying the long-range transport of air pollutants, their temporal changes resulting from chemical and photochemical reactions, and their interactions with the environment. It incorporates crucial physical processes such as advection, diffusion, deposition, emissions, and chemical transformations. The model allows for the analysis of pollutant concentrations over time, specifically focusing on sulfur, nitrogen, ammonia, ammonium ions, nitrogen radicals, and hydrocarbons, which have significant implications for environmental, agricultural, and public health concerns. The geographic scope of the model encompasses Europe, the Mediterranean, and parts of Asia and Africa, with an approximate area coverage of km.
To effectively handle the complexity of the model, it is divided into three subsystems or submodels, each targeting specific physical and chemical processes. By discretizing these submodels and utilizing parallel computing on powerful supercomputers, the model can be executed efficiently in real-time, enabling practical problem-solving within reasonable timeframes [
8,
9].
Chemical reactions play a pivotal role in the model [
43]. The equations within the model accurately represent the system by accounting for chemical reactions. The presence of these reactions contributes to the nonlinearity and “rigidity” of the equation system [
43]. The model employs the compressed CBM-IV (carbon bond mechanism) chemical scheme, which has been enhanced in [
8]. It encompasses 35 pollutants and 116 chemical reactions, with 69 reactions being time-dependent and 47 being time-independent. This chemical scheme is well-suited for investigating scenarios involving high pollutant concentrations.
Among the model components, chemical reactions are the most challenging and time-consuming, with 69 time-dependent and 47 time-independent reactions requiring careful consideration.
The rate constant in chemical reactions signifies the reaction rate when reactant concentrations are at 1 mol/L, as described by the law of mass action discovered by Guldberg and Waage [
30]. Therefore, the intensity of the chemical rate constant directly influences the rate of chemical processes.
The model is described mathematically by [
8,
10,
31] through the following system of partial differential equations:
The number q of equations in (10) is equal to the number of pollutants that are studied by the model. The other quantities included in the model are described below:
—the pollutant concentrations,
—the wind components along the coordinate axes,
—diffusion coefficients,
—the emission in the spatial domain,
—the dry and wet deposition coefficients, respectively, (),
—nonlinear functions describing chemical reactions between pollutants.
The region of study and the computational domain is shown on
Figure 2.
The UNI-DEM spatial domain, utilizing a stereographic geographic projection, comprises a surface plane that measures (4800 km × 4800 km). This plane encompasses Europe and its surrounding regions. Each of the ten horizontal levels is discretized using a grid with dimensions of (10 km × 10 km). This discretization ensures an ample number of cells, accommodating even small European countries such as Denmark and Bulgaria [
10].
The same spatial domain was discretized into a grid with a resolution of 10 × 10 km. Although this refinement significantly increases computational requirements, the comparison between results obtained on the coarse and fine grids demonstrates the value of these efforts, particularly when utilizing the 3-D versions with 10 non-equidistant layers in the vertical direction. However, it was not feasible to acquire input data, including emission and meteorological data, at this high-resolution grid. Instead, the available emission data on the 50 km grid were evenly distributed across 25 smaller grid squares obtained during the transition to the 10 km resolution. To prepare meteorological data for the fine grid, simple linear interpolation is employed, both spatially and temporally.
At the surface level, there are a total of
grid squares, each measuring (10 km × 10 km). The model typically runs with a time step of 30 s, spanning a continuous period of 16 years [
31].
Several conditions specified in [
8] are assumed. Firstly, the spatial derivatives in the system of PDEs (10) are directly discretized. Secondly, the first-order backward differentiation formula is applied to solve the resulting system of ODEs that arise from the discretization of spatial derivatives. Thirdly, the chosen chemical scheme is the CBM-IV scheme, involving 56 chemical species. Finally, the model is executed for a duration of 16 years.
Under these assumptions, each time step requires the processing of sets of nonlinear algebraic equations. Each of these sets contains equations. To solve these nonlinear algebraic equations, iterative methods are employed, resulting in the solution of very large systems of linear algebraic equations within an inner loop at each time step. The number of these systems during a one-year loop is estimated to be substantial, approximately or even higher.
The UNI-DEM, within the context of DIGITAL AIR, was executed using a total of 14 distinct scenarios spanning a continuous period of 16 years from 1989 to 2004. These scenarios encompass various conditions and factors. The first among the selected five scenarios served as the baseline, providing a reference point for comparison. The subsequent three scenarios were constructed based on assumptions regarding future temperature increases, derived from the conclusions drawn in the IPCC report. The fifth scenario incorporated an additional aspect, considering the anticipated rise in natural emissions of certain air pollutants.
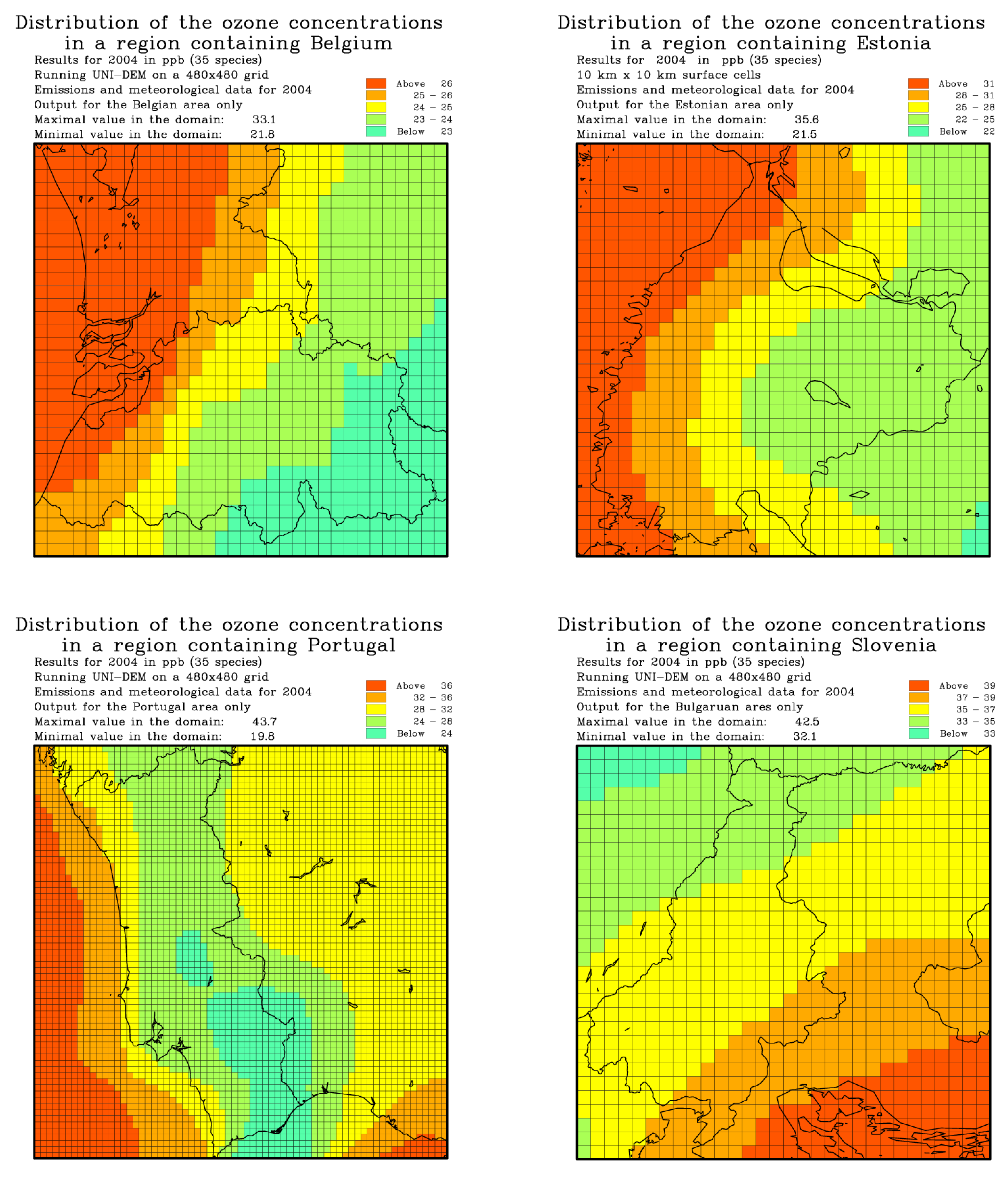
Figure 3 illustrates the capability of UNI-DEM to generate dependable outcomes even for the smaller countries in Europe.
The baseline scenario uses actual meteorological data and actual emissions data in Europe and its surroundings over the selected period of 16 consecutive years (1989 to 2004), whose data are obtained from the EMEP (European Monitoring and Evaluation Programme) database (for detailed information on the Basic scenarios and other scenarios in the digital twin, see [
7]).
The definitions presented in [
7] outline the First Climate Scenario, which focuses solely on changes in temperature. To visualize the anticipated temperature patterns in Europe, the scenario employs annual temperature changes recommended in various IPCC specialist reports [
44]. These changes are used to create a map representing future temperature expectations for the first horizontal level of the digital twin’s spatial domain, known as UNI-DEM. This level consists of a grid with dimensions of
cells. The study in [
7] reveals that the mean annual temperature change within each cell of the first horizontal level of UNI-DEM corresponds to the prescribed values from the IPCC reports for each of the selected 16 years. The approach adopted in [
7] assumes that the expected temperature increase in a particular cell during a given hour between 1989 and 2004 falls within the range of
. It is demonstrated that the temperature in this cell at a specific hour experiences an increase in
, where
is a randomly generated and uniformly distributed quantity in the interval
. Consequently, the mathematical expectation of the average annual temperature increase in any cell within the first level of the spatial domain, across any year within the 16-year interval, is equal to
.
Based on the conclusions derived from the IPCC reports, it is projected that extreme events will intensify in the future. Specifically, the Second Climate Scenario, which was analyzed, indicates that maximum daily temperatures will rise, leading to an increased frequency of hot days in terrestrial areas. Additionally, a majority of land regions will experience elevated minimum temperatures, fewer occurrences of cold days, and a decrease in frosty days. Moreover, the diurnal temperature range will shrink in terrestrial regions. These anticipated changes have been taken into consideration in the Second Climate Scenario, and although it incorporates temperature variations similar to those in the First Climate Scenario, it introduces two additional modifications. Firstly, nighttime temperatures are increased by a greater proportion in comparison to daytime temperatures. Secondly, during summer periods, hotter days experience a larger temperature increase.
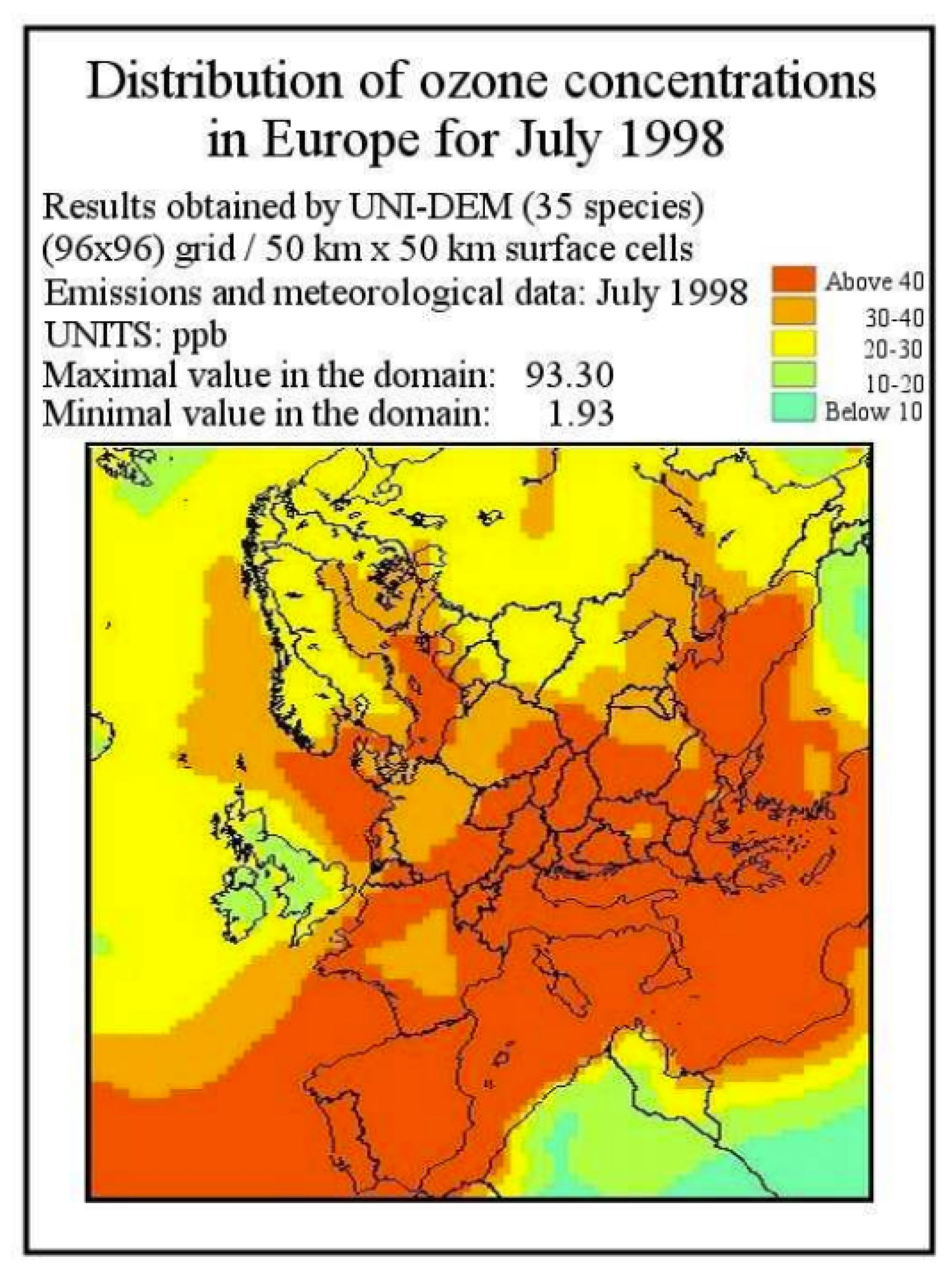
The Third Climate Scenario, which is the most advanced of the three scenarios, incorporates further findings from the IPCC experts. This scenario expands upon the Second Climate Scenario by considering the following conclusions: increased winter precipitation across land and water, reduced precipitation in continental Europe, adjustments in humidity data, a 10% increase in winter cloud cover, and maintaining the same cloud cover as the Second Climate Scenario during summer. The expected average annual temperature changes remain unchanged. Notably, the Third Climate Scenario is the only one visualized in [
7].
The significance of natural (biological) emissions is progressively growing and emerging as a crucial factor. There are at least two underlying factors contributing to this rise. Firstly, there has been a continuous reduction in human-made (anthropogenic) emissions in numerous European countries over the past two to three decades. Secondly, anticipated climatic changes and elevated temperatures are expected to stimulate an increase in natural (biological) emissions. Consequently, it is valuable to develop and implement scenarios incorporating higher natural (biological) emissions. Several scenarios incorporating recommended adjustments to the magnitude of biological (natural) emissions, are employed to address this objective in [
7,
45,
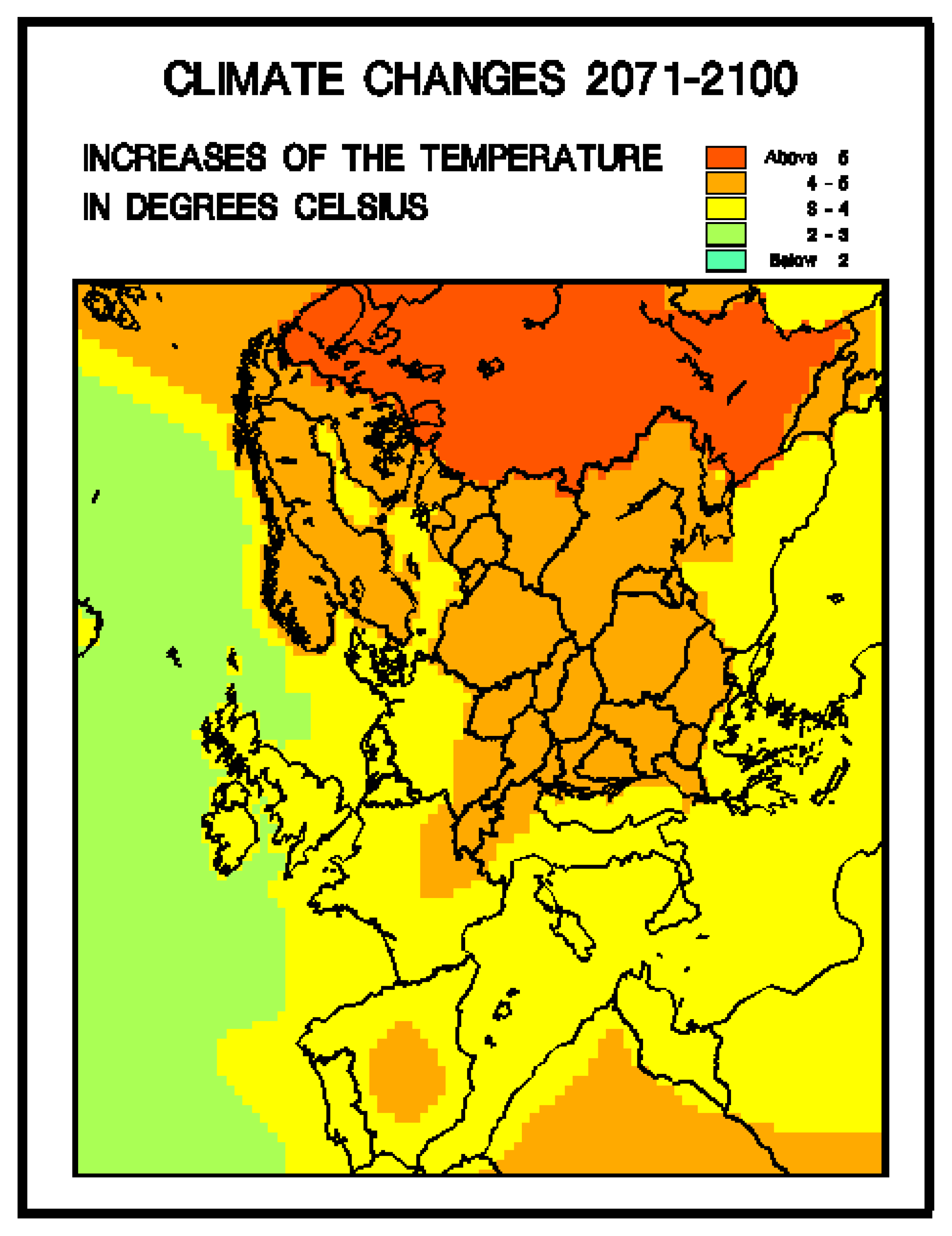
46]. Anticipated temperature rises within the initial horizontal level of the UNI-DEM spatial domain as indicated by the findings of the IPCC reports are shown on
Figure 4.
The subsequent analysis will delve into the outcomes obtained across the entire domain of UNI-DEM using the climatic scenarios discussed earlier. Our primary focus will be on evaluating the ozone levels not only throughout Europe but also in specific cities within the region. Of particular concern are instances of high ozone concentrations, as they can have detrimental effects, especially on vulnerable groups such as individuals with respiratory conditions such as asthma. Therefore, we will present detailed findings regarding the extent of these concentrations in various parts of Europe. Specifically, our investigation centers around identifying the occurrence of “bad days”. To qualify as a “bad day”, we examine the maximum value, denoted as , of the 8 h average ozone concentrations at a given location in Europe on any given day. If exceeds 60 ppb at least once during that day, it is categorized as a “bad day”. It is imperative to ensure that the number of “bad days” remains within acceptable limits, preferably not exceeding 25 per year as recommended in the Ozone Directive issued by the EU Parliament in 2002.
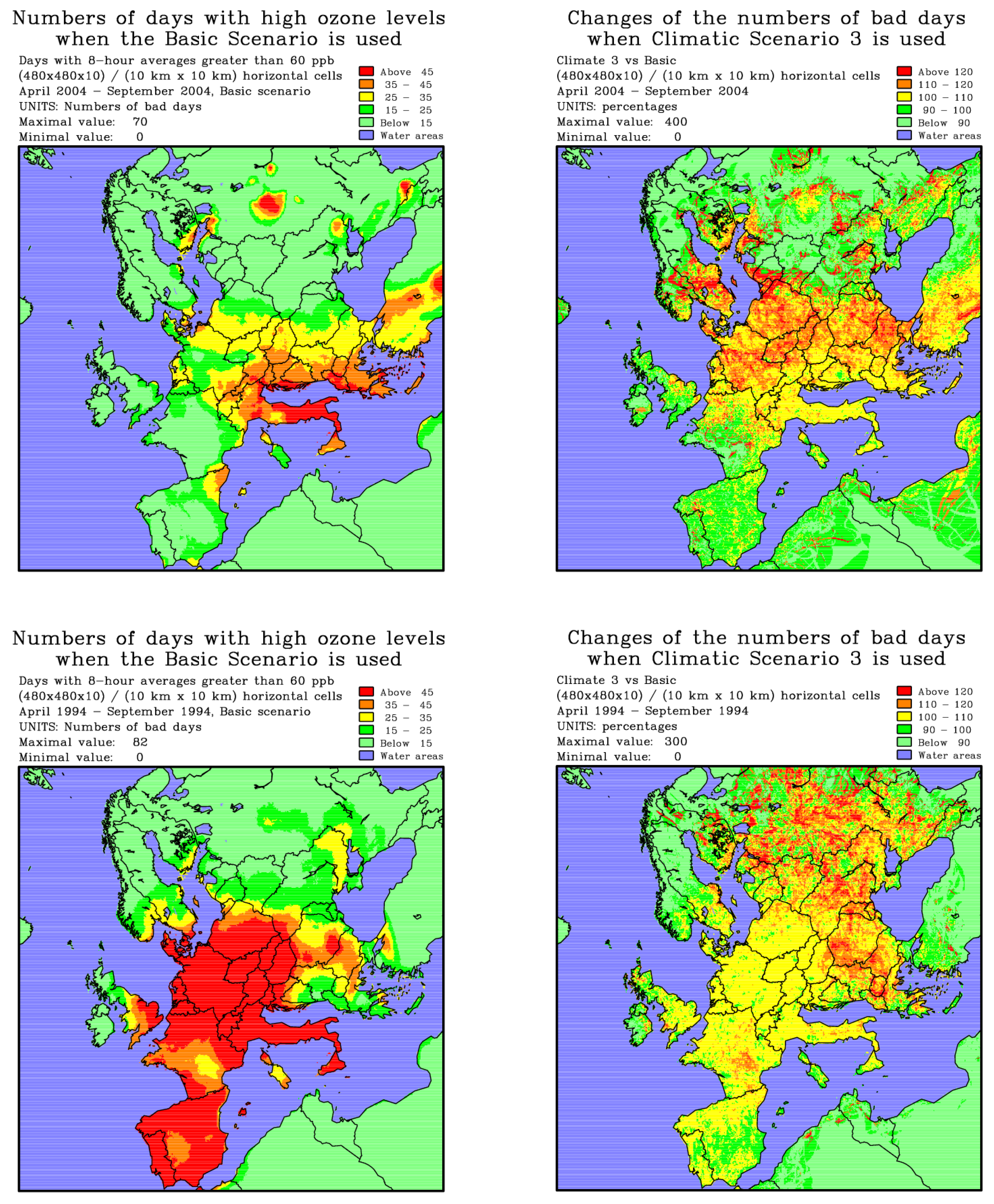
Figure 5 provides visual representations illustrating the distribution of “bad days” throughout Europe. The distribution and frequency of “bad days” in different regions of Europe exhibit significant variability from year to year, as evident in the two left-hand side plots, which depict results from the Basic Scenario for the years 1994 and 2004. Implementation of the Third Climatic Scenario generally leads to an increase in the occurrence of “bad days.” The magnitude of these changes can be substantial, as indicated in the plots on the right, which present the percentage increases in the number of “bad days” for the selected years. Across numerous parts of Europe, the number of “bad days” exceeds the recommended limit of 25 days, demonstrating a considerable level of exceedance.
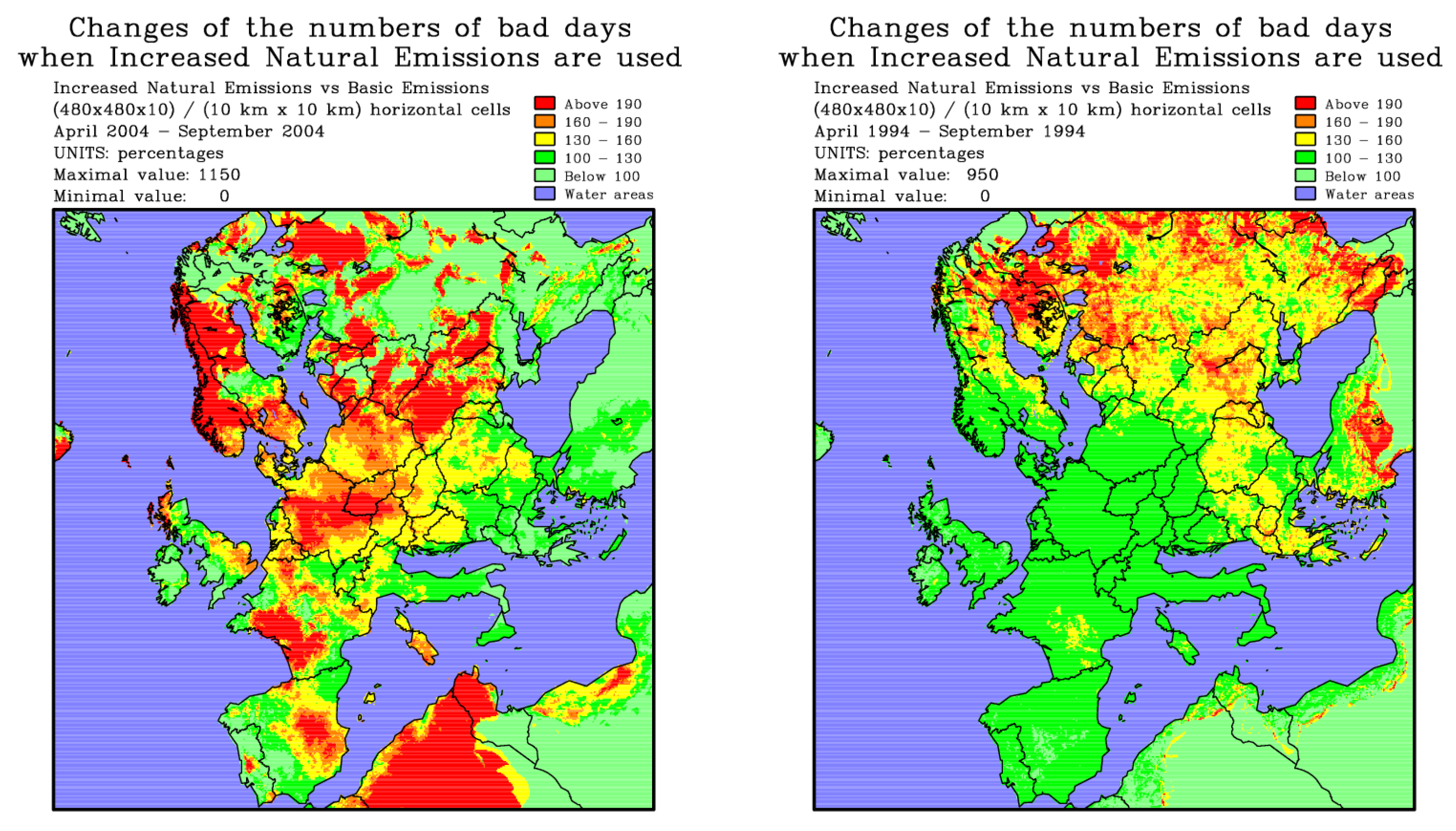
Figure 6 presents certain outcomes obtained in the surface domain of UNI-DEM by utilizing the impact of natural (biogenic) emissions on ozone levels in Europe. The two plots reveal significant variations across different regions of Europe and from one year to another. These changes can be substantial and exhibit distinct patterns. Overall, there is a consistent trend observed wherein the increase in biogenic (natural) emissions results in a substantial rise in the frequency of “bad days” across numerous parts of Europe.
4. Preliminary Calculations with UNI-DEM
By definition, SA includes models, input parameters, and output parameters. In this study, anthropogenic emissions and chemical reaction rate constants are considered as input parameters and pollutant concentrations as output parameters. Mathematically, the input parameters are treated as normally distributed random variables (which is established in [
10]) whose mathematical expectation is
. The spatial domain of UNI-DEM is discretized by
nodes in the three-dimensional version of UNI-DEM.
UNI-DEM experiments were conducted for the period 1994–1998. It is important to pay attention to the fact that a specific year is less important in climate research, because it takes about 30 years to change the climate scenario. The season of the year and the region for which the corresponding climate study was made are much more important. Therefore, a relatively long period in the past was chosen to allow us to compare the results for the data produced by the digital twin with the actual measured pollution data in that period. Furthermore, this comparison shows a high (and previously estimated precision of the digital twin) precision.
The (10) was considered leaving only the adders describing the emissions and chemical reactions. As they do not depend on spatial variables, (10) is reduced to a system of ODEs
where
is the concentration value
at the point
of the grid at time
t.
The different stages and components of the SA scheme for UNI-DEM (SA-DEM) is given in
Figure 7.
The UNI-DEM model is employed at a fixed location within the mesh, and a smaller system known as the “box model” [
10] is utilized for sensitivity analysis purposes. The box model represents a reduced system that can be solved repeatedly without computational difficulties, unlike the entire model, which involves solving large systems of ODEs at each time step and can be computationally challenging due to its size (containing millions of equations). In the sensitivity studies, the box model is solved multiple times while varying the rate constants of chemical reactions using a perturbation parameter
, where
. Through this computational procedure, it was observed that the concentrations of pollutants are primarily sensitive to changes in the rate constants of the third and twenty-second time-dependent reactions, as well as a sixth time-independent reaction. These initial findings guided the subsequent comprehensive SA employing the aforementioned approaches to obtain more accurate and precise results.
In previous studies [
47,
48], the identification of critical rate constants of chemical reactions based on a specific criterion was performed. Ozone, known as a highly hazardous air pollutant, was the focus of investigation. The analysis focused on the average concentrations of ozone (
) during the summer month of July because it is recognized as the period with the highest ozone concentration.
By iteratively solving the system defined by (
10) while varying the rate constants of chemical reactions using a perturbation parameter
ranging from 0.1 to 2.0, the most influential rate constants were determined. Notably, the rate constant of the 22nd time-dependent chemical reaction was found to exert the most significant impact on the concentration of ozone (
). The effects of this specific rate constant on the concentrations of other pollutants, such as nitrogen dioxide (
), sulfur dioxide (
), peroxide radicals (
), and nitric oxide (
), are illustrated in
Figure 8. However, the influence on sulfur dioxide concentrations was practically negligible.
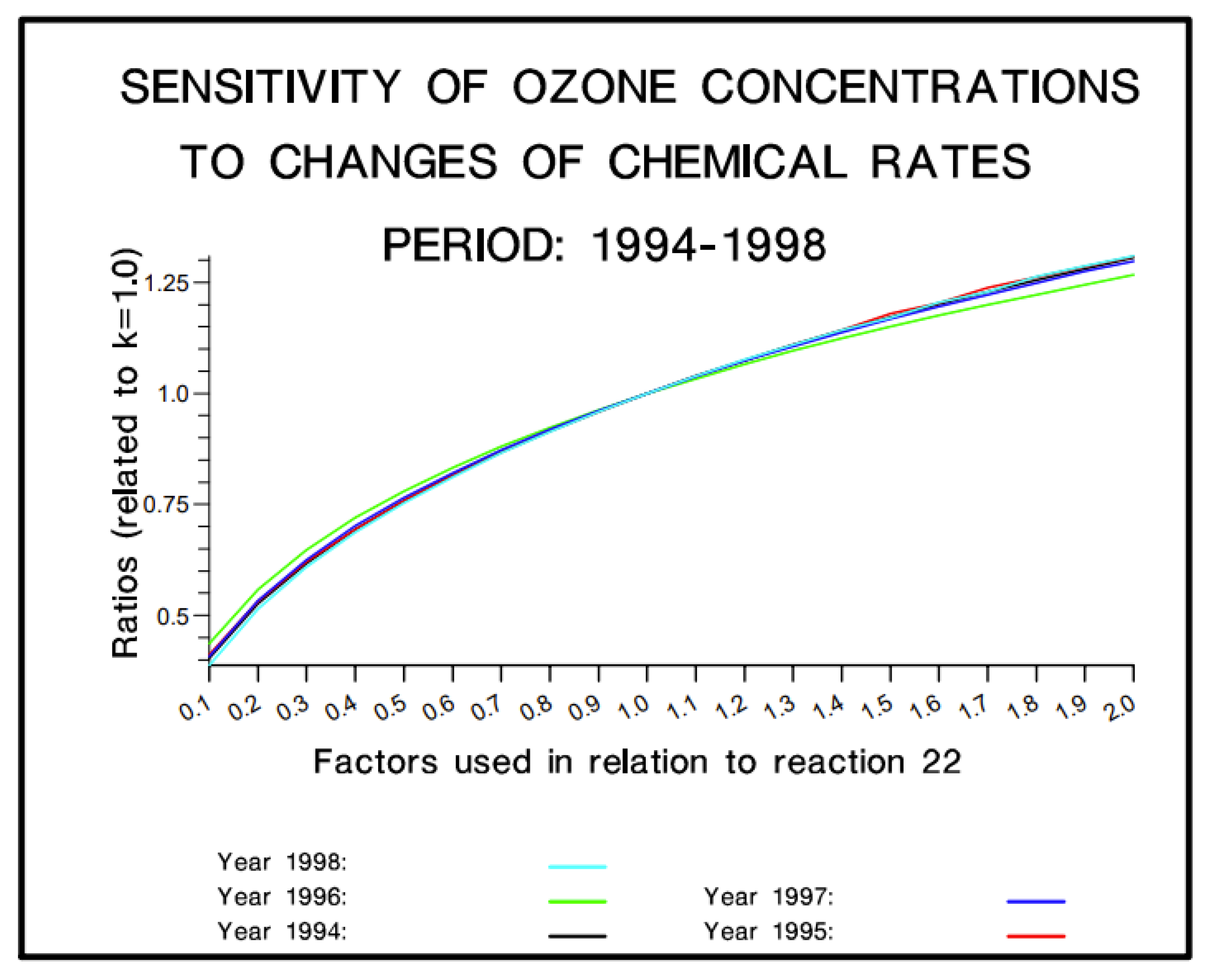
Furthermore, it was observed that the influence of the rate constant from the CMB IV chemical reaction on ozone concentration remained relatively consistent across different years. In other words, the pattern of concentration change in response to variations in the perturbation parameter showed a similar trend over time. This behavior is demonstrated in
Figure 9.
It is also found that the concentrations of
are most significantly affected by the following chemical reactions:
(time-dependent) and
(time-independent) reactions of CBM-IV ([
8]). The simplified chemical equations of these reactions are as follows:
Not all reactions involve ozone; instead, significant ozone precursors are involved. The UNI-DEM calculations primarily focus on obtaining the monthly average concentrations of various hazardous chemical species or groups of species. These concentrations are determined based on the specific chemical scheme and are calculated at grid points within the designated area. The input parameters in focus are the chemical reaction rates, whereas the output parameters of interest are the concentrations of pollutants.
To perform the UNI-DEM calculations, a set of perturbation parameters is used within a six-dimensional hypercube ranging from 0.6 to 1.4. The values of are chosen along the edges of the hypercube, starting from the vertex representing the Basic Scenario with true emissions and extending to all other vertices. Along each edge, the samples are uniformly distributed by decrementing all variable coordinates by a fixed step of 0.1.
The generated data represent relationships of the form:
where
s corresponds to the contaminant (ranging from 1 to 35). The denominator
represents the maximum average monthly value of pollutant concentration
s without any perturbations, calculated at the coordinates
, and
are the grid indices of that point. The numerator represents the concentration value of the pollutant of interest for a specific set of perturbation parameter values
, calculated at the point
. Thus, the input data consist of pollutant concentrations normalized with respect to the maximum monthly mean value.
Before proceeding to the calculation of the Global Sensitivity Indices (GSIs) using Sobol’s method, an approximation is performed.
During the UNI-DEM calculations, tables of model function values are generated. These tables depict the relationship between ozone concentration values at fixed perturbation parameter values
, calculated at the point where the averaged maximum concentration is reached, and the corresponding averaged maximum for
. Because the sensitivity analysis assumes that the model is represented by a function as defined in Equation (
1), the first step involves using an approximation technique to create a continuous function with analytically specified properties.
The approximation step using polynomials of different degrees was investigated. We utilize second-degree polynomials, characterized by 28 unknown coefficients, as a means of approximation. These polynomials, denoted as , are employed to estimate the mesh function associated with the s-th chemical species:
To evaluate the precision of the approximation, we employ the squared 2-vector norm. This norm, denoted as , is computed as the sum of squared differences between the values of the polynomial evaluated at specific points and the corresponding table values . Here, belongs to the interval , and represents the table values obtained from running the UNI-DEM model.
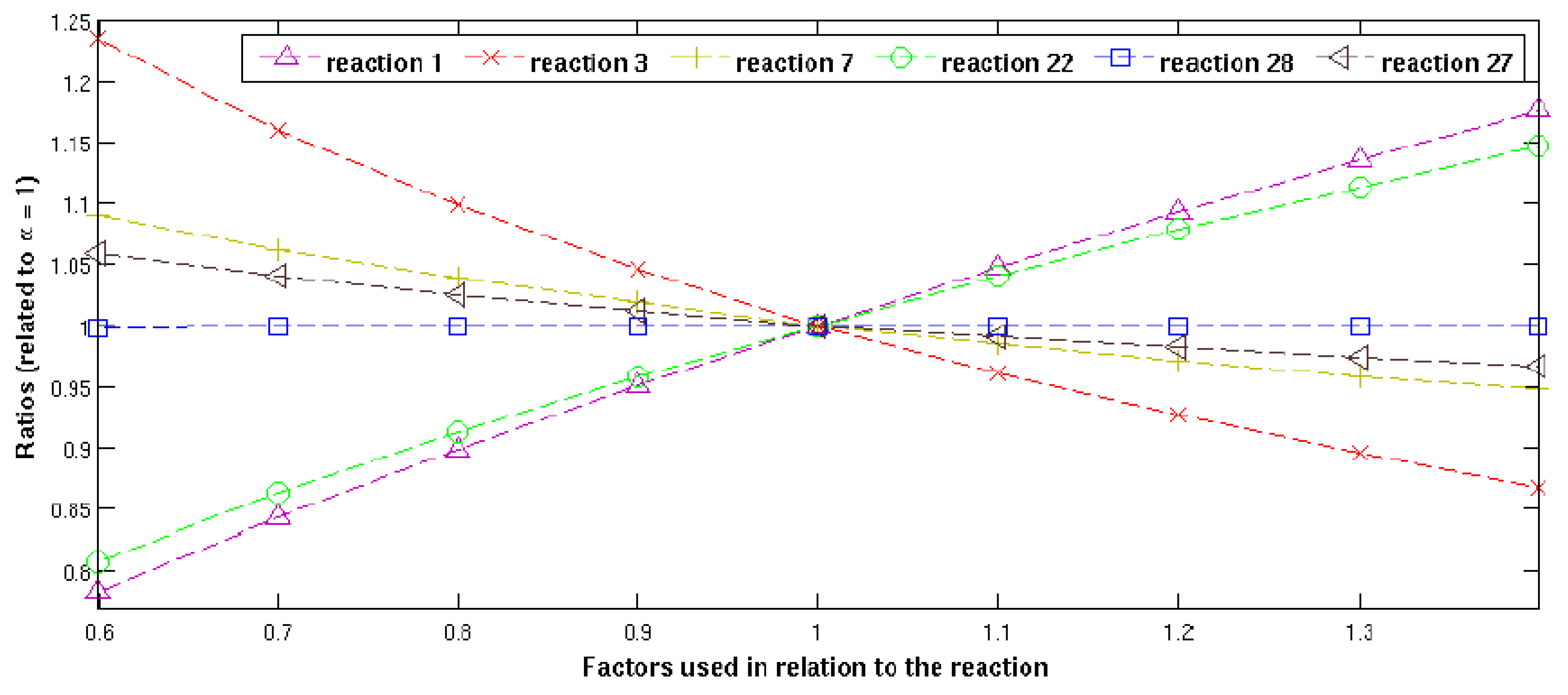
To examine the impact of different rate constants of chemical reactions on air pollution concentrations, a numerical investigation was conducted in [
48]. Specifically, only one input value of the model was altered while keeping the others fixed at 1.0. The results analysis, focusing on the reactions considered by the CBM-IV scheme, revealed the following observations: the reaction rates
exert a highly significant influence on the concentrations of thee ozone, whereas the impact of reaction rates and
, although less pronounced, remain significant. Conversely, the influence of reaction rate
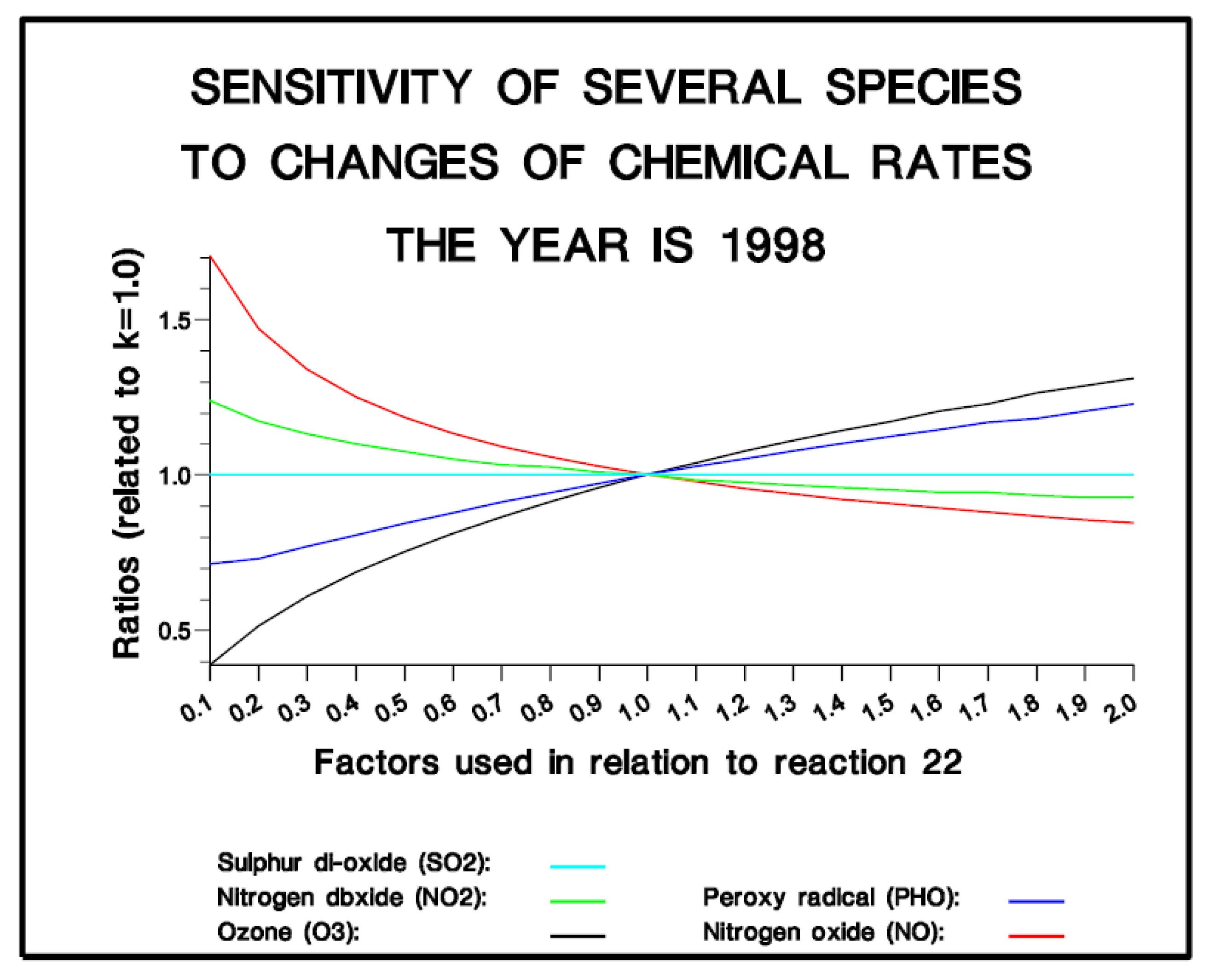
can be disregarded. The investigation of the impact of changes in chemical rates on ozone concentrations for Genova on July 1998 is given in
Figure 10.
For the SA regarding input emissions, our focus is on examining the impact of perturbing anthropogenic emissions, given as input data, on the UNI-DEM output. Specifically, we study the sensitivity of monthly average ammonia concentrations in relation to these emissions perturbations.
The input data themselves consist of four different components
:
Similar to how chemical reaction rate constants are determined, the initial step of the calculations involves generating the necessary input data for conducting the sensitivity analysis (SA). In our specific case, this entails conducting a series of experiments using UNI-DEM and introducing specific perturbations to the emission data.
The outputs commonly used in UNI-DEM are the monthly average concentrations of various dangerous chemical species (or groups of species, depending on the specific chemical scheme) calculated at the grid points within the simulation area. Our focus for the SA is on the following chemical pollutants:
In fact, UNI-DEM produces aggregated concentrations of ammonium sulphate and ammonium nitrate. Therefore, the latter sum of pollutants is considered to be one aggregated pollutant in our further study.
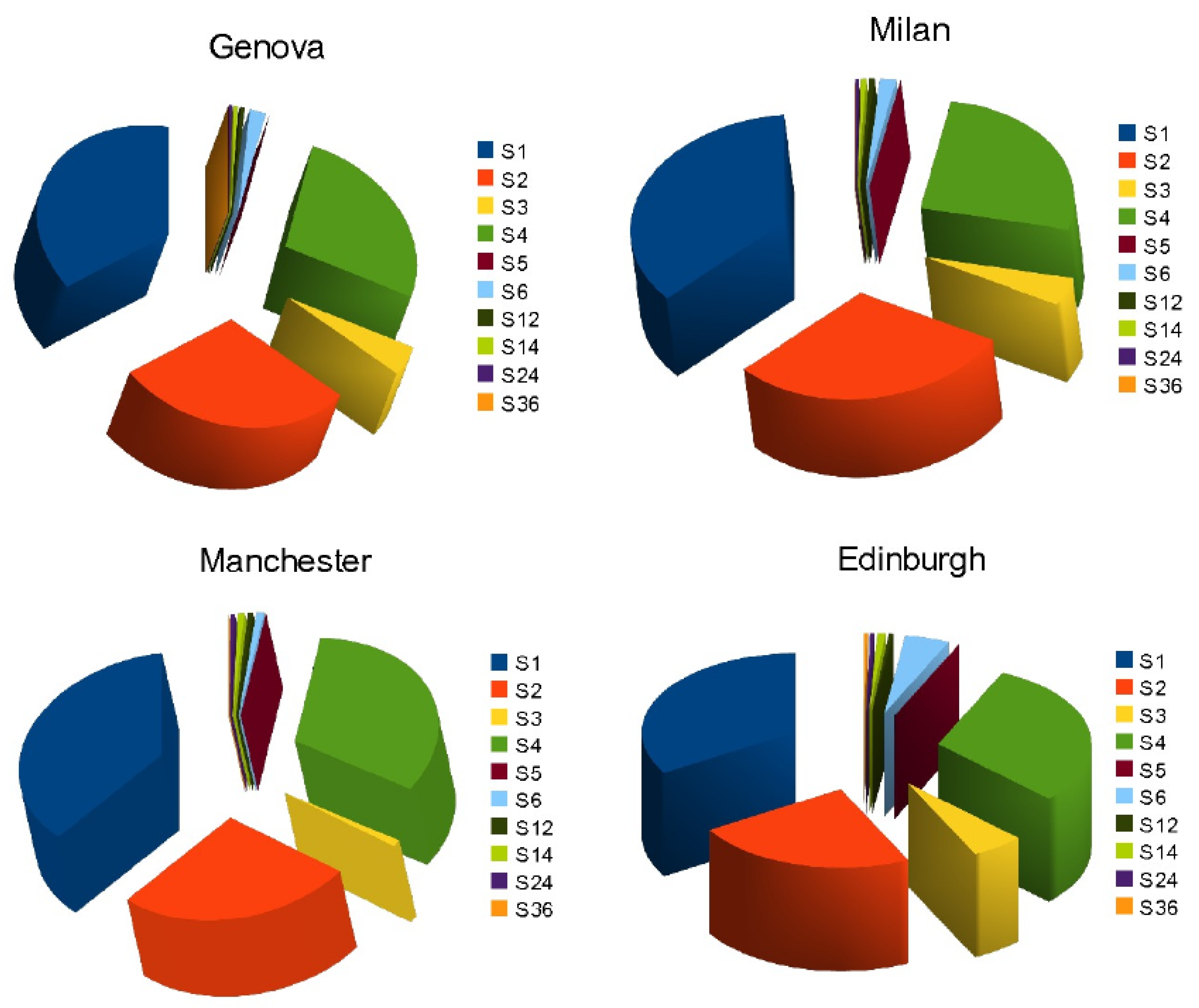
Regarding the grid points of the computational domain three European cities with different climates and with different climatic conditions and pollution levels are selected in [
47,
49]: (i) Milan, (ii) Manchester, and (iii) Edinburgh.
Results from a large number of UNI-DEM operations with the following reduced emissions
are needed for this SA study. The dedicated version of UNI-DEM is used in [
47] to perform the necessary calculations for a set of different values of
in the area under the (in our case, the four-dimensional hypercubic region
and its subregion
).
Following the parallel computations described in [
47], a total of 15 tables were generated. Each table corresponds to a specific edge in the hypercube and contains model function values for reduced emissions adjacent to the
vertices. These tables consist of nine columns, representing the results for each of the three pollutants, denoted as
in the selected three cities. The cities are identified by their closest grid point coordinates
. Within each column, the ratios
are presented. These ratios represent the average monthly concentration of pollutant
s for a given set of parameter values
, uniformly distributed over the corresponding edge of the hypercube and divided by the corresponding concentration value for the baseline scenario where
. Notably, all the data in the tables are normalized with respect to the baseline scenario, hence the presence of the value 1 as the first entry in each column (corresponding to
). These tables serve as the basis for defining nine mesh functions (pertaining to different pollutants and locations) at various points within the hypercubic region, determined by the different values of
. The mesh functions derived from these tables are subsequently utilized as input data for the subsequent stage of the study [
47].
The stage of approximation plays a vital role in bridging the gap between generating experimental data and applying mathematical techniques for sensitivity analysis. The accuracy of the resulting sensitivity indices greatly depends on the precise approximation of the data. Therefore, it is crucial to explore and identify suitable approximation tools for the table function.
We employ second-degree polynomials as a means of approximation, following the methodology described in [
50]. Specifically, for the
s-th chemical species, we utilize the polynomial
to approximate the values provided in the corresponding table. The polynomial takes the form:
To assess the accuracy of the approximation, we utilize the squared 2-vector norm. This norm is computed as: , where , and represents the corresponding values obtained from the table through the execution of UNI-DEM.
It has been demonstrated that using higher degrees of approximating polynomials introduces more degrees of freedom, resulting in a larger number of unknown coefficients to be determined. The computation of these coefficients involves minimizing a functional, typically the sum of squared differences between the values of the grid function and the values of the approximating polynomial. However, employing high-degree polynomials does not necessarily lead to improved accuracy. In fact, it can lead to inferior results, such as less accurate calculation of very small polynomial coefficients. Additionally, high-degree polynomials can exhibit excessive flexibility for real mesh functions, similar to the well-known Gibbs phenomenon [
30], where increasing the polynomial order worsens the approximation in the uniform norm. Considering these factors, the decision to use second-degree polynomials as the primary approximation tool in this study was based on the aforementioned reasons.
5. Methods and Algorithms
Consider the following multidimensional problem:
where
and
.
The most widely used quasi Monte Carlo algorithm, namely the
Sobol sequence [
51,
52,
53] is defined by:
where
are the set of permutations on every
subsequent points of the van der Corput sequence [
54], defined by
when
. In binary, for the Sobol sequence we have that:
, where
is the set of direction numbers [
55].
The description of the modified Sobol sequences MCA-MSS-1, MCA-MSS-2, MCA-MSS-2S can be found in [
56,
57].
Until now, the best available modification of the Sobol sequence is the superconvergent Sobol–Burkardt method SOBOL-BURK based on the routines INSOBL and GOSOBL in ACM TOMS Algorithm 647 and ACM TOMS Algorithm 659 and Burkardt modification [
58,
59,
60,
61,
62]. The original code can only compute the next element of the sequence. Our modification allows the user to specify the index of the desired element.
One of the best available methods for SA is also the DigitalSobol sequence DIGIT-SOBOL; this is a super-convergent digital sequence that is used for generating matrices based on an implementation of the Sobol sequence with 21,201 dimensions [
63].
Now, to improve the Sobol sequence, we will define lattices.
Definition 10 ([
64]).
An N-point rank-one lattice rule in d dimensions is a quasi-Monte Carlo method with cubature pointswhere is known as the generating vector, and is an d dimensional integer vector having no common factors with N. The corresponding quasi Monte Carlo approximation formula is given by:
Definition 11 ([
64]).
For a given function class F, the worst-case error is defined as In this study, we also construct two new super-convergent lattices based on component by component construction (CBC) method [
65] of rank-one lattices with corresponding generating vectors with prime power of points with product weights LAT-PROD and with order-dependent weights LAT-ORDER. The worst-case error for the product weight lattice is given by
and the worst-case error for the order-dependent weight lattice is given by
It is proven in [
66] that CBC method achieves optimal rate of convergence in weighted Korobov space
and optimal rate of convergence in weighted Sobolev space
for
for the corresponding product weight and order-dependent weight lattice. This explain the fact that the constructed lattice outperforms the modified Sobol sequences.
6. Numerical Results
In this section, we will present some numerical results concerning UNI-DEM’ SIs for the chosen European cities.
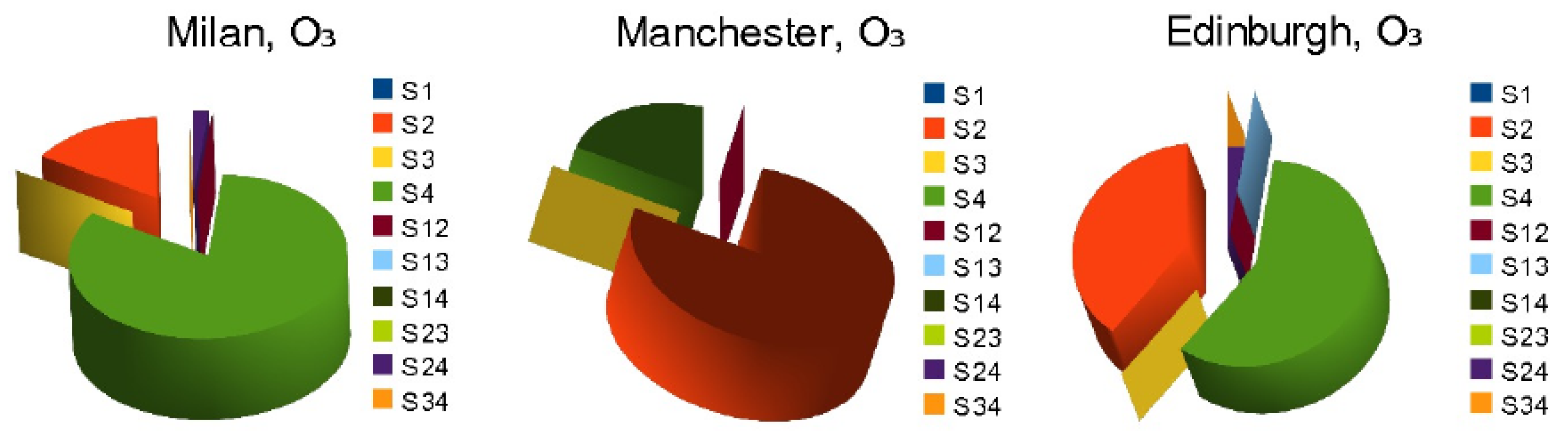
Table 1 contains the first-, second-, and total-order SIs of the considered model inputs. The results on the first- and second-order SIs of the ozone in Milan, Genova, Manchester, and Edinburgh, for July 1998, are represented graphically in
Figure 11.
The results for the first- and second-order SIs for ammonia, ozone, and ammonium sulphate and ammonium nitrate in Milan, Manchester, and Edinburgh are presented numerically in
Table 2.
The graphical representation in
Figure 12 displays the findings regarding the first- and second-order SIs of ozone in Milan, Manchester, and Edinburgh during January 1997.
They were obtained by applying VBM and in particular correlated sampling to compute all possible sensitivity measures to study the influence of four selected groups of air pollutant emissions over the concentration of the three important air pollutants mentioned above.
The described above advanced stochastic algorithms are applied to sensitivity studies with respect to input emission levels (SSIEL) and in accordance to some chemical reactions rates (SSCRR) of the concentration variations of UNI-DEM pollutants [
47,
48]. We denote the estimated quantity with EQ, the reference value with RF, the relative error with RE, and the approximate evaluation with AE.
For the SSIEL, we will investigate SA of the model output (in terms of mean monthly concentrations of several important pollutants—in our case, this is ammonia in Milan) in accordance with the perturbation of input emissions defined in the previous section.
For SSIEL, the results for REs for the AE of the
, and
are shown in
Table 3, where the quantities are represented by eight-dimensional integrals.
In the case of the SSCRR, we will investigate the ozone concentration in Genova according to the rate variation of these chemical reactions: ##
(time-dependent) and
(time-independent) of the CBM-IV scheme [
8].
In the case of the SSCRR, the results for REs for the AE of the
and
, using the stochastic algorithms, are shown in
Table 4, where the quantities are represented by 12-dimensional integrals.
7. Discussion and Applicability
We could make the following comments about the chemical reaction rates:
It can be expected that the values of the higher-order SIs are relatively small and close to zero, given that the values of the SIs of the TSIs are close to each other. UNI-DEM mathematical model is additive based on the selected input parameters, specifically, the rates of chemical reactions.
A new important input parameter, the rate of the time-dependent chemical reaction #1, has been identified.
The findings of this study align completely with the conclusions drawn in a previous study regarding the significance of model inputs.
The following comments can be made in the case of input emissions regarding the different cities.
On ammonia concentrations:
The most influential pollutant emissions are the ammonia emissions themselves, accounting for 81–89% of the impact. Sulfur dioxide emissions also have a notable influence (11–18%), with the largest impact observed in the Manchester area. This pattern is consistent across all three cities examined, although the influence in the southernmost city, Milan, is slightly higher. Higher-order effects are almost negligible, except for a joint effect (0.1–0.6%) of the two aforementioned groups of air pollutants. Total effects primarily consist of the corresponding main effects, but in Manchester and Edinburgh, there is a slight contribution from the joint effect of ammonia and sulfur dioxide emissions.
On ozone concentrations:
The most influential pollutant emissions in Milan and Edinburgh are anthropogenic hydrocarbons (59–83%), whereas nitrogen oxides play a dominant role (79%) in Manchester. In the areas of Milan and Edinburgh, nitrogen oxides emissions (16–39%) have a significant influence. The impact of nitrogen oxides emissions and anthropogenic hydrocarbons is relatively balanced in Edinburgh. Second-order interaction effects in Manchester are almost negligible (even ), whereas in Milan and Edinburgh, the joint effect accounts for approximately 2%. Total effects are primarily driven by the corresponding main effects, but Milan and Edinburgh also exhibit a slight contribution from the joint effects of anthropogenic hydrocarbons and nitrogen oxides emissions.
On ammonium sulfate and ammonium nitrate concentrations:
The most influential pollutant emissions are sulfur dioxide emissions (58–82%), with ammonia emissions also having a significant but smaller impact (15–39%). In Manchester, the influence of ammonia and sulfur dioxide emissions is comparatively balanced. All four groups of pollutants have an influence on the considered important species, with nitrogen oxides and anthropogenic hydrocarbons exhibiting a slight but not negligible effect. Second-order effects in the Manchester area are mostly negligible, except for . In Edinburgh, three second-order interaction effects contribute to the corresponding total effects (0.1–3.3%).
The following observations for SIs can be made regarding the SSIEL:
From
Table 3, it can be deduced that the most effective algorithms of all of the first-order SIs and TSIs, the most accurate is the order-dependent weight lattice, except for
and
, where the Sobol–Burkardt algorithm produces better results.
The product weight lattice is generally worse than the order-dependent lattice, but it produce the same relative error for and .
In [
67], it is emphasized that having the smallest possible SIs is crucial for the model. In our case, these smallest SIs are
and
, and the order-dependent weight lattice outperform the other sequences for these SIs, but for
the digital Sobol algorithm produced the same relative error as the order-dependent weight lattice.
Generally, in the case of SSIEL, our lattice sequences yield significantly better results than the original Sobol sequence and its modifications, namely MCA-MSS-1, 2, and 2S.
Similarly, in the case of the SSCRR, the following can be observed:
For a sample size of
in
Table 4, order-dependent weight lattice produces the best results for most of the cases, except
,
,
,
,
,
, and
.
As mentioned earlier, having the smallest possible SIs is crucial for the model. In this case, these smallest SIs are , , and , and the product weight lattice produce better results than the other algorithms for these SIs, only in the case of Sobol–Burkardt produce the same result as product weight lattice.
The digital Sobol sequence is the most accurate for , , and , whereas Sobol–Burkardt is the most accurate for .
Generally, the order-dependent weighted and product weighted lattice significantly outperforms the original Sobol sequence and its modifications, MCA-MSS-1, -2, and -2S.
In conclusion, the two developed lattices are the most effective approaches among the benchmarked methods, as indicated by the relative error values. For some of the SIs, the most well-known Sobol algorithms, the digital Sobol and Sobol–Burkardt algorithms, produce slightly better results, but this is not the case for the smallest in value SIs. When applied to multidimensional air pollution sensitivity analysis, these sequences demonstrate superiority over the majority of existing methods. It should be noted that the lattice with a generating vector consisting of a prime number of points and with product weights produce the best results for the smallest in value SIs for the second case of SSCRR, whereas the lattice with the generating vector, a prime number of points, and order-dependent weights produces the most accurate results for the smallest in value SIs for the first case of SSIEL.
8. Conclusions
This study focuses on the application of a sophisticated digital twin named DIGITAL AIR to examine the problem of high air pollution levels in different regions of Europe. The study employs a range of tools and techniques to effectively investigate this issue.
The UNI-DEM mathematical model plays a central role in this study, requiring the implementation of highly efficient and accurate numerical algorithms. These algorithms are executed on state-of-the-art supercomputers to ensure reliable and precise simulations of air pollution dynamics.
To support the modeling efforts, extensive datasets are utilized, encompassing meteorological data, emission data, and geographical information. These datasets provide essential input parameters for the simulations and contribute to the overall accuracy and reliability of the findings.
To account for future climate changes and their impact on air pollution, the study incorporates carefully designed climatic scenarios. These scenarios consider the anticipated increase in temperatures and the corresponding changes in natural (biogenic) emissions. By incorporating these future projections, the study aims to provide insights into the potential long-term effects of climate change on air quality.
Visualizing the obtained numerical results is an integral part of the study, and graphical programs are employed for this purpose. These programs enable the researchers to analyze and interpret the simulation outcomes in a visually accessible manner, facilitating a comprehensive understanding of the complex air pollution patterns.
Additionally, this study introduces a further exploration of DIGITAL AIR through a multidimensional sensitivity analysis conducted using advanced stochastic methods based on superconvergent lattice sequences. This analysis aims to investigate the sensitivity of the model and its outputs to variations in input parameters and uncertainties. By employing stochastic techniques, the study can account for the inherent randomness and variability in the system, leading to a more comprehensive understanding of the model’s behavior and its robustness in different scenarios.
In summary, this research utilizes the DIGITAL AIR digital twin and employs a range of tools, including the UNI-DEM mathematical model, extensive datasets, carefully designed climatic scenarios, and graphical programs for visualization. The investigation is extended through a sensitivity analysis using advanced stochastic methods based on powerful lattice and digital sequences, contributing to a more comprehensive understanding of air pollution dynamics and the potential impacts of climate change.
The current version of UNI-DEM, although a powerful mathematical model for air pollution analysis, has certain limitations that should be acknowledged. One notable limitation is that it does not account for PM10 (consists of small particles suspended in the air, such as dust, pollen, soot, and other solid or liquid pollutants) in its calculations. These particles are small enough to be inhaled into the respiratory system, posing potential health risks. Monitoring and controlling PM10 levels is crucial for assessing air quality and understanding its impact on human health and the environment. However, future iterations of UNI-DEM are expected to address this limitation by incorporating PM10 data and considering their impact on air pollution dynamics. By taking into account this important particulate matter, the model will provide a more comprehensive and accurate representation of air quality, contributing to a deeper understanding of the factors influencing air pollution levels.
In future research, a more comprehensive comparison will be conducted between the newly developed lattice approach and the most advanced digital sequences. The aim will be to explore and evaluate the performance of these methods in greater detail. Moreover, the results of our study presented in this paper through sensitivity analysis will have a multifaceted and highly significant impact. By utilizing the insights gained from our sensitivity analysis, the mathematical model will provide a more precise assessment of agricultural losses. Additionally, it will serve a crucial role in estimating the detrimental effects of emissions on human health.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}