
Two-Stage Decomposition Multi-Scale Nonlinear Ensemble Model with Error-Correction-Coupled Gaussian Process for Wind Speed Forecast

Abstract
:1. Introduction
- (1)
- Many researchers used a single decomposition technique to obtain subsequences with different characteristics, which makes research easier because subsequences have more regular and simpler patterns than the original data series. However, there are still a few complex subsequences after once decomposition. Therefore, two-step decomposition is adopted to preprocess the original data and fully extract complicated features to the largest extent.
- (2)
- With the increase in the number of subsequences, the error accumulation problem is also increasingly apparent as each subsequence will be fed into a model separately and each model has its own errors. To alleviate the error accumulation problem, the high dimensional data are reduced to low dimensional ones by an auto encoder, which can not only save useful information in a data series but also simplify the modelling process.
- (3)
- The proposed model is based on the idea of “divide and conquer”, which can effectively handle distinct subseries through training different models. Instead of linear integration which is simply adding the results of subsequences, Xgboost is used to integrate the predictive results of subseries, which is an effective nonlinear ensemble process and shows superior performance.
- (4)
- In previous studies, the integrated results are seen as the final predictive results. However, in our proposed model there is an error correction strategy which is used for correcting the predictive values. Therefore, if the residual values include useful information, the proposed model still has the potential to dig them out.
- (5)
- The model proposed in this study does not stop at point prediction, but utilizes the Gaussian process to generate the interval prediction, which can show the potential uncertainty and the reliability of predictive results.
2. Related Methodology
2.1. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise
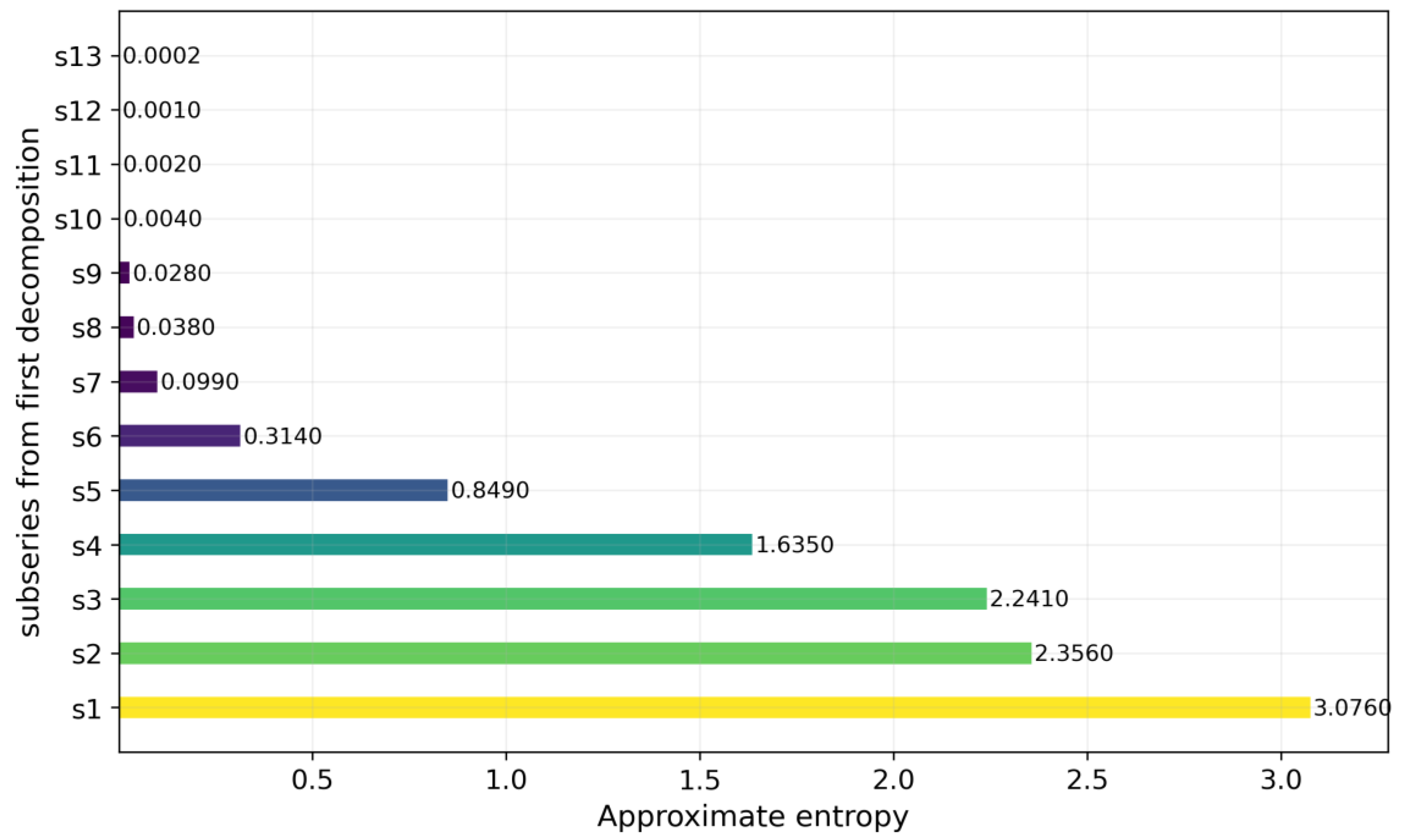
2.2. Approximate Entropy
2.3. Singular Spectrum Analysis
2.4. Auto Encoder
2.5. Elastic Neural Network
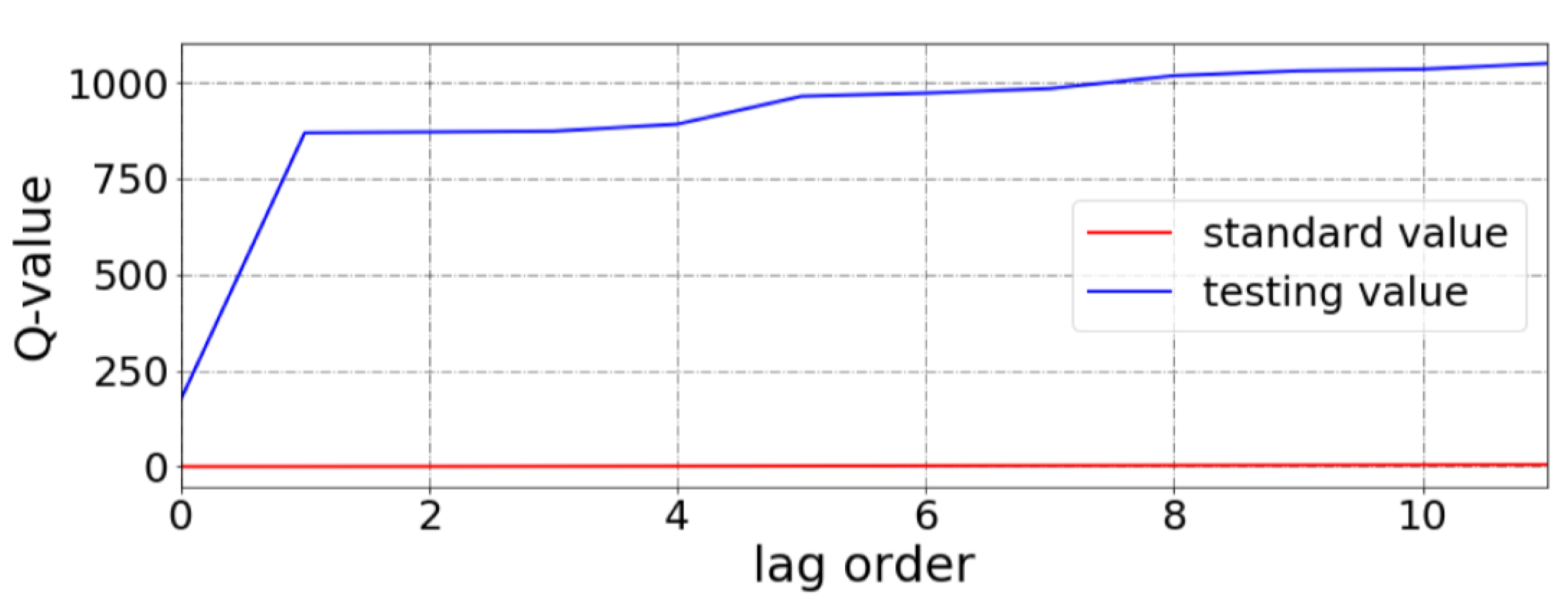
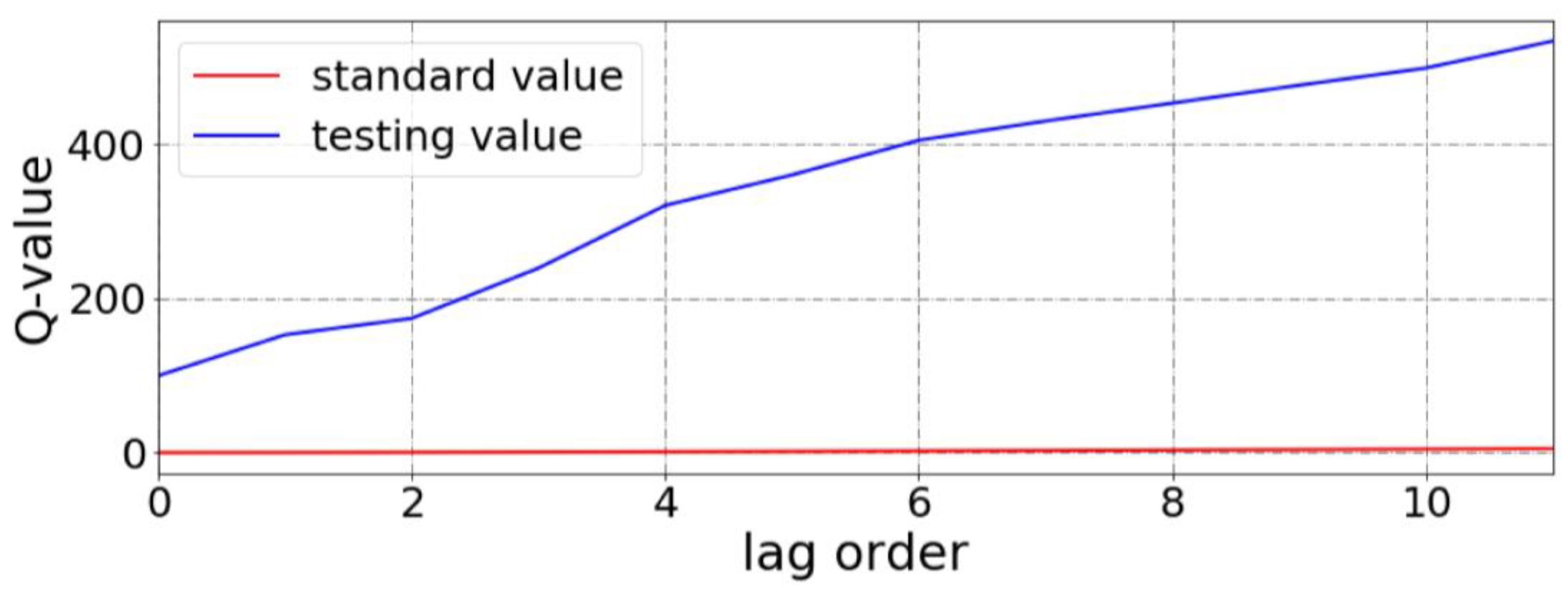
2.6. White Noise Test
2.7. Extreme Gradient Boosting
2.8. Gaussian Process
3. Proposed Model and the Evaluation Criteria
3.1. Proposed Model
- (1)
- CEEMDAN combined with AE is the first decomposition step where the raw data are decomposed in an effort to extract the features.
- (2)
- SSA decomposition is the secondary decomposition process where the focus is on the subsequence with the highest AE value. The first two steps are seen as the whole decomposition system which stresses the different features of the data series.
- (3)
- When the decomposition process is finished, the number of the subsequences will be too large which will bring a low efficiency in computation. Therefore, an auto encoder is used to realize the dimensionality reduction task to reduce the number of the subsequences.
- (4)
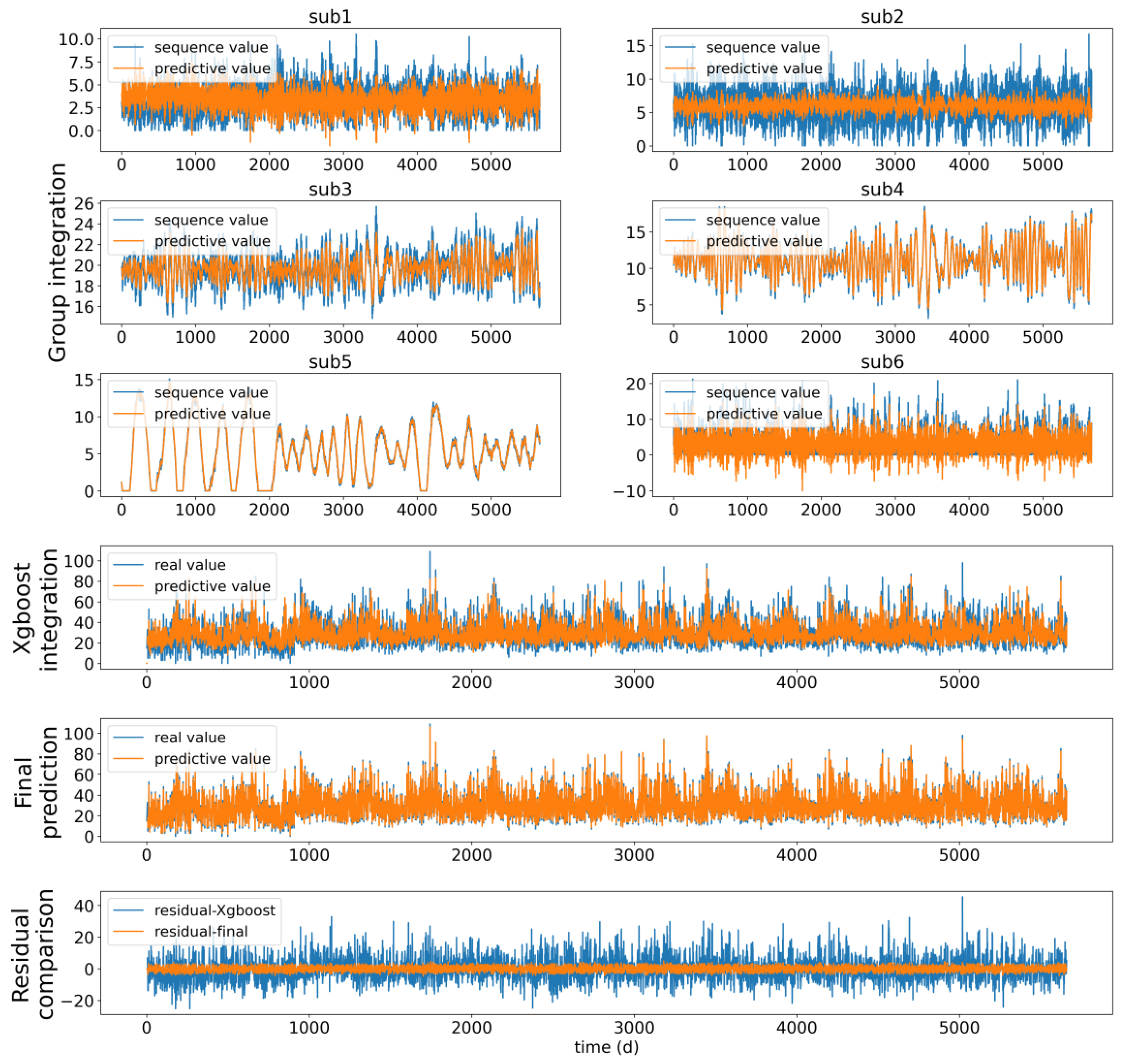
- Each subsequence will go through the elastic neural network to generate the sub-result, after obtaining these sub-results, Xgboost will generate the first prediction result based on sub-results. This process can be seen as a two-step nonlinear learning process.
- (5)
- Error correction is another innovation in the proposed model, which can correct the first predictive results and achieve a higher accuracy. Here, the white noise test is used to verify whether the predictive results should be corrected.
- (6)
- The last step is to generate the interval prediction. GP has the ability of interval generation which will be used in this paper, and this will bring a high fault tolerance and low uncertainty.
3.2. Evaluation Criteria
4. Case Study
4.1. Data Collection
4.2. Point Prediction
4.2.1. Case I: Wind Speed from Dingxin
4.2.2. Case II: Test with Wind Speed from Wushan
4.2.3. Case III: Test with Wind Speed from Yongchang
4.2.4. Case IV: Test with Wind Speed from Jingtai
4.3. Interval Prediction
4.4. Analysis and Discussion
- (1)
- The proposed model applies a secondary decomposition process which contains CEEMDAN and SSA while some existing studies only use one-step decomposition. For this reason, the first cases applied a one-step decomposition. The next steps remained the same as the proposed model. The RMSE and MAE values showed obvious increases with the secondary decomposition. More specifically, the RMSE values of the four cases were, respectively, 8 times, 6 times, 6.5 times and 13 times larger than that of the proposed model; the MAE values of the comparative model were also several times larger than the proposed one. The increase in the MAPE values was also apparent in the four cases and the value increased by 45.49%, 32.03%, 31.58%, and 40.62%, respectively. Then, for the interval prediction, the CP values of the first two cases decreased by about 0.2, while the MWP values increased by about 0.2 and 0.03. It can be seen that in the third and fourth cases, the CP values showed a slight increase while the MWP values showed a multifold increase. The experiment demonstrates that the one-step decomposition will neglect some information in the series which means the feature extraction still has room for improvement. Moreover, it proves that the two-step decomposition is necessary.
- (2)
- There are a large number of studies investigating the study process on the original dataset, so in the second model, the whole decomposition process was deleted entirely as a comparative group. The RMSE values of the second comparative model were dozens of times larger than the proposed model as well as the MAE values in all cases. Similarly, the MAPE values were several times larger than the proposed model’s. In addition, the CP value of the first case showed an apparent decrease by 0.334, and the MWP value increased to 2.4638. For the next three cases, the CP values showed no great difference, but the MWP values all became far from satisfactory. Obviously, using the original dataset directly means that all the features are given the same weight, which can greatly affect the prediction ability in practice.
- (3)
- The third model turned the original two-step learning process to a one-step integration. For certain, the process became easier to operate, but the accuracy and fault tolerance were both influenced. The most obvious changes were the increase in the MAPE value in case 1 by 33.66% and the increase in the MWP value in case 3, which was multiplied 9.96 times. The simplified process brought not only the decline in the point prediction accuracy, but also a negative effect on the certainty. Sometimes, a simple one-step integration does offer a good performance, but it also causes risks that the features are not fully captured and the learning process is insufficient. Thus, in an effort to complete the learning process and pay as much attention as possible to all the features, it is highly recommended to apply a two-step learning process.
- (4)
- The proposed model applies nonlinear integration as an important process in the point prediction period. In some classic methods, linear accumulation is always utilized, so the fourth model replaced the Xgboost integration with linear accumulation. It was learned from the results that the accuracy greatly decreased. The RMSE values were much larger than that in the proposed model in the four cases. The MAE values increased by the similar multiples accordingly. The MAPE values showed a distinct increase as well and the values of the four cases increased by 129.99%, 88.50%, 72.54% and 55.81%, respectively. Meanwhile, in the interval prediction process, differences in the CP values were not really evident, but when it came to MWP values, the values increased by 7.6663, 2.0659, 4.2418 and 4.5723, which means the gap between the boundaries widened and this will bring large uncertainty. Linear integration takes the least time to operate and it is the easiest way to generate results, but doing this means the ignorance of nonlinear features, and, as a result, the prediction accuracy is far from satisfactory.
- (5)
- Finally, as the residual correction strategy is another notable part in the proposed model, to further demonstrate the significance of this, the fifth model eliminated the residual correction process. Drawn from the table, the RMSE values of the four cases increased by 0.06, 0.04, 0.02, and 0.01, respectively, together with an increase in the MAE values in the first three cases, by 0.05, 0.04, and 0.02, respectively. While for the interval prediction, the CP values showed a great decline, and the gap narrowed further, with decreases of 1165.50 times, 535.38 times, 236.50 times, and 127.47 times in four cases. It has been said that MWP values cannot be too large or too small, and in this experiment, the MWP with too small values will turn the interval prediction to the results that are quite alike with the point prediction. In other words, the residual correction must not be neglected. The residual series is always neglected by researchers while, as a matter of fact, some features in the residual series remain unnoticed. The application of the residual correction strategy means the capturing of all the possible information and, by doing this, the performance will be the most precise.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chinmoy, L.; Iniyan, S.; Goic, R. Modeling wind power investments, policies and social benefits for deregulated electricity market—A review. Appl. Energy 2019, 242, 364–377. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Chen, B.; Pan, G.F.; Zhao, Y. A novel hybrid model based on VMD-WT and PCA-BP-RBF neural network for short-term wind speed forecasting. Energy Convers. Manag. 2019, 195, 180–197. [Google Scholar] [CrossRef]
- Chen, C.; Liu, H. Dynamic ensemble wind speed prediction model based on hybrid deep reinforcement learning. Adv. Eng. Inform. 2021, 48, 101290. [Google Scholar] [CrossRef]
- Liu, H.; Yu, C.M.; Yu, C.Q.; Chen, C.; Wu, H.P. A novel axle temperature forecasting method based on decomposition, reinforcement learning optimization and neural network. Adv. Eng. Inform. 2020, 44, 101089. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.N.; Srikanth, N. A Comparative Study of Empirical Mode Decomposition-Based Short-Term Wind Speed Forecasting Methods. IEEE Trans. Sustain. Energy 2017, 6, 236–244. [Google Scholar] [CrossRef]
- Zhou, J.G.; Xu, X.L.; Huo, X.J.; Li, Y.S. Forecasting Models for Wind Power Using Extreme-Point Symmetric Mode Decomposition and Artificial Neural Networks. Sustainability 2019, 11, 650. [Google Scholar] [CrossRef] [Green Version]
- Fei, S.W. A hybrid model of EMD and multiple-kernel RVR algorithm for wind speed prediction. Int. J. Electr. Power Energy Syst. 2016, 78, 910–915. [Google Scholar] [CrossRef]
- Ye, R.; Suganthan, P.N.; Srikanth, N. A Novel Empirical Mode Decomposition With Support Vector Regression for Wind Speed Forecasting. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1793–1798. [Google Scholar] [CrossRef]
- Qolipour, M.; Mostafaeipour, A.; Mohammad, S.M.; Arabnia, H.R. Prediction of wind speed using a new Grey-extreme learning machine hybrid algorithm: A case study. Energy Environ. 2019, 30, 44–62. [Google Scholar] [CrossRef]
- Cheng, Z.S.; Wang, J.Y. A new combined model based on multi-objective salp swarm optimization for wind speed forecasting. Appl. Soft Comput. 2020, 92, 106294. [Google Scholar] [CrossRef]
- Huang, Y.S.; Liu, S.J.; Yang, L. Wind Speed Forecasting Method Using EEMD and the Combination Forecasting Method Based on GPR and LSTM. Sustainability 2018, 10, 3693. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.S.; Wang, J. A combination forecasting approach applied in multistep wind speed forecasting based on a data processing strategy and an optimized artificial intelligence algorithm. Appl. Energy 2018, 230, 1108–1125. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.W.; Li, Y.F. Comparison of two new intelligent wind speed forecasting approaches based on Wavelet Packet Decomposition, Complete Ensemble Empirical Mode Decomposition with Adaptive Noise and Artificial Neural Networks. Energy Convers. Manag. 2018, 155, 188–200. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Fu, W.L.; Wang, K.; Zhou, J.Z.; Xu, Y.H.; Tan, J.W.; Chen, T. A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Multi-Scale Dominant Ingredient Chaotic Analysis, KELM and Synchronous Optimization Strategy. Sustainability 2019, 11, 1804. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.L.; Lin, H.X. Short-Term Wind Speed Forecasting Based on Hybrid Variational Mode Decomposition and Least Squares Support Vector Machine Optimized by Bat Algorithm Model. Sustainability 2019, 11, 652. [Google Scholar] [CrossRef] [Green Version]
- Moreno, S.R.; Mariani, V.C.; Coelho, L.D. Hybrid multi-stage decomposition with parametric model applied to wind speed forecasting in Brazilian Northeast. Renew. Energy 2021, 164, 1508–1526. [Google Scholar] [CrossRef]
- Shukur, B.O.; Lee, M.H. Daily wind speed forecasting through hybrid KF-ANN model based on ARIMA. Renew. Energy 2015, 76, 637–647. [Google Scholar] [CrossRef]
- Aasim, S.S.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar] [CrossRef]
- Sharma, S.K.; Ghosh, S. Short-term wind speed forecasting: Application of linear and non-linear time series models. Int. J. Green Energy 2016, 13, 1490–1500. [Google Scholar] [CrossRef]
- Li, L.X.; Miao, S.H.; Tu, Q.Y.; Duan, S.M.; Li, Y.W.; Han, J. Dynamic dependence modelling of wind power uncertainty considering heteroscedastic effect. Int. J. Electr. Power Energy Syst. 2020, 116, 105556. [Google Scholar] [CrossRef]
- Lucheroni, C.; Boland, J.; Ragno, C. Scenario generation and probabilistic forecasting analysis of spatio-temporal wind speed series with multivariate autoregressive volatility models. Appl. Energy 2019, 239, 1226–1241. [Google Scholar] [CrossRef]
- Baomar, H.; Bentley, P.J. Autonomous flight cycles and extreme landings of airliners beyond the current limits and capabilities using artificial neural networks. Appl. Intell. 2021, 51, 6349–6375. [Google Scholar] [CrossRef]
- Luo, X.J.; Oyedele, L.O.; Ajayi, A.O.; Monyei, C.G.; Akinade, O.O.; Akanbi, L.A. Development of an IoT-based big data platform for day-ahead prediction of building heating and cooling demands. Adv. Eng. Inform. 2019, 41, 100926. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Pan, G.F.; Zhang, C.H.; Zhao, Y. Wind speed prediction research with EMD-BP based on Lorenz disturbance. J. Electr. Eng. 2019, 70, 198–207. [Google Scholar] [CrossRef] [Green Version]
- Ren, C.; An, N.; Wang, J.Z.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowl.-Based Syst. 2014, 56, 226–239. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Li, Y.F.; Zhang, L. Comparison of four Adaboost algorithm based artificial neural networks in wind speed predictions. Energy Convers. Manag. 2015, 92, 67–81. [Google Scholar] [CrossRef]
- Wang, S.X.; Zhang, N.; Wu, L.; Wang, Y.M. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Jiang, P.; Li, R.R.; Zhang, K.Q. Two combined forecasting models based on singular spectrum analysis and intelligent optimized algorithm for short-term windspeed. Neural Comput. Appl. 2016, 30, 1–19. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.K.; Xie, L.P.; Shen, Y.; Zhang, K.J. Direct interval forecasting of wind speed using radial basis function neural networks in a multi-objective optimization framework. Neurocomputing 2016, 205, 53–63. [Google Scholar] [CrossRef]
- Dalibor, P.; Shahaboddin, S.; Nor, B.A.; Hadi, S.; Ainuddin, W.A.W.; Milan, P.; Erfan, Z.; Seyed, M.A.M. An appraisal of wind speed distribution prediction by soft computing methodologies: A comparative study. Energy Convers. Manag. 2014, 84, 133–139. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Zhang, C.H.; Sun, J.B.; Guo, J.J. Improved Wind Speed Prediction Using Empirical Mode Decomposition. Adv. Electr. Comput. Eng. 2018, 18, 3–10. [Google Scholar] [CrossRef]
- Wu, Z.Q.; Jia, W.J.; Zhao, L.R.; Wu, C.H. Maximum wind power tracking based on cloud RBF neural network. Renew. Energy 2016, 86, 466–472. [Google Scholar] [CrossRef]
- Song, J.J.; Wang, J.Z.; Lu, H.Y. A novel combined model based on advanced optimization algorithm for short-term wind speed forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Thoranin, S. A new class of MODWT-SVM-DE hybrid model emphasizing on simplification structure in data pre-processing: A case study of annual electricity consumptions. Appl. Soft Comput. 2017, 54, 150–163. [Google Scholar] [CrossRef]
- Fu, C.; Li, G.Q.; Lin, K.P.; Zhang, H.J. Short-Term Wind Power Prediction Based on Improved Chicken Algorithm Optimization Support Vector Machine. Sustainability 2019, 11, 512. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.R.; Zhao, H.R.; Guo, S. Short-Term Wind Electric Power Forecasting Using a Novel Multi-Stage Intelligent Algorithm. Sustainability 2018, 10, 881. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.X. A novel short-term multi-input-multi-output prediction model of wind speed and wind power with LSSVM based on improved ant colony algorithm optimization. Cluster Comput. 2019, 22, S3293–S3300. [Google Scholar] [CrossRef]
- Sun, W.; Liu, M.H.; Liang, Y. Wind Speed Forecasting Based on FEEMD and LSSVM Optimized by the Bat Algorithm. Energies 2015, 8, 6585–6607. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Yan, M.; Xie, B.L.; Yang, H.Q.; Ma, H. An automatic real-time bus schedule redesign method based on bus arrival time prediction. Adv. Eng. Inform. 2021, 48, 101295. [Google Scholar] [CrossRef]
- Zheng, H.; Wu, Y.H. A XGBoost Model with Weather Similarity Analysis and Feature Engineering for Short-Term Wind Power Forecasting. Appl. Sci. 2019, 9, 3019. [Google Scholar] [CrossRef] [Green Version]
- Cai, R.; Xie, S.; Wang, B.Z.; Yang, R.J.; Xu, D.S.; He, Y. Wind Speed Forecasting Based on Extreme Gradient Boosting. IEEE Access. 2020, 8, 175063–175069. [Google Scholar] [CrossRef]
- Chakraborty, D.; Elhegazy, H.; Elzarka, H.; Gutierrez, L. A novel construction cost prediction model using hybrid natural and light gradient boosting. Adv. Eng. Inform. 2020, 46, 101201. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Equation |
|---|---|
| MAE | |
| RMSE | |
| MAPE | |
| MWP | |
| CP |
| Dataset | Dingxin | Wushan | Yongchang | Jingtai |
|---|---|---|---|---|
| Starting date | 1 January 1955 | 1 January 1969 | 1 January 1960 | 1 October 1956 |
| Ending date | 31 December 2016 | 31 December 2016 | 31 December 2016 | 31 December 2016 |
| Samples | 22,645 | 17,531 | 20,819 | 21,975 |
| Mean | 30.790 | 29.740 | 29.157 | 25.677 |
| Min | 0 | 0 | 0 | 0 |
| Max | 143 | 103 | 139 | 127 |
| Std. | 16.398 | 12.358 | 13.970 | 15.082 |
| Normal test | 8136.28 | 2528.81 | 15,631.97 | 12,534.76 |
| Sub 1 | Sub 2 | Sub 3 | Sub 4 | Sub 5 | Sub 6 | |
|---|---|---|---|---|---|---|
| alpha | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| ratio | 0.001 | 0.001 | 0.001 | 0.899 | 0.001 | 0.001 |
| Xgboost-integration | Xgboost-residual correction | |||||
| max_depth | subsample | colsample_bytree | max_depth | subsample | colsample_bytree | |
| 5 | 0.8 | 0.7 | 70 | 0.75 | 0.6 | |
| Sub 1 | Sub 2 | Sub 3 | Sub 4 | Sub 5 | |
|---|---|---|---|---|---|
| alpha | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
| ratio | 0.616 | 1 | 0.01 | 0.01 | 1 |
| Xgboost-integration | Xgboost-residual correction | ||||
| max_depth | subsample | colsample_bytree | max_depth | subsample | colsample_bytree |
| 3 | 0.7 | 0.65 | 105 | 0.7 | 0.65 |
| Sub 1 | Sub 2 | Sub 3 | |||
|---|---|---|---|---|---|
| alpha | 0.01 | 0.01 | 0.01 | ||
| ratio | 0.192 | 0.01 | 1 | ||
| Xgboost-integration | Xgboost-residual correction | ||||
| max_depth | subsample | colsample_bytree | max_depth | subsample | colsample_bytree |
| 12 | 0.75 | 0.85 | 100 | 0.5 | 0.8 |
| Sub 1 | Sub 2 | Sub 3 | Sub 4 | Sub 5 | |
|---|---|---|---|---|---|
| alpha | 0.01 | 0.01 | 0.01 | 0.01 | 0.04 |
| ratio | 0.01 | 1 | 0.01 | 0.01 | 0.01 |
| Xgboost-integration | Xgboost-residual correction | ||||
| max_depth | subsample | colsample_bytree | max_depth | subsample | colsample_bytree |
| 13 | 0.55 | 0.7 | 110 | 0.6 | 0.5 |
| Mean | cov | lik | |
|---|---|---|---|
| Case 1 | 1 | −1,1,−7 | 5 |
| Case 2 | 1 | −5,6,−1 | 3 |
| Case 3 | 1 | −1,0,−7 | 5 |
| Case 4 | 1 | 1,−3,−2 | 3 |
| Model | Case | Measure | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | CP | MWP | ||
| Proposed model | Case 1 | 0.02 | 0.01 | 5.74% | 0.9993 | 1.3986 |
| Case 2 | 0.02 | 0.01 | 5.08% | 0.9881 | 0.6960 | |
| Case 3 | 0.02 | 0.01 | 5.96% | 0.9992 | 0.3784 | |
| Case 4 | 0.01 | 0.01 | 6.25% | 0.9498 | 0.2422 | |
| CEEMDAN-elastic neural network -two-step Xgboost | Case 1 | 0.16 | 0.12 | 51.23% | 0.7928 | 1.2404 |
| Case 2 | 0.12 | 0.09 | 37.11% | 0.7850 | 0.7338 | |
| Case 3 | 0.13 | 0.09 | 37.54% | 1 | 5.0851 | |
| Case 4 | 0.13 | 0.09 | 46.87% | 1 | 3.6869 | |
| Elastic neural network- two-step Xgboost | Case 1 | 0.15 | 0.11 | 49.88% | 0.6653 | 2.4638 |
| Case 2 | 0.12 | 0.09 | 35.93% | 1 | 2.2888 | |
| Case 3 | 0.12 | 0.08 | 34.47% | 0.9590 | 4.4455 | |
| Case 4 | 0.11 | 0.08 | 41.74% | 1 | 2.8217 | |
| CEEMDAN-AE- SSA-AE-elastic neural network | Case 1 | 0.12 | 0.09 | 39.40% | 0.9610 | 2.9545 |
| Case 2 | 0.08 | 0.07 | 29.03% | 0.9400 | 1.6599 | |
| Case 3 | 0.07 | 0.06 | 23.67% | 0.9760 | 3.7672 | |
| Case 4 | 0.08 | 0.09 | 29.03% | 1 | 2.9151 | |
| CEEMDAN-AE- SSA-AE-elastic neural network- linear accumulation | Case 1 | 0.27 | 0.23 | 135.73% | 1 | 9.0649 |
| Case 2 | 0.21 | 0.18 | 93.58% | 0.9470 | 2.7619 | |
| Case 3 | 0.25 | 0.23 | 78.50% | 0.9560 | 4.5932 | |
| Case 4 | 0.19 | 0.16 | 62.06% | 0.9970 | 4.8145 | |
| CEEMDAN-AE- SSA-AE-elastic neural network- Xgboost integration | Case 1 | 0.08 | 0.06 | 24.28% | 0.6797 | 0.0012 |
| Case 2 | 0.06 | 0.05 | 18.99% | 0.7508 | 0.0013 | |
| Case 3 | 0.04 | 0.03 | 12.56% | 0.2810 | 0.0016 | |
| Case 4 | 0.02 | 0.01 | 8.12% | 0.1578 | 0.0019 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; He, M.; Qiu, S. Two-Stage Decomposition Multi-Scale Nonlinear Ensemble Model with Error-Correction-Coupled Gaussian Process for Wind Speed Forecast. Atmosphere 2023, 14, 395. https://doi.org/10.3390/atmos14020395
Wang J, He M, Qiu S. Two-Stage Decomposition Multi-Scale Nonlinear Ensemble Model with Error-Correction-Coupled Gaussian Process for Wind Speed Forecast. Atmosphere. 2023; 14(2):395. https://doi.org/10.3390/atmos14020395
Chicago/Turabian StyleWang, Jujie, Maolin He, and Shiyao Qiu. 2023. "Two-Stage Decomposition Multi-Scale Nonlinear Ensemble Model with Error-Correction-Coupled Gaussian Process for Wind Speed Forecast" Atmosphere 14, no. 2: 395. https://doi.org/10.3390/atmos14020395