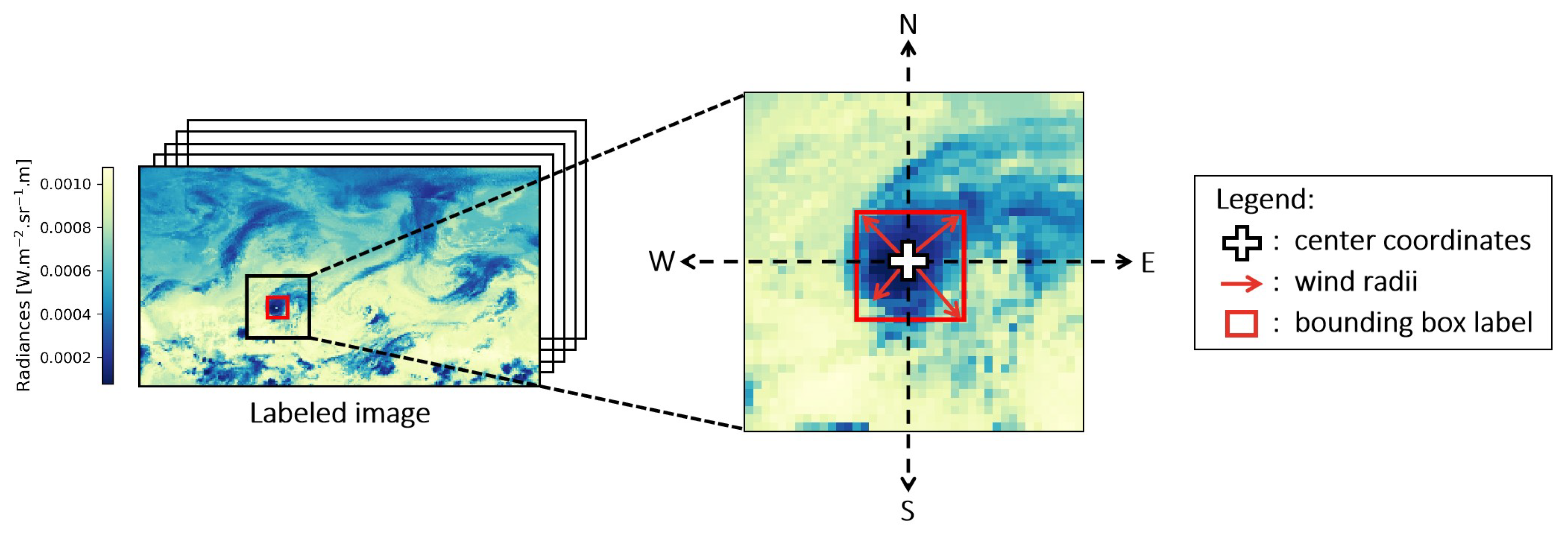
1. Introduction
A tropical cyclone (TC) is a large-scale air mass that rotates around a strong center of low atmospheric pressure, accompanied by intense variation in physical variables such as temperature, wind speed, and pressure, inducing events such as heavy rain, storm surges, flooding, etc. [
1]. It is characterized by a warm core and circular wind motion around a well-defined center, clockwise in the southern hemisphere and anti-clockwise in the northern hemisphere. According to the Atlantic Oceanographic and Meteorological Laboratory from the National Oceanic and Atmospheric Administration (NOAA), if its maximum sustained wind is under 34 knots (about 63 km/h), it is called a tropical depression [
1]. When the wind exceeds that threshold, it becomes a tropical storm. Once it exceeds 64 knots, it is classified as a hurricane. In this study, we focused on detecting TCs with maximum sustained wind of at least 34 knots (tropical storms and hurricanes). More explanation is provided in
Section 2.3. Due to its destructive potency, human losses, physical and economic damages can be significant. It is, therefore, essential to be able to automatically detect TCs to mitigate their risk and potentially analyze their characteristics.
As the understanding of TC remains incomplete, predicting TC activity is a challenging task. Prevalent physical models for TC detection are near real-time two-stage detectors with spatial search and temporal correlation based on thresholded criteria using high-resolution climate data (vorticity, vertical temperatures, sea-level temperature and pressure) [
2,
3]. Such algorithms aim to identify and track TCs in gridded climate data or even in unstructured grids [
4] and connect them into a trajectory. Bourdin et al. [
5] intercompared four physical models on the European Centre for Medium-Range Weather Forecasts (ECMWF) Reanalysis 5th generation (ERA5). Such methodologies have been frequently used in the past decades [
4] and show great ability, and potential in assessing TC activity [
6,
7]. With the enhancement of computational resources, high-resolution climate datasets have been growing increasingly. Studies demonstrate that the use in climate models of datasets with higher horizontal resolution shows great promise in improving the prediction of TCs [
7,
8]. The downside of this type of method is that they often require setting up a number of well-defined rules or thresholds. However, complex weather phenomena such as TCs remain difficult to quantify and predict [
9].
A frequently used method is the CLImatology and PERsistence (CLIPER) model [
10], used as a baseline in most statistical forecasting. It is based on linear regression and uses predictors related to climatology and persistence, such as current storm location, storm motion, maximum sustained wind speed, and previous storm motion. Later on, many studies proposed methods based on the CLIPER model [
11,
12].
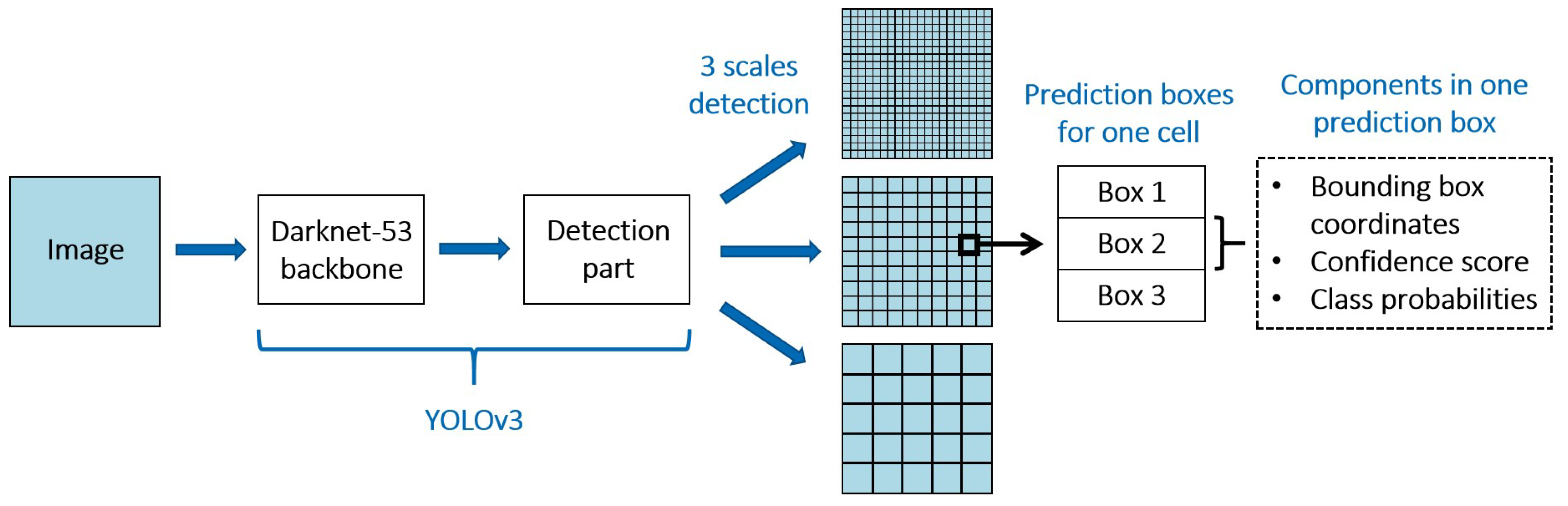
With the emergence of machine learning (ML) and, more particularly, neural network (NN) applications, such methods can be effectively applied in the meteorological domain. The advantage of such techniques over more traditional ones is that ML does not require any assumption: in contrast with explicit models based on thresholded criteria, ML techniques implicitly learn from a given set of examples from real life to provide and resolve complex and ambiguous features [
9]. It can, therefore, be advantageous to use NNs to detect complex weather systems such as TCs, which are difficult to describe and quantify. Deep learning (DL) models have the advantage of being able to process high quantities of data, which is a key point as huge volumes of data are being continuously generated by satellites, radar, or ground-based instruments. Shi et al. [
13] used an object detection model named Single Shot Detector (SSD) to detect extratropical cyclones at different stages (developing, mature, and declining). For their part, Kumler-Bonfanti et al. [
9] used deep learning image segmentation models using the U-Net architecture to segment images and identify the areas of tropical and extratropical cyclones. Input data contained data from current
t,
t − 1, and
t− 2 time steps for the starting
t time step, giving a sense of time and cyclone rotation to the model. Both approaches have been successful in detecting cyclones.
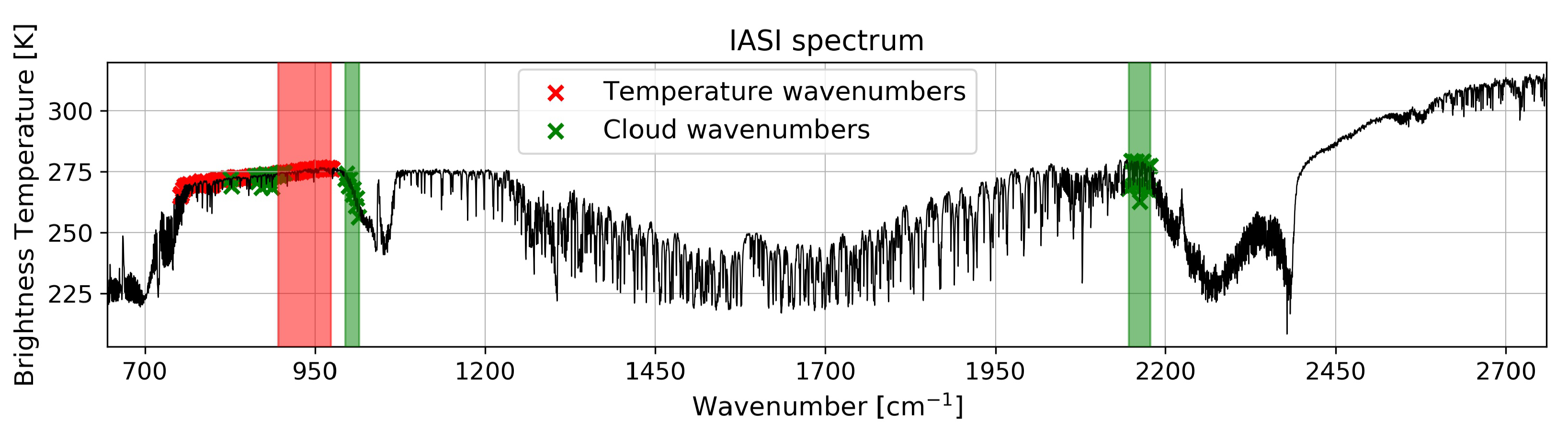
In this paper, we used data from the Infrared Atmospheric Sounding Interferometer (IASI) [
14] on board the Metop satellites (more information on IASI is provided in
Section 2.1). IASI is a passive remote sensor that measures the thermal infrared radiation (i.e., heat) as it exits land, through the atmosphere, and into space. It is, therefore, not the typical sensor/imager used to monitor cyclonic activity. However, it is largely used for numerical weather prediction [
15] and to monitor the atmospheric composition [
14,
16]. Due to its excellent stability, IASI is a reference instrument that is used to calibrate other infrared sensors [
17,
18]. IASI radiance data is made available by the European Organisation for the Exploitation of Meteorological Satellites (EUMETSAT) dissemination system so that near real-time processing of the data is possible. More than 4 million IASI spectra covering the entire Earth are collected per day (17 Terabytes per year), from which a significant part (about 70%) is affected by the presence of clouds. Most of these cloud-contaminated data are discarded in retrieval processes of chemical species like CO, O
or NH
for instance [
14,
19]. Here we will exploit all the IASI data in an attempt to develop the value of these usually discarded cloudy data. No other instruments and no wind data are used.
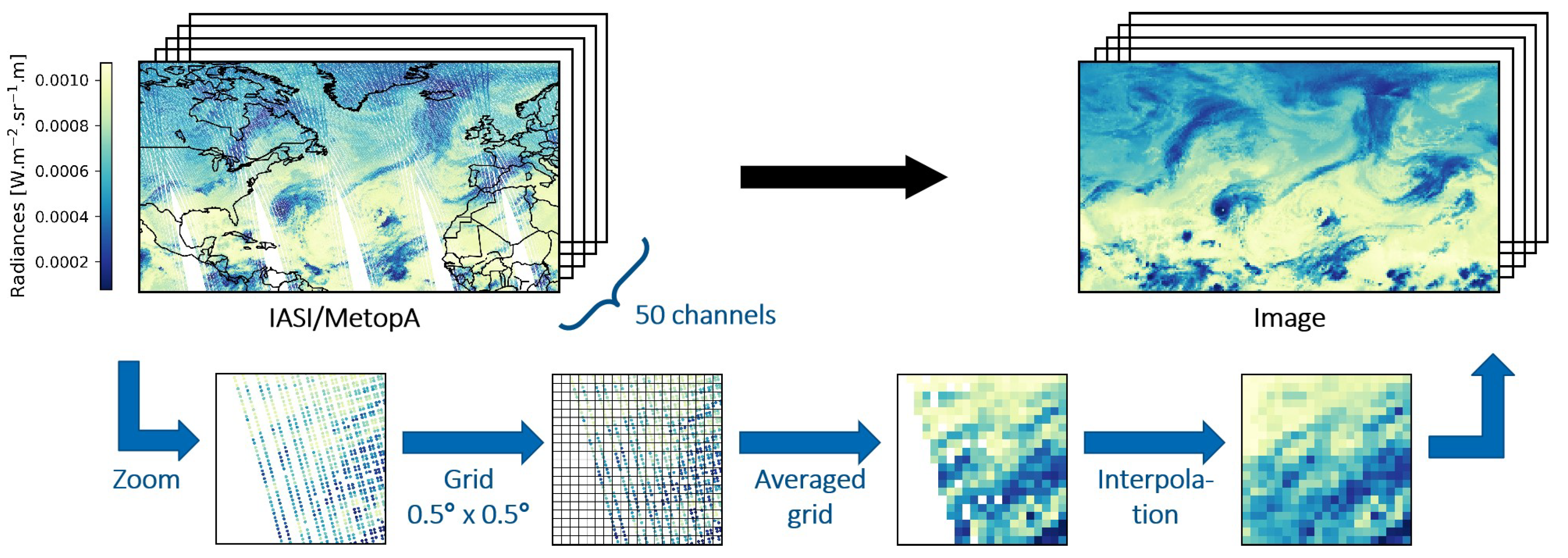
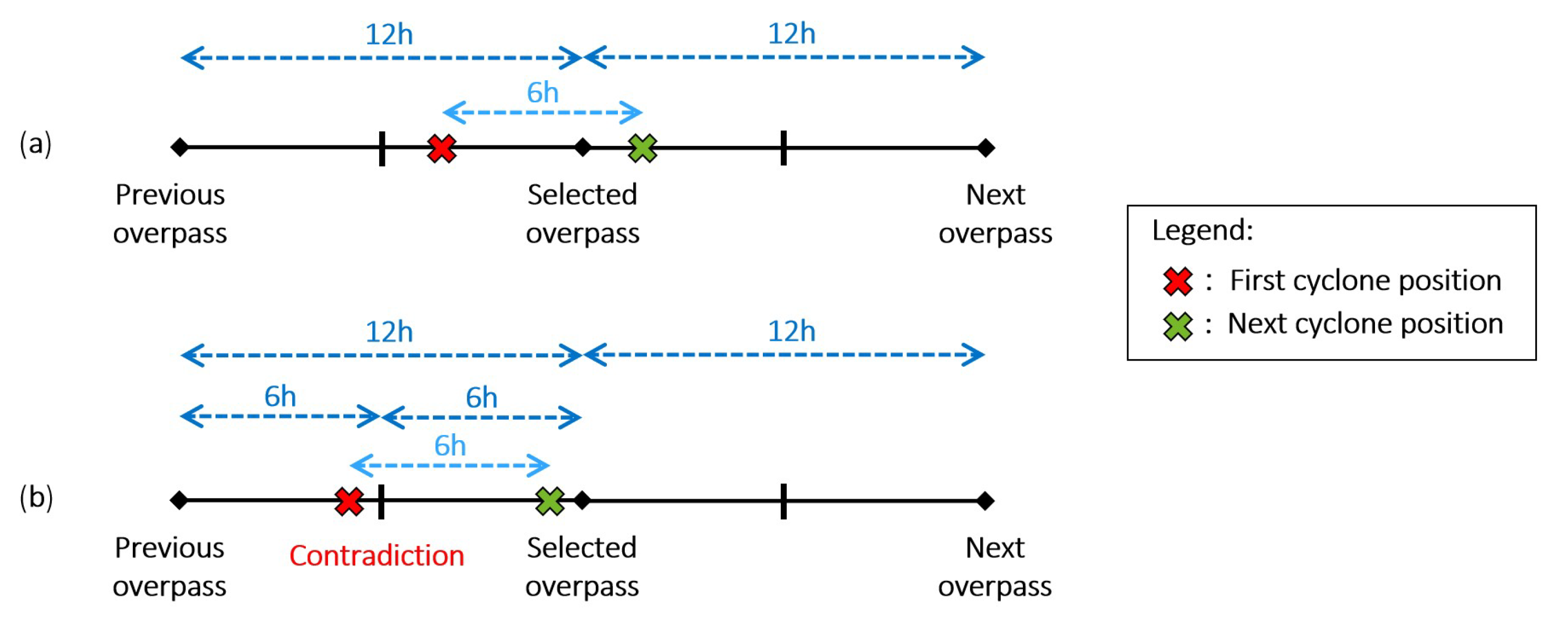
We attempt to detect TC activity in the North Atlantic Basin (between 5° and 75° N of latitude and between −110° and 18° E of longitude) using a deep learning object detection model applied to a TC dataset we created from IASI data. To our knowledge, no previous study attempted to exploit the added value of infrared sensors, such as IASI and their “raw” measurements, in the detection of TCs. The aim of the paper is to assess the performance of the YOLOv3 object detection model and the potential of the IASI data in the TC detection problem. The paper is organized as follows. In
Section 2, we present the IASI data and the YOLOv3 model, as well as the dataset creation, from the processing of the IASI data to the labeling procedure. In
Section 3, we describe the experiments performed on the model, assess its performance, and analyze its predictions. Finally, conclusions are presented in
Section 4.
4. Conclusions
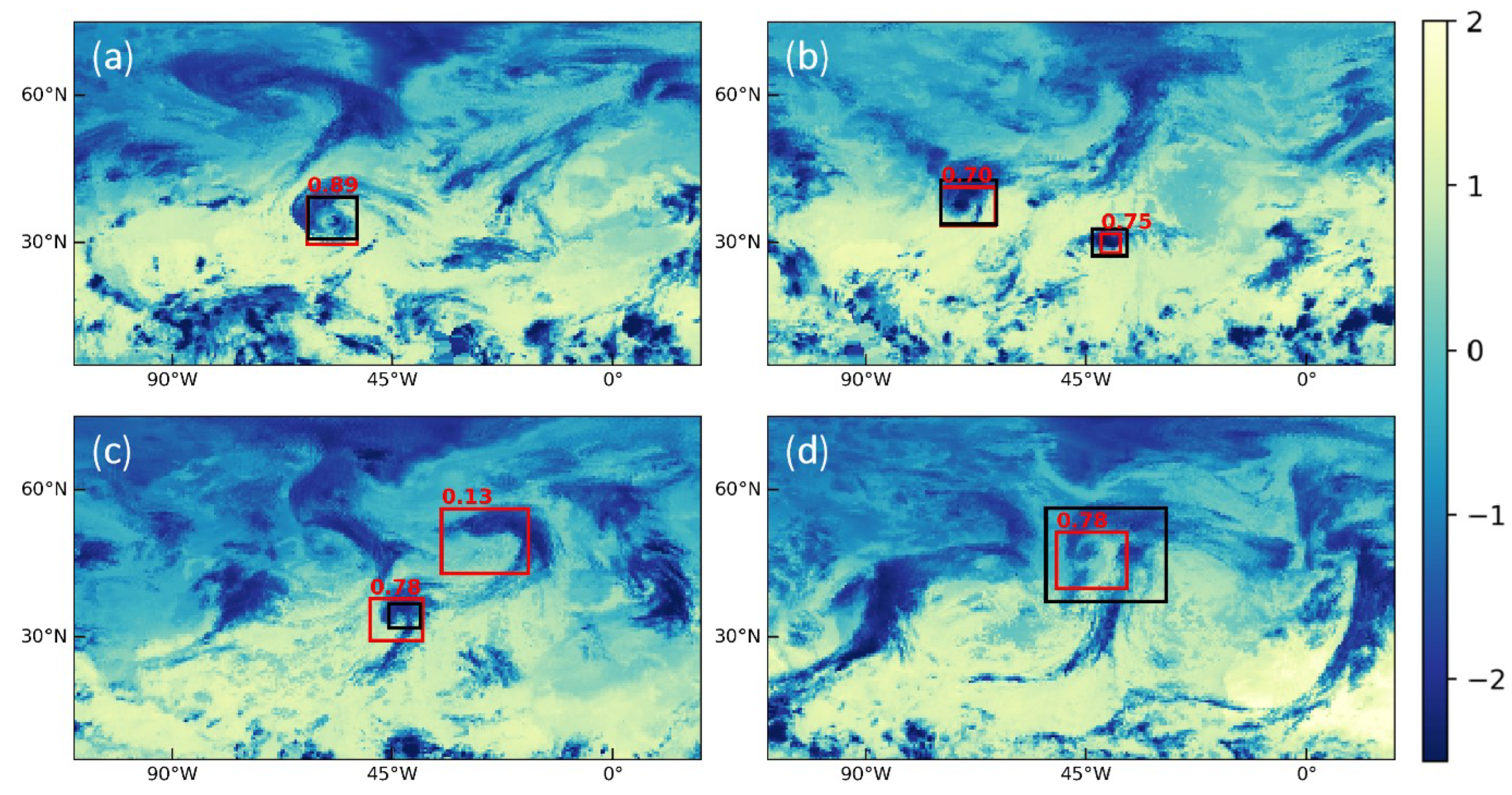
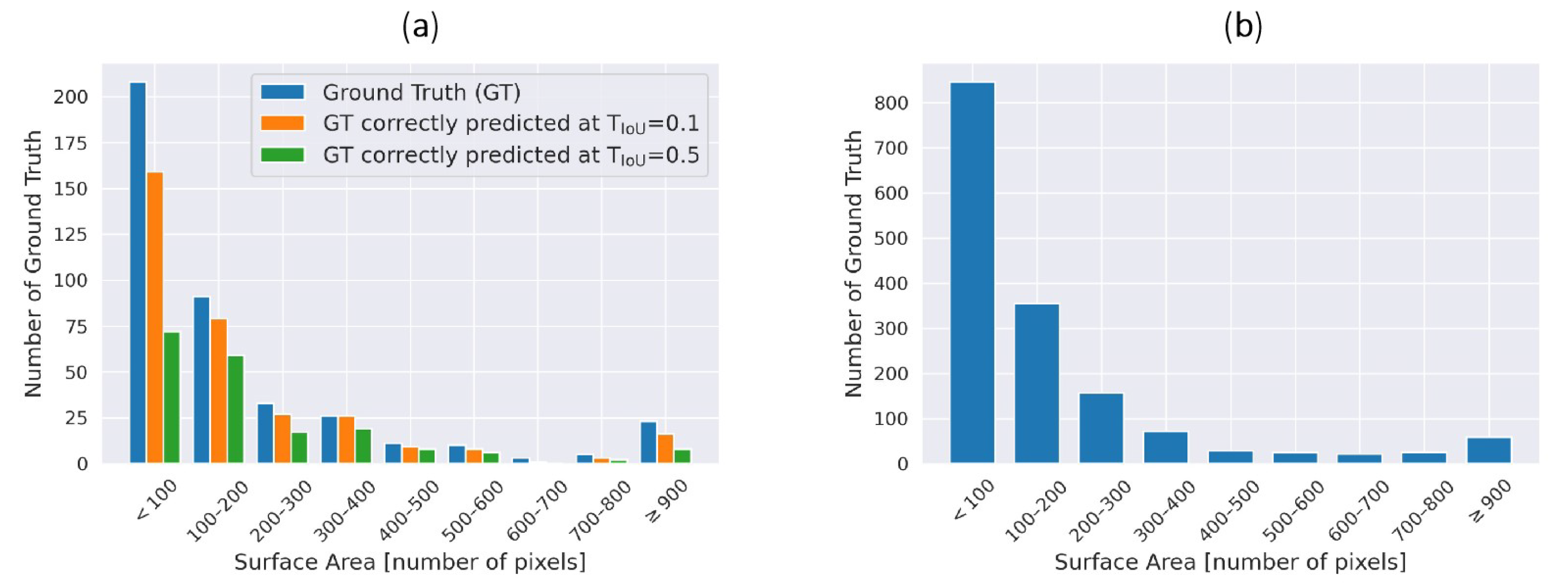
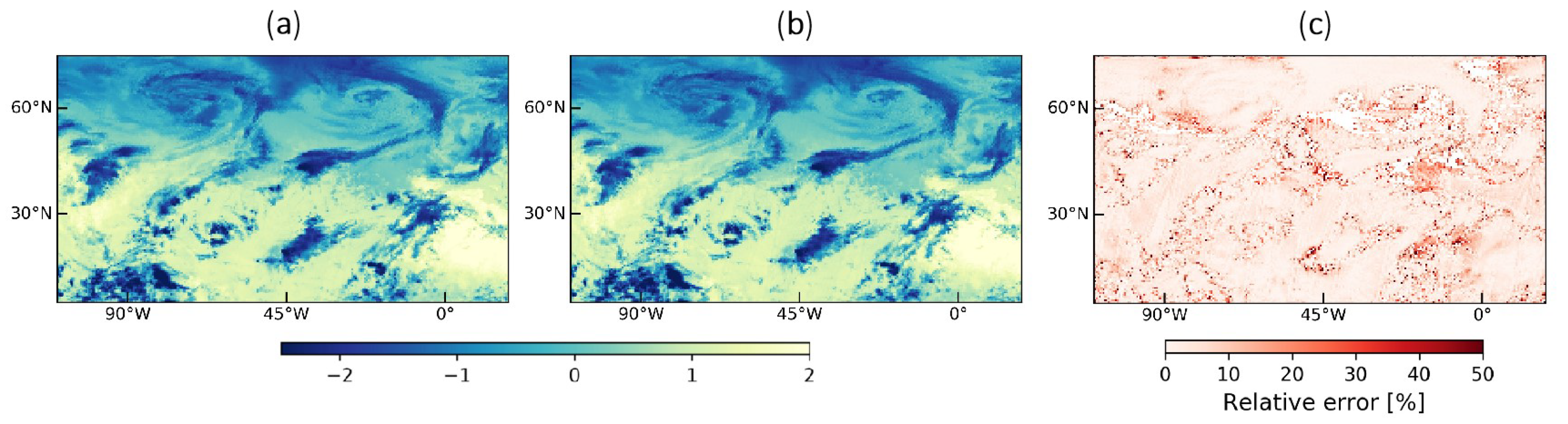
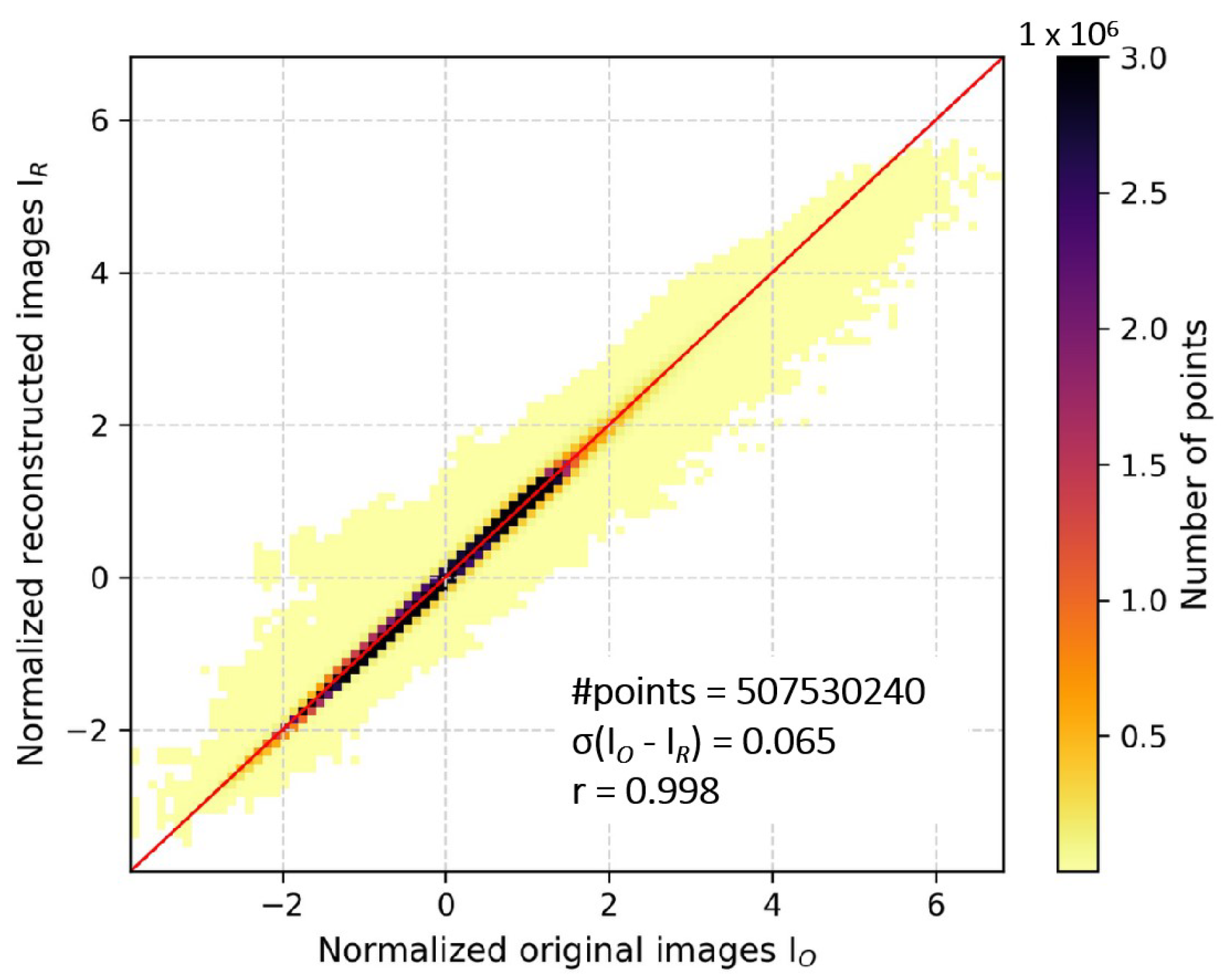
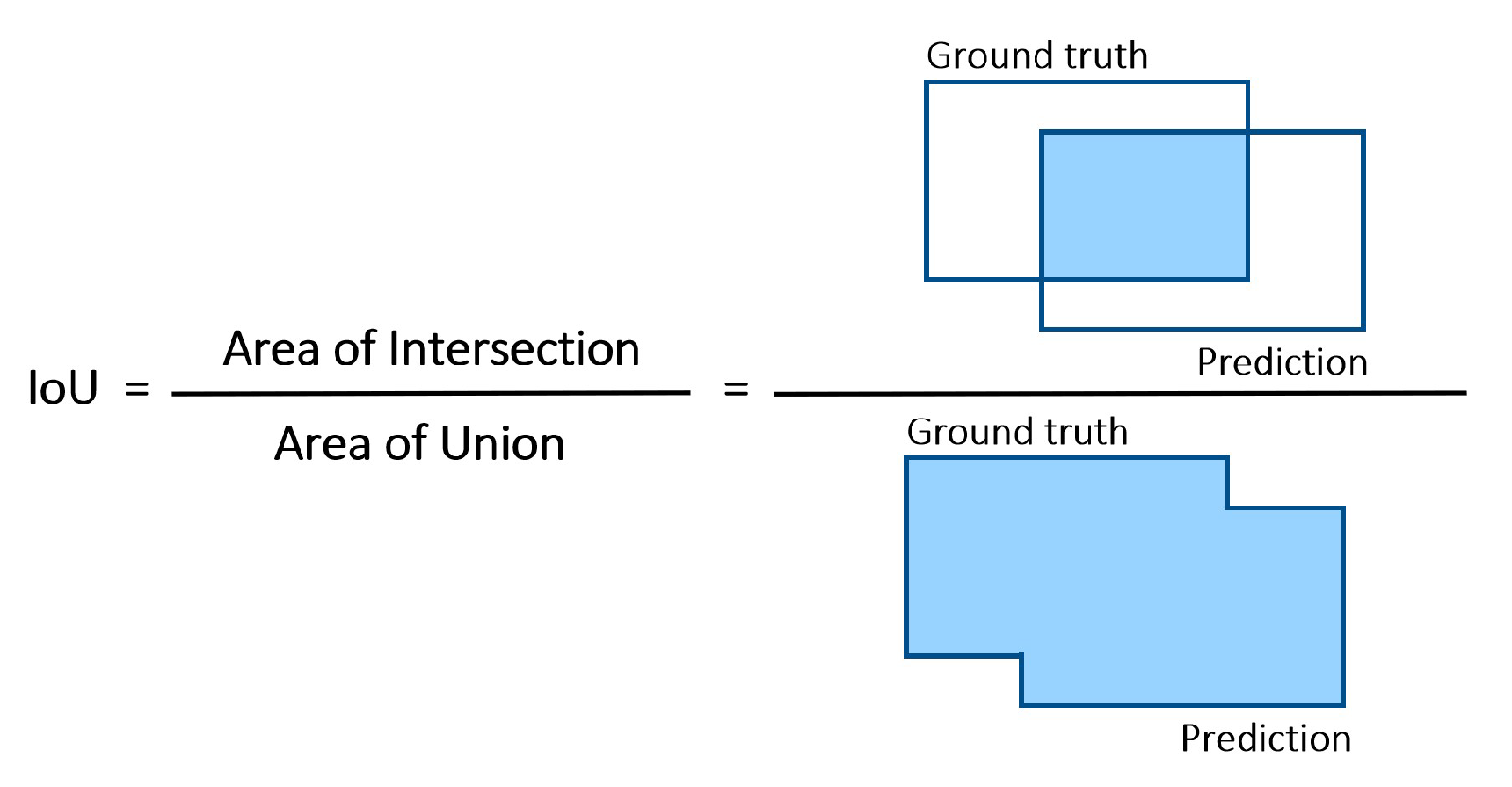
In this paper, we attempted to detect TCs in the North Atlantic Basin. We proposed a framework to process a selection of 50 channels from IASI radiance data into multi-channel images, as well as a labeling procedure using the HURDAT2 database. YOLOv3 object detection model has been trained on this dataset, firstly using three channels, then using an autoencoder to exploit all 50 channels. IASI data are not combined with other instruments’ data to form the dataset, and no wind data are used. We achieved promising results with Average Precision at threshold 0.1 (AP@.1) of 78.31%, although AP@.5 gave lower results (31.05%), hinting at a lack of precision of the model in its predictions, more particularly in the size of the predicted boxes.
The model could further be optimized by fine-tuning the hyperparameters. Application of the proposed framework could be extended to other models, such as the two-stage model Faster R-CNN [
29] or other single-stage models such as SSD [
26]. Further improvements to the input data could be explored, such as using other IASI products or channels, trying different interpolation methods (linear, cubic), or applying more advanced data augmentation techniques. For instance, Pang et al. [
31] used a deep convolutional generative adversarial network (DCGAN) to generate new images. Our method could be adapted to other regions outside the North Atlantic Basin, provided that tracks of TCs are available there. Other similar sensors to IASI could be used instead, such as the Atmospheric InfraRed Sounder (AIRS), the Moderate Resolution Imaging Spectroradiometer (MODIS), the Spinning Enhanced Visible and Infrared Imager (SEVIRI), on polar orbits (two crossing per day) or on geostationary orbits (many observations per day).
This study shows the ability of TIR instruments to act as valuable inputs into detection models. The IASI mission is planned to fly till at least 2028. It will be completed by the IASI-New Generation series of instruments [
40,
41] that will be launched on the Metop-Second Generation series of satellites starting 2024–2025 and running until at least 2045. A new era of TC detection will, therefore, be possible from infrared sensors for decades to come.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












