
An Improved Air Quality Index Machine Learning-Based Forecasting with Multivariate Data Imputation Approach


Abstract
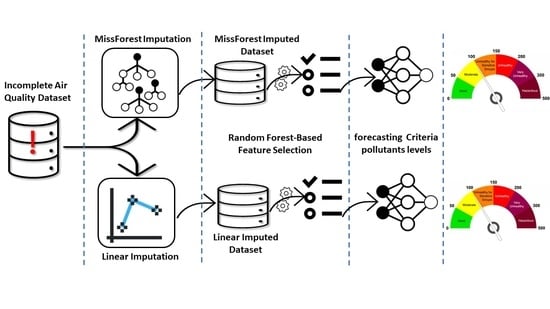
:
1. Introduction
1.1. Background and Motivation
1.2. Related Work
1.3. Our Contribution
- Proposing a reliable and tested solution for the enduring issue of missing meteorological and air quality observations.
- Employing the random forest (RF) model during the data pre-processing stage, i.e., missing data imputation and feature selection. The literature shows that the RF model has been primarily used as the final forecasting model and it has promising results. In the current work, the robustness of the RF model is tested when employed as an intermediate model rather than the final forecasting model.
- Fairly and comprehensively testing the effect of the data imputation approach on data used to build the final forecasting models. In our paper, the comparison between the two imputation techniques was performed on 6 CAP forecasting models, i.e., a total of 12; 6 for each imputation technique. This approach helped thoroughly investigate the superiority of one imputation technique over the other. Also, as a final step, the AQI values of the corresponding critical pollutant(s) were also estimated to test the impact of the imputation approach.
1.4. Paper Structure
2. Materials and Methods
2.1. Theory: MissForest
- Initialization: In this step, all missing observations of a specific variable are substituted by the mean value of this variable; a mean single imputation is performed as an initial step.
- Imputation: The imputation of missing data is performed in sequential order of missing entries for each variable. The variable with the missing entries being imputed is treated as a target variable (dependent variable) for training the RF model [30]. Other variables are used as predictors for this target variable. The complete non-missing entries of the target variable are used for training the RF model, whereas the missing ones are replaced by the estimated values using the trained model [29].
- Repetition: Step 2 is repeated for all variables with missing entries by assigning other variables to be the predictors to build the RF model.
- End: When the RF models for all the variables with missing entries are trained, the first imputation iteration is achieved. Then, steps 2 and 3 are repeated until the stopping criteria are reached. The stopping criteria are based on the mean square error (MSE) of the trained RF models. When the MSE of iteration (i) is higher than the MSE of the previous iterations, i.e., (i-1), the imputation process stops, and the final results are those determined from the previous iteration [29,31].
2.2. Data Description and Feature Engineering
2.2.1. Raw Data Sources and Pre-Analysis
- Concentrations of different gaseous and particulate pollutants.
- Meteorological conditions, e.g., ambient temperature and pressure, wind speed, wind direction, relative humidity, etc.
- (1)
- removing zero/span values;
- (2)
- removing readings that were below or above analyzer’s limit;
- (3)
- removing zero readings if zero was not considered a reading; and
- (4)
- removing some potential outliers that were obvious, such as spikes in concentrations, repeated values, i.e., data remaining the same for hours, or a sudden drop in concentration but still in the normal range of observed data.
2.2.2. Data Splitting
2.2.3. Missing Data Imputation
2.2.4. Feature Engineering (Extraction)
2.2.5. Data Scaling
2.3. Feature Selection
2.3.1. Feature Filtering and Selection
2.3.2. Lag Feature Selection
2.4. Forecasting Targets
3. Results and Discussion
3.1. Ozone (O3)
3.2. Nitrogen Dioxide (NO2)
3.3. Sulfur Dioxide (SO2)
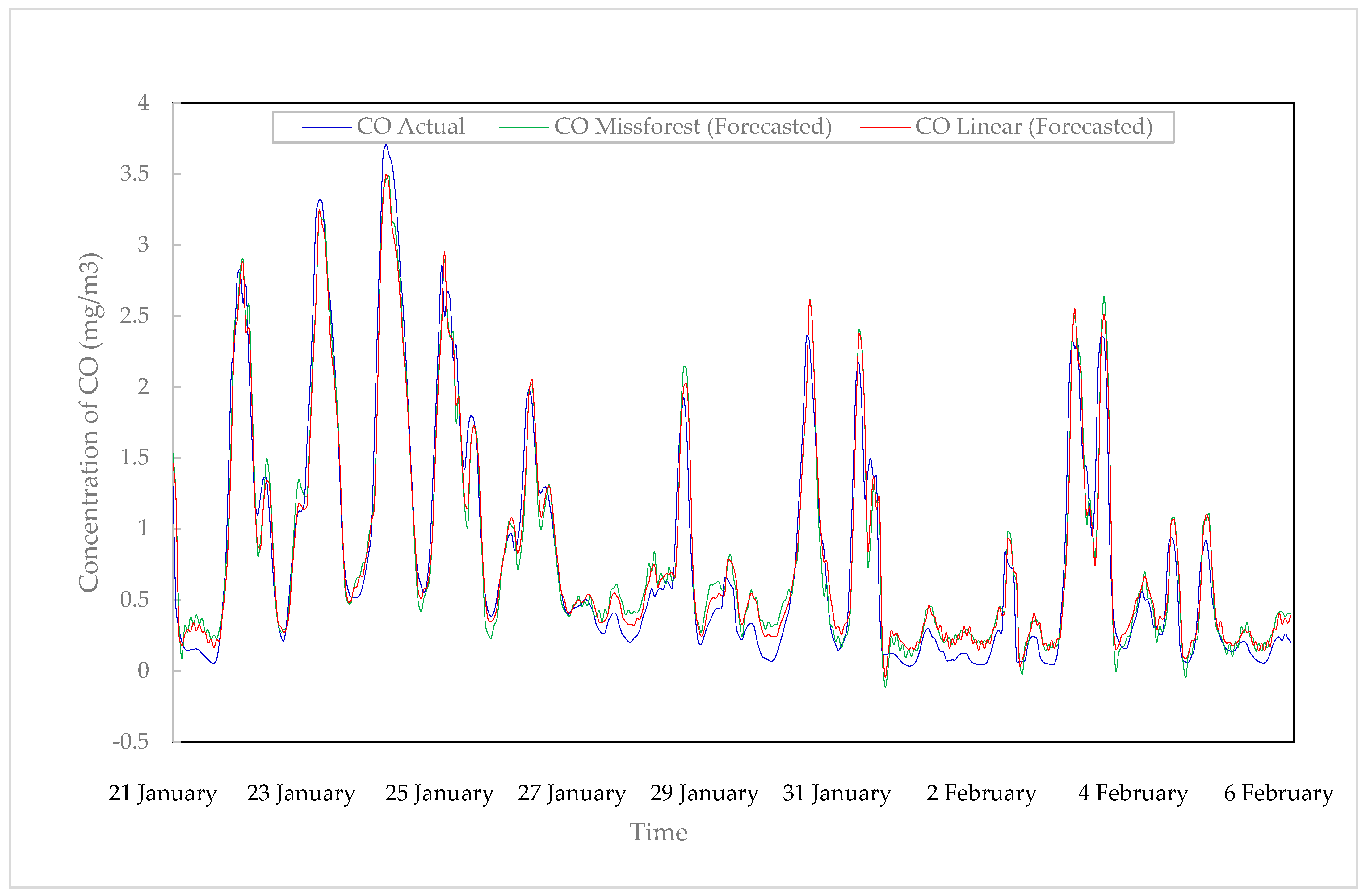
3.4. Carbon Monoxide (CO)
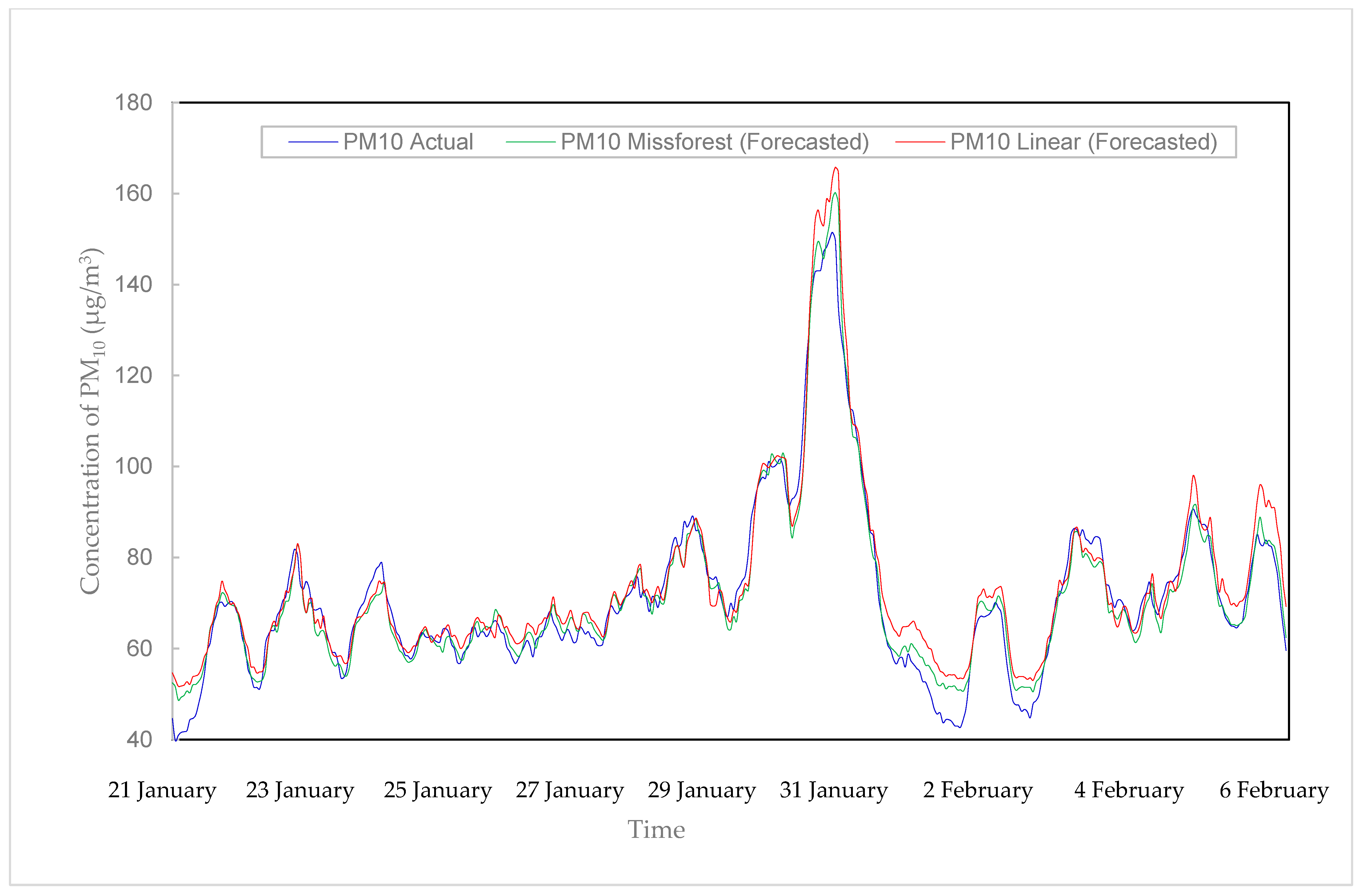
3.5. Particulate Matter-10 (PM10)
3.6. Particulate Matter-2.5 (PM2.5)
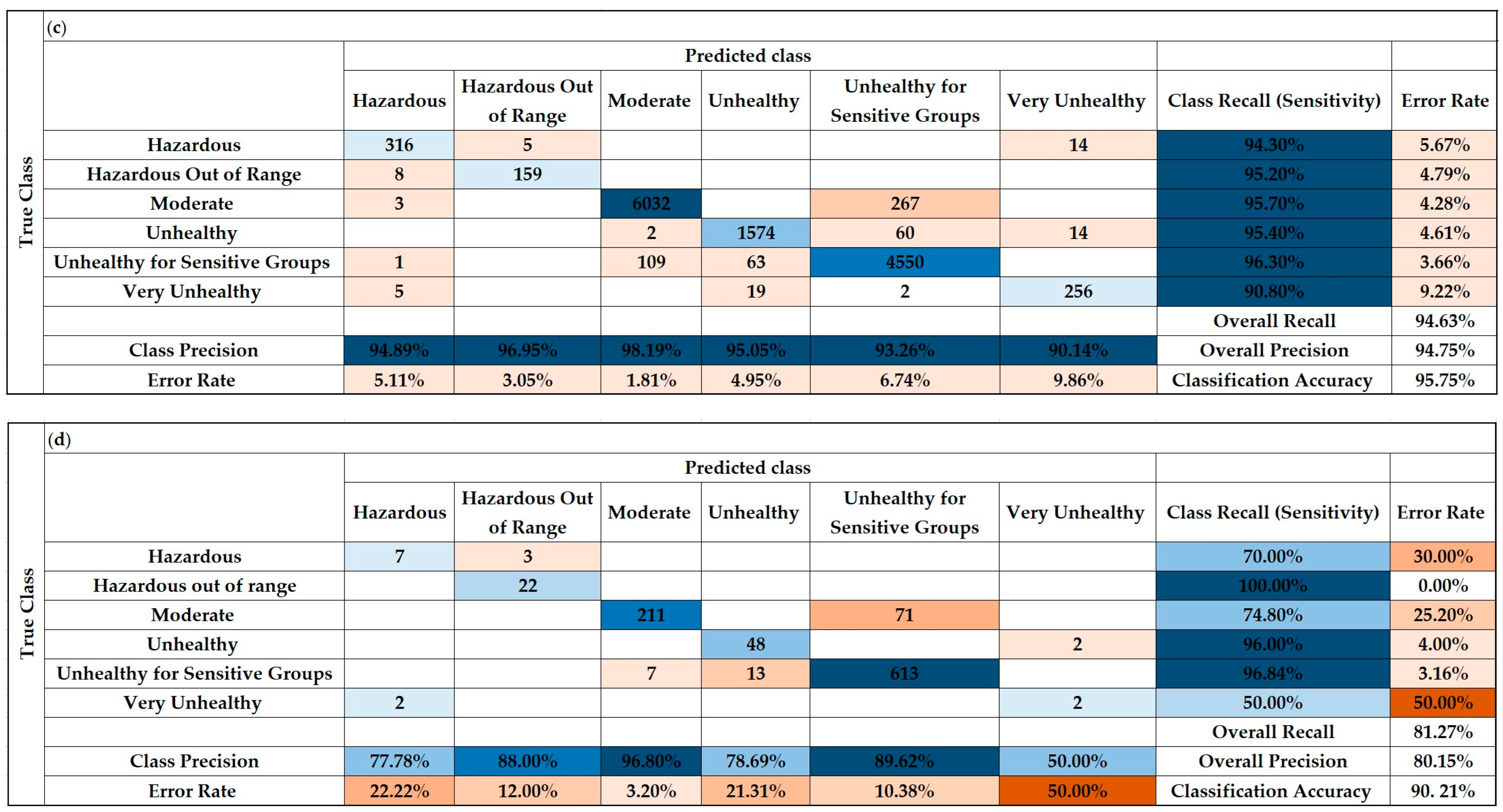
3.7. Hourly Forecast of Air Quality Index (AQI)
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramadan, A. Detailed analysis of power generation and water desalination sector emissions-part 1: Criteria pollutants and BTEX. Int. J. Environ. Sci. Technol. 2022, 19, 763–774. [Google Scholar] [CrossRef]
- Thomas, R.J.; Turkelboom, F. An Integrated Livelihoods-Based Approach to Combat Desertification in Marginal Drylands. In The Future of Drylands; Springer: Dordrecht, The Netherlands, 2008; pp. 631–646. [Google Scholar]
- Nanney, R.D.; Fryrear, D.W.; Zobeck, T.M. Wind Erosion Prediction and Control. Water Sci. Technol. 1993, 28, 519–527. [Google Scholar] [CrossRef]
- Al-Dousari, A.; Ramadan, A.; Al-Qattan, A.; Al-Ateeqi, S.; Dashti, H.; Ahmed, M.; Al-Dousari, N.; Al-Hashash, N.; Othman, A. Cost and Effect of Native Vegetation Change on Aeolian Sand, Dust, Microclimate and Sustainable Energy in Kuwait. J. Taibah Univ. Sci. 2020, 14, 628–639. [Google Scholar] [CrossRef]
- Al-Kulaib, A. Weather and Climate of Kuwait; Al-Qabas Press: Kuwait City, Kuwait, 1992. [Google Scholar]
- Al-Dousari, A.; Doronzo, D.; Ahmed, M. Types, Indications and Impact Evaluation of Sand and Dust Storms Trajectories in the Arabian Gulf. Sustainability 2017, 9, 1526. [Google Scholar] [CrossRef] [Green Version]
- Blott, S.; Al-Dousari, A.M.; Pye, K.; Saye, E.S. Three-Dimensional Characterization of Sand Grain Shape and Surface Texture Using a Nitrogen Gas Adsorption Technique. J. Sediment. Res. 2004, 74, 156. [Google Scholar] [CrossRef]
- Al-Dousari, A.; Al-Enezi, A.; Al-Awadhi, J. Textural Variations within Different Representative Types of Dune Sediments in Kuwait. Arab. J. Geosci. 2008, 1, 17–31. [Google Scholar] [CrossRef]
- World Health Organization. Particulate matter (PM2.5 and PM10), ozone, nitrogen dioxide, sulfur dioxide and carbon monoxide. In WHO Global Air Quality Guidelines; World Health Organization: Geneva, Switzerland, 2021; Licence: CC BY-NC-SA 3.0 IGO. [Google Scholar]
- Anenberg, S.C.; Henze, D.K.; Tinney, V.; Kinney, P.L.; Raich, W.; Fann, N.; Malley, C.S.; Roman, H.; Lamsal, L.; Duncan, B.; et al. Estimates of the Global Burden of Ambient PM2.5, Ozone, and NO2 on Asthma Incidence and Emergency Room Visits. Environ. Health Perspect. 2018, 126, 1289. [Google Scholar] [CrossRef] [Green Version]
- Balluz, L.; Wen, X.; Town, M.; Shire, J.; Qualter, J.; Mokdad, A. Ischemic Heart Disease and Ambient Air Pollution of Particulate Matter 2.5 in 51 Counties in the U.S. Public Health Rep. 2007, 122, 626–633. [Google Scholar] [CrossRef]
- Brunekreef, B.; Forsberg, B. Epidemiological Evidence of Effects of Coarse Airborne Particles on Health. Eur. Respir. J. 2005, 26, 309–318. [Google Scholar] [CrossRef]
- Laden, F.; Schwartz, J.; Speizer, F.; Dockery, D. Reduction in Fine Particulate Air Pollution and Mortality—Extended Follow-up of the Harvard Six Cities Study. Am. J. Respir. Crit. Care Med. 2006, 173, 667–672. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, J.; Dockery, D.; Neas, L. Is Daily Mortality Associated Specifically with Fine Particles? J. Air Waste Manag. Assoc. 1996, 46, 927–939. [Google Scholar] [CrossRef] [PubMed]
- Kaku, K.C.; Reid, J.S.; Reid, E.A.; Ross-Langerman, K.; Piketh, S.; Cliff, S.; Al Mandoos, A.; Broccardo, S.; Zhao, Y.; Zhang, J.; et al. Investigation of the Relative Fine and Coarse Mode Aerosol Loadings and Properties in the Southern Arabian Gulf Region. Atmos. Res. 2016, 169, 171–182. [Google Scholar] [CrossRef] [Green Version]
- Alolayan, M.A.; Brown, K.W.; Evans, J.S.; Bouhamra, W.S.; Koutrakis, P. Source Apportionment of Fine Particles in Kuwait City. Sci. Total Environ. 2013, 448, 14–25. [Google Scholar] [CrossRef]
- National Air Quality Strategy; Kingdom of Bahrain Supreme Council for Environment (SCE): Seef, Bahrain, 2020.
- Ramanathan, V. Climate Change, Air Pollution, and Health: Common Sources, Similar Impacts, and Common Solutions. In Health of People, Health of Planet and Our Responsibility; Springer International Publishing: Cham, Switzerland, 2020; pp. 49–59. [Google Scholar] [CrossRef]
- Connell, D.W. Basic Concepts of Environmental Chemistry; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar] [CrossRef]
- USEPA. Technical Assistance Document for the Reporting of Daily Air Quality—The Air Quality Index (AQI); United States Environmental Protection Agency: Durham, NC, USA, 2013; pp. 1–28.
- Lim, S.Y.; Chin, L.Y.; Mah, P.; Wee, J. Arima and Integrated Arfima Models for Forecasting Air Pollution Index in Shah Alam, Selangor. Malays. J. Anal. Sci. 2008, 12, 257–263. [Google Scholar]
- Zhu, J. Comparison of ARIMA Model and Exponential Smoothing Model on 2014 Air Quality Index in Yanqing County, Beijing, China. Appl. Comput. Math. 2015, 4, 456. [Google Scholar] [CrossRef] [Green Version]
- Karthikeyani, S.; Rathi, S. A Survey On Air Quality Prediction Using Traditional Statistics Method. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2020, 6, 942–946. [Google Scholar] [CrossRef]
- Zhang, P.G. Time Series Forecasting Using a Hybrid ARIMA and Neural Network Model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Wang, C.Y.; Zhang, W.Y.; Wang, J.J.; Zhao, W.F. The Prediction of SO2 Pollutant Concentration Using a RBF Neural Network. Appl. Mech. Mater. 2011, 55–57, 1392–1396. [Google Scholar] [CrossRef]
- Cai, M.; Yin, Y.; Xie, M. Prediction of Hourly Air Pollutant Concentrations near Urban Arterials Using Artificial Neural Network Approach. Transp. Res. Part D Transp. Environ. 2009, 14, 32–41. [Google Scholar] [CrossRef]
- Castelli, M.; Clemente, F.M.; Popovič, A.; Silva, S.; Vanneschi, L. A Machine Learning Approach to Predict Air Quality in California. Complexity 2020, 2020, 8049504. [Google Scholar] [CrossRef]
- Sankar Ganesh, S.; Arulmozhivarman, P.; Tatavarti, R. Forecasting Air Quality Index Using an Ensemble of Artificial Neural Networks and Regression Models. J. Intell. Syst. 2017, 28, 893–903. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A Survey of Optimization Methods from a Machine Learning Perspective. arXiv 2019, arXiv:1906.06821. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, S.; Lynn, H.S. Accuracy of Random-Forest-Based Imputation of Missing Data in the Presence of Non-Normality, Non-Linearity, and Interaction. BMC Med. Res. Methodol. 2020, 20, 199. [Google Scholar] [CrossRef]
- Athiyarath, S.; Paul, M.; Krishnaswamy, S. A Comparative Study and Analysis of Time Series Forecasting Techniques. SN Comput. Sci. 2020, 1, 175. [Google Scholar] [CrossRef]
- Tealab, A. Time Series Forecasting Using Artificial Neural Networks Methodologies: A Systematic Review. Futur. Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Wu, B. An Introduction to Neural Networks and Their Applications in Manufacturing. J. Intell. Manuf. 1992, 3, 391–403. [Google Scholar] [CrossRef]
- Sarigül, M.; Avci, M. Performance Comparison of Different Momentum Techniques on Deep Reinforcement Learning. J. Inf. Telecommun. 2018, 2, 205–216. [Google Scholar] [CrossRef] [Green Version]
- Lever, J.; Krzywinski, M.; Altman, N. Points of Significance: Model Selection and Overfitting. Nat. Methods 2016, 13, 703–704. [Google Scholar] [CrossRef]
- Arhami, M.; Kamali, N.; Rajabi, M.M. Predicting Hourly Air Pollutant Levels Using Artificial Neural Networks Coupled with Uncertainty Analysis by Monte Carlo Simulations. Environ. Sci. Pollut. Res. 2013, 20, 4777–4789. [Google Scholar] [CrossRef]
- Nawi, N.M.; Atomi, W.H.; Rehman, M.Z. The Effect of Data Pre-Processing on Optimized Training of Artificial Neural Networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef] [Green Version]
- Brick, T.R.; Koffer, R.E.; Gerstorf, D.; Ram, N. Feature Selection Methods for Optimal Design of Studies for Developmental Inquiry. J. Gerontol. Ser. B 2018, 73, 113–123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Degenhardt, F.; Seifert, S.; Szymczak, S. Evaluation of Variable Selection Methods for Random Forests and Omics Data Sets. Brief. Bioinform. 2019, 20, 492–503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gnana Sheela, K.; Deepa, S.N. An Intelligent Computing Model for Wind Speed Prediction in Renewable Energy Systems. Procedia Eng. 2012, 30, 380–385. [Google Scholar] [CrossRef] [Green Version]
- Gressling, T. 84 Automated Machine Learning; De Gruyter: Berlin, Germany, 2020. [Google Scholar] [CrossRef]
- Ettouney, R.S.; Mjalli, F.S.; Zaki, J.G.; El-Rifai, M.A.; Ettouney, H.M. Forecasting of Ozone Pollution Using Artificial Neural Networks. Manag. Environ. Qual. An Int. J. 2009, 20, 668–683. [Google Scholar] [CrossRef]
- Díaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A Hybrid ARIMA and Artificial Neural Networks Model to Forecast Particulate Matter in Urban Areas: The Case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef] [Green Version]
- Samal, K.K.R.; Panda, A.K.; Babu, K.S.; Das, S.K. An Improved Pollution Forecasting Model with Meteorological Impact Using Multiple Imputation and Fine-Tuning Approach. Sustain. Cities Soc. 2021, 70, 102923. [Google Scholar] [CrossRef]
- Lin, Y.; Zhao, L.; Li, H.; Sun, Y. Air Quality Forecasting Based on Cloud Model Granulation. Eurasip J. Wirel. Commun. Netw. 2018, 2018, 106. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Kumar, P.; Kumar, Y. Time Series Data Prediction Using IoT and Machine Learning Technique. Procedia Comput. Sci. 2020, 167, 373–381. [Google Scholar] [CrossRef]
- Yu, R.; Yang, Y.; Yang, L.; Han, G.; Move, O. RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems. Sensors 2016, 16, 86. [Google Scholar] [CrossRef] [Green Version]
- Belavadi, S.V.; Rajagopal, S.; Ranjani, R.; Mohan, R. Air Quality Forecasting Using LSTM RNN and Wireless Sensor Networks. Procedia Comput. Sci. 2020, 170, 241–248. [Google Scholar] [CrossRef]
- Arora, H.; Solanki, A. Prediction of Air Quality Index in Metro Cities Using Time Series Forecasting Models Page No: 3052. J. Xi’an Univ. Archit. Technol. 2020, XII, 3052–3067. [Google Scholar]
- Singh, A. Air Pollution Forecasting and Performance Using Advanced Time Series and Deep Learning Approach for Gurgaon. Ph.D. Thesis, National College of Ireland, Dublin, Ireland, 2019. [Google Scholar]














{kind=link}
{kind=link}
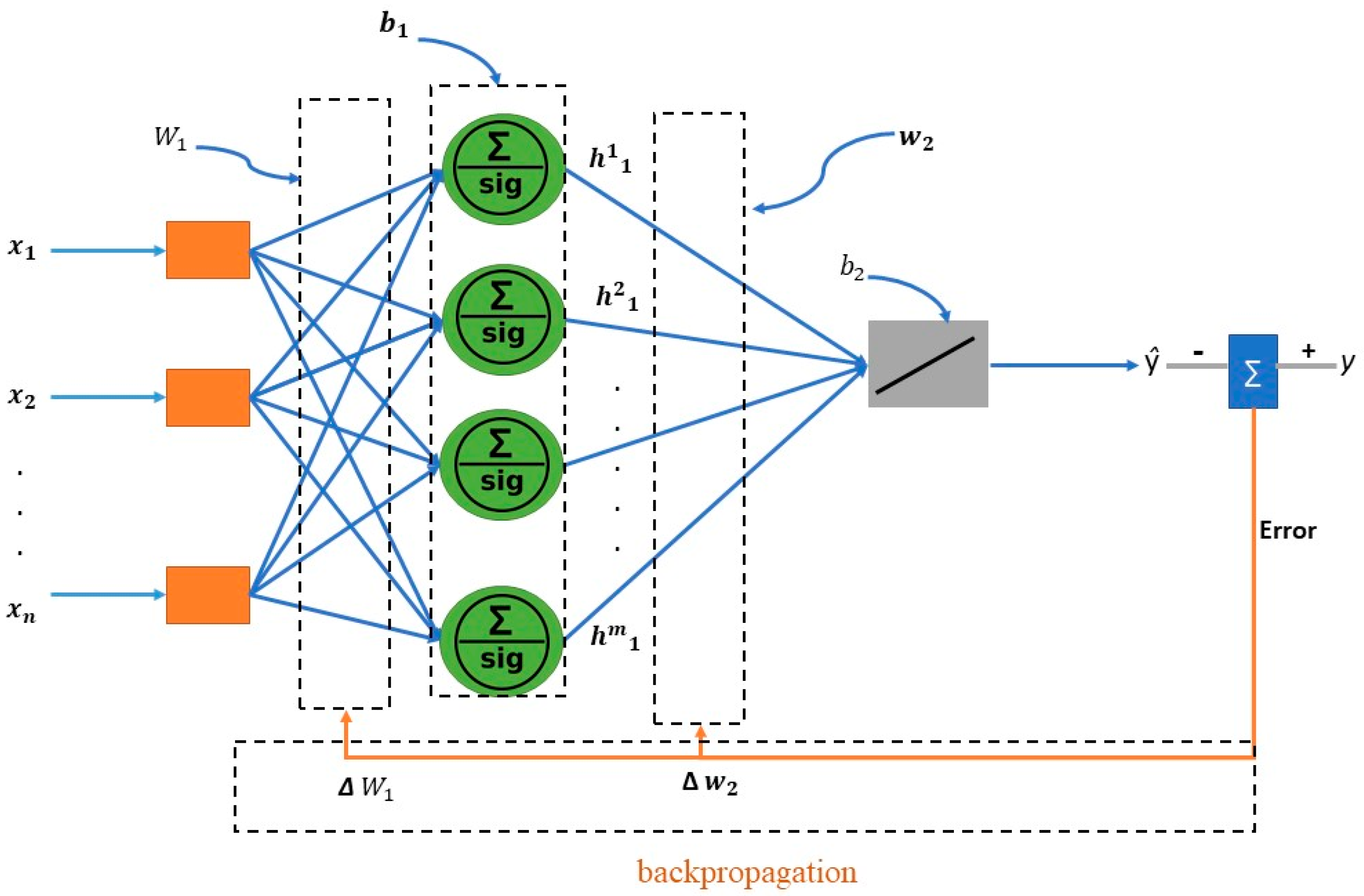{kind=link}
{kind=link}
{kind=link}
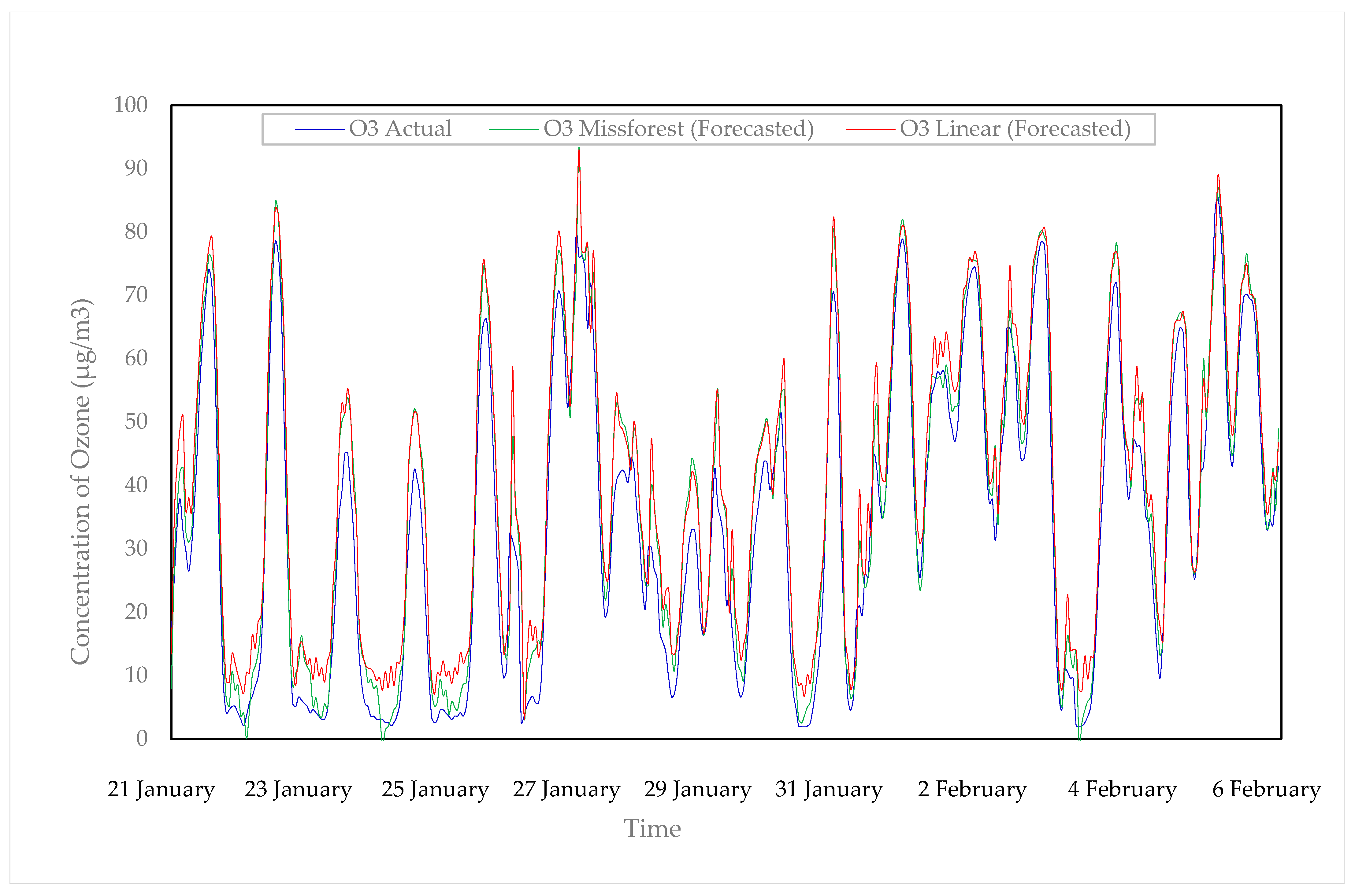{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index Value | Level of Health Concern | Description |
|---|---|---|
| 0–50 | Good | Air quality is satisfactory. |
| 51–100 | Moderate | Air quality is acceptable; however, there may be moderate health concerns for groups with unusual sensitivity to air pollution for some pollutants. |
| 101–150 | Unhealthy for sensitive groups | Only sensitive groups may experience health effects. |
| 151–200 | Unhealthy | All individuals may start to experience health effects. Sensitive groups may experience more severe effects. |
| 201–300 | Very unhealthy | Health alert: everyone may experience serious health effects. |
| 301–500 | Hazardous | Health warning for emergency conditions. |
| Type | Variable | Measurement Unit |
|---|---|---|
| Meteorological | Temperature | °C |
| Wind speed | m/s | |
| Wind direction | deg | |
| Relative humidity | % | |
| Criteria gases level | CO | mg/m3 |
| NO2 | µg/m3 | |
| O3 | µg/m3 | |
| PM10 | µg/m3 | |
| PM2.5 | µg/m3 | |
| SO2 | µg/m3 |
| Variable | Missing Rate (%) |
|---|---|
| NO2 | 10.96% |
| PM2.5 | 10.36% |
| O3 | 10.30% |
| SO2 | 8.01% |
| PM10 | 7.89% |
| CO | 6.70% |
| Temperature | 4.59% |
| Relative humidity | 1.89% |
| Wind speed | 1.16% |
| Wind direction | 1.16% |
| Time (year, month, day, hour) | 0% |
| Target | O3 Conc. | SO2 Conc. | NO2 Conc. | CO Conc. | PM10 Conc | PM2.5 Conc | |
|---|---|---|---|---|---|---|---|
| Variable | |||||||
| Year | * | * | * | * | * | * | |
| sine month | * | * | * | * | * | * | |
| cosine month | * | * | * | * | * | * | |
| sine day | * | * | * | * | * | * | |
| cosine day | * | * | * | * | * | * | |
| sine hour | * | * | * | * | Rejected | Rejected | |
| cosine hour | * | * | * | * | * | * | |
| O3 Conc. | * | * | * | * | * | ||
| SO2 Conc. | * | * | * | * | * | ||
| NO2 Conc. | * | * | * | * | |||
| CO Conc. | * | * | * | * | * | ||
| PM10 Conc. | * | * | * | * | * | ||
| PM2.5 Conc. | * | * | * | * | * | ||
| Wind Speed | * | * | * | * | * | * | |
| Wind direction | * | * | * | Tentative | * | * | |
| Temperature | * | * | * | * | * | * | |
| Relative Humidity | * | * | * | * | * | * | |

| Pollutant | Optimal No. of Nodes (MissForest-Imputed Dataset) | Optimal No. of Nodes (Linear-Imputed Dataset) |
|---|---|---|
| PM10 | 20 | 12 |
| PM2.5 | 18 | 16 |
| O3 | 12 | 12 |
| NO2 | 10 | 12 |
| SO2 | 16 | 18 |
| CO | 14 | 16 |
| MissForest-Imputed Dataset | Linear-Imputed Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | MSE | RMSE [µg/m3] | MAE [µg/m3] | R2 | MSE | RMSE [µg/m3] | MAE [µg/m3] | ||
| O3 | Training | 0.9715 | 26.795 | 5.176 | 4.033 | 0.972 | 28.451 | 5.334 | 4.223 |
| Testing | 0.929 | 31.112 | 5.578 | 4.554 | 0.874 | 55.234 | 7.432 | 6.561 | |
| NO2 | Training | 0.839 | 166.621 | 12.908 | 9.164 | 0.865 | 142.798 | 11.95 | 7.864 |
| Testing | 0.778 | 160.365 | 12.664 | 9.985 | 0.764 | 144.797 | 12.033 | 9.948 | |
| SO2 | Training | 0.529 | 297.395 | 17.245 | 6.611 | 0.486 | 455.128 | 21.334 | 7.199 |
| Testing | 0.511 | 191.015 | 13.821 | 6.01 | 0.334 | 261.052 | 16.157 | 9.745 | |
| CO * | Training | 0.919 | 0.025 | 0.158 | 0.097 | 0.927 | 0.023 | 0.153 | 0.088 |
| Testing | 0.917 | 0.045 | 0.211 | 0.169 | 0.921 | 0.041 | 0.201 | 0.158 | |
| PM10 | Training | 0.978 | 252.386 | 15.887 | 6.14 | 0.974 | 371.863 | 19.284 | 7.577 |
| Testing | 0.969 | 482.345 | 21.962 | 7.979 | 0.978 | 347.359 | 18.638 | 9.403 | |
| PM2.5 | Training | 0.977 | 27.957 | 5.287 | 2.462 | 0.979 | 26.208 | 5.119 | 2.356 |
| Testing | 0.971 | 14.109 | 3.756 | 2.784 | 0.974 | 12.751 | 3.571 | 2.889 | |
| MissForest-Imputed Dataset | Linear-Imputed Dataset | |||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| R2 | 0.81 | 0.93 | 0.78 | 0.98 |
| MSE | 131.25 | 95.18 | 178.56 | 297.05 |
| RMSE | 11.46 | 9.76 | 13.36 | 17.24 |
| MAE | 3.00 | 3.27 | 3.34 | 4.69 |
| Condition | Training MissForest-Imputed | Testing MissForest-Imputed |
| Category = True and Critical pollutant = True | 12597 | 924 |
| Category = False and Critical pollutant = True | 551 | 76 |
| Category = True and Critical pollutant = False | 276 | 1 |
| Category = False and Critical pollutant = False | 35 | 0 |
| Condition | Training Linear-Imputed | Testing Linear-Imputed |
| Category = True and Critical pollutant = True | 12636 | 901 |
| Category = False and Critical pollutant = True | 536 | 98 |
| Category = True and Critical pollutant = False | 251 | 2 |
| Category = False and Critical pollutant = False | 36 | 0 |
| Forecasting Method | Imputation Method | Forecasting Target(s) | Evaluation Metrics | Ref. |
|---|---|---|---|---|
| ANN | MissForest + linear imputation | CAPs + AQI (1 h) | Accuracy: 92.48% (missForest)/90.31% (Linear) RMSE: 9.76 (missForest)/17.24 (Linear) | Current work |
| Random forest | N/A | AQI (1 h) | 81.6% classification accuracy | [48] |
| LSTM -RNN | Values of the previous week at the same time were used to fill gaps. If that last week’s values were also missing, mean imputation was used | CAP levels in two regions in India, using two data sources (1–5 h) | RMSE: 30–40 ppm (source 1)/0–5 ppm (source 2) | [49] |
| SVM | 2nd order polynomial to impute missing observations in pollutants levels and meteorological data | CAPs + AQI (1 h) | Accuracy: 94.1% (on unseen validation data) | [27] |
| RBF NN | N/A | SO2 (24 h) | MAPE: 9.91% | [25] |
| SVR, NAR, CMG | Mean value imputation | CAPs + AQI (24 h) | Accuracy (on AQI): CMG: 71.43% SVR: 57.14% NAR: 28.57% | [46] |
| Linear regression | Expectation-Maximization algorithm | AQI (24 h) | MAE: 7.57 | [47] |
| Compared different statistical, ML, and DL methods for forecasting | K-NN for missing data imputation with varying missingness rates | PM2.5 (96 h multi-step-ahead forecasting) with different combinations of meteorological features to investigate their importance and effect on forecasting accuracy | Multiple error metrics were compared for all the forecasting methods; the Convolutional-LSTM–SDAE model surpassed other models with RMSE = 24 μg/m3 | [45] |
| SARIMA | Mean and median imputation | NO2 (24 h) SO2 (24 h) | MAPE: 3% (NO2)/7% (SO2) | [50] |
| Compared different forecasting methods | Seasonal adjustment coupled with linear interpolation | AQI (8 h) | The additive regression PROPHET model outperformed other forecasting models with RMSE = 9.00 (AQI) | [51] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkabbani, H.; Ramadan, A.; Zhu, Q.; Elkamel, A. An Improved Air Quality Index Machine Learning-Based Forecasting with Multivariate Data Imputation Approach. Atmosphere 2022, 13, 1144. https://doi.org/10.3390/atmos13071144
Alkabbani H, Ramadan A, Zhu Q, Elkamel A. An Improved Air Quality Index Machine Learning-Based Forecasting with Multivariate Data Imputation Approach. Atmosphere. 2022; 13(7):1144. https://doi.org/10.3390/atmos13071144
Chicago/Turabian StyleAlkabbani, Hanin, Ashraf Ramadan, Qinqin Zhu, and Ali Elkamel. 2022. "An Improved Air Quality Index Machine Learning-Based Forecasting with Multivariate Data Imputation Approach" Atmosphere 13, no. 7: 1144. https://doi.org/10.3390/atmos13071144