4.1. Data Used
We obtained the air pollutant concentrations from Ministry of Ecology and Environment of the People’s Republic of China. Meteorological variables are obtained from China meteorological administration. The concentrations of carbon monoxide (), nitrogen dioxide (), ozone (), particulate matter (PM) and sulfur dioxide () are monitored. The data basis consists daily values corresponding to the 2-year period between January 2016 and December 2017.
Furthermore, the air monitoring stations do not monitor the level of meteorological variables. Thus, we select the nearest meteorological stations to represent the levels of the meteorological variables in the air monitoring stations. However, the distances of some air monitoring stations and meteorological stations are too far. Consequently, only three air monitoring stations, Ma Lian Kou, Sha Po Tou and Ma Yuan are selected for this research.
Figure 2 and
Table 1 showed the geographical regions of Ningxia and the locations of air monitoring stations.
Ma Lian Kou is located at the foot of Helan mountain in Yinchuan city and belongs to the northern Yellow river diversion irrigation area. Sha Po Tou is located in the central arid zone, near the Tengger Desert and on the Bank of the Yellow River. Ma Yuan is located in Guyuan city and belongs to the southern mountainous area. A descriptive statistics of these parameters in three monitoring stations for the studied period is presented in
Table 2, including minimum, mean, median and maximum levels of the 12 input parameters and the concentrations of air pollutants during 2016–2017.
Figure 3,
Figure 4 and
Figure 5 show the diurnal variations of air pollutant concentrations in three selected monitoring stations.
In Ma Lian Kou, the concentrations of fluctuated enormously, with maxima of 38.24 g/m in January 2016, and 4.59 g/m in August 2016, respectively. These maxima correspond to the winter months. Concentration minima of took place during the summer months. Its values were 0.0722 g/m and 0.1053 g/m in April and August 2016.
Similarly, the concentrations of fluctuated significantly with several maxima of 54 and 51 g/m in December 2016, respectively. These maxima correspond to the days of highest energy consumption in homes due to heating and a greater density of cars on the roads during the winter season. Likewise, the minima in the concentrations corresponded to the spring months.
The concentrations of also fluctuated considerably, with maxima of 213 g/m in June 2016, and 208 g/m in May 2016, respectively. These maxima corresponded to the summer months. Concentration minima of took place in September 2016, its values were 13.375 g/m and 20.3 g/m in September. This trend is general throughout the studied years, since the formation of is associated with photochemical reactions, which requires the presence of strong sunlight as a catalyst.
In a similar way, the concentrations of went up and down slightly but remained quite stable at around 70 g/m with two spikes at 307 g/m in May 2016 and March 2016, and a minimum of 6.9 g/m in August 2016 and 11.4 g/m in September 2016.
Similarly, the concentrations of went up and down slightly but remained quite stable at around 33 g/m with two spikes at 195 g/m in May 2016 and September 2016, and a minimum of 6.1 g/m in August 2016. went up and down slightly but remained quite stable at around 32 g/m with two spikes at 182 g/m and 143 g/m in January 2016.
It is shown that the trends of air pollutant concentrations at the three monitoring stations are generally different, and the concentrations of air pollutants in Ma Yuan are the lowest. Therefore, the differences of air pollutant concentrations are closely related to geographical locations.
The meteorological variables such as ground surface minimum temperature, maximum and mean temperature, minimum relative humidity and maximum relative humidity, air minimum temperature, maximum and mean temperature, minimum, mean, maximum wind speed, sunshine duration supplied by the China meteorological data service center, their units were °C, m/s, and hour, respectively. The meteorological variables were recorded on a daily basis.
Table 3 show that the minimum of air temperature (
) ranged from −15 in January to 27 °C in July, while the maximum of air temperatures (
) varied from −10 °C in January to 41 °C in July. The average sun shine of duration (ssd) was 6.7 h with the minimum and maximum values of 0h and 14 h appearing in November and June, respectively at Ma Lian Kou station.
4.2. Selection of the Influential Factors
The selection of input parameters is generally based on the prior knowledge of the formation of the air pollutants and the correlation analysis. Through the descriptive analysis of the air pollutant concentrations and the meteorological variables, we can select the most important input parameters and understand which are the dominant factors for the formation and diffusion of air pollutants. Generally, the levels of air pollutant concentrations are associated with emission sources, the formation of secondary pollutants and wind speed, air temperature and ground surface temperature, etc. It is well known that air pollutants and weather conditions are associated with each other in a complex relationship. With the increase of air temperature, the stronger the atmospheric convection activity, the more unstable the air stratification, which is conducive to the diffusion and dilution of pollutants. The air pollutant concentrations were closely related to the change of meteorological factors. Furthermore, relative humidity shows significant negative effect on the concentrations of
and
, because precipitation will wash out the atmospheric particles. It can be seen from
Table 4 that there is a strong negative correlation between wind speed and air pollutant concentration, significant negative effect demonstrates the fact that low concentrations are linked with high wind speed in Ningxia. It is shown in
Figure 4a that the concentration of
was higher in hot summer due to the high radiation and temperature, and lower in winter. The ground surface temperatures have the strongest correlations with the air pollutant concentrations, which is due to the enhancement of ultraviolet radiation, the increase of temperature, the enhancement of the decomposition of oxygen molecules, and the increase of the photochemical reaction rate of
formation, resulting in the increase of air pollutant concentrations. The obtained results show that there are strong relationships between ground surface temperatures have and the concentrations of the majority of pollutants in the region of Ningxia. Moreover, air pollutant concentrations have a close relationship with the concentrations at previous time. There is a high possibility of mutual conversion between
and other pollutants, especially
.
and
are negatively correlated with air temperature. Furthermore, the concentrations of
may have a notable influence on the concentrations of
. High levels of particulate matter in Ningxia are mostly caused by sand storms and construction activities near the monitoring stations. High temperature can result in enhanced re-suspension of road dust. Meteorological variables are used for the prediction of air pollutant concentrations.
We only consider variables with a coefficient of correlation greater than 0.30 as input dataset [
35]. According to the correlation coefficient matrix shown in
Table 4, there is a negative relationship between the concentrations of
and air temperature and wind speed, respectively. Hence the combinations of other air pollutant concentrations, the air pollutant concentrations one day in advance and meteorological variables for each air pollutant concentration are chosen as the input dataset. And we obtained the selected meteorological variables for every pollutant in
Table 5.
4.3. Experimental Results and Interpretations
For the purposes of comparisons, FFANN-BP, DTR and RFR models are trained in order to predict air pollutant concentrations in the three monitoring stations of Ningxia at a local scale. In this study, DTR, FFANN-BP and RFR were used to evaluate the ability of two-layer random forest model to estimate air pollutant concentrations. The data from 1 January 2016 to 30 June 2017 is used for model training, and the remaining is used for model prediction. It is trained on DTR, FFANN-BP and RFR, and the parameters are fine tuned according to the experimental results. The flowchart of our method is shown in
Figure 6.
The initial values of the parameters are set according to the algorithmic characteristics and parameter-adjustment experience of different models, and the grid search provided by scikit learn is used for super parameter optimization. In this paper, the base model of random forest is DTR, and the alternative values of the number of DTRs are set as 10, 20, 30, 40 and 50. Other super parameters such as the maximum number of samples and the minimum number of segmented samples of the leaf nodes use the default minimum value. The final number of DTRs is 20. The stopping criterion is met if there is no improvement in the after ten iterations, in combination with a maximum number of iterations equal to 500. The optimal parameters of FFANN-BP are that the least mean square error as 0.001, max training time as 1000, and learning rate as 0.15. The size of the network and learning parameters greatly affect prediction performance. The best network structure trained is 5 input nodes and 12 hidden nodes. The output layer has only one neuron, corresponding to the air pollutant concentrations. It has been demonstrated that the BFGS algorithm is the most efficient method to solve the optimization of the object function because of its speed and robustness. Due to space constraints, this paper only shows the experimental results of Ma Lian Kou air monitoring station.
To verify the performances of the DTR, FFANN-BP and RFR used in this study,
Table 6 shows the RMSE,
, MAE and MAPE between the measured and predicted values of air pollutant concentrations of the above three models at Ma Lian Kou, Sha Po Tou and Ma Yuan air monitoring stations. The
of the three machine learning models is between 0.44 and 0.99, it is shown that the values of these statistical parameters for the three models are all within the recommended range. The RMSE of each model is between 0.25 and 126.7, and the RMSE of the RFR model is the lowest. Compared with the MAE, the RFR model has the lowest MAE of 6.93, followed by the FFANN-BP model of 7.74, and the DTR model has the highest MAE of 10.6. For MAPE, the RFR model is also the lowest among the three models of 17.56. It can be found that RFR shows good experimental results. The time series plots are also shown in
Figure 7 to depict the relationships between the observed and predicted data. These results indicate the important goodness of fit of the RFR to the observed data. Following the same methodology, fitting were also made for the other air pollutants as dependent variables using DTR, FFANN-BP and RFR with the results as follows. It is shown that RFR is the best model for predicting the concentration of air pollutant concentrations in the three air monitoring stations at a local scale, since the correlation coefficient of RFR equal to 0.99.
The time series plot of the ground measured air pollutant concentrations and the predictions by DTR, FFANN-BP and RFR are shown in
Figure 7,
Figure 8 and
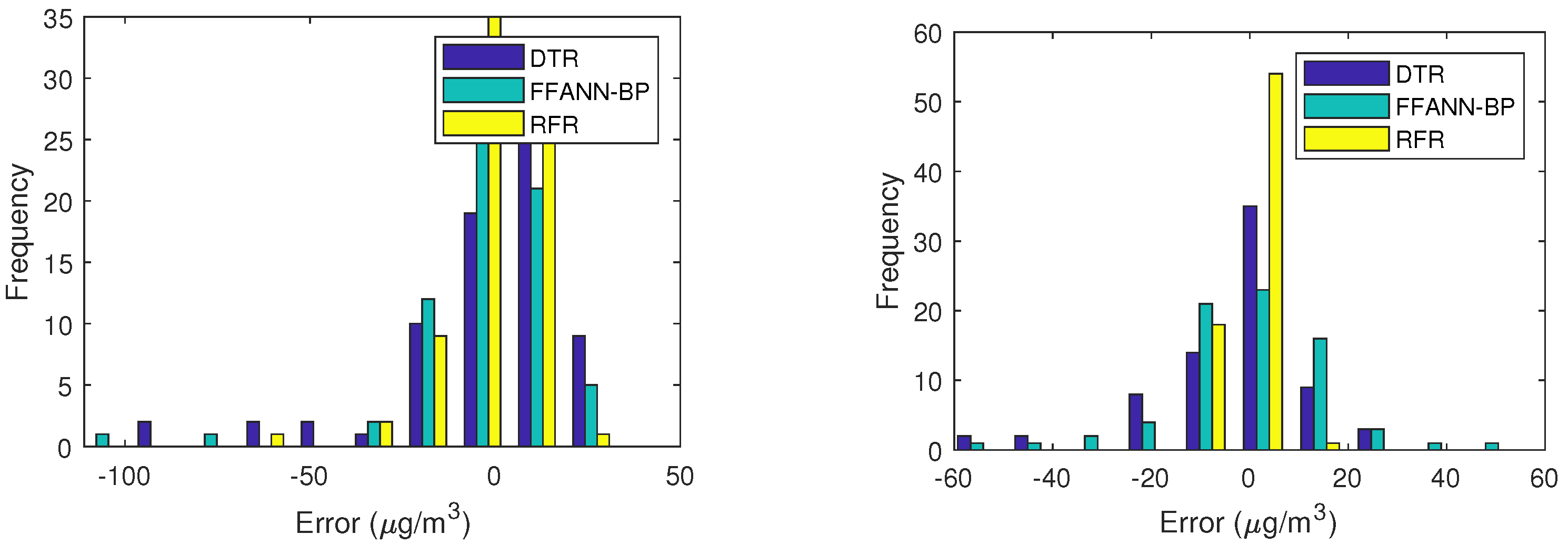
Figure 9. It can be observed that there is a higher agreement between the observed and predicted data. It is also shown that the predicted concentrations of RFR are closer to the observed data than those of the DTR and FFANN-BP, meaning that the RFR improves the predicted performance of air pollutant concentrations. We also employ the histograms to provide further insight into the relationship of the predictors with air pollutant concentrations in
Figure 10,
Figure 11 and
Figure 12. RFR for air pollutant concentrations is very good since the histogram of RMSE is very steep and it is also considerable for the other pollutants in
Figure 10,
Figure 11 and
Figure 12. At the same time, according to the construction time of the models, RMSE, MAE, MAPE are analyzed to evaluate the model. The prediction accuracy and model construction efficiency of different machine learning models are compared and analyzed. Appropriate variables are selected for the prediction of air pollutant concentrations. In terms of prediction accuracy, the RFR model has the best prediction ability, followed by the FFANN-BP model, and the DTR model. RFRs have stable accuracy and good prediction capability. The results show that RFR not only increases the performance of the prediction of air pollutant concentrations in Ningxia, but also discriminates the influential factors and reduces the dimension of the data, therefore reduces the time complexity of the algorithm.
RFR uses the average reduction of node impurity to describe the importance of the variables. The greater the reduction of node impurity by a factor, the more important the factor becomes. The importance of variables in the decision tree model is measured in the form of weight. The greater the weight of a factor, the stronger the influence of the factor in affecting the concentration of air pollutants. In this research, the importance of each factor on the prediction of air pollutant concentration is further analyzed.
Figure 13,
Figure 14 and
Figure 15 and
Table 7 show the analysis of the most important features of DTR and RFR for six air pollutant at Ma Lian Kou. The characteristic variables considered include meteorological factors, air pollutant concentrations of the previous day.
For
, it can be seen that the concentrations of
rank first and contribute the most. For
, it can be seen that
concentrations rank first and contribute the most. For
, it can be seen that ground surface temperature ranks first and contributes the most. For
, it can be seen that
concentration ranks first and contributes the most. For
, it can be seen that
concentration ranks first and contributes the most. For
, it can be seen that
concentration ranks first and contributes the most. As shown in
Table 5, the weight importance of temperature, relative humidity and air pressure are 14 and 25 in turn, indicating that ground surface temperature and relative humidity have the greatest impact on the concentration of air pollutants predicted by DTR, followed by air pressure and precipitation, and wind speed has the least impact.
Figure 13,
Figure 14 and
Figure 15 and
Table 7 shows the importance analysis of various influencing factors when we use decision tree and random forest algorithm to predict the concentration of various air pollutants in 2016. As shown in
Figure 13,
Figure 14 and
Figure 15 and
Table 7, for CO,
is the most important factors in both methods. For
,
is the most important factor. For ozone, the ground surface temperature is the most important factor.
and
are the most important influencing factors for each other.
is the most important factor in the prediction of
.
Table 8 shows the running time of the three algorithms on the concentrations of six pollutants in Ma Lian Kou in 2016. It can be seen from the
Table 8 that the running time of DTR is the shortest due to its simple structure, FFANN-BP model takes the longest time to build, followed by RFR model. The running time of RFR is much lower than that of FFANN-BP. This is enough to reflect that RFR has low time complexity.
Due to the randomness of the three methods, the accuracy of the three methods cannot be evaluated by one experimental result. Therefore, this paper runs 1000 Monte Carlo experiments and takes the average of the running results to evaluate the accuracy of the three methods. The results in
Table 9 show that the accuracy and prediction stability of RFR are better than the other two methods.
The performances achieved highlight that for the extreme concentrations of air pollutants, the performance of the DTR is not significant. The reason is that the construction project of this period is particularly high in Ningxia. However, RFR still acceptedly performs even with the sudden occurrence of such event. For the particulate matter, we find the decrease in performance of DTR and FFANN-BP, making the variance of the concentrations of the particulate matter larger. However, RFR is still more adaptable than FFANN-BP and DTR. It shows that the DTR model has poor prediction ability in using the meteorological elements to predict air pollutant concentrations, and it is recommended to use the RFR model to predict air pollutant concentrations.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}