1. Introduction
The scale of recent changes across the climate system as a whole and the present state of many aspects of the climate system are unprecedented over many centuries to many thousands of years. The frequency of occurrence of extreme weather events is increasing in many parts of the planet. Rain events have increased in frequency and intensity since the 1950s over most of Earth’s surface, with the available observational data identifying trends in human-induced climate change as the main driver [
1]. Climate change has innumerable impacts worldwide, which can be observed in terms of its repercussions on sea level rise, heat waves, storms, drought, floods, reduction of glaciers, economic instability, and the destruction of ecosystems, among others. Rain affects daily life in many ways, its distribution in space and time directly has repercussions on the availability of fresh water, which is vital for the sustenance of life [
2]. Weather is an integral part of daily life and has enormous impact on the economy, public health, and safety in the worldwide. Extreme rain events causing flooding and triggering landslides have significant socioeconomic impacts on society [
3,
4]. In central and southeastern Mexico, floods occur as a result of the convergence of intertropical air masses that causes intense rainfall in a short period of time, with the natural drainage network being insufficient to cope with these high rainfall amounts, causing the overflow of rivers, lakes, and lagoons. Such flooding causes significant economic losses every year in the agricultural, livestock, and infrastructure sectors, in addition to directly affecting human lives and livelihoods. One of the important issues concerning flooding in both Mexico and other countries is the need for rapid assessment of damage on which basis mitigation strategies can be formulated and applied [
5].
Satellite images have become widely used for monitoring flooding in various parts of the world. They allow wider extents and/or specific areas of flooding to be observed. In addition, satellite images are available in diverse spatial, temporal, and spectral resolutions, meaning that they can provide high-quality results and useful information. Synthetic aperture radar (SAR) can operate under a variety of meteorological conditions [
6]. However, because of the way in which they are obtained, SAR images require careful processing prior to analysis [
7].
The complexity of monitoring events using SAR images increases when studying tropical areas on account of the density and height of vegetation. The backscatter of waves emitted by the SAR sensor suffers distortions and double-bouncing effects caused by vegetation, which limits the detection of flooded areas. However, proposals have been made to improve the ability of the SAR method to obtain information of interest [
8,
9,
10].
The use of optical multispectral satellite images and digital elevation models (DEMs) as complements to SAR images has the potential to increase the accuracy of classification based on the better spectral correlation between the optical sensors with their respective topographic and water-body information [
11]. Combining these two types of image processing allows the extent and depth of flooding to be better detected, analyzed, and monitored [
12,
13,
14].
DEMs are geospatial data of great importance in studies related to detection, monitoring, diagnosis, prediction and indirect estimation of depth of flood events [
15,
16]. DEMs are generated using different methods and technologies. Pure LIDAR data (raw data) have inherent errors due to obstacles and terrain conditions, which is why a set of cleaning procedures are usually applied [
17,
18]. Such procedures include interpolation techniques, which allowed us to obtain a DEM with a vertical and horizontal resolution of 5 m.
Timely information about floodwater depth is important for directing rescue and relief resources and determining road closures and accessibility. Once available, flood depth information can also be used for post-event analysis of property damage and flood-risk assessment. Several approaches for quantifying flood depth using remote sensing-based flood maps have been proposed; one of them is [
19], who used “Floodwater Depth Estimation Tool (FwDET)”, developed to augment remote sensing analysis by calculating water depth based on an inundation map with an associated digital elevation model (DEM).
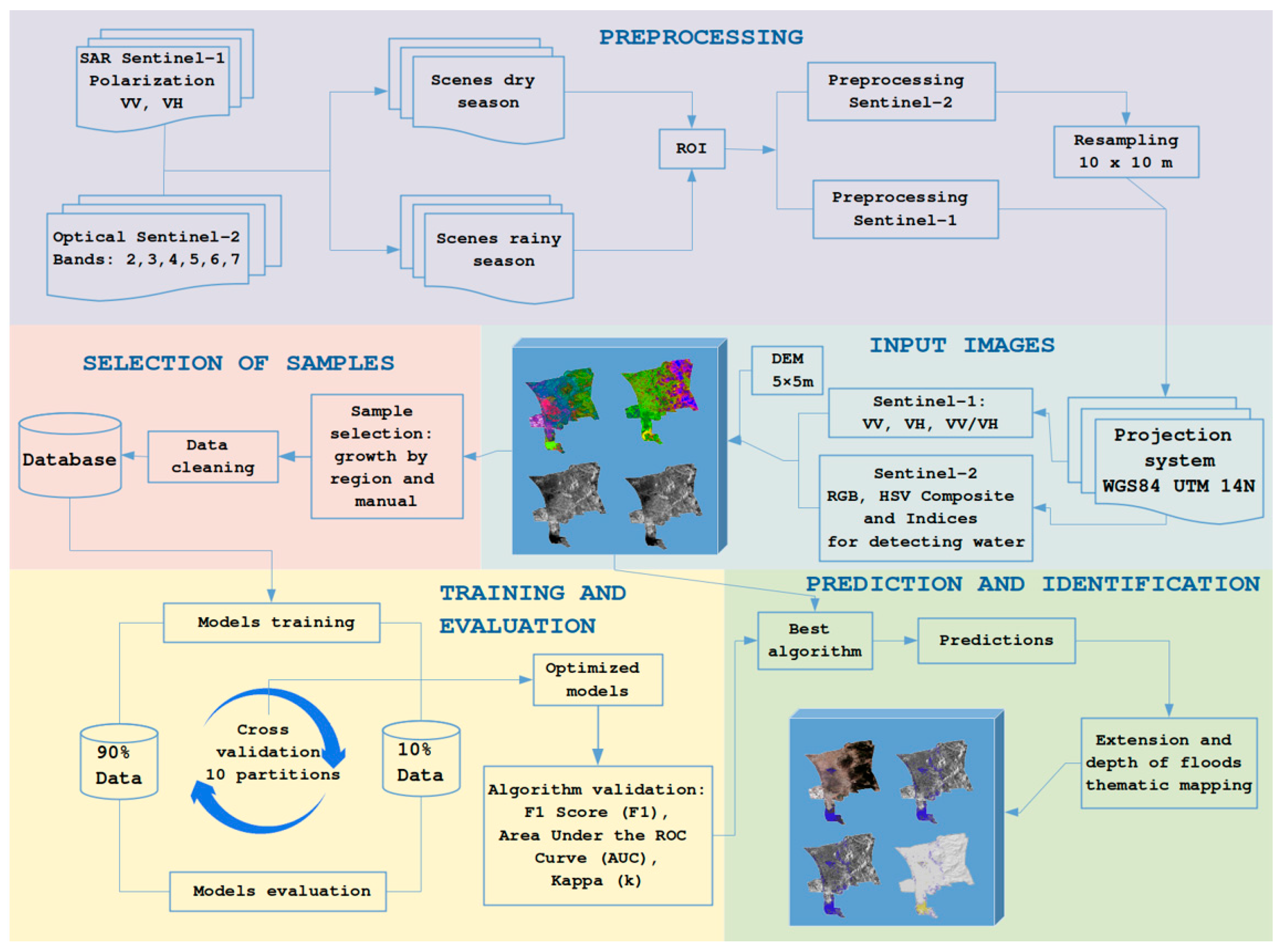
Furthermore, current computational power enables the implementation of machine-learning techniques for modeling multi-dimensional problems. In agriculture, these techniques have been used for estimating the height of crops, extent of irrigation, and extent and depth of flooding, as well as for identifying pests and diseases [
20]. One of the key tasks in detecting flooding is classification, for which machine learning algorithms have shown superior performance to traditional binary segmentation methods [
21].
Machine learning (ML) models based on decision trees can use the input dataset (Sentinel-1 SAR, Optical Sentinel-2, and DEM), to establish rules that allow it to classify the set into the categories specified by previous tags [
11,
17,
22]. The algorithm selects the best attribute or characteristics (image pixels) and recursively partitions the labeled data until the following rule is met: all samples belong to the same attribute, there are no more samples, or there are no more features to perform the division [
22]. The integration of remote sensing to ML algorithms has obtained a good performance in the detection water bodies [
22,
23]. One of the advantages of ML algorithms is flexibility of training with a smaller training set; and due to its structure, training and prediction times are shorter, maintaining a good precision [
24].
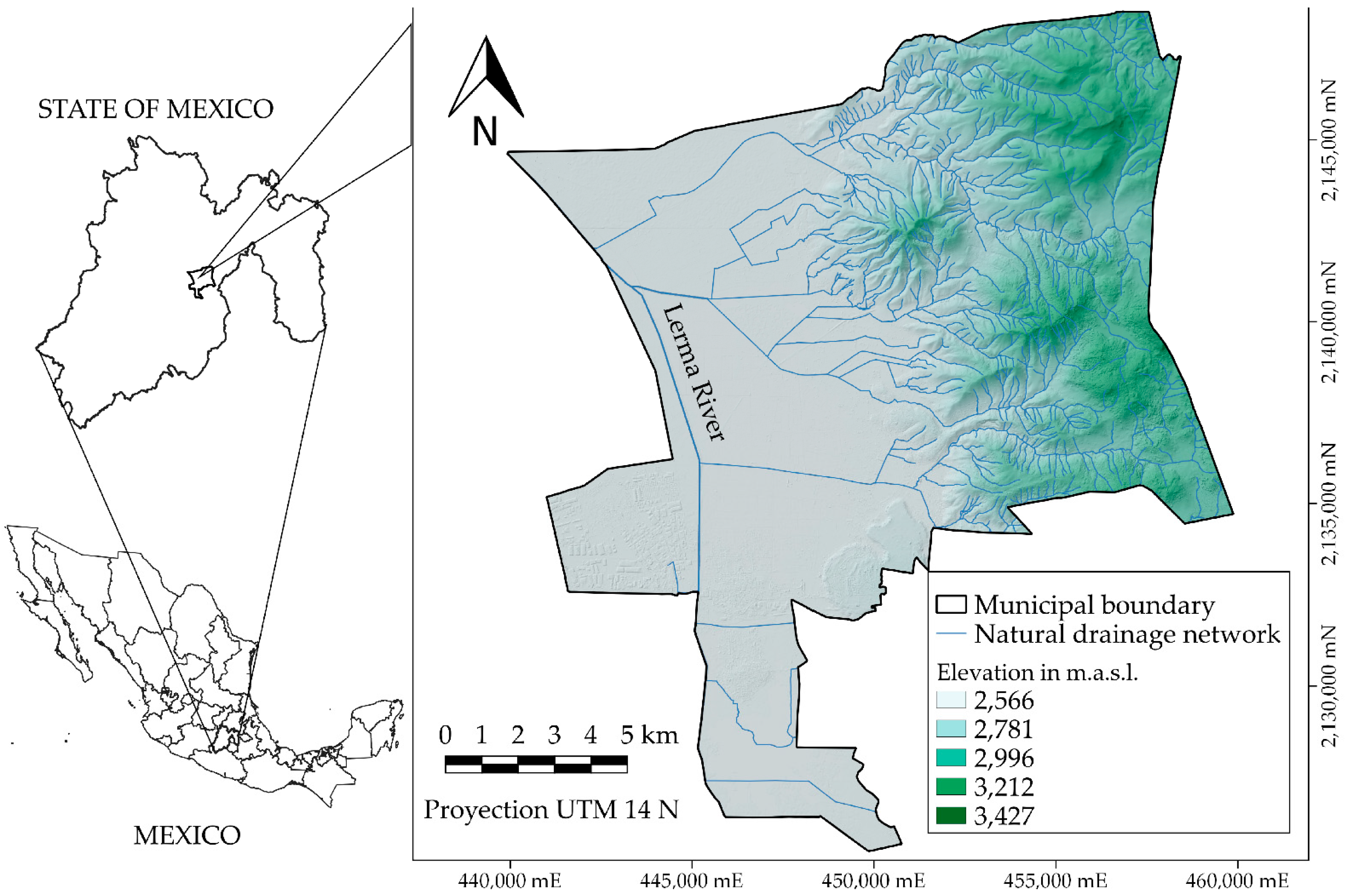
In central and southeastern Mexico, floods occur every year because of the intense rainfall during the period from June to October, with surface runoff caused by deforestation and also due to effects of climate change [
25,
26]. Although some previous studies have used SAR image analysis and processing methods to monitor recurrent floods in the southern part of the country, traditional classification techniques were used in most investigations. Some of them used Radarsat-2 and Sentinel-1 SAR images to track flooding using single and dual polarizations; others evaluated the Sentinel-1 data for describing the spatial and temporal variability of water bodies [
27,
28,
29,
30]. The objective of this research was to evaluate and compare the performance of two assembly algorithms: gradient boosting (GB) and random forest (RF) for different combinations of Sentinel-1 SAR images, Sentinel-2 optical images, indexes to detect water bodies, and DEMs for monitoring the extent and depth of flooding generated by excess rainfall.
4. Discussion
The presence of clouds, fog, and atmospheric particles in Sentinel-2 optical images can place limitations on detecting phenomena during rainy periods, as such conditions decrease solar illumination. During image processing, it is necessary to homogenize the histograms and normalize values of the RGB composite [
63]. In SAR image processing, backscatter values are converted to backscatter coefficients (dB) to increase scene contrast and enhance visual differences between target classes.
The results obtained using machine learning algorithms (models) in this research indicate that, of the analyzed inputs, the combination of Sentinel-2, Sentinel-1, and DEM obtained more reliable results than other combinations [
64,
65], and the more robust and efficient model was gradient boosting algorithm to classify water bodies and flooded areas. The use of optical images with SAR images forms a complementation that can reduce Type I and II classification errors in the two analyzed machine learning algorithms (GB and RF). However, if a multiclass classification is to be carried out, then the use of optical images is necessary, as it allows a wide variety of shades and textures to be distinguished, which can be perfectly correlated to detect different uses and land covers, such as bodies of water and flooded areas [
66,
67]. In addition, SAR images can be used to identify bodies of water with aquatic vegetation, lagoons, rivers, lakes, and irrigation canals using VV polarization; however, the potential of SAR for monitoring floods is limited by the similarity of backscatter values in (shallow) flooded areas with soils without vegetation with high moisture content [
68].
For the dry season, the utilized algorithms (GB and RF) detect similar regions of water bodies. The difference between the output maps lies in the compact regions, where the GB algorithm detects a larger area of water bodies than RF. For this season, the GB algorithm has the best performance for combination 15, generated by using Sentinel 2, Sentinel-1, and DEM (HSV composite, VV polarization, and DEM) with F1m = 0.997, AUC = 0.999, and K = 0.994.
For the rainy season, the models detect very similar spatial distributions of water bodies and flooded areas. There is a difference in the number of pixels that make up each region: GB identifies 1835.7 ha of flooded areas, and RF identifies 1623.98 ha. This difference is due to the identification by GB of pixels as “water” in small valleys located on the slopes of mountains. The best combination for both the RF and GB algorithms for the rainy season is combination 8, with F1m = 0.9861 and K = 0.9721 and F1m = 0.9858 and K = 0.9716, respectively.
In the comparison of the indexes derived from Sentinel-2 for detecting bodies of water for both algorithms (GB and RF); the best performance for the dry season is obtained with the reformulated automated water extraction index (AWEISH, combination 7) [
42]; and the best performance for the rainy season is obtained with the automated water withdrawal index (AWEI, combination 6) [
42]. The performance of the models does not improve significantly, when these indexes are integrated but the classification accuracy of the models increases with integration with the DEM.
According to
Table 6 and
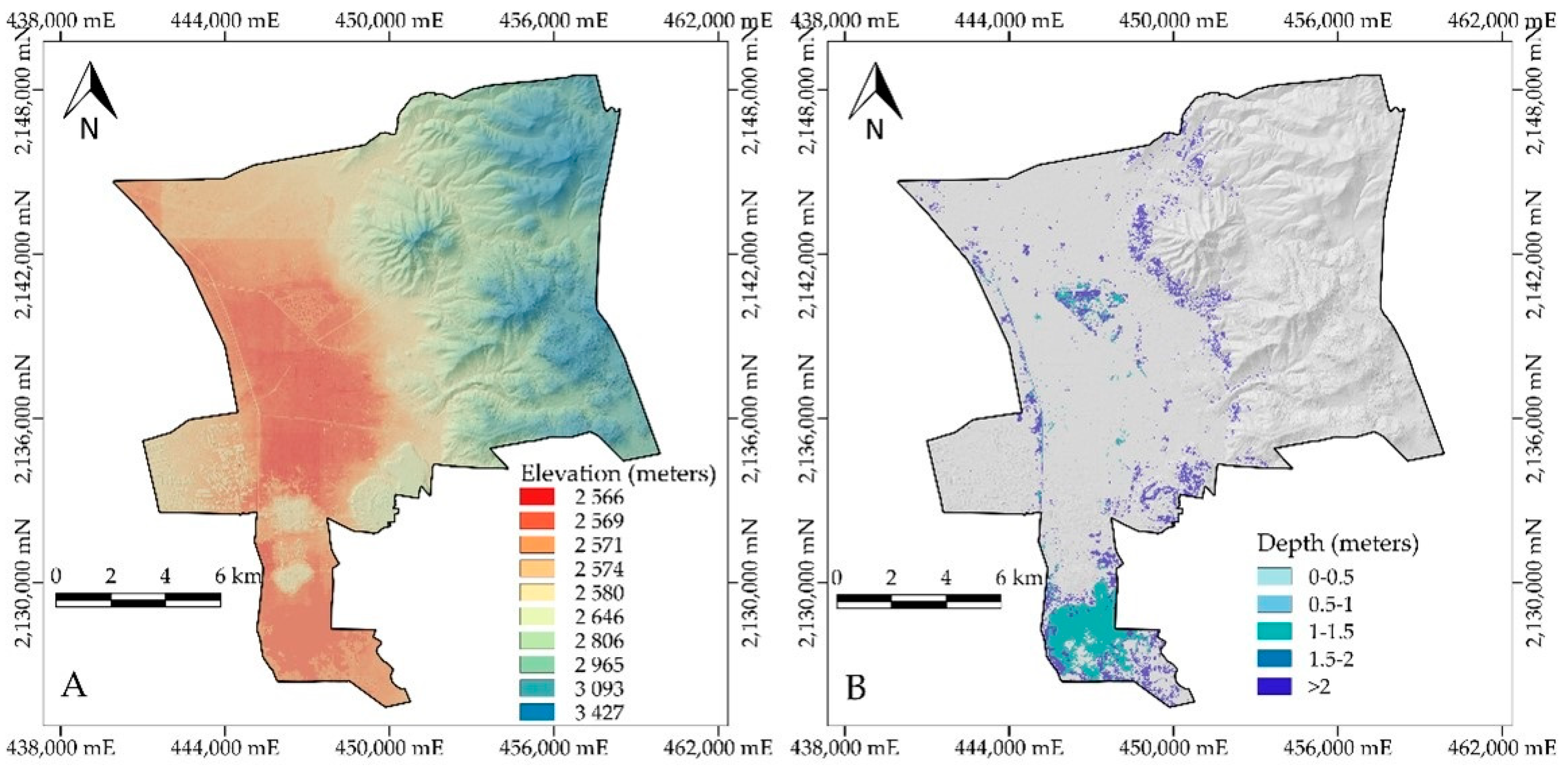
Table 9, the GB algorithm reports an extent of flooded areas of 1113.36 ha, and the evaluation metrics show that this model is superior to RF. The maps of flood extent obtained with both algorithms show a high degree of similarity. The depth of flooding in agricultural plots located in the central part of the Lerma valley and on the left bank of the Lerma River is less than 1 m, but in some parts of the lagoons, depths of 1–2 m are observed.
One of the advantages of this research is that the proposed methodology generates maps that show the extent of floods in a short time, whose results are validated using comparison metrics (F1m, AUC, and Kappa) using the best model.
5. Conclusions
In this study, we assessed 16 combinations of Sentinel-1 synthetic aperture radar (SAR) images, Sentinel-2 optical images, and DEM data to evaluate the performance of two widely used machine learning algorithms for providing information about flooding extent and depth, with a case study of flooding in the Municipality of Lerma de Villada, central Mexico.
To identify flooded areas, the combination of Sentinel-2 optical images, SAR Sentinel-1, and DEM, with GB and RF algorithms, gives more reliable results if we used only Sentinel-2 or Sentinel-1 for binary classification (water and non-water).
Determination of flooded areas requires independently analyzing the two seasons (dry and rainy) because meteorological conditions strongly affect the optical images in the rainy season and consequently generate a combined model that predicts high numbers of false positives.
For the three analysis inputs (Sentinel-2 + MDE, Sentinel-1 + MDE, and Sentinel-2 + Sentinel-1 + DEM) for both seasons (dry and rainy), the ensemble algorithms (GB and RF) show acceptable performance, with GB being slightly superior according to performance metrics.
For the detection of bodies of water in the dry season, the metrics indicate that the best algorithm is GB with combination 15 (F1m = 0.9973, AUC = 0.9999, K = 0.9945); however, the model gives a 0.27% classification error on the set of samples with which it was trained and evaluated. For the identification of flooded areas in the rainy season, with the same GB algorithm, the best results are obtained with combination 16 (F1m = 0.9953, AUC = 0.9999, and K = 0.9905); however, the model shows a 0.47% classification error on the set of samples with which it was trained and evaluated.
The GB algorithm generates the best result for the extent of flooding, with an area of 1113.36 hectares, with flooding depth ranging is <1.0 m.
The output maps of both the extent and depth of flooding should allow planning and execution of flood mitigation actions in a more timely manner and with a higher degree of accuracy than could otherwise be achieved.
This research aims to be the basis and approach to the implementation of machine learning algorithms applied to flood monitoring in southeastern Mexico. For future work, it is recommended to incorporate field validations and case studies elsewhere in order to obtain better calibrated models.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}