Statistical Learning of the Worst Regional Smog Extremes with Dynamic Conditional Modeling



Abstract
:1. Introduction
Roadmap
2. Preliminary Analysis of Smog in the Vast Region of Beijing–Tianjin–Hebei
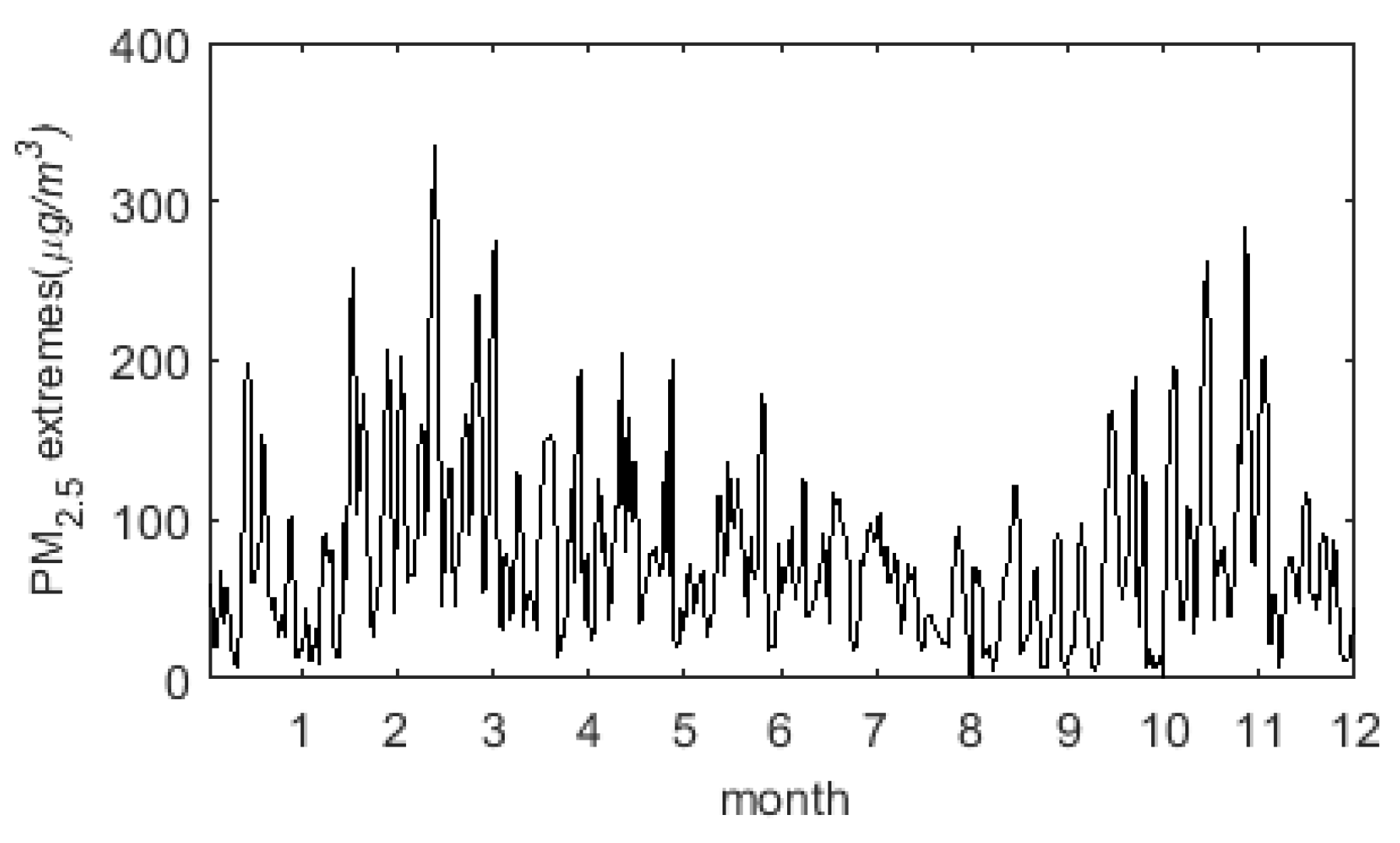
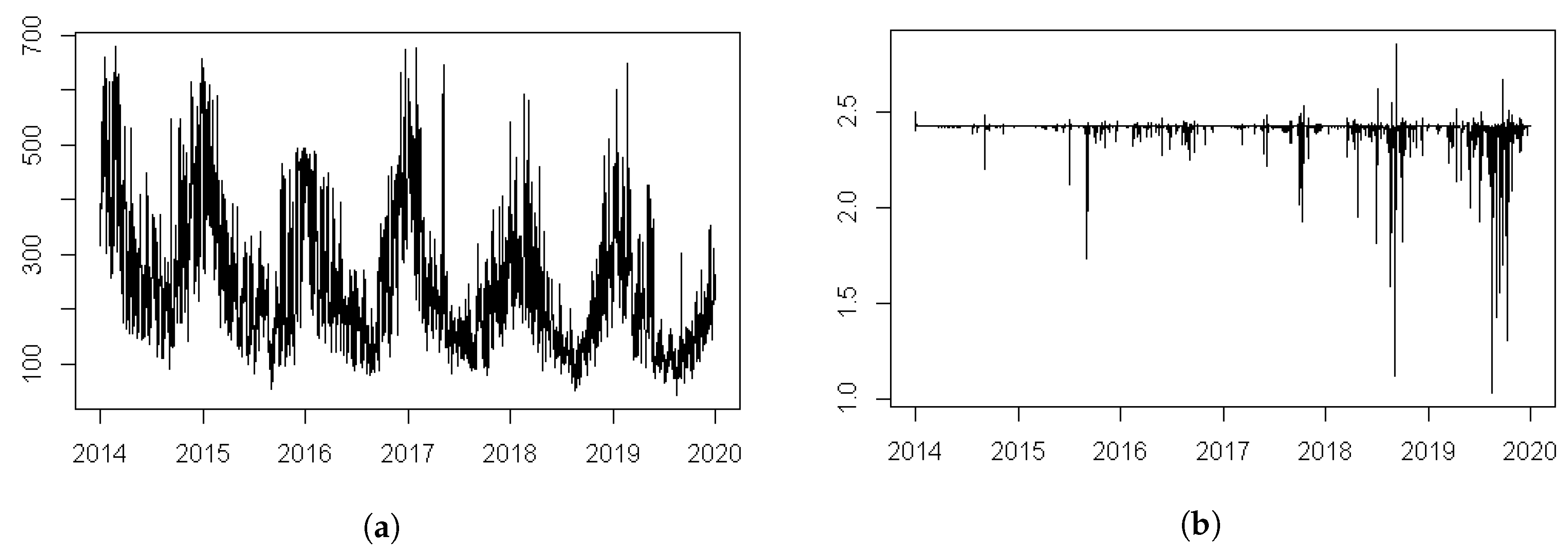
2.1. Which Time Scale of PM Data Is to Be Analyzed?
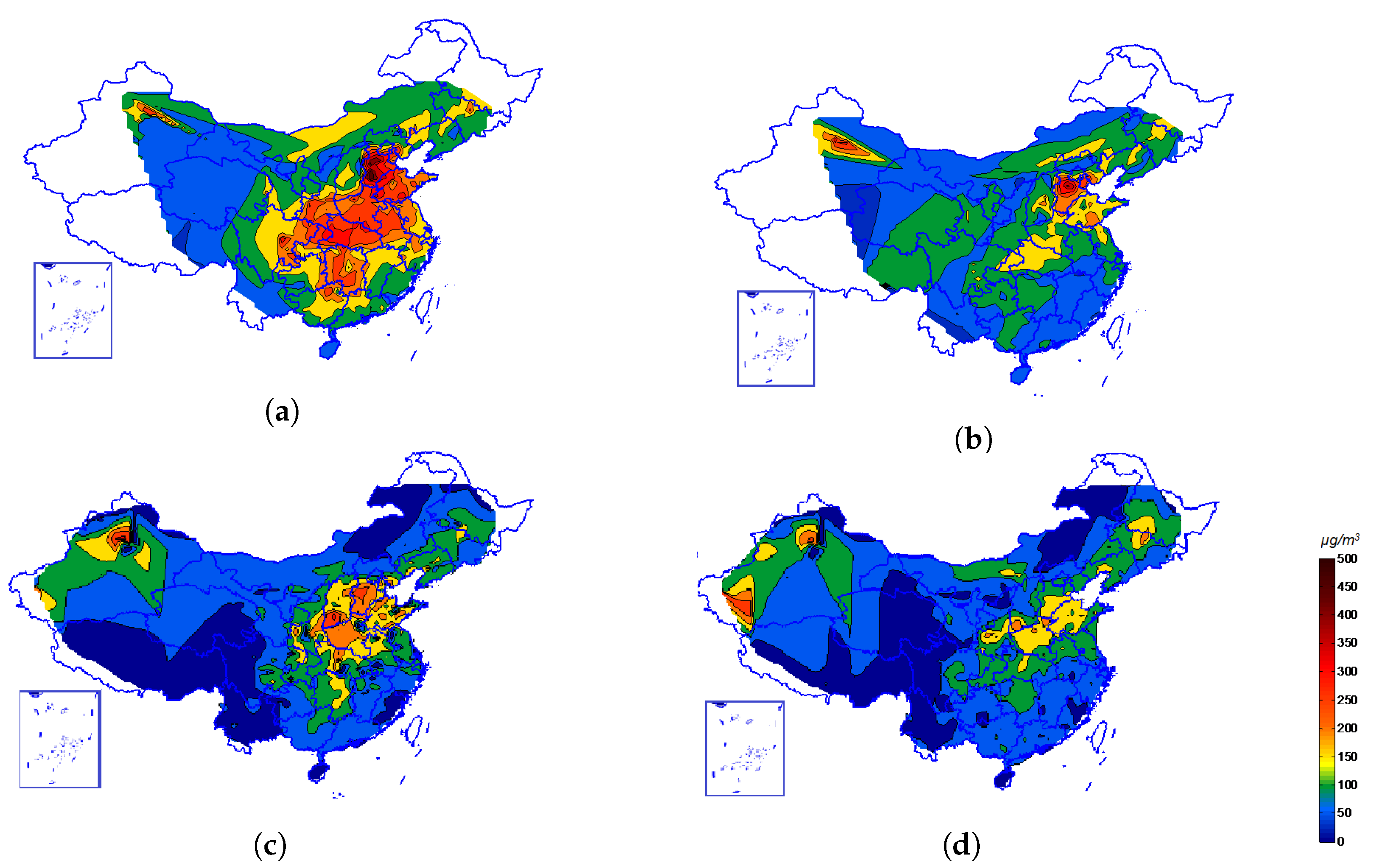
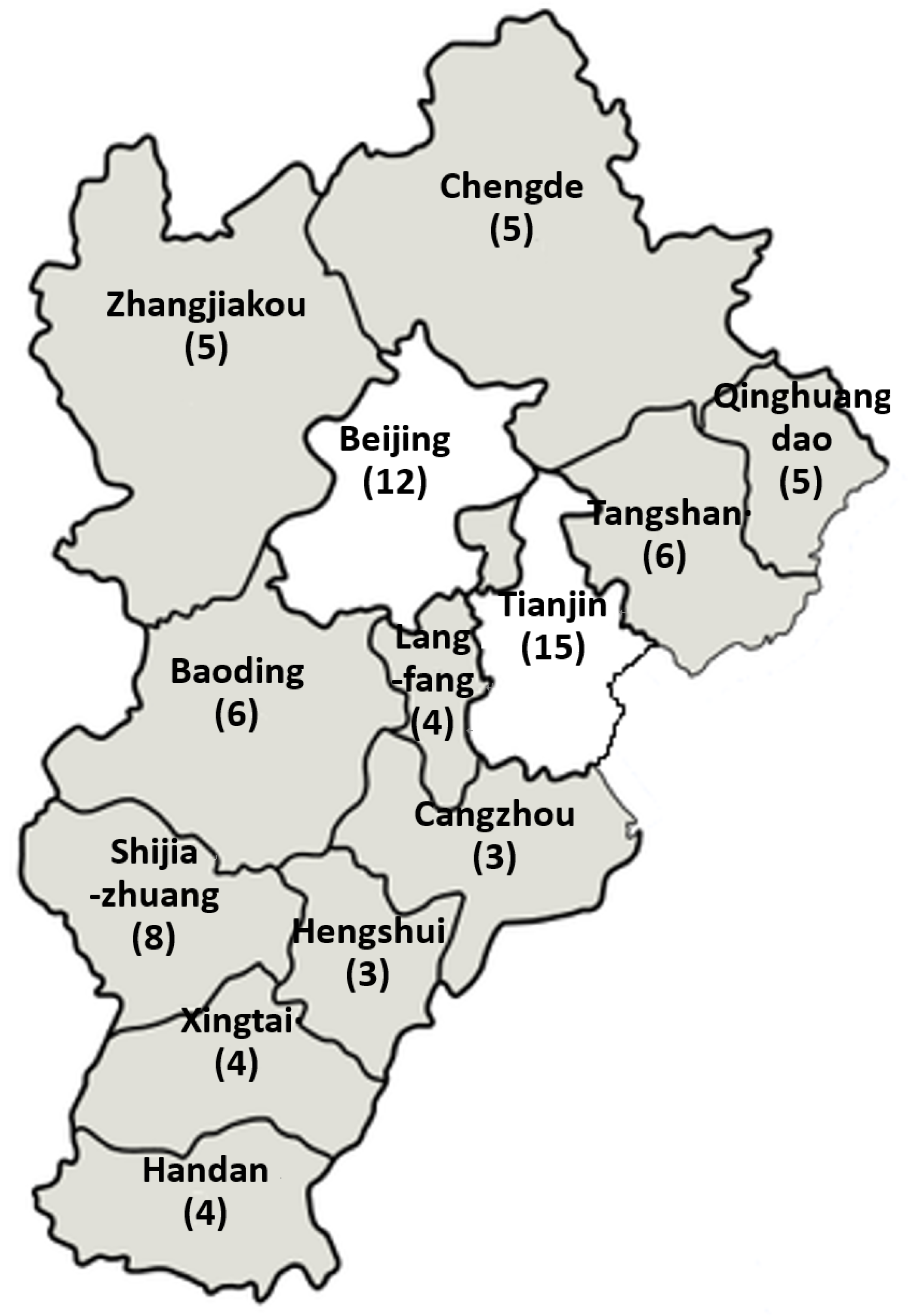
2.2. The Geographical Region to Be Focused on
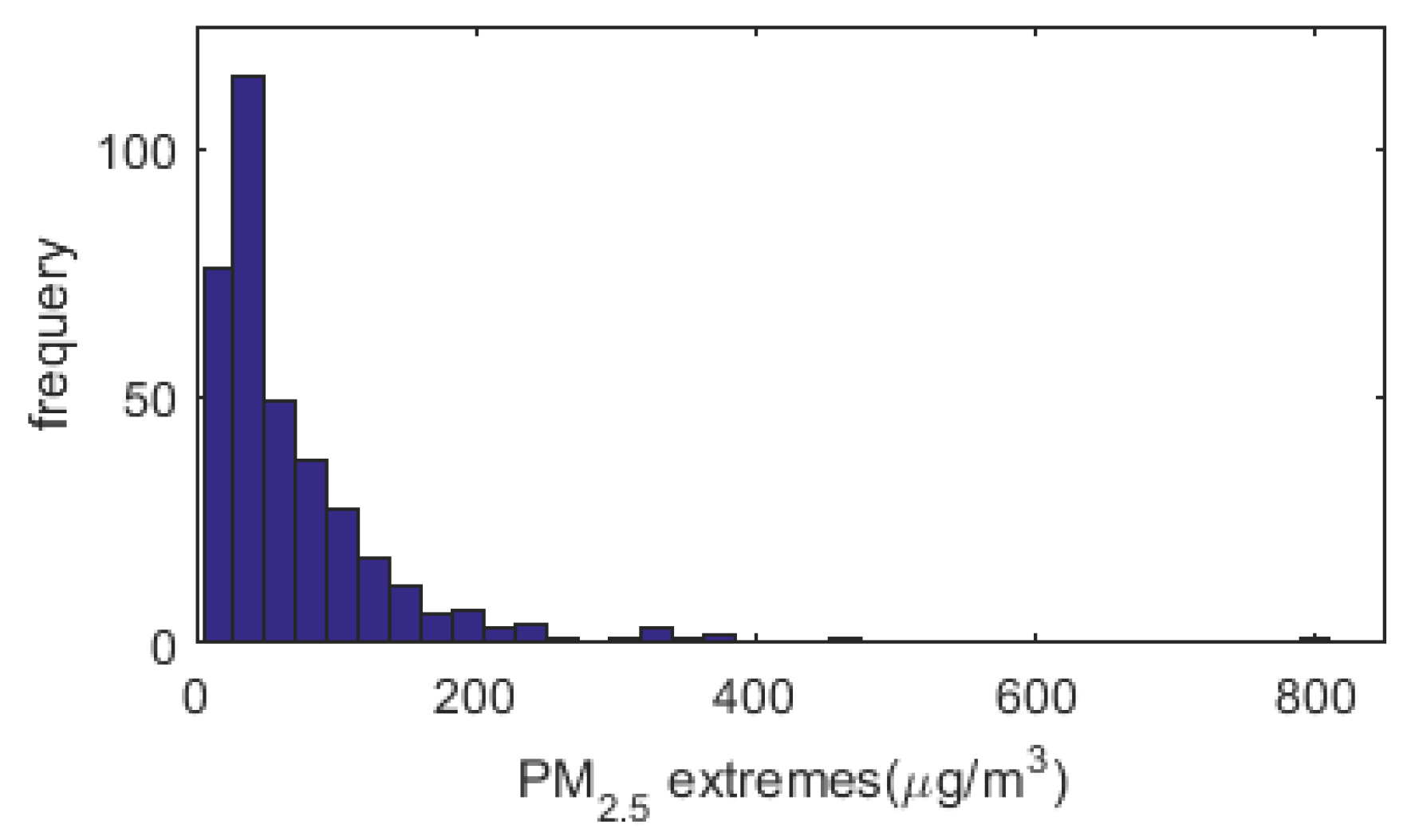
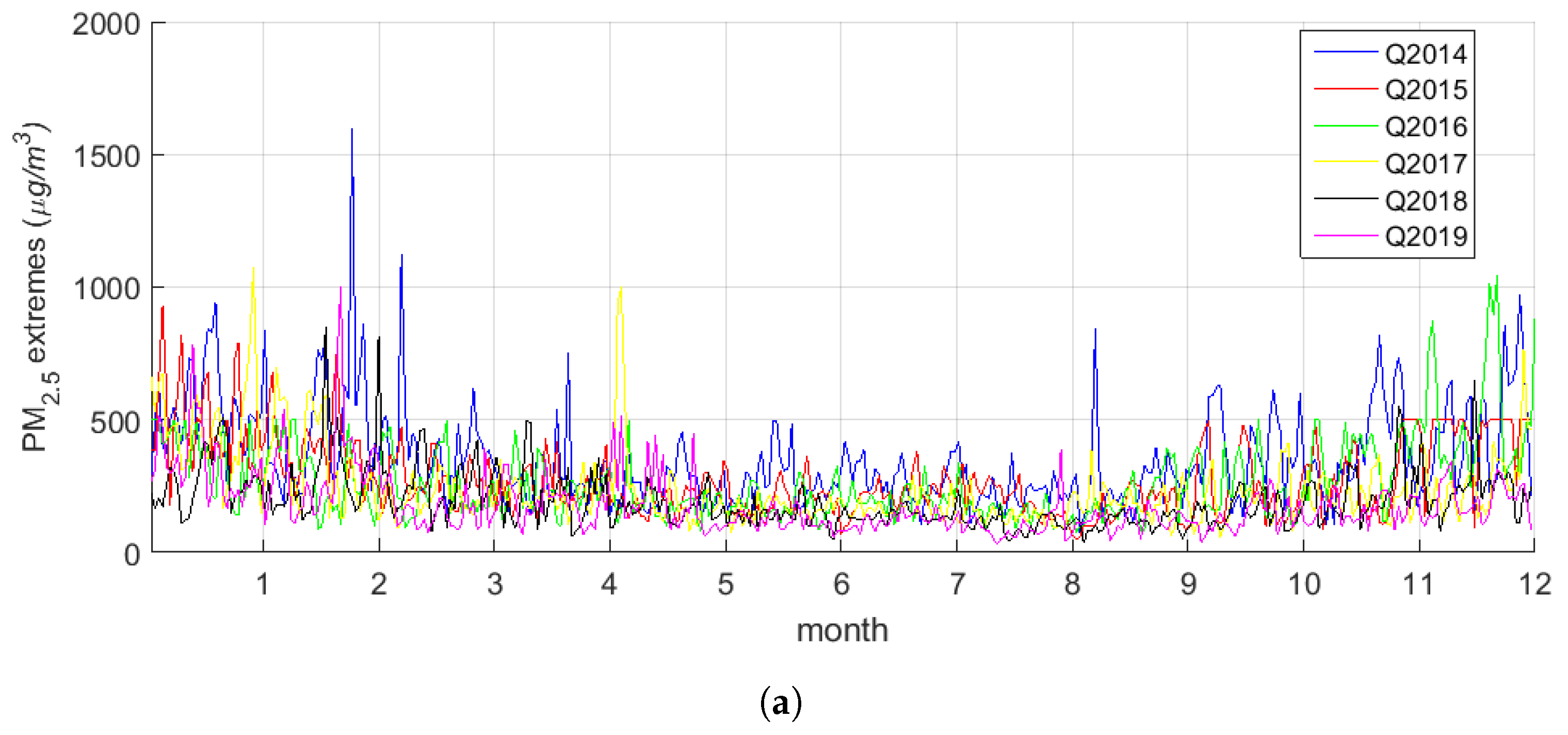
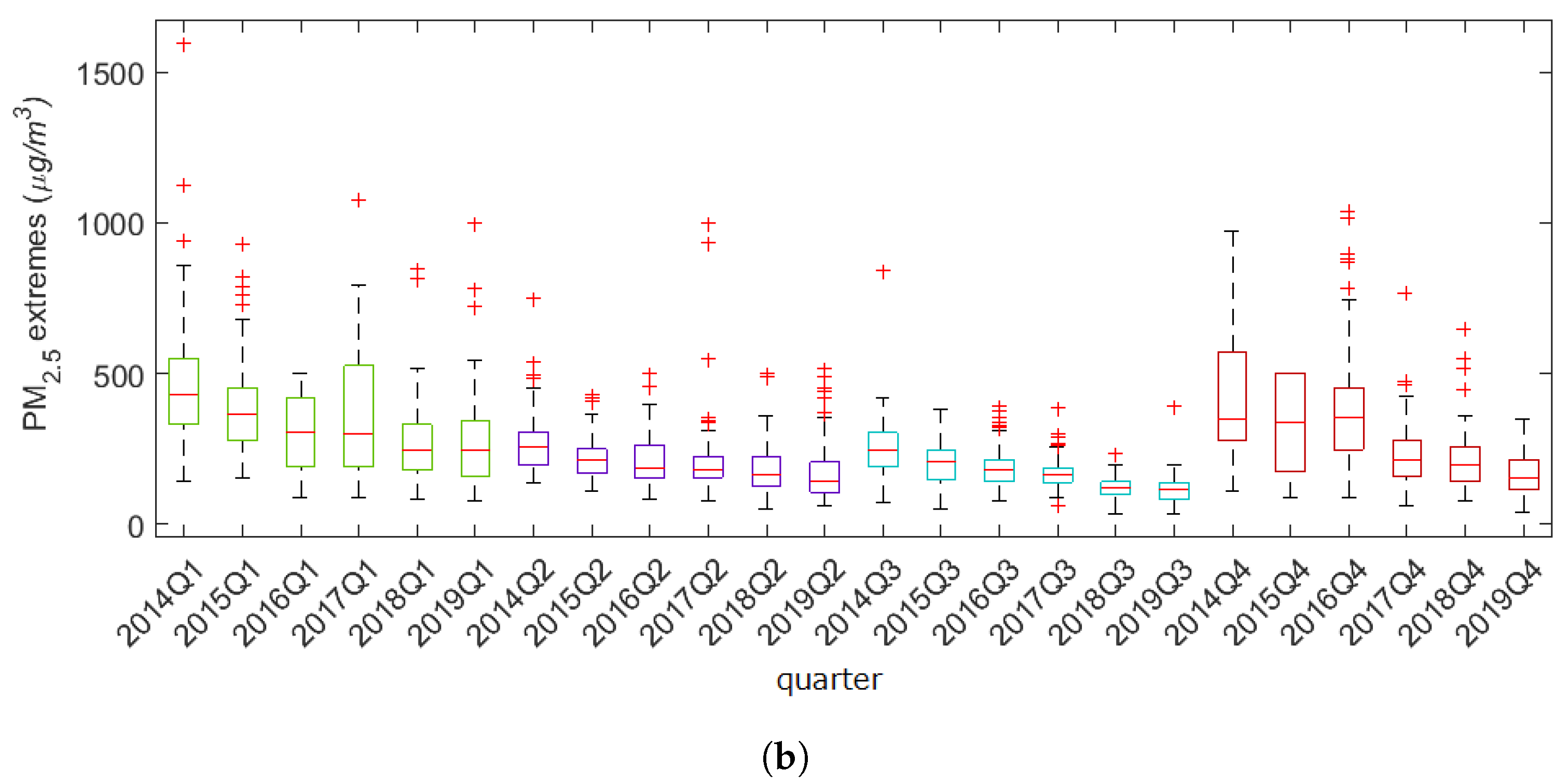
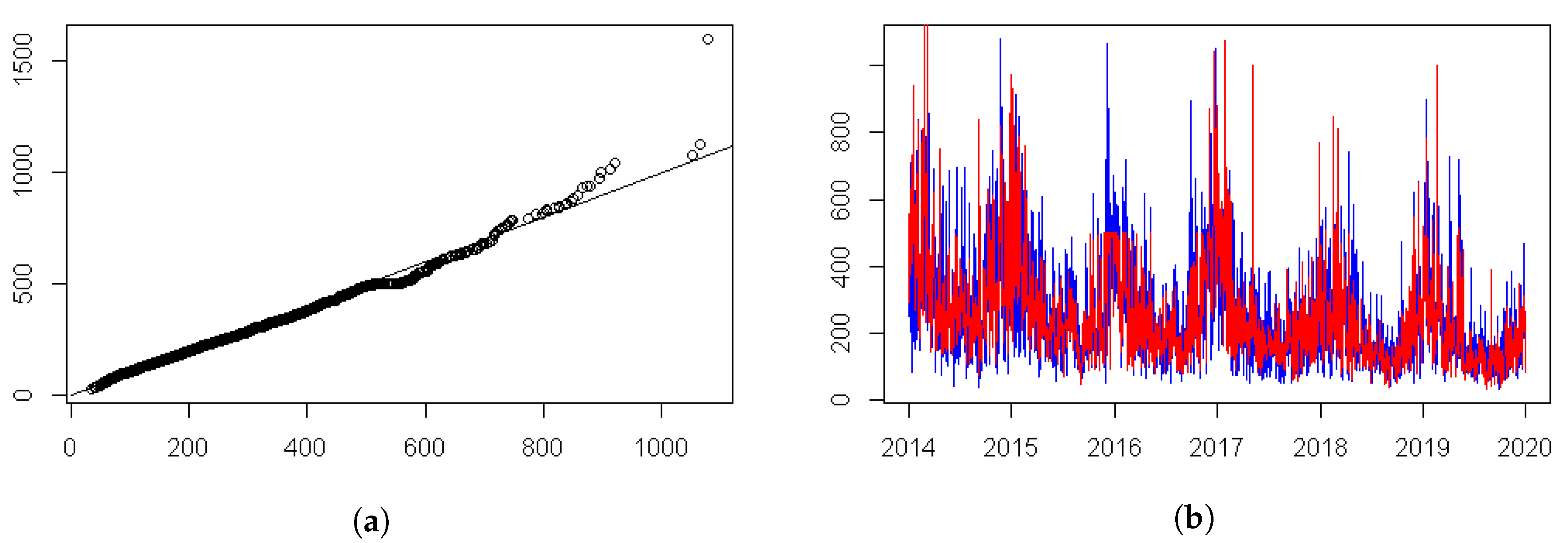
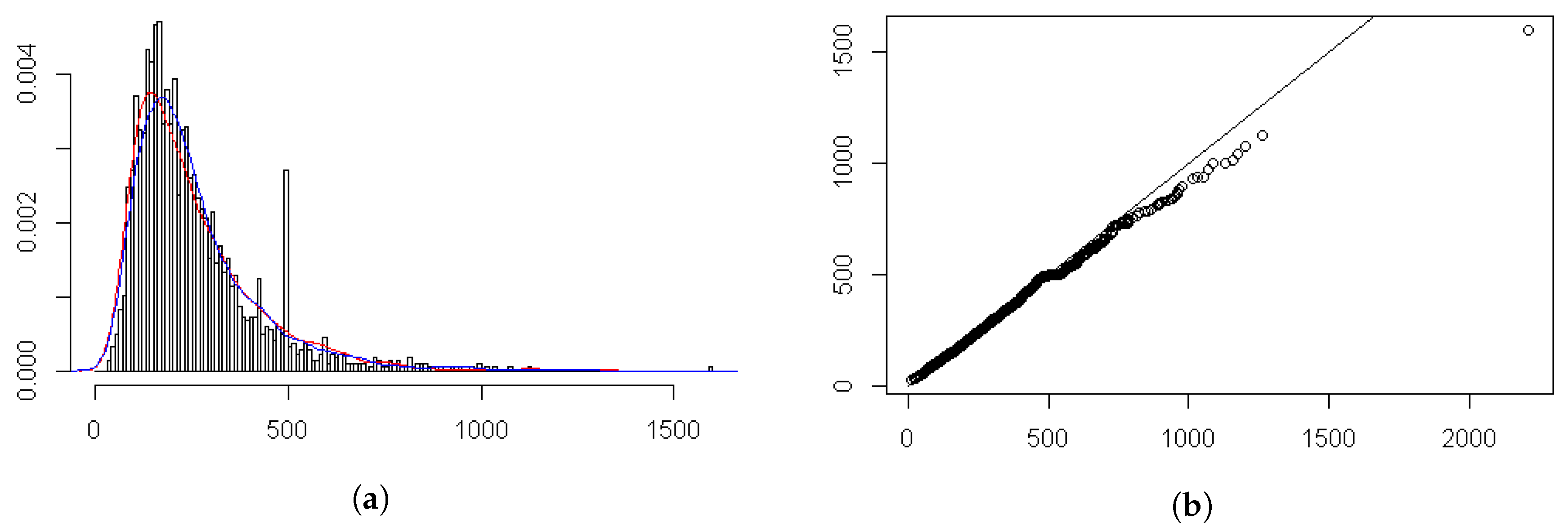
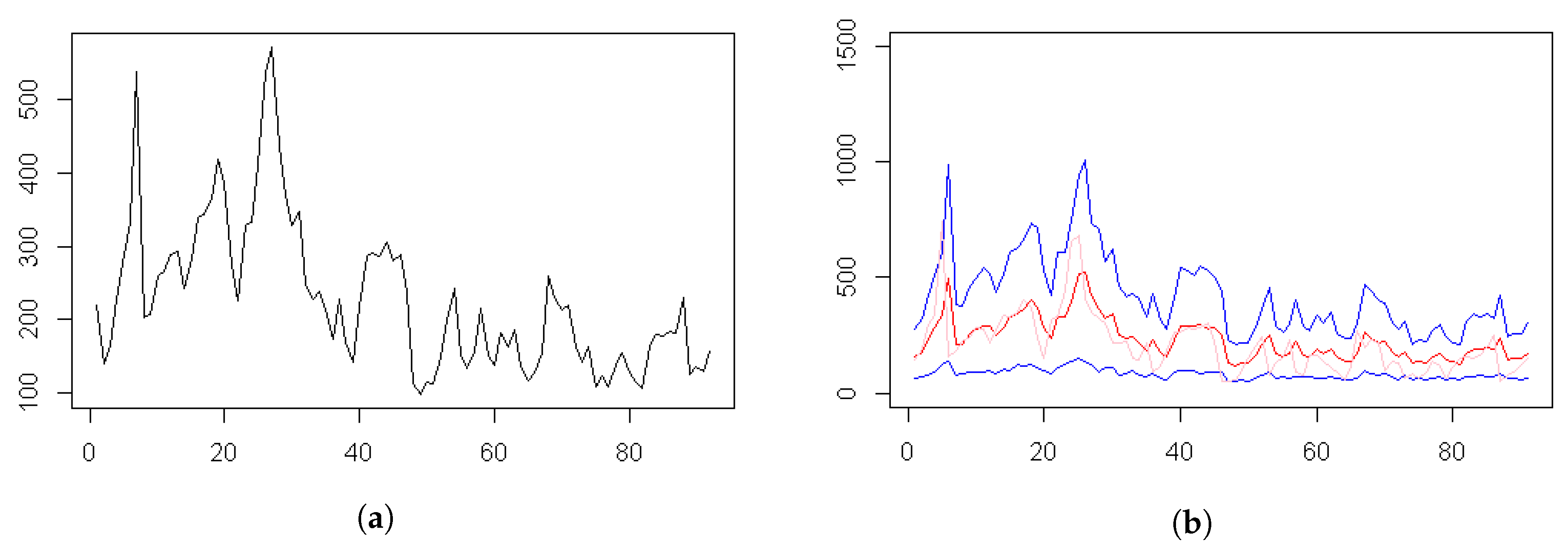
2.3. Why Model the Extremes Rather than the Average Levels?
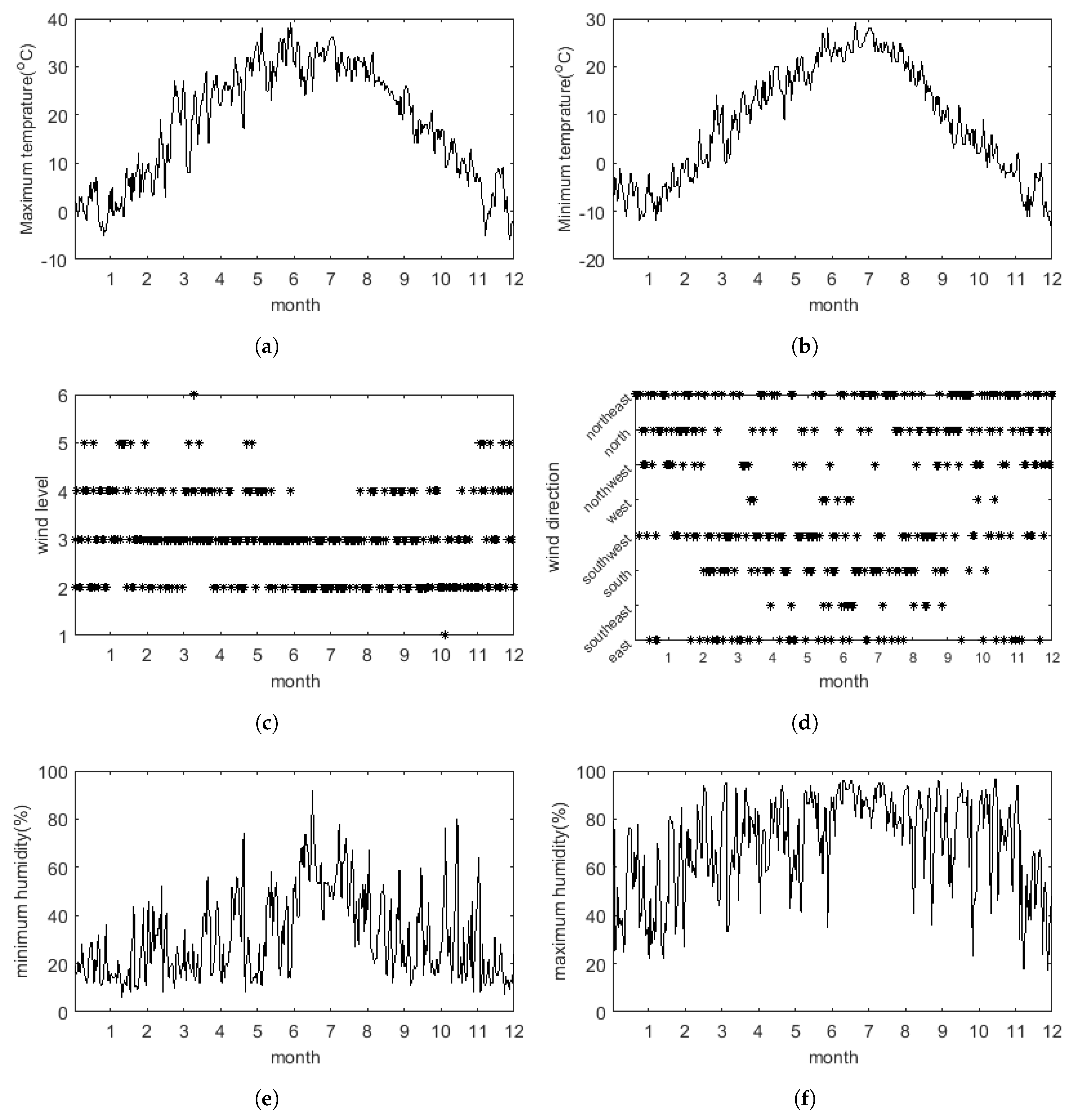
2.4. The Study Approach and the Inclusion of Meteorological Variables
3. Model Specification
3.1. The Proposed General Model
3.2. Parameter Estimation and Asymptotic Properties
4. Numerical Studies Using Simulations
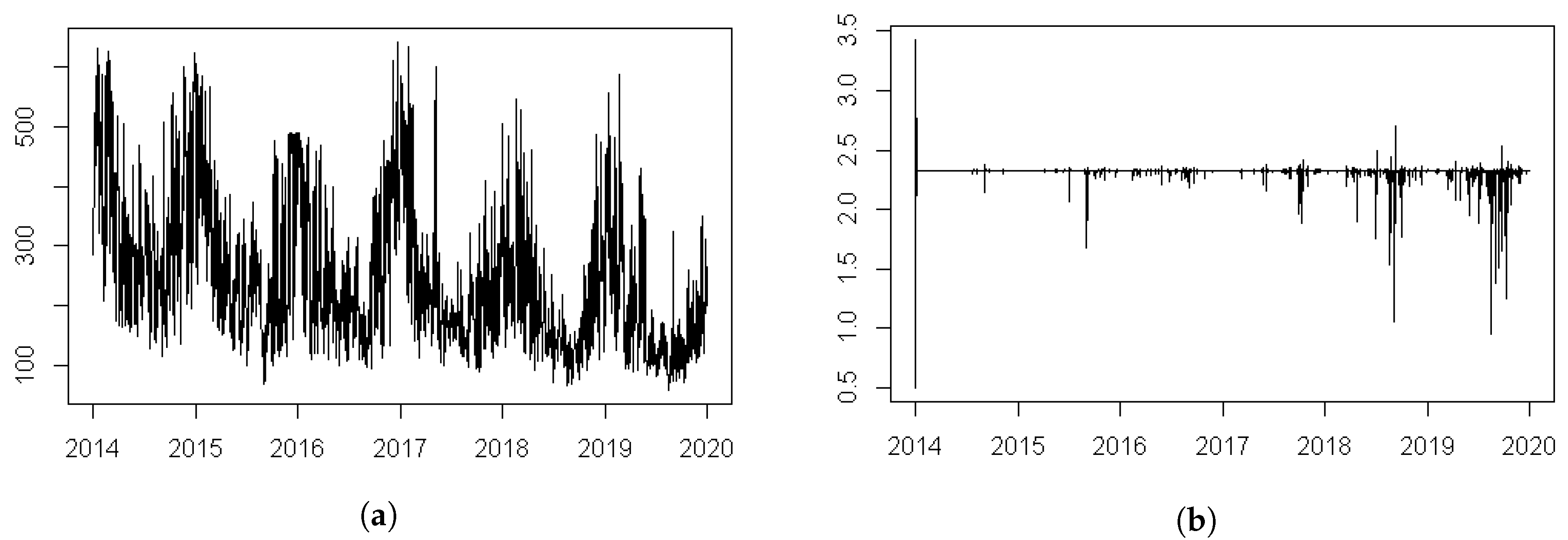
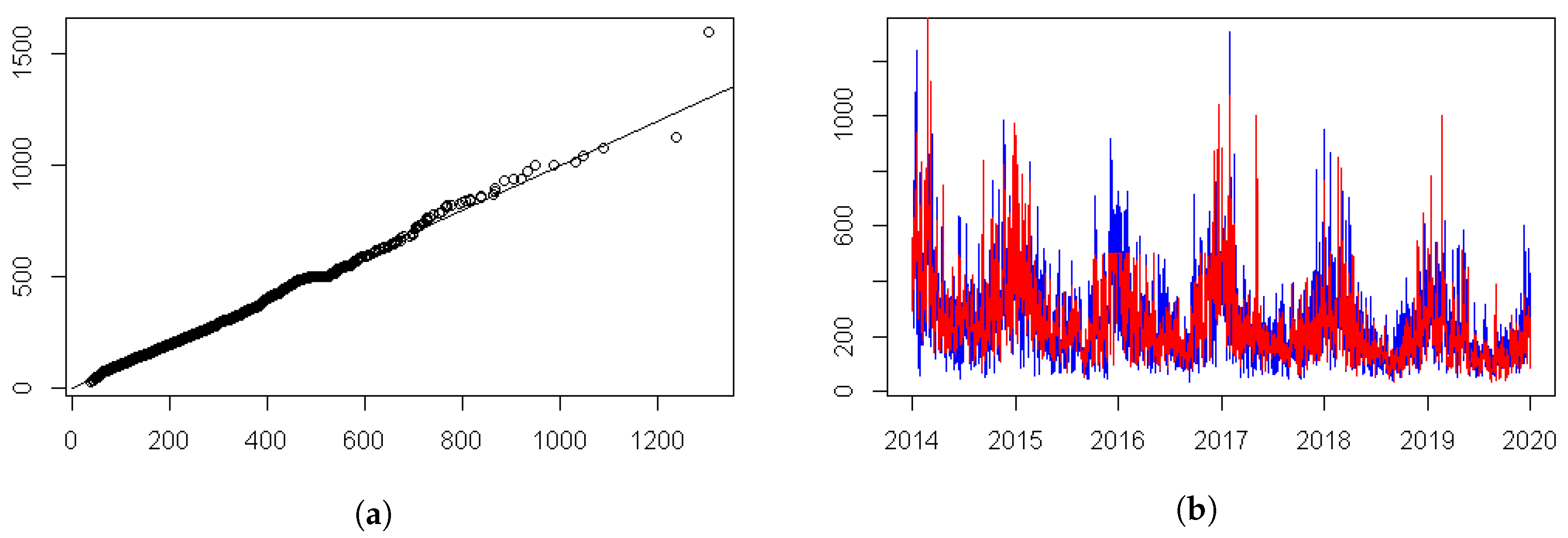
5. Real Data Inferences
5.1. Inference without Weather Factors
5.2. Inference with Weather Factors
6. Conclusions and Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A. Technical Arguments
Appendix A.1. Proof of Theorem 1
Appendix A.1.1. Proof of Lemma A1
Appendix A.1.2. Proof of Lemma A2
Appendix A.2. Technical Lemmas
Appendix A.3. Proof of Theorem 2
Appendix A.4. Proof of Theorem 3
Appendix A.5. Proof of Proposition 1
Appendix A.6. First and the Second Order Partial Derivatives of lt (θ)
Appendix B. Algorithms Computation Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
- Smith, R.L. Extreme value analysis of environmental time series: An application to trend detection in ground-level ozone. Stat. Sci. 1989, 4, 367–377. [Google Scholar] [CrossRef]
- Yiou, P.; Goubanova, K.; Li, Z.X.; Nogaj, M. Weather regime dependence of extreme value statistics for summer temperature and precipitation. Nonlinear Process. Geophys. 2008, 15, 365–378. [Google Scholar] [CrossRef] [Green Version]
- Smith, R.L.; Grady, A.M.; Hegerl, G.C. Extreme precipitation trends over the continental United States. In Proceedings of the 15th Aha Hulikoa Hawaiian Winter Workshop, Honolulu, HI, USA, 5 November 2007. [Google Scholar]
- Reich, B.J.; Shaby, B.A. A hierarchical max-stable spatial model for extreme precipitation. Ann. Appl. Stat. 2012, 6, 1430–1451. [Google Scholar] [CrossRef] [PubMed]
- Cooley, D.; Nychka, D.; Naveau, P. Bayesian spatial modeling of extreme precipitation return levels. J. Am. Stat. Assoc. 2017, 102, 824–840. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, C.; Cui, Q. Random threshold driven tail dependence measures with application to precipitation data analysis. Stat. Sin. 2017, 27, 685–709. [Google Scholar]
- Naveau, P.; Nogaj, M.; Ammann, C.; Yiou, P.; Cooley, D.; Jomelli, V. Statistical methods for the analysis of climate extremes. C. R. Geosci. 2005, 337, 1013–1022. [Google Scholar] [CrossRef]
- Gilleland, E.; Brown, B.G.; Ammann, C.M. Spatial extreme value analysis to project extremes of large-scale indicators for severe weather. Environmetrics 2013, 24, 418–432. [Google Scholar] [CrossRef] [Green Version]
- Kempter, G.; Wild, K. Extreme weather is the new normal. Electr. Light Power 2013, 91, 20–22. [Google Scholar]
- Mannshardt, E.; Benedict, K.; Jenkins, S.; Keating, M.; Mintz, D. Analysis of short-term ozone and PM2.5 measurements: Characteristics and relationships for air sensor messaging. J. Air Waste Manag. 2017, 67, 462–474. [Google Scholar] [CrossRef] [Green Version]
- Mannshardt, E.; Naess, L. Air quality in the USA. Significance 2018, 15, 24–27. [Google Scholar] [CrossRef]
- Xu, H.; Bi, X.H.; Zheng, W.W.; Wu, J.H.; Feng, Y.C. Particulate matter mass and chemical component concentrations over four Chinese cities along the western Pacific coast. Environ. Sci. Pollut. Res. Int. 2015, 22, 1940–1953. [Google Scholar] [CrossRef]
- Chang, S.Y. The Characteristics of PM2.5 and Its Chemical Compositions between Different Prevailing Wind Patterns in Guangzhou. Aerosol Air. Qual. Res. 2013, 13, 1373–1383. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Song, Y.; Mao, Y.; Mao, Z.; Wu, Y.; Li, M.; Huang, X.; He, Q.; Hu, M. Chemical characteristics and source apportionment of PM2.5 during the harvest season in eastern China’s agricultural regions. Atmos. Environ. 2014, 92, 442–448. [Google Scholar] [CrossRef]
- Yang, F.; Tan, J.; Zhao, Q.; Du, Z.; He, K.; Ma, Y.; Duan, F.; Chen, G.; Zhao, Q. Characteristics of PM2.5 speciation in representative megacities and across China. Atmos. Chem. Phys. 2011, 11, 1025–1051. [Google Scholar] [CrossRef]
- Huang, R.J.; Zhang, Y.; Bozzetti, C.; Ho, K.F.; Cao, J.J.; Han, Y.; Daellenbach, K.R.; Slowik, J.G.; Platt, S.M.; Canonaco, F. High secondary aerosol contribution to particulate pollution during haze events in China. Nature 2014, 514, 218–222. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Wang, G.; Song, G.; Zamora, M.L.; Qi, Y.; Yun, L.; Wang, W.; Min, H.; Yuan, W. Formation of Urban Fine Particulate Matter. Chem. Rev. 2015, 115, 3803–3855. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Chen, J.; Cheng, T.; Zhang, R.; Wang, X. Particle number concentration, size distribution and chemical composition during haze and photochemical smog episodes in Shanghai. J. Environ. Sci. 2014, 26, 1894–1902. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Li, J.; Zhang, Y.; Liu, D.; Ding, P.; Shen, C.; Shen, K.; He, Q.; Ding, X.; Wang, X. Source Apportionment Using Radiocarbon and Organic Tracers for PM2.5 Carbonaceous Aerosols in Guangzhou, South China: Contrasting Local- and Regional-Scale Haze Events. Environ. Sci. Technol. 2014, 48, 12002–12011. [Google Scholar] [CrossRef] [Green Version]
- Huang, K.; Zhuang, G.; Wang, Q.; Fu, J.S.; Lin, Y.; Liu, T.; Han, L.; Deng, C. Extreme haze pollution in Beijing during January 2013: Chemical characteristics, formation mechanism and role of fog processing. Atmos. Chem. Phys. 2014, 14, 479–486. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhang, N.; Liu, Z.; Sun, Y.; Ji, D.; Wang, Y. The Influence of Climate Factors, Meteorological Conditions, and Boundary-Layer Structure on Severe Haze Pollution in the Beijing-Tianjin-Hebei Region during January 2013. Adv. Meteorol. 2015, 2014, 1–14. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, X.; Ding, Y.; Liu, Y.; Zhang, H.; Wang, Y.; Zhong, J. The impact of meteorological changes from 2013 to 2017 on PM2.5 mass reduction in key regions in China. Sci. China Earth Sci. 2019, 62, 1885–1902. [Google Scholar] [CrossRef]
- Chen, J. Impact of Relative Humidity and Water Soluble Constituents of PM2.5 on Visibility Impairment in Beijing, China. Aerosol Air. Qual. Res. 2014, 14, 260–268. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Zou, T.; Guo, B.; Li, S.; Zhang, H.; Zhang, S.; Huang, H.; Chen, S.X. Assessing Beijing’s PM2.5 pollution: Severity, weather impact, APEC and winter heating. Proc. R. Soc. A 2015, 471. [Google Scholar] [CrossRef] [Green Version]
- Requia, W.J.; Jhun, I.; Coull, B.A.; Koutrakis, P. Climate impact on ambient PM2.5 elemental concentration in the United States: A trend analysis over the last 30?years. Environ. Int. 2019, 131, 104888. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Fu, J.; Jiang, D.; Hu, W.; Dong, D.; Huang, Y.; Zhao, M. Spatio-Temporal Variation of PM2.5 Concentrations and Their Relationship with Geographic and Socioeconomic Factors in China. Int. J. Environ. Res. Public Health 2013, 11, 173–186. [Google Scholar] [CrossRef] [Green Version]
- Donkelaar, A.V.; Martin, R.V.; Brauer, M.; Kahn, R.; Levy, R.; Verduzco, C.; Villeneuve, P.J. Global Estimates of Ambient Fine Particulate Matter Concentrations from Satellite-Based Aerosol Optical Depth: Development and Application. Environ. Health Perspect. 2010, 118, 847–855. [Google Scholar] [CrossRef] [Green Version]
- Donkelaar, A.V.; Martin, R.V.; Brauer, M.; Boys, B.L. Use of Satellite Observations for Long-Term Exposure Assessment of Global Concentrations of Fine Particulate Matter. Environ. Health Perspect. 2015, 123, 135–143. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.; Jiang, W.; Wang, B.; Fang, J.; Lang, J.; Tian, G.; Jiang, J.; Zhu, T.F. Inhalable microorganisms in Beijing’s PM2.5 and PM10 pollutants during a severe smog event. Environ. Sci. Technol. 2014, 48, 1499–1507. [Google Scholar] [CrossRef]
- Guo, S.; Hu, M.; Zamora, M.L.; Peng, J.; Shang, D.; Zheng, J.; Du, Z.; Wu, Z.; Shao, M.; Zeng, L. Elucidating severe urban haze formation in China. Proc. Natl. Acad. Sci. USA 2014, 111, 17373–17378. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Tie, X.; Zhang, Q.; Liu, X.; Gao, Q.; Li, X.; Gao, Y. Analysis of the causes of heavy aerosol pollution in Beijing, China: A case study with the WRF-Chem model. Particuology 2015, 20, 32–40. [Google Scholar] [CrossRef]
- Uno, I.; Sugimoto, N.; Shimizu, A.; Yumimoto, K.; Hara, Y.; Wang, Z. Record Heavy PM2.5 Air Pollution over China in January 2013: Vertical and Horizontal Dimensions. Sci. Online Lett. Atmos. Sola 2014, 10, 136–140. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Jiang, Q.; Wang, Z.; Fu, P.; Li, J.; Yang, T.; Yin, Y. Investigation of the sources and evolution processes of severe haze pollution in Beijing in January 2013. J. Geophys. Res. Atmos. 2014, 119, 4380–4398. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, F.; Niu, C.; Wang, H.; Zhang, X. Red warning for air pollution in China: Exploring residents’ perceptions of the first two red warnings in Beijing. Environ. Res. 2018, 161, 540–545. [Google Scholar] [CrossRef]
- Deng, L.; Zhang, Z. Assessing the features of extreme smog in China and the differentiated treatment strategy. Proc. R. Soc. A 2018, 474. [Google Scholar] [CrossRef] [Green Version]
- Wu, H. Breathing in Delhi Air Equivalent to Smoking 44 Cigarettes a Day; CNN: New Delhi, India, 2017; Available online: https://www.cnn.com/2017/11/10/health/delhi-pollution-equivalent-cigarettes-a-day/index.html (accessed on 10 May 2020).
- Bell, J.E.; Brown, C.L.; Conlon, K.; Herring, S.; Kunkel, K.E.; Lawrimore, J.; Luber, G.; Schreck, C.; Smith, A.; Uejio, C. Changes in extreme events and the potential impacts on human health. J. Air. Waste. Manag. 2018, 68, 265–287. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.M.; He, L.Y. Welfare loss of China’s air pollution: How to make personal vehicle transportation policy. China Econ. Rev. 2014, 31, 106–118. [Google Scholar] [CrossRef]
- Pearson, J.F.; Bachireddy, C.; Shyamprasad, S.; Goldfine, A.B.; Brownstein, J.S. Association Between Fine Particulate Matter and Diabetes Prevalence in the U.S. Diabetes Care 2010, 33, 2196–2201. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.H.; Zhong, N.S. Effect on health from smoking and use of solid fuel in China. Lancet 2008, 372, 1445–1446. [Google Scholar] [CrossRef]
- Watts, J. China: The air pollution capital of the world. Lancet 2005, 366, 1761–1762. [Google Scholar] [CrossRef]
- Fang, X.; Fang, B.; Wang, C.; Xia, T.; Bottai, M.; Fang, F.; Cao, Y. Relationship between fine particulate matter, weather condition and daily non-accidental mortality in Shanghai, China: A Bayesian approach. PLoS ONE 2017, 12, e0187933. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Han, Y.; Tang, X.; Zhu, J.; Zhu, T. Estimating adult mortality attributable to PM2.5 exposure in China with assimilated PM2.5 concentrations based on a ground monitoring network. Sci. Total Environ. 2016, 568, 1253–1262. [Google Scholar] [CrossRef] [PubMed]
- Huo, H.; Zhang, Q.; Guan, D.; Su, X.; Zhao, H.; He, K. Examining air pollution in China using production- and consumption-based emissions accounting approaches. Environ. Sci. Technol. 2014, 48, 14139–14147. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.Y.; Zhang, Q.; Davis, S.J.; Guan, D.; Liu, Z.; Huo, H.; Lin, J.T.; Liu, W.D.; He, K.B. Assessment of China’s virtual air pollution transport embodied in trade by a consumption-based emission inventory. Atmos. Chem. Phys. 2015, 15, 6815. [Google Scholar] [CrossRef] [Green Version]
- Muller, N.Z.; Mendelsohn, R.; Nordhaus, W. Environmental Accounting for Pollution in the United States Economy. Am. Econ. Rev. 2011, 101, 1649–1675. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.H. The Sociological Analysis on the Smog of China: The Pesrpective of Complex Risk Society. J. North-East Asian Cult. 2014, 1, 211–225. [Google Scholar] [CrossRef]
- Dombry, C. Existence and consistency of the maximum likelihood estimators for the extreme value index within the block maxima framework. Bernoulli 2015, 21, 420–436. [Google Scholar] [CrossRef]
- Davison, A.C.; Huser, R.; Thibaud, E. Spatial extremes. In Handbook of Environmental and Ecological Statistics; Gelfand, A.E., Fuentes, M., Smith, R.L., Eds.; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Huser, R.G.; Wadsworth, J.L. Modeling spatial processes with unknown extremal dependence class. J. Am. Stat. Assoc. 2018. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Zhang, Z.; Chen, R. Modeling maxima with autoregressive conditional Fréchet model. J. Econ. 2018, 207, 325–351. [Google Scholar] [CrossRef]
- Kunkel, K.E.; Palecki, M.A.; Hubbard, K.G.; Robinson, D.A.; Redmond, K.T.; Easterling, D.R. Trend identification in twentieth-century U.S. snowfall: The challenges. J. Atmos. Ocean. Technol. 2007, 24, 64–73. [Google Scholar] [CrossRef]
- Guo, R.; Zhang, C.; Zhang, Z. Maximum independent component analysis with application to EEG data. Stat. Sci. 2020, 35, 145–157. [Google Scholar] [CrossRef]
- Gavronski, P.G.; Ziegelmann, F.A. Measuring Systemic Risk via GAS models and Extreme Value Theory: Revisiting the 2007 Financial Crisis. Financ. Res. Lett. 2020. [Google Scholar] [CrossRef]
- U.S. EPA. Revised Air Quality Standards for Particle Pollution and Updates to the Air Quality Index. 2012. Available online: https://www.epa.gov/sites/production/files/2016-04/documents/overview_factsheet.pdf (accessed on 10 May 2020).
- Chen, Y.; Ebenstein, A.; Greenstone, M.; Li, H. Evidence on the impact of sustained exposure to air pollution on life expectancy from China’s Huai River policy. Proc. Natl. Acad. Sci. USA 2013, 110, 12936–12941. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, H.; Zhang, S.; Xu, J.; Lu, X.; Jin, J.; Wang, C. Estimating and source analysis of surface pm2.5 concentration in the beijing-tianjin-hebei region based on modis data and air trajectories. Int. J. Remote Sens. 2016, 37, 4799–4817. [Google Scholar] [CrossRef]
- Cheng, Y.; He, K.; Du, Z.; Zheng, M.; Duan, F.; Ma, Y. Humidity plays an important role in the PM2.5 pollution in Beijing. Environ. Pollut. 2015, 197, 68–75. [Google Scholar] [CrossRef] [PubMed]
- Leadbetter, M.R.; Lindgren, G.; Rootzén, H. Extremes and Related Properties of Random Sequences and Processes; Springer Science & Business Media: Berlin, Germany, 1983. [Google Scholar]
- Mao, G.; Zhang, Z. Stochastic tail index model for high frequency financial data with Bayesian analysis. J. Econ. 2018, 205, 470–487. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Hutson, A.D. The exponentiated Weibull family: Some properties and a flood data application. Commun. Stat. Theor. Methods 1996, 25, 3059–3083. [Google Scholar] [CrossRef]
- Hawkins, T.W.; Holland, L.A. Synoptic and local weather conditions associated with PM2.5 concentration in Carlisle, Pennsylvania. Middle States Geogr. 2010, 43, 72–84. [Google Scholar]
- Chen, Z.; Xie, X.; Cai, J.; Chen, D.; Gao, B.; He, B.; Cheng, N.; Xu, B. Understanding meteorological influences on PM2.5 concentrations across China: A temporal and spatial perspective. Atmos. Chem. Phys. 2018, 18, 5343–5358. [Google Scholar] [CrossRef] [Green Version]
- Smith, R. Maximum likelihood estimation in a class of nonregular cases. Biometrika 1985, 72, 67–90. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econ. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- De Gooijer, J.G. Elements of Nonlinear Time Series Analysis and Forecasting; Springer: Berlin, Germany, 2017. [Google Scholar]
- Hastie, T.J.; Tibshirani, R.J. Generalized Additive Models; Chapman & Hall: Boca Raton, FL, USA, 1990. [Google Scholar]
- Thomas, W.Y. Vector Generalized Linear and Additive Models: With an Implementation in R; Springer: New York, NY, USA, 2015. [Google Scholar]
- Nieto, P.G.; Antón, J.Á.; Vilán, J.V.; García-Gonzalo, E. Air quality modeling in the Oviedo urban area (NW Spain) by using multivariate adaptive regression splines. Environ. Sci. Pollut. Res. 2015, 22, 6642–6659. [Google Scholar] [CrossRef] [PubMed]
- Shahraiyni, H.T.; Shahsavani, D.; Sargazi, S.; Habibi Nokhandan, M. Evaluation of MARS for the spatial distribution modeling of carbon monoxide in an urban area. Atmos. Pollut. Res. 2015, 6, 581–588. [Google Scholar] [CrossRef] [Green Version]
- Stasinopoulos, M.D.; Rigby, R.A.; Heller, G.Z.; Voudouris, V.; De Bastiani, F. Flexible Regression and Smoothing Using GAMLSS in R; Chapman and Hall: London, UK, 2017. [Google Scholar]
- Chan, K.; Tong, H. A Note on Noisy Chaos. J. R. Stat. Soc. B 1994, 56, 301–311. [Google Scholar] [CrossRef]
- Birkhoff, G.D. Proof of the ergodic theorem. Proc. Nat. Acad. Sci. USA 1931, 17, 656–660. [Google Scholar] [CrossRef] [PubMed]
- Billingsley, P. The Lindeberg-Levy theorem for martingales. Proc. Am. Math. Soc. 1961, 12, 788–792. [Google Scholar]
- Makelainen, T.; Schmidt, K.; Styan, G. On the existence and uniqueness of the maximum likelihood estimate of a vector-valued parameter in fixed-size samples. Ann. Stat. 1981, 9, 758–767. [Google Scholar] [CrossRef]













| Q2014 | Q2015 | Q2016 | Q2017 | Q2018 | Q2019 | |
|---|---|---|---|---|---|---|
| Mean | 351 | 281 | 267 | 239 | 195 | 180 |
| Median | 302 | 241 | 228 | 192 | 163 | 144 |
| Maximum | 1597 | 929 | 1040 | 1076 | 850 | 1000 |
| Minimum | 74 | 49 | 78 | 58 | 36 | 33 |
| Std. Dev. | 186 | 144 | 149 | 146 | 109 | 117 |
| Skewness | 1.8 | 1.1 | 1.8 | 2.3 | 2.0 | 2.4 |
| Kurtosis | 9.1 | 4.5 | 7.9 | 10.0 | 9.7 | 12.6 |
| Parameter | True Value | Mean (SC1) | SD (SC1) | Mean (SC2) | SD (SC2) | Ratio |
|---|---|---|---|---|---|---|
| 4.677 | 4.781 | 3.022 | 4.719 | 1.961 | 0.649 | |
| 5.387 | 5.394 | 1.837 | 5.392 | 1.266 | 0.689 | |
| 1.912 | 1.890 | 2.595 | 1.900 | 1.795 | 0.692 | |
| −2.219 | −2.230 | 7.863 | −2.224 | 4.951 | 0.630 | |
| 3.439 | 3.479 | 2.668 | 3.455 | 1.687 | 0.632 | |
| 2.398 | 2.387 | 6.065 | 2.394 | 3.825 | 0.631 |
| Parameter | True Value | Mean (SC1) | SD (SC1) | Mean (SC2) | SD (SC2) |
|---|---|---|---|---|---|
| 4.624 × | 4.695 × | 3.499 | 4.642 × | 2.237 | |
| 6.010 | 6.021 | 2.337 × | 6.016 | 1.443 × | |
| 1.257 × | 1.235 × | 3.090 × | 1.250 × | 2.004 × | |
| −1.437 | −1.434 | 1.133 × | −1.440 | 6.263 × | |
| 2.237 × | 2.256 × | 1.998 × | 2.240 × | 1.111 × | |
| 9.283 × | 9.442 × | 1.011 × | 9.291 | 6.166 × | |
| 2.622 × | 2.649 × | 5.506 × | 2.627 × | 3.143 × | |
| 1.021 × | 1.035 × | 1.730 × | 1.022 × | 9.577 × | |
| 7.165 × | 6.783 × | 3.045 × | 7.566 × | 1.956 × | |
| −1.488 × | −1.511 × | 3.131 × | −1.490 × | 1.867 × | |
| −1.042 × | −1.066 × | 2.770 × | −1.045 × | 1.701 × | |
| −8.835 × | −8.782 × | 3.093 × | −8.797 × | 1.713 × | |
| −4.190 | −4.270 × | 2.890 × | −4.253 × | 1.759 | |
| 1.992 | 2.320 × | 3.699 × | 1.949 × | 2.289 | |
| 4.577 × | 4.703 × | 2.594 × | 4.575 × | 1.520 | |
| 2.572 | 2.574 | 6.617 × | 2.575 | 4.271 × |
| Parameter | Fitted Value | SD |
|---|---|---|
| 3.218 × | 3.457 × | |
| 4.885 | 1.081 × | |
| 2.461 × | 1.682 × | |
| −2.195 | 4.443 × | |
| 4.613 × | 1.549 × | |
| 2.320 | 1.814 × |
| Parameter | Fitted Value | SD |
|---|---|---|
| 3.299 × | 4.216 × | |
| 5.420 | 1.174 × | |
| 1.731 × | 1.770 × | |
| −1.786 | 8.367 × | |
| 3.724 × | 1.467 × | |
| 7.685 × | 5.057 × | |
| 2.761 × | 7.391 × | |
| 1.531 × | 6.882 × | |
| 1.392 × | 2.335 × | |
| −1.230 × | 1.846 × | |
| −1.660 × | 2.203 × | |
| −1.239 × | 2.478 × | |
| −8.593 × | 2.371 × | |
| −1.864 × | 3.288 × | |
| 1.769 × | 1.957 × | |
| 2.408 | 1.835 × |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, L.; Yu, M.; Zhang, Z. Statistical Learning of the Worst Regional Smog Extremes with Dynamic Conditional Modeling. Atmosphere 2020, 11, 665. https://doi.org/10.3390/atmos11060665
Deng L, Yu M, Zhang Z. Statistical Learning of the Worst Regional Smog Extremes with Dynamic Conditional Modeling. Atmosphere. 2020; 11(6):665. https://doi.org/10.3390/atmos11060665
Chicago/Turabian StyleDeng, Lu, Mengxin Yu, and Zhengjun Zhang. 2020. "Statistical Learning of the Worst Regional Smog Extremes with Dynamic Conditional Modeling" Atmosphere 11, no. 6: 665. https://doi.org/10.3390/atmos11060665