Figure 1.
Problems in pear recognition.
Figure 1.
Problems in pear recognition.
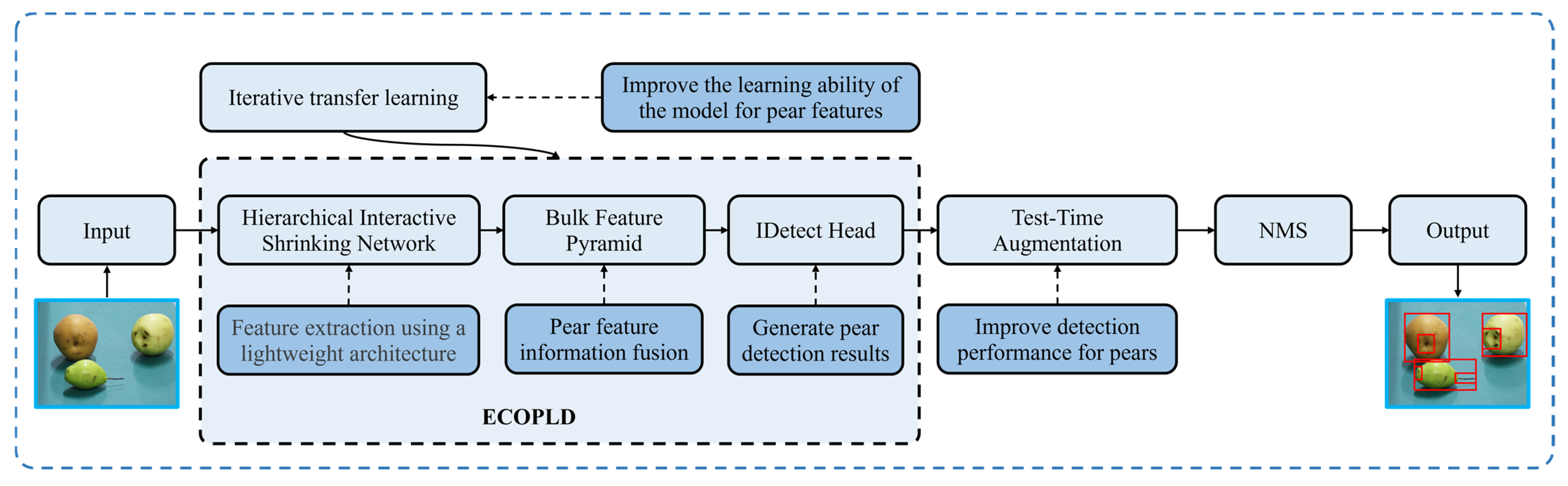
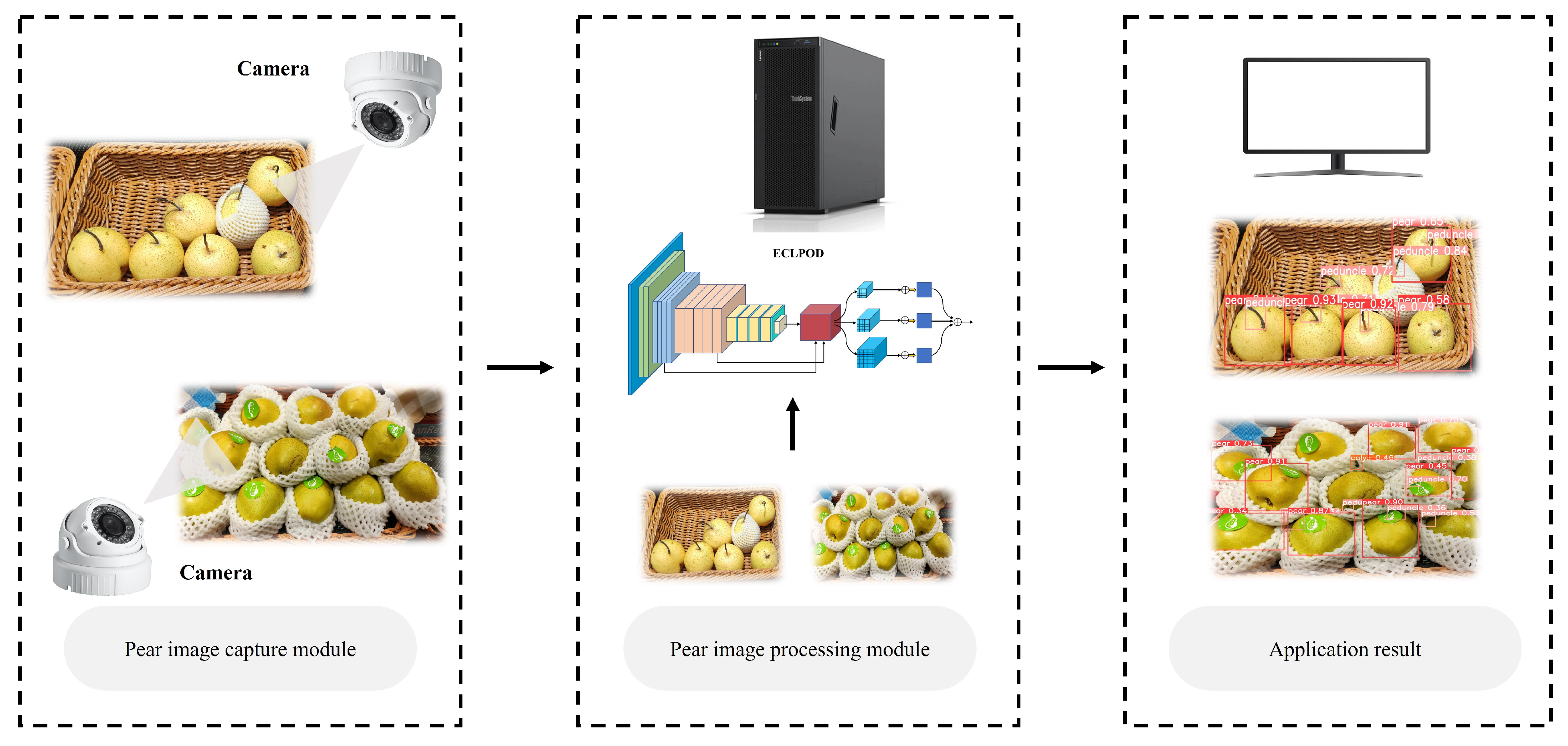
Figure 2.
Workflow of the ECLPOD.
Figure 2.
Workflow of the ECLPOD.
Figure 3.
Components of experimental data and data collection methods: (A) represents the location information of a single pear in the near, medium, and far environment. (B) represents the location information of a small number of pears in the near, medium, and far environment. (C) represents the location information of multiple pears in near, medium, and far environments. (D) represents pear position information in a dark environment, an environment with more shade, an environment with strong light, and an environment with focus deviation. (E) represents the data acquisition process for the dataset.
Figure 3.
Components of experimental data and data collection methods: (A) represents the location information of a single pear in the near, medium, and far environment. (B) represents the location information of a small number of pears in the near, medium, and far environment. (C) represents the location information of multiple pears in near, medium, and far environments. (D) represents pear position information in a dark environment, an environment with more shade, an environment with strong light, and an environment with focus deviation. (E) represents the data acquisition process for the dataset.
Figure 4.
Structure of the ECLPOD: (A) The parameter transfer process of the network’s backbone. (B) The main structure of the ECLPOD. (C) The structure of the HISNet. (D) The main structure of the BFP module. (E) The ACS policies are ITL and TTA.
Figure 4.
Structure of the ECLPOD: (A) The parameter transfer process of the network’s backbone. (B) The main structure of the ECLPOD. (C) The structure of the HISNet. (D) The main structure of the BFP module. (E) The ACS policies are ITL and TTA.
Figure 5.
Data enhancement of pictures during training. The meanings of the numbers in the boxes in the pictures are as follows: 0 represents pear, 1 represents fruit stalk, 2 represents fruit calyx, and 3 represents defect.
Figure 5.
Data enhancement of pictures during training. The meanings of the numbers in the boxes in the pictures are as follows: 0 represents pear, 1 represents fruit stalk, 2 represents fruit calyx, and 3 represents defect.
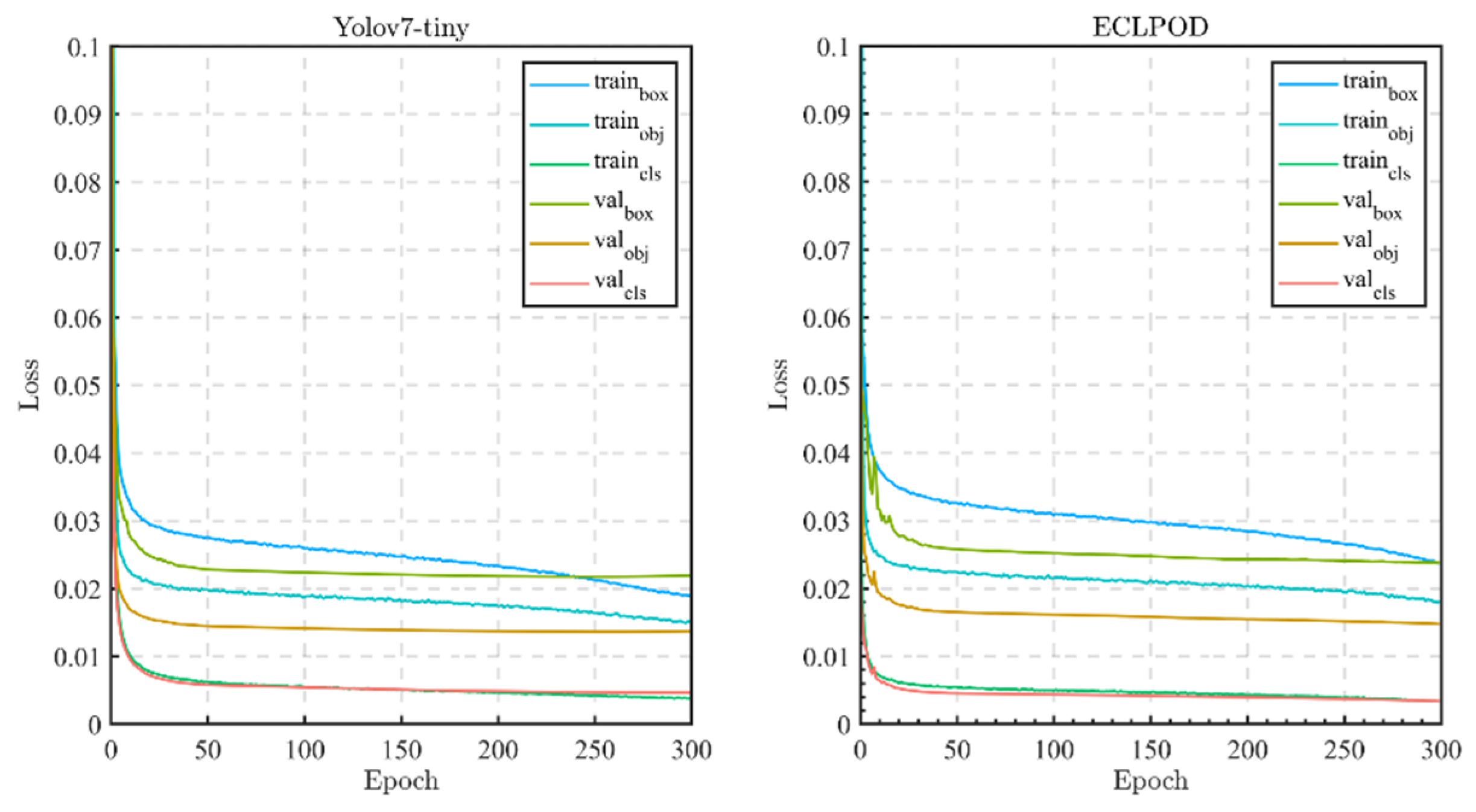
Figure 6.
Loss changes during training and verification.
Figure 6.
Loss changes during training and verification.
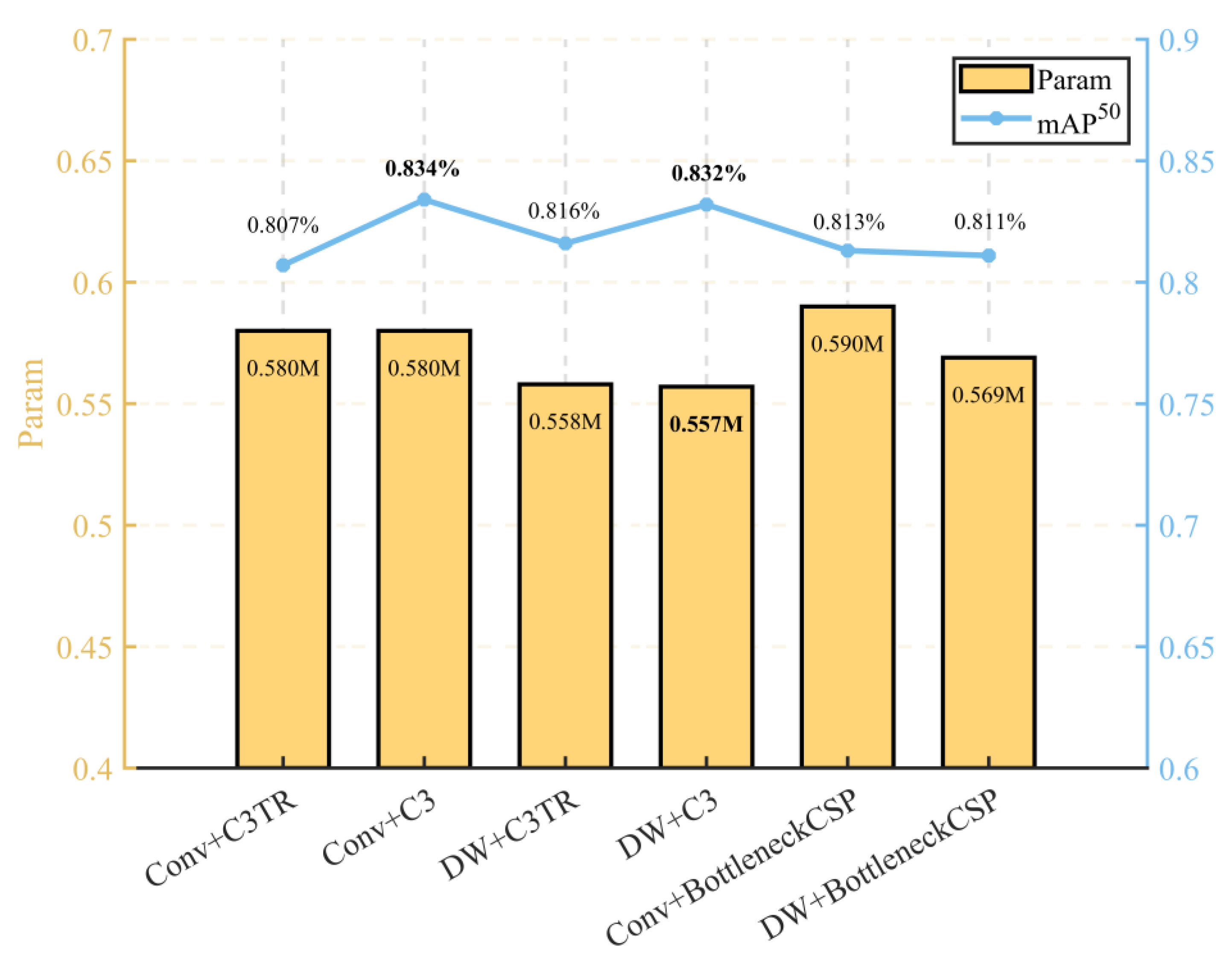
Figure 7.
Analysis of the effectiveness of DW block and C3.
Figure 7.
Analysis of the effectiveness of DW block and C3.
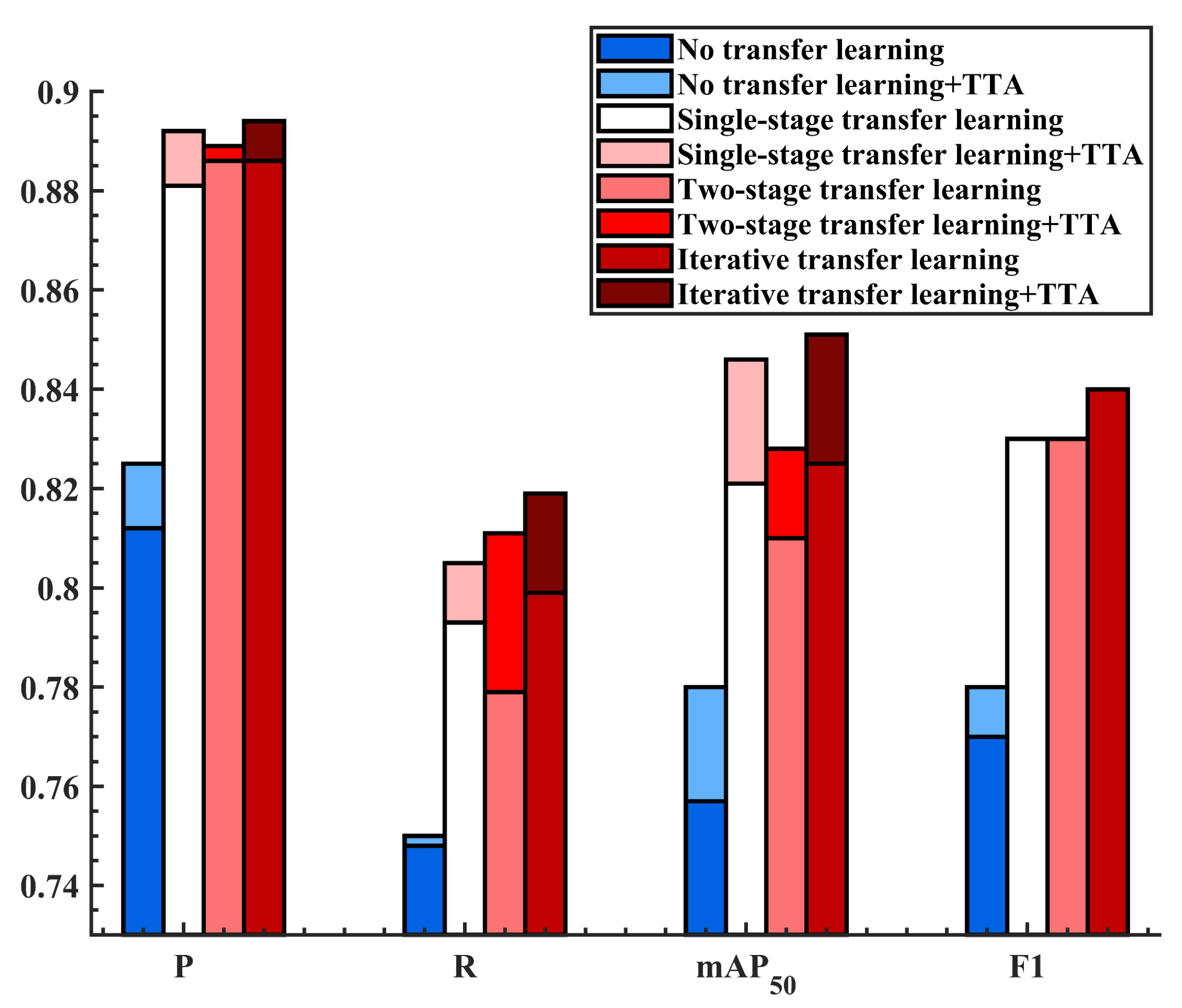
Figure 8.
Comparison of different learning strategies.
Figure 8.
Comparison of different learning strategies.
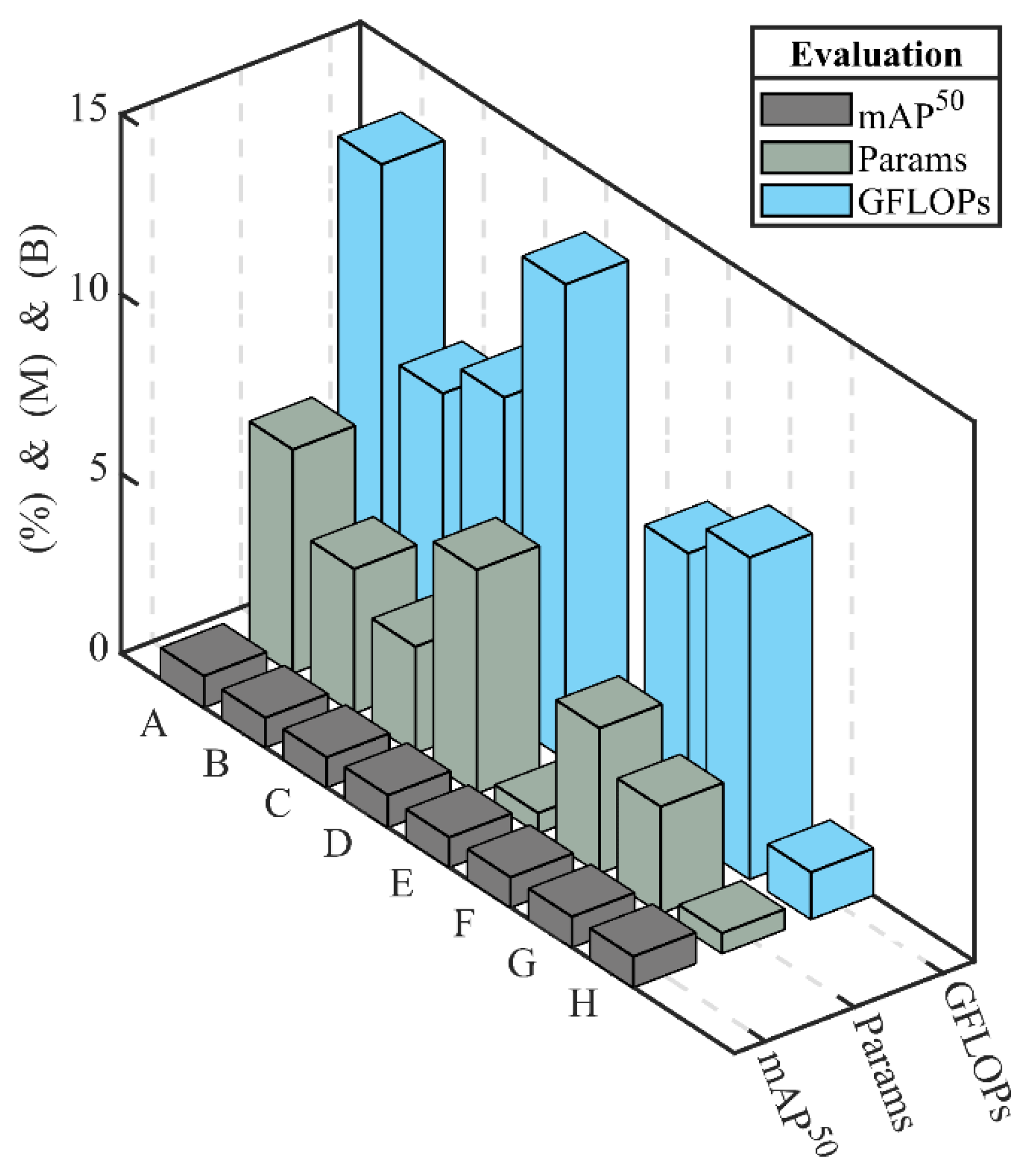
Figure 9.
ECLPOD single ablation experiment: group A is the experimental result of YOLOv7-tiny; groups B (A + HISNet), C (A + BFP), and D (A + ACS) are the unidirectional ablation results; groups E (B + BFP), F (B + ACS), and G (C + ACS) are the bidirectional ablation results; and group H is the experimental result of the ECLPOD.
Figure 9.
ECLPOD single ablation experiment: group A is the experimental result of YOLOv7-tiny; groups B (A + HISNet), C (A + BFP), and D (A + ACS) are the unidirectional ablation results; groups E (B + BFP), F (B + ACS), and G (C + ACS) are the bidirectional ablation results; and group H is the experimental result of the ECLPOD.
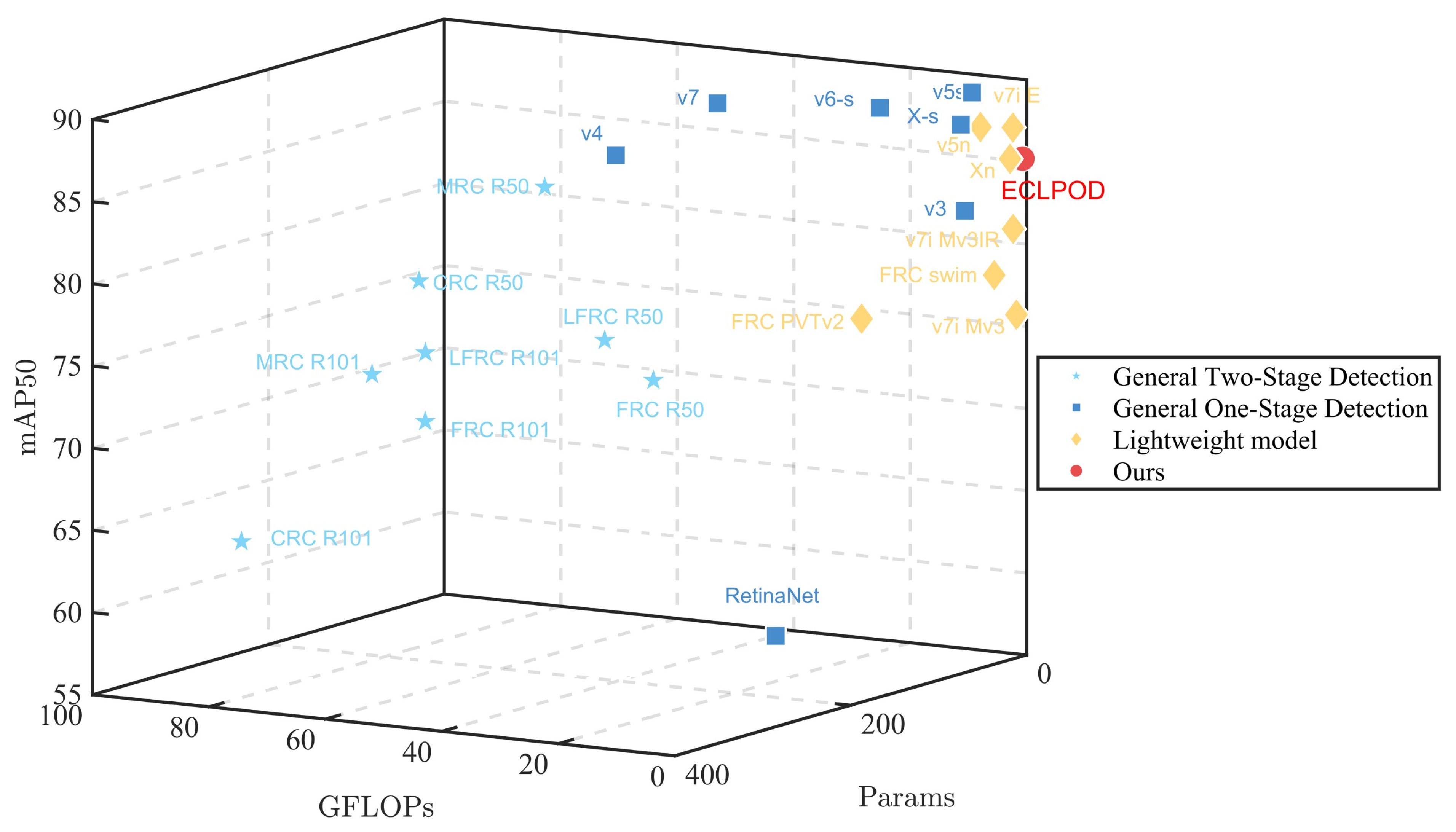
Figure 10.
Comparison between different models and the ECLPOD. Network interpretation: FRC stands for Faster R-CNN, MRC stands for Mask R-CNN, CRC stands for Cascade R-CNN, LFRC stands for LibraFaster R-CNN, RetinaNet stands for RetinaNet; and v3, v4, v5, v6, v7, and x represent YOLOv3, YOLOv4, YOLOv5, YOLOv6, YOLOv7, and YOLO-X, respectively. Backbone description: R50, R101, PVT, swin, Mv3IR, respectively represent ResNet-50, ResNet-101, the pyramid vision transformer, Swin transformer, and MobileNetv3.
Figure 10.
Comparison between different models and the ECLPOD. Network interpretation: FRC stands for Faster R-CNN, MRC stands for Mask R-CNN, CRC stands for Cascade R-CNN, LFRC stands for LibraFaster R-CNN, RetinaNet stands for RetinaNet; and v3, v4, v5, v6, v7, and x represent YOLOv3, YOLOv4, YOLOv5, YOLOv6, YOLOv7, and YOLO-X, respectively. Backbone description: R50, R101, PVT, swin, Mv3IR, respectively represent ResNet-50, ResNet-101, the pyramid vision transformer, Swin transformer, and MobileNetv3.
Figure 11.
Anti-jamming comparison of the models. To facilitate the display of test results, the analysis results are enlarged. Among them, (a) is a dark environment, (b) is a light environment, (c) is subjected to texture attacks, (d) is a salt and pepper noise environment, and (e) is an image compression environment.
Figure 11.
Anti-jamming comparison of the models. To facilitate the display of test results, the analysis results are enlarged. Among them, (a) is a dark environment, (b) is a light environment, (c) is subjected to texture attacks, (d) is a salt and pepper noise environment, and (e) is an image compression environment.
Figure 12.
Generalization Performance Analysis.
Figure 12.
Generalization Performance Analysis.
Figure 13.
Detection of different defect situations.
Figure 13.
Detection of different defect situations.
Table 1.
Abbreviations table.
Table 1.
Abbreviations table.
| Abbreviation | Explanation |
|---|
| ECLPOD | Extremely Compressed Lightweight Model for Pear Object Detection |
| HISNet | Hierarchical Interactive Shrinking Network |
| BFP | Bulk Feature Pyramid |
| LNBA | Learnable Based on Normalized Attention |
| ACS | Accuracy Compensation Strategy |
| ITL | Iterative transfer learning |
| TTA | Test Time Augmentation |
Table 2.
Symbol explanation table.
Table 2.
Symbol explanation table.
| Symbol | Explanation |
|---|
| The value at of the channel feature map after deep convolution. |
| The value at position in the final output feature map. |
| The effective receptive field area of the convolution kernel. |
| The weight of depth convolution. |
| The weight of point-by-point convolution. |
| The computation of ordinary convolution. |
| The computational amount of depth-separable convolution. |
| The input feature map of the LNBA model. |
| The output feature map of the LNBA model. |
| A feature normalization of input features. |
| The normalized BN layer weight. |
| Value of the information bottleneck. |
Table 3.
Overview of deep learning-based sorting methods.
Table 3.
Overview of deep learning-based sorting methods.
| Years | Methods | Advantages | Disadvantages | Dataset |
|---|
| 2020 | Detection and classification of bruises on pears based on thermal images [21] | The accuracy rate of pear bruise detection reached 99.25% | Equipment is too complicated | 4371 |
| 2021 | Deep learning based on residual networks for automatic sorting of bananas [22] | Accurate summary of banana quality grades | Bananas are not targeted | 600 |
| 2021 | Waste management using an automatic sorting system for carrot fruit based on image processing techniques and improved deep neural networks [23] | Carrots were graded with an accuracy of 93.9 percent | The model is simple and does not fully exploit the characteristics of the data | 878 |
| 2022 | Apple stem/calyx real-time recognition using the YOLOv5 algorithm for an automatic fruit loading system [11] | Adjusting fruit posture through the fruit calyx and fruit stalk helped achieve an accuracy rate of 93.89% | The application scenario is simple | 7660 |
| 2022 | Appearance quality classification method for Huangguan pear under complex backgrounds based on instance segmentation and semantic segmentation [24] | Accurate identification of diseased Crown pears | The three-stage model is too complex for practical application | 5562 |
| 2023 | An efficient classification process using supervised deep learning and robot positioning based on embedded PD-FLC [25] | Real-time identification and classification of fruits | Does not consider the occlusion of the fruit | 6600 |
| 2023 | Sorting of fresh tea leaf using deep learning and air blowing [26] | It better solves the decline in recognition accuracy caused by the mixed grades of fresh tea leaves | Only the use of simple cases is considered | 6400 |
| 2023 | Application of deep learning diagnoses for multiple trait sorting in peach fruit [27] | Diagnosis is possible through RGB images without the need for complex equipment | Unable to detect internal defects | 1512 |
Table 4.
The number of labels in the dataset.
Table 4.
The number of labels in the dataset.
| Dataset Setting | Labels with Pears | Labels with Peduncle | Labels with Calyx | Labels with Defect | Total Labels | Labels per Image |
|---|
| Train set | 43,148 | 31,722 | 15,376 | 2087 | 92,333 | 4.51 |
| Val set | 18,496 | 13,664 | 6543 | 919 | 39,622 | 4.52 |
| Robust set | 10,937 | 6333 | 5049 | 414 | 22,733 | 4.20 |
Table 5.
Software and hardware environment settings.
Table 5.
Software and hardware environment settings.
Hardware
environment | CPU | 32 vCPU Intel(R) Xeon(R)
Platinum 8350C CPU @ 2.60 GHz |
| RAM | 43 GB |
| Video memory | 24 GB |
| GPU | NVIDIA GeForce RTX 3090 |
Software
environment | OS | Linux |
| Miniconda conda3 | Python 3.8.10 (ubuntu20.04) |
| Cuda 11.3 | Torch 1.9.1 + cu111 |
| CUDNN 8005 | Torchaudio 0.9.1 |
| Torchvision 0.10.1 + cu111 | YOLOAir-v1.0 |
| MMCV-full 1.6.1 | MMdet 2.25.1 |
Table 6.
Experimental parameter settings.
Table 6.
Experimental parameter settings.
| Parameter Category | Parameter Name | Parameter Setting |
|---|
| SGD optimizer | Initial learning rate | 0.01 |
| Weight decay | 5 × 10−4 |
| Momentum | 0.937 |
| Learning rate decay | 0.005 |
| Input data parameters | Size of input images | (640,640) |
| Batch size | 32 |
| Training epochs | 300 |
| IoU threshold | 0.6 |
Table 7.
Model performance comparison.
Table 7.
Model performance comparison.
| Evaluation | YOLOv7-Tiny | ECLPOD |
|---|
| APpear | 99.43(−0.02~+0.03) | 99.44(−0.02~+0.05) |
| APpeduncle | 93.42(−0.02~+0.05) | 91.23(−0.08~+0.11) |
| APcalyx | 81.11(−0.13~+0.11) | 78.50(−0.07~+0.14) |
| AP50 | 87.10(−0.04~+0.08) | 83.10(−0.09~+0.15) |
| AP50:95 | 58.20(−0.05~+0.09) | 52.72(−0.06~+0.12) |
| F1 | 0.84 | 0.84 |
| FPS | 106 | 112 |
| Params(M) | 6.02 | 0.55 |
Table 8.
Visual comparison of the networks.
Table 9.
Comparing the HISNet with other lightweight networks.
Table 9.
Comparing the HISNet with other lightweight networks.
| Method | Param | GFLOPs | mAP50 | APpear |
|---|
| YOLOV7-tiny | 6.21 M | 13.20 | 87.10(−0.04~+0.08) | 99.43(−0.01~+0.01) |
| +Mobilenetv3-InvertedResidual [38] | 4.82 M | 8.11 | 80.90(−0.13~+0.11) | 99.42(−0.03~+0.02) |
| +ShuffleNet V2 [39] | 5.39 M | 9.74 | 77.90(−0.17~+0.12) | 99.23(−0.02~+0.04) |
| +HISNet | 4.01 M | 7.82 | 82.10(−0.08~+0.15) | 99.51(−0.01~+0.02) |
Table 10.
Comparison of the effect of attention.
Table 10.
Comparison of the effect of attention.
| Method | F1 | Param | GFLOPs | mAP50 |
|---|
| Without Attention | 0.84 | 0.557 M | 1.3 | 82.5(−0.07~+0.11) |
| +CA [40] | 0.83 | 0.562 M | 1.3 | 80.7(−0.13~+0.12) |
| +CBAM [41] | 0.83 | 0.562 M | 1.3 | 81.9(−0.11~+0.09) |
| +LNBA | 0.84 | 0.558 M | 1.3 | 83.2(−0.09~+0.07) |
Table 11.
Training results for different learning strategies.
Table 11.
Training results for different learning strategies.
| Method | P | R | F1 | mAP50 |
|---|
| No transfer learning | 81.20 | 74.80 | 77.00 | 75.70(−0.27~+0.19) |
| No transfer learning (+TTA) | 82.50 | 75.00 | 78.00 | 78.01(−0.24~+0.15) |
| Single-stage transfer learning | 88.10 | 79.30 | 83.00 | 82.10(−0.16~+0.06) |
| Single-stage transfer learning (+TTA) | 89.20 | 80.50 | 84.60 | 83.24(−0.14~+0.04) |
| Two-stage transfer learning | 88.60 | 77.90 | 83.00 | 81.00(−0.18~+0.11) |
| Two-stage transfer learning (+TTA) | 88.90 | 81.10 | 82.80 | 83.02(−0.11~+0.15) |
| Iterative transfer learning | 88.60 | 81.42 | 82.00 | 83.20(−0.09~+0.15) |
| Iterative transfer learning (+TTA) | 90.10 | 82.90 | 83.10 | 85.20(−0.07~+0.14) |
Table 12.
ECLPOD single ablation experiment.
Table 12.
ECLPOD single ablation experiment.
| Group | Method | F1 | Params | GFLOPs | mAP50 |
|---|
| A | YOLOv7-tiny | 0.84 | 6.22 | 13.20 | 87.11(−0.06~+0.11) |
| B | +HIS | 0.79 | 4.01 | 7.94 | 82.17(−0.13~+0.16) |
| C | +BFP | 0.77 | 2.96 | 8.94 | 83.41(−0.15~+0.22) |
| D | +ACS | 0.85 | 6.21 | 13.20 | 89.22(−0.04~+0.14) |
| E | +HIS+BFP | 0.82 | 0.56 | 1.30 | 83.21(−0.06~+0.08) |
| F | +HIS+ACS | 0.82 | 4.03 | 7.94 | 83.32(−0.06~+0.13) |
| G | +BFP+ACS | 0.81 | 2.96 | 8.94 | 84.83(−0.09~+0.12) |
| H | +HIS+BFP+ACS | 0.83 | 0.55 | 1.30 | 85.20(−0.07~+0.14) |
Table 13.
Comparison of different models.
Table 13.
Comparison of different models.
| Method | Backbone | Precision | Param(M) | GFLOPs | mAP50 |
|---|
| General Two-Stage Detection |
| Faster R-CNN | ResNet-50 | 81.1 | 40.54 | 156.04 | 72.61(−0.31~+0.21) |
| Faster R-CNN | ResNet-101 | 79.5 | 60.52 | 283.14 | 71.32(−0.29~+0.26) |
| Cascade R-CNN | ResNet-50 | 83.4 | 68.94 | 234.47 | 78.81(−0.25~+0.17) |
| Cascade R-CNN | ResNet-101 | 74.7 | 87.93 | 310.55 | 63.41(−0.43~+0.56) |
| Mask R-CNN | ResNet-50 | 88.9 | 43.76 | 258.22 | 85.85(−0.18~+0.11) |
| Mask R-CNN | ResNet-101 | 80.2 | 62.65 | 329.54 | 74.84(−0.24~+0.31) |
| LibraFaster R-CNN | ResNet-50 | 82.0 | 41.1 | 207.73 | 75.82(−0.22~+0.19) |
| LibraFaster R-CNN | ResNet-101 | 81.5 | 60.39 | 283.8 | 75.57(−0.18~+0.26) |
| General One-Stage Detection |
| RetinaNet | ResNet-18 | 60.3 | 19.68 | 155.11 | 57.89(−1.31~+0.87) |
| YOLOv3 | DarkNet-53 | 89.3 | 8.67 | 12.90 | 81.91(−0.15~+0.13) |
| YOLOv4 | CSPDarknet-53 | 89.9 | 52.51 | 119.70 | 85.32(−0.11~+0.04) |
| YOLOv5-s | CSPDarknet-53 | 91.7 | 7.02 | 15.80 | 89.24(−0.07~+0.04) |
| YOLOX-s | CSPDarknet | 89.9 | 8.05 | 21.80 | 86.36(−0.08~+0.14) |
| YOLOv6-s | Efficientrep | 90.8 | 18.4 | 45.10 | 88.37(−0.12~+0.03) |
| YOLOv7 | E-ElAN | 91.9 | 37.2 | 105.20 | 88.87(−0.04~+0.08) |
| YOLOv7-tiny | E-ElAN | 91.2 | 6.01 | 13.00 | 87.12(−0.07~+0.11) |
| Lightweight model |
| Faster R-CNN | Swim | 85.2 | 4.22 | 9.12 | 78.10(−0.3~+0.04) |
| Faster R-CNN | PVTv2 | 84.3 | 6.8 | 142.89 | 77.41(−0.15~+0.18) |
| YOLOv5-n | CSPDarknet-53 | 89.4 | 1.76 | 4.10 | 85.17(−0.11~+0.03) |
| YOLOX-n | CSPDarknet | 89.7 | 2.02 | 5.70 | 85.22(−0.08~+0.11) |
| YOLOv7-tiny | Mobilenetv3-bench | 81.2 | 1.4 | 2.40 | 75.71(−0.21~+0.16) |
| YOLOv7-tiny | Mobilenetv3-InvertedResidual | 88.3 | 1.9 | 2.80 | 80.91(−0.13~+0.11) |
| Ours |
| ECLPOD | HISNet | 90.1 | 0.55 | 1.30 | 85.20(−0.07~+0.14) |
Table 14.
Comparison of test results.
Table 15.
Experimental results of one-way ANOVA.
Table 15.
Experimental results of one-way ANOVA.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















