
Research and Validation of Potato Late Blight Detection Method Based on Deep Learning
Abstract
:1. Introduction
- (1)
- To attain fine-grained disease classification by leveraging classical lightweight classification networks. To evaluate the performance of each model based on classification accuracy and model complexity to identify the model that exhibits the highest generalization ability, which will serve as the foundation for further research.
- (2)
- To optimize the chosen base model by reducing the number of model parameters and increasing the speed of inference, while ensuring that classification accuracy is not compromised.
- (3)
- To evaluate the feasibility and effectiveness of running the model on hardware, the optimized model was deployed on an embedded device.
2. Materials and Methods
2.1. Image Data Acquisition
2.2. Images Annotation
- (1)
- Leaf annotation
- (2)
- Disease spot annotation
- Production of leaf foreground image: the label image obtained after the labeling of the leaf will be converted into a binary image to obtain a mask image of the leaf, and then it will be bit-operated with the original image to obtain an image containing only the foreground of the leaf.
- Extraction of the super green features of the image: calculation of the vegetation index EXG of the foreground image of the leaf, as well as the transformation of its color space from three channels to a single channel to obtain a greyscale image.
- Acquisition of non-spotted areas: set the gray value of the pixels with a gray value between 30 and 200 to 0 and the rest to 255. The image is changed from a grey-scale image to a binary image with a black background and diseased areas in white and non-diseased areas in black.
- Get the diseased area: the non-diseased area and the leaf mask image are bit-operated, and then morphological operations are performed to eliminate the fine outline of the leaf edge to obtain a complete mask image of the diseased area.
- Creating a labeled image of the spot: iterate through all the pixels of the image, reassigning those with a gray value of 255 for all three channels—r, g, and b. Pixels with a gray value of 255 are reassigned.
2.3. Image Data Expansion
2.4. Methodologies
2.4.1. ShuffleNetV2
2.4.2. Attention Module
- (1)
- SE Module
- (2)
- CBAM Module
- (3)
- ECA Module
2.4.3. Reduce Network Depth
2.4.4. Reduce the 1 × 1 Convolutions
2.4.5. Experimental Environment
2.5. Evaluation of Model Performance
- (1)
- Accuracy evaluation index
- (2)
- Complexity evaluation index
3. Results and Discussion
3.1. Base Model Performance Comparison
3.2. Model Improvement Strategies
3.2.1. Type, Location, and Number of Attention Modules
3.2.2. Reducing Network Depth
3.2.3. Reduce the 1 × 1 Convolutions
3.3. Ablation Experiment
3.4. Performance of Fine-Grained Classification of Potato Leaf Diseases
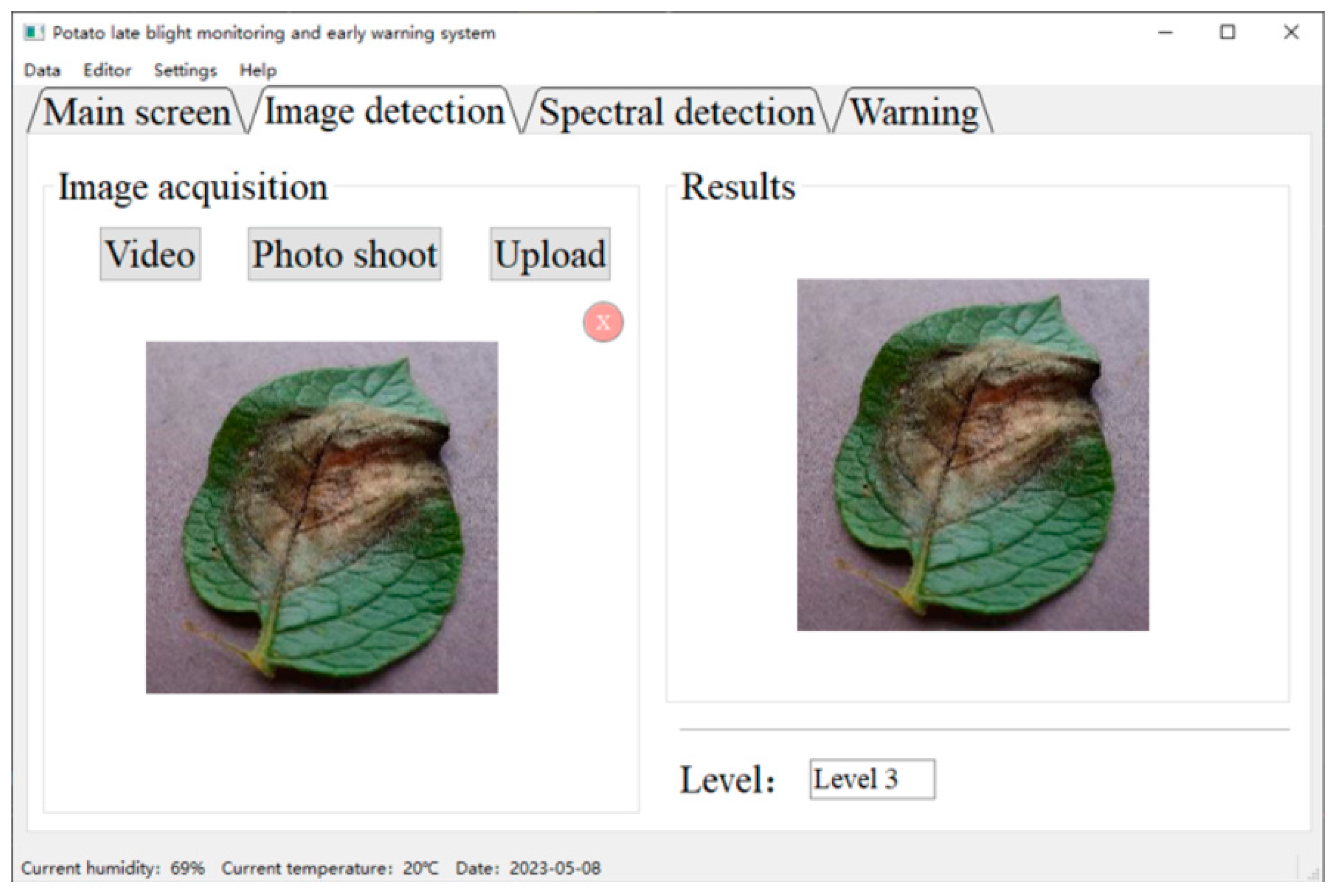
3.5. Embedded Device Deployment
4. Conclusions and Prospect
4.1. Conclusions
- (1)
- The MobileNet, ShuffleNet, GhostNet, and SqueezeNet pre-trained models, based on the ImageNet dataset, were migrated to the fine-grained classification task using migration training and evaluated comprehensively based on several metrics, including classification accuracy and model complexity. In comparison, the 0.75 MobileNetV3l model has the lowest number of parameters, the ShuffleNetV2 2× model has the fastest inference speed on GPU and CPU, and the GhostNet model has the highest accuracy. Finally, the ShuffleNetV2 2× model, which offers faster CPU inference speed, is chosen as the basic model while ensuring classification accuracy.
- (2)
- The ShuffleNetV2 2× model was improved by introducing the attention mechanism and adjusting the network structure, and the improvement strategies were: introducing the attention mechanism module, reducing the network depth, and decreasing the number of 1 × 1 convolutions. Compared with the base model, the number of parameters and computational effort of the improved model are substantially reduced, while the classification accuracy increases by 0.85%, and the inference speed on the CPU increases from 25.7 frames per second to 30.2 frames per second. The improved model better balances infer time and accuracy under the premise of reducing model complexity.
- (3)
- The improved model was deployed and tested in an embedded device, and the overall classification precision was 94%, the average time required for single image detection was 3.27 s, and it had high recognition precision and fast detection speed, which provided important technical support to realize automatic identification of potato late blight diseases.
4.2. Prospect
- (1)
- Enhanced Dataset: Recognizing the importance of data quality and diversity, we will emphasize the need for expanding the potato late blight dataset. This can include gathering more labeled images from different regions, capturing variations in lighting conditions, and incorporating images with different stages and severities of late blight infection.
- (2)
- Multi-Disease Detection: Given the overlap of symptoms in various plant diseases, we will discuss the possibility of extending the developed deep learning model to detect other plant diseases or multiple diseases simultaneously. This expansion would provide a comprehensive solution for agricultural disease management.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Actual Category | Prediction Category | Memory Occupancy (%) | CPU Occupancy (%) | Infer Time (s) |
|---|---|---|---|---|---|
| 1 | Late blight Level 2 | Late blight Level 2 | 38.30 | 3.90 | 3.30 |
| 2 | Late blight Level 3 | Late blight Level 3 | 38.50 | 15.70 | 3.26 |
| 3 | Late blight Level 2 | Late blight Level 2 | 38.40 | 11.80 | 3.30 |
| 4 | Late blight Level 1 | Late blight Level 1 | 38.70 | 10.40 | 3.27 |
| 5 | Late blight Level 3 | Late blight Level 3 | 38.50 | 17.30 | 3.29 |
| 6 | Late blight Level 1 | Late blight Level 1 | 38.80 | 14.30 | 3.29 |
| 7 | Late blight Level 2 | Late blight Level 2 | 38.80 | 13.70 | 3.28 |
| 8 | Late blight Level 3 | Late blight Level 3 | 38.60 | 15.40 | 3.30 |
| 9 | Late blight Level 2 | Late blight Level 2 | 38.60 | 14.30 | 3.26 |
| 10 | Late blight Level 2 | Late blight Level 2 | 38.90 | 17.30 | 3.24 |
| 11 | Late blight Level 1 | Late blight Level 1 | 38.60 | 10.20 | 3.26 |
| 12 | Late blight Level 3 | Late blight Level 3 | 38.40 | 4.10 | 3.25 |
| 13 | Late blight Level 1 | Late blight Level 1 | 38.60 | 8.00 | 3.24 |
| 14 | Late blight Level 3 | Late blight Level 3 | 38.30 | 8.00 | 3.29 |
| 15 | Late blight Level 1 | Late blight Level 1 | 38.50 | 2.00 | 3.27 |
| 16 | Late blight Level 2 | Late blight Level 2 | 38.40 | 8.00 | 3.27 |
| 17 | Late blight Level 2 | Late blight Level 2 | 38.60 | 2.00 | 3.27 |
| 18 | Healthy | Healthy | 37.80 | 4.00 | 3.24 |
| 19 | Healthy | Healthy | 38.10 | 4.00 | 3.22 |
| 20 | Healthy | Healthy | 38.20 | 8.00 | 3.27 |
| 21 | Healthy | Healthy | 38.40 | 5.90 | 3.25 |
| 22 | Healthy | Healthy | 38.20 | 2.00 | 3.29 |
| 23 | Healthy | Healthy | 38.20 | 4.00 | 3.24 |
| 24 | Healthy | Healthy | 38.40 | 10.00 | 3.23 |
| 25 | Healthy | Healthy | 38.30 | 5.90 | 3.22 |
| 26 | Healthy | Healthy | 38.50 | 9.80 | 3.30 |
| 27 | Healthy | Healthy | 38.40 | 4.00 | 3.23 |
| 28 | Healthy | Healthy | 38.50 | 4.20 | 3.22 |
| 29 | Healthy | Healthy | 38.60 | 4.10 | 3.29 |
| 30 | Healthy | Healthy | 38.40 | 6.10 | 3.22 |
| 31 | Healthy | Healthy | 38.60 | 8.00 | 3.23 |
| 32 | Healthy | Healthy | 38.60 | 2.00 | 3.29 |
| 33 | Healthy | Healthy | 38.70 | 6.00 | 3.25 |
| 34 | Healthy | Healthy | 38.80 | 6.00 | 3.22 |
| 35 | Healthy | Healthy | 38.80 | 6.10 | 3.22 |
| 36 | Healthy | Healthy | 38.90 | 6.00 | 3.21 |
| 37 | Healthy | Healthy | 38.80 | 7.80 | 3.23 |
| 38 | Late blight Level 1 | Late blight Level 1 | 38.80 | 9.80 | 3.27 |
| 39 | Late blight Level 1 | Healthy | 38.90 | 6.10 | 3.29 |
| 40 | Late blight Level 1 | Late blight Level 1 | 38.80 | 7.70 | 3.24 |
| 41 | Late blight Level 1 | Late blight Level 2 | 38.80 | 4.10 | 3.28 |
| 42 | Late blight Level 1 | Late blight Level 1 | 38.80 | 9.80 | 3.24 |
| 43 | Late blight Level 2 | Late blight Level 2 | 38.90 | 8.00 | 3.26 |
| 44 | Late blight Level 2 | Late blight Level 2 | 38.90 | 10.00 | 3.26 |
| 45 | Late blight Level 2 | Late blight Level 2 | 39.10 | 2.00 | 3.27 |
| 46 | Late blight Level 3 | Late blight Level 3 | 38.90 | 2.00 | 3.27 |
| 47 | Late blight Level 3 | Late blight Level 3 | 38.90 | 6.10 | 3.29 |
| 48 | Late blight Level 3 | Late blight Level 3 | 39.10 | 4.00 | 3.30 |
| 49 | Late blight Level 3 | Late blight Level 3 | 39.00 | 8.00 | 3.25 |
| 50 | Late blight Level 3 | Late blight Level 3 | 39.20 | 6.30 | 3.30 |
| 51 | Late blight Level 2 | Late blight Level 2 | 39.20 | 6.10 | 3.28 |
| 52 | Late blight Level 1 | Late blight Level 1 | 39.30 | 4.00 | 3.26 |
| 53 | Late blight Level 1 | Late blight Level 1 | 39.30 | 6.10 | 3.26 |
| 54 | Late blight Level 1 | Late blight Level 1 | 39.20 | 8.00 | 3.27 |
| 55 | Late blight Level 2 | Late blight Level 2 | 39.10 | 7.80 | 3.26 |
| 56 | Late blight Level 1 | Late blight Level 1 | 39.20 | 6.00 | 3.33 |
| 57 | Late blight Level 1 | Late blight Level 1 | 39.30 | 7.80 | 3.28 |
| 58 | Late blight Level 1 | Late blight Level 1 | 39.40 | 2.00 | 3.30 |
| 59 | Late blight Level 2 | Late blight Level 2 | 39.30 | 6.10 | 3.30 |
| 60 | Late blight Level 1 | Early blight Level 1 | 39.40 | 3.90 | 3.27 |
| 61 | Late blight Level 2 | Late blight Level 2 | 39.40 | 7.50 | 3.28 |
| 62 | Late blight Level 3 | Late blight Level 3 | 39.40 | 4.00 | 3.29 |
| 63 | Late blight Level 2 | Late blight Level 2 | 39.60 | 6.00 | 3.28 |
| 64 | Late blight Level 2 | Late blight Level 1 | 39.50 | 4.00 | 3.27 |
| 65 | Late blight Level 1 | Late blight Level 1 | 39.50 | 6.00 | 3.29 |
| 66 | Late blight Level 3 | Late blight Level 3 | 39.50 | 4.10 | 3.29 |
| 67 | Late blight Level 3 | Late blight Level 3 | 39.50 | 4.10 | 3.27 |
| 68 | Late blight Level 3 | Late blight Level 3 | 39.60 | 6.00 | 3.25 |
| 69 | Late blight Level 3 | Late blight Level 3 | 39.70 | 2.00 | 3.28 |
| 70 | Late blight Level 3 | Late blight Level 3 | 39.70 | 10.00 | 3.27 |
| 71 | Late blight Level 1 | Late blight Level 1 | 39.70 | 8.00 | 3.26 |
| 72 | Late blight Level 2 | Late blight Level 2 | 39.60 | 4.00 | 3.30 |
| 73 | Late blight Level 2 | Late blight Level 2 | 39.70 | 8.00 | 3.25 |
| 74 | Late blight Level 2 | Late blight Level 2 | 39.90 | 7.80 | 3.28 |
| 75 | Late blight Level 2 | Early blight Level 1 | 39.70 | 6.00 | 3.27 |
| 76 | Late blight Level 1 | Late blight Level 1 | 39.80 | 7.80 | 3.03 |
| 77 | Late blight Level 3 | Late blight Level 3 | 40.00 | 6.10 | 3.26 |
| 78 | Late blight Level 3 | Early blight Level 2 | 39.80 | 4.00 | 3.25 |
| 79 | Late blight Level 3 | Late blight Level 3 | 39.80 | 4.10 | 3.27 |
| 80 | Late blight Level 3 | Late blight Level 3 | 39.80 | 7.80 | 3.26 |
| 81 | Healthy | Healthy | 39.90 | 7.80 | 3.26 |
| 82 | Healthy | Healthy | 39.80 | 4.00 | 3.24 |
| 83 | Healthy | Healthy | 39.90 | 9.80 | 3.27 |
| 84 | Healthy | Healthy | 39.90 | 7.80 | 3.30 |
| 85 | Healthy | Healthy | 40.00 | 2.00 | 3.28 |
| 86 | Healthy | Healthy | 40.00 | 4.20 | 3.28 |
| 87 | Healthy | Healthy | 40.10 | 7.80 | 3.27 |
| 88 | Healthy | Healthy | 40.10 | 6.10 | 3.26 |
| 89 | Healthy | Healthy | 40.30 | 2.00 | 3.28 |
| 90 | Healthy | Healthy | 40.30 | 8.00 | 3.25 |
| 91 | Healthy | Healthy | 40.20 | 2.00 | 3.29 |
| 92 | Healthy | Healthy | 40.40 | 4.00 | 3.32 |
| 93 | Healthy | Healthy | 40.20 | 6.00 | 3.31 |
| 94 | Healthy | Healthy | 40.20 | 8.00 | 3.28 |
| 95 | Healthy | Healthy | 40.30 | 5.90 | 3.27 |
| 96 | Healthy | Healthy | 40.30 | 6.10 | 3.29 |
| 97 | Healthy | Healthy | 40.40 | 8.00 | 3.29 |
| 98 | Healthy | Healthy | 40.30 | 9.80 | 3.30 |
| 99 | Healthy | Healthy | 40.40 | 8.00 | 3.28 |
| 100 | Healthy | Healthy | 39.10 | 7.80 | 3.53 |
References
- Sun, D.X.; Shi, M.F.; Wang, Y.; Chen, X.P.; Liu, Y.H.; Zhang, J.L.; Qin, S.H. Effects of partial substitution of chemical fertilizers with organic fertilizers on potato agronomic traits, yield and quality. J. Gansu Agric. Univ. 2023. [Google Scholar] [CrossRef]
- Liu, P.; Chai, S.; Chang, L.; Zhang, F.; Sun, W.; Zhang, H.; Liu, X.; Li, H. Effects of Straw Strip Covering on Yield and Water Use Efficiency of Potato cultivars with Different Maturities in Rain-Fed Area of Northwest China. Agriculture 2023, 13, 402. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, Y.; Guo, T.; Qiao, Y.; He, Y.; Zhang, Y.; Huang, Y. AGHRNet: An attention ghost-HRNet for confirmation of catch-and-shake locations in jujube fruits vibration harvesting. Comput. Electron. Agric. 2023, 210, 107921. [Google Scholar] [CrossRef]
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Huo, Y. Faster Mean-shift: GPU-accelerated Embedding-clustering for Cell Segmentation and Tracking. Med. Image Anal. 2021, 71, 102048. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Liu, Q.; Jha, A.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.J.; Millis, B.A.; Huo, Y. VoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding based Deep Learning. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Virtual, 17–19 September 2021. [Google Scholar]
- You, L.; Jiang, H.; Hu, J.; Chang, C.; Chen, L.; Cui, X.; Zhao, M. GPU-accelerated Faster Mean Shift with euclidean distance metrics. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Virtual, 27 June–1 July 2022. [Google Scholar]
- Zheng, Z.; Hu, Y.; Yang, H.; Qiao, Y.; He, Y.; Zhang, Y.; Huang, Y. AFFU-Net: Attention feature fusion U-Net with hybrid loss for winter jujube crack detection. Comput. Electron. Agric. 2022, 198, 107049. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit Image Classification Model Based on MobileNetV2 with Deep Transfer Learning Technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing Image Annotation Technique of Fruit Classification Using a Deep Learning Approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- Gulzar, Y.; Hamid, Y.; Soomro, A.B.; Alwan, A.A.; Journaux, L. A Convolution Neural Network-Based Seed Classification System. Symmetry 2020, 12, 2018. [Google Scholar] [CrossRef]
- Aggarwal, S.; Gupta, S.; Gupta, D.; Gulzar, Y.; Juneja, S.; Alwan, A.A.; Nauman, A. An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images. Sustainability 2023, 15, 1695. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, S.; Sun, C.; Qi, L.; Ma, X.; Wang, W. A deep convolutional neural network-based method for detecting rice spike blight. Trans. Chin. Soc. Agric. Eng. 2017, 169–176. [Google Scholar] [CrossRef]
- Rahman, C.R.; Arko, P.S.; Ali, M.E.; Khan, M.A.I.; Apon, S.H.; Nowrin, F.; Wasif, A. Identification and recognition of rice diseases and pests using convolutional neural networks. Biosyst. Eng. 2020, 194, 112–120. [Google Scholar] [CrossRef] [Green Version]
- Barman, U.; Sahu, D.; Barman, G.G.; Das, J. Comparative assessment of deep learning to detect the leaf diseases of potato based on data augmentation. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020. [Google Scholar]
- Chen, J.; Zhang, D.; Nanehkaran, Y.A.; Li, D. Detection of rice plant diseases based on deep transfer learning. J. Sci. Food Agric. 2020, 100, 3246–3256. [Google Scholar] [CrossRef]
- Suarez Baron, M.J.; Gomez, A.L.; Diaz, J.E.E. Supervised Learning-Based Image Classification for the Detection of Late Blight in Potato Crops. Appl. Sci. 2022, 12, 9371. [Google Scholar] [CrossRef]
- Eser, S. A deep learning based approach for the detection of diseases in pepper and potato leaves. Anadolu Tarım Bilim. Derg. 2021, 36, 167–178. [Google Scholar]
- Hughes, D.; Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar]
- GB/T 17980.34-2000; Pesticides Field Efficacy Test Guidelines (I) Fungicide Control of Potato Late Blight. The Ministry of Agriculture and Rural Affairs of the People’s Republic of China: Beijing, China, 2000.
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Świnouście, Poland, 9–12 May 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, H.; Qiu, W.; Zhang, L. Improved ShuffleNet V2 for Lightweight Crop Disease Identification. Comput. Eng. Appl. 2022, 58, 260–268. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 February 2020. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Hong, H.; Lin, J.; Huang, F. Tomato disease detection and classification by deep learning. In Proceedings of the International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; IEEE: New York, NY, USA, 2020; pp. 25–29. [Google Scholar]
- Osama, R.; Ashraf, N.E.H.; Yasser, A.; AbdelFatah, S.; El Masry, N.; AbdelRaouf, A. Detecting plant’s diseases in Greenhouse using Deep Learning. In Proceedings of the 2020 2nd Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 24–26 October 2020; IEEE: New York, NY, USA, 2020; pp. 75–80. [Google Scholar]
- Rozaqi, A.J.; Sunyoto, A. Identification of disease in potato leaves using Convolutional Neural Network (CNN) algorithm. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; IEEE: New York, NY, USA, 2020; pp. 72–76. [Google Scholar]










| Percentage of Spots (%) | Disease Level | Number of Single Background Images | Number of Single Background Images | ||||
|---|---|---|---|---|---|---|---|
| Early Blight | Late Blight | Healthy | Early Blight | Late Blight | Healthy | ||
| <1 | Healthy | / | / | 1582 | / | / | 50 |
| 1~15 | Level 1 | 613 | 462 | / | 54 | 51 | / |
| 15~40 | Level 2 | 341 | 428 | / | 45 | 89 | / |
| >40 | Level 3 | 46 | 110 | / | 12 | 60 | / |
| Layer | Output Size | Kernel Size | Stride | Repeats | Number of Output Channels | |||
|---|---|---|---|---|---|---|---|---|
| 0.5× | 1× | 1.5× | 2× | |||||
| Image | 224 × 224 | 3 | 3 | 3 | 3 | |||
| Conv1 | 112 × 112 | 3 × 3 | 2 | 1 | 24 | 24 | 24 | 24 |
| MaxPool | 56 × 56 | 3 × 3 | 2 | |||||
| Stage 2 | 28 × 28 | 2 | 1 | 48 | 116 | 176 | 244 | |
| 28 × 28 | 1 | 3 | ||||||
| Stage 3 | 14 × 14 | 2 | 1 | 96 | 232 | 352 | 488 | |
| 14 × 14 | 1 | 7 | ||||||
| Stage 4 | 7 × 7 | 2 | 1 | 192 | 464 | 704 | 976 | |
| 7 × 7 | 1 | 3 | ||||||
| Conv 5 | 7 × 7 | 1 × 1 | 1 | 1 | 1024 | 1024 | 1024 | 2048 |
| Global Pool | 1 × 1 | 1 × 1 | ||||||
| FC | ||||||||
| Configuration | Parameter |
|---|---|
| CPU | 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30 GHz |
| GPU | NVIDIA GeForce RTX 3050 Ti |
| Programming language | Python 3.7 |
| Deep learning framework | Tensorflow2.0 |
| Operating system | Windows 11 |
| Model | Accuracy (%) | Parameters (106) | FLOPs (109) | Model Size (MB) | Infer Time (ms) | |
|---|---|---|---|---|---|---|
| GPU | CPU | |||||
| 0.25 MobileNetV1 | 89.62 | 0.22 | 0.08 | 1.04 | 13.23 | 24.56 |
| 0.5 MobileNetV1 | 93.43 | 0.83 | 0.30 | 3.37 | 19.13 | 31.67 |
| 0.75 MobileNetV1 | 93.50 | 1.84 | 0.66 | 7.21 | 21.86 | 32.96 |
| 1.0 MobileNetV1 | 93.50 | 3.24 | 1.15 | 12.54 | 21.97 | 34.09 |
| 0.5 MobileNetV2 | 91.88 | 0.50 | 0.18 | 2.26 | 25.08 | 36.82 |
| 0.75 MobileNetV2 | 93.64 | 1.07 | 0.40 | 4.45 | 25.25 | 38.53 |
| 1.0 MobileNetV2 | 94.14 | 1.85 | 0.57 | 7.41 | 26.31 | 37.62 |
| 1.3 MobileNetV2 | 94.70 | 3.07 | 0.97 | 12.08 | 27.94 | 38.43 |
| 0.75 MobileNetV3s | 71.96 | 1.44 | 0.10 | 5.84 | 26.16 | 37.80 |
| 1.0 MobileNetV3s | 84.18 | 1.54 | 0.13 | 6.22 | 28.23 | 39.83 |
| 0.75 MobileNetV3l | 95.27 | 1.72 | 0.31 | 7.16 | 31.63 | 42.29 |
| 1.0 MobileNetV3l | 95.13 | 2.84 | 0.43 | 11.43 | 31.92 | 44.71 |
| ShuffleNetV1 0.25× | 79.52 | 0.07 | 0.04 | 0.93 | 35.79 | 46.38 |
| ShuffleNetV1 0.5× | 84.32 | 0.24 | 0.08 | 1.58 | 36.89 | 48.85 |
| ShuffleNetV1 1× | 88.28 | 0.90 | 0.26 | 4.06 | 38.32 | 51.39 |
| ShuffleNetV2 0.5× | 90.75 | 0.36 | 0.08 | 1.80 | 26.34 | 36.01 |
| ShuffleNetV2 1× | 93.29 | 1.28 | 0.29 | 5.31 | 26.61 | 37.21 |
| ShuffleNetV2 2× | 95.41 | 5.39 | 1.17 | 21.01 | 29.85 | 38.83 |
| GhostNet | 95.62 | 2.54 | 0.27 | 10.35 | 34.59 | 46.07 |
| SqueezeNet | 89.62 | 0.73 | 0.53 | 2.91 | 19.77 | 30.80 |
| Model | Accuracy (%) | Parameters (106) | FLOPs (109) | Infer Time (ms) | |
|---|---|---|---|---|---|
| GPU | CPU | ||||
| ShuffleNetV2-SE-A-6 | 95.69 | 5.59 | 1.17 | 29.95 | 39.86 |
| ShuffleNetV2-SE-A-9 | 96.12 | 5.63 | 1.17 | 30.88 | 40.88 |
| ShuffleNetV2-SE-A-12 | 96.54 | 5.67 | 1.17 | 33.24 | 42.17 |
| ShuffleNetV2-SE-B-6 | 95.42 | 5.59 | 1.17 | 32.72 | 40.43 |
| ShuffleNetV2-SE-B-9 | 96.05 | 5.63 | 1.17 | 32.79 | 41.56 |
| ShuffleNetV2-SE-B-12 | 95.59 | 5.67 | 1.17 | 34.21 | 42.73 |
| ShuffleNetV2-SE-C-6 | 95.97 | 5.71 | 1.17 | 30.60 | 40.75 |
| ShuffleNetV2-SE-C-9 | 96.05 | 5.87 | 1.17 | 31.48 | 41.51 |
| ShuffleNetV2-SE-C-12 | 96.12 | 6.02 | 1.17 | 33.64 | 42.15 |
| ShuffleNetV2-ECA-A-6 | 95.76 | 5.39 | 1.17 | 29.86 | 38.87 |
| ShuffleNetV2-ECA-A-9 | 96.33 | 5.39 | 1.17 | 30.22 | 38.98 |
| ShuffleNetV2-ECA-A-12 | 96.19 | 5.39 | 1.17 | 33.17 | 39.99 |
| ShuffleNetV2-ECA-B-6 | 95.32 | 5.39 | 1.17 | 29.53 | 38.95 |
| ShuffleNetV2-ECA-B-9 | 95.62 | 5.39 | 1.17 | 31.01 | 39.15 |
| ShuffleNetV2-ECA-B-12 | 96.05 | 5.39 | 1.17 | 32.12 | 40.45 |
| ShuffleNetV2-ECA-C-6 | 96.19 | 5.39 | 1.17 | 29.51 | 38.90 |
| ShuffleNetV2-ECA-C-9 | 96.12 | 5.39 | 1.17 | 30.90 | 39.89 |
| ShuffleNetV2-ECA-C-12 | 95.55 | 5.39 | 1.17 | 31.13 | 40.12 |
| ShuffleNetV2-CBAM-A-6 | 95.55 | 5.59 | 1.18 | 42.08 | 51.67 |
| ShuffleNetV2-CBAM-A-9 | 95.76 | 5.63 | 1.18 | 46.77 | 54.76 |
| ShuffleNetV2-CBAM-A-12 | 96.33 | 5.67 | 1.18 | 48.35 | 62.17 |
| ShuffleNetV2-CBAM-B-6 | 95.55 | 5.59 | 1.18 | 38.86 | 50.46 |
| ShuffleNetV2-CBAM-B-9 | 95.42 | 5.63 | 1.18 | 44.64 | 56.75 |
| ShuffleNetV2-CBAM-B-12 | 96.12 | 5.67 | 1.18 | 52.53 | 60.99 |
| ShuffleNetV2-CBAM-C-6 | 95.76 | 5.71 | 1.18 | 38.29 | 51.57 |
| ShuffleNetV2-CBAM-C-9 | 95.44 | 5.87 | 1.18 | 46.64 | 55.26 |
| ShuffleNetV2-CBAM-C-12 | 96.12 | 6.02 | 1.18 | 53.10 | 62.39 |
| Model | Accuracy (%) | Parameters (106) | FLOPs (109) | Infer Time (ms) | |
|---|---|---|---|---|---|
| GPU | CPU | ||||
| ShuffleNetV2-484 | 95.41 | 5.39 | 1.17 | 29.85 | 38.83 |
| ShuffleNetV2-384 | 95.27 | 5.36 | 1.12 | 29.14 | 37.08 |
| ShuffleNetV2-284 | 94.99 | 5.33 | 1.07 | 27.17 | 36.29 |
| ShuffleNetV2-474 | 95.90 | 5.27 | 1.12 | 27.70 | 36.81 |
| ShuffleNetV2-464 | 96.12 | 5.14 | 1.08 | 26.01 | 35.61 |
| ShuffleNetV2-454 | 96.12 | 5.02 | 1.03 | 24.60 | 34.68 |
| ShuffleNetV2-483 | 95.69 | 4.91 | 1.12 | 27.53 | 36.45 |
| ShuffleNetV2-482 | 95.62 | 4.42 | 1.08 | 24.79 | 35.12 |
| ShuffleNetV2-374 | 94.70 | 5.24 | 1.07 | 26.65 | 35.61 |
| ShuffleNetV2-264 | 94.70 | 5.08 | 0.98 | 27.23 | 36.32 |
| ShuffleNetV2-473 | 96.40 | 4.78 | 1.08 | 26.01 | 35.53 |
| ShuffleNetV2-462 | 95.41 | 4.17 | 0.98 | 24.71 | 35.01 |
| ShuffleNetV2-373 | 94.92 | 4.75 | 1.03 | 24.82 | 35.12 |
| Model | Accuracy (%) | Parameters (106) | FLOPs (109) | Infer Time(ms) | |
|---|---|---|---|---|---|
| GPU | CPU | ||||
| ShuffleNetV2 | 95.41 | 5.39 | 1.17 | 29.85 | 38.83 |
| ShuffleNetV2-s2_3 | 95.55 | 5.08 | 1.10 | 29.75 | 38.17 |
| ShuffleNetV2-s1_3 | 96.12 | 5.08 | 1.10 | 29.75 | 37.96 |
| ShuffleNetV2-s1_6 | 94.21 | 4.76 | 1.03 | 29.09 | 37.08 |
| ShuffleNetV2-s1_9 | 93.43 | 4.45 | 0.96 | 25.32 | 36.08 |
| ShuffleNetV2-s1_3-s2_3 | 95.48 | 4.76 | 1.03 | 25.86 | 36.27 |
| Model | Accuracy (%) | Parameters (106) | Model Size (MB) | FLOPs (109) | Infer Time (ms) | |
|---|---|---|---|---|---|---|
| GPU | CPU | |||||
| ShuffleNetV2 2× | 95.41 | 5.39 | 21.01 | 1.17 | 29.85 | 38.83 |
| ShuffleNetV2 2×—S1 | 96.19 | 5.39 | 21.01 | 1.17 | 29.51 | 38.90 |
| ShuffleNetV2 2×—S2 | 96.40 | 4.78 | 18.64 | 1.08 | 26.01 | 35.53 |
| ShuffleNetV2 2×—S3 | 95.48 | 4.76 | 17.34 | 1.03 | 25.86 | 36.27 |
| ShuffleNetV2 2×—S1–S2 | 96.63 | 4.78 | 18.64 | 1.08 | 27.34 | 36.90 |
| ShuffleNetV2 2×—S2–S3 | 95.62 | 4.15 | 16.23 | 0.93 | 27.42 | 34.40 |
| ShuffleNetV2 2×—S1–S3 | 96.01 | 4.76 | 17.34 | 1.03 | 26.80 | 36.28 |
| ShuffleNetV2 2×—S1–S2–S3 | 96.36 | 4.15 | 16.23 | 0.93 | 26.82 | 33.10 |
| Category | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| Healthy | 99.72 | 100.00 | 99.86 |
| Early blight Level 1 | 95.93 | 92.18 | 94.02 |
| Early blight Level 2 | 91.52 | 92.57 | 92.04 |
| Early blight Level 3 | 98.25 | 99.41 | 98.83 |
| Late blight Level 1 | 95.34 | 90.61 | 92.91 |
| Late blight Level 2 | 87.96 | 92.82 | 90.32 |
| Late blight Level 3 | 96.56 | 97.11 | 96.83 |
| Literature | Time | Detection Objects | Datasets | Model | Accuracy (%) | Parameters (106) |
|---|---|---|---|---|---|---|
| Hong et al. [33] | 2020 | tomato | Plant Village | DenseNet_XCeption | 97.10 | 29.20 |
| XCeption | 93.17 | 22.80 | ||||
| ResNet_50 | 86.56 | 25.50 | ||||
| Osama et al. [34] | 2020 | tomato | Plant Village | Fast.ai | 94.80 | \ |
| Keras | 86.30 | \ | ||||
| Rozaqi et al. [35] | 2020 | potato | Plant Village | CNN | 92.00 | 6.81 |
| Our Research | 2023 | potato | AI Challenger + Plant Village | ShuffleNetV2 2×—S1–S2–S3 | 95.04 | 4.15 |
| Category | Number | Precision (%) |
|---|---|---|
| Healthy | 40 | 100.0 |
| Late blight Level 1 | 20 | 85.0 |
| Late blight Level 2 | 20 | 90.0 |
| Late blight Level 3 | 20 | 95.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Hou, B.; Yu, C.; Yang, H.; Wang, C.; Shi, X.; Hu, Y. Research and Validation of Potato Late Blight Detection Method Based on Deep Learning. Agronomy 2023, 13, 1659. https://doi.org/10.3390/agronomy13061659
Feng J, Hou B, Yu C, Yang H, Wang C, Shi X, Hu Y. Research and Validation of Potato Late Blight Detection Method Based on Deep Learning. Agronomy. 2023; 13(6):1659. https://doi.org/10.3390/agronomy13061659
Chicago/Turabian StyleFeng, Junzhe, Bingru Hou, Chenhao Yu, Huanbo Yang, Chao Wang, Xiaoyi Shi, and Yaohua Hu. 2023. "Research and Validation of Potato Late Blight Detection Method Based on Deep Learning" Agronomy 13, no. 6: 1659. https://doi.org/10.3390/agronomy13061659