
Developing and Testing Remote-Sensing Indices to Represent within-Field Variation of Wheat Yields: Assessment of the Variation Explained by Simple Models



Abstract
:1. Introduction
- Which vegetation indices perform best? Can combinations of vegetation indices representing information about biomass and chlorophyll provide improvements compared to a single index?
- What growth stage, automatically detected based on analysis of remote-sensing time series, is best? Can data from multiple growth stages help predictions?
- Can the raw Landsat bands add further information to improve predictions compared to those based on the vegetation indices alone, or do pre-formulated vegetation indices contain most of the valuable information?
- How well do predictions represent the within-field variation of actual yields and of yield ranking?
- How well do predictions represent within-field yield variation over multiple years as compared with for a single year?
2. Materials and Methods
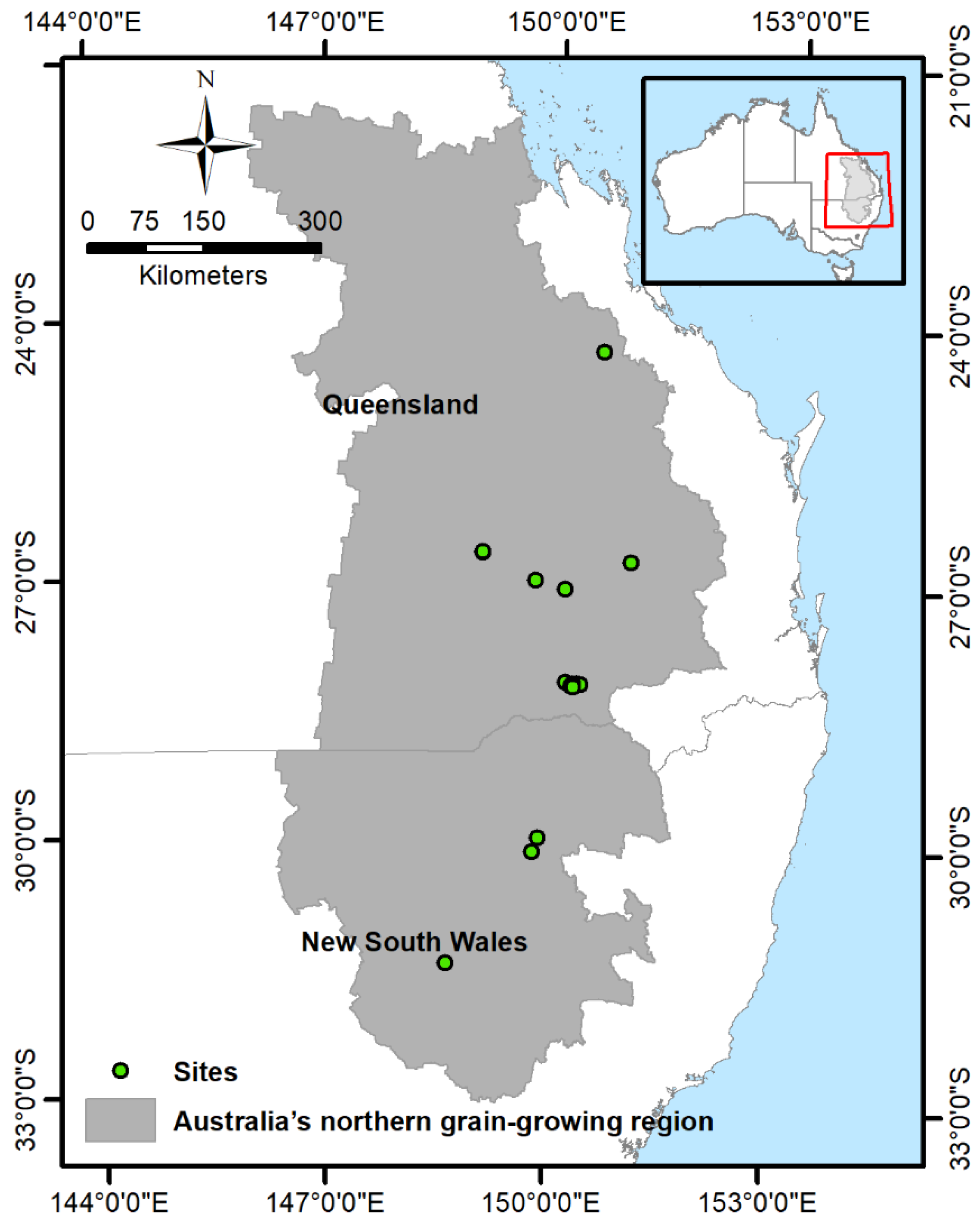
2.1. Study Area
2.2. Datasets and Pre-Processing
2.2.1. Crop Yield Monitored Data
2.2.2. Satellite Data
2.2.3. Selection of Vegetation Indices
2.2.4. Imagery Selection
2.2.5. Set of Covariates
- A single index, one stage (e.g., NDVI—peak stage);
- Two indices from different VI groups (see Table 2), both from the same stage (e.g., a combination of NDVI and CVI in peak stage);
- A single index, all stages (e.g., NDVI from the pre-peak, peak, and post-peak stages);
- Combinations selected via a stepwise analysis, see Section 2.3.2, allowing any combinations of vegetation index and stage or raw Landsat bands and stage.
2.3. Statistical Methods for Developing and Assesing the Yield Index
2.3.1. The Linear Mixed-Effect Model
2.3.2. Stepwise Analysis
2.3.3. Cross-Validation
3. Results
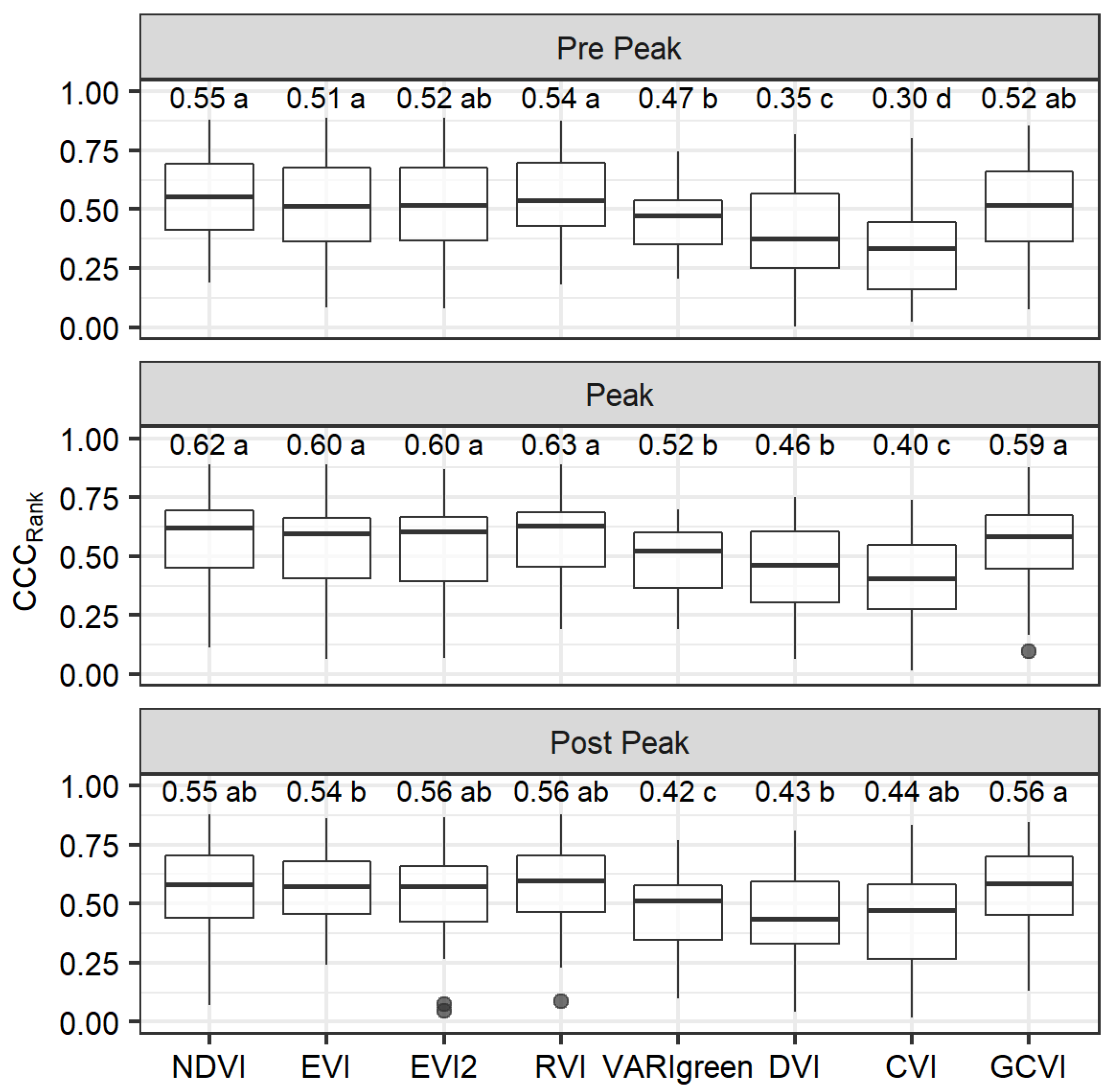
3.1. Single-Index Models
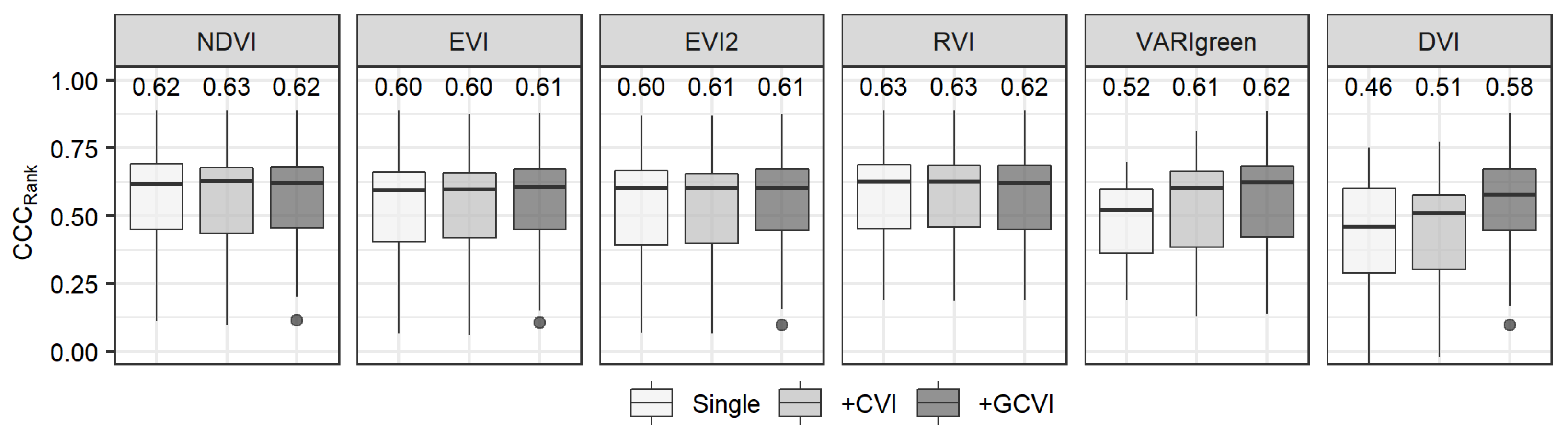
3.2. Multi-Index Models
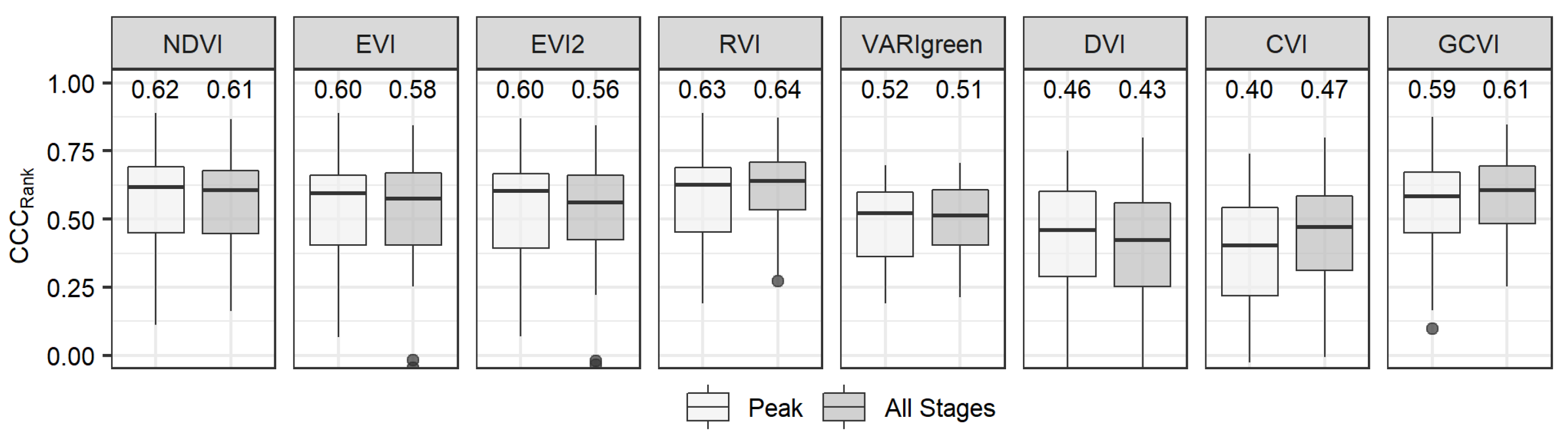
3.3. Multi-Stages Model
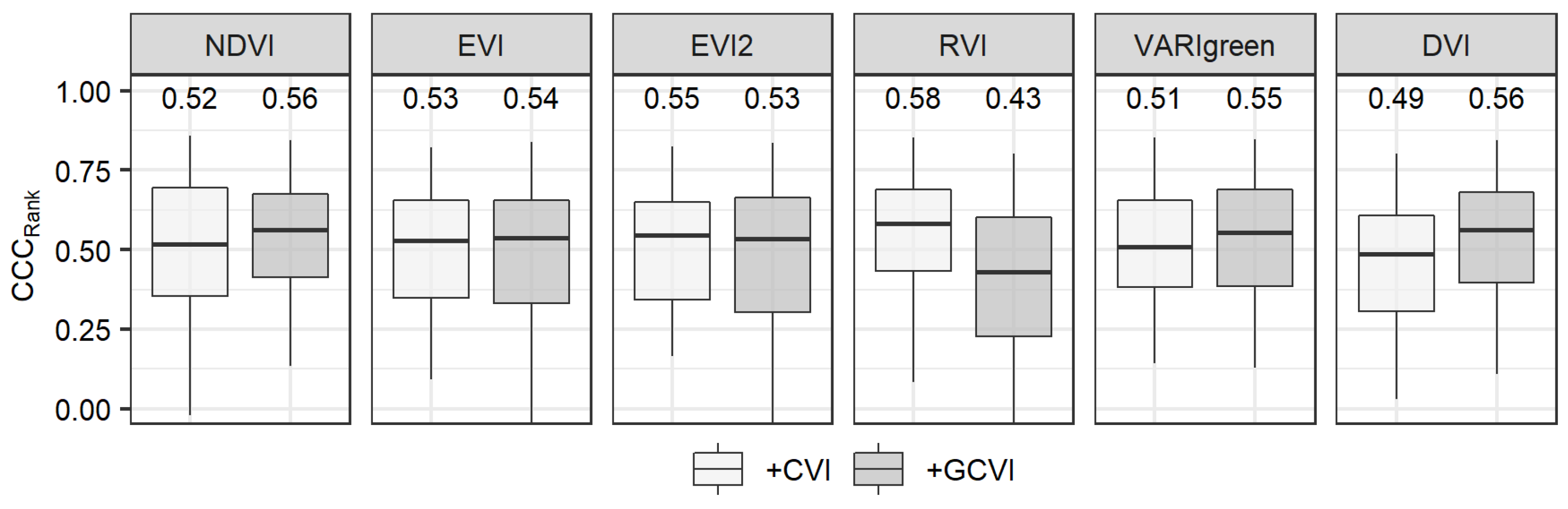
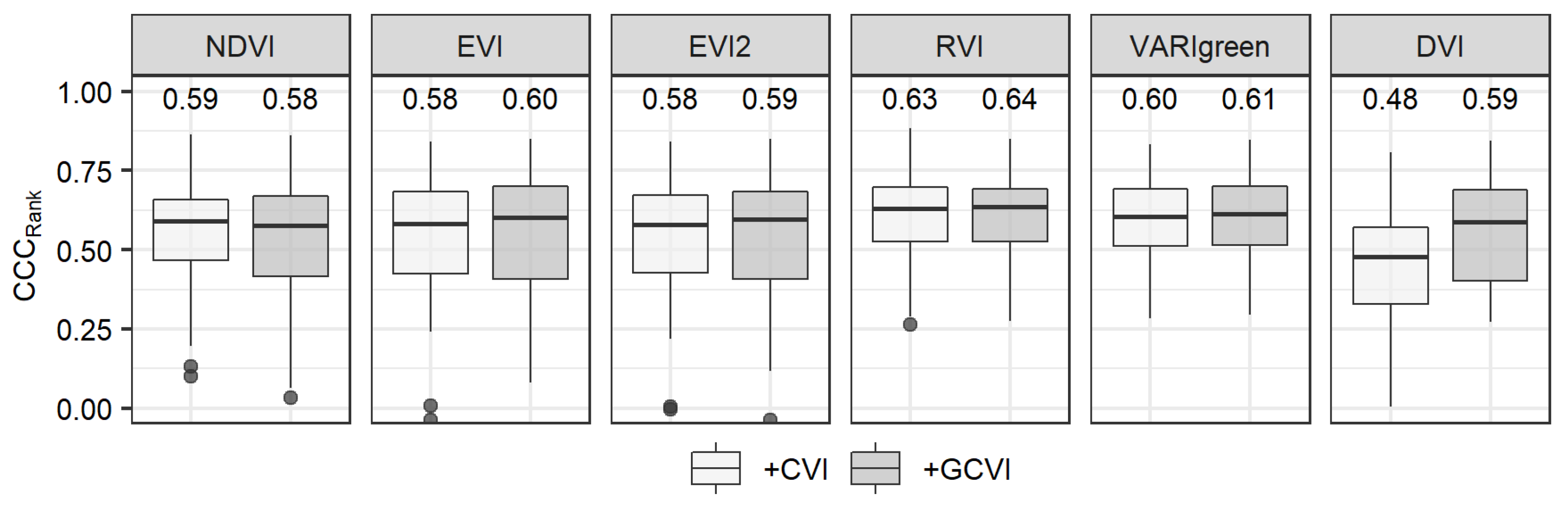
3.4. Stepwise Analysis
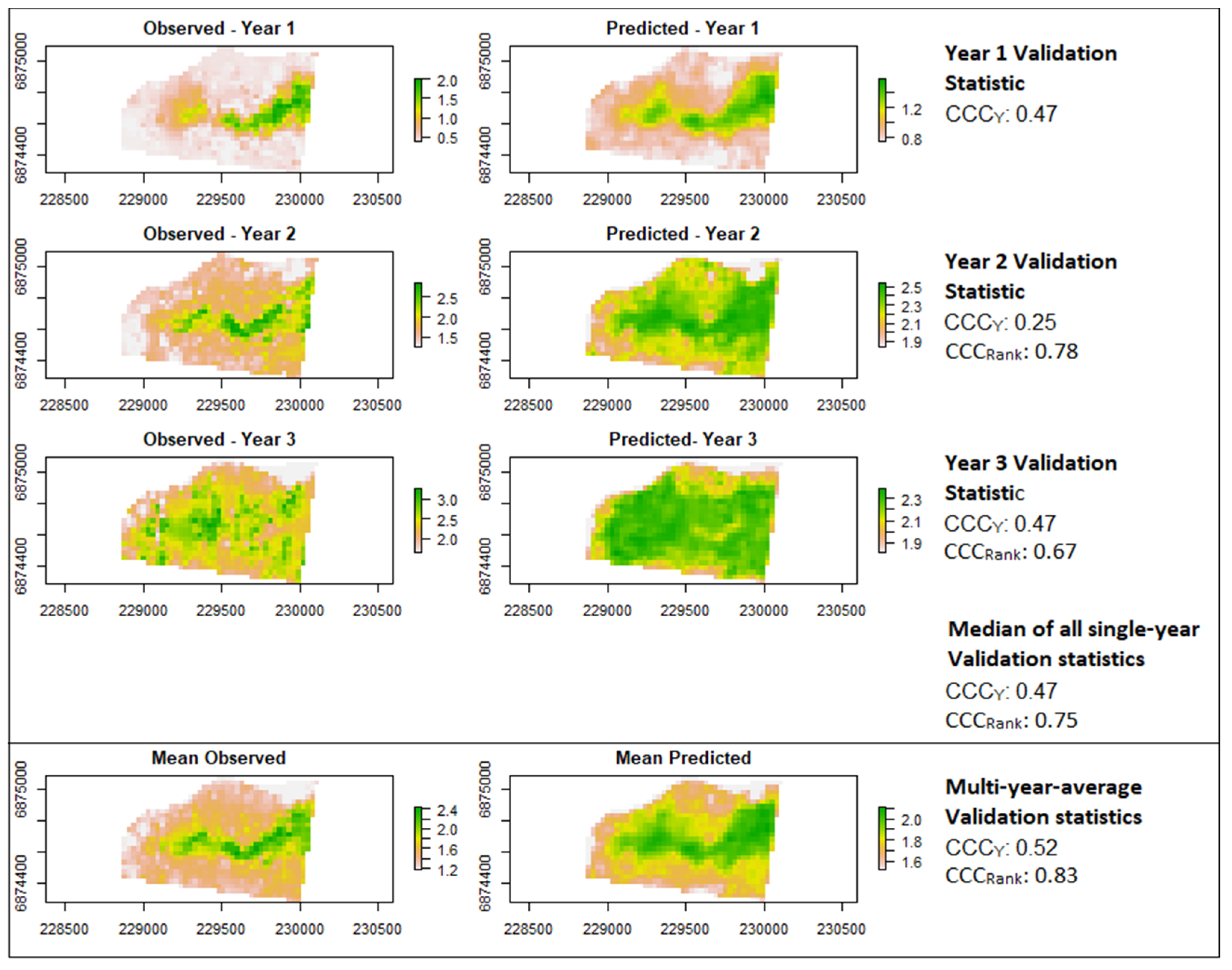
3.5. Comparing Multi-Year Average Prediction and Single Year Prediction
4. Discussion
4.1. Selection of Vegetation Indices and Stages for Simple Yield-Prediction Models
4.2. Another Metric Assesing Properties of Yield Predictions
4.3. Stepwise Results Revealed Some Simple Models
4.4. Multi-Year Analyses and Implications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B

Appendix C

References
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–459. [Google Scholar] [CrossRef]
- Dang, Y.P.; Pringle, M.J.; Schmidt, M.; Dalal, R.C.; Apan, A. Identifying the spatial variability of soil constraints using multi-year remote sensing. Field Crop. Res. 2011, 123, 248–258. [Google Scholar] [CrossRef]
- Dang, Y.P.; Dalal, R.C.; Christopher, J.; Apan, A.A.; Pringle, M.J.; Bailey, K.; Biggs, A.J.W. Managing Subsoil Constraints Advanced Techniques for Managing Subsoil Constraints Project Results Book; Grains Research & Development Corporation: Canberra, ACT, Australia, 2010. [Google Scholar]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.; Gao, X.; Ferreira, L. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Zhao, Y.; Potgieter, A.B.; Zhang, M.; Wu, B.; Hammer, G.L. Predicting wheat yield at the field scale by combining high-resolution Sentinel-2 satellite imagery and crop modelling. Remote Sens. 2020, 12, 1024. [Google Scholar] [CrossRef] [Green Version]
- Filippi, P.; Jones, E.J.; Wimalathunge, N.S.; Somarathna, P.D.S.N.; Pozza, L.E.; Ugbaje, S.U.; Jephcott, T.G.; Paterson, S.E.; Whelan, B.M.; Bishop, T.F.A. An approach to forecast grain crop yield using multi-layered, multi-farm data sets and machine learning. Precis. Agric. 2019, 20, 1015–1029. [Google Scholar] [CrossRef]
- Basso, B.; Ritchie, J.T.; Pierce, F.J.; Braga, R.P.; Jones, J.W. Spatial validation of crop models for precision agriculture. Agric. Syst. 2001, 68, 97–112. [Google Scholar] [CrossRef]
- Colwell, J.E.; Rice, D.P.; Nalepka, R.F. Wheat yield forecasts using Landsat data. In Proceedings of the Eleventh International Symposium on Remote Sensing of Environment, Ann Arbor, MI, USA, 25–29 April 1977; pp. 1245–1254. [Google Scholar]
- Kastens, J.H.; Kastens, T.L.; Kastens, D.L.A.; Price, K.P.; Martinko, E.A.; Lee, R.Y. Image masking for crop yield forecasting using AVHRR NDVI time series imagery. Remote Sens. Environ. 2005, 99, 341–356. [Google Scholar] [CrossRef]
- Lai, Y.R.; Pringle, M.J.; Kopittke, P.M.; Menzies, N.W.; Orton, T.G.; Dang, Y.P. An empirical model for prediction of wheat yield, using time-integrated Landsat NDVI. Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 99–108. [Google Scholar] [CrossRef]
- Yang, C.; Everitt, J.H.; Bradford, J.M. Airborne hyperspectral imagery and linear spectral unmixing for mapping variation in crop yield. Precis. Agric. 2007, 8, 279–296. [Google Scholar] [CrossRef]
- Al-Gaadi, K.A.; Hassaballa, A.A.; Tola, E.; Kayad, A.G.; Madugundu, R.; Alblewi, B.; Assiri, F. Prediction of potato crop yield using precision agriculture techniques. PLoS ONE 2016, 11, e0162219. [Google Scholar] [CrossRef]
- Bai, T.; Zhang, N.; Mercatoris, B.; Chen, Y. Jujube yield prediction method combining Landsat 8 vegetation index and the phenological length. Comput. Electron. Agric. 2019, 162, 1011–1027. [Google Scholar] [CrossRef]
- Goodwin, A.W.; Lindsey, L.E.; Harrison, S.K.; Paul, P.A. Estimating wheat yield with normalized difference vegetation index and fractional green canopy cover. Crop. Forage Turfgrass Manag. 2018, 4, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Hancock, D.W.; Dougherty, C.T. Relationships between blue-and red-based vegetation indices and leaf area and yield of alfalfa. Crop Sci. 2007, 47, 2547–2556. [Google Scholar] [CrossRef]
- Jurečka, F.; Lukas, V.; Hlavinka, P.; Semerádová, D.; Žalud, Z.; Trnka, M. Estimating crop yields at the field level using landsat and modis products. Acta Univ. Agric. Silvic. Mendel. Brun. 2018, 66, 1141–1150. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Wang, J.; Bao, Y.; Huang, W.; Ma, Z.; Zhao, C. Predicting winter wheat condition, grain yield and protein content using multi-temporal EnviSat-ASAR and Landsat TM satellite images. Int. J. Remote Sens. 2006, 27, 737–753. [Google Scholar] [CrossRef]
- Lobell, D.B.; Asner, G.P. Comparison of earth observing-1 ALI and Landsat ETM+ for crop identification and yield prediction in Mexico. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1277–1282. [Google Scholar] [CrossRef]
- Mokhtari, A.; Noory, H.; Vazifedoust, M. Improving crop yield estimation by assimilating LAI and inputting satellite-based surface incoming solar radiation into SWAP model. Agric. For. Meteorol. 2018, 250–251, 159–170. [Google Scholar] [CrossRef]
- Sulik, J.J.; Long, D.S. Spectral considerations for modeling yield of canola. Remote Sens. Environ. 2016, 184, 161–174. [Google Scholar] [CrossRef] [Green Version]
- Flood, N.; Danaher, T.; Gill, T.; Gillingham, S. An operational scheme for deriving standardised surface reflectance from landsat TM/ETM+ and SPOT HRG imagery for eastern Australia. Remote Sens. 2013, 5, 83–109. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Liu, J.; Pattey, E.; Jégo, G. Assessment of vegetation indices for regional crop green LAI estimation from Landsat images over multiple growing seasons. Remote Sens. Environ. 2012, 123, 347–358. [Google Scholar] [CrossRef]
- Wei, C.; Huang, J.; Wang, X.; Blackburn, G.A.; Zhang, Y.; Wang, S.; Mansaray, L.R. Hyperspectral characterization of freezing injury and its biochemical impacts in oilseed rape leaves. Remote Sens. Environ. 2017, 195, 56–66. [Google Scholar] [CrossRef] [Green Version]
- Gitelson, A.A.; Viña, A.; Arkebauer, T.J.; Rundquist, D.C.; Keydan, G.; Leavitt, B. Remote estimation of leaf area index and green leaf biomass in maize canopies. Geophys. Res. Lett. 2003, 30. [Google Scholar] [CrossRef] [Green Version]
- Kobayashi, N.; Tani, H.; Wang, X.; Sonobe, R. Crop classification using spectral indices derived from Sentinel-2A imagery. J. Inf. Telecommun. 2020, 4, 67–90. [Google Scholar] [CrossRef]
- Richardson, A.J.; Wiegand, C.L. Distinguishing Vegetation from Soil Background Information* A gray mapping technique allows delineation of any Landsat scene into vegetative cover stages, degrees of soil brightness, and water. Photogammetric Eng. Remote Sens. 1977, 43, 1541–1552. [Google Scholar]
- Hunt, E.R.; T Daughtry, C.S.; H Eitel, J.U.; Long, D.S. Remote sensing leaf chlorophyll content using a visible band index. Agron. J. 2011, 103, 1090–1099. [Google Scholar] [CrossRef] [Green Version]
- Pinheiro, J.; Bates, D. Mixed-Effects Models in S and S-PLUS; Springer: New York, NY, USA, 2006; ISBN 9781441903174. [Google Scholar]
- Bates, D.; Maechler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Kiado, A., Ed.; Springer: New York, NY, USA, 1998; pp. 199–213. ISBN 9781461272489. [Google Scholar]
- Lin, L.I. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biomatrics 1989, 45, 255–268. [Google Scholar] [CrossRef]
- Lobell, D.B.; Asner, G.P. Moisture effects on soil reflectance. Soil Sci. Soc. Am. J. 2002, 66, 722–727. [Google Scholar] [CrossRef]
- Lobell, D.B.; Ortiz-Monasterio, J.I.; Gurrola, F.C.; Valenzuela, L. Identification of saline soils with multiyear remote sensing of crop yields. Soil Sci. Soc. Am. J. 2007, 71, 777–783. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fields | Year | Fields | Year |
|---|---|---|---|
| Field 1 | 2007, 2008 | Field 13 | 2002, 2005, 2009 |
| Field 2 | 2003, 2008 | Field 14 | 2002, 2005, 2009 |
| Field 3 | 2006, 2008 | Field 15 | 2002, 2007, 2009 |
| Field 4 | 2015 | Field 16 | 2001 |
| Field 5 | 2016 | Field 17 | 2001 |
| Field 6 | 2015 | Field 18 | 2001 |
| Field 7 | 2009 | Field 19 | 2001, 2005, 2009 |
| Field 8 | 2006, 2009 | Field 20 | 2003, 2004 |
| Field 9 | 2002, 2005, 2009 | Field 21 | 2002, 2005, 2009 |
| Field 10 | 2002, 2005, 2009 | Field 22 | 2001, 2002, 2009 |
| Field 11 | 2003 | Field 23 | 2002, 2003, 2007 |
| Field 12 | 2003, 2005, 2009 |
| Index | Equation |
|---|---|
| Canopy Structural-Related Indices (VISTR) | |
| Normalised difference vegetation index (NDVI) | |
| Enhanced Vegetation Index (EVI) | |
| Enhanced Vegetation Index 2 (EVI2) | |
| Ratio Vegetation Index (RVI) | |
| Visible Atmospherically Resistant Index Green (VARIgreen) | |
| Difference Vegetation Index (DVI) | |
| Chlorophyll-related indices (VICHL) | |
| Chlorophyll Vegetation Index (CVI) | |
| Green Chlorophyll Vegetation Index (GCVI) |
| Models | CCCRank | CCCY |
|---|---|---|
| ||
| NDVI Peak | 0.62 | 0.19 |
| EVI Peak | 0.60 | 0.13 |
| EVI2 Peak | 0.60 | 0.14 |
| RVI Peak | 0.63 | 0.10 |
| GCVI Peak | 0.59 | 0.11 |
| ||
| NDVI Peak-CVI Peak | 0.63 | 0.18 |
| RVI Peak-CVI Peak | 0.63 | 0.11 |
| NDVI Peak-GCVI Peak | 0.62 | 0.14 |
| RVI Peak-GCVI Peak | 0.62 | 0.10 |
| VARIgreen Peak-GCVI Peak | 0.62 | 0.13 |
| ||
| NDVI All Stages | 0.61 | 0.17 |
| EVI All Stages | 0.58 | 0.13 |
| EVI2 All Stages | 0.56 | 0.13 |
| RVI All Stages | 0.64 | 0.12 |
| GCVI All Stages | 0.61 | 0.16 |
| ||
| S1 = GCVI Post Peak | 0.56 | 0.11 |
| S2 = S1 and EVI Pre Peak | 0.63 | 0.17 |
| S3 = S2 and EVI2 Peak | 0.62 | 0.19 |
| S4 = S3 and VARIgreen Post Peak | 0.62 | 0.19 |
| S5 = S4 and SWIR1 Post Peak | 0.60 | 0.17 |
| Steps | Covariate Added to Model | AIC |
|---|---|---|
| 1 | S1 = GCVI Post Peak | 3626 |
| 2 | S2 = S1 and EVI Pre Peak | −9881 |
| 3 | S3 = S2 and EVI2 Peak | −17,753 |
| 4 | S4 = S3 and VARIgreen Post Peak | −20,700 |
| 5 | S5 = S4 and SWIR1 Post Peak | −22,649 |
| 6 | S6 = S5 and SWIR1 Peak | −24,778 |
| Single Year | Long-Term | |||
|---|---|---|---|---|
| Fields | CCCY | CCCRank | CCCY | CCCRank |
| Field 1 | 0.02 | 0.64 | 0.21 | 0.73 |
| Field 2 | 0.13 | 0.68 | 0.12 | 0.78 |
| Field 3 | 0.02 | 0.36 | 0.24 | 0.42 |
| Field 8 | 0.07 | 0.63 | 0.05 | 0.75 |
| Field 9 | 0.18 | 0.64 | 0.25 | 0.85 |
| Field 10 | 0.17 | 0.67 | 0.13 | 0.67 |
| Field 12 | 0.26 | 0.57 | 0.12 | 0.69 |
| Field 13 | 0.16 | 0.81 | 0.21 | 0.86 |
| Field 14 | 0.13 | 0.24 | 0.17 | 0.47 |
| Field 15 | 0.00 | 0.24 | 0.08 | 0.57 |
| Field 19 | 0.32 | 0.61 | 0.31 | 0.66 |
| Field 20 | 0.27 | 0.55 | 0.24 | 0.62 |
| Field 21 | 0.47 | 0.74 | 0.79 | 0.85 |
| Field 22 | 0.41 | 0.61 | 0.48 | 0.70 |
| Field 23 | 0.47 | 0.75 | 0.52 | 0.83 |
| Median | 0.17 | 0.63 | 0.21 | 0.70 |
| Mean | 0.21 | 0.58 | 0.26 | 0.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ulfa, F.; Orton, T.G.; Dang, Y.P.; Menzies, N.W. Developing and Testing Remote-Sensing Indices to Represent within-Field Variation of Wheat Yields: Assessment of the Variation Explained by Simple Models. Agronomy 2022, 12, 384. https://doi.org/10.3390/agronomy12020384
Ulfa F, Orton TG, Dang YP, Menzies NW. Developing and Testing Remote-Sensing Indices to Represent within-Field Variation of Wheat Yields: Assessment of the Variation Explained by Simple Models. Agronomy. 2022; 12(2):384. https://doi.org/10.3390/agronomy12020384
Chicago/Turabian StyleUlfa, Fathiyya, Thomas G. Orton, Yash P. Dang, and Neal W. Menzies. 2022. "Developing and Testing Remote-Sensing Indices to Represent within-Field Variation of Wheat Yields: Assessment of the Variation Explained by Simple Models" Agronomy 12, no. 2: 384. https://doi.org/10.3390/agronomy12020384