
A New Framework for Winter Wheat Yield Prediction Integrating Deep Learning and Bayesian Optimization

Abstract
:1. Introduction
2. Materials and Data
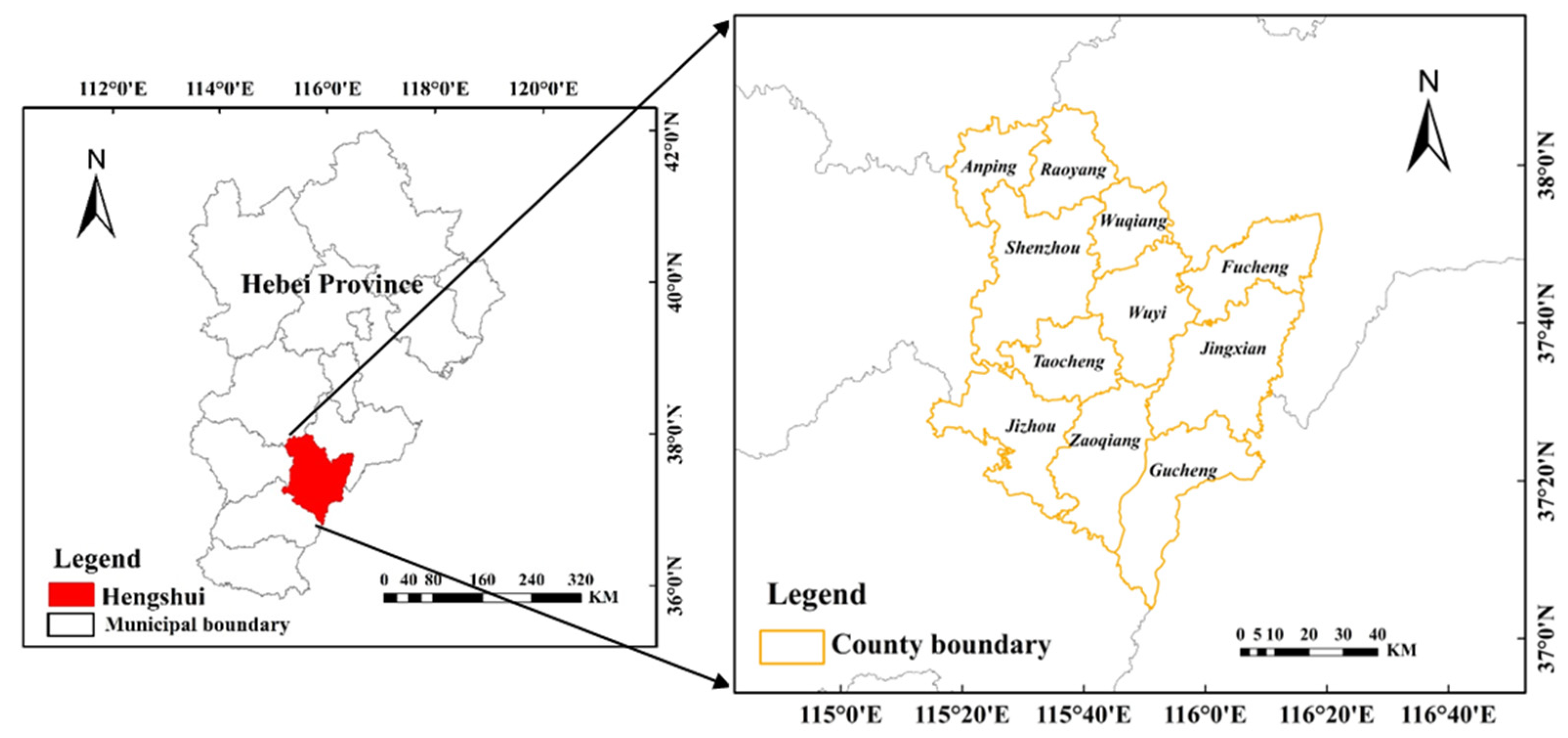
2.1. Study Area
2.2. Winter Wheat Yield and Planting Distribution
2.3. Remote Sensing Data
2.4. Gross Primary Productivity
2.5. Meteorological Data
2.6. Data Preprocessing
3. Methodology
3.1. Long Short-Term Memory
3.2. Bayesian Optimization of LSTM Hyperparameters

3.3. Model Performance Evaluation
4. Results and Analysis
4.1. Performance of LSTM Hyperparameter Combination Output Based on Bayesian Optimization
4.2. Yield Estimation Performance for Different Combinations of Inputs
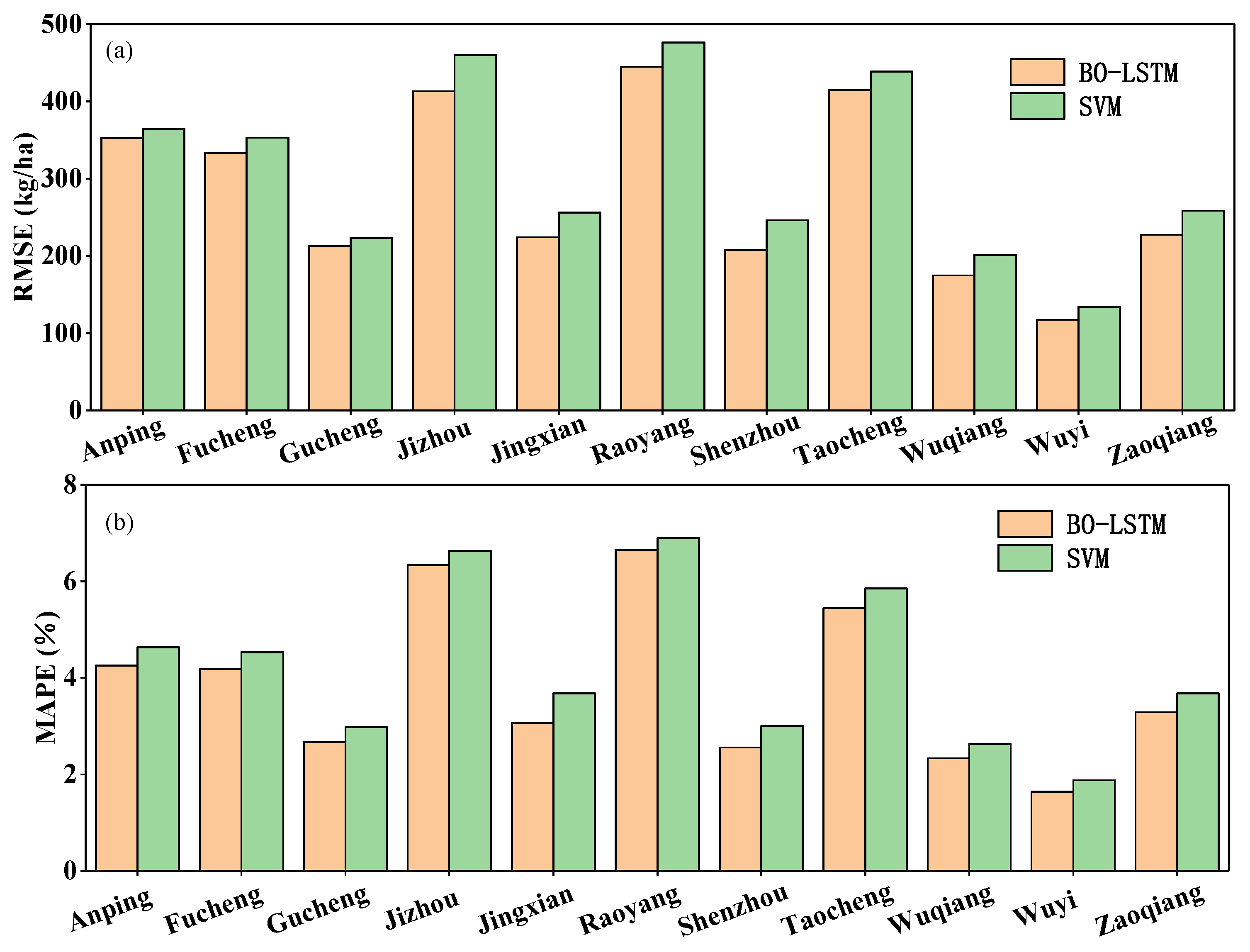
4.3. Comparison with Other Methods
5. Discussion
6. Conclusions
- (1)
- Using Bayesian optimization of LSTM neural network model hyperparameters can achieve identification of the optimal combination of hyperparameters in a shorter period of time.
- (2)
- Multi-temporal remote sensing data based on BO-LSTM model combined with meteorological data can provide effective information to obtain more accurate yield prediction models to estimate regional scale winter wheat yield.
- (3)
- Among the three prediction models, BO-LSTM achieves higher yield estimation accuracy relative to Lasso and SVM.
- (4)
- There is some spatial variation in the estimated yield advantage in different areas, and our method is more suitable for places where crop cultivation is concentrated, far from urban building sites and with less residential land.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shewry, P.-R.; Hey, S.-J. The contribution of wheat to human diet and health. Food Energy Secur. 2015, 4, 178–202. [Google Scholar] [CrossRef]
- Tilman, D.; Balzer, C.; Hill, J.; Befort, B.L. Global food demand and the sustainable intensification of agriculture. Proc. Natl. Acad. Sci. USA 2011, 108, 20260–20264. [Google Scholar] [CrossRef] [Green Version]
- Lesk, C.; Rowhani, P.; Ramankutty, N. Influence of extreme weather disasters on global crop production. Nature 2016, 529, 84–87. [Google Scholar] [CrossRef] [Green Version]
- Lesk, C.; Coffel, E.; Winter, J.; Ray, D.; Zscheischler, J.; Seneviratne, S.-I.; Horton, R. Stronger temperature–moisture couplings exacerbate the impact of climate warming on global crop yields. Nat. Food 2021, 2, 683–691. [Google Scholar] [CrossRef]
- Chipanshi, A.; Zhang, Y.; Kouadio, L.; Newlands, N.; Davidson, A.; Hill, H.; Warren, R.; Qian, B.; Daneshfar, B.; Bedard, F.; et al. Evaluation of the Integrated Canadian Crop Yield Forecaster (ICCYF) model for in-season prediction of crop yield across the Canadian agricultural landscape. Agric. For. Meteorol. 2015, 206, 137–150. [Google Scholar] [CrossRef] [Green Version]
- Yan, K.; Pu, J.; Park, T.; Xu, B.; Zeng, Y.; Yan, G.; Weiss, M.; Knyazikhin, Y.; Myneni, R.-B. Performance stability of the MODIS and VIIRS LAI algorithms inferred from analysis of long time series of products. Remote Sens. Environ. 2021, 260, 112438. [Google Scholar] [CrossRef]
- de la Casa, A.; Ovando, G.; Díaz, G. Linking data of ENSO, NDVI-MODIS and crops yield as a base of an early warning system for agriculture in Córdoba, Argentina. Remote Sens. Appl. 2021, 22, 100480. [Google Scholar]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Chang, L.Y.; Duc, H.N.; Nguyen, L.D. Prediction of rice crop yield using MODIS EVI−LAI data in the Mekong Delta, Vietnam. Int. J. Remote Sens. 2013, 34, 7275–7292. [Google Scholar] [CrossRef]
- Peng, B.; Guan, K.; Zhou, W.; Jiang, C.; Frankenberg, C.; Sun, Y.; He, L.; Köhler, P. Assessing the benefit of satellite-based Solar-Induced Chlorophyll Fluorescence in crop yield prediction. Int. J. Appl. Earth Obs. Geoinf. 2020, 90, 102126. [Google Scholar] [CrossRef]
- Sakamoto, T.; Gitelson, A.A.; Arkebauer, T. MODIS-based corn grain yield estimation model incorporating crop phenology information. Remote Sens. Environ. 2013, 131, 215–231. [Google Scholar] [CrossRef]
- Hao, S.; Ryu, D.; Western, A.; Perry, E.; Bogena, H.; Franssen, H.J.H. Performance of a wheat yield prediction model and factors influencing the performance: A review and meta-analysis. Agric. Syst. 2021, 194, 103278. [Google Scholar] [CrossRef]
- Jones, E.J.; Bishop, T.F.A.; Malone, B.P.; Hulme, P.J.; Whelan, B.M.; Filippi, P. Identifying causes of crop yield variability with interpretive machine learning. Comput. Electron. Agric. 2022, 192, 106632. [Google Scholar] [CrossRef]
- Wang, M.M.; Rengasamy, P.; Wang, Z.C.; Yang, F.; Ma, H.Y.; Huang, L.H.; Liu, M.; Yang, H.Y.; Li, J.P.; An, F.H.; et al. Identification of the most limiting factor for rice yield using soil data collected before planting and during the reproductive stage. Land Degrad. Dev. 2018, 29, 2310–2320. [Google Scholar] [CrossRef]
- Hernández, C.M.; Faye, A.; Ly, M.O.; Stewart, Z.P.; Vara Prasad, P.V.; Bastos, L.M.; Nieto, L.; Carcedo, A.J.P.; Ciampitti, I.A. Soil and Climate Characterization to Define Environments for Summer Crops in Senegal. Sustainability 2021, 13, 11739. [Google Scholar] [CrossRef]
- Chu, Z.; Yu, J. An end-to-end model for rice yield prediction using deep learning fusion. Comput. Electron. Agric. 2020, 174, 105471. [Google Scholar] [CrossRef]
- Tedesco-Oliveira, D.; Pereira Da Silva, R.; Maldonado, W.; Zerbato, C. Convolutional neural networks in predicting cotton yield from images of commercial fields. Comput. Electron. Agric. 2020, 171, 105307. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-Level Soybean Yield Prediction Using Deep CNN-LSTM Model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [Green Version]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Rumelhart, D.-E.; Hinton, G.-E.; Williams, R.-J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.; Luo, Y.; Cao, J.; Tao, F. Combining Optical, Fluorescence, Thermal Satellite, and Environmental Data to Predict County-Level Maize Yield in China Using Machine Learning Approaches. Remote Sens. 2019, 12, 21. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Haider, S.; Naqvi, S.; Akram, T.; Umar, G.; Shahzad, A.; Sial, M.; Khaliq, S.; Kamran, M. LSTM Neural Network Based Forecasting Model for Wheat Production in Pakistan. Agronomy 2019, 9, 72. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Hu, H.; Zhong, R.; Xu, J.; Xu, J.; Huang, J.; Wang, S.; Ying, Y.; Lin, T. A deep learning approach to conflating heterogeneous geospatial data for corn yield estimation: A case study of the US Corn Belt at the county level. Glob. Chang. Biol. 2020, 26, 1754–1766. [Google Scholar] [CrossRef]
- Tian, H.; Wang, P.; Tansey, K.; Zhang, J.; Zhang, S.; Li, H. An LSTM neural network for improving wheat yield estimates by integrating remote sensing data and meteorological data in the Guanzhong Plain, PR China. Agric. For. Meteorol. 2021, 310, 108629. [Google Scholar] [CrossRef]
- Li, L.; Wang, B.; Feng, P.; Wang, H.; He, Q.; Wang, Y.; Liu, D.L.; Li, Y.; He, J.; Feng, H.; et al. Crop yield forecasting and associated optimum lead time analysis based on multi-source environmental data across China. Agric. For. Meteorol. 2021, 308–309, 108558. [Google Scholar] [CrossRef]
- Batten, A.J.; Thorpe, J.; Piegari, R.I.; Rosland, A. A Resampling Based Grid Search Method to Improve Reliability and Robustness of Mixture-Item Response Theory Models of Multimorbid High-Risk Patients. IEEE J. Biomed. Health Inform. 2020, 24, 1780–1787. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Ji, G.; Wang, S. A Comprehensive Survey on Particle Swarm Optimization Algorithm and Its Applications. Math. Probl. Eng. 2015, 2015, 931256. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, K.-K.; Hassanien, A.-E.; Afify, H.-M. Classification of Ear Imagery Database using Bayesian Optimization based on CNN-LSTM Architecture. J. Digit. Imaging 2022, 35, 947–961. [Google Scholar] [CrossRef]
- Goay, C.-H.; Ahmad, N.-S.; Goh, P. Transient Simulations of High-Speed Channels Using CNN-LSTM With an Adaptive Successive Halving Algorithm for Automated Hyperparameter Optimizations. IEEE Access 2021, 9, 127644–127663. [Google Scholar] [CrossRef]
- Liu, X.; Shi, Q.; Liu, Z.; Yuan, J. Using LSTM Neural Network Based on Improved PSO and Attention Mechanism for Predicting the Effluent COD in a Wastewater Treatment Plant. IEEE Access 2021, 9, 146082–146096. [Google Scholar] [CrossRef]
- Chen, X.; Wang, W.; Chen, J.; Zhu, X.; Shen, M.; Gan, L.; Cao, X. Does any phenological event defined by remote sensing deserve particular attention? An examination of spring phenology of winter wheat in Northern China. Ecol. Indic. 2020, 116, 106456. [Google Scholar] [CrossRef]
- Xiao, D.; Tao, F.; Liu, Y.; Shi, W.; Wang, M.; Liu, F.; Zhang, S.; Zhu, Z. Observed changes in winter wheat phenology in the North China Plain for 1981–2009. Int. J. Biometeorol. 2013, 57, 275–285. [Google Scholar] [CrossRef] [PubMed]
- Du, Y. The Influence of Atmospheric Aerosol’s Direct Radiation Effect on Winter Wheat GPP in North China. Master’s Thesis, Chinese Academy of Agricultural Sciences, Beijing, China, 2021. [Google Scholar]
- Fu, S.; Kong, L.; Zhou, H.; Liu, W. Spatial|temporal distribution characteristics of grain yield and its potential productivity in the Jing river basin and their relationships with MODIS-GPP. Agric. Res. Arid Areas 2020, 38, 192–199. [Google Scholar]
- Varghese, R.; Behera, M.-D. Annual and seasonal variations in gross primary productivity across the agro-climatic regions in India. Environ. Monit. Assess. 2019, 191, 631. [Google Scholar] [CrossRef]
- Abatzoglou, J.T.; Dobrowski, S.Z.; Parks, S.A.; Hegewisch, K.C. TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015. Sci. Data 2018, 5, 170191. [Google Scholar] [CrossRef] [Green Version]
- Abdi, O. Climate-Triggered Insect Defoliators and Forest Fires Using Multitemporal Landsat and TerraClimate Data in NE Iran: An Application of GEOBIA TreeNet and Panel Data Analysis. Sensors 2019, 19, 3965. [Google Scholar] [CrossRef] [Green Version]
- Salvacion, A.-R. Mapping meteorological drought hazard in the Philippines using SPI and SPEI. Spat. Inf. Res. 2021, 29, 949–960. [Google Scholar] [CrossRef]
- Gómez-Pineda, E.; Hammond, W.M.; Trejo-Ramirez, O.; Gil-Fernández, M.; Allen, C.D.; Blanco-García, A.; Sáenz-Romero, C. Drought years promote bark beetle outbreaks in Mexican forests of Abies religiosa and Pinus pseudostrobus. For. Ecol. Manag. 2022, 505, 119944. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Zhang, J.; Han, J.; Xie, J. Integrating Multi-Source Data for Rice Yield Prediction across China using Machine Learning and Deep Learning Approaches. Agric. For. Meteorol. 2021, 297, 108275. [Google Scholar] [CrossRef]
- Sepp, H.; Jürgen, S. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Huang, W. Study on the Effect of LSTM Hyper-Parameter Tuning for Prediction of River Discharge. J. Xihua Univ. 2020, 39, 23–29. [Google Scholar]
- Jiang, M.; Chen, Y. Survey on Bayesian optimization algorithm. Comput. Eng. Des. 2010, 31, 3254–3259. [Google Scholar]
- Lin, L.-I.-K. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biometrics 1989, 45, 255. [Google Scholar] [CrossRef]
- Feng, P.; Wang, B.; Liu, D.L.; Waters, C.; Xiao, D.; Shi, L.; Yu, Q. Dynamic wheat yield forecasts are improved by a hybrid approach using a biophysical model and machine learning technique. Agric. For. Meteorol. 2020, 285–286, 107922. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, S.; Wang, X.; Chen, B.; Chen, J.; Wang, J.; Huang, M.; Wang, Z.; Ma, L.; Wang, P.; et al. Exploring the superiority of solar-induced chlorophyll fluorescence data in predicting wheat yield using machine learning and deep learning methods. Comput. Electron. Agric. 2022, 192, 106612. [Google Scholar] [CrossRef]
- Trindade, F.; Fulginiti, L.-E.; Perrin, R.-K. Crop Yield Growth along the 41st Parallel: Contributions of Environmental vs. Human-Controlled Factors Environmental vs. Human-Controlled Factors. Cornhusker Econ. 2020, 1074. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Range | Parameter Meaning |
|---|---|---|
| NumHiddenUnits | (200, 600) | Number of hidden units |
| MaxEpochs | (200, 800) | Maximum number of epochs |
| MiniBatchSize | (8, 20) | Size of mini batch |
| InitialLearnRate | 0.01 | Initial learning rate |
| Dropout | (0.1, 0.7) | Abstention factor |
| SolverName | adam | Solver for training network |
| LearnRateSchedule | piecewise | Learning rate strategy |
| Objective function | RMSE |
| Methods | NumOfUnits | MaxEpochs | MinBatchSize | DropoutLayer | Time/min | RMSE |
|---|---|---|---|---|---|---|
| Bayesian optimization | 202 | 314 | 9 | 0.1 | 14 | 149.51 |
| 335 | 501 | 10 | 0.1 | 14 | 181.57 | |
| 354 | 510 | 11 | 0.025 | 14 | 182.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di, Y.; Gao, M.; Feng, F.; Li, Q.; Zhang, H. A New Framework for Winter Wheat Yield Prediction Integrating Deep Learning and Bayesian Optimization. Agronomy 2022, 12, 3194. https://doi.org/10.3390/agronomy12123194
Di Y, Gao M, Feng F, Li Q, Zhang H. A New Framework for Winter Wheat Yield Prediction Integrating Deep Learning and Bayesian Optimization. Agronomy. 2022; 12(12):3194. https://doi.org/10.3390/agronomy12123194
Chicago/Turabian StyleDi, Yan, Maofang Gao, Fukang Feng, Qiang Li, and Huijie Zhang. 2022. "A New Framework for Winter Wheat Yield Prediction Integrating Deep Learning and Bayesian Optimization" Agronomy 12, no. 12: 3194. https://doi.org/10.3390/agronomy12123194