
Ginger Seeding Detection and Shoot Orientation Discrimination Using an Improved YOLOv4-LITE Network

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Processing
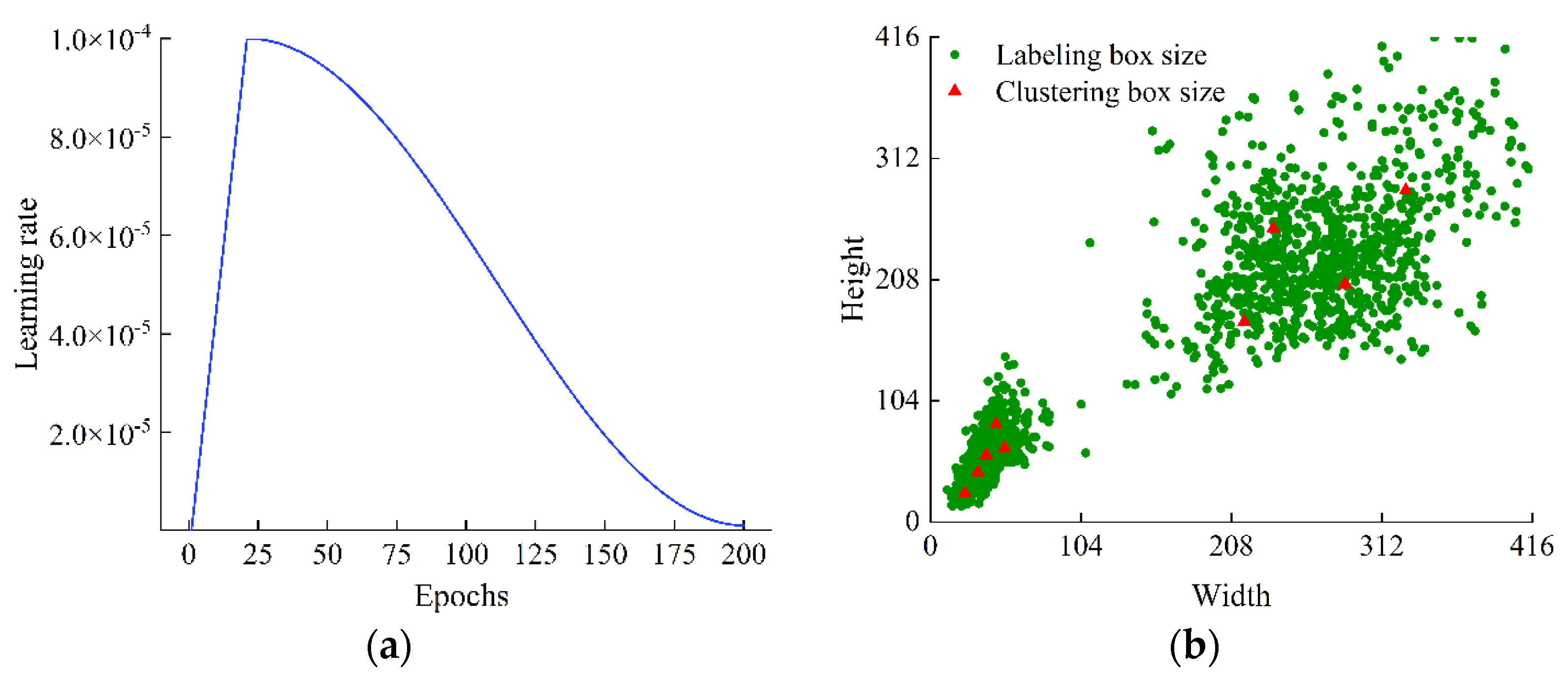
2.1.1. Data Acquisition and Annotation
2.1.2. Data Enhancement
2.2. Overall Technical Route
- Construction and training of a YOLOv4-LITE network. This study used the MobileNetv2 network to replace the original CSPDarknet53, to solve the model redundancy caused by the more complex backbone network.
- The introduction of an attention mechanism and Do-Conv convolution. This study introduced an attention mechanism and Do-Conv into YOLOv4-LITE, to improve the recognition of smaller ginger shoots.
- Model performance analysis and experimental validation. The performance of the improved model was tested, and the improvements proposed in this study were verified and analyzed sequentially.
2.3. Method of Discriminating Ginger Shoot Orientation
2.3.1. YOLOv4 Model
- Based on Darknet53, CSPDarknet53 borrows the cross-stage partial (CSP) from CSPNet and adds a CSP on each of the five residual blocks, which enhances the learning ability of CNN and can maintain a high performance while lowering the weight of the network. CBL (convolution, batch normalization, and Leak-ReLU) is the most common module in YOLOv4 and includes convolutional (Conv) layers, batch normalization layers, and activation layer constructs.
- This paper adds a spatial pyramid pooling (SPP) structure after CSPDarknet53, which effectively increases the perceptual field of the backbone network. It uses the maximum pooling operations with convolution kernels of 1 × 1, 5 × 5, 9 × 9, and 13 × 13, respectively, to obtain four feature maps in different scales, and then fuses them in a concatenated manner.
- In CNN networks, shallow features contain richer target location information, such as contours and textures, and less semantic information. However, the deeper features contain richer semantic information, and the object location information is coarse. Therefore, our network adopts a feature pyramid network (FPN) structure, which passes the deep semantic information through up-sampling, thus fusing the shallow layers’ semantic information and location information.
- Borrowing from the bottom-up path augmentation method in PANet [49], two-path aggregation network (PAN) structures are added after FPN, which transmits the underlying location information by down-sampling, thus fusing location information with the semantic information of higher levels.
- YOLOv4 loss function includes bounding regression loss (Lcoord), based on the complete intersection over union CIoU (LCIoU), confidence loss (Lconf), and classification loss (Lcls). The loss function is formulated as follows:
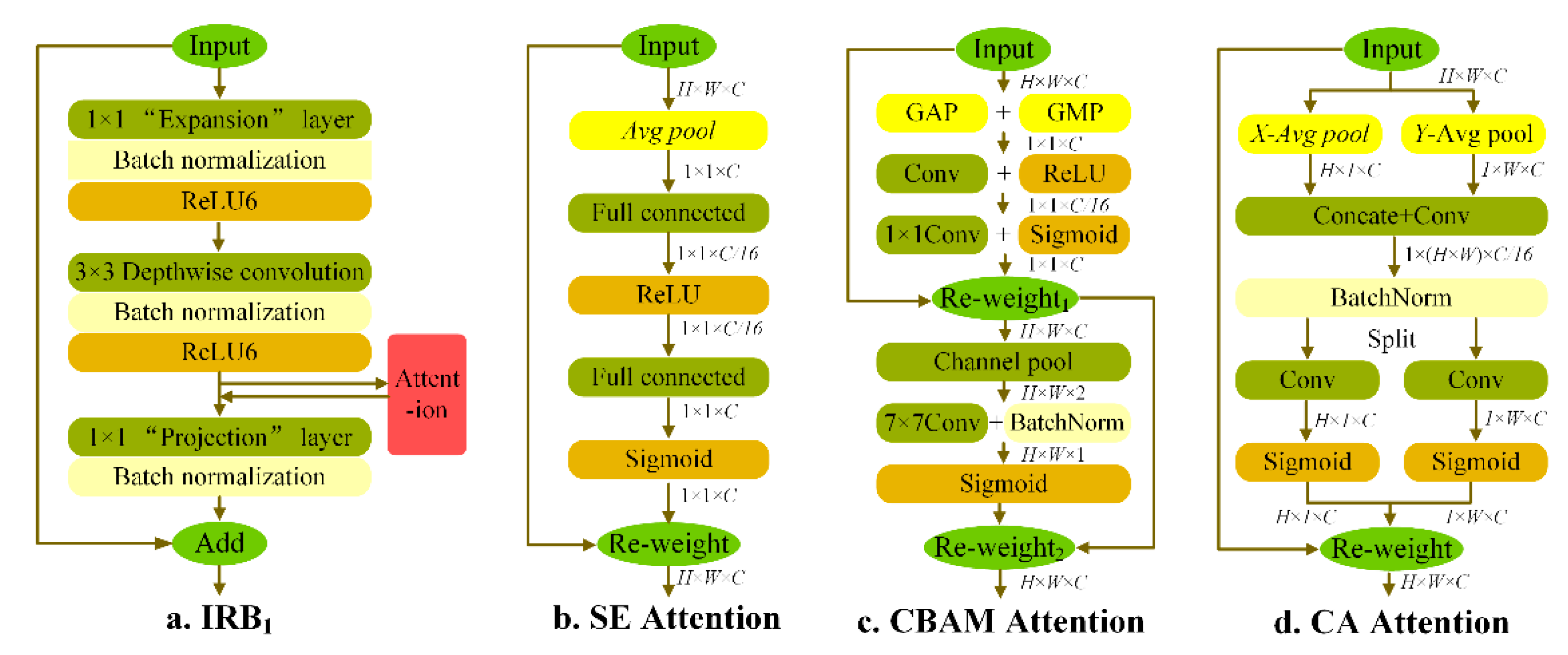
2.3.2. YOLOv4-LITE Network Design
2.3.3. Coordinate Attention Module
2.3.4. Do-Conv Convolution
2.3.5. Focal Loss Function
2.3.6. Identification Method of Ginger Shoot Orientation
2.4. Method of Discriminating Ginger Shoot Orientation
3. Results and Discussion
3.1. Result Analysis
3.2. Discussion of the Improved Algorithm
3.2.1. Performance Comparison of Feature Map Extraction Network
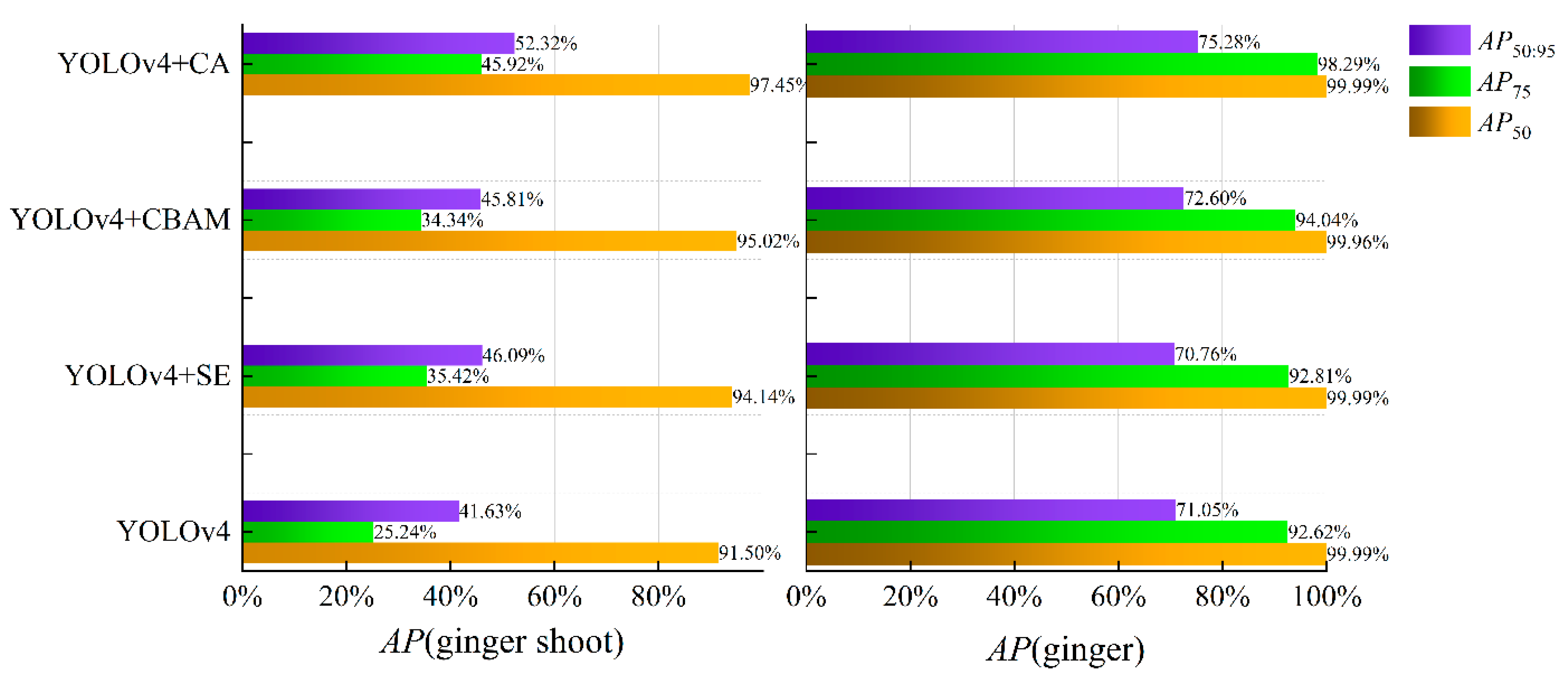
3.2.2. Different Attention Mechanisms Comparative Experiment
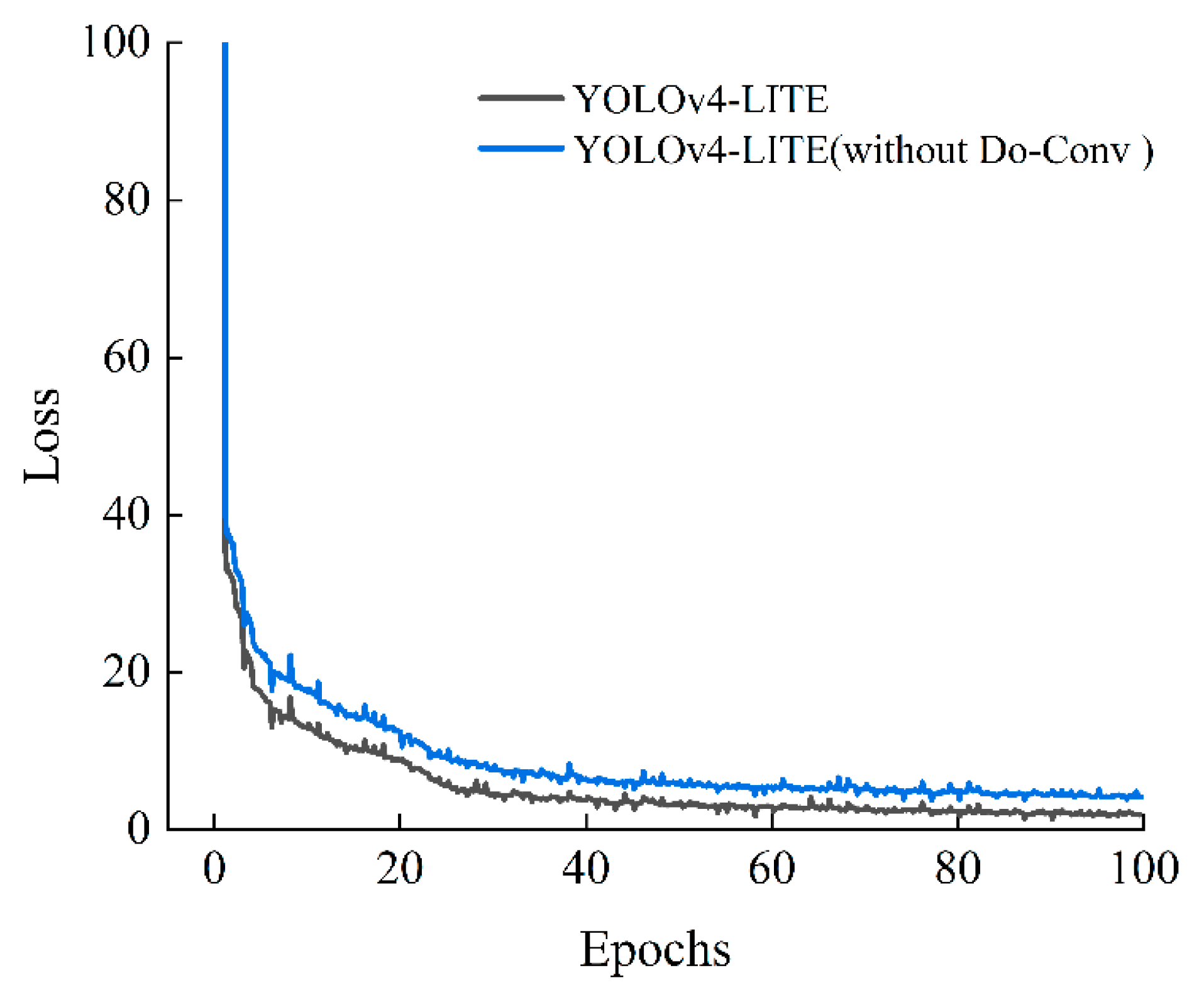
3.2.3. Analysis of Do-Conv Convolution
3.3. Performance Comparison of the Overall Algorithm
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Retana-Cordero, M.; Fisher, P.R.; Gómez, C. Modeling the Effect of Temperature on Ginger and Turmeric Rhizome Sprouting. Agronomy 2021, 11, 1931. [Google Scholar] [CrossRef]
- Sang, S.; Snook, H.D.; Tareq, F.S.; Fasina, Y. Precision Research on Ginger: The Type of Ginger Matters. J. Agric. Food Chem. 2020, 68, 8517–8523. [Google Scholar] [CrossRef]
- Liu, S.; Chen, M.; He, T.; Ren, C. Review of China’s ginger market in 2018 and market outlook in 2019. China Veget. 2019, 2, 1–4. [Google Scholar]
- Zhang, K.; Jiang, H.; Liu, P.; Zhang, Y. Prediction of ginger planting area based on GM(1,N) model. J. Chin. Agric. Mech. 2020, 41, 139–143. [Google Scholar]
- Tao, W. Technical specifications for the safe production of ginger. In Laiwu Ginger, 1st ed.; China Agricultural Science and Technology Press: Beijing, China, 2010; pp. 78–79. [Google Scholar]
- Mahender, B.; Reddy, P.S.S.; Sivaram, G.T.; Balakrishna, M.; Prathap, B. Effect of seed rhizome size and plant spacing on growth, yield and quality of ginger (Zingiber officinale rosc.) under coconut cropping system. Plant Arch. 2015, 15, 769–774. [Google Scholar]
- Liu, J. Biological properties of ginger. In Laiwu Ginger, 1st ed.; China Agricultural Science and Technology Press: Beijing, China, 2013; pp. 76–77. [Google Scholar]
- Hordofa, T.S.; Tolossa, T.T. Cultivation and postharvest handling practices affecting yield and quality of major spices crops in Ethiopia: A review. Cogent Food Agric. 2020, 6. [Google Scholar] [CrossRef]
- Ren, S.; Li, C. Analysis of the current situation and development of the ginger industry in China. China Veget. 2021, 8, 8–11. [Google Scholar]
- Xiong, X.; Duan, L.; Liu, L.; Tu, H.; Yang, P.; Wu, D.; Chen, G.; Xiong, L.; Yang, W.; Liu, Q. Panicle-SEG: A robust image segmentation method for rice panicles in the field based on deep learning and superpixel optimization. Plant Methods 2017, 13, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wang, G.; Dong, Z.; Wei, X.; Wu, M.; Song, H.; Amankwah, S.O.Y. Identifying Cotton Fields from Remote Sensing Images Using Multiple Deep Learning Networks. Agronomy 2021, 11, 174. [Google Scholar] [CrossRef]
- Gahrouei, O.; McNairn, H.; Hosseini, M.; Homayouni, S. Estimation of Crop Biomass and Leaf Area Index from Multitemporal and Multispectral Imagery Using Machine Learning Approaches. Can. J. Remote Sens. 2020, 46, 84–99. [Google Scholar] [CrossRef]
- Bahrami, H.; Homayouni, S.; Safari, A.; Mirzaei, S.; Mahdianpari, M.; Reisi-Gahrouei, O. Deep Learning-Based Estimation of Crop Biophysical Parameters Using Multi-Source and Multi-Temporal Remote Sensing Observations. Agronomy 2021, 11, 1363. [Google Scholar] [CrossRef]
- Wang, C.; Xiao, Z. Lychee Surface Defect Detection Based on Deep Convolutional Neural Networks with GAN-Based Data Augmentation. Agronomy 2021, 11, 1500. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, C.; Xiao, D.; Huang, Q. An Enhanced Insect Pest Counter Based on Saliency Map and Improved Non-Maximum Suppression. Insects 2021, 12, 705. [Google Scholar] [CrossRef]
- Parvathi, S.; Selvi, S.T. Detection of maturity stages of coconuts in complex background using Faster R-CNN model. Biosyst. Eng. 2021, 202, 119–132. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiao, L.; Dong, S.; Zhang, S.; Xie, C.; Wang, H. AF-RCNN: An anchor-free convolutional neural network for multi-categories agricultural pest detection. Comput. Electron. Agric. 2020, 174, 105522. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ammar, A.; Koubaa, A.; Benjdira, B. Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images. Agronomy 2021, 11, 1458. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Suo, R.; Gao, F.; Zhou, Z.; Fu, L.; Song, Z.; Dhupia, J.; Li, R.; Cui, Y. Improved multi-classes kiwifruit detection in orchard to avoid collisions during robotic picking. Comput. Electron. Agric. 2021, 182, 106052. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, E.S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multiBox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Koirala, A.; Walsh, K.B.; Wang, Z.; Anderson, N. Deep Learning for Mango (Mangifera indica) Panicle Stage Classification. Agronomy 2020, 10, 143. [Google Scholar] [CrossRef] [Green Version]
- Hou, J.; Fang, L.; Wu, Y.; Li, Y.; Xi, R. Rapid recognition and orientation determination of ginger shoots with deep learning. Trans. Chin. Soc. Agric. Eng. 2021, 37, 213–222. [Google Scholar]
- Cai, K.; Miao, X.; Wang, W.; Pang, H.; Liu, Y.; Song, J. A modified YOLOv3 model for fish detection based on MobileNetv1 as backbone. Aquac. Eng. 2020, 91, 102117. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Liu, L.H.; Yang, L.; Zhang, D.X. Real-time visual localization of the picking points for a ridge-planting strawberry harvesting robot. IEEE Access 2020, 8, 116556–116568. [Google Scholar] [CrossRef]
- Lui, S.; Lu, S.; Li, Z.; Hong, T.; Xue, Y.; Wu, B. Orange recognition method using improved YOLOv3-LITE lightweight neural network. Trans. Chin. Soc. Agric. Eng. 2019, 35, 205–214. [Google Scholar]
- Ying, B.; Xu, Y.; Zhang, S.; Shi, Y.; Liu, L. Weed detection in images of carrot fields based on improved YOLO v4. Trait. Signal 2021, 38, 341–348. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An attribution-based pruning method for real-time mango detection with YOLO network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Bazame, H.C.; Molin, J.P.; Althoff, D.; Martello, M. Detection, classification, and mapping of coffee fruits during harvest with computer vision. Comput. Electron. Agric. 2021, 183, 106066. [Google Scholar] [CrossRef]
- Buzzy, M.; Thesma, V.; Davoodi, M.; Mohammadpour Velni, J. Real-Time Plant Leaf Counting Using Deep Object Detection Networks. Sensors 2020, 20, 6896. [Google Scholar] [CrossRef]
- Parico, A.I.B.; Ahamed, T. Real Time Pear Fruit Detection and Counting Using YOLOv4 Models and Deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kang, J.; Liu, L.; Zhang, F.; Shen, C.; Wang, N.; Shao, L. Semantic segmentation model of cotton roots in-situ image based on attention mechanism. Comput. Electron. Agric. 2021, 189, 106370. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Duan, Q. Transfer learning and SE-ResNet152 networks-based for small-scale unbalanced fish species identification. Comput. Electron. Agric. 2021, 180, 105878. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid Detection and Counting of Wheat Ears in the Field Using YOLOv4 with Attention Module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Tang, Z.; Yang, J.; Li, Z.; Qi, F. Grape disease image classification based on lightweight convolution neural networks and channelwise attention. Comput. Electron. Agric. 2020, 178, 105735. [Google Scholar] [CrossRef]
- Li, G.; Huang, X.; Ai, J.; Yi, Z.; Xie, W. Lemon-YOLO: An efficient object detection method for lemons in the natural environment. IET Image Process. 2021, 15, 1998–2009. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, S. Broken corn detection based on an adjusted YOLO with focal loss. IEEE Access 2019, 7, 68281–68289. [Google Scholar] [CrossRef]
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Cao, J.; Li, Y.; Sun, M.; Chen, Y.; Lischinski, D.; Cohen-Or, D.; Chen, B.; Tu, C. DO-Conv: Depthwise over-parameterized convolutional layer. arXiv 2020, arXiv:2006.12030. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lee, D.; Kim, J.; Jung, K. Improving Object Detection Quality by Incorporating Global Contexts via Self-Attention. Electronics 2021, 10, 90. [Google Scholar] [CrossRef]
- Li, Z.; Yang, Y.; Li, Y.; Guo, R.; Yang, J.; Yue, J. A solanaceae disease recognition model based on SE-Inception. Comput. Electron. Agric. 2020, 178, 105792. [Google Scholar] [CrossRef]
- Ma, L.; Xie, W.; Huang, H. Convolutional neural network based obstacle detection for unmanned surface vehicle. Math. Biosci. Eng. 2020, 17, 845–861. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Wu, Q.; Yin, X.; Jian, B.; Wang, H.; He, D.; Song, H. Lameness detection of dairy cows based on the YOLOv3 deep learning algorithm and a relative step size characteristic vector. Biosyst. Eng. 2020, 189, 150–163. [Google Scholar] [CrossRef]
- Zhang, X.; Kang, X.; Feng, N.; Liu, G. Automatic recognition of dairy cow mastitis from thermal images by a deep learning detector. Comput. Electron. Agric. 2020, 178, 105754. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv4 | No. | Type | Output Size | Stride | Numbers |
|---|---|---|---|---|---|
| MobileNetv2 | - | Input | 416 × 416 × 3 | - | - |
| 0 | CBL | 208 × 208 × 32 | 2 | 1 | |
| 1–4 | IRB2 | 208 × 208 × 16 | 2 | 1 | |
| 5–11 | IRB1 | 104 × 104 × 24 | 1 | 2 | |
| 12–22 | IRB2 | 52 × 52 × 32 | 2 | 3 | |
| 23-37 | IRB2 | 52 × 52 × 64 | 2 | 4 | |
| 38-49 | IRB1 | 26 × 26 × 96 | 1 | 3 | |
| 50–60 | IRB2 | 13 × 13 × 160 | 2 | 3 | |
| 61–64 | IRB2 | 13 × 13 × 320 | 2 | 1 | |
| 65 | Conv 1 × 1 | 13 × 13 × 1280 | 1 | 1 | |
| SPP | 66–68 | CBL(F4) | 13 × 13 × 640 | 1 | 3 |
| 69–73 | Max-pooling | 13 × 13× 640 | 1 | 3 | |
| FPN + PANet | 74–76 | CBL | 13 × 13 × 640 | 1 | 3 |
| 77 | CBL | 13 × 13 × 48 | 1 | 1 | |
| 78 | Up-sample | 26 × 26 × 48 | - | 1 | |
| 79–80 | Route + CBL | 26 × 26 × 48 | 1 | 1 | |
| 81 | Concatenate | 26 × 26 × 96 | - | 1 | |
| 82–86 | CBL(F3) | 26 × 26 × 48 | 1 | 5 | |
| 87 | CBL | 26 × 26 × 16 | 1 | 1 | |
| 88 | Up-sample | 52 × 52 × 16 | - | 1 | |
| 89–90 | Route + CBL | 52 × 52 × 16 | 1 | 1 | |
| 91 | Concatenate(F2) | 52×52 × 32 | - | 1 | |
| 92–96 | CBL(P2) | 52 × 52 × 16 | 1 | 5 | |
| Head | 97 | CBL | 52 × 52 × 32 | 1 | 1 |
| 98 | Conv 1 × 1 | 52 × 52 × 21 | 1 | 1 | |
| 99 | Detection | - | - | 1 | |
| FPN + PANet | 100–101 | Route + CBL | 26 × 26 × 48 | 2 | 1 |
| 102 | Concatenate | 26 × 26 × 96 | - | 1 | |
| 103–107 | CBL(P3) | 26 × 26 × 48 | 1 | 5 | |
| Head | 108 | CBL | 26 × 26 × 96 | 1 | 1 |
| 109 | Conv 1 × 1 | 26 × 26 × 21 | 1 | 1 | |
| 110 | Detection | - | - | 1 | |
| FPN + PANet | 111–112 | Route + CBL | 13 × 13 × 640 | 2 | 1 |
| 113 | Concatenate | 13 × 13 × 1280 | - | 1 | |
| 114–118 | CBL(P4) | 13 × 13 × 640 | 1 | 5 | |
| Head | 119 | CBL | 13 × 13 × 1280 | 1 | 1 |
| 120 | Conv | 13 × 13 × 21 | 1 | 1 | |
| 121 | Detection | - | - | 1 |
| Configuration | Parameter |
|---|---|
| CPU | Intel core I9-9900K |
| GPU | Nvidia GTX 2080Ti GPU |
| Operating system | Ubuntu 18.04 |
| Accelerated environment | CUDA 10.0 CUDNN 7.0 |
| Development environment | PyCharm professional edition |
| Library | Python 3.6, Pytorch1.5.1, Opencv4.2.0 |
| Model | TP | FP | FN | P/% | R/% | F1-Score/% |
|---|---|---|---|---|---|---|
| YOLOv4 | 414 | 23 | 21 | 94.74 | 95.17 | 94.95 |
| YOLOv4-LITE | 419 | 21 | 16 | 95.23 | 96.32 | 95.77 |
| Backbone Network | AP50/% (Shoot) | AP50/% (Ginger) | Size/MB | Params/M | GFlops |
|---|---|---|---|---|---|
| CSPDarknet53 | 98.22 | 99.99 | 264.6 | 63.94 | 29.883 |
| MobileNetv2 | 97.45 | 99.99 | 115 | 47.99 | 8.741 |
| Model | AP50/% (Ginger Shoot) | AP50/% (Shoot) | mAP/% | Params/M | GFlops |
|---|---|---|---|---|---|
| YOLOv4-LITE | 97.45 | 99.99 | 98.72 | 47.99 | 8.741 |
| YOLOv4-LITE (without Do-Conv) | 95.27 | 99.99 | 97.63 | 47.99 | 8.741 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, L.; Wu, Y.; Li, Y.; Guo, H.; Zhang, H.; Wang, X.; Xi, R.; Hou, J. Ginger Seeding Detection and Shoot Orientation Discrimination Using an Improved YOLOv4-LITE Network. Agronomy 2021, 11, 2328. https://doi.org/10.3390/agronomy11112328
Fang L, Wu Y, Li Y, Guo H, Zhang H, Wang X, Xi R, Hou J. Ginger Seeding Detection and Shoot Orientation Discrimination Using an Improved YOLOv4-LITE Network. Agronomy. 2021; 11(11):2328. https://doi.org/10.3390/agronomy11112328
Chicago/Turabian StyleFang, Lifa, Yanqiang Wu, Yuhua Li, Hongen Guo, Hua Zhang, Xiaoyu Wang, Rui Xi, and Jialin Hou. 2021. "Ginger Seeding Detection and Shoot Orientation Discrimination Using an Improved YOLOv4-LITE Network" Agronomy 11, no. 11: 2328. https://doi.org/10.3390/agronomy11112328