
Concentration Prediction of Polymer Insulation Aging Indicator-Alcohols in Oil Based on Genetic Algorithm-Optimized Support Vector Machines

 , , and
, , and
Abstract
:1. Introduction
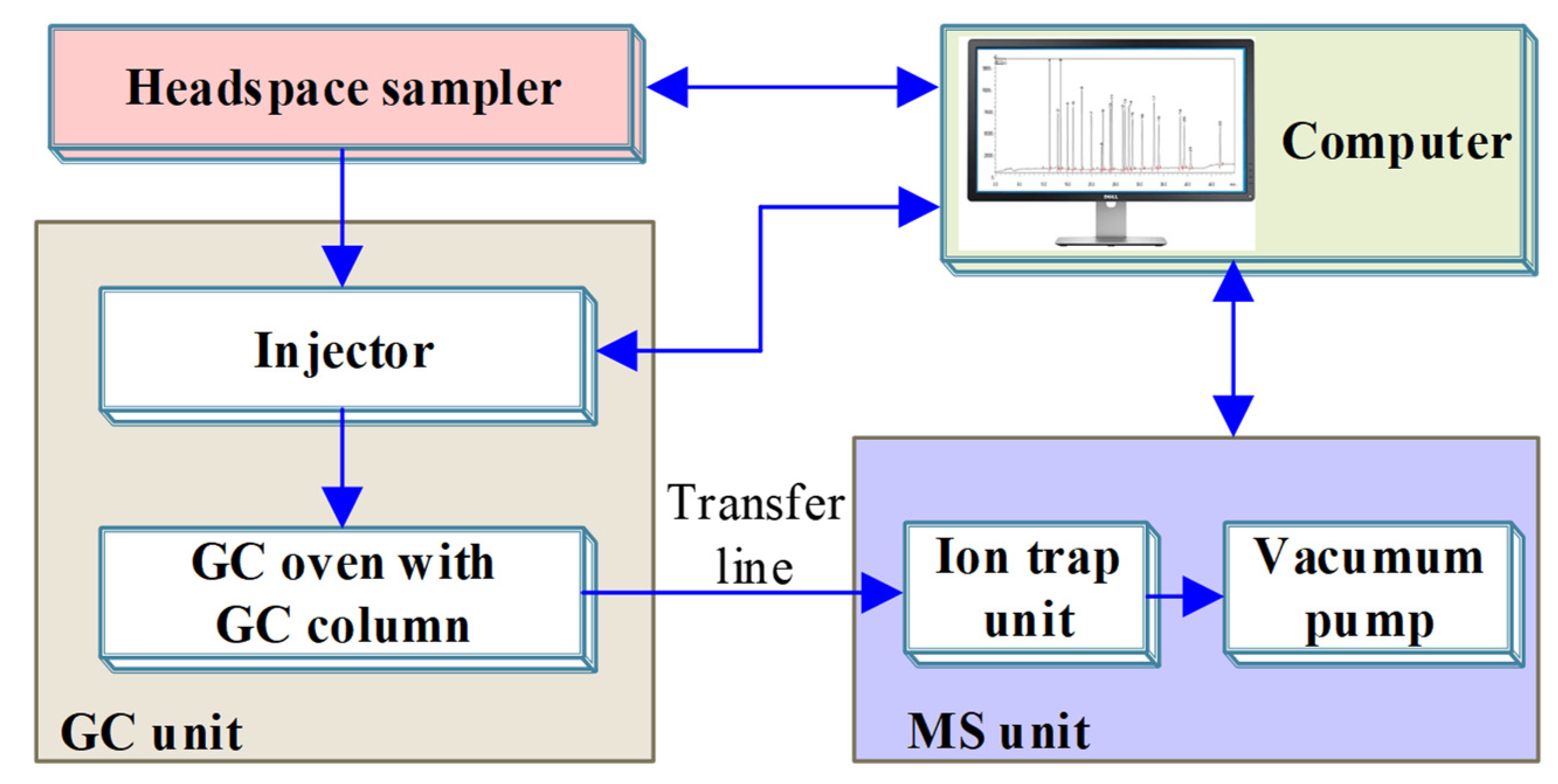
2. Alcohols Generation and Experimental Setup
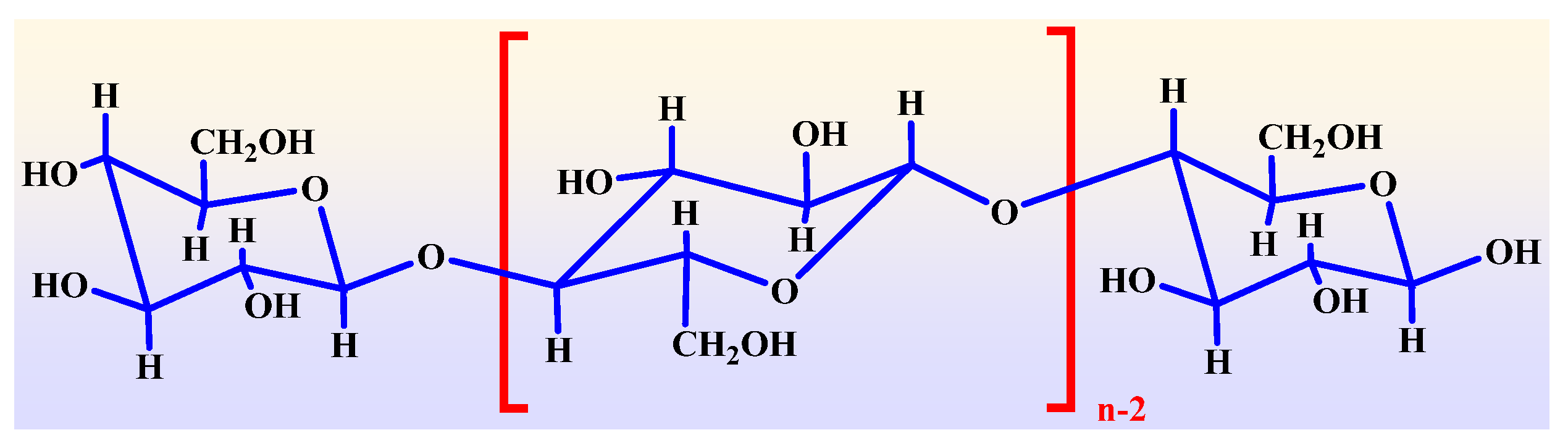
2.1. Generation of Methanol and Ethanol
2.2. Sample Preparation and Parameters Measurement
3. Prediction Model of Methanol and Ethanol Concentration Based on GA-SVM
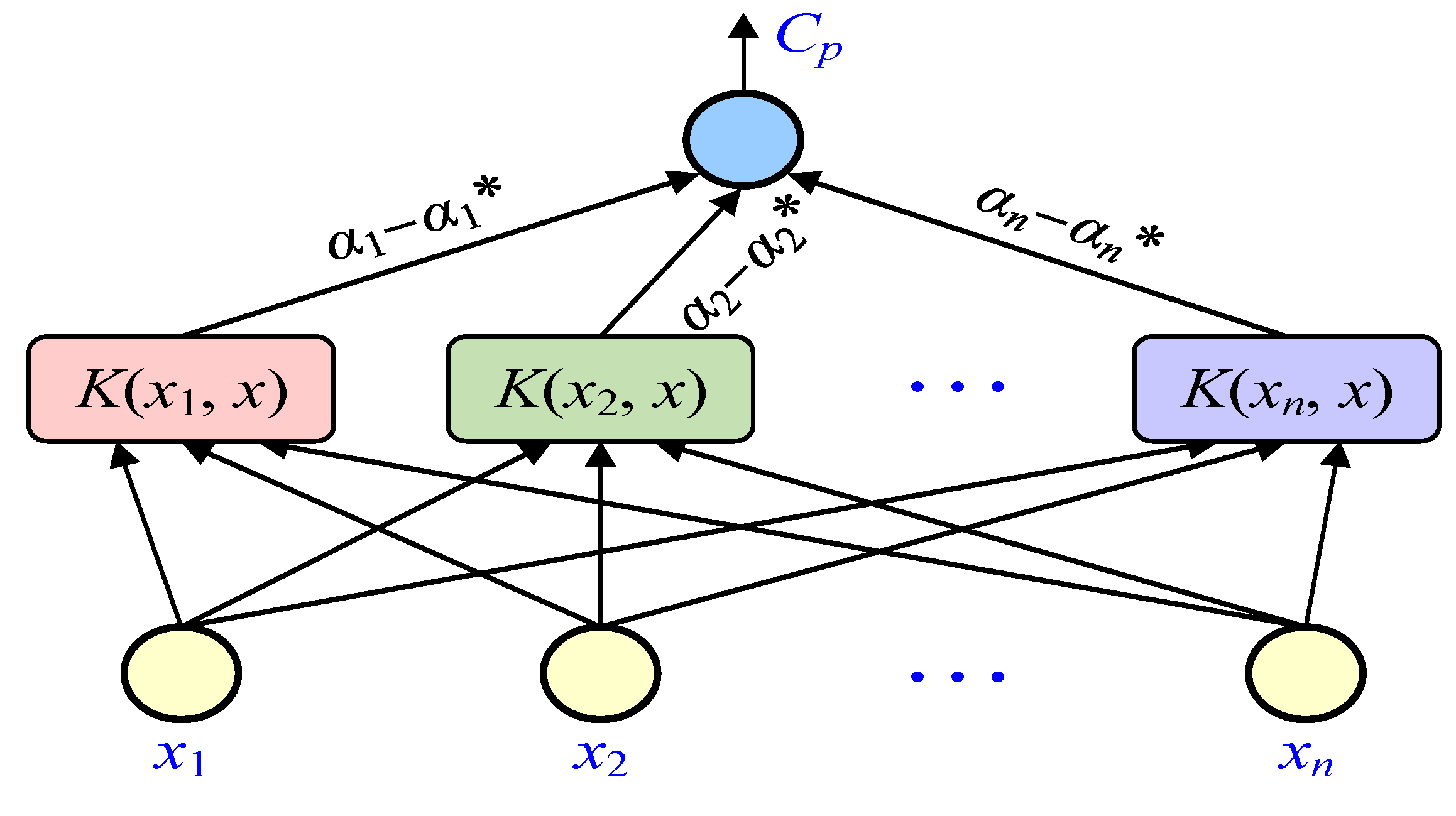
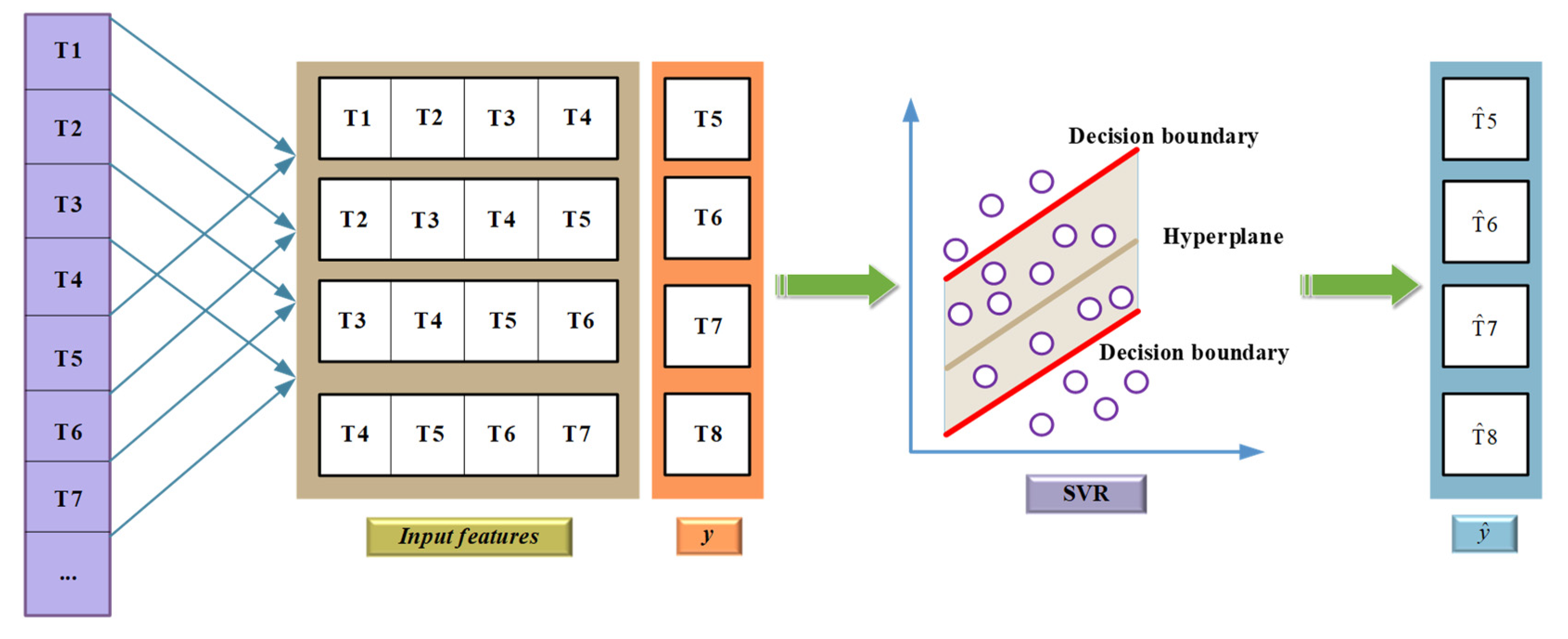
3.1. Support Vector Machine Regression Model
- (a)
- It was assumed that the methanol and ethanol concentrations in the oil are not affected by measurement errors;
- (b)
- It was assumed that the methanol and ethanol concentrations in the oil are not affected by external environmental factors;
- (c)
- It was assumed that the methanol and ethanol concentrations at different aging stages correspond to the concentrations during the transformer operation for 0–35 years.
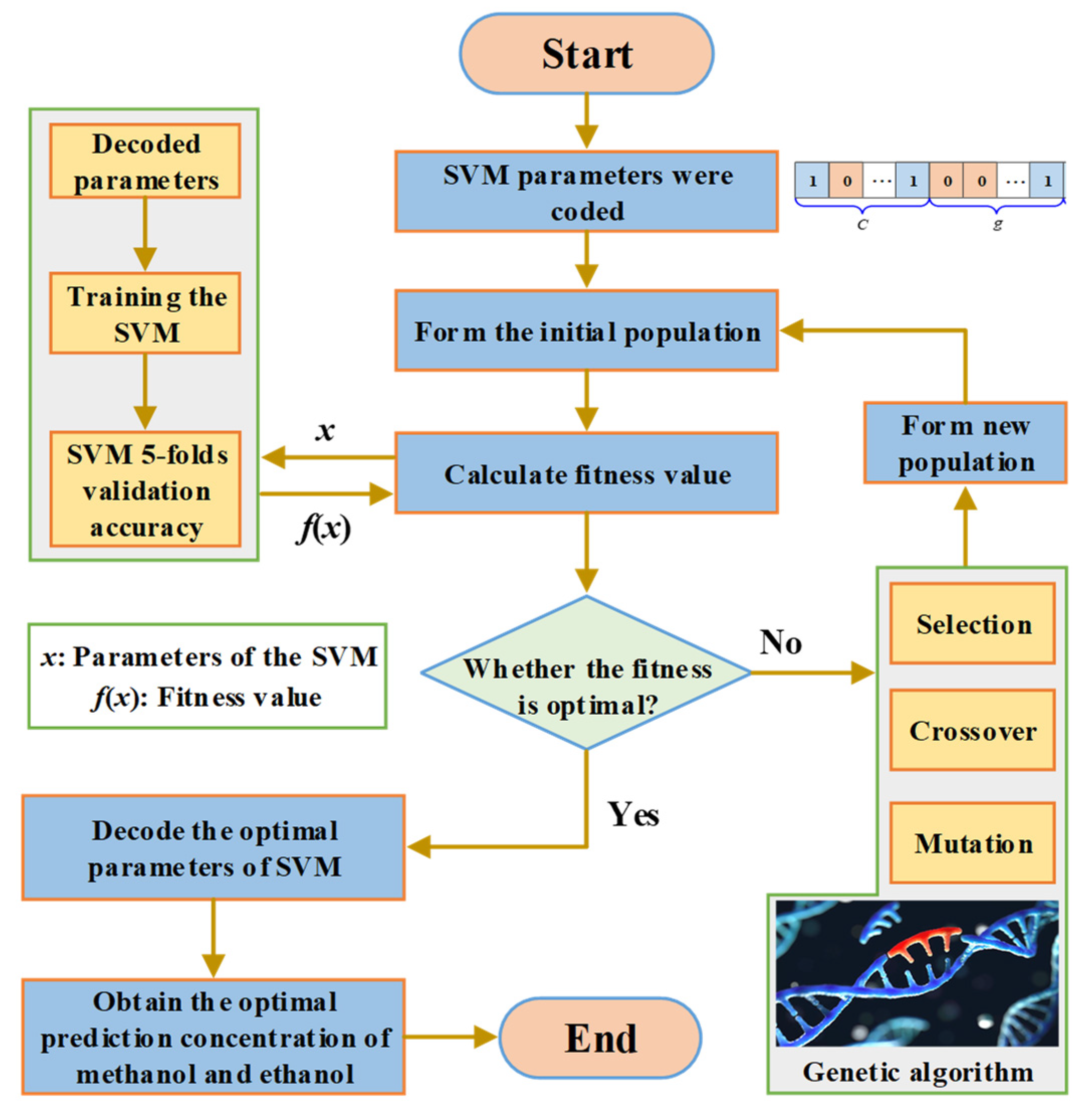
3.2. Optimization of Hyperparameters of SVM Based on GA Algorithm
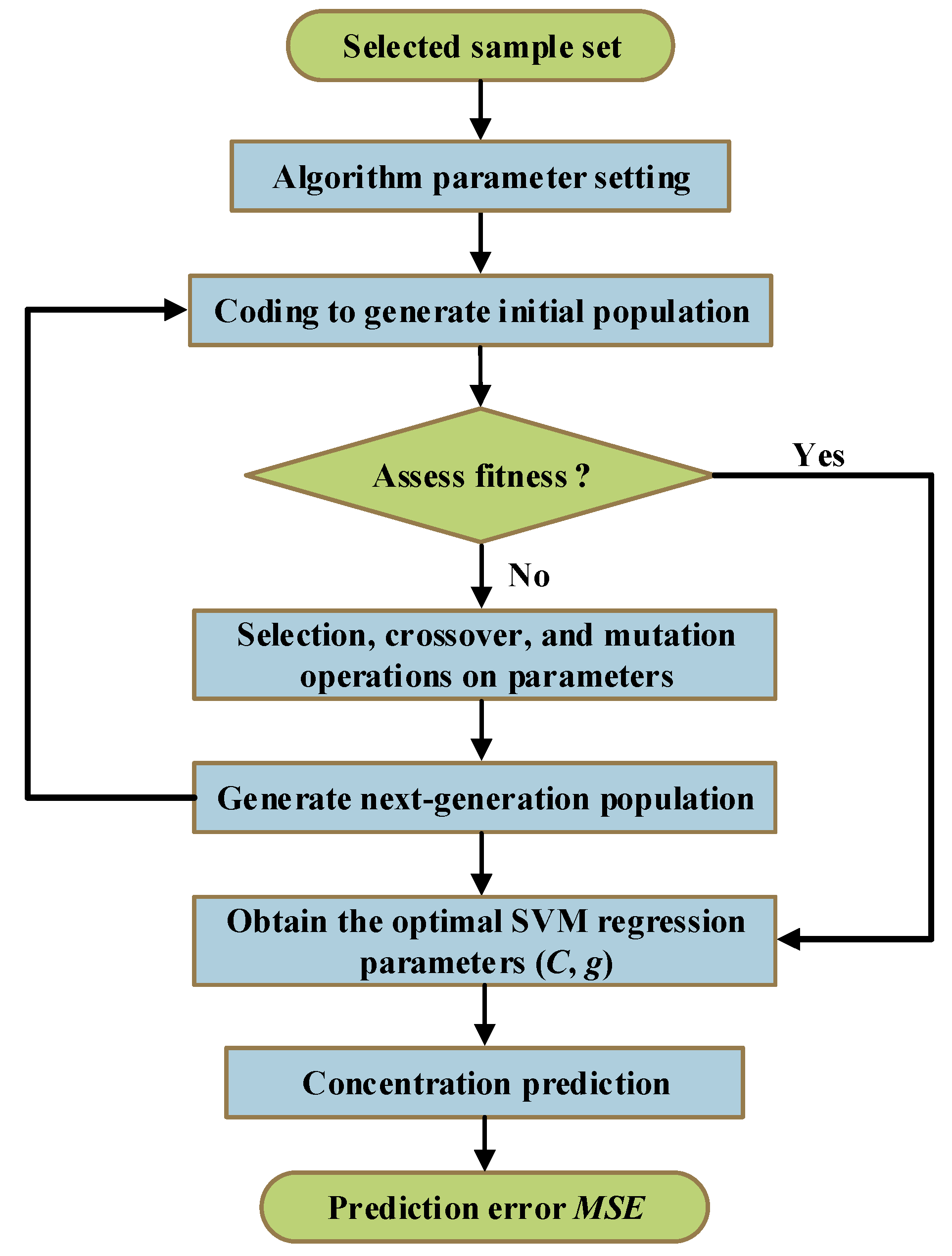
3.3. The Prediction Steps of the GA-SVM Model
- (1)
- The penalty factor C and kernel function parameter g were initialized, and binary coding was utilized to encode C and g;
- (2)
- Various parameters of the GA algorithm were set according to Table 2;
- (3)
- SVM training was performed on the initial population, and the fitness of the individual was calculated according to the recognition rate of the training samples;
- (4)
- The selection, crossover, and mutation operations on parameters were performed according to individual fitness to obtain a new generation of populations. Then, SVM training was performed on the new population to calculate individual fitness;
- (5)
- Fitness was assessed by checking whether the population satisfied the termination condition. If the termination condition was met, the individual with the greatest fitness was output as the optimal parameter, and the optimal parameter was used for prediction. Otherwise, the evolutionary algebra was increased, and the process was repeated from step 4 to continue running the program;
- (6)
- The measured and predicted values of methanol and ethanol concentrations were compared, and the MSE of the corresponding prediction models were obtained.
4. Prediction Process of the Concentration of Methanol and Ethanol
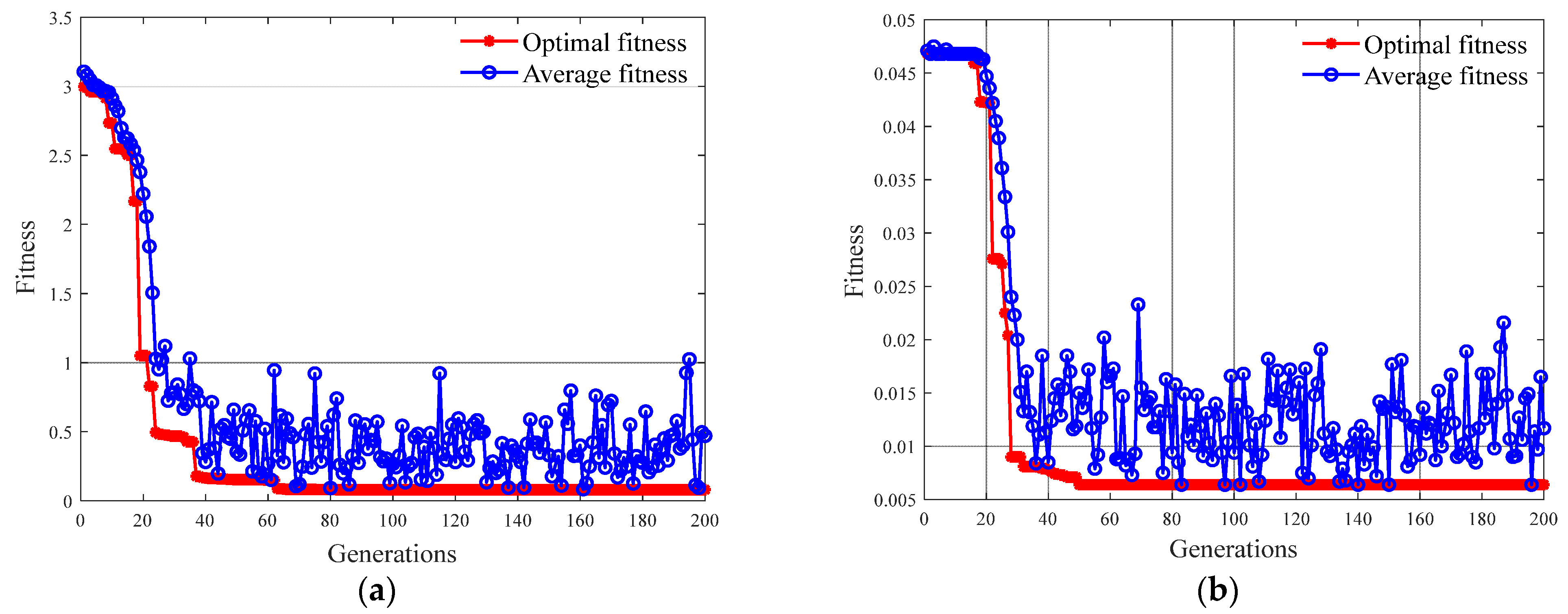
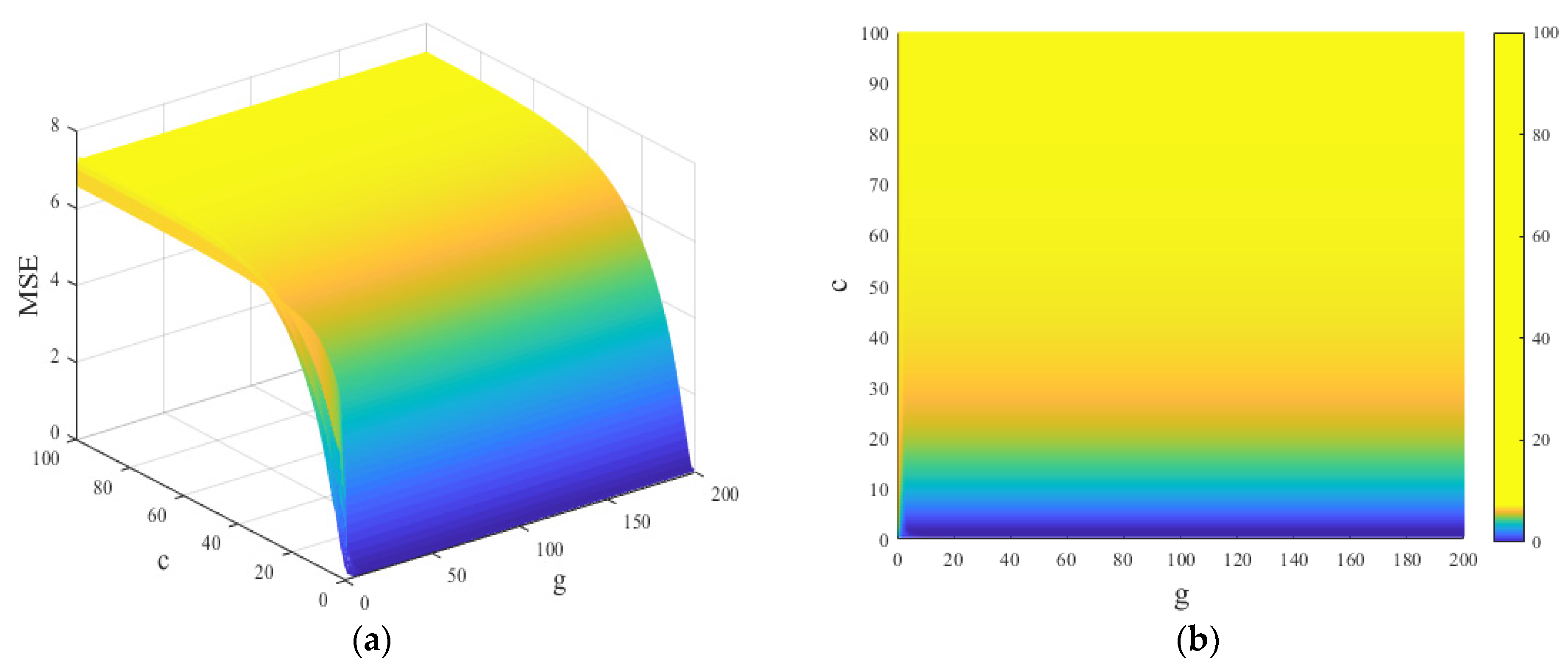
4.1. The Prediction Results of GA-SVM
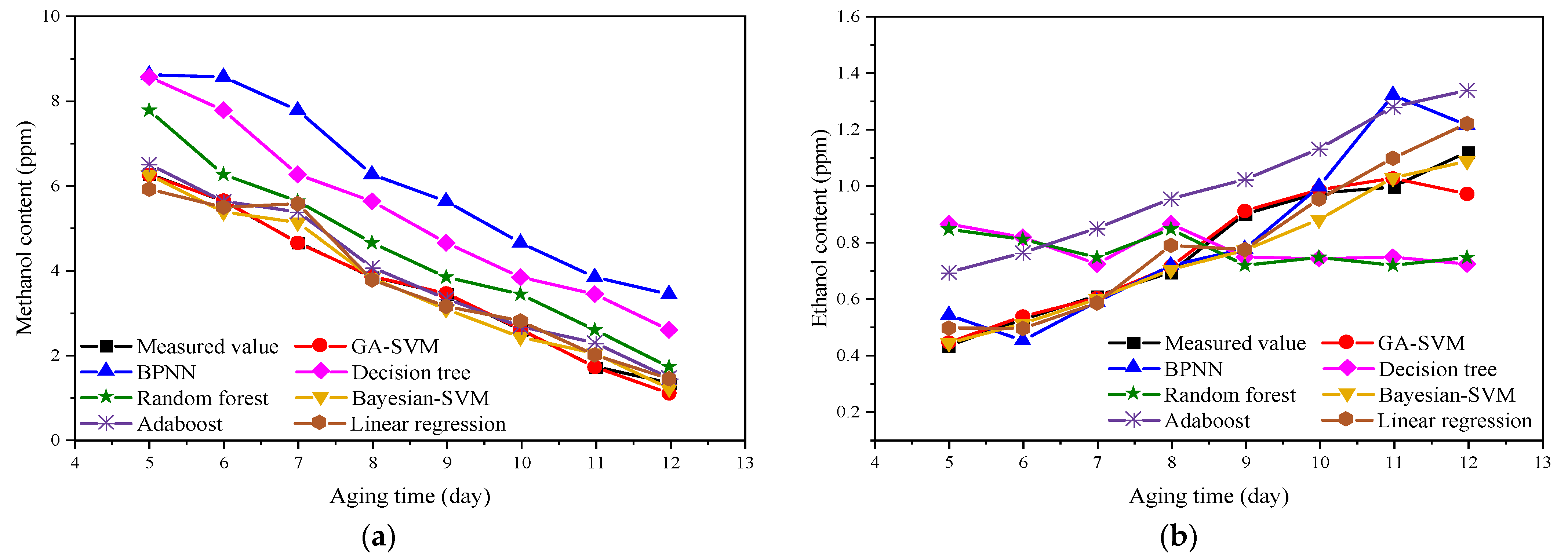
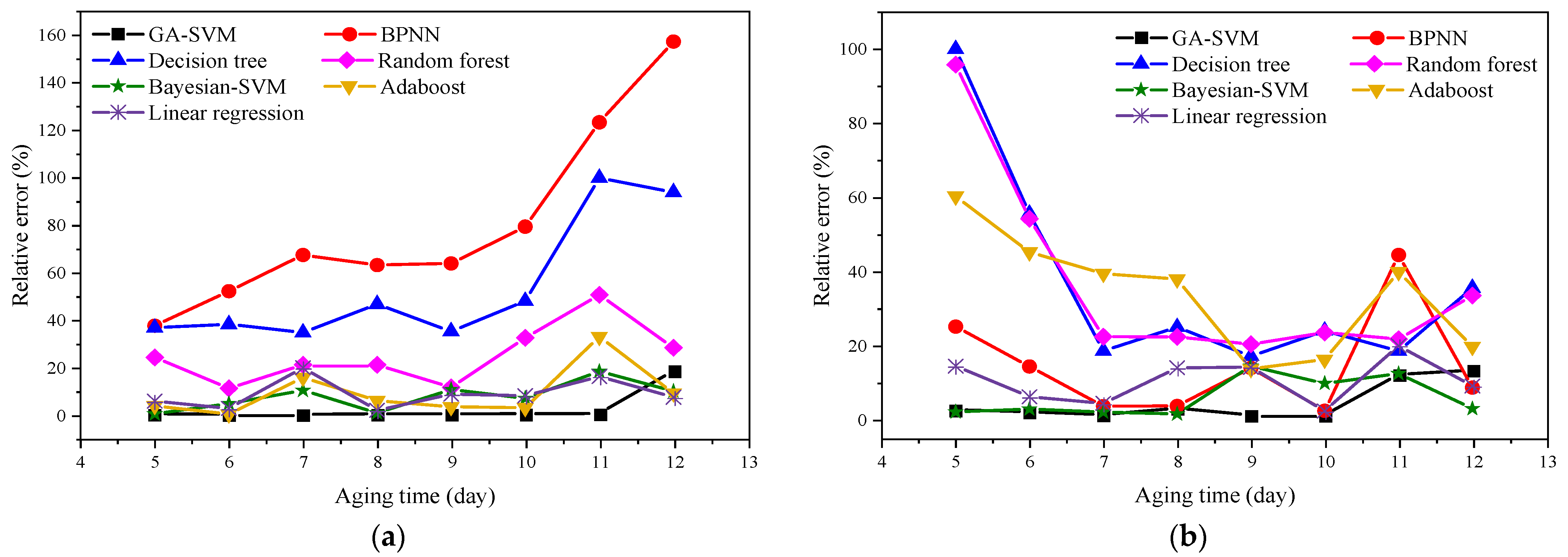
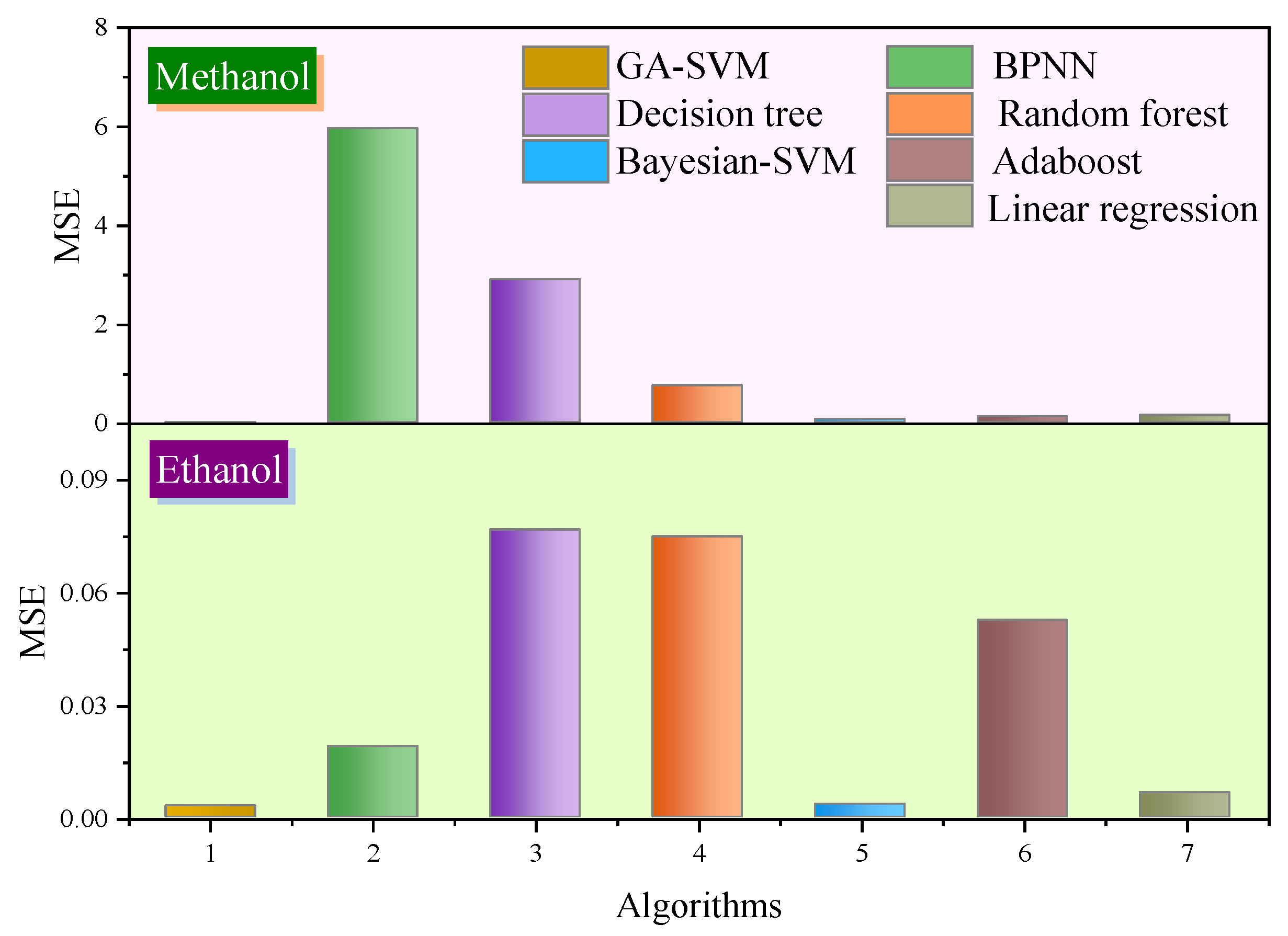
4.2. Comparison of Prediction Results of Different Intelligent Algorithms
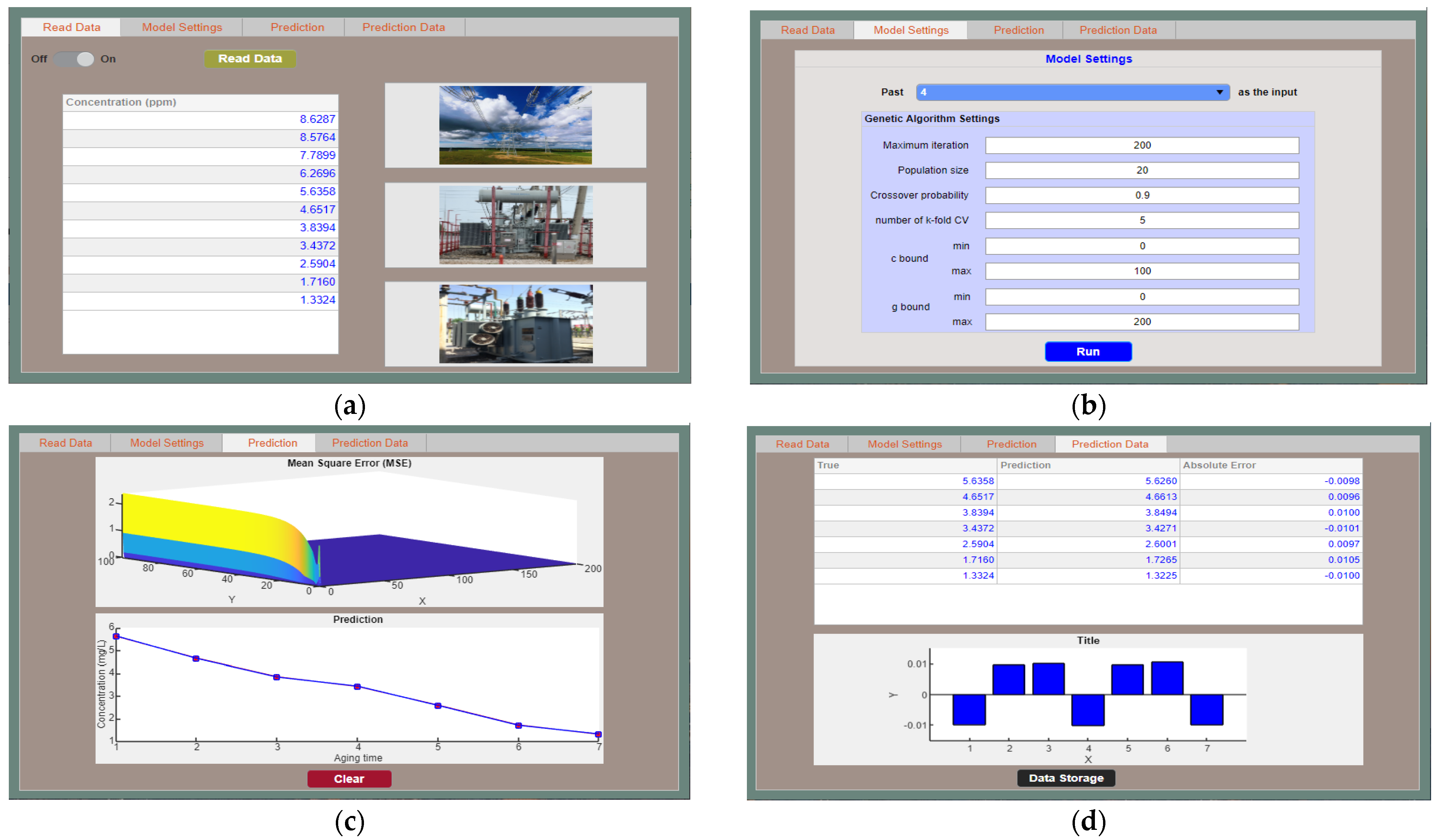
5. Software Construction of Prediction Model
6. Conclusions
- (1)
- The average MSE of methanol concentration prediction based on GA-SVM reached 0.008, and the average MSE of ethanol concentration prediction reached 0.003. The undeniable limitation is that a large volume of experimental data is difficult to obtain, but the proposed method in this research has a higher prediction accuracy and can be applied to the concentration prediction of methanol and ethanol;
- (2)
- The predicted concentrations of methanol and ethanol in the prediction model were obtained based on the data of the first four samples, which improved the accuracy of the prediction. The optimization of parameters had a significant impact on the prediction results of SVM. The GA-SVM prediction model introduced in this paper can overcome the blindness of the parameter selection of the traditional model;
- (3)
- The prediction accuracy of the oil alcohol prediction model studied in this paper was acceptable. In any case, the experimental sample data were small, and some prediction errors were inevitable, but they can provide points of reference for the prediction of alcohol concentration. In further research, long-term aging experiments will be conducted, and more data will be obtained for concentration prediction;
- (4)
- Additionally, according to the prediction method of alcohol concentration based on GA-SVM, an industrial software program was developed to facilitate the later methanol and ethanol concentration prediction and parameter adjustment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liao, W.; Yang, D.; Wang, Y.; Ren, X. Fault diagnosis of power transformers using graph convolutional network. CSEE J. Power Energy Syst. 2021, 7, 241–249. [Google Scholar]
- Fan, X.; Liu, J.; Lai, B.; Zhang, Y.; Zhang, C. FDS Measurement-Based Moisture Estimation Model for Transformer Oil-Paper Insulation Including the Aging Effect. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Fernández-Diego, C.; Ortiz, A.; Carrascal, I.; Fernández, I.; Renedo, C. Kinetic Assessment of Mechanical Properties of a Cellulose Board Aged in Mineral Oil and Synthetic Ester. Polymers 2021, 13, 4150. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, H.; Fan, X.; Zhang, Y.; Zhang, C. Aging evaluation for transformer oil-immersed cellulose insulation by using frequency dependent dielectric modulus technique. Cellulose 2021, 28, 2387–2401. [Google Scholar] [CrossRef]
- Mishra, D.; Pradhan, A.K.; Baral, A.; Chakravorti, S. Reduction of time domain insulation response measurement duration for fast and effective diagnosis of power transformer. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 1932–1940. [Google Scholar] [CrossRef]
- Fan, X.; Liu, J.; Zhang, Y.; Ding, Z.; Wang, Q. Polarization loss analysis and ageing characterisation of transformer oil-immersed insulation by using decoupled frequency domain spectroscopy. High Volt. 2021, 1–12. [Google Scholar] [CrossRef]
- Forouhari, S.; Abu-Siada, A. Application of adaptive neuro fuzzy inference system to support power transformer life estimation and asset management decision. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 845–852. [Google Scholar] [CrossRef]
- Nezami, M.M.; Wani, S.A.; Khan, S.A.; Khera, N.; Sohail, S. A Comb-Type Capacitive 2-FAL Sensor for Transformer Oil With Improved Sensitivity. IEEE Trans. Instrum. Meas. 2020, 69, 4524–4532. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Zhang, Y.; Lai, B.; Jiao, J. Analysis of low-frequency polarisation behaviour for oil-paper insulation using logarithmic-derivative spectroscopy. High Volt. 2021, 6, 460–469. [Google Scholar] [CrossRef]
- Feng, D.W.; Yang, L.J.; Liao, R.J.; Zhou, L.W.; Lin, Y.D. Effect of moisture content on the production and partitioning of furfural in oil-paper insulation. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 2389–2397. [Google Scholar] [CrossRef]
- Rao, U.M.; Fofana, I.; Betie, A.; Senoussaoui, M.L.; Brahami, M.; Briosso, E. Condition monitoring of in-service oil-filled transformers: Case studies and experience. IEEE Electr. Insul. Mag. 2019, 35, 33–42. [Google Scholar] [CrossRef]
- Gilbert, R.; Jalbert, J.; Duchesne, S.; Tetreault, P.; Morin, B.; Denos, Y. Kinetics of the production of chain-end groups and methanol from the depolymerization of cellulose during the ageing of paper/oil systems. Part 2: Thermally-upgraded insulating papers. Cellulose 2010, 17, 253–269. [Google Scholar] [CrossRef]
- Rodriguez-Celis, E.M.; Duchesne, S.; Jalbert, J.; Ryadi, M. Understanding ethanol versus methanol formation from insulating paper in power transformers. Cellulose 2015, 22, 3225–3236. [Google Scholar] [CrossRef] [Green Version]
- Bicen, Y.; Aras, F.; Kirkici, H. Lifetime estimation and monitoring of power transformer considering annual load factors. IEEE Trans. Dielectr. Electr. Insul. 2014, 21, 1360–1367. [Google Scholar] [CrossRef]
- Ma, X.; Hu, H.; Shang, Y.Z. A New Method for Transformer Fault Prediction Based on Multifeature Enhancement and Refined Long Short-Term Memory. IEEE Trans. Instrum. Meas. 2021, 70, 2512111. [Google Scholar] [CrossRef]
- Lu, S.X.; Lin, G.Y.; Que, H.K.; Li, M.J.J.; Wei, C.H.; Wang, J.K. Grey relational analysis using Gaussian process regression method for dissolved gas concentration prediction. Int. J. Mach. Learn. Cyber. 2019, 10, 1313–1322. [Google Scholar] [CrossRef]
- Zheng, H.B.; Zhang, Y.Y.; Liu, J.F.; Wei, H.; Zhao, J.H.; Liao, R.J. A novel model based on wavelet LS-SVM integrated improved PSO algorithm for forecasting of dissolved gas contents in power transformers. Electr. Power Syst. Res. 2018, 155, 196–205. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, H.; Xie, Z.; Wang, Z.; Chen, L.; Lin, X.; Ding, H.; Li, Z.; Xiong, W. Combined forecasting method of dissolved gases concentration and its application in condition-based maintenance. IEEE Trans. Power Deliv. 2019, 34, 1269–1279. [Google Scholar] [CrossRef]
- Ghunem, R.A.; Assaleh, K.; El-Hag, A.H. Artificial neural networks with stepwise regression for predicting transformer oil furan content. IEEE Trans. Dielectr. Electr. Insul. 2012, 19, 414–420. [Google Scholar] [CrossRef]
- Shaban, K.B.; El-Hag, A.H.; Benhmed, K. Prediction of transformer furan levels. IEEE Trans. Power Deliv. 2016, 31, 1778–1779. [Google Scholar] [CrossRef]
- Hardian, R.; Liang, Z.; Zhang, X.; Szekely, G. Artificial intelligence: The silver bullet for sustainable materials development. Green Chem. 2020, 22, 7521–7528. [Google Scholar] [CrossRef]
- Gurnani, R.; Kamal, D.; Tran, H.; Sahu, H.; Scharm, K.; Ashraf, U.; Ramprasad, R. PolyG2G: A novel machine learning algorithm applied to the generative design of polymer dielectrics. Chem. Mater. 2021, 33, 7008–7016. [Google Scholar] [CrossRef]
- Cordova, L.; Walton, H.; Biswas, E.; Monroe, K.; Quirino, R.; Alper, H. Data-driven approach to decipher the role of triglyceride composition on the thermomechanical properties of thermosetting polymers using vegetable and microbial oils. ACS Appl. Polym. Mater. 2021, 3, 4485–4494. [Google Scholar] [CrossRef]
- Kumar, S.; Ignacz, G.; Szekely, G. Synthesis of covalent organic frameworks using sustainable solvents and machine learning. Green Chem. 2021, 23, 8932–8939. [Google Scholar] [CrossRef]
- Teymouri, A.; Vahidi, B. CO2/CO concentration ratio: A complementary method for determining the degree of polymerization of power transformer paper insulation. IEEE Electr. Insul. Mag. 2017, 33, 24–30. [Google Scholar] [CrossRef]
- Liu, Y.; Chao, N.; Zhao, T.; Tong, Y.; Jia, C. Mechanism and numerical model of bubble effect in oil-paper insulation based on microtubule model. IEEE Trans. Dielectr. Electr. Insul. 2020, 27, 1529–1537. [Google Scholar] [CrossRef]
- Jalbert, J.; Rodriguez-Celis, E.; Duchesne, S.; Morin, B.; Ryadi, M.; Gilbert, R. Kinetics of the production of chain-end groups and methanol from the depolymerization of cellulose during the ageing of paper/oil systems. Part 3: Extension of the study under temperature conditions over 120 °C. Cellulose 2015, 22, 829–848. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Zheng, H.; Zhu, M.; Li, Y. Microscopic reaction mechanism of the production of methanol during the thermal aging of cellulosic insulating paper. Cellulose 2020, 27, 2455–2467. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, H.; Fan, X.; Zhang, Y. Investigation on formation mechanisms of methanol during cellulose insulation aging based on molecular dynamics simulation. IEEE Access 2021, 9, 6890–6898. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, H.; Geng, C.; Fan, X.; Zhang, Y. Aging assessment model of transformer insulation based on furfural indicator under different oil/pressboard ratios and oil change. IEEE Trans. Dielectr. Electr. Insul. 2021, 28, 1061–1069. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Zhang, C.; Lai, C.S.; Zhang, Y.; Zheng, H.; Lai, L.L.; Zhang, E. Moisture diagnosis of transformer oil-immersed insulation with intelligent technique and frequency-domain spectroscopy. IEEE Trans. Industr. Inform. 2021, 17, 4624–4634. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Materials Type | Parameters | Value |
|---|---|---|
| Insulating oil | tanδ | 4 × 10−4 |
| Pour point | ≤−45 °C | |
| Flash point | 135 °C | |
| Manufacturer | Sinopec Group Co. Ltd., Chongqing, China | |
| Insulating paper | Thickness | 1 mm |
| TS | MD: 138.79 MPa, CMD: 97.14 MPa | |
| Density | 1.09 g/cm3 | |
| Manufacturer | Weidmann high voltage insulation Co. Ltd., Taizhou, China |
| Parameters | Settings |
|---|---|
| Maximum iteration | 200 |
| Population size | 20 |
| Mutation probability | 0.03 |
| Crossover probability | 0.9 |
| Range of penalty factor C | (0, 100) |
| Range of kernel function parameter g | (0, 1000) |
| Parameter | Best C | Best g | Mutation Probability | MSE |
|---|---|---|---|---|
| Methanol | 50.7794 | 0.5016 | 0.0832 | 0.0780 |
| Ethanol | 68.1133 | 0.7896 | 0.0212 | 0.0034 |
| Indicator | Aging Time (day) | Measured Value | GA-SVM | BPNN | Decision Tree | Random Forest | Bayesian-SVM | Adaboost | Linear Regression |
|---|---|---|---|---|---|---|---|---|---|
| Methanol | 5 | 6.2696 | 6.2506 | 8.6207 | 8.5684 | 7.7820 | 6.2511 | 6.5027 | 5.9141 |
| 6 | 5.6358 | 5.6466 | 8.5684 | 7.7820 | 6.2617 | 5.3741 | 5.6257 | 5.4871 | |
| 7 | 4.6517 | 4.6425 | 7.7820 | 6.2617 | 5.6278 | 5.1281 | 5.3797 | 5.5711 | |
| 8 | 3.8394 | 3.8507 | 6.2617 | 5.6278 | 4.6438 | 3.8121 | 4.0637 | 3.7701 | |
| 9 | 3.4372 | 3.4481 | 5.6278 | 4.6438 | 3.8314 | 3.0731 | 3.3247 | 3.1411 | |
| 10 | 2.5904 | 2.6009 | 4.6438 | 3.8314 | 3.4292 | 2.4131 | 2.6647 | 2.7961 | |
| 11 | 1.7160 | 1.7073 | 3.8314 | 3.4292 | 2.5825 | 2.0291 | 2.2807 | 1.9921 | |
| 12 | 1.3324 | 1.0849 | 3.4292 | 2.5825 | 1.7081 | 1.2011 | 1.4527 | 1.4301 | |
| Ethanol | 5 | 0.4317 | 0.4429 | 0.5398 | 0.8638 | 0.8455 | 0.4403 | 0.6920 | 0.4939 |
| 6 | 0.5247 | 0.5356 | 0.4499 | 0.8164 | 0.8091 | 0.5102 | 0.7618 | 0.4928 | |
| 7 | 0.6089 | 0.6014 | 0.5876 | 0.7215 | 0.7447 | 0.5972 | 0.8488 | 0.5830 | |
| 8 | 0.6915 | 0.7125 | 0.7165 | 0.8638 | 0.8455 | 0.7016 | 0.9532 | 0.7876 | |
| 9 | 0.8995 | 0.9099 | 0.7749 | 0.7461 | 0.7170 | 0.7705 | 1.0221 | 0.7727 | |
| 10 | 0.9736 | 0.9848 | 0.9961 | 0.7407 | 0.7450 | 0.8792 | 1.1308 | 0.9518 | |
| 11 | 0.9950 | 1.0261 | 1.3216 | 0.7461 | 0.7170 | 1.0281 | 1.2797 | 1.0971 | |
| 12 | 1.1191 | 0.9704 | 1.2150 | 0.7215 | 0.7447 | 1.0871 | 1.3387 | 1.2201 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Zhang, H.; Wang, Y.; Luo, Y.; He, J.; Yu, X.; Zhang, Y.; Liu, J.; Shuang, F. Concentration Prediction of Polymer Insulation Aging Indicator-Alcohols in Oil Based on Genetic Algorithm-Optimized Support Vector Machines. Polymers 2022, 14, 1449. https://doi.org/10.3390/polym14071449
Wu S, Zhang H, Wang Y, Luo Y, He J, Yu X, Zhang Y, Liu J, Shuang F. Concentration Prediction of Polymer Insulation Aging Indicator-Alcohols in Oil Based on Genetic Algorithm-Optimized Support Vector Machines. Polymers. 2022; 14(7):1449. https://doi.org/10.3390/polym14071449
Chicago/Turabian StyleWu, Shuyue, Heng Zhang, Yuxuan Wang, Yiwen Luo, Jiaxuan He, Xiaotang Yu, Yiyi Zhang, Jiefeng Liu, and Feng Shuang. 2022. "Concentration Prediction of Polymer Insulation Aging Indicator-Alcohols in Oil Based on Genetic Algorithm-Optimized Support Vector Machines" Polymers 14, no. 7: 1449. https://doi.org/10.3390/polym14071449