
Predicting Flow Stress Behavior of an AA7075 Alloy Using Machine Learning Methods
 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
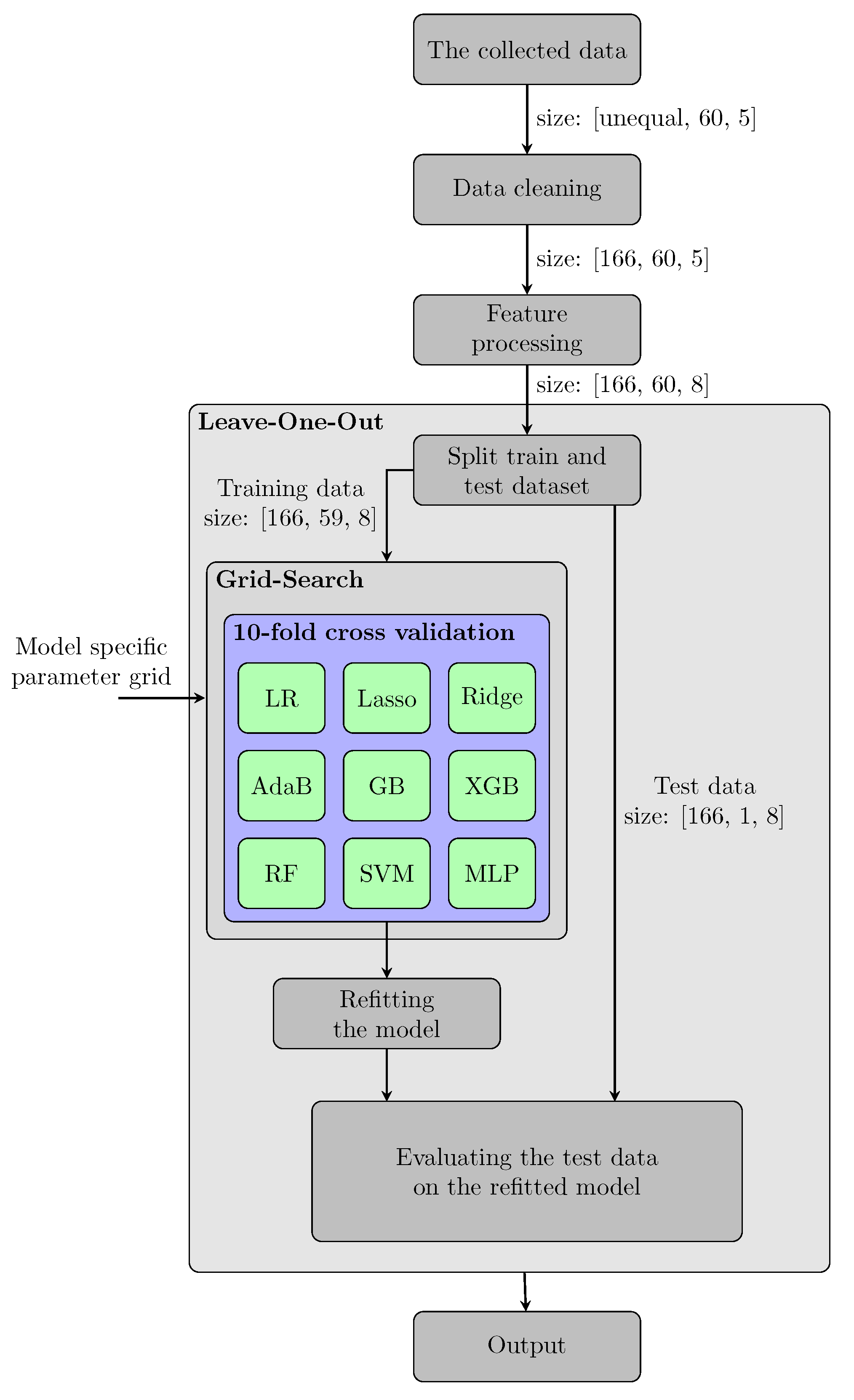
2. Materials and Methods
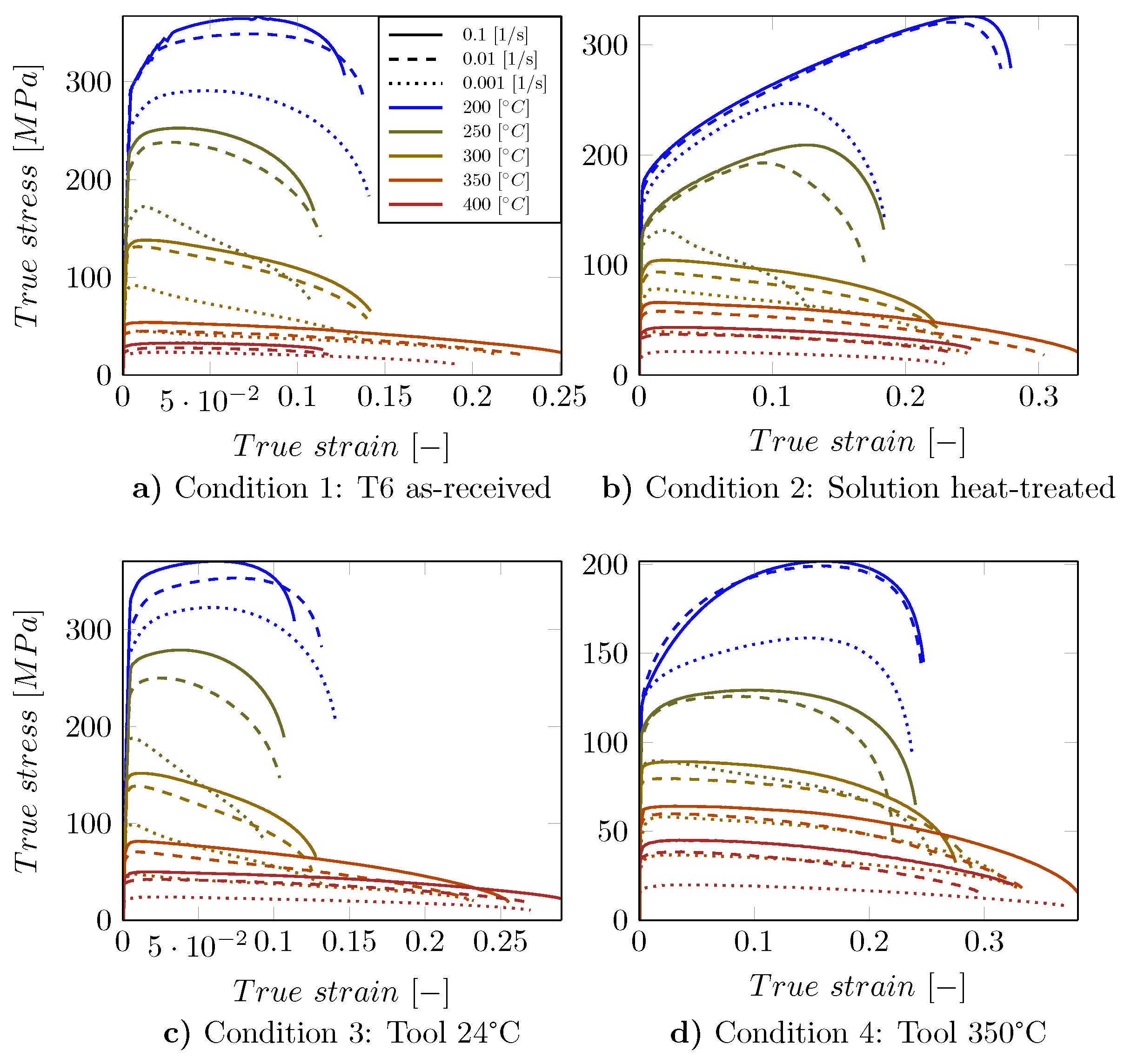
2.1. Data and Experimental Setup
2.1.1. Condition 1: T6 As-Received (Figure 2a)
2.1.2. Condition 2: Solution Heat-Treated (Figure 2b)
2.1.3. Condition 3: Tool 24 C (Figure 2c)
2.1.4. Condition 4: Tool 350 C (Figure 2d)
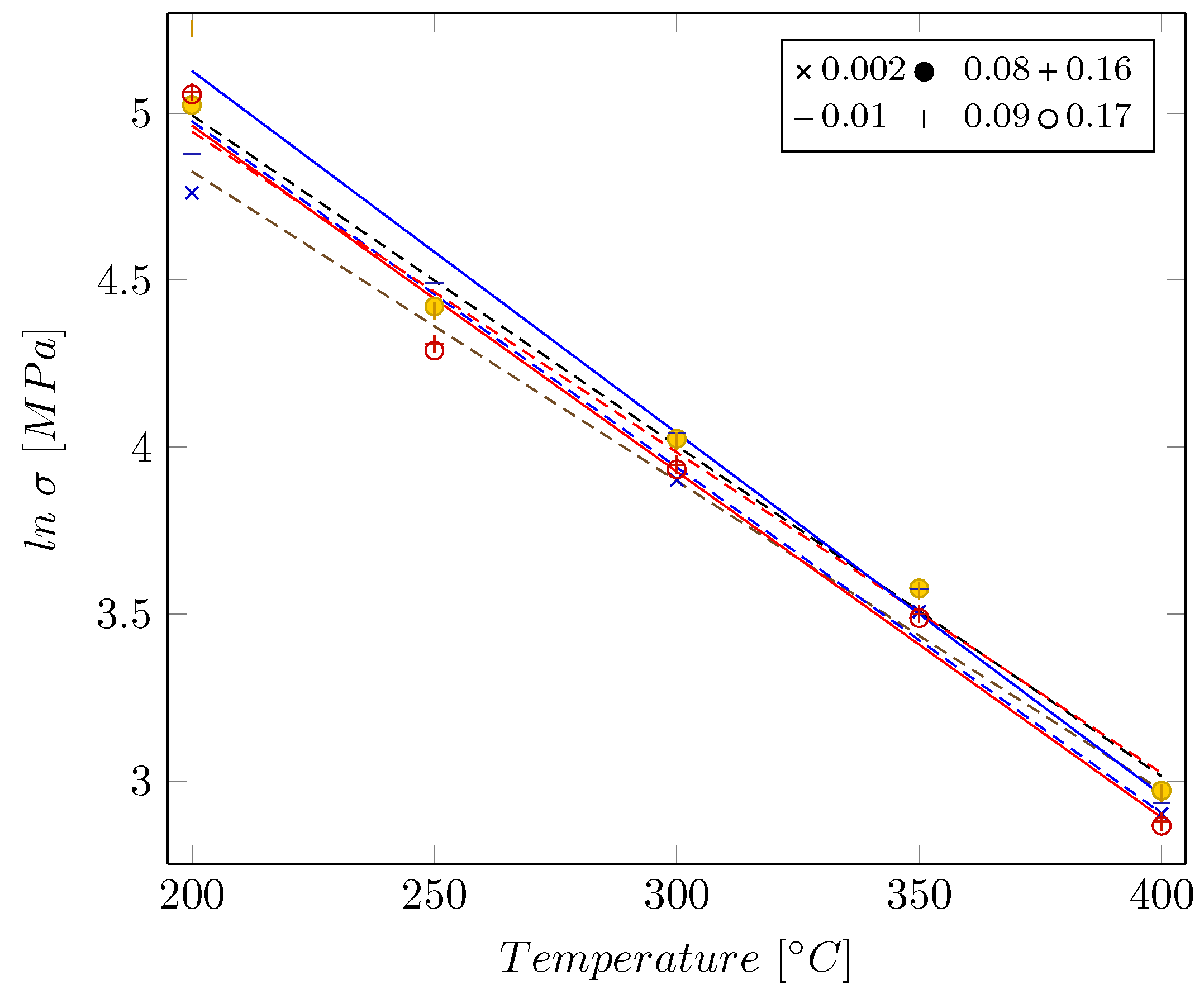
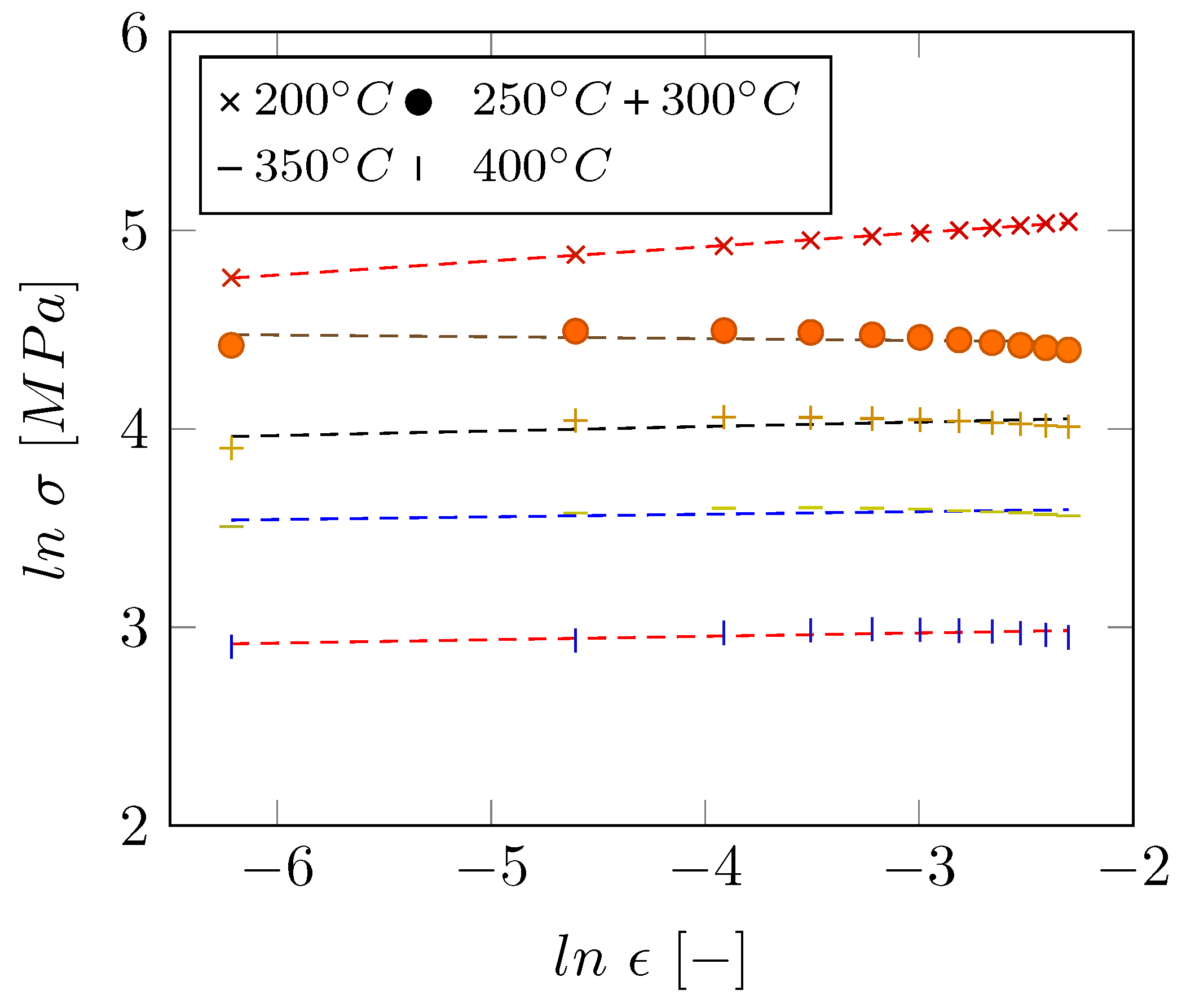
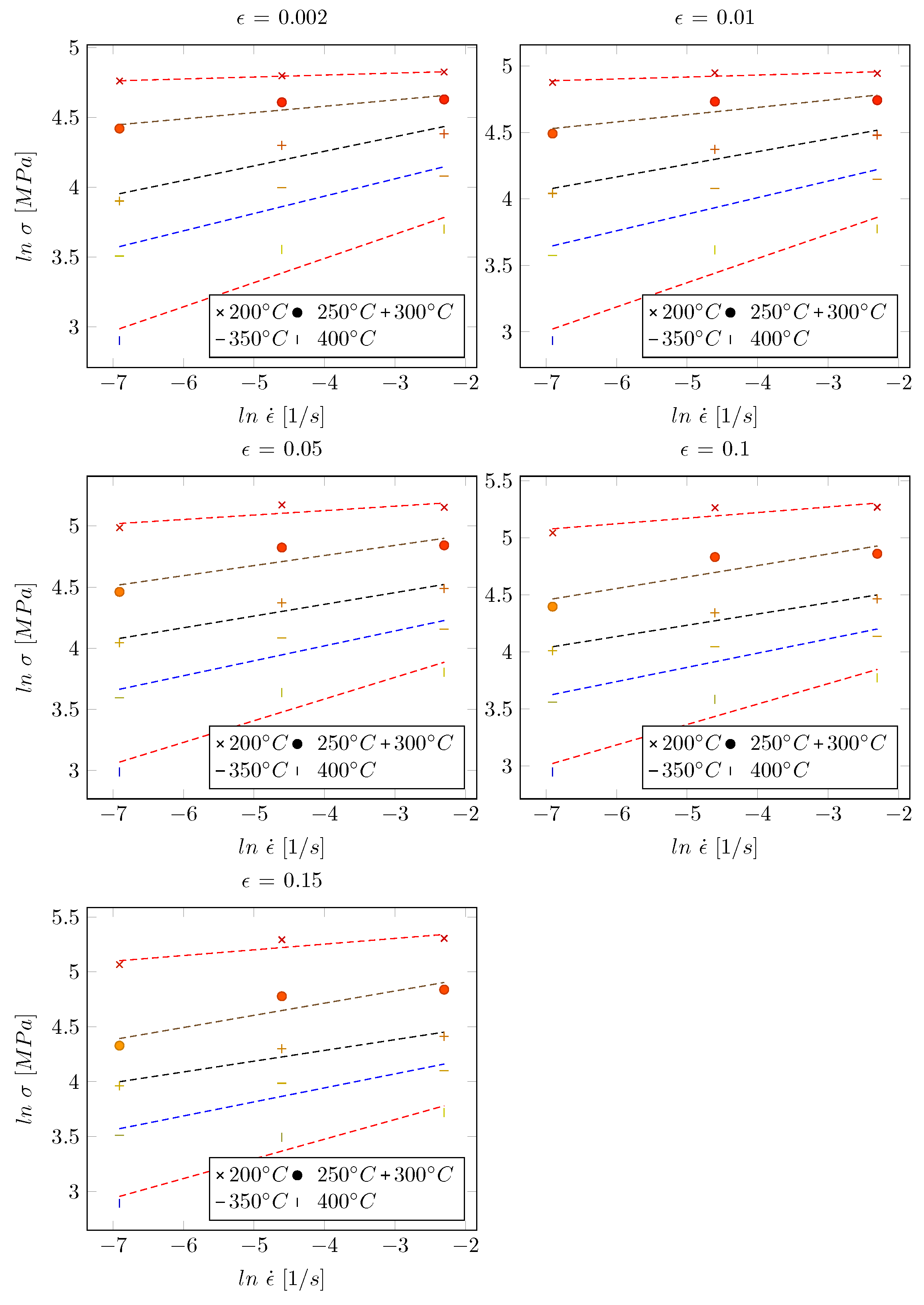
2.2. Zerilli–Armstrong Model
2.3. Machine Learning Methods
2.3.1. Linear Regression
2.3.2. Kernel Methods
2.3.3. Ensemble Learning
2.3.4. Neural Networks
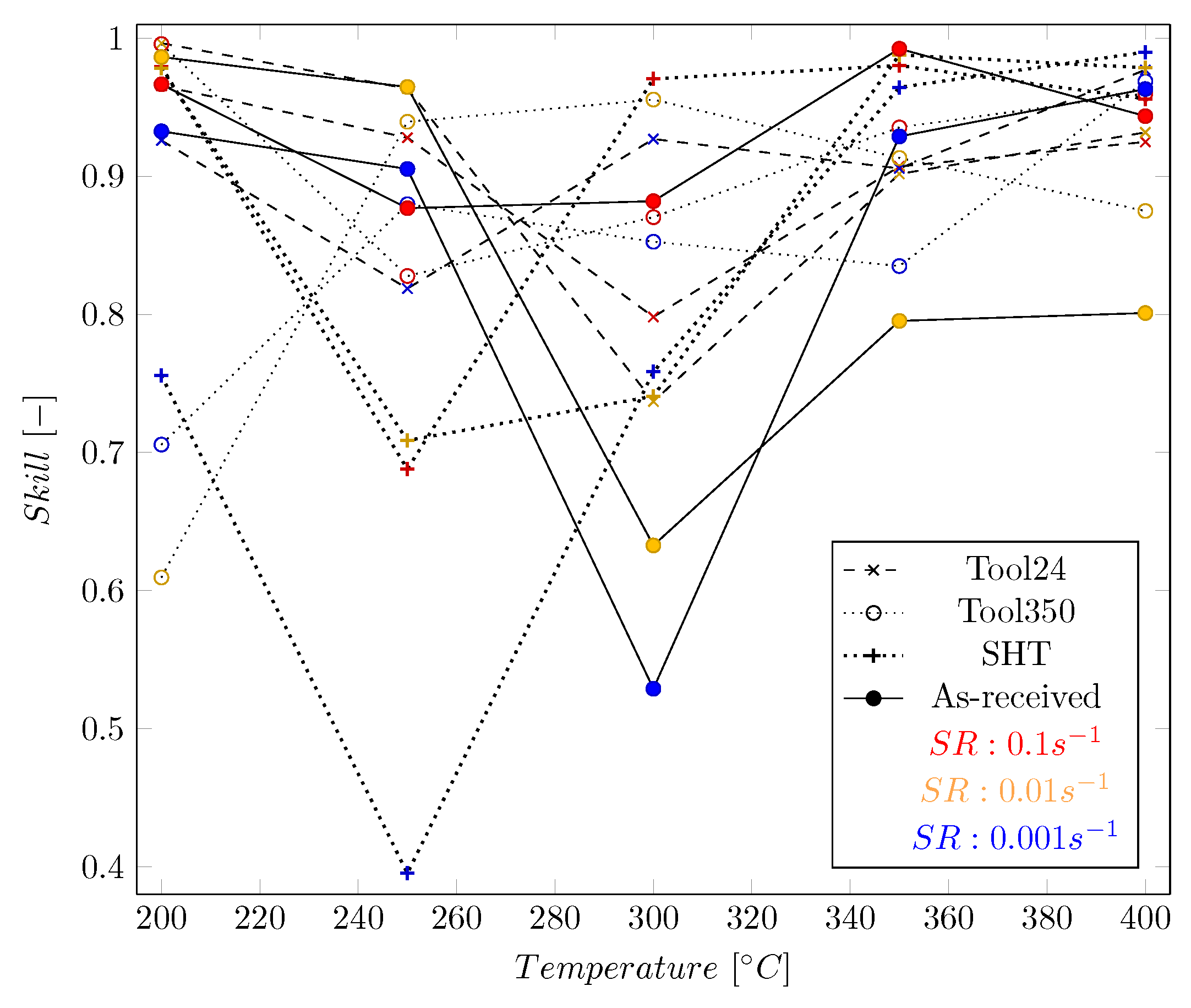
3. Results and Discussion
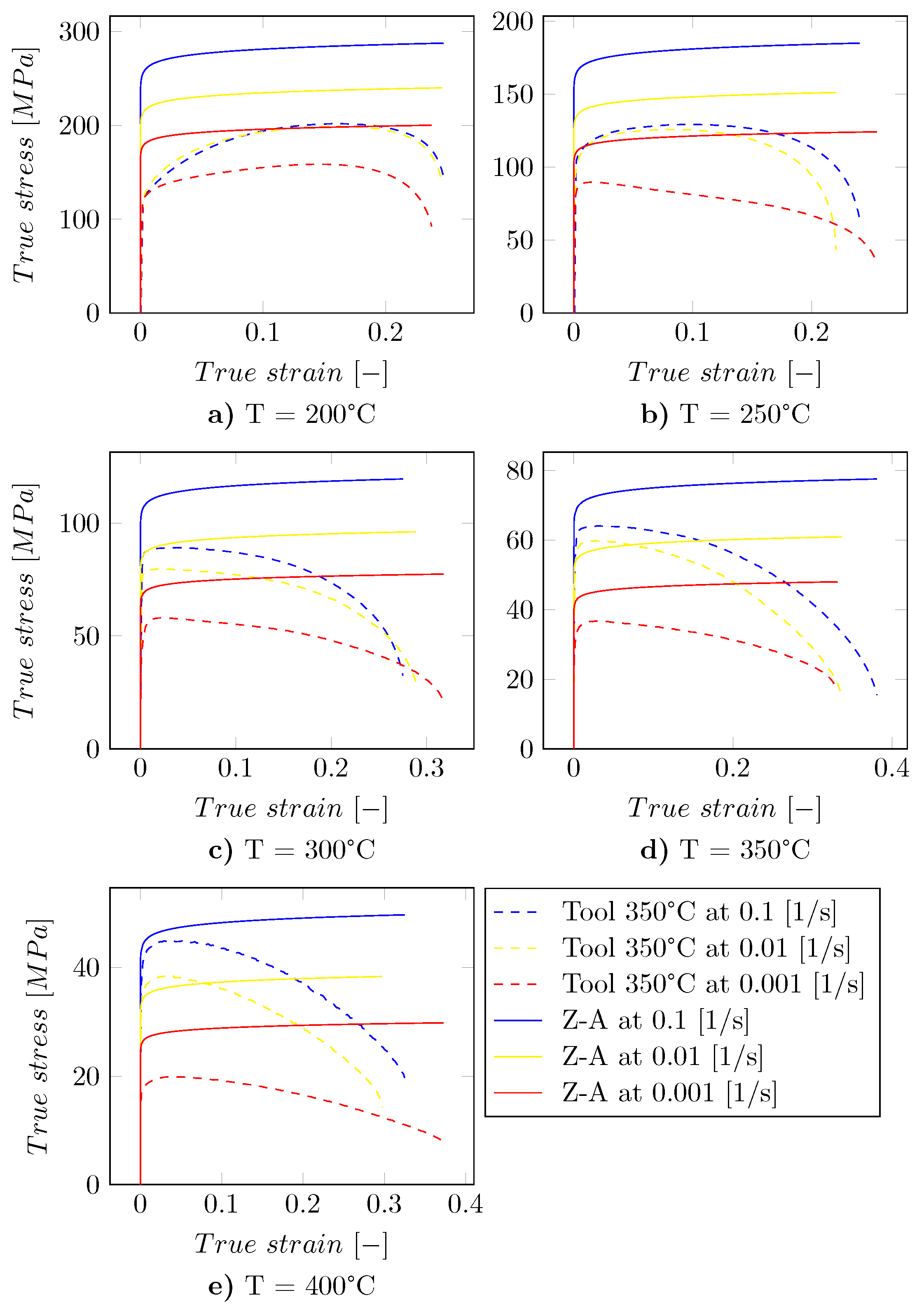
3.1. Results of the Zerilli–Armstrong Model
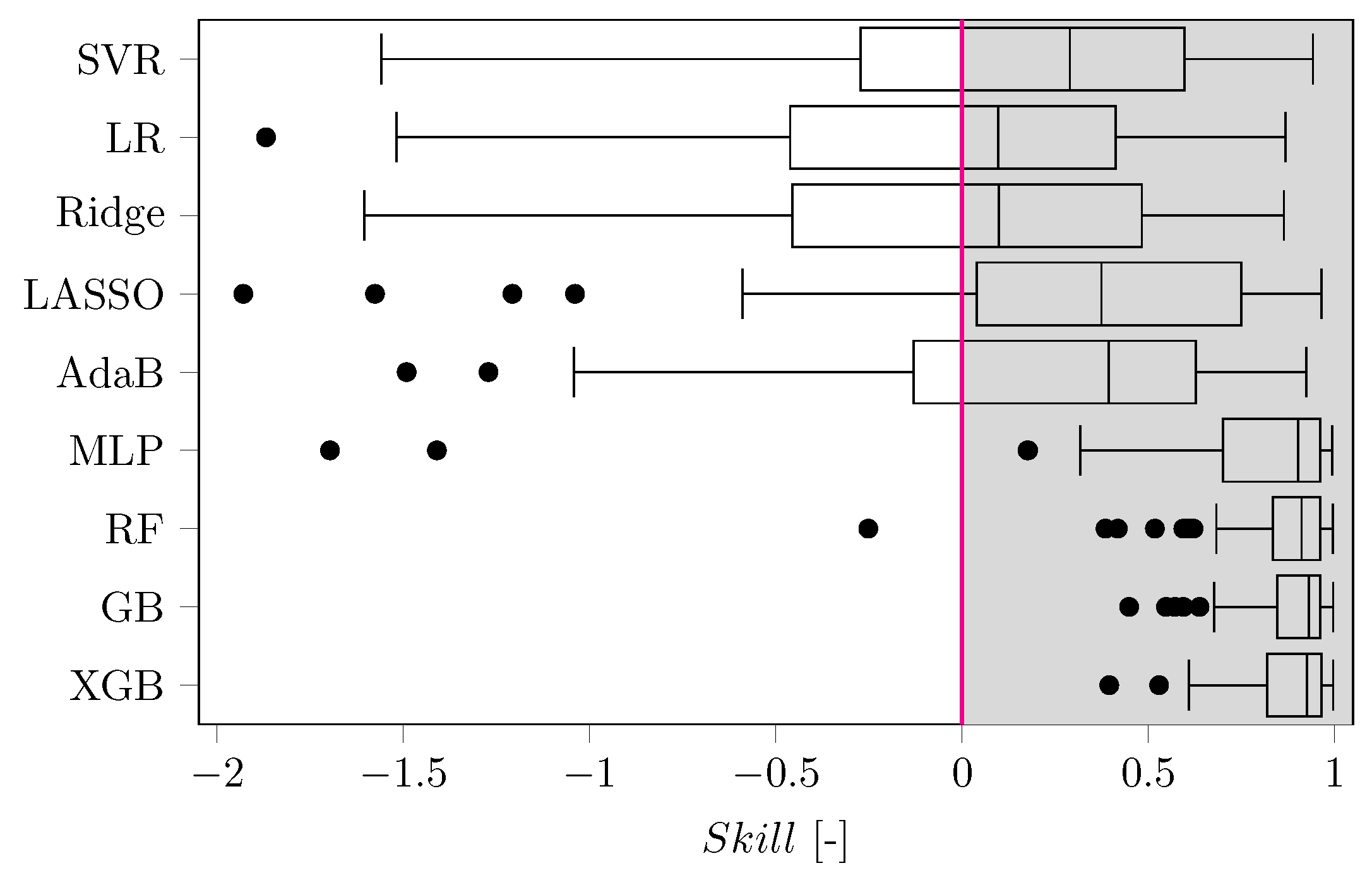
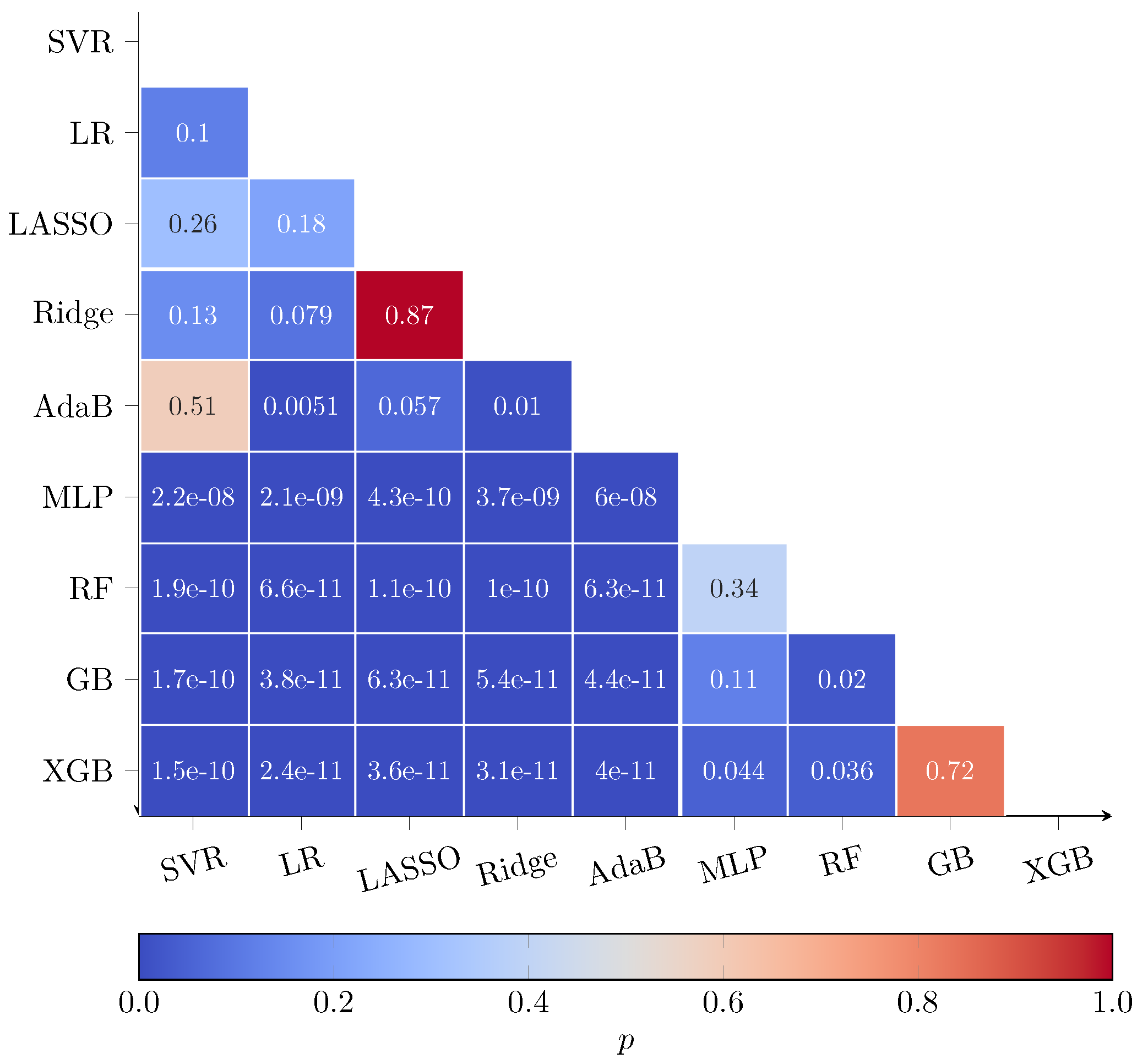
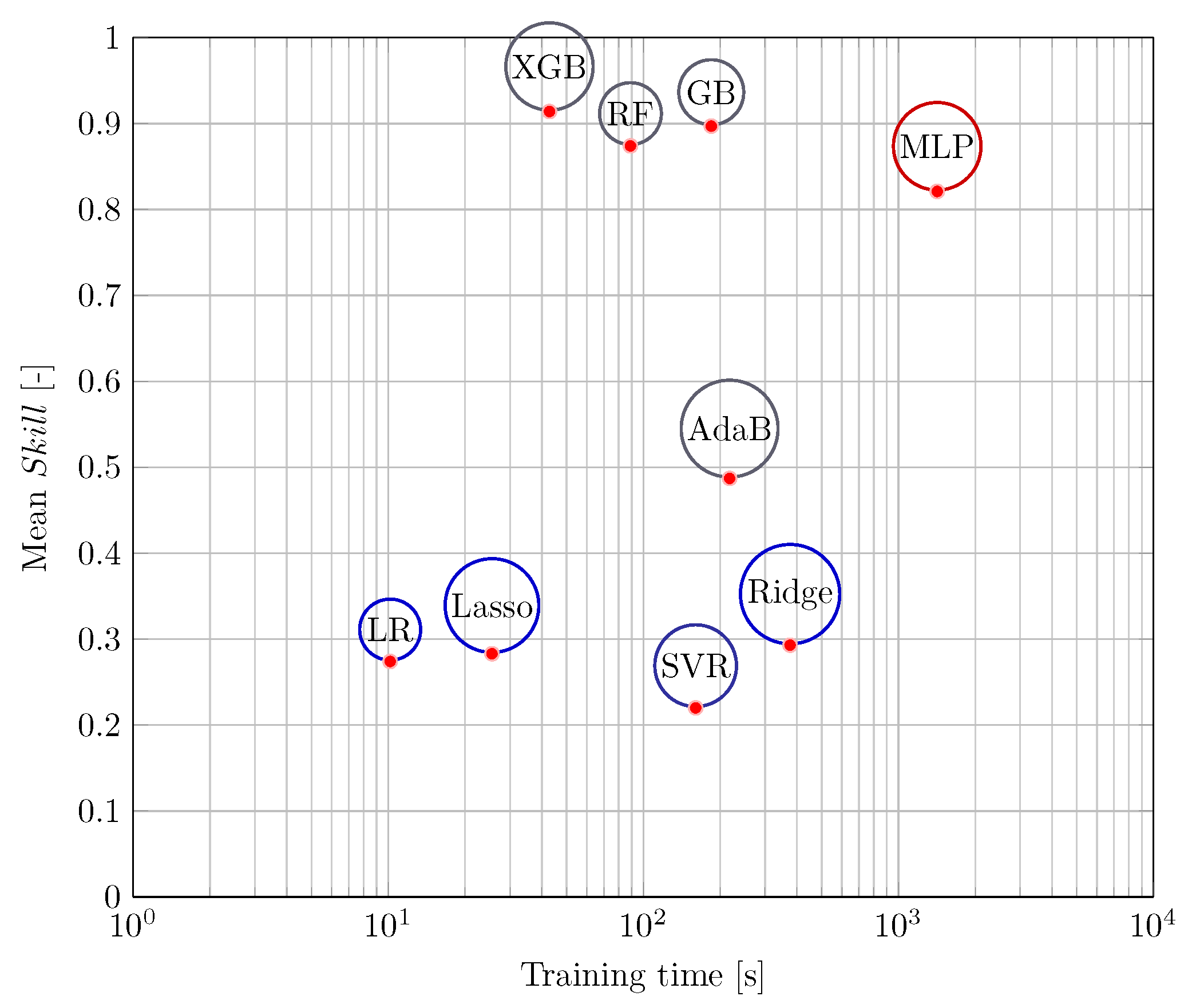
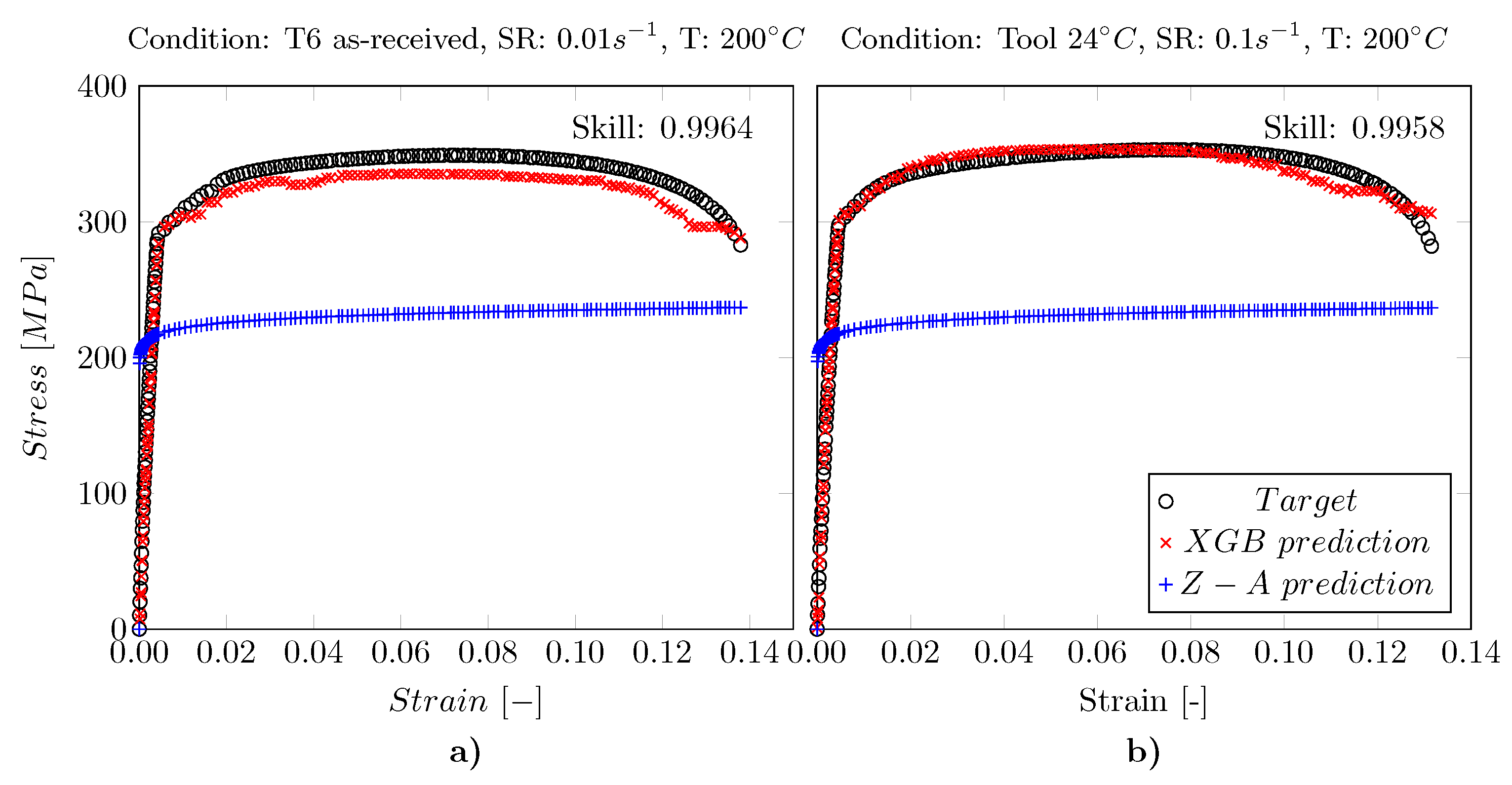
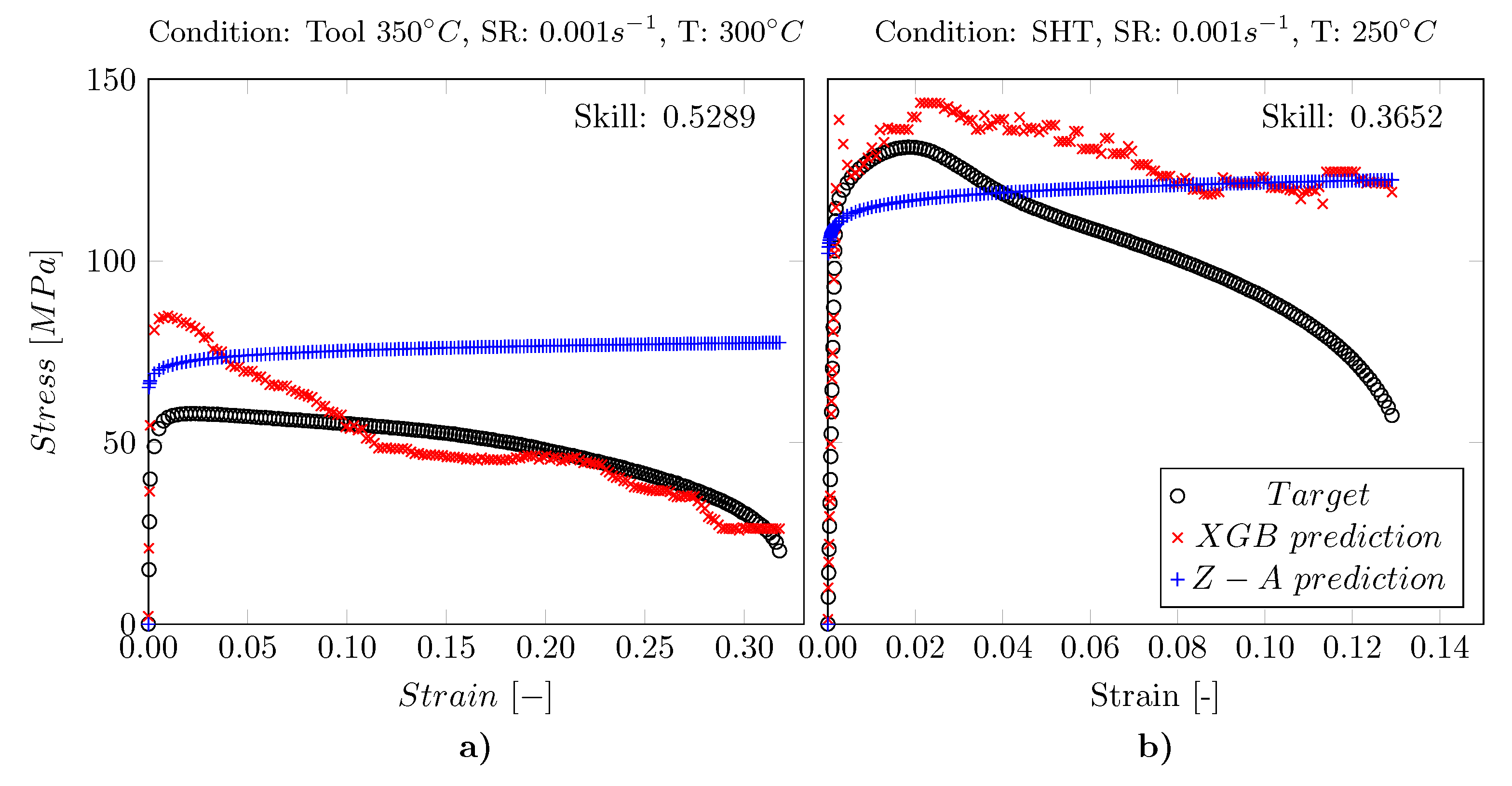
3.2. Comparison to ML Based Approaches
3.3. Results of the eXtreme Gradient Boosting
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirsch, J. Recent Development in Aluminium for Automotive Applications. Trans. Nonferrous Met. Soc. China 2014, 24, 1995–2002. [Google Scholar] [CrossRef]
- Scharifi, E.; Sajadifar, S.V.; Moeini, G.; Weidig, U.; Böhm, S.; Niendorf, T.; Steinhoff, K. Dynamic Tensile Deformation of High Strength Aluminum Alloys Processed Following Novel Thermomechanical Treatment Strategies. Adv. Eng. Mater. 2020, 22, 2000193. [Google Scholar] [CrossRef]
- Li, L.T.; Lin, Y.; Zhou, H.M.; Jiang, Y.Q. Modeling the High-Temperature Creep Behaviors of 7075 and 2124 Aluminum Alloys by Continuum Damage Mechanics Model. Comput. Mater. Sci. 2013, 73, 72–78. [Google Scholar] [CrossRef]
- Senthil, K.; Iqbal, M.; Chandel, P.; Gupta, N. Study of the Constitutive Behavior of 7075-T651 Aluminum Alloy. Int. J. Impact Eng. 2017, 108, 171–190. [Google Scholar] [CrossRef]
- Sajadifar, S.V.; Scharifi, E.; Weidig, U.; Steinhoff, K.; Niendorf, T. Performance of Thermo-Mechanically Processed AA7075 Alloy at Elevated Temperatures—From Microstructure to Mechanical Properties. Metals 2020, 10, 884. [Google Scholar] [CrossRef]
- Lu, J.; Song, Y.; Hua, L.; Zheng, K.; Dai, D. Thermal Deformation Behavior and Processing Maps of 7075 Aluminum Alloy Sheet Based on Isothermal Uniaxial Tensile Tests. J. Alloys Compd. 2018, 767, 856–869. [Google Scholar] [CrossRef]
- Lin, Y.C.; Li, L.T.; Fu, Y.X.; Jiang, Y.Q. Hot Compressive Deformation Behavior of 7075 Al Alloy under Elevated Temperature. J. Mater. Sci. 2012, 47, 1306–1318. [Google Scholar] [CrossRef]
- Cerri, E.; Evangelista, E.; Forcellese, A.; McQueen, H. Comparative Hot Workability of 7012 and 7075 Alloys after Different Pretreatments. Mater. Sci. Eng. A 1995, 197, 181–198. [Google Scholar] [CrossRef]
- McQueen, H.; Ryan, N. Constitutive Analysis in Hot Working. Mater. Sci. Eng. A 2002, 322, 43–63. [Google Scholar] [CrossRef]
- Xiao, W.; Wang, B.; Wu, Y.; Yang, X. Constitutive Modeling of Flow Behavior and Microstructure Evolution of AA7075 in Hot Tensile Deformation. Mater. Sci. Eng. A 2018, 712, 704–713. [Google Scholar] [CrossRef]
- Zhu, D.Y.; Zhen, L.; Lin, C.; Shao, W.Z. High Temperature Deformation Mechanism of 7075 Aluminum Alloy. Key Eng. Mater. 2007, 353–358, 691–694. [Google Scholar] [CrossRef]
- Mirzaie, T.; Mirzadeh, H.; Cabrera, J.M. A Simple Zerilli–Armstrong Constitutive Equation for Modeling and Prediction of Hot Deformation Flow Stress of Steels. Mech. Mater. 2016, 94, 38–45. [Google Scholar] [CrossRef]
- Zerilli, F.J. Dislocation Mechanics-Based Constitutive Equations. Metall. Mater. Trans. A 2004, 35, 2547–2555. [Google Scholar] [CrossRef]
- Khan, A.S.; Liang, R. Behaviors of Three BCC Metal over a Wide Range of Strain Rates and Temperatures: Experiments and Modeling. Int. J. Plast. 1999, 15, 1089–1109. [Google Scholar] [CrossRef]
- Zerilli, F.J.; Armstrong, R.W. Dislocation-mechanics-based Constitutive Relations for Material Dynamics Calculations. J. Appl. Phys. 1987, 61, 1816–1825. [Google Scholar] [CrossRef]
- Sajadifar, S.; Yapici, G. High Temperature Flow Response Modeling of Ultra-Fine Grained Titanium. Metals 2015, 5, 1315–1327. [Google Scholar] [CrossRef]
- Haghdadi, N.; Zarei-Hanzaki, A.; Khalesian, A.; Abedi, H. Artificial Neural Network Modeling to Predict the Hot Deformation Behavior of an A356 Aluminum Alloy. Mater. Des. 2013, 49, 386–391. [Google Scholar] [CrossRef]
- Li, K.; Pan, Q.; Li, R.; Liu, S.; Huang, Z.; He, X. Constitutive Modeling of the Hot Deformation Behavior in 6082 Aluminum Alloy. J. Mater. Eng. Perform. 2019, 28, 981–994. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, J.; Zhong, J. Application of Neural Networks to Predict the Elevated Temperature Flow Behavior of a Low Alloy Steel. Comput. Mater. Sci. 2008, 43, 752–758. [Google Scholar] [CrossRef]
- Bahrami, A.; Mousavi Anijdan, S.; Ekrami, A. Prediction of Mechanical Properties of DP Steels Using Neural Network Model. J. Alloys Compd. 2005, 392, 177–182. [Google Scholar] [CrossRef]
- Hodgson, P.; Kong, L.; Davies, C. The Prediction of the Hot Strength in Steels with an Integrated Phenomenological and Artificial Neural Network Model. J. Mater. Process. Technol. 1999, 87, 131–138. [Google Scholar] [CrossRef]
- Song, S.H. A Comparison Study of Constitutive Equation, Neural Networks, and Support Vector Regression for Modeling Hot Deformation of 316L Stainless Steel. Materials 2020, 13, 3766. [Google Scholar] [CrossRef]
- Li, B.; Pan, Q.; Yin, Z. Microstructural Evolution and Constitutive Relationship of Al–Zn–Mg Alloy Containing Small Amount of Sc and Zr during Hot Deformation Based on Arrhenius-Type and Artificial Neural Network Models. J. Alloys Compd. 2014, 584, 406–416. [Google Scholar] [CrossRef]
- Sani, S.A.; Ebrahimi, G.; Vafaeenezhad, H.; Kiani-Rashid, A. Modeling of Hot Deformation Behavior and Prediction of Flow Stress in a Magnesium Alloy Using Constitutive Equation and Artificial Neural Network (ANN) Model. J. Magnes. Alloy. 2018, 6, 134–144. [Google Scholar] [CrossRef]
- Quan, G.; Zou, Z.; Wang, T.; Liu, B.; Li, J. Modeling the Hot Deformation Behaviors of As-Extruded 7075 Aluminum Alloy by an Artificial Neural Network with Back-Propagation Algorithm. High Temp. Mater. Process. 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Sheikh-Ahmad, J.; Twomey, J. ANN Constitutive Model for High Strain-Rate Deformation of Al 7075-T6. J. Mater. Process. Technol. 2007, 186, 339–345. [Google Scholar] [CrossRef]
- Desu, R.K.; Guntuku, S.C.; B, A.; Gupta, A.K. Support Vector Regression Based Flow Stress Prediction in Austenitic Stainless Steel 304. Procedia Mater. Sci. 2014, 6, 368–375. [Google Scholar] [CrossRef]
- Song, S.H. Random Forest Approach in Modeling the Flow Stress of 304 Stainless Steel during Deformation at 700–900 °C. Materials 2021, 14, 1812. [Google Scholar] [CrossRef]
- Sajadifar, S.V.; Scharifi, E.; Weidig, U.; Steinhoff, K.; Niendorf, T. Effect of Tool Temperature on Mechanical Properties and Microstructure of Thermo-Mechanically Processed AA6082 and AA7075 Aluminum Alloys. HTM J. Heat Treat. Mater. 2020, 75, 177–191. [Google Scholar] [CrossRef]
- Scharifi, E.; Knoth, R.; Weidig, U. Thermo-Mechanical Forming Procedure of High Strength Aluminum Sheet with Improved Mechanical Properties and Process Efficiency. Procedia Manuf. 2019, 29, 481–489. [Google Scholar] [CrossRef]
- Scharifi, E.; Savaci, U.; Kavaklioglu, Z.B.; Weidig, U.; Turan, S.; Steinhoff, K. Effect of Thermo-Mechanical Processing on Quench-Induced Precipitates Morphology and Mechanical Properties in High Strength AA7075 Aluminum Alloy. Mater. Charact. 2021, 174, 111026. [Google Scholar] [CrossRef]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API Design for Machine Learning Software: Experiences from the Scikit-Learn Project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: San Francisco, CA, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support Vector Regression Machines. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; Mozer, M.C., Jordan, M., Petsche, T., Eds.; MIT Press: Cambridge, MA, USA, 1997; Volume 9, pp. 155–161. [Google Scholar]
- Bottou, L.; Chapelle, O.; DeCoste, D.; Weston, J. Support Vector Machine Solvers. In Large-Scale Kernel Machines; MIT Press: Cambridge, MA, USA, 2007; pp. 1–27. [Google Scholar]
- Basak, D.; Pal, S.; Patranabis, D. Support Vector Regression. Neural Inf. Process.-Lett. Rev. 2007, 11, 203–224. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Mendes-Moreira, J.; Soares, C.; Jorge, A.M.; Sousa, J.F.D. Ensemble Approaches for Regression: A Survey. ACM Comput. Surv. 2012, 45, 1–40. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; Goos, G., Hartmanis, J., van Leeuwen, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1857, pp. 1–15. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10, Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2016, arXiv:1511.07289. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Lin, Y.; Chen, X.M. A critical review of experimental results and constitutive descriptions for metals and alloys in hot working. Mater. Des. 2011, 32, 1733–1759. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Yang, H.; Bu, H.; Li, M.; Lu, X. Prediction of Flow Stress of Annealed 7075 Al Alloy in Hot Deformation Using Strain-Compensated Arrhenius and Neural Network Models. Materials 2021, 14, 5986. [Google Scholar] [CrossRef] [PubMed]
- Puchi-Cabrera, E.S.; Staia, M.H.; Ochoa-Pérez, E.; Barbera-Sosa, J.G.L.; Santana, Y.Y.; Villalobos-Gutiérrez, C.; Picón-Chaparro, J.R. Simple constitutive analysis of AA 7075-T6 aluminium alloy deformed at low deformation temperatures. Mater. Sci. Technol. 2012, 28, 668–679. [Google Scholar] [CrossRef]
- Zhang, D.N.; Shangguan, Q.Q.; Xie, C.J.; Liu, F. A modified Johnson–Cook model of dynamic tensile behaviors for 7075-T6 aluminum alloy. J. Alloys Compd. 2015, 619, 186–194. [Google Scholar] [CrossRef]
- Dingel, K.; Liehr, A.; Vogel, M.; Degener, S.; Meier, D.; Niendorf, T.; Ehresmann, A.; Sick, B. AI—Based On The Fly Design of Experiments in Physics and Engineering. In Proceedings of the 2021 IEEE International Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C), Virtual Conference, 27 September–1 October 2021; pp. 150–153. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Element | Si | Fe | Cu | Mn | Mg | Cr | Zn | Ti | Zr | Al |
|---|---|---|---|---|---|---|---|---|---|---|
| AA7075 (Wt.- %) | 0.10 | 0.11 | 1.59 | 0.03 | 2.38 | 0.20 | 5.57 | 0.03 | 0.04 | Balanced |
| Categories | Model | Source | Hyperparameter | Hyperparameterspace |
|---|---|---|---|---|
| Linear Regression | LR | Sklearn [32] | degree | 1, 2, …, 12 |
| LASSO | Sklearn [32] | alpha degree | 0.1, 0.2, …, 1.0 1, 2, …, 12 | |
| Ridge | Sklearn [32] | alpha degree | 0.1, 0.2, …, 1.0 1, 2, …, 12 | |
| Kernel | SVR | Sklearn [32] | epsilon C kernel degree | 0.1, 0.2, …, 0.5 1, 10, 100, 1000 linear, poly, rbf 2, 3, …, 12 |
| Ensemble | AdaB | Sklearn [32] | no. of estimators | 10, 50, 100, 200, 500 |
| RF | Sklearn [32] | no. of estimators max_depth | 10, 50, 100, 200, 500 3, 6, …, 15 | |
| GB | Sklearn [32] | learning rate no. of estimators max_depth | 0.1, 0.3, 0.5 10, 50, 100, 200, 500 3, 6, …, 15 | |
| XGB | XGBoost [33] | learning rate no. of estimators max_depth | 0.1, 0.3, 0.5 10, 50, 100, 200, 500 3, 6, …, 15 | |
| Neural Network | MLP | PyTorch [34] | learning rate dropout rate n_layer size_layer | 0.001, 0.01, 0.1, 0.2 0.05, 0.1, 0.2 2, 3, 4 16, 32, 64, 128, 256 |
| Z–A | SVR | LR | Ridge | LASSO | AdaB | MLP | RF | GB | XGB | |
|---|---|---|---|---|---|---|---|---|---|---|
| Mean [MPa] | 2347 | 1830 | 1704 | 1659 | 1683 | 1204 | 421 | 295 | 242 | 201 |
| [-] | 0 | 0.220 | 0.274 | 0.293 | 0.283 | 0.487 | 0.821 | 0.874 | 0.897 | 0.914 |
| Std [-] | 0 | 0.878 | 0.789 | 0.787 | 0.850 | 0.740 | 0.468 | 0.200 | 0.124 | 0.124 |
| Training time [s] | 0.1 | 160 | 10 | 376 | 25 | 217 | 1419 | 89 | 184 | 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Decke, J.; Engelhardt, A.; Rauch, L.; Degener, S.; Sajadifar, S.V.; Scharifi, E.; Steinhoff, K.; Niendorf, T.; Sick, B. Predicting Flow Stress Behavior of an AA7075 Alloy Using Machine Learning Methods. Crystals 2022, 12, 1281. https://doi.org/10.3390/cryst12091281
Decke J, Engelhardt A, Rauch L, Degener S, Sajadifar SV, Scharifi E, Steinhoff K, Niendorf T, Sick B. Predicting Flow Stress Behavior of an AA7075 Alloy Using Machine Learning Methods. Crystals. 2022; 12(9):1281. https://doi.org/10.3390/cryst12091281
Chicago/Turabian StyleDecke, Jens, Anna Engelhardt, Lukas Rauch, Sebastian Degener, Seyed Vahid Sajadifar, Emad Scharifi, Kurt Steinhoff, Thomas Niendorf, and Bernhard Sick. 2022. "Predicting Flow Stress Behavior of an AA7075 Alloy Using Machine Learning Methods" Crystals 12, no. 9: 1281. https://doi.org/10.3390/cryst12091281