
A Comprehensive Evaluation and Benchmarking of Convolutional Neural Networks for Melanoma Diagnosis

Abstract
:Simple Summary
Abstract
1. Introduction
- The proposed study provides an appropriate and powerful linkage between the multi-criteria decision-making techniques and the objective performance evaluation criteria, which are typically used to evaluate the deep learning models. This integration with decision-making schemes helps to rank the learning models based on multiple conflicting criteria and select the optimal model in our case study.
- This is the first study that introduces the application of a multi-criteria decision-making approach based on merging entropy and PROMETHEE methods to help prioritize the deep convolutional neural networks used for melanoma diagnosis and select the optimal model considering various criteria.
- This study presents a comprehensive evaluation of 19 convolutional neural network models with a two-class classifier. The models are trained and evaluated on a dataset of 991 dermoscopic images considering 10 performance evaluation metrics.
- The findings of our investigations would aid and expedite the timely deployment of artificial intelligence (AI)–assisted CAD systems to clinics and hospitals with regard to easing model selection under different criteria.
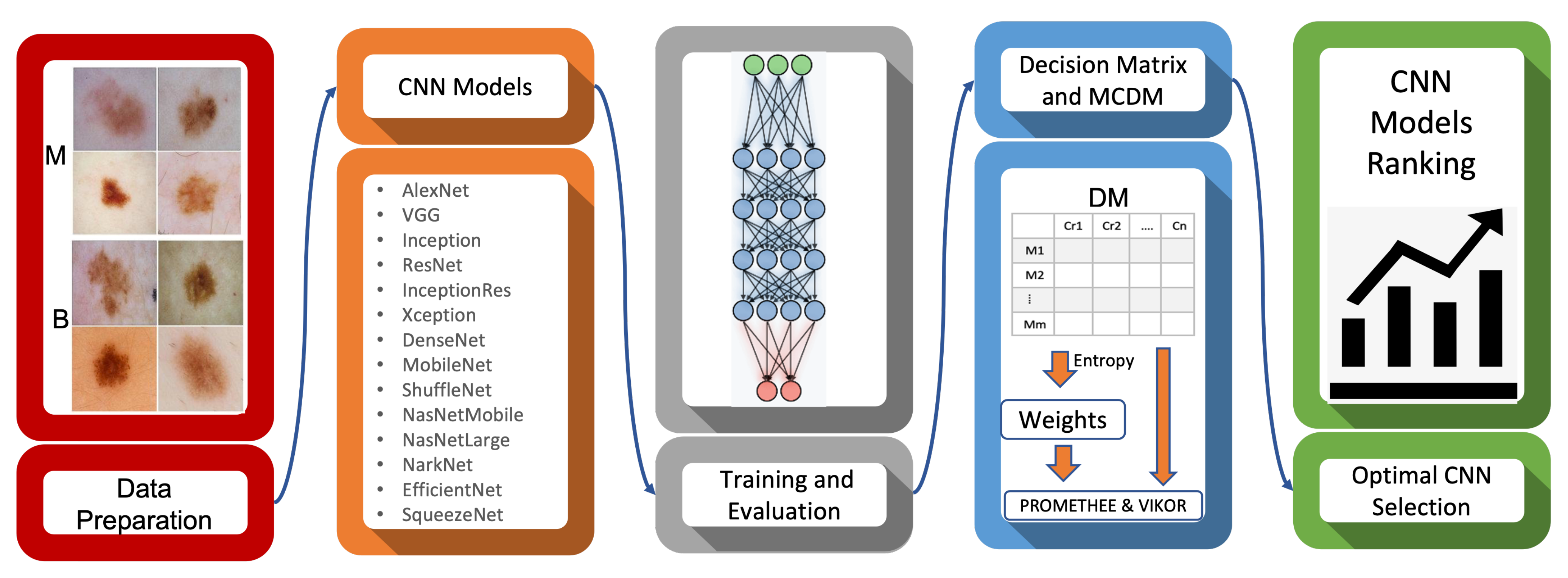
2. Materials and Methods
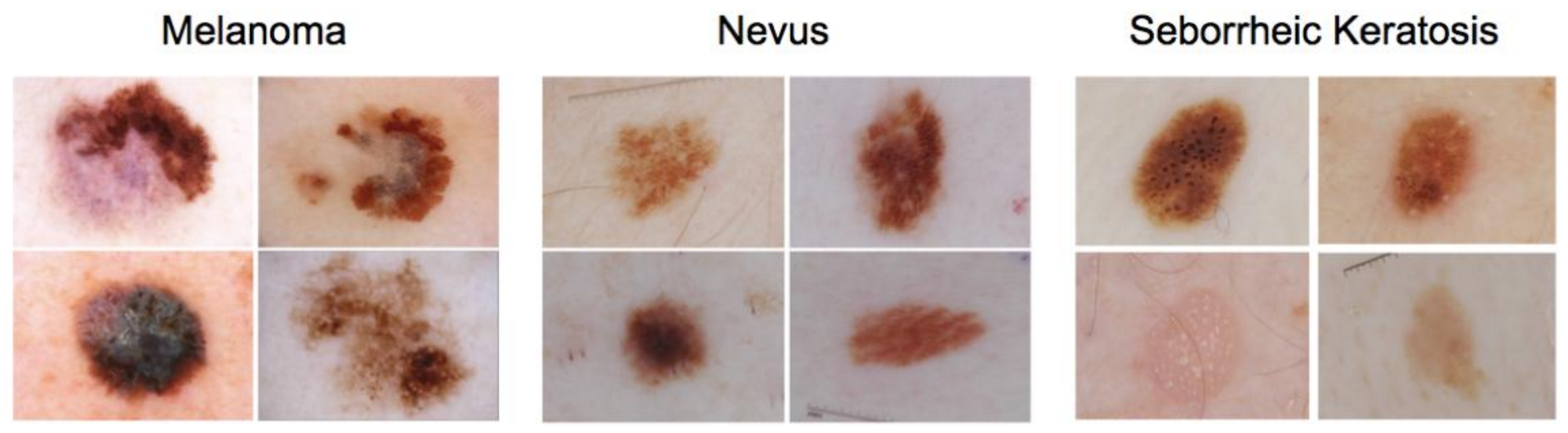
2.1. Materials
2.2. Methods
2.2.1. Pre-Trained Convolutional Neural Network Models (CNNs)
- AlexNet: In 2012, AlexNet [24] substantially surpassed all previous classification methods, winning the ImageNet Large Scale Visual Recognition Competition (ILSVRC) by reducing top-5 error from 26% to 15.33%. The network’s design was similar to the LeNet network developed by Yann LeCun et al. [25], but it was deeper, with more filters per layer and layered convolutional layers. , , convolutions filters, max pooling, dropout, data augmentation, ReLU activations, and SGD with momentum were all included. After each convolutional layer, added ReLU activations were added. AlexNet was trained using two Nvidia Geforce GTX 580 GPUs for six days, which is why their network is divided into two pipelines.
- VGG16,19: Simonyan and Zisserman presented the VGG architecture in 2014 [26]. It is a straightforward design, with only blocks made up of an incremental number of convolution layers and 3 × 3 filters. Furthermore, max-pooling blocks follow convolution blocks to reduce the size of the activation maps obtained. Finally, a classification block is employed, consisting of two dense layers and a final output layer. The numbers 16 and 19 refer to how many weighted layers each network includes. On the other hand, this network has a couple of drawbacks: it takes too long to learn and has a lot of parameters.
- InceptionV1,V3: Google implemented inception building blocks in GoogLeNet (Inceptionv1) [27]. These blocks function well together and result in a model that is easy to generalize. GoogLeNet is made up of nine Inception modules that are stacked one on top of the other. There are a total of 27 layers, 5 of which are pooling layers. The total number of layers used in the network design is about 100. New revisions of the model appeared as the model was updated regularly. Inception-v2 and Inception-v3 [28] were released within a short time gap in 2015. Except for a few features, Inception-v2 integrates all of GoogLeNet’s features. Filter banks were increased in width in Inception-v2 to eliminate the “representational bottleneck”. All of the changes from Inception-v2 were included in Inception-v3. Furthermore, Inception-v3 underwent additional changes, such as the use of a higher resolution input and the use of the RMSProp optimiser, which significantly reduced the cost function.
- InceptionResNetV2: Inception V4 was launched in 2016 by Google researchers in conjunction with Inception-ResNet. By implementing Inception-V4, the main goal of this network architecture was to reduce the complexity of the Inception V3 model, which provided state-of-the-art accuracy on the ILSVRC2015 challenge. This architecture also investigates the use of residual networks on the Inception model [29].
- ResNet18,50,101: The ResNet architecture, founded by He et al. in 2015 [30], was a major turning point in the introduction of an extraordinary form of architecture focused on “modules” or “networks within networks”. The principle of residual connections was first implemented in these networks. ResNet comes in various sizes and numbers of layers—such as ResNet18, RerNet50, and RerNet101—but the most common is ResNet50, which has 50 layers with weights. Despite having many more layers than the VGG, ResNet50 needs nearly five times less memory. This is because, instead of dense layers, this network uses a layer called GlobalAveragePooling in the classification stage, which transforms the 2D feature maps of the last layer in the feature extraction stage into an n-classes vector that is used to measure the likelihood of belonging to each class.
- DenseNet201: DenseNet [31] is very similar to ResNet, but there are a few key differences. DenseNet concatenates the output of the previous layer with the output of the next layer. At the same time, ResNet follows an additive approach that combines the previous layer (identity) with the next layer. DenseNet model was founded mainly to address the vanishing gradient’s impact on high-level neural networks’ layers. Using the composite function operation, the previous layer’s output becomes the second layer’s input. Convolution, pooling, batch normalization, and non-linear activation layers form this composite process. DenseNet comes in a variety of types, including DenseNet-121, DenseNet-169, and DenseNet-201. The numbers represent the number of the neural network’s layer.
- Xception: Xception [32] is an extension of the Inception architecture that uses depthwise separable convolutions to replace the regular Inception modules. The mapping of cross-channel and spatial correlations in the feature maps of convolutional neural networks can be fully decoupled in this network. The authors called their proposed architecture Xception, which stands for “Extreme Inception,” since this hypothesis is a stronger version of the hypothesis that underlies the Inception architecture. In a nutshell, the Xception architecture is a depthwise separable convolution layers stack with residual connections. This makes it very simple to establish and change the architecture.
- MobileNet: MobileNet [33] is a convolutional neural network designed for mobile and embedded vision uses. They are based on a streamlined architecture that builds lightweight deep neural networks with low latency for mobile and embedded devices, using depthwise separable convolutions. The width multiplier and resolution multiplier parameters are added to make it easier to tune MobileNet. The depthwise convolution in MobileNets applies a single filter to each input channel. After that, the pointwise convolution applies a convolution to combine the depthwise convolution’s outputs. A separate layer for filtering and a separate layer for combining are used in depthwise separable convolution. This factorization has the effect of reducing the computation and model size drastically.
- NASNetMobile and NASNetLarge: Google Brain built Neural Architecture Search (NASNet) [34]. The authors suggested that an architectural building block be detected on a small dataset and then transferred to a larger dataset. They generally look for the best convolutional layer or cell on a small dataset first, then stack together more copies of this cell to extend to the larger dataset. A new regularization technique called ScheduledDropPath was proposed, which significantly enhances the generalization of the NASNet models. With a smaller model size and lower complexity, the NASNet method achieves state-of-the-art results. While the overall architecture of NASNet is predefined, the blocks or cells are not. Alternatively, a reinforcement learning search technique is used to find them. The authors developed different versions of NASNets with different computational requirements. The larger model, NASNetlarge, is a convolutional neural network trained on over onen million images from the ImageNet database, while the smaller model, NASNetMobile, is optimized for mobile devices.
- ShuffleNet: ShuffleNet [35] is a convolutional neural network optimized for mobile devices with minimal processing capacity developed by Megvii Inc. (Face++). The network architecture design considers two new operations to lower computation costs while retaining accuracy: pointwise group convolution and channel shuffle. It specializes in common mobile platforms, such as drones, robots, and smartphones, and aims for the best accuracy in minimal computational resources.
- DarkNet19,53: The backbone of YOLOv2 is a convolutional neural network called Darknet-19 [36]. It generally employs filters and twice the number of channels after each pooling phase, similar to VGG models. It leverages global average pooling to produce predictions and filters to compress the feature representation among convolutions, identical to the work on Network in Network (NIN). Batch normalization is a technique for stabilizing training and accelerating convergence. Darknet-53 [37], on the other hand, is a convolutional neural network that serves as the backbone for the YOLOv3 object detection method. The utilization of residual connections and more layers are an enhancement over its predecessor, Darknet-19.
- EfficientNetB0: EfficientNetB0 [38] is a convolutional neural network that scales depth, width, and resolution dimensions, using a compound coefficient. Unlike the traditional methodology, which arbitrarily scales network dimensions, the EfficientNetB0 scaling strategy scales network dimensions with a set of predetermined scaling coefficients. According to the compound scaling approach, if the input image is larger, the network needs more layers and channels to widen the receptive field and catch more fine-grained patterns on the larger image. In addition to squeeze-and-excitation blocks [39], the base of EfficientNet is built on MobileNetV2’s inverted bottleneck residual blocks [33].
- SqueezeNet: DeepScale, UC Berkeley, and Stanford University collaborated to develop SqueezeNet [40]. With 50× fewer parameters, SqueezeNet reaches AlexNet-level accuracy on ImageNet. Additionally, the authors were able to compress SqueezeNet to less than 0.5 MB, using model compression approaches (510× smaller than AlexNet). Smaller convolutional neural networks (CNNs) require less communication across servers during distributed training and less bandwidth. They are also more feasible to be deployed on FPGAs and hardware with restricted computational resources and limited memory.
2.2.2. Benchmarking Criteria
- Accuracy: this metric measures how close the predicted value is to the actual data values. It can be defined using the following formula:: True Positive, : True Negative, : False Positive, : False Negative
- Classification error: This refers to the number of samples incorrectly classified (false positives and false negatives). It can be defined as follows:
- Precision: The precision metric tests the ability of the classifier to reject irrelevant samples. The formula of this metric can be defined as follows:
- Sensitivity: The sensitivity metric measures the proportion of the correctly detected relevant samples. It can be represented as follows:
- F1-Score: The F1-score can be obtained by the weighted average of sensitivity (recall) and precision, where the relative contribution of both recall and precision to the F1-score are equal. The F1-score can be defined as follows:where =
- Specificity: It describes the ability of the classifier to detect the true negative rate. The formula of specificity can be defined using the following equation:
- False-Positive Rate (FPR): This is the proportion of negative examples wrongly categorized as positive. This metric is also known as the miss rate and is represented as follows:
- False-Negative rate (FNR): This is the proportion of negative examples wrongly categorized as positive. This metric is also known as the fall-out rate. This evaluation criterion is introduced as follows:
- Matthews Correlation Coefficient (MCC): The MCC is a correlation coefficient that yields a value between and for actual and estimated binary classifications. A coefficient of shows ideal prediction, 0 shows random prediction, and indicates complete disagreement between predictions and the ground truth. The MCC can be defined as follows:
- CNN Complexity: This refers to the number of parameters existing in the pre-trained CNN.
2.2.3. Multi-Criteria Decision Making (MCDM)
- Entropy: This method computes relative weights by objectively interpreting the relative intensities of the criteria significance based on data discrimination [45]. MDCM’s generated decision matrix is defined by m alternatives (19 CNN models) and k criteria (10 criteria), which are represented as follows:From the constructed decision matrix , the procedure of entropy weighting method described in [45] is followed to measure the weights . refers to each entry in the , where , . The steps of the entropy weighting method [45] are described as follows:Step1: Normalizing the decision matrix using the following equation:Step2: Measuring the entropy value for each criterion as follows:Step3: Determining the inherent contrast intensity of each criterion as follows:Step4: The entropy weights of criteria are then defined as follows:
- PROMETHEE: The PROMETHEE is an outranking approach for ranking and selecting a finite collection of alternatives based on often competing criteria. Compared to other multi-criteria analysis methods, PROMETHEE II is an uncomplicated complete (not partial) ranking method in terms of conception and application. The stepwise procedure of PROMETHEE II can be defined as follows, giving the provided decision matrix and the weights of criteria:Step 1: Determining of deviations based on pairwise comparisons as follows:where refers to the difference between the evaluations of a and b on each criterion.Step 2: Preference function application:where denotes the preference of alternative a with regard to alternative b on each criterion, as a function of .Step 3: Calculating an overall or global preference index using the following formula:where of a over b represents the weighted sum for each criterion, and is the weight related to the j th criterion.Step 4: Calculating the partial ranking PROMETHEE I (outranking flows) using the following equations:where and represent the positive outranking flow and negative outranking flow for each alternative, respectively.Step 5: Calculating the complete ranking PROMETHEE II (outranking flows) using the following equations:where represents the outranking flow for each alternative.
- VIKOR: The VIKOR approach [44] was initially developed to optimize complex systems that involve various parameters. Using the predefined weights, the VIKOR provides a compromise ranking list and suggests a compromise solution. VIKOR creates a multi-criteria rating index based on a specific “closeness” metric to the “ideal” solutions [44]. The VIKOR methodology’s compromise ranking algorithm can be described as follows, giving the provided decision matrix and the weights of criteria.Step1: Determining the best value as and the worst value as of the criteria as . This also leads to configure the criteria as beneficial and non-beneficial values. The beneficial attributes require being maximized, while the non-beneficial ones need to be minimized, which are identified as follows:Rule1: Best value for beneficial criteria is , and for non-beneficial is ,Rule2: Worst value for beneficial criteria is , and for non-beneficial is .Step2: Determining the values of and , where using the following equations:where are the weights of criteria computed using the entropy method.Step3: Determining the values of and as follows:Step4: Determining the values of ; where and v is defined as the weight of the scheme of “the majority of criteria” using the following equation:Step5: Ranking the alternatives by sorting the values of in ascending order.
3. Experimental Results and Discussion
3.1. Experimental Setup and Training
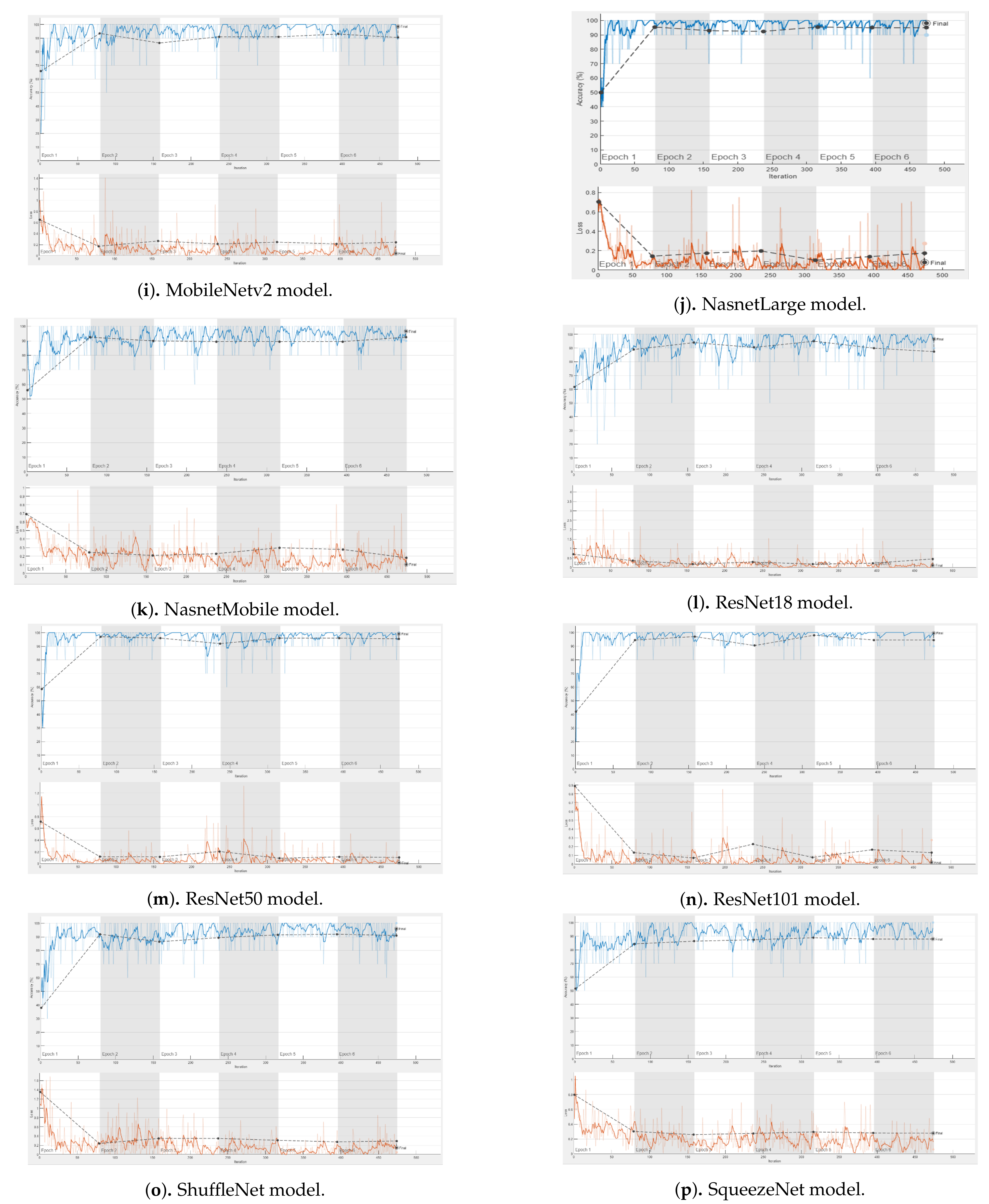
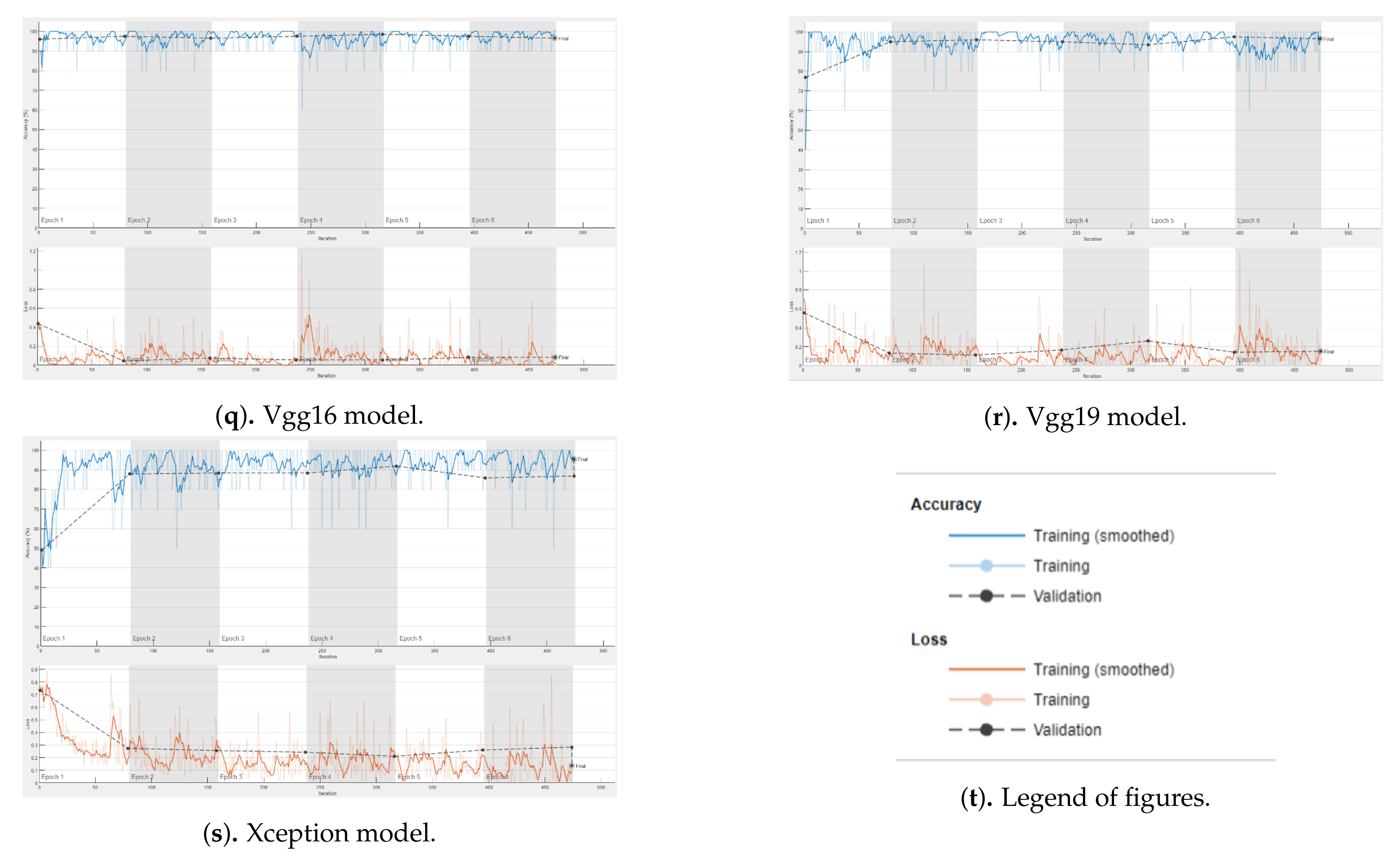
3.2. Results of the Experiments and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DL | Deep Learning |
| CNN | Convolutional Neural Networks |
| M | Malignant |
| B | Benign |
| CAD | Computer-Aided Diagnosis |
| FPR | False Positive Rate |
| FNR | False Negative Rate |
| MCDM | Multi-Criteria Decision Making |
| PROMETHEE | Preference Ranking Organization Method for Enrichment of Evaluations |
| VIKOR | Visekriterijumska Optimizacija I Kompromisno Resenje |
Appendix A



References
- Ries, L.A.; Harkins, D.; Krapcho, M.; Mariotto, A.; Miller, B.; Feuer, E.J.; Clegg, L.X.; Eisner, M.; Horner, M.J.; Howlader, N.; et al. SEER Cancer Statistics Review 1975–2003. National Cancer Institute . 2006. Available online: https://seer.cancer.gov/archive/csr/1975_2003/ (accessed on 5 September 2021).
- Skin Cancer Statistics. Available online: https://www.nhs.uk/conditions/non-melanoma-skin-cancer/ (accessed on 1 May 2021).
- Non-Melanoma Skin Cancer Statistics. Available online: https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/non-melanoma-skin-cancer (accessed on 1 May 2021).
- Melanoma Skin Cancer Statistics. Available online: https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/melanoma-skin-cancer (accessed on 1 May 2021).
- Rosendahl, C.; Tschandl, P.; Cameron, A.; Kittler, H. Diagnostic accuracy of dermatoscopy for melanocytic and nonmelanocytic pigmented lesions. J. Am. Acad. Dermatol. 2011, 64, 1068–1073. [Google Scholar] [CrossRef] [PubMed]
- Nirmal, B. Dermatoscopy: Physics and principles. Indian J. Dermatopathol. Diagn. Dermatol. 2017, 4, 27. [Google Scholar] [CrossRef]
- Pan, Y.; Gareau, D.S.; Scope, A.; Rajadhyaksha, M.; Mullani, N.A.; Marghoob, A.A. Polarized and nonpolarized dermoscopy: The explanation for the observed differences. Arch. Dermatol. 2008, 144, 828–829. [Google Scholar] [CrossRef] [PubMed]
- Smith, D.; Bowden, T. Using the ABCDE approach to assess the deteriorating patient. Nurs. Stand. 2017, 32, 51. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics. CA Cancer J. Clin. 2021, 71, 7–33. [Google Scholar] [CrossRef]
- Glazer, A.M.; Rigel, D.S. Analysis of trends in geographic distribution of US dermatology workforce density. JAMA Dermatol. 2017, 153, 472–473. [Google Scholar] [CrossRef]
- Skin Cancer Check-Ups a Long Time Coming as Australia Faces Huge Shortage of Dermatologists. Available online: https://www.abc.net.au/news/2021-06-14/gps-to-help-ease-growing-skin-specialist-waiting-times/100211834 (accessed on 27 August 2021).
- Eedy, D. Dermatology: A specialty in crisis. Clin. Med. 2015, 15, 509. [Google Scholar] [CrossRef] [Green Version]
- Royal College of Physicians Dermatology. London: RCP. Available online: www.rcplondon.ac.uk/sites/default/files/dermatology.pdf (accessed on 27 August 2021).
- British Association of Dermatologists Clinical Services. London: BAD. Available online: www.bad.org.uk/healthcare-professionals/clinical-services/ (accessed on 27 August 2021).
- Alzahrani, S.; Al-Nuaimy, W.; Al-Bander, B. Seven-point checklist with convolutional neural networks for melanoma diagnosis. In Proceedings of the 2019 8th European Workshop on Visual Information Processing (EUVIP), Rome, Italy, 28–31 October 2019; pp. 211–216. [Google Scholar]
- Nami, N.; Giannini, E.; Burroni, M.; Fimiani, M.; Rubegni, P. Teledermatology: State-of-the-art and future perspectives. Expert Rev. Dermatol. 2012, 7, 1–3. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 168–172. [Google Scholar]
- Naeem, A.; Farooq, M.S.; Khelifi, A.; Abid, A. Malignant melanoma classification using deep learning: Datasets, performance measurements, challenges and opportunities. IEEE Access 2020, 8, 110575–110597. [Google Scholar] [CrossRef]
- Pérez, E.; Reyes, O.; Ventura, S. Convolutional neural networks for the automatic diagnosis of melanoma: An extensive experimental study. Med. Image Anal. 2021, 67, 101858. [Google Scholar] [CrossRef] [PubMed]
- Keeney, R.L.; Raiffa, H.; Meyer, R.F. Decisions with Multiple Objectives: Preferences and Value Trade-Offs; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Baltussen, R.; Niessen, L. Priority setting of health interventions: The need for multi-criteria decision analysis. Cost Eff. Resour. Alloc. 2006, 4, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thokala, P.; Devlin, N.; Marsh, K.; Baltussen, R.; Boysen, M.; Kalo, Z.; Longrenn, T.; Mussen, F.; Peacock, S.; Watkins, J.; et al. Multiple criteria decision analysis for health care decision making—An introduction: Report 1 of the ISPOR MCDA Emerging Good Practices Task Force. Value Health 2016, 19, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Jahan, A.; Edwards, K.L.; Bahraminasab, M. Multi-Criteria Decision Analysis for Supporting the Selection of Engineering Materials in Product Design; Butterworth-Heinemann: Oxford, UK, 2016. [Google Scholar]
- Ivlev, I.; Vacek, J.; Kneppo, P. Multi-criteria decision analysis for supporting the selection of medical devices under uncertainty. Eur. J. Oper. Res. 2015, 247, 216–228. [Google Scholar] [CrossRef]
- Behzadian, M.; Kazemzadeh, R.B.; Albadvi, A.; Aghdasi, M. PROMETHEE: A comprehensive literature review on methodologies and applications. Eur. J. Oper. Res. 2010, 200, 198–215. [Google Scholar] [CrossRef]
- Liou, J.J.; Tsai, C.Y.; Lin, R.H.; Tzeng, G.H. A modified VIKOR multiple-criteria decision method for improving domestic airlines service quality. J. Air Transp. Manag. 2011, 17, 57–61. [Google Scholar] [CrossRef]
- Hainmueller, J. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies. Political Anal. 2012, 20, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | #Layers | #Learnable Layers | Network Size (MB) | Input Image Size | #Para (Millions) |
|---|---|---|---|---|---|
| AlexNet [24] | 25 | 8 | 227 | 61 | |
| Vgg16 [26] | 41 | 16 | 515 | 138 | |
| Vgg19 [26] | 47 | 19 | 535 | 144 | |
| GoogleNet (Inceptionv1) [27] | 144 | 22 | 27 | 7 | |
| Inceptionv3 [28] | 315 | 48 | 89 | 23.9 | |
| ResNet18 [30] | 71 | 18 | 44 | 11.7 | |
| ResNet50 [30] | 177 | 50 | 96 | 25.6 | |
| ResNet101 [30] | 347 | 101 | 167 | 44.6 | |
| InceptionResv2 [29] | 824 | 164 | 209 | 55.9 | |
| Xception [32] | 170 | 71 | 85 | 22.9 | |
| DenseNet201 [31] | 708 | 201 | 77 | 20 | |
| MobileNetv2 [33] | 154 | 53 | 13 | 3.5 | |
| ShuffleNet [35] | 172 | 50 | 5.4 | 1.4 | |
| NasnetMobile [34] | 913 | * | 20 | 5.3 | |
| NasnetLarge [34] | 1243 | * | 332 | 88.9 | |
| DarkNet19 [36] | 64 | 19 | 78 | 20.8 | |
| DarkNet53 [37] | 184 | 53 | 155 | 41.6 | |
| EfficientNetB0 [38] | 290 | 82 | 20 | 5.3 | |
| SqueezeNet [40] | 68 | 18 | 5.2 | 1.24 |
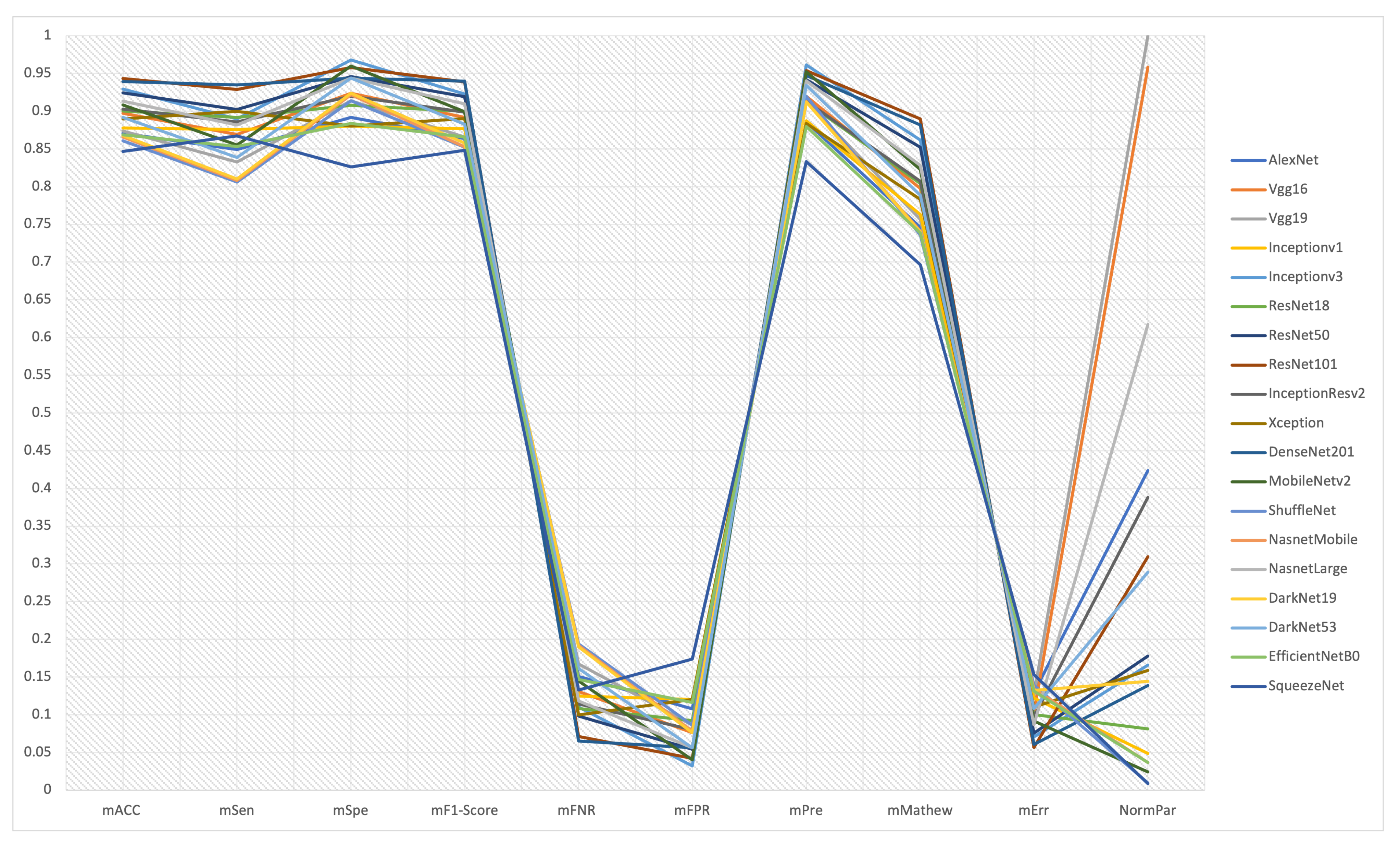
| Network | mACC ± sACC | mSen ± sSen | mSpe ± sSpe | mF1 ± sF1 | mFNR ± sFNR | mFPR ± sFPR | mPre ± sPre | mMathew ± sMathew | mErr ± sErr |
|---|---|---|---|---|---|---|---|---|---|
| AlexNet [24] | 87.07 ± 5.11 | 84.9 ± 10.95 | 89.2 ± 3.7 | 86.39 ± 6.28 | 15.1 ± 10.95 | 10.8 ± 3.7 | 88.57 ± 3.49 | 74.6 ± 9.87 | 12.93 ± 5.11 |
| Vgg16 [26] | 89.7 ± 6.23 | 86.94 ± 9.34 | 92.4 ± 6.5 | 89.18 ± 6.9 | 13.06 ± 9.34 | 7.6 ± 6.5 | 91.98 ± 6.4 | 79.76 ± 12.1 | 10.3 ± 6.23 |
| Vgg19 [26] | 87.37 ± 7.01 | 83.27 ± 11 | 91.4 ± 10.33 | 86.58 ± 7.76 | 16.73 ± 11 | 8.6 ± 10.33 | 91.29 ± 9.02 | 75.64 ± 13.38 | 12.63 ± 7.01 |
| GoogleNet (Inceptionv1) [27] | 87.78 ± 5.87 | 87.55 ± 8.88 | 88 ± 11 | 87.65 ± 5.92 | 12.45 ± 8.88 | 12 ± 11 | 88.71 ± 9.11 | 76.3 ± 11.22 | 12.22 ± 5.87 |
| Inceptionv3 [28] | 92.93 ± 8.01 | 88.98 ± 11.82 | 96.8 ± 4.32 | 92.29 ± 9.05 | 11.02 ± 11.82 | 3.2 ± 4.32 | 96.11 ± 5.49 | 86.18 ± 15.55 | 7.07 ± 8.01 |
| ResNet18 [30] | 90 ± 5.68 | 89.18 ± 4.71 | 90.8 ± 10.13 | 89.97 ± 5.38 | 10.82 ± 4.71 | 9.2 ± 10.13 | 91.23 ± 9.32 | 80.41 ± 11.34 | 10 ± 5.68 |
| ResNet50 [30] | 92.42 ± 7.07 | 90.2 ± 11.24 | 94.6 ± 5.22 | 91.95 ± 7.81 | 9.8 ± 11.24 | 5.4 ± 5.22 | 94.2 ± 5.69 | 85.21 ± 13.85 | 7.58 ± 7.07 |
| ResNet101 [30] | 94.34 ± 7.28 | 92.86 ± 12.14 | 95.8 ± 3.19 | 93.89 ± 8.26 | 7.14 ± 12.14 | 4.2 ± 3.19 | 95.36 ± 3.94 | 88.96 ± 14.02 | 5.66 ± 7.28 |
| InceptionResv2 [29] | 90.3 ± 7.96 | 88.57 ± 10.54 | 92 ± 5.79 | 89.87 ± 8.63 | 11.43 ± 10.54 | 8 ± 5.79 | 91.34 ± 6.77 | 80.71 ± 15.82 | 9.7 ± 7.96 |
| Xception [32] | 88.99 ± 6.79 | 90 ± 7.85 | 88 ± 8.8 | 89.02 ± 6.68 | 10 ± 7.85 | 12 ± 8.8 | 88.39 ± 8.06 | 78.3 ± 13.59 | 11.01 ± 6.79 |
| DenseNet201 [31] | 93.94 ± 4.97 | 93.47 ± 3.86 | 94.4 ± 8.73 | 93.96 ± 4.7 | 6.53 ± 3.86 | 5.6 ± 8.73 | 94.75 ± 7.64 | 88.15 ± 9.6 | 6.06 ± 4.97 |
| MobileNetv2 [33] | 90.81 ± 7.24 | 85.51 ± 11.95 | 96 ± 3.39 | 89.9 ± 8.14 | 14.49 ± 11.95 | 4 ± 3.39 | 95.23 ± 4.32 | 82.25 ± 13.98 | 9.19 ± 7.24 |
| ShuffleNet [35] | 86.06 ± 6.84 | 80.61 ± 9.16 | 91.4 ± 14.33 | 85.24 ± 6.46 | 19.39 ± 9.16 | 8.6 ± 14.33 | 91.99 ± 11.52 | 73.6 ± 13.19 | 13.94 ± 6.84 |
| NasnetMobile [34] | 86.57 ± 6.47 | 80.82 ± 12.71 | 92.2 ± 5.97 | 85.25 ± 7.87 | 19.18 ± 12.71 | 7.8 ± 5.97 | 91.28 ± 5.36 | 74.09 ± 12.12 | 13.43 ± 6.47 |
| NasnetLarge [34] | 91.31 ± 7.08 | 88.16 ± 7.24 | 94.4 ± 7.7 | 90.96 ± 7.22 | 11.84 ± 7.24 | 5.6 ± 7.7 | 94.04 ± 7.9 | 82.84 ± 14.17 | 8.69 ± 7.08 |
| DarkNet19 [36] | 86.77 ± 4.14 | 81.02 ± 5.43 | 92.4 ± 3.36 | 85.79 ± 4.65 | 18.98 ± 5.43 | 7.6 ± 3.36 | 91.22 ± 3.95 | 73.98 ± 8.15 | 13.23 ± 4.14 |
| DarkNet53 [37] | 89.19 ± 6.15 | 83.88 ± 9.88 | 94.4 ± 2.97 | 88.26 ± 7.22 | 16.12 ± 9.88 | 5.6 ± 2.97 | 93.42 ± 4 | 78.87 ± 11.79 | 10.81 ± 6.15 |
| EfficientNetB0 [38] | 86.87 ± 3.44 | 85.31 ± 3.86 | 88.4 ± 4.88 | 86.56 ± 3.51 | 14.69 ± 3.86 | 11.6 ± 4.88 | 87.96 ± 4.91 | 73.86 ± 7.03 | 13.13 ± 3.44 |
| SqueezeNet [40] | 84.65 ± 2.38 | 86.73 ± 4.95 | 82.6 ± 6.19 | 84.83 ± 2.31 | 13.27 ± 4.95 | 17.4 ± 6.19 | 83.34 ± 4.8 | 69.66 ± 4.75 | 15.35 ± 2.38 |
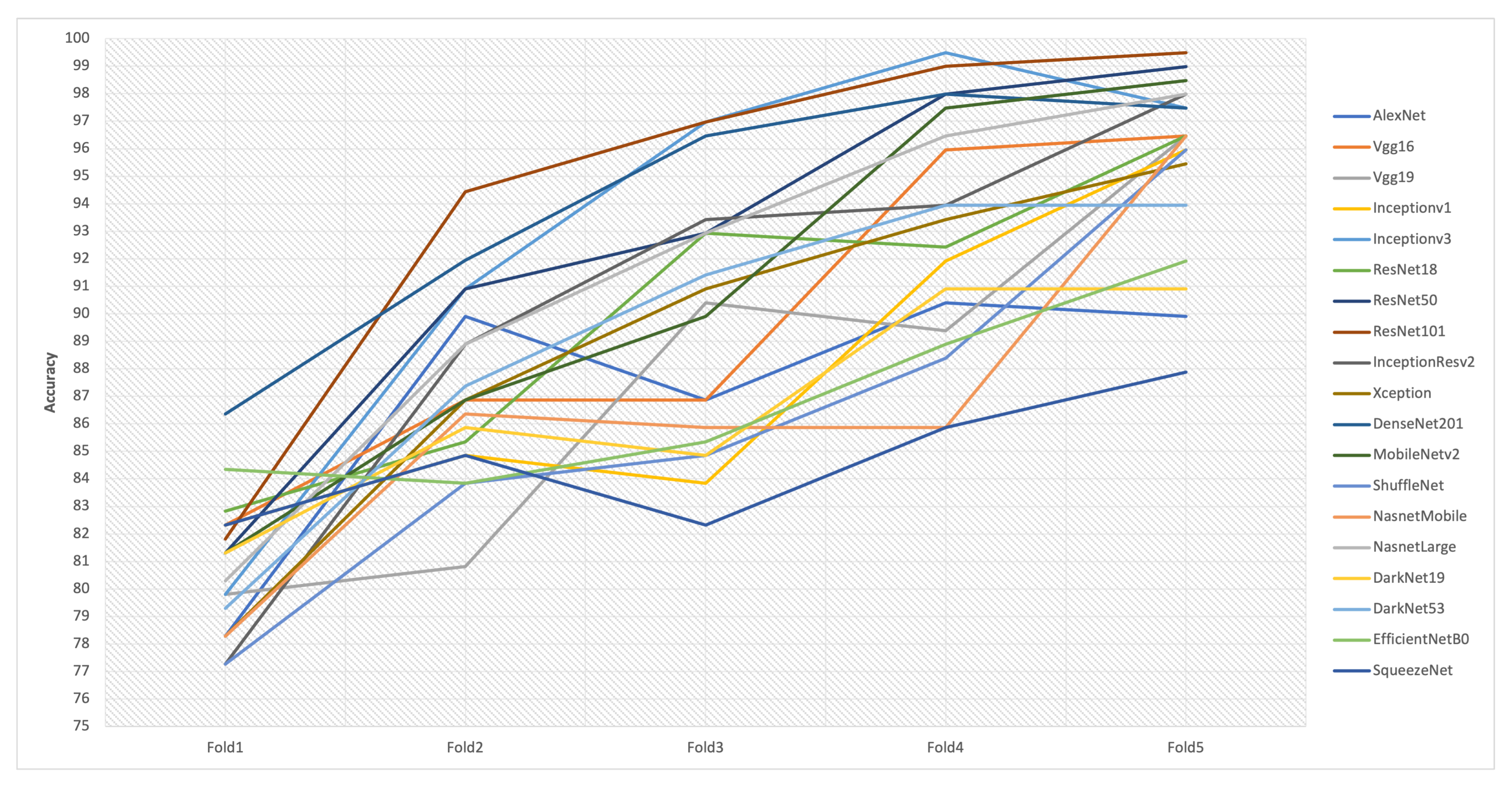
| Model | Fold1 | Fold2 | Fold3 | Fold4 | Fold5 |
|---|---|---|---|---|---|
| AlexNet | 78.28 | 89.9 | 86.87 | 90.4 | 89.9 |
| Vgg16 | 82.32 | 86.87 | 86.87 | 95.96 | 96.46 |
| Vgg19 | 79.8 | 80.81 | 90.4 | 89.39 | 96.46 |
| Inceptionv1 | 82.32 | 84.85 | 83.84 | 91.92 | 95.96 |
| Inceptionv3 | 79.8 | 90.91 | 96.97 | 99.49 | 97.47 |
| ResNet18 | 82.83 | 85.35 | 92.93 | 92.42 | 96.46 |
| ResNet50 | 81.31 | 90.91 | 92.93 | 97.98 | 98.99 |
| ResNet101 | 81.82 | 94.44 | 96.97 | 98.99 | 99.49 |
| InceptionResv2 | 77.27 | 88.89 | 93.43 | 93.94 | 97.98 |
| Xception | 78.28 | 86.87 | 90.91 | 93.43 | 95.45 |
| DenseNet201 | 86.36 | 91.94 | 96.46 | 97.98 | 97.47 |
| MobileNetv2 | 81.31 | 86.87 | 89.9 | 97.47 | 98.48 |
| ShuffleNet | 77.27 | 83.84 | 84.85 | 88.38 | 95.96 |
| NasnetMobile | 78.28 | 86.36 | 85.86 | 85.86 | 96.46 |
| NasnetLarge | 80.3 | 88.89 | 92.93 | 96.46 | 97.98 |
| DarkNet19 | 81.31 | 85.86 | 84.85 | 90.91 | 90.91 |
| DarkNet53 | 79.29 | 87.37 | 91.41 | 93.94 | 93.94 |
| EfficientNetB0 | 84.34 | 83.84 | 85.35 | 88.89 | 91.92 |
| SqueezeNet | 82.32 | 84.85 | 82.32 | 85.86 | 87.88 |
| Alter./ Cr. | ACC | Sen | Spe | F1-Score | FNR | FPR | Pre | MCC | Err | Para |
|---|---|---|---|---|---|---|---|---|---|---|
| AlexNet | 0.9229 | 0.9083 | 0.9215 | 0.9194 | 0.4325 | 0.2963 | 0.9215 | 0.8386 | 0.4377 | 0.0203 |
| Vgg16 | 0.9508 | 0.9301 | 0.9545 | 0.9491 | 0.5000 | 0.4211 | 0.9570 | 0.8966 | 0.5495 | 0.0090 |
| Vgg19 | 0.9261 | 0.8909 | 0.9442 | 0.9215 | 0.3903 | 0.3721 | 0.9498 | 0.8503 | 0.4481 | 0.0086 |
| Inceptionv1 | 0.9305 | 0.9367 | 0.9091 | 0.9328 | 0.5245 | 0.2667 | 0.9230 | 0.8577 | 0.4632 | 0.1771 |
| Inceptionv3 | 0.9851 | 0.9520 | 1.0000 | 0.9822 | 0.5926 | 1.0000 | 1.0000 | 0.9688 | 0.8006 | 0.0519 |
| ResNet18 | 0.9540 | 0.9541 | 0.9380 | 0.9575 | 0.6035 | 0.3478 | 0.9492 | 0.9039 | 0.5660 | 0.1060 |
| ResNet50 | 0.9796 | 0.9650 | 0.9773 | 0.9786 | 0.6663 | 0.5926 | 0.9801 | 0.9578 | 0.7467 | 0.0484 |
| ResNet101 | 1.0000 | 0.9935 | 0.9897 | 0.9993 | 0.9146 | 0.7619 | 0.9922 | 1.0000 | 1.0000 | 0.0278 |
| InceptionResv2 | 0.9572 | 0.9476 | 0.9504 | 0.9565 | 0.5713 | 0.4000 | 0.9504 | 0.9073 | 0.5835 | 0.0222 |
| Xception | 0.9433 | 0.9629 | 0.9091 | 0.9474 | 0.6530 | 0.2667 | 0.9197 | 0.8802 | 0.5141 | 0.0541 |
| DenseNet201 | 0.9958 | 1.0000 | 0.9752 | 1.0000 | 1.0000 | 0.5714 | 0.9858 | 0.9909 | 0.9340 | 0.0620 |
| MobileNetv2 | 0.9626 | 0.9148 | 0.9917 | 0.9568 | 0.4507 | 0.8000 | 0.9908 | 0.9246 | 0.6159 | 0.3543 |
| ShuffleNet | 0.9122 | 0.8624 | 0.9442 | 0.9072 | 0.3368 | 0.3721 | 0.9571 | 0.8273 | 0.4060 | 0.8857 |
| NasnetMobile | 0.9176 | 0.8647 | 0.9525 | 0.9073 | 0.3405 | 0.4103 | 0.9497 | 0.8328 | 0.4214 | 0.2340 |
| NasnetLarge | 0.9679 | 0.9432 | 0.9752 | 0.9681 | 0.5515 | 0.5714 | 0.9785 | 0.9312 | 0.6513 | 0.0139 |
| DarkNet19 | 0.9198 | 0.8668 | 0.9545 | 0.9130 | 0.3440 | 0.4211 | 0.9491 | 0.8316 | 0.4278 | 0.0596 |
| DarkNet53 | 0.9454 | 0.8974 | 0.9752 | 0.9393 | 0.4051 | 0.5714 | 0.9720 | 0.8866 | 0.5236 | 0.0298 |
| EfficientNetB0 | 0.9208 | 0.9127 | 0.9132 | 0.9212 | 0.4445 | 0.2759 | 0.9152 | 0.8303 | 0.4311 | 0.2340 |
| SqueezeNet | 0.8973 | 0.9279 | 0.8533 | 0.9028 | 0.4921 | 0.1839 | 0.8671 | 0.7830 | 0.3687 | 1.0000 |
| Model | : PROMETHEE | Q: VIKOR | PROMETHEE | VIKOR |
|---|---|---|---|---|
| AlexNet | −86.54004365 | 0.78423285 | 15 | 15 |
| Vgg16 | 16.31877628 | 0.51048488 | 8 | 9 |
| Vgg19 | −63.8124359 | 0.74766659 | 13 | 13 |
| Inceptionv1 | −57.19966687 | 0.68096691 | 12 | 12 |
| Inceptionv3 | 132.2050634 | 0.18466346 | 3 | 3 |
| ResNet18 | 15.25546934 | 0.4614654 | 9 | 8 |
| ResNet50 | 115.1633097 | 0.21251132 | 4 | 4 |
| ResNet101 | 150.8418215 | 0 | 1 | 1 |
| InceptionResv2 | 28.425464 | 0.4496109 | 7 | 7 |
| Xception | −29.98203689 | 0.60787425 | 11 | 11 |
| DenseNet201 | 133.2355605 | 0.07998389 | 2 | 2 |
| MobileNetv2 | 72.89230795 | 0.42167181 | 6 | 6 |
| ShuffleNet | −106.9819714 | 0.8594925 | 18 | 18 |
| NasnetMobile | −89.20093646 | 0.84854 | 16 | 17 |
| NasnetLarge | 73.3193101 | 0.33461685 | 5 | 5 |
| DarkNet19 | −76.30565263 | 0.81073772 | 14 | 16 |
| DarkNet53 | 1.456682009 | 0.56957337 | 10 | 10 |
| EfficientNetB0 | −95.9301979 | 0.78239429 | 17 | 14 |
| SqueezeNet | −133.1608231 | 1 | 19 | 19 |
| Model Rank | PROPMETHEE | VIKOR |
|---|---|---|
| 1 | ResNet101 | ResNet101 |
| 2 | DenseNet201 | DenseNet201 |
| 3 | Inceptionv3 | Inceptionv3 |
| 4 | ResNet50 | ResNet50 |
| 5 | NasnetLarge | NasnetLarge |
| 6 | MobileNetv2 | MobileNetv2 |
| 7 | InceptionResv2 | InceptionResv2 |
| 8 | Vgg16 | ResNet18 |
| 9 | ResNet18 | Vgg16 |
| 10 | DarkNet53 | DarkNet53 |
| 11 | Xception | Xception |
| 12 | Inceptionv1 | Inceptionv1 |
| 13 | Vgg19 | Vgg19 |
| 14 | DarkNet19 | EfficientNetB0 |
| 15 | AlexNet | AlexNet |
| 16 | NasnetMobile | DarkNet19 |
| 17 | EfficientNetB0 | NasnetMobile |
| 18 | ShuffleNet | ShuffleNet |
| 19 | SqueezeNet | SqueezeNet |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzahrani, S.; Al-Bander, B.; Al-Nuaimy, W. A Comprehensive Evaluation and Benchmarking of Convolutional Neural Networks for Melanoma Diagnosis. Cancers 2021, 13, 4494. https://doi.org/10.3390/cancers13174494
Alzahrani S, Al-Bander B, Al-Nuaimy W. A Comprehensive Evaluation and Benchmarking of Convolutional Neural Networks for Melanoma Diagnosis. Cancers. 2021; 13(17):4494. https://doi.org/10.3390/cancers13174494
Chicago/Turabian StyleAlzahrani, Saeed, Baidaa Al-Bander, and Waleed Al-Nuaimy. 2021. "A Comprehensive Evaluation and Benchmarking of Convolutional Neural Networks for Melanoma Diagnosis" Cancers 13, no. 17: 4494. https://doi.org/10.3390/cancers13174494