
Reinforcement Learning for Precision Oncology


Abstract
:Simple Summary
Abstract
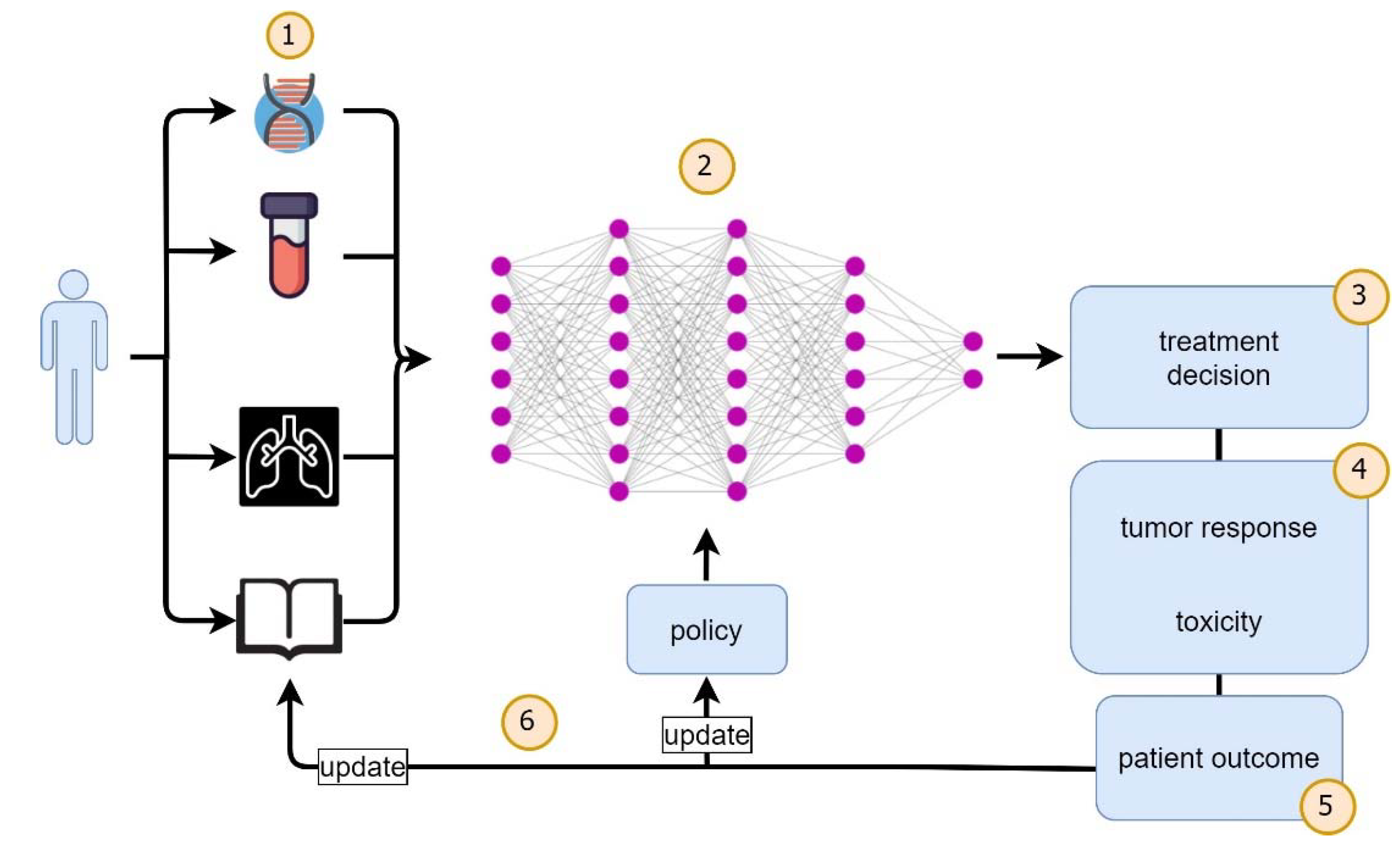
1. Introduction
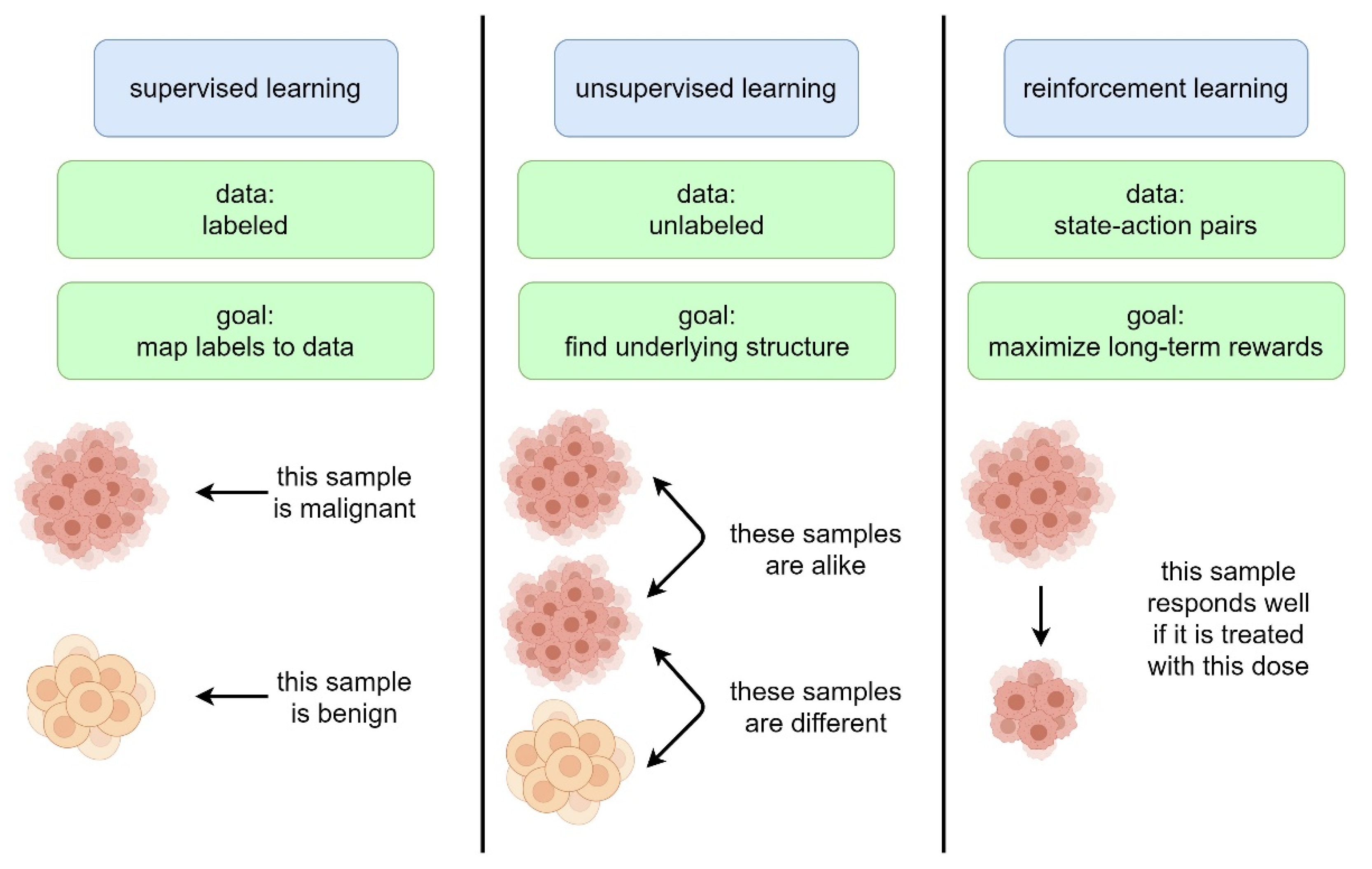
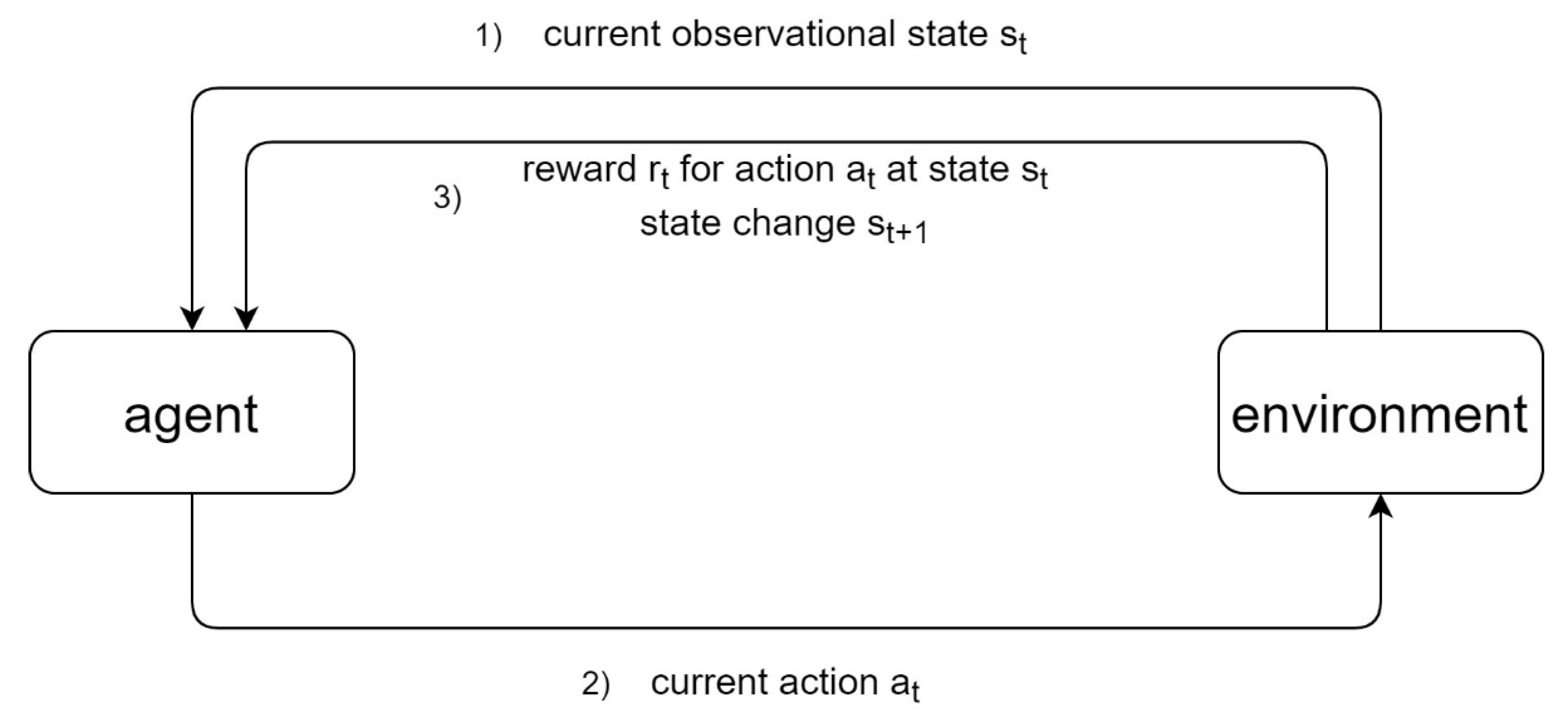
2. Overview of Reinforcement Learning
3. Recent Studies of Reinforcement Learning in Malignant Disease
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Topol, E.J. High-Performance Medicine: The Convergence of Human and Artificial Intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- He, J.; Baxter, S.L.; Xu, J.; Xu, J.; Zhou, X.; Zhang, K. The Practical Implementation of Artificial Intelligence Technologies in Medicine. Nat. Med. 2019, 25, 30–36. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson: Boston, MA, USA, 2020; ISBN 978-0-13-461099-3. [Google Scholar]
- Rodríguez-Ruiz, A.; Krupinski, E.; Mordang, J.-J.; Schilling, K.; Heywang-Köbrunner, S.H.; Sechopoulos, I.; Mann, R.M. Detection of Breast Cancer with Mammography: Effect of an Artificial Intelligence Support System. Radiology 2019, 290, 305–314. [Google Scholar] [CrossRef]
- Perek, S.; Kiryati, N.; Zimmerman-Moreno, G.; Sklair-Levy, M.; Konen, E.; Mayer, A. Classification of Contrast-Enhanced Spectral Mammography (CESM) Images. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 249–257. [Google Scholar] [CrossRef]
- Massafra, R.; Bove, S.; Lorusso, V.; Biafora, A.; Comes, M.C.; Didonna, V.; Diotaiuti, S.; Fanizzi, A.; Nardone, A.; Nolasco, A.; et al. Radiomic Feature Reduction Approach to Predict Breast Cancer by Contrast-Enhanced Spectral Mammography Images. Diagnostics 2021, 11, 684. [Google Scholar] [CrossRef] [PubMed]
- Amoroso, N.; Pomarico, D.; Fanizzi, A.; Didonna, V.; Giotta, F.; La Forgia, D.; Latorre, A.; Monaco, A.; Pantaleo, E.; Petruzzellis, N.; et al. A Roadmap towards Breast Cancer Therapies Supported by Explainable Artificial Intelligence. Appl. Sci. 2021, 11, 4881. [Google Scholar] [CrossRef]
- Comes, M.C.; La Forgia, D.; Didonna, V.; Fanizzi, A.; Giotta, F.; Latorre, A.; Martinelli, E.; Mencattini, A.; Paradiso, A.V.; Tamborra, P.; et al. Early Prediction of Breast Cancer Recurrence for Patients Treated with Neoadjuvant Chemotherapy: A Transfer Learning Approach on DCE-MRIs. Cancers 2021, 13, 2298. [Google Scholar] [CrossRef]
- Dembrower, K.; Wåhlin, E.; Liu, Y.; Salim, M.; Smith, K.; Lindholm, P.; Eklund, M.; Strand, F. Effect of Artificial Intelligence-Based Triaging of Breast Cancer Screening Mammograms on Cancer Detection and Radiologist Workload: A Retrospective Simulation Study. Lancet Digit. Health 2020, 2, e468–e474. [Google Scholar] [CrossRef]
- Jafari, M.; Wang, Y.; Amiryousefi, A.; Tang, J. Unsupervised Learning and Multipartite Network Models: A Promising Approach for Understanding Traditional Medicine. Front. Pharmacol. 2020, 11, 1319. [Google Scholar] [CrossRef] [PubMed]
- Awada, H.; Durmaz, A.; Gurnari, C.; Kishtagari, A.; Meggendorfer, M.; Kerr, C.M.; Kuzmanovic, T.; Durrani, J.; Shreve, J.; Nagata, Y.; et al. Machine Learning Integrates Genomic Signatures for Subclassification Beyond Primary and Secondary Acute Myeloid Leukemia. Blood 2021. [Google Scholar] [CrossRef]
- Yu, K.-H.; Beam, A.L.; Kohane, I.S. Artificial Intelligence in Healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- Campbell, M.; Hoane, A.J.; Hsu, F. Deep Blue. Artif. Intell. 2002, 134, 57–83. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef] [PubMed]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep Reinforcement Learning Framework for Autonomous Driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef] [Green Version]
- National Research Council (US) Committee on A Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease; The National Academies Collection: Reports funded by National Institutes of Health; National Academies Press (US): Washington, DC, USA, 2011; ISBN 978-0-309-22222-8. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0-262-35270-3. [Google Scholar]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2018, arXiv:1701.07274. [Google Scholar]
- Travassos, G.; Barros, M. Contributions of In Virtuo and In Silico Experiments for the Future of Empirical Studies in Software Engineering Contributions of In Virtuo and In Silico Experiments for the Future of Empirical Studies in Software Engineering. In The Future of Empirical Studies in Software Engineering: Proceedings of the ESEIW 2003 Workshop on Empirical Stuides in Software Engineering (WSESE 2003), Rome, Italy, 29 September 2003; Springer: Berlin/Heidelberg, Germany, 2004; Volume 2, p. 117. [Google Scholar]
- Jonsson, A. Deep Reinforcement Learning in Medicine. KDD 2019, 5, 18–22. [Google Scholar] [CrossRef] [PubMed]
- Watkins, C.; Dayan, P. Q-Learning. Proc. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, B.; Murphy, S.A. Dynamic Treatment Regimes. Annu. Rev. Stat. Its Appl. 2014, 1, 447–464. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement Learning in Healthcare: A Survey. arXiv 2020, arXiv:1908.08796. [Google Scholar]
- Padmanabhan, R.; Meskin, N.; Haddad, W.M. Reinforcement Learning-Based Control of Drug Dosing for Cancer Chemotherapy Treatment. Math. Biosci. 2017, 293, 11–20. [Google Scholar] [CrossRef]
- Ebrahimi Zade, A.; Shahabi Haghighi, S.; Soltani, M. Reinforcement Learning for Optimal Scheduling of Glioblastoma Treatment with Temozolomide. Comput. Methods Programs Biomed. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Yazdjerdi, P.; Meskin, N.; Al-Naemi, M.; Al Moustafa, A.-E.; Kovács, L. Reinforcement Learning-Based Control of Tumor Growth under Anti-Angiogenic Therapy. Comput. Methods Programs Biomed. 2019, 173, 15–26. [Google Scholar] [CrossRef]
- Daoud, S.; Mdhaffar, A.; Jmaiel, M.; Freisleben, B. Q-Rank: Reinforcement Learning for Recommending Algorithms to Predict Drug Sensitivity to Cancer Therapy. IEEE J. Biomed. Health Inform. 2020, 24, 3154–3161. [Google Scholar] [CrossRef]
- Maier, C.; Hartung, N.; Kloft, C.; Huisinga, W.; Wiljes, J. de Reinforcement Learning and Bayesian Data Assimilation for Model-Informed Precision Dosing in Oncology. CPT Pharmacomet. Syst. Pharmacol. 2021, 10, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Kosorok, M.R.; Zeng, D. Reinforcement Learning Design for Cancer Clinical Trials. Stat. Med. 2009, 28, 3294–3315. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Y.; Zeng, D.; Socinski, M.A.; Kosorok, M.R. Reinforcement Learning Strategies for Clinical Trials in Nonsmall Cell Lung Cancer. Biometrics 2011, 67, 1422–1433. [Google Scholar] [CrossRef]
- Yauney, G.; Shah, P. Reinforcement Learning with Action-Derived Rewards for Chemotherapy and Clinical Trial Dosing Regimen Selection. In Proceedings of the Machine Learning for Healthcare Conference, PMLR, Stanford, CA, USA, 16–18 August 2018; pp. 161–226. [Google Scholar]
- Liu, Y.; Logan, B.; Liu, N.; Xu, Z.; Tang, J.; Wang, Y. Deep Reinforcement Learning for Dynamic Treatment Regimes on Medical Registry Data. Healthc. Inform. 2017, 2017, 380–385. [Google Scholar] [CrossRef] [PubMed]
- Krakow, E.F.; Hemmer, M.; Wang, T.; Logan, B.; Arora, M.; Spellman, S.; Couriel, D.; Alousi, A.; Pidala, J.; Last, M.; et al. Tools for the Precision Medicine Era: How to Develop Highly Personalized Treatment Recommendations From Cohort and Registry Data Using Q-Learning. Am. J. Epidemiol. 2017, 186, 160–172. [Google Scholar] [CrossRef] [Green Version]
- Boldrini, L.; Bibault, J.-E.; Masciocchi, C.; Shen, Y.; Bittner, M.-I. Deep Learning: A Review for the Radiation Oncologist. Front. Oncol. 2019, 9, 977. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Stojadinovic, S.; Hrycushko, B.; Wardak, Z.; Lau, S.; Lu, W.; Yan, Y.; Jiang, S.B.; Zhen, X.; Timmerman, R.; et al. A Deep Convolutional Neural Network-Based Automatic Delineation Strategy for Multiple Brain Metastases Stereotactic Radiosurgery. PLoS ONE 2017, 12, e0185844. [Google Scholar] [CrossRef] [Green Version]
- Charron, O.; Lallement, A.; Jarnet, D.; Noblet, V.; Clavier, J.-B.; Meyer, P. Automatic Detection and Segmentation of Brain Metastases on Multimodal MR Images with a Deep Convolutional Neural Network. Comput. Biol. Med. 2018, 95, 43–54. [Google Scholar] [CrossRef]
- Trullo, R.; Petitjean, C.; Ruan, S.; Dubray, B.; Nie, D.; Shen, D. Segmentation of Organs at Risk in Thoracic CT Images Using a Sharpmask Architecture and Conditional Random Fields. Proc. IEEE Int. Symp. Biomed. Imaging 2017, 2017, 1003–1006. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Men, K.; Dai, J.; Li, Y. Automatic Segmentation of the Clinical Target Volume and Organs at Risk in the Planning CT for Rectal Cancer Using Deep Dilated Convolutional Neural Networks. Med. Phys. 2017, 44, 6377–6389. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.; Ghate, A.; Phillips, M.H. A Markov Decision Process Approach to Temporal Modulation of Dose Fractions in Radiation Therapy Planning. Phys. Med. Biol. 2009, 54, 4455–4476. [Google Scholar] [CrossRef] [Green Version]
- Tseng, H.-H.; Luo, Y.; Cui, S.; Chien, J.-T.; Haken, R.K.T.; Naqa, I.E. Deep Reinforcement Learning for Automated Radiation Adaptation in Lung Cancer. Med. Phys. 2017, 44, 6690–6705. [Google Scholar] [CrossRef]
- Jalalimanesh, A.; Shahabi Haghighi, H.; Ahmadi, A.; Soltani, M. Simulation-Based Optimization of Radiotherapy: Agent-Based Modeling and Reinforcement Learning. Math. Comput. Simul. 2017, 133, 235–248. [Google Scholar] [CrossRef]
- Moreau, G.; François-Lavet, V.; Desbordes, P.; Macq, B. Reinforcement Learning for Radiotherapy Dose Fractioning Automation. Biomedicines 2021, 9, 214. [Google Scholar] [CrossRef]
- Hrinivich, W.T.; Lee, J. Artificial Intelligence-Based Radiotherapy Machine Parameter Optimization Using Reinforcement Learning. Med. Phys. 2020, 47, 6140–6150. [Google Scholar] [CrossRef]
- Shen, C.; Nguyen, D.; Chen, L.; Gonzalez, Y.; McBeth, R.; Qin, N.; Jiang, S.B.; Jia, X. Operating a Treatment Planning System Using a Deep-Reinforcement Learning-Based Virtual Treatment Planner for Prostate Cancer Intensity-Modulated Radiation Therapy Treatment Planning. Med. Phys. 2020, 47, 2329–2336. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, C.; Sheng, Y.; Palta, M.; Czito, B.; Willett, C.; Zhang, J.; Jensen, P.J.; Yin, F.-F.; Wu, Q.; et al. An Interpretable Planning Bot for Pancreas Stereotactic Body Radiation Therapy. Int. J. Radiat. Oncol. Biol. Phys. 2021, 109, 1076–1085. [Google Scholar] [CrossRef] [PubMed]
- Gottesman, O.; Johansson, F.; Komorowski, M.; Faisal, A.; Sontag, D.; Doshi-Velez, F.; Celi, L.A. Guidelines for Reinforcement Learning in Healthcare. Nat. Med. 2019, 25, 16–18. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M.; De Pietro, G.; Paragliola, G. Reinforcement Learning for Intelligent Healthcare Applications: A Survey. Artif. Intell. Med. 2020, 109, 101964. [Google Scholar] [CrossRef]
- Sondik, E.J. The Optimal Control of Partially Observable Markov Processes Over the Infinite Horizon: Discounted Costs. Oper. Res. 1978, 26, 282–304. [Google Scholar] [CrossRef]
- Shortreed, S.M.; Laber, E.; Lizotte, D.J.; Stroup, T.S.; Pineau, J.; Murphy, S.A. Informing Sequential Clinical Decision-Making through Reinforcement Learning: An Empirical Study. Mach. Learn. 2011, 84, 109–136. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, Y.; Kosorok, M.R. Q-Learning with Censored Data. Annu. Stat. 2012, 40, 529–560. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwartz, L.H.; Seymour, L.; Litière, S.; Ford, R.; Gwyther, S.; Mandrekar, S.; Shankar, L.; Bogaerts, J.; Chen, A.; Dancey, J.; et al. RECIST 1.1—Standardisation and Disease-Specific Adaptations: Perspectives from the RECIST Working Group. Eur. J. Cancer 2016, 62, 138–145. [Google Scholar] [CrossRef] [Green Version]
- Trotti, A.; Colevas, A.D.; Setser, A.; Rusch, V.; Jaques, D.; Budach, V.; Langer, C.; Murphy, B.; Cumberlin, R.; Coleman, C.N.; et al. CTCAE v3.0: Development of a Comprehensive Grading System for the Adverse Effects of Cancer Treatment. Semin. Radiat. Oncol. 2003, 13, 176–181. [Google Scholar] [CrossRef]
- Ross, M.K.; Wei, W.; Ohno-Machado, L. “Big Data” and the Electronic Health Record. Yearb. Med. Inform. 2014, 23, 97–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Torabi, F.; Warnell, G.; Stone, P. Behavioral Cloning from Observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Ho, J.; Gupta, J.K.; Ermon, S. Model-Free Imitation Learning with Policy Optimization. arXiv 2016, arXiv:1605.08478. [Google Scholar]
- Ng, A.Y.; Russell, S. Algorithms for Inverse Reinforcement Learning. In Proceedings of the 17th International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; Morgan Kaufmann: San Francisco, CA, USA, 2000; pp. 663–670. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship Learning via Inverse Reinforcement Learning. In Proceedings of the 21st International Conference on Machine learning, Banff, AB, Canada, 4–8 July 2004; Association for Computing Machinery: New York, NY, USA, 2004; p. 1. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete Problems in AI Safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight Experience Replay. arXiv 2018, arXiv:1707.01495. [Google Scholar]
- Fürnkranz, J.; Hüllermeier, E. (Eds.) Preference Learning; Springer: Berlin/Heidelberg, Germany, 2011; ISBN 978-3-642-14124-9. [Google Scholar]
- Wirth, C.; Fürnkranz, J.; Neumann, G. Model-Free Preference-Based Reinforcement Learning. AAAI 2016, 30, 2222–2228. [Google Scholar]
- de Jonge, M.E.; Huitema, A.D.R.; Schellens, J.H.M.; Rodenhuis, S.; Beijnen, J.H. Individualised Cancer Chemotherapy: Strategies and Performance of Prospective Studies on Therapeutic Drug Monitoring with Dose Adaptation: A Review. Clin. Pharmacol. 2005, 44, 147–173. [Google Scholar] [CrossRef]
- Liu, C.; Xu, X.; Hu, D. Multiobjective Reinforcement Learning: A Comprehensive Overview. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 385–398. [Google Scholar] [CrossRef]
- García, J.; Fernández, F. A Comprehensive Survey on Safe Reinforcement Learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Castelvecchi, D. Can We Open the Black Box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2017, arXiv:1606.03490. [Google Scholar]
- Grote, T.; Berens, P. On the Ethics of Algorithmic Decision-Making in Healthcare. J. Med. Ethics 2020, 46, 205–211. [Google Scholar] [CrossRef] [Green Version]
- Azuaje, F. Artificial Intelligence for Precision Oncology: Beyond Patient Stratification. NPJ Precis. Oncol. 2019, 3, 1–5. [Google Scholar] [CrossRef]
- Humphreys, P. The Philosophical Novelty of Computer Simulation Methods. Synthese 2009, 169, 615–626. [Google Scholar] [CrossRef] [Green Version]
- Madumal, P.; Miller, T.; Sonenberg, L.; Vetere, F. Explainable Reinforcement Learning through a Causal Lens. AAAI 2020, 34, 2493–2500. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning; Lulu: Morrisville, NC, USA, 2020; ISBN 978-0-244-76852-2. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable Artificial Intelligence: A Survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 210–215. [Google Scholar]
- McDougall, R.J. Computer Knows Best? The Need for Value-Flexibility in Medical AI. J. Med. Ethics 2019, 45, 156–160. [Google Scholar] [CrossRef] [PubMed]
- Nardini, C. Machine Learning in Oncology: A Review. Ecancermedicalscience 2020, 14, 1065. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Term | Symbol | Description |
|---|---|---|
| Reinforcement Learning | RL | operates in a simulated environment with distinct behavior to receive rewards |
| Environment | E | consumes actions to produce rewards for an agent; based on a model/simulation/observations/data |
| Agent | RL decision instance, performing actions to change states | |
| Action | a | performed by an agent to change to another state, i.e., interact with the environment |
| State | s | abstract relation of the agent to the environment, starting and end point of an action |
| Reward | r | gain for an action of the access of a state |
| Reward Function | R | entirety of all rewards for actions/states |
| Cumulative Reward | CR | aggregated rewards of subsequent actions/states; should be maximized as the learning/optimization objective |
| Policy | π | defines an action for each state; result of learning/optimization process |
| Aspect | Variant | Description | Pro | Contra |
|---|---|---|---|---|
| Environment | Model-Based | distinct rule-based/simulation-based feedback for the agent | covers corner cases, potentially high feedback quality | complex to set up |
| Model-Free | data-based (observation/retro-perspective) feedback | easy to set up, no abstraction | no corner cases, potentially low feedback quality | |
| Reward | V (State-Based) | rewards when accessing a state (relation to E) | fewer states, easy to model | more abstraction, static (less intuitive) view |
| Q (Action-Based) | rewards when executing an action (changing E) | more actions, fewer abstraction, extensive to model | more actions, dynamic (intuitive) view | |
| Concluding Learning | rewards when finalizing a sequence of decisions | long term-oriented, aims for global objectives | provides no local guidance, complex evaluation | |
| Temporal Difference Learning | rewards after each decision | provides no local guidance, easy evaluation | short term-oriented, aims for local objectives | |
| Access | Online | access of the agent to the E in a (restricted) stream-based way | less information to process for the agent, smaller solution space | potentially non-optimal solutions (policy) |
| Batch-Based | access of the agent to the entire environment E | globally optimized solutions (policy) | more information to process, large solution space | |
| Dynamics | Static Reward Function | each piece of feedback from the E is encoded in states, resulting in constant rewards | easier E, smaller solution space | potentially coarse-grained decisions/optimization |
| Dynamic Reward Function | feedback from E is encoded in attributes, resulting in variable rewards | potentially fine-grained decisions/optimization | complex E, large solution space | |
| Markov Assumption | no influence from previous decisions | smaller solution space | potentially insufficient decision impact modeling | |
| No Markov Assumption | decision history has influence on rewards | complex decision modeling | large solution space | |
| Representation | Table-/Map-Based | simple state transition/action modeling | easy to create, transparent | complex to maintain and show, grows exponentially with number of states |
| Graph-Based | intuitive state machine modeling | easy to maintain, transparent, scales with number of states | complex to create and show | |
| Deep Neural Net | DL-based modeling | easy to create, scales with number of states | low transparency, complex to show |
| Reference | Main Goal | Environment/Cohort | Model-Based | Model-Free | V (State-Based) | Q (Action-Based) | Markov Assumption | No Markov Assumption | Table-/Map-Based | Deep Learning | Code Availability |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [30] | Evaluation of an RL-based drug controller to enhance therapeutic effect on simulated tumors while sparing normal tissue without the necessity to disclose underlying system dynamics to the RL agent | 15 simulated cancer patients | X | X | X | X | |||||
| [31] | Comparison of an RL-guided temozolomide treatment schedule to conventional clinical regimen | simulated glioblastoma tumor growth model | X | X | X | X | |||||
| [32] | RL-based optimization of anti-angiogenic therapy with endostatin in a simulated tumor growth model with dynamic patient parameters | simulated tumor growth model, simulated patient | X | X | X | X | X | ||||
| [33] | Prediction of chemotherapy sensitivity in breast cancer cell lines with available multi-omics data by ranking suitable prediction algorithms using Q-rank | drug sensitivity data of 53 breast cancer cell lines | X | X | X | X | X | ||||
| [34] | Evaluation of data assimilation techniques in combination with RL for dose adjustments of chemotherapy in simulated patients using absolute neutrophile count as a surrogate endpoint | simulated patients | X | X | X | X | X | ||||
| [36] | RL-based dose adjustments for chemotherapy and initiation of second-line therapy while accounting for patient censoring | simulated clinical trial of stage IIIB/IV non-small cell lung cancer patients | X | X | X | X | |||||
| [37] | Deep RL-guided dosing regimens with temozolomide or procarbazine, CCNU and vincristine using action-derived rewards | simulated clinical trial using a glioblastoma tumor growth model | X | X | X | X | |||||
| [38] | Evaluation of RL-guided prevention and treatment of acute and chronic graft-versus-host disease | registry data from 6021 AML patients who underwent allogeneic stem cell transplantation | X | X | X | X | |||||
| [39] | Evaluation of RL-guided prevention and treatment of acute and chronic graft-versus-host disease | registry data from 11,141 patients who underwent allogeneic stem cell transplantation | X | X | X | X |
| Reference | Main Goal | Environment/Cohort | Model-Based | Model-Free | V (State-Based) | Q (Action-Based) | Markov Assumption | No Markov Assumption | Table-/Map-Based | Deep Learning | Code Availability |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [45] | Development of adaptive fractionation schemes based on mathematical modeling with a Markov decision process | Simulated environment of target volumes and organs at risk | X | X | X | X | |||||
| [46] | Evaluation of a multi-step deep learning model for radiation dose adjustments in a retrospective and augmented patient cohort compared to clinical treatment plans | Retrospective data of 114 non-small cell lung cancer patients and augmented data from a generative adversarial net | X | X | X | X | |||||
| [47] | Proof of concept of an RL agent for adaptive irradiation dosing and fractionation schemes | Simulated tumor growth model | X | X | X | X | |||||
| [48] | Comparison of adaptive dose fractionation schemes to clinical treatment regimens | Simulated tumor growth model | X | X | X | X | X | ||||
| [49] | RL to guide volumetric modulated arc therapy with machine parameter optimization and comparison between on-target and off-target doses | Retrospective data of 40 patients with prostate cancer | X | X | X | X | |||||
| [50] | Training and evaluation of a RL-based deep virtual treatment planner | Retrospective data of 74 patients with prostate cancer | X | X | X | X | |||||
| [51] | Optimization of on-target and off-target dosing for stereotactic body irradiation in pancreatic cancer | Retrospective data of 16 patients with pancreatic cancer | X | X | X | X |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eckardt, J.-N.; Wendt, K.; Bornhäuser, M.; Middeke, J.M. Reinforcement Learning for Precision Oncology. Cancers 2021, 13, 4624. https://doi.org/10.3390/cancers13184624
Eckardt J-N, Wendt K, Bornhäuser M, Middeke JM. Reinforcement Learning for Precision Oncology. Cancers. 2021; 13(18):4624. https://doi.org/10.3390/cancers13184624
Chicago/Turabian StyleEckardt, Jan-Niklas, Karsten Wendt, Martin Bornhäuser, and Jan Moritz Middeke. 2021. "Reinforcement Learning for Precision Oncology" Cancers 13, no. 18: 4624. https://doi.org/10.3390/cancers13184624