
An Arrhythmia Classification Model Based on Vision Transformer with Deformable Attention

Abstract
:1. Introduction
2. Methods
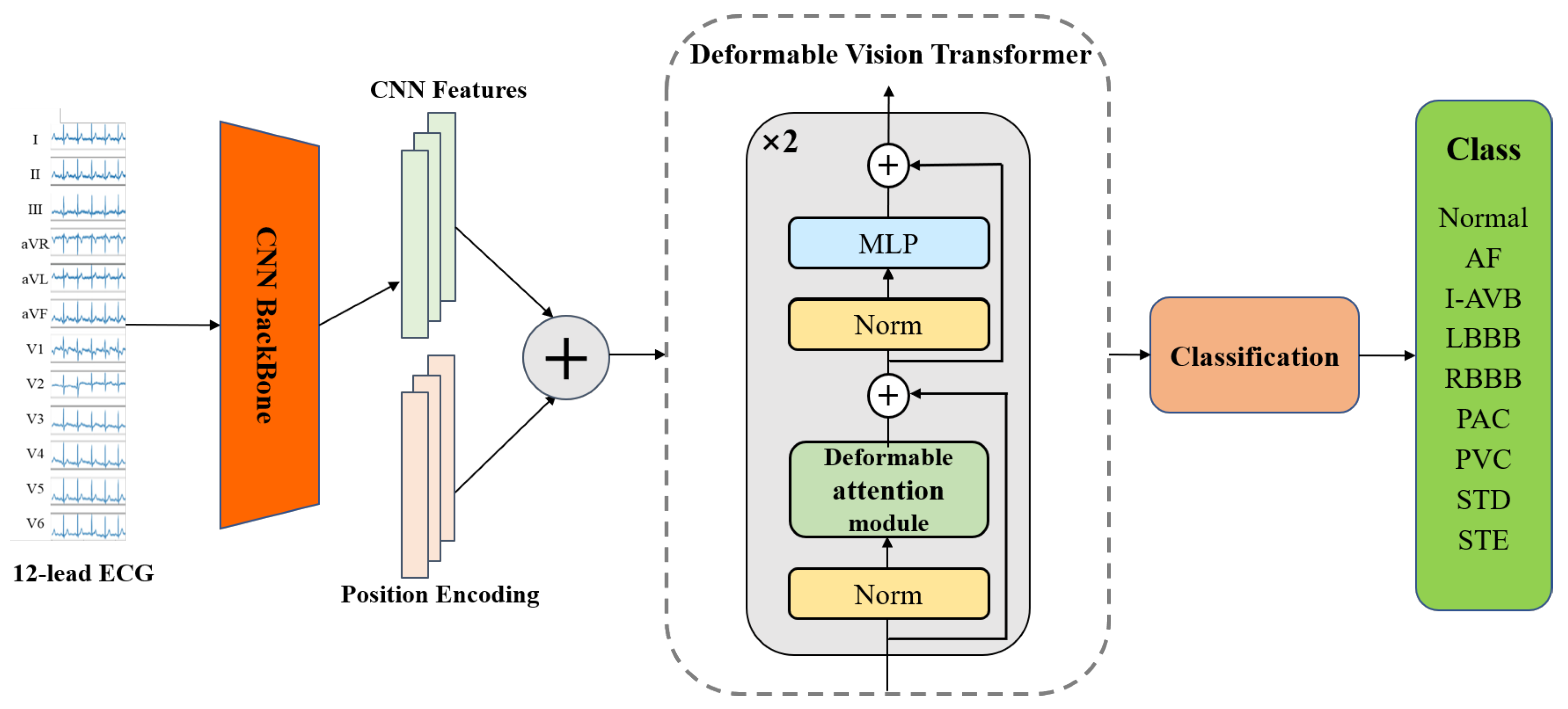
2.1. Model Architecture
2.2. CNN-Based Backbone
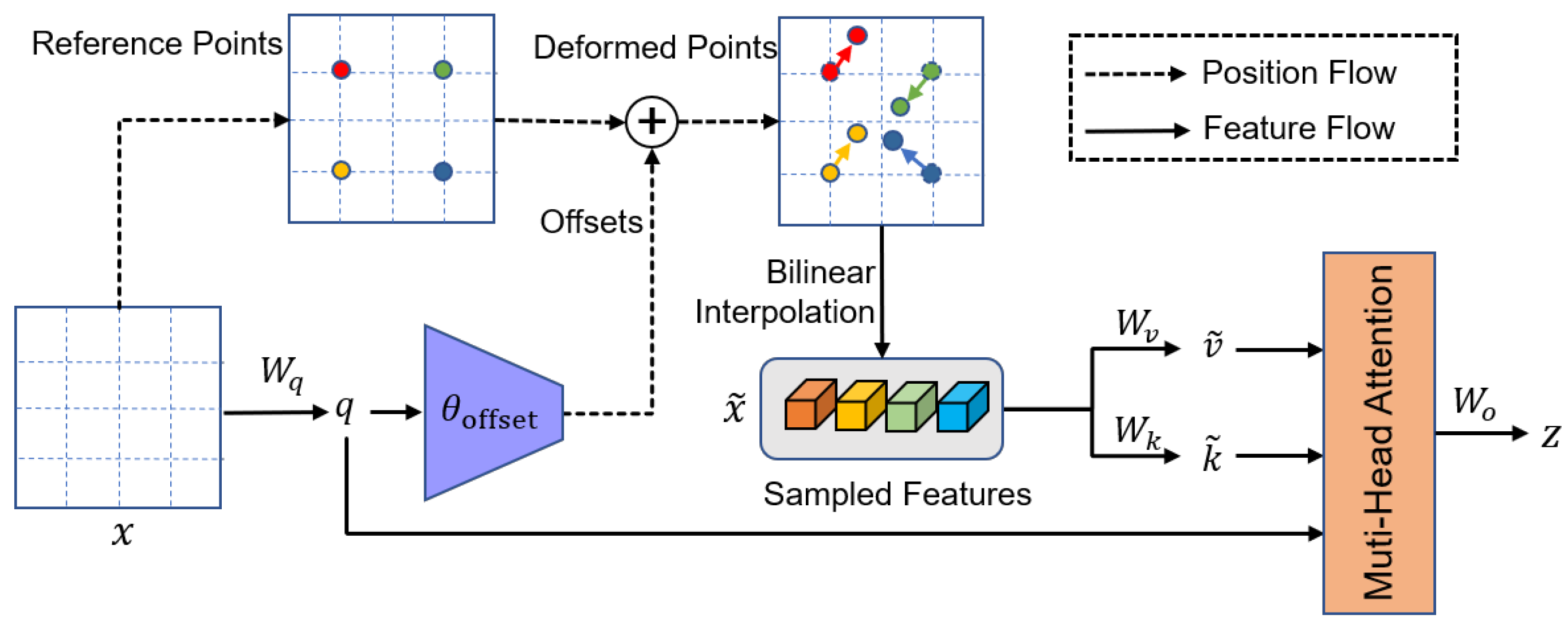
2.3. Deformable Vision Transformer
Deformable Attention Module
2.4. Classification Layer
3. Experiments and Results
3.1. Data Description and Experiment Setup
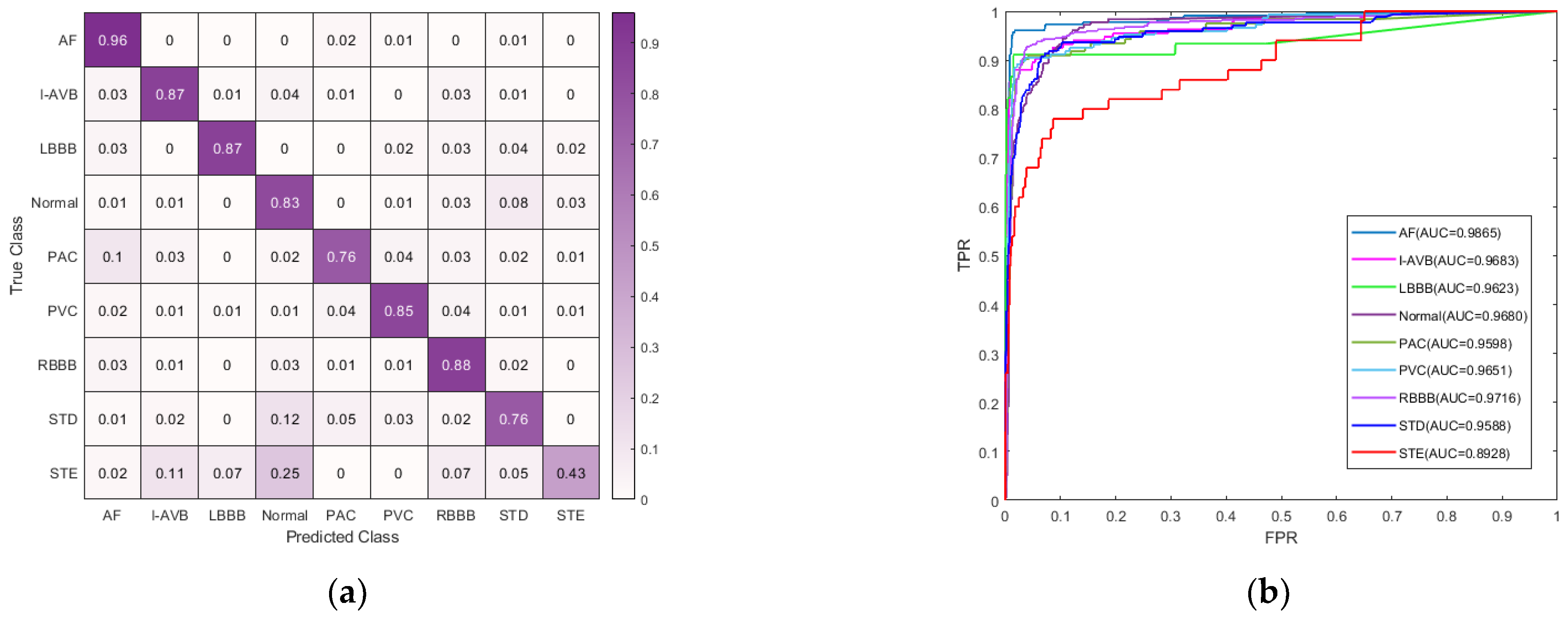
3.2. Classification Performance
3.2.1. Evaluation Metrics
3.2.2. Comparison with Existing Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, R.; Chen, J.; Zhou, L. A transformer-based deep neural network for arrhythmia detection using continuous ECG signals. Comput. Biol. Med. 2022, 144, 105325. [Google Scholar] [CrossRef]
- Kibos, A.S.; Knight, B.P.; Essebag, V.; Fishberger, S.B.; Tintoiu, I.C. Cardiac Arrhythmias: From Basic Mechanism to State-of-the-Art Management; Springer: London, UK, 2014; pp. 43–60. [Google Scholar]
- Hanna, E.B.; Glancy, D.L. ST-segment depression and T-wave inversion: Classification, differential diagnosis, and caveats. Clevel. Clin. J. Med. 2011, 78, 404. [Google Scholar] [CrossRef] [PubMed]
- Shiyovich, A.; Wolak, A.; Yacobovich, L.; Grosbard, A.; Katz, A. Accuracy of diagnosing atrial flutter and atrial fibrillation from a surface electrocardiogram by hospital physicians: Analysis of data from internal medicine departments. Am. J. Med. Sci. 2010, 340, 271–275. [Google Scholar] [CrossRef] [PubMed]
- Schläpfer, J.; Wellens, H.J. Computer-Interpreted Electrocardiograms: Benefits and Limitations. J. Am. Coll. Cardiol. 2017, 70, 1183–1192. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Baloglu, U.B.; Talo, M.; Yildirim, O.; Tan, R.S.; Acharya, U.R. Classification of Myocardial Infarction with Multi-Lead ECG Signals and Deep CNN. Pattern Recognit. Lett. 2019, 122, 23–30. [Google Scholar] [CrossRef]
- Saadatnejad, S.; Oveisi, M.; Hashemi, M. LSTM-based ECG classification for continuous monitoring on personal wearable devices. IEEE J. Biomed. Health Inform. 2019, 24, 515–523. [Google Scholar] [CrossRef]
- Qin, L.; Wang, X.; Li, S.; Wen, J.; Gao, X. An End-to-End 12-Leading Electrocardiogram Diagnosis System Based on Deformable Convolutional Neural Network with Good Antinoise Ability. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-time patient-specific ecg classification by 1-D convolutional neural networks. IEEE Trans. Biomed. Eng. 2016, 63, 664–675. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Hannun, A.Y.; Haghpanahi, M.; Bourn, C.; Ng, A.Y. Cardiologist-level arrhythmia detection with convolutional neural networks. arXiv 2017, arXiv:1707.01836. [Google Scholar]
- Acharya, U.R.; Fujita, H.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M. Application of deep convolutional neural network for automated detection of myocardial infarction using ECG signals. Inf. Sci. 2017, 415, 190–198. [Google Scholar] [CrossRef]
- He, R.; Wang, K.; Zhao, N.; Liu, Y.; Yuan, Y.; Li, Q.; Zhang, H. Automatic detection of atrial fibrillation based on continuous wavelet transform and 2D convolutional neural networks. Front. Physiol. 2018, 9, 1206. [Google Scholar] [CrossRef]
- Jun, T.J.; Nguyen, H.M.; Kang, D.; Kim, D.; Kim, D.; Kim, Y.-H. ECG arrhythmia classification using a 2-D convolutional neural network. arXiv 2018, arXiv:1804.06812. [Google Scholar]
- Elola, A.; Aramendi, E.; Irusta, U.; Picón, A.; Owens, P.; Idris, A. Deep neural networks for ECG-based pulse detection during out-of-hospital cardiac arrest. Entropy 2019, 21, 305. [Google Scholar] [CrossRef]
- Dubatovka, A.; Buhmann, J.M. Automatic Detection of Atrial Fibrillation from Single-Lead ECG Using Deep Learning of the Cardiac Cycle. BME Front. 2022, 2022, 2765–8031. [Google Scholar] [CrossRef]
- Krasteva, V.; Ménétré, S.; Didon, J.-P.; Jekova, I. Fully convolutional deep neural networks with optimized hyperparameters for detection of shockable and non-shockable rhythms. Sensors 2020, 20, 2875. [Google Scholar] [CrossRef]
- Jekova, I.; Krasteva, V. Optimization of End-to-End Convolutional Neural Networks for Analysis of Out-of-Hospital Cardiac Arrest Rhythms during Cardiopulmonary Resuscitation. Sensors 2021, 21, 4105. [Google Scholar] [CrossRef]
- Qiu, X.; Liang, S.; Meng, L.; Zhang, Y.; Liu, F. Exploiting Feature Fusion and Long-term Context Dependencies for Simultaneous ECG Heartbeat Segmentation and Classification. Int. J. Data Sci. Anal. 2021, 11, 181–193. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, C.; Liu, Y.; Yang, H.; Fu, D.; Wang, H.; Zhang, P. A Global and Updatable ECG Beat Classification System Based on Recurrent Neural Networks and Active Learning. Inf. Sci. 2019, 501, 523–542. [Google Scholar] [CrossRef]
- Chen, T.-M.; Huang, C.-H.; Shih, E.S.; Hu, Y.-F.; Hwang, M.-J. Detection and Classification of Cardiac Arrhythmias by a Challenge-Best Deep Learning Neural Network Model. iScience 2020, 23, 100886. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. NeurIPS 2017, 30, 5998–6008. [Google Scholar]
- Onan, A.; Korukolu, S. Exploring Performance of Instance Selection Methods in Text Sentiment Classification. In Artificial Intelligence Perspectives in Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 167–179. [Google Scholar]
- Onan, A.; Korukolu, S. A Feature Selection Model Based on Genetic Rank Aggregation for Text Sentiment Classification. J. Inf. Sci. 2017, 43, 25–38. [Google Scholar] [CrossRef]
- Onan, A. Sentiment Analysis on Product Reviews Based on Weighted Word Embeddings and Deep Neural Networks. Concurr. Comput. Pract. Exp. 2020, 33, e5909. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. Available online: https://openaccess.thecvf.com/content/ICCV2021/html/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.html (accessed on 27 April 2023).
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Pleiss, G.; Van Der Maaten, L.; Weinberger, K. Convolutional Networks with Dense Connectivity. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 44, 8704–8716. [Google Scholar] [CrossRef]
- Yan, G.; Liang, S.; Zhang, Y.; Liu, F. Fusing Transformer Model with Temporal Features for ECG Heartbeat Classification. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 898–905. [Google Scholar]
- Natarajan, A.; Chang, Y.; Mariani, S.; Rahman, A.; Boverman, G.; Vij, S.; Rubin, J. A Wide and Deep Transformer Neural Network for 12-Lead ECG Classification. In Proceedings of the 2020 Computing in Cardiology, Rimini, Italy, 13–16 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Che, C.; Zhang, P.; Zhu, M.; Qu, Y.; Jin, B. Constrained Transformer Network for ECG Signal Processing and Arrhythmia Classification. BMC Med. Inform. Decis. Mak. 2021, 21, 184. [Google Scholar] [CrossRef]
- Martínez, J.P.; Almeida, R.; Olmos, S.; Rocha, A.P.; Laguna, P. A Wavelet-Based ECG Delineator: Evaluation on Standard Databases. IEEE Trans. Biomed. Eng. 2004, 51, 570–581. [Google Scholar] [CrossRef]
- Pan, J.; Tompkins, W.J. A Real-Time QRS Detection Algorithm. IEEE Trans. Biomed. Eng. 1985, 32, 230–236. [Google Scholar] [CrossRef]
- Shang, L.; Yang, Q.; Wang, J.; Li, S.; Lei, W. Detection of Rail Surface Defects Based on CNN Image Recognition and Classification. In Proceedings of the 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon-si, Republic of Korea, 11–14 February 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 45–51. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning Deep Transformer Models for Machine Translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Baevski, A.; Auli, M. Adaptive Input Representations for Neural Language Modeling. arXiv 2018. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Liu, F.; Liu, C.; Zhao, L.; Zhang, X.; Kwee, E.N.Y. An Open Access Database for Evaluating the Algorithms of Electrocardiogram Rhythm and Morphology Abnormality Detection. J. Med. Imaging Health Inform. 2018, 8, 1368–1373. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 99, 2999–3007. [Google Scholar]
- Mostayed, A.; Luo, J.; Shu, X.; Wee, W. Classification of 12-Lead ECG Signals with Bi-directional LSTM Network. arXiv 2018, arXiv:1811.02090. [Google Scholar]
- Tomasic, I.; Petrovic, N.; Linden, M.; Rashkovska, A. Comparison of Publicly Available Beat Detection Algorithms Performances on the ECGs Obtained by a Patch ECG Device. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 275–278. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | F1 Score | ||||||
|---|---|---|---|---|---|---|---|
| ResNet [30] | LSTM [8] | VGG-16 [10] | Mostayed et al., 2018 [46] | Chen et al., 2020 [22] | Che et al., 2021 [34] | CNN-DVIT | |
| N | 0.730 | 0.730 | 0.750 | 0.702 | 0.795 | 0.817 | 0.831 |
| AF | 0.882 | 0.792 | 0.861 | 0.815 | 0.897 | 0.858 | 0.924 |
| I-AVB | 0.877 | 0.763 | 0.874 | 0.767 | 0.865 | 0.878 | 0.887 |
| LBBB | 0.786 | 0.848 | 0.857 | 0.847 | 0.821 | 0.800 | 0.905 |
| RBBB | 0.905 | 0.909 | 0.918 | 0.898 | 0.911 | 0.872 | 0.935 |
| PAC | 0.487 | 0.268 | 0.333 | 0.397 | 0.734 | 0.618 | 0.704 |
| PVC | 0.733 | 0.763 | 0.859 | 0.807 | 0.852 | 0.830 | 0.842 |
| STD | 0.784 | 0.800 | 0.814 | 0.768 | 0.788 | 0.711 | 0.823 |
| STE | 0.444 | 0.105 | 0.462 | 0.286 | 0.509 | 0.686 | 0.610 |
| Average F1 | 0.737 | 0.664 | 0.748 | 0.699 | 0.797 | 0.786 | 0.829 |
| DMHA | MHSA | DWS-CNN | CNN | Average | ||
|---|---|---|---|---|---|---|
| F1 | Precision | Recall | ||||
| ✓ | ✓ | 0.797 | 0.751 | 0.860 | ||
| ✓ | ✓ | 0.789 | 0.775 | 0.825 | ||
| ✓ | ✓ | 0.819 | 0.814 | 0.830 | ||
| ✓ | ✓ | 0.829 | 0.819 | 0.849 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Zhang, M.; Qiu, L.; Wang, L.; Yu, Y. An Arrhythmia Classification Model Based on Vision Transformer with Deformable Attention. Micromachines 2023, 14, 1155. https://doi.org/10.3390/mi14061155
Dong Y, Zhang M, Qiu L, Wang L, Yu Y. An Arrhythmia Classification Model Based on Vision Transformer with Deformable Attention. Micromachines. 2023; 14(6):1155. https://doi.org/10.3390/mi14061155
Chicago/Turabian StyleDong, Yanfang, Miao Zhang, Lishen Qiu, Lirong Wang, and Yong Yu. 2023. "An Arrhythmia Classification Model Based on Vision Transformer with Deformable Attention" Micromachines 14, no. 6: 1155. https://doi.org/10.3390/mi14061155