
Design of GPU Network-on-Chip for Real-Time Video Super-Resolution Reconstruction
Abstract
:1. Introduction
- (1)
- The paper proposes a deep learning SR algorithm combined with LUT, which enables the algorithm to be efficiently implemented on the GPU.
- (2)
- The proposed video SR algorithm has been implemented in real-time on a GPU by elaborate optimization strategy: storage access optimization, conditional branching function optimization, and threading optimization.
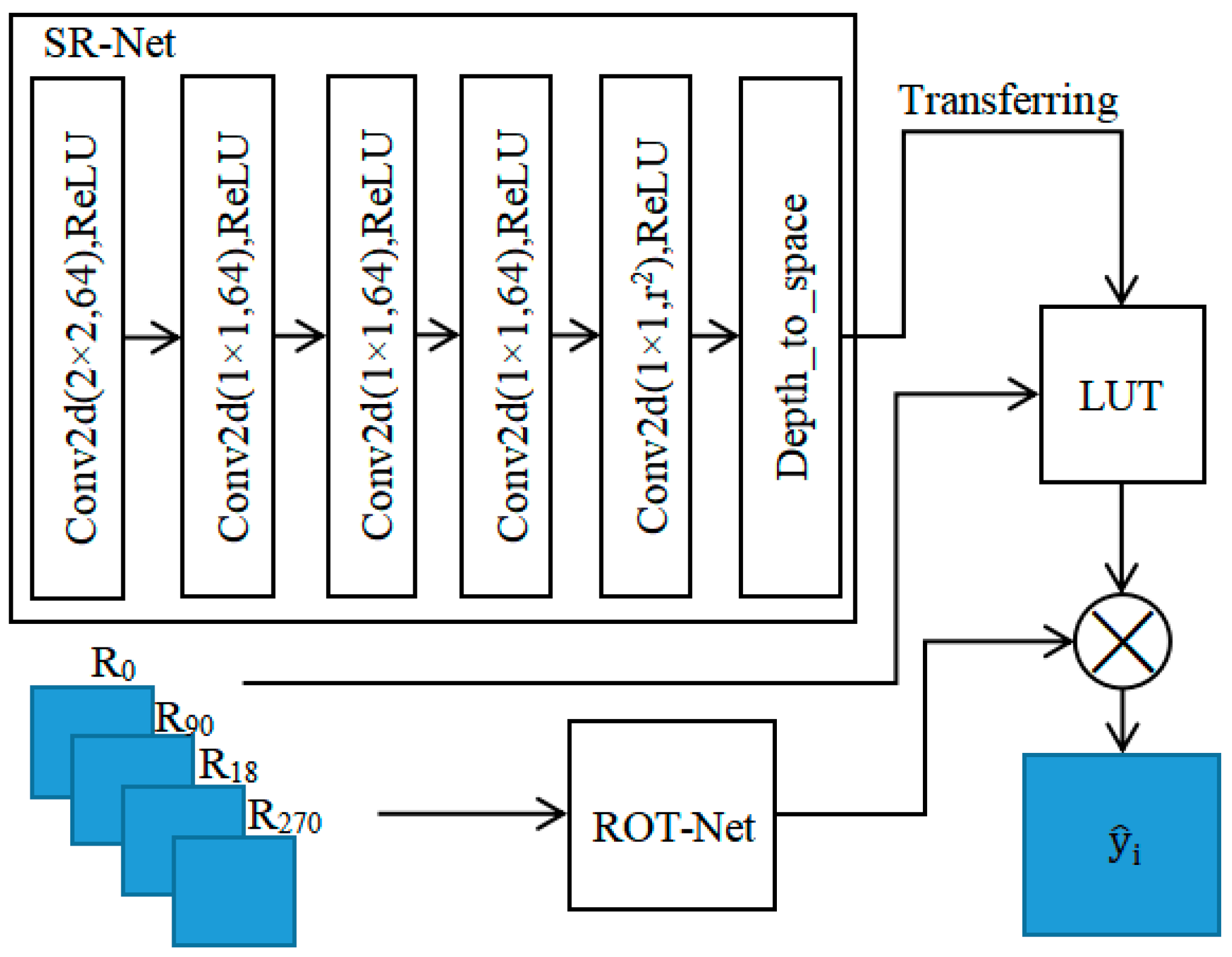
2. Design of a SR Network Based on Deep Learning and LUT
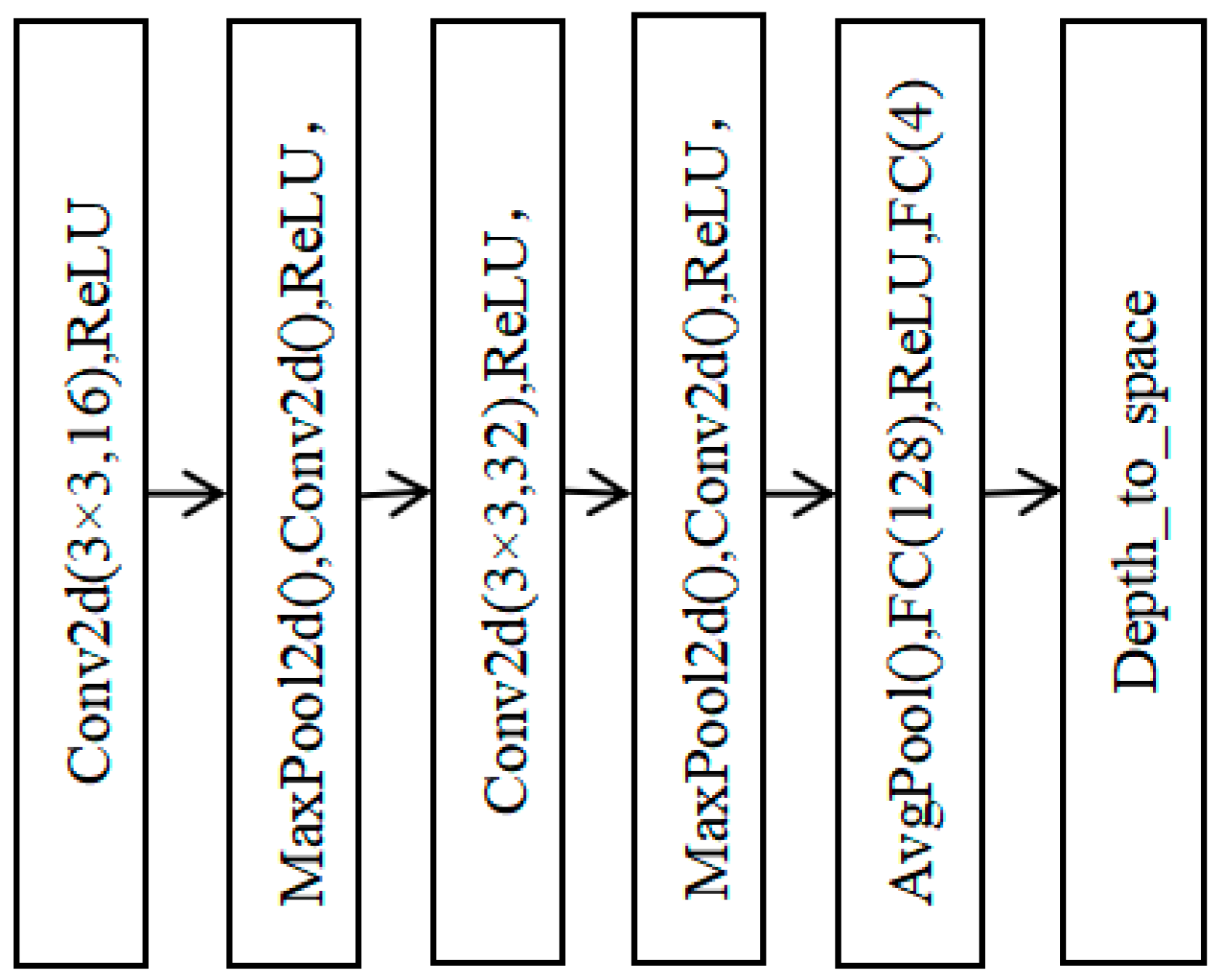
2.1. Design of Video SR Network
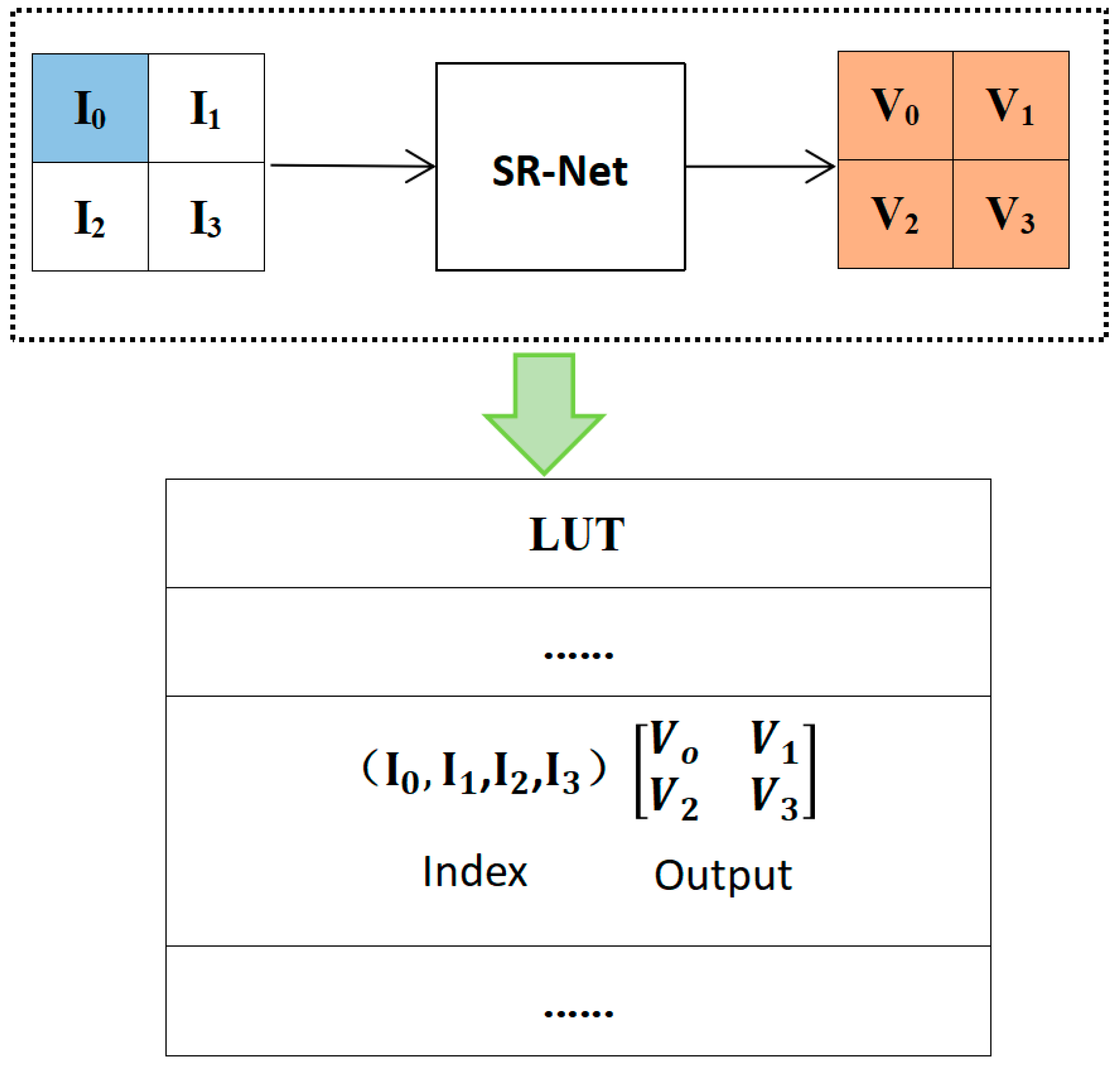
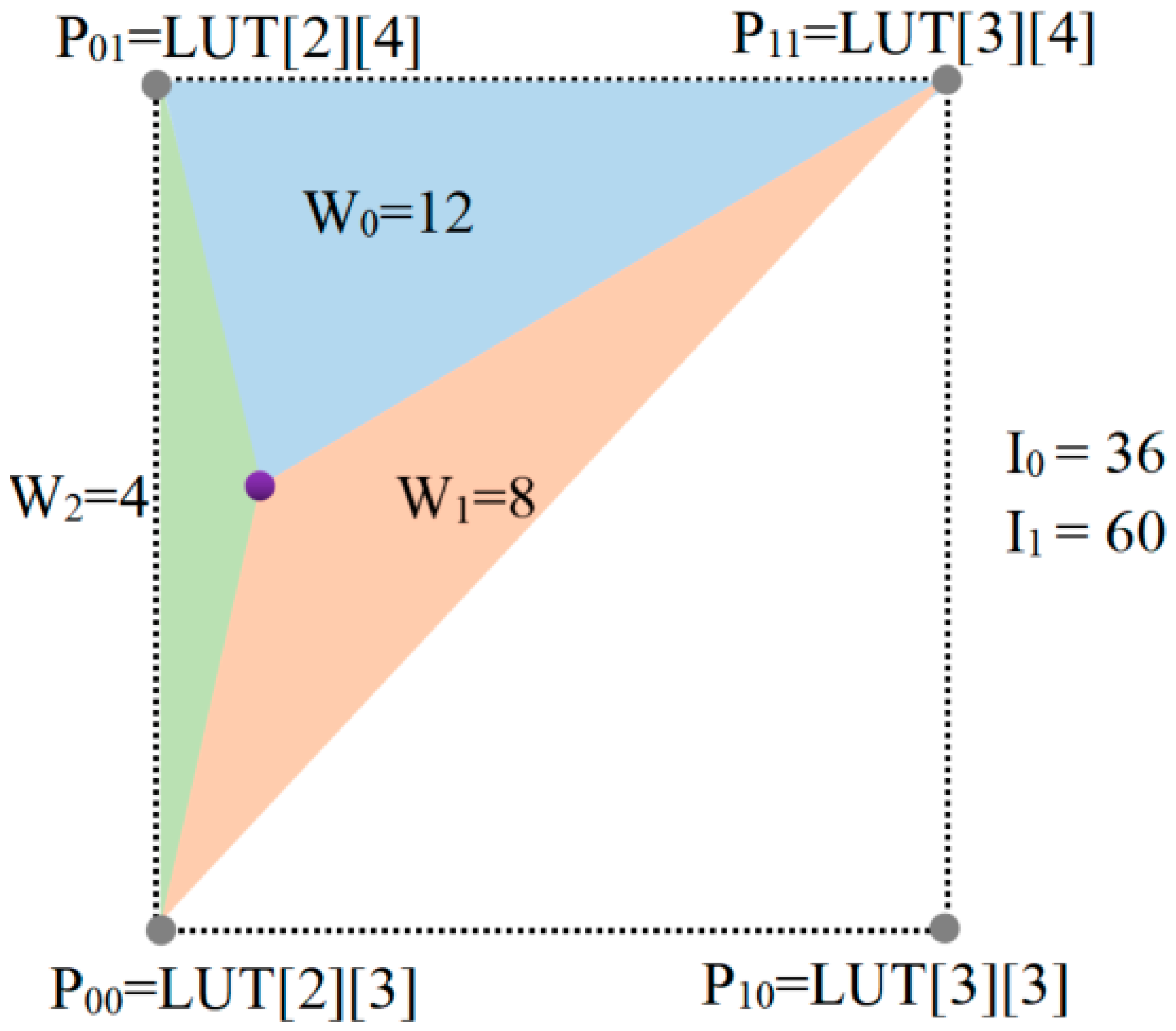
2.2. LUT and Interpolation Design
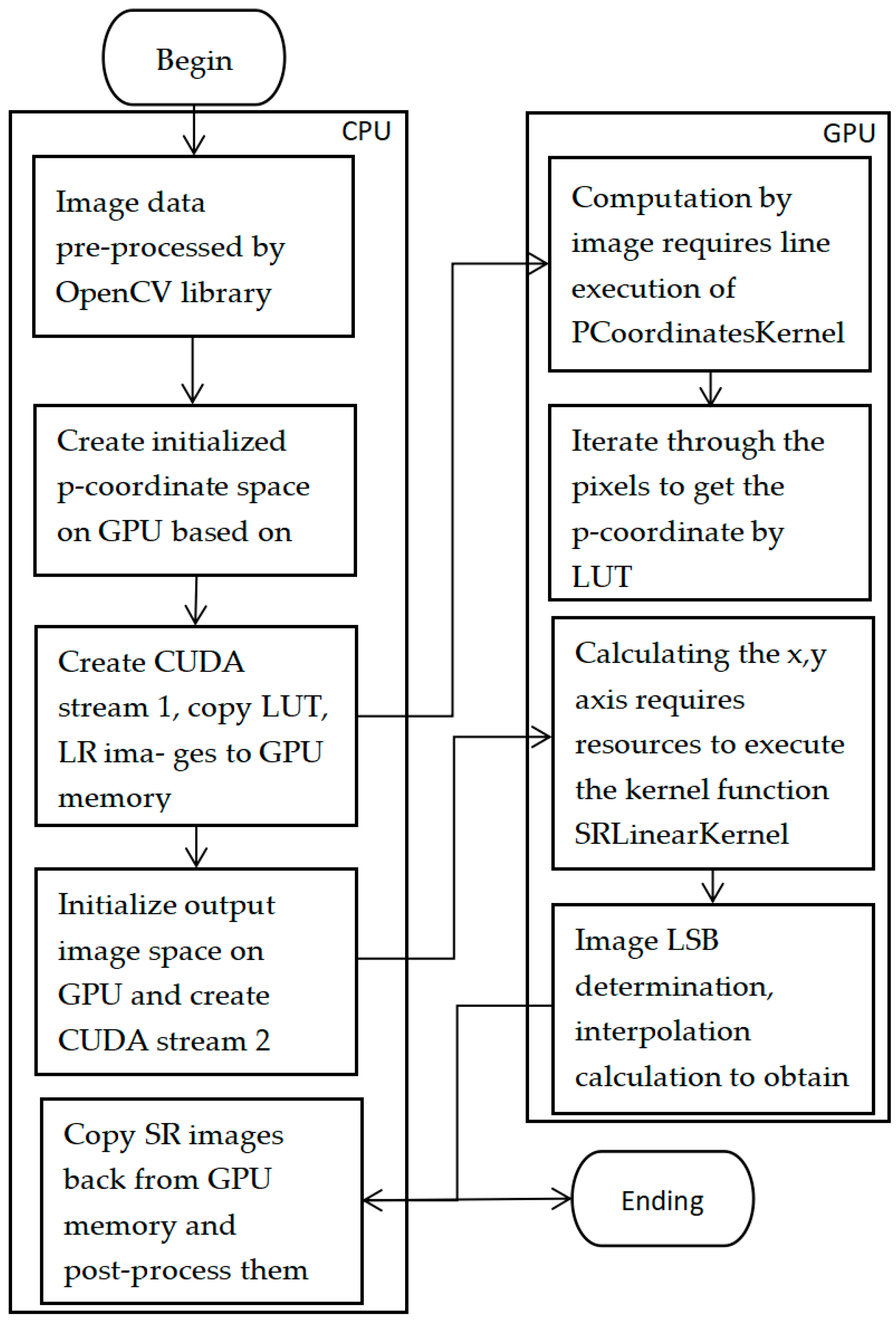
3. GPU On-Chip Optimization Implementation of the Algorithm
3.1. Implementation of the Parallel SR Algorithm Based on CUDA
3.2. Optimization Strategy for Algorithms on CUDA
- (1)
- Storage access optimization
- (2)
- Conditional branching function optimization
- (3)
- Threading optimization
4. Experimental Results and Analysis
4.1. Algorithm Ablation Experiment
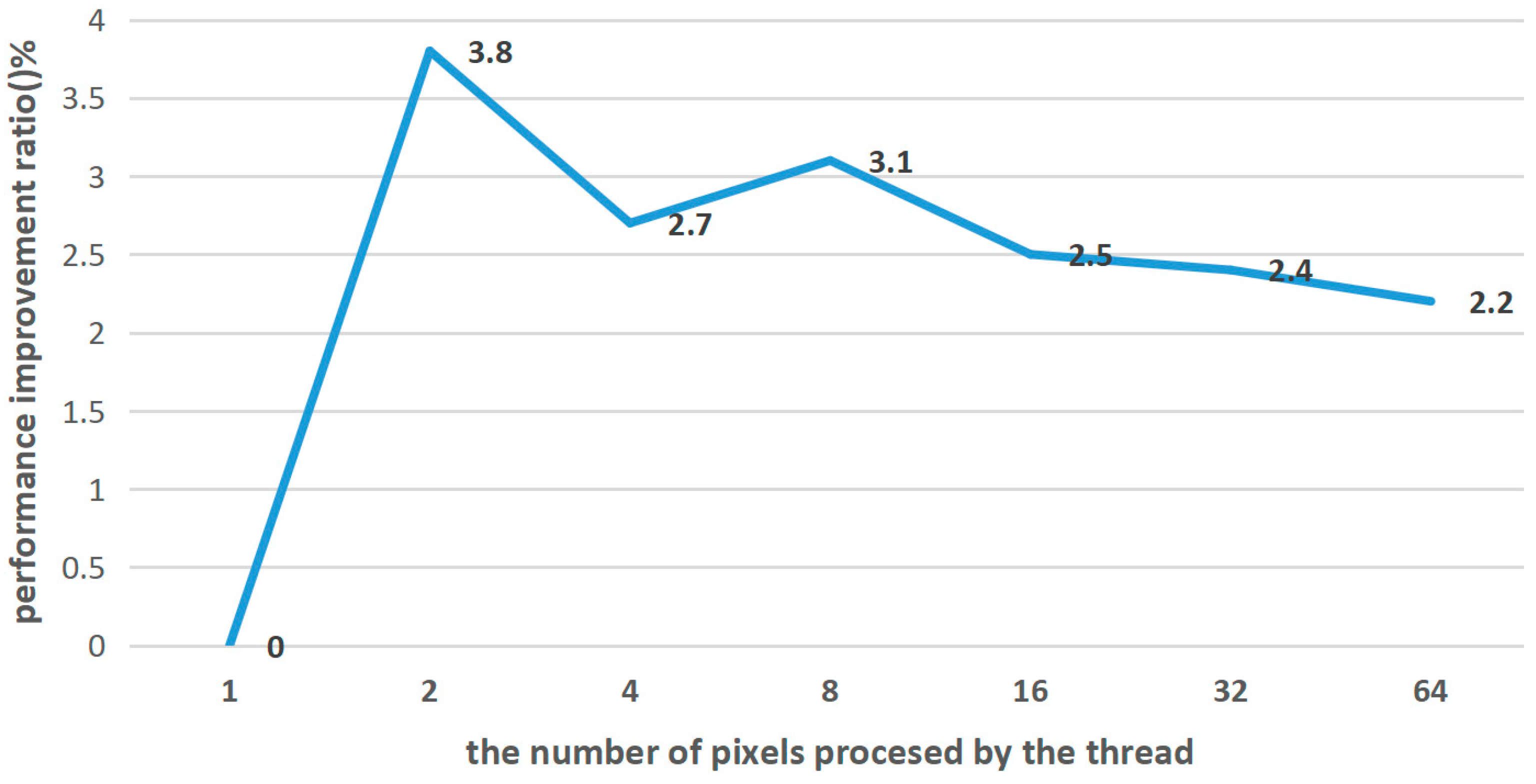
4.1.1. Thread Allocation Ablation Experiment
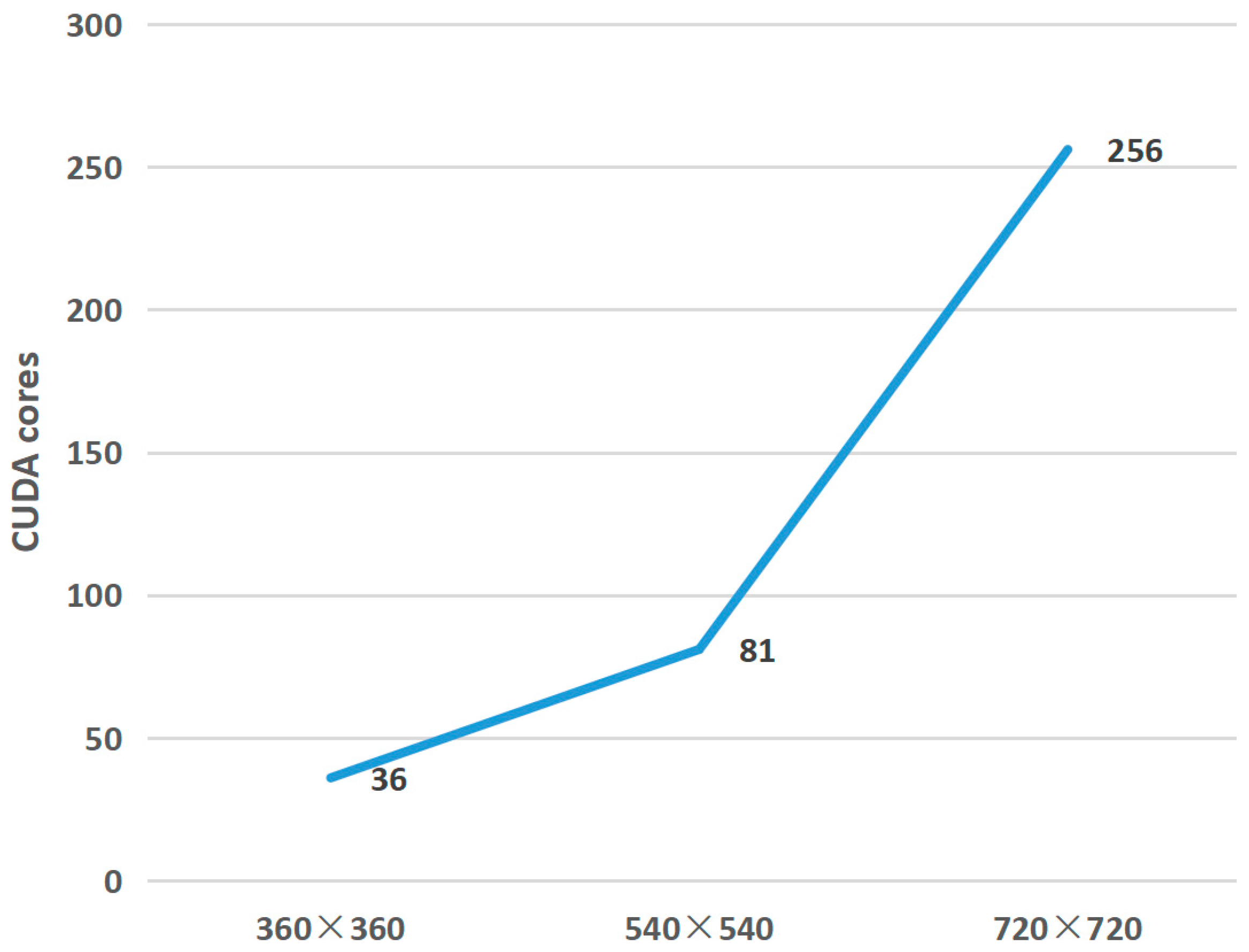
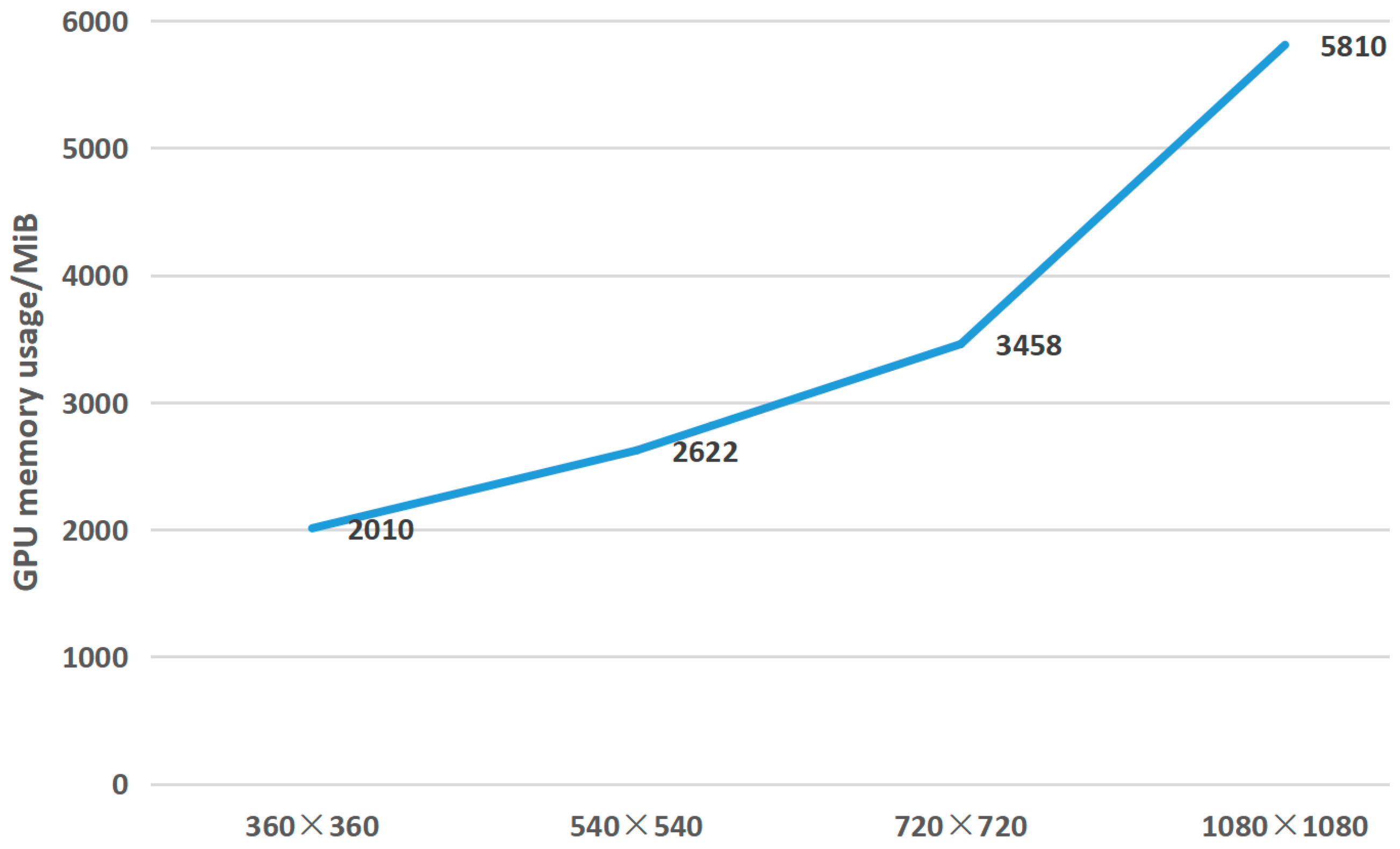
4.1.2. Image Ablation Experiment with Different Resolution
4.2. Network-on-Chip Performance Comparison with Classical SR Algorithms
4.3. Real Video Testing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407. [Google Scholar] [CrossRef]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar] [CrossRef]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight Image Super-Resolution with Information Multi-distillation Network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar] [CrossRef]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback Network for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3862–3871. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5689–5698. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, C.; Song, C.; Tang, Y.; Li, H. Real-Time Super-Resolution System of 4K-Video Based on Deep Learning. In Proceedings of the 2021 IEEE 32nd International Conference on Application-Specific Systems, Architectures and Processors, Orlando, FL, USA, 6–8 September 2021; pp. 69–76. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, C.; Tang, Y. Explore Efficient LUT-based Architecture for Quantized Convolutional Neural Networks on FPGA. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines, Fayetteville, AR, USA, 3–5 May 2020; p. 232. [Google Scholar] [CrossRef]
- Gomez-Rodriguez, J.R.; Sandoval-Arechiga, R.; Ibarra-Delgado, S.; Rodriguez-Abdala, V.I.; Vazquez-Avila, J.L.; Parra-Michel, R. A Survey of Software-Defined Networks-on-Chip: Motivations, Challenges and Opportunities. Micromachines 2021, 12, 183. [Google Scholar] [CrossRef] [PubMed]
- Demirbas, D.; Akturk, I.; Ozturk, O.; Güdükbay, U. Application-Specific Heterogeneous Network-on-Chip Design. Comput. J. 2018, 57, 1117–1131. [Google Scholar] [CrossRef]
- Pharr, M.; Fernando, R. GPU Gems 2: Programming Techniques for High-Performance Graphics and General-Purpose Computation; Addison-Wesley Professional: Boston, MA, USA, 2005; pp. 200–300. [Google Scholar]
- Zeng, H.; Cai, J.; Li, L.; Cao, Z.; Zhang, L. Learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2058–2073. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Lu, C.; Yan, D.; Zhao, Y. Learning Pixel-Adaptive Weights for Portrait Photo Retouching. arXiv 2021, arXiv:2112.03536. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Peng, J.; Ma, Y.; Wang, X.; Song, F.; Yan, Y. Real-Time Image Enhancer via Learnable Spatial-Aware 3D Lookup Tables. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2451–2460. [Google Scholar] [CrossRef]
- Jo, Y.; Kim, S.J. Practical single-image super-resolution using look-up table. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 18–20 December 2021; pp. 691–700. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar] [CrossRef]
- Kasson, J.M.; Nin, S.I.; Plouffe, W.; Hafner, J.L. Performing Color Space Conversions with Three-Dimensional Linear Interpolation. J. Electron. Imaging 1995, 4, 226–251. [Google Scholar] [CrossRef]
- Zhang, S.; Chu, Y. GPU High Performance Computing: CUDA; China Waterpower Press: Beijing, China, 2009; pp. 40–70. [Google Scholar]
- Kirk, D.B.; Hwu, W.M.W. Programming Massively Parallel Processors; Tsinghua University Press: Beijing, China, 2010; pp. 150–220. [Google Scholar]
- Lu, F.S.; Song, J.Q.; Yin, F.K.; Zhang, L.L. Survey of CPU/GPU Synergetic Parallel Computing. Comput. Sci. 2011, 38, 5–10. [Google Scholar]
- Huang, Y.; Wang, Q.B.; Feng, J.K.; Xing, Z.B.; Fan, D.; Tan, X.L.; Lü, M.H. Rapid calculation of local topographic correction based on GPU parallel prism method. J. Surv. Mapp. 2020, 49, 1430–1437. [Google Scholar]
- Fan, Z. CUDA Programming Fundamentals and Practice; Tsinghua University Press: Beijing, China, 2020; pp. 19–22+55. [Google Scholar]
- Fang, L.; Wang, M.; Li, D.; Pan, J. A CPU/GPU modulation transfer compensation method for high-resolution satellite imagery with load distribution. J. Surv. Mapp. 2014, 43, 598–606. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada; 2001; pp. 416–423. [Google Scholar] [CrossRef]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Chang, H.; Yeung, D.-Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; p. 1. [Google Scholar] [CrossRef]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-Up Using Sparse-Representations. In Proceedings of the Curves and Surfaces–7th International Conference, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar] [CrossRef]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar] [CrossRef]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 15 June 2014; pp. 111–126. [Google Scholar] [CrossRef]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Runtime | Size | Set5 | Set14 | BSDS100 | Urban100 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||||
| Interpolation | Nearest | 4 ms * | - | 26.25 | 0.7372 | 24.65 | 0.6529 | 25.03 | 0.6293 | 22.17 | 0.6154 |
| Bilinear | 16 ms * | - | 27.55 | 0.7884 | 25.42 | 0.6792 | 25.54 | 0.6460 | 22.69 | 0.6346 | |
| Bicubic | 60 ms * | - | 28.42 | 0.8101 | 26.00 | 0.7023 | 25.96 | 0.6672 | 23.14 | 0.6574 | |
| LUT | SR-LUT-V [17] | 15 ms * | 1 MB | 29.22 | 0.8304 | 26.65 | 0.7258 | 26.33 | 0.6880 | 23.68 | 0.6852 |
| SR-LUT-F [17] | 34 ms * | 77 kB | 29.77 | 0.8429 | 26.99 | 0.7372 | 26.57 | 0.6990 | 23.94 | 0.6971 | |
| SR-LUT-S [17] | 91 ms * | 1.274 MB | 29.82 | 0.8478 | 27.01 | 0.7355 | 26.53 | 0.6953 | 24.02 | 0.6990 | |
| Our | 10 ms ” | 2.974 MB | 29.89 | 0.8494 | 27.52 | 0.7614 | 26.89 | 0.7118 | 24.03 | 0.7082 | |
| Sparse coding | NE+LLE [29] | 7016 ms * | 1.434 MB | 29.62 | 0.8404 | 26.82 | 0.7346 | 26.49 | 0.6970 | 23.84 | 0.6942 |
| Zeyde et al. [30] | 8797 ms * | 1.434 MB | 26.69 | 0.8429 | 26.90 | 0.7354 | 26.53 | 0.6968 | 23.90 | 0.6962 | |
| ANR [31] | 1715 ms * | 1.434 MB | 29.70 | 0.8422 | 26.86 | 0.7368 | 26.52 | 0.6992 | 23.89 | 0.6964 | |
| A+ [32] | 1748 ms * | 15.171 MB | 30.27 | 0.8602 | 27.30 | 0.7498 | 26.73 | 0.7088 | 24.33 | 0.7189 | |
| DNN | FSRCNN [2] | 75 ms ” | 12 K † | 30.71 | 0.8656 | 27.60 | 0.7543 | 26.96 | 0.7129 | 24.61 | 0.7263 |
| CARN-M [33] | 270 ms ” | 412 K † | 31.82 | 0.8898 | 28.29 | 0.7747 | 27.42 | 0.7305 | 25.62 | 0.7694 | |
| RRDB [6] | 1780 ms ” | 16,698 K † | 32.68 | 0.8999 | 28.88 | 0.7891 | 27.82 | 0.7444 | 27.02 | 0.8146 | |
| EDSR [8] | 130 ms ” | 1300 K † | 32.46 | 0.8968 | 28.80 | 0.7876 | 27.71 | 0.7420 | 26.64 | 0.8033 | |
| IMDN [4] | 55 ms ” | 715 K † | 32.21 | 0.8948 | 28.58 | 0.7811 | 27.56 | 0.7353 | 26.04 | 0.7838 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Z.; Du, J.; Qiao, Y. Design of GPU Network-on-Chip for Real-Time Video Super-Resolution Reconstruction. Micromachines 2023, 14, 1055. https://doi.org/10.3390/mi14051055
Peng Z, Du J, Qiao Y. Design of GPU Network-on-Chip for Real-Time Video Super-Resolution Reconstruction. Micromachines. 2023; 14(5):1055. https://doi.org/10.3390/mi14051055
Chicago/Turabian StylePeng, Zhiyong, Jiang Du, and Yulong Qiao. 2023. "Design of GPU Network-on-Chip for Real-Time Video Super-Resolution Reconstruction" Micromachines 14, no. 5: 1055. https://doi.org/10.3390/mi14051055