
Hybrid Optimization Algorithm Based on Double Particle Swarm in 3D NoC Mapping

Abstract
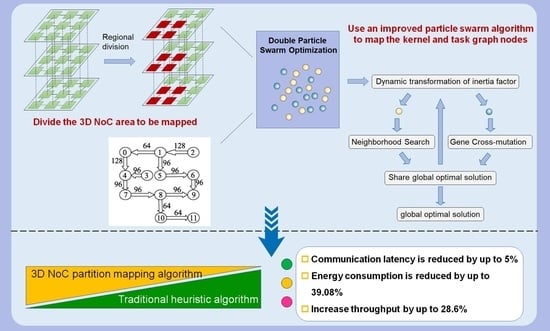
:
1. Introduction
2. System and Computation Model
2.1. Task Graph
2.2. 3D NoC Topology
2.3. Communication Power Consumption Model
2.4. Delay Model
2.5. Thermal-Aware Model
3. Proposed Algorithm
3.1. Regional Division
- The temperature metrics of each node are calculated based on the energy consumption value and added to the temperature queue (lines 1–3), then arranged in ascending order. The smallest temperature node is found as the initial division node and added to the resource node group (lines 4–5).
- 2.
- Iterate through all nodes connected by TSV technology in the group and add them to the queue (lines 7–9). If there are no more vertically adjacent (connected by TSV) nodes, the horizontally adjacent (connected by common link) nodes of all nodes in the group are added to the queue .
- 3.
- The sum of the horizontal Manhattan distances from the nodes in the queue to the nodes in the are calculated (lines 11–12). The values are then added to the queue and sorted, and the minimum value is selected (lines 23–29). If multiple nodes have the same horizontal distance to the , their effect on the thermal resistance value in the is calculated (lines 13–15). The minimum operator node is then selected and added to the group (lines 16–22).
- 4.
- If the number of nodes in the is less than the number of nodes in the graph, steps 2 to 4 are repeated.
| Algorithm 1: NoC Regional Division Algorithm |
| Inputs: |
| : NoC topology graph |
| : The number of NoC resource nodes in the three dimensions |
| : Resource node with coordinates x, y, z |
| : Application task graph of the application, where the number of the task graph is |
| : Assumed power consumption of each alternative node |
| Ensure: |
| : Group of resource node |
| Optimal offloading policy A, the total overhead C |
| 1: For u є 𝑈 do |
| 2: temperature list: |
| 3: End for |
| 4: Get the coordinate of the |
| 5: . |
| 6: While do |
| 7: If Zt + 1 ≤ Z then |
| 8: |
| 9: |
| 10: Else |
| 11: |
| 12: |
| 13: If then |
| 14: |
| 15: |
| 16: If then |
| 17: |
| 18: . |
| 19: Else |
| 20: |
| 21: |
| 22: End if |
| 23: Else if then |
| 24: |
| 25: |
| 26: Else |
| 27: |
| 28: |
| 29: End if |
| 30: End if |
| 31: End while |
3.2. Double Particle Swarm Based Thermal-Aware Mapping Algorithm
3.2.1. Dynamic Transformation of the Inertia Factor
3.2.2. Neighborhood Search
3.2.3. Gene Cross-Mutation
3.2.4. Double Particle Swarm Optimization
- Initialization: the velocity and position of the particles, based on the initialized position information, are substituted into Equations (9) and (12) to calculate the initial fitness value (lines 1–2). The forbidden table is initialized for the neighborhood search (line 3).
- The particle population that joins the neighborhood search feature is defined as the list of fitness values as , the particle population that joins the genetic variation feature as , and the list of fitness values as (lines 5–7).
- Particle evolution: the inertia factor of particles is updated according to Equation (15) and the particle position is updated according to Equation (17) (lines 8–11).
- The cross-variation state of particles in is evaluated according to Equation (16) (lines 12–17).
- The diversity of particles in is evaluated, and if the diversity value is less than the predetermined threshold, is added to the forbidden table and is reset to the suboptimal solution of fitness in (lines 18–23). Step 2 is repeated.
| Algorithm 2: DPSO |
| Inputs: |
| : NoC topology graph |
| VG: Group of resource node |
| : The number of NoC resource nodes in the three dimensions |
| : Resource node with coordinates x, y, and z |
| Population: Maximum particle number |
| Output: : Mapping relation of TG to VG |
| 1: Initializes particle positions and velocities in a random range: , |
| 2: Calculates the fitness of each particle: , |
| 3: Initializes forbidden table: |
| 4: For do |
| 5: updates pop fitness with Equation (9) and Equation (12): |
| 6: |
| 7: |
| 8: updates inertia factor according to Equation (15) |
| 9: updates particle position according to Equation (17) |
| 10: |
| 11: |
| 12: updates mutation probability |
| 13: For do |
| 14: |
| 15: |
| 16: End if |
| 17: End for |
| 18: sorts according to |
| 19: If then |
| 20: |
| 21: searches neighborhood, updates if there is a better solution |
| 22: |
| 23: End if |
| 24: End of |
4. Simulation and Results
4.1. Experience Environment
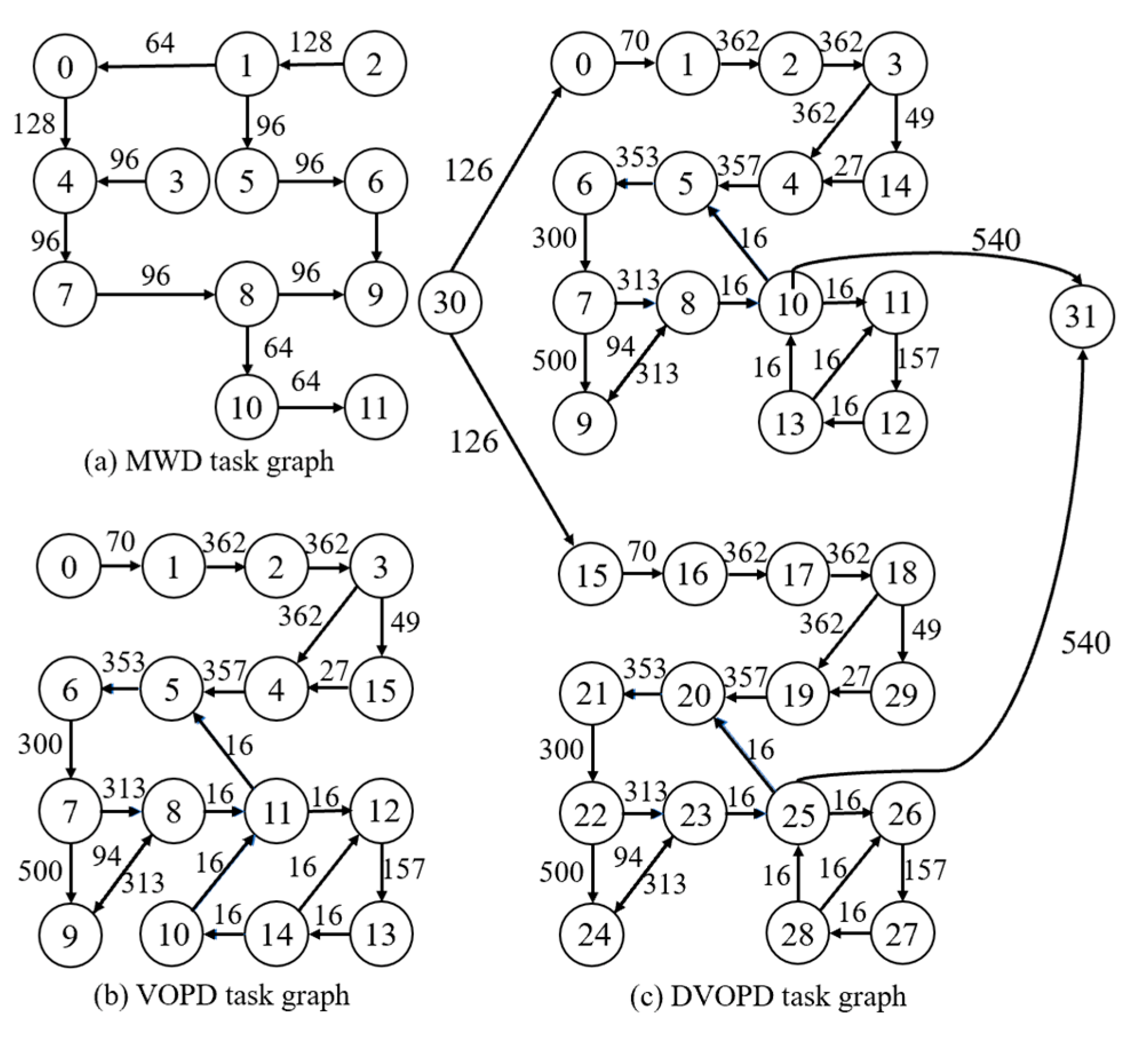
4.2. Experimental Task Graph
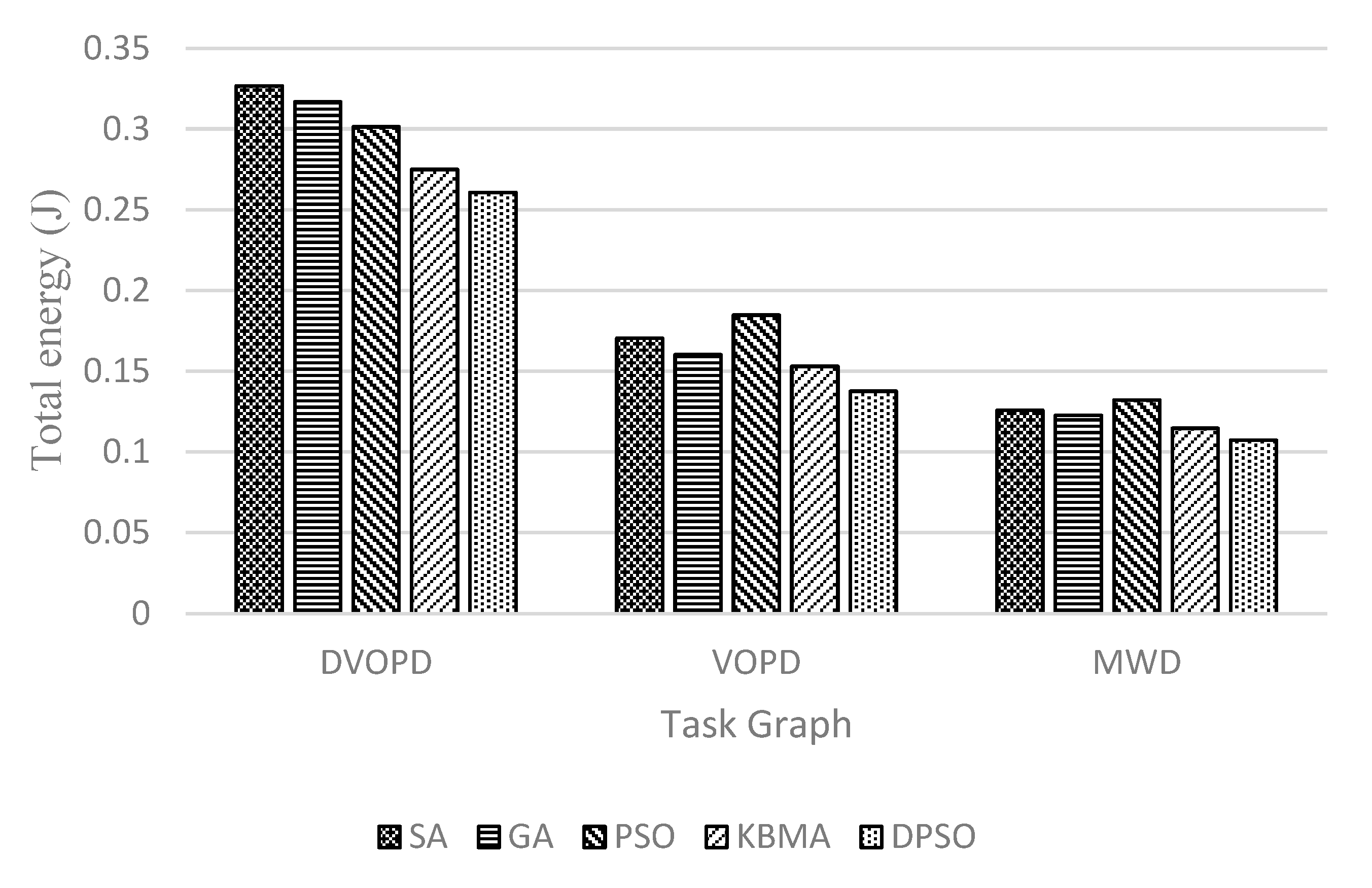
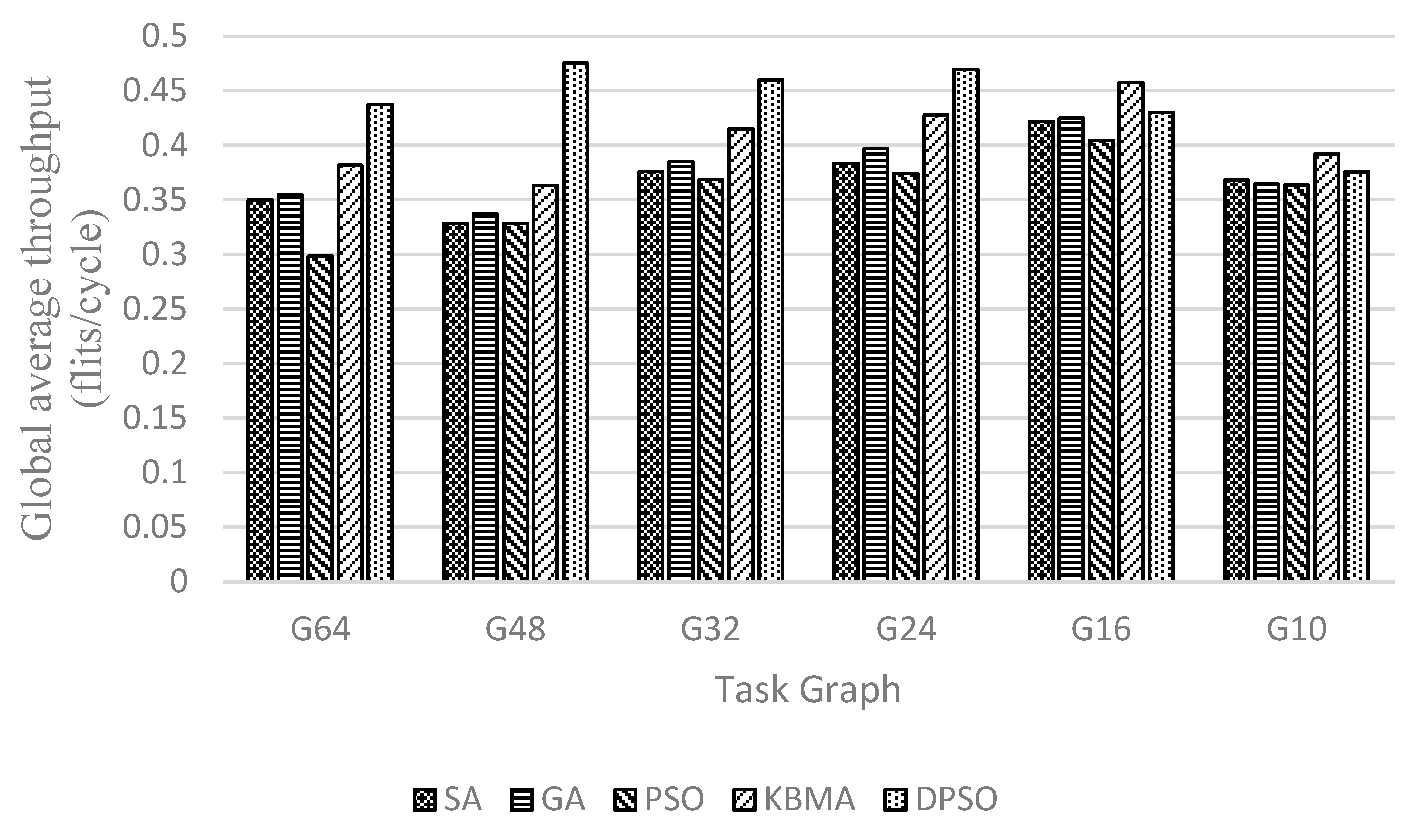
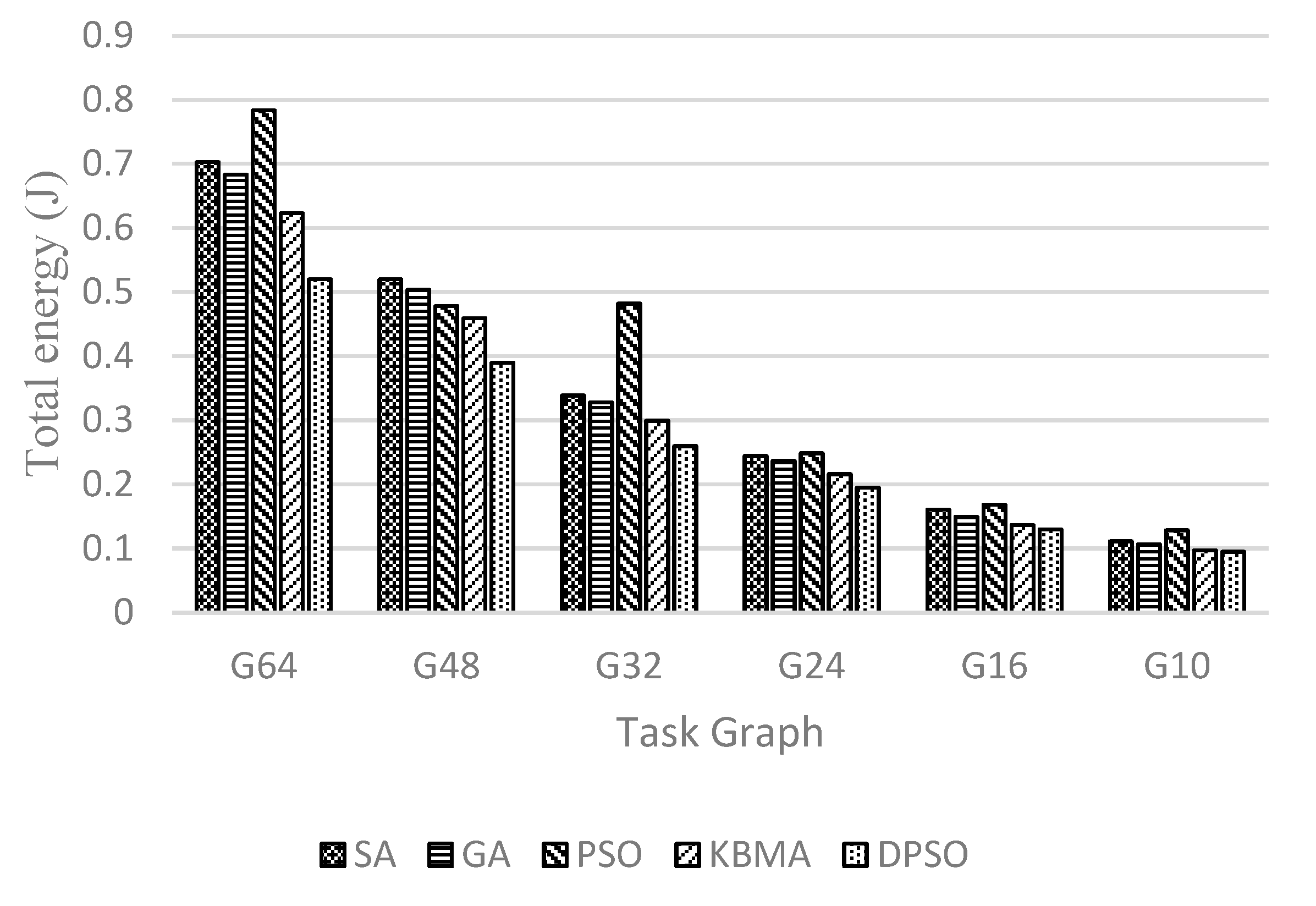
4.3. Performance Comparison
4.3.1. Experimental Results of the Traditional NoC Task Map
4.3.2. Results of Randomized Task Graphs
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Skadron, K.; Stan, M.R.; Huang, W.; Velusamy, S.; Sankaranarayanan, K.; Tarjan, D. Temperature-aware microarchitecture. In Proceedings of the 30th Annual International Symposium on Computer Architecture, San Diego, CA, USA, 9–11 June 2003; pp. 2–13. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Xie, Y.; Vijaykrishnan, N.; Irwin, M.J. On-chip Bus Thermal Analysis and Optimization. In Proceedings of the Design Automation & Test in Europe Conference, Munich, Germany, 6–10 March 2006; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Hertl, M.; Weidmann, D.; Ngai, A. An advanced reliability improvement and failure analysis approach to thermal stress issues in IC packages. In Proceedings of the Physical and Failure Analysis of Integrated Circuits, IPFA 2009, 16th IEEE International Symposium on the IEEE, Suzhou, China, 30 June–4 July 2009. [Google Scholar]
- Liu, G.; Ming, F.; Gang, Q. Neighbor-aware dynamic thermal management for multi-core platform. In Proceedings of the Conference on Design, Automation and Test in Europe, Dresden, Germany, 12–16 March 2012. [Google Scholar]
- Chakraborty, A.; Duraisami, K.; Sathanur, A.; Sithambaram, P.; Macii, A.; Macii, E.; Poncino, M. Implementation of a thermal management unit for canceling temperature-dependent clock skew variations. Integr. VLSI J. 2008, 4, 2–8. [Google Scholar] [CrossRef]
- Shafifique, M.; Garg, S.; Henkel, J.; Marculescu, D. The EDA challenges in the dark silicon era. In Proceedings of the Design Automation Conference, San Francisco, CA, USA, 1–5 June 2014; pp. 1–6. [Google Scholar]
- Shafifique, M.; Garg, S.; Henkel, J.; Marculescu, D.J.; Henkel, H.; Khdr, S.; Pagani, A.; Shafifique, M. New trends in dark silicon. In Proceedings of the Design Automation Conference, San Francisco, CA, USA, 7–11 June 2015; pp. 1–6. [Google Scholar]
- Fang, J.; Yu, L.; Liu, S.; Lu, J.; Chen, T. KL_GA: An application mapping algorithm for mesh-of-tree (MoT) architecture in network-on-chip design. J. Supercomput. 2015, 71, 4056–4071. [Google Scholar] [CrossRef] [Green Version]
- Jayshree, D.; Seetharaman, G.; Pati, D. Energy consumption and performance comparison of DE optimization and PSO-based IP-core mapping technique for 2D and 3D network-on-chip. Semicond. Sci. Technol. 2021, 36, 085015. [Google Scholar] [CrossRef]
- De Barros, J.B.; Sampaio, R.C.; Llanos, C.H. 2019 An adaptive discrete particle swarm optimization for mapping real-time applications onto network-on-a-chip based MPSoCs Proc. In Proceedings of the 32nd Symposium on Integrated Circuits and Systems Design ser. SBCCI 19, Sao Paulo, Brazil, 26–30 August 2019; ACM: New York, NY, USA, 2019; pp. 5–6. [Google Scholar]
- Keley, M.; Khademzadeh, A.; Hosseinzadeh, M.; Center, I. Efficient mapping algorithm on mesh-based NoCs in terms of cellular learning automata. Int. Arab J. Inf. Technol. 2019, 16, 312–322. [Google Scholar]
- Li, B.; Wang, X.; Singh, A.K.; Mak, T. On runtime communication- and thermal-aware application mapping in 3D NoC. In Proceedings of the 2017 Eleventh IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Seoul, Republic of Korea, 19–20 October 2017; pp. 1–8. [Google Scholar]
- Gan, Y.; Guo, H.; Zhou, Z. 3D NoC Low-Power Mapping Optimization Based on Improved Genetic Algorithm. Micromachines 2021, 12, 1217. [Google Scholar] [CrossRef] [PubMed]
- Aravindhan, A.; Gopalakrishnan, L.; Ko, S. KBMA: A knowledge-based multi-objective application mapping approach for 3D NoC. IET Comput. Digit. Tech. 2019, 13, 324–334. [Google Scholar]
- Nalci, Y.; Kullu, P.; Tosun, S.; Ozturk, O. ILP formulation and heuristic method for energy-aware application mapping on 3D-NoCs. J. Supercomput. 2021, 77, 2667–2680. [Google Scholar] [CrossRef]
- Zhang, J.X.; Yang, G.H. Low-Complexity Tracking Control of Strict-Feedback Systems with Unknown Control Directions. in IEEE Trans. Autom. Control 2019, 64, 5175–5182. [Google Scholar] [CrossRef]
- Ding, W.; Wang, Q.G.; Zhang, J.X. Analysis and prediction of COVID-19 epidemic in South Africa. ISA Trans. 2022, 124, 182–190. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Dai, L. Image enhancement based on rough set and fractional order differentiator. Fractal Fract. 2022, 6, 214. [Google Scholar] [CrossRef]
- Manna, K.; Swami, S.; Chattopadhyay, S.; Sengupta, I. Integrated through-silicon via placement and application mapping for 3D mesh-based NoC design. ACM Trans. Embed. Comput. Syst. 2016, 16, 24. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhang, L.; Han, Y.; Li, X. Thermal-Constrained Task Allocation for Interconnect Energy Reduction in 3-D Homogeneous MPSoCs. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 21, 239–249. [Google Scholar] [CrossRef]
- Dick, R.P.; Rhodes, D.L.; Wolf, W. TGFF: Task graphs for free. In Proceedings of the Sixth International Workshop on Hardware/Software Codesign. (CODES/CASHE’98), Seattle, WA, USA, 18 March 1998; pp. 97–101. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network parameters | |
| Flit size | 128 bits |
| Latency Router | 2 cycles, link 1 cycle |
| Buffer depth | 4 flits |
| Routing algorithm | XYZ routing |
| Baseline topology | |
| Configuration of Many-core Simulator | |
| Core Architecture | Intel Pentium 4 |
| Baseline Frequency | 1.9 GHz |
| Hotspot Parameters | |
| Die size [mm] | 0.5 × 0.5 |
| Specific heat capacity [J/(m3 × K)] | 1.75 × 106 |
| Resistivity [(m − K)/W] | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, J.; Cai, H.; Lv, X. Hybrid Optimization Algorithm Based on Double Particle Swarm in 3D NoC Mapping. Micromachines 2023, 14, 628. https://doi.org/10.3390/mi14030628
Fang J, Cai H, Lv X. Hybrid Optimization Algorithm Based on Double Particle Swarm in 3D NoC Mapping. Micromachines. 2023; 14(3):628. https://doi.org/10.3390/mi14030628
Chicago/Turabian StyleFang, Juan, Huayi Cai, and Xin Lv. 2023. "Hybrid Optimization Algorithm Based on Double Particle Swarm in 3D NoC Mapping" Micromachines 14, no. 3: 628. https://doi.org/10.3390/mi14030628