
Efficient Layer-Wise N:M Sparse CNN Accelerator with Flexible SPEC: Sparse Processing Element Clusters

Abstract
:1. Introduction
2. Background
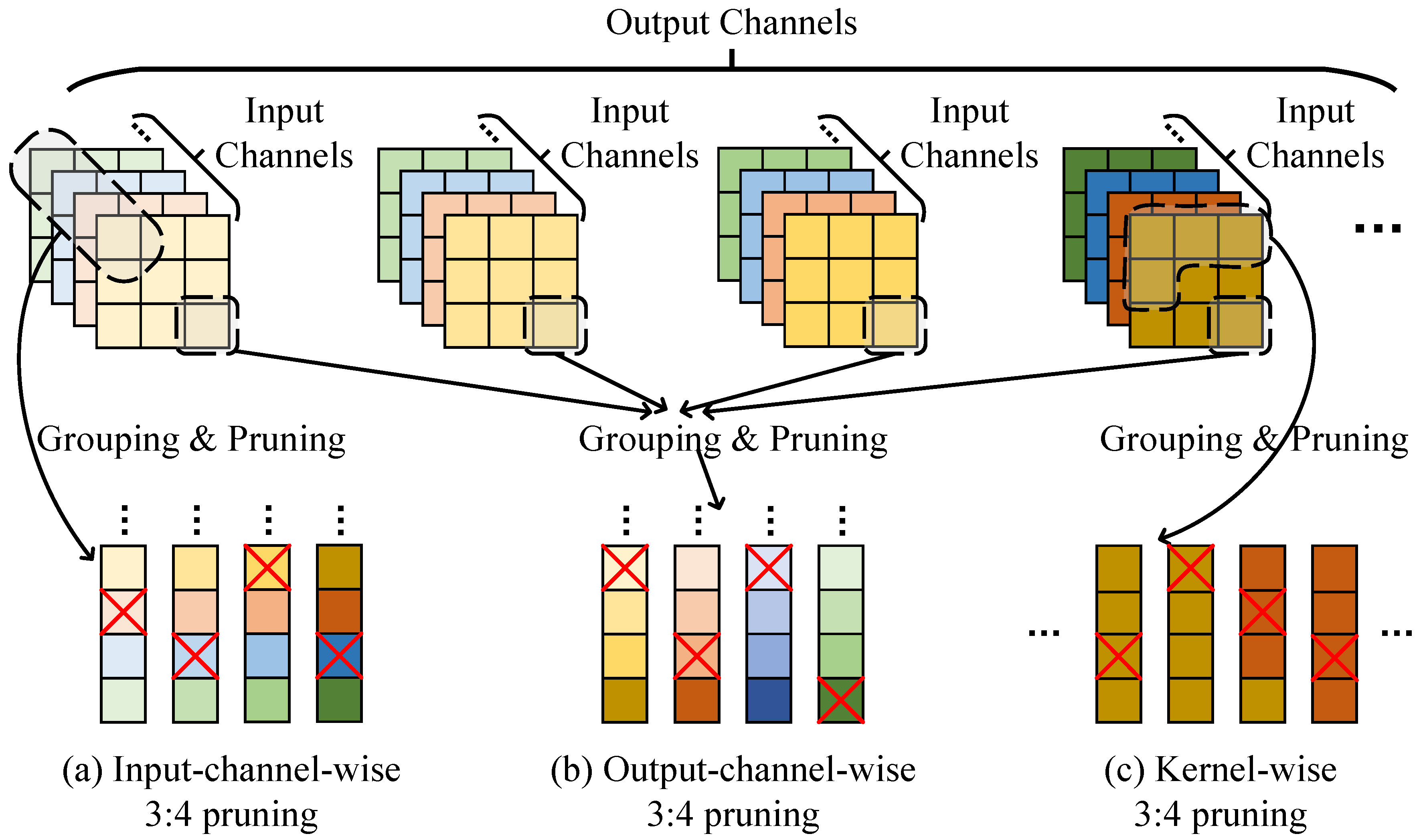
3. Algorithm-Hardware Co-Analysis
4. Hardware Architecture for Layer-Wise N:M Sparse CNNs
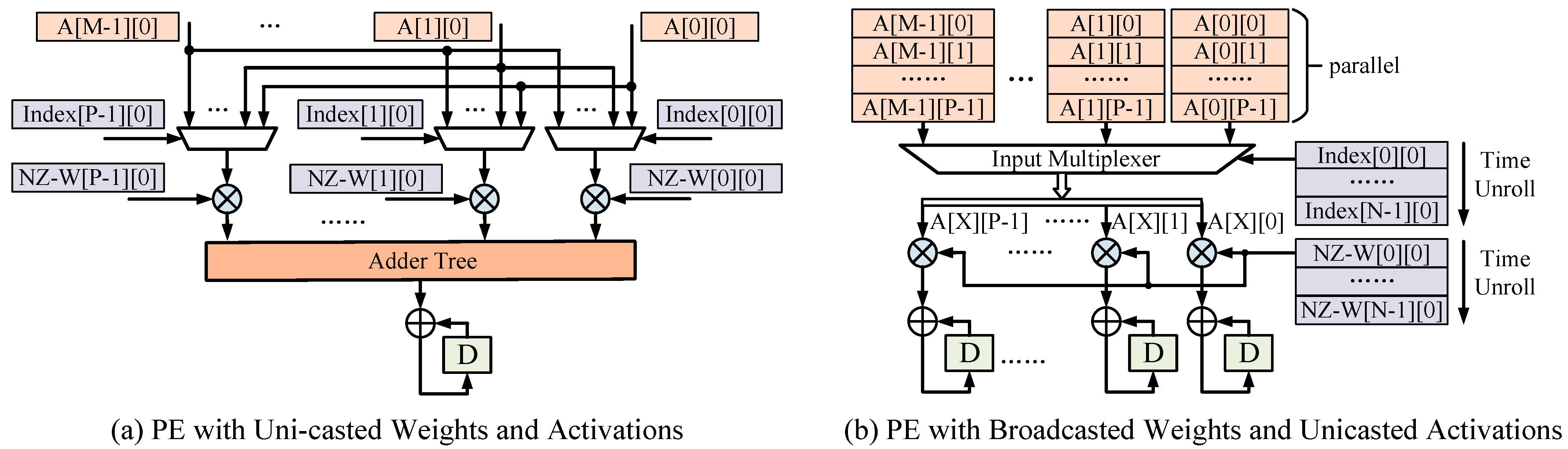
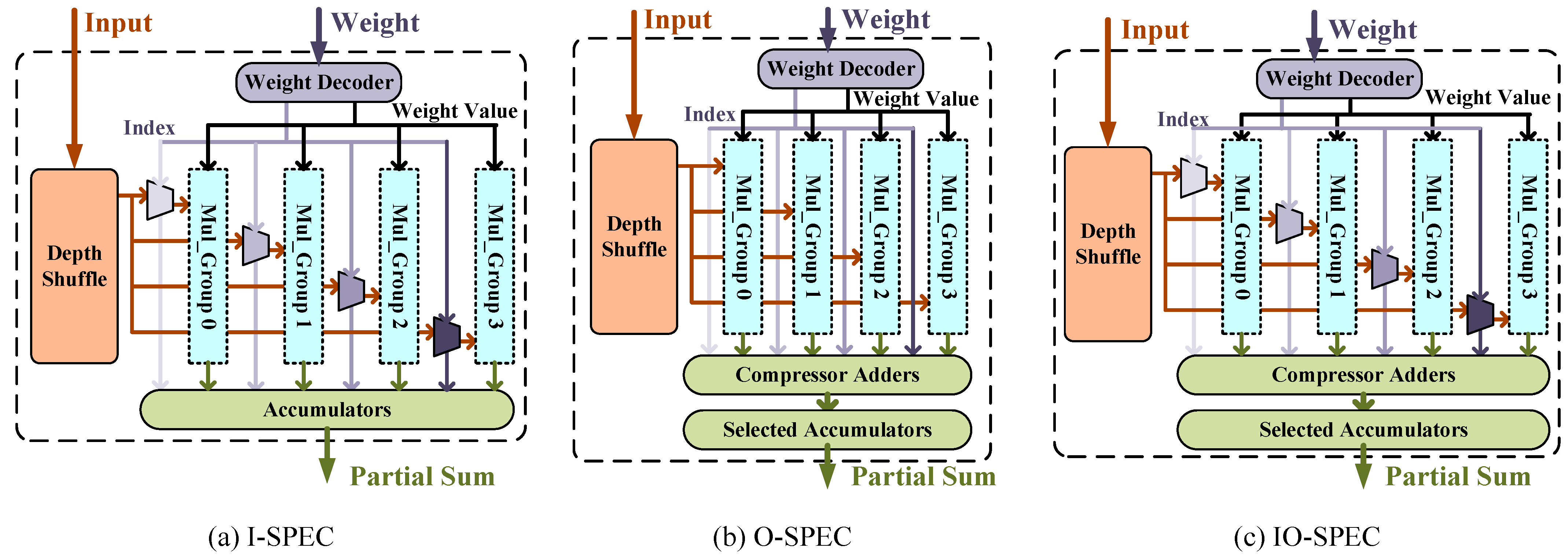
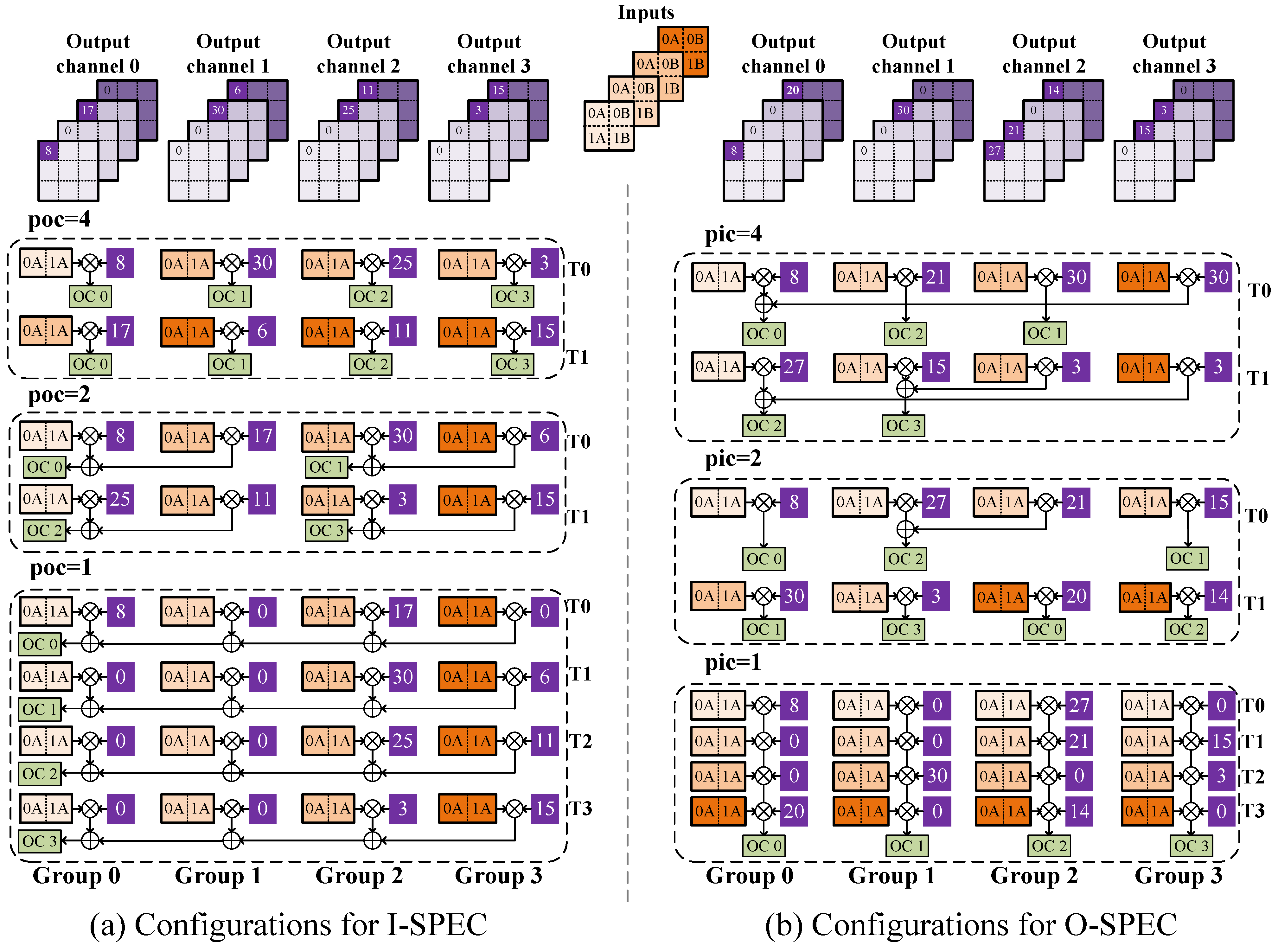
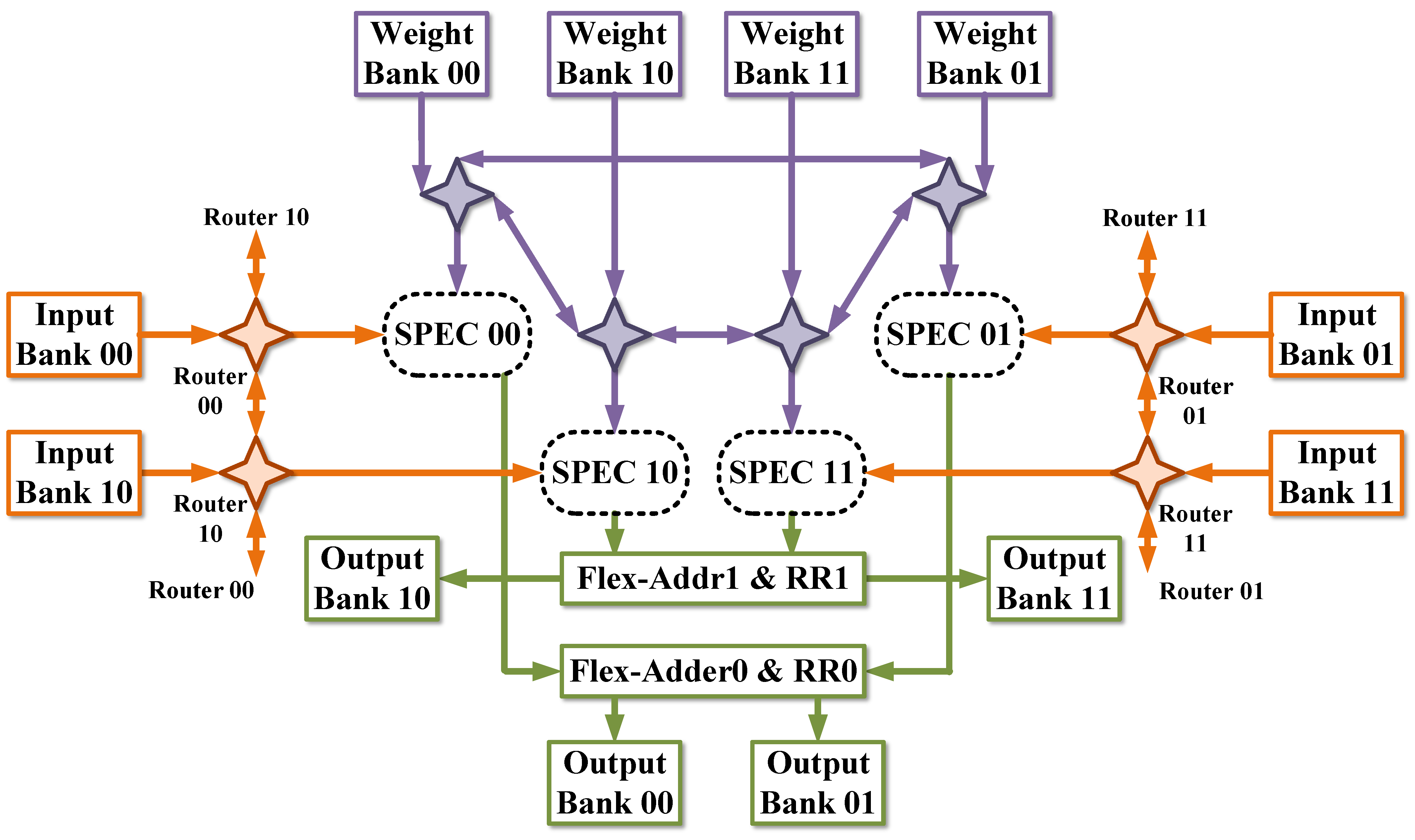
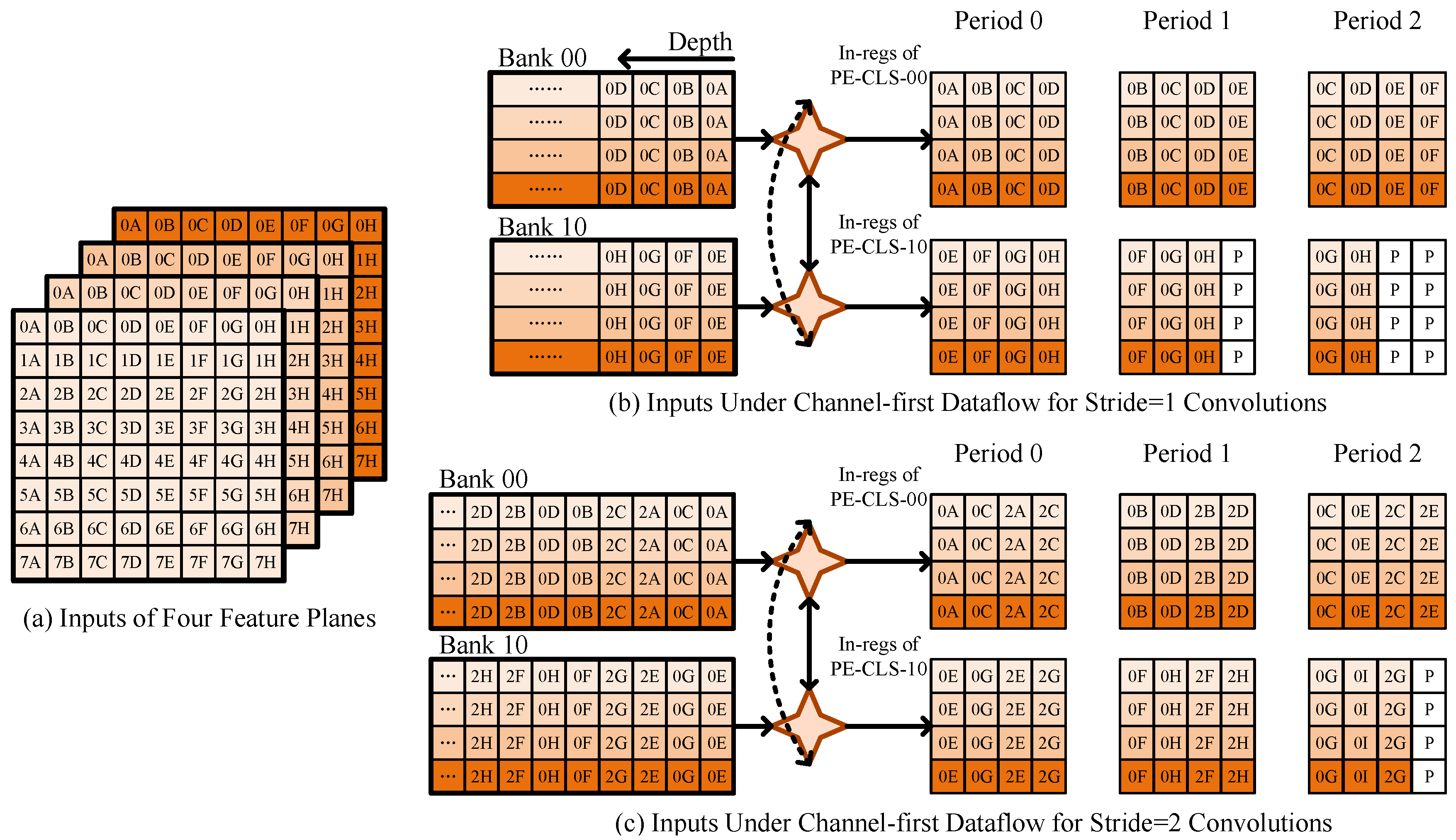
4.1. Flexible Sparse Processing-Element Clusters
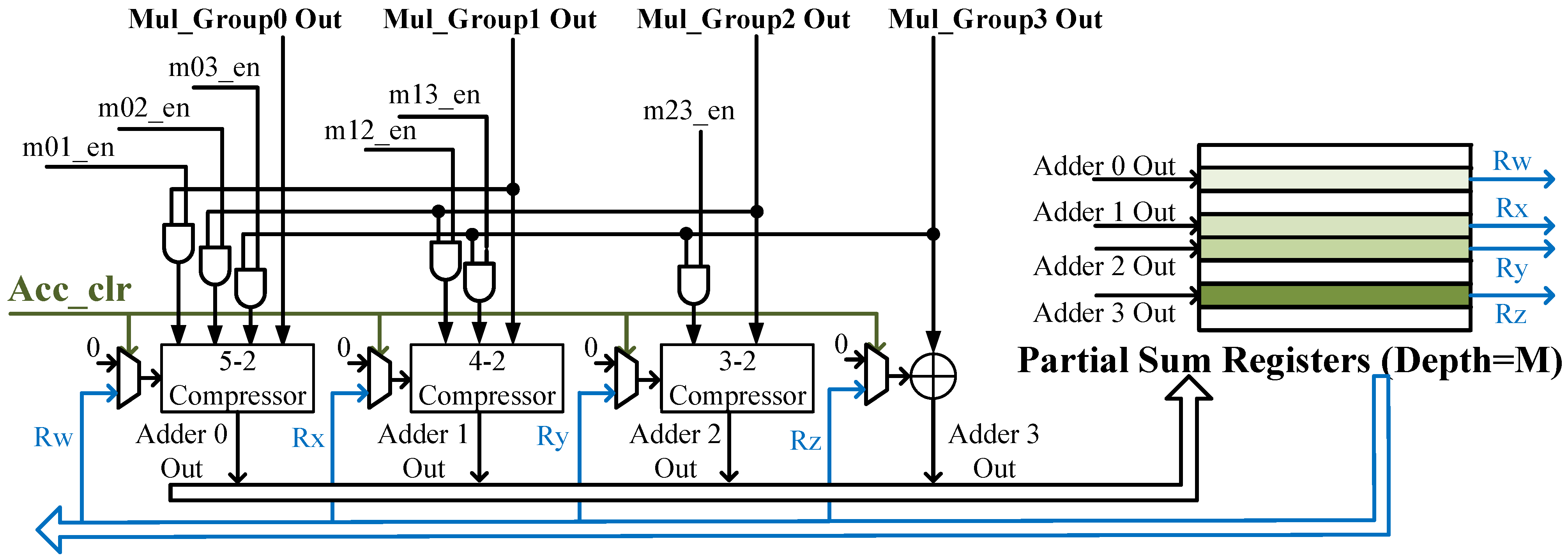
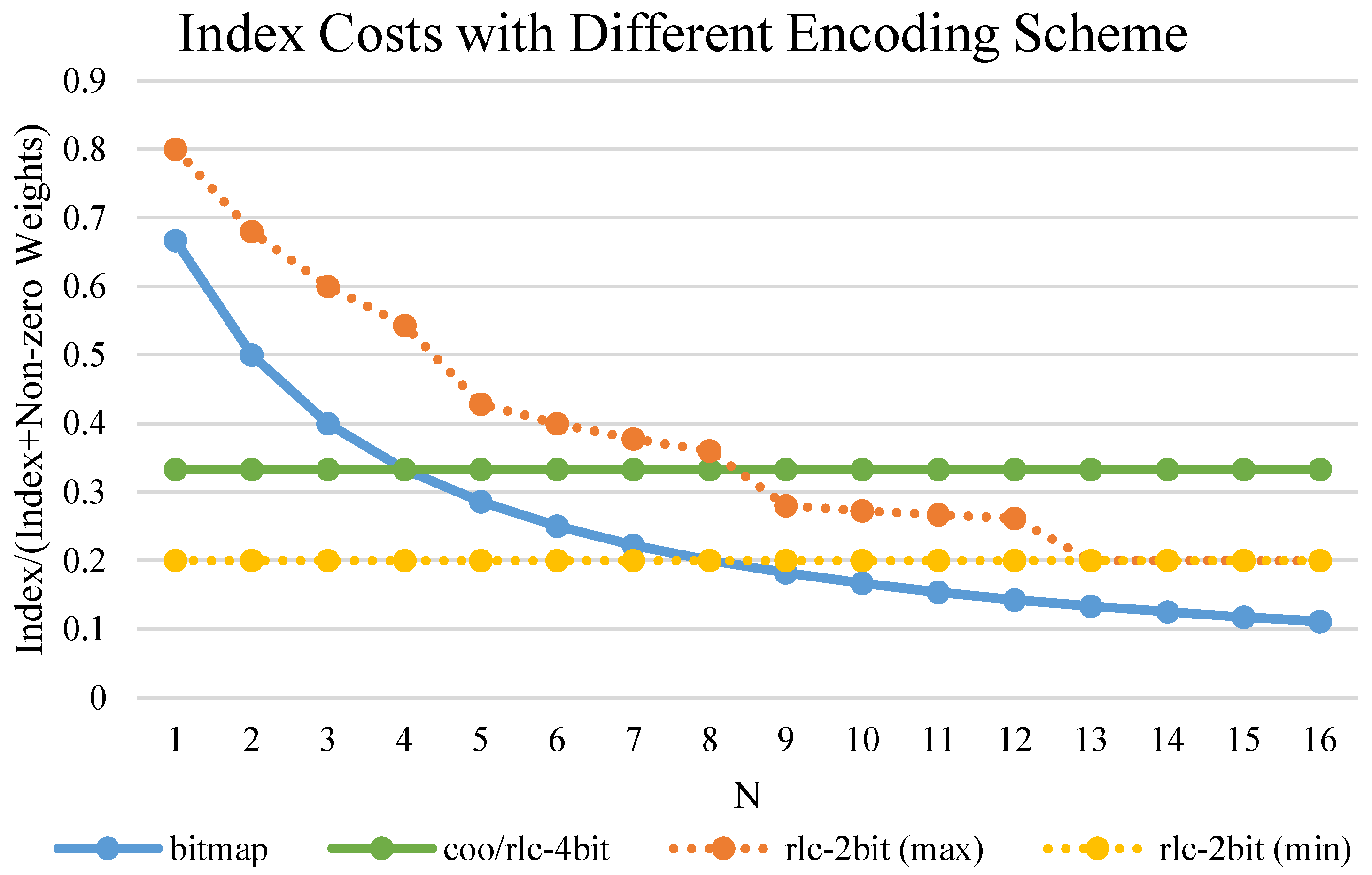
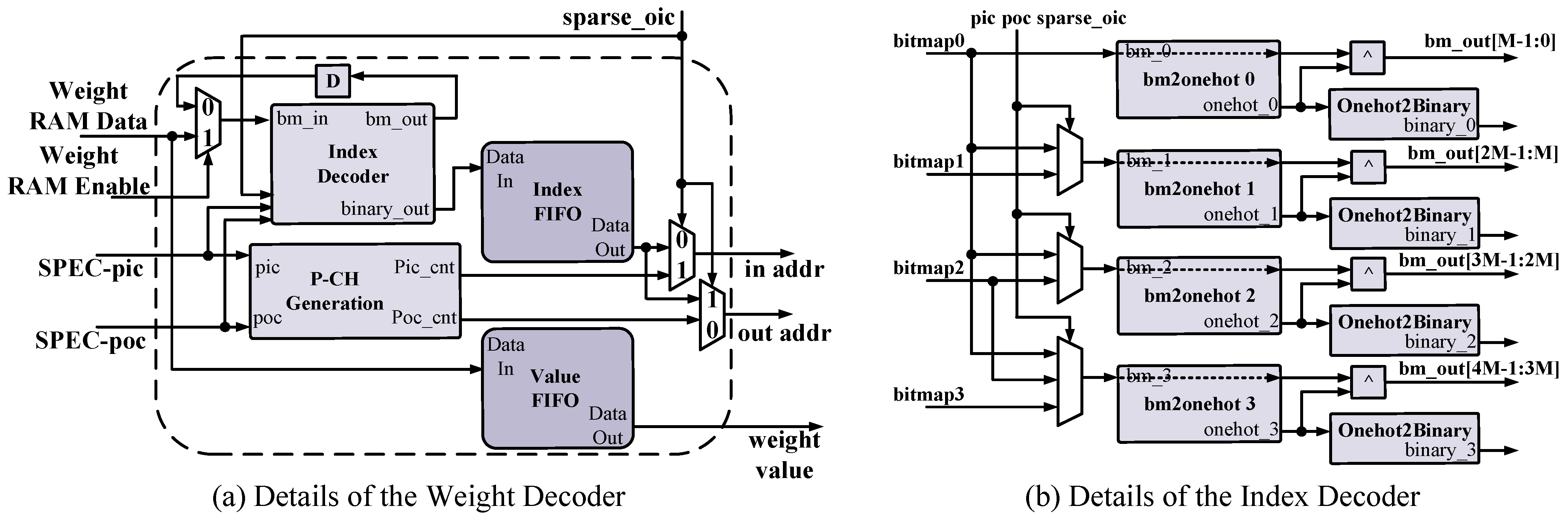
4.2. Weight Encoding and Decoding for the Layer-Wise N:M Sparse Pattern
4.3. Overall Architecture
5. Experiments and Results
5.1. Algorithm Evaluation
5.2. Hardware
5.2.1. Hardware Performances of Proposed Architectures
5.2.2. Evaluation and Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems (NeurIps), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chang, X.; Pan, H.; Lin, W.; Gao, H. A Mixed-Pruning Based Framework for Embedded Convolutional Neural Network Acceleration. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1706–1715. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wang, J.; Yu, S.; Yuan, Z.; Yue, J.; Yuan, Z.; Liu, R.; Wang, Y.; Yang, H.; Li, X.; Liu, Y. PACA: A Pattern Pruning Algorithm and Channel-Fused High PE Utilization Accelerator for CNNs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 5043–5056. [Google Scholar] [CrossRef]
- Song, Y.; Wu, B.; Yuan, T.; Liu, W. A High-Speed CNN Hardware Accelerator with Regular Pruning. In Proceedings of the 23rd International Symposium on Quality Electronic Design (ISQED 2022), Santa Clara, CA, USA, 6–7 April 2022; pp. 1–5. [Google Scholar]
- Zhou, A.; Ma, Y.; Zhu, J.; Liu, J.; Zhang, Z.; Yuan, K.; Sun, W.; Li, H. Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Sun, W.; Zhou, A.; Stuijk, S.; Wijnhoven, R.G.J.; Nelson, A.; Li, H.; Corporaal, H. DominoSearch: Find layer-wise fine-grained N:M sparse schemes from dense neural networks. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021 (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 20721–20732. [Google Scholar]
- Cao, S.; Zhang, C.; Yao, Z.; Xiao, W.; Nie, L.; Zhan, D.; Liu, Y.; Wu, M.; Zhang, L. Efficient and Effective Sparse LSTM on FPGA with Bank-Balanced Sparsity. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA 2019), Seaside, CA, USA, 24–26 February 2019; pp. 63–72. [Google Scholar]
- Mishra, A.K.; Latorre, J.A.; Pool, J.; Stosic, D.; Stosic, D.; Venkatesh, G.; Yu, C.; Micikevicius, P. Accelerating Sparse Deep Neural Networks. arXiv 2021, arXiv:2104.08378. [Google Scholar]
- Fang, C.; Zhou, A.; Wang, Z. An Algorithm-Hardware Co-Optimized Framework for Accelerating N:M Sparse Transformers. IEEE Trans. Very Large Scale Integr. Syst. 2022, 30, 1573–1586. [Google Scholar] [CrossRef]
- Liu, Z.G.; Whatmough, P.N.; Zhu, Y.; Mattina, M. S2TA: Exploiting Structured Sparsity for Energy-Efficient Mobile CNN Acceleration. In Proceedings of the IEEE International Symposium on High-Performance Computer Architecture (HPCA 2022), Seoul, Republic of Korea, 2–6 April 2022; pp. 573–586. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhang, T.; Ye, S.; Feng, X.; Ma, X.; Zhang, K.; Li, Z.; Tang, J.; Liu, S.; Lin, X.; Liu, Y.; et al. StructADMM: Achieving Ultrahigh Efficiency in Structured Pruning for DNNs. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 2259–2273. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.; Lu, L.; Xie, J. OMNI: A Framework for Integrating Hardware and Software Optimizations for Sparse CNNs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2021, 40, 1648–1661. [Google Scholar] [CrossRef]
- Yuan, T.; Liu, W.; Han, J.; Lombardi, F. High Performance CNN Accelerators Based on Hardware and Algorithm Co-Optimization. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 250–263. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.B.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the ACM International Conference on Multimedia (MM’14), Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Dave, S.; Baghdadi, R.; Nowatzki, T.; Avancha, S.; Shrivastava, A.; Li, B. Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights. Proc. IEEE 2021, 109, 1706–1752. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, T.; Emer, J.S.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Topics Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Lin, J.; Wang, Z.; Wei, J. An Efficient and Flexible Accelerator Design for Sparse Convolutional Neural Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 2936–2949. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, M.; Guo, C.; Leng, J.; Liang, Y.; Chen, Q.; Guo, M.; Zhu, Y. Characterizing and Demystifying the Implicit Convolution Algorithm on Commercial Matrix-Multiplication Accelerators. In Proceedings of the IEEE International Symposium on Workload Characterization (IISWC 2021), Storrs, CT, USA, 7–9 November 2021; pp. 214–225. [Google Scholar]
- Chen, Y.; Emer, J.S.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. In Proceedings of the 43rd ACM/IEEE Annual International Symposium on Computer Architecture (ISCA 2016), Seoul, Republic of Korea, 18–22 June 2016; pp. 367–379. [Google Scholar]
- Zhu, C.; Huang, K.; Yang, S.; Zhu, Z.; Zhang, H.; Shen, H. An Efficient Hardware Accelerator for Structured Sparse Convolutional Neural Networks on FPGAs. IEEE Trans. Very Large Scale Integr. Syst. 2020, 28, 1953–1965. [Google Scholar] [CrossRef]
- Lu, L.; Xie, J.; Huang, R.; Zhang, J.; Lin, W.; Liang, Y. An Efficient Hardware Accelerator for Sparse Convolutional Neural Networks on FPGAs. In Proceedings of the 27th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM 2019), San Diego, CA, USA, 28 April–1 May 2019; pp. 17–25. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Uniform | N:M Configuration | Top-1 Acc(%) | Sparsity |
|---|---|---|---|---|
| [8] | Dense | Dense | 77.30% | 0% |
| SR-STE [8] | Uniform | 2:4 | 77.00% | 50% |
| SR-STE [8] | Uniform | 4:8 | 77.40% | 50% |
| SR-STE [9] | Uniform | 4:16 | 76.50% | 75% |
| SR-STE [8] | Uniform | 2:8 | 76.20% | 75% |
| SR-STE [8] | Uniform | 1:4 | 75.30% | 75% |
| SR-STE [9] | Uniform | 2:16 | 74.40% | 87.50% |
| DS [9] | Layer-wise | N:16 | 75.70% | 87.50% |
| SR-STE [9] | Uniform | 1:16 | 70.70% | 93.75% |
| SR-STE [9] | Uniform | 2:32 | 71.50% | 93.75% |
| DS [9] | Layer-wise | N:32 | 73.50% | 93.75% |
| N | N = 1 | N = 2 | ||
|---|---|---|---|---|
| Encoding | COO | COO | COO | Bitmap |
| Networks Accuracy | Alexnet | VGG-16 | Resnet-18 | Resnet-50 |
|---|---|---|---|---|
| Dense | 56.553% | 71.082% | 69.649% | 76.033% |
| Input-Channel Sparse | 55.559% | 70.720% | 68.935% | 75.329% |
| Output-Channel Sparse | 55.743% | 70.755% | 68.749% | 75.327% |
| Architectures | ISA | OSA | IOSA |
|---|---|---|---|
| FPGA Platform | Xilinx ZCU102 | Xilinx VCU118 | Xilinx VCU118 |
| DSP Utilization | 1024 | 4096 | 4096 |
| (40%) | (60%) | (60%) | |
| Logic Utilization | 500 K | 600 K | 645 K |
| (84%) | (23%) | (25%) | |
| BRAM Utilization 1 | 320 | 320 | 320 |
| (18%) | (7%) | (7%) |
| [25] | Ours | [25] | Ours | [21] | [24] | Ours | [25] | Ours | |
|---|---|---|---|---|---|---|---|---|---|
| CNN Type | Alexnet | VGG-16 | Resnet-50 | ||||||
| Device | Xilinx | Xilinx | Intel | Xilinx | |||||
| ZCU102 | ZCU102 | SX660 | ZCU102 | ||||||
| Pattern 1 | U | L | U | L | U | S | L | U | L |
| Sparsity (%) | 10.80 | 37.50 | 11.70 | 37.50 | 45.00 | 45.00 | 50.00 | 23.5 | 25.00 |
| MAC Reduction (%) | 65.1 | 62.5 | 67.4 | 62.5 | - | 52.3 | 50 | - | 75 |
| Frequency (MHz) | 200 | 200 | 200 | 200 | 170 | 200 | 200 | 200 | 200 |
| Precision (bits) | 16 | 8 | 16 | 8 | 8 | 16 | 8 | 16 | 8 |
| DSP Utilization | 1144 | 1024 | 1144 | 1024 | 512 | 1344 | 1024 | 1144 | 1024 |
| LUT Utilization | 552 K (92%) | 500 K (84%) | 552 K (92%) | 500 K (84%) | 102.6 K (41%) | 390 K (65%) | 500 K (84%) | 552 K (92%) | 500 K (84%) |
| BRAM Utilization 2 | 912 (48%) | 320 (18%) | 912 (48%) | 320 (18%) | 465 (22%) | 1460 (80%) | 320 (18%) | 912 (48%) | 320 (18%) |
| Performance (image/s) | 446 | 434 | 31 | 35 | 23 | 57 | 83 | 149 | 150 |
| Power (W) | 23.5 | 15.0 | 23.5 | 15.0 | 4.6 | 15.4 | 15.00 | 23.5 | 15.00 |
| Power Efficiency | 18.98 | 28.93 | 1.32 | 2.33 | 5.00 | 3.70 | 5.53 | 6.34 | 10.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Zhu, M.; Lu, S.; Wang, Z. Efficient Layer-Wise N:M Sparse CNN Accelerator with Flexible SPEC: Sparse Processing Element Clusters. Micromachines 2023, 14, 528. https://doi.org/10.3390/mi14030528
Xie X, Zhu M, Lu S, Wang Z. Efficient Layer-Wise N:M Sparse CNN Accelerator with Flexible SPEC: Sparse Processing Element Clusters. Micromachines. 2023; 14(3):528. https://doi.org/10.3390/mi14030528
Chicago/Turabian StyleXie, Xiaoru, Mingyu Zhu, Siyuan Lu, and Zhongfeng Wang. 2023. "Efficient Layer-Wise N:M Sparse CNN Accelerator with Flexible SPEC: Sparse Processing Element Clusters" Micromachines 14, no. 3: 528. https://doi.org/10.3390/mi14030528