
Highly Concurrent TCP Session Connection Management System on FPGA Chip

Abstract
:1. Introduction
- (1)
- We implemented the hardware processing logic of the TCP protocol in the FPGA, which includes protocol parsering and frame encapsulation of the sending and receiving data paths, as well as connection state maintenance including establishment and teardown.
- (2)
- The solution provides a multi-level state management mechanism, using on-chip storage resources and off-chip storage devices to jointly maintain the TCP session connection state including four-tuples. The method supports high-performance data transmission for 128 TCP connections and state maintenance for hundreds of thousands of long TCP connections. Thereby achieving a balance of high throughput and high scalability within limited hardware resources.
- (3)
- The solution is completely designed with the hardware description language Verilog, and provides stateful data processing logic based on hardware timing transmission, which has high stability and portability.
2. Related Work
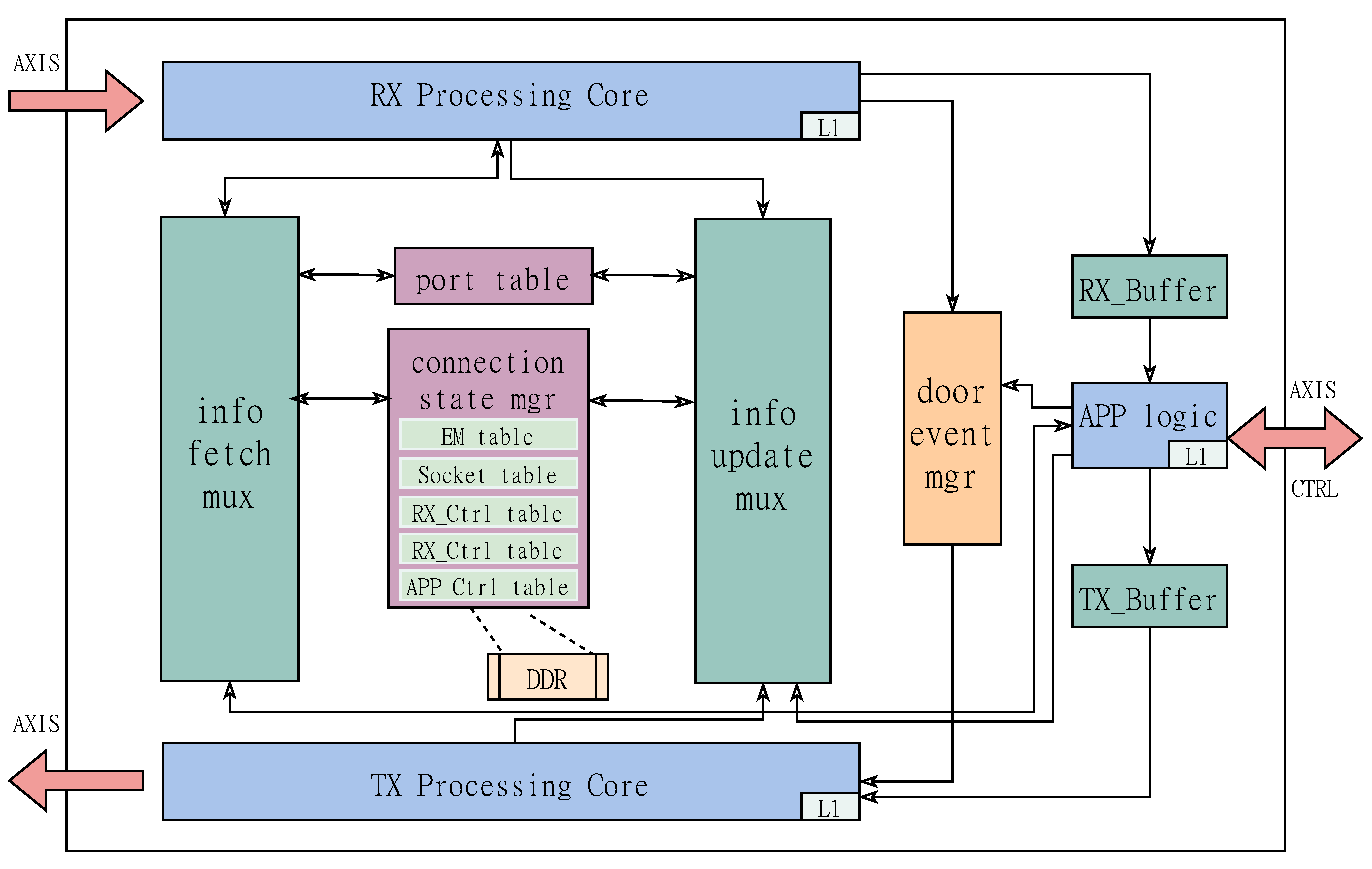
3. TOE Architecture
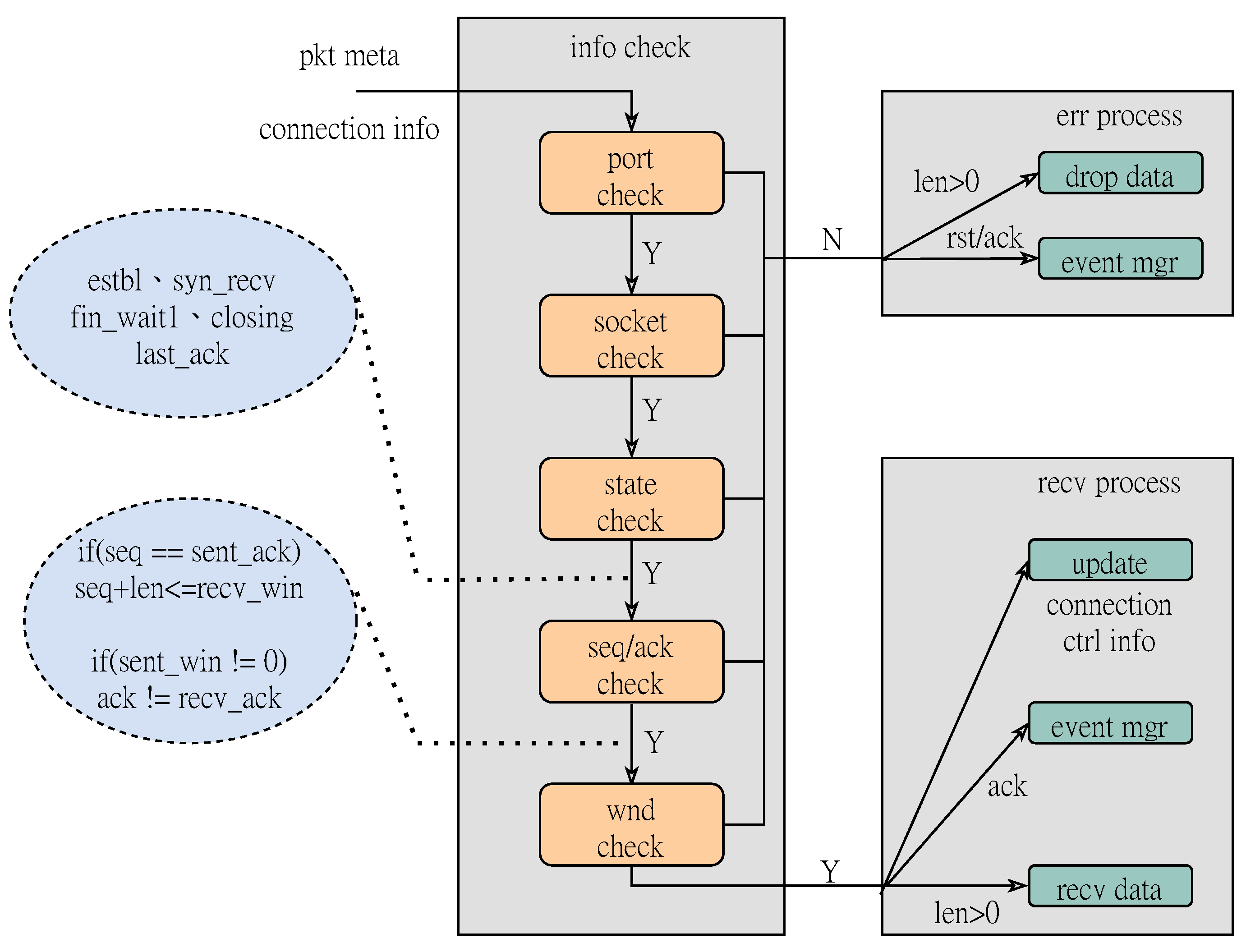
3.1. RX Processing Core
3.2. TX Processing Core
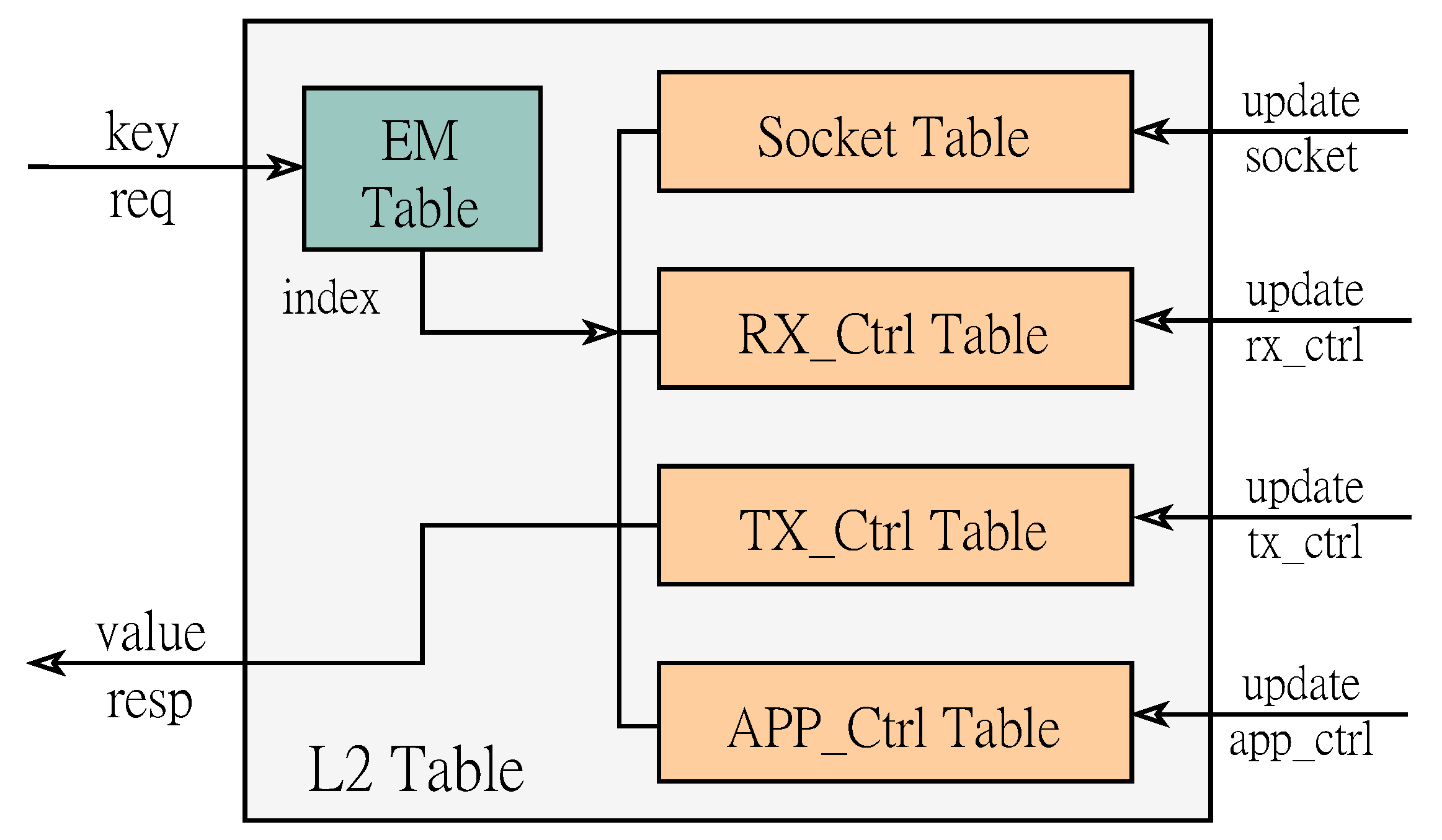
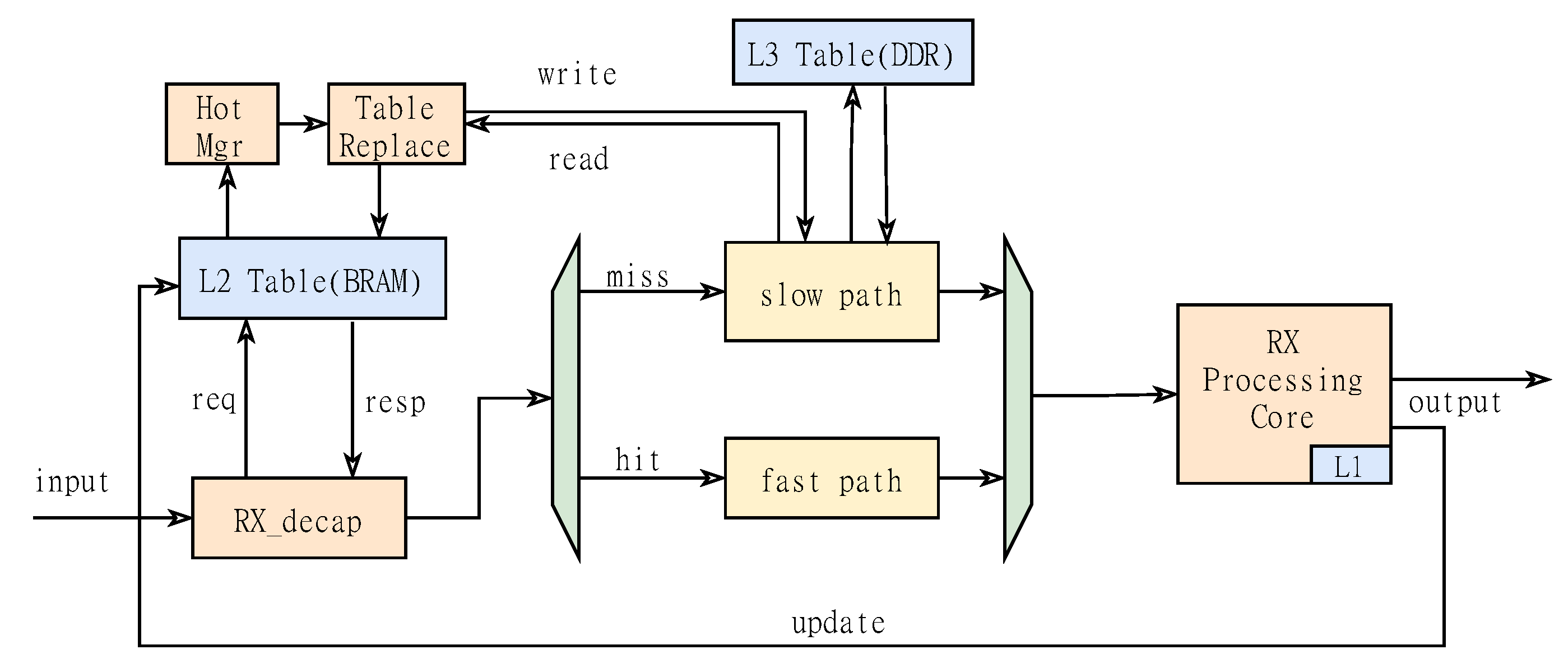
3.3. Multi-Level Cache State Management Mechanism
3.4. State Table Update Logic
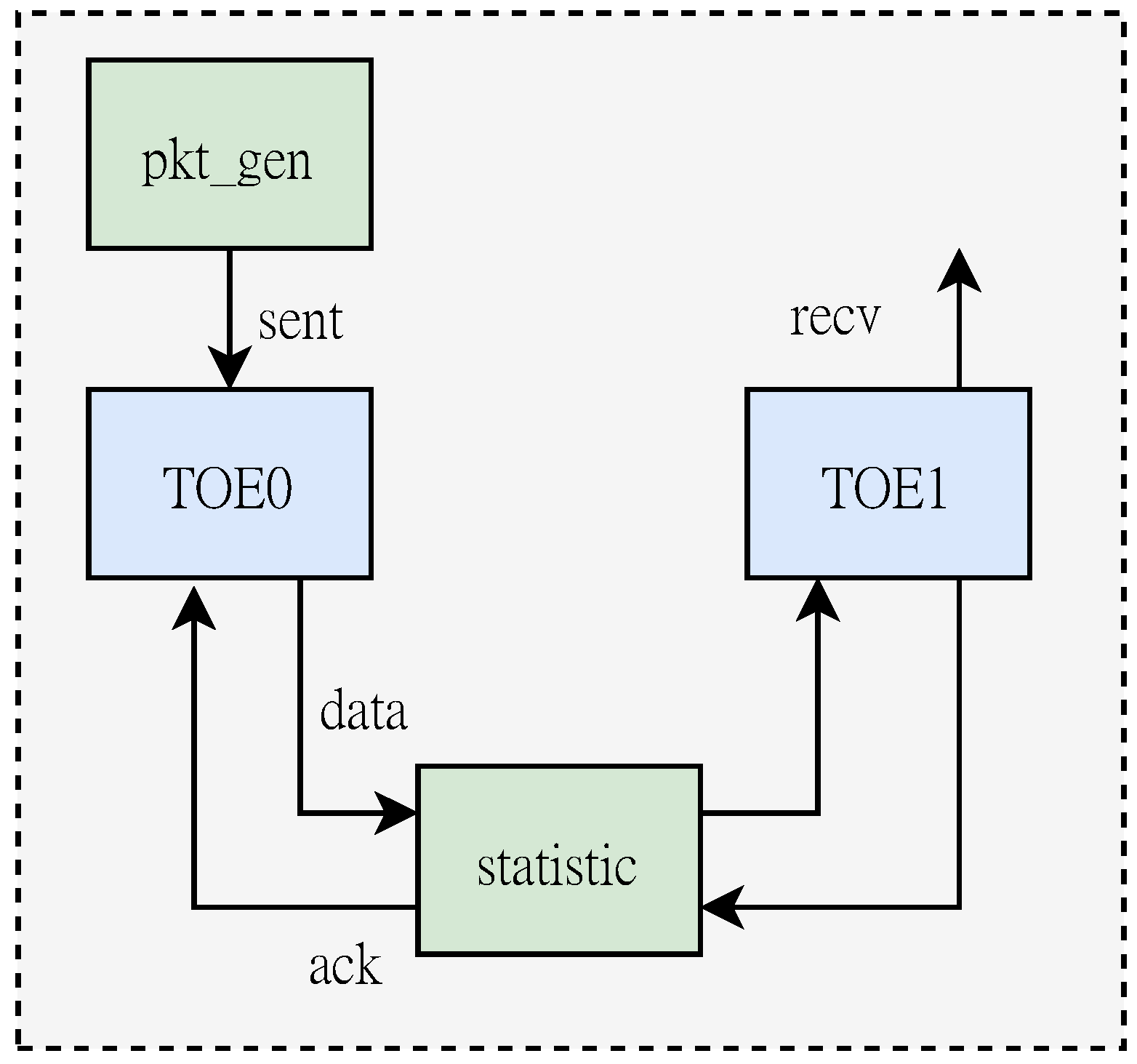
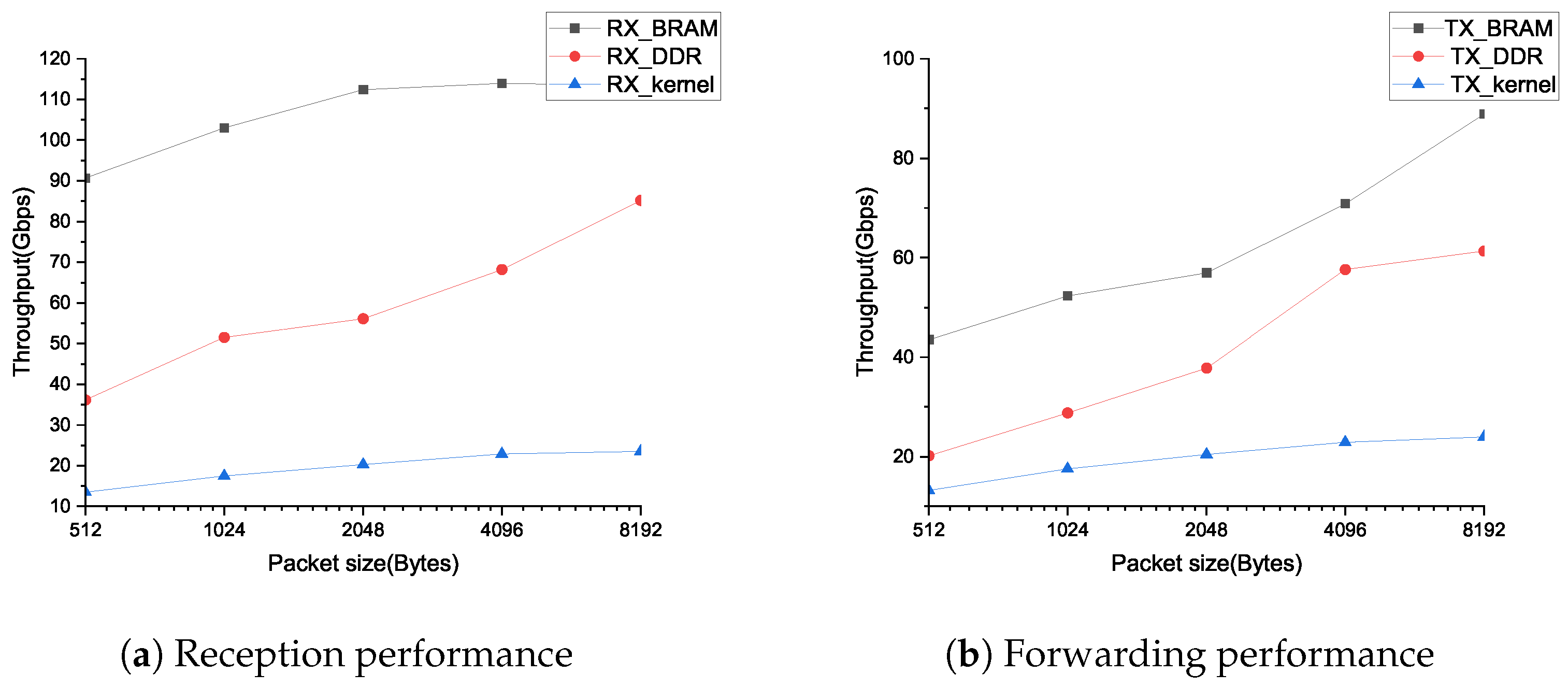
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Niemiec, G.S.; Batista, L.M.; Schaeffer-Filho, A.E.; Nazar, G.L. A survey on fpga support for the feasible execution of virtualized network functions. IEEE Commun. Surv. Tutorials 2019, 22, 504–525. [Google Scholar] [CrossRef]
- Bondan, L.; Wauter, T.; Volckaert, B.; De Turck, F.; Granville, L.Z. Nfv anomaly detection: Case study through a security module. IEEE Commun. Mag. 2022, 60, 18–24. [Google Scholar] [CrossRef]
- Paolucci, F.; Cugini, F.; Castoldi, P.; Osiński, T. Enhancing 5 g sdn/nfv edge with p4 data plane programmability. IEEE Netw. 2021, 35, 154–160. [Google Scholar] [CrossRef]
- Hennessy, J.; Patterson, D. Computer Architecture, 6th ed.; Morgan Kaufmann: San Francisco, CA, USA, 2019; pp. 2–67. [Google Scholar]
- Technical White Paper of Data Processing Unit. Available online: https://114.215.223.121/zkls/zkys/dpu_whitepaper.html (accessed on 10 January 2023).
- Lin, X.; Chen, Y.; Li, X.; Mao, J.; He, J.; Xu, W.; Shi, Y. Scalable kernel tcp design and implementation for short-lived connections. ACM SIGARCH Comput. Archit. News. 2016, 44, 339–352. [Google Scholar] [CrossRef]
- Yasukata, K.; Honda, M.; Santry, D.; Eggert, L. StackMap: Low-Latency Networking with the OS Stack and Dedicated NICs. In Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC 16), Denver, CO, USA, 22–24 June 2016; pp. 43–56. [Google Scholar]
- Pesterev, A.; Strauss, J.; Zeldovich, N.; Morris, R.T. Improving network connection locality on multicore systems. In Proceedings of the 7th ACM European Conference on Computer Systems, Bern, Switzerland, 10–13 April 2012; pp. 337–350. [Google Scholar]
- PF_RING. 2022. Available online: https://www.ntop.org/products/packet-capture/pf_ring (accessed on 10 January 2023).
- Belay, A.; Prekas, G.; Primorac, M.; Klimovic, A.; Grossman, S.; Kozyrakis, C.; Bugnion, E. The ix operating system: Combining low latency, high throughput, and efficiency in a protected dataplane. ACM Trans. Comput. Syst. (TOCS) 2016, 34, 1–39. [Google Scholar] [CrossRef]
- Peter, S.; Li, J.; Zhang, I.; Ports, D.R.K.; Woos, D.; Krishnamurthy, A.; Anderson, T.; Roscoe, T. Arrakis: The operating system is the control plane. ACM Trans. Comput. Syst. (TOCS) 2015, 33, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Kaufmann, A.; Stamler, T.; Peter, S.; Sharma, N.K.; Krishnamurthy, A.; Anderson, T. Tas: Tcp acceleration as an os service. In Proceedings of the Fourteenth EuroSys Conference 2019, Dresden, Germany, 25–28 March 2019; pp. 1–16. [Google Scholar]
- Intel Tofino. Available online: https://www.intel.com/content/www/us/en/products/network-io/programmable-ethernet-switch/tofino-series.html (accessed on 10 January 2023).
- Ma, X.; Yang, F.; Yuan, G.; An, X. Overview of SmartNIC. Comput. Res. Dev. 2022, 59, 1–21. [Google Scholar]
- Sha, M.; Guo, Z.; Song, M.; Wang, K. A Survey of the Application of FPGA in High Speed Network Processing. Netw. New Media Technol. 2021, 10, 1–11. [Google Scholar]
- Sutter, G.; Ruiz, M.; Lopez-Buedo, S.; Alonso, G. Fpga-based tcp/ip checksum offloading engine for 100 gbps networks. In Proceedings of the 2018 IEEE International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 3–5 December 2018; pp. 1–6. [Google Scholar]
- 10G Ultra-Low Latency TCP/IP and UDP/IP Offload Engine. 2022. Available online: https://www.xilinx.com/products/intellectual-property/1-1pho713.html (accessed on 10 January 2023).
- TOE100G-IP Core (TCP Offloading Engine IP Core). 2022. Available online: https://www.xilinx.com/products/intellectual-property/1-1h1z8sm.html (accessed on 10 January 2023).
- Shashidhara, R.; Stamler, T.; Kaufmann, A.; Peter, S. FlexTOE: Flexible TCP Offload with Fine-Grained Parallelism. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022; pp. 87–102. [Google Scholar]
- Moon, Y.; Lee, S.; Jamshed, M.A.; Park, K. AccelTCP: Accelerating Network Applications with Stateful TCP Offloading. In Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), Santa Clara, CA, USA, 25–27 February 2020; pp. 77–92. [Google Scholar]
- Langenbach, U.; Berthe, A.; Traskov, B.; Weide, S.; Hofmann, K.; Gregorius, P. A 10 gbe tcp/ip hardware stack as part of a protocol acceleration platform. In Proceedings of the 2013 IEEE Third International Conference on Consumer Electronics? Berlin (ICCE-Berlin), Berlin, Germany, 8–11 September 2013; pp. 381–384. [Google Scholar]
- Ding, L.; Kang, P.; Yin, W.; Wang, L. Hardware tcp offload engine based on 10-gbps ethernet for low-latency network communication. In Proceedings of the 2016 IEEE International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 269–272. [Google Scholar]
- Gao, J.; Yin, W.; Luk, W.-S.; Wang, L. Scalable multi-session tcp offload engine for latency-sensitive applications. In Proceedings of the 2020 IEEE China Semiconductor Technology International Conference(CSTIC), Shanghai, China, 26 June–17 July 2020; pp. 1–3. [Google Scholar]
- Ji, Y.; Hu, Q.-S. 40 gbps multi-connection tcp/ip offload engine. In Proceedings of the 2011 IEEE International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 9–11 November 2011; pp. 1–5. [Google Scholar]
- Sidler, D.; Alonso, G.; Blott, M.; Karras, K.; Vissers, K.; Carley, R. Scalable 10 Gbps tcp/ip stack architecture for reconfigurable hardware. In Proceedings of the 2015 IEEE 23rd Annual International Symposium on Field-Programmable Custom Computing Machines, Vancouver, BC, Canada, 2–6 May 2015; pp. 36–43. [Google Scholar]
- Ruiz, M.; Sidler, D.; Sutter, G.; Alonso, G.; López-Buedo, S. Limago: An fpga-based open-source 100 gbe tcp/ip stack. In Proceedings of the 2019 29th IEEE International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 286–292. [Google Scholar]
- Bianchi, G.; Welzl, M.; Tulumello, A.; Belocchi, G.; Faltelli, M.; Pontarelli, S. A fully portable tcp implementation using xfsms. In Proceedings of the ACM SIGCOMM 2018 Conference on Posters and Demos, Budapest, Hungary, 20–25 August 2018; pp. 99–101. [Google Scholar]
- He, Z.; Parravicini, D.; Petrica, L.; O’Brien, K.; Alonso, G.; Blott, M. Accl: Fpga-accelerated collectives over 100 gbps tcp-ip. In Proceedings of the 2021 IEEE/ACM International Workshop on Heterogeneous High-Performance Reconfigurable Computing (H2RC), St. Louis, MO, USA, 14 November 2021; pp. 33–43. [Google Scholar]
- TCPIP-1G/10G: 1G/10G TCP/IP Hardware Stack. Available online: https://china.xilinx.com/products/intellectual-property/1-1q4obv9.html#productspecs (accessed on 10 January 2023).
- 1K Session 10G TCP & UDP Offload Engine. Full Offload. Available online: https://china.xilinx.com/products/intellectual-property/1-58v1ep.html (accessed on 10 January 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Guo, Y.; Guo, Z. Highly Concurrent TCP Session Connection Management System on FPGA Chip. Micromachines 2023, 14, 385. https://doi.org/10.3390/mi14020385
Wang K, Guo Y, Guo Z. Highly Concurrent TCP Session Connection Management System on FPGA Chip. Micromachines. 2023; 14(2):385. https://doi.org/10.3390/mi14020385
Chicago/Turabian StyleWang, Ke, Yunfei Guo, and Zhichuan Guo. 2023. "Highly Concurrent TCP Session Connection Management System on FPGA Chip" Micromachines 14, no. 2: 385. https://doi.org/10.3390/mi14020385