
LiteST-Net: A Hybrid Model of Lite Swin Transformer and Convolution for Building Extraction from Remote Sensing Image

Abstract
:
1. Introduction
- (1)
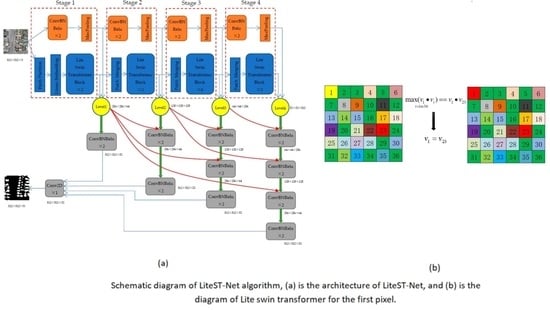
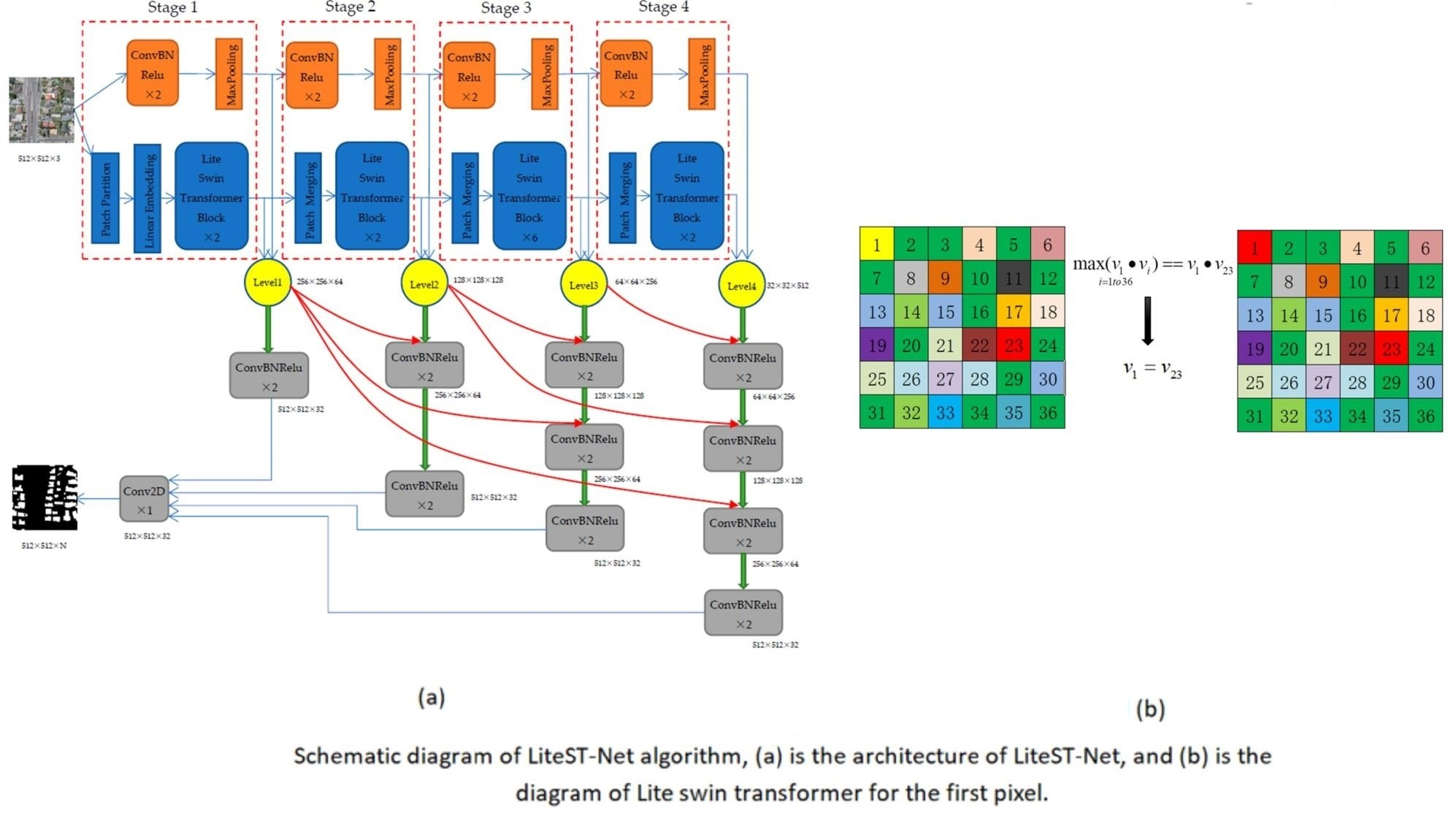
- A simplified Swin transformer called Lite Swin transformer is proposed. The Q, K, and V matrices of the transformer are simplified into only a V matrix. The contribution weight between pixels is calculated as VVT. The output feature value is replaced by the V value of the pixel with the largest weight rather than the weighted sum of all pixels. In this way, the model has fewer parameters and faster calculation speed.
- (2)
- A model integrating Lite Swin transformer and CNN is proposed. In the model, the features extracted from the two are fused at all levels and upsampled step by step.
- (3)
- We conduct experiments on common open datasets and compare the performance with that of common network models.
2. Methodology and Materials
2.1. LiteST-Net Architecture
2.2. Lite Swin Transformer
| Algorithm 1: Lite Swin transformer |
| Input: feature map, window size |
| Output: V |
| 1: Cut the feature map into small feature maps according to the window size |
| 2: for small feature in small feature maps |
| 3: Flatten small feature to get a series of Tokens, marked as A |
| 4: Multiply A by WV to get the V of all Tokens |
| 5: For each token, calculate the inner product of all other tokens and it, and the formula is VVT |
| 6: for v in V |
| 7: take v of the token with the largest inner product to replace its v |
| 8: end for |
| 9: reshape V as same as small feature |
| 10: end for |
| 11: Splice V as same shape as original input feature map |
| 12: Move the window position by half the window size, and perform steps 1-11 again |
| 13: Return V |
2.3. WHU Building Dataset and Preprocessing
2.4. Massachusetts Building Dataset and Preprocessing
3. Experiment and Results
3.1. Hardware and Software for Experiment
3.2. Evaluation Metrics
3.3. Results on the WHU Building Dataset
3.4. Results on the Massachusetts Building Dataset
4. Discussion
4.1. Ablation Experiment
4.2. Generalizations Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Dornaika, F.; Moujahid, A.; El Merabet, Y.; Ruichek, Y. Building detection from orthophotos using a machine learning approach: An empirical study on image segmentation and descriptors. Expert Syst. Appl. 2016, 58, 130–142. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Zhang, C.; Fraser, C.S. Improved building detection using texture information. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 38, 143–148. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 5, 161–172. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Wang, Q.; Miao, Z. Extracting manmade objects from high spatial resolution remote sensing images via fast level set evolutions. IEEE Trans. Geosci. Remote Sens. 2014, 53, 883–899. [Google Scholar]
- Zhang, T.; Huang, X.; Wen, D.; Li, J. Urban building density estimation from high-resolution imagery using multiple features and support vector regression. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3265–3280. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. Available online: https://arxiv.org/abs/1409.1556 (accessed on 3 July 2021).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 Medical Image Computing and Computer Assisted Intervention, Piscataway, NJ, USA, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words:Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. arXiv 2020, arXiv:2012.15840. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.N.; Zhang, Z.J.; Zhang, W.C.; Zhang, C.R.; Li, W.D.; Zhao, T. Semantic segmentation of urban buildings from vhr remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Liu, Y.H.; Zhou, J.; Qi, W.H.; Li, X.L.; Gross, L.; Shao, Q.; Zhao, Z.G.; Ni, L.; Fan, X.W.; Li, Z.Q. Arc-net: An efficient network for building extraction from high-resolution aerial images. IEEE Access 2020, 8, 154997–155010. [Google Scholar] [CrossRef]
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building extraction from high-resolution aerial imagery using a generative adversarial network with spatial and channel attention mechanisms. Remote Sens. 2019, 11, 917. [Google Scholar] [CrossRef] [Green Version]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked autoencoders driven by semi-supervised learning for building extraction from near infrared remote sensing imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Cheng, D.; Liao, R.; Fidler, S.; Urtasun, R. Darnet: Deep active ray network for building segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7431–7439. [Google Scholar]
- Chen, J.; Zhang, D.; Wu, Y.; Chen, Y.; Yan, X. A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery. Remote Sens. 2022, 14, 2276. [Google Scholar] [CrossRef]
- Na, Y.; Kim, J.H.; Lee, K.; Park, J.; Hwang, J.Y.; Choi, J.P. Domain Adaptive Transfer Attack (DATA)-based Segmentation Networks for Building Extraction from Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5171–5182. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. NeighborLoss: A Loss Function Considering Spatial Correlation for Semantic Segmentation of Remote Sensing Image. IEEE Access 2021, 9, 75641–75649. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, L.; Liu, L.; Hu, H.; Tao, W. URNet: A U-Shaped Residual Network for Lightweight Image Super-Resolution. Remote Sens. 2021, 13, 3848. [Google Scholar] [CrossRef]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Miao, Y.; Jiang, S.; Xu, Y.; Wang, D. Feature Residual Analysis Network for Building Extraction from Remote Sensing Images. Appl. Sci. 2022, 12, 5095. [Google Scholar] [CrossRef]
- Liu, H.; Cao, F.; Wen, C.; Zhang, Q. Lightweight multi-scale residual networks with attention for image super-resolution. Knowl. Based Syst. 2020, 203, 106103. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Tian, Q.; Zhao, Y.; Li, Y.; Chen, J.; Chen, X.; Qin, K. Multiscale building extraction with refined attention pyramid networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8011305. [Google Scholar] [CrossRef]
- Das, P.; Chand, S. AttentionBuildNet for Building Extraction from Aerial Imagery. In Proceedings of the 2021 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 19–20 February 2021; pp. 576–580. [Google Scholar]
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-attention in reconstruction bias U-Net for semantic segmentation of building rooftops in optical remote sensing images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Cai, J.; Chen, Y. MHA-Net: Multipath Hybrid Attention Network for building footprint extraction from high-resolution remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5807–5817. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, S.; Chen, J.; Chen, B.; Wang, X.; Hao, D.; Sun, L. Rice Yield Prediction and Model Interpretation Based on Satellite and Climatic Indicators Using a Transformer Method. Remote Sens. 2022, 14, 5045. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. MSST-Net: A Multi-Scale Adaptive Network for Building Extraction from Remote Sensing Images Based on Swin Transformer. Remote Sens. 2021, 13, 4743. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Guo, W.; Yu, A.; Tong, X.; Schmitt, M. Multiscale feature learning by transformer for building extraction from satellite images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2503605. [Google Scholar] [CrossRef]
- Chen, K.; Zou, Z.; Shi, Z. Building Extraction from Remote Sensing Images with Sparse Token Transformers. Remote Sens. 2021, 13, 4441. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Meng, X.; Li, R. Building extraction with vision Transformer. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5625711. [Google Scholar] [CrossRef]
- Ji, S.P.; Wei, S.Q. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448–459. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder | Methods | mIoU (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| CNN | SegNet | 83.8 | 83.5 | 96.4 |
| DeepLab V3 | 84.6 | 84.3 | 96.7 | |
| PSPNet | 86.7 | 86.8 | 97.0 | |
| SPNet | 87.3 | 87.5 | 97.2 | |
| CFENet | 88.1 | 88.2 | 97.5 | |
| Shift Pooling PSPNet | 89.1 | 89.4 | 97.7 | |
| Transformer | SETR | 83.5 | 83.1 | 96.3 |
| MSST-Net | 88.0 | 88.2 | 97.4 | |
| BuildFormer | 90.2 | 90.6 | 97.9 | |
| LiteST-Net | 92.1 | 92.5 | 98.4 |
| Encoder | Methods | mIoU (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| CNN | SegNet | 69.9 | 66.7 | 90.7 |
| DeepLab V3 | 67.5 | 63.8 | 89.3 | |
| PSPNet | 71.8 | 70.0 | 90.8 | |
| SPNet | 70.6 | 68.0 | 90.6 | |
| CFENet | 71.4 | 68.7 | 91.4 | |
| Shift Pooling PSPNet | 75.4 | 74.3 | 92.6 | |
| Transformer | SETR | 67.9 | 63.5 | 90.2 |
| MSST-Net | 71.0 | 68.6 | 90.9 | |
| BuildFormer | 72.9 | 70.7 | 92.0 | |
| LiteST-Net | 76.5 | 76.1 | 92.5 |
| Methods | Params (M) |
|---|---|
| CFENet | 44.06 |
| Shift Pooling PSPNet | 42.69 |
| MSST-Net | 16.28 |
| BuildFormer | 18.08 |
| LiteST-Net (Swin transformer) | 20.97 |
| LiteST-Net (Lite Swin transformer) | 18.03 |
| Methods | mIoU (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|
| LiteST-Net (original Swin transformer + multi-level Conv) | 91.8 | 92.2 | 98.3 |
| LiteST-Net (Lite Swin transformer + last level Conv) | 91.3 | 91.7 | 98.2 |
| LiteST-Net (Lite Swin transformer + multi-level Conv) | 92.1 | 92.5 | 98.4 |
| Methods | mIoU of Validation Dataset (%) | mIoU of Test Dataset (%) | Test Validation (%) |
|---|---|---|---|
| SegNet | 86.3 | 83.8 | −2.5 |
| DeepLab V3 | 85.2 | 84.6 | −0.6 |
| PSPNet | 87.4 | 86.7 | −0.7 |
| SPNet | 87.9 | 87.3 | −0.6 |
| CFENet | 89.0 | 88.1 | −0.9 |
| Shift Pooling PSPNet | 89.6 | 89.1 | −0.5 |
| SETR | 82.8 | 83.5 | 0.7 |
| MSST-Net | 88.1 | 88.0 | −0.1 |
| BuildFormer | 91.5 | 90.2 | −1.3 |
| LiteST-Net | 92.6 | 92.1 | −0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, W.; Zhang, X.; Shi, J.; Wang, J. LiteST-Net: A Hybrid Model of Lite Swin Transformer and Convolution for Building Extraction from Remote Sensing Image. Remote Sens. 2023, 15, 1996. https://doi.org/10.3390/rs15081996
Yuan W, Zhang X, Shi J, Wang J. LiteST-Net: A Hybrid Model of Lite Swin Transformer and Convolution for Building Extraction from Remote Sensing Image. Remote Sensing. 2023; 15(8):1996. https://doi.org/10.3390/rs15081996
Chicago/Turabian StyleYuan, Wei, Xiaobo Zhang, Jibao Shi, and Jin Wang. 2023. "LiteST-Net: A Hybrid Model of Lite Swin Transformer and Convolution for Building Extraction from Remote Sensing Image" Remote Sensing 15, no. 8: 1996. https://doi.org/10.3390/rs15081996