5.2. Comparison with Other Methods
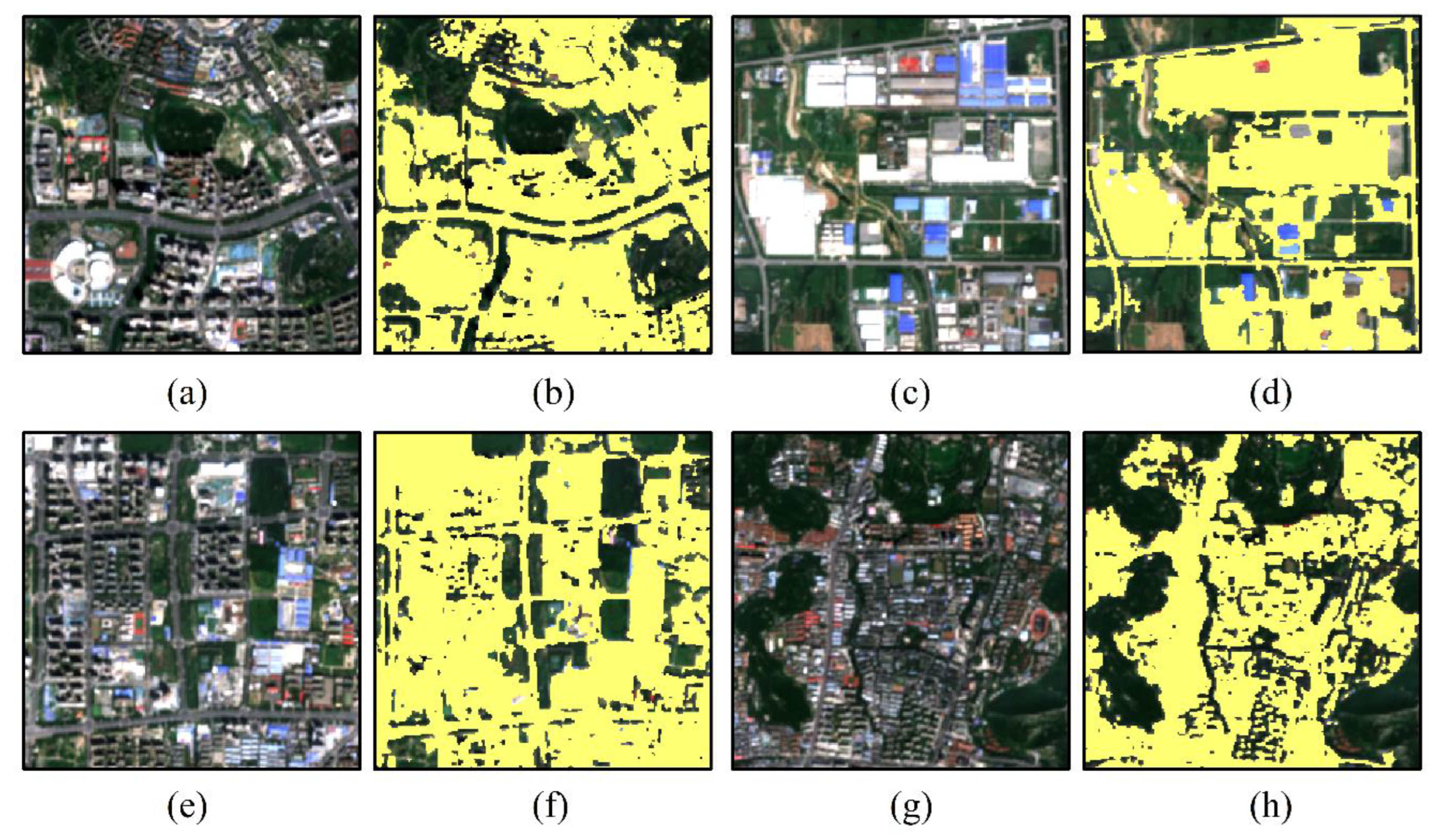
In this section, we focus on the advantage of the proposed method over other ISA mapping methods. In order to verify the influence of different classification methods on the extraction results of ISA, we compared the improved Deeplabv3+ model with traditional classification methods and classic CNN semantic segmentation models. The experimental results showed that the accuracy of the ISA produced by SVM and RF was inferior to that of the improved Deeplabv3+ deep learning method, and the classification results had an obvious salt-and-pepper effect. The reason could be that classical machine learning methods are insufficient to mine the deep features of spectral and spatial information and lack the ability to capture the high-level representative features when compared to deep learning models, leading to a performance gap in ISA mapping, whereas the deep CNN could extract high-level discriminative features. The results revealed that deep CNN could mine more representative features for ISA mapping.
We examined the superiority of the improved Deeplabv3+ through a comparison with a classical CNN semantic segmentation network such as FCN8, U-Net, and original Deeplabv3+. The FCN8 model realizes semantic segmentation through the full convolution network structure, yet there was still room to improve the segmentation accuracy and other aspects. For example, the FCN8 model is not only not precise enough for the contour and edge classification results of the ISA, but also its sensitivity to detail is low, and the spatial relationship between pixels is not fully considered, resulting in small objects in the image being easily ignored. In addition, the FCN8 model fuses the high-level and low-level semantic information through the addition operation, while the ISA data generated by the FCN8 model have a blurred boundary due to the inclusion of inadequate low-level features containing affluent texture information.
The U-Net model is an improved structure based on FCN [
26], which combines the characteristics of transposed convolution and the jump network. One of the differences with the FCN network is that there are a large number of feature channels in the up-sampling part of the U-Net network, which allows the network to propagate context information to higher-resolution layers. When implementing the up-sampling operation to restore the size the feature map to its original size, the U-Net model integrated more low-level features with rich textures into high-level features; therefore, the boundary of the ISA result was relatively clear, and the ISA extraction accuracy was relatively high. However, although the U-Net model combines the features of different scales of the corresponding compression channel through jump connection, its transmission features are relatively simple, resulting in its limited generalization ability for multi-scale features. Especially in high-resolution remote sensing images, due to the complex background of ground objects, there will be many sparse ISA with small coverage areas and irregular shapes, and its network structure will inevitably lose significant details, such as small ISA, which makes it difficult to accurately extract data.
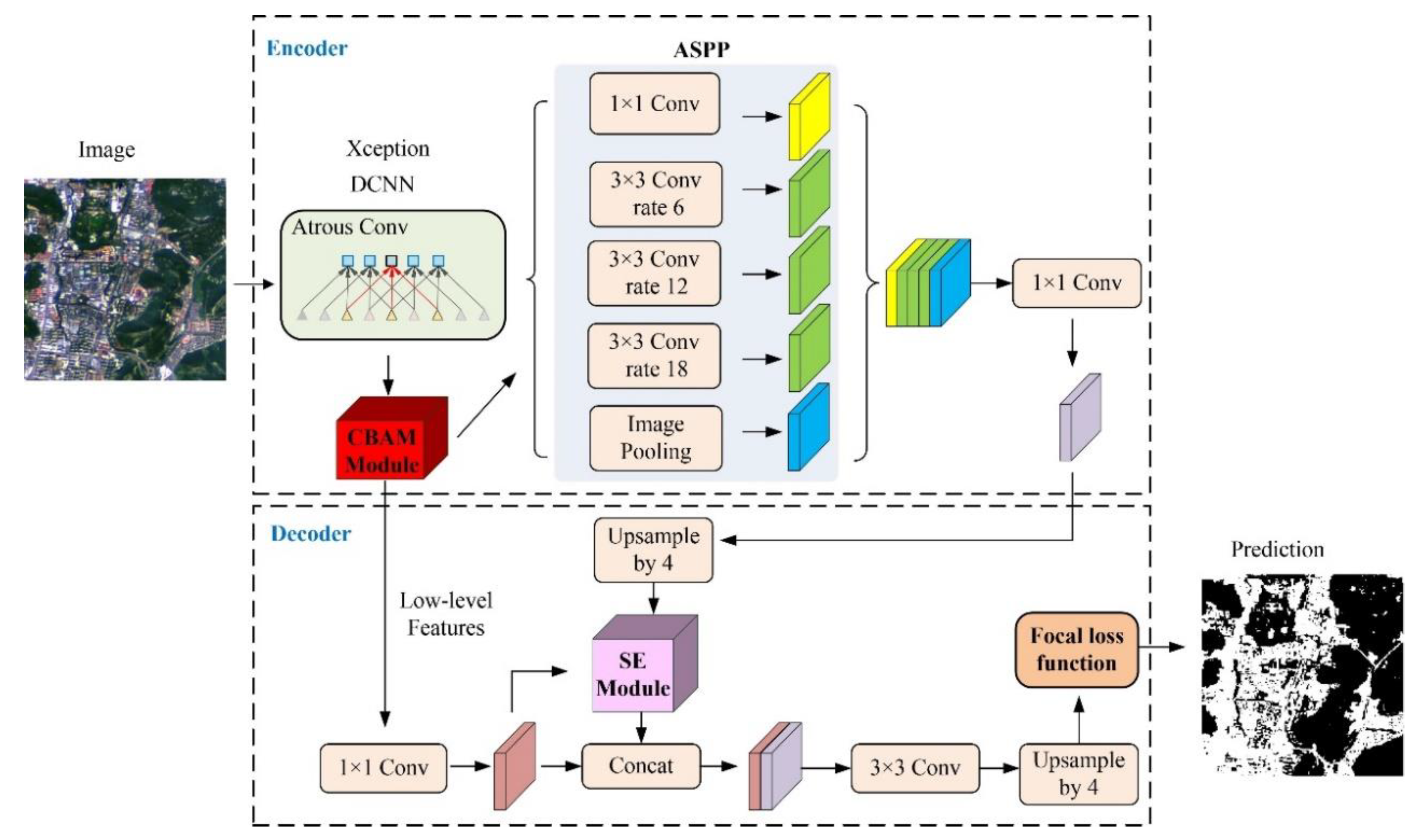
DeepLabv3+ employed the encoder-decoder structure where DeepLabv3 was used to encode the rich contextual information, and a simple yet effective decoder module was adopted to recover the object boundaries. One could also apply the atrous convolution to extract the encoder features, which include shallow features, deep features and multi-scale features at an arbitrary resolution, depending on the available computation resources. Moreover, the addition of the Xception model and atrous separable convolution made the DeepLabv3+ model faster and stronger. The performance of the model was significantly improved, which resulted in the relatively clearer boundary of the ISA result and the further improved accuracy of ISA extraction.
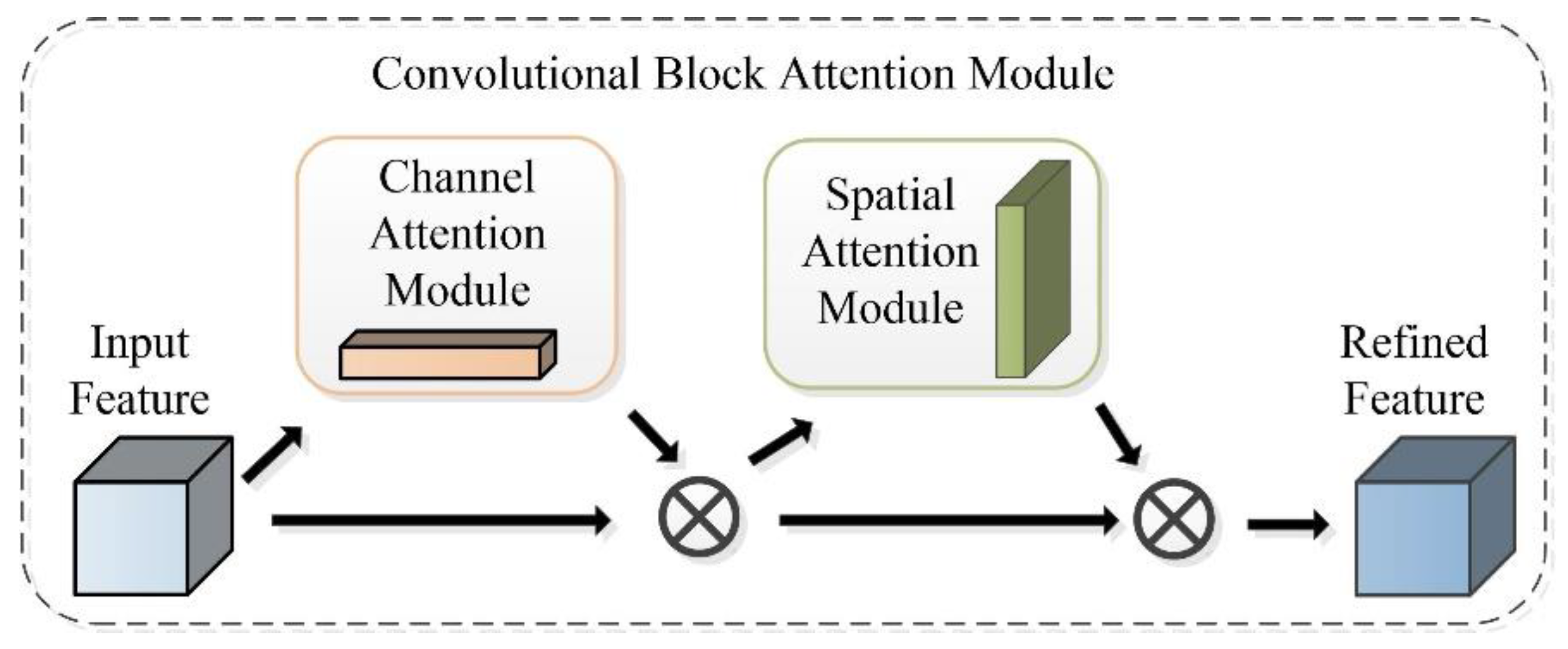
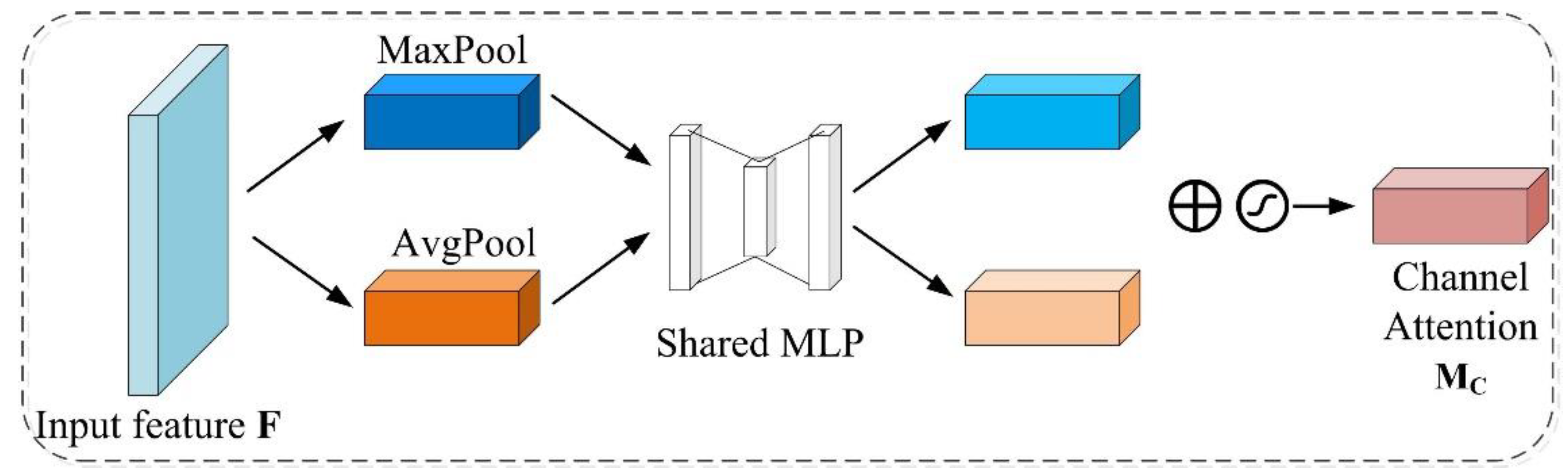
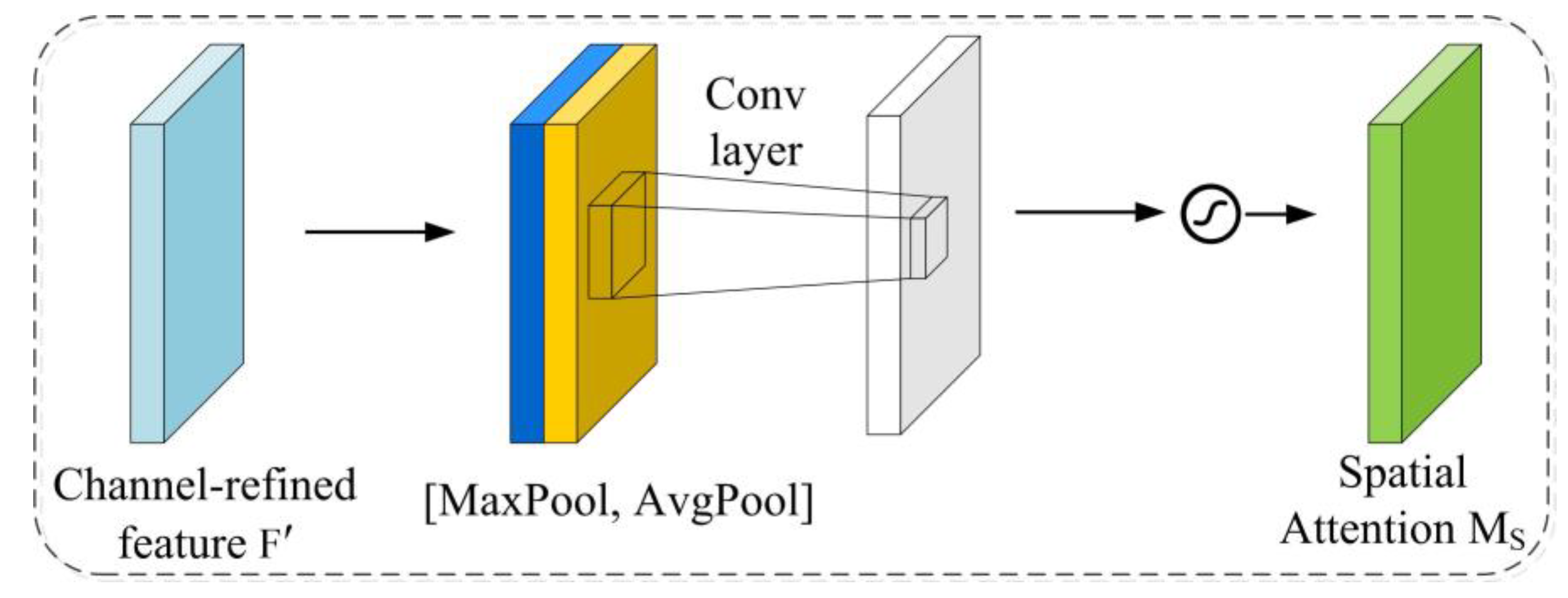
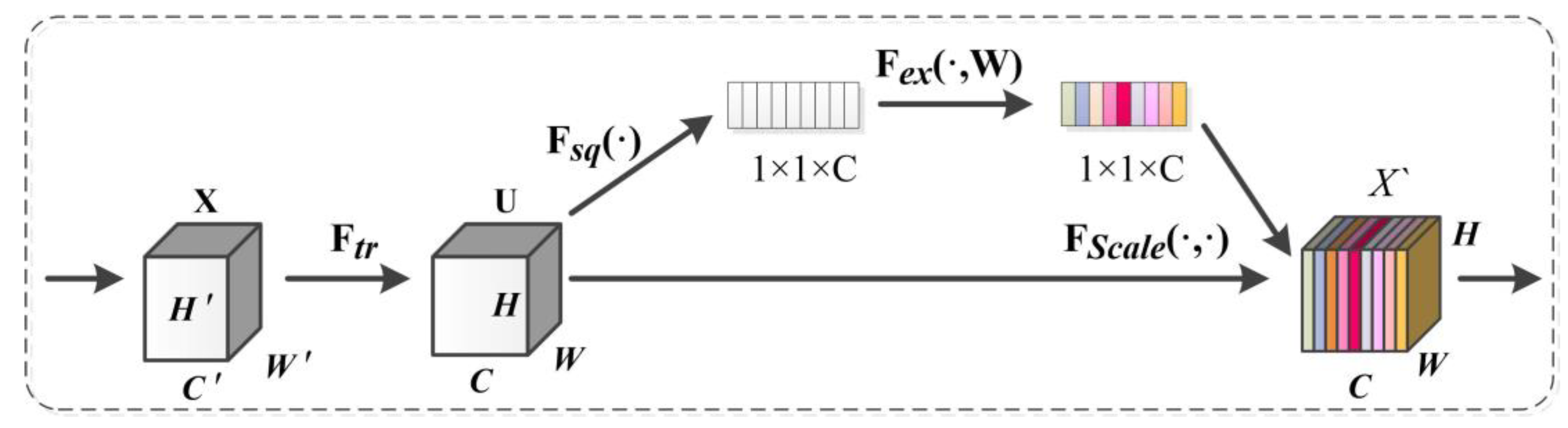
The improved Deeplabv3+ model integrates the dual-attention CBAM module, SE module and focal loss function into the Deeplabv3+ model, which can improve importance of the different location and channel of the feature maps, as well as enhance the identification ability of the network to ISA. As can be seen in
Table 3 and
Table 4, the Precision, Recall, F1 and IoU of the proposed method in this paper had the highest overall performance accuracy, which proves the effectiveness of this method. Therefore, the proposed method has more advantages in ISA mapping with Sentinel-2 and can achieve accurate ISA extraction.
Meanwhile, it is necessary to discuss the limitations of our method through comparison with previous studies on ISA mapping. In a previous study conducted by Zhang et al., combined multispectral optical data and dual polarization SAR data to identify urban impervious surfaces. In their studies, Zhang et al.’s resulting Precision, Recall, IoU and F1 reached 89.33%, 90.37%, 81.56% and 89.85%, respectively, as calculated from their confusion matrix [
35]. Compared to the accuracy of our method, the Precision, IoU and F1 of their research were improved by approximately 7.09%, 4.55% and 2.85%, respectively, which may have been due to the fact that a large volume of test samples was selected and that the Sentinel-2 single-source data with only 4 bands were used in our study. The number of the test samples in their study was 1028 for impervious surfaces (DIS + BIS) and 1607 for pervious surfaces, respectively, while the number of the test samples in our study was 566,623 for ISA and 481,953 for pervious surfaces, respectively. We believe that a large volume of test samples is more reliable for our ISA mapping model validation. Moreover, the introduction of TerraSAR-X data with a 3 m resolution in their study improved the classification accuracy to a certain extent. Nevertheless, from the perspective of visual interpretation, the results of the ISA extracted by the proposed method in this study are highly matched with the corresponding true-color images, indicating that the proposed method still has a powerful ISA identification ability.
Moreover, applying our improved model to other remote sensing images or Sentinel-2 images without atmospheric correction or other pre-processing operations may affect the accuracy of ISA mapping. In addition, due to the fact that architectural styles vary from region to region, such as significant differences in architectural styles between northern and southern in China, the presented model may also lead to a reduced classification accuracy. For this case, the ISA mapping model needs to be fine-tuned using a small number of samples from new scenes to derive the satisfactory accuracy of ISA mapping.
In general, there is still much room for improvement in the extraction of ISA information from high-resolution remote sensing images. With the continuous development of network architectures and remote sensing technology, further progress will be made in the extraction of data on urban ISA via deep learning.
5.3. The Reason for the Change of ISA
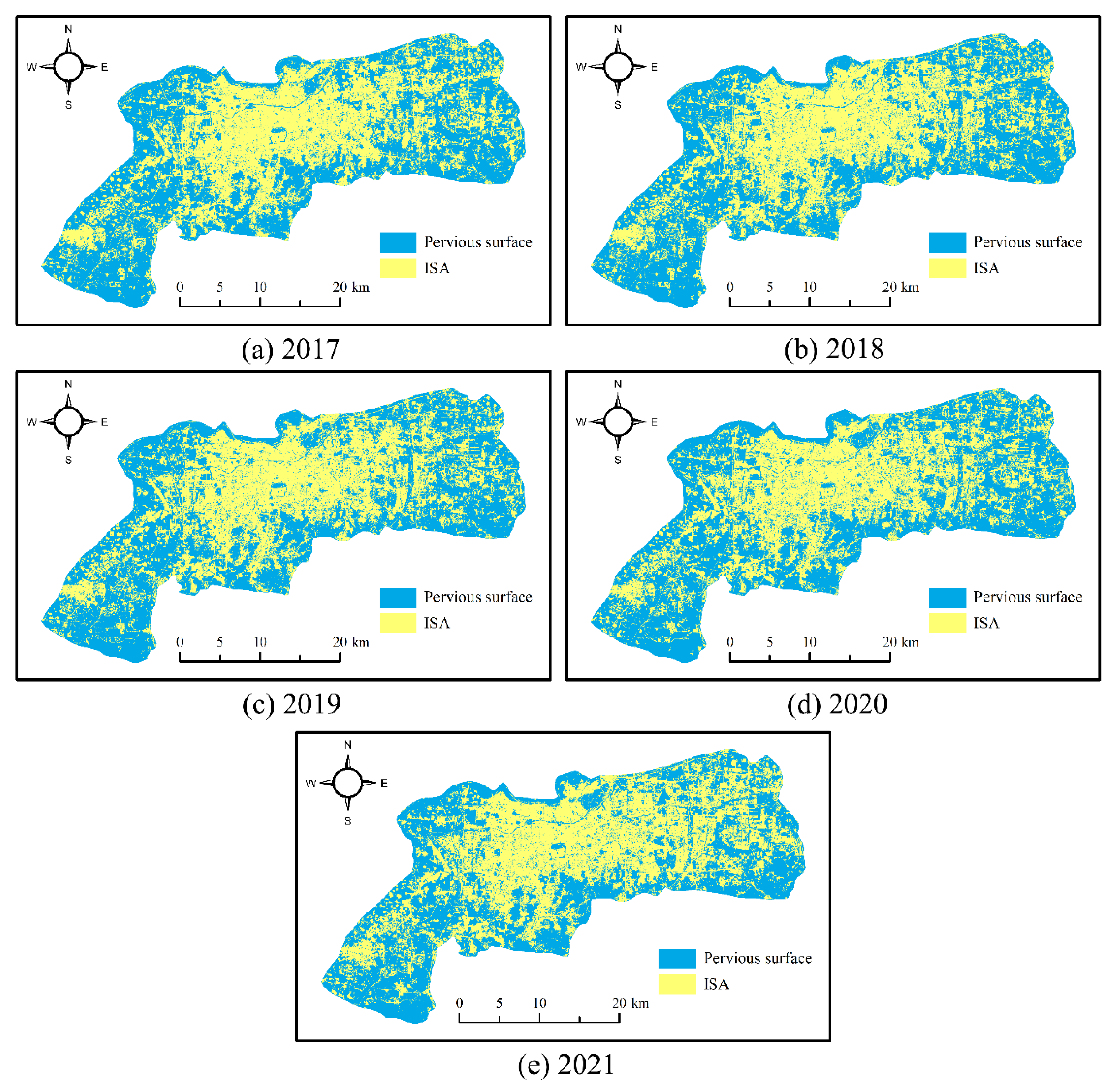
In this section, we discuss the factors that led to the change of the ISA. The ISA statistical data are shown in
Table 5. It can be observed that the ISA has shown a growth-decrease-growth change in the past five years, whereas the area change was small and belonged to normal fluctuation. For 2017–2018, the ISA increased slightly, which was attributed to the stable economic performance and continuous population growth by checking the 2018 Jinan National Economic and Social Development Statistical Bulletin (
http://jntj.jinan.gov.cn/art/2019/4/17/art_18254_2903837.html, accessed on 1 April 2023). From 2018 to 2020, the ISA continued to decline, which may have been due to the demolition of old buildings and villages on the urban fringe referring to the General Urban Planning of Jinan City (2011–2020) (
http://www.jinan.gov.cn/art/2016/8/29/art_28170_3349927.html, accessed on 1 April 2023). In 2020, the ISA area reached its minimum value during the whole period, which may have been due to the fact that the complex economic situation, especially the severe impact of the COVID-19, hindered the progress of the construction project based on the Statistical Bulletin on National Economic and Social Development of Jinan City in 2020 (
http://jntj.jinan.gov.cn/art/2021/4/2/art_18254_4742150.html, accessed on 1 April 2023). In 2021, a significant increase of the ISA area occurred, which was closely related to the accelerated implementation of the strategy of “Strengthening the Provincial Capital” and the recovery of construction projects caused by the better COVID-19 situation through checking the Statistical Bulletin on National Economic and Social Development of Jinan City in 2021 (
http://jntj.jinan.gov.cn/art/2022/3/4/art_18254_4745381.html, accessed on 1 April 2023).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}