
Tree Species Classification Based on ASDER and MALSTM-FCN

Abstract
:1. Introduction
1.1. Feature Optimization and Separation Metrics in Tree Species Classification
1.2. Tree Species Time-Series Classifier and Deep Learning Time-Series Model
- Creating targeted separability metrics for tree species classification feature optimization based on the desired feature construction method;
- Using deep learning, which has the advantages of strong scalability and the ability to mine deep information, to construct a reasonable time series classifier and improve the accuracy of tree species classification.
2. Research Area and Data
2.1. Research Area and Sample Collection
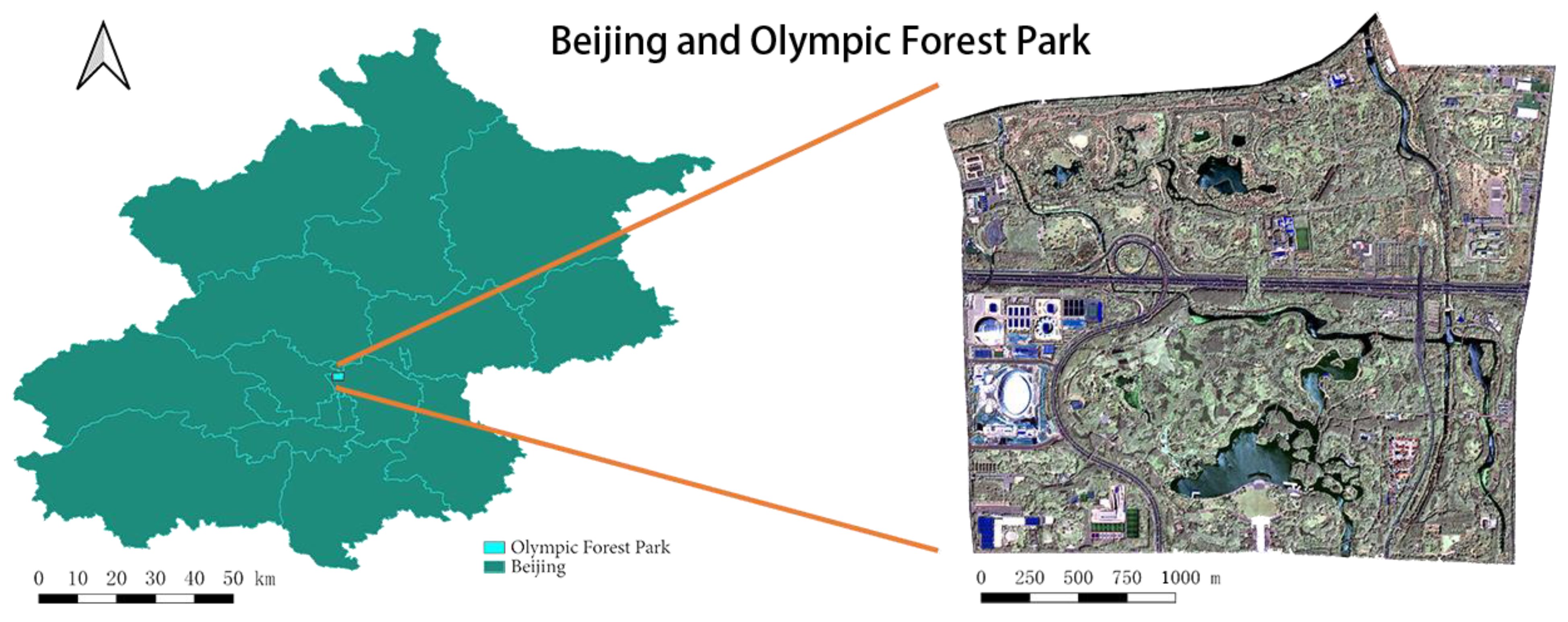
2.1.1. Research Area Introduction
2.1.2. Sample Collection
2.2. Introduction of Remote Sensing Data
3. Methods
3.1. Image Pre-Processing and Image Segmentation
3.2. ASDER-Based Feature Optimization
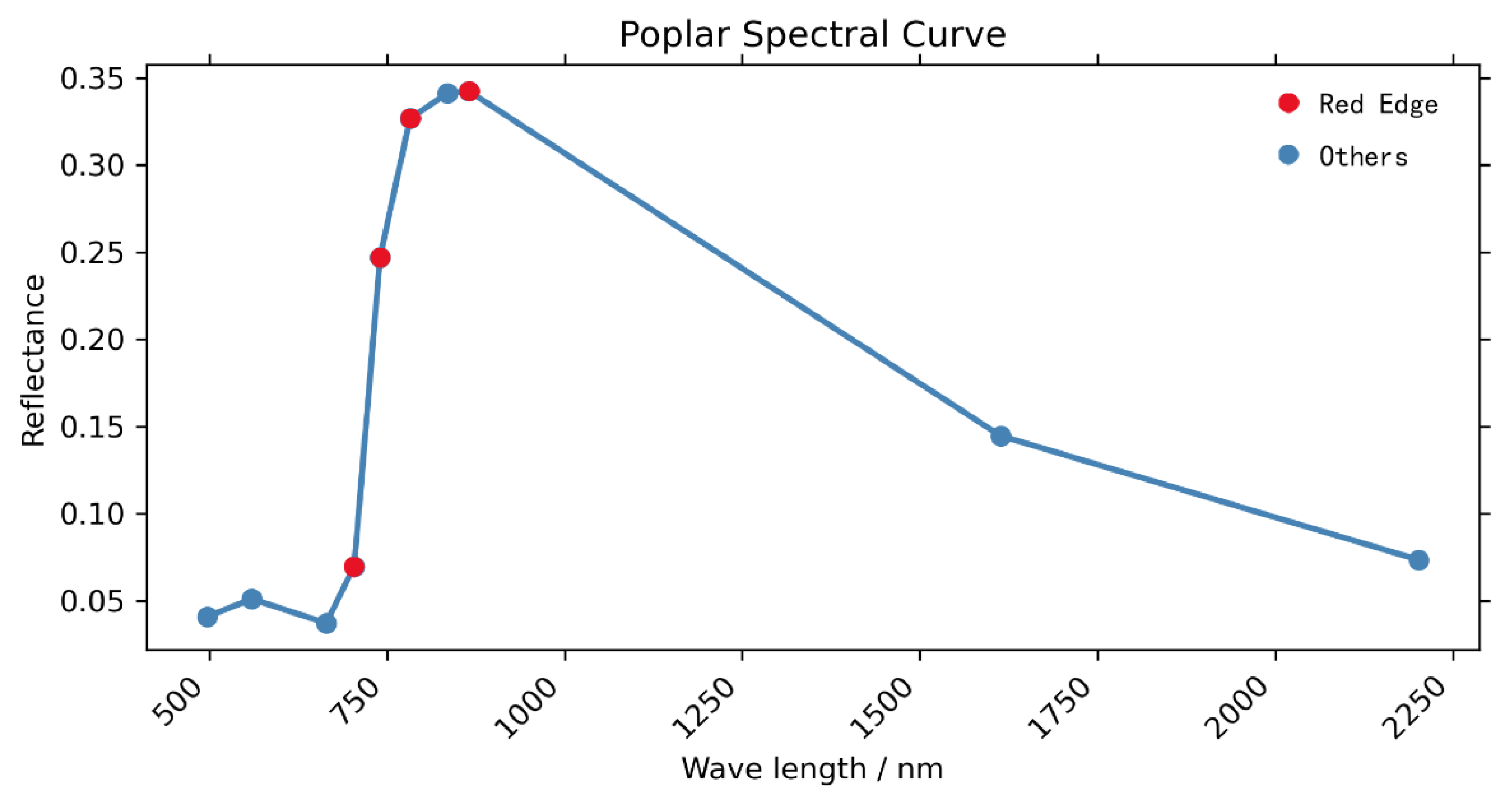
3.2.1. Normalized Difference Method and Separability Metrics
- The variance can only evaluate the separation in one dimension and cannot take into account the overall spatial information;
- The distance-based separation calculation does not take direction into account very well.
3.2.2. Introduction to ASDER
3.3. MALSTM-FCN Tree Species Time-Series Classification
3.4. Accuracy Assessment
4. Experiment
4.1. Spectral Feature Optimization
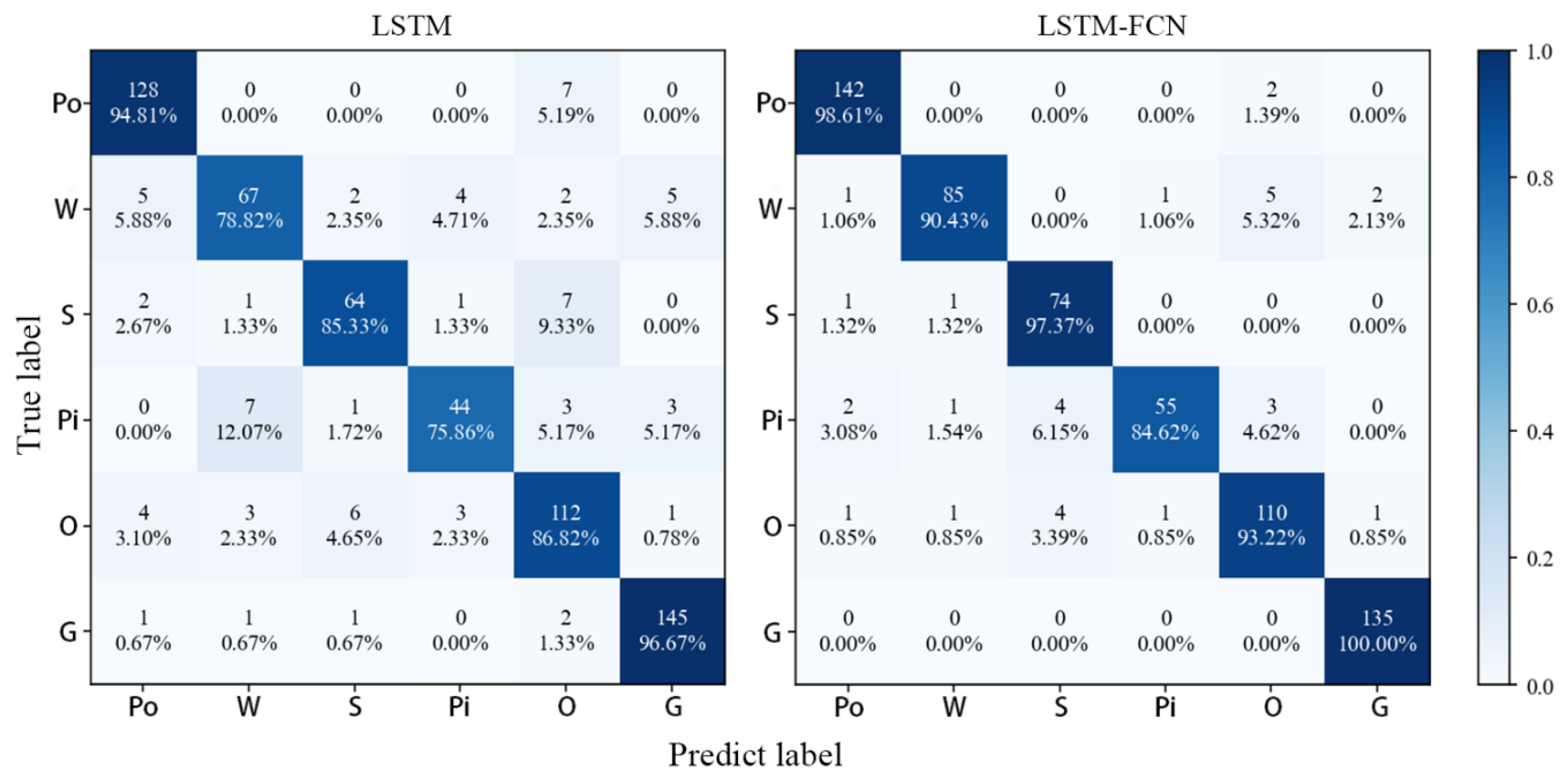
4.2. MALSTM-FCN Tree Species Classification Results
5. Discussion
5.1. Validity of ASDER
5.2. MALSTM-FCN Structure Advantages
6. Conclusions
- This paper proposed a separability metric ASDER based on standard deviation ellipse and angle weights. This metric provides a new separability evaluation standard for features constructed using the normalized difference method, which solves the problem of the lack of distinguishability in traditional separability metrics based on distance and variance in normalized difference features. This paper demonstrates the rationality of ASDER by deriving the dispersion degree between the sample points of different classes in a two-dimensional coordinate system. The experimental results demonstrate the effectiveness of incorporating the ASDER as a feature optimization criterion to improve classification accuracy.
- This paper presents the construction of the MALSTM-FCN model, with the addition of a multi-head self-attention mechanism to enhance the LSTM branch. The self-attention mechanism is utilized to compute the product of feature similarity between different temporal phases and the feature itself, thereby enhancing the correlation between features. The self-attention mechanism effectively addresses the problem of insufficient global consideration caused by the gradual loss of feature information from previous temporal phases during the computation process of LSTM. By using a multi-head perception method to obtain multi-layer semantic information between temporal features, this paper further improves classification accuracy.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhong, C.; Liu, Y.; Gao, P.; Chen, W.; Li, H.; Hou, Y.; Nuremanguli, T.; Ma, H. Landslide mapping with remote sensing: Challenges and opportunities. Int. J. Remote Sens. 2020, 41, 1555–1581. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Souza, C.M., Jr.; Shimbo, J.Z.; Rosa, M.R.; Parente, L.L.; Alencar, A.A.; Rudorff, B.F.T.; Hasenack, H.; Matsumoto, M.; Ferreira, L.G.; Souza-Filho, P.W.M. Reconstructing three decades of land use and land cover changes in brazilian biomes with landsat archive and earth engine. Remote Sens. 2020, 12, 2735. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Xu, L.; Ming, D.; Zhou, W.; Bao, H.; Chen, Y.; Ling, X. Farmland extraction from high spatial resolution remote sensing images based on stratified scale pre-estimation. Remote Sens. 2019, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Feng, J.; Jiao, L.; Liu, F.; Sun, T.; Zhang, X. Unsupervised feature selection based on maximum information and minimum redundancy for hyperspectral images. Pattern Recognit. 2016, 51, 295–309. [Google Scholar] [CrossRef]
- Campos, P.; Álvarez, A.; Oviedo, J.L.; Ovando, P.; Mesa, B.; Caparrós, A. Income and Ecosystem Service Comparisons of Refined National and Agroforestry Accounting Frameworks: Application to Holm Oak Open Woodlands in Andalusia, Spain. Forests 2020, 11, 185. [Google Scholar] [CrossRef] [Green Version]
- McDonald, G.T.; Lane, M.B. Converging global indicators for sustainable forest management. For. Policy Econ. 2004, 6, 63–70. [Google Scholar] [CrossRef]
- Arthur, M.A.; Alexander, H.D.; Dey, D.C.; Schweitzer, C.J.; Loftis, D.L. Refining the Oak-Fire Hypothesis for Management of Oak-Dominated Forests of the Eastern United States. J. For. 2012, 110, 257–266. [Google Scholar] [CrossRef]
- Pu, R. Mapping Tree Species Using Advanced Remote Sensing Technologies: A State-of-the-Art Review and Perspective. J. Remote Sens. 2021, 2021, 9812624. [Google Scholar] [CrossRef]
- Zhang, B.; Zhao, L.; Zhang, X. Three-dimensional convolutional neural network model for tree species classification using airborne hyperspectral images. Remote Sens. Environ. 2020, 247, 111938. [Google Scholar] [CrossRef]
- Sothe, C.; Dalponte, M.; Almeida, C.M.; Schimalski, M.B.; Lima, C.L.; Liesenberg, V.; Miyoshi, G.T.; Tommaselli, A.M. Tree Species Classification in a Highly Diverse Subtropical Forest Integrating UAV-Based Photogrammetric Point Cloud and Hyperspectral Data. Remote Sens. 2019, 11, 1338. [Google Scholar] [CrossRef] [Green Version]
- Onishi, M.; Ise, T. Explainable identification and mapping of trees using UAV RGB image and deep learning. Sci. Rep. 2021, 11, 903. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree species classification with random forest using very high spatial resolution 8-band WorldView-2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Carleer, A.; Wolff, E. Exploitation of very high resolution satellite data for tree species identification. Photogramm. Eng. Remote Sens. 2004, 70, 135–140. [Google Scholar] [CrossRef] [Green Version]
- Dalponte, M.; Ørka, H.O.; Gobakken, T.; Gianelle, D.; Næsset, E. Tree Species Classification in Boreal Forests with Hyperspectral Data. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2632–2645. [Google Scholar] [CrossRef]
- Zhang, J.; Rivard, B.; Sánchez-Azofeifa, A.; Castro-Esau, K. Intra- and inter-class spectral variability of tropical tree species at La Selva, Costa Rica: Implications for species identification using HYDICE imagery. Remote Sens. Environ. 2006, 105, 129–141. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1353691. [Google Scholar] [CrossRef] [Green Version]
- Michałowska, M.; Rapiński, J. A review of tree species classification based on airborne LiDAR data and applied classifiers. Remote Sens. 2021, 13, 353. [Google Scholar] [CrossRef]
- Hovi, A.; Korhonen, L.; Vauhkonen, J.; Korpela, I. LiDAR waveform features for tree species classification and their sensitivity to tree- and acquisition related parameters. Remote Sens. Environ. 2016, 173, 224–237. [Google Scholar] [CrossRef]
- Heinzel, J.; Koch, B. Exploring full-waveform LiDAR parameters for tree species classification. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 152–160. [Google Scholar] [CrossRef]
- Wessel, M.; Brandmeier, M.; Tiede, D. Evaluation of different machine learning algorithms for scalable classification of tree types and tree species based on Sentinel-2 data. Remote Sens. 2018, 10, 1419. [Google Scholar] [CrossRef] [Green Version]
- Persson, M.; Lindberg, E.; Reese, H. Tree Species Classification with Multi-Temporal Sentinel-2 Data. Remote Sens. 2018, 10, 1794. [Google Scholar] [CrossRef] [Green Version]
- Hościło, A.; Lewandowska, A. Mapping forest type and tree species on a regional scale using multi-temporal Sentinel-2 data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef] [Green Version]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Hartling, S.; Sagan, V.; Sidike, P.; Maimaitijiang, M.; Carron, J. Urban tree species classification using a WorldView-2/3 and LiDAR data fusion approach and deep learning. Sensors 2019, 19, 1284. [Google Scholar] [CrossRef] [Green Version]
- Heinzel, J.; Koch, B. Investigating multiple data sources for tree species classification in temperate forest and use for single tree delineation. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 101–110. [Google Scholar] [CrossRef]
- Cao, K.; Zhang, X. An improved res-unet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Miyoshi, G.T.; Arruda, M.D.; Osco, L.P.; Marcato Junior, J.; Gonçalves, D.N.; Imai, N.N.; Tommaselli, A.M.; Honkavaara, E.; Gonçalves, W.N. A Novel Deep Learning Method to Identify Single Tree Species in UAV-Based Hyperspectral Images. Remote Sens. 2020, 12, 1294. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Zhang, R.; Cox, J.; Duling, D.; Sarle, W. Massively parallel feature selection: An approach based on variance preservation. Mach. Learn. 2013, 92, 195–220. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Ji, M.; Zhang, C.; Bao, H. A Variance Minimization Criterion to Feature Selection Using Laplacian Regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2013–2025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Munson, M.A.; Caruana, R. On Feature Selection, Bias-Variance, and Bagging. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Bled, Slovenia, 7–11 September 2009; pp. 144–159. [Google Scholar]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote Sensing Scene Classification Using Multilayer Stacked Covariance Pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Wang, R.; Guo, H.; Davis, L.S.; Dai, Q. Covariance discriminative learning: A natural and efficient approach to image set classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2496–2503. [Google Scholar]
- Shahee, S.A.; Ananthakumar, U. An effective distance based feature selection approach for imbalanced data. Appl. Intell. 2020, 50, 717–745. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, D. Feature selection with effective distance. Neurocomputing 2016, 215, 100–109. [Google Scholar] [CrossRef]
- Liang, J.; Yang, S.; Winstanley, A. Invariant optimal feature selection: A distance discriminant and feature ranking based solution. Pattern Recognit. 2008, 41, 1429–1439. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Akram, T.; Javed, M.Y.; Saba, T.; Rehman, A. A framework of human detection and action recognition based on uniform segmentation and combination of Euclidean distance and joint entropy-based features selection. EURASIP J. Image Video Process. 2017, 2017, 89. [Google Scholar] [CrossRef]
- Banka, H.; Dara, S. A Hamming distance based binary particle swarm optimization (HDBPSO) algorithm for high dimensional feature selection, classification and validation. Pattern Recognit. Lett. 2015, 52, 94–100. [Google Scholar] [CrossRef]
- Bruzzone, L.; Roli, F.; Serpico, S.B. An extension of the Jeffreys-Matusita distance to multiclass cases for feature selection. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1318–1321. [Google Scholar] [CrossRef] [Green Version]
- Xuan, G.; Chai, P.; Wu, M. Bhattacharyya distance feature selection. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; Volume 192, pp. 195–199. [Google Scholar]
- Qi, Y.; Su, B.; Lin, X.; Zhou, H. A new feature selection method based on feature distinguishing ability and network influence. J. Biomed. Inform. 2022, 128, 104048. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, G.; Gao, W. Distinguishing two types of labels for multi-label feature selection. Pattern Recognit. 2019, 95, 72–82. [Google Scholar] [CrossRef]
- Grabska, E.; Hostert, P.; Pflugmacher, D.; Ostapowicz, K. Forest Stand Species Mapping Using the Sentinel-2 Time Series. Remote Sens. 2019, 11, 1197. [Google Scholar] [CrossRef] [Green Version]
- Immitzer, M.; Neuwirth, M.; Böck, S.; Brenner, H.; Vuolo, F.; Atzberger, C. Optimal Input Features for Tree Species Classification in Central Europe Based on Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 2599. [Google Scholar] [CrossRef] [Green Version]
- Praticò, S.; Solano, F.; Di Fazio, S.; Modica, G. Machine Learning Classification of Mediterranean Forest Habitats in Google Earth Engine Based on Seasonal Sentinel-2 Time-Series and Input Image Composition Optimisation. Remote Sens. 2021, 13, 586. [Google Scholar] [CrossRef]
- Sheeren, D.; Fauvel, M.; Josipović, V.; Lopes, M.; Planque, C.; Willm, J.; Dejoux, J.-F. Tree Species Classification in Temperate Forests Using Formosat-2 Satellite Image Time Series. Remote Sens. 2016, 8, 734. [Google Scholar] [CrossRef] [Green Version]
- Xi, Y.; Ren, C.; Tian, Q.; Ren, Y.; Dong, X.; Zhang, Z. Exploitation of Time Series Sentinel-2 Data and Different Machine Learning Algorithms for Detailed Tree Species Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7589–7603. [Google Scholar] [CrossRef]
- Zhou, Y.n.; Luo, J.; Feng, L.; Yang, Y.; Chen, Y.; Wu, W. Long-short-term-memory-based crop classification using high-resolution optical images and multi-temporal SAR data. GIScience Remote Sens. 2019, 56, 1170–1191. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Jiang, W. Time series classification: Nearest neighbor versus deep learning models. SN Appl. Sci. 2020, 2, 721. [Google Scholar] [CrossRef] [Green Version]
- Fejfar, J.; Šťastný, J.; Cepl, M. Time series classification using k-Nearest neighbours, Multilayer Perceptron and Learning Vector Quantization algorithms. Acta Univ. Agric. Silvic. Mendel. Brun. 2012, 2, 69–72. [Google Scholar] [CrossRef] [Green Version]
- Arias del Campo, F.; Guevara Neri, M.C.; Vergara Villegas, O.O.; Cruz Sánchez, V.G.; Ochoa Domínguez, H.d.J.; García Jiménez, V. Auto-adaptive multilayer perceptron for univariate time series classification. Expert Syst. Appl. 2021, 181, 115147. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Cui, Z.; Chen, W.; Chen, Y. Multi-scale convolutional neural networks for time series classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks. In Proceedings of the Web-Age Information Management, Macau, China, 16–18 June 2014; pp. 298–310. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Nanopoulos, A.; Alcock, R.; Manolopoulos, Y. Feature-based classification of time-series data. Int. J. Comput. Res. 2001, 10, 49–61. [Google Scholar]
- Schütt, K.T.; Sauceda, H.E.; Kindermans, P.-J.; Tkatchenko, A.; Müller, K.-R. Schnet–a deep learning architecture for molecules and materials. J. Chem. Phys. 2018, 148, 241722. [Google Scholar] [CrossRef]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Li, X.; Peng, L.; Hu, Y.; Shao, J.; Chi, T. Deep learning architecture for air quality predictions. Environ. Sci. Pollut. Res. 2016, 23, 22408–22417. [Google Scholar] [CrossRef]
- Dong, L.; Hu, J.; Wu, Y. Ecological Concepts of Plants Planning in Beijing Olympic Forest Park. Chin. Landsc. Archit. 2006, 22, 34–38. [Google Scholar]
- Blake, R.; Mangiameli, P. The effects and interactions of data quality and problem complexity on classification. J. Data Inf. Qual. 2011, 2, 1–28. [Google Scholar] [CrossRef]
- Fan, G.; Chen, F.; Li, Y.; Liu, B.; Fan, X. Development and Testing of a New Ground Measurement Tool to Assist in Forest GIS Surveys. Forests 2019, 10, 643. [Google Scholar] [CrossRef] [Green Version]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII, Warsaw, Poland, 11–13 September 2017; pp. 37–48. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Rousel, J.; Haas, R.; Schell, J.; Deering, D. Monitoring vegetation systems in the great plains with ERTS. In Proceedings of the Third Earth Resources Technology Satellite—1 Symposium; NASA SP-351, Washington, DC, USA, 10–14 December 1973; pp. 309–317. [Google Scholar]
- Witten, D.M.; Tibshirani, R. Covariance-regularized regression and classification for high dimensional problems. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2009, 71, 615–636. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuzel, O.; Porikli, F.; Meer, P. Region Covariance: A Fast Descriptor for Detection and Classification. In Proceedings of the Computer Vision—ECCV 2006, Graz, Austria, 7–13 May 2006; pp. 589–600. [Google Scholar]
- Friedman, J.H. On Bias, Variance, 0/1—Loss, and the Curse-of-Dimensionality. Data Min. Knowl. Discov. 1997, 1, 55–77. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical methods for research workers. In Breakthroughs in Statistics; Springer: Berlin, Germany, 1992; pp. 66–70. [Google Scholar]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Andrew, G. Analysis of variance—Why it is more important than ever. Ann. Stat. 2005, 33, 1–53. [Google Scholar] [CrossRef] [Green Version]
- Swain, P.H. Pattern Recognition: A Basis for Remote Sensing Data Analysis; Purdue University: West Lafayette, IN, USA, 1973. [Google Scholar]
- Csiszár, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Yuill, R.S. The standard deviational ellipse; an updated tool for spatial description. Geogr. Ann. Ser. B Hum. Geogr. 1971, 53, 28–39. [Google Scholar] [CrossRef]
- Lefever, D.W. Measuring geographic concentration by means of the standard deviational ellipse. Am. J. Sociol. 1926, 32, 88–94. [Google Scholar] [CrossRef]
- Wang, B.; Shi, W.; Miao, Z. Confidence analysis of standard deviational ellipse and its extension into higher dimensional Euclidean space. PLoS ONE 2015, 10, e0118537. [Google Scholar] [CrossRef] [PubMed]
- Gong, J. Clarifying the standard deviational ellipse. Geogr. Anal. 2002, 34, 155–167. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM Fully Convolutional Networks for Time Series Classification. IEEE Access 2018, 6, 1662–1669. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, Y.; Sa, J.; Chung, Y.; Park, D.; Lee, S. Resource-Efficient Pet Dog Sound Events Classification Using LSTM-FCN Based on Time-Series Data. Sensors 2018, 18, 4019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moukafih, Y.; Hafidi, H.; Ghogho, M. Aggressive Driving Detection Using Deep Learning-based Time Series Classification. In Proceedings of the 2019 IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), Sofia, Bulgaria, 3–5 July 2019; pp. 1–5. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H. Insights Into LSTM Fully Convolutional Networks for Time Series Classification. IEEE Access 2019, 7, 67718–67725. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Include | Number |
|---|---|---|
| Populus Class | Chinese white poplar (Populus tomentosa) * Korean white poplar (Populus davidiana Dode) White poplar (Populus alba L.) | 514 |
| Willow Class | Weeping willow (Salix babylonica L.) Chinese willow (Salix matsudana Koidz) | 300 |
| Sophora Class | Japanese pagoda tree (Sophora japonica Linn. var. japonica f. oligophylla Franch.) Jinye pagoda tree (Sophora japonica cv. jinye) Black locust (Robinia pseudoacacia L.) | 249 |
| Pine Class | Masson’s pine (Pinus massoniana Lamb.) Chinese red pine (Pinus tabuliformis Carr.) | 178 |
| Other Tree Species | Chinese ash (Fraxinus chinensis Roxb.) Tree of heaven (Ailanthus altissima) Chinese toon (Toona sinensis (A. Juss.) Roem.) Else | 384 |
| Grassland | 479 |
| Date of Data | |||||||
|---|---|---|---|---|---|---|---|
| 2021/1/2 | 2021/1/24 | 2021/3/20 | 2021/5/2 | 2021/8/2 | 2021/10/1 | 2021/10/26 | 2021/12/3 |
| 2021/1/4 | 2021/1/29 | 2021/3/25 | 2021/5/7 | 2021/8/10 | 2021/10/11 | 2021/11/10 | 2021/12/5 |
| 2021/1/9 | 2021/2/3 | 2021/4/7 | 2021/5/29 | 2021/8/17 | 2021/10/16 | 2021/11/13 | 2021/12/13 |
| 2021/1/12 | 2021/2/6 | 2021/4/14 | 2021/6/1 | 2021/8/27 | 2021/10/19 | 2021/11/23 | 2021/12/18 |
| 2021/1/17 | 2021/2/8 | 2021/4/17 | 2021/6/3 | 2021/9/1 | 2021/10/21 | 2021/11/25 | 2021/12/20 |
| 2021/1/22 | 2021/2/26 | 2021/4/19 | 2021/6/21 | 2021/9/29 | 2021/10/24 | 2021/11/30 | 2021/12/30 |
| Combination of Tree Species | Time Phase | Band First | Band Second | Rate (%) | Angle (°) |
|---|---|---|---|---|---|
| Populus Class AND Willow Class | 2021/5/2 | Band_3 | Band_8 | 1.235 | 5.225 |
| 2021/5/2 | Band_3 | Band_7 | 1.326 | 5.476 | |
| 2021/4/17 | Band_3 | Band_8 | 1.389 | 4.914 | |
| Populus Class AND Sophora Class | 2021/4/17 | Band_3 | Band_8 | 0.000 | 9.385 |
| 2021/4/19 | Band_3 | Band_8 | 0.000 | 9.385 | |
| 2021/4/17 | Band_3 | Band_7 | 0.041 | 9.294 | |
| Populus Class AND Pine Class | 2021/12/20 | Band_2 | Band_8 | 0.784 | 8.481 |
| 2021/12/13 | Band_2 | Band_8 | 0.792 | 8.704 | |
| 2021/12/13 | Band_2 | Band_6 | 0.864 | 11.524 | |
| Willow Class AND Sophora Class | 2021/4/7 | Band_8 | Band_12 | 1.201 | 12.303 |
| 2021/4/7 | Band_6 | Band_12 | 1.334 | 11.866 | |
| 2021/4/14 | Band_8 | Band_12 | 1.420 | 12.086 | |
| Willow Class AND Pine Class | 2021/2/3 | Band_4 | Band_6 | 1.695 | 12.514 |
| 2021/1/29 | Band_4 | Band_6 | 1.944 | 11.270 | |
| 2021/2/6 | Band_4 | Band_6 | 1.965 | 10.680 | |
| Sophora Class AND Pine Class | 2021/12/30 | Band_4 | Band_8 | 0.563 | 12.674 |
| 2021/2/6 | Band_4 | Band_8 | 0.640 | 11.445 | |
| 2021/2/3 | Band_4 | Band_6 | 0.696 | 14.573 |
| First Species | Second Species | Band First | Band Second | FP Rate (%) | FN Rate (%) |
|---|---|---|---|---|---|
| Populus Class | Willow Class | Band_3 | Band_8 | 5.28 | 6.19 |
| Band_4 | Band_8 | 8.06 | 16.19 | ||
| Populus Class | Sophora Class | Band_3 | Band_8 | 1.39 | 1.15 |
| Band_4 | Band_8 | 0.83 | 0.00 | ||
| Populus Class | Pine Class | Band_2 | Band_8 | 0.30 | 4.01 |
| Band_4 | Band_8 | 0.30 | 3.21 | ||
| Willow Class | Sophora Class | Band_8 | Band_12 | 10.95 | 3.44 |
| Band_4 | Band_8 | 12.86 | 4.01 | ||
| Willow Class | Pine Class | Band_4 | Band_6 | 7.62 | 24.08 |
| Band_4 | Band_8 | 10.95 | 24.88 |
| Combination of Tree Species | Band First | Band Second | Combination of Tree Species | Band First | Band Second |
|---|---|---|---|---|---|
| Populus Class AND Willow Class | Band_3 | Band_8 | Willow Class AND Sophora Class | Band_8 | Band_12 |
| Band_3 | Band_7 | Band_6 | Band_12 | ||
| Band_3 | Band_6 | Band_4 | Band_8 | ||
| Populus Class AND Sophora Class | Band_3 | Band_8 | Willow Class AND Pine Class | Band_4 | Band_6 |
| Band_3 | Band_7 | Band_4 | Band_5 | ||
| Band_8 | Band_11 | Band_3 | Band_6 | ||
| Populus Class AND Pine Class | Band_4 | Band_6 | Sophora Class AND Pine Class | Band_4 | Band_8 |
| Band_8 | Band_11 | Band_4 | Band_6 | ||
| Band_3 | Band_6 | Band_4 | Band_7 |
| Band Combine | Var Max | Var Sum | Entropy Sum | Band Combine | Var Max | Var Sum | Entropy Sum |
|---|---|---|---|---|---|---|---|
| Band_2–6 | 0.043 * | 0.305 | 3.870 | Band_4–6 | 0.028 | 0.392 | 4.501 |
| Band_2–8 | 0.038 | 0.261 | 3.535 | Band_4–7 | 0.029 | 0.398 | 4.593 |
| Band_3–6 | 0.029 | 0.263 | 3.150 | Band_4–8 | 0.028 | 0.345 | 4.312 |
| Band_3–7 | 0.030 | 0.277 | 3.333 | Band_6–12 | 0.020 | 0.384 | 3.787 |
| Band_3–8 | 0.027 | 0.238 | 2.993 | Band_8–11 | 0.019 | 0.316 | 2.832 |
| Band_4–5 | 0.017 | 0.181 | 2.552 | Band_8–12 | 0.018 | 0.378 | 3.538 |
| Exp | With Band_4–5 | Without Band_4–5 | Index by Var and Entropy |
|---|---|---|---|
| Ave1 | 88.58% | 87.53% | 87.78% |
| Ave2 | 88.45% | 87.08% | 87.34% |
| Exp | MALSTM-FCN | LSTM | LSTM-FCN |
|---|---|---|---|
| Ave1 | 95.28% | 88.58% | 94.94% |
| Ave2 | 95.20% | 88.45% | 94.94% |
| Exp | Epoch | Acc |
|---|---|---|
| only Multi-head Attention (Exp1) | 500 | 95.89% |
| total Transformer Encoder (Exp2) | 500 | 95.36% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Ming, D.; Xu, L.; Ling, X. Tree Species Classification Based on ASDER and MALSTM-FCN. Remote Sens. 2023, 15, 1723. https://doi.org/10.3390/rs15071723
Luo H, Ming D, Xu L, Ling X. Tree Species Classification Based on ASDER and MALSTM-FCN. Remote Sensing. 2023; 15(7):1723. https://doi.org/10.3390/rs15071723
Chicago/Turabian StyleLuo, Hongjian, Dongping Ming, Lu Xu, and Xiao Ling. 2023. "Tree Species Classification Based on ASDER and MALSTM-FCN" Remote Sensing 15, no. 7: 1723. https://doi.org/10.3390/rs15071723