
Improving Pre-Training and Fine-Tuning for Few-Shot SAR Automatic Target Recognition

Abstract
:1. Introduction
1.1. Background
1.2. Related Work
1.3. Motivation
1.4. Contribution
- A novel framework for few-shot SAR image target recognition is proposed.
- A style transfer model is introduced to style transfer the optical image target recognition dataset to generate a SAR-like image style target recognition dataset. This dataset is used as the base class dataset for the model, and the model is trained to successfully eliminate the cross-domain problem between the base class dataset and the novel class dataset.
- The introduction of the deep BDC pooling layer method effectively fits the characteristics of SAR image targets and increases the importance of target contour features, thus effectively improving the accuracy of target recognition.
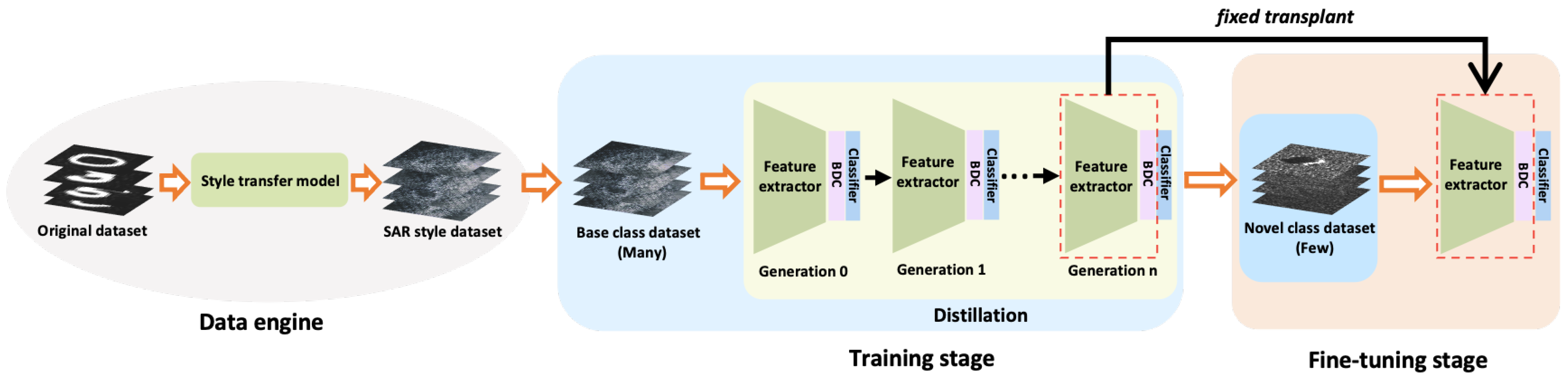
2. Methodology
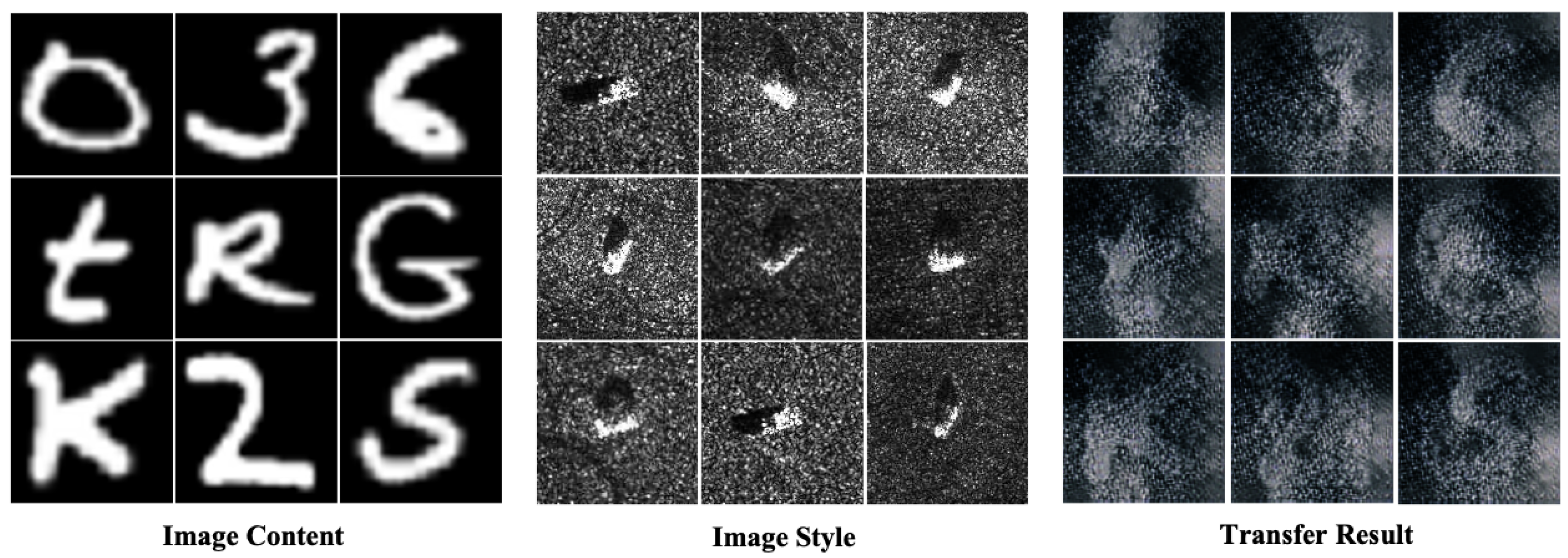
2.1. Data Engine
2.2. Deep Brownian Distance Covariance
- (1)
- The reduced-dimensional convolutional features are rearranged to produce the expression , where h and w are the spatial height and width, respectively, and d is the number of channels. Each column in the table may be seen as an observation of the random vector X.
- (2)
- Calculate the Euclidean distance square matrix , where represents the squared Euclidean distance between the kth and lth columns of X, and then square it to produce the Euclidean distance matrix .
- (3)
- After removing the row and column means as well as the overall mean from the distance matrix, the BDC matrix may be derived.
2.3. Sequential Self-Distillation
2.4. Baseline
3. Experiments
3.1. Experimental Dataset
3.2. Experimental Setup
3.3. Style Transfer Visualization
3.4. Ablation Study
3.5. Comparative Experiment of Replacing Different Backbones
3.6. Comparative Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SAR | Synthetic aperture radar |
| ATR | Automatic target recognition |
| ROI | Region containing the target of interest |
| DeepBDC | Deep Brownian distance covariance |
References
- Novak, L.M.; Owirka, G.J.; Brower, W.S.; Weaver, A.L. The automatic target-recognition system in SAIP. Linc. Lab. J. 1997, 10. [Google Scholar]
- Ikeuchi, K.; Wheeler, M.D.; Yamazaki, T.; Shakunaga, T. Model-based SAR ATR system. In Proceedings of the Aerospace/Defense Sensing and Controls, Orlando, FL, USA, 8–12 April 1996. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A.C. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar]
- Hertzmann, A. Painterly rendering with curved brush strokes of multiple sizes. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 19–24 July 1998. [Google Scholar]
- Frigo, O.; Sabater, N.; Delon, J.; Hellier, P. Split and Match: Example-Based Adaptive Patch Sampling for Unsupervised Style Transfer. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July2016; pp. 553–561. [Google Scholar]
- Winnemöller, H.; Olsen, S.C.; Gooch, B. Real-time video abstraction. ACM Trans. Graph. 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Texture Synthesis Using Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), 2015; Available online: https://papers.nips.cc/paper/2015 (accessed on 10 March 2023).
- Li, C.; Wand, M. Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2479–2486. [Google Scholar]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. ArtFlow: Unbiased Image Style Transfer via Reversible Neural Flows. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 862–871. [Google Scholar]
- An, J.; Li, T.; Huang, H.; Shen, L.; Wang, X.; Tang, Y.; Ma, J.; Liu, W.; Luo, J. Real-time Universal Style Transfer on High-resolution Images via Zero-channel Pruning. arXiv 2020, arXiv:2006.09029. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.M.; Wierstra, D.; Lillicrap, T.P. Meta-Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Zhao, X.; Lv, X.; Cai, J.; Guo, J.; Zhang, Y.; Qiu, X.; Wu, Y. Few-Shot SAR-ATR Based on Instance-Aware Transformer. Remote Sens. 2022, 14, 1884. [Google Scholar] [CrossRef]
- Yue, Z.; Gao, F.; Xiong, Q.; Sun, J.; Hussain, A.; Zhou, H. A novel few-shot learning method for synthetic aperture radar image recognition. Neurocomputing 2021, 465, 215–227. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.P.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), 2016; Available online: https://researchr.org/publication/nips-2016 (accessed on 10 March 2023).
- Xie, J.; Long, F.; Lv, J.; Wang, Q.; Li, P. Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7962–7971. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Department of Computer Sciences, University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Aggarwal, C.C.; Kong, X.; Gu, Q.; Han, J.; Philip, S.Y. Active learning: A survey. In Data Classification; Chapman and Hall/CRC: London, UK, 2014; pp. 599–634. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. In Proceedings of the 2020 International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Adriana, R.; Nicolas, B.; Ebrahimi, K.S.; Antoine, C.; Carlo, G.; Yoshua, B. Fitnets: Hints for thin deep nets. Proc. ICLR 2015, 2. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3713–3722. [Google Scholar]
- Mahmoud, A.S.; Mohamed, S.A.; Moustafa, M.S.; El-Khorib, R.A.; Abdelsalam, H.M.; El-Khodary, I.A. Training compact change detection network for remote sensing imagery. IEEE Access 2021, 9, 90366–90378. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4320–4328. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Self-distillation as instance-specific label smoothing. Adv. Neural Inf. Process. Syst. 2020, 33, 2184–2195. [Google Scholar]
- Shen, C.; Wang, X.; Song, J.; Sun, L.; Song, M. Amalgamating knowledge towards comprehensive classification. In Proceedings of the AAAI Conference on Artificial Intelligence; 2019; Volume 33, pp. 3068–3075. Available online: https://ojs.aaai.org/index.php/AAAI/issue/view/246 (accessed on 10 March 2023).
- Fu, Y.; Li, S.; Zhao, H.; Wang, W.; Fang, W.; Zhuang, Y.; Pan, Z.; Li, X. Elastic knowledge distillation by learning from recollection. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Sz’ekely, G.J.; Rizzo, M.L. Brownian distance covariance. Ann. Appl. Stat. 2009, 3, 1236–1265. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Furlanello, T.; Lipton, Z.; Tschannen, M.; Itti, L.; Anandkumar, A. Born again neural networks. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1607–1616. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. DeepEMD: Few-Shot Image Classification With Differentiable Earth Mover’s Distance and Structured Classifiers. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12200–12210. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. DeepEMD: Differentiable Earth Mover’s Distance for Few-Shot Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [CrossRef] [PubMed]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting Local Descriptor Based Image-To-Class Measure for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7253–7260. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), 2017; Available online: https://papers.nips.cc/paper/2017 (accessed on 10 March 2023).
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Case | Data Engine | BDC Layer | Baseline | 10-Way 1-Shot | 10-Way 5-Shot | 10-Way 10-Shot |
|---|---|---|---|---|---|---|
| 1 | ✗ | ✗ | ✔ | 20.13 ± 0.75 | 27.72 ± 0.76 | 31.62 ± 0.74 |
| 2 | ✗ | ✔ | ✔ | 32.57 ± 0.32 | 52.24 ± 0.37 | 56.04 ± 0.31 |
| 3 | ✔ | ✗ | ✔ | 28.90 ± 0.79 | 42.47 ± 0.69 | 49.65 ± 0.72 |
| 4 | ✔ | ✔ | ✔ | 51.62 ± 0.40 | 59.47 ± 0.40 | 77.92 ± 0.32 |
| Backbone | 10-Way 1-Shot (%) | 10-Way 2-Shot (%) | 10-Way 5-Shot (%) | 10-Way 10-Shot (%) |
|---|---|---|---|---|
| ResNet10 | 49.93 ± 0.40 | 58.64 ± 0.39 | 70.53 ± 0.37 | 79.46 ± 0.32 |
| ResNet18 | 51.62 ± 0.40 | 59.47 ± 0.40 | 69.38 ± 0.37 | 77.92 ± 0.32 |
| ResNet34 | 43.56 ± 0.37 | 51.32 ± 0.36 | 61.34 ± 0.35 | 69.82 ± 0.34 |
| ResNet50 | 47.14 ± 0.38 | 55.22 ± 0.38 | 66.34 ± 0.36 | 74.72 ± 0.33 |
| ResNet101 | 45.41 ± 0.37 | 52.59 ± 0.37 | 62.19 ± 0.36 | 69.26 ± 0.34 |
| Method | 10-Way 1-Shot (%) | 10-Way 2-Shot (%) | 10-Way 5-Shot (%) | 10-Way 10-Shot (%) |
|---|---|---|---|---|
| DeepEMD [29] | 36.19 ± 0.46 | 43.49 ± 0.44 | 53.14 ± 0.40 | 59.64 ± 0.39 |
| DeepEMD [30] grid | 35.89 ± 0.43 | 41.15 ± 0.41 | 52.24 ± 0.37 | 56.04 ± 0.31 |
| DeepEMD sample [30] | 35.47 ± 0.44 | 42.39 ± 0.42 | 50.34 ± 0.39 | 52.36 ± 0.28 |
| DN4 [31] | 33.25 ± 0.49 | 44.15 ± 0.45 | 53.48 ± 0.41 | 64.88 ± 0.34 |
| Prototypical [32] | 40.94 ± 0.47 | 54.54 ± 0.44 | 69.42 ± 0.39 | 78.01 ± 0.29 |
| Relation [33] | 36.19 ± 0.46 | 43.49 ± 0.44 | 53.14 ± 0.40 | 59.64 ± 0.39 |
| FTL (Ours) | 49.93 ± 0.40 | 58.64 ± 0.39 | 70.53 ± 0.37 | 79.46 ± 0.32 |
| FTL-dis (Ours) | 51.91 ± 0.40 | 60.76 ± 0.36 | 72.13 ± 0.40 | 81.21 ± 0.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Dong, H.; Deng, B. Improving Pre-Training and Fine-Tuning for Few-Shot SAR Automatic Target Recognition. Remote Sens. 2023, 15, 1709. https://doi.org/10.3390/rs15061709
Zhang C, Dong H, Deng B. Improving Pre-Training and Fine-Tuning for Few-Shot SAR Automatic Target Recognition. Remote Sensing. 2023; 15(6):1709. https://doi.org/10.3390/rs15061709
Chicago/Turabian StyleZhang, Chao, Hongbin Dong, and Baosong Deng. 2023. "Improving Pre-Training and Fine-Tuning for Few-Shot SAR Automatic Target Recognition" Remote Sensing 15, no. 6: 1709. https://doi.org/10.3390/rs15061709