

The Impacts of Quality-Oriented Dataset Labeling on Tree Cover Segmentation Using U-Net: A Case Study in WorldView-3 Imagery

Abstract
:
1. Introduction
2. Materials and Methods
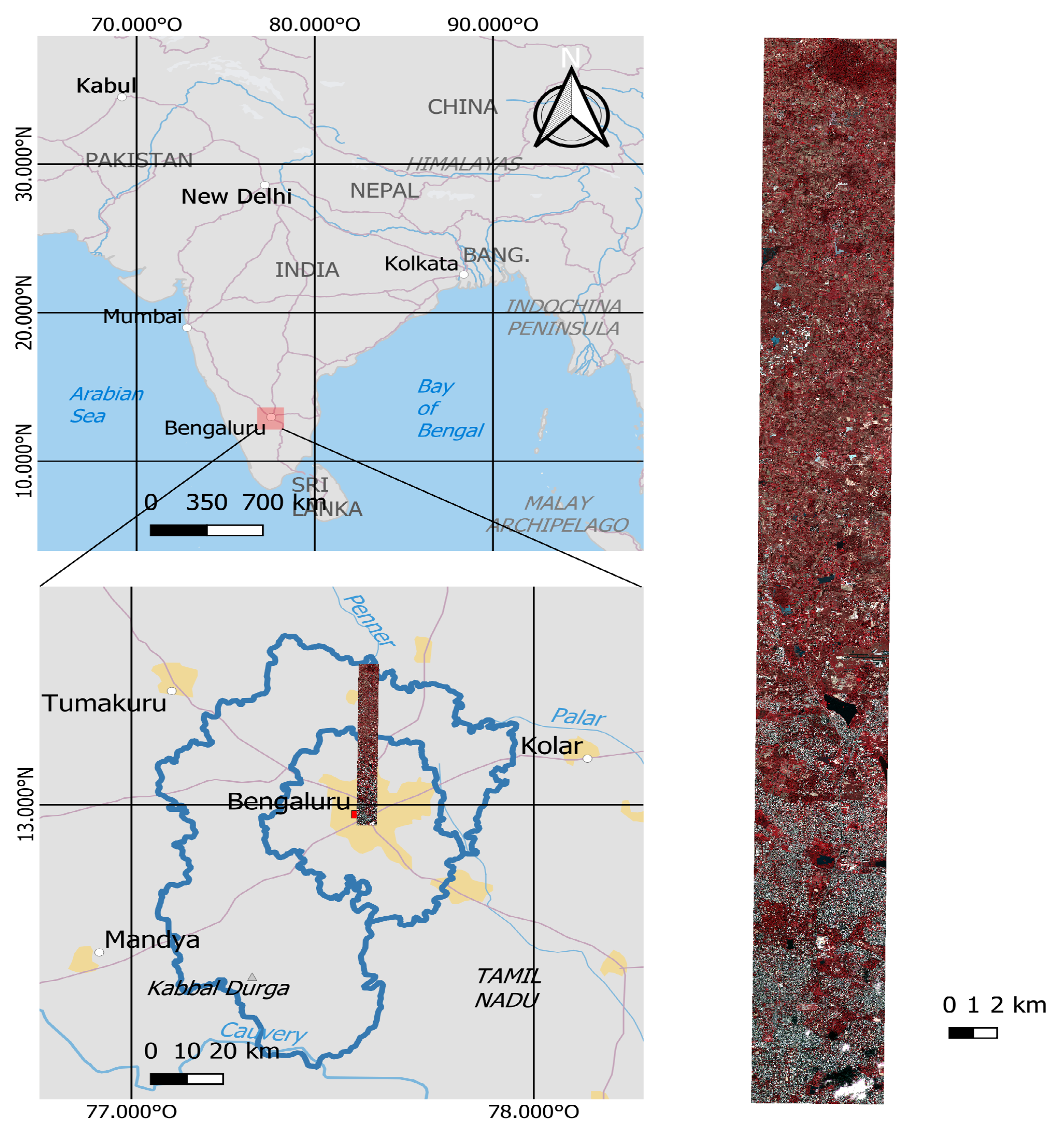
2.1. Study Area and Data Source
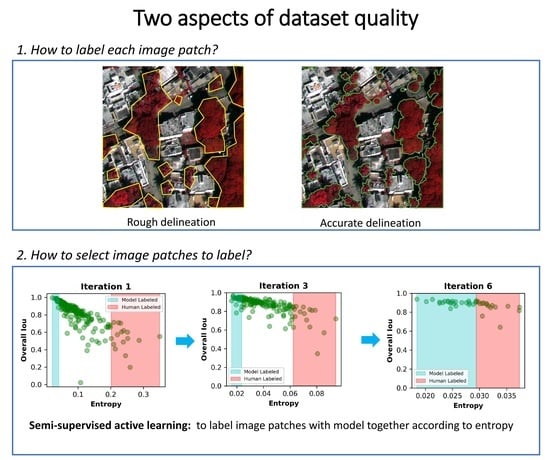
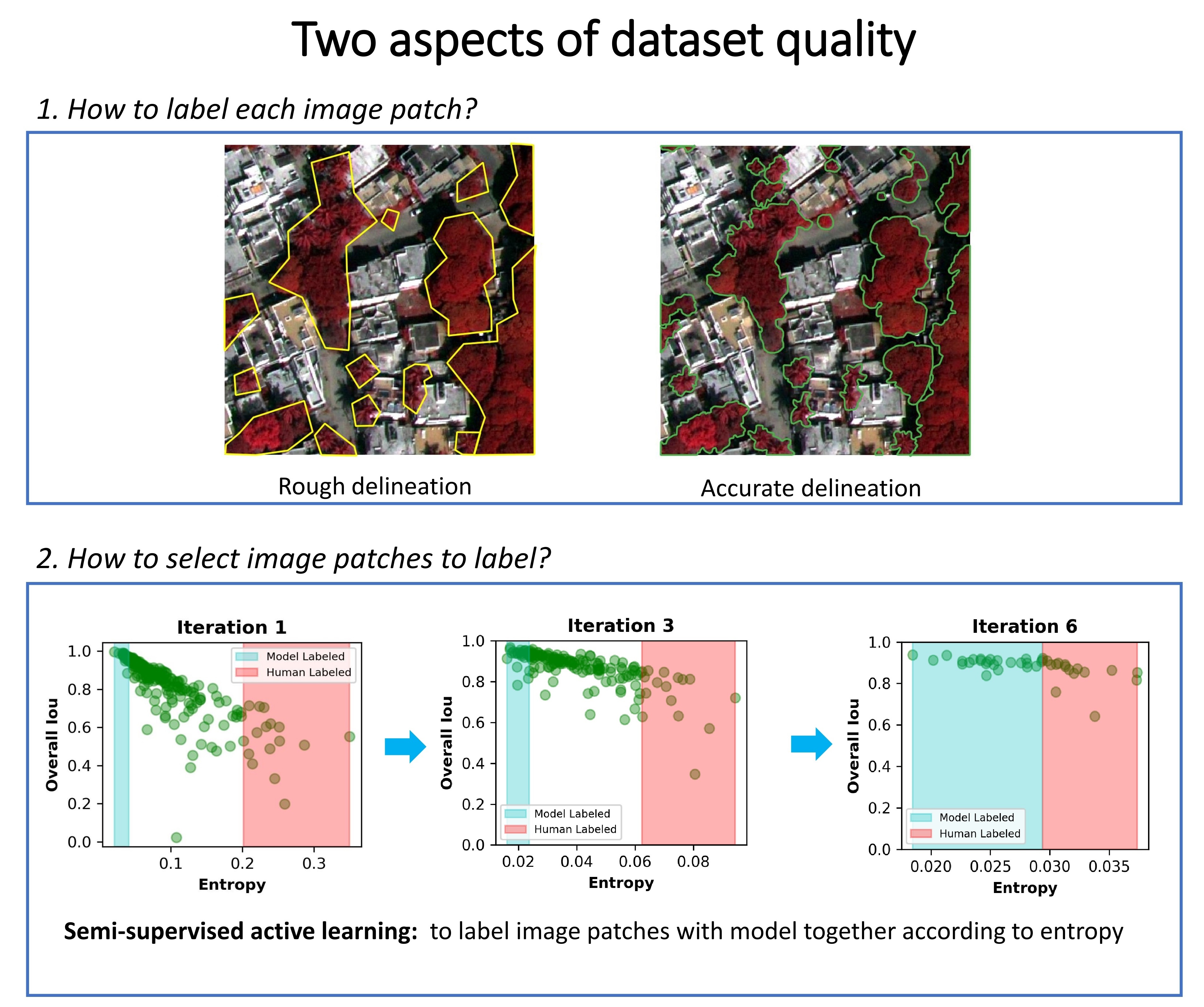
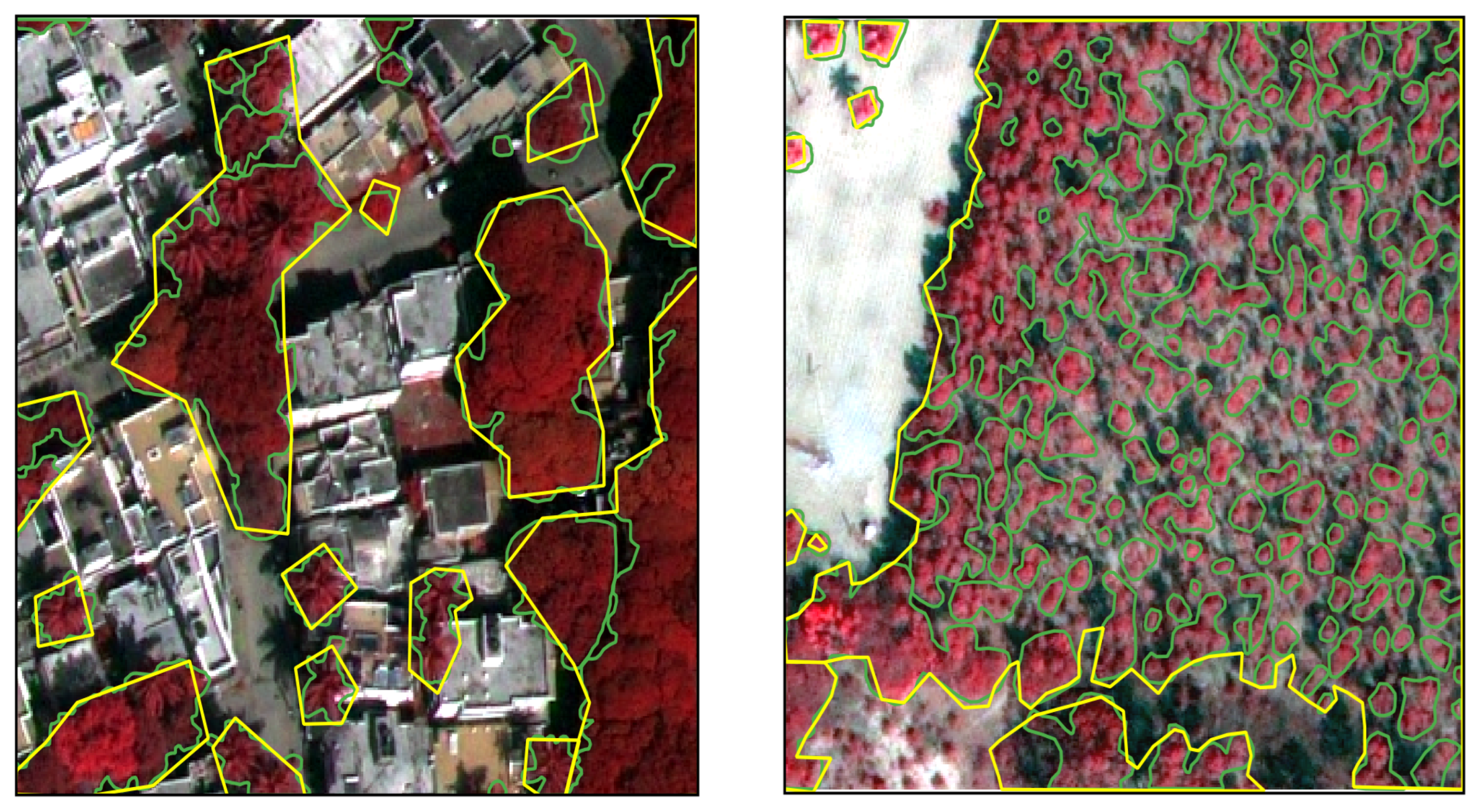
2.2. Dataset Delineation Quality
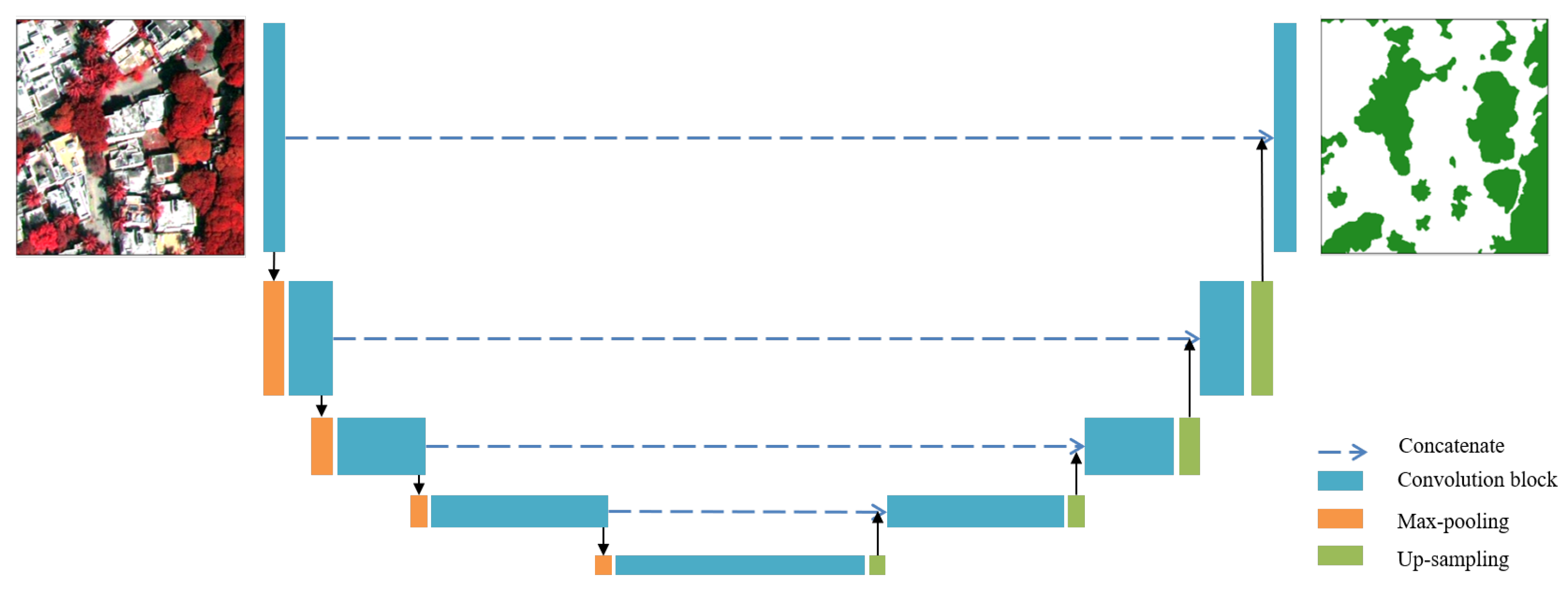
2.3. The U-Net Model
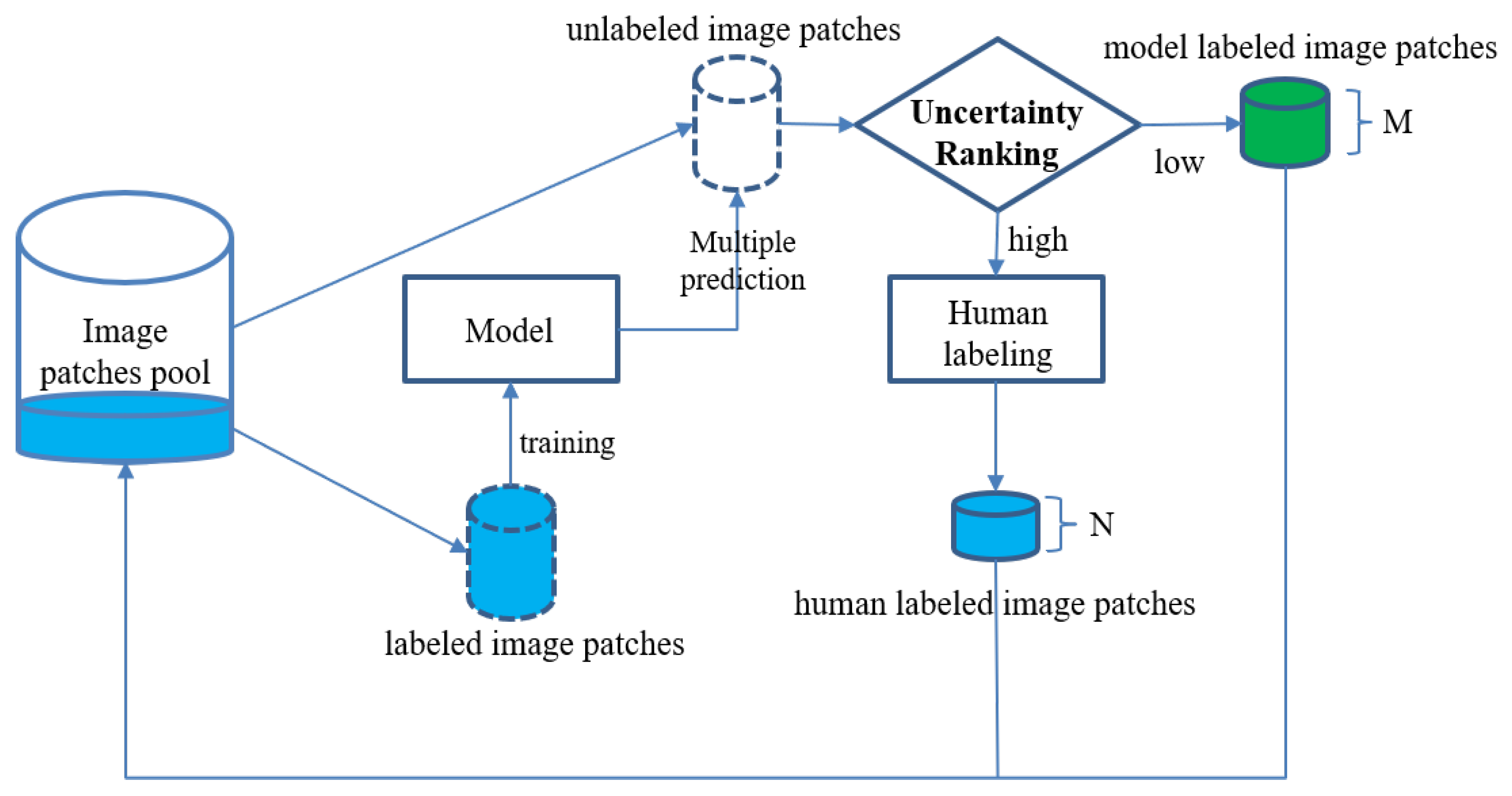
2.4. Semisupervised Active Learning for Image Segmentation
- Label a portion of image patches (we started at 40) to form an initial training dataset. Train an initial model with this dataset.
- Use this model to make predictions for the remaining, unlabeled image patches (we made predictions for patches). Run the uncertainty analysis explained below (1) for the predictions. Sort them according to their uncertainty.
- Manually label the N image patches whose predictions have the highest uncertainty, and accept the M predictions with lowest uncertainty as model-labeled masks. N and M are determined by a percentage and should sum up to the chunk size that was used to increase the dataset (we had a chunk size of 40).
- Incorporate human and model-labeled masks into the (initial) training dataset, and train a new model. Then, go back to step 2 and repeat the process until all data are labeled (we processed the remaining 240 images in chunks of 40, resulting in 6 iterations).
2.5. Metrics
2.6. An Overview of Different Labeling Strategies
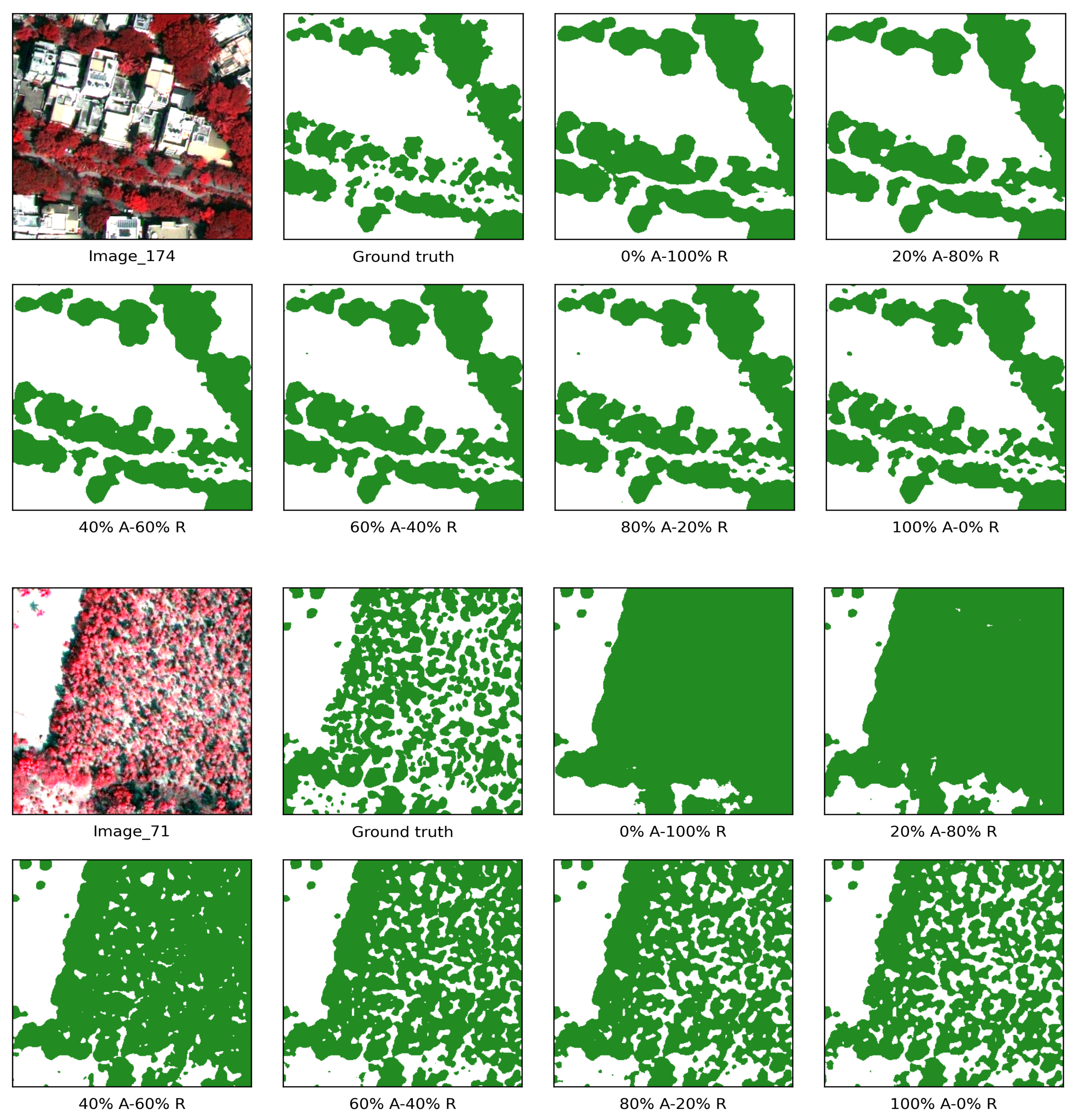
2.7. Comparisons among Datasets with Different Delineation Qualities
3. Results
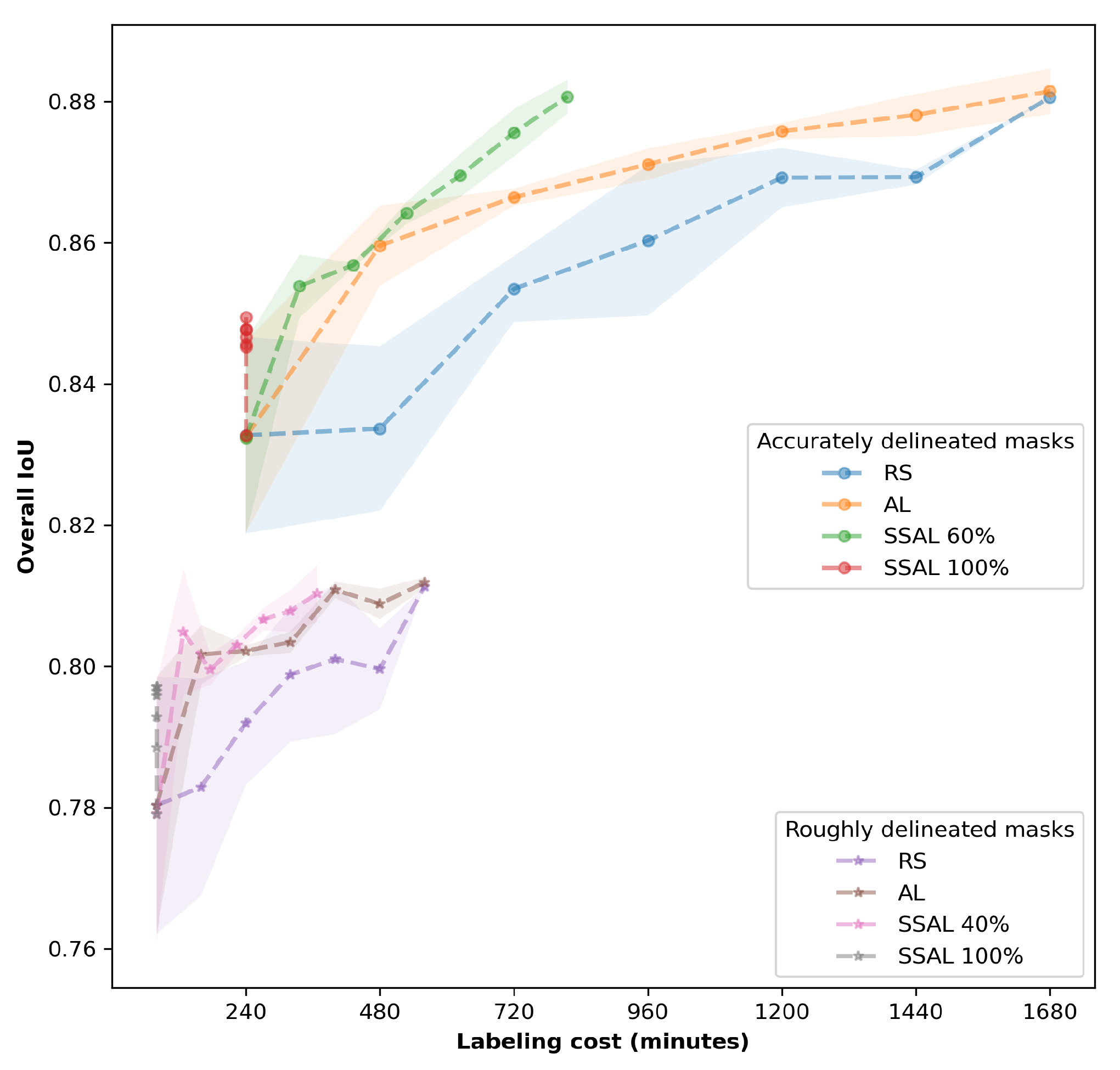
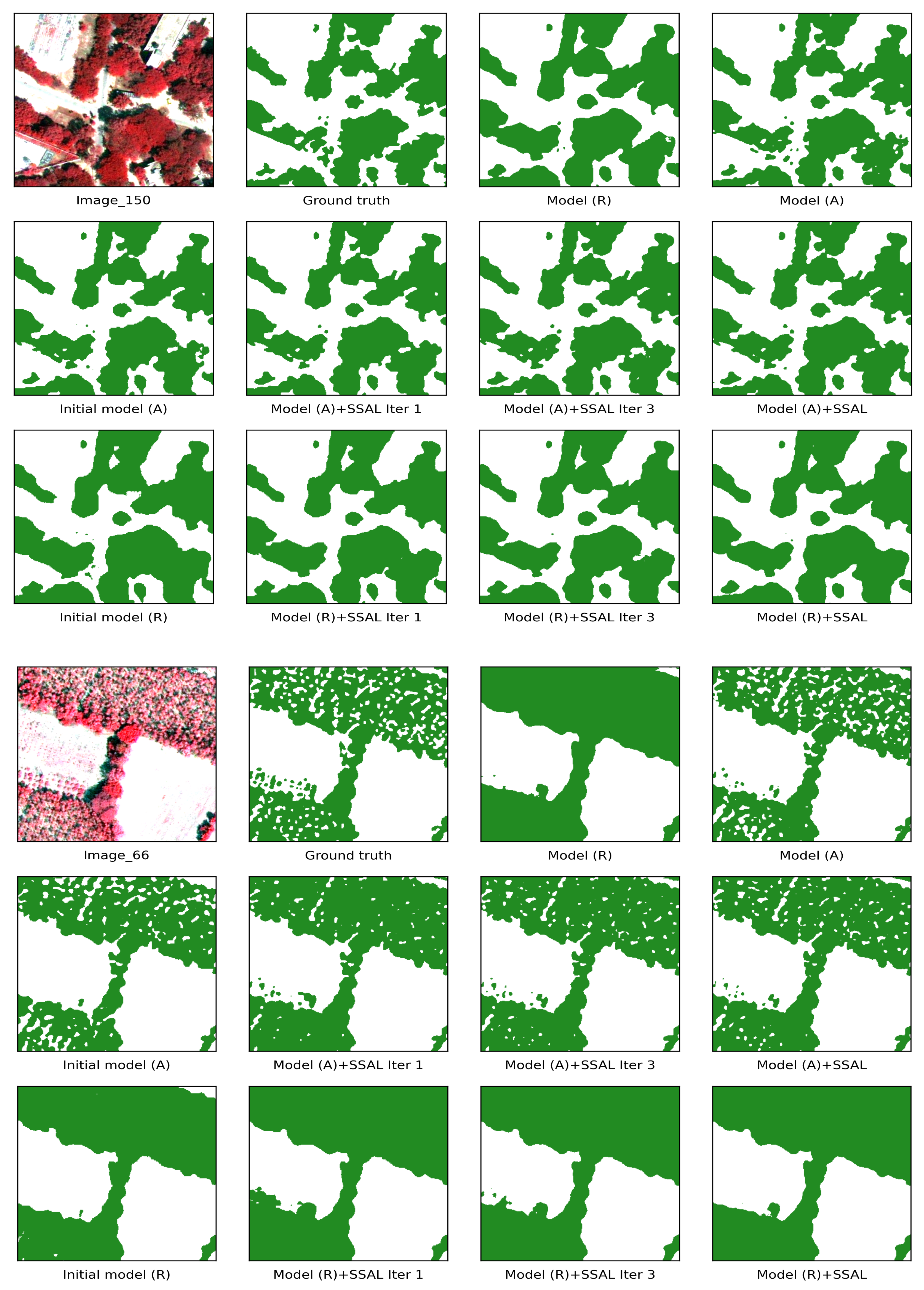
3.1. Comparisons between Different Labeling Strategies
3.2. The Relationship between Entropy and Model-Predicted Tree Cover Accuracy
3.3. Comparisons among Datasets with Different Delineation Qualities
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turner-Skoff, J.B.; Cavender, N. The benefits of trees for livable and sustainable communities. Plants People Planet 2019, 1, 323–335. [Google Scholar] [CrossRef]
- Brockerhoff, E.G.; Barbaro, L.; Castagneyrol, B.; Forrester, D.I.; Gardiner, B.; González-Olabarria, J.R.; Lyver, P.O.; Meurisse, N.; Oxbrough, A.; Taki, H.; et al. Forest biodiversity, ecosystem functioning and the provision of ecosystem services. Biodivers. Conserv. 2017, 26, 3005–3035. [Google Scholar] [CrossRef] [Green Version]
- Tigges, J.; Lakes, T.; Hostert, P. Urban vegetation classification: Benefits of multitemporal RapidEye satellite data. Remote Sens. Environ. 2013, 136, 66–75. [Google Scholar] [CrossRef]
- Yan, J.; Zhou, W.; Han, L.; Qian, Y. Mapping vegetation functional types in urban areas with WorldView-2 imagery: Integrating object-based classification with phenology. Urban For. Urban Green. 2018, 31, 230–240. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Zhu, X.; Tuia, D.; Mou, L.; Xia, G.S.; pei Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Fan, Z.; Zhan, T.; Gao, Z.; Li, R.; Liu, Y.; Zhang, L.; Jin, Z.; Xu, S. Land Cover Classification of Resources Survey Remote Sensing Images Based on Segmentation Model. IEEE Access 2022, 10, 56267–56281. [Google Scholar] [CrossRef]
- Solórzano, J.V.; Mas, J.F.; Gao, Y.; Gallardo-Cruz, J.A. Land use land cover classification with U-net: Advantages of combining sentinel-1 and sentinel-2 imagery. Remote Sens. 2021, 13, 3600. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Yuan, Y.; Liu, G. SDUNet: Road extraction via spatial enhanced and densely connected UNet. Pattern Recognit. 2022, 126, 108549. [Google Scholar] [CrossRef]
- Lv, Z.; Huang, H.; Gao, L.; Benediktsson, J.A.; Zhao, M.; Shi, C. Simple multiscale unet for change detection with heterogeneous remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Brandt, M.; Tucker, C.; Kariryaa, A.; Rasmussen, K.; Abel, C.; Small, J.; Chave, J.; Rasmussen, L.; Hiernaux, P.; Diouf, A.; et al. An unexpectedly large count of trees in the West African Sahara and Sahel. Nature 2020, 587, 78–82. [Google Scholar] [CrossRef]
- Mugabowindekwe, M.; Brandt, M.; Chave, J.; Reiner, F.; Skole, D.L.; Kariryaa, A.; Igel, C.; Hiernaux, P.; Ciais, P.; Mertz, O.; et al. Nation-wide mapping of tree-level aboveground carbon stocks in Rwanda. Nat. Clim. Chang. 2022, 13, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Freudenberg, M.; Magdon, P.; Nölke, N. Individual tree crown delineation in high-resolution remote sensing images based on U-Net. Neural Comput. Appl. 2022, 34, 22197–22207. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Dong, R.; Fu, H.; Yu, L. Large-Scale Oil Palm Tree Detection from High-Resolution Satellite Images Using Two-Stage Convolutional Neural Networks. Remote Sens. 2019, 11, 11. [Google Scholar] [CrossRef] [Green Version]
- Freudenberg, M.; Nölke, N.; Agostini, A.; Urban, K.; Wörgötter, F.; Kleinn, C. Large Scale Palm Tree Detection in High Resolution Satellite Images Using U-Net. Remote Sens. 2019, 11, 312. [Google Scholar] [CrossRef] [Green Version]
- Wagner, F.H.; Sanchez, A.; Tarabalka, Y.; Lotte, R.G.; Ferreira, M.P.; Aidar, M.P.M.; Gloor, E.; Phillips, O.L.; Aragão, L.E.O.C. Using the U-net convolutional network to map forest types and disturbance in the Atlantic rainforest with very high resolution images. Remote Sens. Ecol. Conserv. 2019, 5, 360–375. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Bragagnolo, L.; da Silva, R.V.; Grzybowski, J.M.V. Amazon forest cover change mapping based on semantic segmentation by U-Nets. Ecol. Inform. 2021, 62, 101279. [Google Scholar] [CrossRef]
- John, D.; Zhang, C. An attention-based U-Net for detecting deforestation within satellite sensor imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102685. [Google Scholar] [CrossRef]
- Zhang, C.; Atkinson, P.M.; George, C.; Wen, Z.; Diazgranados, M.; Gerard, F. Identifying and mapping individual plants in a highly diverse high-elevation ecosystem using UAV imagery and deep learning. ISPRS J. Photogramm. Remote Sens. 2020, 169, 280–291. [Google Scholar] [CrossRef]
- Cao, K.; Zhang, X. An Improved Res-UNet Model for Tree Species Classification Using Airborne High-Resolution Images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Jing, L.; Li, H.; Tang, Y. A new individual tree species classification method based on the ResU-Net model. Forests 2021, 12, 1202. [Google Scholar] [CrossRef]
- Men, G.; He, G.; Wang, G. Concatenated Residual Attention UNet for Semantic Segmentation of Urban Green Space. Forests 2021, 12, 1441. [Google Scholar] [CrossRef]
- Graves, S.J.; Asner, G.P.; Martin, R.E.; Anderson, C.B.; Colgan, M.S.; Kalantari, L.; Bohlman, S.A. Tree species abundance predictions in a tropical agricultural landscape with a supervised classification model and imbalanced data. Remote Sens. 2016, 8, 161. [Google Scholar] [CrossRef] [Green Version]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E.; Price, B.S. Effects of training set size on supervised machine-learning land-cover classification of large-area high-resolution remotely sensed data. Remote Sens. 2021, 13, 368. [Google Scholar] [CrossRef]
- Hao, Z.; Post, C.J.; Mikhailova, E.A.; Lin, L.; Liu, J.; Yu, K. How Does Sample Labeling and Distribution Affect the Accuracy and Efficiency of a Deep Learning Model for Individual Tree-Crown Detection and Delineation. Remote Sens. 2022, 14, 1561. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Cui, Z.; Lei, K.; Zuo, Y.; Wang, J.; Hu, X.; Qiu, H. Very High Resolution Images and Superpixel-Enhanced Deep Neural Forest Promote Urban Tree Canopy Detection. Remote Sens. 2023, 15, 519. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A Survey of Deep Active Learning. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Kellenberger, B.; Marcos, D.; Lobry, S.; Tuia, D. Half a Percent of Labels is Enough: Efficient Animal Detection in UAV Imagery Using Deep CNNs and Active Learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9524–9533. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Zhang, D.; Li, Y.; Zhang, R.; Lin, L. Cost-Effective Active Learning for Deep Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2591–2600. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhang, Y.; Chen, J.; Zhang, S.; Chen, D.Z. Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation. In Proceedings of the MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017. [Google Scholar]
- Rodríguez, A.C.; D’Aronco, S.; Schindler, K.; Wegner, J.D. Mapping oil palm density at country scale: An active learning approach. Remote Sens. Environ. 2021, 261, 112479. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Sudhira, H.S.; Nagendra, H. Local Assessment of Bangalore: Graying and Greening in Bangalore—Impacts of Urbanization on Ecosystems, Ecosystem Services and Biodiversity. In Urbanization, Biodiversity and Ecosystem Services: Challenges and Opportunities: A Global Assessment; Springer: Dordrecht, The Netherlands, 2013; pp. 75–91. [Google Scholar] [CrossRef] [Green Version]
- Nagendra, H.; Gopal, D. Street trees in Bangalore: Density, diversity, composition and distribution. Urban For. Urban Green. 2010, 9, 129–137. [Google Scholar] [CrossRef]
- Amro, I.; Mateos, J.; Vega, M.; Molina, R.; Katsaggelos, A.K. A survey of classical methods and new trends in pansharpening of multispectral images. EURASIP J. Adv. Signal Process. 2011, 2011, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The Importance of Skip Connections in Biomedical Image Segmentation. In Proceedings of the Deep Learning and Data Labeling for Medical Applications, Athens, Greece, 21 October 2016; Carneiro, G., Mateus, D., Peter, L., Bradley, A., Tavares, J.M.R.S., Belagiannis, V., Papa, J.P., Nascimento, J.C., Loog, M., Lu, Z., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 179–187. [Google Scholar]
- Wang, J.; Wen, S.; Chen, K.; Yu, J.; Zhou, X.; Gao, P.; Li, C.; Xie, G. Semi-supervised active learning for instance segmentation via scoring predictions. arXiv 2020, arXiv:2012.04829. [Google Scholar]
- Balaram, S.; Nguyen, C.M.; Kassim, A.; Krishnaswamy, P. Consistency-Based Semi-supervised Evidential Active Learning for Diagnostic Radiograph Classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Cham, Switzerland, 2022; pp. 675–685. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: New York, NY, USA, 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Kattenborn, T.; Eichel, J.; Wiser, S.; Burrows, L.; Fassnacht, F.E.; Schmidtlein, S. Convolutional Neural Networks accurately predict cover fractions of plant species and communities in Unmanned Aerial Vehicle imagery. Remote Sens. Ecol. Conserv. 2020, 6, 472–486. [Google Scholar] [CrossRef] [Green Version]
- Pearse, G.D.; Tan, A.Y.; Watt, M.S.; Franz, M.O.; Dash, J.P. Detecting and mapping tree seedlings in UAV imagery using convolutional neural networks and field-verified data. ISPRS J. Photogramm. Remote Sens. 2020, 168, 156–169. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectral Band | Wavelength | Spatial Resolution after Pansharpening |
|---|---|---|
| Blue | 450–510 nm | 30 cm |
| Green | 510–580 nm | 30 cm |
| Yellow | 585–625 nm | 30 cm |
| Red | 630–690 nm | 30 cm |
| Red Edge | 705–745 nm | 30 cm |
| Near IR1 | 770–895 nm | 30 cm |
| Near IR2 | 860–1040 nm | 30 cm |
| Strategy | Human-Labeled (A) | Model-Labeled | Labeling Cost | Tree IoU | Overall IoU |
|---|---|---|---|---|---|
| Accurately delineated dataset | |||||
| AL (A) | 280 | 0 | 1680 | 80.33% | 88.14% |
| SSAL (A) 20% | 232 | 48 | 1392 | 80.10% | 88.02% |
| SSAL (A) 40% | 184 | 96 | 1104 | 80.33% | 88.14% |
| SSAL (A) 60% | 136 | 144 | 816 | 80.17% | 88.07% |
| SSAL (A) 80% | 88 | 192 | 528 | 78.73% | 87.06% |
| SSAL (A) 100% | 40 | 240 | 240 | 74.54% | 84.94% |
| Roughly delineated dataset | |||||
| AL (R) | 280 | 0 | 560 | 71.67% | 81.19% |
| SSAL (R) 20% | 232 | 48 | 464 | 71.63% | 81.20% |
| SSAL (R) 40% | 184 | 96 | 368 | 71.48% | 81.03% |
| SSAL (R) 60% | 136 | 144 | 272 | 70.82% | 80.52% |
| SSAL (R) 80% | 88 | 192 | 176 | 71.02% | 80.57% |
| SSAL (R) 100% | 40 | 240 | 80 | 69.48% | 79.71% |
| Iteration | Human-Labeled | Model-Labeled | Tree IoU | Overall IoU |
|---|---|---|---|---|
| 0 | 40 | 0 | 67.15% | 81.41% |
| 1 | 56 | 24 | 76.37% | 85.96% |
| 2 | 72 | 48 | 76.10% | 85.72% |
| 3 | 88 | 72 | 76.77% | 86.20% |
| 4 | 104 | 96 | 78.23% | 87.00% |
| 5 | 120 | 120 | 79.26% | 87.50% |
| 6 | 136 | 144 | 80.17% | 88.07% |
| Datasets | Human-Labeled (A) | Human-Labeled (R) | Labeling Cost | Tree IoU | Overall IoU |
|---|---|---|---|---|---|
| 100% R | 0 | 280 | 560 | 70.45% | 81.13% |
| 20% A–80% R | 56 | 224 | 784 | 72.78% | 82.69% |
| 40% A–60% R | 112 | 168 | 1008 | 74.85% | 84.43% |
| 60% A–40% R | 168 | 112 | 1232 | 76.14% | 85.62% |
| 80% A–20% R | 224 | 56 | 1456 | 78.24% | 87.01% |
| 100% A | 280 | 0 | 1680 | 79.65% | 88.06% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, T.; Freudenberg, M.; Kleinn, C.; Ecker, A.; Nölke, N. The Impacts of Quality-Oriented Dataset Labeling on Tree Cover Segmentation Using U-Net: A Case Study in WorldView-3 Imagery. Remote Sens. 2023, 15, 1691. https://doi.org/10.3390/rs15061691
Jiang T, Freudenberg M, Kleinn C, Ecker A, Nölke N. The Impacts of Quality-Oriented Dataset Labeling on Tree Cover Segmentation Using U-Net: A Case Study in WorldView-3 Imagery. Remote Sensing. 2023; 15(6):1691. https://doi.org/10.3390/rs15061691
Chicago/Turabian StyleJiang, Tao, Maximilian Freudenberg, Christoph Kleinn, Alexander Ecker, and Nils Nölke. 2023. "The Impacts of Quality-Oriented Dataset Labeling on Tree Cover Segmentation Using U-Net: A Case Study in WorldView-3 Imagery" Remote Sensing 15, no. 6: 1691. https://doi.org/10.3390/rs15061691