1. Introduction
In recent years, object detection has received much attention due to its widespread applications in various fields. When applied to images from nature, traditional object detectors such as RetinaNet [
1], YOLOV5, and Fast-RCNN [
2] have achieved impressive results. However, their results are not satisfactory for drone-captured and remote sensing images. For example, Faster R-CNN [
3], a classical two-stage object detection algorithm, achieves 38.0 mAP on objects from the VisDrone2019 evaluation set with various sizes, but only 6.2 and 20.0 mAP, respectively, on objects with tiny and small sizes. This limitation is mainly caused by three factors: (1) low-resolution features in the deeper layer may not match the diverse size of small objects; (2) qualities such as high densities, large numbers of objects, variable scales, and small occupied areas cause significant challenges; and (3) detecting small objects is more difficult compared with large objects, as the Intersection over Union (IoU) metric can fail to account for situations such as overlapping objects, close proximity between objects, and diverse aerial perspectives.
To tackle these problems, specialized small object detection algorithms have been developed. With the appearance of 4K cameras and civilian drones and the fast development of deep learning and remote sensing technologies, the performance of small object detection using convolutional neural networks (CNNs) has substantially improved. Several methods, such as TPH-YOLOV5, TOOD [
4], PP-YOLOE [
5], UAVs, and SODNet [
6] have obtained impressive results and are widely employed in tasks such as geographical surveys [
7], person identification [
8], flow monitoring [
9], and traffic control. Most of these tasks require processing of high-resolution images. Hence, a number of researchers have attempted to increase the upsampling rate to maintain high-resolution features, for example, in algorithms such as TPH-YOLOV5 [
10] and QueryDet [
11]. Meanwhile, adding penalty terms in the post-processing stage can help to tackle problems associated with high densities. Several post-processing methods, such as Soft-NMS [
12], WBF [
13], and DIoU-NMS [
14], have shown effectiveness in terms of improved performance. In addition, the slicing method [
15] and the shifted window-based self-attention mechanism [
16] have been proposed; these approaches slice images into smaller patches to amplify their local features. Both of these slicing methods have been widely used in small object detection algorithms to achieve better performance [
10,
11,
15]. However, the redundant computations of the traditional slicing method remain, increasing computational costs and reducing detection speed. Thus, in this work our approach focuses on alleviating redundant problems to obtain better accuracy and faster detection speed when employing a small object detection algorithm on remote sensing images.
In this paper, we propose a novel slicing method, ASAHI (Adaptive Slicing-Aided Hyper Inference), which adaptively slices images into a fixed number of patches rather than using a fixed slicing size. By automatically controlling the number of slices, our method greatly reduces redundant computation. In the post-processing stage, we substitute non-maximum suppression (NMS) with Cluster-DIoU-NMS, which reduces the time consumption while maintaining the quality of the results. This approach was motivated by two key observations. First, in SAHI [
15], we found that a fixed slice size leads to different degrees of redundant calculation for images with different resolutions. In particular, at the edge of the image, the redundant calculation rate exceeds the overlapping rate. By contrast, adaptive slicing size is preferable. Second, small object detection most contend with the difficulties posed by close proximity, overlap, and occlusion. NMS is a mainstream post-processing method that is widely used for object detection; however, it does not perform well for high-density objects due to its reliance on a single metric, namely, IoU. This limitation is evident in small object detection. Therefore, combining Cluster-NMS [
17] and DIoU-NMS [
14] is a good scheme.
We evaluated ASAHI on a challenging dataset, VisDrone2019 [
18], which contains a large quantity of small objects in different resolutions. In addition, we tested it on the xView [
19] dataset, which is annotated with bounding boxes and contains large amounts of aerial imagery and complex scenes from around the world. Large-scale experiments show that our method accelerates the inference and post-processing stages by 20–25%, while improving the detection performance by 2.1% compared with the baseline SAHI method [
15].
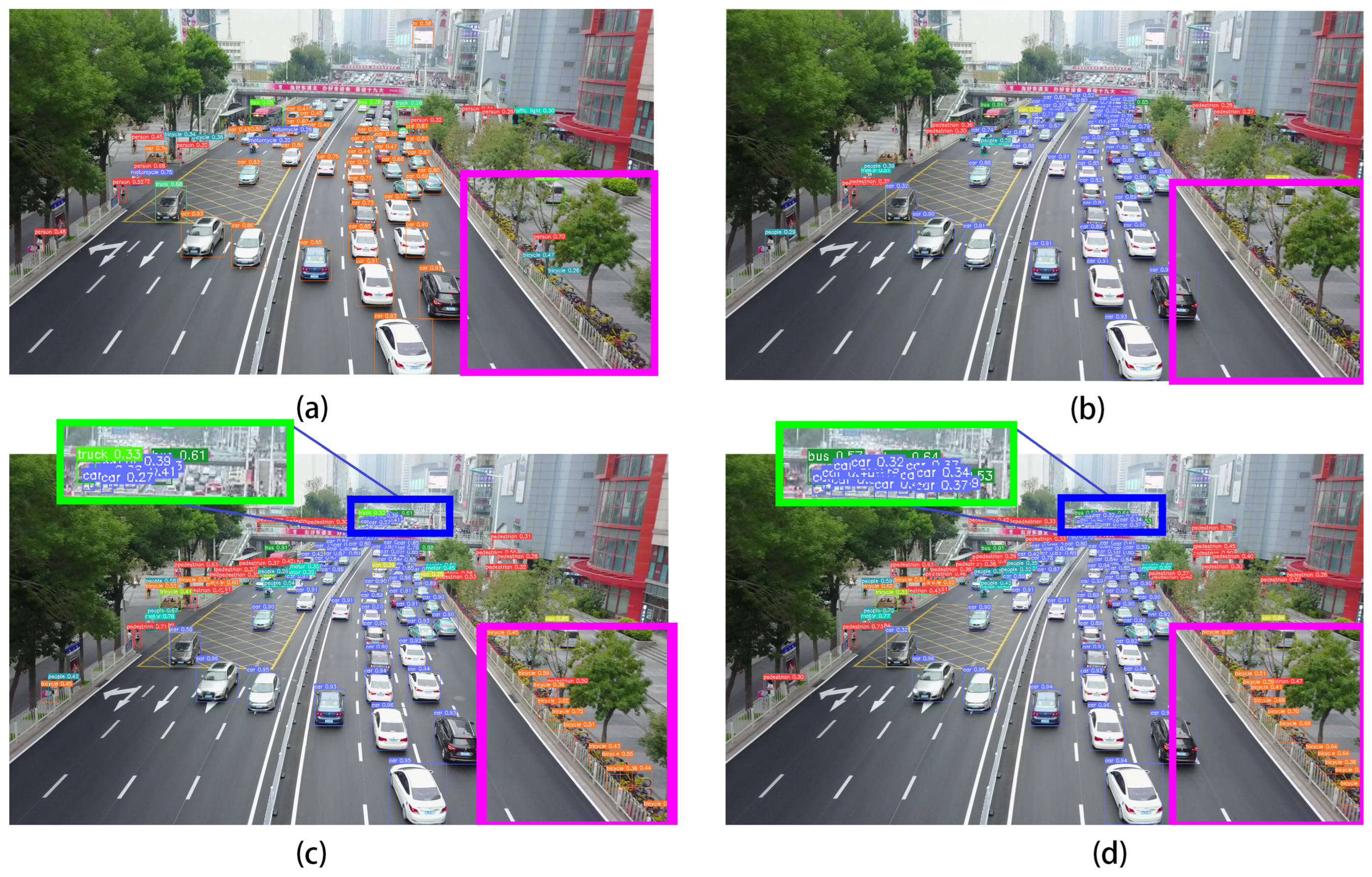
Figure 1 shows the improved results obtained by ASAHI.
The main contributions of this paper are as follows:
We propose a novel slicing method, ASAHI, which can improve detection performance for images of various resolutions and targets at a range of scales by solving the redundancy problems in the previous SAHI method [
15].
We combine ASAHI with the TPH-YOLOV5 framework [
10] to strengthen its sensitivity to the lower features in deeper layers.
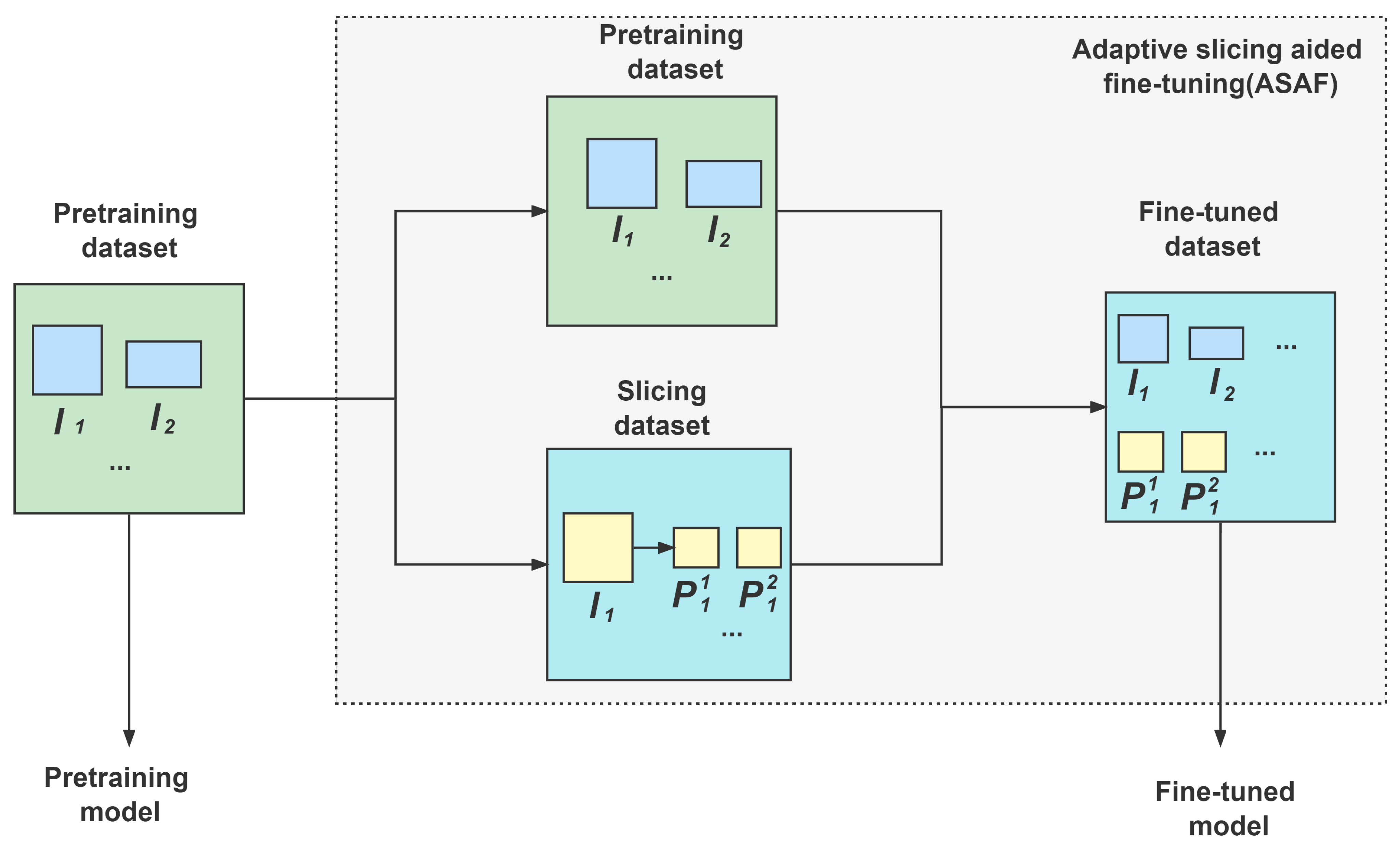
We design an adaptive slicing-aided fine-tuning scheme called ASAF for data augmentation, which is more suitable for ASAHI than other traditional fine-tuning strategies.
We integrate Cluster-DIoU-NMS, a faster Cluster-NMS method with DIoU penalty, in the post-processing stage to improve the accuracy and detection speed of inferences in high-density scenarios.
2. Related Work
Object Detection. The recent CNN-based object detectors can be divided into two main types, namely, single-stage detectors and two-stage detectors. Single-stage detectors, such as YOLOv3 [
20], SSD [
21], RetinaNet [
1], EfficientDet [
22], and YOLOV4 [
23], directly predict the location of the targets; single-stage detection can be regarded as a regression problem. Two-stage detection tends to use the RoIAlign operation [
24] to align an object’s features explicitly. Several typical frameworks, such as R-CNN [
25], SPPNet [
26], DetectoRS [
27], and FPN [
28], utilize a region proposal stage to generate candidate objects and selectively search those parts of an image that have a high probability of belonging to an object. Typically, single-stage detectors are less computationally expensive, while two-stage detectors achieve higher accuracy. However, the performance gap between these two approaches has narrowed recently. For example, YOLOV5 is a classical single-stage detector that uses the CSPDarknet53 architecture, with an SPP layer as the backbone and PANet as the neck. During inference, large numbers of bounding boxes are obtained and then aggregated by CIoU in the post-processing stage. This approach has attracted the attention of researchers because of its convenience and good performance.
Small Object Detection. Small object detection is a challenging task in computer vision due to the difficulties posed by low resolution, high density, variable scales, and small occupation areas. A number of researchers have modified the traditional object detection algorithms with self-attention mechanism such as CBAM [
29], SPANet [
30] and RTANet [
31] to accommodate small object detection. An excellent work is TPH-YOLOV5 [
10]; a state-of-the-art small object detection framework based on YOLOV5, it integrates an additional prediction head for small object detection, a CBAM [
29] framework in the neck, and replaces the original CSP bottleneck blocks with transformer encoder blocks. This increases the detection accuracy for small objects while preserving the speed of inference. Hence, in this work we utilize TPH-YOLOV5 [
10] as our backbone and propose ASAHI to achieve better results.
Postprocessing in Small Object Detection. Post-processing is a crucial part of small object detection. During the inference process, a large number of bounding boxes are generated; however, many of them represent detections of the same target, and a post-processing method must be used to suppress these false detections. In recent years, the DETR method [
32] has replaced the traditional post-processing process; however, the development of this technology is not yet complete. In this paper, we maintain the use of post-processing. NMS is one of the most popular post-processing methods. Several well-known frameworks, such as TPH-YOLOV5 [
10] and SAHI [
15], use NMS in the post-processing stage. Although, NMS is competitive, it has a number of shortcomings due to IoU being the only influence factor in NMS. Thus, adding penalty terms is an efficient way to improve performance or reduce time consumption. For example, GIoU, DIoU, and CIoU add penalties based on the weight of non-overlapping areas, the center point distance between bounding boxes, and the aspect ratio, respectively, to improve detection performance. In addition, several methods have been combined with NMS to achieve better performance in the post-processing stage, such as IBS [
33], a state-of-the-art two-stage algorithm with excellent performance, Soft-NMS [
12], a soft improvement based on NMS with Gaussian algorithm, and Cascade R-CNN + NWD [
34], a classical improved algorithm based on the normalized Wasserstein distance. Our method, ASAHI, focuses on better performance and faster inference. Inspired by LD [
35], we employed a combination of the Cluster-NMS and DIoU-NMS [
14] algorithms to meet our goals.
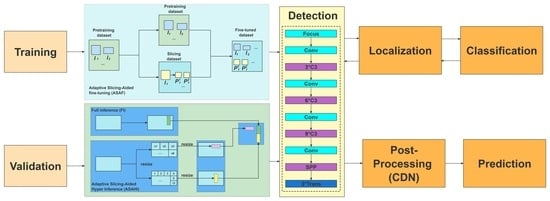
3. The Proposed Method
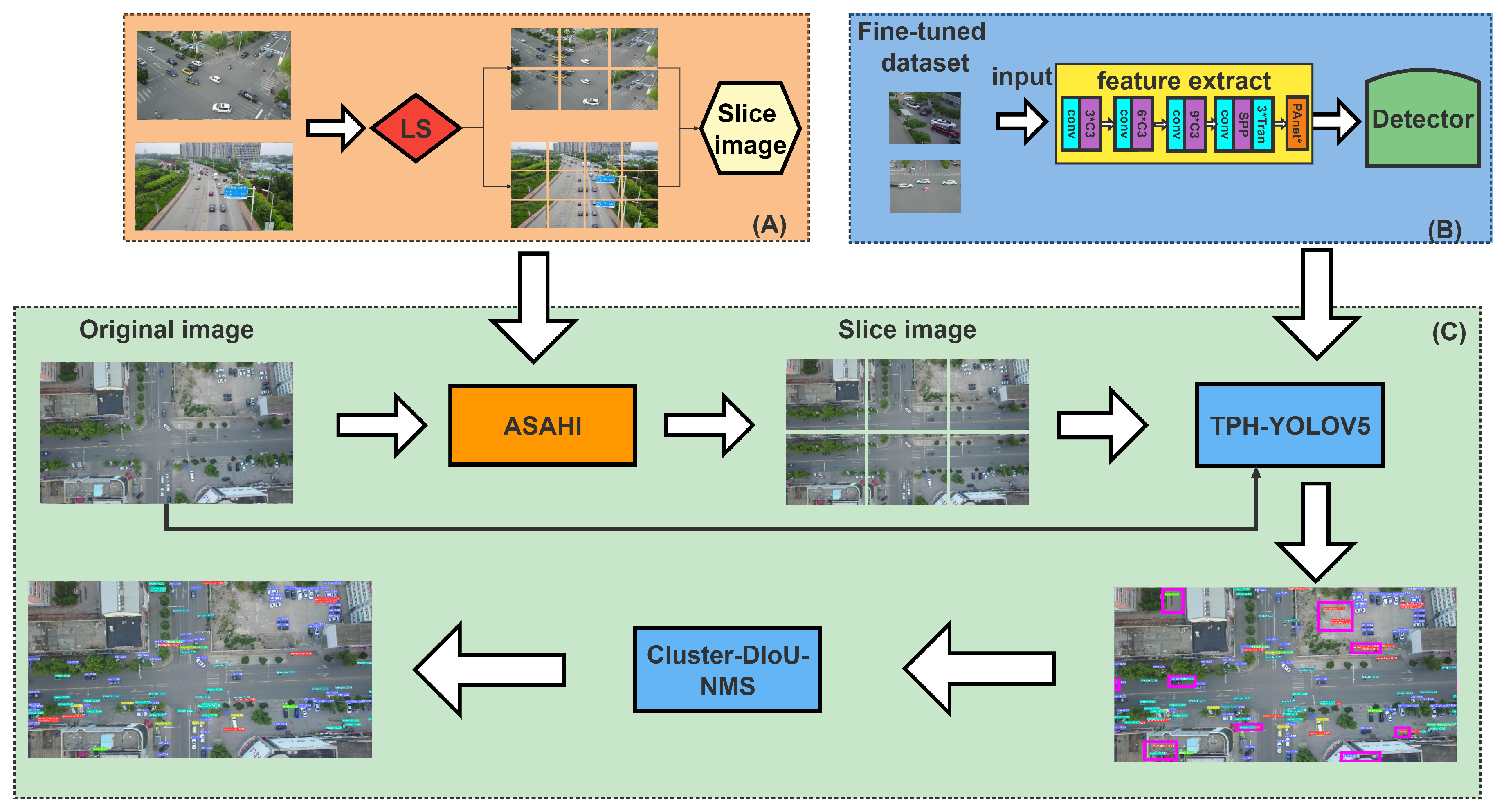
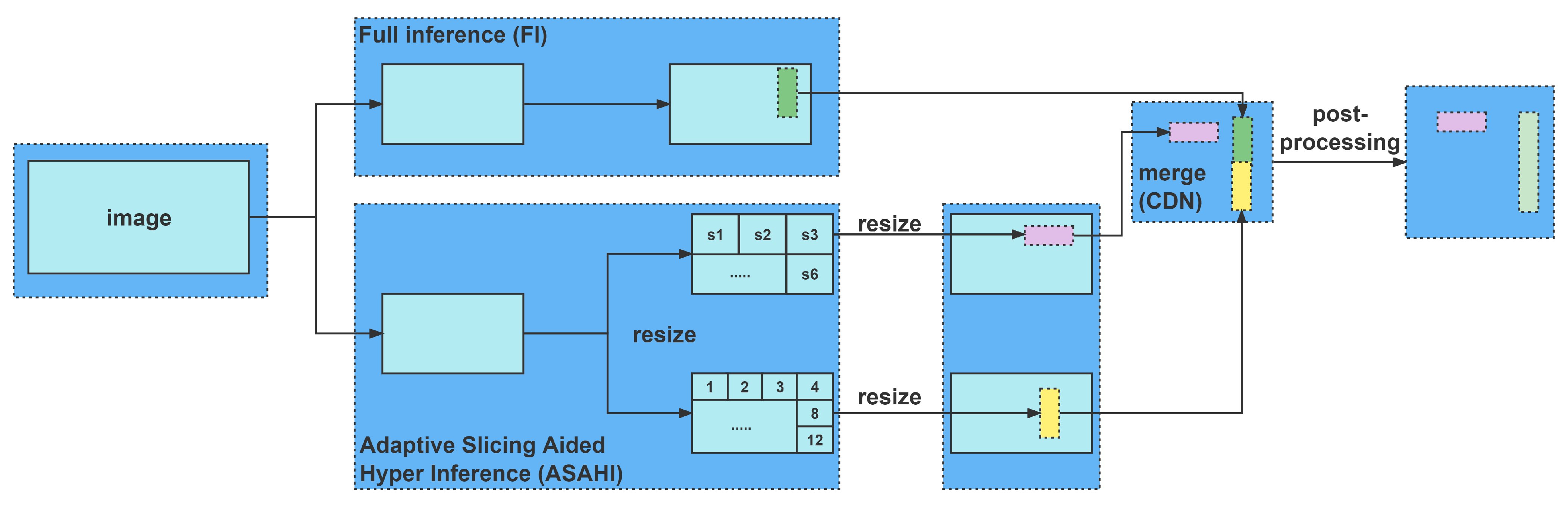
In this paper, with the aim of enhancing small object detection accuracy, we propose a novel slicing method called ASAHI, an overview of which is shown in
Figure 2. The overall process can be simplified as follows: two strategies, full inference (FI) and ASAHI, are applied to the original images simultaneously. In FI, the full images are sent to the inference stage. By contrast, ASAHI adaptively changes the slicing size to control the number of slices according to the image resolution. In the inference stage, the full image and sliced image are processed by TPH-YOLOV5 [
10] to obtain the corresponding bounding boxes. Next, the bounding boxes are resized by the aspect ratio and merged using Cluster-DIoU-NMS to remove the repeatedly identified pre-selected boxes in the post-processing stage. In the remainder of this section, we introduce ASAHI, Cluster-DIoU-NMS, and Adaptive Slicing Aided Fine-tuning (ASAF) in detail.
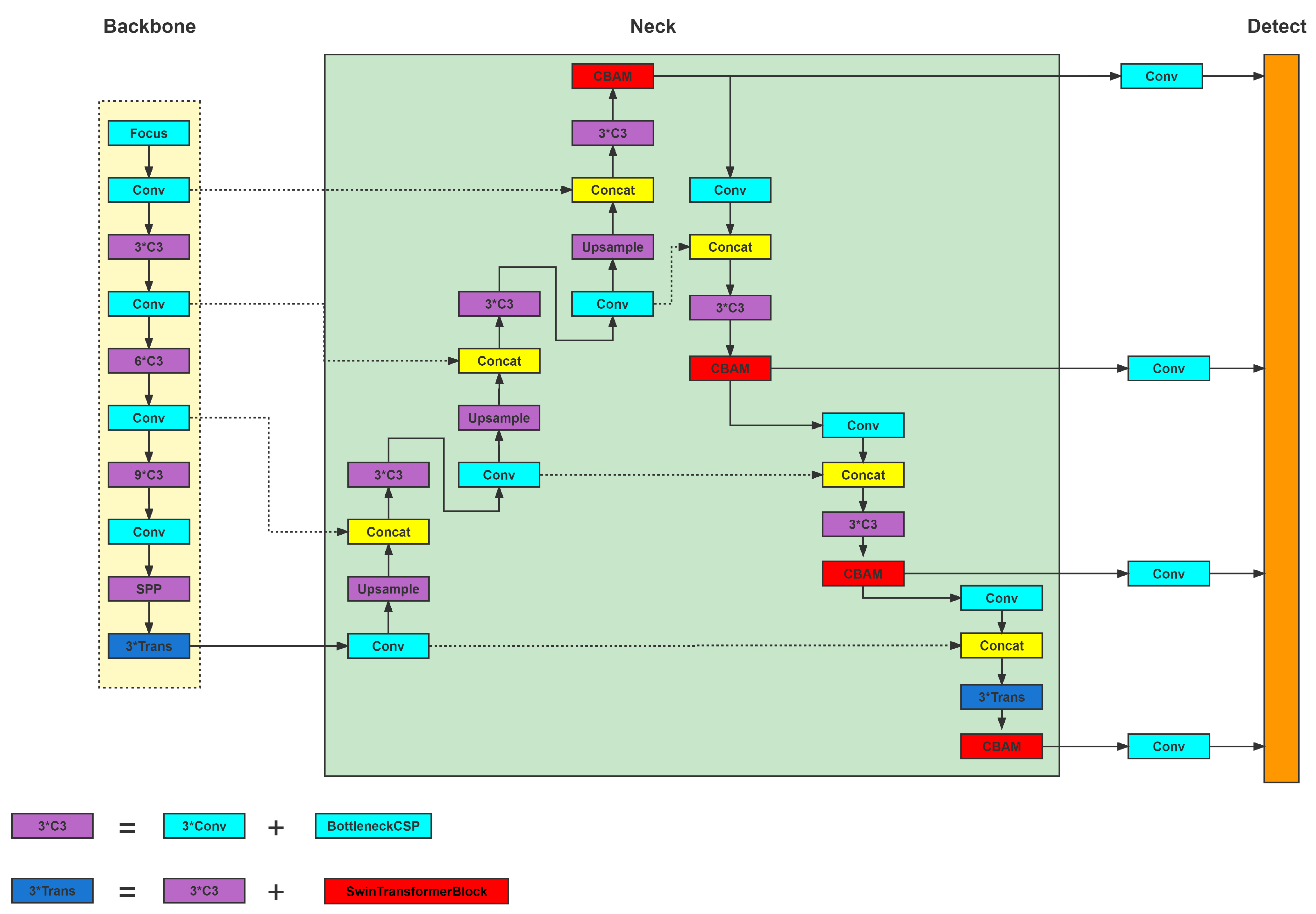
3.1. Overview of TPH-YOLOV5
TPH-YOLOV5 [
10] provides two pre-trained models, yolov5l-xs-1 and yolov5l-xs-2, which were trained at different sizes after resizing. TPH-YOLOV5 [
10] uses the architecture of CSPDarknet53, with three transformer encoder blocks as the backbone, PANet with CBAM [
29] as the neck, and four transformer prediction heads. Considering its excellent performance, ranking fifth in the VisDrone 2021 competition, we selected it as our backbone. Thanks to the code provided by the authors of the study [
10], we used a slight modification in the neck, as shown in
Figure 3, in which the number of CBAM blocks [
29] is reduced by one.
3.2. Adaptive Slicing-Aided Hyper Inference (ASAHI)
By investigating a range of slicing methods, we found that fixed slice sizes inevitably lead to redundant computation in images with different resolutions. When a fixed slice size cannot be used exactly, part of the information from the previous image is included to ensure that the slice is complete; this strategy causes redundant computation, and can pose a problem for merging during post-processing. Our ASAHI approach, as an improved version of the SAHI slicing algorithm, greatly reduces this redundant computation by adaptively changing the slicing size.
During the inference step, as detailed in
Figure 4, the original image is sliced into 6 or 12 overlapping patches according to the image size. Then, each patch is resized, preserving the aspect ratio. After that, the patches are transferred to the merge stage. However, as this form of slicing results in clear defects in the detection of large objects, we use FI to detect the larger objects. Finally, Cluster-DIoU-NMS is used to merge the FI results in order to return them to their original size.
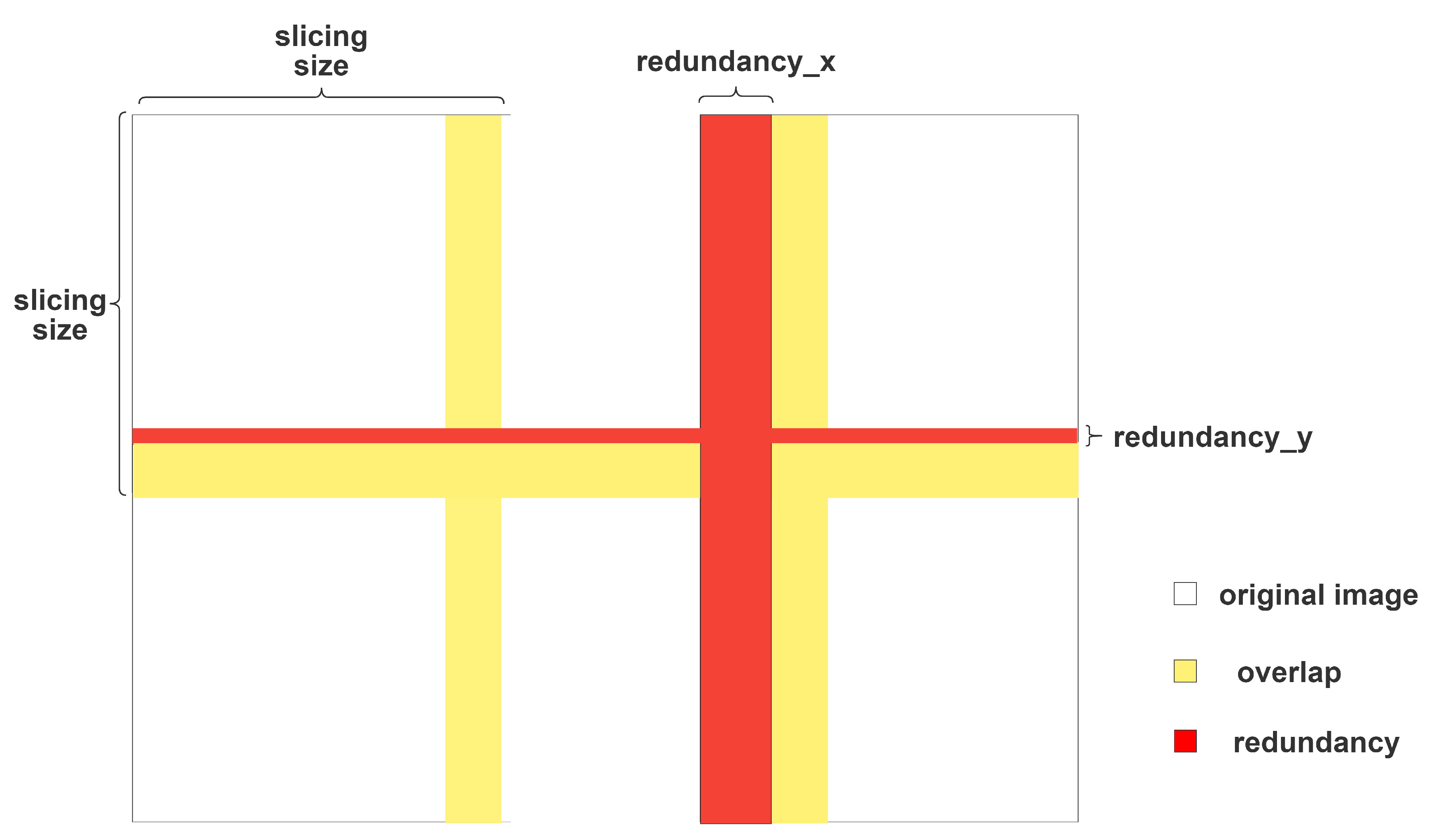
The redundancy in the inference process is shown in
Figure 5, in which
W and
H are the length and width of the input image, respectively, and
l represents the overlapping ratio. In our experiments, we noticed that the performance, as measured by the mAP, decreases if the slice sizes are different in length and width. Hence, our method maintains the same slice size in terms of length and width.
In ASAHI, we set a differentiation threshold as
LS: if the length or width of the image is larger than this threshold, then the image is cut into 12 patches; otherwise, it is cut into 6 patches.
LS can be calculated according to Equation (
1) below. We define the restricted slice size, denoted as restrict_size, to guarantee the slice size fluctuation within restrict_size; here we set it to 512.
After setting the value of
LS, we make sure that our image will be divided into exactly 6 and 12 patches by calculating two extreme cases and taking the maximum value:
Then, we let
a be the number of slices on the horizontal axis and
b the number of slices on the vertical axis. They can be calculated as follows:
We can then calculate the redundant areas in
Figure 5 from the three known values of
W,
H,
l, and
p in Equation (
2), as follows:
After calculating the redundancy of the ASAHI method, we can derive the reduction in redundant computational area compared to the SAHI [
15] method as follows:
The redundant computation generated by SAHI [
15] is decreased through our method. The proportions of the reduced redundant computation for images of various resolutions are shown in
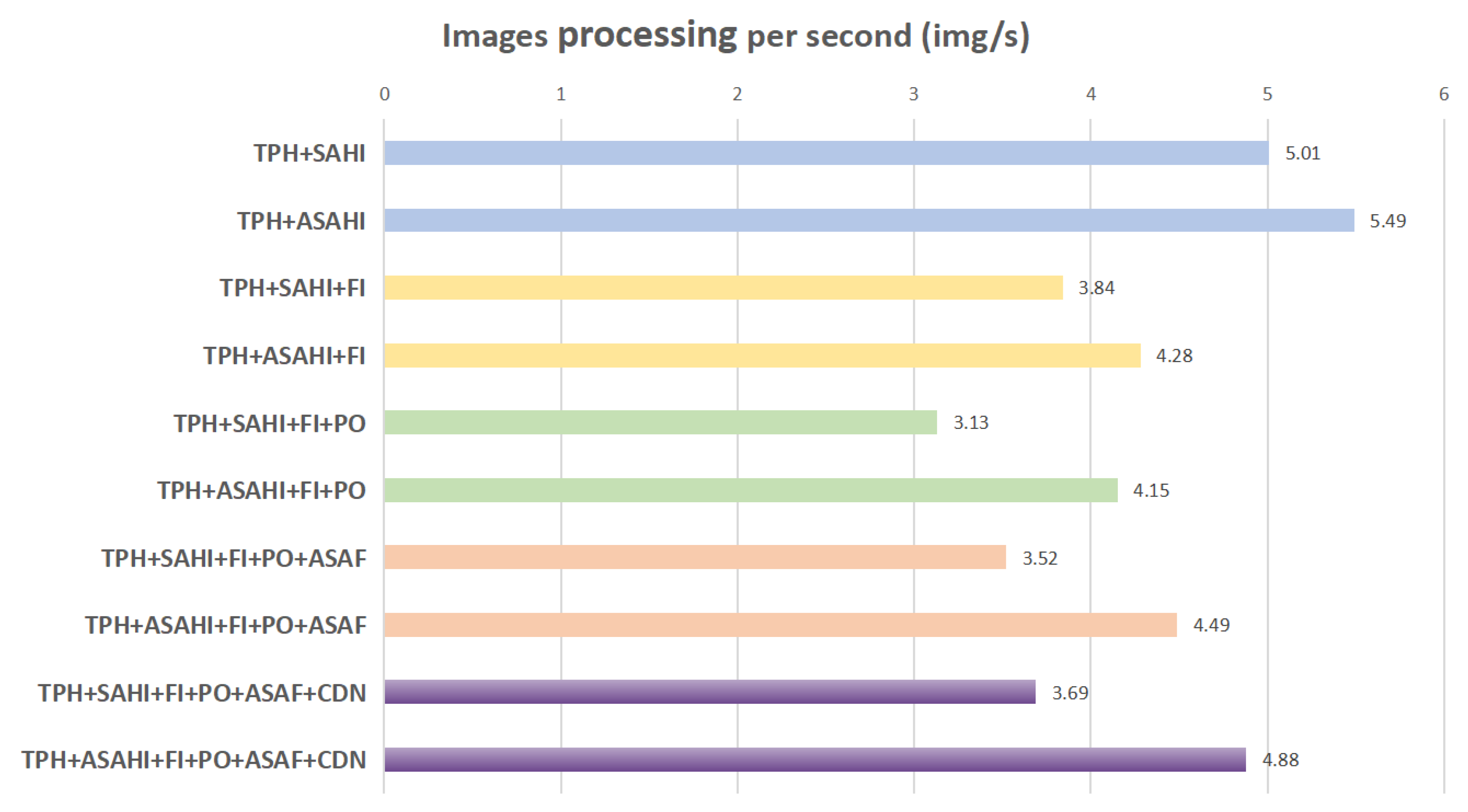
Table 1. As a result of this reduction, ASAHI is able to achieve improved processing speed.
3.3. Cluster-DIoU-NMS
Post-processing is a crucial part of small object detection. Inspired by LD [
35], we employed Cluster-DIoU-NMS in the post-processing stage due to the outstanding performance of Cluster-NMS [
17] and DIoU-NMS [
14]. Briefly, Cluster-DIoU-NMS is a combination of DIoU-NMS [
14] and Cluster-NMS [
17]. We used the structure of Cluster-NMS in order to speed up the detection speed, and replaced the IOU metric with DIoU to improve performance in overlapping scenarios. In other words, the oversuppression issue is addressed by Cluster-NMS and the DIoU parameters are employed to strengthen the accuracy.
DIoU-NMS: In the traditional NMS algorithm, IoU is the only factor considered. However, in practical applications it is difficult to distinguish objects by IoU alone when the distance between two objects is small. Therefore, the overlapping area of the two bounding boxes and the distance of the center point should be considered simultaneously in post-processing; despite this, traditional IoU only takes the overlapping area into account, ignoring the centroid distance. To address this issue, DIoU-NMS [
14] incorporates the distance between the center points of the two boxes as a penalty term. If the IoU between two boxes is relatively large and the distance between the centers is relatively small, the boxes are deemed to be separate objects and are not filtered out. In DIoU,
denotes the diagonal distance of the smallest wrapped box overlaying the two bounding boxes, while
represents the Euclidean distance between the centroids of the two boxes. DIoU is defined as
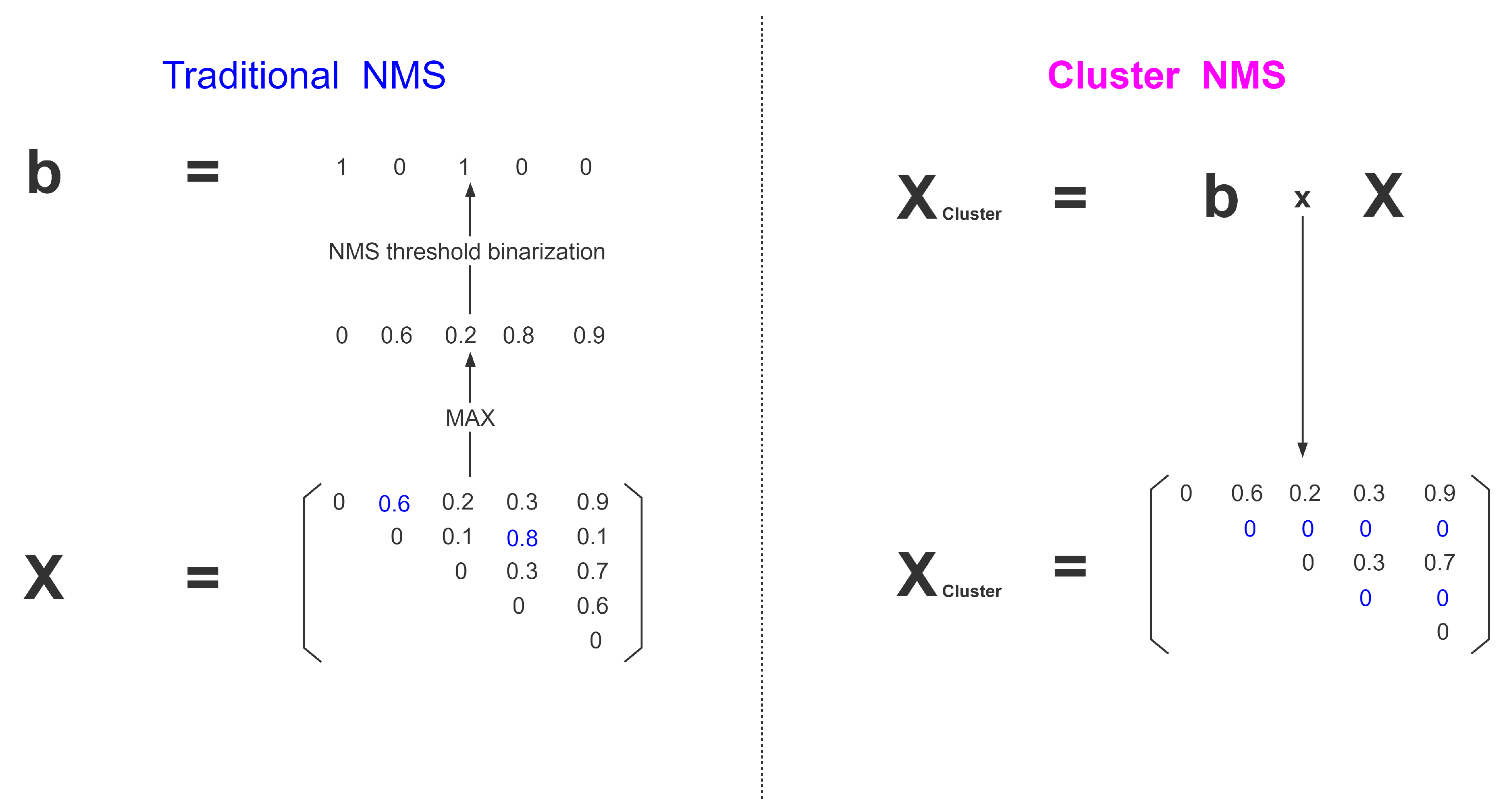
Cluster-NMS: In traditional NMS, as shown in the left of
Figure 6, the matrix
consists of
i rows and
j columns, which are sorted by score and upper triangulation, and each element
represents the computed IoU of the
ith bbox and the
jth bbox. Then, the maximum value is taken for each column and binarized to obtain the resulting sequence
. However, in the blue part of
Figure 6, 0.6 is calculated from the first and second bbox; the IoU exceeds the threshold, and should be suppressed. The first bbox and the second bbox should be considered as one box. Therefore, the bbox in the fourth column of the second row should be excluded, which is computed by the second and fourth bbox. This means that 0.8 should not appear. In contrast, Cluster-NMS employs a simple and effective alteration. Before binarization,
multiplies
to the left by
, which can solve the over-inhibition problem, as shown in the right of
Figure 6.
3.4. Adaptive Slicing-Aided Fine Tuning
In ASAF, the widely used TPH-YOLOv5 object detection framework [
10] provides pre-trained weights on datasets such as VisDrone. This allows the model to be fine-tuned using smaller datasets with shorter training times, rather than training from scratch with large datasets. These pre-trained models provide successful detection performance for similar inputs. In ASAF, as shown in
Figure 7,
are sliced into overlapping patches
by ASAHI to form the sliced dataset. Together with the original pre-trained dataset, we set up our complete fine-tuned dataset. Considering the large number of images after slicing, which imposes a large burden on the training process, we have not used other data augmentation techniques such as rotation, geometric distortions, or photometric distortions.
5. Results and Limitations
Overall, ASAHI achieved good performance and fast inference speed on both the VisDrone2019-DET [
18] and xView [
19] datasets. It is worth noting that the performance on xView [
19] was outstanding; this is notable because the resolution of most images in the xView [
19] dataset is large, which causes significant problems for existing feature extraction algorithms. ASAHI can significantly improve this situation thanks to the proposed adaptive slicing method.
In
Figure 9 and
Figure 10, we exhibit a portion of the detection results of ASAHI on VisDrone and xView for small objects. As can be seen in
Figure 9, ASAHI performs well in various challenging scenes, such as dark scenes (as shown in the third example), scenes with reflections and different shooting angles, and scenes with high density (as shown in the seventh example). Moreover, as shown in
Figure 10, ASAHI performs equally well on remote sensing scenes, such as those with extremely large image resolutions, numerous interference factors (as shown in the first example), and multiple detection categories (as shown in the fourth example).
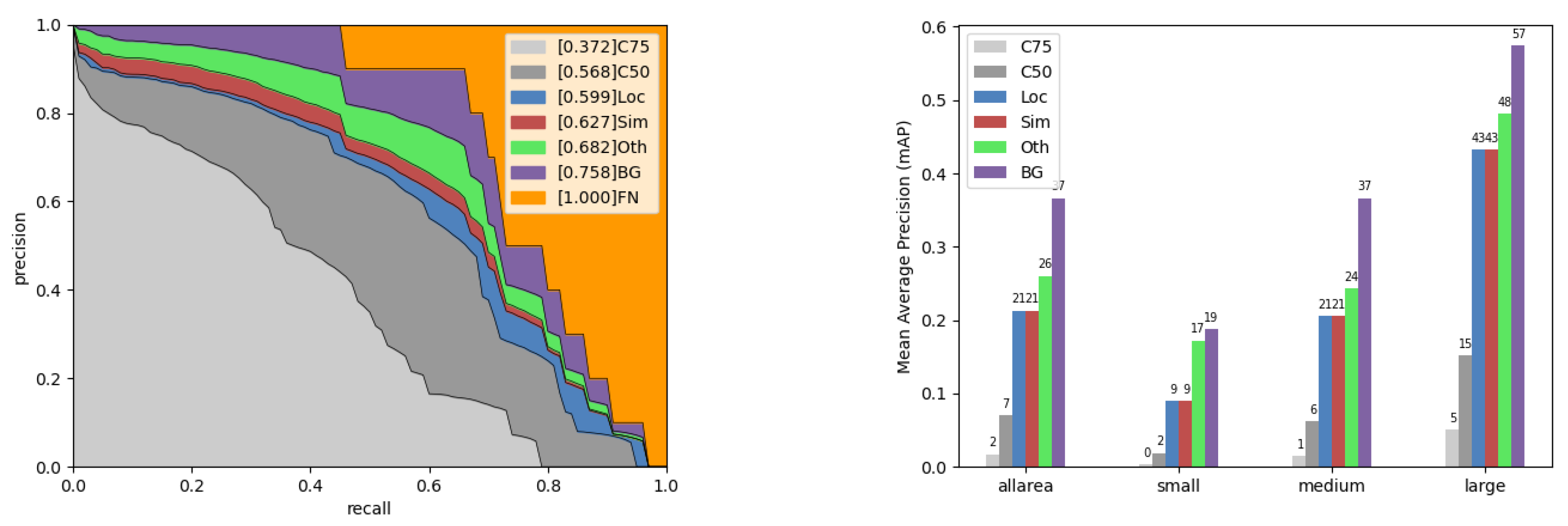
However, this approach has two notable shortcomings: (1) improving the detection accuracy for small objects inevitably leads to a reduction in the detection accuracy for large objects, and (2) a number of error cases remain, such as location and category confusion. The error analysis results of ASAHI on VisDrone and xView are presented on the left and right of
Figure 11, respectively. Among these results, C75 (IoU threshold of 0.75), C50 (IoU threshold of 0.5), Loc (ignore location error), Sim (ignore super-category false positives), Oth (ignore category confusions), BG (ignore all false positives), and FN (ignore all false negatives) in
Figure 11 clearly show that there is room to improve the error in terms of super-category false positives, category confusion, false positives, and false negatives.
6. Conclusions
In this study, we addressed the redundant computation problem of the generic SAHI slicing method [
15]. We proposed a novel adaptive slicing framework, ASAHI, which slices images into a corresponding number of slices rather than using a fixed slice size. This substantially alleviates the problem of redundant computation. TPH-YOLOv5 [
10] was used as the backbone to conduct relevant test experiments on the xView [
19] and VisDrone2019 [
18] datasets. In the post-processing stage, we replaced the traditional NMS with Cluster-NMS to improve the detection speed. Our model realizes improvements in mAP and reduces the time consumption by about 25% compared to SAHI [
15] (baseline). Our method is equally applicable to other YOLO-based models. In future work, we plan to use coordinate attention [
41] and CSWin Transformer [
42] to improve the sensitivity of the proposed method to small objects.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}