

Quantitative Short-Term Precipitation Model Using Multimodal Data Fusion Based on a Cross-Attention Mechanism



Abstract
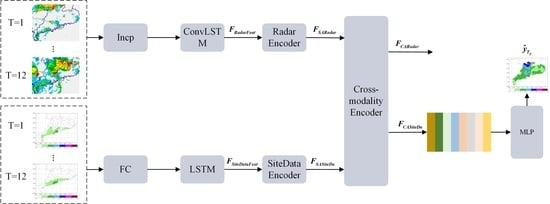
:
1. Introduction
- We propose a new framework called MFCA. MFCA can fuse radar-echo data with station-rainfall data, analyze the spatio-temporal dependence of radar reflectivity and rainfall in the process of rainfall, and predict quantitative short-term precipitation. To our knowledge, we are the first to propose a multimodal-fusion, quantitative short-term precipitation prediction model based on a cross-attention mechanism.
- We present a new feature encoder for radar-echo and station data that uses ConvLSTM, LSTM, and a transformer to extract coded features from different modal weather data. We use the implicit state of each time step as the feature of the time step, and use a transformer to further encode it, and then exchange features through the cross-attention mechanism.
- We validated our model on four real datasets from southeastern China, and compared it with a current, mainstream, advanced, single-mode rainfall prediction model. The results of the experiments confirm the superiority of our model.
2. Related Work
2.1. Spatio-Temporal Model
2.2. Multimodal Fusion Algorithm
2.3. Convection-Allowing Forecast Model
3. Methods
3.1. Problem Description
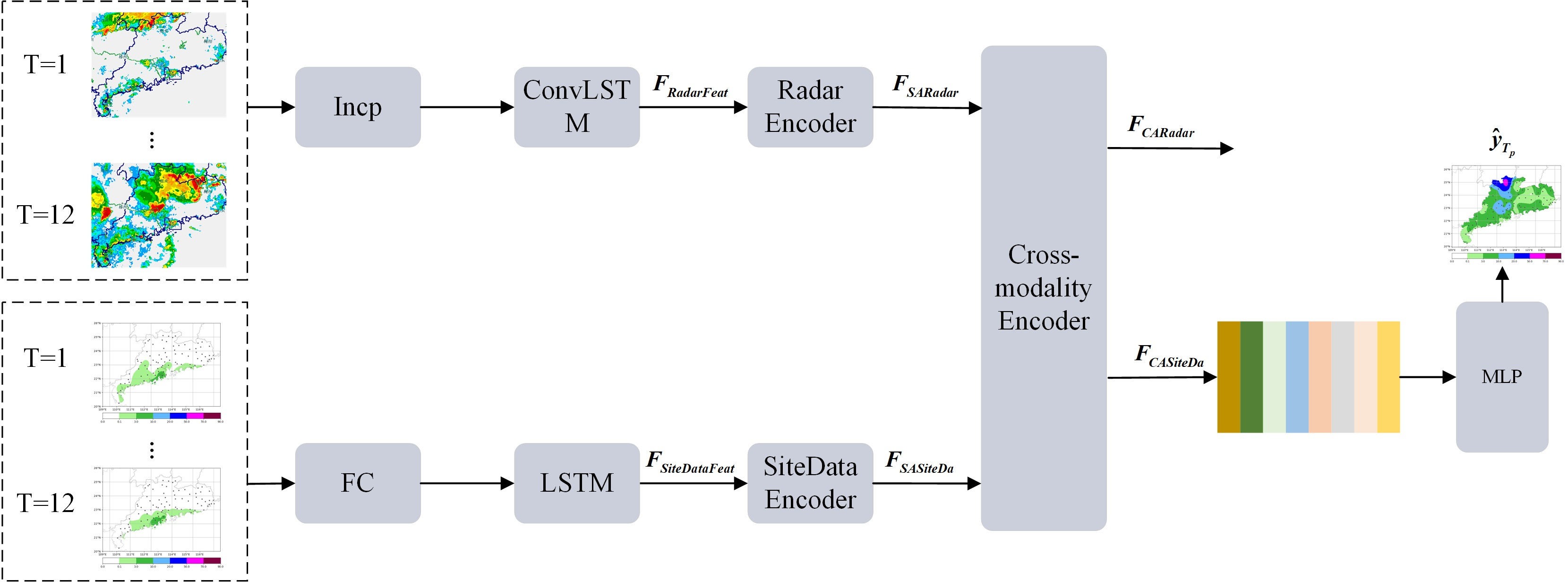
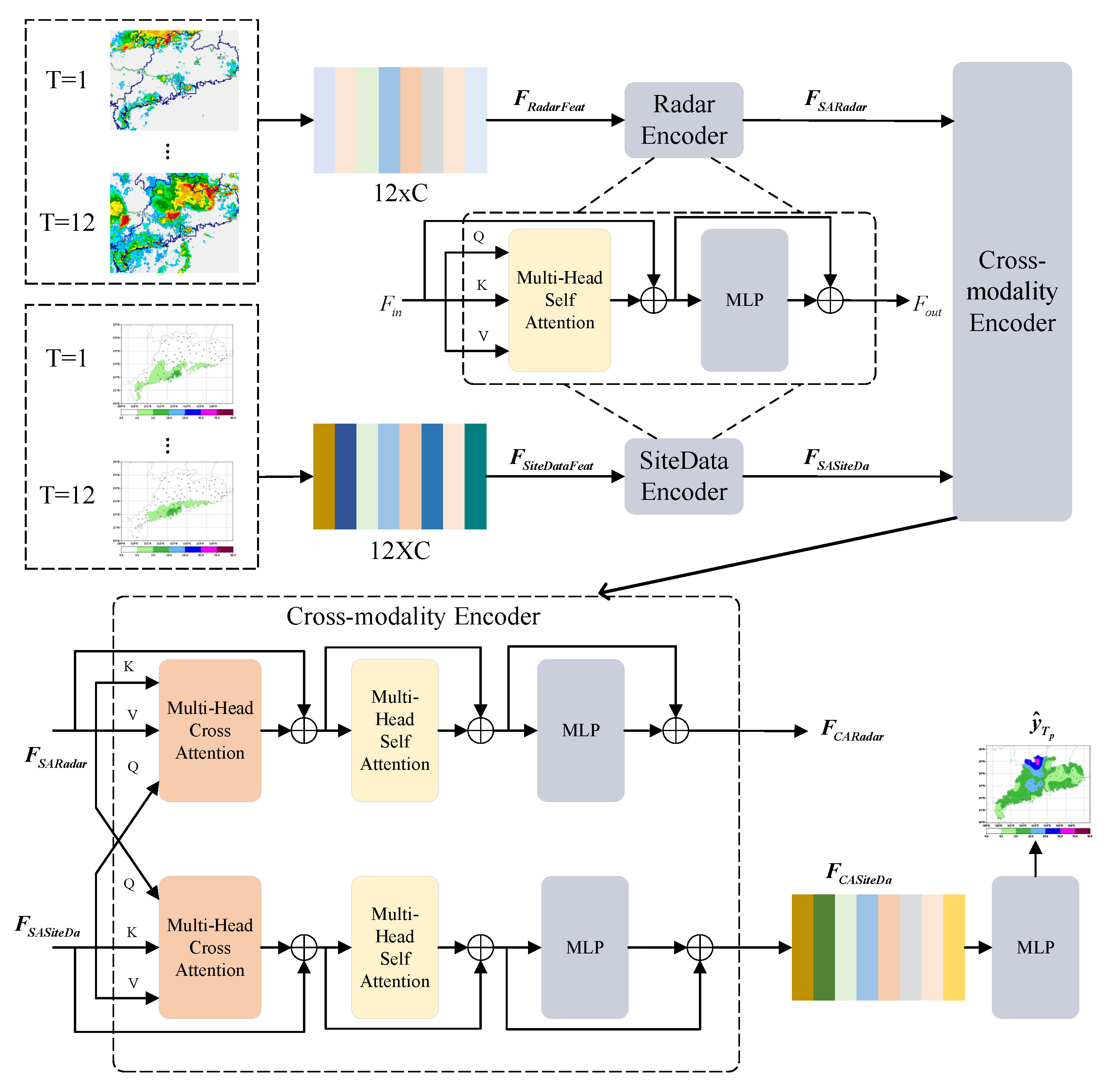
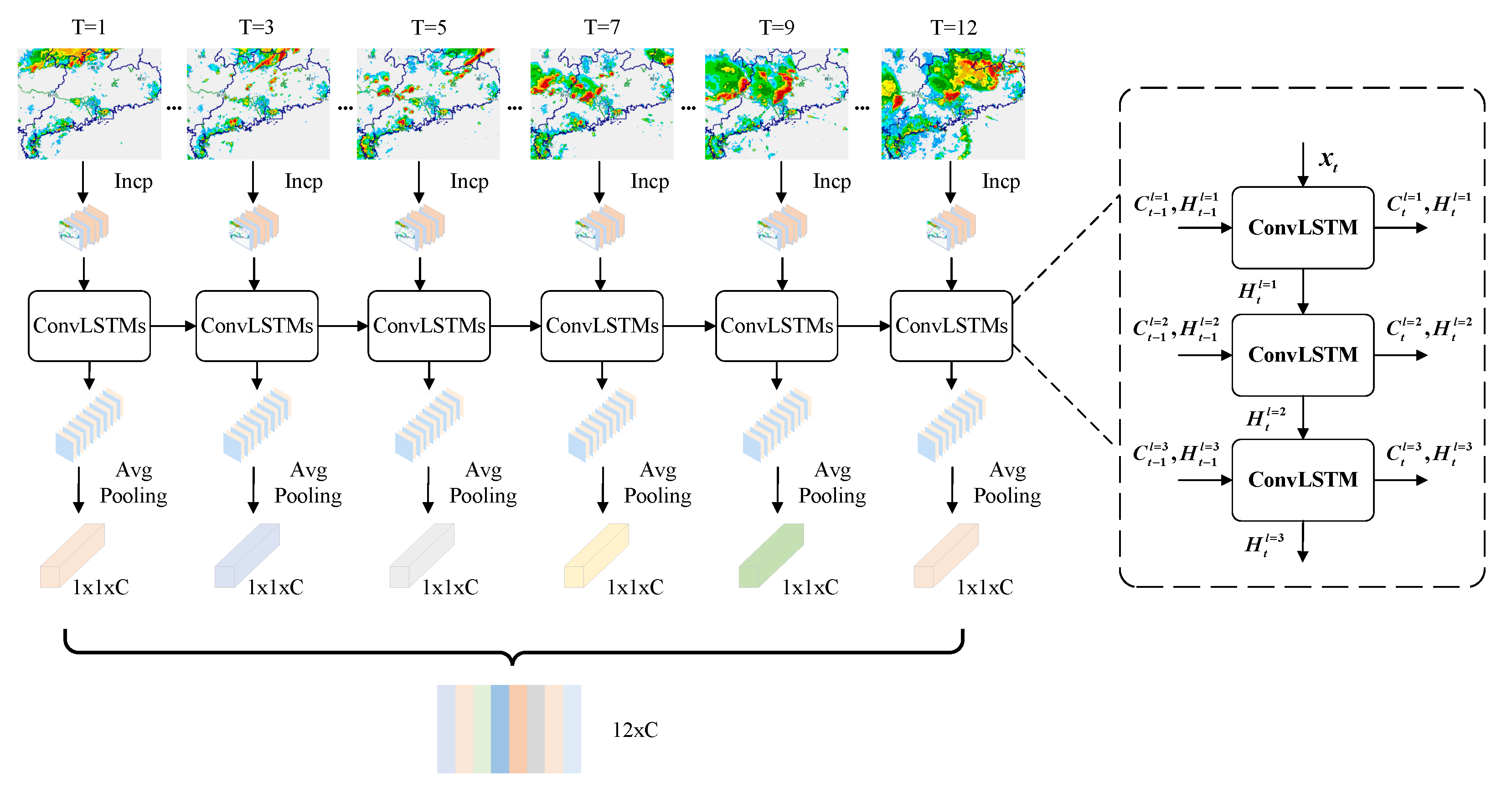
3.2. Network Structure
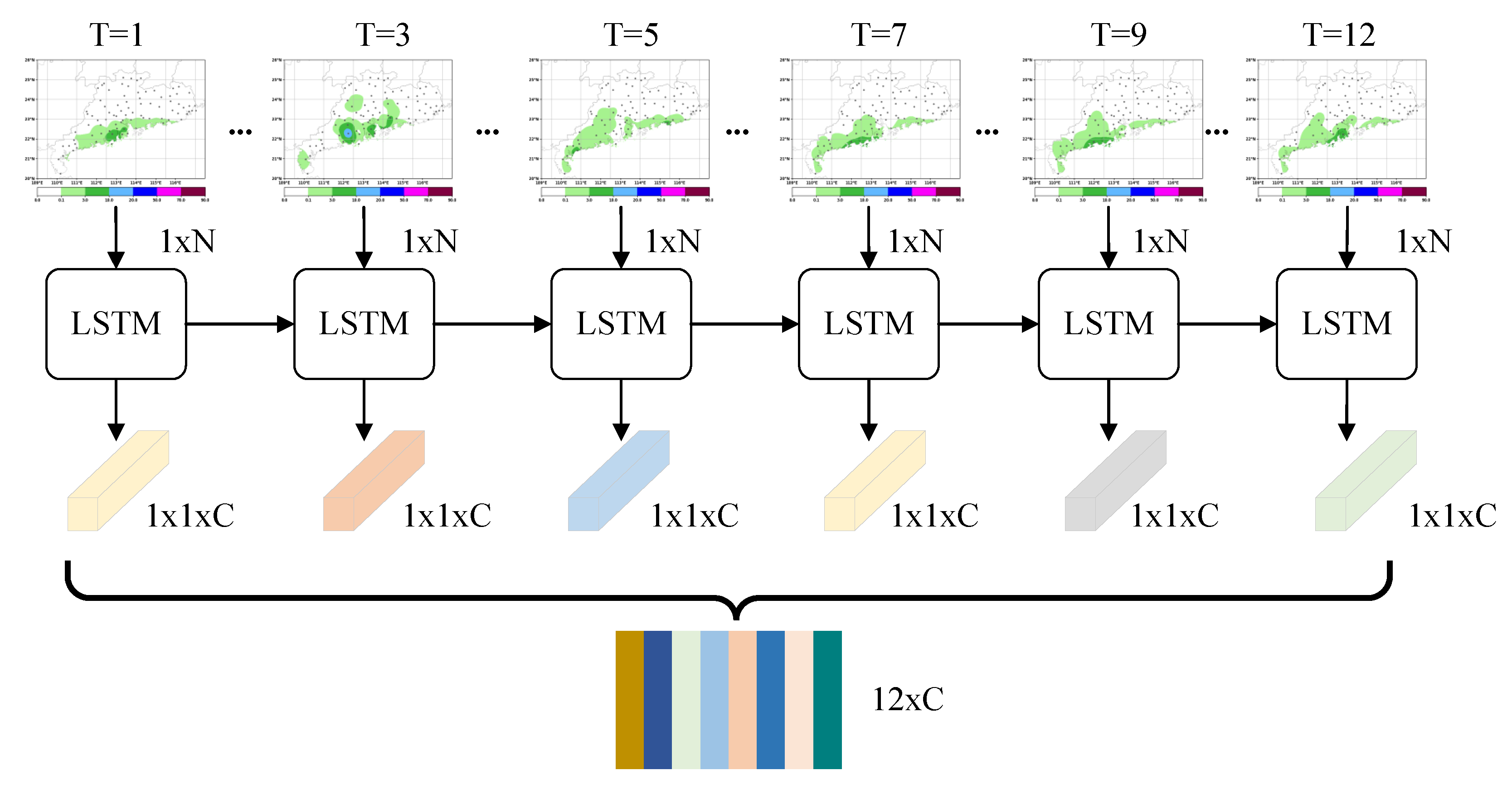
3.2.1. Sequence Feature Encoder
3.2.2. Single-Mode Feature Encoder
3.2.3. Cross-Modal Feature Encoder
3.3. Implementation
| Algorithm 1: Algorithmic flow of MFCA. |
Input:, Output:
|
4. Data and Experimental Configuration
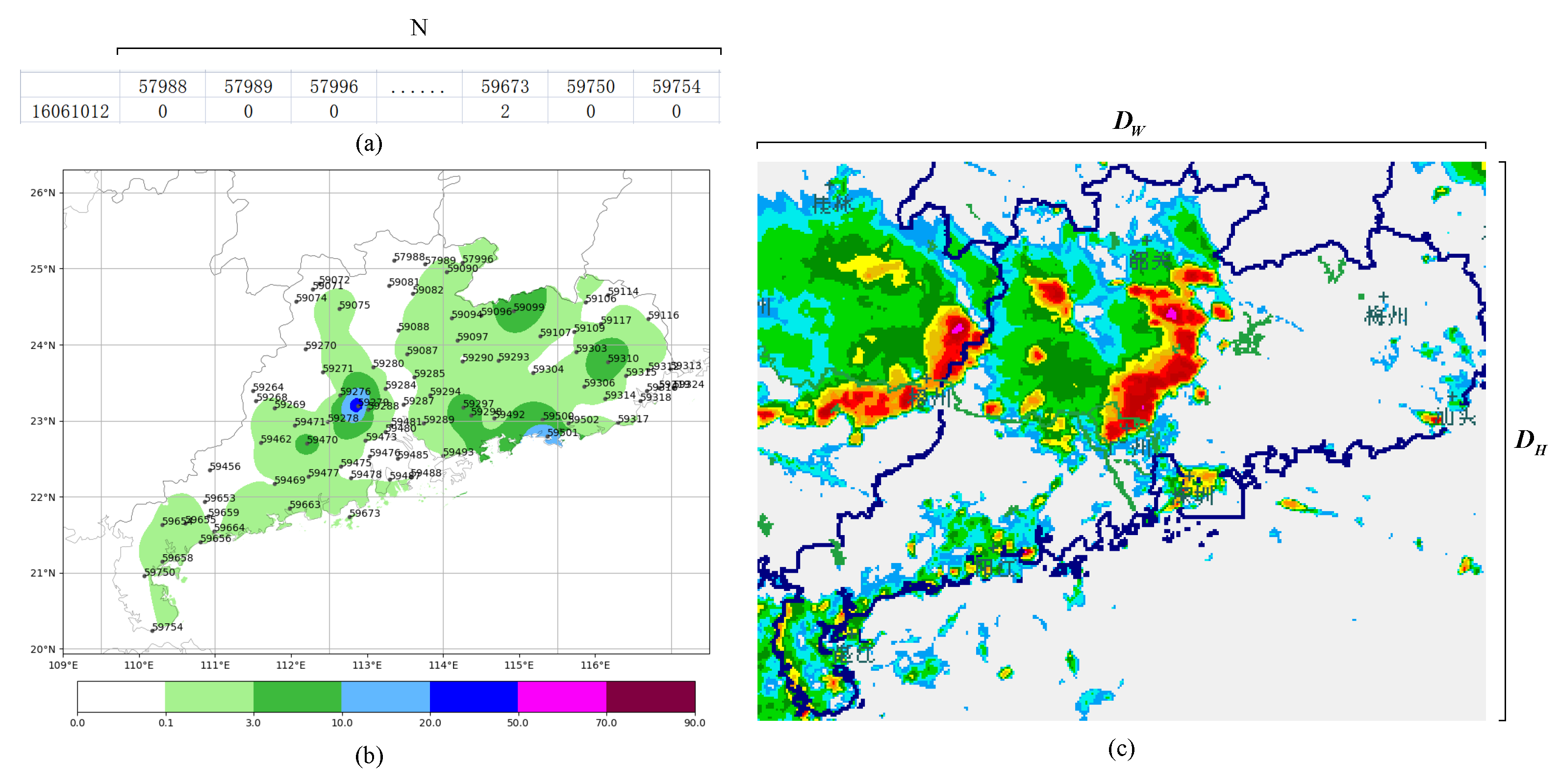
4.1. Data Description and Pretreatment
4.2. Comparing Models and Settings
4.3. Evaluation Criteria
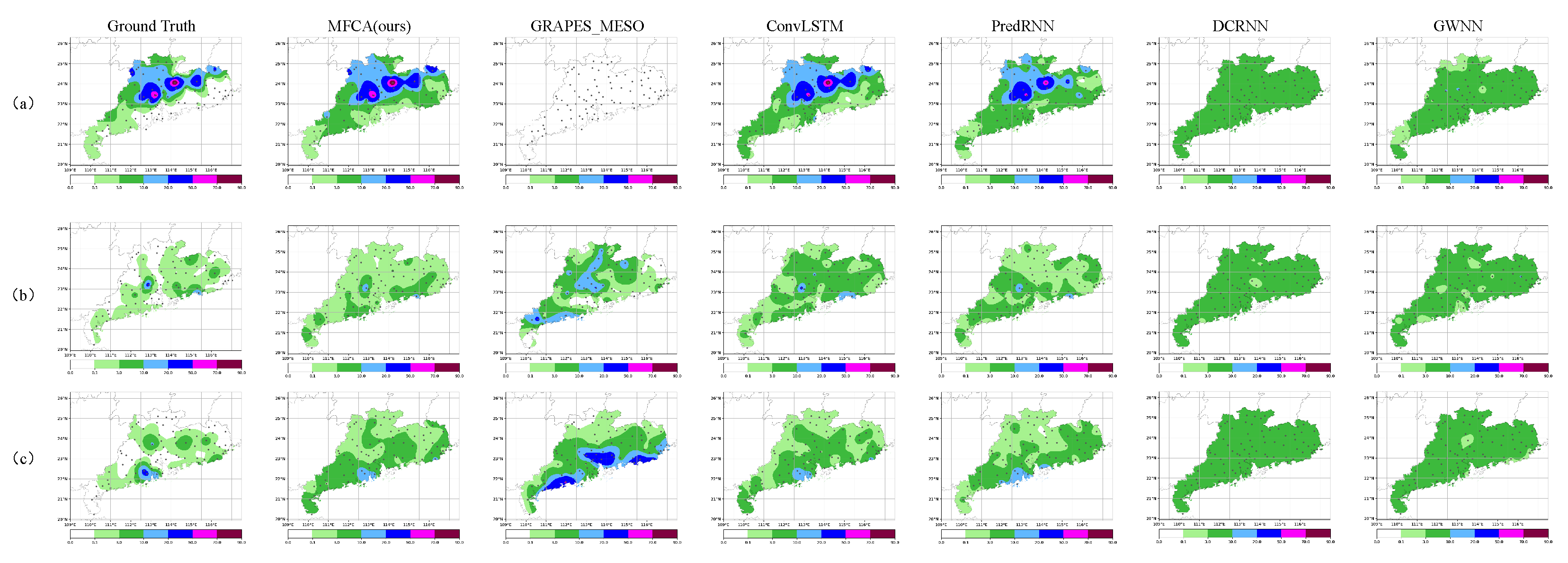
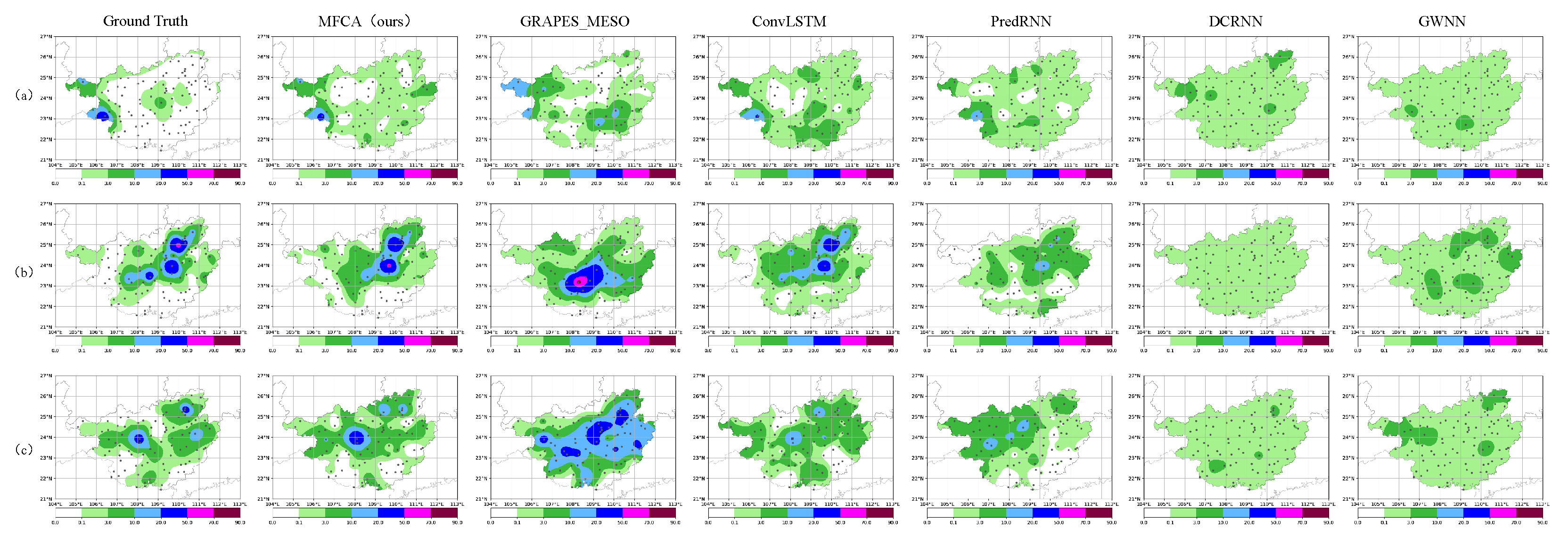
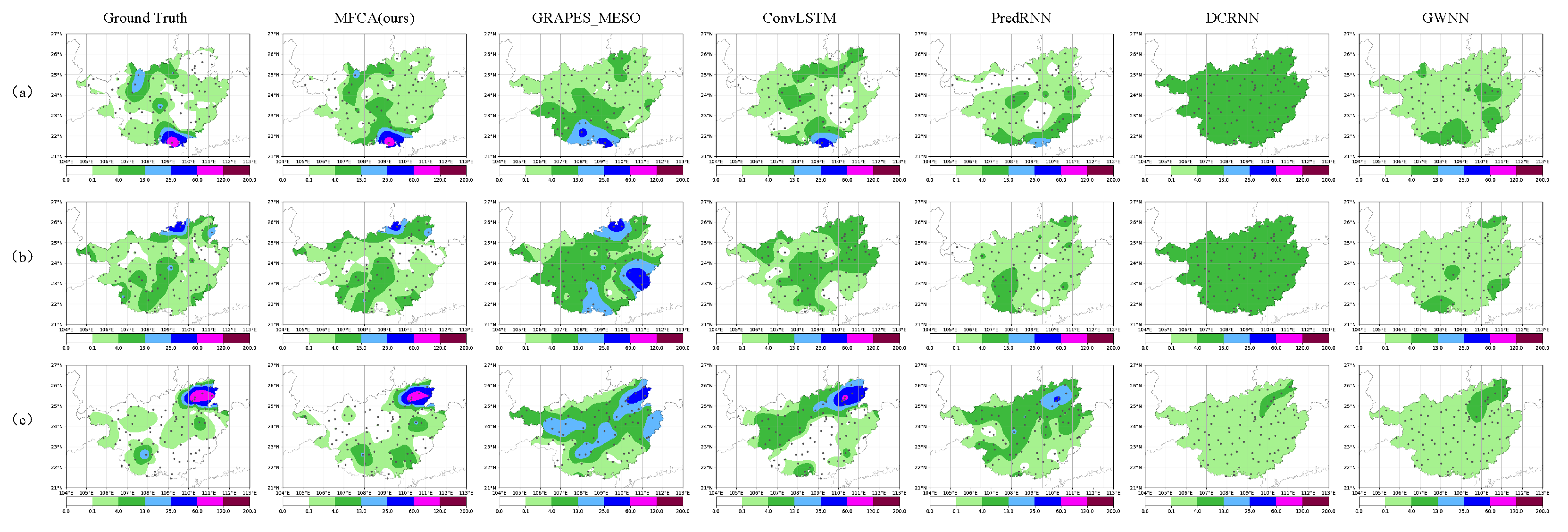
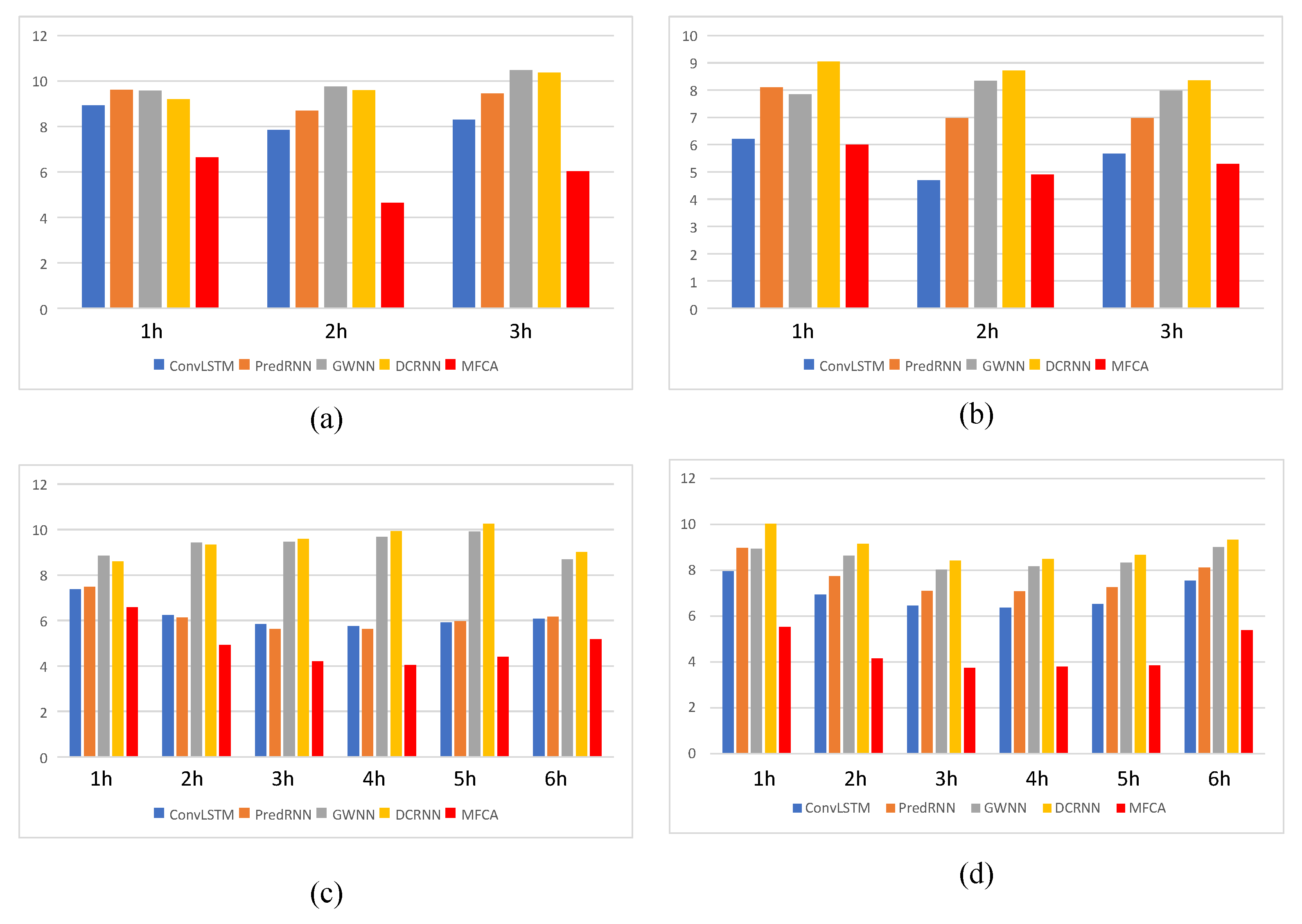
5. Experimental Results and Analysis
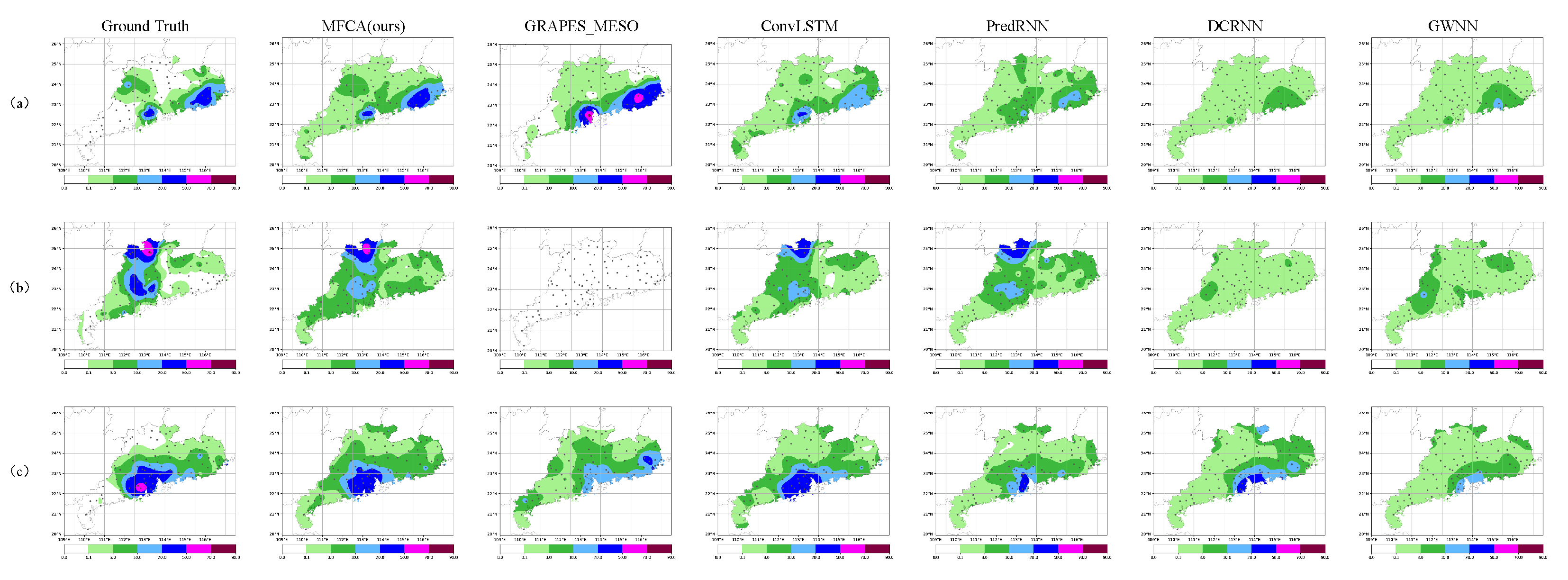
5.1. Performance Comparison
5.2. Ablation Experiment
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shukla, B.P.; Kishtawal, C.M.; Pal, P.K. Satellite-based nowcasting of extreme rainfall events over Western Himalayan region. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 1681–1686. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.c. Convolutional LSTM Network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Chang, Z.; Zhang, X.; Wang, S.; Ma, S.; Ye, Y.; Xinguang, X.; Gao, W. MAU: A Motion-Aware Unit for Video Prediction and Beyond. Adv. Neural Inf. Process. Syst. 2021, 34, 26950–26962. [Google Scholar]
- Pan, T.; Jiang, Z.; Han, J.; Wen, S.; Men, A.; Wang, H. Taylor saves for later: Disentanglement for video prediction using Taylor representation. Neurocomputing 2022, 472, 166–174. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, D.; Ye, Q. Recurrent Thrifty Attention Network for Remote Sensing Scene Recognition. IEEE Trans. Geosci. Remote. Sens. 2021, 59, 8257–8268. [Google Scholar] [CrossRef]
- Kusiak, A.; Wei, X.; Verma, A.P.; Roz, E. Modeling and prediction of rainfall using radar reflectivity data: A data-mining approach. IEEE Trans. Geosci. Remote. Sens. 2012, 51, 2337–2342. [Google Scholar] [CrossRef]
- Pfeifer, P.E.; Deutrch, S.J. A three-stage iterative procedure for space-time modeling phillip. Technometrics 1980, 22, 35–47. [Google Scholar] [CrossRef]
- Tang, T.; Jiao, D.; Chen, T.; Gui, G. Medium- and Long-Term Precipitation Forecasting Method Based on Data Augmentation and Machine Learning Algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 1000–1011. [Google Scholar] [CrossRef]
- Min, M.; Bai, C.; Guo, J.; Sun, F.; Liu, C.; Wang, F.; Xu, H.; Tang, S.; Li, B.; Di, D.; et al. Estimating Summertime Precipitation from Himawari-8 and Global Forecast System Based on Machine Learning. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 2557–2570. [Google Scholar] [CrossRef]
- Chen, H.; Chandrasekar, V.; Cifelli, R.; Xie, P. A Machine Learning System for Precipitation Estimation Using Satellite and Ground Radar Network Observations. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 982–994. [Google Scholar] [CrossRef]
- Pan, Z.; Yuan, F.; Yu, W.; Lei, J.; Ling, N.; Kwong, S. RDEN: Residual Distillation Enhanced Network-Guided Lightweight Synthesized View Quality Enhancement for 3D-HEVC. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6347–6359. [Google Scholar] [CrossRef]
- Luo, C.; Li, X.; Ye, Y. PFST-LSTM: A SpatioTemporal LSTM Model With Pseudoflow Prediction for Precipitation Nowcasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 843–857. [Google Scholar] [CrossRef]
- Manokij, F.; Sarinnapakorn, K.; Vateekul, P. Forecasting Thailand’s Precipitation with Cascading Model of CNN and GRU. In Proceedings of the 2019 11th International Conference on Information Technology and Electrical Engineering (ICITEE), Pattaya, Thailand, 10–11 October 2019; pp. 1–6. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 20. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Wu, Y.; Yang, X.; Tang, Y.; Zhang, C.; Zhang, G.; Zhang, W. Inductive Spatiotemporal Graph Convolutional Networks for Short-Term Quantitative Precipitation Forecasting. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Cui, Y.; Yu, J.; Tao, D.; Tian, Q. Multimodal unified attention networks for vision-and-language interactions. arXiv 2019, arXiv:1908.04107. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Zhang, W.; Han, L.; Sun, J.; Guo, H.; Dai, J. Application of Multi-channel 3D-cube Successive Convolution Network for Convective Storm Nowcasting. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1705–1710. [Google Scholar]
- Lin, C.W.; Yang, S. Geospatial-Temporal Convolutional Neural Network for Video-Based Precipitation Intensity Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1119–1123. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.E.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Deep Learning for Precipitation Nowcasting: A Benchmark and a New Model. Adv. Neural Inf. Process. Syst. 2017, 30, 5617–5627. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. PredRNN: Recurrent neural networks for predictive learning using spatiotemporal LSTMs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 879–888. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Philip, S.Y. Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5123–5132. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, H.; Long, M.; Wang, J.; Yu, P.S. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9154–9162. [Google Scholar]
- Lin, Z.; Li, M.; Zheng, Z.; Cheng, Y.; Yuan, C. Self-attention convlstm for spatiotemporal prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11531–11538. [Google Scholar]
- Rao, Y.; Ni, J.; Zhao, H. Deep Learning Local Descriptor for Image Splicing Detection and Localization. IEEE Access 2020, 8, 25611–25625. [Google Scholar] [CrossRef]
- Sun, L.; Fang, Y.; Chen, Y.; Huang, W.; Wu, Z.; Jeon, B. Multi-Structure KELM With Attention Fusion Strategy for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 121–137. [Google Scholar]
- Sun, L.; Cheng, S.; Zheng, Y.; Wu, Z.; Zhang, J. SPANet: Successive Pooling Attention Network for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 4045–4057. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Sun, Y.; Li, M.; Kuang, G. Multimodal Bilinear Fusion Network With Second-Order Attention-Based Channel Selection for Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 1011–1026. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Xu, B.; Shen, H.; Cao, Q.; Qiu, Y.; Cheng, X. Graph wavelet neural network. arXiv 2019, arXiv:1904.07785. [Google Scholar]
- Bai, J.; Zhu, J.; Song, Y.; Zhao, L.; Hou, Z.; Du, R.; Li, H. A3t-gcn: Attention temporal graph convolutional network for traffic forecasting. ISPRS Int. J. Geo-Inf. 2021, 10, 485. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Yu, P.; Long, M. PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Truth (GT) | |||
| Positive (GT ≥ 0.1) | Negative (GT < 0.1) | ||
| Prediction (PD) | Positive (PD ≥ 0.1) | TP | FP |
| Negative (PD < 0.1) | FN | TN | |
| Methods | Guangdong (3 h) | Guangdong (6 h) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TS0.1 | TS3 | TS10 | TS20 | TS50 | MSE | MAE | TS0.1 | TS3 | TS10 | TS20 | TS50 | MSE | MAE | |
| Ours | 0.37 | 0.44 | 0.62 | 0.61 | 0.44 | 12.1 | 1.96 | 0.54 | 0.48 | 0.63 | 0.67 | 0.59 | 14.5 | 2.75 |
| GRAPES_MESO | 0.26 | 0.18 | 0.14 | 0.12 | 0 | 72 | 3.43 | 0.104 | 0.06 | 0.04 | 0.05 | 0 | 119 | 4.82 |
| DCRNN | 0.36 | 0.24 | 0.10 | 0.02 | 0 | 47.48 | 2.9 | 0.53 | 0.30 | 0.03 | 0.01 | 0 | 87.38 | 4.5 |
| GWNN | 0.36 | 0.25 | 0.09 | 0 | 0 | 47.84 | 3.3 | 0.53 | 0.26 | 0.05 | 0.03 | 0 | 88.81 | 4.52 |
| A3T-GCN | 0.38 | 0.22 | 0 | 0 | 0 | 49.56 | 3.20 | 0.54 | 0.33 | 0.14 | 0.02 | 0 | 115.23 | 5.81 |
| ConvLSTM | 0.36 | 0.39 | 0.52 | 0.44 | 0.1 | 20.96 | 2.5 | 0.53 | 0.40 | 0.59 | 0.56 | 0.48 | 24.7 | 3.55 |
| PredRNN | 0.37 | 0.29 | 0.27 | 0.12 | 0 | 34.04 | 2.8 | 0.54 | 0.39 | 0.52 | 0.49 | 0.3 | 31.27 | 3.89 |
| PredRNN-V2 | 0.38 | 0.35 | 0.37 | 0.29 | 0.06 | 26.82 | 2.7 | 0.52 | 0.42 | 0.52 | 0.50 | 0.3 | 28.22 | 3.71 |
| Guangxi (3 h) | Guangxi (6 h) | |||||||||||||
| Ours | 0.41 | 0.52 | 0.63 | 0.54 | 0.53 | 9.25 | 1.78 | 0.55 | 0.6 | 0.72 | 0.71 | 0.62 | 14.17 | 2.38 |
| GRAPES_MESO | 0.36 | 0.23 | 0.16 | 0.06 | 0 | 51.91 | 2.88 | 0.22 | 0.1 | 0.08 | 0.15 | 0 | 105.99 | 4.48 |
| DCRNN | 0.34 | 0.21 | 0.03 | 0.01 | 0 | 39.38 | 2.7 | 0.50 | 0.27 | 0.03 | 0 | 0 | 103.11 | 5.59 |
| GWNN | 0.34 | 0.24 | 0.04 | 0.01 | 0 | 39.37 | 3.12 | 0.50 | 0.27 | 0.04 | 0 | 0 | 103.89 | 5.41 |
| A3T-GCN | 0.35 | 0.21 | 0.01 | 0 | 0 | 40.71 | 2.90 | 0.50 | 0.29 | 0.07 | 0 | 0 | 102.16 | 5.54 |
| ComvLSTM | 0.39 | 0.37 | 0.51 | 0.35 | 0.22 | 16.37 | 2.49 | 0.53 | 0.47 | 0.58 | 0.53 | 0.42 | 29.83 | 3.57 |
| PredRNN | 0.37 | 0.27 | 0.18 | 0.06 | 0.01 | 32.42 | 2.87 | 0.51 | 0.39 | 0.39 | 0.27 | 0.17 | 48.26 | 4.2 |
| PredRNN-V2 | 0.38 | 0.32 | 0.30 | 0.21 | 0.09 | 25.73 | 2.8 | 0.51 | 0.40 | 0.43 | 0.35 | 0.21 | 39.13 | 3.889 |
| Type | Patch Size/Stride | Input Size | Output Size | MSE | MAE |
|---|---|---|---|---|---|
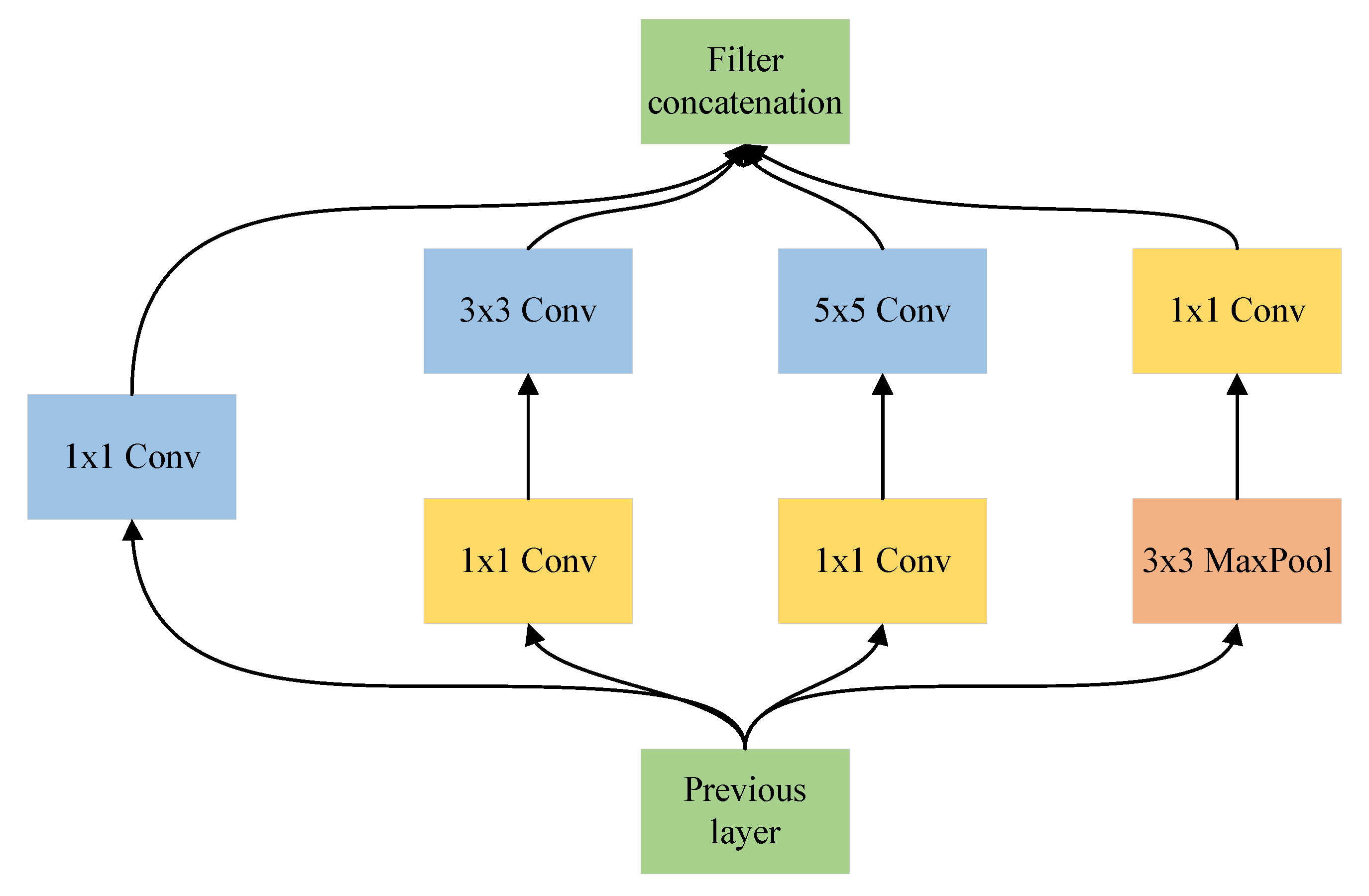
| Inceptionx1 MaxPool | As in Figure 3 | B × S × 1 × 280 × 360 | B × S × 32 × 140 × 180 | 14.50 | 2.75 |
| Conv2d | 3 × 3/2 | B × S × 32 × 140 × 180 | B × S × 64 × 70 × 90 | ||
| Conv2d | 3 × 3/1 | B × S × 64 × 70 × 90 | B × S × 32 × 70 × 90 | ||
| Conv2d | 3 × 3/2 | B × S × 32 × 70 × 90 | B × S × 32 × 35 × 45 | ||
| Inceptionx1 MaxPool | As in Figure 3 | B × S × 1 × 280 × 360 | B × S × 32 × 140 × 180 | 20 | 2.91 |
| Inceptionx1 MaxPool | As in Figure 3 | B × S × 32 × 140 × 180 | B × S × 64 × 70 × 90 | ||
| Conv2d | 3 × 3/2 | B × S × 64 × 70 × 90 | B × S × 32 × 35 × 45 | ||
| Conv2d | 3 × 3/1 | B × S × 32 × 35 × 45 | B × S × 32 × 35 × 45 | ||
| Inceptionx1 MaxPool | As in Figure 3 | B × S × 1 × 280 × 360 | B × S × 32 × 140 × 180 | 27 | 3.1 |
| Inceptionx1 MaxPool | As in Figure 3 | B × S × 32 × 140 × 180 | B × S × 64 × 70 × 90 | ||
| Inceptionx1 MaxPool | As in Figure 3 | B × S × 64 × 70 × 90 | B × S × 32 × 35 × 45 | ||
| Conv2d | 3 × 3/1 | B × S × 32 × 35 × 45 | B × S × 32 × 35 × 45 | ||
| Conv2d | 3 × 3/2 | B × S × 1 × 280 × 360 | B × S × 32 × 140 × 180 | 17.58 | 2.80 |
| Conv2d | 3 × 3/2 | B × S × 32 × 140 × 180 | B × S × 64 × 70 × 90 | ||
| Conv2d | 3 × 3/1 | B × S × 64 × 70 × 90 | B × S × 32 × 70 × 90 | ||
| Conv2d | 3 × 3/2 | B × S × 32 × 70 × 90 | B × S × 32 × 35 × 45 |
| Radar_Layers | Site_Layers | Cross_Layers | MSE | MAE |
|---|---|---|---|---|
| 1 | 2 | 2 | 18.9 | 3.08 |
| 2 | 2 | 2 | 16.58 | 3.02 |
| 3 | 2 | 2 | 14.50 | 2.75 |
| 4 | 2 | 2 | 17.87 | 3.17 |
| 3 | 1 | 1 | 18.60 | 3.24 |
| 3 | 3 | 3 | 19 | 3.21 |
| 3 | 2 | 0 | 21 | 3.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Y.; Qiu, Y.; Sun, L.; Shu, X.; Lu, Z. Quantitative Short-Term Precipitation Model Using Multimodal Data Fusion Based on a Cross-Attention Mechanism. Remote Sens. 2022, 14, 5839. https://doi.org/10.3390/rs14225839
Cui Y, Qiu Y, Sun L, Shu X, Lu Z. Quantitative Short-Term Precipitation Model Using Multimodal Data Fusion Based on a Cross-Attention Mechanism. Remote Sensing. 2022; 14(22):5839. https://doi.org/10.3390/rs14225839
Chicago/Turabian StyleCui, Yingjie, Yunan Qiu, Le Sun, Xinyao Shu, and Zhenyu Lu. 2022. "Quantitative Short-Term Precipitation Model Using Multimodal Data Fusion Based on a Cross-Attention Mechanism" Remote Sensing 14, no. 22: 5839. https://doi.org/10.3390/rs14225839