
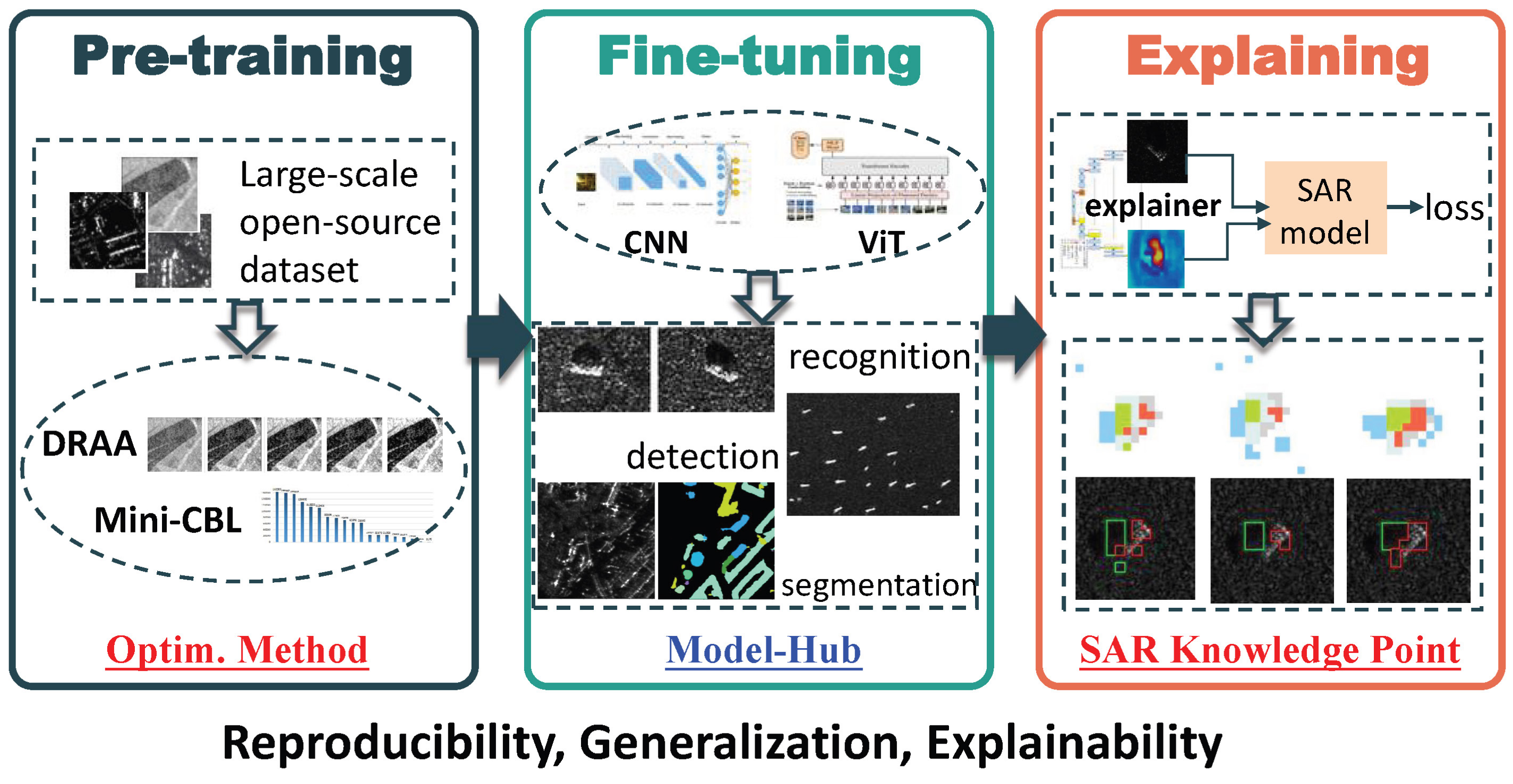
SAR-HUB: Pre-Training, Fine-Tuning, and Explaining

Abstract
:1. Introduction
- 1.
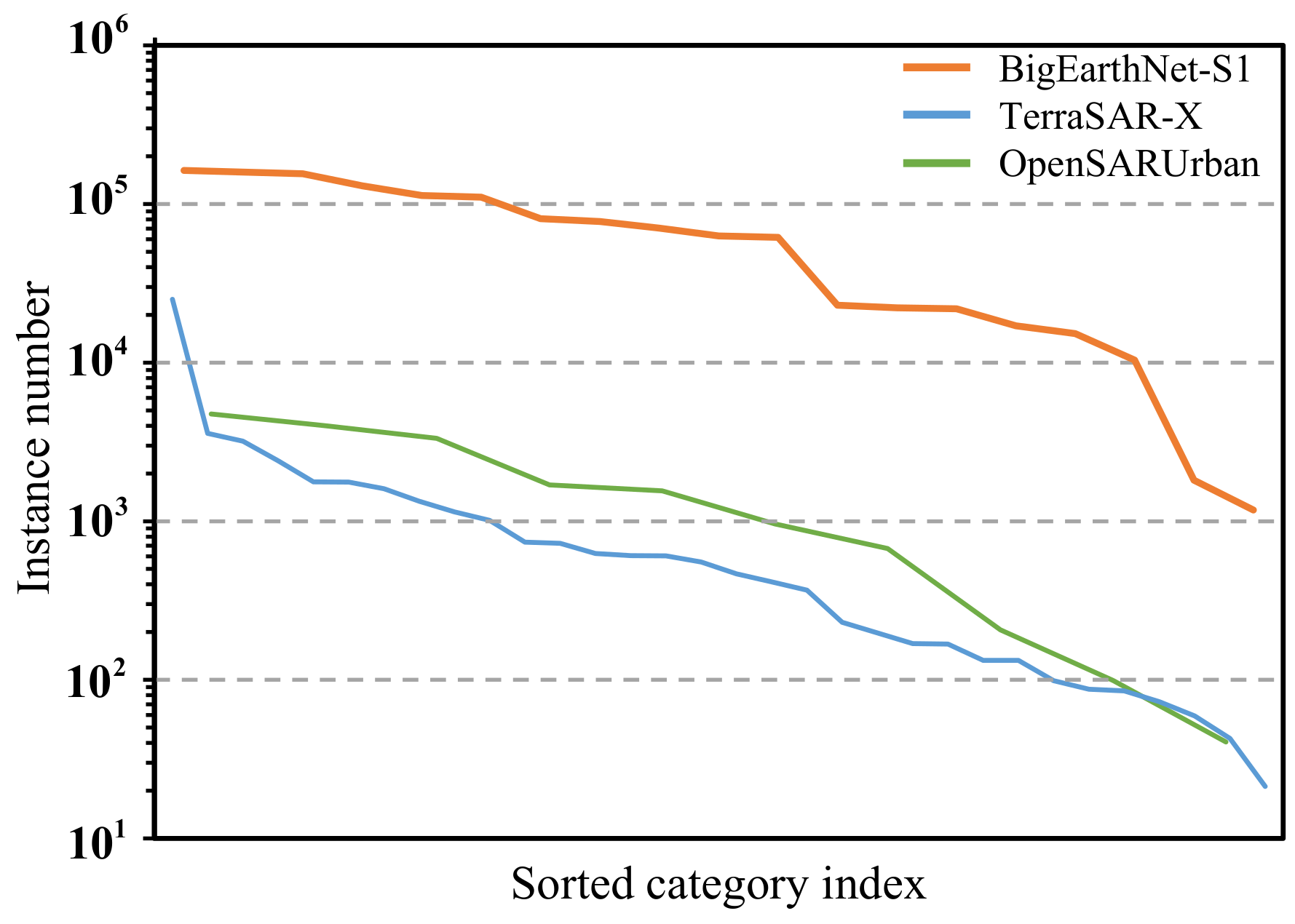
- To address the challenges of data distribution drift and class imbalance problems in different SAR scene image classification datasets, we propose dynamic range adaptive enhancement (DRAE) and mini-batch class-balanced loss (Mini-CBL), which improve the model performance and feature generalization ability.
- 2.
- Motivated by the explanation of knowledge distillation [20], we propose a novel explanation method that quantifies the knowledge of a pre-trained model transferring to SAR downstream tasks. The results can comprehensively demonstrate the benefits of SAR-pre-trained models compared with optical ones.
- 3.
- We contribute this project to the SAR community with reproducibility (open-source code and datasets), generalization (sufficient experiments on different tasks), and explainability (qualitative and quantitative interpretations), available on 15 June 2023 via https://github.com/XAI4SAR/SAR-HUB.
2. Related Work
2.1. Pre-Trained Model in Remote Sensing
2.2. Post Hoc Explanation
3. Method
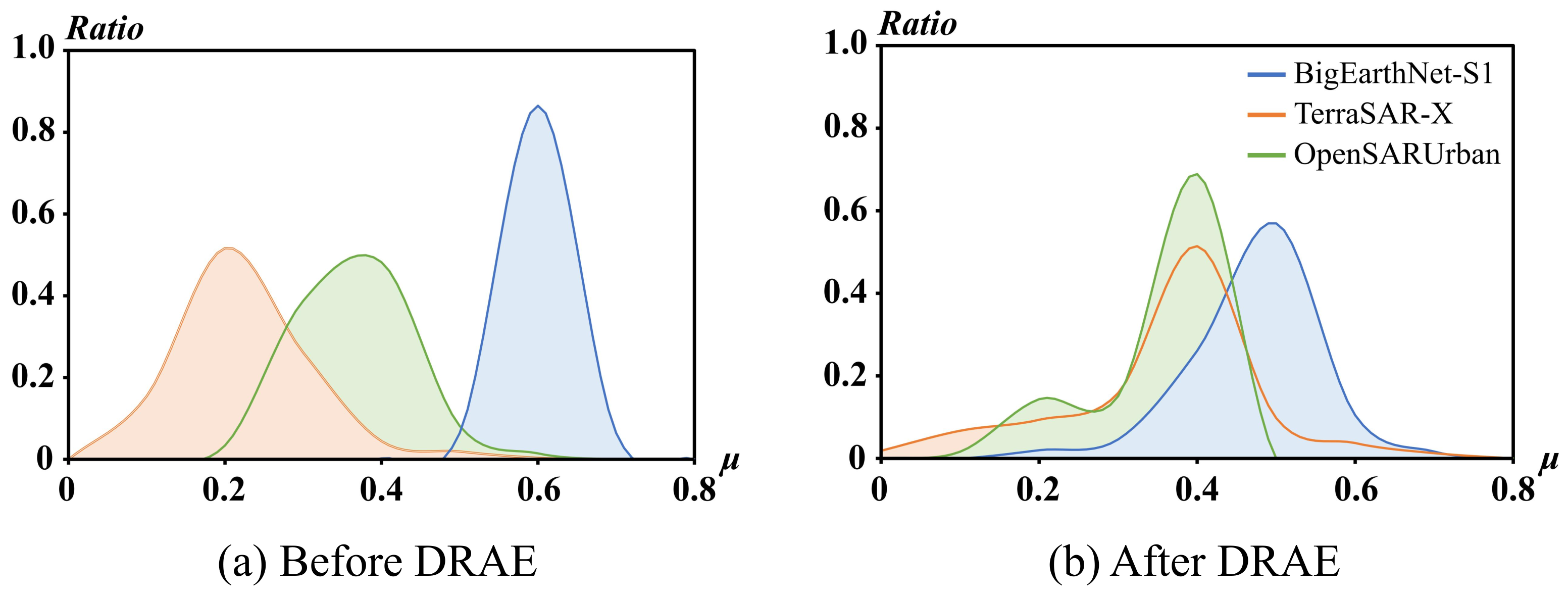
3.1. Dynamic Range Adaptive Enhancement
3.2. Mini-Batch Class-Balanced Loss
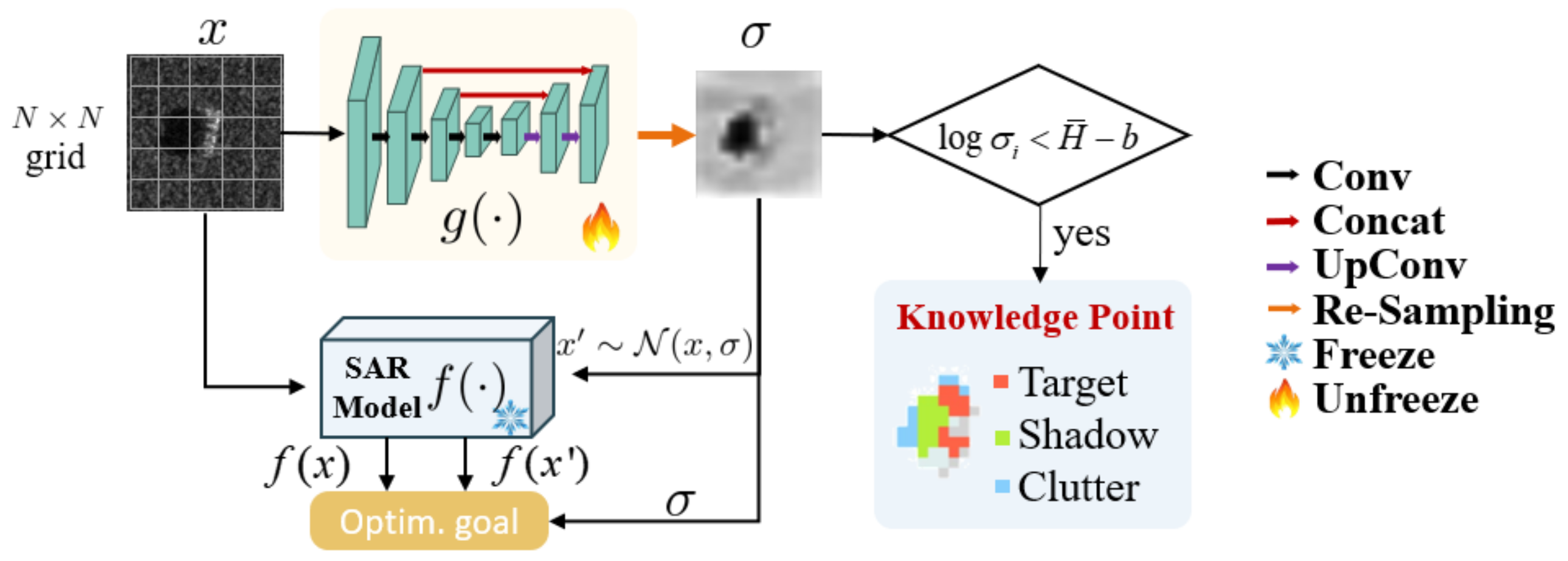
3.3. Knowledge Point Explainer
4. Experiments
4.1. Backbone Models
4.2. Pre-Training: Upstream Task of SAR Scene Classification
4.2.1. Datasets
4.2.2. Experimental Setup
4.2.3. Ablation Study
4.2.4. Effectiveness of DRAE and Mini-CBL
4.3. Fine-Tuning: Downstream Tasks
4.3.1. Target Recognition
4.3.2. Object Detection
4.3.3. Semantic Segmentation
4.4. Explanations
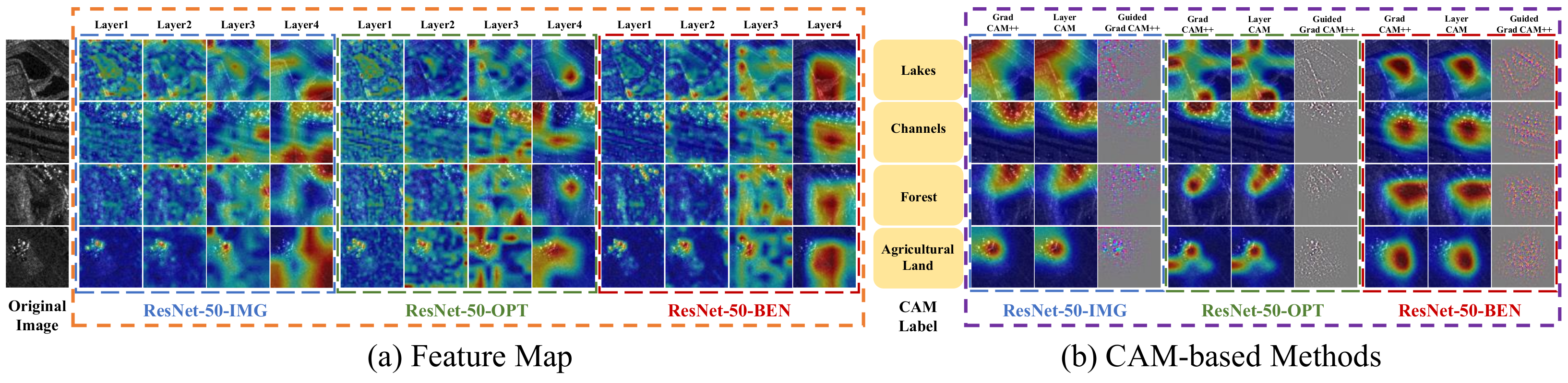
4.4.1. Feature Analysis with Class-Specific Explanations
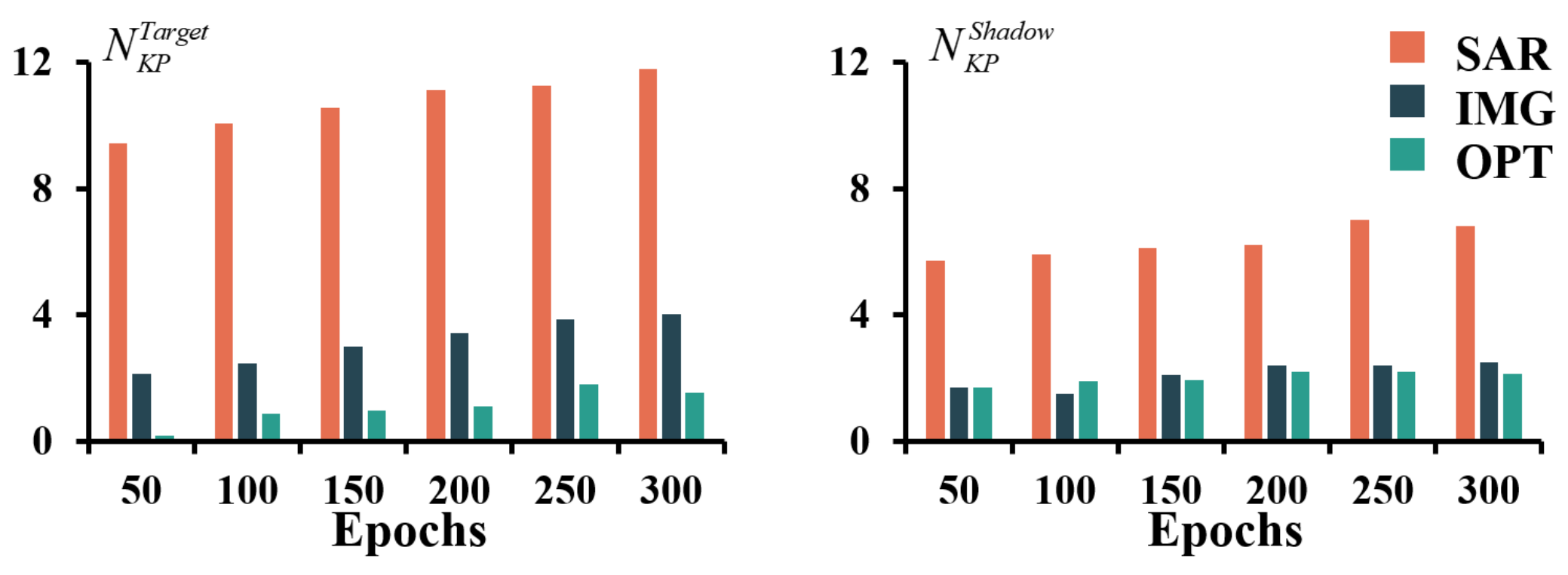
4.4.2. Knowledge Point Explanations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, Z.; Wu, C.; Yao, X.; Zhao, Z.; Huang, X.; Han, J. Physics Inspired Hybrid Attention for SAR Target Recognition. arXiv 2023, arXiv:2309.15697. [Google Scholar]
- Datcu, M.; Huang, Z.; Anghel, A.; Zhao, J.; Cacoveanu, R. Explainable, Physics-Aware, Trustworthy Artificial Intelligence: A paradigm shift for synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2023, 11, 8–25. [Google Scholar] [CrossRef]
- Huang, Z.; Yao, X.; Liu, Y.; Dumitru, C.O.; Datcu, M.; Han, J. Physically explainable CNN for SAR image classification. ISPRS J. Photogramm. Remote Sens. 2022, 190, 25–37. [Google Scholar] [CrossRef]
- Huang, Z.; Datcu, M.; Pan, Z.; Lei, B. Deep SAR-Net: Learning objects from signals. ISPRS J. Photogramm. Remote Sens. 2020, 161, 179–193. [Google Scholar] [CrossRef]
- Huang, Z.; Liu, Y.; Yao, X.; Ren, J.; Han, J. Uncertainty Exploration: Toward Explainable SAR Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Huang, Z.; YAO, X.; HAN, J. Progress and Perspective on Physically Explainable Deep Learning for Synthetic Aperture Radar Image Interpretation. J. Radars 2022, 11, 107–125. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. Ringmo: A remote sensing foundation model with masked image modeling. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–22. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing plain vision transformer towards remote sensing foundation model. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5607315. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, J.; Du, B.; Xia, G.S.; Tao, D. An empirical study of remote sensing pretraining. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–20. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 195–208. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. What, where, and how to transfer in SAR target recognition based on deep CNNs. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2324–2336. [Google Scholar] [CrossRef]
- Huang, Z.; Dumitru, C.O.; Pan, Z.; Lei, B.; Datcu, M. Classification of large-scale high-resolution SAR images with deep transfer learning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 107–111. [Google Scholar] [CrossRef]
- Zhong, C.; Mu, X.; He, X.; Wang, J.; Zhu, M. SAR Target Image Classification Based on Transfer Learning and Model Compression. IEEE Geosci. Remote Sens. Lett. 2019, 16, 412–416. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Zhu, M.; Stanković, L.; Ji, H. Self-matching CAM: A novel accurate visual explanation of CNNs for SAR image interpretation. Remote Sens. 2021, 13, 1772. [Google Scholar] [CrossRef]
- Zhang, Q.; Cheng, X.; Chen, Y.; Rao, Z. Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5099–5113. [Google Scholar] [CrossRef]
- Long, Y.; Xia, G.S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Cha, K.; Seo, J.; Lee, T. A billion-scale foundation model for remote sensing images. arXiv 2023, arXiv:2304.05215. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 24–25. [Google Scholar]
- Sumbul, G.; De Wall, A.; Kreuziger, T.; Marcelino, F.; Costa, H.; Benevides, P.; Caetano, M.; Demir, B.; Markl, V. BigEarthNet-MM: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets]. IEEE Geosci. Remote Sens. Mag. 2021, 9, 174–180. [Google Scholar] [CrossRef]
- Dumitru, C.O.; Schwarz, G.; Datcu, M. Land cover semantic annotation derived from high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2215–2232. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Z.; Yao, W.; Datcu, M.; Yu, W. OpenSARUrban: A Sentinel-1 SAR Image Dataset for Urban Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 187–203. [Google Scholar] [CrossRef]
- Lambers, M.; Nies, H.; Kolb, A. Interactive dynamic range reduction for SAR images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 507–511. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.a. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Gong, C.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications; SPIE: Bellingham, WA, USA, 2019; Volume 11006, pp. 369–386. [Google Scholar]
- Sandia National Laboratory. The Air Force Moving and Stationary Target Recognition Database. Available online: https://www.sdms.afrl.af.mil/index.php?collection=mstar (accessed on 15 May 2023).
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 140303. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. Sar ship detection dataset (ssdd): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Shermeyer, J.; Hogan, D.; Brown, J.; Van Etten, A.; Weir, N.; Pacifici, F.; Hansch, R.; Bastidas, A.; Soenen, S.; Bacastow, T.; et al. SpaceNet 6: Multi-sensor all weather mapping dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 196–197. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 20 January 2023).
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone Model | Methods | Top-1 Accuracy (%) | |||
|---|---|---|---|---|---|
| ResNet-50 [33] | DRAE | Mini-CBL | TSX [27] | BEN [26] | OSU [28] |
| ✗ | ✗ | 71.29 | 62.81 | 55.03 | |
| ✔ | ✗ | 71.77 | 63.87 | 56.01 | |
| ✗ | ✔ | 71.97 | 63.51 | 55.84 | |
| ✔ | ✔ | 72.47 | 64.29 | 56.53 | |
| 0.95 | 0.98 | 0.99 | 1.0 | 1.01 | 1.02 | 1.05 | Variance | |
|---|---|---|---|---|---|---|---|---|
| w/ DRAE (%) | 72.51 | 72.59 | 72.61 | 72.47 | 72.54 | 72.21 | 72.34 | |
| w/o DRAE (%) | 72.14 | 72.17 | 71.89 | 71.77 | 71.54 | 71.31 | 71.33 |
| Backbone Model | Optim. | Top-1 Accuracy(%) | ||
|---|---|---|---|---|
| TSX [27] | BEN [26] | OSU [28] | ||
| ResNet-18 [33] | Mini-CBL (Scratch) | 66.70 | 55.91 | 47.17 |
| CBL (Init.) | 71.59 | 61.97 | 52.94 | |
| Mini-CBL (Init.) | 71.69 | 62.63 | 53.67 | |
| ResNet-50 [33] | Mini-CBL (Scratch) | 67.69 | 56.08 | 45.55 |
| CBL (Init.) | 72.31 | 63.89 | 56.04 | |
| Mini-CBL (Init.) | 72.47 | 64.29 | 56.53 | |
| ResNet-101 [33] | Mini-CBL (Scratch) | 66.70 | 56.71 | 45.47 |
| CBL (Init.) | 67.19 | 59.87 | 50.21 | |
| Mini-CBL (Init.) | 67.28 | 59.37 | 50.78 | |
| SENet-50 [35] | Mini-CBL (Scratch) | 70.94 | 61.77 | 49.04 |
| CBL (Init.) | 71.41 | 63.11 | 51.90 | |
| Mini-CBL (Init.) | 71.77 | 63.79 | 52.64 | |
| MobileNetV3 [36] | Mini-CBL (Scratch) | 65.79 | 57.03 | 44.13 |
| CBL (Init.) | 72.64 | 60.07 | 53.78 | |
| Mini-CBL (Init.) | 72.69 | 61.60 | 54.96 | |
| DenseNet-121 [34] | Mini-CBL (Scratch) | 70.15 | 57.72 | 53.26 |
| CBL (Init.) | 72.77 | 61.99 | 53.68 | |
| Mini-CBL (Init.) | 73.10 | 62.71 | 53.78 | |
| Swin-T [37] | Mini-CBL (Scratch) | 68.41 | 58.87 | 44.04 |
| CBL (Init.) | 77.87 | 66.78 | 59.31 | |
| Mini-CBL (Init.) | 78.43 | 66.74 | 59.95 | |
| Swin-B [37] | Mini-CBL (Scratch) | 74.19 | 60.59 | 46.41 |
| CBL (Init.) | 79.71 | 67.09 | 59.99 | |
| Mini-CBL (Init.) | 81.54 | 67.14 | 60.54 | |
| Target Recognition | Object Detection | Semantic Segmentation | ||
|---|---|---|---|---|
| CNNs | ViTs | |||
| Batch size | 32 | 32 | 4 | 2 |
| Optimizer | SGD | AdamW | SGD | SGD |
| Initialized learning rate | 0.01 | 0.0005 | 0.005 | 0.001 |
| Learning rate decay | StepLR | StepLR | Linear warm up | Poly schedule |
| Momentum | 0.9 | - | 0.9 | 0.9 |
| Weight decay | 0.0001 | 0.0001 | 0.001 | 0.0001 |
| Epochs | 500 | 500 | 36 | 20,000 () |
| Scale | Class | Class Name | Instance No. |
|---|---|---|---|
| Small | 14 | Cargo, Dredging, Fishing, Craft, Passenger, Pilot Vessel, Pleasure Craft, Port Tender, Search Vessel, Tanker, Law Enforcement, Towing, Tug, Wing | 5522 |
| Medium | 13 | Cargo, Dredging, Fishing, Craft, Law Enforcement, Passenger, Pilot Vessel, Pleasure Craft, Tug, Port Tender, Search Vessel, Tanker, Towing | 4813 |
| Large | 7 | Cargo, Dredging, Fishing, Passenger, Tanker, Towing, Search Vessel | 2188 |
| Backbone Model | MSTAR (%) | OpenSARShip (%) | FuSARShip (%) | |||||
|---|---|---|---|---|---|---|---|---|
| 10% Train | 30% Train | 100% Train | SmallScale | MediumScale | LargeSacle | |||
| ResNet-18 [33] | IMG | 83.55 | 93.67 | 97.96 | 64.47 | 81.13 | 90.31 | 71.38 |
| OPT | 79.46 | 95.83 | 98.76 | 64.07 | 80.76 | 91.32 | 70.82 | |
| TSX | 85.94 | 96.95 | 99.88 | 64.78 | 81.21 | 91.04 | 72.86 | |
| BEN | 89.36 | 97.73 | 99.75 | 65.19 | 82.63 | 91.41 | 71.66 | |
| OSU | 87.51 | 97.98 | 99.92 | 64.85 | 81.55 | 90.40 | 71.42 | |
| ResNet-50 [33] | IMG | 84.03 | 95.87 | 98.46 | 64.01 | 81.26 | 88.94 | 70.64 |
| OPT | 85.15 | 95.83 | 98.88 | 63.67 | 80.42 | 88.76 | 70.34 | |
| TSX | 88.91 | 97.94 | 99.71 | 64.61 | 81.41 | 89.95 | 72.68 | |
| BEN | 90.31 | 98.35 | 99.59 | 64.14 | 81.26 | 90.68 | 72.20 | |
| OSU | 90.85 | 97.57 | 99.75 | 64.89 | 81.63 | 90.49 | 71.76 | |
| ResNet-101 [33] | IMG | 82.97 | 94.52 | 99.75 | 64.29 | 80.80 | 89.76 | 66.37 |
| OPT | 84.08 | 93.44 | 99.34 | 63.06 | 80.42 | 90.68 | 66.19 | |
| TSX | 80.54 | 94.97 | 99.67 | 64.32 | 80.76 | 91.22 | 66.49 | |
| BEN | 85.03 | 96.54 | 99.79 | 64.56 | 81.01 | 90.41 | 66.76 | |
| OSU | 83.18 | 96.91 | 99.63 | 64.03 | 80.96 | 91.06 | 67.15 | |
| SENet-50 [35] | IMG | 84.54 | 96.54 | 99.75 | 64.72 | 80.01 | 89.31 | 69.01 |
| OPT | 82.10 | 92.78 | 99.38 | 63.11 | 80.76 | 89.40 | 70.28 | |
| TSX | 79.05 | 92.54 | 99.67 | 63.78 | 80.46 | 91.04 | 71.00 | |
| BEN | 86.14 | 96.87 | 99.84 | 63.53 | 80.88 | 90.68 | 69.86 | |
| OSU | 82.64 | 95.46 | 99.67 | 64.25 | 81.05 | 90.22 | 72.02 | |
| MobileNetV3 [36] | IMG | 62.97 | 87.13 | 99.26 | 63.27 | 80.47 | 90.40 | 69.07 |
| OPT | 73.98 | 90.60 | 99.71 | 63.20 | 80.59 | 90.13 | 69.31 | |
| TSX | 80.49 | 96.37 | 99.71 | 63.24 | 80.69 | 91.27 | 71.06 | |
| BEN | 81.65 | 95.55 | 99.88 | 63.89 | 80.96 | 90.95 | 71.48 | |
| OSU | 77.32 | 91.22 | 99.96 | 62.66 | 80.67 | 90.68 | 70.10 | |
| DenseNet-121 [34] | IMG | 78.56 | 94.80 | 99.55 | 63.83 | 80.71 | 90.31 | 70.82 |
| OPT | 78.72 | 93.57 | 99.42 | 64.25 | 80.80 | 90.40 | 71.54 | |
| TSX | 80.87 | 93.36 | 99.59 | 63.89 | 81.50 | 89.67 | 71.48 | |
| BEN | 85.11 | 95.59 | 99.59 | 64.36 | 81.55 | 90.77 | 73.65 | |
| OSU | 81.07 | 95.34 | 99.75 | 64.80 | 80.96 | 90.59 | 72.86 | |
| Swin-T [37] | IMG | 62.06 | 81.03 | 97.81 | 57.37 | 65.50 | 89.49 | 64.02 |
| OPT | 64.74 | 80.74 | 96.29 | 59.11 | 78.01 | 89.21 | 61.25 | |
| TSX | 67.51 | 86.27 | 98.06 | 61.50 | 80.34 | 90.29 | 70.25 | |
| BEN | 65.11 | 84.86 | 98.23 | 59.98 | 80.26 | 90.06 | 64.08 | |
| OSU | 70.68 | 85.70 | 99.05 | 60.96 | 80.05 | 89.95 | 69.61 | |
| Swin-B [37] | IMG | 69.77 | 82.97 | 97.72 | 61.57 | 80.09 | 88.31 | 64.20 |
| OPT | 72.49 | 87.80 | 97.69 | 58.82 | 80.01 | 88.67 | 68.59 | |
| TSX | 72.78 | 87.18 | 98.52 | 60.34 | 80.26 | 88.76 | 70.88 | |
| BEN | 73.90 | 87.22 | 98.13 | 62.73 | 80.08 | 88.85 | 69.80 | |
| OSU | 78.52 | 91.13 | 98.85 | 62.33 | 80.30 | 90.04 | 68.65 | |
| Model | SSDD | HRSID | LS-SSDD-v1.0 | ||||
|---|---|---|---|---|---|---|---|
| (%) | (%) | (%) | (%) | (%) | (%) | ||
| ResNet-18 [33] | IMG | 65.51 | 94.70 | 49.32 | 71.31 | 21.25 | 64.31 |
| OPT | 61.37 | 94.41 | 46.12 | 72.27 | 21.73 | 64.82 | |
| TSX | 63.69 | 95.08 | 60.61 | 86.77 | 22.86 | 65.79 | |
| BEN | 62.21 | 94.57 | 41.43 | 72.11 | 21.60 | 64.59 | |
| OSU | 62.11 | 94.47 | 46.48 | 67.29 | 22.01 | 63.71 | |
| ResNet-50 [33] | IMG | 60.53 | 93.51 | 60.68 | 87.61 | 21.74 | 64.78 |
| OPT | 63.81 | 94.97 | 60.71 | 87.46 | 21.90 | 65.03 | |
| TSX | 67.38 | 96.91 | 59.48 | 86.21 | 22.58 | 65.69 | |
| BEN | 64.71 | 95.68 | 60.41 | 87.17 | 20.98 | 62.52 | |
| OSU | 68.78 | 97.39 | 61.24 | 88.00 | 22.67 | 66.26 | |
| ResNet-101 [33] | IMG | 61.20 | 93.47 | 55.21 | 84.81 | 22.10 | 63.52 |
| OPT | 64.01 | 95.27 | 54.31 | 82.95 | 21.89 | 62.86 | |
| TSX | 66.18 | 96.15 | 56.71 | 84.34 | 22.82 | 63.37 | |
| BEN | 65.01 | 95.13 | 55.78 | 82.76 | 22.08 | 63.09 | |
| OSU | 64.91 | 95.78 | 56.03 | 83.71 | 22.41 | 63.08 | |
| SENet-50 [35] | IMG | 63.55 | 94.31 | 50.38 | 77.43 | 21.38 | 63.66 |
| OPT | 64.65 | 94.61 | 55.95 | 81.83 | 22.80 | 64.71 | |
| TSX | 64.48 | 94.25 | 56.53 | 82.66 | 24.69 | 67.18 | |
| BEN | 63.32 | 93.41 | 42.50 | 69.52 | 23.85 | 66.07 | |
| OSU | 64.28 | 94.80 | 56.62 | 82.51 | 23.92 | 66.32 | |
| DenseNet-121 [34] | IMG | 21.02 | 60.17 | 27.05 | 55.31 | 10.32 | 34.72 |
| OPT | 22.81 | 60.78 | 27.75 | 55.83 | 10.08 | 33.59 | |
| TSX | 20.27 | 60.38 | 27.01 | 54.95 | 11.26 | 37.68 | |
| BEN | 23.18 | 62.82 | 27.04 | 54.07 | 12.59 | 36.13 | |
| OSU | 22.38 | 62.14 | 28.84 | 56.78 | 11.75 | 36.07 | |
| Swin-T [37] | IMG | 61.68 | 92.73 | 53.94 | 81.01 | 23.18 | 63.62 |
| OPT | 63.35 | 94.57 | 59.07 | 86.73 | 22.93 | 65.12 | |
| TSX | 64.55 | 96.79 | 60.45 | 87.23 | 23.14 | 64.89 | |
| BEN | 64.86 | 95.67 | 53.65 | 81.53 | 23.50 | 66.81 | |
| OSU | 63.28 | 95.75 | 60.66 | 87.19 | 23.36 | 64.94 | |
| Swin-B [37] | IMG | 65.15 | 95.21 | 57.10 | 86.44 | 23.27 | 64.83 |
| OPT | 64.28 | 95.19 | 61.45 | 87.41 | 22.76 | 64.57 | |
| TSX | 65.47 | 96.86 | 61.32 | 87.11 | 23.31 | 66.62 | |
| BEN | 63.31 | 95.58 | 60.93 | 86.49 | 23.92 | 67.31 | |
| OSU | 65.18 | 96.01 | 61.87 | 87.55 | 24.06 | 67.49 | |
| Model | (%) | (%) | P (%) | R (%) | |
|---|---|---|---|---|---|
| ResNet-18 [33] | IMG | 41.38 | 62.23 | 75.47 | 69.45 |
| OPT | 50.08 | 61.38 | 70.32 | 72.73 | |
| TSX | 53.04 | 64.48 | 74.42 | 74.74 | |
| BEN | 52.80 | 63.85 | 73.46 | 74.49 | |
| OSU | 57.23 | 63.55 | 71.89 | 76.24 | |
| ResNet-50 [33] | IMG | 32.28 | 60.63 | 79.54 | 65.47 |
| OPT | 40.46 | 61.82 | 75.06 | 68.98 | |
| TSX | 55.27 | 60.41 | 68.11 | 74.54 | |
| BEN | 44.98 | 62.78 | 74.61 | 71.04 | |
| OSU | 50.95 | 62.79 | 72.32 | 73.46 | |
| ResNet-101 [33] | IMG | 40.32 | 55.32 | 71.70 | 68.53 |
| OPT | 21.93 | 54.60 | 68.04 | 59.83 | |
| TSX | 48.65 | 57.29 | 64.98 | 70.83 | |
| BEN | 42.78 | 55.16 | 64.04 | 63.95 | |
| OSU | 42.26 | 57.60 | 66.19 | 68.45 | |
| SENet-50 [35] | IMG | 25.03 | 56.20 | 70.98 | 61.49 |
| OPT | 28.37 | 55.82 | 67.06 | 62.57 | |
| TSX | 37.90 | 54.01 | 61.69 | 65.37 | |
| BEN | 46.10 | 53.44 | 60.92 | 68.23 | |
| OSU | 36.48 | 53.83 | 61.55 | 64.77 | |
| DenseNet-121 [34] | IMG | 24.28 | 46.94 | 52.64 | 52.82 |
| OPT | 27.53 | 49.35 | 53.21 | 56.32 | |
| TSX | 28.34 | 51.21 | 54.12 | 57.32 | |
| BEN | 26.75 | 52.01 | 55.28 | 56.30 | |
| OSU | 27.38 | 53.75 | 56.71 | 56.84 | |
| Swin-T [37] | IMG | 18.53 | 52.19 | 62.24 | 57.70 |
| OPT | 22.17 | 49.26 | 56.05 | 57.35 | |
| TSX | 40.15 | 52.94 | 60.39 | 65.73 | |
| BEN | 28.47 | 53.82 | 62.55 | 61.83 | |
| OSU | 26.85 | 52.93 | 61.23 | 60.86 | |
| Swin-B [37] | IMG | 20.08 | 51.85 | 60.63 | 58.04 |
| OPT | 22.83 | 51.70 | 59.68 | 58.90 | |
| TSX | 22.86 | 47.75 | 54.52 | 56.64 | |
| BEN | 26.17 | 50.39 | 57.50 | 59.36 | |
| OSU | 32.56 | 48.90 | 56.29 | 60.77 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Kang, X.; Liu, L.; Liu, Y.; Huang, Z. SAR-HUB: Pre-Training, Fine-Tuning, and Explaining. Remote Sens. 2023, 15, 5534. https://doi.org/10.3390/rs15235534
Yang H, Kang X, Liu L, Liu Y, Huang Z. SAR-HUB: Pre-Training, Fine-Tuning, and Explaining. Remote Sensing. 2023; 15(23):5534. https://doi.org/10.3390/rs15235534
Chicago/Turabian StyleYang, Haodong, Xinyue Kang, Long Liu, Yujiang Liu, and Zhongling Huang. 2023. "SAR-HUB: Pre-Training, Fine-Tuning, and Explaining" Remote Sensing 15, no. 23: 5534. https://doi.org/10.3390/rs15235534