1. Introduction
Synthetic aperture radar (SAR) is a microwave sensor based on the scattering characteristics of electromagnetic waves for imaging, which has a certain cloud and ground penetration capability to detect hidden targets. This characteristic makes it suited for marine monitoring, mapping, and military applications. With the continuous exploitation of marine resources, the monitoring of marine vessels based on SAR images has received increasing attention. SAR image object detection aims to automatically locate and identify specific targets from images and has important application prospects in defense and civil fields such as target identification, target detection, marine development, and terrain classification [
1,
2,
3,
4].
The development of SAR image ship detection methods can be divided into two stages [
5]: traditional detection methods represented by constant false alarm rate (CFAR) algorithms and deep learning methods represented by convolutional neural networks. The constant false alarm rate algorithm adaptively adjusts the threshold value using statistical models and sample selection strategies. It has been widely used due to its constant false alarm rate and low complexity. For example, the bilateral CFAR algorithm [
6] takes into account the intensity distribution and spatial distribution when selecting thresholds to improve the accuracy of detection. The two-parameter CFAR [
7] uses log-normal as the statistical model with more accurate parameter estimation and achieves better detection performance in a multi-target environment. The modified CFAR algorithm proposed in the paper [
8] uses variable guard windows to improve its detection performance for the multi-scale scene. Li et al. [
9] propose an adaptive CFAR method based on intensity and texture feature fusion attention contrast mechanism to suppress clutter background and speckle noise with better performance in complex backgrounds and multi-target marine environments. The above CFAR algorithms rely on the land-segmentation algorithm in the nearshore scene, while the adaptive superpixel-level CFAR algorithm [
10] is based on the superpixel segmentation method, which does not require additional land-segmentation algorithm, and its detection performance is still reliable in near-shore scenarios. However, these algorithms are based on the modeling of clutter statistical features, which are more sensitive to the complex shoreline, ocean clutter, and coherent scattering noise, with low detection accuracy and poor generalization [
5]. Currently, deep learning is the mainstream research direction due to its excellent feature extraction capability and end-to-end training process, which is gradually replacing the traditional methods.
In the field of target detection, deep learning methods based on convolutional neural networks have developed rapidly due to the translation invariance and weight-sharing properties of convolution. The existing target detection methods based on convolutional neural networks can be divided into two-stage and one-stage methods. The two-stage network first generates the proposed region in the first stage and then performs classification and correction of the proposed region in the second stage. This method has higher detection accuracy and better detection for small targets, such as region-convolutional neural network (R-CNN) [
11], Fast R-CNN [
12], Faster R-CNN [
13], Sparse R-CNN [
14], etc. The one-stage network does not need to generate proposed regions and directly outputs the classification and location results of the target. Although the accuracy of the one-stage network is generally lower than that of the two-stage network, they have higher detection speed and simple training steps, such as YOLO series [
15,
16,
17,
18,
19,
20,
21,
22], single shot detection (SSD) [
23], RetinaNet [
24], fully convolutional one-stage object detection (FCOS) [
25], etc.
Since the release of the SAR ship detection dataset (SSDD) by Li et al. [
26] in 2017, SAR image ship detection based on convolutional neural networks developed rapidly, and subsequently in, 2019 and 2020, Wang et al. [
27] and Wei et al. [
28] released the SAR-Ship-Dataset and High-Resolution SAR Images Dataset (HRSID), respectively. Additionally, in 2021, Zhang et al. [
29] corrected the mislabeling of the initial version of the SSDD and used a standardized format, which further facilitated the development of the field. In recent years, Shi et al. [
30] proposed a feature aggregation enhancement pyramid network (FAEPN) to enhance the extraction capability of the network for multi-scale targets, taking into account the quality of classification and regression when assigning positive and negative samples. Cui et al. [
31] proposed a dense attention pyramid network (DAPN), which used dense connectivity in the feature pyramid network (FPN) to obtain richer semantic information about each scale and used a convolutional block attention module (CBAM) to enhance the features. Zhang et al. [
32] proposed a quad-feature pyramid network (Quad-FPN) to extract complex multi-scale features, and then replaced non-maximal suppression (NMS) with soft non-maximal suppression (soft-NMS) to improve the detection of densely aligned targets. Li et al. [
4] proposed an attention-guided balanced feature pyramid network (A-BFPN), which contained an enhanced refinement module (ERM) for reducing background interference and a channel attention-guided fusion network for reducing confounding effects in mixed feature maps. Different from the above-mentioned anchor-base network, Zhu et al. [
33] proposed a novel anchor-free network based on FCOS for SAR image target detection, in which a deformable convolution (Dconv) and an improved residual network (IRN) were added to optimize the feature extraction capability of the network. Wu et al. [
34] proposed the instance segmentation-assisted ship detection network (ISASDNet), with a global reasoning module, which achieved good performance in instance segmentation and object detection. Wang et al. [
35] used intersection over union (IoU) K-means to solve the extreme aspect ratio problem and embedded a soft threshold attention module (STA) in the network to suppress the effects of noise and complex backgrounds. Tian et al. [
36] employed an object characteristic-driven image enhancement (OCIE) module to enhance the variety of datasets and explored the dense feature reuse (DFR) module and receptive field expansion (RFE) module to increase the network receptive field and strengthen the transmission of information flow. Wei et al. [
37] adopted a high-resolution feature pyramid network (HRFPN) to make full use of the information in the high-resolution and low-resolution features and proposed a high-resolution ship detection network (HR-SDNet) on this basis.
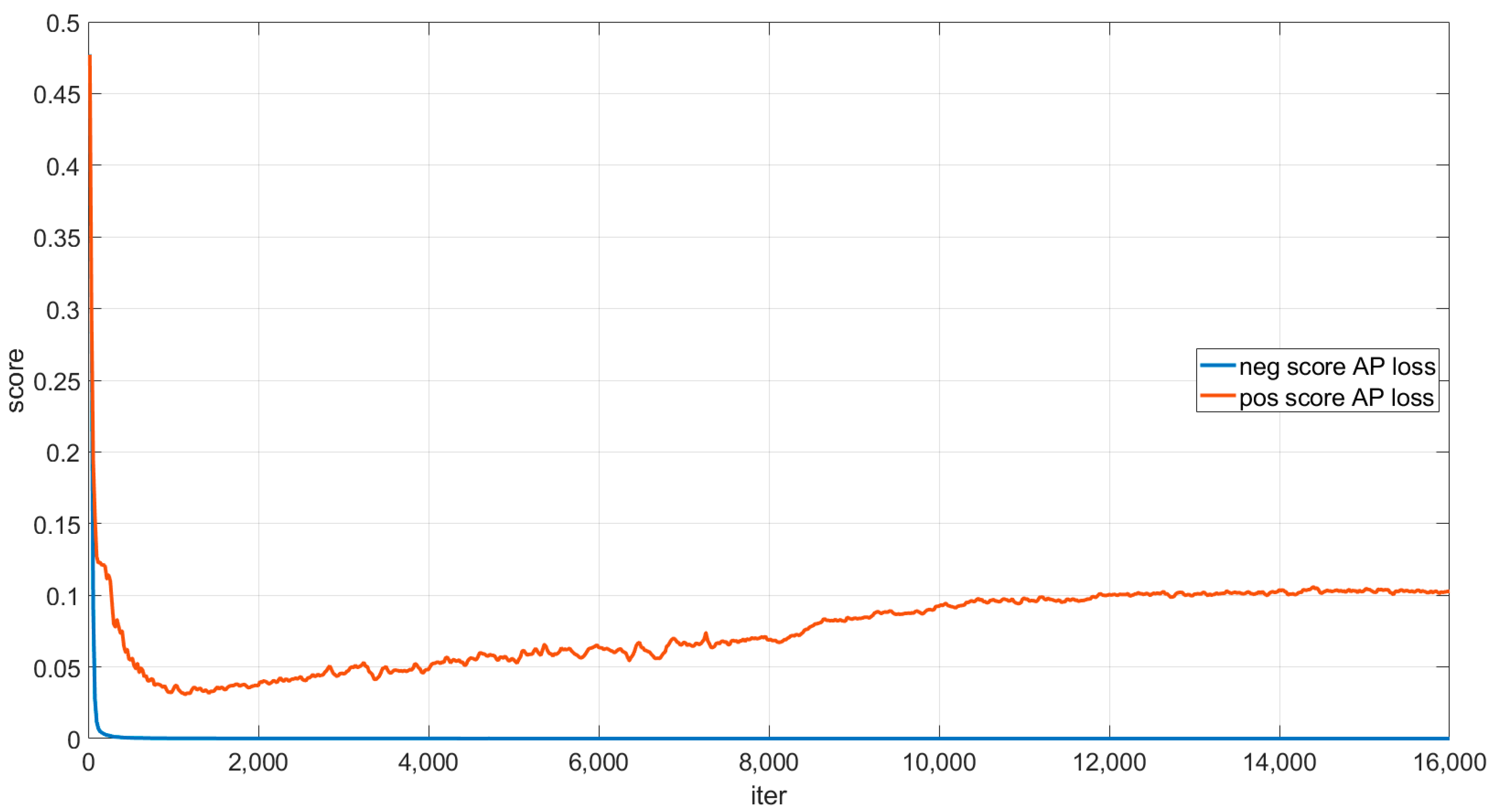
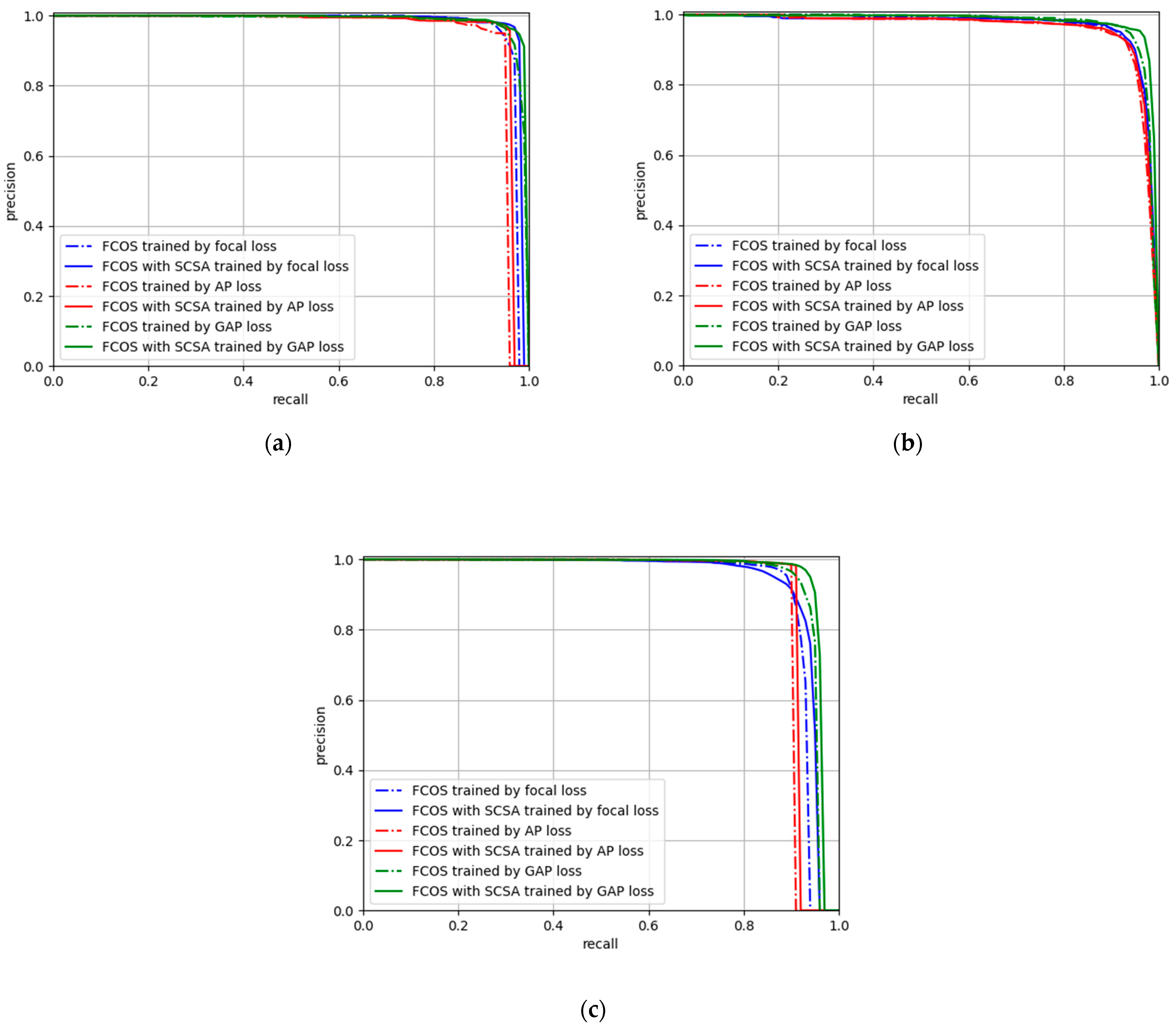
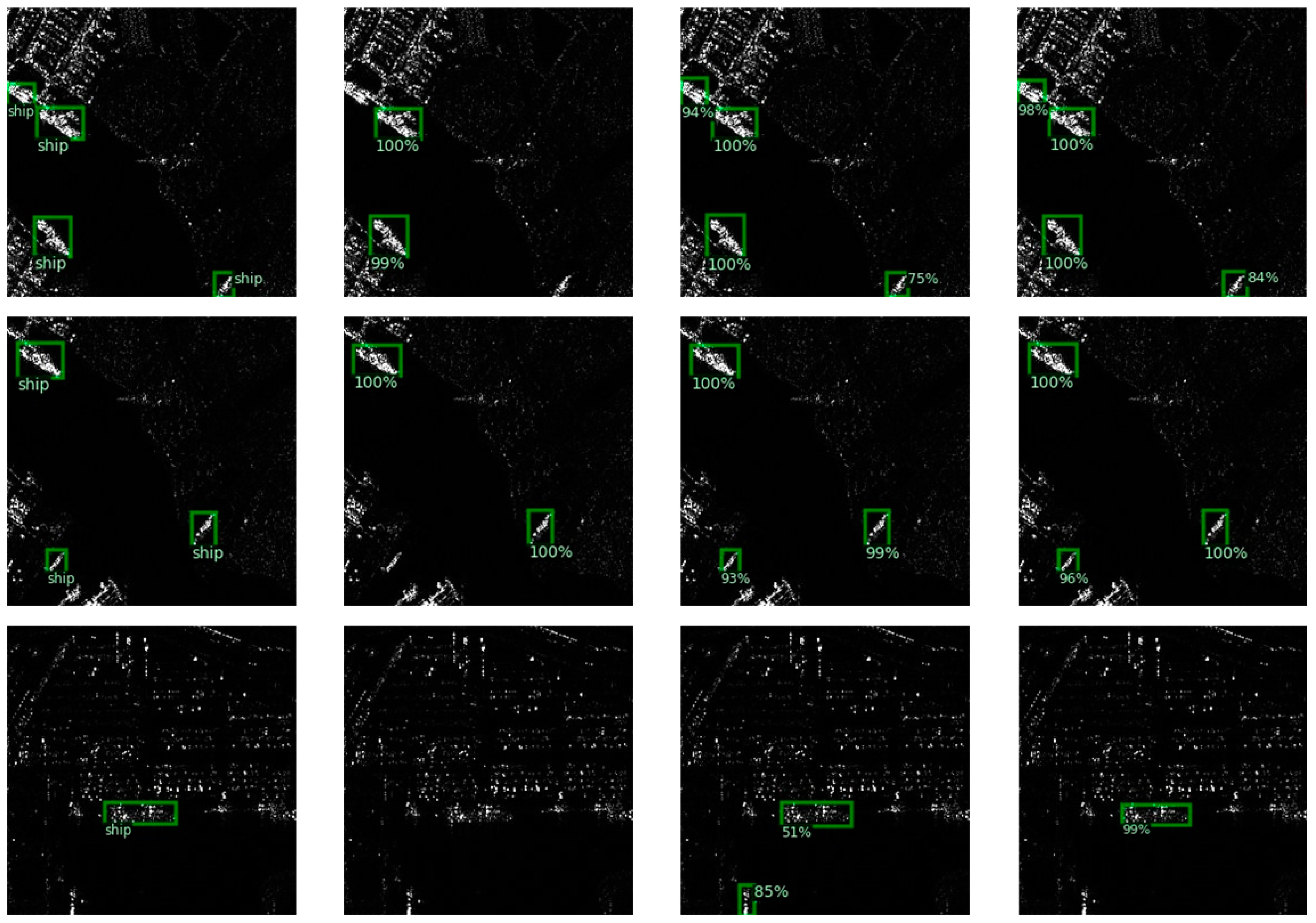
In order to further improve the detection accuracy of the network, in this paper, a new anchor-free spatial cross-scale attention network (SCSA-Net) is proposed, which contains a novel spatial cross-scale attention (SCSA) module that enhances features at different scales while mitigating the interference generated by complex backgrounds such as land. In addition, to solve the “score shift” problem of average accuracy loss (AP loss), this paper improves AP loss and proposes global average accuracy loss (GAP loss). Three widely used datasets are used to experimentally validate the proposed methods and confirm their effectiveness.
The main contributions of our work are as follows:
A novel cross-scale spatial attention module is proposed, which consists of a cross-scale attention module and a spatial attention redistribution module. The former dynamically adjusts the position of network attention by combining information from different scales. The latter redistributes spatial attention to mitigate the influence of complex backgrounds and make the ship more distinctive.
We analyze the reasons why AP loss generates the “score shift” problem and propose a global average accuracy loss (GAP loss) to solve it. Compared to traditional methods using focus loss as the classification loss, training with GAP loss allows the network to optimize directly with the average precision (AP) as the target and to distinguish between positive and negative samples more quickly, achieving better detection results.
We propose an anchor-free spatial cross-scale attention network (SCSA-Net) for ship detection in SAR images, which reached 98.7% AP on the SSDD, 97.9% AP on the SAR-Ship-Dataset and 95.4% AP on the HRSID, achieving state-of-the-art performance.
The remainder of this paper is organized as follows: the second section introduces the proposed method; the third section describes the experiments and analysis of the results; the fourth section discusses and suggests future work; finally, the fifth section summarizes this paper.
5. Conclusions
In this work, a one-stage anchor-free SCSA-Net is developed to accurately detect ship targets in SAR images. To improve the feature extraction ability of the network and reduce the interference of nearshore background to the ship target, an SCSA module is proposed to dynamically enhance the features in space. In addition, a GAP loss is proposed, which enables the network to optimize directly with AP as the target, and solves the “score shift” problem in AP loss, so that it can effectively improve the score of the predicted tar and promote the detection accuracy of the network. We can conclude the experimental results on SSDD, SAR-Ship-Dataset, and HRSID: (1) by using the SCSA module, the accuracy can be improved on all three datasets regardless of whether the training is performed using focal loss, AP loss, or GAP loss. Its effectiveness is confirmed; (2) by using GAP loss for training, the gap between the average classification scores of positive and negative samples can be effectively widened, and the accuracy can be improved with or without the SCSA module; (3) compared with other methods, the SCSA-Net proposed in this paper has higher detection accuracy on all three datasets.
Future work: our future work will focus on reducing the computing scale of the network without affecting its accuracy, and studying the application of arbitrarily oriented objects.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}