


Adaptive Adjacent Layer Feature Fusion for Object Detection in Remote Sensing Images

Abstract
:1. Introduction
- (1)
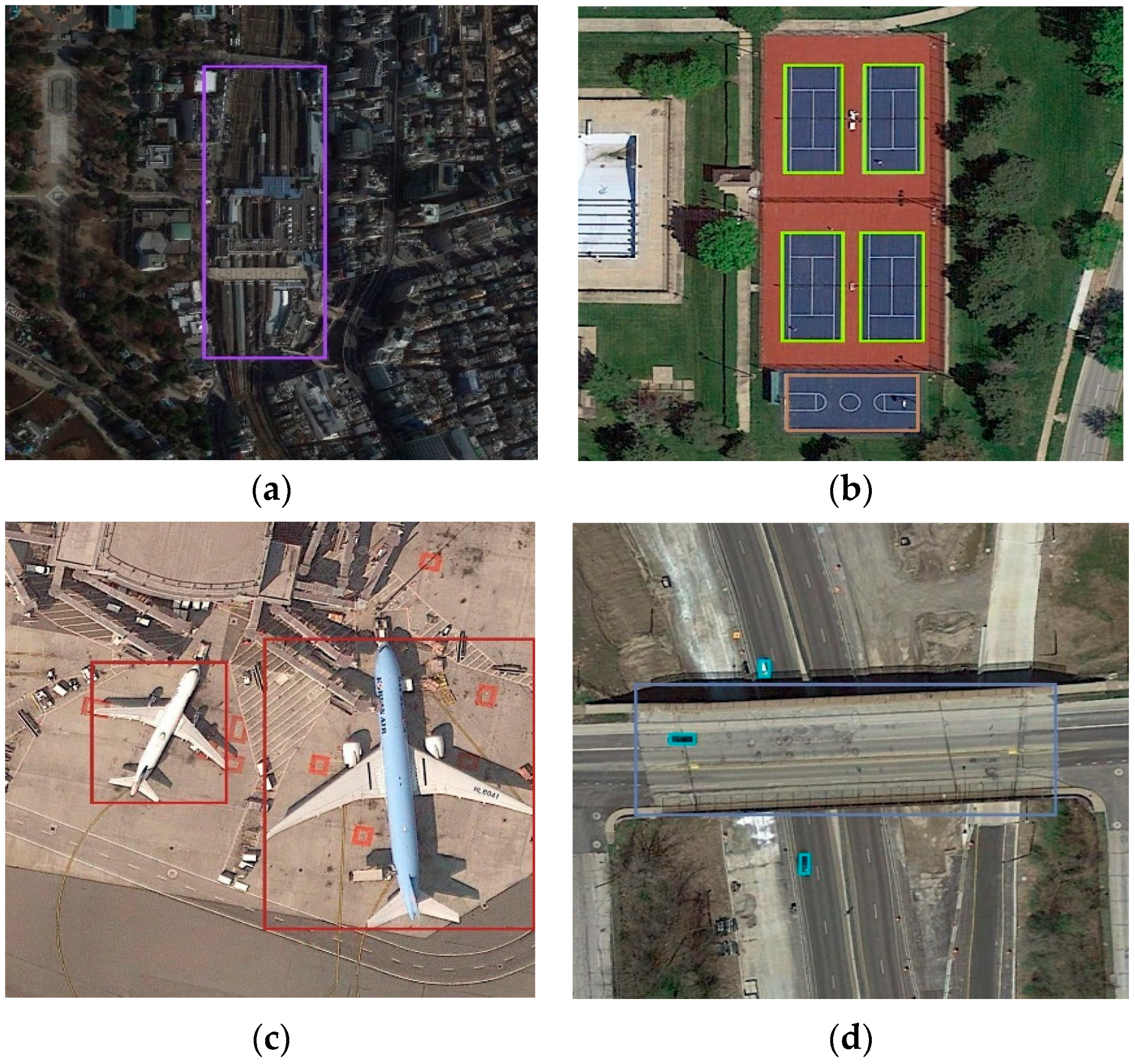
- Remote sensing images have a broader coverage range and more complex backgrounds compared to natural scene images, which severely interfere with object detection. Extracting discriminative features of the objects becomes difficult, as illustrated in Figure 1a, where a train station appears similar to the surrounding buildings. Moreover, backgrounds that resemble the texture or shape of objects can lead to false detections.
- (2)
- Some object categories exhibit high similarity, such as the basketball courts and tennis courts shown in Figure 1b which share similar appearance features. To differentiate between them, it is necessary to utilize texture or contextual information as an auxiliary means.
- (3)
- Objects exhibit significant scale variations, both the inter-class and intra-class objects. Figure 1c demonstrates airplanes of different scales, while Figure 1d depicts vehicles and overpasses with considerable scale differences. These variations undoubtedly increase the difficulty of accurate detection.

- (1)
- An adjacent layer feature fusion enhancement (ALFFE) module is designed to enable the model to embed the discriminative spatial and semantic information. ALFFE fuses adjacent layer features to improve spatial perception and capture high-level object semantics. Involution is employed to overcome the difficulty of extracting object semantic information in complex backgrounds.
- (2)
- In order to make full use of features at different scales, the adaptive spatial feature fusion module (ASFF) is introduced to improve the scale invariance of the features and better adapt to objects of different scales by adaptively fusing the multi-scale features at each spatial location.
- (3)
- Extensive experiments on multiple datasets demonstrate the effectiveness of our method, with state-of-the-art accuracy achieved on the DIOR dataset.
2. Related Work
2.1. One-Stage Object Detection Methods
2.2. Multi-Scale Feature Fusion
3. Methodology
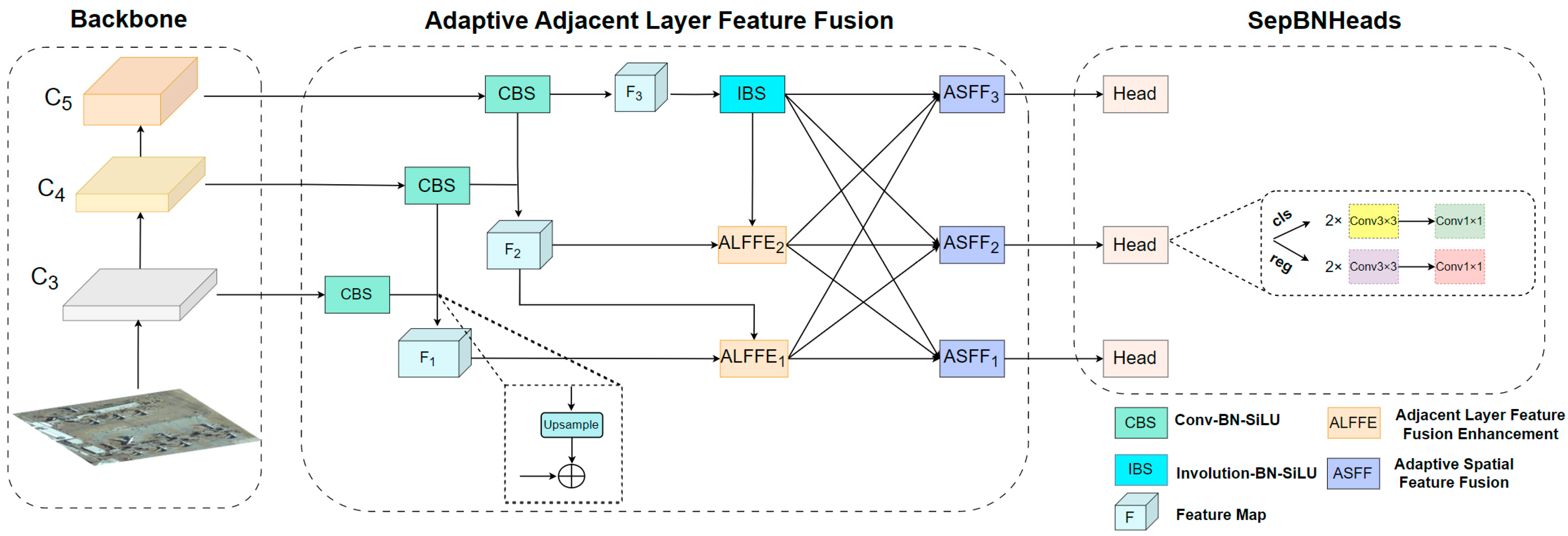
3.1. Overview
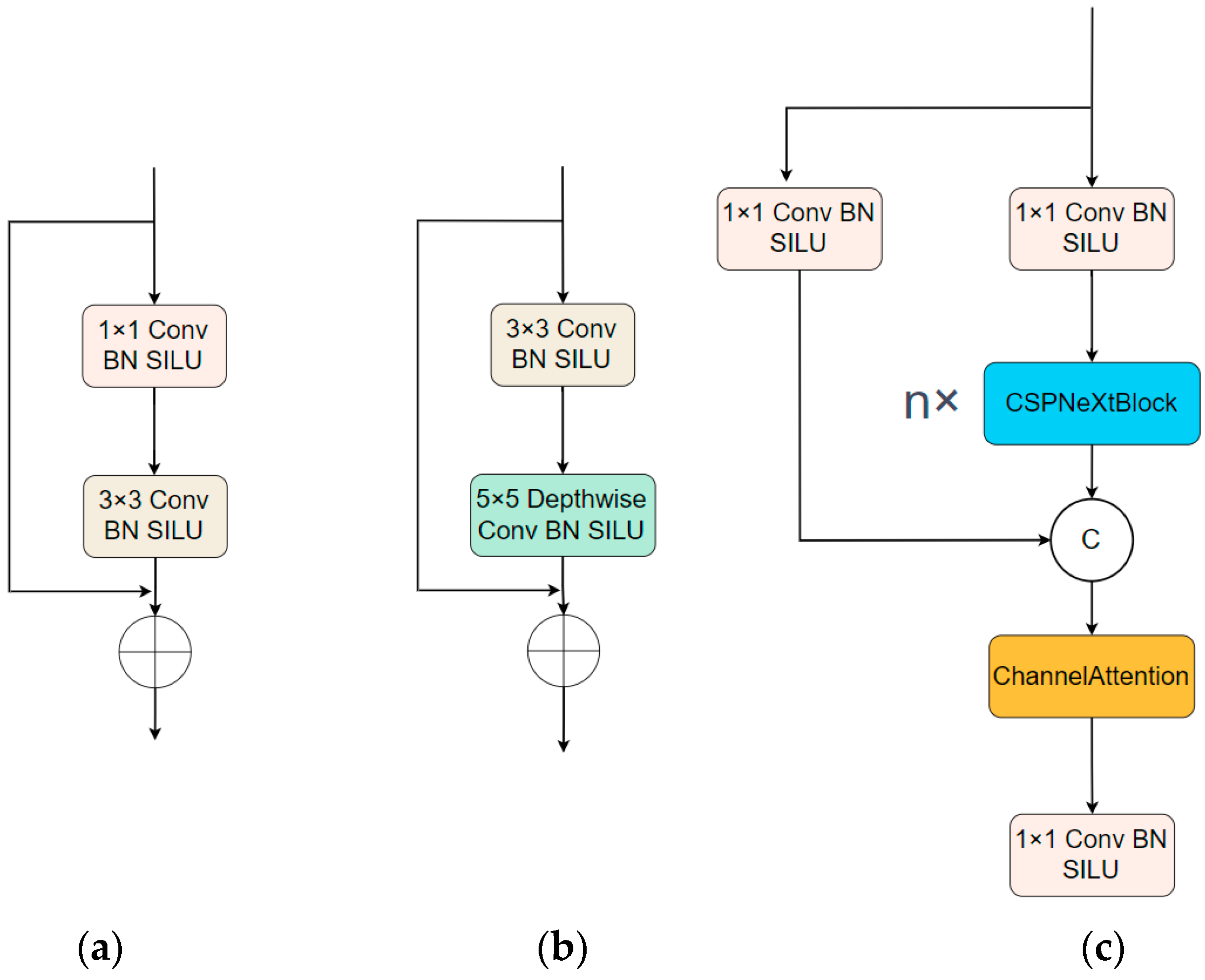
3.2. Involution
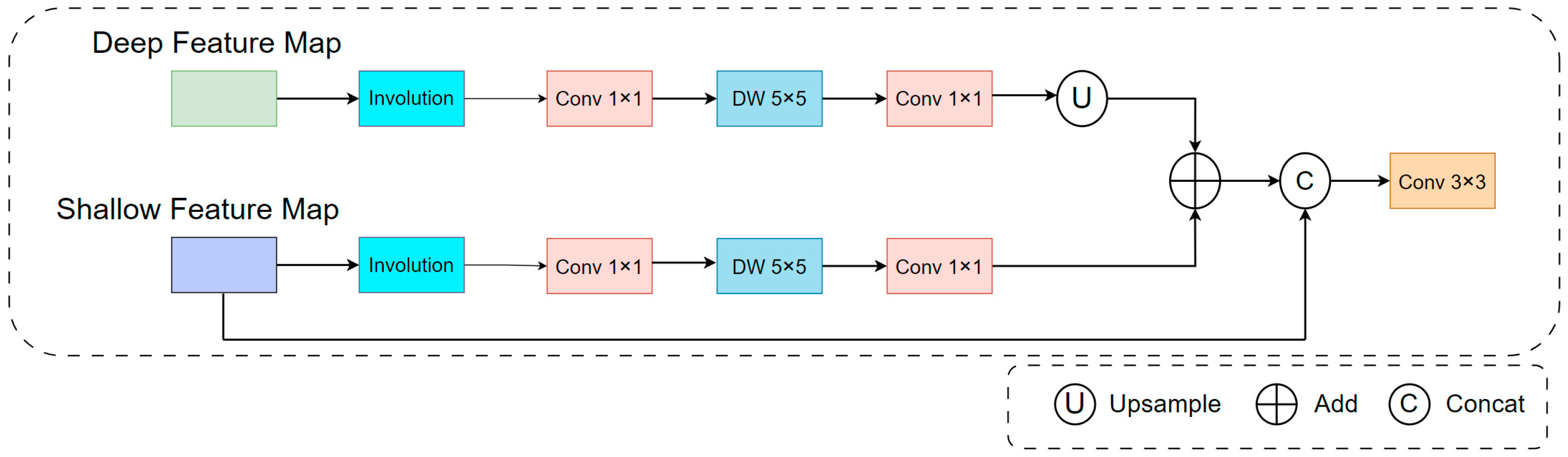
3.3. Adjacent Layer Feature Fusion Enhancement Module
3.4. Adaptive Spatial Feature Fusion
4. Experiment
4.1. Datasets
4.2. Experimental Settings and Evaluation Metrics
- (1)
- Implementation Details
- (2)
- Evaluation Metrics
4.3. Ablation Study
4.4. Quantitative Comparison and Analysis
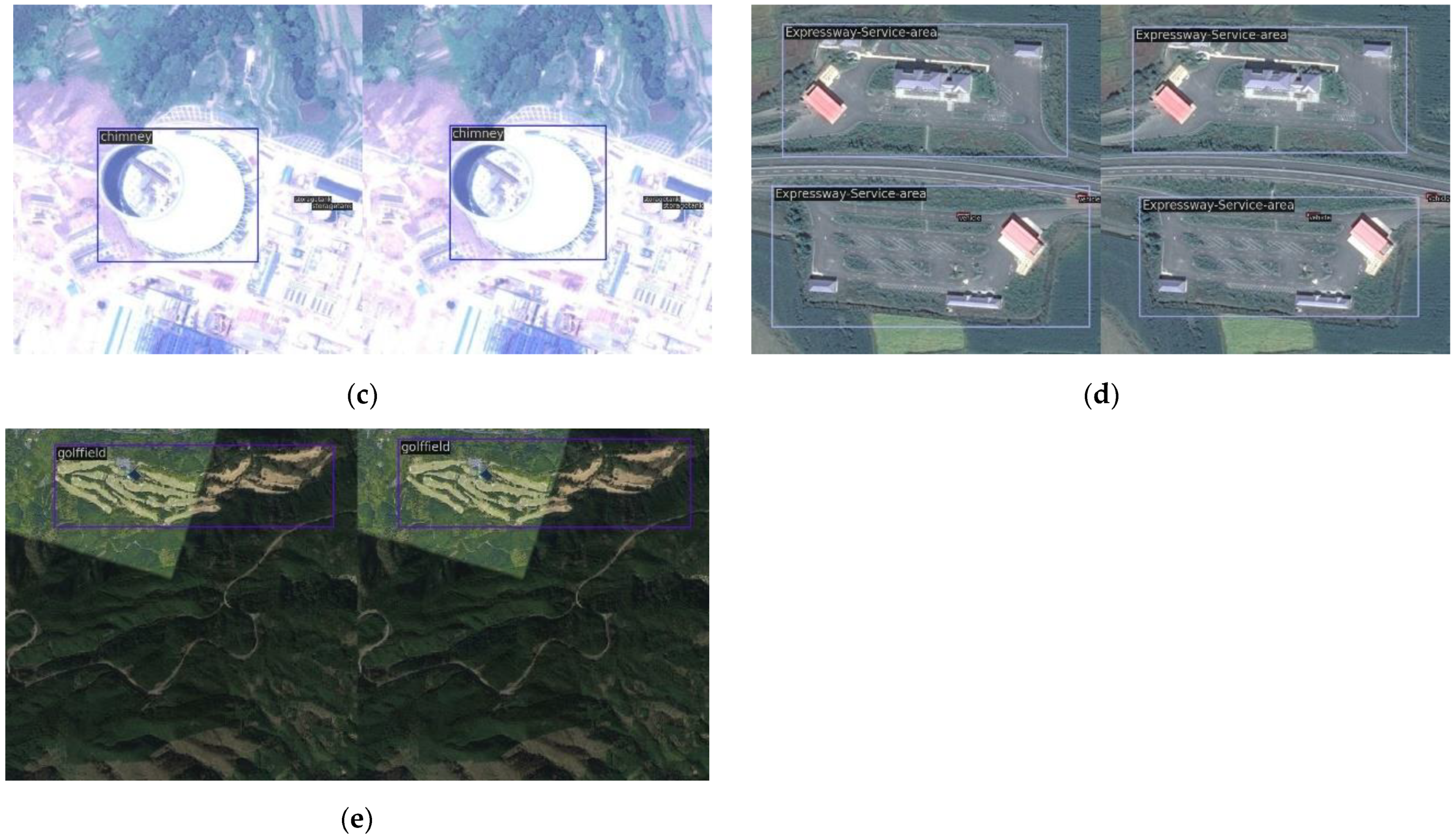
4.5. Visualization and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Salvoldi, M.; Cohen-Zada, A.L.; Karnieli, A. Using the VENµS Super-Spectral Camera for Detecting Moving Vehicles. ISPRS J. Photogramm. Remote Sens. 2022, 192, 33–48. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance Learning for Ship Detection from Synthetic Aperture Radar Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, T.; Huang, S.; Li, K. A Hybrid Optimization Framework for UAV Reconnaissance Mission Planning. Comput. Ind. Eng. 2022, 173, 108653. [Google Scholar] [CrossRef]
- Burochin, J.-P.; Vallet, B.; Brédif, M.; Mallet, C.; Brosset, T.; Paparoditis, N. Detecting Blind Building Façades from Highly Overlapping Wide Angle Aerial Imagery. ISPRS J. Photogramm. Remote Sens. 2014, 96, 193–209. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, L.; Wang, S. Co-Feature and Shape Prior Based Saliency Analysis for Oil Tank Detection in Remote Sensing Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Yokohama, Japan, 2019; pp. 2658–2661. [Google Scholar]
- Wang, W.; Nie, T.; Fu, T.; Ren, J.; Jin, L. A Novel Method of Aircraft Detection Based on High-Resolution Panchromatic Optical Remote Sensing Images. Sensors 2017, 17, 1047. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5966–5978. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Ding, L.; Guo, H.; Liu, S.; Mou, L.; Zhang, J.; Bruzzone, L. Bi-Temporal Semantic Reasoning for the Semantic Change Detection in HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5620014. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yu, D.; Xu, Q.; Liu, X.; Guo, H.; Lu, J.; Lin, Y.; Lv, L. Dual-Resolution and Deformable Multihead Network for Oriented Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 930–945. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Xue, J. Refined One-Stage Oriented Object Detection Method for Remote Sensing Images. IEEE Trans. Image Process. 2022, 31, 1545–1558. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Gong, Z.; Liu, X.; Guo, H.; Lu, J.; Yu, D.; Lin, Y. Multi-Feature Information Complementary Detector: A High-Precision Object Detection Model for Remote Sensing Images. Remote Sens. 2022, 14, 4519. [Google Scholar] [CrossRef]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11218, pp. 765–781. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 1571–1580. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, Y.; Huang, Q.; Pei, X.; Chen, Y.; Jiao, L.; Shang, R. Cross-Layer Attention Network for Small Object Detection in Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2148–2161. [Google Scholar] [CrossRef]
- Dong, X.; Qin, Y.; Fu, R.; Gao, Y.; Liu, S.; Ye, Y.; Li, B. Multiscale Deformable Attention and Multilevel Features Aggregation for Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510405. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, Y.; Li, Z.; Ye, F.; Li, Y. A Dual-Path Multihead Feature Enhancement Detector for Oriented Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6518905. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Rui, T.; Duan, B.; Wang, D. Exploiting Full-Scale Feature for Remote Sensing Object Detection Based on Refined Feature Mining and Adaptive Fusion. IEEE Access 2021, 9, 145422–145434. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Wu, Y.; Zhang, K.; Wang, Q. FRPNet: A Feature-Reflowing Pyramid Network for Object Detection of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8004405. [Google Scholar] [CrossRef]
- Lv, H.; Qian, W.; Chen, T.; Yang, H.; Zhou, X. Multiscale Feature Adaptive Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6511005. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 431–435. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Yuan, Z.; Liu, Z.; Zhu, C.; Qi, J.; Zhao, D. Object Detection in Remote Sensing Images via Multi-Feature Pyramid Network with Receptive Field Block. Remote Sens. 2021, 13, 862. [Google Scholar] [CrossRef]
- Lin, H.; Zhou, J.; Gan, Y.; Vong, C.-M.; Liu, Q. Novel Up-Scale Feature Aggregation for Object Detection in Aerial Images. Neurocomputing 2020, 411, 364–374. [Google Scholar] [CrossRef]
- Xu, T.; Sun, X.; Diao, W.; Zhao, L.; Fu, K.; Wang, H. ASSD: Feature Aligned Single-Shot Detection for Multiscale Objects in Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607117. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented Objects as Pairs of Middle Lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Liu, N.; Celik, T.; Zhao, T.; Zhang, C.; Li, H.-C. AFDet: Toward More Accurate and Faster Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12557–12568. [Google Scholar] [CrossRef]
- Lang, K.; Yang, M.; Wang, H.; Wang, H.; Wang, Z.; Zhang, J.; Shen, H. Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing. Remote Sens. 2022, 14, 5805. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 Ocotber–2 November 2019. [Google Scholar]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614914. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, J.; Liang, X.; Guo, Q. Multiscale Semantic Guidance Network for Object Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6003605. [Google Scholar] [CrossRef]
- Li, W.T.; Li, L.W.; Li, S.Y.; Mou, J.C.; Hei, Y.Q. Efficient Vertex Coordinate Prediction-Based CSP-Hourglass Net for Object OBB Detection in Remote Sensing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6503305. [Google Scholar] [CrossRef]
- Liu, J.; Yang, D.; Hu, F. Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention. Remote Sens. 2022, 14, 427. [Google Scholar] [CrossRef]
- Desai, S.; Ramaswamy, H.G. Ablation-CAM: Visual Explanations for Deep Convolutional Network via Gradient-Free Localization. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; IEEE: Snowmass Village, CO, USA, 2020; pp. 972–980. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP50 | mAP75 | FPS | Parameters (M) |
|---|---|---|---|---|
| Baseline | 74.2 | 58.2 | 34.1 | 15.0 |
| Baseline + ALFFE | 76.5 (+2.1) | 60.1 (+1.9) | 28.0 | 17.9 |
| Baseline + ALFFE + ASFF | 77.1 (+2.9) | 60.8 (+2.6) | 26.6 | 21.7 |
| Method | mAP50 | mAP75 |
|---|---|---|
| Baseline | 88.0 | 77.0 |
| Baseline + ALFFE | 88.6 (+0.6) | 79.8 (+2.8) |
| Baseline + ALFFE + ASFF | 88.9 (+0.9) | 79.0 (+2.0) |
| Method | AP | AI | BD | BC | BR | CH | DA | ESA | ETS | GF | GTF | HA | OV | SH | SD | ST | TC | TS | VE | WM | mAP | Param |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MFPNet | 76.6 | 83.4 | 80.6 | 82.1 | 44.3 | 75.6 | 68.5 | 85.9 | 63.9 | 77.3 | 77.2 | 62.1 | 58.8 | 77.2 | 76.8 | 60.3 | 86.4 | 64.5 | 41.5 | 80.2 | 71.2 | / |
| O2-DNet | 61.2 | 80.1 | 73.7 | 81.4 | 45.2 | 75.8 | 64.8 | 81.2 | 76.5 | 79.5 | 79.7 | 47.2 | 59.3 | 72.6 | 70.5 | 53.7 | 82.6 | 55.9 | 49.1 | 77.8 | 68.4 | / |
| ASSD | 85.6 | 82.4 | 75.8 | 80.5 | 40.7 | 77.6 | 64.7 | 67.1 | 61.7 | 80.8 | 78.6 | 62.0 | 58.0 | 84.9 | 65.3 | 65.3 | 87.9 | 62.4 | 44.5 | 76.3 | 71.1 | / |
| HawkNet | 65.7 | 84.2 | 76.1 | 87.4 | 45.3 | 79 | 64.5 | 82.8 | 72.4 | 82.5 | 74.7 | 50.2 | 59.6 | 89.7 | 66 | 70.8 | 87.2 | 61.4 | 52.8 | 88.2 | 72.0 | / |
| CSFF | 57.2 | 79.6 | 70.1 | 87.4 | 46.1 | 76.6 | 62.7 | 82.6 | 73.2 | 78.2 | 81.6 | 50.7 | 59.5 | 73.3 | 63.4 | 58.5 | 85.9 | 61.9 | 42.9 | 86.9 | 68.0 | / |
| AFDet | 82.4 | 81.5 | 81.9 | 89.8 | 51.7 | 74.9 | 58.7 | 84.2 | 73.3 | 79.5 | 81.0 | 44.2 | 62.0 | 77.8 | 63.2 | 76.9 | 91.0 | 62.5 | 59.3 | 87.1 | 73.2 | 20.29 |
| FRPNet | 64.5 | 82.6 | 77.7 | 81.7 | 47.1 | 69.6 | 50.6 | 80.0 | 71.7 | 81.3 | 77.4 | 78.7 | 82.4 | 62.9 | 72.6 | 67.6 | 81.2 | 65.2 | 52.7 | 89.1 | 71.8 | / |
| CANet | 70.3 | 82.4 | 72.0 | 87.8 | 55.7 | 79.9 | 67.7 | 83.5 | 77.2 | 77.3 | 83.6 | 56.0 | 63.6 | 81.0 | 79.8 | 70.8 | 88.2 | 67.6 | 51.2 | 89.6 | 74.3 | 64.60 |
| Ours | 90.0 | 80.5 | 81.0 | 90.1 | 52.5 | 78.7 | 65.7 | 84.0 | 73.5 | 81.2 | 80.7 | 65.3 | 65.4 | 88.9 | 84.7 | 78.6 | 89.9 | 68.3 | 62.3 | 80.1 | 77.1 | 21.70 |
| Method | Backbone | AP | BD | BC | BR | CR | GTF | HA | PL | SH | ST | TJ | TC | VE | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HRCNN | ResNet-101 | 82.93 | 72.11 | 24.94 | 28.31 | 32.26 | 80.57 | 61.57 | 21.35 | 57.64 | 78.76 | 10.25 | 74.83 | 42.84 | 51.43 |
| FCOS | ResNet-101 | 96.82 | 91.21 | 54.10 | 89.69 | 94.42 | 97.45 | 95.05 | 63.15 | 90.46 | 94.91 | 82.23 | 87.85 | 91.82 | 86.86 |
| Lang et al. | Dark-tiny | 98.94 | 91.61 | 71.30 | 85.31 | 89.98 | 95.89 | 92.11 | 60.79 | 89.72 | 97.28 | 73.15 | 93.61 | 93.43 | 87.16 |
| RepPoints | ResNet-101 | 97.49 | 91.90 | 60.83 | 91.04 | 95.10 | 98.22 | 95.70 | 71.78 | 90.05 | 94.36 | 82.26 | 89.83 | 94.25 | 88.71 |
| Ours | CSPNeXt-m | 97.10 | 89.80 | 84.20 | 90.40 | 89.70 | 90.80 | 90.10 | 77.30 | 90.40 | 90.50 | 84.60 | 90.50 | 90.50 | 88.90 |
| Method | AP | BC | BR | GTF | HA | SH | ST | TC | VE | BF | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ABNet | 100 | 95.98 | 69.04 | 99.86 | 94.26 | 92.58 | 97.77 | 99.26 | 95.62 | 97.76 | 94.21 |
| CANet | 100 | 90.60 | 93.90 | 99.80 | 89.80 | 81.90 | 94.60 | 90.70 | 89.90 | 90.30 | 92.20 |
| MSGNet | 92.93 | 92.02 | 91.07 | 99.98 | 99.09 | 93.68 | 97.90 | 91.82 | 92.22 | 98.60 | 95.53 |
| EVCP | 98.90 | 91.60 | 87.80 | 99.70 | 91.80 | 92.50 | 99.80 | 91.10 | 88.60 | 99.80 | 94.10 |
| Liu et al. | 99.50 | 95.40 | 82.20 | 99.20 | 89.60 | 88.40 | 90.20 | 89.20 | 92.90 | 98.70 | 92.50 |
| Ours | 99.60 | 92.90 | 96.30 | 99.10 | 97.20 | 91.40 | 100 | 90.30 | 90.60 | 99.30 | 95.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Gong, Z.; Guo, H.; Liu, X.; Ding, L.; Zhu, K.; Wang, J. Adaptive Adjacent Layer Feature Fusion for Object Detection in Remote Sensing Images. Remote Sens. 2023, 15, 4224. https://doi.org/10.3390/rs15174224
Zhang X, Gong Z, Guo H, Liu X, Ding L, Zhu K, Wang J. Adaptive Adjacent Layer Feature Fusion for Object Detection in Remote Sensing Images. Remote Sensing. 2023; 15(17):4224. https://doi.org/10.3390/rs15174224
Chicago/Turabian StyleZhang, Xuesong, Zhihui Gong, Haitao Guo, Xiangyun Liu, Lei Ding, Kun Zhu, and Jiaqi Wang. 2023. "Adaptive Adjacent Layer Feature Fusion for Object Detection in Remote Sensing Images" Remote Sensing 15, no. 17: 4224. https://doi.org/10.3390/rs15174224