1. Introduction
The process of change detection in remote sensing images involves the detection of modifications that occur on the Earth’s surface between two separate sets of temporal remote sensing images. This task holds significant importance in remote sensing [
1]. By enabling effective monitoring of surface changes, the application of remote sensing image change detection spans various fields and domains. such as urban built-up area expansion monitoring [
2], natural disaster assessment [
3], and environmental monitoring [
4].
Based on the analysis unit, conventional approaches to remote sensing image change detection can be classified into two categories: pixel-based and object-based methods. Pixel-based methods operate on a pixel-by-pixel basis, extracting spectral and texture features from the input images pixel by pixel. They subsequently utilize predefined thresholds to identify change areas for each pixel. Pixel-based methods include arithmetic image differencing [
5], change vector analysis based on transformations [
6,
7], principal component analysis [
8,
9], and independent component analysis [
10]. Object-based change detection methods first segment the images into super-pixel objects using image segmentation techniques based on spectral and texture features (segmentation methods such as quadtree-based segmentation [
11], multi-resolution segmentation [
12], etc.). Then, in order to derive the outcomes of change detection, the segmented results from different time periods are compared in object-based methods. In contrast to the pixel-based approach, object-based methods consider contextual information but are more affected by the results of image segmentation. Additionally, both pixel-based and object-based approaches need significant manual intervention and are prone to pseudo-changes caused by sensor and illumination conditions.
Over the past few years, deep learning methods have received considerable recognition within the remote sensing domain, prompting researchers to integrate these techniques into various tasks related to remote sensing, including scene classification [
13,
14], semantic segmentation [
15,
16,
17], object detection [
18,
19], and change detection [
20,
21,
22,
23,
24], achieving remarkable performance. Deep learning-based approaches for change detection tasks have the ability to incorporate spatial contextual information during pixel-level change identification in the images. CNN (Convolutional neural network) models, with their excellent feature representation capability and end-to-end simplicity, not only reduce manual intervention but also enhance the accuracy and generalization. CNN-based change detection methods transform the two temporal remote sensing images into high-level features, extract semantic context of change regions by fusing the features of the two time-phased images, and mitigate artificial errors stemming from preprocessing. There are two types of CNN-based change detection methods, categorized based on the fusion strategy utilized: image-level fusion [
25,
26,
27,
28,
29] and feature-level fusion [
30,
31,
32,
33,
34,
35,
36,
37]. In image-level fusion networks, the two remote sensing images from different temporal input as a whole into CNN to obtain a representation of image differences. However, the absence of deep feature extraction from individual temporal images can result in boundary disturbances within the predicted outcomes, thereby constraining the accuracy of change detection. In contrast to image-level fusion networks, feature-level fusion networks employ two networks with shared parameters. These networks independently learn features from individual temporal images and then combine these features as inputs to the classifier, overcoming the limitations mentioned above.
With the development of satellites and airborne sensors, more detailed and objective representations of the surface can be observed, thus offering finer-grained data for detecting surface changes. However, the diversity of surface features, especially the variability in object shapes, the complexity of background objects, as well as differences in weather conditions, imaging angles, and sensors, can easily lead to false detections or missed detections of actual change areas. Additionally, objects in remote sensing images exhibit different sizes, and a robust and generalizable model should be capable of handling various object scales. Moreover, change detection tasks often encounter a substantial class imbalance problem, where the count of unchanged pixels significantly outweighs the count of changed pixels. This presents a significant challenge in deep learning-based change detection methods for high-resolution remote sensing, as it becomes crucial to effectively extract and utilize the abundant feature information from high-resolution imagery to mitigate the influence of pseudo-changes and enhance the accuracy of detection.
To address this challenge and achieve better representation capabilities of deep features, designing deeper and more complex feature extraction networks has gotten significant attention as a primary research focus. Many researchers have put forward several enhanced models to achieve more discriminative feature representations, such as combining Generative Adversarial Networks (GAN) [
38,
39,
40] or Recurrent Neural Networks (RNN) [
41,
42], or using feature extraction models based on the Transformer architecture [
43,
44,
45] to expand the receptive field. Some studies focus on the effective utilization of features, such as using spatial or channel attention mechanisms [
30,
31,
32,
36,
46] or employing multi-scale feature fusion for feature enhancement [
25,
29,
47,
48,
49]. However, along with the increased complexity of the models, there is a proliferation of parameters and redundant feature information. This not only imposes a heavy burden on model training but also increases the risk of pseudo-changes detections due to the presence of excessive redundant information.
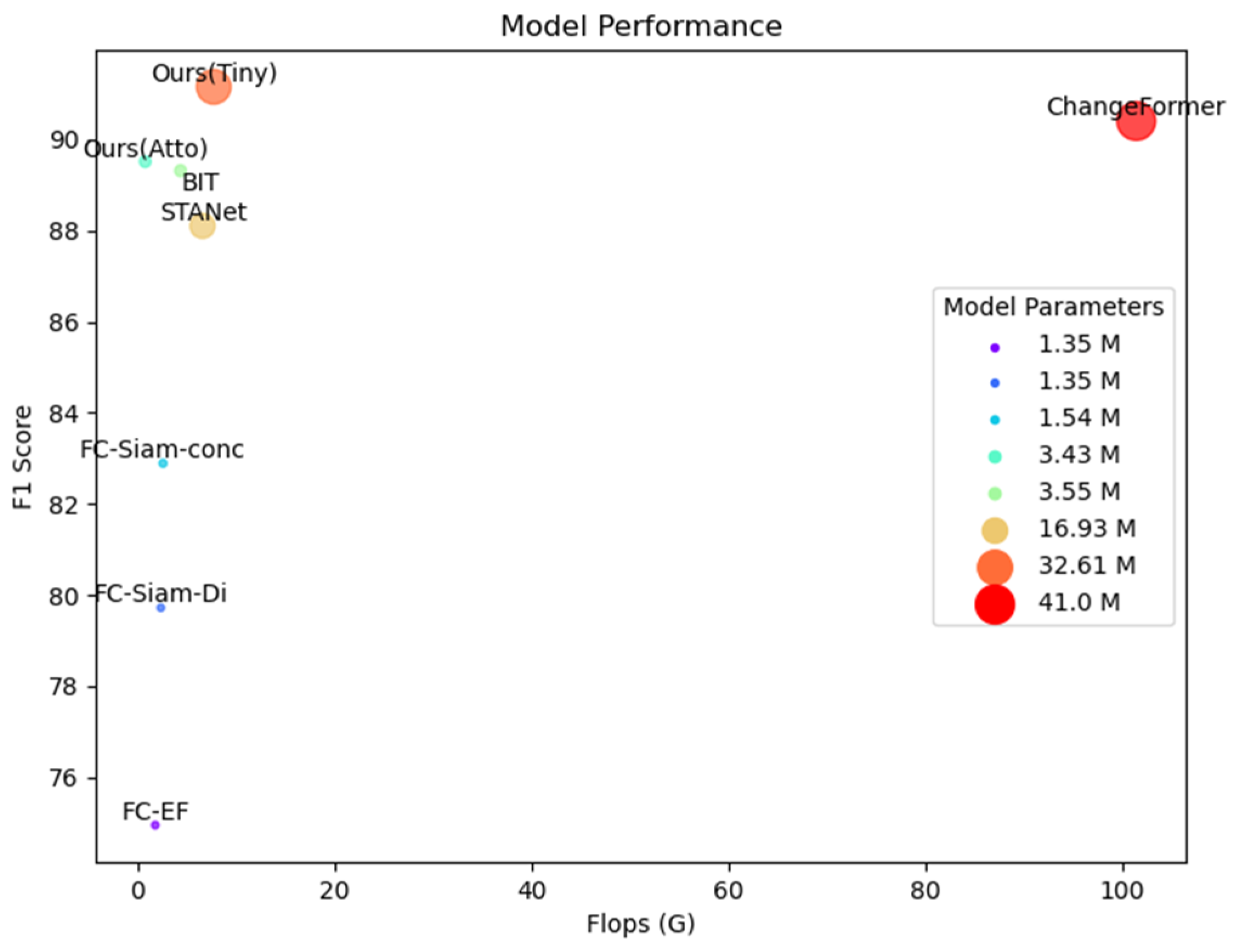
In light of the aforementioned challenges, we present a novel approach called the Multi-Scale Feature Subtraction Fusion Network (MFSFNet). Our network is constructed based on the following four requirements. Firstly, the model should maximize the utilization of feature information derived from the dual-temporal imagery, emphasizing real change areas while reducing the generation of redundant information to minimize false detections caused by complex backgrounds or imaging differences. Secondly, the network must be able to effectively represent features of diverse structures and different sizes of objects. Thirdly, the model should be easy to train, avoiding the issue of gradient vanishing. Lastly, it is essential for the model to effectively tackle the issue of sample imbalance and enhance the accuracy of detection. To address the first two requirements, we extract the dual-temporal imagery multi-scale features and design the Multi-scale Feature Subtraction Fusion (MFSF) module to fuse these features. Unlike existing fusion strategies, our subtraction fusion strategy enhances change features while reducing the interference of redundant features. To meet the third requirement, we use ConvnNext v2-Atto, as the lightweight multi-scale feature encoder with less parameters. We also introduce the Feature Deep Supervision (FDS) module in the decoder to provide additional supervision for deep change features, which improves the model’s feature extraction capability while accelerating convergence. To address the fourth requirement, we incorporate Dice loss into the loss function to mitigate the imbalance between change and non-change pixels. With these efforts, our network can effectively capture change features in high-resolution imagery.
The primary contributions of this work can be summarized as follows:
We propose the MFSFNet for high-resolution remote sensing image change detection. This network enhances change features and reduces redundant pseudo-change features through a multi-scale subtraction fusion strategy.
We utilize a lightweight feature extraction network and introduce a novel deep supervision strategy in the change decoder, which enhances the training performance of the network.
The paper is structured as follows:
Section 1 provides an introduction to the background and problem addressed in this study.
Section 2 discusses relevant literature and related works.
Section 3 presents the comprehensive details of MFSFNet.
Section 4 describes the experimental design, parameter settings, and analysis of the obtained results.
Section 5 offers a discussion of our method. Finally,
Section 6 concludes the paper, summarizing the key findings and contributions.
3. Methods
This section presents a comprehensive overview of the MFSFNet (Multi-Scale Feature Subtraction Fusion Network) architecture, highlighting its key components and functionality. Firstly, we present the MFSFNets flowchart and overall architecture (refer to
Figure 1 and
Figure 2). Then, we describe in detail the MSSF module and the Feature Deep Supervision (FDS) module that we have designed. Lastly, we define the loss function.
3.1. Flowchart and Overall Architecture of MFSFNet
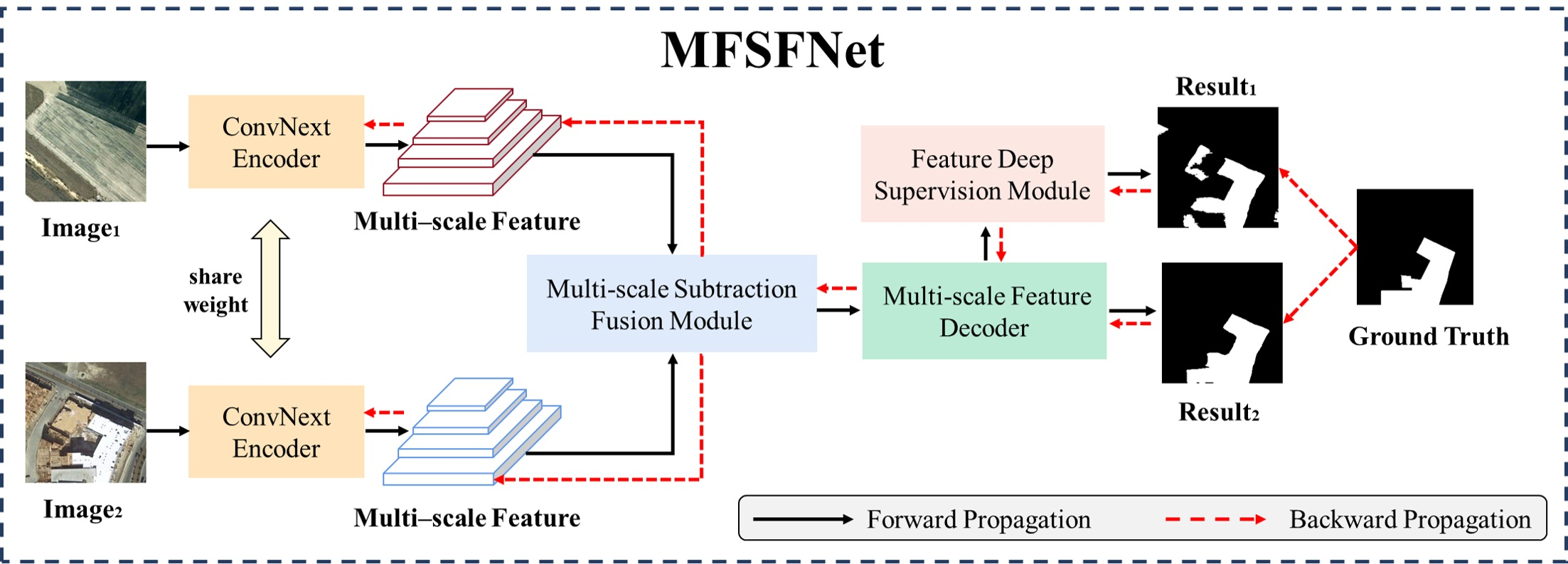
As the flowchart of MFSFNet shown in
Figure 1, firstly, the inputs of MFSFNet are two temporal remote sensing images. Secondly, the images are fed into a weight-shared Siamese CNN to extract multi-scale features based on ConvNext V2. Thirdly, multi-scale features are fused by multi-scale subtraction fusion module. Fourthly, the fused features are decoded by a multi-scale feature decoder. The multiscale feature decoder has two branches, one that outputs the change detection results of the model, and a feature deep supervision branch that generates an additional change detection result through feature deep supervision. Lastly, both results are used with ground truth to compute the loss and perform loss back propagation. The module of feature deep supervision subjects the model to additional supervision. The black solid arrows in the figure show the sinusoidal propagation path of the data and the red dashed arrows show the backward propagation path of the gradient.
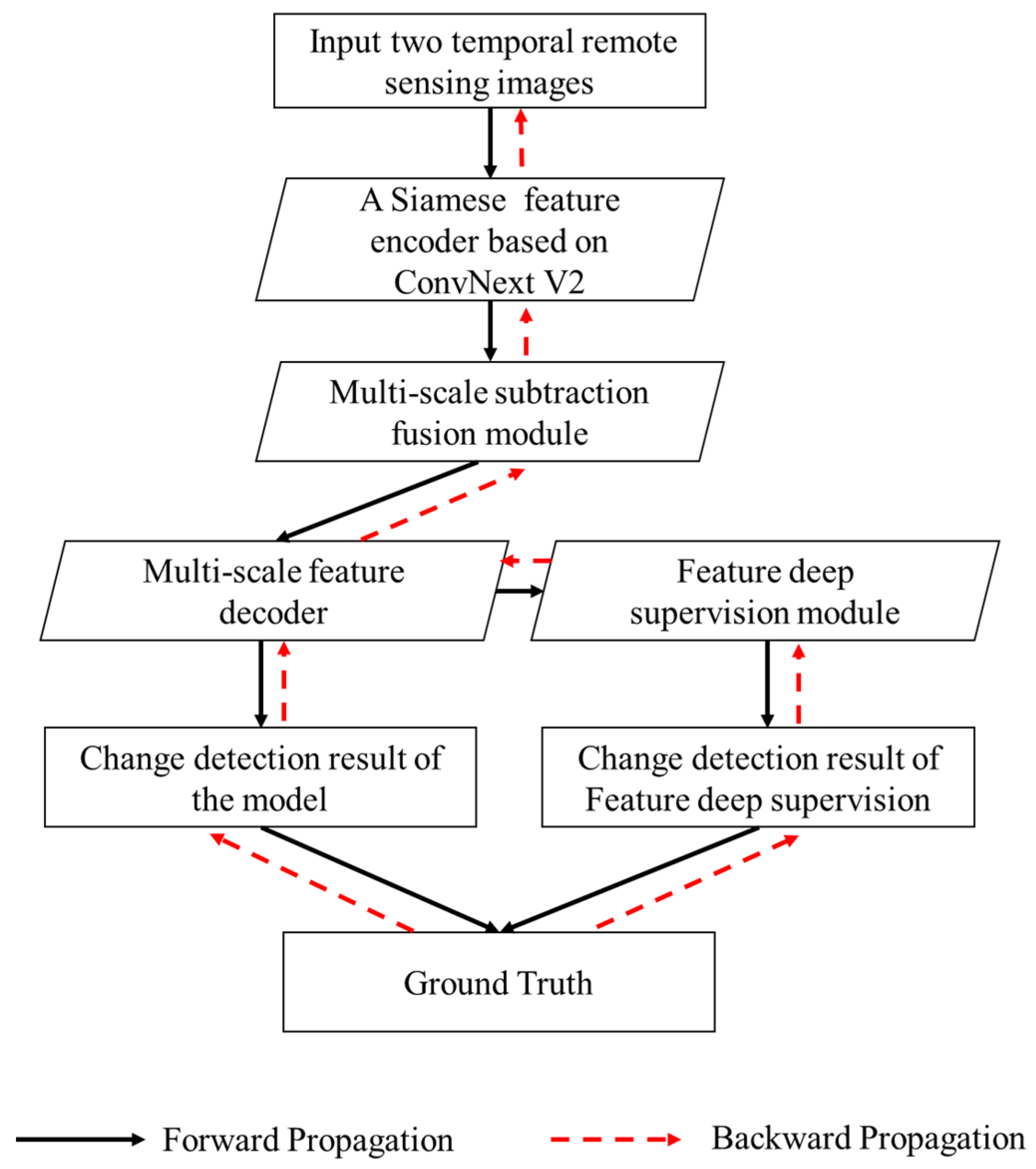
Figure 2 illustrates the overall architecture of MFSFNet. MFSFNet is composed of three components: the Siamese encoder, the Multi-scale Subtraction Feature Fusion (MSSF), and the decoder. The decoder includes the Feature Deep Supervision (FDS) module for multi-scale supervision. Firstly, we employ a ConvNext architecture [
57,
58] as the feature encoder to obtain multi-level features while enhancing the generalization of feature representations, enabling the model to tackle the challenges posed by diverse land cover structures. Secondly, the MSSF module performs feature fusion on different scales. It reduces feature redundancy while emphasizing different-sized objects and minimizing interference from complex background information. This helps to generate more accurate boundaries. Next, the MSSF module’s output features are bottom-up integrated by the decoder as part of the feature decoding process to produce change features. Subsequently, FDS is applied to predict change detection results on different scales of the change features. Multiple predictions are compared with the label, and losses are computed accordingly. Additionally, we incorporate the Dice Loss to increase the model’s attention to object boundaries and alleviate issues related to irregular or misaligned boundaries. Finally, the model achieves convergence through loss backpropagation, resulting in improved change detection results. Overall, the MFSFNet network leverages the Siamese feature encoder, MSSF module, and decoder module to effectively fuse multi-scale features and obtain accurate results. The incorporation of the FDS module enhances the training process by providing multi-scale supervision. The addition of the Dice Loss promotes better handling of object boundaries. Through loss propagation, the model achieves convergence and produces superior change detection outcomes.
3.2. The Siamese Feature Encoder
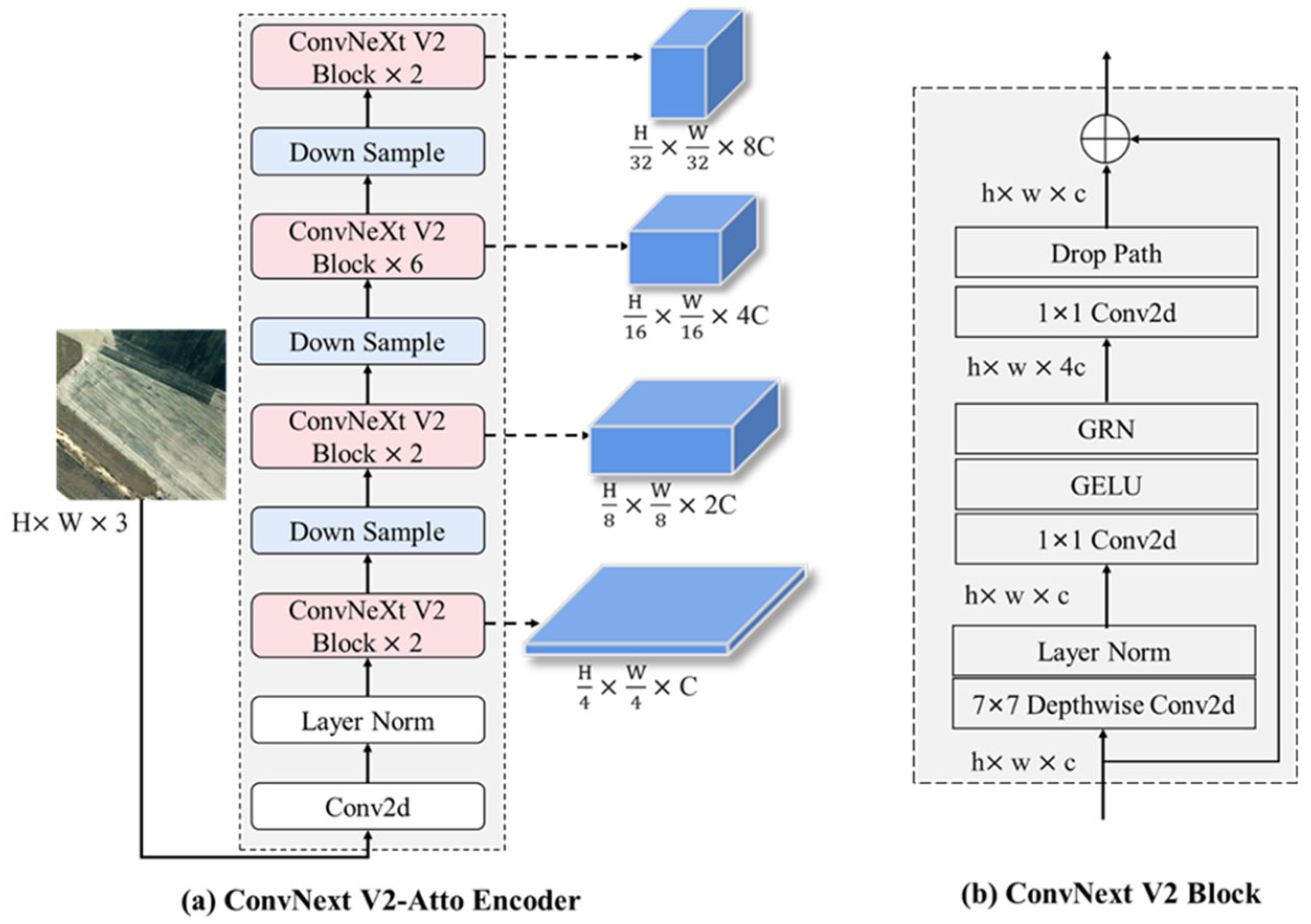
The Siamese feature encoder is responsible for extracting multi-scale change features and semantic features that are essential for change detection. To achieve a generalized representation of both semantic and change features, the improved version of the ConvNext network, called ConvNext V2-Atto [
58], is employed in MFSFNet. ConvNext V2-Atto is a lightweight variant of ConvNextV2, with a small number of network parameters while maintaining good feature generalization. Compared to ConvNextV1 [
57], ConvNext V2 incorporates a fully convolutional masked autoencoder (FCMAE) framework similar to MAE [
59] for pre-training, which enhances the feature extraction capability. The feature encoder based on ConvNext V2-Atto is illustrated in
Figure 3a.
The basic unit of the ConvNext V2-Atto encoder is the ConvNext V2 Block. As shown in
Figure 3b, within each ConvNext V2 Block, the input feature map
of size
undergoes a 7 × 7 Depthwise convolution [
60] and a Layer Norm layer [
61], resulting in the feature map
of size
. Then, a 1 × 1 convolution layer, GeLU activation layer [
62], and Global Response Normalization (GRN) layer [
58] are applied to get the feature map
of size
. The channel count is then restored to
using a 1 × 1 convolution layer and Drop Path layers are employed to prevent overfitting to get
. Finally, an element-wise addition operation is performed between
and the input
, resulting in a feature map
F of size
. In the ConvNext V2-Atto encoder, four groups of ConvNext V2 Blocks with a ratio of {2:2:6:2} are combined with down-sampling layers to generate four feature maps at different scales: size of
,
,
,
, respectively.
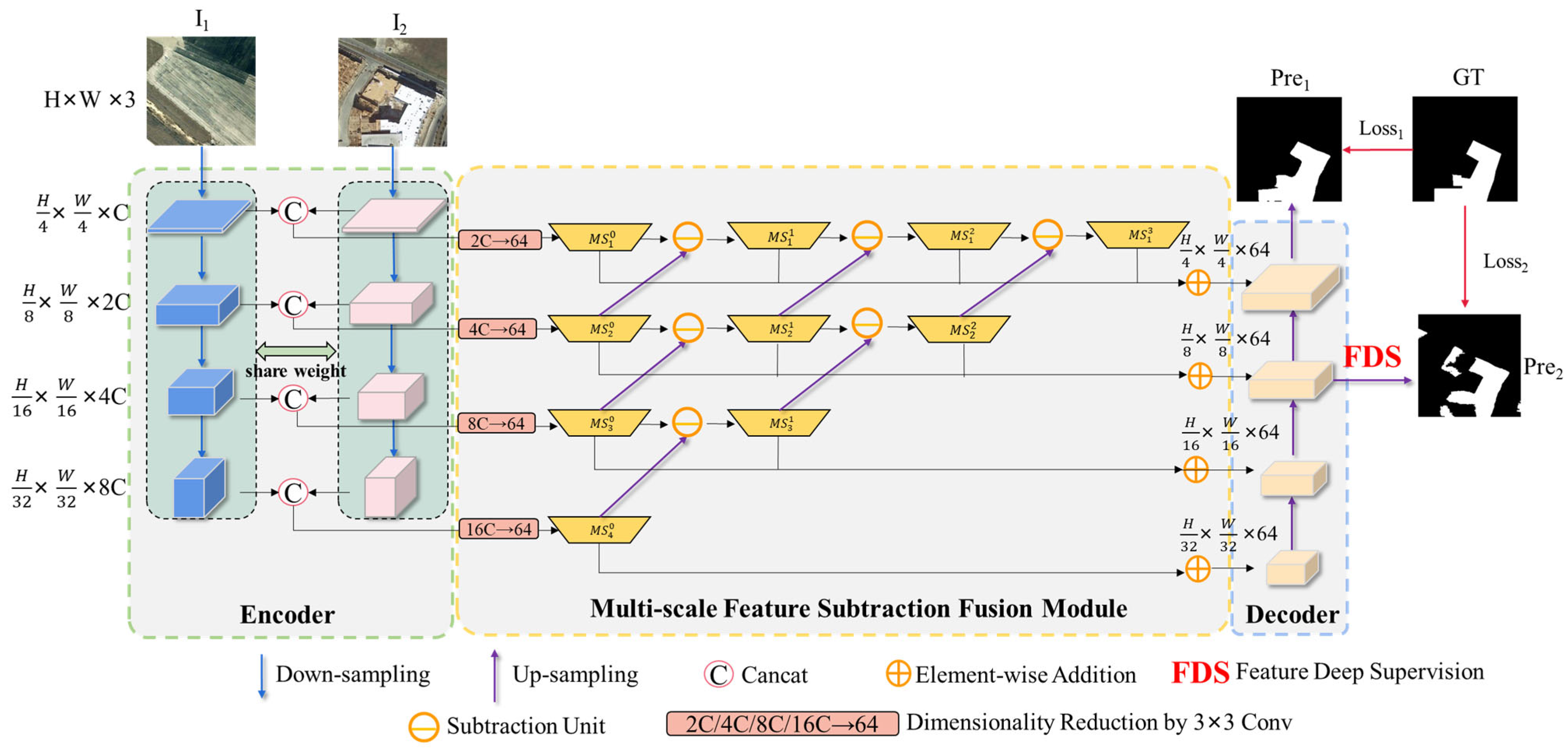
For MFSFNet, two shared-weight ConvNext V2-Atto Encoders are used to get multi-scale features for the two images. The images from two time periods, denoted as image I1 and I2, are inputted into the twin ConvNext V2-Atto Encoders. This allows for obtaining semantic features for each image at four different scales. Specifically, for I1, the multi-scale semantic features are of size , of size , of size , and of size . Similarly, I2 yields the multi-scale semantic features , , , and , which have the same size as the corresponding features of I1.
To obtain multi-scale change features for the objects, the semantic features from the two images are concatenated along the channel dimension at each scale. This concatenation ensures that the change features have the same width and height as the semantic features, but with the channel count being twice that of the semantic features of a single image. Finally, we obtain change features and of sizes , , , and , respectively. These change features serve as the input to the multi-scale subtraction feature fusion module.
3.3. Multi-Scale Feature Subtraction Fusion (MSSF) Module
To enhance the model’s generalization ability for objects at various scales and prioritize features relevant to changes while suppressing irrelevant ones, we introduce the Multi-scale Feature Subtraction Fusion (MFSF) module. This module combines the multi-scale features from the encoder and employs a subtraction fusion method. By subtracting corresponding features from different scales, redundant information during feature fusion is reduced. This subtraction fusion approach enhances the representation of relevant features associated with changes and helps mitigate the interference caused by complex backgrounds. The MFSF module emphasizes discriminative information and improving the accuracy.
To facilitate the fusion of different-scale features, we first employ a 3 × 3 convolutional layer to lessen the dimension of the multi-scale change features and to 64, resulting in , , and . Then, we apply subtraction units to fuse the features not only within the same scale but also between adjacent scales. The subtraction units enhance the change features and emphasize the change regions at different scales.
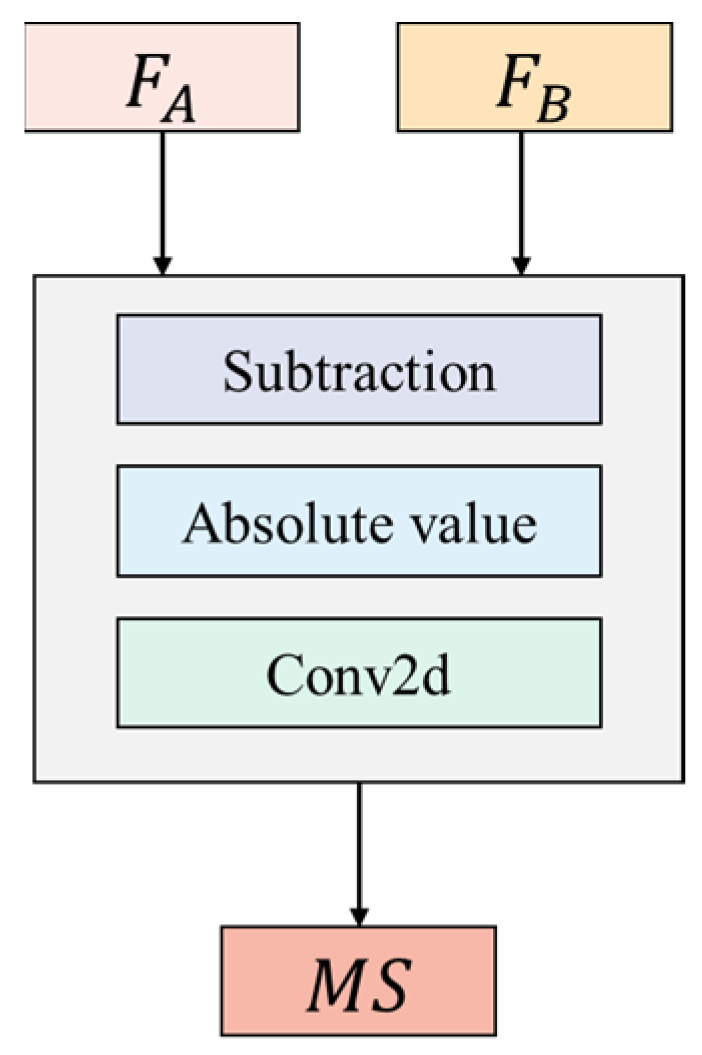
The subtraction unit (
Figure 4) takes inputs
and
.
is derived from the features
at the same scale, while
is obtained by up-sampling the features
from the adjacent scale to match the size of
. The feature fusion is achieved by Equation (1):
where
indices the scale level, and
indices the number of feature fusion operations at each scale level.
denotes a 3 × 3 convolution,
represents the absolute value operation,
indicates element-wise subtraction, and
denotes the up-sampling layer.
represents feature fusion result, which has the same size as
.
The absolute value operation in the subtraction unit serves a similar purpose as an activation function. When performing fusion operations between features of different scales, the features represented by operation results with the same absolute values indicate the same feature differences. Therefore, the absolute value operation is used for activation. If the commonly used ReLU activation function is employed, the negative values would be discarded directly, overlooking a portion of the feature differences, which would affect the effectiveness of the subtraction fusion.
After the multi-scale feature fusion, at each scale
j, the features
are aggregated using element-wise addition to further enhance the focus on the changed features. The computation is performed according to Equation (2):
where
indices the scale level,
represents the feature fusion result after i iterations of subtraction units at scale
j.
denotes the result of adding features at scale j, and its size is the same as
.
will serve as the input to the decoder module.
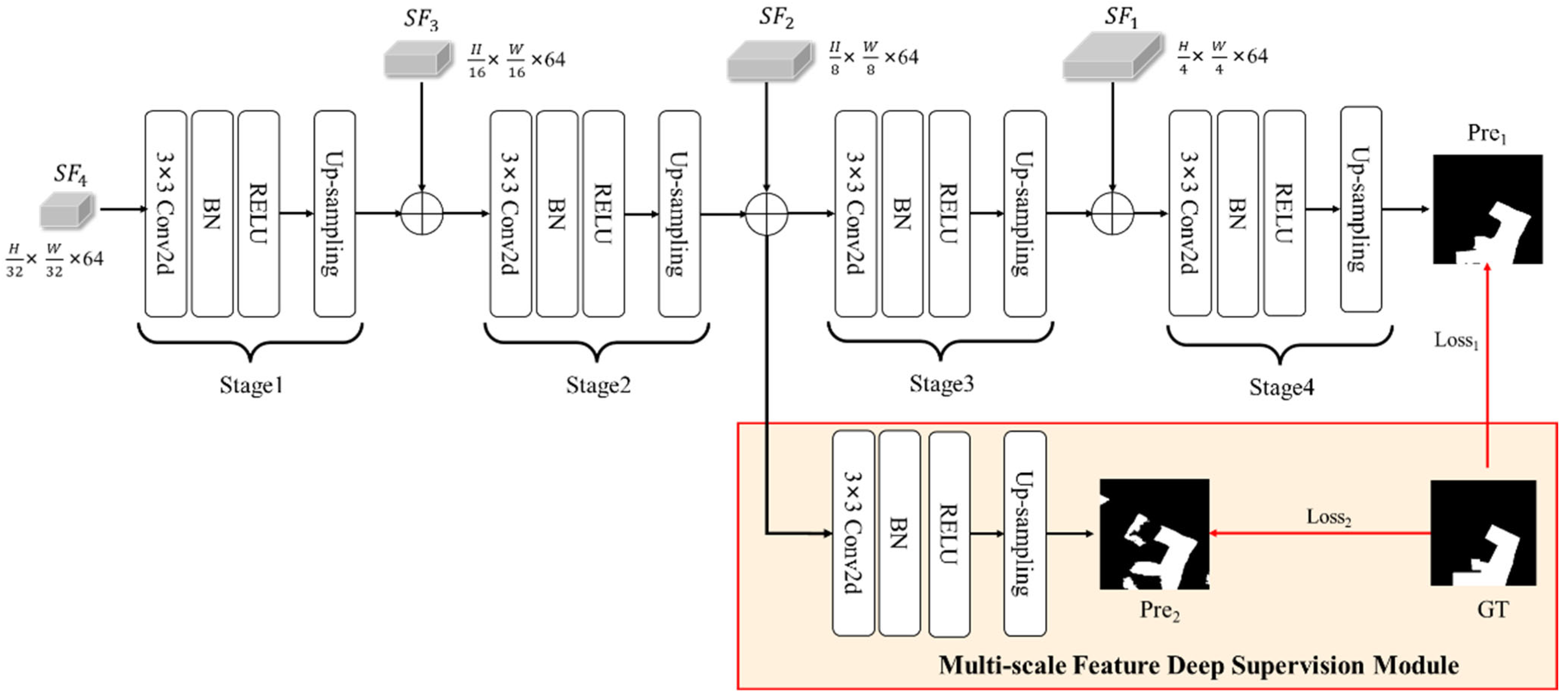
3.4. Decoder and Feature Deep Supervision Module
Due to the varying expressive capabilities of different feature levels in change detection tasks, we employ a FDS module in the multi-scale decoder. By introducing additional supervisory signals at different levels of the network, the network is able to better utilize multi-level feature representations during the learning process.
The decoder of MFSFNet is composed of four stages and a FDS module (
Figure 5). Each stage includes a 3 × 3 convolutional, a batch normalization (BN), a ReLU activation, and an up-sampling. Stages 1 to 3 progressively up-sample the channel dimensions of the input feature maps by a factor of 2, while maintaining a consistent channel dimension of 64. This is done to enable element-wise addition with the multi-scale features from MSSF. In Stage 4, the fused feature map of size
is converted to a change detection result
of size
, which serves as one of the decoder’s outputs. It is then compared with the ground truth (GT) labels to calculate
.
Additionally, when implementing deep supervision, we took into consideration that the feature map sizes of Stage 3 and Stage 4 are closer to the size of the original image compared to Stage 1 and Stage 2. The larger feature maps indicate the presence of more feature information. Therefore, in addition to supervising the output of Stage 4, supervising Stage 3 may yield better results than supervising Stage 1 and Stage 2. This idea is supported by the results of the ablation experiments in
Section 5.1. As a result, we apply deep supervision to the input feature map of Stage 3. In FDS module, Stage 2′s output is fused with
and passed through a series of a 3 × 3 convolutional, a BN, a ReLU activation, and an up-sampling. This generates a change detection result
of size H × W × 1, which is compared with the labels to calculate
. This process represents the multi-scale feature deep supervision. Finally, after training, the decoder of MFSFNet uses the
result as the model’s change detection output.
3.5. Loss Function of MFSFNet
The loss function of MFSFNet consists of two parts: the difference between the decoder’s final output and the GT, denoted as , and the difference between the output of the multi-scale deep supervision module and GT, denoted as . The calculation of both losses follows the same approach.
In MFSFNet, the proposed approach incorporates the Dice loss [
63] along with the binary cross-entropy (BCE) loss to mitigate the issue of class imbalance and alleviate the boundary fuzziness in the results. Therefore, the calculation of
and
is described by Equation (3).
where
, represents the binary maps of the two change detection predictions.
, represents the losses of the two predictions.
denotes the binary cross-entropy loss.
refers to the Dice loss, calculated as described in Equation (5). The coefficients
and
are used, with the common setting in this paper being
= 0.6 and
= 0.4.
can be calculated as follows:
where
denotes the ground truth label and
denotes the predicted probability of change at a specific point (𝑖,𝑗).
The Dice loss [
63] is a metric that can calculated the similarity between two sets from a global viewpoint. It is particularly useful in scenarios where there are only a few positive samples in the image, as it remains effective in such cases. By utilizing the Dice loss, the issue of blurred boundaries caused by the class imbalance in change detection results can be addressed. The calculation of the Dice loss is as follows:
where TP represents the count of correctly predicted positive pixels (true positives), FP represents the count of incorrectly predicted positive pixels (false positives), and FN represents the count of incorrectly predicted negative pixels (false negatives). By considering these values, the Dice loss can effectively evaluate the model in capturing the boundaries and overall similarity of the predicted and true regions in the context of binary classification tasks such as change detection.
The overall loss of MFSFNet is determined by combining
and
through summation, and it can be expressed as follows:
where,
and
represent the change detection prediction results.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}