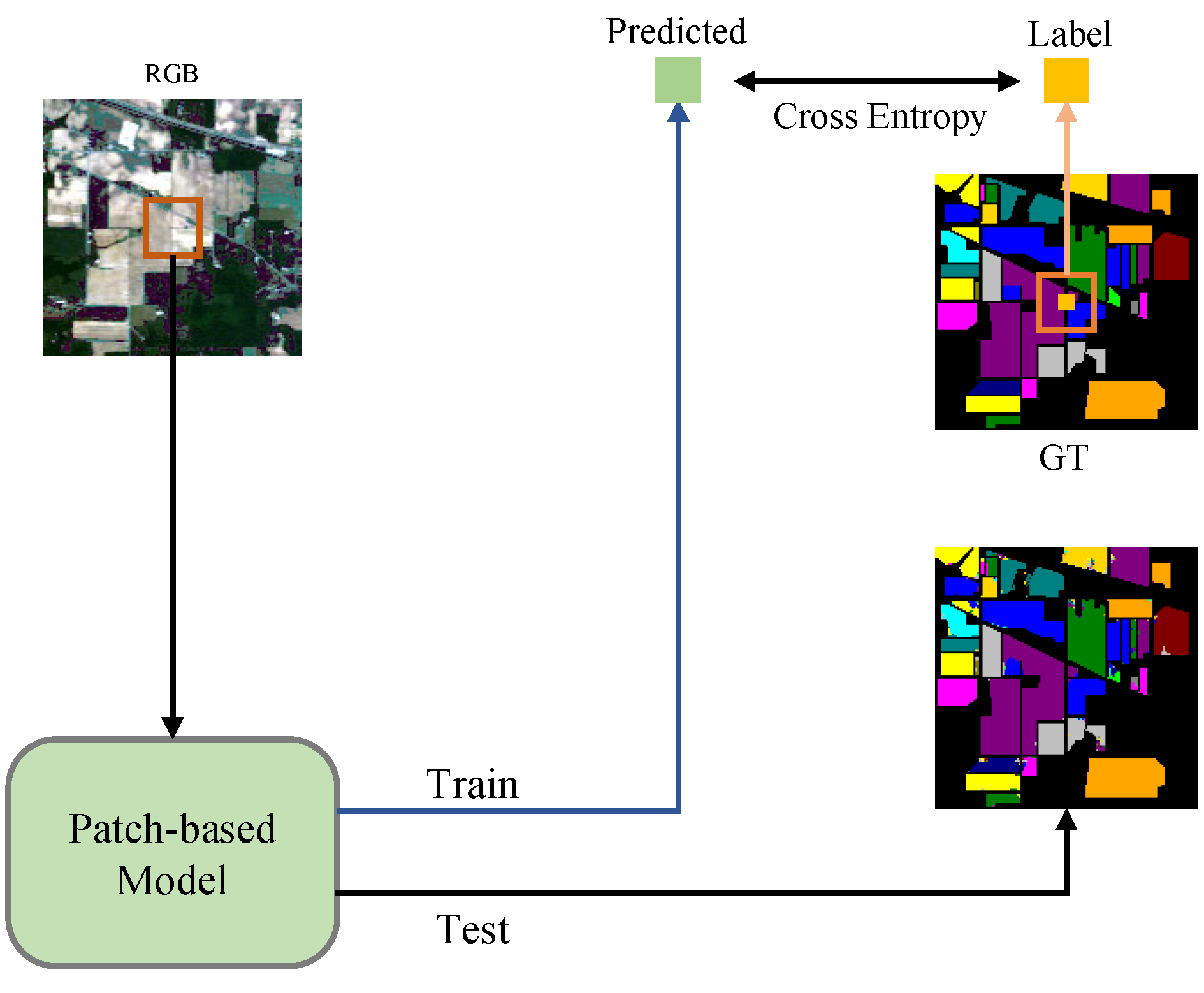
3.1. Experimental Platform Parameter Settings
All experiments were run on Windows 11 and Nvidia GeForce RTX 3060 graphics card, and the models were run on pytorch 1.9. In order to reduce the experimental error, the model selects limited samples from the training set for training, and all experimental results take the average of 5 experiments. For the semantic segmentation method, the optimizer to be selected had the default parameters AdamW optimizer [
43]. The learning rate is
in [
42],
in [
11],
in [
25], and
in [
13,
38]. In order to compare various models more fairly, we set the learning rate to
, and set the epoch to 200 to ensure that the model can fully converge. AdamW is a variant of the Adam optimizer that decouples weight decay from the learning rate and applies it directly to the weight updates to improve stability and prevent overfitting in deep learning models. For patch-based methods, the optimizer to be chosen had a default parameter AdamW optimizer with a learning rate set to
and epoch set to 400.
To evaluate the performance of different models in terms of hyperspectral image classification, overall accuracy (OA), average accuracy (AA), and Kappa coefficient (K) were used as evaluation criteria. OA reflected the total correct classifications, AA considered the correctness within each category, and K accounted for chance agreement to determine the true accuracy and reliability of the predictions. Higher values of OA, AA, and K indicated a better performance in hyperspectral image classification.
In this study, we evaluated the performance of different models for hyperspectral image classification. We used a variety of traditional semantic segmentation methods, including Unet [
44], FPN [
45], Deeplabv3 [
46], and Deeplabv3+ [
47]. For these methods, we used ResNet50 as the backbone to extract features from the input data. We also used several hierarchical backbones, including ConvNeXt [
26], Swin [
13], ResT [
48], PVT [
24], and PoolFormer [
25], and paired them with the UperNet decoder. For SegFormer [
38], we used the proposed decoder, which consisted of fully connected layers. For SGHViT, we also paired this with UperNet as the decoder, as discussed in the ablation experiments section. For the semantic segmentation method, the number of input channels of all models was the same as the bands in
Table 1, and the output was classes + 1, where 1 represented the background.
Regarding the patch-based methods, we used the principal component analysis (PCA) method to reduce the dimensionality of the dataset to a specific size. Specifically, for 1DCNN [
16], we set the patch size to 1 and the number of principal components to 18. For 3DCNN [
17] and Hybrid [
15], we set the patch size to 15 and the number of principal components to 18. For SSFTT [
12], we set the patch size to 11 and the number of principal components to 30.
3.3. Comparative Experiment
We conducted a comparative evaluation of various methods for hyperspectral image classification using a publicly available dataset. The results are presented in
Table 5,
Table 6 and
Table 7. Our analysis showed that the patch-based approach is not very effective for hyperspectral image classification. Ordinary 1DCNN and 3DCNN models have difficulties classifying ground objects with similar spectral characteristics. However, Hybrid, which combines 2DCNN and 3DCNN, can mitigate this limitation to some extent.
We also evaluated SSFTT, which uses a combination of Transformer and CNN to fully extract spatial and spectral features. However, this method is limited by patch-based data-processing methods, which restrict its ability to model the global scene effectively. In contrast, semantic segmentation-based methods can make good use of spatial features for global scene modeling. Nevertheless, most of these methods were designed for three-channel images and did not fully consider the spectral dimension. Additionally, traditional semantic segmentation methods tended to focus on regional features, which could make it challenging to extract deep semantic features. Although models like Unet, FPN, and Deeplabv3 were widely used for various computer vision tasks, they did not perform optimally for hyperspectral semantic segmentation. Moreover, these models tend to have a large number of parameters, which can lead to higher computational costs and memory requirements. In contrast, SGHViT had promising results on hyperspectral semantic segmentation tasks while utilizing significantly fewer parameters and moderate floating-point operations per second (FLOPS). Thus, SGHViT was a more effective choice for hyperspectral semantic segmentation tasks.
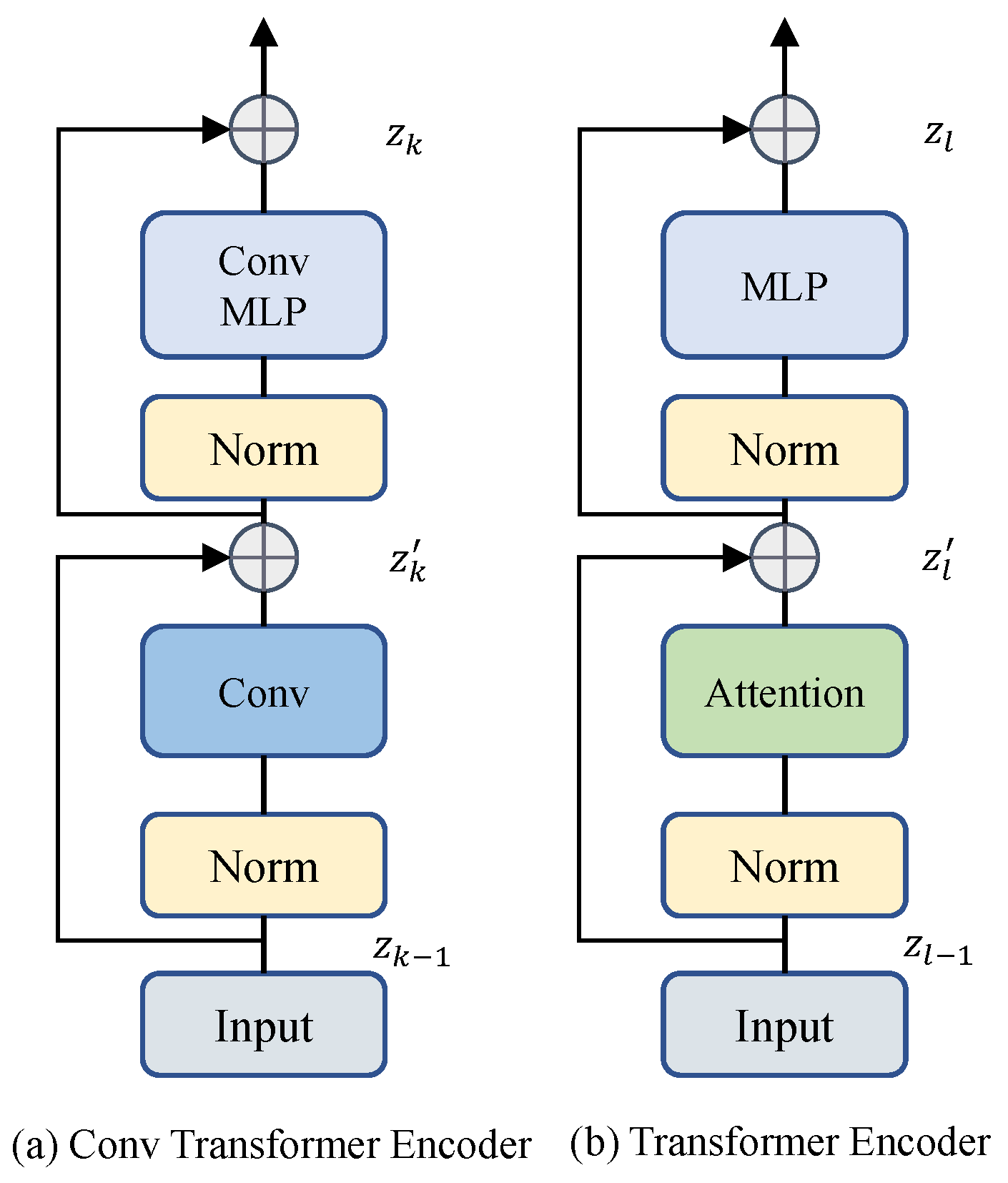
Transformer-based models showed promising results for hyperspectral semantic segmentation tasks. This is attributed to Transformer’s ability to extract features effectively and model spectral dimension information accurately. Swin, SegFormer, ResT, and other Transformer-based models demonstrated impressive potential in hyperspectral semantic segmentation tasks. In particular, SegFormer achieved comparable results to our proposed model on the three datasets, indicating that a simple decoder could often achieve a better performance for hyperspectral semantic segmentation tasks.
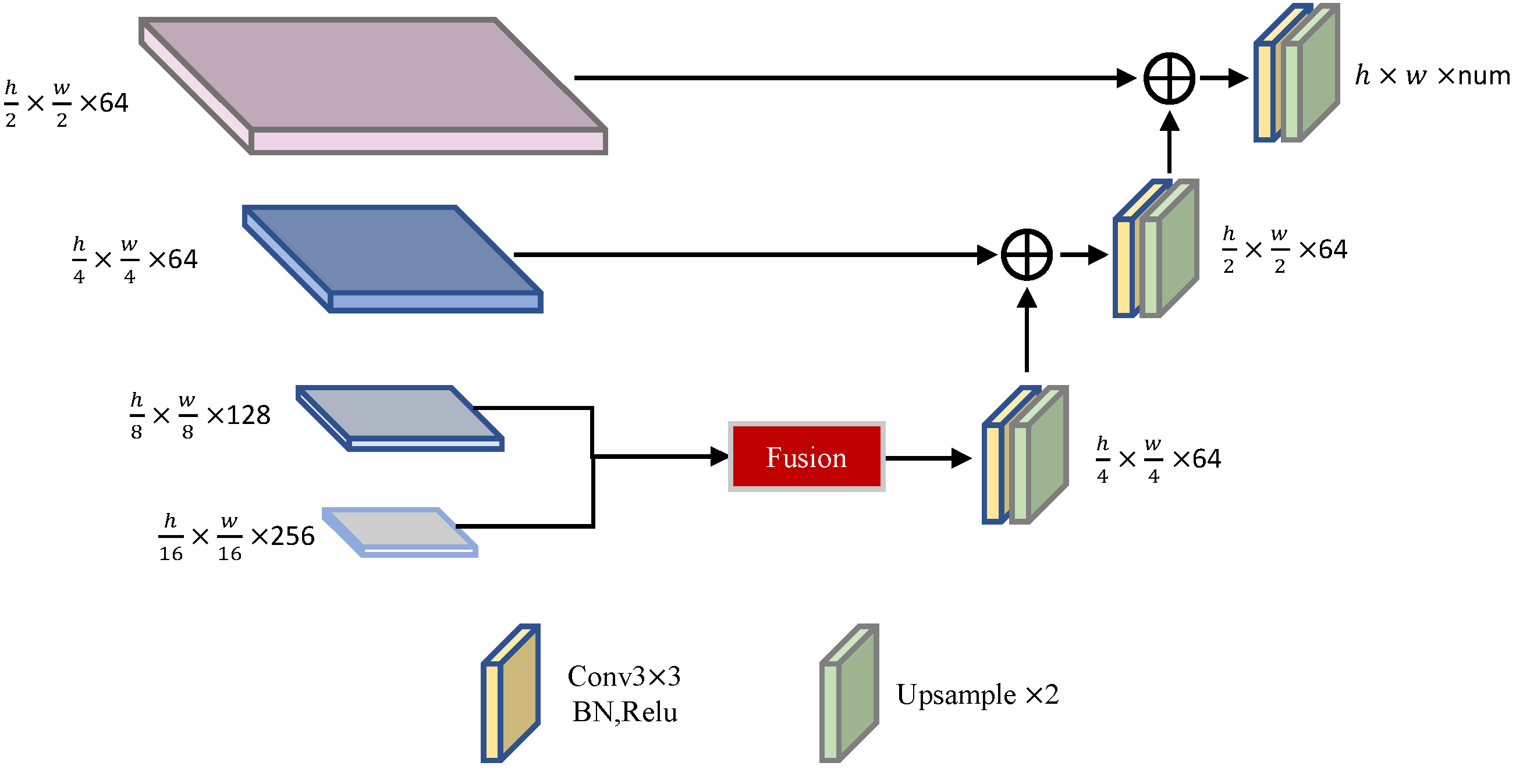
To further improve the performance of our proposed model, we designed a novel decoder architecture that efficiently the transmitted texture information extracted by the upper layers of the model to the decoder. This reduced the misclassification of the model and enhanced its segmentation accuracy. In the ablation experiment section, we compared our decoder architecture with UperNet, and the results demonstrated the effectiveness of our proposed approach.
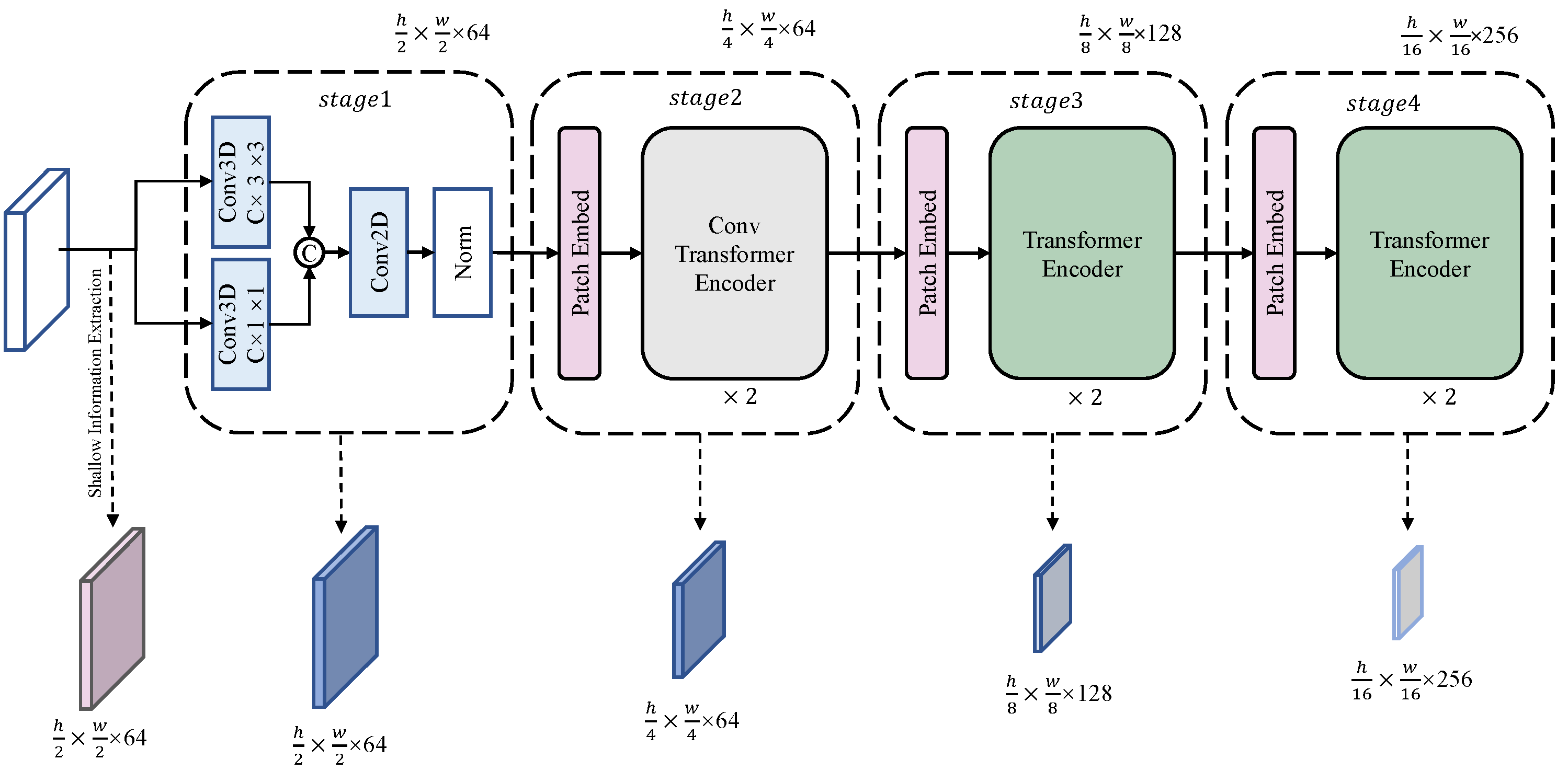
It is worth noting that PoolFormer is a hierarchical model that uses simple pooling modules. It achieved good results on the three datasets, which further confirms the importance of the hierarchical structure in hyperspectral image classification. In our study, we also adopted the traditional hierarchical structure and used stages 1–4 to represent the model structure.
The ConvNeXt experiment provided additional evidence supporting the importance of the hierarchical structure for hyperspectral semantic segmentation tasks. We found that pure convolution-based Transformer-like models cannot fully extract deep semantic information, and therefore cannot achieve a good segmentation performance. To address this limitation, our model combines CNN and Transformer layers to extract shallow and deep information, respectively. Specifically, we used CNN to extract shallow information in the early layers of the model, and Transformer to extract deep information in the later layers.
Our analysis of the AA showed that our proposed method could effectively leverage the shallow spatial detail information of hyperspectral images. Specifically, the shallow layer information extraction module significantly enhanced the model’s ability to extract texture information. At the same time, the segmentation accuracy of the model was also enhanced, and the location of the ground objects generated by the model was limited to the effective area. The incorporation of the Decoder part, which operated on the output of the Transformer layer, further improved the segmentation accuracy of our model. The Decoder part effectively refined the output of the model and ensured that the predicted ground objects were within the valid area of the image. As a result, the AA of our model was significantly higher than other, similar models.
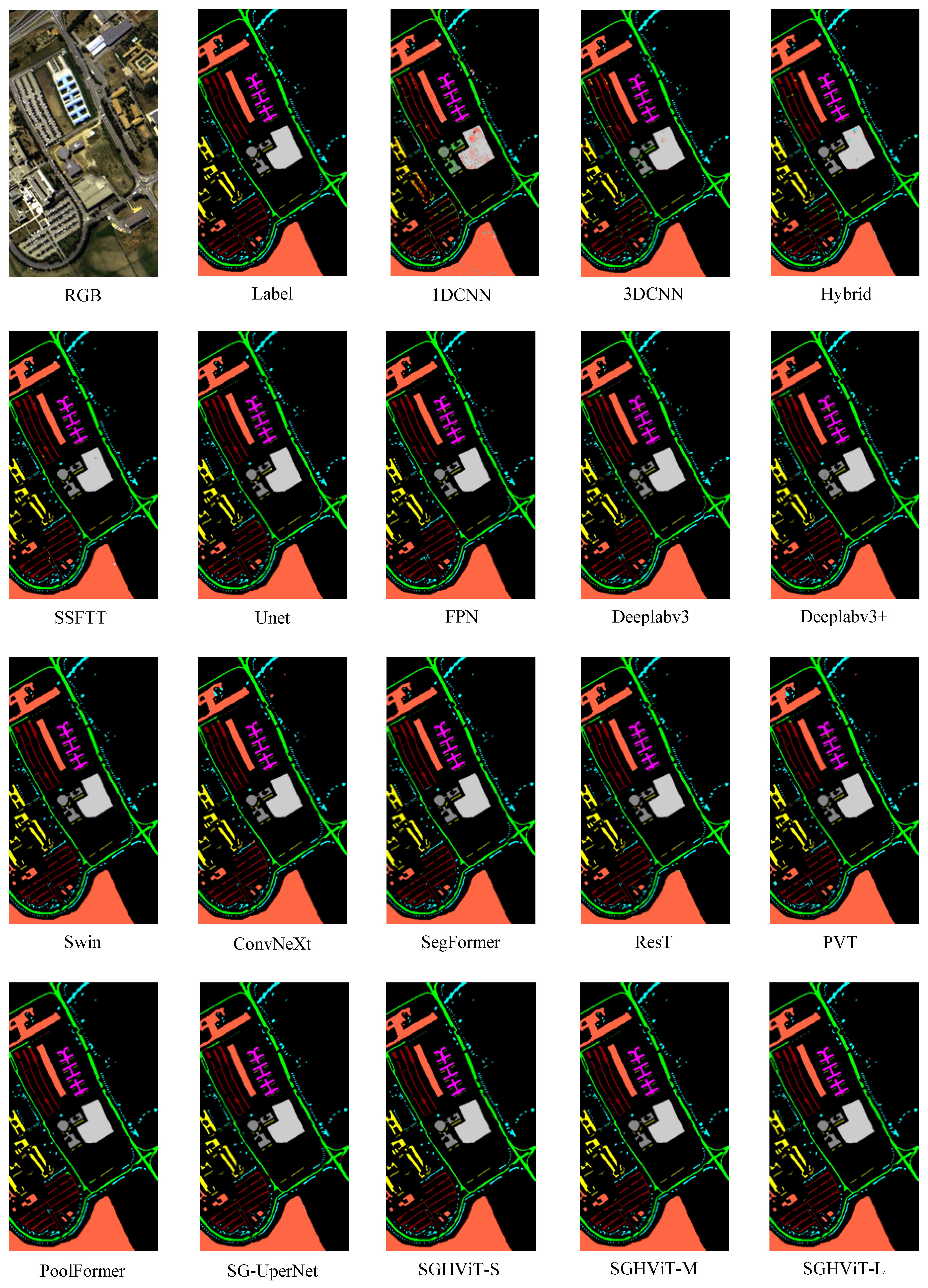
Based on the results presented in
Table 5 and
Figure 6, SGHViT achieved the highest classification accuracy for most ground objects in the IA dataset, with some objects reaching 100%. However, for certain objects, such as alfalfa, corn-notill, corn-mintill, soybean-clean, and stone-Steel-Towers, SGHViT did not achieve optimal results, with a gap of approximately ∼2% compared to the best-performing model. This is because SGHViT needs to fully consider the distribution of various ground objects for classification. The location of these features is concentrated and often difficult to distinguish at the edge.
Figure 6 indicates that 1DCNN and Unet had a high number of misclassifications, while 3DCNN exhibited many misclassifications in certain areas. Hybrid models improved a substantial number of misclassifications, and SSFTT only had misclassifications in the edge areas of ground objects. Models such as FPN, Deeplabv3, and Swin only showed misclassifications for some challenging features. Although SGHViT also exhibits misclassifications for some difficult-to-classify objects, it outperforms the semantic segmentation-based methods, improving classification accuracy for most areas.
According to the results presented in
Table 6 and
Figure 7, SGHViT achieved the best classification accuracy for almost all ground objects in the PU dataset. Specifically, SGHViT achieved 100% accuracy for Gravel, Metal sheets, Bare Soil, and Bitumen, and was only slightly worse than the best-performing model for Meadows, by approximately ∼0.1%.
Figure 7 indicates that patch-based methods did not perform well on the challenging PU dataset, with all methods exhibiting misclassifications in the central area of ground objects. However, semantic segmentation-based methods had no misclassifications in the central region of Bare Soil and other objects. Unet, Deeplabv3, and SegFormer exhibit numerous misclassifications for Asphalt, Shadows, and Trees, whereas SGHViT significantly improves the misclassification of these features, especially Trees and Shadows. Overall, SGHViT demonstrates reasonable classification accuracy for different ground objects and outperforms other methods in terms of comprehensive indicators such as OA, AA, and
K.
Evidenced by the results presented in
Table 7 and
Figure 8, SGHViT achieves the best classification accuracy for most ground objects in the SA dataset, with the exception of fallow-rough-plow, grapes-untrained, corn-senesced-green-weeds, lettuce-romaine-7wk, and vinyard-vertical-trellis.SGHViT achieves 100% accuracy for multiple ground objects.
Figure 8 clearly shows a significant number of misclassifications in the patch-based and Unet methods. However, other models based on semantic segmentation exhibit partial misclassifications for Vinyard_u, Grapes, Lettuce_4wk, Lettuce_5wk, Lettuce_6wk, Lettuce_7wk, and Corn, which are particularly noticeable at the edge between Vinyard_u and Grapes. SGHViT effectively overcomes the aforementioned misclassification issues, exhibiting very few misclassifications for difficult-to-classify objects such as Vinyard_u and Grapes.
3.4. Ablation Experiment
We present the results of the ablation experiments in
Table 8 and
Table 9, where we comprehensively evaluated the impact of different modules on the performance of the model. Specifically, we investigated the effect of stacking Transformer blocks on the model’s performance, as well as the performance impact of our designed Decoder compared to the widely used UperNet [
13,
49].
- (1)
The impact of using different Decoders on the SGHViT backbone.
We evaluated the use of UperNet as the Decoder of our model, and present the results in
Table 8. Specifically, we designed an SG-UperNet model that used SGHViT-S as the backbone and UperNet as the Decoder. Our results showed that using SGHViT-S as the backbone, combined with UperNet, could achieve good results for hyperspectral semantic segmentation tasks. This reflected the ability of SGHViT-S to effectively extract both shallow and deep semantic information from hyperspectral images and model both local and global context.
However, using UperNet as the Decoder could result in a high parameter quantity and computational complexity. To address this, we proposed a simplified LinkNet-like Decoder that could achieve comparable results with a lower computational cost. Our proposed method used the feature maps of stage3 and stage4 from the Transformer module for feature aggregation, and then applied our simplified Decoder to generate the final segmentation map.
- (2)
The effect of using different numbers of Transformer blocks on the SGHViT backbone.
We evaluated the effect of stacking Transformer blocks on the performance of our model, and the specific results are presented in
Table 8. Specifically, we investigated the impact of varying the number of components of SGHViT-S, SGHViT-M, and SGHViT-L, with the number of components set to [1, 1, 1], [2, 2, 2], and [2, 6, 2], respectively.
Our experimental results showed that, as the number of stacked Transformer blocks increased, the performance of our model improved on all three datasets. This demonstrated the effectiveness of our method in leveraging the multi-scale context information of hyperspectral images.
- (3)
The effect of different components.
We conducted ablation experiments to evaluate the impact of different modules on the performance of our model for hyperspectral semantic segmentation tasks. Specifically, we evaluated the relative position encoding module (Pos), shallow feature extraction module (Shallow), and feature aggregation module (Fusion).
Our results showed that the relative position encoding module improved the performance of the model in the classification of lower hyperspectral ground objects and had a positive impact on all three datasets. The shallow feature extraction module also had a crucial impact on the correct classification of ground objects, particularly for dense prediction tasks. The OA, AA, and K indicators of the model without the shallow feature extraction module showed a significant decline, especially on the AA indicator. This highlighted the importance of incorporating shallow spatial detail features in the model to reduce misclassifications.
We also found that the feature aggregation module had a significant impact on hyperspectral images with high spatial resolution. For lower-resolution images, the effect of the module was not as significant. However, the module significantly improved various performance indicators for high-resolution images, which was consistent with the module’s design goal. This demonstrated the necessity of feature aggregation processing on the feature maps extracted by Transformer, as discussed in the previous literature [
38].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}