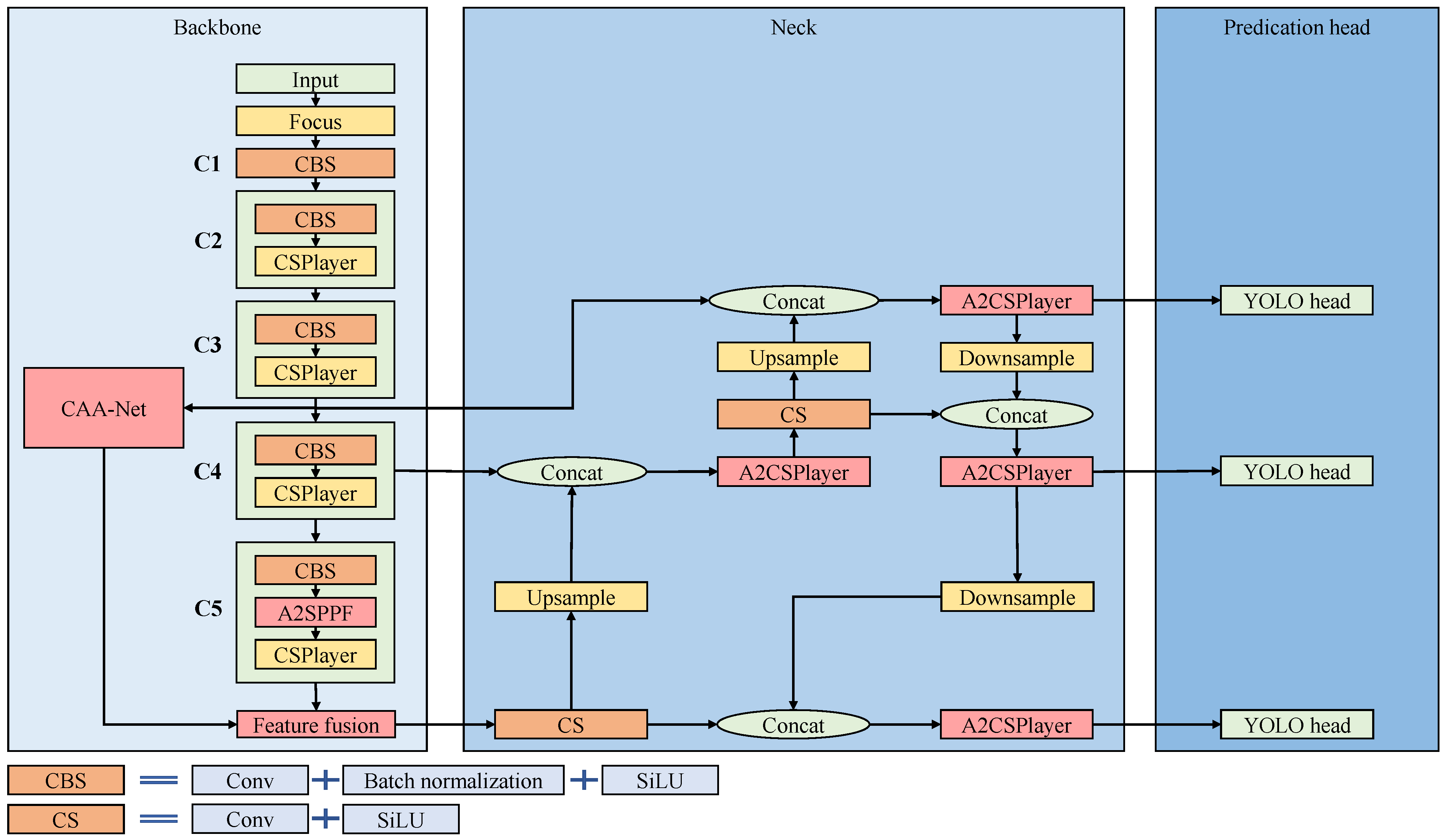
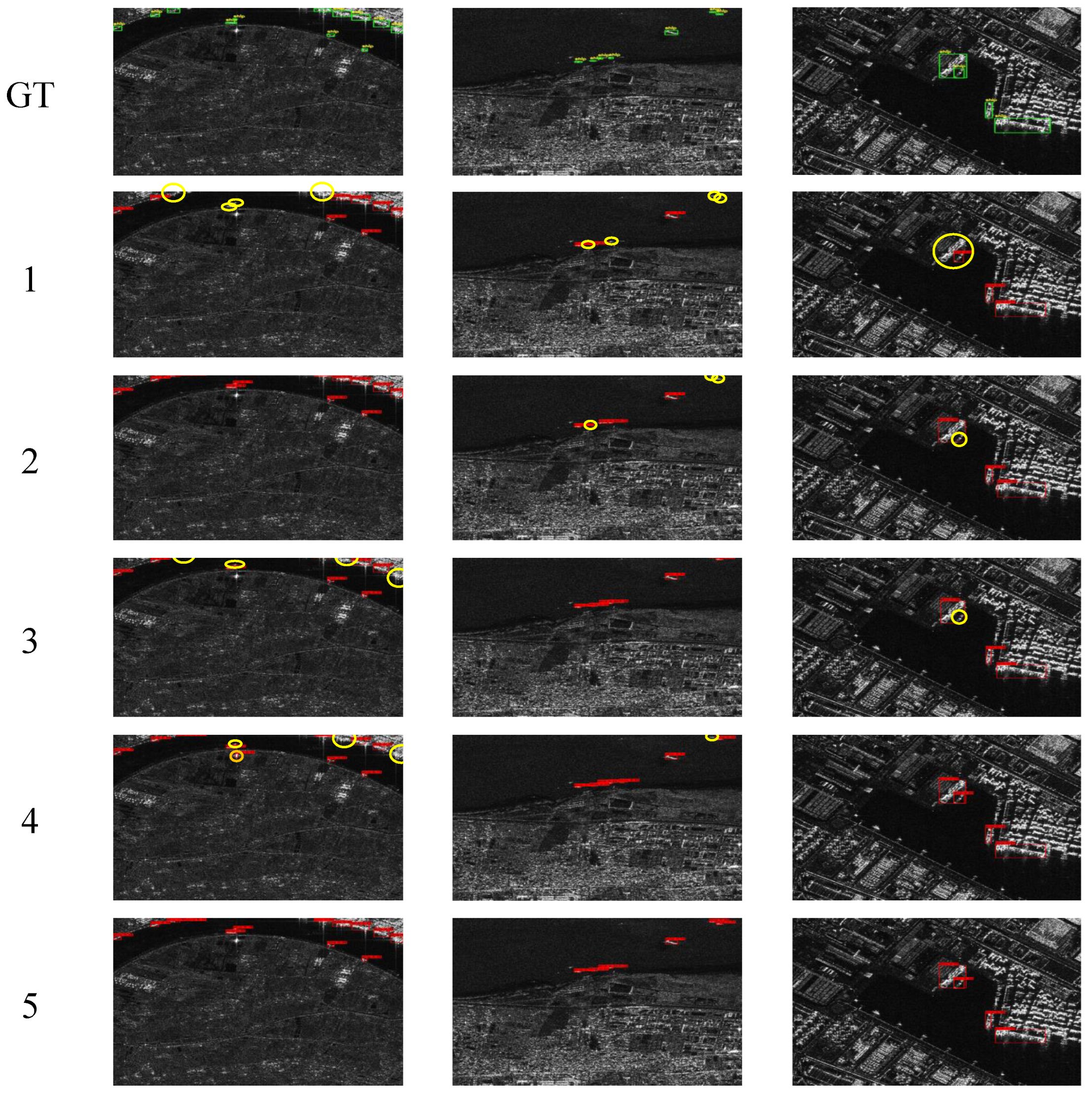
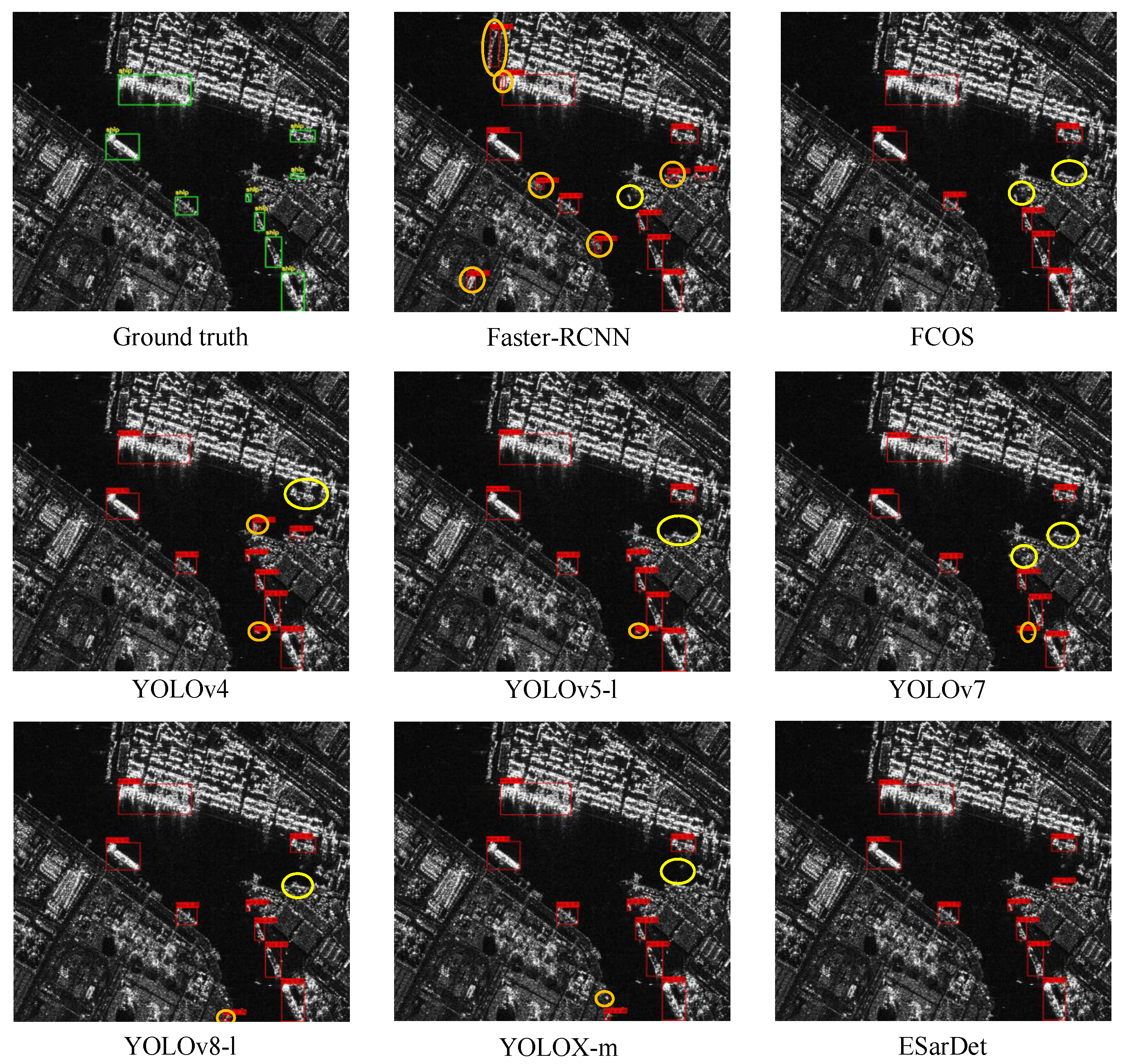
Aiming to achieve efficient ship detection in SAR images, we innovatively design an efficient anchor-free detector, namely ESarDet.
Figure 1 depicts the work flow of the proposed ESarDet. Due to complicated computation and sample imbalance caused by anchor-based methods, we chose the latest lightweight, universal anchor-free object detection model, YOLOX-tiny [
25], as the baseline model. Taking into account the complex backgrounds, large scale variation, small-scale targets, and limited computational resources, three modules are proposed for the baseline model to optimize ship detection performance. First, to improve the detection of small ships in SAR images, we propose CAA-Net, which can effectively fuse context and semantic information. Second, to prevent losing the semantic information of ship targets at the bottom layer and to improve detection efficiency, A2SPPF is designed to replace the SPP in YOLOX-tiny. Lastly, aiming to better detect multi-scale ships, we propose a new convolution block named A2CSPlayer to better fuse feature maps of different scales. In the section that follows, the main components of ESarDet are described in detail.
3.1. CAA-Net
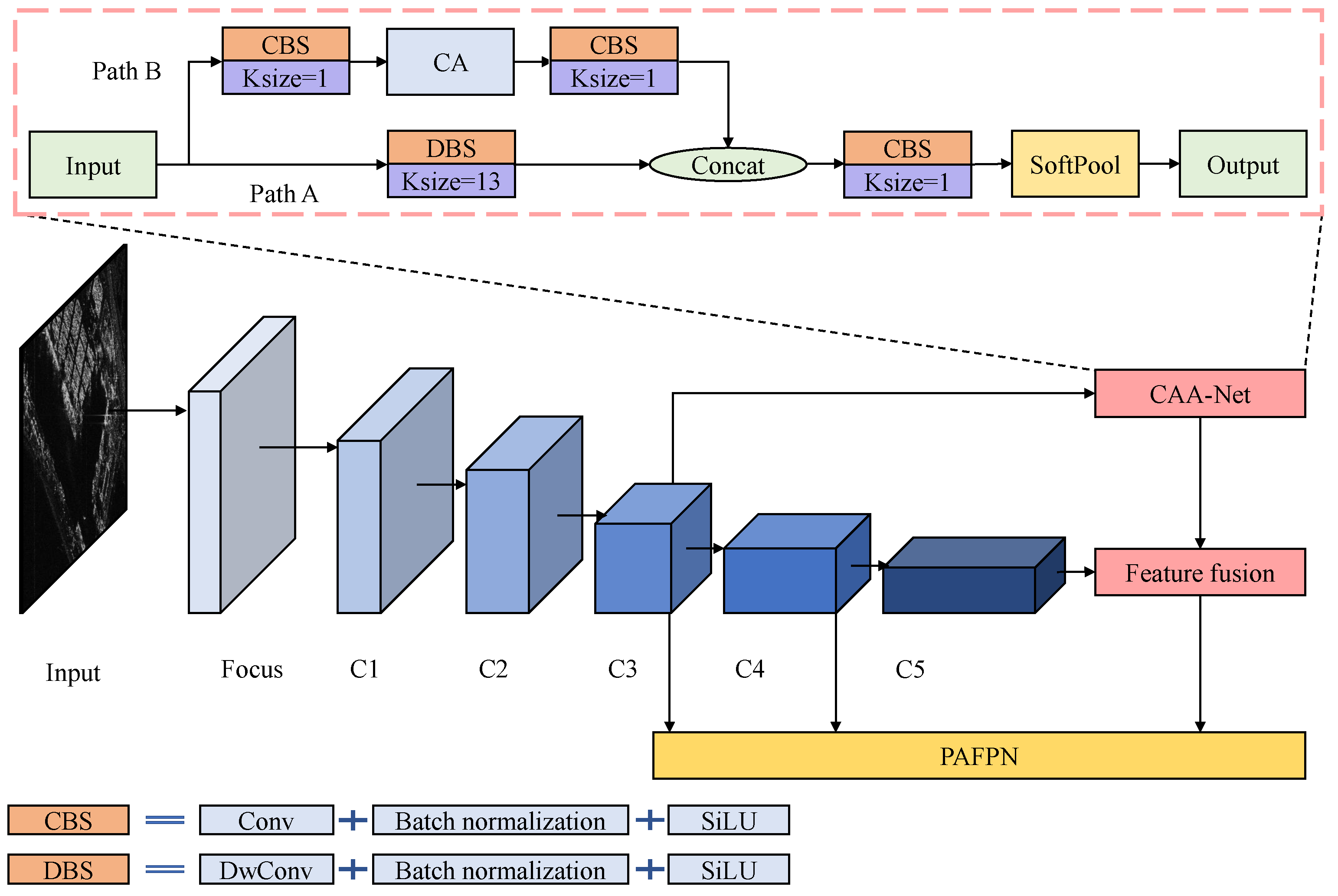
YOLOX-tiny applies a cross-stage partial network (CSPNet) as the backbone, which can enhance the networks’ capacity for learning and reduce memory costs. However, due to the stacking of multiple small kernel convolutions, the ERF of CSPNet is small, which makes it challenging to capture the contextual information of ships. In addition, the network extracts more semantic information but retains less contextual information as the layer’s number of network increases. To address these problems with CSPNet, a context attention auxiliary network (CAA-Net) is proposed to enhance the network’s ability to extract contextual information and to expand the ERF.
Figure 2 depicts the work process of the proposed CAA-Net.
The proposed CAA-Net contains the two path network to process the input feature map C3. In the proposed CAA-Net, path A contains the
depthwise separable convolution (DwConv) block [
34]. Path B contains three parts: a
convolution block, a coordinate attention (CA) module [
35], and a
convolution block. Subsequently, the results of the two paths are concatenated and reshaped via
convolution and SoftPool [
36] to obtain the output of CAA-Net.
Most networks expand the receptive field by stacking convolutions with small kernel sizes. However, stacking small convolutions does not effectively increase the effective receptive field [
37,
38]. A large ERF can help the network better extract the contextual information of ships, especially small ones. The ERF is calculated according to Equation (
1).
where
is a standard deviation that indicates the size of the ERF,
is roughly a Gaussian with mean and variance, and
denotes the Gaussian model of
. Moreover,
m represents the pixel point in the kernel,
k represents the kernel size, and
n denotes the convolution layers.
The ERF of a convolution is proportional to its kernel size and the square root of the number of layers, as demonstrated by the equation. It can be concluded that using a large kernel convolution expands the ERF more effectively than increasing the depth of small convolution layers. The use of large kernel convolution not only expands the effective receptive field but also enhances its ability to extract the contextual information of ships. Therefore, convolution is added to the proposed CAA-Net, expanding the ERF and increasing the extraction of small ship contextual information from SAR images.
Nevertheless, convolution with a large kernel size has a low computational efficiency. In addition, large kernel convolution makes it challenging to extract local features, which play crucial roles in ship detection. We introduce DwConv to increase the computational efficiency and performance of large convolutions to mitigate the aforementioned issues, and the equation of DwConv is shown in Equation (
2).
where
denotes the pointwise convolution operation and
denotes depthwise convolution. Moreover,
represents the feature map’s concatenate operation.
Different from conventional convolution, DwConv decouples the spatial information and cross-channel information of the input feature map. DwConv employs depthwise convolution (DWC) to process the input channel by channel and then concatenates these feature maps, merging them into an output. However, using only DWC to process feature maps may cause a loss of cross-channel information. Thus, pointwise convolution (PWC) is designed, in which convolution is introduced to cope with the cross-channel information. After the whole process mentioned above, a new feature map is generated. Compared with conventional convolution, DwConv significantly reduces the model’s computational cost.
Aiming to balance the contextual information extracted using the large kernel convolution in path A, we add a shortcut path, path B, to CAA-Net. In path B, the input is first processed via a
convolution block, which can prevent network overfitting and increases the generalization ability. Additionally, the
convolution block can deepen the neural network and add more nonlinear information to help extract more features. Moreover, we introduce the CA module, a lightweight attention module, to path B of CAA-Net to better balance the contextual information extracted in path A and enhance the network’s capacity to extract ship location data from SAR images.
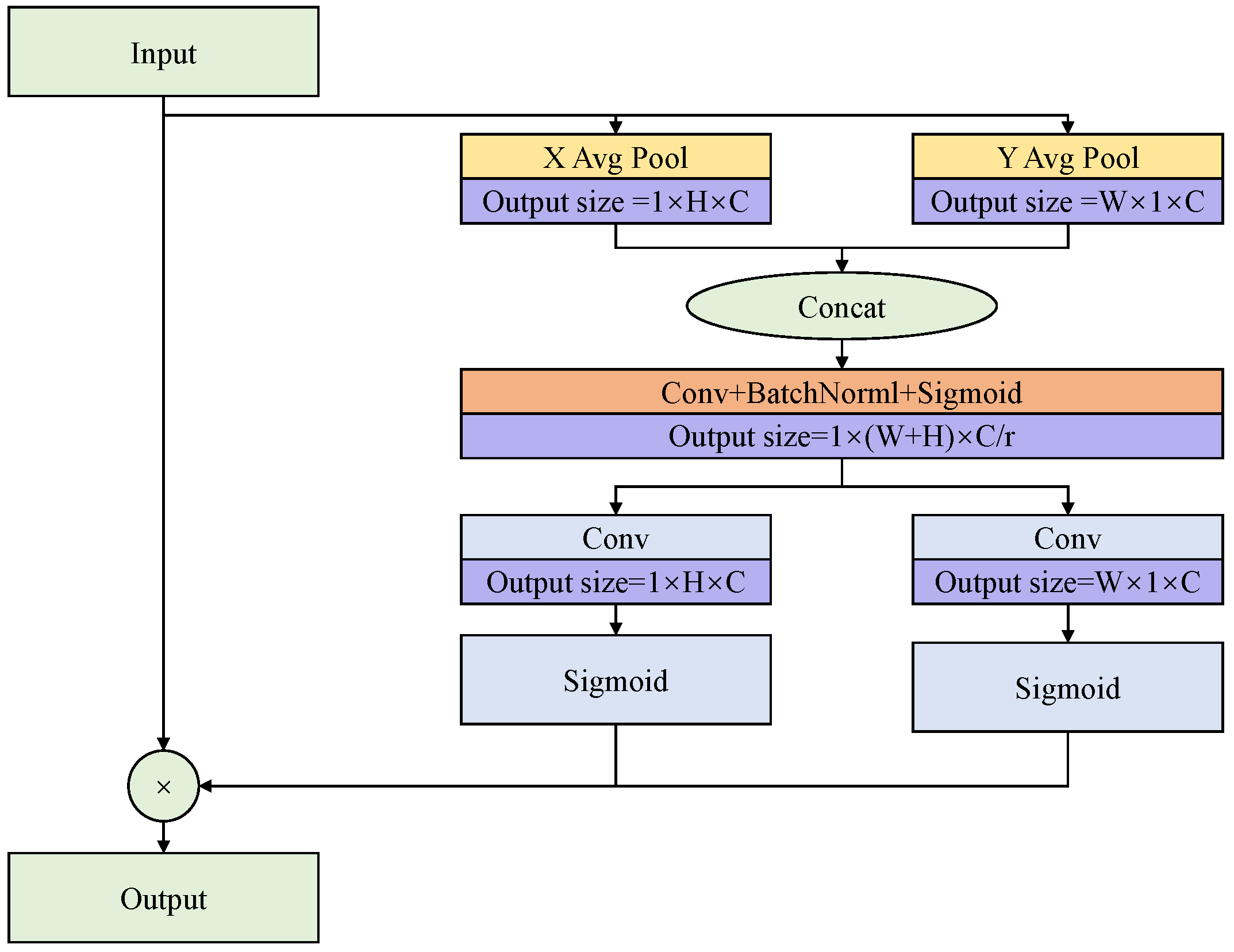
Figure 3 depicts the work process of the CA module.
In particular, the CA module contains two main steps, coordinate information embedding and coordinate attention generation, which can encode channel relations and long-range relations. The input
X is first compressed by X and Y global average pooling to
and
, respectively. After that, the two feature maps are concatenated together. The concatenated results are reshaped to
via a
convolution block (
r = 16 in this paper). The reshaped result is subsequently divided into two distinct feature maps. The two feature maps are transformed into
and
via two additional
convolution and sigmoid functions. Finally, combining the output feature maps into a weighting matrix, the input feature map
X is multiplied by two weighting matrices to refine the weights. The CA module’s operational flow can be summarized as Equations (
3)–(
6).
where
W and
H are the width and height of the input feature map, and
and
denote the results of X Avg Pool and Y Avg Pool, respectively.
,
represents convolution with a kernel size
,
denotes the sigmoid activation function, and
represents the batch normalization operation.
The feature maps, respectively, from path A and path B, are concatenated into a new feature map with a size of . Then, the feature map is reshaped via convolution to .
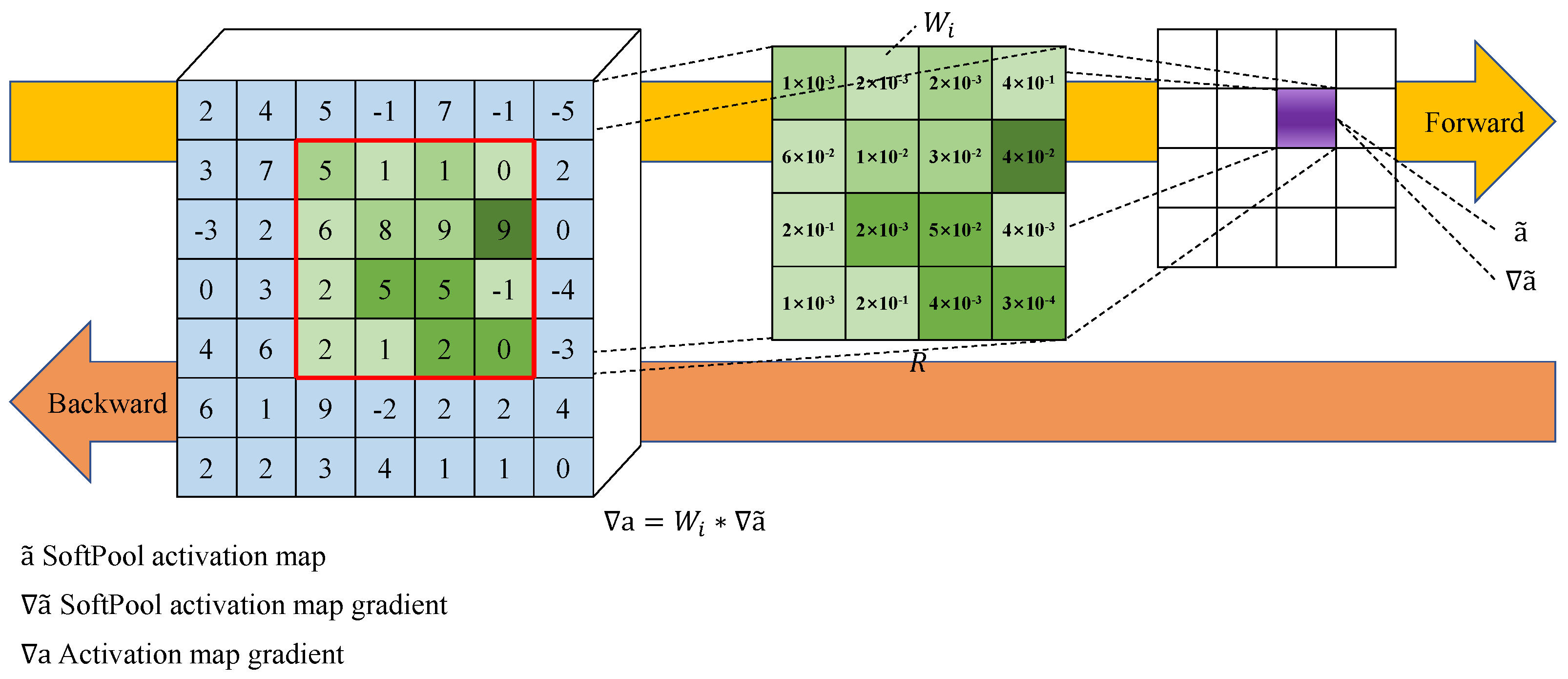
To fuse with the feature map extracted from CSPNet, SoftPool is introduced to downsample the feature map to
, and its operation flow is depicted in
Figure 4. Conventional pooling operations, such as maximum and average pooling, result in the loss of semantic information of the feature map, which affects the precision of SAR ship detection. Unlike conventional pooling operations, SoftPool downsamples the feature map by using softmax of regions, producing normalized results that preserve more semantic information. The forward process of SoftPool can be summarized as Equations (
7) and (
8).
where
R denotes the kernel size of the SoftPool,
e represents the natural exponent,
denotes the input feature map,
is the weights of
, and
is the final output activation map.
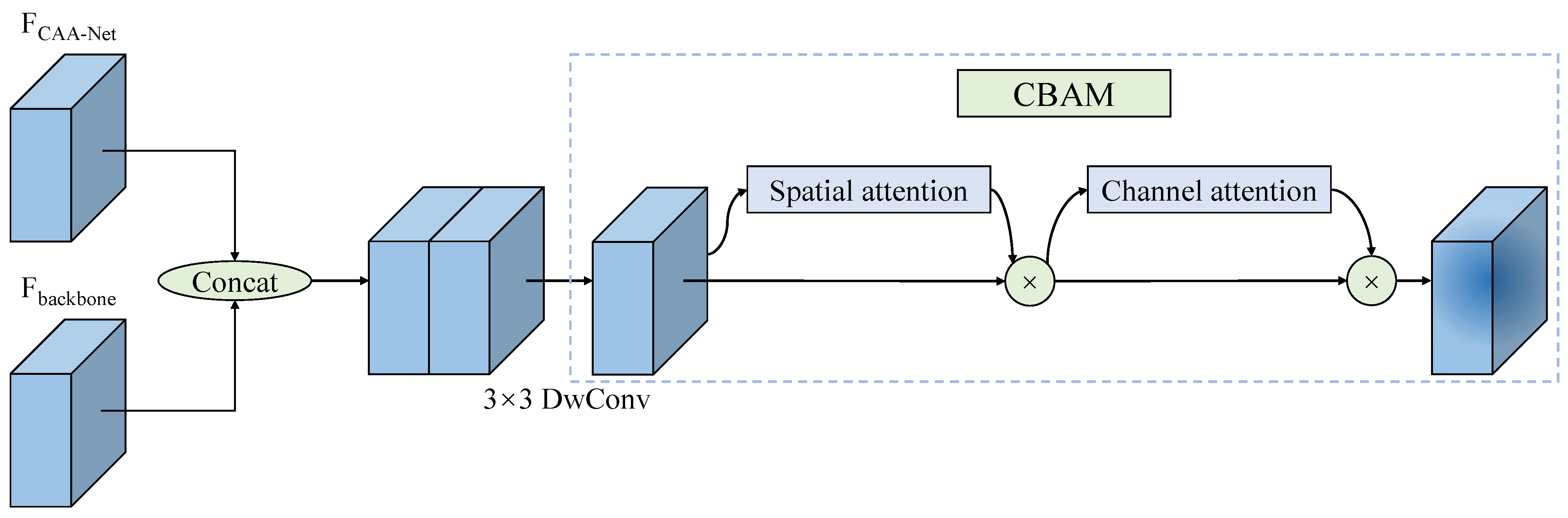
Finally, in order to fuse the contextual information extracted by CAA-Net with the semantic information extracted by the backbone, an efficient feature fusion module is proposed. Its structure is depicted in
Figure 5. The process of the proposed feature fusion module can be summarized in Equations (
9) and (
10).
where
denotes the CBAM attention module, and DBS
3×3 represents a convolution block, which consists of a DwConv with a kernel size of
, batch normalization, and the SiLu activation function.
The feature maps extracted via CAA-Net and the backbone are first concatenated in the feature fusion module. Then, the concatenated result is reshaped via a
DwConv block. To better merge semantic information with contextual information, the convolutional block attention module (CBAM) [
39], a mixed attention module, is subsequently applied to refine the feature map. The CBAM module’s operating principle can be summarized as shown in Equations (
11)–(
13).
where
and
are spatial attention and channel attention modules. MLP is a multilayer perceptron. GAPool and GMPool denote global average pooling (GAPool) and global max pooling (GMPool), respectively. Meanwhile, APool and MPool stand for average pooling (APool) and max pooling (MPool), respectively.
In CBAM, the input feature map will first be calculated via the channel attention submodule. In this submodule, two attention maps are obtained via GAPool and GMPool, respectively. After that, two attention maps are refined independently via a two-layer multilayer perceptron (MLP) and merged by summing the refined feature map. In addition, to normalize the merged results, the sigmoid activation function is also introduced. Finally, to obtain the results of the channel attention submodule, the input is multiplied with the attention map. Then, the spatial attention submodule processes the refined feature map. The feature map, which is processed by the channel attention submodule, is first processed separately by APool and MPool. After that, the two feature maps are concatenated and reshaped via a convolution. As with the channel attention submodule, sigmoid activation functions are also applied to normalize the attention map. The CBAM module’s final result is generated by multiplying the feature map with the attention map extracted by the spatial attention submodule.
3.2. A2SPPF
YOLOX-tiny introduces SPP [
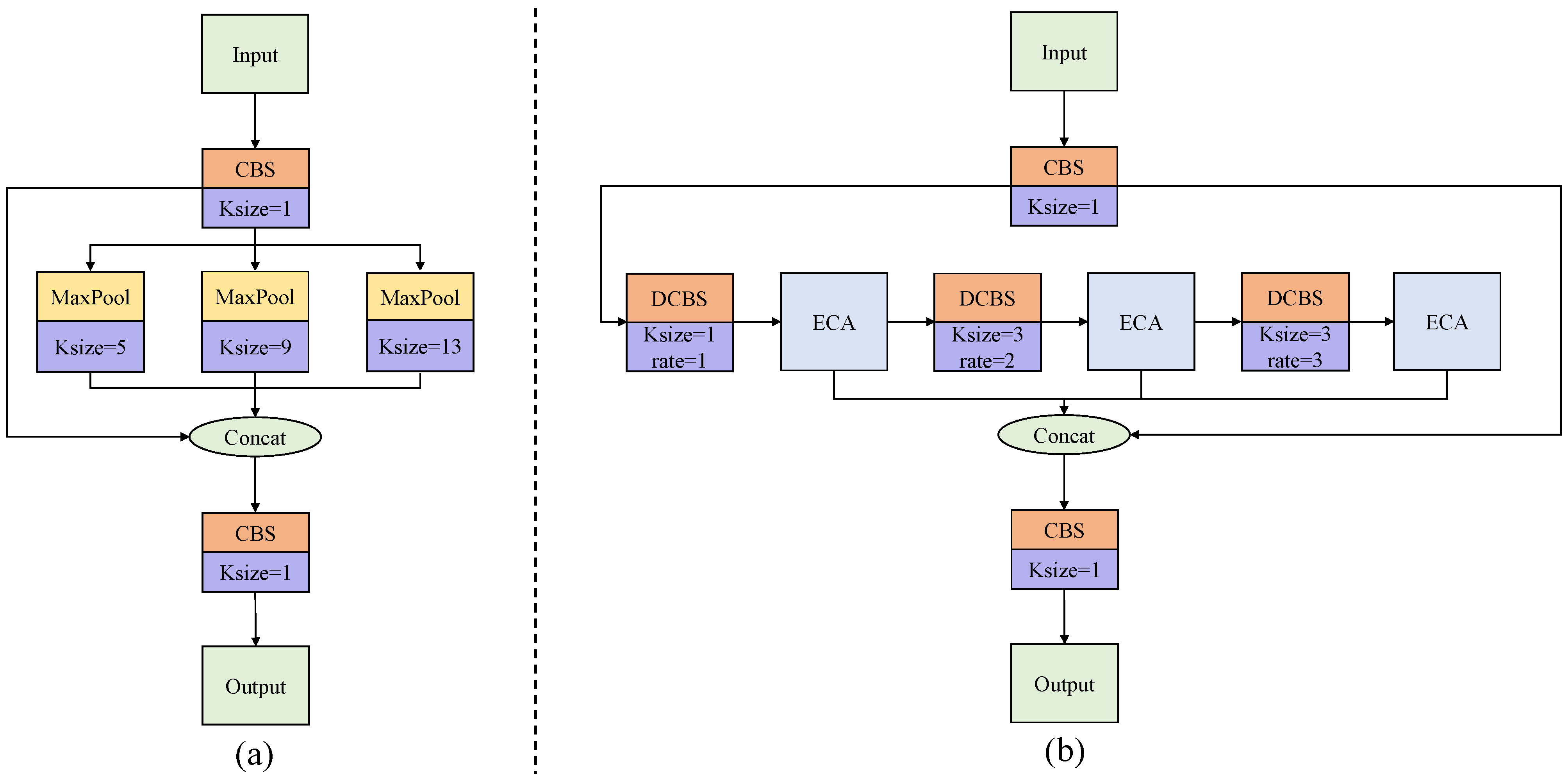
40] in the backbone to remove the fixed-size constraint of the network. As shown in
Figure 6a, in SPP, the input feature map is parallel processed via the three max pooling operation. The three independently processed feature maps are concatenated with a residual feature map and then reshaped via a
convolution block. However, the pooling operations in SPP result in loss of the ship’s semantic information in SAR images. In addition, the parallel processing of three feature maps in SPP leads to a low computational efficiency. Moreover, SPP cannot extract the information in different channels well.
Inspired by [
41,
42,
43], we propose atrous attentive spatial pyramid pooling fast (A2SPPF), and its work flow is depicted in
Figure 6b. In comparison with SPP, the designed A2SPPF employs a serial operation to improve the computational efficiency. Moreover, the proposed A2SPPF replaces the max pooling operation with dilated convolutions with different dilate rates and kernel sizes to expand the ERF and to prevent loss of detailed information in the feature map. The dilation rates of these three dilated convolutions are
, and their kernel sizes are
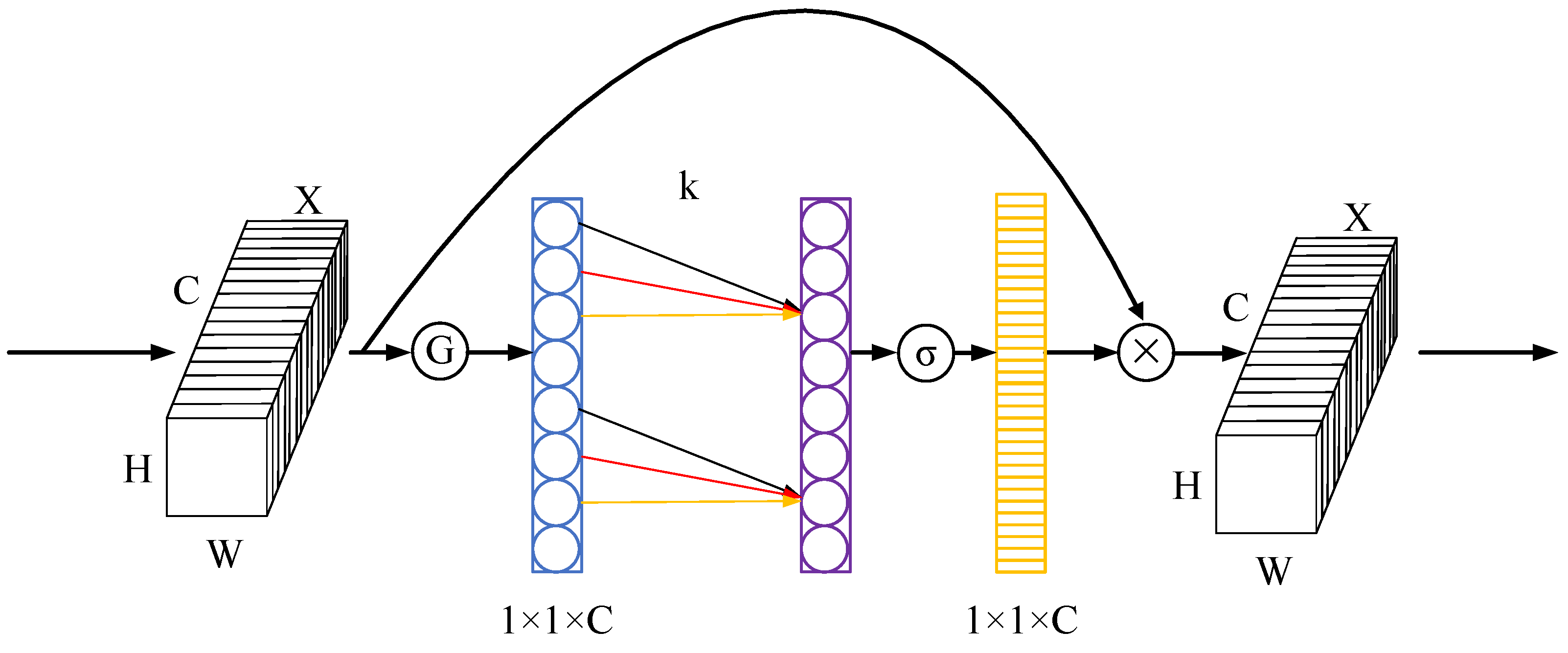
. We also introduce the efficient channel attention (ECA) module, a lightweight attention module [
44], to refine the weights. The structure diagram of the ECA module is depicted in
Figure 7. The ECA operating principle can be summarized as Equation (
14).
where
denotes a 1D convolution with kernel
k, and in this paper,
.
represents the sigmoid activation function. The ECA module obtains a
feature map via GAPool. A 1D convolution and a sigmoid function are subsequently applied to obtain the attention map. Lastly, feature maps are refined by multiplying them with the relevant channels of the input.
Three feature maps, which are processed via the ECA module, are concatenated with the residual feature map. At the end of the proposed A2SPPF, the results are reshaped via a convolution to obtain the final output.
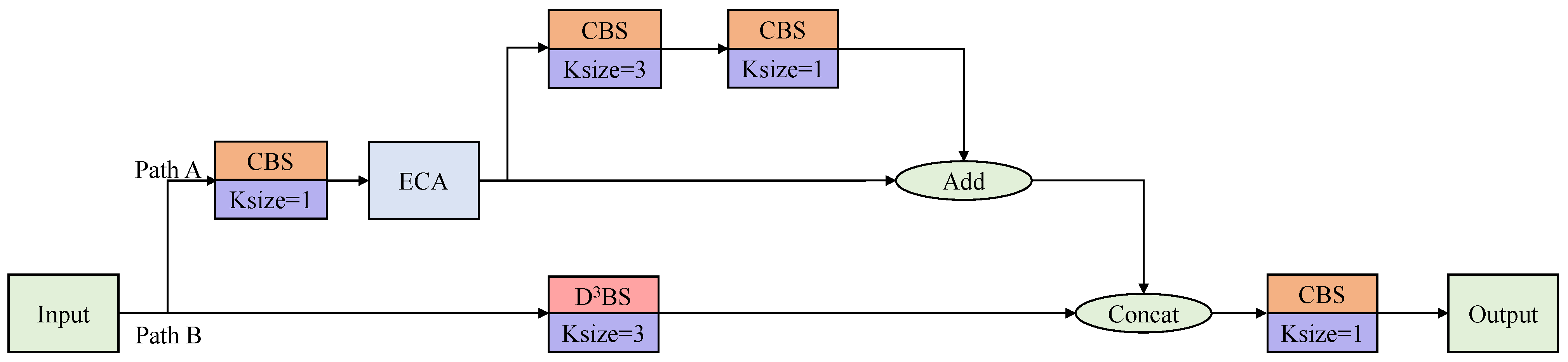
3.3. A2CSPlayer
How to efficiently merge the different scale features extracted from the backbone is an important issue for detecting multi-scale ships in SAR images. YOLOX-tiny introduces PAFPN, in which CSPlayer can effectively merge the feature maps from different scales. The CSPlayer increases the network’s depth by stacking
convolutions, and the bottleneck structure raises the network’s computational efficiency. However, CSPlayer has a small ERF. In addition, it is also challenging for CSPlayer to effectively extract the features of small ships that are scattered in different channels. To achieve more effective fusion of features from different scales, we propose the A2CSPlayer to process the concatenated feature maps. The architecture of the proposed A2CSPlayer is depicted in
Figure 8.
The proposed A2CSPlayer contains two branches. In path A, a
convolution block and an ECA module refine the input feature map
to extract the small ship features scattered in multiple channels. Then, the feature map is split into two parts. In one part, two convolutions with respective kernel sizes of
and
are applied to process the input feature map. Then, the feature map of this part is added to the residual part to generate the final result of path A. The convolution operation of path A can be formulated as Equations (
15) and (
16).
In path B, the input feature map
is processed via the proposed dynamic dilated depthwise separable convolution (
), which has a larger ERF than conventional convolution, and the convolution operation can be expressed as Equation (
17).
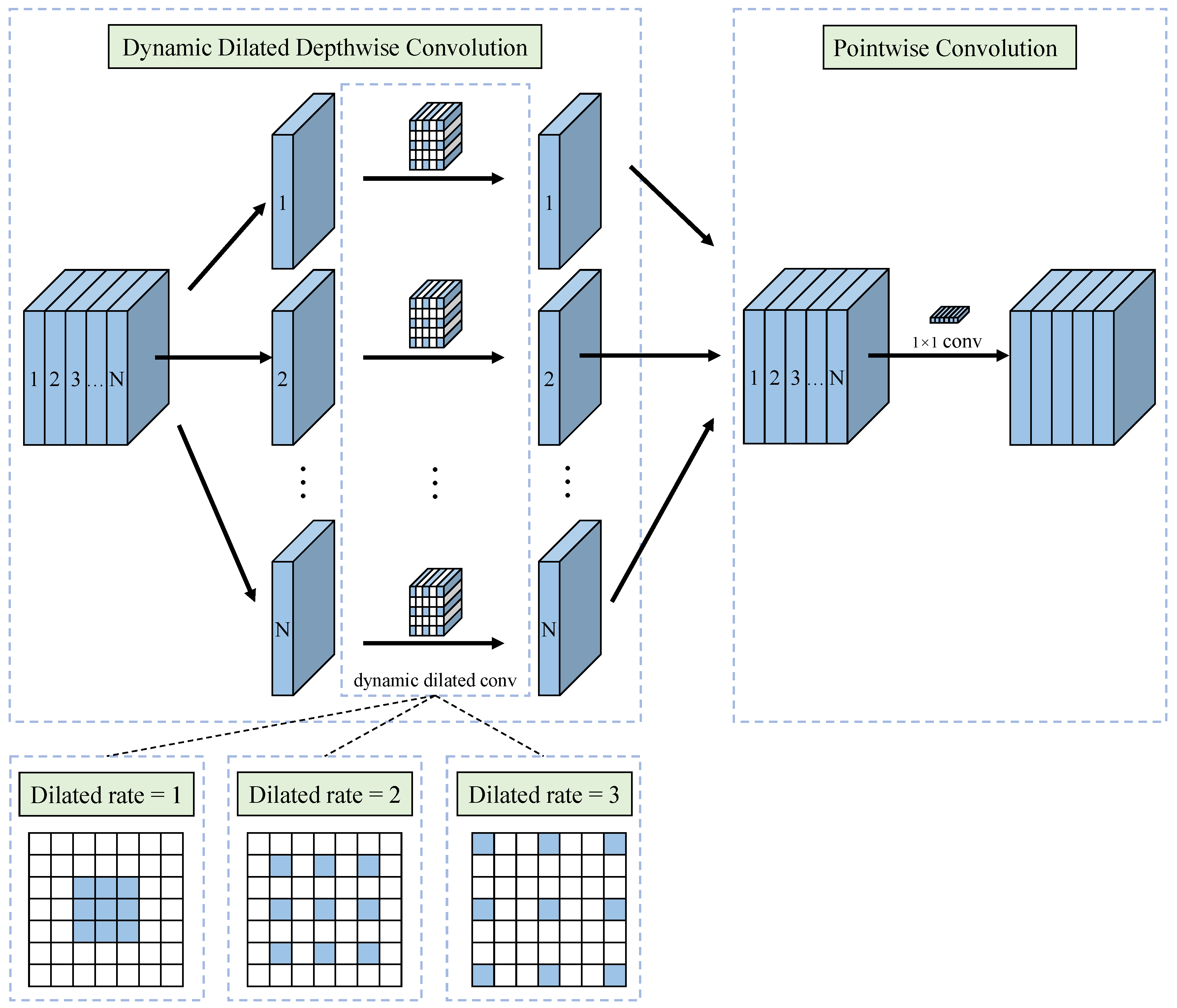
The designed
is shown in
Figure 9. To expand the ERF and to improve the computational efficiency, we first combine DwConv with dilated convolution. To expand the ERF, we substitute the PWC convolution process in DwConv with a dilated convolution. However, feature maps of varying scales have varying widths and heights, and the contextual information they contain varies in scale. To improve the extraction of contextual information, we establish a mapping relationship among the dilation rate of
, the width
and height
of the input image, and the width
and height
of the current feature map.
The proposed mapping relationship should meet both of the following conditions. (1) The dilation rate
increases proportionally with the size of the feature map; (2) to prevent the loss of long-range information due to the large dilation rate, the dilation rate
of the proposed
should be constrained. The proposed mapping relationship is shown in Equation (
18).
where
is a floor operation. In this paper, to meet the two previous conditions above,
k and
b are set to 3 and 0.2, respectively.
Table 1 shows the relationship after calculation among the input image size, the current feature map size, and dilation rate.
After the operation above, the two feature maps obtained from paths A and B are concatenated first. Finally, to obtain the output of the A2CSPlayer, a
convolution block is used to reshape the feature map. The operation can be summarized as Equation (
19).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}