
MC-UNet: Martian Crater Segmentation at Semantic and Instance Levels Using U-Net-Based Convolutional Neural Network




Abstract
:1. Introduction
1.1. U-Net for Image Segmentation
1.2. U-Net for Crater Segmentation
1.3. Unresolved Issues
1.4. Novel Contributions
- (1)
- We present a novel convolutional neural network, i.e., MC-UNet, that is tailored to the task of crater recognition from Mars THEMIS images. The created model MC-UNet has high recognition accuracy of craters, especially when recognizing large-sized craters. Further, MC-UNet is lightweight with fewer parameters, thereby achieving a fast convergence rate with fewer epochs.
- (2)
- We propose a novel, hierarchical-based approach to create the proposed MC-UNet CNN. In particular, first, the structure of the encoder–decoder architecture of MC-UNet is devised, followed by integration of the most-appropriate mechanisms, including downsampling, feature-map fusion and attention. This hierarchical strategy is a particularly effective way to construct an optimal neural network for the task of Martian crater recognition from THEMIS images.
- (3)
- We adopt template matching for the implementation of instance-level Martian crater recognition. By imposing the template matching operation on the prediction map that is predicted by the proposed MC-UNet, potential craters can be progressively identified according to their size.
2. Methodology
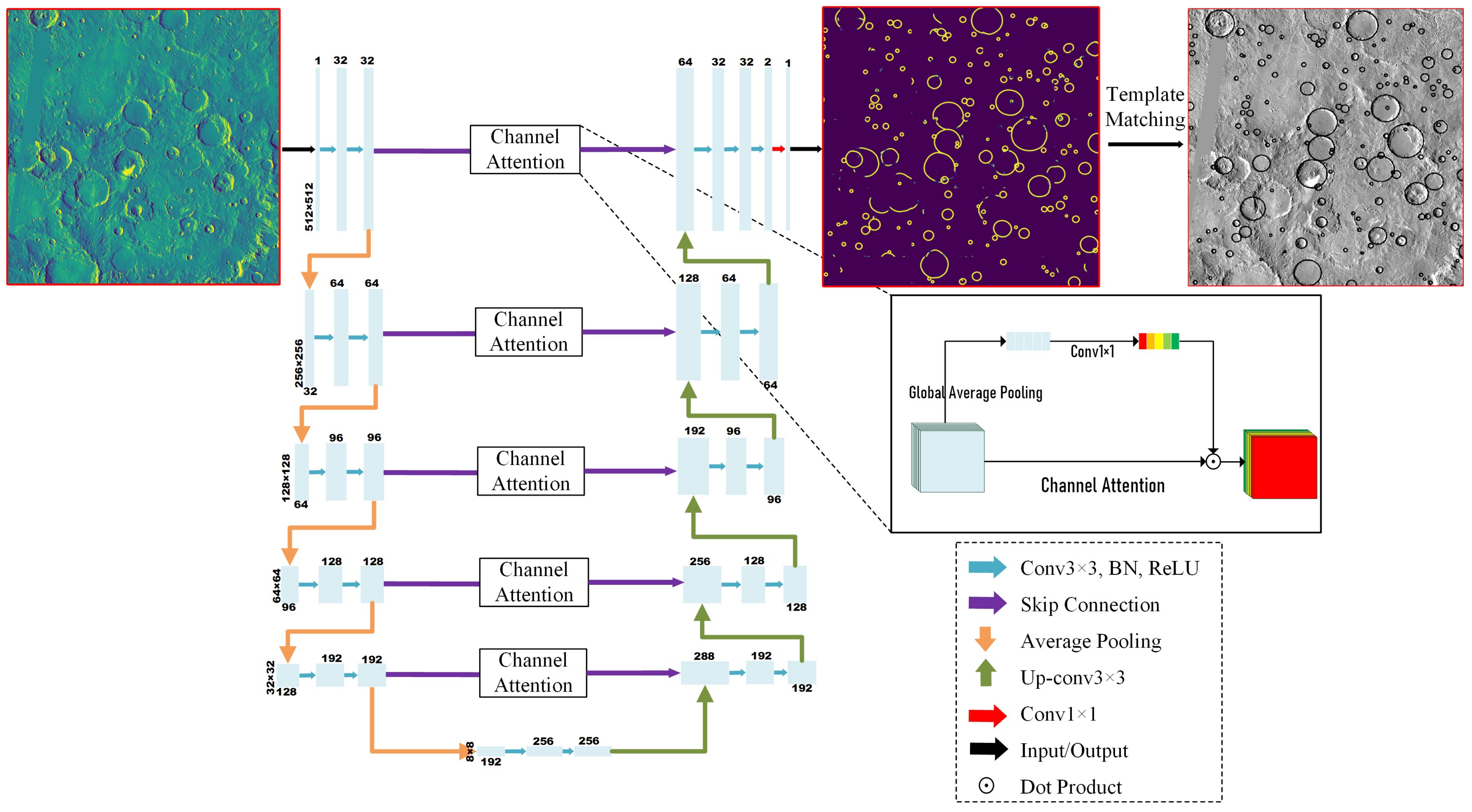
2.1. MC-UNet Framework
2.2. Structure of MC-UNet
2.3. Mechanism of MC-UNet
- (1)
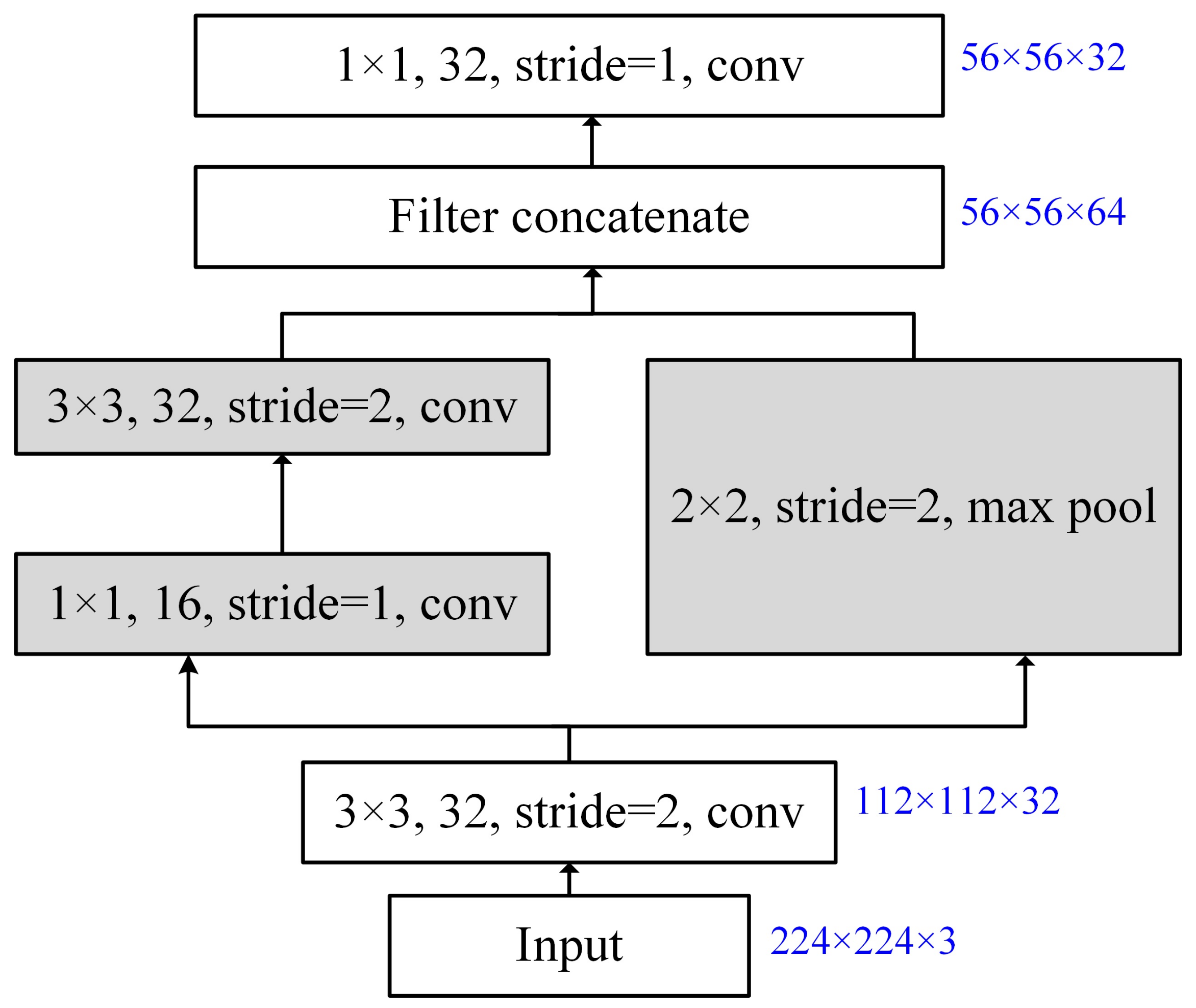
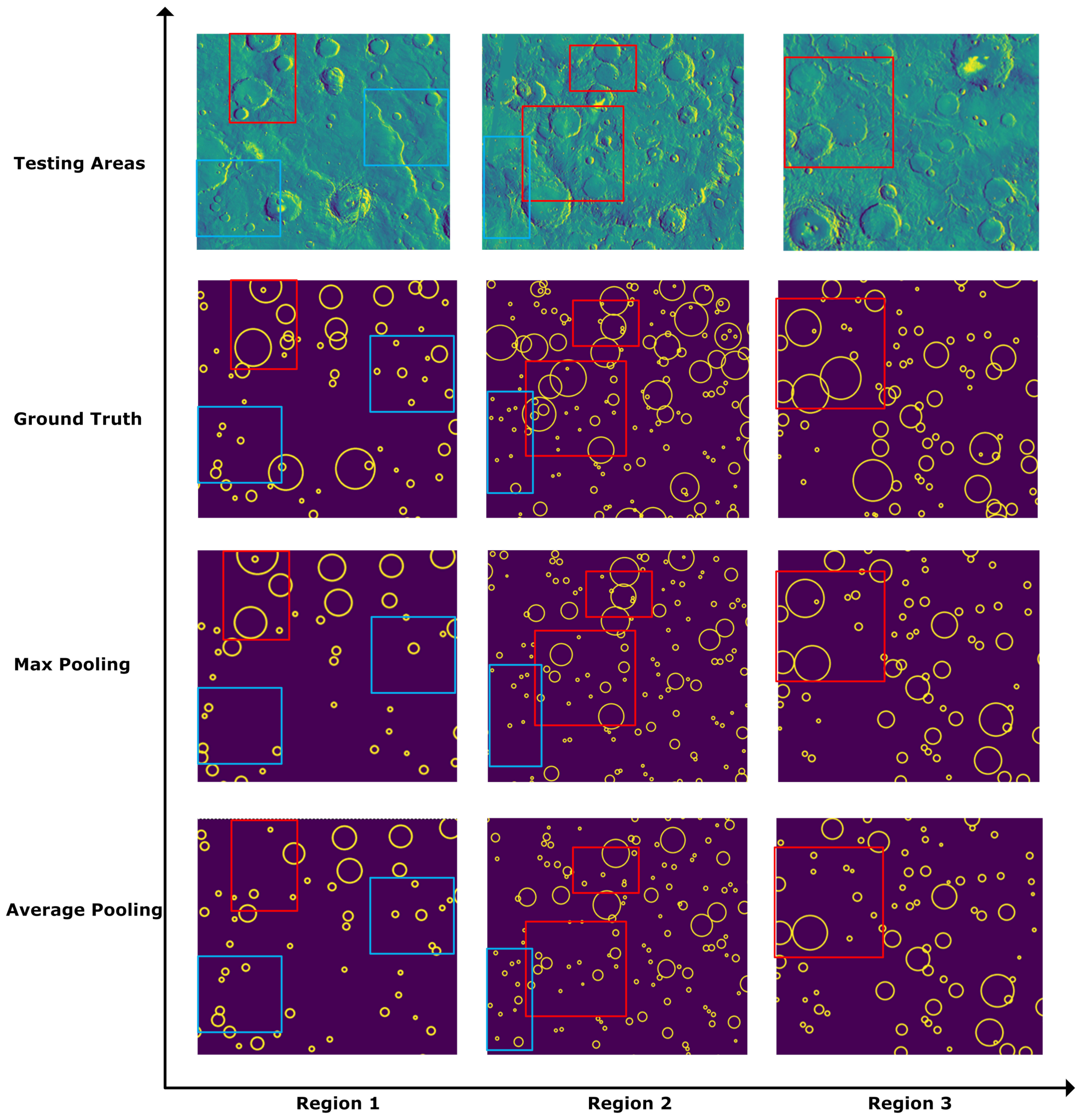
- Downsampling strategy: Downsampling is indispensable in semantic segmentation networks and is usually behind the convolutional layers. Choosing an appropriate downsampling strategy can help the deep learning network expand the receptive field to obtain semantic information at a high level, thereby enhancing the ability of information representation. Some classic semantic segmentation models, e.g., FCN [36], U-Net [17] and SegNet [37], adopt max-pooling downsampling, which selects the maximum value in the receptive field of the pooling kernel. Max pooling emphasizes the foreground information more, i.e., impact crater rim contours of the feature maps; therefore, it strengthens the ability of feature encoding and aggregation of the convolutional layers and enhances the model’s invariance to rotation, translation and scaling. In contrast, average pooling takes the average of all values in the receptive field of the pooling kernel, which implies that the background non-Martian crater contours are more likely to be retained. Although downsampling has strong capability in feature aggregation, one should be aware that the details of the spatial information tend to be lost during a pooling operation. To address such situations, after the traditional convolutional operation, PeleeNet [38] adopts a stem-block module that concatenates the results of max pooling and two consecutive convolutions to finalize the high-level encoding and decrease the loss of information. In this paper, we evaluate Martian crater prediction performance of three pooling strategies, i.e., max pooling, average pooling and stem-block downsampling, from which average pooling is identified as the best one and is hence integrated into MC-UNet for the task of impact crater recognition. We recommend the readers to follow the experiments in Section 3.5 for details.
- (2)
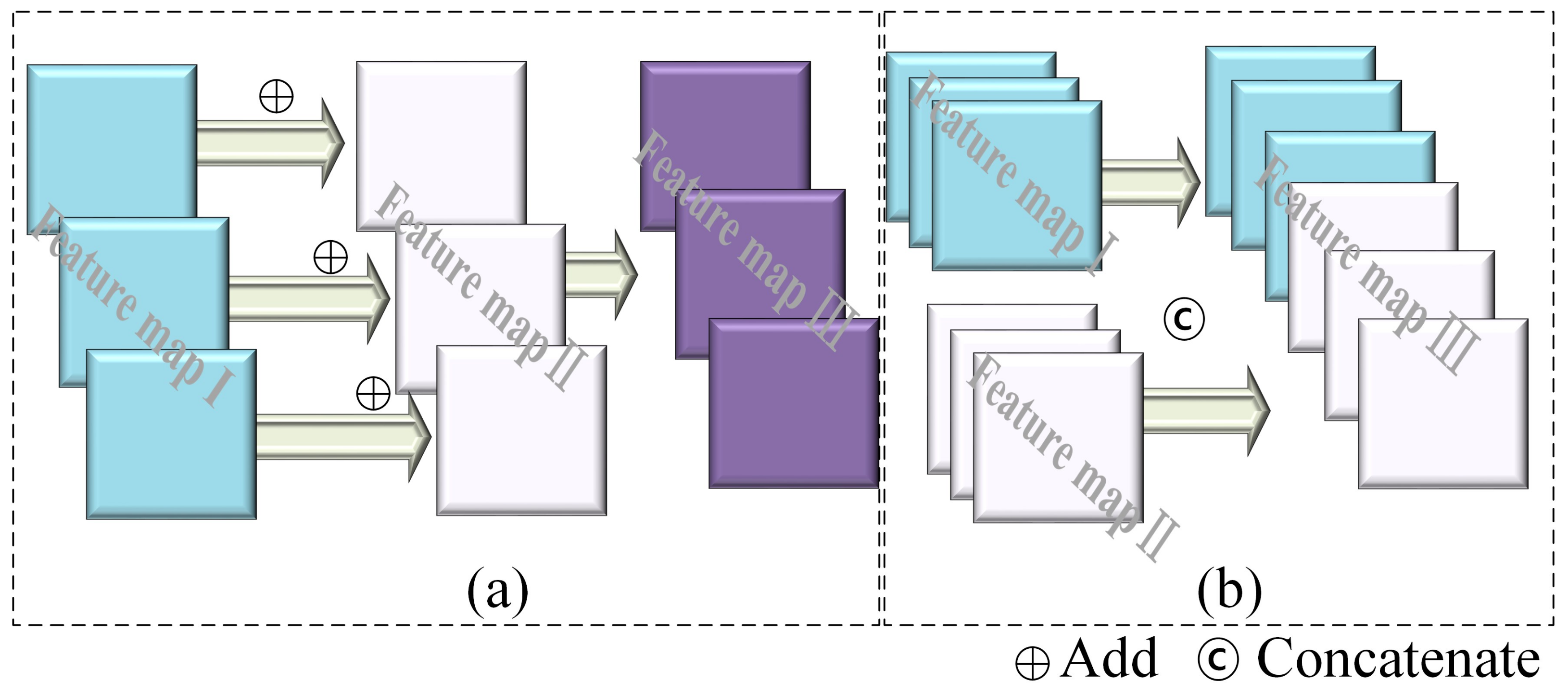
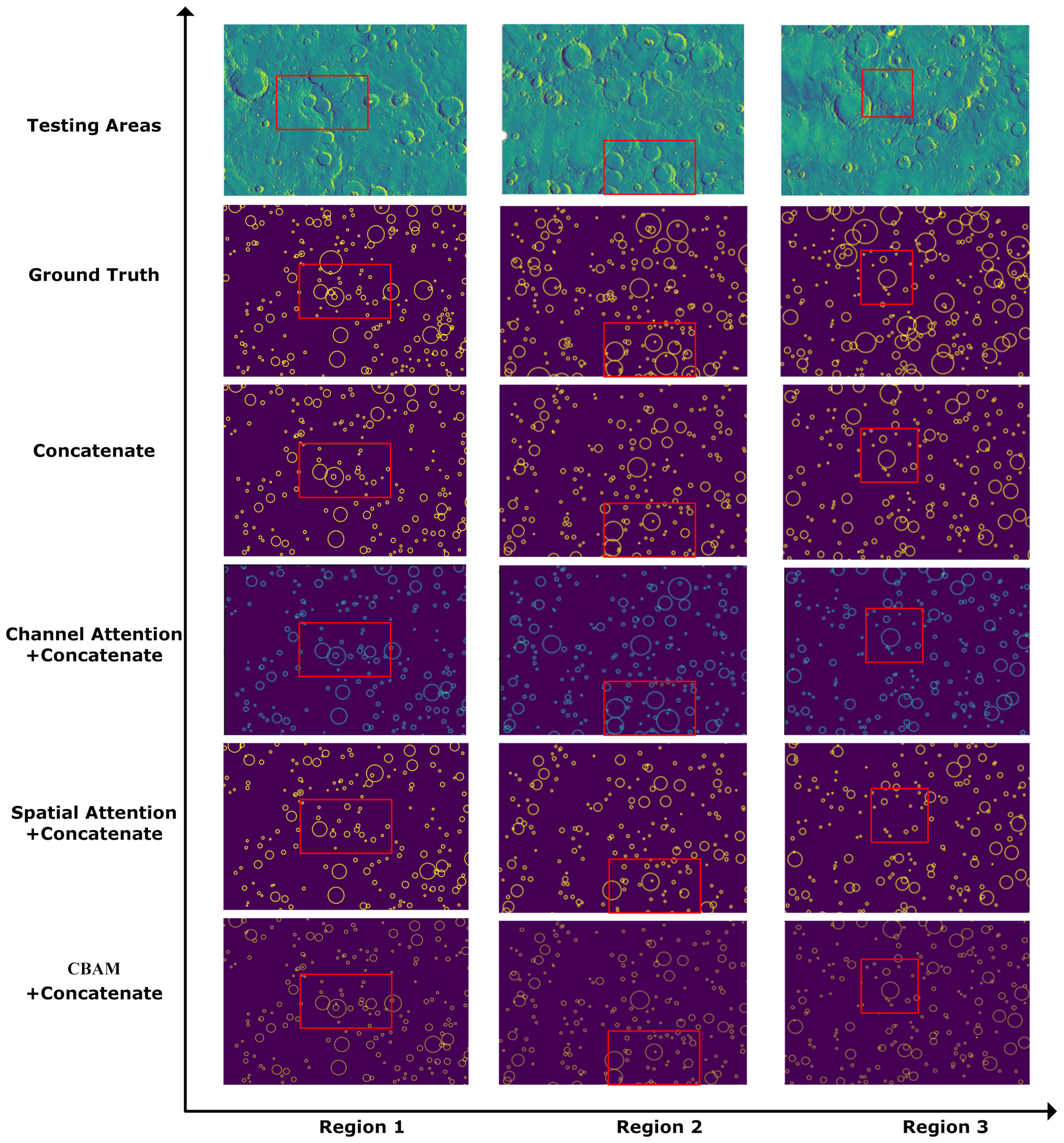
- Feature-map fusion mechanism: The proposed MC-UNet adopts U-Net as a backbone, and it uses a classic skip architecture to combine feature maps from different non-sequential layers. It combines semantic information from the deep, coarse layers and appearance information from the shallow, fine layers [36]. Shallow feature maps tend to capture the overall coarse information, e.g., location, shape and region of impact craters, while more complex patterns such as crater topographic properties and interior morphology are possibly discovered in deeper layers. Figure 3 shows two styles of feature-map fusion, i.e., element-wise adding (Figure 3a) and channel-wise concatenation (Figure 3b). The former is the addition of feature maps and retains the number of channels. The latter is an effective way to stack different feature maps together, which increases the number of channels. These two fusions have been extensively adopted in some classic works. For example, U-Net [17] uses a channel concatenation fusion strategy, while element-wise addition is frequently used in residual networks [33], which are created by stacking multiple residual blocks together to avoid model degeneration with increasing depth. In addition, Crater U-Net [25] also employs element-wise fusion for automatic crater detection on Mars. Inspired by U-Net [17], MC-UNet fuses shallow and deep feature maps by concatenation in the skip-connection architecture, followed by two consecutive convolution operations to merge these feature maps. Through experiments in Section 3.5, we observe that the concatenation fusion style embedded in MC-UNet demonstrates high prediction accuracy not only on semantic crater segmentation but on instance-level crater identification.
- (3)
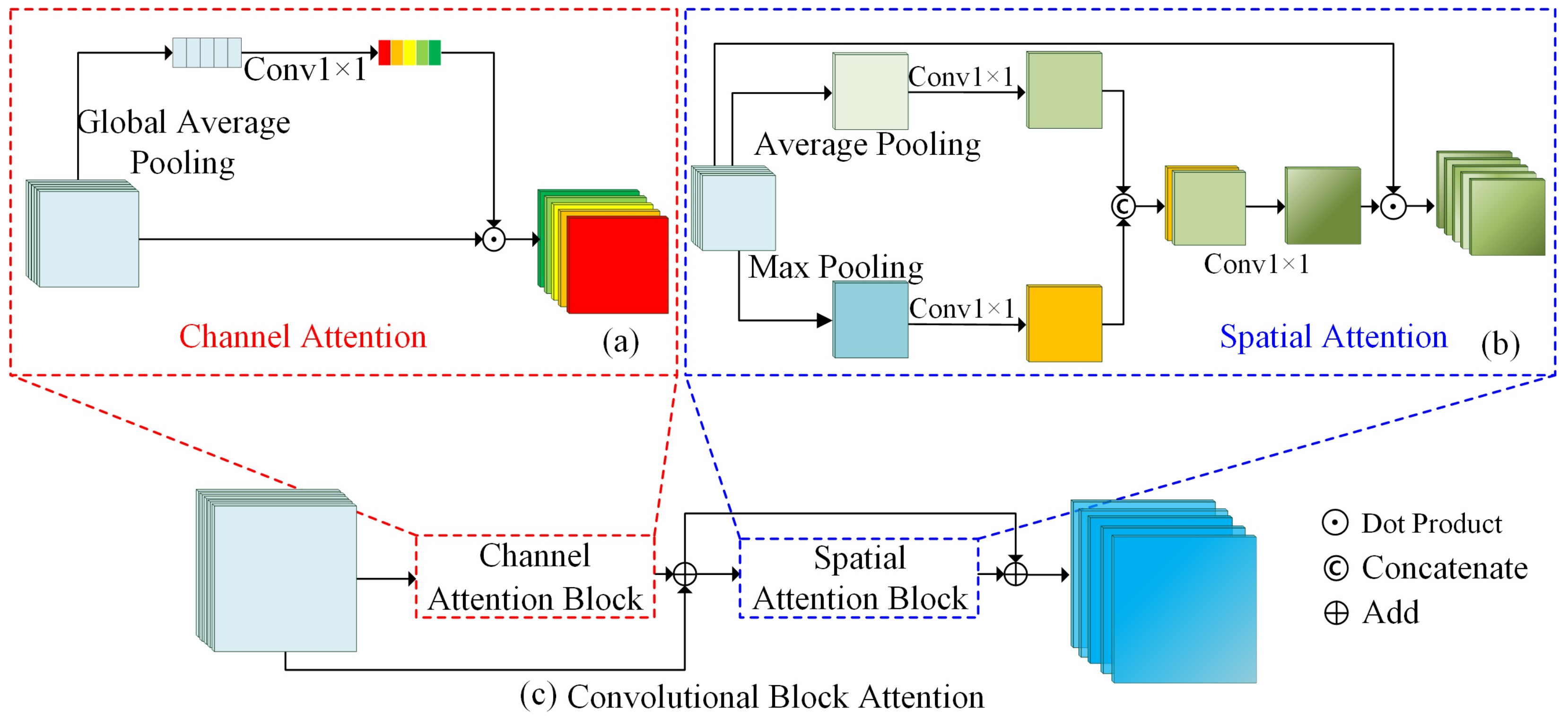
- Attention mechanism: An attention mechanism uses the attention map to weight the feature maps to obtain more refined and highlighted output. More specifically, the attention map is multiplied element-wisely with the input feature map to highlight the regions of interest of input images. Generally, the commonly used attention mechanisms are roughly classified into channel attention, spatial attention and hybrid attention, which integrates channel and spatial attentions. The above three attentions are exhibited in Figure 4. Channel attention (Figure 4a) uses global average pooling to squeeze the spatial information of each layer into one value. Afterward, it commonly uses 1 × 1 convolution to learn a nonlinear and non-mutually exclusive relationship between channels. Spatial attention (Figure 4b) uses average pooling or max pooling operations along the channel axis to squeeze the multiple feature maps into a new spatial context. Then, it usually uses 1 × 1 convolution operations multiple times to learn attention weights, which are multiplied by the input to highlight the informative part of each feature map. Hybrid attention, such as the Convolutional Block Attention Module (CBAM) [39], combines both channel attention and spatial attention in a cascading way to strengthen the extracted feature maps, which provides complementary clues in both channel and spatial dimensions (Figure 4c). In the proposed MC-UNet, we embed these three types of attentions into the skip mechanism of MC-UNet. The experiments show that channel attention can compensate for the loss of fine details in downsampling layers to some extent and exhibits better recognition performance, especially for large-sized Martian craters.
2.4. Template Matching
- (a)
- Circular template generation: We manually create a matrix with size (, and d is the thickness of the ring) as a base plate. Based on this plate, we draw a circle centered on the plate with a radius of . The circle’s thickness (the difference between the radii of inner and outer enclosing circles) is set to , and the corresponding pixel values are set to “1”, while others are set to “0”. In this way, we obtain a circular template with a radius of and thickness of . Considering that the ground truth includes annotations of 2 to 32 km radius Martian craters, we set the range of the circle template as pixels and pixels.
- (b)
- Circular template matching: The circular template slides across the whole binary map . The normalized cross-correlation coefficient between the covered binary map and the circular template is presented in Equation (5):where and represent the circular template and the binary map, respectively. The elements from two tuples and represent the coordinate values of and on the horizontal and vertical axes, respectively. It should be noted that and . If the coefficient is greater than the predefined threshold ( = 0.5), the matching is successful. At this time, statistics such as the template’s radius and position are recorded. The procedures from (a) to (b) are repeated until all the Martian craters with a radius from to have been detected.
- (c)
- Martian crater candidate refinement: The detected crater candidates with varying radii should be further refined by removing the redundant craters according to similarity-based analysis. More specifically, all the detected Martian crater candidates undergo a pairwise comparison to verify whether redundant Martian craters exist. That is, we compare the consistency of position and radius of a pair of craters. We can draw a safe conclusion that one of the impact craters is redundant if they satisfy the the conditions belowwhere and represent the coordinates of the centers of two Martian crater candidates and and represent the radii of crater candidates i and j, respectively. and are two predefined thresholds. In our case, we set = 1.8 pixels and = 1.0 pixels. If the conditions in Equation (6) are true, we just retain the crater candidate with the highest normalized cross-correlation coefficient calculated by Equation (5).
3. Performance Evaluation
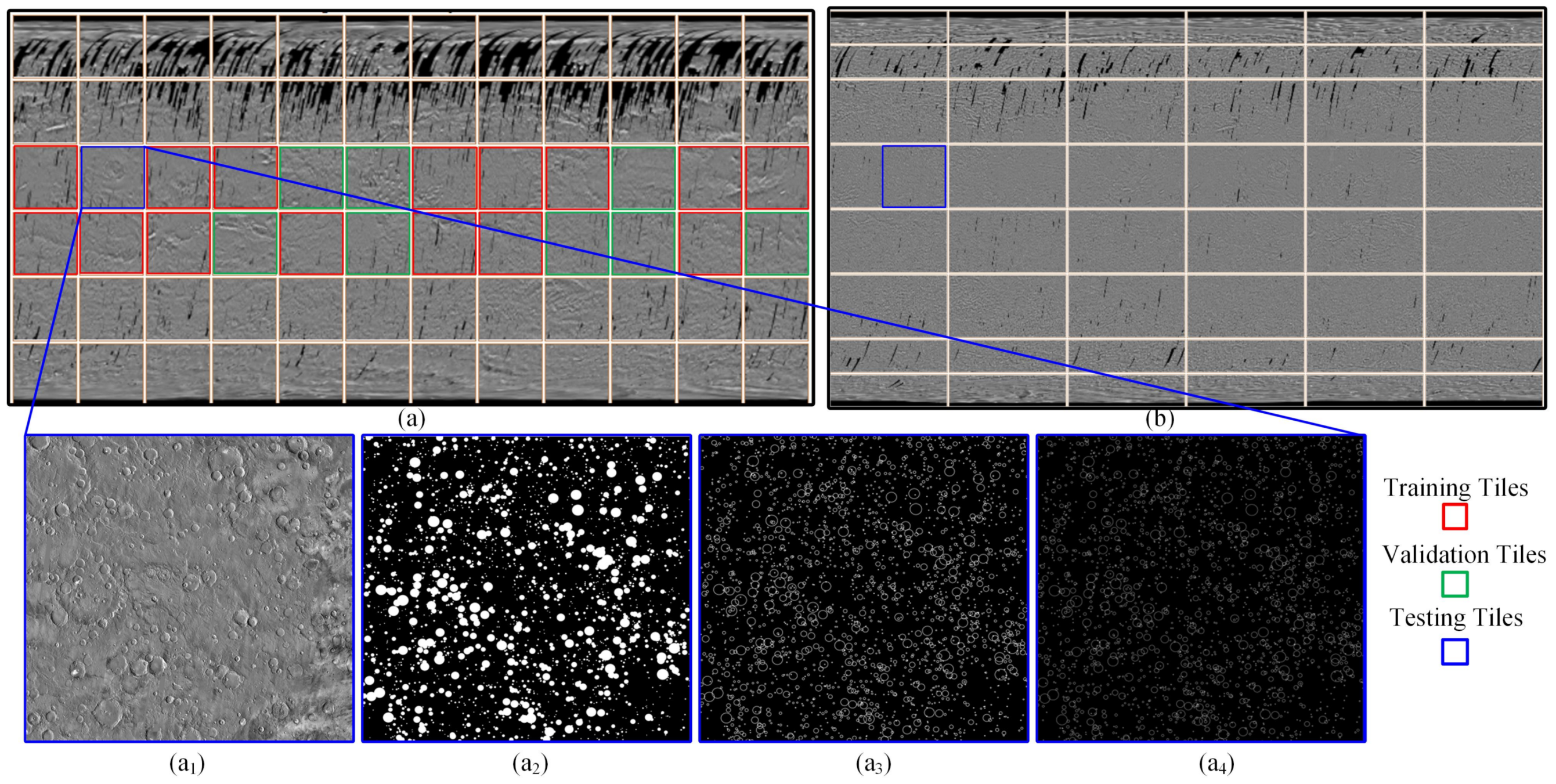
3.1. Dataset Description
3.2. Evaluation Metrics
3.3. Hyperparameter Setting
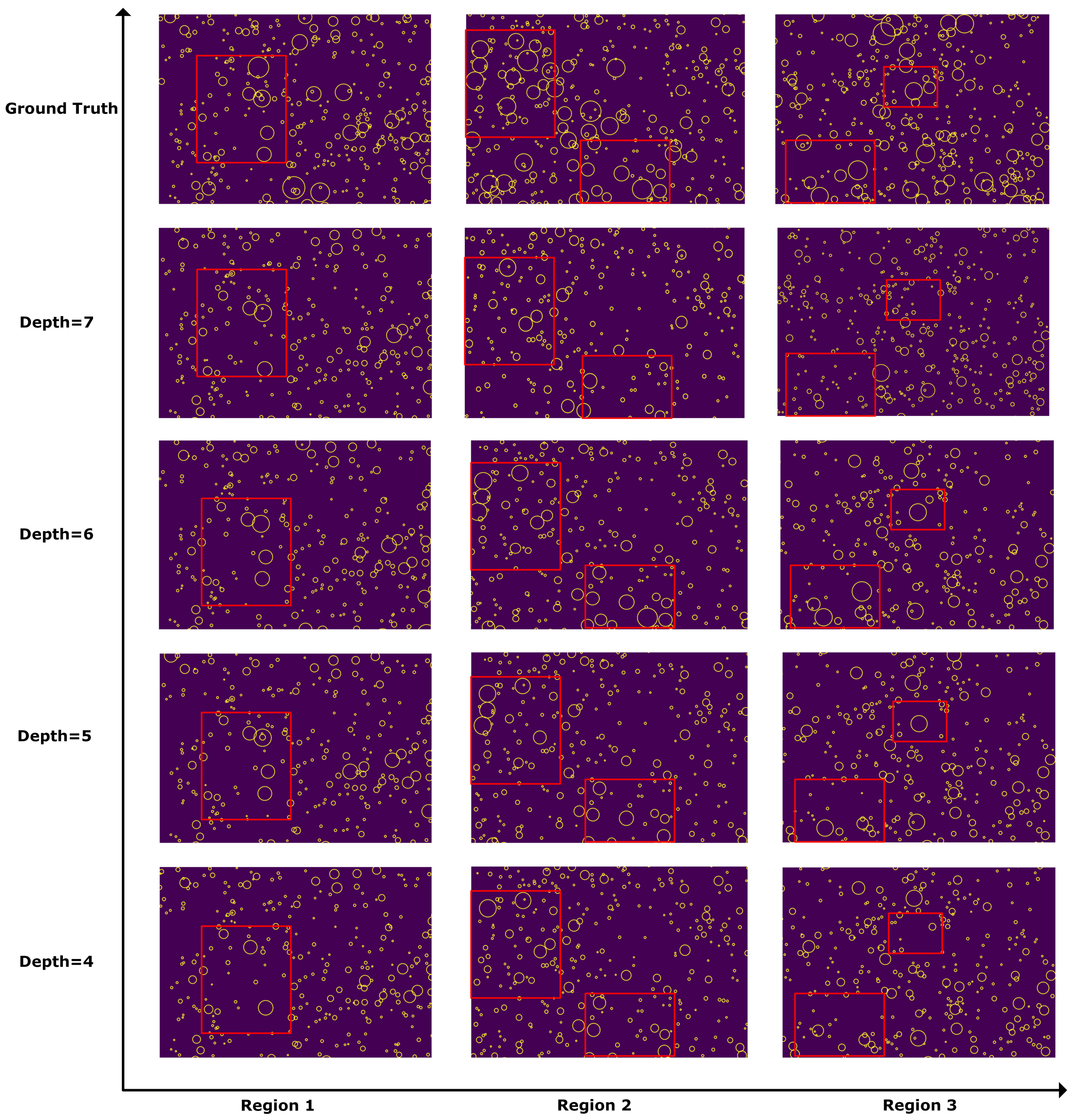
3.4. Structural Experiments
3.5. Mechanism Experiments
3.6. Effects of Structure–Mechanism Combinations
3.7. The Optimal Number of Training Epochs
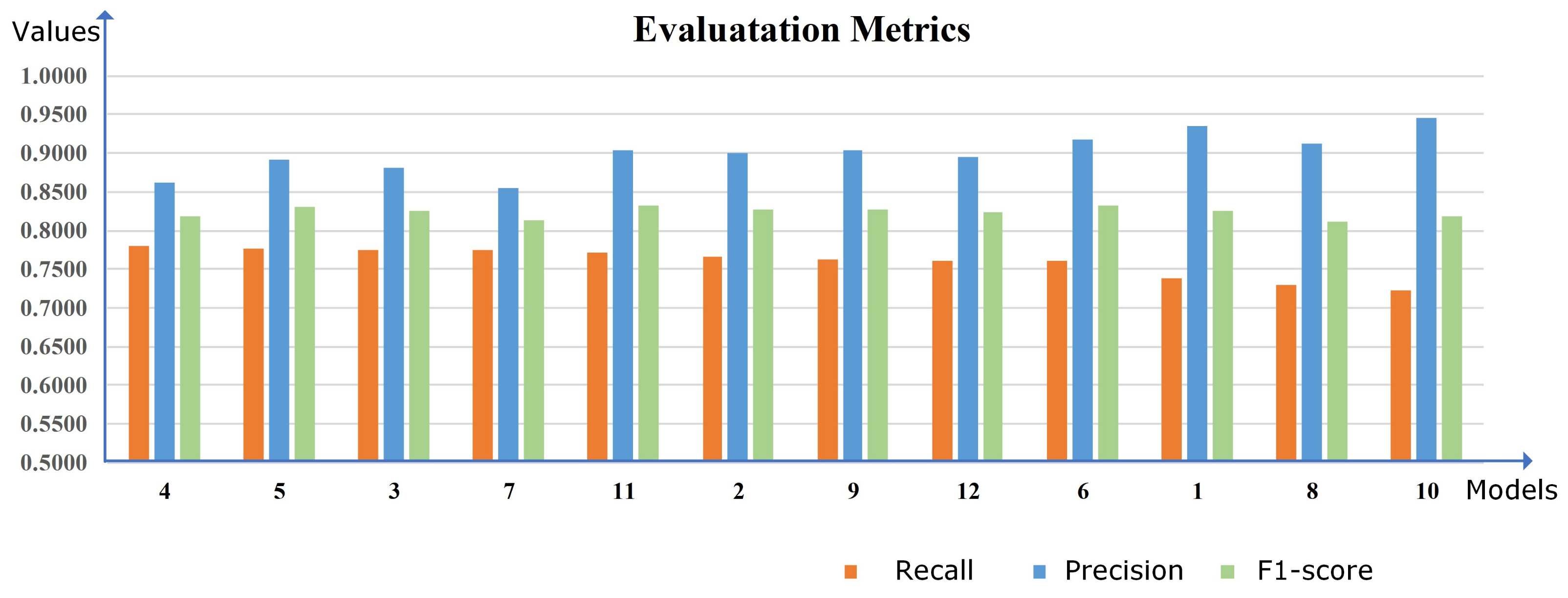
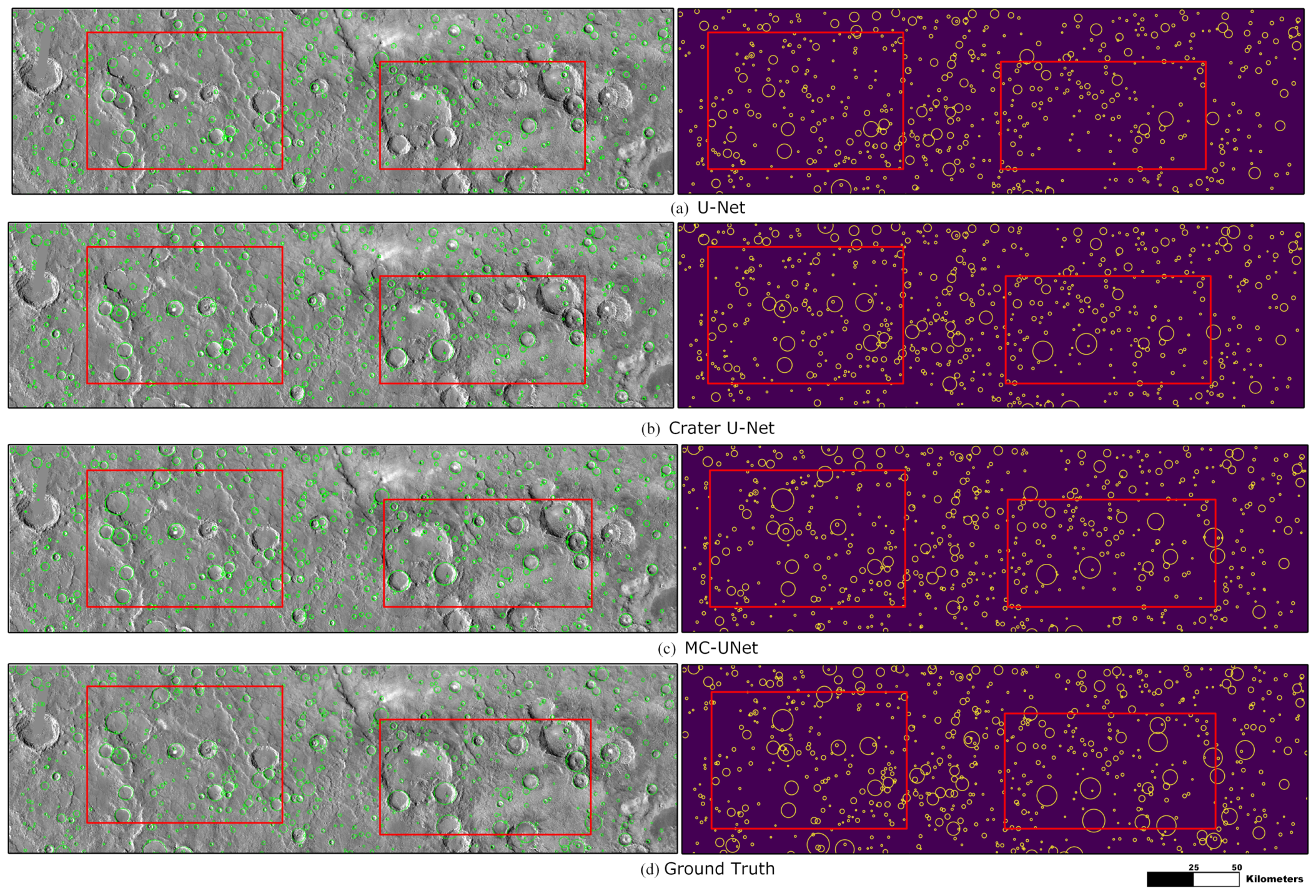
3.8. Performance Comparison with State-of-the-Art Methods
3.9. Performance Comparison on Two Time Periods of Datasets
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pan, L.; Quantin-Nataf, C.; Breton, S.; Michaut, C. The impact origin and evolution of Chryse Planitia on Mars revealed by buried craters. Nat. Commun. 2019, 10, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, D.E.; Viswanathan, V.; Mazarico, E.; Goossens, S.; Head, J.W.; Neumann, G.A.; Zuber, M.T. The Contribution of Small Impact Craters to Lunar Polar Wander. Planet. Sci. J. 2022, 3, 217. [Google Scholar] [CrossRef]
- Thomas, R.J.; Rothery, D.A.; Conway, S.J.; Anand, M. Explosive volcanism in complex impact craters on Mercury and the Moon: Influence of tectonic regime on depth of magmatic intrusion. Earth Planet. Sci. Lett. 2015, 431, 164–172. [Google Scholar] [CrossRef] [Green Version]
- Shuvalov, V.; Artemieva, N.; Kuz’micheva, M.Y.; Losseva, T.; Svettsov, V.; Khazins, V. Crater ejecta: Markers of impact catastrophes. Izv. Phys. Solid Earth 2012, 48, 241–255. [Google Scholar] [CrossRef]
- Neukum, G.; Hiller, K. Martian ages. J. Geophys. Res. Solid Earth 1981, 86, 3097–3121. [Google Scholar] [CrossRef]
- Crater Analysis Techniques Working Group. Standard techniques for presentation and analysis of crater size-frequency data. Icarus 1979, 37, 467–474. [Google Scholar] [CrossRef] [Green Version]
- Udry, A.; Howarth, G.H.; Herd, C.; Day, J.M.; Lapen, T.J.; Filiberto, J. What martian meteorites reveal about the interior and surface of Mars. JGR Planets 2020, 125. [Google Scholar] [CrossRef]
- Moyano-Cambero, C.E.; Trigo-Rodríguez, J.M.; Benito, M.I.; Alonso-Azcárate, J.; Lee, M.R.; Mestres, N.; Martínez-Jiménez, M.; Martín-Torres, F.J.; Fraxedas, J. Petrographic and geochemical evidence for multiphase formation of carbonates in the Martian orthopyroxenite Allan Hills 84001. Meteorit. Planet. Sci. 2017, 52, 1030–1047. [Google Scholar] [CrossRef] [Green Version]
- Lagain, A.; Benedix, G.; Servis, K.; Baratoux, D.; Doucet, L.; Rajšic, A.; Devillepoix, H.; Bland, P.; Towner, M.; Sansom, E.; et al. The Tharsis mantle source of depleted shergottites revealed by 90 million impact craters. Nat. Commun. 2021, 12, 1–9. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Cheng, Y.; Johnson, A.E.; Matthies, L.H.; Olson, C.F. Optical Landmark Detection for Spacecraft Navigation; NASA: Washington, DC, USA, 2003.
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Sawabe, Y.; Matsunaga, T.; Rokugawa, S. Automatic crater detection algorithm for the lunar surface using multiple approaches. J. Remote Sens. Soc. Jpn. 2005, 25, 157–168. [Google Scholar]
- Sawabe, Y.; Matsunaga, T.; Rokugawa, S. Automated detection and classification of lunar craters using multiple approaches. Adv. Space Res. 2006, 37, 21–27. [Google Scholar] [CrossRef]
- Kim, J.R.; Muller, J.P.; van Gasselt, S.; Morley, J.G.; Neukum, G. Automated crater detection, a new tool for Mars cartography and chronology. Photogramm. Eng. Remote Sens. 2005, 71, 1205–1217. [Google Scholar] [CrossRef] [Green Version]
- Bandeira, L.; Saraiva, J.; Pina, P. Impact crater recognition on Mars based on a probability volume created by template matching. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4008–4015. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Saeedizadeh, N.; Minaee, S.; Kafieh, R.; Yazdani, S.; Sonka, M. COVID TV-Unet: Segmenting COVID-19 chest CT images using connectivity imposed Unet. Comput. Methods Programs Biomed. Update 2021, 1, 100007. [Google Scholar] [CrossRef]
- Heidler, K.; Mou, L.; Baumhoer, C.; Dietz, A.; Zhu, X.X. HED-UNet: Combined segmentation and edge detection for monitoring the Antarctic coastline. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar]
- Yu, M.; Chen, X.; Zhang, W.; Liu, Y. AGs-Unet: Building Extraction Model for High Resolution Remote Sensing Images Based on Attention Gates U Network. Sensors 2022, 22, 2932. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1395–1403. [Google Scholar]
- Silburt, A.; Ali-Dib, M.; Zhu, C.; Jackson, A.; Valencia, D.; Kissin, Y.; Tamayo, D.; Menou, K. Lunar crater identification via deep learning. Icarus 2019, 317, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Barker, M.; Mazarico, E.; Neumann, G.; Zuber, M.; Haruyama, J.; Smith, D. A new lunar digital elevation model from the Lunar Orbiter Laser Altimeter and SELENE Terrain Camera. Icarus 2016, 273, 346–355. [Google Scholar] [CrossRef] [Green Version]
- DeLatte, D.M.; Crites, S.T.; Guttenberg, N.; Tasker, E.J.; Yairi, T. Segmentation convolutional neural networks for automatic crater detection on mars. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2944–2957. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Jia, Y.; Liu, L.; Zhang, C. Moon impact crater detection using nested attention mechanism based UNet++. IEEE Access 2021, 9, 44107–44116. [Google Scholar] [CrossRef]
- Hong, Z.; Fan, Z.; Zhou, R.; Pan, H.; Zhang, Y.; Han, Y.; Wang, J.; Yang, S.; Jin, Y. Pyramidal Image Segmentation Based on U-Net for Automatic Multiscale Crater Extraction. Sensors Mater. 2022, 34, 237–250. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Yahyatabar, M.; Jouvet, P.; Cheriet, F. Dense-Unet: A light model for lung fields segmentation in Chest X-Ray images. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), IEEE, Montreal, QC, Canada, 20–24 July 2020; pp. 1242–1245. [Google Scholar]
- Yang, X.; Li, X.; Ye, Y.; Zhang, X.; Zhang, H.; Huang, X.; Zhang, B. Road detection via deep residual dense u-net. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), IEEE, Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 June 2018; pp. 3–19. [Google Scholar]
- Robbins, S.J.; Hynek, B.M. A new global database of Mars impact craters ≥ 1 km: 1. Database creation, properties, and parameters. J. Geophys. Res. Planets 2012, 117, 2011JE003966. [Google Scholar] [CrossRef]
- Zuber, M.T.; Smith, D.; Solomon, S.; Muhleman, D.; Head, J.; Garvin, J.; Abshire, J.; Bufton, J. The Mars Observer laser altimeter investigation. J. Geophys. Res. Planets 1992, 97, 7781–7797. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Channel/Depth | Accuracy | Training Time (s) | Model Size (MB) | Epoch | Recall | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | (16→64→128) / 2 | 0.9803 | 148 | 6.69 | 50 | 0.6426 | 0.9540 | 0.7679 |
| 2 | (16→32→64→128) / 3 | 0.9819 | 124 | 7.12 | 40 | 0.7060 | 0.9045 | 0.7930 |
| 3 | (16→32→48→64→128) / 4 | 0.9821 | 85 | 8.19 | 30 | 0.7157 | 0.8991 | 0.7970 |
| 4 | (16→32→48→64→96→128) / 5 | 0.9819 | 83 | 11.87 | 25 | 0.7055 | 0.9024 | 0.7919 |
| 5 | (16→32→48→64→72→96→128) / 6 | 0.9822 | 96 | 15.88 | 20 | 0.6967 | 0.9435 | 0.8015 |
| 6 | (16→32→48→64→72→96→128→128) / 7 | 0.9824 | 103 | 27.46 | 15 | 0.7038 | 0.8768 | 0.7808 |
| Model | Channel/Depth | EC | Accuracy | Training Time (s) | Model Size (MB) | Epoch | Recall | Precision | -Score | #DC | #MC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | (16→32→48→64→96→128) / 5 | 1.0 | 0.9824 | 83 | 11.87 | 25 | 0.7055 | 0.9024 | 0.7919 | 1763 | 1591 |
| 2 | (24→48→72→96→144→192) / 5 | 1.5 | 0.9827 | 124 | 30.83 | 20 | 0.6448 | 0.9642 | 0.7728 | 1508 | 1454 |
| 3 | (32→64→96→128→192→256) / 5 | 2.0 | 0.9832 | 136 | 54.49 | 20 | 0.7374 | 0.9353 | 0.8247 | 1778 | 1663 |
| 4 | (16→32→48→64→72→96→128) / 6 | 1.0 | 0.9822 | 96 | 15.88 | 20 | 0.6967 | 0.9435 | 0.8015 | 1665 | 1571 |
| 5 | (24→48→72→96→108→144→192) / 6 | 1.5 | 0.9822 | 142 | 38.22 | 20 | 0.7614 | 0.8725 | 0.8132 | 1968 | 1717 |
| 6 | (32→64→96→128 →144→192→256) / 6 | 2.0 | 0.9829 | 159 | 108.16 | 15 | 0.7752 | 0.8543 | 0.8128 | 2046 | 1748 |
| Downsampling | Accuracy | Training Time (s) | Model Size (MB) | Epoch | Recall | Precision | -Score |
|---|---|---|---|---|---|---|---|
| Max Pooling | 0.9832 | 136 | 54.49 | 20 | 0.7374 | 0.9353 | 0.8247 |
| Average Pooling | 0.9835 | 130 | 54.49 | 20 | 0.7796 | 0.8613 | 0.8184 |
| Stem-Block Pooling | 0.9835 | 186 | 58.43 | 170 | 0.7211 | 0.9356 | 0.8073 |
| Model | Configuration | Accuracy | Training Time (s) | Model Size (MB) | Epoch | Recall | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Concat. | 0.9832 | 136 | 54.49 | 20 | 0.7374 | 0.9353 | 0.8246 |
| 2 | Add | 0.9830 | 187 | 47.53 | 20 | 0.7166 | 0.9363 | 0.8118 |
| 3 | CA+Concat. | 0.9833 | 240 | 56.14 | 20 | 0.7654 | 0.9008 | 0.8276 |
| 4 | SA+Concat. | 0.9828 | 252 | 56.14 | 20 | 0.7162 | 0.9411 | 0.8134 |
| 5 | CBAM+Concat. | 0.9836 | 217 | 56.21 | 15 | 0.7752 | 0.8806 | 0.8245 |
| Model | Configuration | Recall | Precision | -Score | #DC | #MC |
|---|---|---|---|---|---|---|
| 1 | 5/MP/Concat. | 0.7374 | 0.9353 | 0.8246 | 1778 | 1663 |
| 2 | 5/MP/Concat./CA | 0.7654 | 0.9008 | 0.8276 | 1916 | 1726 |
| 3 | 5/MP/Concat./CBAM | 0.7752 | 0.8806 | 0.8245 | 1985 | 1748 |
| 4 | 5/AP/Concat. | 0.7796 | 0.8613 | 0.8184 | 2041 | 1758 |
| 5 | 5/AP/Concat./CA | 0.7761 | 0.8910 | 0.8296 | 1964 | 1750 |
| 6 | 5/AP/Concat./CBAM | 0.7610 | 0.9181 | 0.8322 | 1869 | 1716 |
| 7 | 6/MP/Concat. | 0.7752 | 0.8543 | 0.8128 | 2046 | 1748 |
| 8 | 6/MP/Concat./CA | 0.7304 | 0.9120 | 0.8111 | 1806 | 1647 |
| 9 | 6/MP/Concat./CBAM | 0.7631 | 0.9029 | 0.8272 | 1906 | 1721 |
| 10 | 6/AP/Concat. | 0.7220 | 0.9449 | 0.8185 | 1723 | 1628 |
| 11 | 6/AP/Concat./CA | 0.7716 | 0.9034 | 0.8323 | 1926 | 1740 |
| 12 | 6/AP/Concat./CBAM | 0.7614 | 0.8957 | 0.8231 | 1917 | 1717 |
| Model | Epoch | Accuracy | Recall | Precision | -Score | #DC | #MC | MR (pixels) |
|---|---|---|---|---|---|---|---|---|
| 20 | 0.9835 | 0.7761 | 0.8910 | 0.8269 | 1964 | 1750 | 123 | |
| 50 | 0.9830 | 0.7880 | 0.8780 | 0.8306 | 2024 | 1777 | 125 | |
| MC-UNet | 100 | 0.9833 | 0.7916 | 0.8845 | 0.8355 | 2018 | 1785 | 136 |
| 150 | 0.9836 | 0.7698 | 0.8935 | 0.8271 | 1943 | 1736 | 126 | |
| Crater U-Net | 500 | 0.9820 | 0.7933 | 0.8787 | 0.8338 | 2036 | 1789 | 128 |
| Model | Accuracy | Training Time (s) | Model Size (MB) | Epoch | Recall | Precision | -Score | MR (pixels) | RMSE (m) |
|---|---|---|---|---|---|---|---|---|---|
| U-Net | 0.9838 | 393 | 395.46 | 25 | 0.7681 | 0.9183 | 0.8365 | 124 | 55.02 |
| Crater U-Net | 0.9820 | 30 | 8.51 | 500 | 0.7933 | 0.8787 | 0.8338 | 128 | 54.53 |
| MC-UNet | 0.9833 | 156 | 56.14 | 100 | 0.7916 | 0.8845 | 0.8355 | 136 | 54.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Hu, F.; Mathiopoulos, P.T.; Zhang, Z.; Peethambaran, J. MC-UNet: Martian Crater Segmentation at Semantic and Instance Levels Using U-Net-Based Convolutional Neural Network. Remote Sens. 2023, 15, 266. https://doi.org/10.3390/rs15010266
Chen D, Hu F, Mathiopoulos PT, Zhang Z, Peethambaran J. MC-UNet: Martian Crater Segmentation at Semantic and Instance Levels Using U-Net-Based Convolutional Neural Network. Remote Sensing. 2023; 15(1):266. https://doi.org/10.3390/rs15010266
Chicago/Turabian StyleChen, Dong, Fan Hu, P. Takis Mathiopoulos, Zhenxin Zhang, and Jiju Peethambaran. 2023. "MC-UNet: Martian Crater Segmentation at Semantic and Instance Levels Using U-Net-Based Convolutional Neural Network" Remote Sensing 15, no. 1: 266. https://doi.org/10.3390/rs15010266