1. Introduction
As one of the most important basic tasks in computer vision, object detection has attracted the attention of many researchers and has been studied extensively. The main goal of this task is to find the location of an object in an image and label the category that it belongs to. It can be used as a key component in many downstream tasks.
With the rise of deep learning technology, object detection has developed quickly. Architectures can be divided into two-stage and one-stage architectures depending on the processing stage [
1]. For example, the R-CNN family [
2,
3,
4] and its improvements [
5,
6,
7] follow the “coarse-to-fine” pipeline. On the contrary, one-stage architectures, such as the YOLO family [
8,
9,
10,
11], SSD [
12], and RetinaNet [
13], are able to complete detection tasks in one step. Although they have a good running speed, their accuracy is not high compared to two-stage architectures. In addition, models can also be divided into the anchor-base category [
2,
3,
4,
5,
6,
7,
9,
10,
11,
12,
13,
14], which requires multiple anchors of different sizes and proportions, and the anchor-free category [
15,
16,
17,
18], in which the object is represented as a point. The former has higher accuracy, while the latter is easier to train and adjust.
Recently, object detection tasks in arbitrary directions have received more and more attention. In the field of remote sensing detection, oriented detection can not only identify densely packed objects but also ones with a huge aspect ratio.
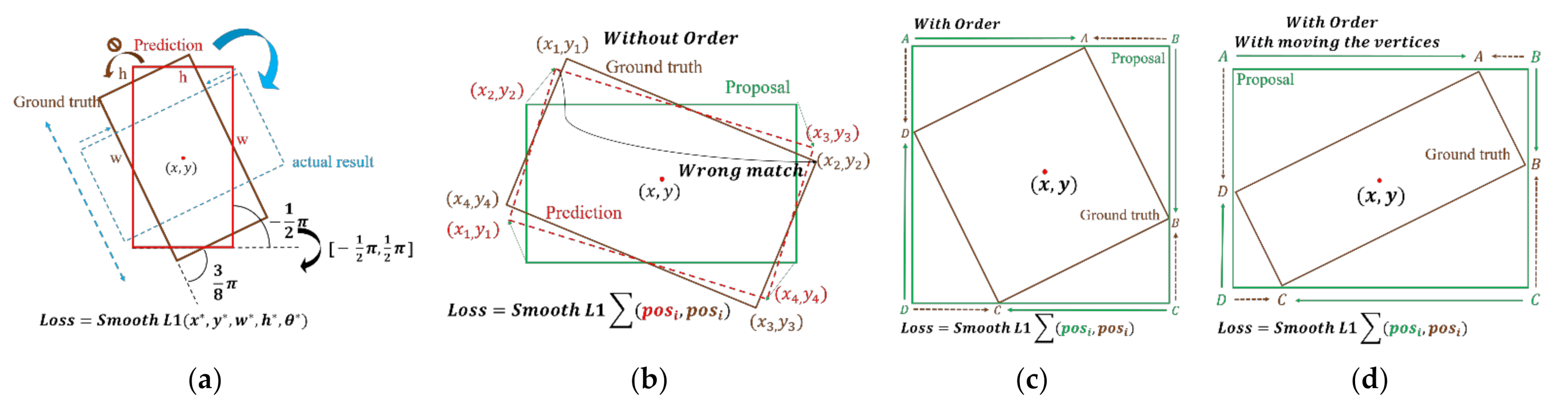
Figure 1 shows the limitations of horizontal object detection.
Most oriented object detectors are adapted from horizontal object detectors, and they can be broadly divided into five-parameter models [
19,
20,
21,
22,
23,
24,
25] and eight-parameter models [
26,
27,
28,
29,
30]. The five-parameter models add an angle parameter (
) and achieve great success. However, these detectors inevitably suffer from the angle boundary problem during training. As shown in
Figure 2a, assuming that the center coordinates of the two boxes coincide (without loss of generality), the red box (Prediction, −1/2π) needs to match the brown box (Ground-truth, 3/8π), something that can be achieved by adjusting the angle and size. An ideal regression method rotates the prediction box counterclockwise without resizing it. However, due to the boundary characteristics of the angle, the prediction box can not achieve its purpose because of the sudden change. Instead, it must rotate 3/8π clockwise and adjust its size simultaneously. SCRDet [
25] introduces IoU-Loss to enable the model to find a better regression method, but it cannot eliminate it.
The eight-parameter models were proposed to solve the angle problems that are present in the five-parameter models. They cover the detection task using a point-based method by directly predicting four vertices. However, such a direct method introduces new problems. First, it is necessary to sort the vertices when calculating the regression loss. Otherwise, the almost identical rectangle will still produce a colossal Loss (as shown in
Figure 2b); secondly, as described in
Figure 2c, the sorted order may still be sub-optimal. In addition to regression, along with a clockwise method (green line), there is an ideal regression method (brown line). RSDet [
31,
32] proposes comparing the Loss after moving the vertexes one unit clockwise and one unit counterclockwise. However, this approach only solves part of the problem. When faced with the situation shown in
Figure 2d, no matter how the adjustments are made, there are still sub-optimal paths (two longer regression paths always exist).
After analyzing the above ranking and regression discontinuity problems, we propose a multi-branch eight-parameter model called Surround-Net. It decomposes the prediction process into multiple branches to take all cases into account in an anchor-free and one-stage way. To improve the model’s consistency during testing and training, a modified multi-branch-aware adaptive Focal Loss function [
13] is creatively proposed so that the classification branch selection can be trained simultaneously. A size-adaptive dense prediction module is proposed to alleviate the imbalance between the positive and negative samples. Moreover, to enhance the model’s performance during localization, this work also presents a novel center vertex attention mechanism and a geometric soft constraint. The results further show that Surround-Net can solve the sub-optimal emerge problem present in previous models and can achieve a competitive result (e.g., 75.875 mAP and 74.071 mAP in 12.57 FPS) in an anchor-free one-stage way. Overall, our contributions are as follows:
A multi-branch anchor-free detector for oriented object detection is proposed and solves the sorting and suboptimal regression problems encountered with eight-parameter models;
To jointly training branch selection and class prediction, we propose a modified Focal Loss function, and a size-adaptived dense prediction module is adopted to alleviate the imbalance between the positive and negative samples;
We propose a center vertex attention mechanism to distinguish the environment area and use soft constraints to refine the detection boxes.
2. Materials and Methods
First, we will provide an overview of the content structure. The architecture of our proposed anchor-free one-stage model is introduced in
Section 2.1.
Section 2.2 elaborates on the multi-branch structure and the adaptive function design for dense predictions as well as on the multi-branch adaptive Focal Loss for joint training. The prediction of the circumscribed rectangle and sliding ratios are discussed in
Section 2.3, and the soft constraints for refinement are introduced in that section as well. Finally, we describe how to encode a rotating detection box using all of the predicted values. The center vertex attention mechanism for feature optimization is introduced in
Section 2.4.
2.1. Architecture
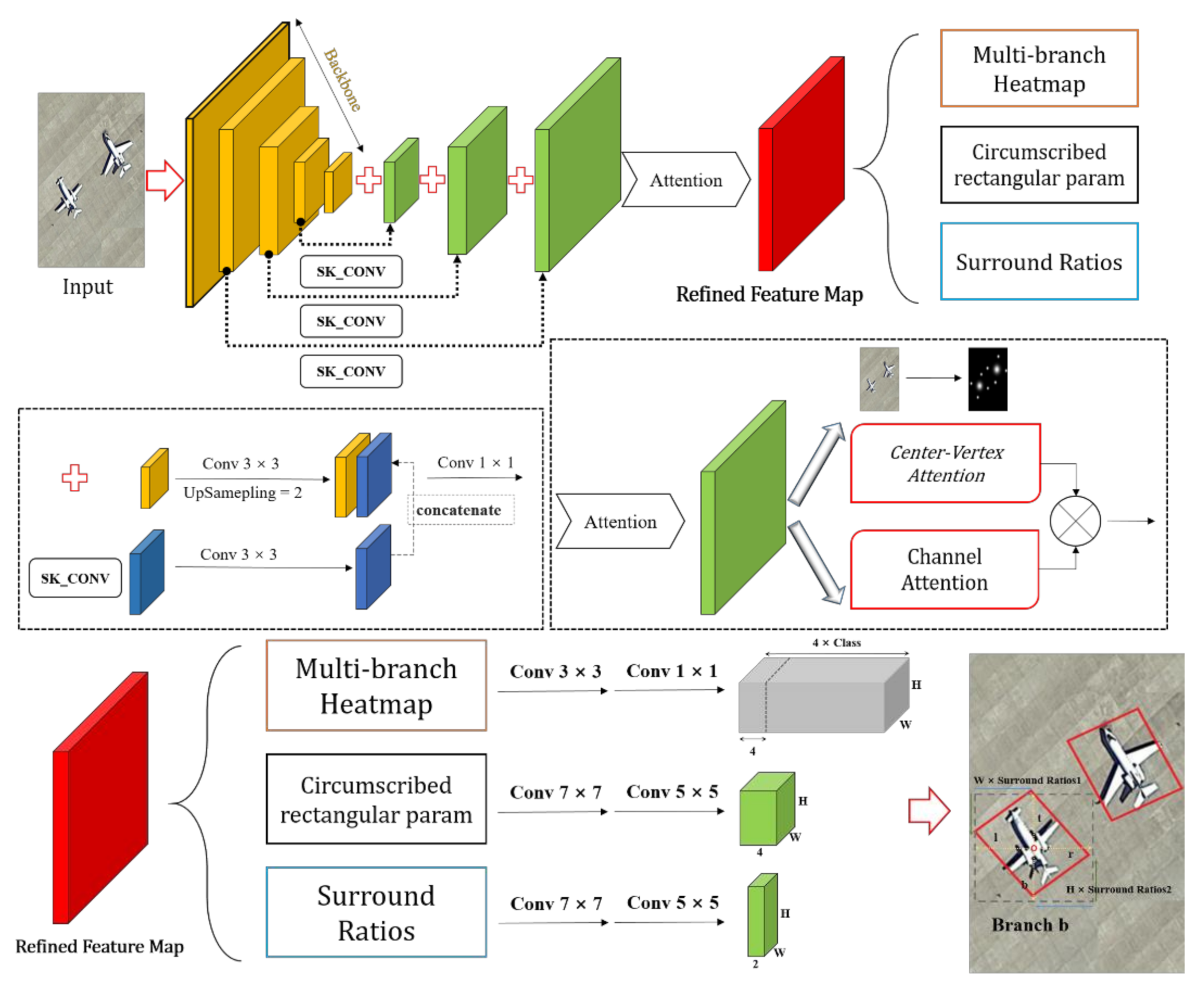
As shown in
Figure 3, the whole pipeline can be divided into the following four cascading modules: the feature extraction module, the feature combination module, the feature refine module, and the prediction head module. Initially, we use 1–5 convolutional ResNet-101 (ResNet-152 for better performance) layers and resize the final output feature map to 1/4 of the original input image size. In the up-sampling process, we first use 3 × 3 convolutions to resize the small-scale feature maps with rich semantic information to the same size as the feature maps from the previous levels. At the same time, the concatenate operation is performed on the feature map from a previous level that contains more delicate details via a 3 × 3 convolution layer. After completing one concatenation layer, it is followed by a 1 × 1 convolutional layer to enhance the fusion of the channel elements in the feature map. Before entering the next up-sampling stage, batch normalization [
33] and Leaky ReLU [
34] were used to normalize the feature map and improve its nonlinear fitting ability. At the tail of the feature combination, an attention module is proposed to refine the feature map. This part will be detailed in
Section 2.4. Inspired by TSD [
35], we also added additional convolutional layers for each prediction head in a decoupled manner.
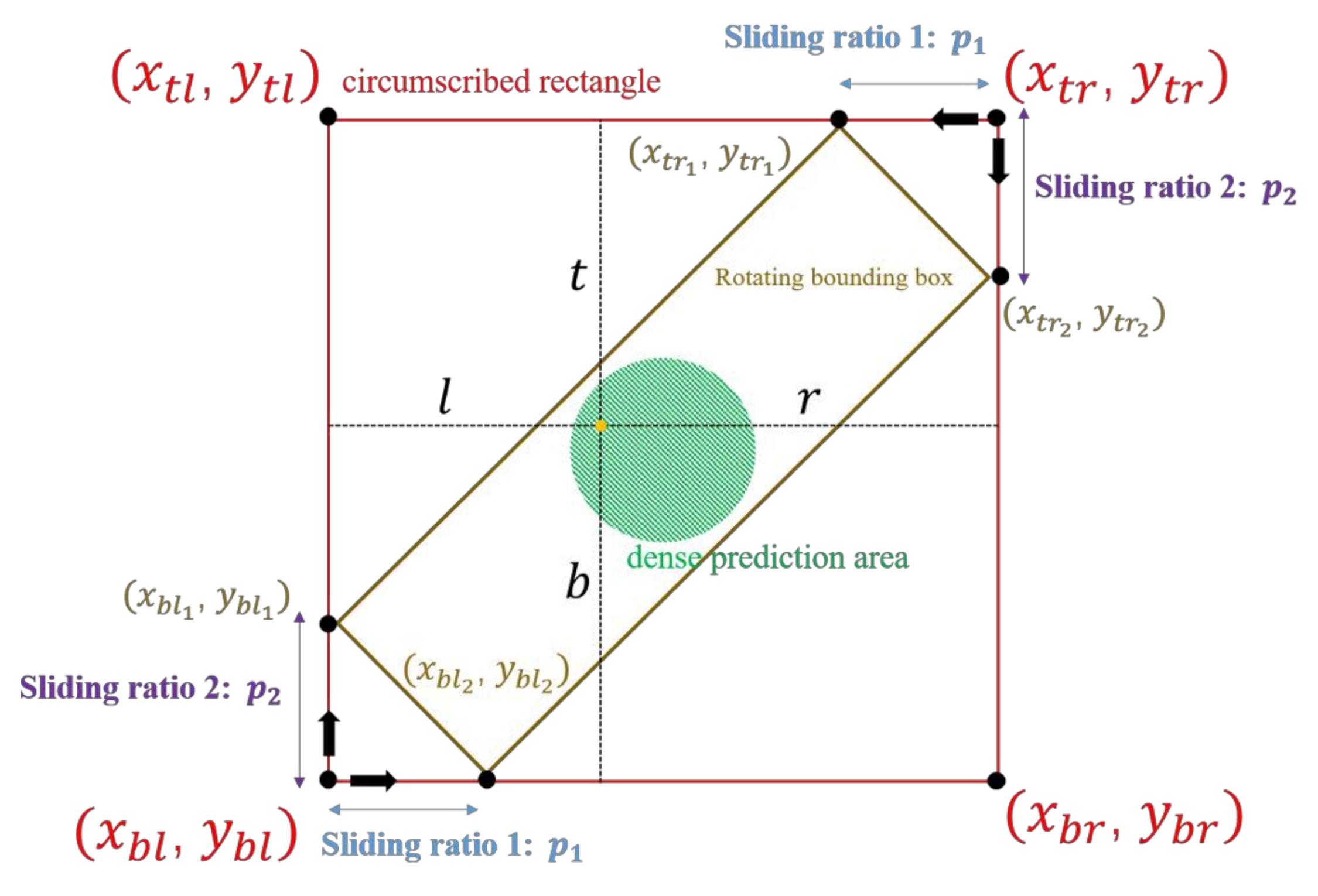
There are three detection heads that follow the following refined feature map: the multi-branch selection and classification head, the circumscribed rectangle prediction head, and the sliding ratio prediction head. For the multi-branch selection and classification head, the number of filters is 4 × C, where C is the number of categories and 4 is the number of different branches; for the circumscribed rectangle prediction head, the number is 4, representing the four distances () from the center point to their corresponding circumscribed rectangle; for the sliding ratio prediction head, the number is 2, representing the two required ratios.
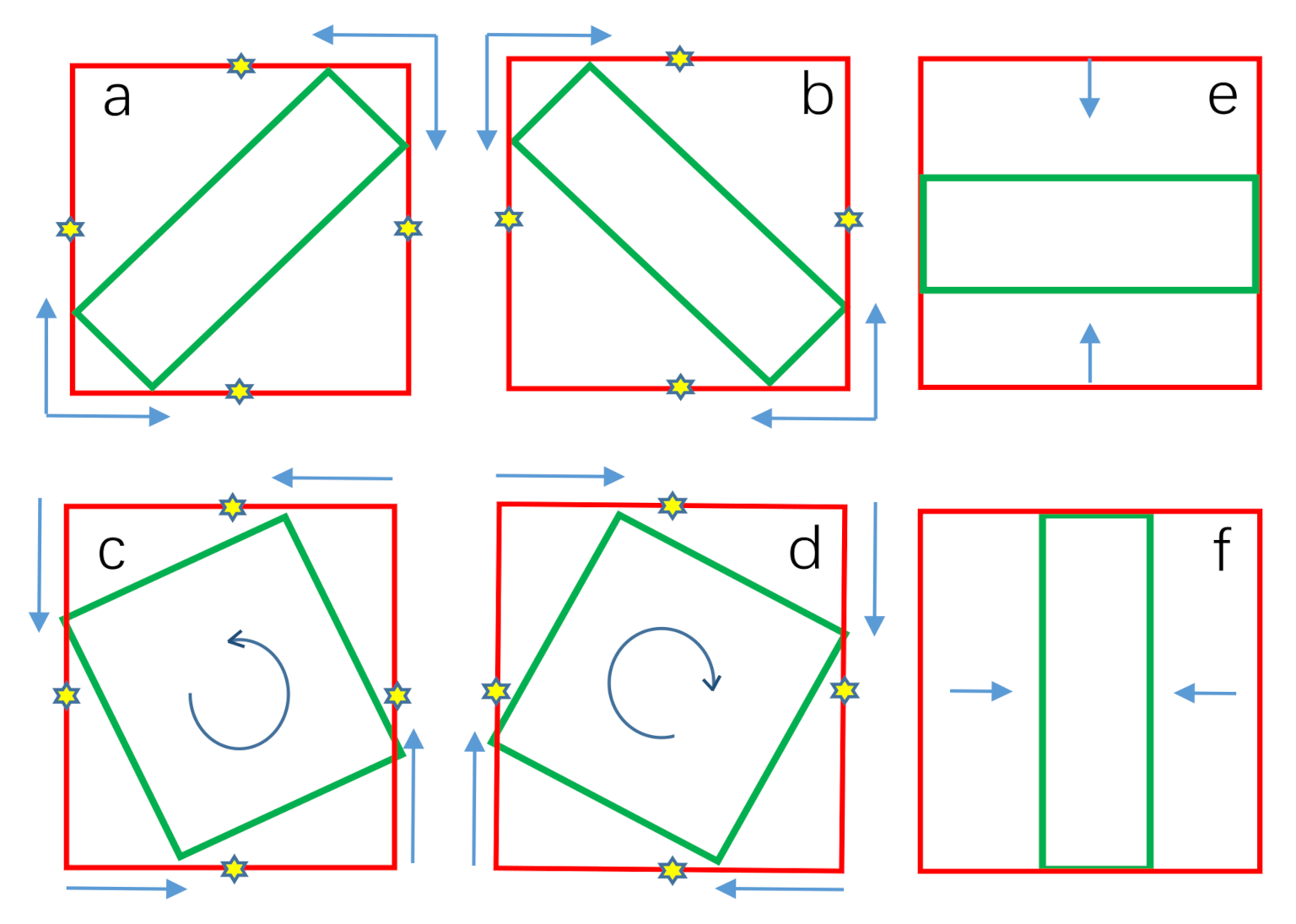
As shown in
Figure 4a–d, we divided the rotating bounding boxes obtained from the circumscribed rectangle into four cases corresponding to the multi-branch selection head.
The yellow star represents the midpoint of the boundary of the circumscribed rectangle. According to the coordinates falling on the boundary, the regression process can be divided into the following two cases:
Figure 4a–d. In the first case, starting from a vertex of the circumscribed rectangle and sliding in the horizontal and vertical directions, a rotating bounding box can be obtained optimally. In the second case, the sliding vertices can be selected either counterclockwise or clockwise. This once again represents an optimal regression method and achieves the same results as RSDet [
31,
32]. The cases corresponding to
Figure 4e,f can be regarded as the prediction of the horizontal bounding box whose sliding ratios are close to 0. Therefore, using the multi-branch regression method, the suboptimal regression problem shown in
Figure 2b–d is solved.
Section 2.2 describes how to use multi-branch prediction to find the best regression method in the above four regression branches.
2.2. Potential Points of the Object
According to
Figure 3, it can be seen that the output of the multi-branch selection and classification head is a heat map in
for an input RGB image in
, where
and
are the height and width of the image and
,
. We expanded the prediction channel and replaced the classification score with the PQES (prediction quality estimated score) (this will be explained in detail later) to measure whether the rotated bounding box obtained through the current branch had the highest IoU (Intersection-over-Union) with the ground truth. To improve the model’s generalization ability to cope with possible artificial labeling errors [
36] and overfitting, we employed an adaptive modified Gaussian kernel function to label smooth the center of the object with the surrounding positions. The kernel of the modified Gaussian function is the following:
(
,
) is the center coordinate of
object on the feature map.
and
are the width and height of the ground-truth bounding box. The element-wise maximum value strategy in which the same category overlaps was adopted. We charged the value of
to cover five standard deviations under the Gaussian distribution, so the value of
was set to 5. Considering that the pixels contained in the actual object in the remote sensing image account for a small proportion of all of the pixels in the image, the imbalance between positive and negative samples will be severe. Therefore, the dense prediction method [
17,
28] was also adopted. However, different from the former, we considered using an adaptive logarithm strategy to alleviate the gap in the size between categories. This was followed by a shape-adaptive positive sample expansion kernel as follows:
The positive sample expansion function follows the following two principles: (1) the coverage is less than or equal to
; (2) the ground-truth boundary cannot be exceeded. We treat
as
and
as
; the above principles can be expressed in a mathematical formula as follows:
The partial derivative of the original function of the variable
is always less than 0, which is a monotonic downward trend. The partial derivative for another variable
is as follows:
Substitute the value of (7) into (4) and let the equation equal 0 as follows:
Find the second partial derivative with respect to the variable
as follows:
Substituting Equations (6) and (8) into Equation (9), we can obtain as follows:
Because the second derivative is greater than 0, it is reasonable to set the value of
to 1.88.
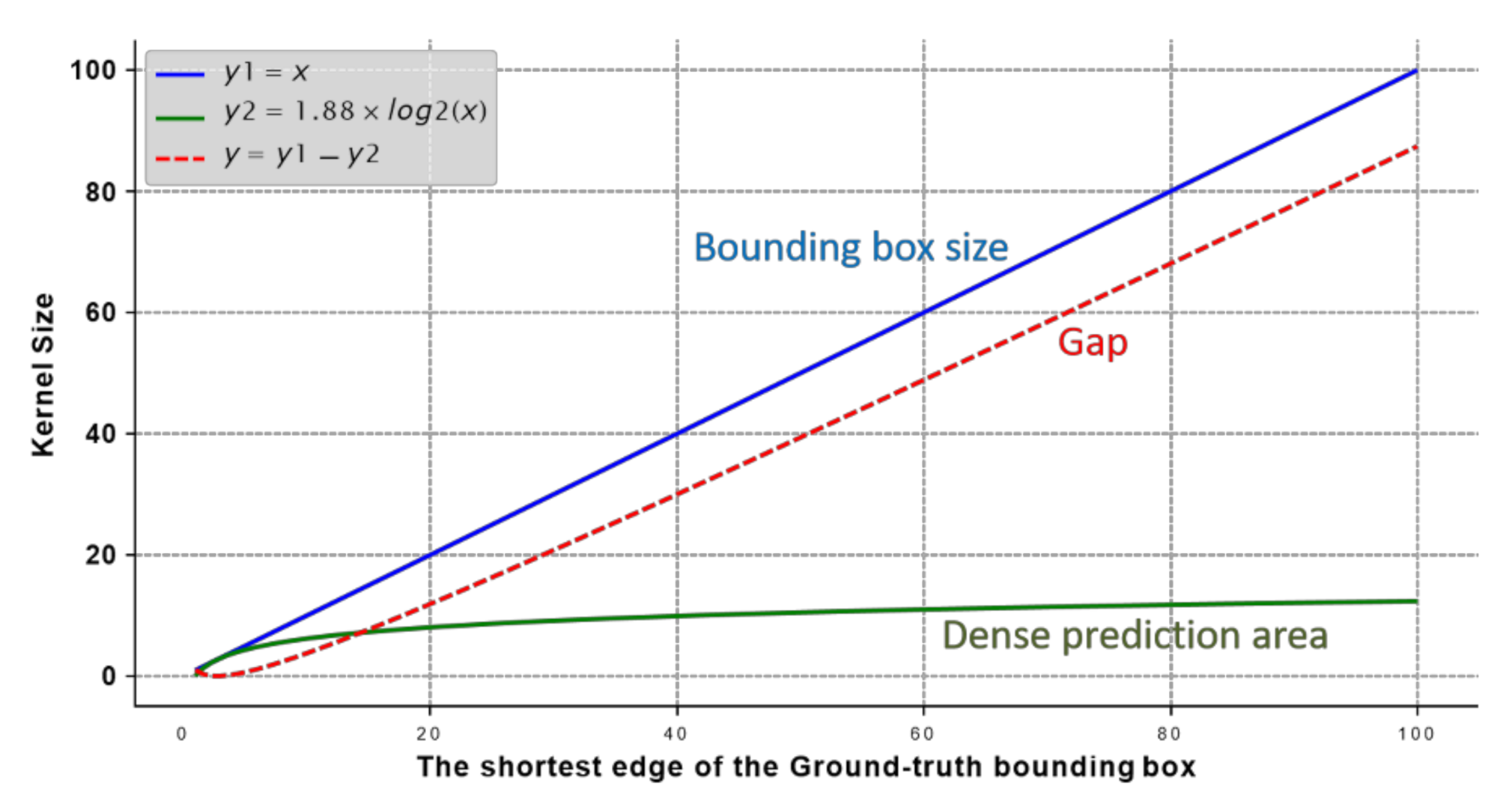
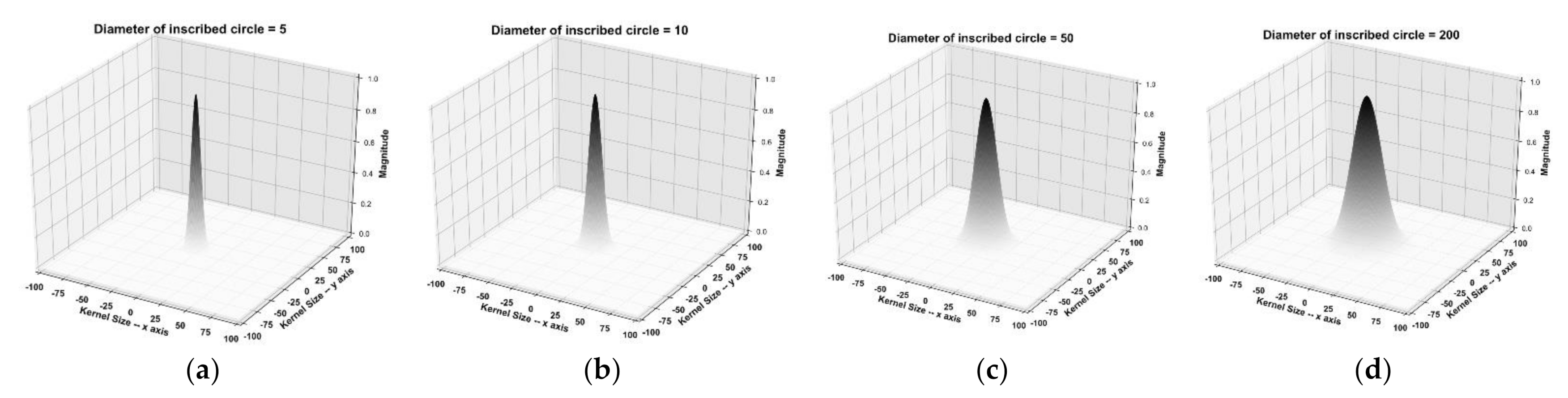
Figure 5 and
Figure 6 show the growth of the corresponding dense prediction intervals as the size of the ground-truth box increases.
We calculated the Loss for each position in the multi-branch selection and classification head tensor, and the targets to be learned can be defined as follows:
is the PQES (prediction quality estimated score) mentioned at the beginning.
is the Intersection-Over-Union (IoU) between the predicted circumscribed bounding box and the real circumscribed bounding box;
is the IoU between the predicted rotating bounding box and the ground truth. For all of the negative samples, the entire
is set to 0. The
and
are the weight factors determined in the subsequent experimental section. Taking the idea of Focal Loss [
13], we propose a new modified multi-branch-aware adaptive Focal Loss function to train the model. The ground truth of the
can likewise be fetched dynamically during the following training process (refer to Equations (12) and (13)):
where
is the supervised value, and
is the prediction.
and
represent the number of all of the samples and positive samples in the feature map, respectively. We need to scale down the contribution of negative samples.
and
follow the Varifocal Loss [
37] setting to make
,
.
2.3. Size Regression of Rectangle
For the regression of the circumscribed rectangle, we calculate the four distances (
) to the circumscribed rectangle bounding box from the feature points and use the GIoU [
38] for training. The loss functions can be documented as follows:
and
reprinted the
predicted circumscribed bounding box and the real one. Utilizing the two sliding ratios, we can deduce the coordinates of the final rotating bounding box. Using the regression method seen in
Figure 4a as an example, the process looks similar to what is observed in
Figure 7 as follows:
We used the Sigmoid function [
39] in the model and multiplied it by a constant 0.5 to make the sliding ratios within (0,0.5) meet the following conditions (
means the four regression ways in
Figure 4):
For training the sliding ratios, a new form of IoU Loss combined with Smooth L1 Loss [
4] and GIoU [
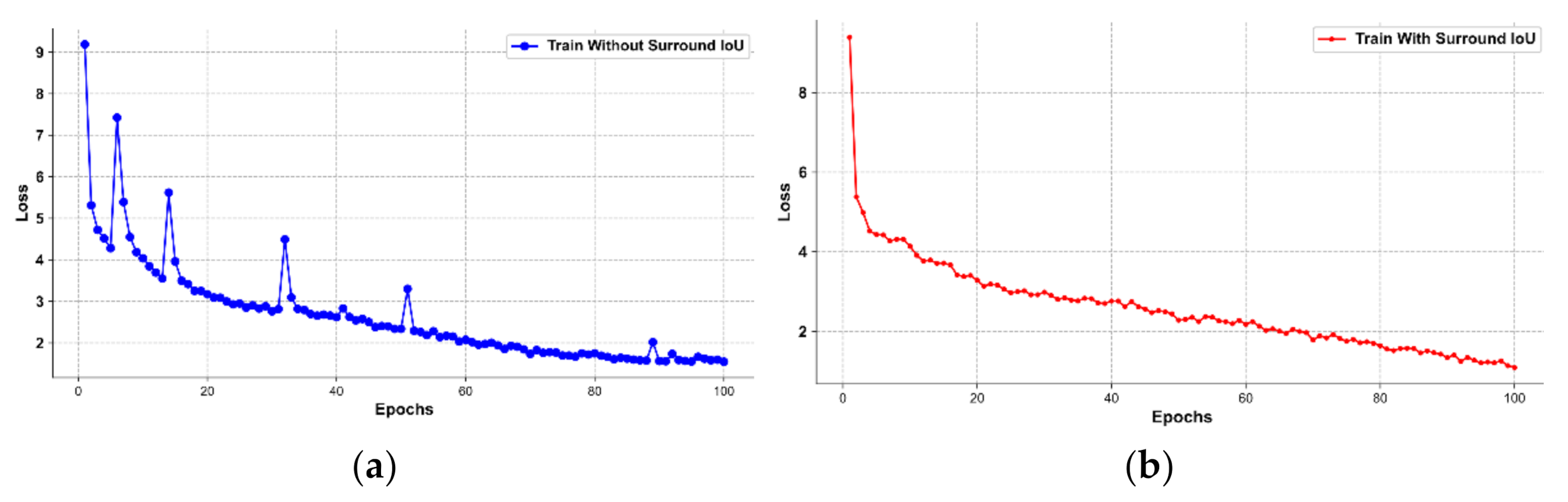
38] Loss called Surround-IoU Loss is adopted as follows:
and
represent the
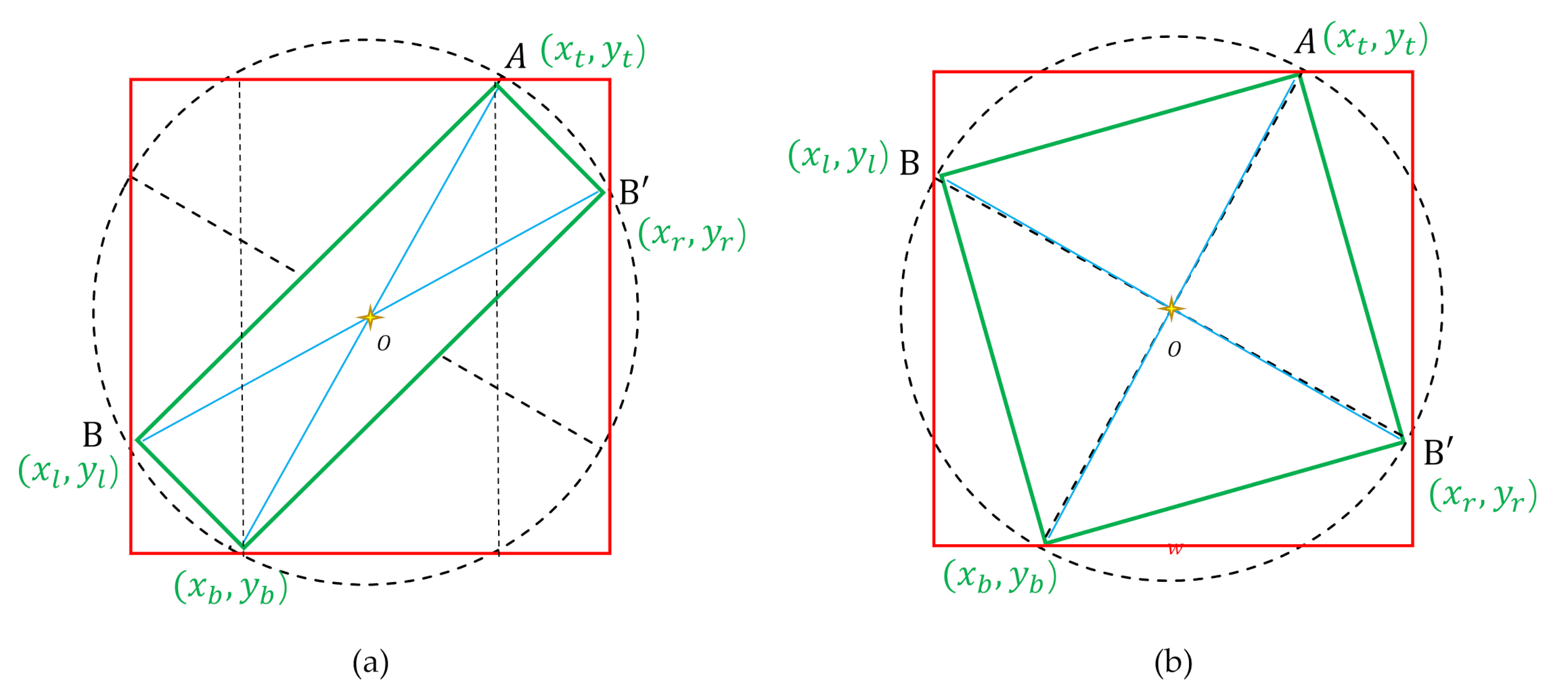
predicted rotating bounding box and the ground truth. Furthermore, the shape of the rotating bounding box cannot safely ensure a rectangular shape. As displayed in
Figure 8, the soft constraints satisfy the following geometric properties:
(
) represents
, and (
) represents
; the rest are
and
. Thus, the soft constraints can be written in the following form:
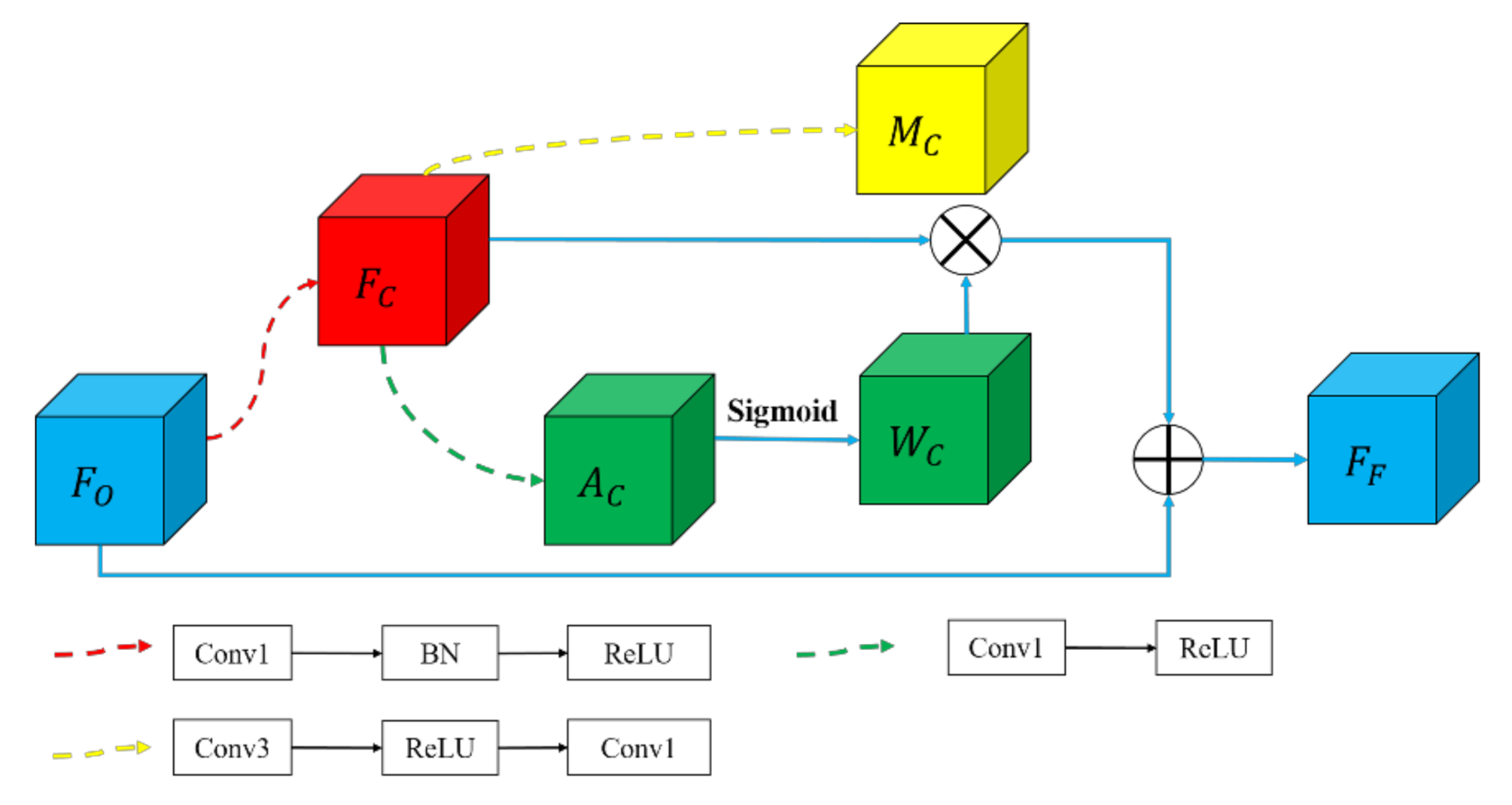
2.4. Center Vertex Attention
Typically, the size of a circumscribed rectangle is always greater than a horizontal one (as shown in
Figure 9). As such, inspired by CBAM [
40], a center vertex attention strategy should be adopted to improve the ability of the model to identify different points. We arranged the attention mechanism based on the mask at the following two sites: the center point and the four vertices of the rotating bounding box. The module architecture is portrayed in
Figure 10.
represents the original feature map,
represents the refined feature map,
represents the center vertex region generated by the modified Gaussian function. The following equation expresses the fusion process and the target to be learned:
We use the same Loss function as CenterNet [
16] for supervision. Moreover, SENet [
41] has also been employed as the auxiliary channel attention network, and the value of the reduction ratio is 16.
The total loss function
can be written as follows (where
represents the number of positive samples in an input image, and
is a hyperparameter for balance):
4. Final Discussion and Conclusions
After analyzing the ranking problems and regression discontinuity problems in the five-parameter and eight-parameter models, we introduced a new one-stage anchor-free model with multi-branch prediction for oriented detection tasks. In order to maintain consistency between classification, localization, and branch selection, we replaced the original classification label with the corresponding PQES (prediction quality-estimated score). Further, we added center vertex spatial attention to ensure that our model fully utilizes features to distinguish the foreground from the background. The soft constraint was also proposed to refine the bounding box. At the same time, to improve the prediction recall and to alleviate the imbalance between positive and negative samples in the anchor-free model, we also adopted a dense prediction strategy.
In the experiment, we first discussed the impact of the weights of the Loss function. The experiments show that the Loss weight should be 1.25, and in PQES, the weights of and should be set to 0.5 and 0.7. Further, we investigated the influence of our three proposed modules. The soft constraint module results in a performance enhancement of 0.7%, and more importantly, it enables the model to output a rectangular detection box that meets the geometric requirements. The dense prediction module improves the performance by 1.13%, while the attention mechanism model improves it by 1.501%. In order to enhance the smoothness of the Loss curve, we adopted the Surround IoU Loss by incorporating location information to train the sliding ratio. In addition, we also conducted experiments and discussions on the effectiveness of multi-branch prediction, which showed that a single regression method will damage the detector’s performance in terms of oriented detection. Finally, we compared the results with the state of the art and visualized the detection results. It can be seen that the model proposed in this paper achieved values of 75.88 mAP and 74.07 mAP at 12.57 FPS, which is a competitive result and represents a trade-off between performance and running speed.
However, it should be noted that there is still a slight gap between Surround-Net and the state of the art. In the anchor-based and two-stage models [
19,
20,
21,
25,
26,
31,
46,
47] listed in
Table 6, the best Surround-Net performance is in a position that is higher than the middle of the ranking list. In the anchor-free and one-stage models [
27,
28,
30,
48,
49,
50,
51,
52,
53], the values representing the best performance in our work are only lower than those achieved by DAFNE [
53]. However, when multi-scale testing technology is not used and Resnet-101 is used as the backbone, the performance of Surround-Net-101 (72.66%) is better than that of DAFNE-101 [
53] (70.75%). In addition, we found a few missed detections (which occur in the first two pictures in the last line of
Figure 16) in some specific categories (Small Vehicle and Ship). It is because the output feature map undergoes 4-fold down-sampling, and some objects may share the same center. As such, reducing the probability of missed detection is particularly important for our future research.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}