
Consolidated Convolutional Neural Network for Hyperspectral Image Classification

 ,
,  ,
, 
Abstract
:
1. Introduction
- 1.
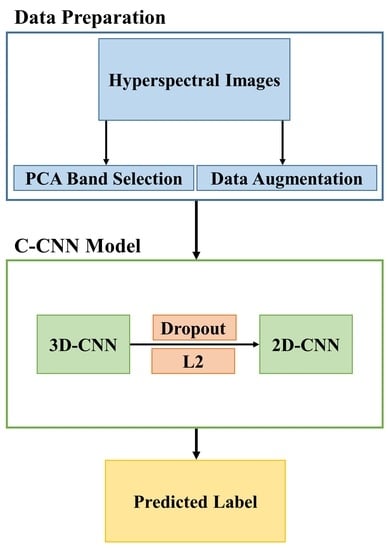
- This paper proposes a consolidated convolutional neural network (C-CNN) that is comprises of a three-dimensional CNN (3D-CNN) joined with a two-dimension CNN (2D-CNN) to produce sufficient accuracy and reduce the computational complexity for HSIs classification.
- 2.
- PCA has been used to reduce the spectral bands of the input HSIs.
- 3.
- Image augmentation methods including rotation and flipping have been applied to increase the number of training samples and reduce the impact of overfitting.
- 4.
- Dropout and L2 were adopted to further reduce the model complexity and prevent overfitting.
- 5.
- The influence of band selection and training sample ratio on the overall accuracy (OA) was investigated.
- 6.
- The impact of window size and multi-GPUs on the OA and processing time was also examined.
2. Methodology
2.1. Proposed Model
2.2. Training and Testing Process
2.3. Data Augmentation
3. Experimental Results
3.1. Experimental Environment and Parameter Settings
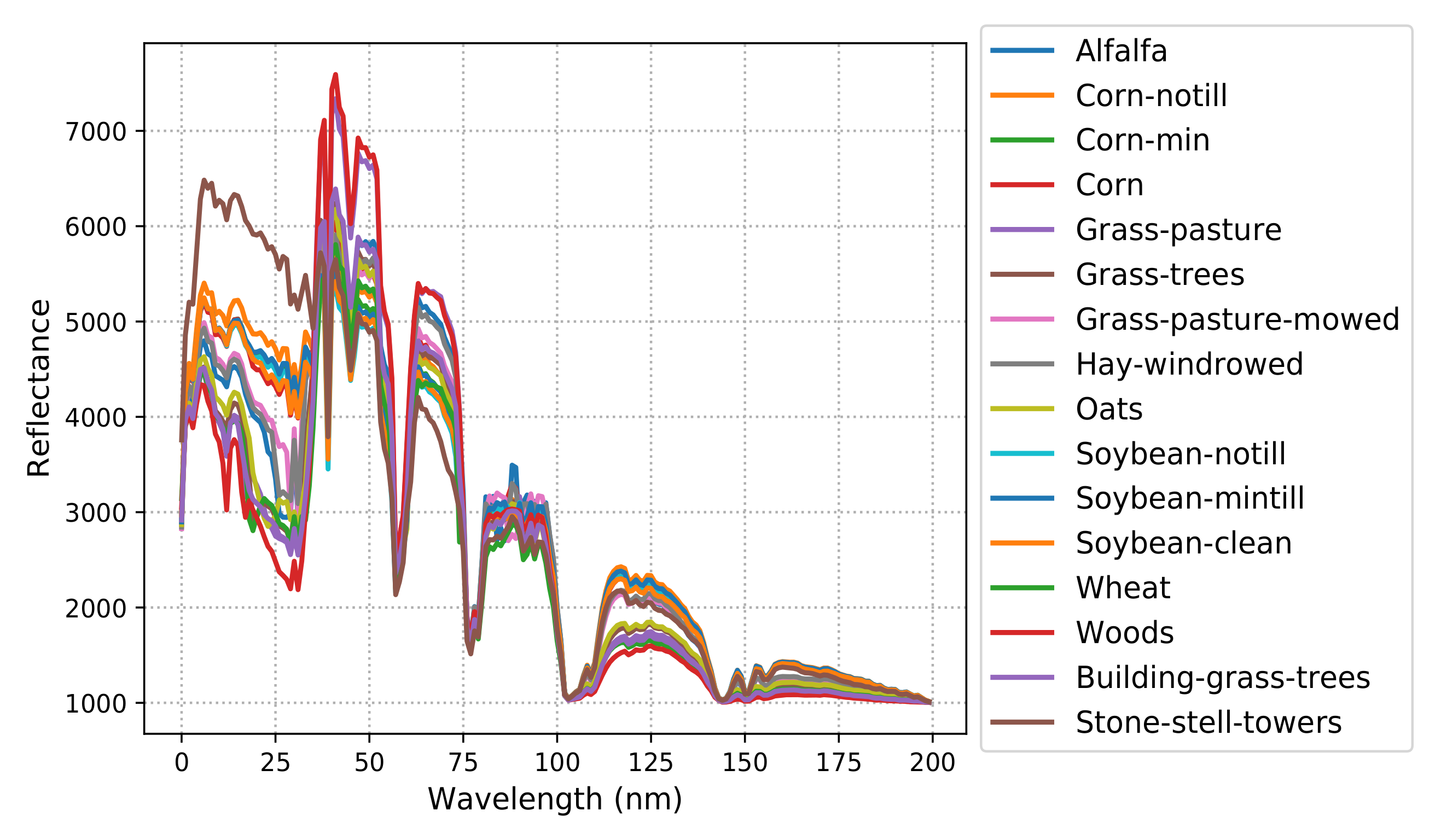
3.2. Datasets
3.3. The Impact of PCA Band Selection Ratio on Overall Accuracy
3.4. The Impact of Window Size on Overall Accuracy and Processing Time
3.5. Comparison with Other Methods
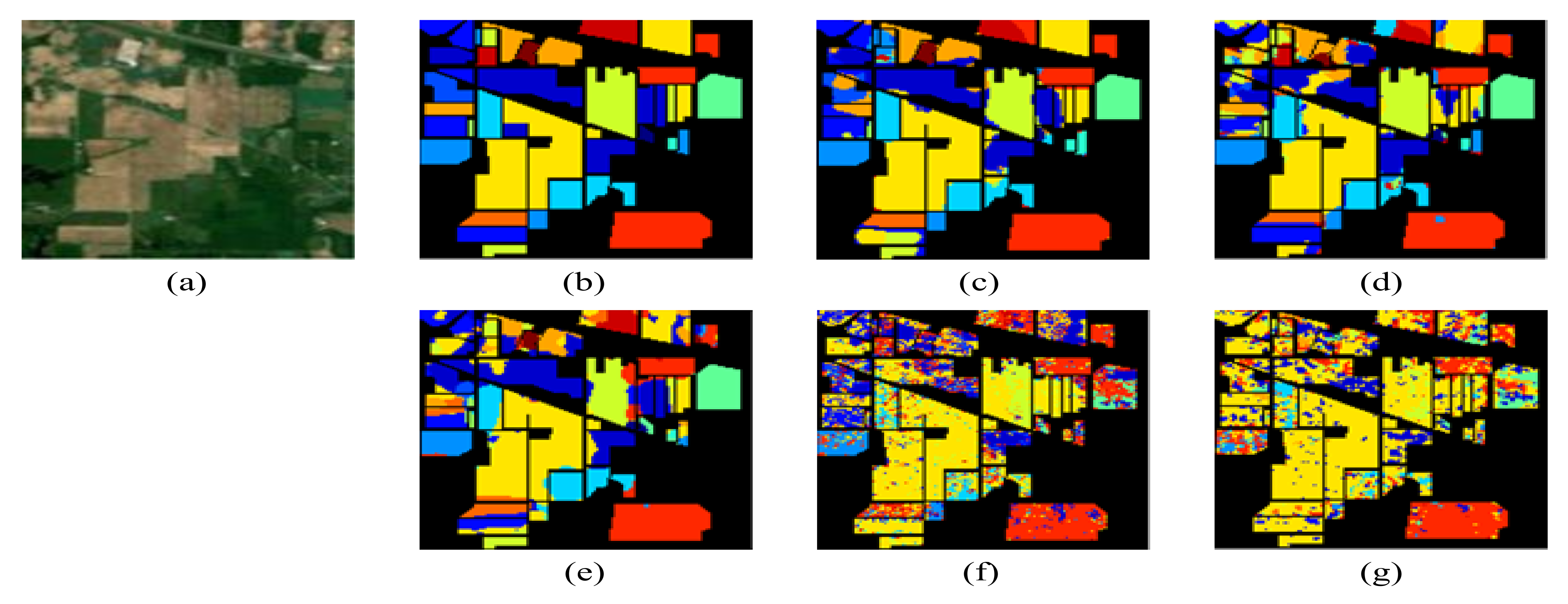
3.5.1. Test Results on Indian Pines Dataset
3.5.2. Test Results on Pavia University Dataset
3.5.3. Test Results on Salinas Scene Dataset
3.6. The Impact of Training Sample Ratio on Overall Accuracy
3.7. The Impact of Multi-GPUs Implementation with NVLink on Processing Time
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, A.; Huang, W.; Dong, Y.; Ye, H.; Ma, H.; Liu, B.; Wu, W.; Ren, Y.; Ruan, C.; Geng, Y. Wheat yellow rust detection using UAV-based hyperspectral technology. Remote Sens. 2021, 13, 123. [Google Scholar] [CrossRef]
- Liu, N.; Townsend, P.A.; Naber, M.R.; Bethke, P.C.; Hills, W.B.; Wang, Y. Hyperspectral imagery to monitor crop nutrient status within and across growing seasons. Remote Sens. Environ. 2021, 255, 112303. [Google Scholar] [CrossRef]
- Lyu, X.; Li, X.; Dang, D.; Dou, H.; Xuan, X.; Liu, S.; Li, M.; Gong, J. A new method for grassland degradation monitoring by vegetation species composition using hyperspectral remote sensing. Ecol. Indic. 2020, 114, 106310. [Google Scholar] [CrossRef]
- Marinelli, D.; Bovolo, F.; Bruzzone, L. A novel change detection method for multitemporal hyperspectral images based on binary hyperspectral change vectors. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4913–4928. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Li, L.; Tao, R.; Du, Q. Hyperspectral change detection based on multiple morphological profiles. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5507312. [Google Scholar] [CrossRef]
- Huang, P.; Guo, Q.; Han, C.; Zhang, C.; Yang, T.; Huang, S. An Improved Method Combining ANN and 1D-Var for the Retrieval of Atmospheric Temperature Profiles from FY-4A/GIIRS Hyperspectral Data. Remote Sens. 2021, 13, 481. [Google Scholar] [CrossRef]
- Calin, M.A.; Calin, A.C.; Nicolae, D.N. Application of airborne and spaceborne hyperspectral imaging techniques for atmospheric research: Past, present, and future. Appl. Spectrosc. Rev. 2021, 56, 289–323. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Pereira, N.S.; Plaza, J.; Plaza, A. Ghostnet for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10378–10393. [Google Scholar] [CrossRef]
- Zhao, B.; Ulfarsson, M.O.; Sveinsson, J.R.; Chanussot, J. Unsupervised and supervised feature extraction methods for hyperspectral images based on mixtures of factor analyzers. Remote Sens. 2020, 12, 1179. [Google Scholar] [CrossRef] [Green Version]
- Paoletti, M.E.; Haut, J.M.; Tao, X.; Miguel, J.P.; Plaza, A. A new GPU implementation of support vector machines for fast hyperspectral image classification. Remote Sens. 2020, 12, 1257. [Google Scholar] [CrossRef] [Green Version]
- Cao, F.; Yang, Z.; Ren, J.; Ling, W.K.; Zhao, H.; Sun, M.; Benediktsson, J.A. Sparse representation-based augmented multinomial logistic extreme learning machine with weighted composite features for spectral—Spatial classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6263–6279. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Ma, J.; Chen, C.; Wang, Z.; Cai, Z.; Wang, L. SuperPCA: A superpixelwise PCA approach for unsupervised feature extraction of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhang, L.; You, J. Hyperspectral image classification based on two-stage subspace projection. Remote Sens. 2018, 10, 1565. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Xu, Z.; Wang, Y.; Jiao, T.; Guo, Q. The use of KPCA over subspaces for cross-scale superpixel based hyperspectral image classification. Remote Sens. Lett. 2021, 12, 470–477. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Afjal, M.I.; Hossain, M.A. Information-theoretic feature selection with segmentation-based folded principal component analysis (PCA) for hyperspectral image classification. Int. J. Remote Sens. 2021, 42, 286–321. [Google Scholar] [CrossRef]
- Seifi Majdar, R.; Ghassemian, H. A probabilistic SVM approach for hyperspectral image classification using spectral and texture features. Int. J. Remote Sens. 2017, 38, 4265–4284. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, G.; Li, X.; Wang, B.; Fu, P. Active semi-supervised random forest for hyperspectral image classification. Remote Sens. 2019, 11, 2974. [Google Scholar] [CrossRef] [Green Version]
- Wang, X. Kronecker Factorization-Based Multinomial Logistic Regression for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Tian, J. Local manifold learning-based k-nearest-neighbor for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4099–4109. [Google Scholar] [CrossRef]
- Wei, W.; Ma, M.; Wang, C.; Zhang, L.; Zhang, P.; Zhang, Y. A novel analysis dictionary learning model based hyperspectral image classification method. Remote Sens. 2019, 11, 397. [Google Scholar] [CrossRef] [Green Version]
- Khotimah, W.N.; Bennamoun, M.; Boussaid, F.; Sohel, F.; Edwards, D. A high-performance spectral-spatial residual network for hyperspectral image classification with small training data. Remote Sens. 2020, 12, 3137. [Google Scholar] [CrossRef]
- Ge, Z.; Cao, G.; Li, X.; Fu, P. Hyperspectral image classification method based on 2D–3D CNN and multibranch feature fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5776–5788. [Google Scholar] [CrossRef]
- Zheng, J.; Feng, Y.; Bai, C.; Zhang, J. Hyperspectral image classification using mixed convolutions and covariance pooling. IEEE Trans. Geosci. Remote Sens. 2020, 59, 522–534. [Google Scholar] [CrossRef]
- Feng, Y.; Zheng, J.; Qin, M.; Bai, C.; Zhang, J. 3D Octave and 2D Vanilla Mixed Convolutional Neural Network for Hyperspectral Image Classification with Limited Samples. Remote Sens. 2021, 13, 4407. [Google Scholar] [CrossRef]
- Farooque, G.; Xiao, L.; Yang, J.; Sargano, A.B. Hyperspectral Image Classification via a Novel Spectral–Spatial 3D ConvLSTM-CNN. Remote Sens. 2021, 13, 4348. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Zou, S.; Zhang, H.; Bai, Y. Hyperspectral image classification with spatial consistence using fully convolutional spatial propagation network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10425–10437. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote sensing image super-resolution via mixed high-order attention network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5183–5196. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Meng, Z.; Li, L.; Jiao, L.; Feng, Z.; Tang, X.; Liang, M. Fully dense multiscale fusion network for hyperspectral image classification. Remote Sens. 2019, 11, 2718. [Google Scholar] [CrossRef] [Green Version]
- Feng, J.; Wu, X.; Shang, R.; Sui, C.; Li, J.; Jiao, L.; Zhang, X. Attention multibranch convolutional neural network for hyperspectral image classification based on adaptive region search. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5054–5070. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep&dense convolutional neural network for hyperspectral image classification. Remote Sens. 2018, 10, 1454. [Google Scholar]
- Acquarelli, J.; Marchiori, E.; Buydens, L.; Tran, T.; van Laarhoven, T. Convolutional neural networks and data augmentation for spectral-spatial classification of hyperspectral images. Networks 2017, 16, 21–40. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. A simplified 2D-3D CNN architecture for hyperspectral image classification based on spatial–spectral fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2485–2501. [Google Scholar] [CrossRef]
- Xu, Q.; Xiao, Y.; Wang, D.; Luo, B. CSA-MSO3DCNN: Multiscale octave 3D CNN with channel and spatial attention for hyperspectral image classification. Remote Sens. 2020, 12, 188. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, M.; Farah, I.R.; Solaiman, B. Hyperspectral imagery classification based on semi-supervised 3-D deep neural network and adaptive band selection. Expert Syst. Appl. 2019, 129, 246–259. [Google Scholar] [CrossRef]
- Zhang, T.; Shi, C.; Liao, D.; Wang, L. A Spectral Spatial Attention Fusion with Deformable Convolutional Residual Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3590. [Google Scholar] [CrossRef]
- Zhang, T.; Shi, C.; Liao, D.; Wang, L. Deep Spectral Spatial Inverted Residual Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 4472. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Cortes, C.; Mohri, M.; Rostamizadeh, A. L2 regularization for learning kernels. arXiv 2012, arXiv:1205.2653. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, A.; Song, S.L.; Chen, J.; Li, J.; Liu, X.; Tallent, N.R.; Barker, K.J. Evaluating modern gpu interconnect: Pcie, nvlink, nv-sli, nvswitch and gpudirect. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 94–110. [Google Scholar] [CrossRef] [Green Version]
- Bera, S.; Shrivastava, V.K. Analysis of various optimizers on deep convolutional neural network model in the application of hyperspectral remote sensing image classification. Int. J. Remote Sens. 2020, 41, 2664–2683. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Pixels | Spatial Resolution | Bands | Wavelength Range | Discarded Bands | Classes |
|---|---|---|---|---|---|---|
| Indian Pines | 20 m/pixel | 224 | 400∼2400 nm | 24 | 16 | |
| Pavia University | 1.3 m/pixel | 103 | 430∼860 nm | 0 | 9 | |
| Salinas Scene | 3.7 m/pixel | 224 | 360∼2500 nm | 20 | 16 |
| IP | PU | SA | |
|---|---|---|---|
| 0.01 | 65.08 | 94.23 | 95.79 |
| 0.02 | 77.55 | 95.88 | 98.21 |
| 0.03 | 80.42 | 96.62 | 99.00 |
| 0.04 | 80.49 | 96.64 | 99.08 |
| 0.05 | 81.32 | 97.68 | 99.06 |
| 0.06 | 82.24 | 98.00 | 99.28 |
| 0.07 | 82.28 | 97.93 | 99.25 |
| 0.08 | 83.57 | 98.25 | 99.28 |
| 0.09 | 83.53 | 98.19 | 99.36 |
| 0.10 | 83.68 | 98.20 | 99.43 |
| Window Size | Overall Accuracy (OA) | Time (Seconds) | ||||
|---|---|---|---|---|---|---|
| IP | PU | SA | IP | PU | SA | |
| 70.26 | 95.46 | 96.24 | 10 | 37 | 54 | |
| 15 × 15 | 83.68 | 98.20 | 99.43 | 39 | 95 | 196 |
| 84.28 | 98.87 | 99.67 | 97 | 210 | 486 | |
| 84.09 | 98.77 | 99.80 | 185 | 395 | 953 | |
| Class | SS-3DCNN [40] | SSAF-DCR [41] | DSSIRNet [42] | C-CNN | C-CNN-Aug |
|---|---|---|---|---|---|
| 1 | 97.96 | 97.82 | 98.88 | 42.00 | 61.93 |
| 2 | 96.49 | 96.03 | 96.65 | 58.15 | 75.82 |
| 3 | 99.53 | 96.39 | 96.64 | 54.27 | 75.75 |
| 4 | 97.47 | 96.00 | 94.81 | 18.34 | 48.47 |
| 5 | 97.21 | 99.51 | 98.62 | 80.90 | 81.69 |
| 6 | 95.24 | 99.09 | 99.13 | 92.99 | 94.75 |
| 7 | 98.88 | 71.13 | 94.18 | 70.00 | 89.29 |
| 8 | 98.51 | 100.0 | 99.92 | 98.46 | 99.32 |
| 9 | 97.73 | 96.90 | 83.71 | 76.50 | 79.83 |
| 10 | 94.44 | 93.11 | 97.07 | 67.67 | 79.50 |
| 11 | 97.83 | 97.14 | 97.65 | 83.06 | 88.41 |
| 12 | 97.70 | 93.58 | 98.69 | 45.38 | 67.12 |
| 13 | 97.24 | 99.69 | 100.0 | 76.06 | 96.49 |
| 14 | 96.47 | 97.05 | 98.78 | 95.69 | 95.46 |
| 15 | 95.81 | 95.13 | 95.76 | 54.27 | 71.68 |
| 16 | 99.83 | 97.63 | 98.70 | 59.24 | 91.85 |
| AA | 97.39 | 95.39 | 96.82 | 67.06 | 81.08 |
| OA | 97.89 | 96.36 | 97.18 | 73.33 | 83.68 |
| Kappa | 98.72 | 95.85 | 96.78 | 69.43 | 81.25 |
| Time (s) | 371 | 47 | 40 | 39 | 39 |
| Class | SS-3DCNN [40] | SSAF-DCR [41] | DSSIRNet [42] | C-CNN | C-CNN-Aug |
|---|---|---|---|---|---|
| 1 | 98.01 | 98.80 | 99.04 | 97.63 | 98.64 |
| 2 | 99.41 | 100.0 | 100.0 | 99.75 | 99.74 |
| 3 | 98.92 | 94.46 | 98.70 | 83.74 | 92.50 |
| 4 | 98.15 | 99.16 | 97.98 | 94.62 | 94.89 |
| 5 | 98.20 | 100.0 | 100.0 | 99.73 | 99.91 |
| 6 | 99.31 | 97.95 | 100.0 | 98.68 | 99.11 |
| 7 | 98.08 | 94.11 | 99.39 | 95.31 | 98.04 |
| 8 | 98.06 | 88.23 | 97.86 | 91.46 | 95.26 |
| 9 | 99.23 | 100.0 | 99.89 | 90.21 | 94.68 |
| AA | 98.60 | 96.96 | 99.20 | 94.57 | 96.98 |
| OA | 98.45 | 97.43 | 99.31 | 97.08 | 98.25 |
| Kappa | 98.53 | 0.97 | 99.05 | 96.13 | 97.68 |
| Time (s) | 265 | 156 | 100 | 79 | 79 |
| Class | SS-3DCNN [40] | SSAF-DCR [41] | DSSIRNet [42] | C-CNN | C-CNN-Aug |
|---|---|---|---|---|---|
| 1 | 96.73 | 100.0 | 100.0 | 99.94 | 99.91 |
| 2 | 98.50 | 99.93 | 100.0 | 99.63 | 99.99 |
| 3 | 96.06 | 98.33 | 99.86 | 99.80 | 99.83 |
| 4 | 98.80 | 96.99 | 99.66 | 99.49 | 98.89 |
| 5 | 97.88 | 97.68 | 99.91 | 99.08 | 99.07 |
| 6 | 98.87 | 100.0 | 100.0 | 99.94 | 99.93 |
| 7 | 96.58 | 100.0 | 100.0 | 99.96 | 99.97 |
| 8 | 98.61 | 92.72 | 99.07 | 98.39 | 99.22 |
| 9 | 98.92 | 99.86 | 100.0 | 100.0 | 99.99 |
| 10 | 98.30 | 98.64 | 99.79 | 97.92 | 98.23 |
| 11 | 98.96 | 96.91 | 97.78 | 99.94 | 99.87 |
| 12 | 99.71 | 97.43 | 100.0 | 99.93 | 99.61 |
| 13 | 98.78 | 96.78 | 99.80 | 99.15 | 99.24 |
| 14 | 98.96 | 99.27 | 98.93 | 98.90 | 98.81 |
| 15 | 98.01 | 91.49 | 98.83 | 98.87 | 99.00 |
| 16 | 98.77 | 100.0 | 100.0 | 99.29 | 99.35 |
| AA | 98.28 | 97.87 | 99.60 | 99.39 | 99.43 |
| OA | 98.29 | 96.53 | 99.35 | 99.22 | 99.43 |
| Kappa | 98.16 | 96.14 | 99.27 | 99.13 | 99.36 |
| Time (s) | 289 | 198 | 219 | 196 | 196 |
| Dataset | C-CNN-Aug, 1 × 2080Ti | C-CNN-Aug, 2 × 2080Ti | Improved% |
|---|---|---|---|
| IP | 32 | 18 | 44 |
| PU | 79 | 45 | 43 |
| SA | 197 | 111 | 44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Y.-L.; Tan, T.-H.; Lee, W.-H.; Chang, L.; Chen, Y.-N.; Fan, K.-C.; Alkhaleefah, M. Consolidated Convolutional Neural Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 1571. https://doi.org/10.3390/rs14071571
Chang Y-L, Tan T-H, Lee W-H, Chang L, Chen Y-N, Fan K-C, Alkhaleefah M. Consolidated Convolutional Neural Network for Hyperspectral Image Classification. Remote Sensing. 2022; 14(7):1571. https://doi.org/10.3390/rs14071571
Chicago/Turabian StyleChang, Yang-Lang, Tan-Hsu Tan, Wei-Hong Lee, Lena Chang, Ying-Nong Chen, Kuo-Chin Fan, and Mohammad Alkhaleefah. 2022. "Consolidated Convolutional Neural Network for Hyperspectral Image Classification" Remote Sensing 14, no. 7: 1571. https://doi.org/10.3390/rs14071571