
Unsupervised Remote Sensing Image Super-Resolution Guided by Visible Images


Abstract
:1. Introduction
- To the best of our knowledge, this is the first work to perform cross-domain SR in the absence of HR/LR image pairs, as well as the first to apply visible images to assist in remote sensing domain image SR;
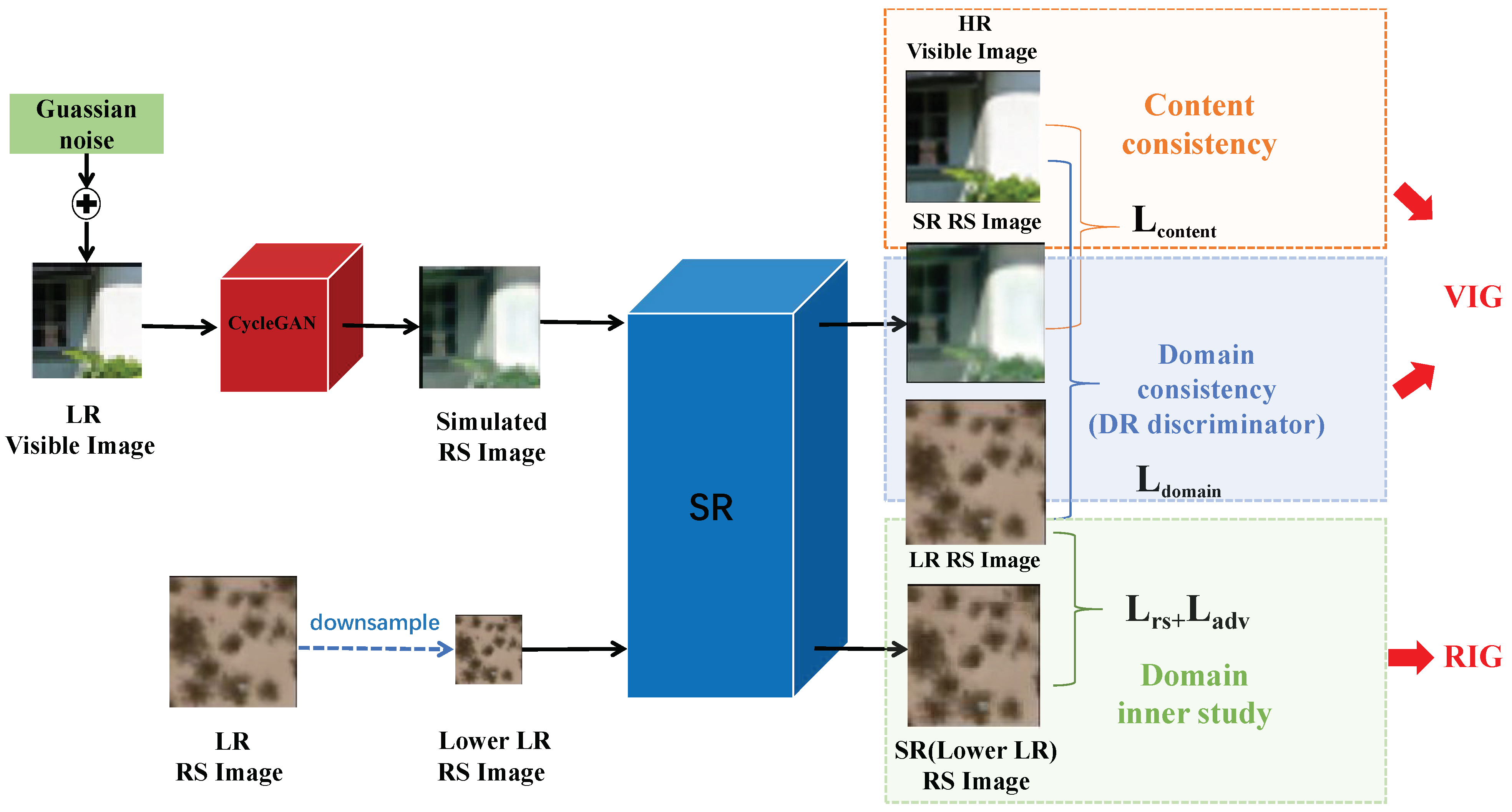
- This paper proposes a novel two-branch network, UVRSR, to produce an SR remote sensing domain image with an HR visible image and an unpaired LR remote sensing image. A CycleGAN-based learnable branch VIG is proposed to dig the rich textures from HR visible images, and another learnable branch, RIG, is built to explore the internal information of remote sensing images;
- We design a novel domain-ruled (DR) discriminator to determine the SR output to the target remote sensing domain without domain shift in the reconstruction;
- Experiments show that UVRSR can achieve superior results when compared with state-of-the-art unpaired and remote sensing SR methods on the remote sensing UC Merced and the NWPU-RESISC45 datasets.
2. Related Work
2.1. Remote Sensing Super-Resolution
2.2. Super-Resolution Frameworks in Deep Learning
2.3. Unpaired Training in Super-Resolution
3. Methodology
3.1. Overall Architecture
3.2. Formulation
3.3. Visible Image Guided Branch Training
3.3.1. CycleGAN
3.3.2. SR Netowrk
3.3.3. DR Discriminator
3.4. Remote Sensing Image-Guided Branch Training
3.5. Total Training
4. Experiments and Analysis
4.1. Datasets
4.1.1. DIV2K
4.1.2. UC Merced
4.1.3. NWPU-RESISC45
4.2. Quality Assessment Metrics
4.3. Implementation Details
4.4. Comparison with State-of-the-Art Methods
5. Discussion
5.1. Effect of Two Learnable Branches
5.2. Role of the DR Discriminator
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| HR | High resolution |
| LR | Low resolution |
| SR | Super resolution |
| UVRSR | Unsupervised visible image-guided |
| Remote sensing image super-resolution network | |
| VIG | Visible image-guided branch |
| RIG | Remote sensing image-guided branch |
| RS | Remote sensing |
| Vis | Visible |
| PSNR | Peak signal-to-noise Ratio |
| IQA | Image quality assessment |
| RoI | Region of interest |
| PI | Perceptual index |
| MVG | Multi-variate Gaussian |
| NSS | Natural scene statistic |
| VT | Visible clean target |
| RT | Remote sensing domain target |
| DR discriminators | Domain-ruled discriminator |
References
- Thies, B.; Bendix, J. Satellite based remote sensing of weather and climate: Recent achievements and future perspectives. Meteorol. Appl. 2011, 8, 262–295. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Fang, L.; Liu, G.; Li, S.; Ghamisi, P.; Benediktsson, J.A. Hyperspectral image classification with squeeze multibias network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1291–1301. [Google Scholar] [CrossRef]
- Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic target detection in high-resolution remote sensing images using spatial sparse coding bag-of-words model. IEEE Trans. Geosci. Remote Sens. 2011, 9, 109–113. [Google Scholar] [CrossRef]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for multi-scale remote sensing target detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Process. 2017, 27, 1100–1111. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5690–5699. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1905–1914. [Google Scholar]
- Ma, C.; Rao, Y.; Cheng, Y.; Chen, C.; Lu, J.; Zhou, J. Structure-preserving super resolution with gradient guidance. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 7769–7778. [Google Scholar]
- Xu, M.; Wang, Z.; Zhu, J.; Jia, X.; Jia, S. Multi-Attention Generative Adversarial Network for Remote Sensing Image Super-Resolution. arXiv 2021, arXiv:2107.06536. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the 2001 IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Qu, Y.; Qi, H.; Kwan, C. Unsupervised sparse dirichlet-net for hyperspectral image super-resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2511–2520. [Google Scholar]
- Wei, Y.; Gu, S.; Li, Y.; Timofte, R.; Jin, L.; Song, H. Unsupervised real-world image super resolution via domain-distance aware training. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13385–13394. [Google Scholar]
- Zhang, Y.; Liu, S.; Dong, C.; Zhang, X.; Yuan, Y. Multiple cycle-in-cycle generative adversarial networks for unsupervised image super-resolution. IEEE Trans. Image Process. 2019, 29, 1101–1112. [Google Scholar] [CrossRef]
- Bulat, A.; Yang, J.; Tzimiropoulos, G. To learn image super-resolution, use a gan to learn how to do image degradation first. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 185–200. [Google Scholar]
- Ji, X.; Cao, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F. Real-world super-resolution via kernel estimation and noise injection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 466–467. [Google Scholar]
- Wei, P.; Xie, Z.; Lu, H.; Zhan, Z.; Ye, Q.; Zuo, W.; Lin, L. Component divide-and-conquer for real-world image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 101–117. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Super-fan: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with gans. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 109–117. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Timofte, R. Unsupervised learning for real-world super-resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 20–26 October 2019; pp. 3408–3416. [Google Scholar]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “zero-shot” super-resolution using deep internal learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3118–3126. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Deng, J. Remote sensing image super-resolution using sparse representation and coupled sparse autoencoder. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2019, 12, 2663–2674. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Coupled adversarial training for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3633–3643. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-enhanced GAN for remote sensing image superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A. Remote sensing image superresolution using deep residual channel attention. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9277–9289. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A new deep generative network for unsupervised remote sensing single-image super-resolution. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6792–6810. [Google Scholar] [CrossRef]
- Wang, J.; Shao, Z.; Lu, T.; Huang, X.; Zhang, R.; Wang, Y. Unsupervised Remoting Sensing Super-Resolution via Migration Image Prior. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Tsai, R. Multiframe image restoration and registration. Adv. Comput. Vis. Image Process. 1984, 1, 317–339. [Google Scholar]
- Tao, H.; Tang, X.; Liu, J.; Tian, J. Superresolution remote sensing image processing algorithm based on wavelet transform and interpolation. In Proceedings of the Image Processing and Pattern Recognition in Remote Sensing, Hangzhou, China, 23–27 October 2002; pp. 259–263. [Google Scholar]
- Wang, S.; Zhuo, L.; Li, X. Spectral imagery super resolution by using of a high resolution panchromatic image. In Proceedings of the IEEE International Conference on Computer Science and Information Technology (ICCSIT 2010), Chengdu, China, 9–11 October 2011; pp. 220–224. [Google Scholar]
- Li, F.; Fraser, D.; Jia, X. Improved IBP for super-resolving remote sensing images. Geogr. Inf. Sci. 2006, 12, 106–111. [Google Scholar] [CrossRef]
- Yuan, Q.; Yan, L.; Li, J.; Zhang, L. Remote sensing image super-resolution via regional spatially adaptive total variation model. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 3073–3076. [Google Scholar]
- Feng, X.; Zhang, W.; Su, X.; Xu, Z. Optical Remote sensing image denoising and super-resolution reconstructing using optimized generative network in wavelet transform domain. Remote Sens. 2021, 13, 1858. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, L.; Li, J.; Zhao, H.; Liu, W.; Li, Y.; Wang, Y.; Chen, H.; Cao, W. Saliency-Guided Remote Sensing Image Super-Resolution. Remote Sens. 2021, 13, 5144. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, Y.; Zhao, L.; Liu, L.; Hu, H.; Tao, W. URNet: A U-Shaped Residual Network for Lightweight Image Super-Resolution. Remote Sens. 2021, 13, 3848. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, X.; Chen, C.; Lu, T.; Wang, Z.; Ma, J. Single image super-resolution via locally regularized anchored neighborhood regression and nonlocal means. IEEE Trans. Multimed. 2016, 19, 15–26. [Google Scholar] [CrossRef]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3517–3526. [Google Scholar]
- Li, B.; Gou, Y.; Gu, S.; Liu, J.Z.; Zhou, J.T.; Peng, X. You only look yourself: Unsupervised and untrained single image dehazing neural network. Int. J. Comput. Vis. 2021, 129, 1754–1767. [Google Scholar] [CrossRef]
- Zhu, H.; Peng, X.; Zhou, J.T.; Yang, S.; Chanderasekh, V.; Li, L.; Lim, J.H. Singe image rain removal with unpaired information: A differentiable programming perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 June–1 February 2019; pp. 9332–9339. [Google Scholar]
- Lu, B.; Chen, J.C.; Chellappa, R. Unsupervised domain-specific deblurring via disentangled representations. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 10225–10234. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Ropinski, T. Total denoising: Unsupervised learning of 3d point cloud cleaning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 20–26 October 2019; pp. 52–60. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Liu, Z.S.; Siu, W.C.; Wang, L.W.; Li, C.T.; Cani, M.P. Unsupervised real image super-resolution via generative variational autoencoder. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 442–443. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Ma, C.; Yang, C.Y.; Yang, X.; Yang, M.H. Learning a no-reference quality metric for single-image super-resolution. Comput. Vis. Image Underst. 2017, 158, 1–16. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class/Method | Bicubic | Haut [38] | EEGAN [37] | ZSSR [33] | Bulat [26] | CinCGAN [31] | UVRSR (Ours) |
|---|---|---|---|---|---|---|---|
| scale factor | |||||||
| APL | 29.12/5.77/5.64 | 31.78/4.22/4.16 | 30.94/2.29/2.14 | 31.36/4.89/4.82 | 29.40/4.71/4.53 | 30.98/2.29/2.24 | 31.16/2.05/2.00 |
| BE | 28.92/5.71/5.64 | 31.72/4.14/4.08 | 30.84/2.25/2.11 | 31.26/4.82/4.99 | 29.16/4.79/4.85 | 30.86/2.25/2.19 | 31.20/2.12/2.07 |
| BU | 28.80/5.85/5.70 | 31.47/4.34/4.27 | 30.57/2.40/2.27 | 31.12/4.86/4.70 | 29.30/4.76/4.62 | 30.62/2.47/2.43 | 30.88/2.22/2.16 |
| FW | 28.39/6.05/5.89 | 31.25/4.48/4.36 | 30.45/2.51/2.56 | 30.87/5.08/4.82 | 28.62/4.95/5.15 | 30.39/2.54/2.63 | 30.53/2.38/2.42 |
| HA | 28.75/5.84/5.79 | 31.52/4.26/4.19 | 30.62/2.38/2.49 | 31.19/5.12/4.74 | 28.67/4.82/4.99 | 30.44/2.41/2.47 | 30.79/2.22/2.29 |
| MR | 29.59/5.42/5.37 | 32.29/3.73/3.57 | 31.43/1.86/1.73 | 31.83/4.43/4.49 | 29.94/4.25/4.06 | 31.26/2.13/2.14 | 31.52/1.65/1.58 |
| OP | 29.32/5.60/5.49 | 32.02/4.20/4.01 | 31.33/1.99/1.91 | 31.73/4.75/4.68 | 29.56/4.60/4.49 | 31.31/2.17/2.06 | 31.62/1.97/2.05 |
| RI | 29.47/5.51/5.43 | 32.07/3.87/3.85 | 31.40/1.94/1.89 | 31.76/4.35/4.27 | 29.81/4.43/4.29 | 31.20/2.15/2.01 | 31.37/1.84/1.76 |
| ST | 29.42/5.57/5.42 | 32.02/4.02/4.06 | 31.33/2.07/2.01 | 31.64/4.62/4.77 | 29.74/4.52/4.36 | 31.27/2.10/2.15 | 31.28/1.87/1.94 |
| TC | 29.18/5.46/5.52 | 31.82/4.15/4.23 | 31.04/2.15/1.99 | 31.39/4.78/4.65 | 29.32/4.82/4.61 | 30.96/2.32/2.11 | 31.24/2.02/1.89 |
| AVG | 29.10/5.68/5.59 | 31.90 /4.13/4.08 | 30.99/2.18/2.11 | 31.42/4.77/4.69 | 29.35/4.67/4.60 | 30.93/2.26/2.23 | 31.16/2.03/2.02 |
| scale factor | |||||||
| APL | 23.82/6.43/6.57 | 28.38/4.53/4.49 | 25.24/2.39/2.42 | 25.76/5.13/4.97 | 23.77/6.77/6.62 | 24.96/2.62/2.58 | 25.20/2.31/2.33 |
| BE | 24.12/6.38/6.52 | 28.53/4.62/4.42 | 25.14/2.45/2.36 | 25.81/4.93/5.09 | 23.85/6.65/6.54 | 25.17/2.56/2.49 | 25.34/2.41/2.34 |
| BU | 23.26/7.09/7.26 | 27.86/4.85/4.93 | 24.32/2.66/2.79 | 24.79/5.42/5.29 | 22.43/7.12/6.95 | 24.21/2.75/2.74 | 24.37/2.54/2.58 |
| FW | 23.32/6.72/6.68 | 28.09/4.77/4.81 | 24.54/2.67/2.72 | 24.96/5.32/5.14 | 22.25/7.23/7.08 | 24.36/2.86/2.75 | 24.76/2.52/2.48 |
| HA | 23.79/6.50/6.52 | 28.22/4.56/4.35 | 24.86/2.59/2.68 | 25.43/5.34/5.26 | 23.54/6.89/6.73 | 24.82/2.55/2.65 | 24.90/2.39/2.37 |
| MR | 24.86/5.93/6.07 | 28.92/4.26/4.17 | 25.52/2.15/2.02 | 26.35/4.52/4.55 | 23.89/6.32/6.37 | 25.31/2.26/2.24 | 25.78/1.96/2.08 |
| OP | 24.25/6.45/6.38 | 28.68/4.39/4.33 | 25.16/2.36/2.42 | 25.88/4.92/4.84 | 23.54/6.80/6.68 | 25.06/2.42/2.39 | 25.29/2.29/2.26 |
| RI | 24.81/6.03/6.11 | 28.85/4.35/4.30 | 25.49/2.23/2.26 | 26.47/4.63/4.68 | 24.07/6.35/6.22 | 25.42/2.31/2.40 | 25.62/2.06/2.14 |
| ST | 24.43/6.29/6.35 | 28.62/4.49/4.42 | 25.22/2.31/2.22 | 26.06/4.85/4.89 | 23.77/6.59/6.80 | 25.29/2.43/2.31 | 25.39/2.29/2.23 |
| TC | 24.19/6.46/6.39 | 28.42/4.44/4.37 | 25.27/2.38/2.49 | 25.56/4.93/4.84 | 23.67/6.75/6.68 | 25.26/2.35/2.29 | 25.32/2.24/2.28 |
| AVG | 24.06/6.43/6.49 | 28.46 /4.53/4.46 | 25.08/2.42/2.44 | 25.71/5.00/4.96 | 23.48/6.75/6.67 | 24.99/2.51/2.49 | 25.20/2.30/2.31 |
| scale factor | |||||||
| APL | 17.46/7.92/7.95 | 20.66/5.88/5.91 | 19.59/5.24/5.15 | 16.95/8.25/8.30 | 16.85/8.56/8.52 | 19.32/5.36/5.18 | 20.85/3.82/3.73 |
| BE | 17.62/7.80/7.72 | 20.77/5.84/5.96 | 19.71/5.06/4.87 | 17.18/8.08/8.15 | 16.92/8.42/8.36 | 19.62/5.39/5.45 | 21.26 /3.65/3.28 |
| BU | 16.70/8.39/8.21 | 19.68/6.54/6.26 | 18.52/5.75/5.61 | 16.33/8.48/8.56 | 16.24/8.92/8.71 | 18.75/5.68/5.59 | 20.15/4.52/4.35 |
| FW | 16.84/8.23/8.06 | 19.92/6.34/6.22 | 18.83/5.53/5.42 | 16.53/8.12/8.09 | 16.04/8.79/8.85 | 18.92/5.62/5.51 | 19.89/4.65/4.55 |
| HA | 17.22/8.10/7.92 | 20.47/5.93/6.05 | 19.27/5.40/5.21 | 16.82/8.34/8.46 | 16.41/8.63/8.69 | 19.25/5.42/5.44 | 20.26/4.05/3.86 |
| MR | 18.56/7.24/7.16 | 21.51/5.32/5.40 | 20.73/4.85/4.62 | 18.71/7.42/7.34 | 19.25/6.87/6.92 | 20.82/4.58/4.53 | 21.49/3.49/3.36 |
| OP | 17.92/7.62/7.56 | 21.04/5.75/5.68 | 20.22/5.03/4.88 | 17.79/7.81/7.77 | 17.64/7.86/7.75 | 20.17/5.11/4.87 | 21.14/3.62/3.65 |
| RI | 18.53/7.36/7.25 | 21.34/5.44/5.56 | 20.39/4.97/4.85 | 18.35/7.52/7.43 | 18.82/7.16/6.92 | 20.47/4.89/4.79 | 21.50/2.81/2.94 |
| ST | 18.24/7.44/7.42 | 21.06/5.68/5.49 | 20.25/4.92/4.76 | 18.02/7.66/7.54 | 18.31/7.58/7.46 | 20.19/5.12/4.82 | 21.25/3.57/3.40 |
| TC | 17.64/7.85/7.79 | 20.88/5.84/5.90 | 19.73/5.06/4.88 | 17.02/8.18/8.38 | 16.95/8.42/8.36 | 20.08/5.04/4.93 | 21.06/3.67/3.54 |
| AVG | 17.67/7.80/7.70 | 20.73/5.86/5.84 | 19.72/5.18/5.03 | 17.37/7.99/8.02 | 17.39/8.12/8.05 | 19.79/5.22/5.11 | 20.88/3.79/3.67 |
| Branches | |||
|---|---|---|---|
| VIG + RIG | 30.79/2.22/2.29 | 24.90/2.39/2.37 | 20.26/4.05/3.86 |
| VIG | 30.66/2.28/2.35 | 24.76/2.44/2.41 | 20.12/4.11/3.93 |
| RIG | 30.72/2.34/2.43 | 24.80/2.52/2.48 | 20.14/4.19/3.98 |
| Inputs of Discriminator | |||
|---|---|---|---|
| SR + VT + RT | 31.16/2.05/2.00 | 25.20/2.31/2.33 | 20.85/3.82/3.73 |
| SR + VT | 30.75/2.10/2.07 | 24.52/2.39/2.38 | 20.28/4.03/3.92 |
| SR + RT | 31.08/2.19/2.13 | 24.92/2.46/2.49 | 20.66/4.18/4.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Tian, Y.; Li, J.; Xu, Y. Unsupervised Remote Sensing Image Super-Resolution Guided by Visible Images. Remote Sens. 2022, 14, 1513. https://doi.org/10.3390/rs14061513
Zhang Z, Tian Y, Li J, Xu Y. Unsupervised Remote Sensing Image Super-Resolution Guided by Visible Images. Remote Sensing. 2022; 14(6):1513. https://doi.org/10.3390/rs14061513
Chicago/Turabian StyleZhang, Zili, Yan Tian, Jianxiang Li, and Yiping Xu. 2022. "Unsupervised Remote Sensing Image Super-Resolution Guided by Visible Images" Remote Sensing 14, no. 6: 1513. https://doi.org/10.3390/rs14061513